Compare commits
61 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
7d4f0a8320 | ||
|
|
4149bc7be8 | ||
|
|
e6316b185e | ||
|
|
a2183be96e | ||
|
|
df39a95925 | ||
|
|
ff859ead85 | ||
|
|
b2be30cb07 | ||
|
|
b9c1a3c5c1 | ||
|
|
9751951d10 | ||
|
|
64c79bde83 | ||
|
|
da0374f360 | ||
|
|
c26b58ba28 | ||
|
|
56f935640a | ||
|
|
85ca6cde49 | ||
|
|
38addbe50d | ||
|
|
924e35b1c3 | ||
|
|
d05ea4dbac | ||
|
|
b5ac93d2ee | ||
|
|
924e264156 | ||
|
|
14c5000ad5 | ||
|
|
d985473f4f | ||
|
|
47e0b2521a | ||
|
|
a319980a7c | ||
|
|
3336dd63f4 | ||
|
|
ae20a721a1 | ||
|
|
a26b1f43e9 | ||
|
|
139a6d8331 | ||
|
|
04ef674195 | ||
|
|
db852a0b11 | ||
|
|
87c3b0e4e2 | ||
|
|
82784a7607 | ||
|
|
f2da855048 | ||
|
|
81b60cf9fe | ||
|
|
c96ba6dec4 | ||
|
|
0f8f250bea | ||
|
|
a3ffaa5d9b | ||
|
|
187ed874e9 | ||
|
|
a30c77e752 | ||
|
|
7e9b9cc7b3 | ||
|
|
d4cef9305a | ||
|
|
a074625121 | ||
|
|
9c55ab35df | ||
|
|
a95474f2b1 | ||
|
|
3e6fe46bc4 | ||
|
|
bc81cea4f4 | ||
|
|
cb0f226962 | ||
|
|
fa56fabed9 | ||
|
|
bdcab87d2f | ||
|
|
ec8b827d26 | ||
|
|
b232c43824 | ||
|
|
ee01e666c5 | ||
|
|
2b0de8ccd9 | ||
|
|
739c57b31b | ||
|
|
c3e0137f22 | ||
|
|
77716108af | ||
|
|
335395adec | ||
|
|
65f8f1a6f7 | ||
|
|
858af8debb | ||
|
|
5f1bbf0b6b | ||
|
|
40cb905ae5 | ||
|
|
e89b4a5de5 |
@@ -1,2 +1,28 @@
|
||||
[alias]
|
||||
dev = "run --package ruff_dev --bin ruff_dev"
|
||||
|
||||
[target.'cfg(all())']
|
||||
rustflags = [
|
||||
# CLIPPY LINT SETTINGS
|
||||
# This is a workaround to configure lints for the entire workspace, pending the ability to configure this via TOML.
|
||||
# See: `https://github.com/rust-lang/cargo/issues/5034`
|
||||
# `https://github.com/EmbarkStudios/rust-ecosystem/issues/22#issuecomment-947011395`
|
||||
"-Dunsafe_code",
|
||||
"-Wclippy::pedantic",
|
||||
# Allowed pedantic lints
|
||||
"-Wclippy::char_lit_as_u8",
|
||||
"-Aclippy::collapsible_else_if",
|
||||
"-Aclippy::collapsible_if",
|
||||
"-Aclippy::implicit_hasher",
|
||||
"-Aclippy::match_same_arms",
|
||||
"-Aclippy::missing_errors_doc",
|
||||
"-Aclippy::missing_panics_doc",
|
||||
"-Aclippy::module_name_repetitions",
|
||||
"-Aclippy::must_use_candidate",
|
||||
"-Aclippy::similar_names",
|
||||
"-Aclippy::too_many_lines",
|
||||
# Disallowed restriction lints
|
||||
"-Wclippy::print_stdout",
|
||||
"-Wclippy::print_stderr",
|
||||
"-Wclippy::dbg_macro",
|
||||
]
|
||||
|
||||
8
.github/ISSUE_TEMPLATE.md
vendored
8
.github/ISSUE_TEMPLATE.md
vendored
@@ -3,8 +3,8 @@ Thank you for taking the time to report an issue! We're glad to have you involve
|
||||
|
||||
If you're filing a bug report, please consider including the following information:
|
||||
|
||||
- A minimal code snippet that reproduces the bug.
|
||||
- The command you invoked (e.g., `ruff /path/to/file.py --fix`), ideally including the `--isolated` flag.
|
||||
- The current Ruff settings (any relevant sections from your `pyproject.toml`).
|
||||
- The current Ruff version (`ruff --version`).
|
||||
* A minimal code snippet that reproduces the bug.
|
||||
* The command you invoked (e.g., `ruff /path/to/file.py --fix`), ideally including the `--isolated` flag.
|
||||
* The current Ruff settings (any relevant sections from your `pyproject.toml`).
|
||||
* The current Ruff version (`ruff --version`).
|
||||
-->
|
||||
|
||||
18
.github/workflows/ci.yaml
vendored
18
.github/workflows/ci.yaml
vendored
@@ -50,13 +50,13 @@ jobs:
|
||||
rustup component add clippy
|
||||
rustup target add wasm32-unknown-unknown
|
||||
- uses: Swatinem/rust-cache@v1
|
||||
- run: cargo clippy --workspace --all-targets --all-features -- -D warnings -W clippy::pedantic
|
||||
- run: cargo clippy -p ruff --target wasm32-unknown-unknown --all-features -- -D warnings -W clippy::pedantic
|
||||
- run: cargo clippy --workspace --all-targets --all-features -- -D warnings
|
||||
- run: cargo clippy -p ruff --target wasm32-unknown-unknown --all-features -- -D warnings
|
||||
|
||||
cargo-test:
|
||||
strategy:
|
||||
matrix:
|
||||
os: [ ubuntu-latest, windows-latest ]
|
||||
os: [ubuntu-latest, windows-latest]
|
||||
runs-on: ${{ matrix.os }}
|
||||
name: "cargo test | ${{ matrix.os }}"
|
||||
steps:
|
||||
@@ -95,8 +95,8 @@ jobs:
|
||||
- run: ./scripts/add_rule.py --name DoTheThing --code PLC999 --linter pylint
|
||||
- run: cargo check
|
||||
- run: |
|
||||
./scripts/add_plugin.py test --url https://pypi.org/project/-test/0.1.0/ --prefix TST
|
||||
./scripts/add_rule.py --name FirstRule --code TST001 --linter test
|
||||
./scripts/add_plugin.py test --url https://pypi.org/project/-test/0.1.0/ --prefix TST
|
||||
./scripts/add_rule.py --name FirstRule --code TST001 --linter test
|
||||
- run: cargo check
|
||||
|
||||
maturin-build:
|
||||
@@ -118,7 +118,7 @@ jobs:
|
||||
name: "spell check"
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: crate-ci/typos@master
|
||||
with:
|
||||
files: .
|
||||
- uses: actions/checkout@v3
|
||||
- uses: crate-ci/typos@master
|
||||
with:
|
||||
files: .
|
||||
|
||||
3
.github/workflows/docs.yaml
vendored
3
.github/workflows/docs.yaml
vendored
@@ -6,10 +6,9 @@ on:
|
||||
- README.md
|
||||
- mkdocs.template.yml
|
||||
- .github/workflows/docs.yaml
|
||||
branches: [ main ]
|
||||
branches: [main]
|
||||
workflow_dispatch:
|
||||
|
||||
|
||||
jobs:
|
||||
mkdocs:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
2
.github/workflows/playground.yaml
vendored
2
.github/workflows/playground.yaml
vendored
@@ -15,7 +15,7 @@ jobs:
|
||||
publish:
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
CF_API_TOKEN_EXISTS: ${{ secrets.CF_API_TOKEN != '' }}
|
||||
CF_API_TOKEN_EXISTS: ${{ secrets.CF_API_TOKEN != '' }}
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: "Install Rust toolchain"
|
||||
|
||||
2
.github/workflows/ruff.yaml
vendored
2
.github/workflows/ruff.yaml
vendored
@@ -138,7 +138,7 @@ jobs:
|
||||
with:
|
||||
target: ${{ matrix.target }}
|
||||
manylinux: auto
|
||||
args: --no-default-features --release --out dist
|
||||
args: --release --out dist
|
||||
- uses: uraimo/run-on-arch-action@v2.5.0
|
||||
if: matrix.target != 'ppc64'
|
||||
name: Install built wheel
|
||||
|
||||
@@ -1,16 +1,19 @@
|
||||
repos:
|
||||
- repo: https://github.com/charliermarsh/ruff-pre-commit
|
||||
rev: v0.0.240
|
||||
hooks:
|
||||
- id: ruff
|
||||
args: [--fix]
|
||||
exclude: ^resources
|
||||
|
||||
- repo: https://github.com/abravalheri/validate-pyproject
|
||||
rev: v0.10.1
|
||||
hooks:
|
||||
- id: validate-pyproject
|
||||
|
||||
- repo: https://github.com/igorshubovych/markdownlint-cli
|
||||
rev: v0.33.0
|
||||
hooks:
|
||||
- id: markdownlint-fix
|
||||
args:
|
||||
- --disable
|
||||
- MD013 # line-length
|
||||
- MD033 # no-inline-html
|
||||
- --
|
||||
|
||||
- repo: local
|
||||
hooks:
|
||||
- id: cargo-fmt
|
||||
@@ -20,12 +23,22 @@ repos:
|
||||
types: [rust]
|
||||
- id: clippy
|
||||
name: clippy
|
||||
entry: cargo clippy --workspace --all-targets --all-features
|
||||
entry: cargo clippy --workspace --all-targets --all-features -- -D warnings
|
||||
language: rust
|
||||
pass_filenames: false
|
||||
- id: ruff
|
||||
name: ruff
|
||||
entry: cargo run -- --no-cache --fix
|
||||
language: rust
|
||||
types_or: [python, pyi]
|
||||
require_serial: true
|
||||
exclude: ^resources
|
||||
- id: dev-generate-all
|
||||
name: dev-generate-all
|
||||
entry: cargo dev generate-all
|
||||
language: rust
|
||||
pass_filenames: false
|
||||
exclude: target
|
||||
|
||||
ci:
|
||||
skip: [cargo-fmt, clippy, dev-generate-all]
|
||||
|
||||
@@ -43,16 +43,18 @@ upgrades.
|
||||
|
||||
`--explain`, `--clean`, and `--generate-shell-completion` are now implemented as subcommands:
|
||||
|
||||
ruff . # Still works! And will always work.
|
||||
ruff check . # New! Also works.
|
||||
```console
|
||||
ruff . # Still works! And will always work.
|
||||
ruff check . # New! Also works.
|
||||
|
||||
ruff --explain E402 # Still works.
|
||||
ruff rule E402 # New! Also works. (And preferred.)
|
||||
ruff --explain E402 # Still works.
|
||||
ruff rule E402 # New! Also works. (And preferred.)
|
||||
|
||||
# Oops! The command has to come first.
|
||||
ruff --format json --explain E402 # No longer works.
|
||||
ruff --explain E402 --format json # Still works!
|
||||
ruff rule E402 --format json # Works! (And preferred.)
|
||||
# Oops! The command has to come first.
|
||||
ruff --format json --explain E402 # No longer works.
|
||||
ruff --explain E402 --format json # Still works!
|
||||
ruff rule E402 --format json # Works! (And preferred.)
|
||||
```
|
||||
|
||||
This change is largely backwards compatible -- most users should experience
|
||||
no change in behavior. However, please note the following exceptions:
|
||||
@@ -60,7 +62,9 @@ no change in behavior. However, please note the following exceptions:
|
||||
* Subcommands will now fail when invoked with unsupported arguments, instead
|
||||
of silently ignoring them. For example, the following will now fail:
|
||||
|
||||
ruff --clean --respect-gitignore
|
||||
```console
|
||||
ruff --clean --respect-gitignore
|
||||
```
|
||||
|
||||
(the `clean` command doesn't support `--respect-gitignore`.)
|
||||
|
||||
|
||||
@@ -106,7 +106,7 @@ Violating these terms may lead to a permanent ban.
|
||||
### 4. Permanent Ban
|
||||
|
||||
**Community Impact**: Demonstrating a pattern of violation of community
|
||||
standards, including sustained inappropriate behavior, harassment of an
|
||||
standards, including sustained inappropriate behavior, harassment of an
|
||||
individual, or aggression toward or disparagement of classes of individuals.
|
||||
|
||||
**Consequence**: A permanent ban from any sort of public interaction within
|
||||
@@ -115,14 +115,12 @@ the community.
|
||||
## Attribution
|
||||
|
||||
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
||||
version 2.0, available at
|
||||
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
||||
version 2.0, available [here](https://www.contributor-covenant.org/version/2/0/code_of_conduct.html).
|
||||
|
||||
Community Impact Guidelines were inspired by [Mozilla's code of conduct
|
||||
enforcement ladder](https://github.com/mozilla/diversity).
|
||||
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
|
||||
For answers to common questions about this code of conduct, see the FAQ at
|
||||
https://www.contributor-covenant.org/faq. Translations are available at
|
||||
https://www.contributor-covenant.org/translations.
|
||||
For answers to common questions about this code of conduct, see the [FAQ](https://www.contributor-covenant.org/faq).
|
||||
Translations are available [here](https://www.contributor-covenant.org/translations).
|
||||
|
||||
123
CONTRIBUTING.md
123
CONTRIBUTING.md
@@ -146,3 +146,126 @@ them to [PyPI](https://pypi.org/project/ruff/).
|
||||
|
||||
Ruff follows the [semver](https://semver.org/) versioning standard. However, as pre-1.0 software,
|
||||
even patch releases may contain [non-backwards-compatible changes](https://semver.org/#spec-item-4).
|
||||
|
||||
## Benchmarks
|
||||
|
||||
First, clone [CPython](https://github.com/python/cpython). It's a large and diverse Python codebase,
|
||||
which makes it a good target for benchmarking.
|
||||
|
||||
```shell
|
||||
git clone --branch 3.10 https://github.com/python/cpython.git resources/test/cpython
|
||||
```
|
||||
|
||||
To benchmark the release build:
|
||||
|
||||
```shell
|
||||
cargo build --release && hyperfine --ignore-failure --warmup 10 \
|
||||
"./target/release/ruff ./resources/test/cpython/ --no-cache" \
|
||||
"./target/release/ruff ./resources/test/cpython/"
|
||||
|
||||
Benchmark 1: ./target/release/ruff ./resources/test/cpython/ --no-cache
|
||||
Time (mean ± σ): 293.8 ms ± 3.2 ms [User: 2384.6 ms, System: 90.3 ms]
|
||||
Range (min … max): 289.9 ms … 301.6 ms 10 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Benchmark 2: ./target/release/ruff ./resources/test/cpython/
|
||||
Time (mean ± σ): 48.0 ms ± 3.1 ms [User: 65.2 ms, System: 124.7 ms]
|
||||
Range (min … max): 45.0 ms … 66.7 ms 62 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Summary
|
||||
'./target/release/ruff ./resources/test/cpython/' ran
|
||||
6.12 ± 0.41 times faster than './target/release/ruff ./resources/test/cpython/ --no-cache'
|
||||
```
|
||||
|
||||
To benchmark against the ecosystem's existing tools:
|
||||
|
||||
```shell
|
||||
hyperfine --ignore-failure --warmup 5 \
|
||||
"./target/release/ruff ./resources/test/cpython/ --no-cache" \
|
||||
"pyflakes resources/test/cpython" \
|
||||
"autoflake --recursive --expand-star-imports --remove-all-unused-imports --remove-unused-variables --remove-duplicate-keys resources/test/cpython" \
|
||||
"pycodestyle resources/test/cpython" \
|
||||
"flake8 resources/test/cpython"
|
||||
|
||||
Benchmark 1: ./target/release/ruff ./resources/test/cpython/ --no-cache
|
||||
Time (mean ± σ): 294.3 ms ± 3.3 ms [User: 2467.5 ms, System: 89.6 ms]
|
||||
Range (min … max): 291.1 ms … 302.8 ms 10 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Benchmark 2: pyflakes resources/test/cpython
|
||||
Time (mean ± σ): 15.786 s ± 0.143 s [User: 15.560 s, System: 0.214 s]
|
||||
Range (min … max): 15.640 s … 16.157 s 10 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Benchmark 3: autoflake --recursive --expand-star-imports --remove-all-unused-imports --remove-unused-variables --remove-duplicate-keys resources/test/cpython
|
||||
Time (mean ± σ): 6.175 s ± 0.169 s [User: 54.102 s, System: 1.057 s]
|
||||
Range (min … max): 5.950 s … 6.391 s 10 runs
|
||||
|
||||
Benchmark 4: pycodestyle resources/test/cpython
|
||||
Time (mean ± σ): 46.921 s ± 0.508 s [User: 46.699 s, System: 0.202 s]
|
||||
Range (min … max): 46.171 s … 47.863 s 10 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Benchmark 5: flake8 resources/test/cpython
|
||||
Time (mean ± σ): 12.260 s ± 0.321 s [User: 102.934 s, System: 1.230 s]
|
||||
Range (min … max): 11.848 s … 12.933 s 10 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Summary
|
||||
'./target/release/ruff ./resources/test/cpython/ --no-cache' ran
|
||||
20.98 ± 0.62 times faster than 'autoflake --recursive --expand-star-imports --remove-all-unused-imports --remove-unused-variables --remove-duplicate-keys resources/test/cpython'
|
||||
41.66 ± 1.18 times faster than 'flake8 resources/test/cpython'
|
||||
53.64 ± 0.77 times faster than 'pyflakes resources/test/cpython'
|
||||
159.43 ± 2.48 times faster than 'pycodestyle resources/test/cpython'
|
||||
```
|
||||
|
||||
You can run `poetry install` from `./scripts` to create a working environment for the above. All
|
||||
reported benchmarks were computed using the versions specified by `./scripts/pyproject.toml`
|
||||
on Python 3.11.
|
||||
|
||||
To benchmark Pylint, remove the following files from the CPython repository:
|
||||
|
||||
```shell
|
||||
rm Lib/test/bad_coding.py \
|
||||
Lib/test/bad_coding2.py \
|
||||
Lib/test/bad_getattr.py \
|
||||
Lib/test/bad_getattr2.py \
|
||||
Lib/test/bad_getattr3.py \
|
||||
Lib/test/badcert.pem \
|
||||
Lib/test/badkey.pem \
|
||||
Lib/test/badsyntax_3131.py \
|
||||
Lib/test/badsyntax_future10.py \
|
||||
Lib/test/badsyntax_future3.py \
|
||||
Lib/test/badsyntax_future4.py \
|
||||
Lib/test/badsyntax_future5.py \
|
||||
Lib/test/badsyntax_future6.py \
|
||||
Lib/test/badsyntax_future7.py \
|
||||
Lib/test/badsyntax_future8.py \
|
||||
Lib/test/badsyntax_future9.py \
|
||||
Lib/test/badsyntax_pep3120.py \
|
||||
Lib/test/test_asyncio/test_runners.py \
|
||||
Lib/test/test_copy.py \
|
||||
Lib/test/test_inspect.py \
|
||||
Lib/test/test_typing.py
|
||||
```
|
||||
|
||||
Then, from `resources/test/cpython`, run: `time pylint -j 0 -E $(git ls-files '*.py')`. This
|
||||
will execute Pylint with maximum parallelism and only report errors.
|
||||
|
||||
To benchmark Pyupgrade, run the following from `resources/test/cpython`:
|
||||
|
||||
```shell
|
||||
hyperfine --ignore-failure --warmup 5 --prepare "git reset --hard HEAD" \
|
||||
"find . -type f -name \"*.py\" | xargs -P 0 pyupgrade --py311-plus"
|
||||
|
||||
Benchmark 1: find . -type f -name "*.py" | xargs -P 0 pyupgrade --py311-plus
|
||||
Time (mean ± σ): 30.119 s ± 0.195 s [User: 28.638 s, System: 0.390 s]
|
||||
Range (min … max): 29.813 s … 30.356 s 10 runs
|
||||
```
|
||||
|
||||
84
Cargo.lock
generated
84
Cargo.lock
generated
@@ -608,15 +608,6 @@ dependencies = [
|
||||
"crypto-common",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "directories"
|
||||
version = "4.0.1"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "f51c5d4ddabd36886dd3e1438cb358cdcb0d7c499cb99cb4ac2e38e18b5cb210"
|
||||
dependencies = [
|
||||
"dirs-sys",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "dirs"
|
||||
version = "4.0.0"
|
||||
@@ -750,7 +741,7 @@ checksum = "0ce7134b9999ecaf8bcd65542e436736ef32ddca1b3e06094cb6ec5755203b80"
|
||||
|
||||
[[package]]
|
||||
name = "flake8-to-ruff"
|
||||
version = "0.0.240"
|
||||
version = "0.0.241"
|
||||
dependencies = [
|
||||
"anyhow",
|
||||
"clap 4.1.4",
|
||||
@@ -945,7 +936,7 @@ version = "1.0.4"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "9f92123bf2fe0d9f1b5df1964727b970ca3b2d0203d47cf97fb1f36d856b6398"
|
||||
dependencies = [
|
||||
"phf 0.11.1",
|
||||
"phf",
|
||||
"rust-stemmers",
|
||||
]
|
||||
|
||||
@@ -1571,15 +1562,6 @@ dependencies = [
|
||||
"indexmap",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "phf"
|
||||
version = "0.10.1"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "fabbf1ead8a5bcbc20f5f8b939ee3f5b0f6f281b6ad3468b84656b658b455259"
|
||||
dependencies = [
|
||||
"phf_shared 0.10.0",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "phf"
|
||||
version = "0.11.1"
|
||||
@@ -1589,36 +1571,16 @@ dependencies = [
|
||||
"phf_shared 0.11.1",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "phf_codegen"
|
||||
version = "0.10.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "4fb1c3a8bc4dd4e5cfce29b44ffc14bedd2ee294559a294e2a4d4c9e9a6a13cd"
|
||||
dependencies = [
|
||||
"phf_generator 0.10.0",
|
||||
"phf_shared 0.10.0",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "phf_codegen"
|
||||
version = "0.11.1"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "a56ac890c5e3ca598bbdeaa99964edb5b0258a583a9eb6ef4e89fc85d9224770"
|
||||
dependencies = [
|
||||
"phf_generator 0.11.1",
|
||||
"phf_generator",
|
||||
"phf_shared 0.11.1",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "phf_generator"
|
||||
version = "0.10.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "5d5285893bb5eb82e6aaf5d59ee909a06a16737a8970984dd7746ba9283498d6"
|
||||
dependencies = [
|
||||
"phf_shared 0.10.0",
|
||||
"rand",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "phf_generator"
|
||||
version = "0.11.1"
|
||||
@@ -1922,7 +1884,7 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "ruff"
|
||||
version = "0.0.240"
|
||||
version = "0.0.241"
|
||||
dependencies = [
|
||||
"anyhow",
|
||||
"bitflags",
|
||||
@@ -1977,7 +1939,7 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "ruff_cli"
|
||||
version = "0.0.240"
|
||||
version = "0.0.241"
|
||||
dependencies = [
|
||||
"annotate-snippets 0.9.1",
|
||||
"anyhow",
|
||||
@@ -2007,14 +1969,13 @@ dependencies = [
|
||||
"similar",
|
||||
"strum",
|
||||
"textwrap",
|
||||
"update-informer",
|
||||
"ureq",
|
||||
"walkdir",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "ruff_dev"
|
||||
version = "0.0.240"
|
||||
version = "0.0.241"
|
||||
dependencies = [
|
||||
"anyhow",
|
||||
"clap 4.1.4",
|
||||
@@ -2035,7 +1996,7 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "ruff_macros"
|
||||
version = "0.0.240"
|
||||
version = "0.0.241"
|
||||
dependencies = [
|
||||
"once_cell",
|
||||
"proc-macro2",
|
||||
@@ -2089,7 +2050,7 @@ dependencies = [
|
||||
[[package]]
|
||||
name = "rustpython-ast"
|
||||
version = "0.2.0"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=4f38cb68e4a97aeea9eb19673803a0bd5f655383#4f38cb68e4a97aeea9eb19673803a0bd5f655383"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=adc23253e4b58980b407ba2760dbe61681d752fc#adc23253e4b58980b407ba2760dbe61681d752fc"
|
||||
dependencies = [
|
||||
"num-bigint",
|
||||
"rustpython-common",
|
||||
@@ -2099,7 +2060,7 @@ dependencies = [
|
||||
[[package]]
|
||||
name = "rustpython-common"
|
||||
version = "0.2.0"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=4f38cb68e4a97aeea9eb19673803a0bd5f655383#4f38cb68e4a97aeea9eb19673803a0bd5f655383"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=adc23253e4b58980b407ba2760dbe61681d752fc#adc23253e4b58980b407ba2760dbe61681d752fc"
|
||||
dependencies = [
|
||||
"ascii",
|
||||
"bitflags",
|
||||
@@ -2124,7 +2085,7 @@ dependencies = [
|
||||
[[package]]
|
||||
name = "rustpython-compiler-core"
|
||||
version = "0.2.0"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=4f38cb68e4a97aeea9eb19673803a0bd5f655383#4f38cb68e4a97aeea9eb19673803a0bd5f655383"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=adc23253e4b58980b407ba2760dbe61681d752fc#adc23253e4b58980b407ba2760dbe61681d752fc"
|
||||
dependencies = [
|
||||
"bincode",
|
||||
"bitflags",
|
||||
@@ -2141,7 +2102,7 @@ dependencies = [
|
||||
[[package]]
|
||||
name = "rustpython-parser"
|
||||
version = "0.2.0"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=4f38cb68e4a97aeea9eb19673803a0bd5f655383#4f38cb68e4a97aeea9eb19673803a0bd5f655383"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=adc23253e4b58980b407ba2760dbe61681d752fc#adc23253e4b58980b407ba2760dbe61681d752fc"
|
||||
dependencies = [
|
||||
"ahash",
|
||||
"anyhow",
|
||||
@@ -2151,8 +2112,8 @@ dependencies = [
|
||||
"log",
|
||||
"num-bigint",
|
||||
"num-traits",
|
||||
"phf 0.10.1",
|
||||
"phf_codegen 0.10.0",
|
||||
"phf",
|
||||
"phf_codegen",
|
||||
"rustc-hash",
|
||||
"rustpython-ast",
|
||||
"rustpython-compiler-core",
|
||||
@@ -2455,8 +2416,8 @@ dependencies = [
|
||||
"dirs",
|
||||
"fnv",
|
||||
"nom",
|
||||
"phf 0.11.1",
|
||||
"phf_codegen 0.11.1",
|
||||
"phf",
|
||||
"phf_codegen",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
@@ -2758,19 +2719,6 @@ version = "0.7.1"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "a156c684c91ea7d62626509bce3cb4e1d9ed5c4d978f7b4352658f96a4c26b4a"
|
||||
|
||||
[[package]]
|
||||
name = "update-informer"
|
||||
version = "0.6.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "152ff185ca29f7f487c51ca785b0f1d85970c4581f4cdd12ed499227890200f5"
|
||||
dependencies = [
|
||||
"directories",
|
||||
"semver",
|
||||
"serde",
|
||||
"serde_json",
|
||||
"ureq",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "ureq"
|
||||
version = "2.6.2"
|
||||
@@ -2782,8 +2730,6 @@ dependencies = [
|
||||
"log",
|
||||
"once_cell",
|
||||
"rustls",
|
||||
"serde",
|
||||
"serde_json",
|
||||
"url",
|
||||
"webpki",
|
||||
"webpki-roots",
|
||||
|
||||
10
Cargo.toml
10
Cargo.toml
@@ -8,7 +8,7 @@ default-members = [".", "ruff_cli"]
|
||||
|
||||
[package]
|
||||
name = "ruff"
|
||||
version = "0.0.240"
|
||||
version = "0.0.241"
|
||||
authors = ["Charlie Marsh <charlie.r.marsh@gmail.com>"]
|
||||
edition = "2021"
|
||||
rust-version = "1.65.0"
|
||||
@@ -46,11 +46,11 @@ num-traits = "0.2.15"
|
||||
once_cell = { version = "1.16.0" }
|
||||
path-absolutize = { version = "3.0.14", features = ["once_cell_cache", "use_unix_paths_on_wasm"] }
|
||||
regex = { version = "1.6.0" }
|
||||
ruff_macros = { version = "0.0.240", path = "ruff_macros" }
|
||||
ruff_macros = { version = "0.0.241", path = "ruff_macros" }
|
||||
rustc-hash = { version = "1.1.0" }
|
||||
rustpython-ast = { features = ["unparse"], git = "https://github.com/RustPython/RustPython.git", rev = "4f38cb68e4a97aeea9eb19673803a0bd5f655383" }
|
||||
rustpython-common = { git = "https://github.com/RustPython/RustPython.git", rev = "4f38cb68e4a97aeea9eb19673803a0bd5f655383" }
|
||||
rustpython-parser = { features = ["lalrpop"], git = "https://github.com/RustPython/RustPython.git", rev = "4f38cb68e4a97aeea9eb19673803a0bd5f655383" }
|
||||
rustpython-ast = { features = ["unparse"], git = "https://github.com/RustPython/RustPython.git", rev = "adc23253e4b58980b407ba2760dbe61681d752fc" }
|
||||
rustpython-common = { git = "https://github.com/RustPython/RustPython.git", rev = "adc23253e4b58980b407ba2760dbe61681d752fc" }
|
||||
rustpython-parser = { features = ["lalrpop"], git = "https://github.com/RustPython/RustPython.git", rev = "adc23253e4b58980b407ba2760dbe61681d752fc" }
|
||||
schemars = { version = "0.8.11" }
|
||||
semver = { version = "1.0.16" }
|
||||
serde = { version = "1.0.147", features = ["derive"] }
|
||||
|
||||
431
README.md
431
README.md
@@ -7,6 +7,7 @@
|
||||
[](https://pypi.python.org/pypi/ruff)
|
||||
[](https://pypi.python.org/pypi/ruff)
|
||||
[](https://github.com/charliermarsh/ruff/actions)
|
||||
[](https://info.jetbrains.com/PyCharm-Webinar-February14-2023.html)
|
||||
|
||||
[**Discord**](https://discord.gg/Z8KbeK24) | [**Docs**](https://beta.ruff.rs/docs/) | [**Playground**](https://play.ruff.rs/)
|
||||
|
||||
@@ -24,16 +25,16 @@ An extremely fast Python linter, written in Rust.
|
||||
<i>Linting the CPython codebase from scratch.</i>
|
||||
</p>
|
||||
|
||||
- ⚡️ 10-100x faster than existing linters
|
||||
- 🐍 Installable via `pip`
|
||||
- 🤝 Python 3.11 compatibility
|
||||
- 🛠️ `pyproject.toml` support
|
||||
- 📦 Built-in caching, to avoid re-analyzing unchanged files
|
||||
- 🔧 Autofix support, for automatic error correction (e.g., automatically remove unused imports)
|
||||
- ⚖️ [Near-parity](#how-does-ruff-compare-to-flake8) with the built-in Flake8 rule set
|
||||
- 🔌 Native re-implementations of dozens of Flake8 plugins, like [flake8-bugbear](https://pypi.org/project/flake8-bugbear/)
|
||||
- ⌨️ First-party editor integrations for [VS Code](https://github.com/charliermarsh/ruff-vscode) and [more](https://github.com/charliermarsh/ruff-lsp)
|
||||
- 🌎 Monorepo-friendly, with [hierarchical and cascading configuration](#pyprojecttoml-discovery)
|
||||
* ⚡️ 10-100x faster than existing linters
|
||||
* 🐍 Installable via `pip`
|
||||
* 🤝 Python 3.11 compatibility
|
||||
* 🛠️ `pyproject.toml` support
|
||||
* 📦 Built-in caching, to avoid re-analyzing unchanged files
|
||||
* 🔧 Autofix support, for automatic error correction (e.g., automatically remove unused imports)
|
||||
* ⚖️ [Near-parity](#how-does-ruff-compare-to-flake8) with the built-in Flake8 rule set
|
||||
* 🔌 Native re-implementations of dozens of Flake8 plugins, like [flake8-bugbear](https://pypi.org/project/flake8-bugbear/)
|
||||
* ⌨️ First-party editor integrations for [VS Code](https://github.com/charliermarsh/ruff-vscode) and [more](https://github.com/charliermarsh/ruff-lsp)
|
||||
* 🌎 Monorepo-friendly, with [hierarchical and cascading configuration](#pyprojecttoml-discovery)
|
||||
|
||||
Ruff aims to be orders of magnitude faster than alternative tools while integrating more
|
||||
functionality behind a single, common interface.
|
||||
@@ -46,32 +47,32 @@ all while executing tens or hundreds of times faster than any individual tool.
|
||||
|
||||
Ruff is extremely actively developed and used in major open-source projects like:
|
||||
|
||||
- [pandas](https://github.com/pandas-dev/pandas)
|
||||
- [FastAPI](https://github.com/tiangolo/fastapi)
|
||||
- [Apache Airflow](https://github.com/apache/airflow)
|
||||
- [SciPy](https://github.com/scipy/scipy)
|
||||
- [Bokeh](https://github.com/bokeh/bokeh)
|
||||
- [Zulip](https://github.com/zulip/zulip)
|
||||
- [Pydantic](https://github.com/pydantic/pydantic)
|
||||
- [Dagster](https://github.com/dagster-io/dagster)
|
||||
- [Dagger](https://github.com/dagger/dagger)
|
||||
- [Sphinx](https://github.com/sphinx-doc/sphinx)
|
||||
- [Hatch](https://github.com/pypa/hatch)
|
||||
- [Jupyter](https://github.com/jupyter-server/jupyter_server)
|
||||
- [Great Expectations](https://github.com/great-expectations/great_expectations)
|
||||
- [Polars](https://github.com/pola-rs/polars)
|
||||
- [Ibis](https://github.com/ibis-project/ibis)
|
||||
- [Synapse (Matrix)](https://github.com/matrix-org/synapse)
|
||||
- [SnowCLI (Snowflake)](https://github.com/Snowflake-Labs/snowcli)
|
||||
- [Saleor](https://github.com/saleor/saleor)
|
||||
- [OpenBB](https://github.com/OpenBB-finance/OpenBBTerminal)
|
||||
- [Home Assistant](https://github.com/home-assistant/core)
|
||||
- [Cryptography (PyCA)](https://github.com/pyca/cryptography)
|
||||
- [cibuildwheel (PyPA)](https://github.com/pypa/cibuildwheel)
|
||||
- [build (PyPA)](https://github.com/pypa/build)
|
||||
- [Babel](https://github.com/python-babel/babel)
|
||||
- [featuretools](https://github.com/alteryx/featuretools)
|
||||
- [meson-python](https://github.com/mesonbuild/meson-python)
|
||||
* [pandas](https://github.com/pandas-dev/pandas)
|
||||
* [FastAPI](https://github.com/tiangolo/fastapi)
|
||||
* [Apache Airflow](https://github.com/apache/airflow)
|
||||
* [SciPy](https://github.com/scipy/scipy)
|
||||
* [Bokeh](https://github.com/bokeh/bokeh)
|
||||
* [Zulip](https://github.com/zulip/zulip)
|
||||
* [Pydantic](https://github.com/pydantic/pydantic)
|
||||
* [Dagster](https://github.com/dagster-io/dagster)
|
||||
* [Dagger](https://github.com/dagger/dagger)
|
||||
* [Sphinx](https://github.com/sphinx-doc/sphinx)
|
||||
* [Hatch](https://github.com/pypa/hatch)
|
||||
* [Jupyter](https://github.com/jupyter-server/jupyter_server)
|
||||
* [Great Expectations](https://github.com/great-expectations/great_expectations)
|
||||
* [Polars](https://github.com/pola-rs/polars)
|
||||
* [Ibis](https://github.com/ibis-project/ibis)
|
||||
* [Synapse (Matrix)](https://github.com/matrix-org/synapse)
|
||||
* [SnowCLI (Snowflake)](https://github.com/Snowflake-Labs/snowcli)
|
||||
* [Saleor](https://github.com/saleor/saleor)
|
||||
* [OpenBB](https://github.com/OpenBB-finance/OpenBBTerminal)
|
||||
* [Home Assistant](https://github.com/home-assistant/core)
|
||||
* [Cryptography (PyCA)](https://github.com/pyca/cryptography)
|
||||
* [cibuildwheel (PyPA)](https://github.com/pypa/cibuildwheel)
|
||||
* [build (PyPA)](https://github.com/pypa/build)
|
||||
* [Babel](https://github.com/python-babel/babel)
|
||||
* [featuretools](https://github.com/alteryx/featuretools)
|
||||
* [meson-python](https://github.com/mesonbuild/meson-python)
|
||||
|
||||
Read the [launch blog post](https://notes.crmarsh.com/python-tooling-could-be-much-much-faster) or
|
||||
the most recent [project update](https://notes.crmarsh.com/ruff-the-first-200-releases).
|
||||
@@ -89,7 +90,7 @@ co-creator of [GraphQL](https://graphql.org/):
|
||||
|
||||
> Why is Ruff a gamechanger? Primarily because it is nearly 1000x faster. Literally. Not a typo. On
|
||||
> our largest module (dagster itself, 250k LOC) pylint takes about 2.5 minutes, parallelized across 4
|
||||
> cores on my M1. Running ruff against our *entire* codebase takes .4 seconds.
|
||||
> cores on my M1. Running ruff against our _entire_ codebase takes .4 seconds.
|
||||
|
||||
[**Bryan Van de Ven**](https://github.com/bokeh/bokeh/pull/12605), co-creator
|
||||
of [Bokeh](https://github.com/bokeh/bokeh/), original author
|
||||
@@ -164,7 +165,6 @@ This README is also available as [documentation](https://beta.ruff.rs/docs/).
|
||||
1. [FAQ](#faq)
|
||||
1. [Contributing](#contributing)
|
||||
1. [Support](#support)
|
||||
1. [Benchmarks](#benchmarks)
|
||||
1. [Reference](#reference)
|
||||
1. [License](#license)
|
||||
|
||||
@@ -230,7 +230,7 @@ Ruff also works with [pre-commit](https://pre-commit.com):
|
||||
```yaml
|
||||
- repo: https://github.com/charliermarsh/ruff-pre-commit
|
||||
# Ruff version.
|
||||
rev: 'v0.0.240'
|
||||
rev: 'v0.0.241'
|
||||
hooks:
|
||||
- id: ruff
|
||||
```
|
||||
@@ -340,13 +340,13 @@ for the pydocstyle plugin.
|
||||
|
||||
If you're wondering how to configure Ruff, here are some **recommended guidelines**:
|
||||
|
||||
- Prefer `select` and `ignore` over `extend-select` and `extend-ignore`, to make your rule set
|
||||
* Prefer `select` and `ignore` over `extend-select` and `extend-ignore`, to make your rule set
|
||||
explicit.
|
||||
- Use `ALL` with discretion. Enabling `ALL` will implicitly enable new rules whenever you upgrade.
|
||||
- Start with a small set of rules (`select = ["E", "F"]`) and add a category at-a-time. For example,
|
||||
* Use `ALL` with discretion. Enabling `ALL` will implicitly enable new rules whenever you upgrade.
|
||||
* Start with a small set of rules (`select = ["E", "F"]`) and add a category at-a-time. For example,
|
||||
you might consider expanding to `select = ["E", "F", "B"]` to enable the popular flake8-bugbear
|
||||
extension.
|
||||
- By default, Ruff's autofix is aggressive. If you find that it's too aggressive for your liking,
|
||||
* By default, Ruff's autofix is aggressive. If you find that it's too aggressive for your liking,
|
||||
consider turning off autofix for specific rules or categories (see: [FAQ](#ruff-tried-to-fix-something-but-it-broke-my-code-what-should-i-do)).
|
||||
|
||||
As an alternative to `pyproject.toml`, Ruff will also respect a `ruff.toml` file, which implements
|
||||
@@ -383,7 +383,8 @@ ruff path/to/code/ --select F401 --select F403 --quiet
|
||||
See `ruff help` for more on Ruff's top-level commands:
|
||||
|
||||
<!-- Begin auto-generated command help. -->
|
||||
```
|
||||
|
||||
```text
|
||||
Ruff: An extremely fast Python linter.
|
||||
|
||||
Usage: ruff [OPTIONS] <COMMAND>
|
||||
@@ -406,12 +407,14 @@ Log levels:
|
||||
|
||||
For help with a specific command, see: `ruff help <command>`.
|
||||
```
|
||||
|
||||
<!-- End auto-generated command help. -->
|
||||
|
||||
Or `ruff help check` for more on the linting command:
|
||||
|
||||
<!-- Begin auto-generated subcommand help. -->
|
||||
```
|
||||
|
||||
```text
|
||||
Run Ruff on the given files or directories (default)
|
||||
|
||||
Usage: ruff check [OPTIONS] [FILES]...
|
||||
@@ -472,14 +475,13 @@ Miscellaneous:
|
||||
The name of the file when passing it through stdin
|
||||
-e, --exit-zero
|
||||
Exit with status code "0", even upon detecting lint violations
|
||||
--update-check
|
||||
Enable or disable automatic update checks
|
||||
|
||||
Log levels:
|
||||
-v, --verbose Enable verbose logging
|
||||
-q, --quiet Print lint violations, but nothing else
|
||||
-s, --silent Disable all logging (but still exit with status code "1" upon detecting lint violations)
|
||||
```
|
||||
|
||||
<!-- End auto-generated subcommand help. -->
|
||||
|
||||
### `pyproject.toml` discovery
|
||||
@@ -639,6 +641,7 @@ The 🛠 emoji indicates that a rule is automatically fixable by the `--fix` com
|
||||
|
||||
<!-- Sections automatically generated by `cargo dev generate-rules-table`. -->
|
||||
<!-- Begin auto-generated sections. -->
|
||||
|
||||
### Pyflakes (F)
|
||||
|
||||
For more, see [Pyflakes](https://pypi.org/project/pyflakes/) on PyPI.
|
||||
@@ -694,6 +697,7 @@ For more, see [Pyflakes](https://pypi.org/project/pyflakes/) on PyPI.
|
||||
For more, see [pycodestyle](https://pypi.org/project/pycodestyle/) on PyPI.
|
||||
|
||||
#### Error (E)
|
||||
|
||||
| Code | Name | Message | Fix |
|
||||
| ---- | ---- | ------- | --- |
|
||||
| E101 | mixed-spaces-and-tabs | Indentation contains mixed spaces and tabs | |
|
||||
@@ -714,6 +718,7 @@ For more, see [pycodestyle](https://pypi.org/project/pycodestyle/) on PyPI.
|
||||
| E999 | syntax-error | SyntaxError: {message} | |
|
||||
|
||||
#### Warning (W)
|
||||
|
||||
| Code | Name | Message | Fix |
|
||||
| ---- | ---- | ------- | --- |
|
||||
| W292 | no-new-line-at-end-of-file | No newline at end of file | 🛠 |
|
||||
@@ -1315,12 +1320,14 @@ For more, see [pygrep-hooks](https://github.com/pre-commit/pygrep-hooks) on GitH
|
||||
For more, see [Pylint](https://pypi.org/project/pylint/) on PyPI.
|
||||
|
||||
#### Convention (PLC)
|
||||
|
||||
| Code | Name | Message | Fix |
|
||||
| ---- | ---- | ------- | --- |
|
||||
| PLC0414 | useless-import-alias | Import alias does not rename original package | 🛠 |
|
||||
| PLC3002 | unnecessary-direct-lambda-call | Lambda expression called directly. Execute the expression inline instead. | |
|
||||
|
||||
#### Error (PLE)
|
||||
|
||||
| Code | Name | Message | Fix |
|
||||
| ---- | ---- | ------- | --- |
|
||||
| PLE0117 | nonlocal-without-binding | Nonlocal name `{name}` found without binding | |
|
||||
@@ -1330,18 +1337,20 @@ For more, see [Pylint](https://pypi.org/project/pylint/) on PyPI.
|
||||
| PLE1142 | await-outside-async | `await` should be used within an async function | |
|
||||
|
||||
#### Refactor (PLR)
|
||||
|
||||
| Code | Name | Message | Fix |
|
||||
| ---- | ---- | ------- | --- |
|
||||
| PLR0133 | constant-comparison | Two constants compared in a comparison, consider replacing `{left_constant} {op} {right_constant}` | |
|
||||
| PLR0133 | comparison-of-constant | Two constants compared in a comparison, consider replacing `{left_constant} {op} {right_constant}` | |
|
||||
| PLR0206 | property-with-parameters | Cannot have defined parameters for properties | |
|
||||
| PLR0402 | consider-using-from-import | Use `from {module} import {name}` in lieu of alias | |
|
||||
| PLR0913 | too-many-args | Too many arguments to function call ({c_args}/{max_args}) | |
|
||||
| PLR0402 | consider-using-from-import | Use `from {module} import {name}` in lieu of alias | 🛠 |
|
||||
| PLR0913 | too-many-arguments | Too many arguments to function call ({c_args}/{max_args}) | |
|
||||
| PLR0915 | too-many-statements | Too many statements ({statements}/{max_statements}) | |
|
||||
| PLR1701 | consider-merging-isinstance | Merge these isinstance calls: `isinstance({obj}, ({types}))` | |
|
||||
| PLR1722 | use-sys-exit | Use `sys.exit()` instead of `{name}` | 🛠 |
|
||||
| PLR1722 | consider-using-sys-exit | Use `sys.exit()` instead of `{name}` | 🛠 |
|
||||
| PLR2004 | magic-value-comparison | Magic value used in comparison, consider replacing {value} with a constant variable | |
|
||||
|
||||
#### Warning (PLW)
|
||||
|
||||
| Code | Name | Message | Fix |
|
||||
| ---- | ---- | ------- | --- |
|
||||
| PLW0120 | useless-else-on-loop | Else clause on loop without a break statement, remove the else and de-indent all the code inside it | |
|
||||
@@ -1402,7 +1411,7 @@ For more, see [flake8-self](https://pypi.org/project/flake8-self/) on PyPI.
|
||||
Download the [Ruff VS Code extension](https://marketplace.visualstudio.com/items?itemName=charliermarsh.ruff),
|
||||
which supports autofix actions, import sorting, and more.
|
||||
|
||||
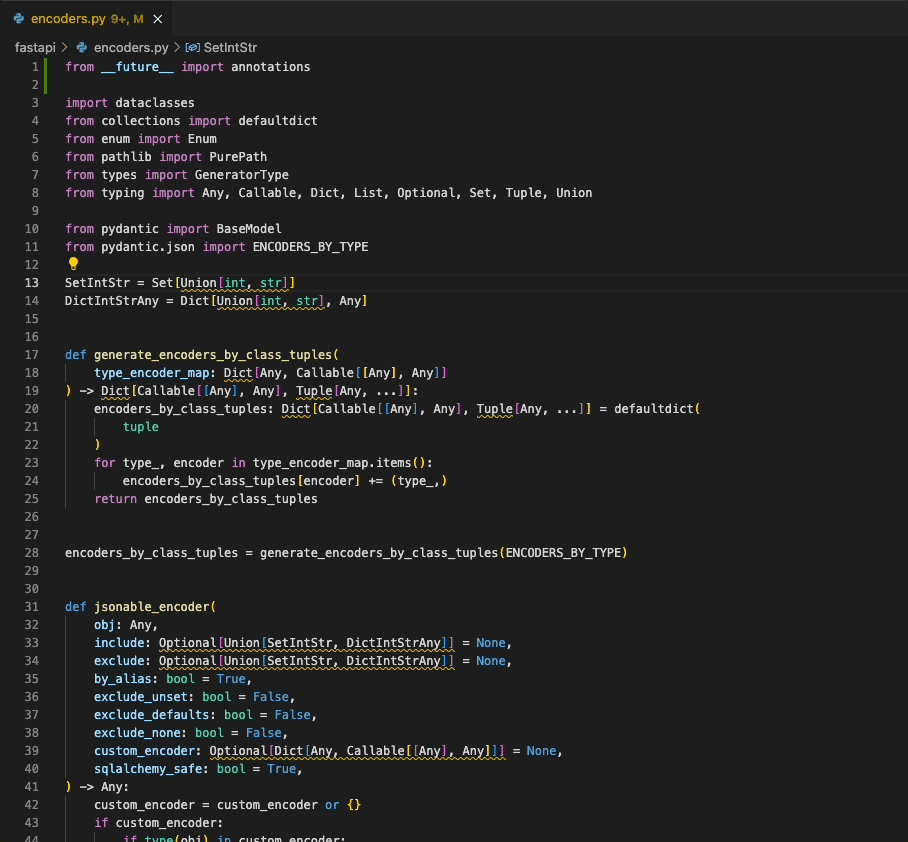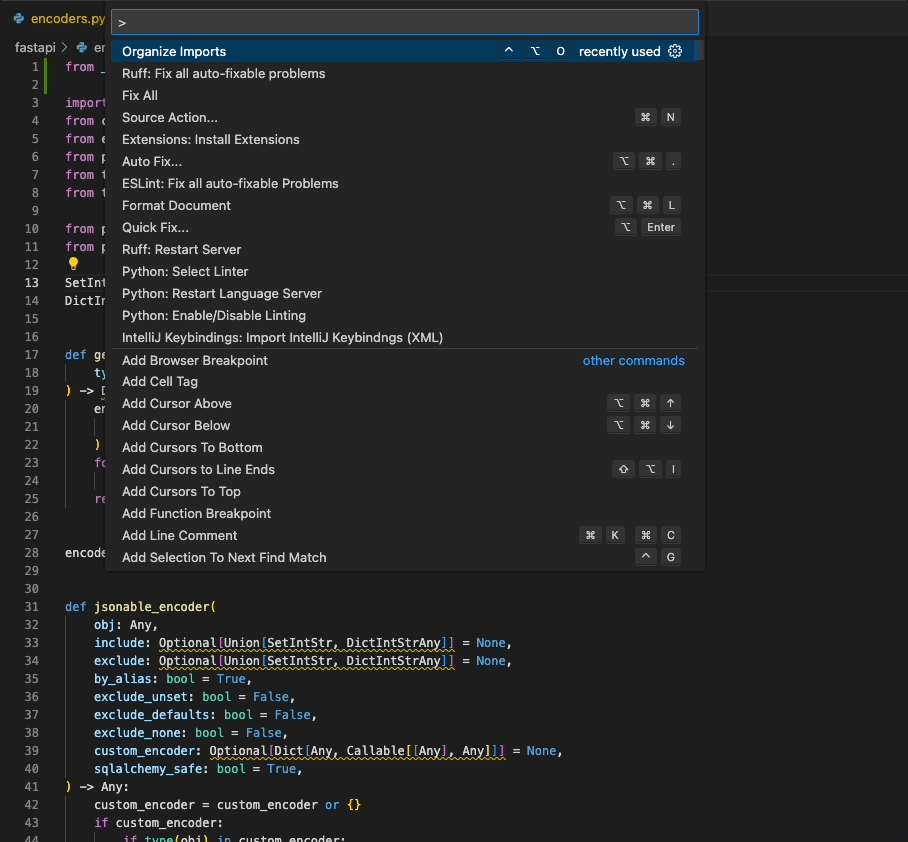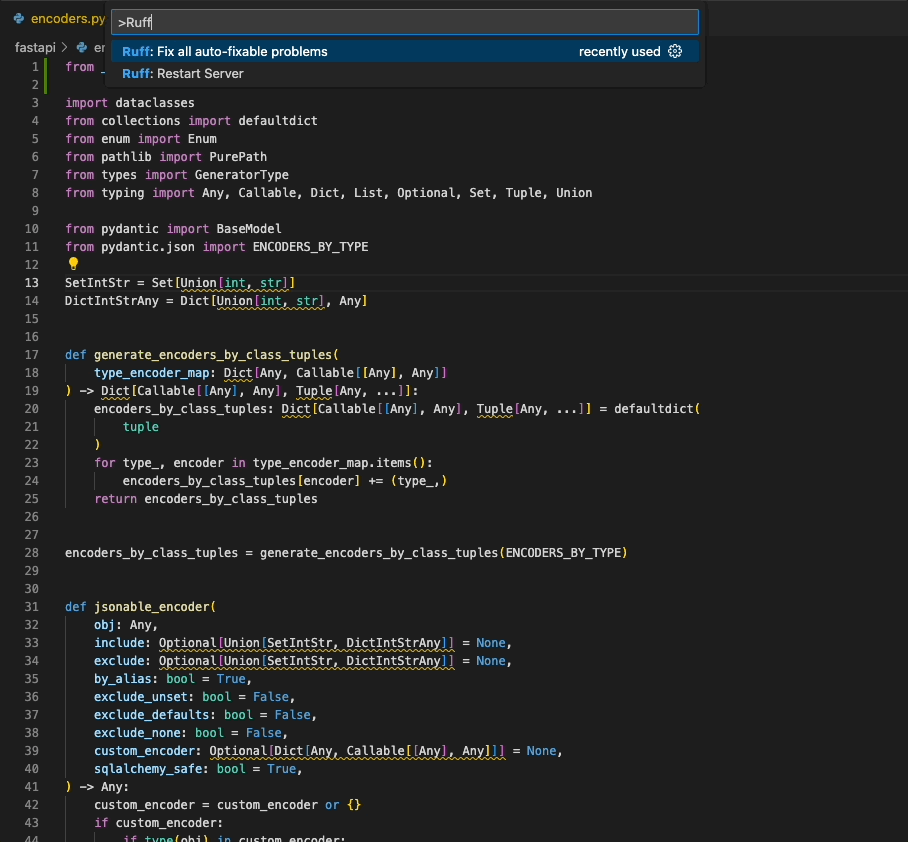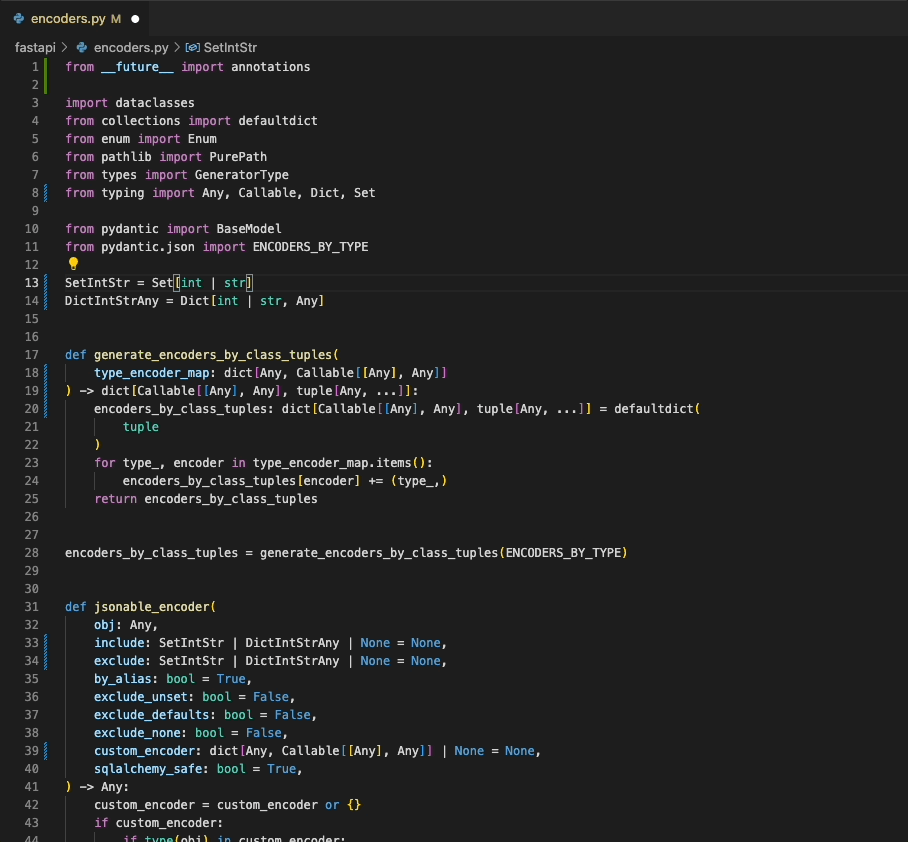
|
||||

|
||||
|
||||
### Language Server Protocol (Official)
|
||||
|
||||
@@ -1547,13 +1556,14 @@ let g:ale_fixers = {
|
||||
```yaml
|
||||
tools:
|
||||
python-ruff: &python-ruff
|
||||
lint-command: 'ruff --config ~/myconfigs/linters/ruff.toml --quiet ${INPUT}'
|
||||
lint-command: "ruff --config ~/myconfigs/linters/ruff.toml --quiet ${INPUT}"
|
||||
lint-stdin: true
|
||||
lint-formats:
|
||||
- '%f:%l:%c: %m'
|
||||
format-command: 'ruff --stdin-filename ${INPUT} --config ~/myconfigs/linters/ruff.toml --fix --exit-zero --quiet -'
|
||||
- "%f:%l:%c: %m"
|
||||
format-command: "ruff --stdin-filename ${INPUT} --config ~/myconfigs/linters/ruff.toml --fix --exit-zero --quiet -"
|
||||
format-stdin: true
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
@@ -1570,8 +1580,8 @@ null_ls.setup({
|
||||
}
|
||||
})
|
||||
```
|
||||
</details>
|
||||
|
||||
</details>
|
||||
|
||||
### PyCharm (External Tool)
|
||||
|
||||
@@ -1644,47 +1654,47 @@ implements all of the `F` rules (which originate from Pyflakes), along with a su
|
||||
Ruff also re-implements some of the most popular Flake8 plugins and related code quality tools
|
||||
natively, including:
|
||||
|
||||
- [autoflake](https://pypi.org/project/autoflake/) ([#1647](https://github.com/charliermarsh/ruff/issues/1647))
|
||||
- [eradicate](https://pypi.org/project/eradicate/)
|
||||
- [flake8-2020](https://pypi.org/project/flake8-2020/)
|
||||
- [flake8-annotations](https://pypi.org/project/flake8-annotations/)
|
||||
- [flake8-bandit](https://pypi.org/project/flake8-bandit/) ([#1646](https://github.com/charliermarsh/ruff/issues/1646))
|
||||
- [flake8-blind-except](https://pypi.org/project/flake8-blind-except/)
|
||||
- [flake8-boolean-trap](https://pypi.org/project/flake8-boolean-trap/)
|
||||
- [flake8-bugbear](https://pypi.org/project/flake8-bugbear/)
|
||||
- [flake8-builtins](https://pypi.org/project/flake8-builtins/)
|
||||
- [flake8-commas](https://pypi.org/project/flake8-commas/)
|
||||
- [flake8-comprehensions](https://pypi.org/project/flake8-comprehensions/)
|
||||
- [flake8-datetimez](https://pypi.org/project/flake8-datetimez/)
|
||||
- [flake8-debugger](https://pypi.org/project/flake8-debugger/)
|
||||
- [flake8-docstrings](https://pypi.org/project/flake8-docstrings/)
|
||||
- [flake8-eradicate](https://pypi.org/project/flake8-eradicate/)
|
||||
- [flake8-errmsg](https://pypi.org/project/flake8-errmsg/)
|
||||
- [flake8-executable](https://pypi.org/project/flake8-executable/)
|
||||
- [flake8-implicit-str-concat](https://pypi.org/project/flake8-implicit-str-concat/)
|
||||
- [flake8-import-conventions](https://github.com/joaopalmeiro/flake8-import-conventions)
|
||||
- [flake8-logging-format](https://pypi.org/project/flake8-logging-format/)
|
||||
- [flake8-no-pep420](https://pypi.org/project/flake8-no-pep420)
|
||||
- [flake8-pie](https://pypi.org/project/flake8-pie/)
|
||||
- [flake8-print](https://pypi.org/project/flake8-print/)
|
||||
- [flake8-pytest-style](https://pypi.org/project/flake8-pytest-style/)
|
||||
- [flake8-quotes](https://pypi.org/project/flake8-quotes/)
|
||||
- [flake8-raise](https://pypi.org/project/flake8-raise/)
|
||||
- [flake8-return](https://pypi.org/project/flake8-return/)
|
||||
- [flake8-self](https://pypi.org/project/flake8-self/)
|
||||
- [flake8-simplify](https://pypi.org/project/flake8-simplify/) ([#998](https://github.com/charliermarsh/ruff/issues/998))
|
||||
- [flake8-super](https://pypi.org/project/flake8-super/)
|
||||
- [flake8-tidy-imports](https://pypi.org/project/flake8-tidy-imports/)
|
||||
- [flake8-type-checking](https://pypi.org/project/flake8-type-checking/)
|
||||
- [flake8-use-pathlib](https://pypi.org/project/flake8-use-pathlib/)
|
||||
- [isort](https://pypi.org/project/isort/)
|
||||
- [mccabe](https://pypi.org/project/mccabe/)
|
||||
- [pandas-vet](https://pypi.org/project/pandas-vet/)
|
||||
- [pep8-naming](https://pypi.org/project/pep8-naming/)
|
||||
- [pydocstyle](https://pypi.org/project/pydocstyle/)
|
||||
- [pygrep-hooks](https://github.com/pre-commit/pygrep-hooks) ([#980](https://github.com/charliermarsh/ruff/issues/980))
|
||||
- [pyupgrade](https://pypi.org/project/pyupgrade/) ([#827](https://github.com/charliermarsh/ruff/issues/827))
|
||||
- [yesqa](https://github.com/asottile/yesqa)
|
||||
* [autoflake](https://pypi.org/project/autoflake/) ([#1647](https://github.com/charliermarsh/ruff/issues/1647))
|
||||
* [eradicate](https://pypi.org/project/eradicate/)
|
||||
* [flake8-2020](https://pypi.org/project/flake8-2020/)
|
||||
* [flake8-annotations](https://pypi.org/project/flake8-annotations/)
|
||||
* [flake8-bandit](https://pypi.org/project/flake8-bandit/) ([#1646](https://github.com/charliermarsh/ruff/issues/1646))
|
||||
* [flake8-blind-except](https://pypi.org/project/flake8-blind-except/)
|
||||
* [flake8-boolean-trap](https://pypi.org/project/flake8-boolean-trap/)
|
||||
* [flake8-bugbear](https://pypi.org/project/flake8-bugbear/)
|
||||
* [flake8-builtins](https://pypi.org/project/flake8-builtins/)
|
||||
* [flake8-commas](https://pypi.org/project/flake8-commas/)
|
||||
* [flake8-comprehensions](https://pypi.org/project/flake8-comprehensions/)
|
||||
* [flake8-datetimez](https://pypi.org/project/flake8-datetimez/)
|
||||
* [flake8-debugger](https://pypi.org/project/flake8-debugger/)
|
||||
* [flake8-docstrings](https://pypi.org/project/flake8-docstrings/)
|
||||
* [flake8-eradicate](https://pypi.org/project/flake8-eradicate/)
|
||||
* [flake8-errmsg](https://pypi.org/project/flake8-errmsg/)
|
||||
* [flake8-executable](https://pypi.org/project/flake8-executable/)
|
||||
* [flake8-implicit-str-concat](https://pypi.org/project/flake8-implicit-str-concat/)
|
||||
* [flake8-import-conventions](https://github.com/joaopalmeiro/flake8-import-conventions)
|
||||
* [flake8-logging-format](https://pypi.org/project/flake8-logging-format/)
|
||||
* [flake8-no-pep420](https://pypi.org/project/flake8-no-pep420)
|
||||
* [flake8-pie](https://pypi.org/project/flake8-pie/)
|
||||
* [flake8-print](https://pypi.org/project/flake8-print/)
|
||||
* [flake8-pytest-style](https://pypi.org/project/flake8-pytest-style/)
|
||||
* [flake8-quotes](https://pypi.org/project/flake8-quotes/)
|
||||
* [flake8-raise](https://pypi.org/project/flake8-raise/)
|
||||
* [flake8-return](https://pypi.org/project/flake8-return/)
|
||||
* [flake8-self](https://pypi.org/project/flake8-self/)
|
||||
* [flake8-simplify](https://pypi.org/project/flake8-simplify/) ([#998](https://github.com/charliermarsh/ruff/issues/998))
|
||||
* [flake8-super](https://pypi.org/project/flake8-super/)
|
||||
* [flake8-tidy-imports](https://pypi.org/project/flake8-tidy-imports/)
|
||||
* [flake8-type-checking](https://pypi.org/project/flake8-type-checking/)
|
||||
* [flake8-use-pathlib](https://pypi.org/project/flake8-use-pathlib/)
|
||||
* [isort](https://pypi.org/project/isort/)
|
||||
* [mccabe](https://pypi.org/project/mccabe/)
|
||||
* [pandas-vet](https://pypi.org/project/pandas-vet/)
|
||||
* [pep8-naming](https://pypi.org/project/pep8-naming/)
|
||||
* [pydocstyle](https://pypi.org/project/pydocstyle/)
|
||||
* [pygrep-hooks](https://github.com/pre-commit/pygrep-hooks) ([#980](https://github.com/charliermarsh/ruff/issues/980))
|
||||
* [pyupgrade](https://pypi.org/project/pyupgrade/) ([#827](https://github.com/charliermarsh/ruff/issues/827))
|
||||
* [yesqa](https://github.com/asottile/yesqa)
|
||||
|
||||
Note that, in some cases, Ruff uses different rule codes and prefixes than would be found in the
|
||||
originating Flake8 plugins. For example, Ruff uses `TID252` to represent the `I252` rule from
|
||||
@@ -1700,8 +1710,8 @@ Beyond the rule set, Ruff suffers from the following limitations vis-à-vis Flak
|
||||
|
||||
There are a few other minor incompatibilities between Ruff and the originating Flake8 plugins:
|
||||
|
||||
- Ruff doesn't implement all the "opinionated" lint rules from flake8-bugbear.
|
||||
- Depending on your project structure, Ruff and isort can differ in their detection of first-party
|
||||
* Ruff doesn't implement all the "opinionated" lint rules from flake8-bugbear.
|
||||
* Depending on your project structure, Ruff and isort can differ in their detection of first-party
|
||||
code. (This is often solved by modifying the `src` property, e.g., to `src = ["src"]`, if your
|
||||
code is nested in a `src` directory.)
|
||||
|
||||
@@ -1743,41 +1753,41 @@ feedback on type errors.
|
||||
|
||||
Today, Ruff can be used to replace Flake8 when used with any of the following plugins:
|
||||
|
||||
- [flake8-2020](https://pypi.org/project/flake8-2020/)
|
||||
- [flake8-annotations](https://pypi.org/project/flake8-annotations/)
|
||||
- [flake8-bandit](https://pypi.org/project/flake8-bandit/) ([#1646](https://github.com/charliermarsh/ruff/issues/1646))
|
||||
- [flake8-blind-except](https://pypi.org/project/flake8-blind-except/)
|
||||
- [flake8-boolean-trap](https://pypi.org/project/flake8-boolean-trap/)
|
||||
- [flake8-bugbear](https://pypi.org/project/flake8-bugbear/)
|
||||
- [flake8-builtins](https://pypi.org/project/flake8-builtins/)
|
||||
- [flake8-commas](https://pypi.org/project/flake8-commas/)
|
||||
- [flake8-comprehensions](https://pypi.org/project/flake8-comprehensions/)
|
||||
- [flake8-datetimez](https://pypi.org/project/flake8-datetimez/)
|
||||
- [flake8-debugger](https://pypi.org/project/flake8-debugger/)
|
||||
- [flake8-docstrings](https://pypi.org/project/flake8-docstrings/)
|
||||
- [flake8-eradicate](https://pypi.org/project/flake8-eradicate/)
|
||||
- [flake8-errmsg](https://pypi.org/project/flake8-errmsg/)
|
||||
- [flake8-executable](https://pypi.org/project/flake8-executable/)
|
||||
- [flake8-implicit-str-concat](https://pypi.org/project/flake8-implicit-str-concat/)
|
||||
- [flake8-import-conventions](https://github.com/joaopalmeiro/flake8-import-conventions)
|
||||
- [flake8-logging-format](https://pypi.org/project/flake8-logging-format/)
|
||||
- [flake8-no-pep420](https://pypi.org/project/flake8-no-pep420)
|
||||
- [flake8-pie](https://pypi.org/project/flake8-pie/)
|
||||
- [flake8-print](https://pypi.org/project/flake8-print/)
|
||||
- [flake8-pytest-style](https://pypi.org/project/flake8-pytest-style/)
|
||||
- [flake8-quotes](https://pypi.org/project/flake8-quotes/)
|
||||
- [flake8-raise](https://pypi.org/project/flake8-raise/)
|
||||
- [flake8-return](https://pypi.org/project/flake8-return/)
|
||||
- [flake8-self](https://pypi.org/project/flake8-self/)
|
||||
- [flake8-simplify](https://pypi.org/project/flake8-simplify/) ([#998](https://github.com/charliermarsh/ruff/issues/998))
|
||||
- [flake8-super](https://pypi.org/project/flake8-super/)
|
||||
- [flake8-tidy-imports](https://pypi.org/project/flake8-tidy-imports/)
|
||||
- [flake8-type-checking](https://pypi.org/project/flake8-type-checking/)
|
||||
- [flake8-use-pathlib](https://pypi.org/project/flake8-use-pathlib/)
|
||||
- [mccabe](https://pypi.org/project/mccabe/)
|
||||
- [pandas-vet](https://pypi.org/project/pandas-vet/)
|
||||
- [pep8-naming](https://pypi.org/project/pep8-naming/)
|
||||
- [pydocstyle](https://pypi.org/project/pydocstyle/)
|
||||
* [flake8-2020](https://pypi.org/project/flake8-2020/)
|
||||
* [flake8-annotations](https://pypi.org/project/flake8-annotations/)
|
||||
* [flake8-bandit](https://pypi.org/project/flake8-bandit/) ([#1646](https://github.com/charliermarsh/ruff/issues/1646))
|
||||
* [flake8-blind-except](https://pypi.org/project/flake8-blind-except/)
|
||||
* [flake8-boolean-trap](https://pypi.org/project/flake8-boolean-trap/)
|
||||
* [flake8-bugbear](https://pypi.org/project/flake8-bugbear/)
|
||||
* [flake8-builtins](https://pypi.org/project/flake8-builtins/)
|
||||
* [flake8-commas](https://pypi.org/project/flake8-commas/)
|
||||
* [flake8-comprehensions](https://pypi.org/project/flake8-comprehensions/)
|
||||
* [flake8-datetimez](https://pypi.org/project/flake8-datetimez/)
|
||||
* [flake8-debugger](https://pypi.org/project/flake8-debugger/)
|
||||
* [flake8-docstrings](https://pypi.org/project/flake8-docstrings/)
|
||||
* [flake8-eradicate](https://pypi.org/project/flake8-eradicate/)
|
||||
* [flake8-errmsg](https://pypi.org/project/flake8-errmsg/)
|
||||
* [flake8-executable](https://pypi.org/project/flake8-executable/)
|
||||
* [flake8-implicit-str-concat](https://pypi.org/project/flake8-implicit-str-concat/)
|
||||
* [flake8-import-conventions](https://github.com/joaopalmeiro/flake8-import-conventions)
|
||||
* [flake8-logging-format](https://pypi.org/project/flake8-logging-format/)
|
||||
* [flake8-no-pep420](https://pypi.org/project/flake8-no-pep420)
|
||||
* [flake8-pie](https://pypi.org/project/flake8-pie/)
|
||||
* [flake8-print](https://pypi.org/project/flake8-print/)
|
||||
* [flake8-pytest-style](https://pypi.org/project/flake8-pytest-style/)
|
||||
* [flake8-quotes](https://pypi.org/project/flake8-quotes/)
|
||||
* [flake8-raise](https://pypi.org/project/flake8-raise/)
|
||||
* [flake8-return](https://pypi.org/project/flake8-return/)
|
||||
* [flake8-self](https://pypi.org/project/flake8-self/)
|
||||
* [flake8-simplify](https://pypi.org/project/flake8-simplify/) ([#998](https://github.com/charliermarsh/ruff/issues/998))
|
||||
* [flake8-super](https://pypi.org/project/flake8-super/)
|
||||
* [flake8-tidy-imports](https://pypi.org/project/flake8-tidy-imports/)
|
||||
* [flake8-type-checking](https://pypi.org/project/flake8-type-checking/)
|
||||
* [flake8-use-pathlib](https://pypi.org/project/flake8-use-pathlib/)
|
||||
* [mccabe](https://pypi.org/project/mccabe/)
|
||||
* [pandas-vet](https://pypi.org/project/pandas-vet/)
|
||||
* [pep8-naming](https://pypi.org/project/pep8-naming/)
|
||||
* [pydocstyle](https://pypi.org/project/pydocstyle/)
|
||||
|
||||
Ruff can also replace [isort](https://pypi.org/project/isort/),
|
||||
[yesqa](https://github.com/asottile/yesqa), [eradicate](https://pypi.org/project/eradicate/),
|
||||
@@ -1953,129 +1963,6 @@ or feel free to [**open a new one**](https://github.com/charliermarsh/ruff/issue
|
||||
|
||||
You can also ask for help on [**Discord**](https://discord.gg/Z8KbeK24).
|
||||
|
||||
## Benchmarks
|
||||
|
||||
First, clone [CPython](https://github.com/python/cpython). It's a large and diverse Python codebase,
|
||||
which makes it a good target for benchmarking.
|
||||
|
||||
```shell
|
||||
git clone --branch 3.10 https://github.com/python/cpython.git resources/test/cpython
|
||||
```
|
||||
|
||||
To benchmark the release build:
|
||||
|
||||
```shell
|
||||
cargo build --release && hyperfine --ignore-failure --warmup 10 \
|
||||
"./target/release/ruff ./resources/test/cpython/ --no-cache" \
|
||||
"./target/release/ruff ./resources/test/cpython/"
|
||||
|
||||
Benchmark 1: ./target/release/ruff ./resources/test/cpython/ --no-cache
|
||||
Time (mean ± σ): 293.8 ms ± 3.2 ms [User: 2384.6 ms, System: 90.3 ms]
|
||||
Range (min … max): 289.9 ms … 301.6 ms 10 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Benchmark 2: ./target/release/ruff ./resources/test/cpython/
|
||||
Time (mean ± σ): 48.0 ms ± 3.1 ms [User: 65.2 ms, System: 124.7 ms]
|
||||
Range (min … max): 45.0 ms … 66.7 ms 62 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Summary
|
||||
'./target/release/ruff ./resources/test/cpython/' ran
|
||||
6.12 ± 0.41 times faster than './target/release/ruff ./resources/test/cpython/ --no-cache'
|
||||
```
|
||||
|
||||
To benchmark against the ecosystem's existing tools:
|
||||
|
||||
```shell
|
||||
hyperfine --ignore-failure --warmup 5 \
|
||||
"./target/release/ruff ./resources/test/cpython/ --no-cache" \
|
||||
"pyflakes resources/test/cpython" \
|
||||
"autoflake --recursive --expand-star-imports --remove-all-unused-imports --remove-unused-variables --remove-duplicate-keys resources/test/cpython" \
|
||||
"pycodestyle resources/test/cpython" \
|
||||
"flake8 resources/test/cpython"
|
||||
|
||||
Benchmark 1: ./target/release/ruff ./resources/test/cpython/ --no-cache
|
||||
Time (mean ± σ): 294.3 ms ± 3.3 ms [User: 2467.5 ms, System: 89.6 ms]
|
||||
Range (min … max): 291.1 ms … 302.8 ms 10 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Benchmark 2: pyflakes resources/test/cpython
|
||||
Time (mean ± σ): 15.786 s ± 0.143 s [User: 15.560 s, System: 0.214 s]
|
||||
Range (min … max): 15.640 s … 16.157 s 10 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Benchmark 3: autoflake --recursive --expand-star-imports --remove-all-unused-imports --remove-unused-variables --remove-duplicate-keys resources/test/cpython
|
||||
Time (mean ± σ): 6.175 s ± 0.169 s [User: 54.102 s, System: 1.057 s]
|
||||
Range (min … max): 5.950 s … 6.391 s 10 runs
|
||||
|
||||
Benchmark 4: pycodestyle resources/test/cpython
|
||||
Time (mean ± σ): 46.921 s ± 0.508 s [User: 46.699 s, System: 0.202 s]
|
||||
Range (min … max): 46.171 s … 47.863 s 10 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Benchmark 5: flake8 resources/test/cpython
|
||||
Time (mean ± σ): 12.260 s ± 0.321 s [User: 102.934 s, System: 1.230 s]
|
||||
Range (min … max): 11.848 s … 12.933 s 10 runs
|
||||
|
||||
Warning: Ignoring non-zero exit code.
|
||||
|
||||
Summary
|
||||
'./target/release/ruff ./resources/test/cpython/ --no-cache' ran
|
||||
20.98 ± 0.62 times faster than 'autoflake --recursive --expand-star-imports --remove-all-unused-imports --remove-unused-variables --remove-duplicate-keys resources/test/cpython'
|
||||
41.66 ± 1.18 times faster than 'flake8 resources/test/cpython'
|
||||
53.64 ± 0.77 times faster than 'pyflakes resources/test/cpython'
|
||||
159.43 ± 2.48 times faster than 'pycodestyle resources/test/cpython'
|
||||
```
|
||||
|
||||
You can run `poetry install` from `./scripts` to create a working environment for the above. All
|
||||
reported benchmarks were computed using the versions specified by `./scripts/pyproject.toml`
|
||||
on Python 3.11.
|
||||
|
||||
To benchmark Pylint, remove the following files from the CPython repository:
|
||||
|
||||
```shell
|
||||
rm Lib/test/bad_coding.py \
|
||||
Lib/test/bad_coding2.py \
|
||||
Lib/test/bad_getattr.py \
|
||||
Lib/test/bad_getattr2.py \
|
||||
Lib/test/bad_getattr3.py \
|
||||
Lib/test/badcert.pem \
|
||||
Lib/test/badkey.pem \
|
||||
Lib/test/badsyntax_3131.py \
|
||||
Lib/test/badsyntax_future10.py \
|
||||
Lib/test/badsyntax_future3.py \
|
||||
Lib/test/badsyntax_future4.py \
|
||||
Lib/test/badsyntax_future5.py \
|
||||
Lib/test/badsyntax_future6.py \
|
||||
Lib/test/badsyntax_future7.py \
|
||||
Lib/test/badsyntax_future8.py \
|
||||
Lib/test/badsyntax_future9.py \
|
||||
Lib/test/badsyntax_pep3120.py \
|
||||
Lib/test/test_asyncio/test_runners.py \
|
||||
Lib/test/test_copy.py \
|
||||
Lib/test/test_inspect.py \
|
||||
Lib/test/test_typing.py
|
||||
```
|
||||
|
||||
Then, from `resources/test/cpython`, run: `time pylint -j 0 -E $(git ls-files '*.py')`. This
|
||||
will execute Pylint with maximum parallelism and only report errors.
|
||||
|
||||
To benchmark Pyupgrade, run the following from `resources/test/cpython`:
|
||||
|
||||
```shell
|
||||
hyperfine --ignore-failure --warmup 5 --prepare "git reset --hard HEAD" \
|
||||
"find . -type f -name \"*.py\" | xargs -P 0 pyupgrade --py311-plus"
|
||||
|
||||
Benchmark 1: find . -type f -name "*.py" | xargs -P 0 pyupgrade --py311-plus
|
||||
Time (mean ± σ): 30.119 s ± 0.195 s [User: 28.638 s, System: 0.390 s]
|
||||
Range (min … max): 29.813 s … 30.356 s 10 runs
|
||||
```
|
||||
|
||||
## Reference
|
||||
|
||||
<!-- Begin section: Settings -->
|
||||
@@ -2084,6 +1971,7 @@ Benchmark 1: find . -type f -name "*.py" | xargs -P 0 pyupgrade --py311-plus
|
||||
|
||||
<!-- Sections automatically generated by `cargo dev generate-options`. -->
|
||||
<!-- Begin auto-generated options sections. -->
|
||||
|
||||
#### [`allowed-confusables`](#allowed-confusables)
|
||||
|
||||
A list of allowed "confusable" Unicode characters to ignore when
|
||||
@@ -2174,10 +2062,10 @@ A list of file patterns to exclude from linting.
|
||||
|
||||
Exclusions are based on globs, and can be either:
|
||||
|
||||
- Single-path patterns, like `.mypy_cache` (to exclude any directory
|
||||
* Single-path patterns, like `.mypy_cache` (to exclude any directory
|
||||
named `.mypy_cache` in the tree), `foo.py` (to exclude any file named
|
||||
`foo.py`), or `foo_*.py` (to exclude any file matching `foo_*.py` ).
|
||||
- Relative patterns, like `directory/foo.py` (to exclude that specific
|
||||
* Relative patterns, like `directory/foo.py` (to exclude that specific
|
||||
file) or `directory/*.py` (to exclude any Python files in
|
||||
`directory`). Note that these paths are relative to the project root
|
||||
(e.g., the directory containing your `pyproject.toml`).
|
||||
@@ -2233,10 +2121,10 @@ specified by `exclude`.
|
||||
|
||||
Exclusions are based on globs, and can be either:
|
||||
|
||||
- Single-path patterns, like `.mypy_cache` (to exclude any directory
|
||||
* Single-path patterns, like `.mypy_cache` (to exclude any directory
|
||||
named `.mypy_cache` in the tree), `foo.py` (to exclude any file named
|
||||
`foo.py`), or `foo_*.py` (to exclude any file matching `foo_*.py` ).
|
||||
- Relative patterns, like `directory/foo.py` (to exclude that specific
|
||||
* Relative patterns, like `directory/foo.py` (to exclude that specific
|
||||
file) or `directory/*.py` (to exclude any Python files in
|
||||
`directory`). Note that these paths are relative to the project root
|
||||
(e.g., the directory containing your `pyproject.toml`).
|
||||
@@ -2810,8 +2698,8 @@ suppress-dummy-args = true
|
||||
Whether to suppress `ANN200`-level violations for functions that meet
|
||||
either of the following criteria:
|
||||
|
||||
- Contain no `return` statement.
|
||||
- Explicit `return` statement(s) all return `None` (explicitly or
|
||||
* Contain no `return` statement.
|
||||
* Explicit `return` statement(s) all return `None` (explicitly or
|
||||
implicitly).
|
||||
|
||||
**Default value**: `false`
|
||||
@@ -3063,10 +2951,11 @@ mark-parentheses = true
|
||||
|
||||
Expected type for multiple argument names in `@pytest.mark.parametrize`.
|
||||
The following values are supported:
|
||||
|
||||
* `csv` — a comma-separated list, e.g.
|
||||
`@pytest.mark.parametrize('name1,name2', ...)`
|
||||
* `tuple` (default) — e.g. `@pytest.mark.parametrize(('name1', 'name2'),
|
||||
...)`
|
||||
* `tuple` (default) — e.g.
|
||||
`@pytest.mark.parametrize(('name1', 'name2'), ...)`
|
||||
* `list` — e.g. `@pytest.mark.parametrize(['name1', 'name2'], ...)`
|
||||
|
||||
**Default value**: `tuple`
|
||||
@@ -3086,10 +2975,11 @@ parametrize-names-type = "list"
|
||||
|
||||
Expected type for each row of values in `@pytest.mark.parametrize` in
|
||||
case of multiple parameters. The following values are supported:
|
||||
* `tuple` (default) — e.g. `@pytest.mark.parametrize(('name1', 'name2'),
|
||||
[(1, 2), (3, 4)])`
|
||||
* `list` — e.g. `@pytest.mark.parametrize(('name1', 'name2'), [[1, 2],
|
||||
[3, 4]])`
|
||||
|
||||
* `tuple` (default) — e.g.
|
||||
`@pytest.mark.parametrize(('name1', 'name2'), [(1, 2), (3, 4)])`
|
||||
* `list` — e.g.
|
||||
`@pytest.mark.parametrize(('name1', 'name2'), [[1, 2], [3, 4]])`
|
||||
|
||||
**Default value**: `tuple`
|
||||
|
||||
@@ -3108,6 +2998,7 @@ parametrize-values-row-type = "list"
|
||||
|
||||
Expected type for the list of values rows in `@pytest.mark.parametrize`.
|
||||
The following values are supported:
|
||||
|
||||
* `tuple` — e.g. `@pytest.mark.parametrize('name', (1, 2, 3))`
|
||||
* `list` (default) — e.g. `@pytest.mark.parametrize('name', [1, 2, 3])`
|
||||
|
||||
@@ -3307,7 +3198,7 @@ exempt-modules = ["typing", "typing_extensions"]
|
||||
|
||||
Enforce TC001, TC002, and TC003 rules even when valid runtime imports
|
||||
are present for the same module.
|
||||
See: https://github.com/snok/flake8-type-checking#strict.
|
||||
See flake8-type-checking's [strict](https://github.com/snok/flake8-type-checking#strict) option.
|
||||
|
||||
**Default value**: `false`
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[package]
|
||||
name = "flake8-to-ruff"
|
||||
version = "0.0.240"
|
||||
version = "0.0.241"
|
||||
edition = "2021"
|
||||
|
||||
[dependencies]
|
||||
|
||||
@@ -1,18 +1,4 @@
|
||||
//! Utility to generate Ruff's `pyproject.toml` section from a Flake8 INI file.
|
||||
#![forbid(unsafe_code)]
|
||||
#![warn(clippy::pedantic)]
|
||||
#![allow(
|
||||
clippy::collapsible_else_if,
|
||||
clippy::collapsible_if,
|
||||
clippy::implicit_hasher,
|
||||
clippy::match_same_arms,
|
||||
clippy::missing_errors_doc,
|
||||
clippy::missing_panics_doc,
|
||||
clippy::module_name_repetitions,
|
||||
clippy::must_use_candidate,
|
||||
clippy::similar_names,
|
||||
clippy::too_many_lines
|
||||
)]
|
||||
|
||||
use std::path::PathBuf;
|
||||
|
||||
@@ -61,7 +47,11 @@ fn main() -> Result<()> {
|
||||
|
||||
// Create Ruff's pyproject.toml section.
|
||||
let pyproject = flake8_to_ruff::convert(&config, &external_config, args.plugin)?;
|
||||
println!("{}", toml::to_string_pretty(&pyproject)?);
|
||||
|
||||
#[allow(clippy::print_stdout)]
|
||||
{
|
||||
println!("{}", toml::to_string_pretty(&pyproject)?);
|
||||
}
|
||||
|
||||
Ok(())
|
||||
}
|
||||
|
||||
@@ -4,10 +4,10 @@ In-browser playground for Ruff. Available [https://ruff.pages.dev/](https://ruff
|
||||
|
||||
## Getting started
|
||||
|
||||
- To build the WASM module, run `wasm-pack build --target web --out-dir playground/src/pkg` from the
|
||||
* To build the WASM module, run `wasm-pack build --target web --out-dir playground/src/pkg` from the
|
||||
root directory.
|
||||
- Install TypeScript dependencies with: `npm install`.
|
||||
- Start the development server with: `npm run dev`.
|
||||
* Install TypeScript dependencies with: `npm install`.
|
||||
* Start the development server with: `npm run dev`.
|
||||
|
||||
## Implementation
|
||||
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
<!DOCTYPE html>
|
||||
<!doctype html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="UTF-8" />
|
||||
|
||||
@@ -7,33 +7,36 @@ build-backend = "maturin"
|
||||
|
||||
[project]
|
||||
name = "ruff"
|
||||
version = "0.0.240"
|
||||
version = "0.0.241"
|
||||
description = "An extremely fast Python linter, written in Rust."
|
||||
authors = [
|
||||
{ name = "Charlie Marsh", email = "charlie.r.marsh@gmail.com" },
|
||||
]
|
||||
maintainers = [
|
||||
{ name = "Charlie Marsh", email = "charlie.r.marsh@gmail.com" },
|
||||
]
|
||||
authors = [{ name = "Charlie Marsh", email = "charlie.r.marsh@gmail.com" }]
|
||||
maintainers = [{ name = "Charlie Marsh", email = "charlie.r.marsh@gmail.com" }]
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.7"
|
||||
license = { file = "LICENSE" }
|
||||
keywords = ["automation", "flake8", "pycodestyle", "pyflakes", "pylint", "clippy"]
|
||||
keywords = [
|
||||
"automation",
|
||||
"flake8",
|
||||
"pycodestyle",
|
||||
"pyflakes",
|
||||
"pylint",
|
||||
"clippy",
|
||||
]
|
||||
classifiers = [
|
||||
"Development Status :: 3 - Alpha",
|
||||
"Environment :: Console",
|
||||
"Intended Audience :: Developers",
|
||||
"License :: OSI Approved :: MIT License",
|
||||
"Operating System :: OS Independent",
|
||||
"Programming Language :: Python",
|
||||
"Programming Language :: Python :: 3.7",
|
||||
"Programming Language :: Python :: 3.8",
|
||||
"Programming Language :: Python :: 3.9",
|
||||
"Programming Language :: Python :: 3.10",
|
||||
"Programming Language :: Python :: 3.11",
|
||||
"Programming Language :: Python :: 3 :: Only",
|
||||
"Topic :: Software Development :: Libraries :: Python Modules",
|
||||
"Topic :: Software Development :: Quality Assurance",
|
||||
"Development Status :: 3 - Alpha",
|
||||
"Environment :: Console",
|
||||
"Intended Audience :: Developers",
|
||||
"License :: OSI Approved :: MIT License",
|
||||
"Operating System :: OS Independent",
|
||||
"Programming Language :: Python",
|
||||
"Programming Language :: Python :: 3.7",
|
||||
"Programming Language :: Python :: 3.8",
|
||||
"Programming Language :: Python :: 3.9",
|
||||
"Programming Language :: Python :: 3.10",
|
||||
"Programming Language :: Python :: 3.11",
|
||||
"Programming Language :: Python :: 3 :: Only",
|
||||
"Topic :: Software Development :: Libraries :: Python Modules",
|
||||
"Topic :: Software Development :: Quality Assurance",
|
||||
]
|
||||
urls = { repository = "https://github.com/charliermarsh/ruff" }
|
||||
|
||||
@@ -42,3 +45,6 @@ bindings = "bin"
|
||||
manifest-path = "ruff_cli/Cargo.toml"
|
||||
python-source = "python"
|
||||
strip = true
|
||||
|
||||
[tool.ruff.per-file-ignores]
|
||||
"setup.py" = ["INP001"]
|
||||
|
||||
@@ -1,7 +1,8 @@
|
||||
import os
|
||||
import sys
|
||||
import sysconfig
|
||||
from pathlib import Path
|
||||
|
||||
if __name__ == "__main__":
|
||||
ruff = os.path.join(sysconfig.get_path("scripts"), "ruff")
|
||||
ruff = Path(sysconfig.get_path("scripts")) / "ruff"
|
||||
sys.exit(os.spawnv(os.P_WAIT, ruff, [ruff, *sys.argv[1:]]))
|
||||
|
||||
37
resources/test/fixtures/flake8_bugbear/B007.py
vendored
37
resources/test/fixtures/flake8_bugbear/B007.py
vendored
@@ -44,4 +44,39 @@ for foo, bar in [(1, 2)]:
|
||||
print(FMT.format(**vars()))
|
||||
|
||||
for foo, bar in [(1, 2)]:
|
||||
print(FMT.format(foo=foo, bar=eval('bar')))
|
||||
print(FMT.format(foo=foo, bar=eval("bar")))
|
||||
|
||||
|
||||
def f():
|
||||
# Fixable.
|
||||
for foo, bar, baz in (["1", "2", "3"],):
|
||||
if foo or baz:
|
||||
break
|
||||
|
||||
|
||||
def f():
|
||||
# Unfixable due to usage of `bar` outside of loop.
|
||||
for foo, bar, baz in (["1", "2", "3"],):
|
||||
if foo or baz:
|
||||
break
|
||||
|
||||
print(bar)
|
||||
|
||||
|
||||
def f():
|
||||
# Fixable.
|
||||
for foo, bar, baz in (["1", "2", "3"],):
|
||||
if foo or baz:
|
||||
break
|
||||
|
||||
bar = 1
|
||||
|
||||
|
||||
def f():
|
||||
# Fixable.
|
||||
for foo, bar, baz in (["1", "2", "3"],):
|
||||
if foo or baz:
|
||||
break
|
||||
|
||||
bar = 1
|
||||
print(bar)
|
||||
|
||||
30
resources/test/fixtures/flake8_self/SLF001.py
vendored
30
resources/test/fixtures/flake8_self/SLF001.py
vendored
@@ -1,13 +1,40 @@
|
||||
class Foo:
|
||||
class BazMeta(type):
|
||||
_private_count = 1
|
||||
|
||||
def __new__(mcs, name, bases, attrs):
|
||||
if mcs._private_count <= 5:
|
||||
mcs.some_method()
|
||||
|
||||
return super().__new__(mcs, name, bases, attrs)
|
||||
|
||||
def some_method():
|
||||
pass
|
||||
|
||||
|
||||
class Bar:
|
||||
_private = True
|
||||
|
||||
@classmethod
|
||||
def is_private(cls):
|
||||
return cls._private
|
||||
|
||||
|
||||
class Foo(metaclass=BazMeta):
|
||||
|
||||
def __init__(self):
|
||||
self.public_thing = "foo"
|
||||
self._private_thing = "bar"
|
||||
self.__really_private_thing = "baz"
|
||||
self.bar = Bar()
|
||||
|
||||
def __str__(self):
|
||||
return "foo"
|
||||
|
||||
def get_bar():
|
||||
if self.bar._private: # SLF001
|
||||
return None
|
||||
return self.bar
|
||||
|
||||
def public_func(self):
|
||||
pass
|
||||
|
||||
@@ -29,3 +56,4 @@ print(foo._private_thing) # SLF001
|
||||
print(foo.__really_private_thing) # SLF001
|
||||
print(foo._private_func()) # SLF001
|
||||
print(foo.__really_private_func(1)) # SLF001
|
||||
print(foo.bar._private) # SLF001
|
||||
|
||||
53
resources/test/fixtures/pyflakes/F811_21.py
vendored
Normal file
53
resources/test/fixtures/pyflakes/F811_21.py
vendored
Normal file
@@ -0,0 +1,53 @@
|
||||
"""Test: noqa directives."""
|
||||
|
||||
from typing_extensions import List, Sequence
|
||||
|
||||
# This should ignore both errors.
|
||||
from typing import ( # noqa: F811
|
||||
List,
|
||||
Sequence,
|
||||
)
|
||||
|
||||
# This should ignore both errors.
|
||||
from typing import ( # noqa
|
||||
List,
|
||||
Sequence,
|
||||
)
|
||||
|
||||
# This should ignore both errors.
|
||||
from typing import (
|
||||
List, # noqa: F811
|
||||
Sequence, # noqa: F811
|
||||
)
|
||||
|
||||
# This should ignore both errors.
|
||||
from typing import (
|
||||
List, # noqa
|
||||
Sequence, # noqa
|
||||
)
|
||||
|
||||
# This should ignore the first error.
|
||||
from typing import (
|
||||
List, # noqa: F811
|
||||
Sequence,
|
||||
)
|
||||
|
||||
# This should ignore both errors.
|
||||
from typing import ( # noqa
|
||||
List,
|
||||
Sequence,
|
||||
)
|
||||
|
||||
# This should ignore both errors.
|
||||
from typing import List, Sequence # noqa: F811
|
||||
|
||||
# This should ignore both errors.
|
||||
from typing import List, Sequence # noqa
|
||||
|
||||
|
||||
def f():
|
||||
# This should ignore both errors.
|
||||
from typing import ( # noqa: F811
|
||||
List,
|
||||
Sequence,
|
||||
)
|
||||
3
resources/test/fixtures/pyflakes/F822_1.py
vendored
Normal file
3
resources/test/fixtures/pyflakes/F822_1.py
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
a = 1
|
||||
|
||||
__all__ = list(["a", "b"])
|
||||
@@ -9,6 +9,7 @@ from collections import OrderedDict as o_dict
|
||||
import os.path as path # [consider-using-from-import]
|
||||
import os.path as p
|
||||
import foo.bar.foobar as foobar # [consider-using-from-import]
|
||||
import foo.bar.foobar as foobar, sys # [consider-using-from-import]
|
||||
import os
|
||||
import os as OS
|
||||
from sys import version
|
||||
|
||||
@@ -6,6 +6,10 @@ __all__ += {"world"} # [invalid-all-format]
|
||||
|
||||
__all__ = {"world"} + ["Hello"] # [invalid-all-format]
|
||||
|
||||
__all__ = {"world"} + list(["Hello"]) # [invalid-all-format]
|
||||
|
||||
__all__ = list(["Hello"]) + {"world"} # [invalid-all-format]
|
||||
|
||||
__all__ = (x for x in ["Hello", "world"]) # [invalid-all-format]
|
||||
|
||||
__all__ = {x for x in ["Hello", "world"]} # [invalid-all-format]
|
||||
@@ -17,3 +21,11 @@ __all__ = ("Hello",)
|
||||
__all__ = ["Hello"] + ("world",)
|
||||
|
||||
__all__ = [x for x in ["Hello", "world"]]
|
||||
|
||||
__all__ = list(["Hello", "world"])
|
||||
|
||||
__all__ = list({"Hello", "world"})
|
||||
|
||||
__all__ = list(["Hello"]) + list(["world"])
|
||||
|
||||
__all__ = tuple(["Hello"]) + ("world",)
|
||||
|
||||
@@ -4,8 +4,12 @@ __all__ = (
|
||||
Worm,
|
||||
)
|
||||
|
||||
__all__ = list([None, "Fruit", "Worm"]) # [invalid-all-object]
|
||||
|
||||
|
||||
class Fruit:
|
||||
pass
|
||||
|
||||
|
||||
class Worm:
|
||||
pass
|
||||
|
||||
@@ -1,3 +1,8 @@
|
||||
# Too may statements (2/1) for max_statements=1
|
||||
def f(x):
|
||||
pass
|
||||
|
||||
|
||||
def f(x):
|
||||
def g(x):
|
||||
pass
|
||||
|
||||
6
resources/test/fixtures/ruff/RUF005.py
vendored
6
resources/test/fixtures/ruff/RUF005.py
vendored
@@ -37,3 +37,9 @@ second = first + [
|
||||
# touch
|
||||
6,
|
||||
]
|
||||
|
||||
[] + foo + [
|
||||
]
|
||||
|
||||
[] + foo + [ # This will be preserved, but doesn't prevent the fix
|
||||
]
|
||||
|
||||
@@ -1,2 +1,7 @@
|
||||
[tool.ruff]
|
||||
src = ["."]
|
||||
|
||||
# This will make sure that `exclude` paths are rooted
|
||||
# to where the configuration file was found; this file exists
|
||||
# in a `resources/test` hierarchy.
|
||||
exclude = ["resources"]
|
||||
|
||||
4
resources/test/package/resources/ignored.py
Normal file
4
resources/test/package/resources/ignored.py
Normal file
@@ -0,0 +1,4 @@
|
||||
# This file should be ignored, but it would otherwise trigger
|
||||
# an unused import error:
|
||||
|
||||
import math
|
||||
@@ -7,7 +7,7 @@ behaviors.
|
||||
|
||||
Running from the repo root should pick up and enforce the appropriate settings for each package:
|
||||
|
||||
```
|
||||
```console
|
||||
∴ cargo run resources/test/project/
|
||||
resources/test/project/examples/.dotfiles/script.py:1:1: I001 Import block is un-sorted or un-formatted
|
||||
resources/test/project/examples/.dotfiles/script.py:1:8: F401 `numpy` imported but unused
|
||||
@@ -22,7 +22,7 @@ Found 7 errors.
|
||||
|
||||
Running from the project directory itself should exhibit the same behavior:
|
||||
|
||||
```
|
||||
```console
|
||||
∴ (cd resources/test/project/ && cargo run .)
|
||||
examples/.dotfiles/script.py:1:1: I001 Import block is un-sorted or un-formatted
|
||||
examples/.dotfiles/script.py:1:8: F401 `numpy` imported but unused
|
||||
@@ -38,7 +38,7 @@ Found 7 errors.
|
||||
Running from the sub-package directory should exhibit the same behavior, but omit the top-level
|
||||
files:
|
||||
|
||||
```
|
||||
```console
|
||||
∴ (cd resources/test/project/examples/docs && cargo run .)
|
||||
docs/file.py:1:1: I001 Import block is un-sorted or un-formatted
|
||||
docs/file.py:8:5: F841 Local variable `x` is assigned to but never used
|
||||
@@ -49,7 +49,7 @@ Found 2 errors.
|
||||
`--config` should force Ruff to use the specified `pyproject.toml` for all files, and resolve
|
||||
file paths from the current working directory:
|
||||
|
||||
```
|
||||
```console
|
||||
∴ (cargo run -- --config=resources/test/project/pyproject.toml resources/test/project/)
|
||||
resources/test/project/examples/.dotfiles/script.py:1:8: F401 `numpy` imported but unused
|
||||
resources/test/project/examples/.dotfiles/script.py:2:17: F401 `app.app_file` imported but unused
|
||||
@@ -67,7 +67,7 @@ Found 9 errors.
|
||||
Running from a parent directory should "ignore" the `exclude` (hence, `concepts/file.py` gets
|
||||
included in the output):
|
||||
|
||||
```
|
||||
```console
|
||||
∴ (cd resources/test/project/examples && cargo run -- --config=docs/ruff.toml .)
|
||||
docs/docs/concepts/file.py:5:5: F841 Local variable `x` is assigned to but never used
|
||||
docs/docs/file.py:1:1: I001 Import block is un-sorted or un-formatted
|
||||
@@ -79,7 +79,7 @@ Found 4 errors.
|
||||
|
||||
Passing an excluded directory directly should report errors in the contained files:
|
||||
|
||||
```
|
||||
```console
|
||||
∴ cargo run resources/test/project/examples/excluded/
|
||||
resources/test/project/examples/excluded/script.py:1:8: F401 `os` imported but unused
|
||||
Found 1 error.
|
||||
@@ -88,7 +88,7 @@ Found 1 error.
|
||||
|
||||
Unless we `--force-exclude`:
|
||||
|
||||
```
|
||||
```console
|
||||
∴ cargo run resources/test/project/examples/excluded/ --force-exclude
|
||||
warning: No Python files found under the given path(s)
|
||||
∴ cargo run resources/test/project/examples/excluded/script.py --force-exclude
|
||||
|
||||
@@ -40,7 +40,7 @@
|
||||
]
|
||||
},
|
||||
"exclude": {
|
||||
"description": "A list of file patterns to exclude from linting.\n\nExclusions are based on globs, and can be either:\n\n- Single-path patterns, like `.mypy_cache` (to exclude any directory named `.mypy_cache` in the tree), `foo.py` (to exclude any file named `foo.py`), or `foo_*.py` (to exclude any file matching `foo_*.py` ). - Relative patterns, like `directory/foo.py` (to exclude that specific file) or `directory/*.py` (to exclude any Python files in `directory`). Note that these paths are relative to the project root (e.g., the directory containing your `pyproject.toml`).\n\nFor more information on the glob syntax, refer to the [`globset` documentation](https://docs.rs/globset/latest/globset/#syntax).\n\nNote that you'll typically want to use [`extend-exclude`](#extend-exclude) to modify the excluded paths.",
|
||||
"description": "A list of file patterns to exclude from linting.\n\nExclusions are based on globs, and can be either:\n\n* Single-path patterns, like `.mypy_cache` (to exclude any directory named `.mypy_cache` in the tree), `foo.py` (to exclude any file named `foo.py`), or `foo_*.py` (to exclude any file matching `foo_*.py` ). * Relative patterns, like `directory/foo.py` (to exclude that specific file) or `directory/*.py` (to exclude any Python files in `directory`). Note that these paths are relative to the project root (e.g., the directory containing your `pyproject.toml`).\n\nFor more information on the glob syntax, refer to the [`globset` documentation](https://docs.rs/globset/latest/globset/#syntax).\n\nNote that you'll typically want to use [`extend-exclude`](#extend-exclude) to modify the excluded paths.",
|
||||
"type": [
|
||||
"array",
|
||||
"null"
|
||||
@@ -57,7 +57,7 @@
|
||||
]
|
||||
},
|
||||
"extend-exclude": {
|
||||
"description": "A list of file patterns to omit from linting, in addition to those specified by `exclude`.\n\nExclusions are based on globs, and can be either:\n\n- Single-path patterns, like `.mypy_cache` (to exclude any directory named `.mypy_cache` in the tree), `foo.py` (to exclude any file named `foo.py`), or `foo_*.py` (to exclude any file matching `foo_*.py` ). - Relative patterns, like `directory/foo.py` (to exclude that specific file) or `directory/*.py` (to exclude any Python files in `directory`). Note that these paths are relative to the project root (e.g., the directory containing your `pyproject.toml`).\n\nFor more information on the glob syntax, refer to the [`globset` documentation](https://docs.rs/globset/latest/globset/#syntax).",
|
||||
"description": "A list of file patterns to omit from linting, in addition to those specified by `exclude`.\n\nExclusions are based on globs, and can be either:\n\n* Single-path patterns, like `.mypy_cache` (to exclude any directory named `.mypy_cache` in the tree), `foo.py` (to exclude any file named `foo.py`), or `foo_*.py` (to exclude any file matching `foo_*.py` ). * Relative patterns, like `directory/foo.py` (to exclude that specific file) or `directory/*.py` (to exclude any Python files in `directory`). Note that these paths are relative to the project root (e.g., the directory containing your `pyproject.toml`).\n\nFor more information on the glob syntax, refer to the [`globset` documentation](https://docs.rs/globset/latest/globset/#syntax).",
|
||||
"type": [
|
||||
"array",
|
||||
"null"
|
||||
@@ -556,7 +556,7 @@
|
||||
]
|
||||
},
|
||||
"suppress-none-returning": {
|
||||
"description": "Whether to suppress `ANN200`-level violations for functions that meet either of the following criteria:\n\n- Contain no `return` statement. - Explicit `return` statement(s) all return `None` (explicitly or implicitly).",
|
||||
"description": "Whether to suppress `ANN200`-level violations for functions that meet either of the following criteria:\n\n* Contain no `return` statement. * Explicit `return` statement(s) all return `None` (explicitly or implicitly).",
|
||||
"type": [
|
||||
"boolean",
|
||||
"null"
|
||||
@@ -702,7 +702,7 @@
|
||||
]
|
||||
},
|
||||
"parametrize-names-type": {
|
||||
"description": "Expected type for multiple argument names in `@pytest.mark.parametrize`. The following values are supported: * `csv` — a comma-separated list, e.g. `@pytest.mark.parametrize('name1,name2', ...)` * `tuple` (default) — e.g. `@pytest.mark.parametrize(('name1', 'name2'), ...)` * `list` — e.g. `@pytest.mark.parametrize(['name1', 'name2'], ...)`",
|
||||
"description": "Expected type for multiple argument names in `@pytest.mark.parametrize`. The following values are supported:\n\n* `csv` — a comma-separated list, e.g. `@pytest.mark.parametrize('name1,name2', ...)` * `tuple` (default) — e.g. `@pytest.mark.parametrize(('name1', 'name2'), ...)` * `list` — e.g. `@pytest.mark.parametrize(['name1', 'name2'], ...)`",
|
||||
"anyOf": [
|
||||
{
|
||||
"$ref": "#/definitions/ParametrizeNameType"
|
||||
@@ -713,7 +713,7 @@
|
||||
]
|
||||
},
|
||||
"parametrize-values-row-type": {
|
||||
"description": "Expected type for each row of values in `@pytest.mark.parametrize` in case of multiple parameters. The following values are supported: * `tuple` (default) — e.g. `@pytest.mark.parametrize(('name1', 'name2'), [(1, 2), (3, 4)])` * `list` — e.g. `@pytest.mark.parametrize(('name1', 'name2'), [[1, 2], [3, 4]])`",
|
||||
"description": "Expected type for each row of values in `@pytest.mark.parametrize` in case of multiple parameters. The following values are supported:\n\n* `tuple` (default) — e.g. `@pytest.mark.parametrize(('name1', 'name2'), [(1, 2), (3, 4)])` * `list` — e.g. `@pytest.mark.parametrize(('name1', 'name2'), [[1, 2], [3, 4]])`",
|
||||
"anyOf": [
|
||||
{
|
||||
"$ref": "#/definitions/ParametrizeValuesRowType"
|
||||
@@ -724,7 +724,7 @@
|
||||
]
|
||||
},
|
||||
"parametrize-values-type": {
|
||||
"description": "Expected type for the list of values rows in `@pytest.mark.parametrize`. The following values are supported: * `tuple` — e.g. `@pytest.mark.parametrize('name', (1, 2, 3))` * `list` (default) — e.g. `@pytest.mark.parametrize('name', [1, 2, 3])`",
|
||||
"description": "Expected type for the list of values rows in `@pytest.mark.parametrize`. The following values are supported:\n\n* `tuple` — e.g. `@pytest.mark.parametrize('name', (1, 2, 3))` * `list` (default) — e.g. `@pytest.mark.parametrize('name', [1, 2, 3])`",
|
||||
"anyOf": [
|
||||
{
|
||||
"$ref": "#/definitions/ParametrizeValuesType"
|
||||
@@ -844,7 +844,7 @@
|
||||
}
|
||||
},
|
||||
"strict": {
|
||||
"description": "Enforce TC001, TC002, and TC003 rules even when valid runtime imports are present for the same module. See: https://github.com/snok/flake8-type-checking#strict.",
|
||||
"description": "Enforce TC001, TC002, and TC003 rules even when valid runtime imports are present for the same module. See flake8-type-checking's [strict](https://github.com/snok/flake8-type-checking#strict) option.",
|
||||
"type": [
|
||||
"boolean",
|
||||
"null"
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[package]
|
||||
name = "ruff_cli"
|
||||
version = "0.0.240"
|
||||
version = "0.0.241"
|
||||
authors = ["Charlie Marsh <charlie.r.marsh@gmail.com>"]
|
||||
edition = "2021"
|
||||
rust-version = "1.65.0"
|
||||
@@ -51,7 +51,6 @@ serde = { version = "1.0.147", features = ["derive"] }
|
||||
serde_json = { version = "1.0.87" }
|
||||
similar = { version = "2.2.1" }
|
||||
textwrap = { version = "0.16.0" }
|
||||
update-informer = { version = "0.6.0", default-features = false, features = ["pypi"], optional = true }
|
||||
walkdir = { version = "2.3.2" }
|
||||
strum = "0.24.1"
|
||||
|
||||
@@ -60,10 +59,6 @@ assert_cmd = { version = "2.0.4" }
|
||||
strum = { version = "0.24.1" }
|
||||
ureq = { version = "2.5.0", features = [] }
|
||||
|
||||
[features]
|
||||
default = ["update-informer"]
|
||||
update-informer = ["dep:update-informer"]
|
||||
|
||||
[package.metadata.maturin]
|
||||
name = "ruff"
|
||||
# Setting the name here is necessary for maturin to include the package in its builds.
|
||||
|
||||
@@ -1,3 +1,5 @@
|
||||
#![allow(dead_code)]
|
||||
|
||||
use std::path::PathBuf;
|
||||
|
||||
use clap::{command, Parser};
|
||||
@@ -36,7 +38,7 @@ pub enum Command {
|
||||
#[clap(alias = "--explain")]
|
||||
Rule {
|
||||
#[arg(value_parser=Rule::from_code)]
|
||||
rule: &'static Rule,
|
||||
rule: Rule,
|
||||
|
||||
/// Output format
|
||||
#[arg(long, value_enum, default_value = "text")]
|
||||
@@ -209,11 +211,12 @@ pub struct CheckArgs {
|
||||
/// Exit with status code "0", even upon detecting lint violations.
|
||||
#[arg(short, long, help_heading = "Miscellaneous")]
|
||||
pub exit_zero: bool,
|
||||
/// Enable or disable automatic update checks.
|
||||
/// Does nothing and will be removed in the future.
|
||||
#[arg(
|
||||
long,
|
||||
overrides_with("no_update_check"),
|
||||
help_heading = "Miscellaneous"
|
||||
help_heading = "Miscellaneous",
|
||||
hide = true
|
||||
)]
|
||||
update_check: bool,
|
||||
#[clap(long, overrides_with("update_check"), hide = true)]
|
||||
@@ -237,6 +240,7 @@ pub struct CheckArgs {
|
||||
conflicts_with = "statistics",
|
||||
conflicts_with = "stdin_filename",
|
||||
conflicts_with = "watch",
|
||||
conflicts_with = "fix",
|
||||
)]
|
||||
pub add_noqa: bool,
|
||||
/// See the files Ruff will be run against with the current settings.
|
||||
@@ -309,13 +313,13 @@ pub struct LogLevelArgs {
|
||||
impl From<&LogLevelArgs> for LogLevel {
|
||||
fn from(args: &LogLevelArgs) -> Self {
|
||||
if args.silent {
|
||||
LogLevel::Silent
|
||||
Self::Silent
|
||||
} else if args.quiet {
|
||||
LogLevel::Quiet
|
||||
Self::Quiet
|
||||
} else if args.verbose {
|
||||
LogLevel::Verbose
|
||||
Self::Verbose
|
||||
} else {
|
||||
LogLevel::Default
|
||||
Self::Default
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -85,6 +85,10 @@ fn read_sync(cache_dir: &Path, key: u64) -> Result<Vec<u8>, std::io::Error> {
|
||||
fs::read(cache_dir.join(content_dir()).join(format!("{key:x}")))
|
||||
}
|
||||
|
||||
fn del_sync(cache_dir: &Path, key: u64) -> Result<(), std::io::Error> {
|
||||
fs::remove_file(cache_dir.join(content_dir()).join(format!("{key:x}")))
|
||||
}
|
||||
|
||||
/// Get a value from the cache.
|
||||
pub fn get<P: AsRef<Path>>(
|
||||
path: P,
|
||||
@@ -137,3 +141,16 @@ pub fn set<P: AsRef<Path>>(
|
||||
error!("Failed to write to cache: {e:?}");
|
||||
}
|
||||
}
|
||||
|
||||
/// Delete a value from the cache.
|
||||
pub fn del<P: AsRef<Path>>(
|
||||
path: P,
|
||||
package: Option<&P>,
|
||||
settings: &AllSettings,
|
||||
autofix: flags::Autofix,
|
||||
) {
|
||||
drop(del_sync(
|
||||
&settings.cli.cache_dir,
|
||||
cache_key(path, package, &settings.lib, autofix),
|
||||
));
|
||||
}
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
use std::fs::remove_dir_all;
|
||||
use std::io::{self, Read};
|
||||
use std::io::Write;
|
||||
use std::io::{self, BufWriter, Read};
|
||||
use std::path::{Path, PathBuf};
|
||||
use std::time::Instant;
|
||||
|
||||
@@ -11,6 +12,9 @@ use log::{debug, error};
|
||||
use path_absolutize::path_dedot;
|
||||
#[cfg(not(target_family = "wasm"))]
|
||||
use rayon::prelude::*;
|
||||
use serde::Serialize;
|
||||
use walkdir::WalkDir;
|
||||
|
||||
use ruff::cache::CACHE_DIR_NAME;
|
||||
use ruff::linter::add_noqa_to_path;
|
||||
use ruff::logging::LogLevel;
|
||||
@@ -19,8 +23,6 @@ use ruff::registry::{Linter, Rule, RuleNamespace};
|
||||
use ruff::resolver::PyprojectDiscovery;
|
||||
use ruff::settings::flags;
|
||||
use ruff::{fix, fs, packaging, resolver, warn_user_once, AutofixAvailability, IOError};
|
||||
use serde::Serialize;
|
||||
use walkdir::WalkDir;
|
||||
|
||||
use crate::args::{HelpFormat, Overrides};
|
||||
use crate::cache;
|
||||
@@ -136,7 +138,7 @@ pub fn run(
|
||||
|
||||
diagnostics.messages.sort_unstable();
|
||||
let duration = start.elapsed();
|
||||
debug!("Checked files in: {:?}", duration);
|
||||
debug!("Checked {:?} files in: {:?}", paths.len(), duration);
|
||||
|
||||
Ok(diagnostics)
|
||||
}
|
||||
@@ -230,8 +232,10 @@ pub fn show_settings(
|
||||
};
|
||||
let path = entry.path();
|
||||
let settings = resolver.resolve(path, pyproject_strategy);
|
||||
println!("Resolved settings for: {path:?}");
|
||||
println!("{settings:#?}");
|
||||
|
||||
let mut stdout = BufWriter::new(io::stdout().lock());
|
||||
write!(stdout, "Resolved settings for: {path:?}")?;
|
||||
write!(stdout, "{settings:#?}")?;
|
||||
|
||||
Ok(())
|
||||
}
|
||||
@@ -251,12 +255,13 @@ pub fn show_files(
|
||||
}
|
||||
|
||||
// Print the list of files.
|
||||
let mut stdout = BufWriter::new(io::stdout().lock());
|
||||
for entry in paths
|
||||
.iter()
|
||||
.flatten()
|
||||
.sorted_by(|a, b| a.path().cmp(b.path()))
|
||||
{
|
||||
println!("{}", entry.path().to_string_lossy());
|
||||
writeln!(stdout, "{}", entry.path().to_string_lossy())?;
|
||||
}
|
||||
|
||||
Ok(())
|
||||
@@ -272,34 +277,39 @@ struct Explanation<'a> {
|
||||
/// Explain a `Rule` to the user.
|
||||
pub fn rule(rule: &Rule, format: HelpFormat) -> Result<()> {
|
||||
let (linter, _) = Linter::parse_code(rule.code()).unwrap();
|
||||
let mut stdout = BufWriter::new(io::stdout().lock());
|
||||
match format {
|
||||
HelpFormat::Text => {
|
||||
println!("{}\n", rule.as_ref());
|
||||
println!("Code: {} ({})\n", rule.code(), linter.name());
|
||||
writeln!(stdout, "{}\n", rule.as_ref())?;
|
||||
writeln!(stdout, "Code: {} ({})\n", rule.code(), linter.name())?;
|
||||
|
||||
if let Some(autofix) = rule.autofixable() {
|
||||
println!(
|
||||
writeln!(
|
||||
stdout,
|
||||
"{}",
|
||||
match autofix.available {
|
||||
AutofixAvailability::Sometimes => "Autofix is sometimes available.\n",
|
||||
AutofixAvailability::Always => "Autofix is always available.\n",
|
||||
}
|
||||
);
|
||||
)?;
|
||||
}
|
||||
println!("Message formats:\n");
|
||||
|
||||
writeln!(stdout, "Message formats:\n")?;
|
||||
|
||||
for format in rule.message_formats() {
|
||||
println!("* {format}");
|
||||
writeln!(stdout, "* {format}")?;
|
||||
}
|
||||
}
|
||||
HelpFormat::Json => {
|
||||
println!(
|
||||
writeln!(
|
||||
stdout,
|
||||
"{}",
|
||||
serde_json::to_string_pretty(&Explanation {
|
||||
code: rule.code(),
|
||||
linter: linter.name(),
|
||||
summary: rule.message_formats()[0],
|
||||
})?
|
||||
);
|
||||
)?;
|
||||
}
|
||||
};
|
||||
Ok(())
|
||||
@@ -307,6 +317,7 @@ pub fn rule(rule: &Rule, format: HelpFormat) -> Result<()> {
|
||||
|
||||
/// Clear any caches in the current directory or any subdirectories.
|
||||
pub fn clean(level: LogLevel) -> Result<()> {
|
||||
let mut stderr = BufWriter::new(io::stderr().lock());
|
||||
for entry in WalkDir::new(&*path_dedot::CWD)
|
||||
.into_iter()
|
||||
.filter_map(Result::ok)
|
||||
@@ -315,7 +326,11 @@ pub fn clean(level: LogLevel) -> Result<()> {
|
||||
let cache = entry.path().join(CACHE_DIR_NAME);
|
||||
if cache.is_dir() {
|
||||
if level >= LogLevel::Default {
|
||||
eprintln!("Removing cache at: {}", fs::relativize_path(&cache).bold());
|
||||
writeln!(
|
||||
stderr,
|
||||
"Removing cache at: {}",
|
||||
fs::relativize_path(&cache).bold()
|
||||
)?;
|
||||
}
|
||||
remove_dir_all(&cache)?;
|
||||
}
|
||||
|
||||
@@ -2,7 +2,7 @@ use itertools::Itertools;
|
||||
use serde::Serialize;
|
||||
use strum::IntoEnumIterator;
|
||||
|
||||
use ruff::registry::{Linter, LinterCategory, RuleNamespace};
|
||||
use ruff::registry::{Linter, RuleNamespace, UpstreamCategory};
|
||||
|
||||
use crate::args::HelpFormat;
|
||||
|
||||
@@ -12,14 +12,18 @@ pub fn linter(format: HelpFormat) {
|
||||
for linter in Linter::iter() {
|
||||
let prefix = match linter.common_prefix() {
|
||||
"" => linter
|
||||
.categories()
|
||||
.upstream_categories()
|
||||
.unwrap()
|
||||
.iter()
|
||||
.map(|LinterCategory(prefix, ..)| prefix)
|
||||
.map(|UpstreamCategory(prefix, ..)| prefix.as_ref())
|
||||
.join("/"),
|
||||
prefix => prefix.to_string(),
|
||||
};
|
||||
println!("{:>4} {}", prefix, linter.name());
|
||||
|
||||
#[allow(clippy::print_stdout)]
|
||||
{
|
||||
println!("{:>4} {}", prefix, linter.name());
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -28,10 +32,10 @@ pub fn linter(format: HelpFormat) {
|
||||
.map(|linter_info| LinterInfo {
|
||||
prefix: linter_info.common_prefix(),
|
||||
name: linter_info.name(),
|
||||
categories: linter_info.categories().map(|cats| {
|
||||
categories: linter_info.upstream_categories().map(|cats| {
|
||||
cats.iter()
|
||||
.map(|LinterCategory(prefix, name, ..)| LinterCategoryInfo {
|
||||
prefix,
|
||||
.map(|UpstreamCategory(prefix, name, ..)| LinterCategoryInfo {
|
||||
prefix: prefix.as_ref(),
|
||||
name,
|
||||
})
|
||||
.collect()
|
||||
@@ -39,7 +43,10 @@ pub fn linter(format: HelpFormat) {
|
||||
})
|
||||
.collect();
|
||||
|
||||
println!("{}", serde_json::to_string_pretty(&linters).unwrap());
|
||||
#[allow(clippy::print_stdout)]
|
||||
{
|
||||
println!("{}", serde_json::to_string_pretty(&linters).unwrap());
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -6,8 +6,9 @@ use std::ops::AddAssign;
|
||||
use std::path::Path;
|
||||
|
||||
use anyhow::Result;
|
||||
use colored::Colorize;
|
||||
use log::debug;
|
||||
use ruff::linter::{lint_fix, lint_only};
|
||||
use ruff::linter::{lint_fix, lint_only, LinterResult};
|
||||
use ruff::message::Message;
|
||||
use ruff::settings::{flags, AllSettings, Settings};
|
||||
use ruff::{fix, fs};
|
||||
@@ -67,38 +68,69 @@ pub fn lint_path(
|
||||
let contents = fs::read_file(path)?;
|
||||
|
||||
// Lint the file.
|
||||
let (messages, fixed) = if matches!(autofix, fix::FixMode::Apply | fix::FixMode::Diff) {
|
||||
let (transformed, fixed, messages) = lint_fix(&contents, path, package, &settings.lib)?;
|
||||
if fixed > 0 {
|
||||
if matches!(autofix, fix::FixMode::Apply) {
|
||||
write(path, transformed)?;
|
||||
} else if matches!(autofix, fix::FixMode::Diff) {
|
||||
let mut stdout = io::stdout().lock();
|
||||
TextDiff::from_lines(&contents, &transformed)
|
||||
.unified_diff()
|
||||
.header(&fs::relativize_path(path), &fs::relativize_path(path))
|
||||
.to_writer(&mut stdout)?;
|
||||
stdout.write_all(b"\n")?;
|
||||
stdout.flush()?;
|
||||
let (
|
||||
LinterResult {
|
||||
data: messages,
|
||||
error: parse_error,
|
||||
},
|
||||
fixed,
|
||||
) = if matches!(autofix, fix::FixMode::Apply | fix::FixMode::Diff) {
|
||||
if let Ok((result, transformed, fixed)) = lint_fix(&contents, path, package, &settings.lib)
|
||||
{
|
||||
if fixed > 0 {
|
||||
if matches!(autofix, fix::FixMode::Apply) {
|
||||
write(path, transformed.as_bytes())?;
|
||||
} else if matches!(autofix, fix::FixMode::Diff) {
|
||||
let mut stdout = io::stdout().lock();
|
||||
TextDiff::from_lines(contents.as_str(), &transformed)
|
||||
.unified_diff()
|
||||
.header(&fs::relativize_path(path), &fs::relativize_path(path))
|
||||
.to_writer(&mut stdout)?;
|
||||
stdout.write_all(b"\n")?;
|
||||
stdout.flush()?;
|
||||
}
|
||||
}
|
||||
(result, fixed)
|
||||
} else {
|
||||
// If we fail to autofix, lint the original source code.
|
||||
let result = lint_only(&contents, path, package, &settings.lib, autofix.into());
|
||||
let fixed = 0;
|
||||
(result, fixed)
|
||||
}
|
||||
(messages, fixed)
|
||||
} else {
|
||||
let messages = lint_only(&contents, path, package, &settings.lib, autofix.into())?;
|
||||
let result = lint_only(&contents, path, package, &settings.lib, autofix.into());
|
||||
let fixed = 0;
|
||||
(messages, fixed)
|
||||
(result, fixed)
|
||||
};
|
||||
|
||||
// Re-populate the cache.
|
||||
if let Some(metadata) = metadata {
|
||||
cache::set(
|
||||
path,
|
||||
package.as_ref(),
|
||||
&metadata,
|
||||
settings,
|
||||
autofix.into(),
|
||||
&messages,
|
||||
);
|
||||
if let Some(err) = parse_error {
|
||||
// Notify the user of any parse errors.
|
||||
#[allow(clippy::print_stderr)]
|
||||
{
|
||||
eprintln!(
|
||||
"{}{} {}{}{} {err}",
|
||||
"error".red().bold(),
|
||||
":".bold(),
|
||||
"Failed to parse ".bold(),
|
||||
fs::relativize_path(path).bold(),
|
||||
":".bold()
|
||||
);
|
||||
}
|
||||
|
||||
// Purge the cache.
|
||||
cache::del(path, package.as_ref(), settings, autofix.into());
|
||||
} else {
|
||||
// Re-populate the cache.
|
||||
if let Some(metadata) = metadata {
|
||||
cache::set(
|
||||
path,
|
||||
package.as_ref(),
|
||||
&metadata,
|
||||
settings,
|
||||
autofix.into(),
|
||||
&messages,
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
Ok(Diagnostics { messages, fixed })
|
||||
@@ -114,45 +146,80 @@ pub fn lint_stdin(
|
||||
autofix: fix::FixMode,
|
||||
) -> Result<Diagnostics> {
|
||||
// Lint the inputs.
|
||||
let (messages, fixed) = if matches!(autofix, fix::FixMode::Apply | fix::FixMode::Diff) {
|
||||
let (transformed, fixed, messages) = lint_fix(
|
||||
let (
|
||||
LinterResult {
|
||||
data: messages,
|
||||
error: parse_error,
|
||||
},
|
||||
fixed,
|
||||
) = if matches!(autofix, fix::FixMode::Apply | fix::FixMode::Diff) {
|
||||
if let Ok((result, transformed, fixed)) = lint_fix(
|
||||
contents,
|
||||
path.unwrap_or_else(|| Path::new("-")),
|
||||
package,
|
||||
settings,
|
||||
)?;
|
||||
) {
|
||||
if matches!(autofix, fix::FixMode::Apply) {
|
||||
// Write the contents to stdout, regardless of whether any errors were fixed.
|
||||
io::stdout().write_all(transformed.as_bytes())?;
|
||||
} else if matches!(autofix, fix::FixMode::Diff) {
|
||||
// But only write a diff if it's non-empty.
|
||||
if fixed > 0 {
|
||||
let text_diff = TextDiff::from_lines(contents, &transformed);
|
||||
let mut unified_diff = text_diff.unified_diff();
|
||||
if let Some(path) = path {
|
||||
unified_diff.header(&fs::relativize_path(path), &fs::relativize_path(path));
|
||||
}
|
||||
|
||||
if matches!(autofix, fix::FixMode::Apply) {
|
||||
// Write the contents to stdout, regardless of whether any errors were fixed.
|
||||
io::stdout().write_all(transformed.as_bytes())?;
|
||||
} else if matches!(autofix, fix::FixMode::Diff) {
|
||||
// But only write a diff if it's non-empty.
|
||||
if fixed > 0 {
|
||||
let text_diff = TextDiff::from_lines(contents, &transformed);
|
||||
let mut unified_diff = text_diff.unified_diff();
|
||||
if let Some(path) = path {
|
||||
unified_diff.header(&fs::relativize_path(path), &fs::relativize_path(path));
|
||||
let mut stdout = io::stdout().lock();
|
||||
unified_diff.to_writer(&mut stdout)?;
|
||||
stdout.write_all(b"\n")?;
|
||||
stdout.flush()?;
|
||||
}
|
||||
|
||||
let mut stdout = io::stdout().lock();
|
||||
unified_diff.to_writer(&mut stdout)?;
|
||||
stdout.write_all(b"\n")?;
|
||||
stdout.flush()?;
|
||||
}
|
||||
}
|
||||
|
||||
(messages, fixed)
|
||||
(result, fixed)
|
||||
} else {
|
||||
// If we fail to autofix, lint the original source code.
|
||||
let result = lint_only(
|
||||
contents,
|
||||
path.unwrap_or_else(|| Path::new("-")),
|
||||
package,
|
||||
settings,
|
||||
autofix.into(),
|
||||
);
|
||||
let fixed = 0;
|
||||
|
||||
// Write the contents to stdout anyway.
|
||||
if matches!(autofix, fix::FixMode::Apply) {
|
||||
io::stdout().write_all(contents.as_bytes())?;
|
||||
}
|
||||
|
||||
(result, fixed)
|
||||
}
|
||||
} else {
|
||||
let messages = lint_only(
|
||||
let result = lint_only(
|
||||
contents,
|
||||
path.unwrap_or_else(|| Path::new("-")),
|
||||
package,
|
||||
settings,
|
||||
autofix.into(),
|
||||
)?;
|
||||
);
|
||||
let fixed = 0;
|
||||
(messages, fixed)
|
||||
(result, fixed)
|
||||
};
|
||||
|
||||
if let Some(err) = parse_error {
|
||||
#[allow(clippy::print_stderr)]
|
||||
{
|
||||
eprintln!(
|
||||
"{}{} Failed to parse {}: {err}",
|
||||
"error".red().bold(),
|
||||
":".bold(),
|
||||
path.map_or_else(|| "-".into(), fs::relativize_path).bold()
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
Ok(Diagnostics { messages, fixed })
|
||||
}
|
||||
|
||||
@@ -2,9 +2,6 @@
|
||||
//! to automatically update the `ruff help` output in the `README.md`.
|
||||
//!
|
||||
//! For the actual Ruff library, see [`ruff`].
|
||||
#![forbid(unsafe_code)]
|
||||
#![warn(clippy::pedantic)]
|
||||
#![allow(clippy::must_use_candidate, dead_code)]
|
||||
|
||||
mod args;
|
||||
|
||||
|
||||
@@ -1,28 +1,20 @@
|
||||
#![forbid(unsafe_code)]
|
||||
#![warn(clippy::pedantic)]
|
||||
#![allow(
|
||||
clippy::match_same_arms,
|
||||
clippy::missing_errors_doc,
|
||||
clippy::module_name_repetitions,
|
||||
clippy::too_many_lines
|
||||
)]
|
||||
|
||||
use std::io::{self};
|
||||
use std::path::PathBuf;
|
||||
use std::process::ExitCode;
|
||||
use std::sync::mpsc::channel;
|
||||
|
||||
use ::ruff::logging::{set_up_logging, LogLevel};
|
||||
use ::ruff::resolver::PyprojectDiscovery;
|
||||
use ::ruff::settings::types::SerializationFormat;
|
||||
use ::ruff::{fix, fs, warn_user_once};
|
||||
use anyhow::Result;
|
||||
use args::{Args, CheckArgs, Command};
|
||||
use clap::{CommandFactory, Parser, Subcommand};
|
||||
use colored::Colorize;
|
||||
use notify::{recommended_watcher, RecursiveMode, Watcher};
|
||||
|
||||
use ::ruff::logging::{set_up_logging, LogLevel};
|
||||
use ::ruff::resolver::PyprojectDiscovery;
|
||||
use ::ruff::settings::types::SerializationFormat;
|
||||
use ::ruff::settings::CliSettings;
|
||||
use ::ruff::{fix, fs, warn_user_once};
|
||||
use args::{Args, CheckArgs, Command};
|
||||
use printer::{Printer, Violations};
|
||||
use ruff::settings::CliSettings;
|
||||
|
||||
pub(crate) mod args;
|
||||
mod cache;
|
||||
@@ -31,8 +23,6 @@ mod diagnostics;
|
||||
mod iterators;
|
||||
mod printer;
|
||||
mod resolve;
|
||||
#[cfg(all(feature = "update-informer"))]
|
||||
pub mod updates;
|
||||
|
||||
fn inner_main() -> Result<ExitCode> {
|
||||
let mut args: Vec<_> = std::env::args_os().collect();
|
||||
@@ -62,16 +52,19 @@ fn inner_main() -> Result<ExitCode> {
|
||||
{
|
||||
let default_panic_hook = std::panic::take_hook();
|
||||
std::panic::set_hook(Box::new(move |info| {
|
||||
eprintln!(
|
||||
r#"
|
||||
#[allow(clippy::print_stderr)]
|
||||
{
|
||||
eprintln!(
|
||||
r#"
|
||||
{}: `ruff` crashed. This indicates a bug in `ruff`. If you could open an issue at:
|
||||
|
||||
https://github.com/charliermarsh/ruff/issues/new?title=%5BPanic%5D
|
||||
|
||||
quoting the executed command, along with the relevant file contents and `pyproject.toml` settings, we'd be very appreciative!
|
||||
"#,
|
||||
"error".red().bold(),
|
||||
);
|
||||
"error".red().bold(),
|
||||
);
|
||||
}
|
||||
default_panic_hook(info);
|
||||
}));
|
||||
}
|
||||
@@ -80,7 +73,7 @@ quoting the executed command, along with the relevant file contents and `pyproje
|
||||
set_up_logging(&log_level)?;
|
||||
|
||||
match command {
|
||||
Command::Rule { rule, format } => commands::rule(rule, format)?,
|
||||
Command::Rule { rule, format } => commands::rule(&rule, format)?,
|
||||
Command::Linter { format } => commands::linter::linter(format),
|
||||
Command::Clean => commands::clean(log_level)?,
|
||||
Command::GenerateShellCompletion { shell } => {
|
||||
@@ -111,6 +104,7 @@ fn check(args: CheckArgs, log_level: LogLevel) -> Result<ExitCode> {
|
||||
}
|
||||
if cli.show_files {
|
||||
commands::show_files(&cli.files, &pyproject_strategy, &overrides)?;
|
||||
return Ok(ExitCode::SUCCESS);
|
||||
}
|
||||
|
||||
// Extract options that are included in `Settings`, but only apply at the top
|
||||
@@ -160,9 +154,15 @@ fn check(args: CheckArgs, log_level: LogLevel) -> Result<ExitCode> {
|
||||
}
|
||||
|
||||
if cli.add_noqa {
|
||||
if !matches!(autofix, fix::FixMode::None) {
|
||||
warn_user_once!("--fix is incompatible with --add-noqa.");
|
||||
}
|
||||
let modifications = commands::add_noqa(&cli.files, &pyproject_strategy, &overrides)?;
|
||||
if modifications > 0 && log_level >= LogLevel::Default {
|
||||
println!("Added {modifications} noqa directives.");
|
||||
#[allow(clippy::print_stderr)]
|
||||
{
|
||||
eprintln!("Added {modifications} noqa directives.");
|
||||
}
|
||||
}
|
||||
return Ok(ExitCode::SUCCESS);
|
||||
}
|
||||
@@ -171,7 +171,7 @@ fn check(args: CheckArgs, log_level: LogLevel) -> Result<ExitCode> {
|
||||
|
||||
if cli.watch {
|
||||
if !matches!(autofix, fix::FixMode::None) {
|
||||
warn_user_once!("--fix is not enabled in watch mode.");
|
||||
warn_user_once!("--fix is unsupported in watch mode.");
|
||||
}
|
||||
if format != SerializationFormat::Text {
|
||||
warn_user_once!("--format 'text' is used in watch mode.");
|
||||
@@ -255,14 +255,10 @@ fn check(args: CheckArgs, log_level: LogLevel) -> Result<ExitCode> {
|
||||
}
|
||||
}
|
||||
|
||||
// Check for updates if we're in a non-silent log level.
|
||||
#[cfg(feature = "update-informer")]
|
||||
if update_check
|
||||
&& !is_stdin
|
||||
&& log_level >= LogLevel::Default
|
||||
&& atty::is(atty::Stream::Stdout)
|
||||
{
|
||||
drop(updates::check_for_updates());
|
||||
if update_check {
|
||||
warn_user_once!(
|
||||
"update-check has been removed; setting it will cause an error in a future version."
|
||||
);
|
||||
}
|
||||
|
||||
if !cli.exit_zero {
|
||||
@@ -292,7 +288,10 @@ pub fn main() -> ExitCode {
|
||||
match inner_main() {
|
||||
Ok(code) => code,
|
||||
Err(err) => {
|
||||
eprintln!("{}{} {err:?}", "error".red().bold(), ":".bold());
|
||||
#[allow(clippy::print_stderr)]
|
||||
{
|
||||
eprintln!("{}{} {err:?}", "error".red().bold(), ":".bold());
|
||||
}
|
||||
ExitCode::FAILURE
|
||||
}
|
||||
}
|
||||
|
||||
@@ -75,7 +75,7 @@ pub struct Printer<'a> {
|
||||
}
|
||||
|
||||
impl<'a> Printer<'a> {
|
||||
pub fn new(
|
||||
pub const fn new(
|
||||
format: &'a SerializationFormat,
|
||||
log_level: &'a LogLevel,
|
||||
autofix: &'a fix::FixMode,
|
||||
@@ -122,7 +122,7 @@ impl<'a> Printer<'a> {
|
||||
if num_fixable > 0 {
|
||||
writeln!(
|
||||
stdout,
|
||||
"{num_fixable} potentially fixable with the --fix option."
|
||||
"[*] {num_fixable} potentially fixable with the --fix option."
|
||||
)?;
|
||||
}
|
||||
}
|
||||
@@ -475,17 +475,31 @@ fn num_digits(n: usize) -> usize {
|
||||
|
||||
/// Print a single `Message` with full details.
|
||||
fn print_message<T: Write>(stdout: &mut T, message: &Message) -> Result<()> {
|
||||
let label = format!(
|
||||
"{}{}{}{}{}{} {} {}",
|
||||
relativize_path(Path::new(&message.filename)).bold(),
|
||||
":".cyan(),
|
||||
message.location.row(),
|
||||
":".cyan(),
|
||||
message.location.column(),
|
||||
":".cyan(),
|
||||
message.kind.rule().code().red().bold(),
|
||||
message.kind.body(),
|
||||
);
|
||||
let label = if message.kind.fixable() {
|
||||
format!(
|
||||
"{}{}{}{}{}{} {} [*] {}",
|
||||
relativize_path(Path::new(&message.filename)).bold(),
|
||||
":".cyan(),
|
||||
message.location.row(),
|
||||
":".cyan(),
|
||||
message.location.column(),
|
||||
":".cyan(),
|
||||
message.kind.rule().code().red().bold(),
|
||||
message.kind.body(),
|
||||
)
|
||||
} else {
|
||||
format!(
|
||||
"{}{}{}{}{}{} {} {}",
|
||||
relativize_path(Path::new(&message.filename)).bold(),
|
||||
":".cyan(),
|
||||
message.location.row(),
|
||||
":".cyan(),
|
||||
message.location.column(),
|
||||
":".cyan(),
|
||||
message.kind.rule().code().red().bold(),
|
||||
message.kind.body(),
|
||||
)
|
||||
};
|
||||
writeln!(stdout, "{label}")?;
|
||||
if let Some(source) = &message.source {
|
||||
let commit = message.kind.commit();
|
||||
@@ -540,16 +554,29 @@ fn print_grouped_message<T: Write>(
|
||||
row_length: usize,
|
||||
column_length: usize,
|
||||
) -> Result<()> {
|
||||
let label = format!(
|
||||
" {}{}{}{}{} {} {}",
|
||||
" ".repeat(row_length - num_digits(message.location.row())),
|
||||
message.location.row(),
|
||||
":".cyan(),
|
||||
message.location.column(),
|
||||
" ".repeat(column_length - num_digits(message.location.column())),
|
||||
message.kind.rule().code().red().bold(),
|
||||
message.kind.body(),
|
||||
);
|
||||
let label = if message.kind.fixable() {
|
||||
format!(
|
||||
" {}{}{}{}{} {} [*] {}",
|
||||
" ".repeat(row_length - num_digits(message.location.row())),
|
||||
message.location.row(),
|
||||
":".cyan(),
|
||||
message.location.column(),
|
||||
" ".repeat(column_length - num_digits(message.location.column())),
|
||||
message.kind.rule().code().red().bold(),
|
||||
message.kind.body(),
|
||||
)
|
||||
} else {
|
||||
format!(
|
||||
" {}{}{}{}{} {} {}",
|
||||
" ".repeat(row_length - num_digits(message.location.row())),
|
||||
message.location.row(),
|
||||
":".cyan(),
|
||||
message.location.column(),
|
||||
" ".repeat(column_length - num_digits(message.location.column())),
|
||||
message.kind.rule().code().red().bold(),
|
||||
message.kind.body(),
|
||||
)
|
||||
};
|
||||
writeln!(stdout, "{label}")?;
|
||||
if let Some(source) = &message.source {
|
||||
let commit = message.kind.commit();
|
||||
|
||||
@@ -1,75 +0,0 @@
|
||||
use std::fs::{create_dir_all, read_to_string, File};
|
||||
use std::io::Write;
|
||||
use std::path::{Path, PathBuf};
|
||||
|
||||
use anyhow::Result;
|
||||
use colored::Colorize;
|
||||
|
||||
const CARGO_PKG_NAME: &str = env!("CARGO_PKG_NAME");
|
||||
const CARGO_PKG_VERSION: &str = env!("CARGO_PKG_VERSION");
|
||||
|
||||
fn cache_dir() -> &'static str {
|
||||
"./.ruff_cache"
|
||||
}
|
||||
|
||||
fn file_path() -> PathBuf {
|
||||
Path::new(cache_dir()).join(".update-informer")
|
||||
}
|
||||
|
||||
/// Get the "latest" version for which the user has been informed.
|
||||
fn get_latest() -> Result<Option<String>> {
|
||||
let path = file_path();
|
||||
if path.exists() {
|
||||
Ok(Some(read_to_string(path)?.trim().to_string()))
|
||||
} else {
|
||||
Ok(None)
|
||||
}
|
||||
}
|
||||
|
||||
/// Set the "latest" version for which the user has been informed.
|
||||
fn set_latest(version: &str) -> Result<()> {
|
||||
create_dir_all(cache_dir())?;
|
||||
let path = file_path();
|
||||
let mut file = File::create(path)?;
|
||||
file.write_all(version.trim().as_bytes())?;
|
||||
Ok(())
|
||||
}
|
||||
|
||||
/// Update the user if a newer version is available.
|
||||
pub fn check_for_updates() -> Result<()> {
|
||||
use update_informer::{registry, Check};
|
||||
|
||||
let informer = update_informer::new(registry::PyPI, CARGO_PKG_NAME, CARGO_PKG_VERSION);
|
||||
|
||||
if let Some(new_version) = informer
|
||||
.check_version()
|
||||
.ok()
|
||||
.flatten()
|
||||
.map(|version| version.to_string())
|
||||
{
|
||||
// If we've already notified the user about this version, return early.
|
||||
if let Some(latest_version) = get_latest()? {
|
||||
if latest_version == new_version {
|
||||
return Ok(());
|
||||
}
|
||||
}
|
||||
set_latest(&new_version)?;
|
||||
|
||||
let msg = format!(
|
||||
"A new version of {pkg_name} is available: v{pkg_version} -> {new_version}",
|
||||
pkg_name = CARGO_PKG_NAME.italic().cyan(),
|
||||
pkg_version = CARGO_PKG_VERSION,
|
||||
new_version = new_version.green()
|
||||
);
|
||||
|
||||
let cmd = format!(
|
||||
"Run to update: {cmd} {pkg_name}",
|
||||
cmd = "pip3 install --upgrade".green(),
|
||||
pkg_name = CARGO_PKG_NAME.green()
|
||||
);
|
||||
|
||||
println!("\n{msg}\n{cmd}");
|
||||
}
|
||||
|
||||
Ok(())
|
||||
}
|
||||
@@ -31,8 +31,10 @@ fn test_stdin_error() -> Result<()> {
|
||||
.failure();
|
||||
assert_eq!(
|
||||
str::from_utf8(&output.get_output().stdout)?,
|
||||
"-:1:8: F401 `os` imported but unused\nFound 1 error.\n1 potentially fixable with the \
|
||||
--fix option.\n"
|
||||
r#"-:1:8: F401 [*] `os` imported but unused
|
||||
Found 1 error.
|
||||
[*] 1 potentially fixable with the --fix option.
|
||||
"#
|
||||
);
|
||||
Ok(())
|
||||
}
|
||||
@@ -54,8 +56,10 @@ fn test_stdin_filename() -> Result<()> {
|
||||
.failure();
|
||||
assert_eq!(
|
||||
str::from_utf8(&output.get_output().stdout)?,
|
||||
"F401.py:1:8: F401 `os` imported but unused\nFound 1 error.\n1 potentially fixable with \
|
||||
the --fix option.\n"
|
||||
r#"F401.py:1:8: F401 [*] `os` imported but unused
|
||||
Found 1 error.
|
||||
[*] 1 potentially fixable with the --fix option.
|
||||
"#
|
||||
);
|
||||
Ok(())
|
||||
}
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[package]
|
||||
name = "ruff_dev"
|
||||
version = "0.0.240"
|
||||
version = "0.0.241"
|
||||
edition = "2021"
|
||||
|
||||
[dependencies]
|
||||
@@ -11,9 +11,9 @@ libcst = { git = "https://github.com/charliermarsh/LibCST", rev = "f2f0b7a487a87
|
||||
once_cell = { version = "1.16.0" }
|
||||
ruff = { path = ".." }
|
||||
ruff_cli = { path = "../ruff_cli" }
|
||||
rustpython-ast = { features = ["unparse"], git = "https://github.com/RustPython/RustPython.git", rev = "4f38cb68e4a97aeea9eb19673803a0bd5f655383" }
|
||||
rustpython-common = { git = "https://github.com/RustPython/RustPython.git", rev = "4f38cb68e4a97aeea9eb19673803a0bd5f655383" }
|
||||
rustpython-parser = { features = ["lalrpop"], git = "https://github.com/RustPython/RustPython.git", rev = "4f38cb68e4a97aeea9eb19673803a0bd5f655383" }
|
||||
rustpython-ast = { features = ["unparse"], git = "https://github.com/RustPython/RustPython.git", rev = "adc23253e4b58980b407ba2760dbe61681d752fc" }
|
||||
rustpython-common = { git = "https://github.com/RustPython/RustPython.git", rev = "adc23253e4b58980b407ba2760dbe61681d752fc" }
|
||||
rustpython-parser = { features = ["lalrpop"], git = "https://github.com/RustPython/RustPython.git", rev = "adc23253e4b58980b407ba2760dbe61681d752fc" }
|
||||
schemars = { version = "0.8.11" }
|
||||
serde_json = { version = "1.0.91" }
|
||||
strum = { version = "0.24.1", features = ["strum_macros"] }
|
||||
|
||||
@@ -1,13 +1,14 @@
|
||||
//! Generate CLI help.
|
||||
#![allow(clippy::print_stdout, clippy::print_stderr)]
|
||||
|
||||
use crate::utils::replace_readme_section;
|
||||
use anyhow::Result;
|
||||
use std::str;
|
||||
|
||||
const COMMAND_HELP_BEGIN_PRAGMA: &str = "<!-- Begin auto-generated command help. -->";
|
||||
const COMMAND_HELP_BEGIN_PRAGMA: &str = "<!-- Begin auto-generated command help. -->\n";
|
||||
const COMMAND_HELP_END_PRAGMA: &str = "<!-- End auto-generated command help. -->";
|
||||
|
||||
const SUBCOMMAND_HELP_BEGIN_PRAGMA: &str = "<!-- Begin auto-generated subcommand help. -->";
|
||||
const SUBCOMMAND_HELP_BEGIN_PRAGMA: &str = "<!-- Begin auto-generated subcommand help. -->\n";
|
||||
const SUBCOMMAND_HELP_END_PRAGMA: &str = "<!-- End auto-generated subcommand help. -->";
|
||||
|
||||
#[derive(clap::Args)]
|
||||
@@ -33,12 +34,12 @@ pub fn main(args: &Args) -> Result<()> {
|
||||
print!("{subcommand_help}");
|
||||
} else {
|
||||
replace_readme_section(
|
||||
&format!("```\n{command_help}\n```\n"),
|
||||
&format!("```text\n{command_help}\n```\n\n"),
|
||||
COMMAND_HELP_BEGIN_PRAGMA,
|
||||
COMMAND_HELP_END_PRAGMA,
|
||||
)?;
|
||||
replace_readme_section(
|
||||
&format!("```\n{subcommand_help}\n```\n"),
|
||||
&format!("```text\n{subcommand_help}\n```\n\n"),
|
||||
SUBCOMMAND_HELP_BEGIN_PRAGMA,
|
||||
SUBCOMMAND_HELP_END_PRAGMA,
|
||||
)?;
|
||||
|
||||
@@ -1,3 +1,5 @@
|
||||
#![allow(clippy::print_stdout, clippy::print_stderr)]
|
||||
|
||||
use std::fs;
|
||||
use std::path::PathBuf;
|
||||
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
//! Generate a Markdown-compatible listing of configuration options.
|
||||
#![allow(clippy::print_stdout, clippy::print_stderr)]
|
||||
|
||||
use anyhow::Result;
|
||||
use itertools::Itertools;
|
||||
@@ -7,7 +8,7 @@ use ruff::settings::options_base::{ConfigurationOptions, OptionEntry, OptionFiel
|
||||
|
||||
use crate::utils::replace_readme_section;
|
||||
|
||||
const BEGIN_PRAGMA: &str = "<!-- Begin auto-generated options sections. -->";
|
||||
const BEGIN_PRAGMA: &str = "<!-- Begin auto-generated options sections. -->\n";
|
||||
const END_PRAGMA: &str = "<!-- End auto-generated options sections. -->";
|
||||
|
||||
#[derive(clap::Args)]
|
||||
|
||||
@@ -1,13 +1,14 @@
|
||||
//! Generate a Markdown-compatible table of supported lint rules.
|
||||
#![allow(clippy::print_stdout, clippy::print_stderr)]
|
||||
|
||||
use anyhow::Result;
|
||||
use itertools::Itertools;
|
||||
use ruff::registry::{Linter, LinterCategory, Rule, RuleNamespace};
|
||||
use ruff::registry::{Linter, Rule, RuleNamespace, UpstreamCategory};
|
||||
use strum::IntoEnumIterator;
|
||||
|
||||
use crate::utils::replace_readme_section;
|
||||
|
||||
const TABLE_BEGIN_PRAGMA: &str = "<!-- Begin auto-generated sections. -->";
|
||||
const TABLE_BEGIN_PRAGMA: &str = "<!-- Begin auto-generated sections. -->\n";
|
||||
const TABLE_END_PRAGMA: &str = "<!-- End auto-generated sections. -->";
|
||||
|
||||
const TOC_BEGIN_PRAGMA: &str = "<!-- Begin auto-generated table of contents. -->";
|
||||
@@ -50,10 +51,10 @@ pub fn main(args: &Args) -> Result<()> {
|
||||
for linter in Linter::iter() {
|
||||
let codes_csv: String = match linter.common_prefix() {
|
||||
"" => linter
|
||||
.categories()
|
||||
.upstream_categories()
|
||||
.unwrap()
|
||||
.iter()
|
||||
.map(|LinterCategory(prefix, ..)| prefix)
|
||||
.map(|UpstreamCategory(prefix, ..)| prefix.as_ref())
|
||||
.join(", "),
|
||||
prefix => prefix.to_string(),
|
||||
};
|
||||
@@ -93,11 +94,12 @@ pub fn main(args: &Args) -> Result<()> {
|
||||
table_out.push('\n');
|
||||
}
|
||||
|
||||
if let Some(categories) = linter.categories() {
|
||||
for LinterCategory(prefix, name, selector) in categories {
|
||||
table_out.push_str(&format!("#### {name} ({prefix})"));
|
||||
if let Some(categories) = linter.upstream_categories() {
|
||||
for UpstreamCategory(prefix, name) in categories {
|
||||
table_out.push_str(&format!("#### {name} ({})", prefix.as_ref()));
|
||||
table_out.push('\n');
|
||||
generate_table(&mut table_out, selector);
|
||||
table_out.push('\n');
|
||||
generate_table(&mut table_out, prefix);
|
||||
}
|
||||
} else {
|
||||
generate_table(&mut table_out, &linter);
|
||||
|
||||
@@ -1,20 +1,6 @@
|
||||
//! This crate implements an internal CLI for developers of Ruff.
|
||||
//!
|
||||
//! Within the ruff repository you can run it with `cargo dev`.
|
||||
#![forbid(unsafe_code)]
|
||||
#![warn(clippy::pedantic)]
|
||||
#![allow(
|
||||
clippy::collapsible_else_if,
|
||||
clippy::collapsible_if,
|
||||
clippy::implicit_hasher,
|
||||
clippy::match_same_arms,
|
||||
clippy::missing_errors_doc,
|
||||
clippy::missing_panics_doc,
|
||||
clippy::module_name_repetitions,
|
||||
clippy::must_use_candidate,
|
||||
clippy::similar_names,
|
||||
clippy::too_many_lines
|
||||
)]
|
||||
|
||||
mod generate_all;
|
||||
mod generate_cli_help;
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
//! Print the AST for a given Python file.
|
||||
#![allow(clippy::print_stdout, clippy::print_stderr)]
|
||||
|
||||
use std::fs;
|
||||
use std::path::PathBuf;
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
//! Print the `LibCST` CST for a given Python file.
|
||||
#![allow(clippy::print_stdout, clippy::print_stderr)]
|
||||
|
||||
use std::fs;
|
||||
use std::path::PathBuf;
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
//! Print the token stream for a given Python file.
|
||||
#![allow(clippy::print_stdout, clippy::print_stderr)]
|
||||
|
||||
use std::fs;
|
||||
use std::path::PathBuf;
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
//! Run round-trip source code generation on a given Python file.
|
||||
#![allow(clippy::print_stdout, clippy::print_stderr)]
|
||||
|
||||
use std::fs;
|
||||
use std::path::PathBuf;
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[package]
|
||||
name = "ruff_macros"
|
||||
version = "0.0.240"
|
||||
version = "0.0.241"
|
||||
edition = "2021"
|
||||
|
||||
[lib]
|
||||
|
||||
@@ -176,7 +176,7 @@ impl Parse for FieldAttributes {
|
||||
input.parse::<Comma>()?;
|
||||
}
|
||||
|
||||
Ok(FieldAttributes {
|
||||
Ok(Self {
|
||||
default,
|
||||
value_type,
|
||||
example: textwrap::dedent(&example).trim_matches('\n').to_string(),
|
||||
|
||||
@@ -29,7 +29,7 @@ pub fn define_rule_mapping(mapping: &Mapping) -> proc_macro2::TokenStream {
|
||||
.extend(quote! {Self::#name => <#path as Violation>::message_formats(),});
|
||||
rule_autofixable_match_arms.extend(quote! {Self::#name => <#path as Violation>::AUTOFIX,});
|
||||
rule_code_match_arms.extend(quote! {Self::#name => #code_str,});
|
||||
rule_from_code_match_arms.extend(quote! {#code_str => Ok(&Rule::#name), });
|
||||
rule_from_code_match_arms.extend(quote! {#code_str => Ok(Rule::#name), });
|
||||
diagkind_code_match_arms.extend(quote! {Self::#name(..) => &Rule::#name, });
|
||||
diagkind_body_match_arms.extend(quote! {Self::#name(x) => Violation::message(x), });
|
||||
diagkind_fixable_match_arms
|
||||
@@ -96,7 +96,7 @@ pub fn define_rule_mapping(mapping: &Mapping) -> proc_macro2::TokenStream {
|
||||
match self { #rule_code_match_arms }
|
||||
}
|
||||
|
||||
pub fn from_code(code: &str) -> Result<&'static Self, FromCodeError> {
|
||||
pub fn from_code(code: &str) -> Result<Self, FromCodeError> {
|
||||
match code {
|
||||
#rule_from_code_match_arms
|
||||
_ => Err(FromCodeError::Unknown),
|
||||
@@ -148,6 +148,6 @@ impl Parse for Mapping {
|
||||
let _: Token![,] = input.parse()?;
|
||||
entries.push((code, path, name));
|
||||
}
|
||||
Ok(Mapping { entries })
|
||||
Ok(Self { entries })
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,18 +1,4 @@
|
||||
//! This crate implements internal macros for the `ruff` library.
|
||||
#![forbid(unsafe_code)]
|
||||
#![warn(clippy::pedantic)]
|
||||
#![allow(
|
||||
clippy::collapsible_else_if,
|
||||
clippy::collapsible_if,
|
||||
clippy::implicit_hasher,
|
||||
clippy::match_same_arms,
|
||||
clippy::missing_errors_doc,
|
||||
clippy::missing_panics_doc,
|
||||
clippy::module_name_repetitions,
|
||||
clippy::must_use_candidate,
|
||||
clippy::similar_names,
|
||||
clippy::too_many_lines
|
||||
)]
|
||||
|
||||
use proc_macro::TokenStream;
|
||||
use syn::{parse_macro_input, DeriveInput, ItemFn};
|
||||
|
||||
@@ -21,7 +21,7 @@ def snake_case(name: str) -> str:
|
||||
).lstrip("_")
|
||||
|
||||
|
||||
def main(*, name: str, code: str, linter: str) -> None:
|
||||
def main(*, name: str, code: str, linter: str) -> None: # noqa: PLR0915
|
||||
"""Generate boilerplate for a new rule."""
|
||||
# Create a test fixture.
|
||||
with (ROOT_DIR / "resources/test/fixtures" / dir_name(linter) / f"{code}.py").open(
|
||||
|
||||
91
scripts/generate_known_standard_library.py
Normal file
91
scripts/generate_known_standard_library.py
Normal file
@@ -0,0 +1,91 @@
|
||||
"""Vendored from [scripts/mkstdlibs.py in PyCQA/isort](https://github.com/PyCQA/isort/blob/e321a670d0fefdea0e04ed9d8d696434cf49bdec/scripts/mkstdlibs.py).
|
||||
|
||||
Only the generation of the file has been modified for use in this project.
|
||||
"""
|
||||
|
||||
from pathlib import Path
|
||||
|
||||
from sphinx.ext.intersphinx import fetch_inventory
|
||||
|
||||
URL = "https://docs.python.org/{}/objects.inv"
|
||||
PATH = Path("src") / "python" / "sys.rs"
|
||||
VERSIONS = [
|
||||
("3", "7"),
|
||||
("3", "8"),
|
||||
("3", "9"),
|
||||
("3", "10"),
|
||||
("3", "11"),
|
||||
]
|
||||
|
||||
|
||||
class FakeConfig: # noqa: D101
|
||||
intersphinx_timeout = None
|
||||
tls_verify = True
|
||||
user_agent = ""
|
||||
|
||||
|
||||
class FakeApp: # noqa: D101
|
||||
srcdir = ""
|
||||
config = FakeConfig()
|
||||
|
||||
|
||||
with PATH.open("w") as f:
|
||||
f.write(
|
||||
"""\
|
||||
//! This file is generated by `scripts/generate_known_standard_library.py`
|
||||
use once_cell::sync::Lazy;
|
||||
use rustc_hash::{FxHashMap, FxHashSet};
|
||||
|
||||
use crate::settings::types::PythonVersion;
|
||||
|
||||
// See: https://pycqa.github.io/isort/docs/configuration/options.html#known-standard-library
|
||||
pub static KNOWN_STANDARD_LIBRARY: Lazy<FxHashMap<PythonVersion, FxHashSet<&'static str>>> =
|
||||
Lazy::new(|| {
|
||||
FxHashMap::from_iter([
|
||||
""",
|
||||
)
|
||||
for version_info in VERSIONS:
|
||||
version = ".".join(version_info)
|
||||
url = URL.format(version)
|
||||
invdata = fetch_inventory(FakeApp(), "", url)
|
||||
|
||||
# Any modules we want to enforce across Python versions stdlib can be included in set init
|
||||
modules = {
|
||||
"_ast",
|
||||
"posixpath",
|
||||
"ntpath",
|
||||
"sre_constants",
|
||||
"sre_parse",
|
||||
"sre_compile",
|
||||
"sre",
|
||||
}
|
||||
for module in invdata["py:module"]:
|
||||
root, *_ = module.split(".")
|
||||
if root not in ["__future__", "__main__"]:
|
||||
modules.add(root)
|
||||
|
||||
f.write(
|
||||
f"""\
|
||||
(
|
||||
PythonVersion::Py{"".join(version_info)},
|
||||
FxHashSet::from_iter([
|
||||
""",
|
||||
)
|
||||
for module in sorted(modules):
|
||||
f.write(
|
||||
f"""\
|
||||
"{module}",
|
||||
""",
|
||||
)
|
||||
f.write(
|
||||
"""\
|
||||
]),
|
||||
),
|
||||
""",
|
||||
)
|
||||
f.write(
|
||||
"""\
|
||||
])
|
||||
});
|
||||
""",
|
||||
)
|
||||
@@ -1,11 +1,19 @@
|
||||
[project]
|
||||
name = "scripts"
|
||||
version = "0.0.1"
|
||||
dependencies = ["sphinx"]
|
||||
|
||||
[tool.ruff]
|
||||
select = ["ALL"]
|
||||
ignore = [
|
||||
"E501", # line-too-long
|
||||
"INP001", # implicit-namespace-package
|
||||
"PLR2004", # magic-value-comparison
|
||||
"S101", # assert-used
|
||||
"EM"
|
||||
"E501", # line-too-long
|
||||
"INP001", # implicit-namespace-package
|
||||
"PL", # pylint
|
||||
"S101", # assert-used
|
||||
"EM", # errmgs
|
||||
]
|
||||
unfixable = [
|
||||
"RUF100", # unused-noqa
|
||||
]
|
||||
|
||||
[tool.ruff.pydocstyle]
|
||||
|
||||
@@ -7,32 +7,36 @@ adjusts the images in the README.md to support the given target.
|
||||
import argparse
|
||||
from pathlib import Path
|
||||
|
||||
URL = "https://user-images.githubusercontent.com/1309177/{}.svg"
|
||||
URL_LIGHT = URL.format("212613257-5f4bca12-6d6b-4c79-9bac-51a4c6d08928")
|
||||
URL_DARK = URL.format("212613422-7faaf278-706b-4294-ad92-236ffcab3430")
|
||||
|
||||
# https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax#specifying-the-theme-an-image-is-shown-to
|
||||
GITHUB = """
|
||||
GITHUB = f"""
|
||||
<p align="center">
|
||||
<picture align="center">
|
||||
<source media="(prefers-color-scheme: dark)" srcset="https://user-images.githubusercontent.com/1309177/212613422-7faaf278-706b-4294-ad92-236ffcab3430.svg">
|
||||
<source media="(prefers-color-scheme: light)" srcset="https://user-images.githubusercontent.com/1309177/212613257-5f4bca12-6d6b-4c79-9bac-51a4c6d08928.svg">
|
||||
<img alt="Shows a bar chart with benchmark results." src="https://user-images.githubusercontent.com/1309177/212613257-5f4bca12-6d6b-4c79-9bac-51a4c6d08928.svg">
|
||||
<source media="(prefers-color-scheme: dark)" srcset="{URL_DARK}">
|
||||
<source media="(prefers-color-scheme: light)" srcset="{URL_LIGHT}">
|
||||
<img alt="Shows a bar chart with benchmark results." src="{URL_LIGHT}">
|
||||
</picture>
|
||||
</p>
|
||||
"""
|
||||
|
||||
# https://github.com/pypi/warehouse/issues/11251
|
||||
PYPI = """
|
||||
PYPI = f"""
|
||||
<p align="center">
|
||||
<img alt="Shows a bar chart with benchmark results." src="https://user-images.githubusercontent.com/1309177/212613257-5f4bca12-6d6b-4c79-9bac-51a4c6d08928.svg">
|
||||
<img alt="Shows a bar chart with benchmark results." src="{URL_LIGHT}">
|
||||
</p>
|
||||
"""
|
||||
|
||||
# https://squidfunk.github.io/mkdocs-material/reference/images/#light-and-dark-mode
|
||||
MK_DOCS = """
|
||||
MK_DOCS = f"""
|
||||
<p align="center">
|
||||
<img alt="Shows a bar chart with benchmark results." src="https://user-images.githubusercontent.com/1309177/212613257-5f4bca12-6d6b-4c79-9bac-51a4c6d08928.svg#only-light">
|
||||
<img alt="Shows a bar chart with benchmark results." src="{URL_LIGHT}#only-light">
|
||||
</p>
|
||||
|
||||
<p align="center">
|
||||
<img alt="Shows a bar chart with benchmark results." src="https://user-images.githubusercontent.com/1309177/212613422-7faaf278-706b-4294-ad92-236ffcab3430.svg#only-dark">
|
||||
<img alt="Shows a bar chart with benchmark results." src="{URL_DARK}#only-dark">
|
||||
</p>
|
||||
"""
|
||||
|
||||
|
||||
2
setup.py
2
setup.py
@@ -9,7 +9,7 @@ Unsupported installation method
|
||||
===============================
|
||||
ruff no longer supports installation with `python setup.py install`.
|
||||
Please use `python -m pip install .` instead.
|
||||
"""
|
||||
""",
|
||||
)
|
||||
sys.exit(1)
|
||||
|
||||
|
||||
@@ -30,11 +30,11 @@ impl<'a> From<&'a Expr> for HashableExpr<'a> {
|
||||
}
|
||||
|
||||
impl<'a> HashableExpr<'a> {
|
||||
pub(crate) fn from_expr(expr: &'a Expr) -> Self {
|
||||
pub(crate) const fn from_expr(expr: &'a Expr) -> Self {
|
||||
Self(expr)
|
||||
}
|
||||
|
||||
pub(crate) fn as_expr(&self) -> &'a Expr {
|
||||
pub(crate) const fn as_expr(&self) -> &'a Expr {
|
||||
self.0
|
||||
}
|
||||
}
|
||||
|
||||
@@ -445,7 +445,7 @@ pub fn is_assignment_to_a_dunder(stmt: &Stmt) -> bool {
|
||||
|
||||
/// Return `true` if the [`Expr`] is a singleton (`None`, `True`, `False`, or
|
||||
/// `...`).
|
||||
pub fn is_singleton(expr: &Expr) -> bool {
|
||||
pub const fn is_singleton(expr: &Expr) -> bool {
|
||||
matches!(
|
||||
expr.node,
|
||||
ExprKind::Constant {
|
||||
@@ -479,7 +479,7 @@ pub fn find_keyword<'a>(keywords: &'a [Keyword], keyword_name: &str) -> Option<&
|
||||
}
|
||||
|
||||
/// Return `true` if an [`Expr`] is `None`.
|
||||
pub fn is_const_none(expr: &Expr) -> bool {
|
||||
pub const fn is_const_none(expr: &Expr) -> bool {
|
||||
matches!(
|
||||
&expr.node,
|
||||
ExprKind::Constant {
|
||||
@@ -490,7 +490,7 @@ pub fn is_const_none(expr: &Expr) -> bool {
|
||||
}
|
||||
|
||||
/// Return `true` if an [`Expr`] is `True`.
|
||||
pub fn is_const_true(expr: &Expr) -> bool {
|
||||
pub const fn is_const_true(expr: &Expr) -> bool {
|
||||
matches!(
|
||||
&expr.node,
|
||||
ExprKind::Constant {
|
||||
@@ -560,19 +560,34 @@ pub fn collect_arg_names<'a>(arguments: &'a Arguments) -> FxHashSet<&'a str> {
|
||||
|
||||
/// Returns `true` if a statement or expression includes at least one comment.
|
||||
pub fn has_comments<T>(located: &Located<T>, locator: &Locator) -> bool {
|
||||
has_comments_in(
|
||||
Range::new(
|
||||
Location::new(located.location.row(), 0),
|
||||
Location::new(located.end_location.unwrap().row() + 1, 0),
|
||||
),
|
||||
locator,
|
||||
)
|
||||
let start = if match_leading_content(located, locator) {
|
||||
located.location
|
||||
} else {
|
||||
Location::new(located.location.row(), 0)
|
||||
};
|
||||
let end = if match_trailing_content(located, locator) {
|
||||
located.end_location.unwrap()
|
||||
} else {
|
||||
Location::new(located.end_location.unwrap().row() + 1, 0)
|
||||
};
|
||||
has_comments_in(Range::new(start, end), locator)
|
||||
}
|
||||
|
||||
/// Returns `true` if a [`Range`] includes at least one comment.
|
||||
pub fn has_comments_in(range: Range, locator: &Locator) -> bool {
|
||||
lexer::make_tokenizer(locator.slice_source_code_range(&range))
|
||||
.any(|result| result.map_or(false, |(_, tok, _)| matches!(tok, Tok::Comment(..))))
|
||||
for tok in lexer::make_tokenizer(locator.slice_source_code_range(&range)) {
|
||||
match tok {
|
||||
Ok((_, tok, _)) => {
|
||||
if matches!(tok, Tok::Comment(..)) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
Err(_) => {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
}
|
||||
false
|
||||
}
|
||||
|
||||
/// Returns `true` if a call is an argumented `super` invocation.
|
||||
@@ -673,18 +688,18 @@ pub fn to_relative(absolute: Location, base: Location) -> Location {
|
||||
}
|
||||
}
|
||||
|
||||
/// Return `true` if a `Stmt` has leading content.
|
||||
pub fn match_leading_content(stmt: &Stmt, locator: &Locator) -> bool {
|
||||
let range = Range::new(Location::new(stmt.location.row(), 0), stmt.location);
|
||||
/// Return `true` if a [`Located`] has leading content.
|
||||
pub fn match_leading_content<T>(located: &Located<T>, locator: &Locator) -> bool {
|
||||
let range = Range::new(Location::new(located.location.row(), 0), located.location);
|
||||
let prefix = locator.slice_source_code_range(&range);
|
||||
prefix.chars().any(|char| !char.is_whitespace())
|
||||
}
|
||||
|
||||
/// Return `true` if a `Stmt` has trailing content.
|
||||
pub fn match_trailing_content(stmt: &Stmt, locator: &Locator) -> bool {
|
||||
/// Return `true` if a [`Located`] has trailing content.
|
||||
pub fn match_trailing_content<T>(located: &Located<T>, locator: &Locator) -> bool {
|
||||
let range = Range::new(
|
||||
stmt.end_location.unwrap(),
|
||||
Location::new(stmt.end_location.unwrap().row() + 1, 0),
|
||||
located.end_location.unwrap(),
|
||||
Location::new(located.end_location.unwrap().row() + 1, 0),
|
||||
);
|
||||
let suffix = locator.slice_source_code_range(&range);
|
||||
for char in suffix.chars() {
|
||||
@@ -698,11 +713,11 @@ pub fn match_trailing_content(stmt: &Stmt, locator: &Locator) -> bool {
|
||||
false
|
||||
}
|
||||
|
||||
/// If a `Stmt` has a trailing comment, return the index of the hash.
|
||||
pub fn match_trailing_comment(stmt: &Stmt, locator: &Locator) -> Option<usize> {
|
||||
/// If a [`Located`] has a trailing comment, return the index of the hash.
|
||||
pub fn match_trailing_comment<T>(located: &Located<T>, locator: &Locator) -> Option<usize> {
|
||||
let range = Range::new(
|
||||
stmt.end_location.unwrap(),
|
||||
Location::new(stmt.end_location.unwrap().row() + 1, 0),
|
||||
located.end_location.unwrap(),
|
||||
Location::new(located.end_location.unwrap().row() + 1, 0),
|
||||
);
|
||||
let suffix = locator.slice_source_code_range(&range);
|
||||
for (i, char) in suffix.chars().enumerate() {
|
||||
@@ -753,11 +768,10 @@ pub fn binding_range(binding: &Binding, locator: &Locator) -> Range {
|
||||
binding.kind,
|
||||
BindingKind::ClassDefinition | BindingKind::FunctionDefinition
|
||||
) {
|
||||
if let Some(source) = &binding.source {
|
||||
identifier_range(source, locator)
|
||||
} else {
|
||||
binding.range
|
||||
}
|
||||
binding
|
||||
.source
|
||||
.as_ref()
|
||||
.map_or(binding.range, |source| identifier_range(source, locator))
|
||||
} else {
|
||||
binding.range
|
||||
}
|
||||
@@ -959,7 +973,7 @@ pub fn followed_by_multi_statement_line(stmt: &Stmt, locator: &Locator) -> bool
|
||||
}
|
||||
|
||||
/// Return `true` if a `Stmt` is a docstring.
|
||||
pub fn is_docstring_stmt(stmt: &Stmt) -> bool {
|
||||
pub const fn is_docstring_stmt(stmt: &Stmt) -> bool {
|
||||
if let StmtKind::Expr { value } = &stmt.node {
|
||||
matches!(
|
||||
value.node,
|
||||
|
||||
@@ -6,9 +6,10 @@ use rustpython_parser::lexer;
|
||||
use rustpython_parser::lexer::Tok;
|
||||
|
||||
use crate::ast::helpers::any_over_expr;
|
||||
use crate::ast::types::{Binding, BindingKind, Scope};
|
||||
use crate::ast::types::{BindingKind, Scope};
|
||||
use crate::ast::visitor;
|
||||
use crate::ast::visitor::Visitor;
|
||||
use crate::checkers::ast::Checker;
|
||||
|
||||
bitflags! {
|
||||
#[derive(Default)]
|
||||
@@ -20,9 +21,9 @@ bitflags! {
|
||||
|
||||
/// Extract the names bound to a given __all__ assignment.
|
||||
pub fn extract_all_names(
|
||||
checker: &Checker,
|
||||
stmt: &Stmt,
|
||||
scope: &Scope,
|
||||
bindings: &[Binding],
|
||||
) -> (Vec<String>, AllNamesFlags) {
|
||||
fn add_to_names(names: &mut Vec<String>, elts: &[Expr], flags: &mut AllNamesFlags) {
|
||||
for elt in elts {
|
||||
@@ -38,13 +39,66 @@ pub fn extract_all_names(
|
||||
}
|
||||
}
|
||||
|
||||
fn extract_elts<'a>(
|
||||
checker: &'a Checker,
|
||||
expr: &'a Expr,
|
||||
) -> (Option<&'a Vec<Expr>>, AllNamesFlags) {
|
||||
match &expr.node {
|
||||
ExprKind::List { elts, .. } => {
|
||||
return (Some(elts), AllNamesFlags::empty());
|
||||
}
|
||||
ExprKind::Tuple { elts, .. } => {
|
||||
return (Some(elts), AllNamesFlags::empty());
|
||||
}
|
||||
ExprKind::ListComp { .. } => {
|
||||
// Allow comprehensions, even though we can't statically analyze them.
|
||||
return (None, AllNamesFlags::empty());
|
||||
}
|
||||
ExprKind::Call {
|
||||
func,
|
||||
args,
|
||||
keywords,
|
||||
..
|
||||
} => {
|
||||
// Allow `tuple()` and `list()` calls.
|
||||
if keywords.is_empty() && args.len() <= 1 {
|
||||
if checker.resolve_call_path(func).map_or(false, |call_path| {
|
||||
call_path.as_slice() == ["", "tuple"]
|
||||
|| call_path.as_slice() == ["", "list"]
|
||||
}) {
|
||||
if args.is_empty() {
|
||||
return (None, AllNamesFlags::empty());
|
||||
}
|
||||
match &args[0].node {
|
||||
ExprKind::List { elts, .. }
|
||||
| ExprKind::Set { elts, .. }
|
||||
| ExprKind::Tuple { elts, .. } => {
|
||||
return (Some(elts), AllNamesFlags::empty());
|
||||
}
|
||||
ExprKind::ListComp { .. }
|
||||
| ExprKind::SetComp { .. }
|
||||
| ExprKind::GeneratorExp { .. } => {
|
||||
// Allow comprehensions, even though we can't statically analyze
|
||||
// them.
|
||||
return (None, AllNamesFlags::empty());
|
||||
}
|
||||
_ => {}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
_ => {}
|
||||
}
|
||||
(None, AllNamesFlags::INVALID_FORMAT)
|
||||
}
|
||||
|
||||
let mut names: Vec<String> = vec![];
|
||||
let mut flags = AllNamesFlags::empty();
|
||||
|
||||
// Grab the existing bound __all__ values.
|
||||
if let StmtKind::AugAssign { .. } = &stmt.node {
|
||||
if let Some(index) = scope.values.get("__all__") {
|
||||
if let BindingKind::Export(existing) = &bindings[*index].kind {
|
||||
if let Some(index) = scope.bindings.get("__all__") {
|
||||
if let BindingKind::Export(existing) = &checker.bindings[*index].kind {
|
||||
names.extend_from_slice(existing);
|
||||
}
|
||||
}
|
||||
@@ -56,45 +110,36 @@ pub fn extract_all_names(
|
||||
StmtKind::AugAssign { value, .. } => Some(value),
|
||||
_ => None,
|
||||
} {
|
||||
match &value.node {
|
||||
ExprKind::List { elts, .. } | ExprKind::Tuple { elts, .. } => {
|
||||
add_to_names(&mut names, elts, &mut flags);
|
||||
}
|
||||
ExprKind::BinOp { left, right, .. } => {
|
||||
let mut current_left = left;
|
||||
let mut current_right = right;
|
||||
while let Some(elts) = match ¤t_right.node {
|
||||
ExprKind::List { elts, .. } => Some(elts),
|
||||
ExprKind::Tuple { elts, .. } => Some(elts),
|
||||
_ => {
|
||||
flags |= AllNamesFlags::INVALID_FORMAT;
|
||||
None
|
||||
}
|
||||
} {
|
||||
if let ExprKind::BinOp { left, right, .. } = &value.node {
|
||||
let mut current_left = left;
|
||||
let mut current_right = right;
|
||||
loop {
|
||||
// Process the right side, which should be a "real" value.
|
||||
let (elts, new_flags) = extract_elts(checker, current_right);
|
||||
flags |= new_flags;
|
||||
if let Some(elts) = elts {
|
||||
add_to_names(&mut names, elts, &mut flags);
|
||||
match ¤t_left.node {
|
||||
ExprKind::BinOp { left, right, .. } => {
|
||||
current_left = left;
|
||||
current_right = right;
|
||||
}
|
||||
ExprKind::List { elts, .. } | ExprKind::Tuple { elts, .. } => {
|
||||
add_to_names(&mut names, elts, &mut flags);
|
||||
break;
|
||||
}
|
||||
_ => {
|
||||
flags |= AllNamesFlags::INVALID_FORMAT;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// Process the left side, which can be a "real" value or the "rest" of the
|
||||
// binary operation.
|
||||
if let ExprKind::BinOp { left, right, .. } = ¤t_left.node {
|
||||
current_left = left;
|
||||
current_right = right;
|
||||
} else {
|
||||
let (elts, new_flags) = extract_elts(checker, current_left);
|
||||
flags |= new_flags;
|
||||
if let Some(elts) = elts {
|
||||
add_to_names(&mut names, elts, &mut flags);
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
ExprKind::ListComp { .. } => {
|
||||
// Allow list comprehensions, even though we can't statically analyze them.
|
||||
// TODO(charlie): Allow `list()` and `tuple()` calls too, and extract the members
|
||||
// from them (even if, e.g., it's `list({...})`).
|
||||
}
|
||||
_ => {
|
||||
flags |= AllNamesFlags::INVALID_FORMAT;
|
||||
} else {
|
||||
let (elts, new_flags) = extract_elts(checker, value);
|
||||
flags |= new_flags;
|
||||
if let Some(elts) = elts {
|
||||
add_to_names(&mut names, elts, &mut flags);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -23,7 +23,7 @@ pub struct Range {
|
||||
}
|
||||
|
||||
impl Range {
|
||||
pub fn new(location: Location, end_location: Location) -> Self {
|
||||
pub const fn new(location: Location, end_location: Location) -> Self {
|
||||
Self {
|
||||
location,
|
||||
end_location,
|
||||
@@ -87,8 +87,11 @@ pub struct Scope<'a> {
|
||||
pub kind: ScopeKind<'a>,
|
||||
pub import_starred: bool,
|
||||
pub uses_locals: bool,
|
||||
/// A map from bound name to binding index.
|
||||
pub values: FxHashMap<&'a str, usize>,
|
||||
/// A map from bound name to binding index, for live bindings.
|
||||
pub bindings: FxHashMap<&'a str, usize>,
|
||||
/// A map from bound name to binding index, for bindings that were created in the scope but
|
||||
/// rebound (and thus overridden) later on in the same scope.
|
||||
pub rebounds: FxHashMap<&'a str, Vec<usize>>,
|
||||
}
|
||||
|
||||
impl<'a> Scope<'a> {
|
||||
@@ -98,7 +101,8 @@ impl<'a> Scope<'a> {
|
||||
kind,
|
||||
import_starred: false,
|
||||
uses_locals: false,
|
||||
values: FxHashMap::default(),
|
||||
bindings: FxHashMap::default(),
|
||||
rebounds: FxHashMap::default(),
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -175,13 +179,13 @@ impl<'a> Binding<'a> {
|
||||
}
|
||||
}
|
||||
|
||||
pub fn used(&self) -> bool {
|
||||
pub const fn used(&self) -> bool {
|
||||
self.runtime_usage.is_some()
|
||||
|| self.synthetic_usage.is_some()
|
||||
|| self.typing_usage.is_some()
|
||||
}
|
||||
|
||||
pub fn is_definition(&self) -> bool {
|
||||
pub const fn is_definition(&self) -> bool {
|
||||
matches!(
|
||||
self.kind,
|
||||
BindingKind::ClassDefinition
|
||||
|
||||
@@ -28,7 +28,6 @@ use crate::ast::{branch_detection, cast, helpers, operations, visitor};
|
||||
use crate::docstrings::definition::{Definition, DefinitionKind, Docstring, Documentable};
|
||||
use crate::noqa::Directive;
|
||||
use crate::python::builtins::{BUILTINS, MAGIC_GLOBALS};
|
||||
use crate::python::future::ALL_FEATURE_NAMES;
|
||||
use crate::python::typing;
|
||||
use crate::python::typing::{Callable, SubscriptKind};
|
||||
use crate::registry::{Diagnostic, Rule};
|
||||
@@ -44,9 +43,8 @@ use crate::rules::{
|
||||
use crate::settings::types::PythonVersion;
|
||||
use crate::settings::{flags, Settings};
|
||||
use crate::source_code::{Indexer, Locator, Stylist};
|
||||
use crate::violations::DeferralKeyword;
|
||||
use crate::visibility::{module_visibility, transition_scope, Modifier, Visibility, VisibleScope};
|
||||
use crate::{autofix, docstrings, noqa, violations, visibility};
|
||||
use crate::{autofix, docstrings, noqa, visibility};
|
||||
|
||||
const GLOBAL_SCOPE_INDEX: usize = 0;
|
||||
|
||||
@@ -55,7 +53,7 @@ type DeferralContext<'a> = (Vec<usize>, Vec<RefEquality<'a, Stmt>>);
|
||||
#[allow(clippy::struct_excessive_bools)]
|
||||
pub struct Checker<'a> {
|
||||
// Input data.
|
||||
path: &'a Path,
|
||||
pub(crate) path: &'a Path,
|
||||
package: Option<&'a Path>,
|
||||
autofix: flags::Autofix,
|
||||
noqa: flags::Noqa,
|
||||
@@ -76,7 +74,9 @@ pub struct Checker<'a> {
|
||||
pub(crate) parents: Vec<RefEquality<'a, Stmt>>,
|
||||
pub(crate) depths: FxHashMap<RefEquality<'a, Stmt>, usize>,
|
||||
pub(crate) child_to_parent: FxHashMap<RefEquality<'a, Stmt>, RefEquality<'a, Stmt>>,
|
||||
// A stack of all bindings created in any scope, at any point in execution.
|
||||
pub(crate) bindings: Vec<Binding<'a>>,
|
||||
// Map from binding index to indexes of bindings that redefine it in other scopes.
|
||||
pub(crate) redefinitions: IntMap<usize, Vec<usize>>,
|
||||
pub(crate) exprs: Vec<RefEquality<'a, Expr>>,
|
||||
pub(crate) scopes: Vec<Scope<'a>>,
|
||||
@@ -86,6 +86,7 @@ pub struct Checker<'a> {
|
||||
deferred_type_definitions: Vec<(&'a Expr, bool, DeferralContext<'a>)>,
|
||||
deferred_functions: Vec<(&'a Stmt, DeferralContext<'a>, VisibleScope)>,
|
||||
deferred_lambdas: Vec<(&'a Expr, DeferralContext<'a>)>,
|
||||
deferred_for_loops: Vec<(&'a Stmt, DeferralContext<'a>)>,
|
||||
deferred_assignments: Vec<DeferralContext<'a>>,
|
||||
// Body iteration; used to peek at siblings.
|
||||
body: &'a [Stmt],
|
||||
@@ -100,7 +101,7 @@ pub struct Checker<'a> {
|
||||
in_literal: bool,
|
||||
in_subscript: bool,
|
||||
in_type_checking_block: bool,
|
||||
seen_import_boundary: bool,
|
||||
pub(crate) seen_import_boundary: bool,
|
||||
futures_allowed: bool,
|
||||
annotations_future_enabled: bool,
|
||||
except_handlers: Vec<Vec<Vec<&'a str>>>,
|
||||
@@ -147,6 +148,7 @@ impl<'a> Checker<'a> {
|
||||
deferred_type_definitions: vec![],
|
||||
deferred_functions: vec![],
|
||||
deferred_lambdas: vec![],
|
||||
deferred_for_loops: vec![],
|
||||
deferred_assignments: vec![],
|
||||
// Body iteration.
|
||||
body: &[],
|
||||
@@ -212,7 +214,7 @@ impl<'a> Checker<'a> {
|
||||
/// Return the current `Binding` for a given `name`.
|
||||
pub fn find_binding(&self, member: &str) -> Option<&Binding> {
|
||||
self.current_scopes()
|
||||
.find_map(|scope| scope.values.get(member))
|
||||
.find_map(|scope| scope.bindings.get(member))
|
||||
.map(|index| &self.bindings[*index])
|
||||
}
|
||||
|
||||
@@ -352,7 +354,7 @@ where
|
||||
source: Some(RefEquality(stmt)),
|
||||
context,
|
||||
});
|
||||
scope.values.insert(name, index);
|
||||
scope.bindings.insert(name, index);
|
||||
}
|
||||
}
|
||||
|
||||
@@ -382,7 +384,7 @@ where
|
||||
source: Some(RefEquality(stmt)),
|
||||
context,
|
||||
});
|
||||
scope.values.insert(name, index);
|
||||
scope.bindings.insert(name, index);
|
||||
}
|
||||
|
||||
// Mark the binding in the defining scopes as used too. (Skip the global scope
|
||||
@@ -390,7 +392,7 @@ where
|
||||
for (name, range) in names.iter().zip(ranges.iter()) {
|
||||
let mut exists = false;
|
||||
for index in self.scope_stack.iter().skip(1).rev().skip(1) {
|
||||
if let Some(index) = self.scopes[*index].values.get(&name.as_str()) {
|
||||
if let Some(index) = self.scopes[*index].bindings.get(&name.as_str()) {
|
||||
exists = true;
|
||||
self.bindings[*index].runtime_usage = usage;
|
||||
}
|
||||
@@ -400,7 +402,7 @@ where
|
||||
if !exists {
|
||||
if self.settings.rules.enabled(&Rule::NonlocalWithoutBinding) {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::NonlocalWithoutBinding {
|
||||
pylint::rules::NonlocalWithoutBinding {
|
||||
name: name.to_string(),
|
||||
},
|
||||
*range,
|
||||
@@ -586,8 +588,8 @@ where
|
||||
pylint::rules::property_with_parameters(self, stmt, decorator_list, args);
|
||||
}
|
||||
|
||||
if self.settings.rules.enabled(&Rule::TooManyArgs) {
|
||||
pylint::rules::too_many_args(self, args, stmt);
|
||||
if self.settings.rules.enabled(&Rule::TooManyArguments) {
|
||||
pylint::rules::too_many_arguments(self, args, stmt);
|
||||
}
|
||||
|
||||
if self.settings.rules.enabled(&Rule::TooManyStatements) {
|
||||
@@ -720,17 +722,7 @@ where
|
||||
}
|
||||
StmtKind::Return { .. } => {
|
||||
if self.settings.rules.enabled(&Rule::ReturnOutsideFunction) {
|
||||
if let Some(&index) = self.scope_stack.last() {
|
||||
if matches!(
|
||||
self.scopes[index].kind,
|
||||
ScopeKind::Class(_) | ScopeKind::Module
|
||||
) {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::ReturnOutsideFunction,
|
||||
Range::from_located(stmt),
|
||||
));
|
||||
}
|
||||
}
|
||||
pyflakes::rules::return_outside_function(self, stmt);
|
||||
}
|
||||
}
|
||||
StmtKind::ClassDef {
|
||||
@@ -827,25 +819,14 @@ where
|
||||
}
|
||||
StmtKind::Import { names } => {
|
||||
if self.settings.rules.enabled(&Rule::MultipleImportsOnOneLine) {
|
||||
if names.len() > 1 {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::MultipleImportsOnOneLine,
|
||||
Range::from_located(stmt),
|
||||
));
|
||||
}
|
||||
pycodestyle::rules::multiple_imports_on_one_line(self, stmt, names);
|
||||
}
|
||||
|
||||
if self
|
||||
.settings
|
||||
.rules
|
||||
.enabled(&Rule::ModuleImportNotAtTopOfFile)
|
||||
{
|
||||
if self.seen_import_boundary && stmt.location.column() == 0 {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::ModuleImportNotAtTopOfFile,
|
||||
Range::from_located(stmt),
|
||||
));
|
||||
}
|
||||
pycodestyle::rules::module_import_not_at_top_of_file(self, stmt);
|
||||
}
|
||||
if self.settings.rules.enabled(&Rule::RewriteCElementTree) {
|
||||
pyupgrade::rules::replace_c_element_tree(self, stmt);
|
||||
@@ -941,7 +922,7 @@ where
|
||||
pylint::rules::useless_import_alias(self, alias);
|
||||
}
|
||||
if self.settings.rules.enabled(&Rule::ConsiderUsingFromImport) {
|
||||
pylint::rules::use_from_import(self, alias);
|
||||
pylint::rules::use_from_import(self, stmt, alias, names);
|
||||
}
|
||||
|
||||
if let Some(asname) = &alias.node.asname {
|
||||
@@ -1070,12 +1051,7 @@ where
|
||||
.rules
|
||||
.enabled(&Rule::ModuleImportNotAtTopOfFile)
|
||||
{
|
||||
if self.seen_import_boundary && stmt.location.column() == 0 {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::ModuleImportNotAtTopOfFile,
|
||||
Range::from_located(stmt),
|
||||
));
|
||||
}
|
||||
pycodestyle::rules::module_import_not_at_top_of_file(self, stmt);
|
||||
}
|
||||
|
||||
if self.settings.rules.enabled(&Rule::UnnecessaryFutureImport)
|
||||
@@ -1170,21 +1146,14 @@ where
|
||||
}
|
||||
|
||||
if self.settings.rules.enabled(&Rule::FutureFeatureNotDefined) {
|
||||
if !ALL_FEATURE_NAMES.contains(&&*alias.node.name) {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::FutureFeatureNotDefined {
|
||||
name: alias.node.name.to_string(),
|
||||
},
|
||||
Range::from_located(alias),
|
||||
));
|
||||
}
|
||||
pyflakes::rules::future_feature_not_defined(self, alias);
|
||||
}
|
||||
|
||||
if self.settings.rules.enabled(&Rule::LateFutureImport)
|
||||
&& !self.futures_allowed
|
||||
{
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::LateFutureImport,
|
||||
pyflakes::rules::LateFutureImport,
|
||||
Range::from_located(stmt),
|
||||
));
|
||||
}
|
||||
@@ -1207,7 +1176,7 @@ where
|
||||
[*(self.scope_stack.last().expect("No current scope found"))];
|
||||
if !matches!(scope.kind, ScopeKind::Module) {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::ImportStarNotPermitted {
|
||||
pyflakes::rules::ImportStarNotPermitted {
|
||||
name: helpers::format_import_from(
|
||||
level.as_ref(),
|
||||
module.as_deref(),
|
||||
@@ -1220,7 +1189,7 @@ where
|
||||
|
||||
if self.settings.rules.enabled(&Rule::ImportStarUsed) {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::ImportStarUsed {
|
||||
pyflakes::rules::ImportStarUsed {
|
||||
name: helpers::format_import_from(
|
||||
level.as_ref(),
|
||||
module.as_deref(),
|
||||
@@ -1592,7 +1561,8 @@ where
|
||||
.rules
|
||||
.enabled(&Rule::UnusedLoopControlVariable)
|
||||
{
|
||||
flake8_bugbear::rules::unused_loop_control_variable(self, target, body);
|
||||
self.deferred_for_loops
|
||||
.push((stmt, (self.scope_stack.clone(), self.parents.clone())));
|
||||
}
|
||||
if self
|
||||
.settings
|
||||
@@ -1800,7 +1770,7 @@ where
|
||||
let globals = operations::extract_globals(body);
|
||||
for (name, stmt) in operations::extract_globals(body) {
|
||||
if self.scopes[GLOBAL_SCOPE_INDEX]
|
||||
.values
|
||||
.bindings
|
||||
.get(name)
|
||||
.map_or(true, |index| {
|
||||
matches!(self.bindings[*index].kind, BindingKind::Annotation)
|
||||
@@ -1816,7 +1786,7 @@ where
|
||||
source: Some(RefEquality(stmt)),
|
||||
context: self.execution_context(),
|
||||
});
|
||||
self.scopes[GLOBAL_SCOPE_INDEX].values.insert(name, index);
|
||||
self.scopes[GLOBAL_SCOPE_INDEX].bindings.insert(name, index);
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1864,7 +1834,7 @@ where
|
||||
let globals = operations::extract_globals(body);
|
||||
for (name, stmt) in &globals {
|
||||
if self.scopes[GLOBAL_SCOPE_INDEX]
|
||||
.values
|
||||
.bindings
|
||||
.get(name)
|
||||
.map_or(true, |index| {
|
||||
matches!(self.bindings[*index].kind, BindingKind::Annotation)
|
||||
@@ -1880,7 +1850,7 @@ where
|
||||
source: Some(RefEquality(stmt)),
|
||||
context: self.execution_context(),
|
||||
});
|
||||
self.scopes[GLOBAL_SCOPE_INDEX].values.insert(name, index);
|
||||
self.scopes[GLOBAL_SCOPE_INDEX].bindings.insert(name, index);
|
||||
}
|
||||
}
|
||||
|
||||
@@ -2197,7 +2167,7 @@ where
|
||||
.enabled(&Rule::StringDotFormatInvalidFormat)
|
||||
{
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::StringDotFormatInvalidFormat {
|
||||
pyflakes::rules::StringDotFormatInvalidFormat {
|
||||
message: pyflakes::format::error_to_string(&e),
|
||||
},
|
||||
location,
|
||||
@@ -2641,8 +2611,8 @@ where
|
||||
{
|
||||
pylint::rules::unnecessary_direct_lambda_call(self, expr, func);
|
||||
}
|
||||
if self.settings.rules.enabled(&Rule::UseSysExit) {
|
||||
pylint::rules::use_sys_exit(self, func);
|
||||
if self.settings.rules.enabled(&Rule::ConsiderUsingSysExit) {
|
||||
pylint::rules::consider_using_sys_exit(self, func);
|
||||
}
|
||||
|
||||
// flake8-pytest-style
|
||||
@@ -2753,41 +2723,17 @@ where
|
||||
}
|
||||
ExprKind::Yield { .. } => {
|
||||
if self.settings.rules.enabled(&Rule::YieldOutsideFunction) {
|
||||
let scope = self.current_scope();
|
||||
if matches!(scope.kind, ScopeKind::Class(_) | ScopeKind::Module) {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::YieldOutsideFunction {
|
||||
keyword: DeferralKeyword::Yield,
|
||||
},
|
||||
Range::from_located(expr),
|
||||
));
|
||||
}
|
||||
pyflakes::rules::yield_outside_function(self, expr);
|
||||
}
|
||||
}
|
||||
ExprKind::YieldFrom { .. } => {
|
||||
if self.settings.rules.enabled(&Rule::YieldOutsideFunction) {
|
||||
let scope = self.current_scope();
|
||||
if matches!(scope.kind, ScopeKind::Class(_) | ScopeKind::Module) {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::YieldOutsideFunction {
|
||||
keyword: DeferralKeyword::YieldFrom,
|
||||
},
|
||||
Range::from_located(expr),
|
||||
));
|
||||
}
|
||||
pyflakes::rules::yield_outside_function(self, expr);
|
||||
}
|
||||
}
|
||||
ExprKind::Await { .. } => {
|
||||
if self.settings.rules.enabled(&Rule::YieldOutsideFunction) {
|
||||
let scope = self.current_scope();
|
||||
if matches!(scope.kind, ScopeKind::Class(_) | ScopeKind::Module) {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::YieldOutsideFunction {
|
||||
keyword: DeferralKeyword::Await,
|
||||
},
|
||||
Range::from_located(expr),
|
||||
));
|
||||
}
|
||||
pyflakes::rules::yield_outside_function(self, expr);
|
||||
}
|
||||
if self.settings.rules.enabled(&Rule::AwaitOutsideAsync) {
|
||||
pylint::rules::await_outside_async(self, expr);
|
||||
@@ -2870,7 +2816,7 @@ where
|
||||
.enabled(&Rule::PercentFormatUnsupportedFormatCharacter)
|
||||
{
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::PercentFormatUnsupportedFormatCharacter {
|
||||
pyflakes::rules::PercentFormatUnsupportedFormatCharacter {
|
||||
char: c,
|
||||
},
|
||||
location,
|
||||
@@ -2884,7 +2830,7 @@ where
|
||||
.enabled(&Rule::PercentFormatInvalidFormat)
|
||||
{
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::PercentFormatInvalidFormat {
|
||||
pyflakes::rules::PercentFormatInvalidFormat {
|
||||
message: e.to_string(),
|
||||
},
|
||||
location,
|
||||
@@ -3074,8 +3020,8 @@ where
|
||||
);
|
||||
}
|
||||
|
||||
if self.settings.rules.enabled(&Rule::ConstantComparison) {
|
||||
pylint::rules::constant_comparison(self, left, ops, comparators);
|
||||
if self.settings.rules.enabled(&Rule::ComparisonOfConstant) {
|
||||
pylint::rules::comparison_of_constant(self, left, ops, comparators);
|
||||
}
|
||||
|
||||
if self.settings.rules.enabled(&Rule::MagicValueComparison) {
|
||||
@@ -3537,7 +3483,7 @@ where
|
||||
let name_range =
|
||||
helpers::excepthandler_name_range(excepthandler, self.locator).unwrap();
|
||||
|
||||
if self.current_scope().values.contains_key(&name.as_str()) {
|
||||
if self.current_scope().bindings.contains_key(&name.as_str()) {
|
||||
self.handle_node_store(
|
||||
name,
|
||||
&Expr::new(
|
||||
@@ -3551,7 +3497,7 @@ where
|
||||
);
|
||||
}
|
||||
|
||||
let definition = self.current_scope().values.get(&name.as_str()).copied();
|
||||
let definition = self.current_scope().bindings.get(&name.as_str()).copied();
|
||||
self.handle_node_store(
|
||||
name,
|
||||
&Expr::new(
|
||||
@@ -3569,12 +3515,12 @@ where
|
||||
if let Some(index) = {
|
||||
let scope = &mut self.scopes
|
||||
[*(self.scope_stack.last().expect("No current scope found"))];
|
||||
&scope.values.remove(&name.as_str())
|
||||
&scope.bindings.remove(&name.as_str())
|
||||
} {
|
||||
if !self.bindings[*index].used() {
|
||||
if self.settings.rules.enabled(&Rule::UnusedVariable) {
|
||||
let mut diagnostic = Diagnostic::new(
|
||||
violations::UnusedVariable {
|
||||
pyflakes::rules::UnusedVariable {
|
||||
name: name.to_string(),
|
||||
},
|
||||
name_range,
|
||||
@@ -3604,7 +3550,7 @@ where
|
||||
if let Some(index) = definition {
|
||||
let scope = &mut self.scopes
|
||||
[*(self.scope_stack.last().expect("No current scope found"))];
|
||||
scope.values.insert(name, index);
|
||||
scope.bindings.insert(name, index);
|
||||
}
|
||||
}
|
||||
None => walk_excepthandler(self, excepthandler),
|
||||
@@ -3799,7 +3745,7 @@ impl<'a> Checker<'a> {
|
||||
source: None,
|
||||
context: ExecutionContext::Runtime,
|
||||
});
|
||||
scope.values.insert(builtin, index);
|
||||
scope.bindings.insert(builtin, index);
|
||||
}
|
||||
}
|
||||
|
||||
@@ -3839,11 +3785,11 @@ impl<'a> Checker<'a> {
|
||||
.map(|index| &self.scopes[*index])
|
||||
}
|
||||
|
||||
pub fn in_exception_handler(&self) -> bool {
|
||||
pub const fn in_exception_handler(&self) -> bool {
|
||||
self.in_exception_handler
|
||||
}
|
||||
|
||||
pub fn execution_context(&self) -> ExecutionContext {
|
||||
pub const fn execution_context(&self) -> ExecutionContext {
|
||||
if self.in_type_checking_block
|
||||
|| self.in_annotation
|
||||
|| self.in_deferred_string_type_definition
|
||||
@@ -3866,9 +3812,9 @@ impl<'a> Checker<'a> {
|
||||
.iter()
|
||||
.rev()
|
||||
.enumerate()
|
||||
.find(|(_, scope_index)| self.scopes[**scope_index].values.contains_key(&name))
|
||||
.find(|(_, scope_index)| self.scopes[**scope_index].bindings.contains_key(&name))
|
||||
{
|
||||
let existing_binding_index = self.scopes[*scope_index].values.get(&name).unwrap();
|
||||
let existing_binding_index = self.scopes[*scope_index].bindings.get(&name).unwrap();
|
||||
let existing = &self.bindings[*existing_binding_index];
|
||||
let in_current_scope = stack_index == 0;
|
||||
if !matches!(existing.kind, BindingKind::Builtin)
|
||||
@@ -3894,7 +3840,7 @@ impl<'a> Checker<'a> {
|
||||
if matches!(binding.kind, BindingKind::LoopVar) && existing_is_import {
|
||||
if self.settings.rules.enabled(&Rule::ImportShadowedByLoopVar) {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::ImportShadowedByLoopVar {
|
||||
pyflakes::rules::ImportShadowedByLoopVar {
|
||||
name: name.to_string(),
|
||||
line: existing.range.location.row(),
|
||||
},
|
||||
@@ -3912,13 +3858,21 @@ impl<'a> Checker<'a> {
|
||||
))
|
||||
{
|
||||
if self.settings.rules.enabled(&Rule::RedefinedWhileUnused) {
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::RedefinedWhileUnused {
|
||||
let mut diagnostic = Diagnostic::new(
|
||||
pyflakes::rules::RedefinedWhileUnused {
|
||||
name: name.to_string(),
|
||||
line: existing.range.location.row(),
|
||||
},
|
||||
binding_range(&binding, self.locator),
|
||||
));
|
||||
);
|
||||
if let Some(parent) = binding.source.as_ref() {
|
||||
if matches!(parent.node, StmtKind::ImportFrom { .. })
|
||||
&& parent.location.row() != binding.range.location.row()
|
||||
{
|
||||
diagnostic.parent(parent.location);
|
||||
}
|
||||
}
|
||||
self.diagnostics.push(diagnostic);
|
||||
}
|
||||
}
|
||||
} else if existing_is_import && binding.redefines(existing) {
|
||||
@@ -3931,7 +3885,7 @@ impl<'a> Checker<'a> {
|
||||
}
|
||||
|
||||
let scope = self.current_scope();
|
||||
let binding = if let Some(index) = scope.values.get(&name) {
|
||||
let binding = if let Some(index) = scope.bindings.get(&name) {
|
||||
if matches!(self.bindings[*index].kind, BindingKind::Builtin) {
|
||||
// Avoid overriding builtins.
|
||||
binding
|
||||
@@ -3970,8 +3924,14 @@ impl<'a> Checker<'a> {
|
||||
// Don't treat annotations as assignments if there is an existing value
|
||||
// in scope.
|
||||
let scope = &mut self.scopes[*(self.scope_stack.last().expect("No current scope found"))];
|
||||
if !(matches!(binding.kind, BindingKind::Annotation) && scope.values.contains_key(name)) {
|
||||
scope.values.insert(name, binding_index);
|
||||
if !(matches!(binding.kind, BindingKind::Annotation) && scope.bindings.contains_key(name)) {
|
||||
if let Some(rebound_index) = scope.bindings.insert(name, binding_index) {
|
||||
scope
|
||||
.rebounds
|
||||
.entry(name)
|
||||
.or_insert_with(Vec::new)
|
||||
.push(rebound_index);
|
||||
}
|
||||
}
|
||||
|
||||
self.bindings.push(binding);
|
||||
@@ -3996,7 +3956,7 @@ impl<'a> Checker<'a> {
|
||||
}
|
||||
}
|
||||
|
||||
if let Some(index) = scope.values.get(&id.as_str()) {
|
||||
if let Some(index) = scope.bindings.get(&id.as_str()) {
|
||||
// Mark the binding as used.
|
||||
let context = self.execution_context();
|
||||
self.bindings[*index].mark_used(scope_id, Range::from_located(expr), context);
|
||||
@@ -4026,7 +3986,7 @@ impl<'a> Checker<'a> {
|
||||
.unwrap_or_default();
|
||||
if has_alias {
|
||||
// Mark the sub-importation as used.
|
||||
if let Some(index) = scope.values.get(full_name) {
|
||||
if let Some(index) = scope.bindings.get(full_name) {
|
||||
self.bindings[*index].mark_used(
|
||||
scope_id,
|
||||
Range::from_located(expr),
|
||||
@@ -4043,7 +4003,7 @@ impl<'a> Checker<'a> {
|
||||
.unwrap_or_default();
|
||||
if has_alias {
|
||||
// Mark the sub-importation as used.
|
||||
if let Some(index) = scope.values.get(full_name.as_str()) {
|
||||
if let Some(index) = scope.bindings.get(full_name.as_str()) {
|
||||
self.bindings[*index].mark_used(
|
||||
scope_id,
|
||||
Range::from_located(expr),
|
||||
@@ -4068,7 +4028,7 @@ impl<'a> Checker<'a> {
|
||||
let mut from_list = vec![];
|
||||
for scope_index in self.scope_stack.iter().rev() {
|
||||
let scope = &self.scopes[*scope_index];
|
||||
for binding in scope.values.values().map(|index| &self.bindings[*index]) {
|
||||
for binding in scope.bindings.values().map(|index| &self.bindings[*index]) {
|
||||
if let BindingKind::StarImportation(level, module) = &binding.kind {
|
||||
from_list.push(helpers::format_import_from(
|
||||
level.as_ref(),
|
||||
@@ -4080,7 +4040,7 @@ impl<'a> Checker<'a> {
|
||||
from_list.sort();
|
||||
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::ImportStarUsage {
|
||||
pyflakes::rules::ImportStarUsage {
|
||||
name: id.to_string(),
|
||||
sources: from_list,
|
||||
},
|
||||
@@ -4114,7 +4074,7 @@ impl<'a> Checker<'a> {
|
||||
}
|
||||
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::UndefinedName { name: id.clone() },
|
||||
pyflakes::rules::UndefinedName { name: id.clone() },
|
||||
Range::from_located(expr),
|
||||
));
|
||||
}
|
||||
@@ -4146,9 +4106,14 @@ impl<'a> Checker<'a> {
|
||||
{
|
||||
if matches!(self.current_scope().kind, ScopeKind::Function(..)) {
|
||||
// Ignore globals.
|
||||
if !self.current_scope().values.get(id).map_or(false, |index| {
|
||||
matches!(self.bindings[*index].kind, BindingKind::Global)
|
||||
}) {
|
||||
if !self
|
||||
.current_scope()
|
||||
.bindings
|
||||
.get(id)
|
||||
.map_or(false, |index| {
|
||||
matches!(self.bindings[*index].kind, BindingKind::Global)
|
||||
})
|
||||
{
|
||||
pep8_naming::rules::non_lowercase_variable_in_function(self, expr, parent, id);
|
||||
}
|
||||
}
|
||||
@@ -4260,8 +4225,7 @@ impl<'a> Checker<'a> {
|
||||
}
|
||||
_ => false,
|
||||
} {
|
||||
let (all_names, all_names_flags) =
|
||||
extract_all_names(parent, current, &self.bindings);
|
||||
let (all_names, all_names_flags) = extract_all_names(self, parent, current);
|
||||
|
||||
if self.settings.rules.enabled(&Rule::InvalidAllFormat)
|
||||
&& matches!(all_names_flags, AllNamesFlags::INVALID_FORMAT)
|
||||
@@ -4318,11 +4282,11 @@ impl<'a> Checker<'a> {
|
||||
|
||||
let scope =
|
||||
&mut self.scopes[*(self.scope_stack.last().expect("No current scope found"))];
|
||||
if scope.values.remove(&id.as_str()).is_none()
|
||||
if scope.bindings.remove(&id.as_str()).is_none()
|
||||
&& self.settings.rules.enabled(&Rule::UndefinedName)
|
||||
{
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::UndefinedName {
|
||||
pyflakes::rules::UndefinedName {
|
||||
name: id.to_string(),
|
||||
},
|
||||
Range::from_located(expr),
|
||||
@@ -4390,7 +4354,7 @@ impl<'a> Checker<'a> {
|
||||
.enabled(&Rule::ForwardAnnotationSyntaxError)
|
||||
{
|
||||
self.diagnostics.push(Diagnostic::new(
|
||||
violations::ForwardAnnotationSyntaxError {
|
||||
pyflakes::rules::ForwardAnnotationSyntaxError {
|
||||
body: expression.to_string(),
|
||||
},
|
||||
range,
|
||||
@@ -4481,6 +4445,28 @@ impl<'a> Checker<'a> {
|
||||
}
|
||||
}
|
||||
|
||||
fn check_deferred_for_loops(&mut self) {
|
||||
self.deferred_for_loops.reverse();
|
||||
while let Some((stmt, (scopes, parents))) = self.deferred_for_loops.pop() {
|
||||
self.scope_stack = scopes.clone();
|
||||
self.parents = parents.clone();
|
||||
|
||||
if let StmtKind::For { target, body, .. } | StmtKind::AsyncFor { target, body, .. } =
|
||||
&stmt.node
|
||||
{
|
||||
if self
|
||||
.settings
|
||||
.rules
|
||||
.enabled(&Rule::UnusedLoopControlVariable)
|
||||
{
|
||||
flake8_bugbear::rules::unused_loop_control_variable(self, stmt, target, body);
|
||||
}
|
||||
} else {
|
||||
unreachable!("Expected ExprKind::Lambda");
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn check_dead_scopes(&mut self) {
|
||||
if !(self.settings.rules.enabled(&Rule::UnusedImport)
|
||||
|| self.settings.rules.enabled(&Rule::ImportStarUsage)
|
||||
@@ -4535,7 +4521,7 @@ impl<'a> Checker<'a> {
|
||||
.iter()
|
||||
.map(|scope| {
|
||||
scope
|
||||
.values
|
||||
.bindings
|
||||
.values()
|
||||
.map(|index| &self.bindings[*index])
|
||||
.filter(|binding| {
|
||||
@@ -4558,13 +4544,13 @@ impl<'a> Checker<'a> {
|
||||
.rules
|
||||
.enabled(&Rule::GlobalVariableNotAssigned)
|
||||
{
|
||||
for (name, index) in &scope.values {
|
||||
for (name, index) in &scope.bindings {
|
||||
let binding = &self.bindings[*index];
|
||||
if matches!(binding.kind, BindingKind::Global) {
|
||||
if let Some(stmt) = &binding.source {
|
||||
if matches!(stmt.node, StmtKind::Global { .. }) {
|
||||
diagnostics.push(Diagnostic::new(
|
||||
violations::GlobalVariableNotAssigned {
|
||||
pylint::rules::GlobalVariableNotAssigned {
|
||||
name: (*name).to_string(),
|
||||
},
|
||||
binding.range,
|
||||
@@ -4581,7 +4567,7 @@ impl<'a> Checker<'a> {
|
||||
}
|
||||
|
||||
let all_binding: Option<&Binding> = scope
|
||||
.values
|
||||
.bindings
|
||||
.get("__all__")
|
||||
.map(|index| &self.bindings[*index]);
|
||||
let all_names: Option<Vec<&str>> =
|
||||
@@ -4595,9 +4581,9 @@ impl<'a> Checker<'a> {
|
||||
if let Some(all_binding) = all_binding {
|
||||
if let Some(names) = &all_names {
|
||||
for &name in names {
|
||||
if !scope.values.contains_key(name) {
|
||||
if !scope.bindings.contains_key(name) {
|
||||
diagnostics.push(Diagnostic::new(
|
||||
violations::UndefinedExport {
|
||||
pyflakes::rules::UndefinedExport {
|
||||
name: name.to_string(),
|
||||
},
|
||||
all_binding.range,
|
||||
@@ -4613,7 +4599,7 @@ impl<'a> Checker<'a> {
|
||||
// unused. Note that we only store references in `redefinitions` if
|
||||
// the bindings are in different scopes.
|
||||
if self.settings.rules.enabled(&Rule::RedefinedWhileUnused) {
|
||||
for (name, index) in &scope.values {
|
||||
for (name, index) in &scope.bindings {
|
||||
let binding = &self.bindings[*index];
|
||||
|
||||
if matches!(
|
||||
@@ -4636,13 +4622,22 @@ impl<'a> Checker<'a> {
|
||||
|
||||
if let Some(indices) = self.redefinitions.get(index) {
|
||||
for index in indices {
|
||||
diagnostics.push(Diagnostic::new(
|
||||
violations::RedefinedWhileUnused {
|
||||
let rebound = &self.bindings[*index];
|
||||
let mut diagnostic = Diagnostic::new(
|
||||
pyflakes::rules::RedefinedWhileUnused {
|
||||
name: (*name).to_string(),
|
||||
line: binding.range.location.row(),
|
||||
},
|
||||
binding_range(&self.bindings[*index], self.locator),
|
||||
));
|
||||
binding_range(rebound, self.locator),
|
||||
);
|
||||
if let Some(parent) = &rebound.source {
|
||||
if matches!(parent.node, StmtKind::ImportFrom { .. })
|
||||
&& parent.location.row() != rebound.range.location.row()
|
||||
{
|
||||
diagnostic.parent(parent.location);
|
||||
}
|
||||
};
|
||||
diagnostics.push(diagnostic);
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -4654,7 +4649,8 @@ impl<'a> Checker<'a> {
|
||||
if let Some(all_binding) = all_binding {
|
||||
if let Some(names) = &all_names {
|
||||
let mut from_list = vec![];
|
||||
for binding in scope.values.values().map(|index| &self.bindings[*index])
|
||||
for binding in
|
||||
scope.bindings.values().map(|index| &self.bindings[*index])
|
||||
{
|
||||
if let BindingKind::StarImportation(level, module) = &binding.kind {
|
||||
from_list.push(helpers::format_import_from(
|
||||
@@ -4666,9 +4662,9 @@ impl<'a> Checker<'a> {
|
||||
from_list.sort();
|
||||
|
||||
for &name in names {
|
||||
if !scope.values.contains_key(name) {
|
||||
if !scope.bindings.contains_key(name) {
|
||||
diagnostics.push(Diagnostic::new(
|
||||
violations::ImportStarUsage {
|
||||
pyflakes::rules::ImportStarUsage {
|
||||
name: name.to_string(),
|
||||
sources: from_list.clone(),
|
||||
},
|
||||
@@ -4708,7 +4704,7 @@ impl<'a> Checker<'a> {
|
||||
.copied()
|
||||
.collect()
|
||||
};
|
||||
for (.., index) in &scope.values {
|
||||
for (.., index) in &scope.bindings {
|
||||
let binding = &self.bindings[*index];
|
||||
|
||||
if let Some(diagnostic) =
|
||||
@@ -4742,7 +4738,7 @@ impl<'a> Checker<'a> {
|
||||
let mut ignored: FxHashMap<BindingContext, Vec<UnusedImport>> =
|
||||
FxHashMap::default();
|
||||
|
||||
for (name, index) in &scope.values {
|
||||
for (name, index) in &scope.bindings {
|
||||
let binding = &self.bindings[*index];
|
||||
|
||||
let full_name = match &binding.kind {
|
||||
@@ -4834,7 +4830,7 @@ impl<'a> Checker<'a> {
|
||||
let multiple = unused_imports.len() > 1;
|
||||
for (full_name, range) in unused_imports {
|
||||
let mut diagnostic = Diagnostic::new(
|
||||
violations::UnusedImport {
|
||||
pyflakes::rules::UnusedImport {
|
||||
name: full_name.to_string(),
|
||||
ignore_init,
|
||||
multiple,
|
||||
@@ -4860,7 +4856,7 @@ impl<'a> Checker<'a> {
|
||||
let multiple = unused_imports.len() > 1;
|
||||
for (full_name, range) in unused_imports {
|
||||
let mut diagnostic = Diagnostic::new(
|
||||
violations::UnusedImport {
|
||||
pyflakes::rules::UnusedImport {
|
||||
name: full_name.to_string(),
|
||||
ignore_init,
|
||||
multiple,
|
||||
@@ -5109,7 +5105,7 @@ impl<'a> Checker<'a> {
|
||||
pydocstyle::rules::ends_with_period(self, &docstring);
|
||||
}
|
||||
if self.settings.rules.enabled(&Rule::NonImperativeMood) {
|
||||
pydocstyle::rules::non_imperative_mood::non_imperative_mood(self, &docstring);
|
||||
pydocstyle::rules::non_imperative_mood(self, &docstring);
|
||||
}
|
||||
if self.settings.rules.enabled(&Rule::NoSignature) {
|
||||
pydocstyle::rules::no_signature(self, &docstring);
|
||||
@@ -5261,6 +5257,7 @@ pub fn check_ast(
|
||||
checker.check_deferred_type_definitions();
|
||||
let mut allocator = vec![];
|
||||
checker.check_deferred_string_type_definitions(&mut allocator);
|
||||
checker.check_deferred_for_loops();
|
||||
|
||||
// Check docstrings.
|
||||
checker.check_definitions();
|
||||
|
||||
@@ -13,7 +13,7 @@ pub fn check_file_path(
|
||||
|
||||
// flake8-no-pep420
|
||||
if settings.rules.enabled(&Rule::ImplicitNamespacePackage) {
|
||||
if let Some(diagnostic) = implicit_namespace_package(path, package) {
|
||||
if let Some(diagnostic) = implicit_namespace_package(path, package, &settings.src) {
|
||||
diagnostics.push(diagnostic);
|
||||
}
|
||||
}
|
||||
|
||||
@@ -5,12 +5,12 @@ use rustpython_parser::ast::Location;
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::fix::Fix;
|
||||
use crate::noqa;
|
||||
use crate::noqa::{is_file_exempt, Directive};
|
||||
use crate::registry::{Diagnostic, DiagnosticKind, Rule};
|
||||
use crate::rule_redirects::get_redirect_target;
|
||||
use crate::rules::ruff::rules::{UnusedCodes, UnusedNOQA};
|
||||
use crate::settings::{flags, Settings};
|
||||
use crate::violations::UnusedCodes;
|
||||
use crate::{noqa, violations};
|
||||
|
||||
pub fn check_noqa(
|
||||
diagnostics: &mut Vec<Diagnostic>,
|
||||
@@ -106,7 +106,7 @@ pub fn check_noqa(
|
||||
let end = start + lines[row][start_byte..end_byte].chars().count();
|
||||
|
||||
let mut diagnostic = Diagnostic::new(
|
||||
violations::UnusedNOQA { codes: None },
|
||||
UnusedNOQA { codes: None },
|
||||
Range::new(Location::new(row + 1, start), Location::new(row + 1, end)),
|
||||
);
|
||||
if matches!(autofix, flags::Autofix::Enabled)
|
||||
@@ -137,7 +137,7 @@ pub fn check_noqa(
|
||||
valid_codes.push(code);
|
||||
} else {
|
||||
if let Ok(rule) = Rule::from_code(code) {
|
||||
if settings.rules.enabled(rule) {
|
||||
if settings.rules.enabled(&rule) {
|
||||
unmatched_codes.push(code);
|
||||
} else {
|
||||
disabled_codes.push(code);
|
||||
@@ -160,7 +160,7 @@ pub fn check_noqa(
|
||||
let end = start + lines[row][start_byte..end_byte].chars().count();
|
||||
|
||||
let mut diagnostic = Diagnostic::new(
|
||||
violations::UnusedNOQA {
|
||||
UnusedNOQA {
|
||||
codes: Some(UnusedCodes {
|
||||
disabled: disabled_codes
|
||||
.iter()
|
||||
|
||||
@@ -32,11 +32,7 @@ pub fn compose_module_path(module: &NameOrAttribute) -> String {
|
||||
NameOrAttribute::A(attr) => {
|
||||
let name = attr.attr.value;
|
||||
let prefix = compose_call_path(&attr.value);
|
||||
if let Some(prefix) = prefix {
|
||||
format!("{prefix}.{name}")
|
||||
} else {
|
||||
name.to_string()
|
||||
}
|
||||
prefix.map_or_else(|| name.to_string(), |prefix| format!("{prefix}.{name}"))
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -22,9 +22,9 @@ impl Flags {
|
||||
.iter_enabled()
|
||||
.any(|rule_code| matches!(rule_code.lint_source(), LintSource::Imports))
|
||||
{
|
||||
Flags::NOQA | Flags::ISORT
|
||||
Self::NOQA | Self::ISORT
|
||||
} else {
|
||||
Flags::NOQA
|
||||
Self::NOQA
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -84,11 +84,9 @@ pub(crate) fn section_contexts<'a>(
|
||||
section_name: context.section_name,
|
||||
previous_line: context.previous_line,
|
||||
line: context.line,
|
||||
following_lines: if let Some(end) = end {
|
||||
following_lines: end.map_or(context.following_lines, |end| {
|
||||
&lines[context.original_index + 1..end]
|
||||
} else {
|
||||
context.following_lines
|
||||
},
|
||||
}),
|
||||
original_index: context.original_index,
|
||||
is_last_section: end.is_none(),
|
||||
});
|
||||
|
||||
@@ -12,9 +12,9 @@ pub enum FixMode {
|
||||
impl From<bool> for FixMode {
|
||||
fn from(value: bool) -> Self {
|
||||
if value {
|
||||
FixMode::Apply
|
||||
Self::Apply
|
||||
} else {
|
||||
FixMode::None
|
||||
Self::None
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -27,7 +27,7 @@ pub struct Fix {
|
||||
}
|
||||
|
||||
impl Fix {
|
||||
pub fn deletion(start: Location, end: Location) -> Self {
|
||||
pub const fn deletion(start: Location, end: Location) -> Self {
|
||||
Self {
|
||||
content: String::new(),
|
||||
location: start,
|
||||
|
||||
@@ -65,11 +65,17 @@ pub fn convert(
|
||||
let plugins = plugins.unwrap_or_else(|| {
|
||||
let from_options = plugin::infer_plugins_from_options(flake8);
|
||||
if !from_options.is_empty() {
|
||||
eprintln!("Inferred plugins from settings: {from_options:#?}");
|
||||
#[allow(clippy::print_stderr)]
|
||||
{
|
||||
eprintln!("Inferred plugins from settings: {from_options:#?}");
|
||||
}
|
||||
}
|
||||
let from_codes = plugin::infer_plugins_from_codes(&referenced_codes);
|
||||
if !from_codes.is_empty() {
|
||||
eprintln!("Inferred plugins from referenced codes: {from_codes:#?}");
|
||||
#[allow(clippy::print_stderr)]
|
||||
{
|
||||
eprintln!("Inferred plugins from referenced codes: {from_codes:#?}");
|
||||
}
|
||||
}
|
||||
from_options.into_iter().chain(from_codes).collect()
|
||||
});
|
||||
|
||||
@@ -72,7 +72,7 @@ struct State {
|
||||
}
|
||||
|
||||
impl State {
|
||||
fn new() -> Self {
|
||||
const fn new() -> Self {
|
||||
Self {
|
||||
seen_sep: true,
|
||||
seen_colon: false,
|
||||
|
||||
@@ -32,9 +32,9 @@ pub(crate) fn ignores_from_path<'a>(
|
||||
HashableGlobMatcher,
|
||||
HashableHashSet<Rule>,
|
||||
)],
|
||||
) -> Result<FxHashSet<&'a Rule>> {
|
||||
let (file_path, file_basename) = extract_path_names(path)?;
|
||||
Ok(pattern_code_pairs
|
||||
) -> FxHashSet<&'a Rule> {
|
||||
let (file_path, file_basename) = extract_path_names(path).expect("Unable to parse filename");
|
||||
pattern_code_pairs
|
||||
.iter()
|
||||
.filter_map(|(absolute, basename, codes)| {
|
||||
if basename.is_match(file_basename) {
|
||||
@@ -58,7 +58,7 @@ pub(crate) fn ignores_from_path<'a>(
|
||||
None
|
||||
})
|
||||
.flatten()
|
||||
.collect())
|
||||
.collect()
|
||||
}
|
||||
|
||||
/// Convert any path to an absolute path (based on the current working
|
||||
|
||||
@@ -35,7 +35,7 @@ impl Default for StateMachine {
|
||||
}
|
||||
|
||||
impl StateMachine {
|
||||
pub fn new() -> Self {
|
||||
pub const fn new() -> Self {
|
||||
Self {
|
||||
state: State::ExpectModuleDocstring,
|
||||
bracket_count: 0,
|
||||
|
||||
18
src/lib.rs
18
src/lib.rs
@@ -4,20 +4,6 @@
|
||||
//! and subject to change drastically.
|
||||
//!
|
||||
//! [Ruff]: https://github.com/charliermarsh/ruff
|
||||
#![forbid(unsafe_code)]
|
||||
#![warn(clippy::pedantic)]
|
||||
#![allow(
|
||||
clippy::collapsible_else_if,
|
||||
clippy::collapsible_if,
|
||||
clippy::implicit_hasher,
|
||||
clippy::match_same_arms,
|
||||
clippy::missing_errors_doc,
|
||||
clippy::missing_panics_doc,
|
||||
clippy::module_name_repetitions,
|
||||
clippy::must_use_candidate,
|
||||
clippy::similar_names,
|
||||
clippy::too_many_lines
|
||||
)]
|
||||
|
||||
mod assert_yaml_snapshot;
|
||||
mod ast;
|
||||
@@ -47,19 +33,17 @@ pub mod settings;
|
||||
pub mod source_code;
|
||||
mod vendor;
|
||||
mod violation;
|
||||
mod violations;
|
||||
mod visibility;
|
||||
|
||||
use cfg_if::cfg_if;
|
||||
pub use rule_selector::RuleSelector;
|
||||
pub use rules::pycodestyle::rules::IOError;
|
||||
pub use violation::{AutofixKind, Availability as AutofixAvailability};
|
||||
pub use violations::IOError;
|
||||
|
||||
cfg_if! {
|
||||
if #[cfg(not(target_family = "wasm"))] {
|
||||
pub mod packaging;
|
||||
|
||||
|
||||
mod lib_native;
|
||||
pub use lib_native::check;
|
||||
} else {
|
||||
|
||||
@@ -49,7 +49,7 @@ pub fn check(path: &Path, contents: &str, autofix: bool) -> Result<Vec<Diagnosti
|
||||
directives::extract_directives(&tokens, directives::Flags::from_settings(&settings));
|
||||
|
||||
// Generate diagnostics.
|
||||
let diagnostics = check_path(
|
||||
let result = check_path(
|
||||
path,
|
||||
packaging::detect_package_root(path, &settings.namespace_packages),
|
||||
contents,
|
||||
@@ -61,7 +61,7 @@ pub fn check(path: &Path, contents: &str, autofix: bool) -> Result<Vec<Diagnosti
|
||||
&settings,
|
||||
autofix.into(),
|
||||
flags::Noqa::Enabled,
|
||||
)?;
|
||||
);
|
||||
|
||||
Ok(diagnostics)
|
||||
Ok(result.data)
|
||||
}
|
||||
|
||||
@@ -6,7 +6,7 @@ use serde::Serialize;
|
||||
use wasm_bindgen::prelude::*;
|
||||
|
||||
use crate::directives;
|
||||
use crate::linter::check_path;
|
||||
use crate::linter::{check_path, LinterResult};
|
||||
use crate::registry::Rule;
|
||||
use crate::rules::{
|
||||
flake8_annotations, flake8_bandit, flake8_bugbear, flake8_builtins, flake8_errmsg,
|
||||
@@ -187,7 +187,9 @@ pub fn check(contents: &str, options: JsValue) -> Result<JsValue, JsValue> {
|
||||
let directives = directives::extract_directives(&tokens, directives::Flags::empty());
|
||||
|
||||
// Generate checks.
|
||||
let diagnostics = check_path(
|
||||
let LinterResult {
|
||||
data: diagnostics, ..
|
||||
} = check_path(
|
||||
Path::new("<filename>"),
|
||||
None,
|
||||
contents,
|
||||
@@ -199,8 +201,7 @@ pub fn check(contents: &str, options: JsValue) -> Result<JsValue, JsValue> {
|
||||
&settings,
|
||||
flags::Autofix::Enabled,
|
||||
flags::Noqa::Enabled,
|
||||
)
|
||||
.map_err(|e| e.to_string())?;
|
||||
);
|
||||
|
||||
let messages: Vec<ExpandedMessage> = diagnostics
|
||||
.into_iter()
|
||||
|
||||
321
src/linter.rs
321
src/linter.rs
@@ -1,10 +1,11 @@
|
||||
use std::borrow::Cow;
|
||||
use std::path::Path;
|
||||
|
||||
use anyhow::Result;
|
||||
use anyhow::{anyhow, Result};
|
||||
use colored::Colorize;
|
||||
use rustpython_parser::error::ParseError;
|
||||
use rustpython_parser::lexer::LexResult;
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::autofix::fix_file;
|
||||
use crate::checkers::ast::check_ast;
|
||||
use crate::checkers::filesystem::check_file_path;
|
||||
@@ -17,13 +18,31 @@ use crate::doc_lines::{doc_lines_from_ast, doc_lines_from_tokens};
|
||||
use crate::message::{Message, Source};
|
||||
use crate::noqa::add_noqa;
|
||||
use crate::registry::{Diagnostic, LintSource, Rule};
|
||||
use crate::rules::pycodestyle;
|
||||
use crate::settings::{flags, Settings};
|
||||
use crate::source_code::{Indexer, Locator, Stylist};
|
||||
use crate::{directives, fs, rustpython_helpers, violations};
|
||||
use crate::{directives, fs, rustpython_helpers};
|
||||
|
||||
const CARGO_PKG_NAME: &str = env!("CARGO_PKG_NAME");
|
||||
const CARGO_PKG_REPOSITORY: &str = env!("CARGO_PKG_REPOSITORY");
|
||||
|
||||
/// A [`Result`]-like type that returns both data and an error. Used to return diagnostics even in
|
||||
/// the face of parse errors, since many diagnostics can be generated without a full AST.
|
||||
pub struct LinterResult<T> {
|
||||
pub data: T,
|
||||
pub error: Option<ParseError>,
|
||||
}
|
||||
|
||||
impl<T> LinterResult<T> {
|
||||
const fn new(data: T, error: Option<ParseError>) -> Self {
|
||||
Self { data, error }
|
||||
}
|
||||
|
||||
fn map<U, F: FnOnce(T) -> U>(self, f: F) -> LinterResult<U> {
|
||||
LinterResult::new(f(self.data), self.error)
|
||||
}
|
||||
}
|
||||
|
||||
/// Generate `Diagnostic`s from the source code contents at the
|
||||
/// given `Path`.
|
||||
#[allow(clippy::too_many_arguments)]
|
||||
@@ -39,9 +58,10 @@ pub fn check_path(
|
||||
settings: &Settings,
|
||||
autofix: flags::Autofix,
|
||||
noqa: flags::Noqa,
|
||||
) -> Result<Vec<Diagnostic>> {
|
||||
) -> LinterResult<Vec<Diagnostic>> {
|
||||
// Aggregate all diagnostics.
|
||||
let mut diagnostics: Vec<Diagnostic> = vec![];
|
||||
let mut diagnostics = vec![];
|
||||
let mut error = None;
|
||||
|
||||
// Collect doc lines. This requires a rare mix of tokens (for comments) and AST
|
||||
// (for docstrings), which demands special-casing at this level.
|
||||
@@ -80,7 +100,7 @@ pub fn check_path(
|
||||
.iter_enabled()
|
||||
.any(|rule_code| matches!(rule_code.lint_source(), LintSource::Imports));
|
||||
if use_ast || use_imports || use_doc_lines {
|
||||
match rustpython_helpers::parse_program_tokens(tokens, "<filename>") {
|
||||
match rustpython_helpers::parse_program_tokens(tokens, &path.to_string_lossy()) {
|
||||
Ok(python_ast) => {
|
||||
if use_ast {
|
||||
diagnostics.extend(check_ast(
|
||||
@@ -115,13 +135,9 @@ pub fn check_path(
|
||||
}
|
||||
Err(parse_error) => {
|
||||
if settings.rules.enabled(&Rule::SyntaxError) {
|
||||
diagnostics.push(Diagnostic::new(
|
||||
violations::SyntaxError {
|
||||
message: parse_error.error.to_string(),
|
||||
},
|
||||
Range::new(parse_error.location, parse_error.location),
|
||||
));
|
||||
pycodestyle::rules::syntax_error(&mut diagnostics, &parse_error);
|
||||
}
|
||||
error = Some(parse_error);
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -151,8 +167,7 @@ pub fn check_path(
|
||||
|
||||
// Ignore diagnostics based on per-file-ignores.
|
||||
if !diagnostics.is_empty() && !settings.per_file_ignores.is_empty() {
|
||||
let ignores = fs::ignores_from_path(path, &settings.per_file_ignores)?;
|
||||
|
||||
let ignores = fs::ignores_from_path(path, &settings.per_file_ignores);
|
||||
if !ignores.is_empty() {
|
||||
diagnostics.retain(|diagnostic| !ignores.contains(&diagnostic.kind.rule()));
|
||||
}
|
||||
@@ -175,7 +190,7 @@ pub fn check_path(
|
||||
);
|
||||
}
|
||||
|
||||
Ok(diagnostics)
|
||||
LinterResult::new(diagnostics, error)
|
||||
}
|
||||
|
||||
const MAX_ITERATIONS: usize = 100;
|
||||
@@ -202,7 +217,10 @@ pub fn add_noqa_to_path(path: &Path, settings: &Settings) -> Result<usize> {
|
||||
directives::extract_directives(&tokens, directives::Flags::from_settings(settings));
|
||||
|
||||
// Generate diagnostics, ignoring any existing `noqa` directives.
|
||||
let diagnostics = check_path(
|
||||
let LinterResult {
|
||||
data: diagnostics,
|
||||
error,
|
||||
} = check_path(
|
||||
path,
|
||||
None,
|
||||
&contents,
|
||||
@@ -214,8 +232,24 @@ pub fn add_noqa_to_path(path: &Path, settings: &Settings) -> Result<usize> {
|
||||
settings,
|
||||
flags::Autofix::Disabled,
|
||||
flags::Noqa::Disabled,
|
||||
)?;
|
||||
);
|
||||
|
||||
// Log any parse errors.
|
||||
if let Some(err) = error {
|
||||
#[allow(clippy::print_stderr)]
|
||||
{
|
||||
eprintln!(
|
||||
"{}{} {}{}{} {err:?}",
|
||||
"error".red().bold(),
|
||||
":".bold(),
|
||||
"Failed to parse ".bold(),
|
||||
fs::relativize_path(path).bold(),
|
||||
":".bold()
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
// Add any missing `# noqa` pragmas.
|
||||
add_noqa(
|
||||
path,
|
||||
&diagnostics,
|
||||
@@ -226,15 +260,14 @@ pub fn add_noqa_to_path(path: &Path, settings: &Settings) -> Result<usize> {
|
||||
)
|
||||
}
|
||||
|
||||
/// Generate `Diagnostic`s (optionally including any autofix
|
||||
/// patches) from source code content.
|
||||
/// Generate a [`Message`] for each [`Diagnostic`] triggered by the given source code.
|
||||
pub fn lint_only(
|
||||
contents: &str,
|
||||
path: &Path,
|
||||
package: Option<&Path>,
|
||||
settings: &Settings,
|
||||
autofix: flags::Autofix,
|
||||
) -> Result<Vec<Message>> {
|
||||
) -> LinterResult<Vec<Message>> {
|
||||
// Tokenize once.
|
||||
let tokens: Vec<LexResult> = rustpython_helpers::tokenize(contents);
|
||||
|
||||
@@ -252,7 +285,7 @@ pub fn lint_only(
|
||||
directives::extract_directives(&tokens, directives::Flags::from_settings(settings));
|
||||
|
||||
// Generate diagnostics.
|
||||
let diagnostics = check_path(
|
||||
let result = check_path(
|
||||
path,
|
||||
package,
|
||||
contents,
|
||||
@@ -264,109 +297,12 @@ pub fn lint_only(
|
||||
settings,
|
||||
autofix,
|
||||
flags::Noqa::Enabled,
|
||||
)?;
|
||||
);
|
||||
|
||||
// Convert from diagnostics to messages.
|
||||
let path_lossy = path.to_string_lossy();
|
||||
Ok(diagnostics
|
||||
.into_iter()
|
||||
.map(|diagnostic| {
|
||||
let source = if settings.show_source {
|
||||
Some(Source::from_diagnostic(&diagnostic, &locator))
|
||||
} else {
|
||||
None
|
||||
};
|
||||
Message::from_diagnostic(diagnostic, path_lossy.to_string(), source)
|
||||
})
|
||||
.collect())
|
||||
}
|
||||
|
||||
/// Generate `Diagnostic`s from source code content, iteratively autofixing
|
||||
/// until stable.
|
||||
pub fn lint_fix(
|
||||
contents: &str,
|
||||
path: &Path,
|
||||
package: Option<&Path>,
|
||||
settings: &Settings,
|
||||
) -> Result<(String, usize, Vec<Message>)> {
|
||||
let mut contents = contents.to_string();
|
||||
|
||||
// Track the number of fixed errors across iterations.
|
||||
let mut fixed = 0;
|
||||
|
||||
// As an escape hatch, bail after 100 iterations.
|
||||
let mut iterations = 0;
|
||||
|
||||
// Continuously autofix until the source code stabilizes.
|
||||
loop {
|
||||
// Tokenize once.
|
||||
let tokens: Vec<LexResult> = rustpython_helpers::tokenize(&contents);
|
||||
|
||||
// Map row and column locations to byte slices (lazily).
|
||||
let locator = Locator::new(&contents);
|
||||
|
||||
// Detect the current code style (lazily).
|
||||
let stylist = Stylist::from_contents(&contents, &locator);
|
||||
|
||||
// Extra indices from the code.
|
||||
let indexer: Indexer = tokens.as_slice().into();
|
||||
|
||||
// Extract the `# noqa` and `# isort: skip` directives from the source.
|
||||
let directives =
|
||||
directives::extract_directives(&tokens, directives::Flags::from_settings(settings));
|
||||
|
||||
// Generate diagnostics.
|
||||
let diagnostics = check_path(
|
||||
path,
|
||||
package,
|
||||
&contents,
|
||||
tokens,
|
||||
&locator,
|
||||
&stylist,
|
||||
&indexer,
|
||||
&directives,
|
||||
settings,
|
||||
flags::Autofix::Enabled,
|
||||
flags::Noqa::Enabled,
|
||||
)?;
|
||||
|
||||
// Apply autofix.
|
||||
if let Some((fixed_contents, applied)) = fix_file(&diagnostics, &locator) {
|
||||
if iterations < MAX_ITERATIONS {
|
||||
// Count the number of fixed errors.
|
||||
fixed += applied;
|
||||
|
||||
// Store the fixed contents.
|
||||
contents = fixed_contents.to_string();
|
||||
|
||||
// Increment the iteration count.
|
||||
iterations += 1;
|
||||
|
||||
// Re-run the linter pass (by avoiding the break).
|
||||
continue;
|
||||
}
|
||||
|
||||
eprintln!(
|
||||
r#"
|
||||
{}: Failed to converge after {} iterations.
|
||||
|
||||
This likely indicates a bug in `{}`. If you could open an issue at:
|
||||
|
||||
{}/issues/new?title=%5BInfinite%20loop%5D
|
||||
|
||||
quoting the contents of `{}`, along with the `pyproject.toml` settings and executed command, we'd be very appreciative!
|
||||
"#,
|
||||
"warning".yellow().bold(),
|
||||
MAX_ITERATIONS,
|
||||
CARGO_PKG_NAME,
|
||||
CARGO_PKG_REPOSITORY,
|
||||
fs::relativize_path(path),
|
||||
);
|
||||
}
|
||||
|
||||
// Convert to messages.
|
||||
let path_lossy = path.to_string_lossy();
|
||||
let messages = diagnostics
|
||||
result.map(|diagnostics| {
|
||||
diagnostics
|
||||
.into_iter()
|
||||
.map(|diagnostic| {
|
||||
let source = if settings.show_source {
|
||||
@@ -376,7 +312,146 @@ quoting the contents of `{}`, along with the `pyproject.toml` settings and execu
|
||||
};
|
||||
Message::from_diagnostic(diagnostic, path_lossy.to_string(), source)
|
||||
})
|
||||
.collect();
|
||||
return Ok((contents, fixed, messages));
|
||||
.collect()
|
||||
})
|
||||
}
|
||||
|
||||
/// Generate `Diagnostic`s from source code content, iteratively autofixing
|
||||
/// until stable.
|
||||
pub fn lint_fix<'a>(
|
||||
contents: &'a str,
|
||||
path: &Path,
|
||||
package: Option<&Path>,
|
||||
settings: &Settings,
|
||||
) -> Result<(LinterResult<Vec<Message>>, Cow<'a, str>, usize)> {
|
||||
let mut transformed = Cow::Borrowed(contents);
|
||||
|
||||
// Track the number of fixed errors across iterations.
|
||||
let mut fixed = 0;
|
||||
|
||||
// As an escape hatch, bail after 100 iterations.
|
||||
let mut iterations = 0;
|
||||
|
||||
// Track whether the _initial_ source code was parseable.
|
||||
let mut parseable = false;
|
||||
|
||||
// Continuously autofix until the source code stabilizes.
|
||||
loop {
|
||||
// Tokenize once.
|
||||
let tokens: Vec<LexResult> = rustpython_helpers::tokenize(&transformed);
|
||||
|
||||
// Map row and column locations to byte slices (lazily).
|
||||
let locator = Locator::new(&transformed);
|
||||
|
||||
// Detect the current code style (lazily).
|
||||
let stylist = Stylist::from_contents(&transformed, &locator);
|
||||
|
||||
// Extra indices from the code.
|
||||
let indexer: Indexer = tokens.as_slice().into();
|
||||
|
||||
// Extract the `# noqa` and `# isort: skip` directives from the source.
|
||||
let directives =
|
||||
directives::extract_directives(&tokens, directives::Flags::from_settings(settings));
|
||||
|
||||
// Generate diagnostics.
|
||||
let result = check_path(
|
||||
path,
|
||||
package,
|
||||
&transformed,
|
||||
tokens,
|
||||
&locator,
|
||||
&stylist,
|
||||
&indexer,
|
||||
&directives,
|
||||
settings,
|
||||
flags::Autofix::Enabled,
|
||||
flags::Noqa::Enabled,
|
||||
);
|
||||
|
||||
if iterations == 0 {
|
||||
parseable = result.error.is_none();
|
||||
} else {
|
||||
// If the source code was parseable on the first pass, but is no
|
||||
// longer parseable on a subsequent pass, then we've introduced a
|
||||
// syntax error. Return the original code.
|
||||
if parseable && result.error.is_some() {
|
||||
#[allow(clippy::print_stderr)]
|
||||
{
|
||||
eprintln!(
|
||||
r#"
|
||||
{}: Autofix introduced a syntax error. Reverting all changes.
|
||||
|
||||
This indicates a bug in `{}`. If you could open an issue at:
|
||||
|
||||
{}/issues/new?title=%5BAutofix%20error%5D
|
||||
|
||||
...quoting the contents of `{}`, along with the `pyproject.toml` settings and executed command, we'd be very appreciative!
|
||||
"#,
|
||||
"error".red().bold(),
|
||||
CARGO_PKG_NAME,
|
||||
CARGO_PKG_REPOSITORY,
|
||||
fs::relativize_path(path),
|
||||
);
|
||||
}
|
||||
return Err(anyhow!("Autofix introduced a syntax error"));
|
||||
}
|
||||
}
|
||||
|
||||
// Apply autofix.
|
||||
if let Some((fixed_contents, applied)) = fix_file(&result.data, &locator) {
|
||||
if iterations < MAX_ITERATIONS {
|
||||
// Count the number of fixed errors.
|
||||
fixed += applied;
|
||||
|
||||
// Store the fixed contents.
|
||||
transformed = Cow::Owned(fixed_contents);
|
||||
|
||||
// Increment the iteration count.
|
||||
iterations += 1;
|
||||
|
||||
// Re-run the linter pass (by avoiding the break).
|
||||
continue;
|
||||
}
|
||||
|
||||
#[allow(clippy::print_stderr)]
|
||||
{
|
||||
eprintln!(
|
||||
r#"
|
||||
{}: Failed to converge after {} iterations.
|
||||
|
||||
This indicates a bug in `{}`. If you could open an issue at:
|
||||
|
||||
{}/issues/new?title=%5BInfinite%20loop%5D
|
||||
|
||||
...quoting the contents of `{}`, along with the `pyproject.toml` settings and executed command, we'd be very appreciative!
|
||||
"#,
|
||||
"error".red().bold(),
|
||||
MAX_ITERATIONS,
|
||||
CARGO_PKG_NAME,
|
||||
CARGO_PKG_REPOSITORY,
|
||||
fs::relativize_path(path),
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
// Convert to messages.
|
||||
let path_lossy = path.to_string_lossy();
|
||||
return Ok((
|
||||
result.map(|diagnostics| {
|
||||
diagnostics
|
||||
.into_iter()
|
||||
.map(|diagnostic| {
|
||||
let source = if settings.show_source {
|
||||
Some(Source::from_diagnostic(&diagnostic, &locator))
|
||||
} else {
|
||||
None
|
||||
};
|
||||
Message::from_diagnostic(diagnostic, path_lossy.to_string(), source)
|
||||
})
|
||||
.collect()
|
||||
}),
|
||||
transformed,
|
||||
fixed,
|
||||
));
|
||||
}
|
||||
}
|
||||
|
||||
@@ -48,20 +48,20 @@ macro_rules! notify_user {
|
||||
|
||||
#[derive(Debug, Default, PartialOrd, Ord, PartialEq, Eq, Copy, Clone)]
|
||||
pub enum LogLevel {
|
||||
// No output (+ `log::LevelFilter::Off`).
|
||||
/// No output ([`log::LevelFilter::Off`]).
|
||||
Silent,
|
||||
// Only show lint violations, with no decorative output (+ `log::LevelFilter::Off`).
|
||||
/// Only show lint violations, with no decorative output ([`log::LevelFilter::Off`]).
|
||||
Quiet,
|
||||
// All user-facing output (+ `log::LevelFilter::Info`).
|
||||
/// All user-facing output ([`log::LevelFilter::Info`]).
|
||||
#[default]
|
||||
Default,
|
||||
// All user-facing output (+ `log::LevelFilter::Debug`).
|
||||
/// All user-facing output ([`log::LevelFilter::Debug`]).
|
||||
Verbose,
|
||||
}
|
||||
|
||||
impl LogLevel {
|
||||
#[allow(clippy::trivially_copy_pass_by_ref)]
|
||||
fn level_filter(&self) -> log::LevelFilter {
|
||||
const fn level_filter(&self) -> log::LevelFilter {
|
||||
match self {
|
||||
LogLevel::Default => log::LevelFilter::Info,
|
||||
LogLevel::Verbose => log::LevelFilter::Debug,
|
||||
@@ -83,6 +83,7 @@ pub fn set_up_logging(level: &LogLevel) -> Result<()> {
|
||||
));
|
||||
})
|
||||
.level(level.level_filter())
|
||||
.level_for("globset", log::LevelFilter::Warn)
|
||||
.chain(std::io::stderr())
|
||||
.apply()?;
|
||||
Ok(())
|
||||
|
||||
@@ -196,7 +196,6 @@ fn add_noqa_inner(
|
||||
output.push_str(line_ending);
|
||||
}
|
||||
Directive::Codes(_, start_byte, _, existing) => {
|
||||
println!("existing: {:?}", existing);
|
||||
// Reconstruct the line based on the preserved rule codes.
|
||||
// This enables us to tally the number of edits.
|
||||
let mut formatted = String::with_capacity(line.len());
|
||||
@@ -242,8 +241,8 @@ mod tests {
|
||||
use crate::noqa::{add_noqa_inner, NOQA_LINE_REGEX};
|
||||
use crate::registry::Diagnostic;
|
||||
use crate::rules::pycodestyle::rules::AmbiguousVariableName;
|
||||
use crate::rules::pyflakes;
|
||||
use crate::source_code::LineEnding;
|
||||
use crate::violations;
|
||||
|
||||
#[test]
|
||||
fn regex() {
|
||||
@@ -276,7 +275,7 @@ mod tests {
|
||||
assert_eq!(output, format!("{contents}\n"));
|
||||
|
||||
let diagnostics = vec![Diagnostic::new(
|
||||
violations::UnusedVariable {
|
||||
pyflakes::rules::UnusedVariable {
|
||||
name: "x".to_string(),
|
||||
},
|
||||
Range::new(Location::new(1, 0), Location::new(1, 0)),
|
||||
@@ -300,7 +299,7 @@ mod tests {
|
||||
Range::new(Location::new(1, 0), Location::new(1, 0)),
|
||||
),
|
||||
Diagnostic::new(
|
||||
violations::UnusedVariable {
|
||||
pyflakes::rules::UnusedVariable {
|
||||
name: "x".to_string(),
|
||||
},
|
||||
Range::new(Location::new(1, 0), Location::new(1, 0)),
|
||||
@@ -325,7 +324,7 @@ mod tests {
|
||||
Range::new(Location::new(1, 0), Location::new(1, 0)),
|
||||
),
|
||||
Diagnostic::new(
|
||||
violations::UnusedVariable {
|
||||
pyflakes::rules::UnusedVariable {
|
||||
name: "x".to_string(),
|
||||
},
|
||||
Range::new(Location::new(1, 0), Location::new(1, 0)),
|
||||
|
||||
1331
src/python/sys.rs
1331
src/python/sys.rs
File diff suppressed because it is too large
Load Diff
536
src/registry.rs
536
src/registry.rs
@@ -7,14 +7,14 @@ use strum_macros::{AsRefStr, EnumIter};
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::fix::Fix;
|
||||
use crate::rules;
|
||||
use crate::violation::Violation;
|
||||
use crate::{rules, violations};
|
||||
|
||||
ruff_macros::define_rule_mapping!(
|
||||
// pycodestyle errors
|
||||
E101 => rules::pycodestyle::rules::MixedSpacesAndTabs,
|
||||
E401 => violations::MultipleImportsOnOneLine,
|
||||
E402 => violations::ModuleImportNotAtTopOfFile,
|
||||
E401 => rules::pycodestyle::rules::MultipleImportsOnOneLine,
|
||||
E402 => rules::pycodestyle::rules::ModuleImportNotAtTopOfFile,
|
||||
E501 => rules::pycodestyle::rules::LineTooLong,
|
||||
E711 => rules::pycodestyle::rules::NoneComparison,
|
||||
E712 => rules::pycodestyle::rules::TrueFalseComparison,
|
||||
@@ -26,73 +26,73 @@ ruff_macros::define_rule_mapping!(
|
||||
E741 => rules::pycodestyle::rules::AmbiguousVariableName,
|
||||
E742 => rules::pycodestyle::rules::AmbiguousClassName,
|
||||
E743 => rules::pycodestyle::rules::AmbiguousFunctionName,
|
||||
E902 => violations::IOError,
|
||||
E999 => violations::SyntaxError,
|
||||
E902 => rules::pycodestyle::rules::IOError,
|
||||
E999 => rules::pycodestyle::rules::SyntaxError,
|
||||
// pycodestyle warnings
|
||||
W292 => rules::pycodestyle::rules::NoNewLineAtEndOfFile,
|
||||
W505 => rules::pycodestyle::rules::DocLineTooLong,
|
||||
W605 => rules::pycodestyle::rules::InvalidEscapeSequence,
|
||||
// pyflakes
|
||||
F401 => violations::UnusedImport,
|
||||
F402 => violations::ImportShadowedByLoopVar,
|
||||
F403 => violations::ImportStarUsed,
|
||||
F404 => violations::LateFutureImport,
|
||||
F405 => violations::ImportStarUsage,
|
||||
F406 => violations::ImportStarNotPermitted,
|
||||
F407 => violations::FutureFeatureNotDefined,
|
||||
F501 => violations::PercentFormatInvalidFormat,
|
||||
F502 => violations::PercentFormatExpectedMapping,
|
||||
F503 => violations::PercentFormatExpectedSequence,
|
||||
F504 => violations::PercentFormatExtraNamedArguments,
|
||||
F505 => violations::PercentFormatMissingArgument,
|
||||
F506 => violations::PercentFormatMixedPositionalAndNamed,
|
||||
F507 => violations::PercentFormatPositionalCountMismatch,
|
||||
F508 => violations::PercentFormatStarRequiresSequence,
|
||||
F509 => violations::PercentFormatUnsupportedFormatCharacter,
|
||||
F521 => violations::StringDotFormatInvalidFormat,
|
||||
F522 => violations::StringDotFormatExtraNamedArguments,
|
||||
F523 => violations::StringDotFormatExtraPositionalArguments,
|
||||
F524 => violations::StringDotFormatMissingArguments,
|
||||
F525 => violations::StringDotFormatMixingAutomatic,
|
||||
F541 => violations::FStringMissingPlaceholders,
|
||||
F601 => violations::MultiValueRepeatedKeyLiteral,
|
||||
F602 => violations::MultiValueRepeatedKeyVariable,
|
||||
F621 => violations::ExpressionsInStarAssignment,
|
||||
F622 => violations::TwoStarredExpressions,
|
||||
F631 => violations::AssertTuple,
|
||||
F632 => violations::IsLiteral,
|
||||
F633 => violations::InvalidPrintSyntax,
|
||||
F634 => violations::IfTuple,
|
||||
F701 => violations::BreakOutsideLoop,
|
||||
F702 => violations::ContinueOutsideLoop,
|
||||
F704 => violations::YieldOutsideFunction,
|
||||
F706 => violations::ReturnOutsideFunction,
|
||||
F707 => violations::DefaultExceptNotLast,
|
||||
F722 => violations::ForwardAnnotationSyntaxError,
|
||||
F811 => violations::RedefinedWhileUnused,
|
||||
F821 => violations::UndefinedName,
|
||||
F822 => violations::UndefinedExport,
|
||||
F823 => violations::UndefinedLocal,
|
||||
F841 => violations::UnusedVariable,
|
||||
F842 => violations::UnusedAnnotation,
|
||||
F901 => violations::RaiseNotImplemented,
|
||||
F401 => rules::pyflakes::rules::UnusedImport,
|
||||
F402 => rules::pyflakes::rules::ImportShadowedByLoopVar,
|
||||
F403 => rules::pyflakes::rules::ImportStarUsed,
|
||||
F404 => rules::pyflakes::rules::LateFutureImport,
|
||||
F405 => rules::pyflakes::rules::ImportStarUsage,
|
||||
F406 => rules::pyflakes::rules::ImportStarNotPermitted,
|
||||
F407 => rules::pyflakes::rules::FutureFeatureNotDefined,
|
||||
F501 => rules::pyflakes::rules::PercentFormatInvalidFormat,
|
||||
F502 => rules::pyflakes::rules::PercentFormatExpectedMapping,
|
||||
F503 => rules::pyflakes::rules::PercentFormatExpectedSequence,
|
||||
F504 => rules::pyflakes::rules::PercentFormatExtraNamedArguments,
|
||||
F505 => rules::pyflakes::rules::PercentFormatMissingArgument,
|
||||
F506 => rules::pyflakes::rules::PercentFormatMixedPositionalAndNamed,
|
||||
F507 => rules::pyflakes::rules::PercentFormatPositionalCountMismatch,
|
||||
F508 => rules::pyflakes::rules::PercentFormatStarRequiresSequence,
|
||||
F509 => rules::pyflakes::rules::PercentFormatUnsupportedFormatCharacter,
|
||||
F521 => rules::pyflakes::rules::StringDotFormatInvalidFormat,
|
||||
F522 => rules::pyflakes::rules::StringDotFormatExtraNamedArguments,
|
||||
F523 => rules::pyflakes::rules::StringDotFormatExtraPositionalArguments,
|
||||
F524 => rules::pyflakes::rules::StringDotFormatMissingArguments,
|
||||
F525 => rules::pyflakes::rules::StringDotFormatMixingAutomatic,
|
||||
F541 => rules::pyflakes::rules::FStringMissingPlaceholders,
|
||||
F601 => rules::pyflakes::rules::MultiValueRepeatedKeyLiteral,
|
||||
F602 => rules::pyflakes::rules::MultiValueRepeatedKeyVariable,
|
||||
F621 => rules::pyflakes::rules::ExpressionsInStarAssignment,
|
||||
F622 => rules::pyflakes::rules::TwoStarredExpressions,
|
||||
F631 => rules::pyflakes::rules::AssertTuple,
|
||||
F632 => rules::pyflakes::rules::IsLiteral,
|
||||
F633 => rules::pyflakes::rules::InvalidPrintSyntax,
|
||||
F634 => rules::pyflakes::rules::IfTuple,
|
||||
F701 => rules::pyflakes::rules::BreakOutsideLoop,
|
||||
F702 => rules::pyflakes::rules::ContinueOutsideLoop,
|
||||
F704 => rules::pyflakes::rules::YieldOutsideFunction,
|
||||
F706 => rules::pyflakes::rules::ReturnOutsideFunction,
|
||||
F707 => rules::pyflakes::rules::DefaultExceptNotLast,
|
||||
F722 => rules::pyflakes::rules::ForwardAnnotationSyntaxError,
|
||||
F811 => rules::pyflakes::rules::RedefinedWhileUnused,
|
||||
F821 => rules::pyflakes::rules::UndefinedName,
|
||||
F822 => rules::pyflakes::rules::UndefinedExport,
|
||||
F823 => rules::pyflakes::rules::UndefinedLocal,
|
||||
F841 => rules::pyflakes::rules::UnusedVariable,
|
||||
F842 => rules::pyflakes::rules::UnusedAnnotation,
|
||||
F901 => rules::pyflakes::rules::RaiseNotImplemented,
|
||||
// pylint
|
||||
PLE0604 => rules::pylint::rules::InvalidAllObject,
|
||||
PLE0605 => rules::pylint::rules::InvalidAllFormat,
|
||||
PLC0414 => violations::UselessImportAlias,
|
||||
PLC3002 => violations::UnnecessaryDirectLambdaCall,
|
||||
PLE0117 => violations::NonlocalWithoutBinding,
|
||||
PLE0118 => violations::UsedPriorGlobalDeclaration,
|
||||
PLE1142 => violations::AwaitOutsideAsync,
|
||||
PLR0206 => violations::PropertyWithParameters,
|
||||
PLR0402 => violations::ConsiderUsingFromImport,
|
||||
PLR0133 => violations::ConstantComparison,
|
||||
PLR1701 => violations::ConsiderMergingIsinstance,
|
||||
PLR1722 => violations::UseSysExit,
|
||||
PLR2004 => violations::MagicValueComparison,
|
||||
PLW0120 => violations::UselessElseOnLoop,
|
||||
PLW0602 => violations::GlobalVariableNotAssigned,
|
||||
PLR0913 => rules::pylint::rules::TooManyArgs,
|
||||
PLC0414 => rules::pylint::rules::UselessImportAlias,
|
||||
PLC3002 => rules::pylint::rules::UnnecessaryDirectLambdaCall,
|
||||
PLE0117 => rules::pylint::rules::NonlocalWithoutBinding,
|
||||
PLE0118 => rules::pylint::rules::UsedPriorGlobalDeclaration,
|
||||
PLE1142 => rules::pylint::rules::AwaitOutsideAsync,
|
||||
PLR0206 => rules::pylint::rules::PropertyWithParameters,
|
||||
PLR0402 => rules::pylint::rules::ConsiderUsingFromImport,
|
||||
PLR0133 => rules::pylint::rules::ComparisonOfConstant,
|
||||
PLR1701 => rules::pylint::rules::ConsiderMergingIsinstance,
|
||||
PLR1722 => rules::pylint::rules::ConsiderUsingSysExit,
|
||||
PLR2004 => rules::pylint::rules::MagicValueComparison,
|
||||
PLW0120 => rules::pylint::rules::UselessElseOnLoop,
|
||||
PLW0602 => rules::pylint::rules::GlobalVariableNotAssigned,
|
||||
PLR0913 => rules::pylint::rules::TooManyArguments,
|
||||
PLR0915 => rules::pylint::rules::TooManyStatements,
|
||||
// flake8-builtins
|
||||
A001 => rules::flake8_builtins::rules::BuiltinVariableShadowing,
|
||||
@@ -147,230 +147,230 @@ ruff_macros::define_rule_mapping!(
|
||||
C416 => rules::flake8_comprehensions::rules::UnnecessaryComprehension,
|
||||
C417 => rules::flake8_comprehensions::rules::UnnecessaryMap,
|
||||
// flake8-debugger
|
||||
T100 => violations::Debugger,
|
||||
T100 => rules::flake8_debugger::rules::Debugger,
|
||||
// mccabe
|
||||
C901 => violations::FunctionIsTooComplex,
|
||||
C901 => rules::mccabe::rules::FunctionIsTooComplex,
|
||||
// flake8-tidy-imports
|
||||
TID251 => rules::flake8_tidy_imports::banned_api::BannedApi,
|
||||
TID252 => rules::flake8_tidy_imports::relative_imports::RelativeImports,
|
||||
// flake8-return
|
||||
RET501 => violations::UnnecessaryReturnNone,
|
||||
RET502 => violations::ImplicitReturnValue,
|
||||
RET503 => violations::ImplicitReturn,
|
||||
RET504 => violations::UnnecessaryAssign,
|
||||
RET505 => violations::SuperfluousElseReturn,
|
||||
RET506 => violations::SuperfluousElseRaise,
|
||||
RET507 => violations::SuperfluousElseContinue,
|
||||
RET508 => violations::SuperfluousElseBreak,
|
||||
RET501 => rules::flake8_return::rules::UnnecessaryReturnNone,
|
||||
RET502 => rules::flake8_return::rules::ImplicitReturnValue,
|
||||
RET503 => rules::flake8_return::rules::ImplicitReturn,
|
||||
RET504 => rules::flake8_return::rules::UnnecessaryAssign,
|
||||
RET505 => rules::flake8_return::rules::SuperfluousElseReturn,
|
||||
RET506 => rules::flake8_return::rules::SuperfluousElseRaise,
|
||||
RET507 => rules::flake8_return::rules::SuperfluousElseContinue,
|
||||
RET508 => rules::flake8_return::rules::SuperfluousElseBreak,
|
||||
// flake8-implicit-str-concat
|
||||
ISC001 => violations::SingleLineImplicitStringConcatenation,
|
||||
ISC002 => violations::MultiLineImplicitStringConcatenation,
|
||||
ISC003 => violations::ExplicitStringConcatenation,
|
||||
ISC001 => rules::flake8_implicit_str_concat::rules::SingleLineImplicitStringConcatenation,
|
||||
ISC002 => rules::flake8_implicit_str_concat::rules::MultiLineImplicitStringConcatenation,
|
||||
ISC003 => rules::flake8_implicit_str_concat::rules::ExplicitStringConcatenation,
|
||||
// flake8-print
|
||||
T201 => violations::PrintFound,
|
||||
T203 => violations::PPrintFound,
|
||||
T201 => rules::flake8_print::rules::PrintFound,
|
||||
T203 => rules::flake8_print::rules::PPrintFound,
|
||||
// flake8-quotes
|
||||
Q000 => rules::flake8_quotes::rules::BadQuotesInlineString,
|
||||
Q001 => rules::flake8_quotes::rules::BadQuotesMultilineString,
|
||||
Q002 => rules::flake8_quotes::rules::BadQuotesDocstring,
|
||||
Q003 => rules::flake8_quotes::rules::AvoidQuoteEscape,
|
||||
// flake8-annotations
|
||||
ANN001 => violations::MissingTypeFunctionArgument,
|
||||
ANN002 => violations::MissingTypeArgs,
|
||||
ANN003 => violations::MissingTypeKwargs,
|
||||
ANN101 => violations::MissingTypeSelf,
|
||||
ANN102 => violations::MissingTypeCls,
|
||||
ANN201 => violations::MissingReturnTypePublicFunction,
|
||||
ANN202 => violations::MissingReturnTypePrivateFunction,
|
||||
ANN204 => violations::MissingReturnTypeSpecialMethod,
|
||||
ANN205 => violations::MissingReturnTypeStaticMethod,
|
||||
ANN206 => violations::MissingReturnTypeClassMethod,
|
||||
ANN401 => violations::DynamicallyTypedExpression,
|
||||
ANN001 => rules::flake8_annotations::rules::MissingTypeFunctionArgument,
|
||||
ANN002 => rules::flake8_annotations::rules::MissingTypeArgs,
|
||||
ANN003 => rules::flake8_annotations::rules::MissingTypeKwargs,
|
||||
ANN101 => rules::flake8_annotations::rules::MissingTypeSelf,
|
||||
ANN102 => rules::flake8_annotations::rules::MissingTypeCls,
|
||||
ANN201 => rules::flake8_annotations::rules::MissingReturnTypePublicFunction,
|
||||
ANN202 => rules::flake8_annotations::rules::MissingReturnTypePrivateFunction,
|
||||
ANN204 => rules::flake8_annotations::rules::MissingReturnTypeSpecialMethod,
|
||||
ANN205 => rules::flake8_annotations::rules::MissingReturnTypeStaticMethod,
|
||||
ANN206 => rules::flake8_annotations::rules::MissingReturnTypeClassMethod,
|
||||
ANN401 => rules::flake8_annotations::rules::DynamicallyTypedExpression,
|
||||
// flake8-2020
|
||||
YTT101 => violations::SysVersionSlice3Referenced,
|
||||
YTT102 => violations::SysVersion2Referenced,
|
||||
YTT103 => violations::SysVersionCmpStr3,
|
||||
YTT201 => violations::SysVersionInfo0Eq3Referenced,
|
||||
YTT202 => violations::SixPY3Referenced,
|
||||
YTT203 => violations::SysVersionInfo1CmpInt,
|
||||
YTT204 => violations::SysVersionInfoMinorCmpInt,
|
||||
YTT301 => violations::SysVersion0Referenced,
|
||||
YTT302 => violations::SysVersionCmpStr10,
|
||||
YTT303 => violations::SysVersionSlice1Referenced,
|
||||
YTT101 => rules::flake8_2020::rules::SysVersionSlice3Referenced,
|
||||
YTT102 => rules::flake8_2020::rules::SysVersion2Referenced,
|
||||
YTT103 => rules::flake8_2020::rules::SysVersionCmpStr3,
|
||||
YTT201 => rules::flake8_2020::rules::SysVersionInfo0Eq3Referenced,
|
||||
YTT202 => rules::flake8_2020::rules::SixPY3Referenced,
|
||||
YTT203 => rules::flake8_2020::rules::SysVersionInfo1CmpInt,
|
||||
YTT204 => rules::flake8_2020::rules::SysVersionInfoMinorCmpInt,
|
||||
YTT301 => rules::flake8_2020::rules::SysVersion0Referenced,
|
||||
YTT302 => rules::flake8_2020::rules::SysVersionCmpStr10,
|
||||
YTT303 => rules::flake8_2020::rules::SysVersionSlice1Referenced,
|
||||
// flake8-simplify
|
||||
SIM115 => violations::OpenFileWithContextHandler,
|
||||
SIM101 => violations::DuplicateIsinstanceCall,
|
||||
SIM102 => violations::NestedIfStatements,
|
||||
SIM103 => violations::ReturnBoolConditionDirectly,
|
||||
SIM105 => violations::UseContextlibSuppress,
|
||||
SIM107 => violations::ReturnInTryExceptFinally,
|
||||
SIM108 => violations::UseTernaryOperator,
|
||||
SIM109 => violations::CompareWithTuple,
|
||||
SIM110 => violations::ConvertLoopToAny,
|
||||
SIM111 => violations::ConvertLoopToAll,
|
||||
SIM112 => violations::UseCapitalEnvironmentVariables,
|
||||
SIM117 => violations::MultipleWithStatements,
|
||||
SIM118 => violations::KeyInDict,
|
||||
SIM201 => violations::NegateEqualOp,
|
||||
SIM202 => violations::NegateNotEqualOp,
|
||||
SIM208 => violations::DoubleNegation,
|
||||
SIM210 => violations::IfExprWithTrueFalse,
|
||||
SIM211 => violations::IfExprWithFalseTrue,
|
||||
SIM212 => violations::IfExprWithTwistedArms,
|
||||
SIM220 => violations::AAndNotA,
|
||||
SIM221 => violations::AOrNotA,
|
||||
SIM222 => violations::OrTrue,
|
||||
SIM223 => violations::AndFalse,
|
||||
SIM300 => violations::YodaConditions,
|
||||
SIM401 => violations::DictGetWithDefault,
|
||||
SIM115 => rules::flake8_simplify::rules::OpenFileWithContextHandler,
|
||||
SIM101 => rules::flake8_simplify::rules::DuplicateIsinstanceCall,
|
||||
SIM102 => rules::flake8_simplify::rules::NestedIfStatements,
|
||||
SIM103 => rules::flake8_simplify::rules::ReturnBoolConditionDirectly,
|
||||
SIM105 => rules::flake8_simplify::rules::UseContextlibSuppress,
|
||||
SIM107 => rules::flake8_simplify::rules::ReturnInTryExceptFinally,
|
||||
SIM108 => rules::flake8_simplify::rules::UseTernaryOperator,
|
||||
SIM109 => rules::flake8_simplify::rules::CompareWithTuple,
|
||||
SIM110 => rules::flake8_simplify::rules::ConvertLoopToAny,
|
||||
SIM111 => rules::flake8_simplify::rules::ConvertLoopToAll,
|
||||
SIM112 => rules::flake8_simplify::rules::UseCapitalEnvironmentVariables,
|
||||
SIM117 => rules::flake8_simplify::rules::MultipleWithStatements,
|
||||
SIM118 => rules::flake8_simplify::rules::KeyInDict,
|
||||
SIM201 => rules::flake8_simplify::rules::NegateEqualOp,
|
||||
SIM202 => rules::flake8_simplify::rules::NegateNotEqualOp,
|
||||
SIM208 => rules::flake8_simplify::rules::DoubleNegation,
|
||||
SIM210 => rules::flake8_simplify::rules::IfExprWithTrueFalse,
|
||||
SIM211 => rules::flake8_simplify::rules::IfExprWithFalseTrue,
|
||||
SIM212 => rules::flake8_simplify::rules::IfExprWithTwistedArms,
|
||||
SIM220 => rules::flake8_simplify::rules::AAndNotA,
|
||||
SIM221 => rules::flake8_simplify::rules::AOrNotA,
|
||||
SIM222 => rules::flake8_simplify::rules::OrTrue,
|
||||
SIM223 => rules::flake8_simplify::rules::AndFalse,
|
||||
SIM300 => rules::flake8_simplify::rules::YodaConditions,
|
||||
SIM401 => rules::flake8_simplify::rules::DictGetWithDefault,
|
||||
// pyupgrade
|
||||
UP001 => violations::UselessMetaclassType,
|
||||
UP003 => violations::TypeOfPrimitive,
|
||||
UP004 => violations::UselessObjectInheritance,
|
||||
UP005 => violations::DeprecatedUnittestAlias,
|
||||
UP006 => violations::UsePEP585Annotation,
|
||||
UP007 => violations::UsePEP604Annotation,
|
||||
UP008 => violations::SuperCallWithParameters,
|
||||
UP009 => violations::PEP3120UnnecessaryCodingComment,
|
||||
UP010 => violations::UnnecessaryFutureImport,
|
||||
UP011 => violations::LRUCacheWithoutParameters,
|
||||
UP012 => violations::UnnecessaryEncodeUTF8,
|
||||
UP013 => violations::ConvertTypedDictFunctionalToClass,
|
||||
UP014 => violations::ConvertNamedTupleFunctionalToClass,
|
||||
UP015 => violations::RedundantOpenModes,
|
||||
UP017 => violations::DatetimeTimezoneUTC,
|
||||
UP018 => violations::NativeLiterals,
|
||||
UP019 => violations::TypingTextStrAlias,
|
||||
UP020 => violations::OpenAlias,
|
||||
UP021 => violations::ReplaceUniversalNewlines,
|
||||
UP022 => violations::ReplaceStdoutStderr,
|
||||
UP023 => violations::RewriteCElementTree,
|
||||
UP024 => violations::OSErrorAlias,
|
||||
UP025 => violations::RewriteUnicodeLiteral,
|
||||
UP026 => violations::RewriteMockImport,
|
||||
UP027 => violations::RewriteListComprehension,
|
||||
UP028 => violations::RewriteYieldFrom,
|
||||
UP029 => violations::UnnecessaryBuiltinImport,
|
||||
UP030 => violations::FormatLiterals,
|
||||
UP031 => violations::PrintfStringFormatting,
|
||||
UP032 => violations::FString,
|
||||
UP033 => violations::FunctoolsCache,
|
||||
UP034 => violations::ExtraneousParentheses,
|
||||
UP001 => rules::pyupgrade::rules::UselessMetaclassType,
|
||||
UP003 => rules::pyupgrade::rules::TypeOfPrimitive,
|
||||
UP004 => rules::pyupgrade::rules::UselessObjectInheritance,
|
||||
UP005 => rules::pyupgrade::rules::DeprecatedUnittestAlias,
|
||||
UP006 => rules::pyupgrade::rules::UsePEP585Annotation,
|
||||
UP007 => rules::pyupgrade::rules::UsePEP604Annotation,
|
||||
UP008 => rules::pyupgrade::rules::SuperCallWithParameters,
|
||||
UP009 => rules::pyupgrade::rules::PEP3120UnnecessaryCodingComment,
|
||||
UP010 => rules::pyupgrade::rules::UnnecessaryFutureImport,
|
||||
UP011 => rules::pyupgrade::rules::LRUCacheWithoutParameters,
|
||||
UP012 => rules::pyupgrade::rules::UnnecessaryEncodeUTF8,
|
||||
UP013 => rules::pyupgrade::rules::ConvertTypedDictFunctionalToClass,
|
||||
UP014 => rules::pyupgrade::rules::ConvertNamedTupleFunctionalToClass,
|
||||
UP015 => rules::pyupgrade::rules::RedundantOpenModes,
|
||||
UP017 => rules::pyupgrade::rules::DatetimeTimezoneUTC,
|
||||
UP018 => rules::pyupgrade::rules::NativeLiterals,
|
||||
UP019 => rules::pyupgrade::rules::TypingTextStrAlias,
|
||||
UP020 => rules::pyupgrade::rules::OpenAlias,
|
||||
UP021 => rules::pyupgrade::rules::ReplaceUniversalNewlines,
|
||||
UP022 => rules::pyupgrade::rules::ReplaceStdoutStderr,
|
||||
UP023 => rules::pyupgrade::rules::RewriteCElementTree,
|
||||
UP024 => rules::pyupgrade::rules::OSErrorAlias,
|
||||
UP025 => rules::pyupgrade::rules::RewriteUnicodeLiteral,
|
||||
UP026 => rules::pyupgrade::rules::RewriteMockImport,
|
||||
UP027 => rules::pyupgrade::rules::RewriteListComprehension,
|
||||
UP028 => rules::pyupgrade::rules::RewriteYieldFrom,
|
||||
UP029 => rules::pyupgrade::rules::UnnecessaryBuiltinImport,
|
||||
UP030 => rules::pyupgrade::rules::FormatLiterals,
|
||||
UP031 => rules::pyupgrade::rules::PrintfStringFormatting,
|
||||
UP032 => rules::pyupgrade::rules::FString,
|
||||
UP033 => rules::pyupgrade::rules::FunctoolsCache,
|
||||
UP034 => rules::pyupgrade::rules::ExtraneousParentheses,
|
||||
UP035 => rules::pyupgrade::rules::ImportReplacements,
|
||||
UP036 => rules::pyupgrade::rules::OutdatedVersionBlock,
|
||||
// pydocstyle
|
||||
D100 => violations::PublicModule,
|
||||
D101 => violations::PublicClass,
|
||||
D102 => violations::PublicMethod,
|
||||
D103 => violations::PublicFunction,
|
||||
D104 => violations::PublicPackage,
|
||||
D105 => violations::MagicMethod,
|
||||
D106 => violations::PublicNestedClass,
|
||||
D107 => violations::PublicInit,
|
||||
D200 => violations::FitsOnOneLine,
|
||||
D201 => violations::NoBlankLineBeforeFunction,
|
||||
D202 => violations::NoBlankLineAfterFunction,
|
||||
D203 => violations::OneBlankLineBeforeClass,
|
||||
D204 => violations::OneBlankLineAfterClass,
|
||||
D205 => violations::BlankLineAfterSummary,
|
||||
D206 => violations::IndentWithSpaces,
|
||||
D207 => violations::NoUnderIndentation,
|
||||
D208 => violations::NoOverIndentation,
|
||||
D209 => violations::NewLineAfterLastParagraph,
|
||||
D210 => violations::NoSurroundingWhitespace,
|
||||
D211 => violations::NoBlankLineBeforeClass,
|
||||
D212 => violations::MultiLineSummaryFirstLine,
|
||||
D213 => violations::MultiLineSummarySecondLine,
|
||||
D214 => violations::SectionNotOverIndented,
|
||||
D215 => violations::SectionUnderlineNotOverIndented,
|
||||
D300 => violations::UsesTripleQuotes,
|
||||
D301 => violations::UsesRPrefixForBackslashedContent,
|
||||
D400 => violations::EndsInPeriod,
|
||||
D401 => rules::pydocstyle::rules::non_imperative_mood::NonImperativeMood,
|
||||
D402 => violations::NoSignature,
|
||||
D403 => violations::FirstLineCapitalized,
|
||||
D404 => violations::NoThisPrefix,
|
||||
D405 => violations::CapitalizeSectionName,
|
||||
D406 => violations::NewLineAfterSectionName,
|
||||
D407 => violations::DashedUnderlineAfterSection,
|
||||
D408 => violations::SectionUnderlineAfterName,
|
||||
D409 => violations::SectionUnderlineMatchesSectionLength,
|
||||
D410 => violations::BlankLineAfterSection,
|
||||
D411 => violations::BlankLineBeforeSection,
|
||||
D412 => violations::NoBlankLinesBetweenHeaderAndContent,
|
||||
D413 => violations::BlankLineAfterLastSection,
|
||||
D414 => violations::NonEmptySection,
|
||||
D415 => violations::EndsInPunctuation,
|
||||
D416 => violations::SectionNameEndsInColon,
|
||||
D417 => violations::DocumentAllArguments,
|
||||
D418 => violations::SkipDocstring,
|
||||
D419 => violations::NonEmpty,
|
||||
D100 => rules::pydocstyle::rules::PublicModule,
|
||||
D101 => rules::pydocstyle::rules::PublicClass,
|
||||
D102 => rules::pydocstyle::rules::PublicMethod,
|
||||
D103 => rules::pydocstyle::rules::PublicFunction,
|
||||
D104 => rules::pydocstyle::rules::PublicPackage,
|
||||
D105 => rules::pydocstyle::rules::MagicMethod,
|
||||
D106 => rules::pydocstyle::rules::PublicNestedClass,
|
||||
D107 => rules::pydocstyle::rules::PublicInit,
|
||||
D200 => rules::pydocstyle::rules::FitsOnOneLine,
|
||||
D201 => rules::pydocstyle::rules::NoBlankLineBeforeFunction,
|
||||
D202 => rules::pydocstyle::rules::NoBlankLineAfterFunction,
|
||||
D203 => rules::pydocstyle::rules::OneBlankLineBeforeClass,
|
||||
D204 => rules::pydocstyle::rules::OneBlankLineAfterClass,
|
||||
D205 => rules::pydocstyle::rules::BlankLineAfterSummary,
|
||||
D206 => rules::pydocstyle::rules::IndentWithSpaces,
|
||||
D207 => rules::pydocstyle::rules::NoUnderIndentation,
|
||||
D208 => rules::pydocstyle::rules::NoOverIndentation,
|
||||
D209 => rules::pydocstyle::rules::NewLineAfterLastParagraph,
|
||||
D210 => rules::pydocstyle::rules::NoSurroundingWhitespace,
|
||||
D211 => rules::pydocstyle::rules::NoBlankLineBeforeClass,
|
||||
D212 => rules::pydocstyle::rules::MultiLineSummaryFirstLine,
|
||||
D213 => rules::pydocstyle::rules::MultiLineSummarySecondLine,
|
||||
D214 => rules::pydocstyle::rules::SectionNotOverIndented,
|
||||
D215 => rules::pydocstyle::rules::SectionUnderlineNotOverIndented,
|
||||
D300 => rules::pydocstyle::rules::UsesTripleQuotes,
|
||||
D301 => rules::pydocstyle::rules::UsesRPrefixForBackslashedContent,
|
||||
D400 => rules::pydocstyle::rules::EndsInPeriod,
|
||||
D401 => rules::pydocstyle::rules::NonImperativeMood,
|
||||
D402 => rules::pydocstyle::rules::NoSignature,
|
||||
D403 => rules::pydocstyle::rules::FirstLineCapitalized,
|
||||
D404 => rules::pydocstyle::rules::NoThisPrefix,
|
||||
D405 => rules::pydocstyle::rules::CapitalizeSectionName,
|
||||
D406 => rules::pydocstyle::rules::NewLineAfterSectionName,
|
||||
D407 => rules::pydocstyle::rules::DashedUnderlineAfterSection,
|
||||
D408 => rules::pydocstyle::rules::SectionUnderlineAfterName,
|
||||
D409 => rules::pydocstyle::rules::SectionUnderlineMatchesSectionLength,
|
||||
D410 => rules::pydocstyle::rules::BlankLineAfterSection,
|
||||
D411 => rules::pydocstyle::rules::BlankLineBeforeSection,
|
||||
D412 => rules::pydocstyle::rules::NoBlankLinesBetweenHeaderAndContent,
|
||||
D413 => rules::pydocstyle::rules::BlankLineAfterLastSection,
|
||||
D414 => rules::pydocstyle::rules::NonEmptySection,
|
||||
D415 => rules::pydocstyle::rules::EndsInPunctuation,
|
||||
D416 => rules::pydocstyle::rules::SectionNameEndsInColon,
|
||||
D417 => rules::pydocstyle::rules::DocumentAllArguments,
|
||||
D418 => rules::pydocstyle::rules::SkipDocstring,
|
||||
D419 => rules::pydocstyle::rules::NonEmpty,
|
||||
// pep8-naming
|
||||
N801 => violations::InvalidClassName,
|
||||
N802 => violations::InvalidFunctionName,
|
||||
N803 => violations::InvalidArgumentName,
|
||||
N804 => violations::InvalidFirstArgumentNameForClassMethod,
|
||||
N805 => violations::InvalidFirstArgumentNameForMethod,
|
||||
N806 => violations::NonLowercaseVariableInFunction,
|
||||
N807 => violations::DunderFunctionName,
|
||||
N811 => violations::ConstantImportedAsNonConstant,
|
||||
N812 => violations::LowercaseImportedAsNonLowercase,
|
||||
N813 => violations::CamelcaseImportedAsLowercase,
|
||||
N814 => violations::CamelcaseImportedAsConstant,
|
||||
N815 => violations::MixedCaseVariableInClassScope,
|
||||
N816 => violations::MixedCaseVariableInGlobalScope,
|
||||
N817 => violations::CamelcaseImportedAsAcronym,
|
||||
N818 => violations::ErrorSuffixOnExceptionName,
|
||||
N801 => rules::pep8_naming::rules::InvalidClassName,
|
||||
N802 => rules::pep8_naming::rules::InvalidFunctionName,
|
||||
N803 => rules::pep8_naming::rules::InvalidArgumentName,
|
||||
N804 => rules::pep8_naming::rules::InvalidFirstArgumentNameForClassMethod,
|
||||
N805 => rules::pep8_naming::rules::InvalidFirstArgumentNameForMethod,
|
||||
N806 => rules::pep8_naming::rules::NonLowercaseVariableInFunction,
|
||||
N807 => rules::pep8_naming::rules::DunderFunctionName,
|
||||
N811 => rules::pep8_naming::rules::ConstantImportedAsNonConstant,
|
||||
N812 => rules::pep8_naming::rules::LowercaseImportedAsNonLowercase,
|
||||
N813 => rules::pep8_naming::rules::CamelcaseImportedAsLowercase,
|
||||
N814 => rules::pep8_naming::rules::CamelcaseImportedAsConstant,
|
||||
N815 => rules::pep8_naming::rules::MixedCaseVariableInClassScope,
|
||||
N816 => rules::pep8_naming::rules::MixedCaseVariableInGlobalScope,
|
||||
N817 => rules::pep8_naming::rules::CamelcaseImportedAsAcronym,
|
||||
N818 => rules::pep8_naming::rules::ErrorSuffixOnExceptionName,
|
||||
// isort
|
||||
I001 => rules::isort::rules::UnsortedImports,
|
||||
I002 => rules::isort::rules::MissingRequiredImport,
|
||||
// eradicate
|
||||
ERA001 => rules::eradicate::rules::CommentedOutCode,
|
||||
// flake8-bandit
|
||||
S101 => violations::AssertUsed,
|
||||
S102 => violations::ExecUsed,
|
||||
S103 => violations::BadFilePermissions,
|
||||
S104 => violations::HardcodedBindAllInterfaces,
|
||||
S105 => violations::HardcodedPasswordString,
|
||||
S106 => violations::HardcodedPasswordFuncArg,
|
||||
S107 => violations::HardcodedPasswordDefault,
|
||||
S108 => violations::HardcodedTempFile,
|
||||
S101 => rules::flake8_bandit::rules::AssertUsed,
|
||||
S102 => rules::flake8_bandit::rules::ExecUsed,
|
||||
S103 => rules::flake8_bandit::rules::BadFilePermissions,
|
||||
S104 => rules::flake8_bandit::rules::HardcodedBindAllInterfaces,
|
||||
S105 => rules::flake8_bandit::rules::HardcodedPasswordString,
|
||||
S106 => rules::flake8_bandit::rules::HardcodedPasswordFuncArg,
|
||||
S107 => rules::flake8_bandit::rules::HardcodedPasswordDefault,
|
||||
S108 => rules::flake8_bandit::rules::HardcodedTempFile,
|
||||
S110 => rules::flake8_bandit::rules::TryExceptPass,
|
||||
S113 => violations::RequestWithoutTimeout,
|
||||
S324 => violations::HashlibInsecureHashFunction,
|
||||
S501 => violations::RequestWithNoCertValidation,
|
||||
S506 => violations::UnsafeYAMLLoad,
|
||||
S508 => violations::SnmpInsecureVersion,
|
||||
S509 => violations::SnmpWeakCryptography,
|
||||
S113 => rules::flake8_bandit::rules::RequestWithoutTimeout,
|
||||
S324 => rules::flake8_bandit::rules::HashlibInsecureHashFunction,
|
||||
S501 => rules::flake8_bandit::rules::RequestWithNoCertValidation,
|
||||
S506 => rules::flake8_bandit::rules::UnsafeYAMLLoad,
|
||||
S508 => rules::flake8_bandit::rules::SnmpInsecureVersion,
|
||||
S509 => rules::flake8_bandit::rules::SnmpWeakCryptography,
|
||||
S612 => rules::flake8_bandit::rules::LoggingConfigInsecureListen,
|
||||
S701 => violations::Jinja2AutoescapeFalse,
|
||||
S701 => rules::flake8_bandit::rules::Jinja2AutoescapeFalse,
|
||||
// flake8-boolean-trap
|
||||
FBT001 => rules::flake8_boolean_trap::rules::BooleanPositionalArgInFunctionDefinition,
|
||||
FBT002 => rules::flake8_boolean_trap::rules::BooleanDefaultValueInFunctionDefinition,
|
||||
FBT003 => rules::flake8_boolean_trap::rules::BooleanPositionalValueInFunctionCall,
|
||||
// flake8-unused-arguments
|
||||
ARG001 => violations::UnusedFunctionArgument,
|
||||
ARG002 => violations::UnusedMethodArgument,
|
||||
ARG003 => violations::UnusedClassMethodArgument,
|
||||
ARG004 => violations::UnusedStaticMethodArgument,
|
||||
ARG005 => violations::UnusedLambdaArgument,
|
||||
ARG001 => rules::flake8_unused_arguments::rules::UnusedFunctionArgument,
|
||||
ARG002 => rules::flake8_unused_arguments::rules::UnusedMethodArgument,
|
||||
ARG003 => rules::flake8_unused_arguments::rules::UnusedClassMethodArgument,
|
||||
ARG004 => rules::flake8_unused_arguments::rules::UnusedStaticMethodArgument,
|
||||
ARG005 => rules::flake8_unused_arguments::rules::UnusedLambdaArgument,
|
||||
// flake8-import-conventions
|
||||
ICN001 => rules::flake8_import_conventions::rules::ImportAliasIsNotConventional,
|
||||
// flake8-datetimez
|
||||
DTZ001 => violations::CallDatetimeWithoutTzinfo,
|
||||
DTZ002 => violations::CallDatetimeToday,
|
||||
DTZ003 => violations::CallDatetimeUtcnow,
|
||||
DTZ004 => violations::CallDatetimeUtcfromtimestamp,
|
||||
DTZ005 => violations::CallDatetimeNowWithoutTzinfo,
|
||||
DTZ006 => violations::CallDatetimeFromtimestamp,
|
||||
DTZ007 => violations::CallDatetimeStrptimeWithoutZone,
|
||||
DTZ011 => violations::CallDateToday,
|
||||
DTZ012 => violations::CallDateFromtimestamp,
|
||||
DTZ001 => rules::flake8_datetimez::rules::CallDatetimeWithoutTzinfo,
|
||||
DTZ002 => rules::flake8_datetimez::rules::CallDatetimeToday,
|
||||
DTZ003 => rules::flake8_datetimez::rules::CallDatetimeUtcnow,
|
||||
DTZ004 => rules::flake8_datetimez::rules::CallDatetimeUtcfromtimestamp,
|
||||
DTZ005 => rules::flake8_datetimez::rules::CallDatetimeNowWithoutTzinfo,
|
||||
DTZ006 => rules::flake8_datetimez::rules::CallDatetimeFromtimestamp,
|
||||
DTZ007 => rules::flake8_datetimez::rules::CallDatetimeStrptimeWithoutZone,
|
||||
DTZ011 => rules::flake8_datetimez::rules::CallDateToday,
|
||||
DTZ012 => rules::flake8_datetimez::rules::CallDateFromtimestamp,
|
||||
// pygrep-hooks
|
||||
PGH001 => violations::NoEval,
|
||||
PGH002 => violations::DeprecatedLogWarn,
|
||||
PGH003 => violations::BlanketTypeIgnore,
|
||||
PGH004 => violations::BlanketNOQA,
|
||||
PGH001 => rules::pygrep_hooks::rules::NoEval,
|
||||
PGH002 => rules::pygrep_hooks::rules::DeprecatedLogWarn,
|
||||
PGH003 => rules::pygrep_hooks::rules::BlanketTypeIgnore,
|
||||
PGH004 => rules::pygrep_hooks::rules::BlanketNOQA,
|
||||
// pandas-vet
|
||||
PD002 => rules::pandas_vet::rules::UseOfInplaceArgument,
|
||||
PD003 => rules::pandas_vet::rules::UseOfDotIsNull,
|
||||
@@ -385,9 +385,9 @@ ruff_macros::define_rule_mapping!(
|
||||
PD015 => rules::pandas_vet::rules::UseOfPdMerge,
|
||||
PD901 => rules::pandas_vet::rules::DfIsABadVariableName,
|
||||
// flake8-errmsg
|
||||
EM101 => violations::RawStringInException,
|
||||
EM102 => violations::FStringInException,
|
||||
EM103 => violations::DotFormatInException,
|
||||
EM101 => rules::flake8_errmsg::rules::RawStringInException,
|
||||
EM102 => rules::flake8_errmsg::rules::FStringInException,
|
||||
EM103 => rules::flake8_errmsg::rules::DotFormatInException,
|
||||
// flake8-pytest-style
|
||||
PT001 => rules::flake8_pytest_style::rules::IncorrectFixtureParenthesesStyle,
|
||||
PT002 => rules::flake8_pytest_style::rules::FixturePositionalArgs,
|
||||
@@ -488,12 +488,12 @@ ruff_macros::define_rule_mapping!(
|
||||
// flake8-self
|
||||
SLF001 => rules::flake8_self::rules::PrivateMemberAccess,
|
||||
// ruff
|
||||
RUF001 => violations::AmbiguousUnicodeCharacterString,
|
||||
RUF002 => violations::AmbiguousUnicodeCharacterDocstring,
|
||||
RUF003 => violations::AmbiguousUnicodeCharacterComment,
|
||||
RUF004 => violations::KeywordArgumentBeforeStarArgument,
|
||||
RUF005 => violations::UnpackInsteadOfConcatenatingToCollectionLiteral,
|
||||
RUF100 => violations::UnusedNOQA,
|
||||
RUF001 => rules::ruff::rules::AmbiguousUnicodeCharacterString,
|
||||
RUF002 => rules::ruff::rules::AmbiguousUnicodeCharacterDocstring,
|
||||
RUF003 => rules::ruff::rules::AmbiguousUnicodeCharacterComment,
|
||||
RUF004 => rules::ruff::rules::KeywordArgumentBeforeStarArgument,
|
||||
RUF005 => rules::ruff::rules::UnpackInsteadOfConcatenatingToCollectionLiteral,
|
||||
RUF100 => rules::ruff::rules::UnusedNOQA,
|
||||
);
|
||||
|
||||
#[derive(EnumIter, Debug, PartialEq, Eq, RuleNamespace)]
|
||||
@@ -644,21 +644,21 @@ pub trait RuleNamespace: Sized {
|
||||
fn url(&self) -> Option<&'static str>;
|
||||
}
|
||||
|
||||
/// The prefix, name and selector for an upstream linter category.
|
||||
pub struct LinterCategory(pub &'static str, pub &'static str, pub RuleCodePrefix);
|
||||
/// The prefix and name for an upstream linter category.
|
||||
pub struct UpstreamCategory(pub RuleCodePrefix, pub &'static str);
|
||||
|
||||
impl Linter {
|
||||
pub fn categories(&self) -> Option<&'static [LinterCategory]> {
|
||||
pub const fn upstream_categories(&self) -> Option<&'static [UpstreamCategory]> {
|
||||
match self {
|
||||
Linter::Pycodestyle => Some(&[
|
||||
LinterCategory("E", "Error", RuleCodePrefix::E),
|
||||
LinterCategory("W", "Warning", RuleCodePrefix::W),
|
||||
UpstreamCategory(RuleCodePrefix::E, "Error"),
|
||||
UpstreamCategory(RuleCodePrefix::W, "Warning"),
|
||||
]),
|
||||
Linter::Pylint => Some(&[
|
||||
LinterCategory("PLC", "Convention", RuleCodePrefix::PLC),
|
||||
LinterCategory("PLE", "Error", RuleCodePrefix::PLE),
|
||||
LinterCategory("PLR", "Refactor", RuleCodePrefix::PLR),
|
||||
LinterCategory("PLW", "Warning", RuleCodePrefix::PLW),
|
||||
UpstreamCategory(RuleCodePrefix::PLC, "Convention"),
|
||||
UpstreamCategory(RuleCodePrefix::PLE, "Error"),
|
||||
UpstreamCategory(RuleCodePrefix::PLR, "Refactor"),
|
||||
UpstreamCategory(RuleCodePrefix::PLW, "Warning"),
|
||||
]),
|
||||
_ => None,
|
||||
}
|
||||
@@ -678,7 +678,7 @@ pub enum LintSource {
|
||||
impl Rule {
|
||||
/// The source for the diagnostic (either the AST, the filesystem, or the
|
||||
/// physical lines).
|
||||
pub fn lint_source(&self) -> &'static LintSource {
|
||||
pub const fn lint_source(&self) -> &'static LintSource {
|
||||
match self {
|
||||
Rule::UnusedNOQA => &LintSource::NoQa,
|
||||
Rule::BlanketNOQA
|
||||
|
||||
@@ -411,6 +411,11 @@ fn is_file_excluded(
|
||||
return true;
|
||||
}
|
||||
}
|
||||
if path == settings.project_root {
|
||||
// Bail out; we'd end up past the project root on the next iteration
|
||||
// (excludes etc. are thus "rooted" to the project).
|
||||
break;
|
||||
}
|
||||
}
|
||||
false
|
||||
}
|
||||
@@ -424,8 +429,13 @@ mod tests {
|
||||
use path_absolutize::Absolutize;
|
||||
|
||||
use crate::fs;
|
||||
use crate::resolver::{is_python_path, match_exclusion};
|
||||
use crate::resolver::{
|
||||
is_file_excluded, is_python_path, match_exclusion, resolve_settings_with_processor,
|
||||
NoOpProcessor, PyprojectDiscovery, Relativity, Resolver,
|
||||
};
|
||||
use crate::settings::pyproject::find_settings_toml;
|
||||
use crate::settings::types::FilePattern;
|
||||
use crate::test::test_resource_path;
|
||||
|
||||
#[test]
|
||||
fn inclusions() {
|
||||
@@ -567,4 +577,30 @@ mod tests {
|
||||
|
||||
Ok(())
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn rooted_exclusion() -> Result<()> {
|
||||
let package_root = test_resource_path("package");
|
||||
let resolver = Resolver::default();
|
||||
let ppd = PyprojectDiscovery::Hierarchical(resolve_settings_with_processor(
|
||||
&find_settings_toml(&package_root)?.unwrap(),
|
||||
&Relativity::Parent,
|
||||
&NoOpProcessor,
|
||||
)?);
|
||||
// src/app.py should not be excluded even if it lives in a hierarchy that should be
|
||||
// excluded by virtue of the pyproject.toml having `resources/*` in it.
|
||||
assert!(!is_file_excluded(
|
||||
&package_root.join("src/app.py"),
|
||||
&resolver,
|
||||
&ppd,
|
||||
));
|
||||
// However, resources/ignored.py should be ignored, since that `resources` is beneath
|
||||
// the package root.
|
||||
assert!(is_file_excluded(
|
||||
&package_root.join("resources/ignored.py"),
|
||||
&resolver,
|
||||
&ppd,
|
||||
));
|
||||
Ok(())
|
||||
}
|
||||
}
|
||||
|
||||
@@ -4,7 +4,116 @@ use rustpython_ast::{Cmpop, Constant, Expr, ExprKind, Located};
|
||||
use crate::ast::types::Range;
|
||||
use crate::checkers::ast::Checker;
|
||||
use crate::registry::{Diagnostic, Rule};
|
||||
use crate::violations;
|
||||
use crate::violation::Violation;
|
||||
|
||||
use crate::define_violation;
|
||||
use ruff_macros::derive_message_formats;
|
||||
|
||||
define_violation!(
|
||||
pub struct SysVersionSlice3Referenced;
|
||||
);
|
||||
impl Violation for SysVersionSlice3Referenced {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!("`sys.version[:3]` referenced (python3.10), use `sys.version_info`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct SysVersion2Referenced;
|
||||
);
|
||||
impl Violation for SysVersion2Referenced {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!("`sys.version[2]` referenced (python3.10), use `sys.version_info`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct SysVersionCmpStr3;
|
||||
);
|
||||
impl Violation for SysVersionCmpStr3 {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!("`sys.version` compared to string (python3.10), use `sys.version_info`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct SysVersionInfo0Eq3Referenced;
|
||||
);
|
||||
impl Violation for SysVersionInfo0Eq3Referenced {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!("`sys.version_info[0] == 3` referenced (python4), use `>=`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct SixPY3Referenced;
|
||||
);
|
||||
impl Violation for SixPY3Referenced {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!("`six.PY3` referenced (python4), use `not six.PY2`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct SysVersionInfo1CmpInt;
|
||||
);
|
||||
impl Violation for SysVersionInfo1CmpInt {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!(
|
||||
"`sys.version_info[1]` compared to integer (python4), compare `sys.version_info` to \
|
||||
tuple"
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct SysVersionInfoMinorCmpInt;
|
||||
);
|
||||
impl Violation for SysVersionInfoMinorCmpInt {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!(
|
||||
"`sys.version_info.minor` compared to integer (python4), compare `sys.version_info` \
|
||||
to tuple"
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct SysVersion0Referenced;
|
||||
);
|
||||
impl Violation for SysVersion0Referenced {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!("`sys.version[0]` referenced (python10), use `sys.version_info`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct SysVersionCmpStr10;
|
||||
);
|
||||
impl Violation for SysVersionCmpStr10 {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!("`sys.version` compared to string (python10), use `sys.version_info`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct SysVersionSlice1Referenced;
|
||||
);
|
||||
impl Violation for SysVersionSlice1Referenced {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!("`sys.version[:1]` referenced (python10), use `sys.version_info`")
|
||||
}
|
||||
}
|
||||
|
||||
fn is_sys(checker: &Checker, expr: &Expr, target: &str) -> bool {
|
||||
checker
|
||||
@@ -34,7 +143,7 @@ pub fn subscript(checker: &mut Checker, value: &Expr, slice: &Expr) {
|
||||
.enabled(&Rule::SysVersionSlice1Referenced)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::SysVersionSlice1Referenced,
|
||||
SysVersionSlice1Referenced,
|
||||
Range::from_located(value),
|
||||
));
|
||||
} else if *i == BigInt::from(3)
|
||||
@@ -44,7 +153,7 @@ pub fn subscript(checker: &mut Checker, value: &Expr, slice: &Expr) {
|
||||
.enabled(&Rule::SysVersionSlice3Referenced)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::SysVersionSlice3Referenced,
|
||||
SysVersionSlice3Referenced,
|
||||
Range::from_located(value),
|
||||
));
|
||||
}
|
||||
@@ -59,14 +168,14 @@ pub fn subscript(checker: &mut Checker, value: &Expr, slice: &Expr) {
|
||||
&& checker.settings.rules.enabled(&Rule::SysVersion2Referenced)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::SysVersion2Referenced,
|
||||
SysVersion2Referenced,
|
||||
Range::from_located(value),
|
||||
));
|
||||
} else if *i == BigInt::from(0)
|
||||
&& checker.settings.rules.enabled(&Rule::SysVersion0Referenced)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::SysVersion0Referenced,
|
||||
SysVersion0Referenced,
|
||||
Range::from_located(value),
|
||||
));
|
||||
}
|
||||
@@ -106,7 +215,7 @@ pub fn compare(checker: &mut Checker, left: &Expr, ops: &[Cmpop], comparators: &
|
||||
.enabled(&Rule::SysVersionInfo0Eq3Referenced)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::SysVersionInfo0Eq3Referenced,
|
||||
SysVersionInfo0Eq3Referenced,
|
||||
Range::from_located(left),
|
||||
));
|
||||
}
|
||||
@@ -126,7 +235,7 @@ pub fn compare(checker: &mut Checker, left: &Expr, ops: &[Cmpop], comparators: &
|
||||
{
|
||||
if checker.settings.rules.enabled(&Rule::SysVersionInfo1CmpInt) {
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::SysVersionInfo1CmpInt,
|
||||
SysVersionInfo1CmpInt,
|
||||
Range::from_located(left),
|
||||
));
|
||||
}
|
||||
@@ -156,7 +265,7 @@ pub fn compare(checker: &mut Checker, left: &Expr, ops: &[Cmpop], comparators: &
|
||||
.enabled(&Rule::SysVersionInfoMinorCmpInt)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::SysVersionInfoMinorCmpInt,
|
||||
SysVersionInfoMinorCmpInt,
|
||||
Range::from_located(left),
|
||||
));
|
||||
}
|
||||
@@ -182,13 +291,13 @@ pub fn compare(checker: &mut Checker, left: &Expr, ops: &[Cmpop], comparators: &
|
||||
if s.len() == 1 {
|
||||
if checker.settings.rules.enabled(&Rule::SysVersionCmpStr10) {
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::SysVersionCmpStr10,
|
||||
SysVersionCmpStr10,
|
||||
Range::from_located(left),
|
||||
));
|
||||
}
|
||||
} else if checker.settings.rules.enabled(&Rule::SysVersionCmpStr3) {
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::SysVersionCmpStr3,
|
||||
SysVersionCmpStr3,
|
||||
Range::from_located(left),
|
||||
));
|
||||
}
|
||||
@@ -202,9 +311,8 @@ pub fn name_or_attribute(checker: &mut Checker, expr: &Expr) {
|
||||
.resolve_call_path(expr)
|
||||
.map_or(false, |call_path| call_path.as_slice() == ["six", "PY3"])
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::SixPY3Referenced,
|
||||
Range::from_located(expr),
|
||||
));
|
||||
checker
|
||||
.diagnostics
|
||||
.push(Diagnostic::new(SixPY3Referenced, Range::from_located(expr)));
|
||||
}
|
||||
}
|
||||
|
||||
@@ -7,10 +7,160 @@ use crate::ast::types::Range;
|
||||
use crate::ast::visitor::Visitor;
|
||||
use crate::ast::{cast, helpers, visitor};
|
||||
use crate::checkers::ast::Checker;
|
||||
use crate::define_violation;
|
||||
use crate::docstrings::definition::{Definition, DefinitionKind};
|
||||
use crate::registry::{Diagnostic, Rule};
|
||||
use crate::violation::{AlwaysAutofixableViolation, Violation};
|
||||
use crate::visibility;
|
||||
use crate::visibility::Visibility;
|
||||
use crate::{violations, visibility};
|
||||
use ruff_macros::derive_message_formats;
|
||||
|
||||
define_violation!(
|
||||
pub struct MissingTypeFunctionArgument {
|
||||
pub name: String,
|
||||
}
|
||||
);
|
||||
impl Violation for MissingTypeFunctionArgument {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let MissingTypeFunctionArgument { name } = self;
|
||||
format!("Missing type annotation for function argument `{name}`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct MissingTypeArgs {
|
||||
pub name: String,
|
||||
}
|
||||
);
|
||||
impl Violation for MissingTypeArgs {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let MissingTypeArgs { name } = self;
|
||||
format!("Missing type annotation for `*{name}`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct MissingTypeKwargs {
|
||||
pub name: String,
|
||||
}
|
||||
);
|
||||
impl Violation for MissingTypeKwargs {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let MissingTypeKwargs { name } = self;
|
||||
format!("Missing type annotation for `**{name}`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct MissingTypeSelf {
|
||||
pub name: String,
|
||||
}
|
||||
);
|
||||
impl Violation for MissingTypeSelf {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let MissingTypeSelf { name } = self;
|
||||
format!("Missing type annotation for `{name}` in method")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct MissingTypeCls {
|
||||
pub name: String,
|
||||
}
|
||||
);
|
||||
impl Violation for MissingTypeCls {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let MissingTypeCls { name } = self;
|
||||
format!("Missing type annotation for `{name}` in classmethod")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct MissingReturnTypePublicFunction {
|
||||
pub name: String,
|
||||
}
|
||||
);
|
||||
impl Violation for MissingReturnTypePublicFunction {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let MissingReturnTypePublicFunction { name } = self;
|
||||
format!("Missing return type annotation for public function `{name}`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct MissingReturnTypePrivateFunction {
|
||||
pub name: String,
|
||||
}
|
||||
);
|
||||
impl Violation for MissingReturnTypePrivateFunction {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let MissingReturnTypePrivateFunction { name } = self;
|
||||
format!("Missing return type annotation for private function `{name}`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct MissingReturnTypeSpecialMethod {
|
||||
pub name: String,
|
||||
}
|
||||
);
|
||||
impl AlwaysAutofixableViolation for MissingReturnTypeSpecialMethod {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let MissingReturnTypeSpecialMethod { name } = self;
|
||||
format!("Missing return type annotation for special method `{name}`")
|
||||
}
|
||||
|
||||
fn autofix_title(&self) -> String {
|
||||
"Add `None` return type".to_string()
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct MissingReturnTypeStaticMethod {
|
||||
pub name: String,
|
||||
}
|
||||
);
|
||||
impl Violation for MissingReturnTypeStaticMethod {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let MissingReturnTypeStaticMethod { name } = self;
|
||||
format!("Missing return type annotation for staticmethod `{name}`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct MissingReturnTypeClassMethod {
|
||||
pub name: String,
|
||||
}
|
||||
);
|
||||
impl Violation for MissingReturnTypeClassMethod {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let MissingReturnTypeClassMethod { name } = self;
|
||||
format!("Missing return type annotation for classmethod `{name}`")
|
||||
}
|
||||
}
|
||||
|
||||
define_violation!(
|
||||
pub struct DynamicallyTypedExpression {
|
||||
pub name: String,
|
||||
}
|
||||
);
|
||||
impl Violation for DynamicallyTypedExpression {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let DynamicallyTypedExpression { name } = self;
|
||||
format!("Dynamically typed expressions (typing.Any) are disallowed in `{name}`")
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Default)]
|
||||
struct ReturnStatementVisitor<'a> {
|
||||
@@ -58,7 +208,7 @@ where
|
||||
{
|
||||
if checker.match_typing_expr(annotation, "Any") {
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::DynamicallyTypedExpression { name: func() },
|
||||
DynamicallyTypedExpression { name: func() },
|
||||
Range::from_located(annotation),
|
||||
));
|
||||
};
|
||||
@@ -115,7 +265,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
.enabled(&Rule::MissingTypeFunctionArgument)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::MissingTypeFunctionArgument {
|
||||
MissingTypeFunctionArgument {
|
||||
name: arg.node.arg.to_string(),
|
||||
},
|
||||
Range::from_located(arg),
|
||||
@@ -145,7 +295,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
{
|
||||
if checker.settings.rules.enabled(&Rule::MissingTypeArgs) {
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::MissingTypeArgs {
|
||||
MissingTypeArgs {
|
||||
name: arg.node.arg.to_string(),
|
||||
},
|
||||
Range::from_located(arg),
|
||||
@@ -175,7 +325,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
{
|
||||
if checker.settings.rules.enabled(&Rule::MissingTypeKwargs) {
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::MissingTypeKwargs {
|
||||
MissingTypeKwargs {
|
||||
name: arg.node.arg.to_string(),
|
||||
},
|
||||
Range::from_located(arg),
|
||||
@@ -192,7 +342,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
if visibility::is_classmethod(checker, cast::decorator_list(stmt)) {
|
||||
if checker.settings.rules.enabled(&Rule::MissingTypeCls) {
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::MissingTypeCls {
|
||||
MissingTypeCls {
|
||||
name: arg.node.arg.to_string(),
|
||||
},
|
||||
Range::from_located(arg),
|
||||
@@ -201,7 +351,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
} else {
|
||||
if checker.settings.rules.enabled(&Rule::MissingTypeSelf) {
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::MissingTypeSelf {
|
||||
MissingTypeSelf {
|
||||
name: arg.node.arg.to_string(),
|
||||
},
|
||||
Range::from_located(arg),
|
||||
@@ -237,7 +387,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
.enabled(&Rule::MissingReturnTypeClassMethod)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::MissingReturnTypeClassMethod {
|
||||
MissingReturnTypeClassMethod {
|
||||
name: name.to_string(),
|
||||
},
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
@@ -252,7 +402,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
.enabled(&Rule::MissingReturnTypeStaticMethod)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::MissingReturnTypeStaticMethod {
|
||||
MissingReturnTypeStaticMethod {
|
||||
name: name.to_string(),
|
||||
},
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
@@ -270,7 +420,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
&& has_any_typed_arg)
|
||||
{
|
||||
let mut diagnostic = Diagnostic::new(
|
||||
violations::MissingReturnTypeSpecialMethod {
|
||||
MissingReturnTypeSpecialMethod {
|
||||
name: name.to_string(),
|
||||
},
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
@@ -293,7 +443,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
.enabled(&Rule::MissingReturnTypeSpecialMethod)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::MissingReturnTypeSpecialMethod {
|
||||
MissingReturnTypeSpecialMethod {
|
||||
name: name.to_string(),
|
||||
},
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
@@ -308,7 +458,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
.enabled(&Rule::MissingReturnTypePublicFunction)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::MissingReturnTypePublicFunction {
|
||||
MissingReturnTypePublicFunction {
|
||||
name: name.to_string(),
|
||||
},
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
@@ -322,7 +472,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
.enabled(&Rule::MissingReturnTypePrivateFunction)
|
||||
{
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::MissingReturnTypePrivateFunction {
|
||||
MissingReturnTypePrivateFunction {
|
||||
name: name.to_string(),
|
||||
},
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
|
||||
@@ -37,8 +37,8 @@ pub struct Options {
|
||||
/// Whether to suppress `ANN200`-level violations for functions that meet
|
||||
/// either of the following criteria:
|
||||
///
|
||||
/// - Contain no `return` statement.
|
||||
/// - Explicit `return` statement(s) all return `None` (explicitly or
|
||||
/// * Contain no `return` statement.
|
||||
/// * Explicit `return` statement(s) all return `None` (explicitly or
|
||||
/// implicitly).
|
||||
pub suppress_none_returning: Option<bool>,
|
||||
#[option(
|
||||
|
||||
@@ -1,13 +1,25 @@
|
||||
use crate::define_violation;
|
||||
use crate::violation::Violation;
|
||||
use ruff_macros::derive_message_formats;
|
||||
use rustpython_ast::{Located, StmtKind};
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::Diagnostic;
|
||||
use crate::violations;
|
||||
|
||||
define_violation!(
|
||||
pub struct AssertUsed;
|
||||
);
|
||||
impl Violation for AssertUsed {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!("Use of `assert` detected")
|
||||
}
|
||||
}
|
||||
|
||||
/// S101
|
||||
pub fn assert_used(stmt: &Located<StmtKind>) -> Diagnostic {
|
||||
Diagnostic::new(
|
||||
violations::AssertUsed,
|
||||
AssertUsed,
|
||||
Range::new(stmt.location, stmt.location.with_col_offset("assert".len())),
|
||||
)
|
||||
}
|
||||
|
||||
@@ -1,5 +1,8 @@
|
||||
use crate::define_violation;
|
||||
use crate::violation::Violation;
|
||||
use num_traits::ToPrimitive;
|
||||
use once_cell::sync::Lazy;
|
||||
use ruff_macros::derive_message_formats;
|
||||
use rustc_hash::FxHashMap;
|
||||
use rustpython_ast::{Constant, Expr, ExprKind, Keyword, Operator};
|
||||
|
||||
@@ -7,7 +10,19 @@ use crate::ast::helpers::{compose_call_path, SimpleCallArgs};
|
||||
use crate::ast::types::Range;
|
||||
use crate::checkers::ast::Checker;
|
||||
use crate::registry::Diagnostic;
|
||||
use crate::violations;
|
||||
|
||||
define_violation!(
|
||||
pub struct BadFilePermissions {
|
||||
pub mask: u16,
|
||||
}
|
||||
);
|
||||
impl Violation for BadFilePermissions {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let BadFilePermissions { mask } = self;
|
||||
format!("`os.chmod` setting a permissive mask `{mask:#o}` on file or directory",)
|
||||
}
|
||||
}
|
||||
|
||||
const WRITE_WORLD: u16 = 0o2;
|
||||
const EXECUTE_GROUP: u16 = 0o10;
|
||||
@@ -61,11 +76,7 @@ fn get_int_value(expr: &Expr) -> Option<u16> {
|
||||
..
|
||||
} => value.to_u16(),
|
||||
ExprKind::Attribute { .. } => {
|
||||
if let Some(path) = compose_call_path(expr) {
|
||||
PYSTAT_MAPPING.get(path.as_str()).copied()
|
||||
} else {
|
||||
None
|
||||
}
|
||||
compose_call_path(expr).and_then(|path| PYSTAT_MAPPING.get(path.as_str()).copied())
|
||||
}
|
||||
ExprKind::BinOp { left, op, right } => {
|
||||
if let (Some(left_value), Some(right_value)) =
|
||||
@@ -101,7 +112,7 @@ pub fn bad_file_permissions(
|
||||
if let Some(int_value) = get_int_value(mode_arg) {
|
||||
if (int_value & WRITE_WORLD > 0) || (int_value & EXECUTE_GROUP > 0) {
|
||||
checker.diagnostics.push(Diagnostic::new(
|
||||
violations::BadFilePermissions { mask: int_value },
|
||||
BadFilePermissions { mask: int_value },
|
||||
Range::from_located(mode_arg),
|
||||
));
|
||||
}
|
||||
|
||||
@@ -1,8 +1,20 @@
|
||||
use crate::define_violation;
|
||||
use crate::violation::Violation;
|
||||
use ruff_macros::derive_message_formats;
|
||||
use rustpython_ast::{Expr, ExprKind};
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::Diagnostic;
|
||||
use crate::violations;
|
||||
|
||||
define_violation!(
|
||||
pub struct ExecUsed;
|
||||
);
|
||||
impl Violation for ExecUsed {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!("Use of `exec` detected")
|
||||
}
|
||||
}
|
||||
|
||||
/// S102
|
||||
pub fn exec_used(expr: &Expr, func: &Expr) -> Option<Diagnostic> {
|
||||
@@ -12,8 +24,5 @@ pub fn exec_used(expr: &Expr, func: &Expr) -> Option<Diagnostic> {
|
||||
if id != "exec" {
|
||||
return None;
|
||||
}
|
||||
Some(Diagnostic::new(
|
||||
violations::ExecUsed,
|
||||
Range::from_located(expr),
|
||||
))
|
||||
Some(Diagnostic::new(ExecUsed, Range::from_located(expr)))
|
||||
}
|
||||
|
||||
@@ -1,14 +1,24 @@
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::Diagnostic;
|
||||
use crate::violations;
|
||||
use crate::violation::Violation;
|
||||
|
||||
use crate::define_violation;
|
||||
use ruff_macros::derive_message_formats;
|
||||
|
||||
define_violation!(
|
||||
pub struct HardcodedBindAllInterfaces;
|
||||
);
|
||||
impl Violation for HardcodedBindAllInterfaces {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
format!("Possible binding to all interfaces")
|
||||
}
|
||||
}
|
||||
|
||||
/// S104
|
||||
pub fn hardcoded_bind_all_interfaces(value: &str, range: &Range) -> Option<Diagnostic> {
|
||||
if value == "0.0.0.0" {
|
||||
Some(Diagnostic::new(
|
||||
violations::HardcodedBindAllInterfaces,
|
||||
*range,
|
||||
))
|
||||
Some(Diagnostic::new(HardcodedBindAllInterfaces, *range))
|
||||
} else {
|
||||
None
|
||||
}
|
||||
|
||||
@@ -1,9 +1,24 @@
|
||||
use crate::define_violation;
|
||||
use crate::violation::Violation;
|
||||
use ruff_macros::derive_message_formats;
|
||||
use rustpython_ast::{ArgData, Arguments, Expr, Located};
|
||||
|
||||
use super::super::helpers::{matches_password_name, string_literal};
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::Diagnostic;
|
||||
use crate::violations;
|
||||
|
||||
define_violation!(
|
||||
pub struct HardcodedPasswordDefault {
|
||||
pub string: String,
|
||||
}
|
||||
);
|
||||
impl Violation for HardcodedPasswordDefault {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let HardcodedPasswordDefault { string } = self;
|
||||
format!("Possible hardcoded password: \"{}\"", string.escape_debug())
|
||||
}
|
||||
}
|
||||
|
||||
fn check_password_kwarg(arg: &Located<ArgData>, default: &Expr) -> Option<Diagnostic> {
|
||||
let string = string_literal(default).filter(|string| !string.is_empty())?;
|
||||
@@ -12,7 +27,7 @@ fn check_password_kwarg(arg: &Located<ArgData>, default: &Expr) -> Option<Diagno
|
||||
return None;
|
||||
}
|
||||
Some(Diagnostic::new(
|
||||
violations::HardcodedPasswordDefault {
|
||||
HardcodedPasswordDefault {
|
||||
string: string.to_string(),
|
||||
},
|
||||
Range::from_located(default),
|
||||
|
||||
@@ -1,9 +1,24 @@
|
||||
use crate::define_violation;
|
||||
use crate::violation::Violation;
|
||||
use ruff_macros::derive_message_formats;
|
||||
use rustpython_ast::Keyword;
|
||||
|
||||
use super::super::helpers::{matches_password_name, string_literal};
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::Diagnostic;
|
||||
use crate::violations;
|
||||
|
||||
define_violation!(
|
||||
pub struct HardcodedPasswordFuncArg {
|
||||
pub string: String,
|
||||
}
|
||||
);
|
||||
impl Violation for HardcodedPasswordFuncArg {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let HardcodedPasswordFuncArg { string } = self;
|
||||
format!("Possible hardcoded password: \"{}\"", string.escape_debug())
|
||||
}
|
||||
}
|
||||
|
||||
/// S106
|
||||
pub fn hardcoded_password_func_arg(keywords: &[Keyword]) -> Vec<Diagnostic> {
|
||||
@@ -16,7 +31,7 @@ pub fn hardcoded_password_func_arg(keywords: &[Keyword]) -> Vec<Diagnostic> {
|
||||
return None;
|
||||
}
|
||||
Some(Diagnostic::new(
|
||||
violations::HardcodedPasswordFuncArg {
|
||||
HardcodedPasswordFuncArg {
|
||||
string: string.to_string(),
|
||||
},
|
||||
Range::from_located(keyword),
|
||||
|
||||
@@ -1,9 +1,24 @@
|
||||
use crate::define_violation;
|
||||
use crate::violation::Violation;
|
||||
use ruff_macros::derive_message_formats;
|
||||
use rustpython_ast::{Constant, Expr, ExprKind};
|
||||
|
||||
use super::super::helpers::{matches_password_name, string_literal};
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::Diagnostic;
|
||||
use crate::violations;
|
||||
|
||||
define_violation!(
|
||||
pub struct HardcodedPasswordString {
|
||||
pub string: String,
|
||||
}
|
||||
);
|
||||
impl Violation for HardcodedPasswordString {
|
||||
#[derive_message_formats]
|
||||
fn message(&self) -> String {
|
||||
let HardcodedPasswordString { string } = self;
|
||||
format!("Possible hardcoded password: \"{}\"", string.escape_debug())
|
||||
}
|
||||
}
|
||||
|
||||
fn is_password_target(target: &Expr) -> bool {
|
||||
let target_name = match &target.node {
|
||||
@@ -35,7 +50,7 @@ pub fn compare_to_hardcoded_password_string(left: &Expr, comparators: &[Expr]) -
|
||||
return None;
|
||||
}
|
||||
Some(Diagnostic::new(
|
||||
violations::HardcodedPasswordString {
|
||||
HardcodedPasswordString {
|
||||
string: string.to_string(),
|
||||
},
|
||||
Range::from_located(comp),
|
||||
@@ -50,7 +65,7 @@ pub fn assign_hardcoded_password_string(value: &Expr, targets: &[Expr]) -> Optio
|
||||
for target in targets {
|
||||
if is_password_target(target) {
|
||||
return Some(Diagnostic::new(
|
||||
violations::HardcodedPasswordString {
|
||||
HardcodedPasswordString {
|
||||
string: string.to_string(),
|
||||
},
|
||||
Range::from_located(value),
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user