Compare commits
19 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
ee4cae97d5 | ||
|
|
2e3787adff | ||
|
|
81b211d1b7 | ||
|
|
1ad72261f1 | ||
|
|
914287d31b | ||
|
|
75bb6ad456 | ||
|
|
04111da3f3 | ||
|
|
2464cf6fe9 | ||
|
|
d34e6c02a1 | ||
|
|
e6611c4830 | ||
|
|
2d23b1ae69 | ||
|
|
5eb03d5e09 | ||
|
|
9f8ef1737e | ||
|
|
1991d618a3 | ||
|
|
2045b739a9 | ||
|
|
53e3dd8548 | ||
|
|
78c9056173 | ||
|
|
8d56e412ef | ||
|
|
3400be18a6 |
{kind=link}
3
.github/workflows/ci.yaml
vendored
3
.github/workflows/ci.yaml
vendored
@@ -42,9 +42,8 @@ jobs:
|
||||
- run: cargo build --all --release
|
||||
- run: ./target/release/ruff_dev generate-all
|
||||
- run: git diff --quiet README.md || echo "::error file=README.md::This file is outdated. Run 'cargo +nightly dev generate-all'."
|
||||
- run: git diff --quiet src/registry_gen.rs || echo "::error file=src/registry_gen.rs::This file is outdated. Run 'cargo +nightly dev generate-all'."
|
||||
- run: git diff --quiet ruff.schema.json || echo "::error file=ruff.schema.json::This file is outdated. Run 'cargo +nightly dev generate-all'."
|
||||
- run: git diff --exit-code -- README.md src/registry_gen.rs ruff.schema.json
|
||||
- run: git diff --exit-code -- README.md ruff.schema.json
|
||||
|
||||
cargo-fmt:
|
||||
name: "cargo fmt"
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
repos:
|
||||
- repo: https://github.com/charliermarsh/ruff-pre-commit
|
||||
rev: v0.0.211
|
||||
rev: v0.0.212
|
||||
hooks:
|
||||
- id: ruff
|
||||
|
||||
|
||||
23
Cargo.lock
generated
23
Cargo.lock
generated
@@ -367,15 +367,6 @@ dependencies = [
|
||||
"winapi",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "codegen"
|
||||
version = "0.2.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "ff61280aed771c3070e7dcc9e050c66f1eb1e3b96431ba66f9f74641d02fc41d"
|
||||
dependencies = [
|
||||
"indexmap",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "codespan-reporting"
|
||||
version = "0.11.1"
|
||||
@@ -744,7 +735,7 @@ checksum = "0ce7134b9999ecaf8bcd65542e436736ef32ddca1b3e06094cb6ec5755203b80"
|
||||
|
||||
[[package]]
|
||||
name = "flake8-to-ruff"
|
||||
version = "0.0.211-dev.0"
|
||||
version = "0.0.212-dev.0"
|
||||
dependencies = [
|
||||
"anyhow",
|
||||
"clap 4.0.32",
|
||||
@@ -1365,9 +1356,9 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "once_cell"
|
||||
version = "1.16.0"
|
||||
version = "1.17.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "86f0b0d4bf799edbc74508c1e8bf170ff5f41238e5f8225603ca7caaae2b7860"
|
||||
checksum = "6f61fba1741ea2b3d6a1e3178721804bb716a68a6aeba1149b5d52e3d464ea66"
|
||||
|
||||
[[package]]
|
||||
name = "oorandom"
|
||||
@@ -1873,7 +1864,7 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "ruff"
|
||||
version = "0.0.211"
|
||||
version = "0.0.212"
|
||||
dependencies = [
|
||||
"annotate-snippets 0.9.1",
|
||||
"anyhow",
|
||||
@@ -1941,11 +1932,10 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "ruff_dev"
|
||||
version = "0.0.211"
|
||||
version = "0.0.212"
|
||||
dependencies = [
|
||||
"anyhow",
|
||||
"clap 4.0.32",
|
||||
"codegen",
|
||||
"itertools",
|
||||
"libcst",
|
||||
"once_cell",
|
||||
@@ -1962,8 +1952,9 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "ruff_macros"
|
||||
version = "0.0.211"
|
||||
version = "0.0.212"
|
||||
dependencies = [
|
||||
"once_cell",
|
||||
"proc-macro2",
|
||||
"quote",
|
||||
"syn",
|
||||
|
||||
@@ -6,7 +6,7 @@ members = [
|
||||
|
||||
[package]
|
||||
name = "ruff"
|
||||
version = "0.0.211"
|
||||
version = "0.0.212"
|
||||
authors = ["Charlie Marsh <charlie.r.marsh@gmail.com>"]
|
||||
edition = "2021"
|
||||
rust-version = "1.65.0"
|
||||
@@ -51,7 +51,7 @@ path-absolutize = { version = "3.0.14", features = ["once_cell_cache", "use_unix
|
||||
quick-junit = { version = "0.3.2" }
|
||||
regex = { version = "1.6.0" }
|
||||
ropey = { version = "1.5.0", features = ["cr_lines", "simd"], default-features = false }
|
||||
ruff_macros = { version = "0.0.211", path = "ruff_macros" }
|
||||
ruff_macros = { version = "0.0.212", path = "ruff_macros" }
|
||||
rustc-hash = { version = "1.1.0" }
|
||||
rustpython-ast = { features = ["unparse"], git = "https://github.com/RustPython/RustPython.git", rev = "4d53c7cb27c0379adf8b51c4d3d0d2174f41d590" }
|
||||
rustpython-common = { git = "https://github.com/RustPython/RustPython.git", rev = "4d53c7cb27c0379adf8b51c4d3d0d2174f41d590" }
|
||||
|
||||
19
README.md
19
README.md
@@ -180,7 +180,7 @@ Ruff also works with [pre-commit](https://pre-commit.com):
|
||||
```yaml
|
||||
- repo: https://github.com/charliermarsh/ruff-pre-commit
|
||||
# Ruff version.
|
||||
rev: 'v0.0.211'
|
||||
rev: 'v0.0.212'
|
||||
hooks:
|
||||
- id: ruff
|
||||
# Respect `exclude` and `extend-exclude` settings.
|
||||
@@ -312,7 +312,7 @@ ruff path/to/code/ --select F401 --select F403
|
||||
See `ruff --help` for more:
|
||||
|
||||
<!-- Begin auto-generated cli help. -->
|
||||
```shell
|
||||
```
|
||||
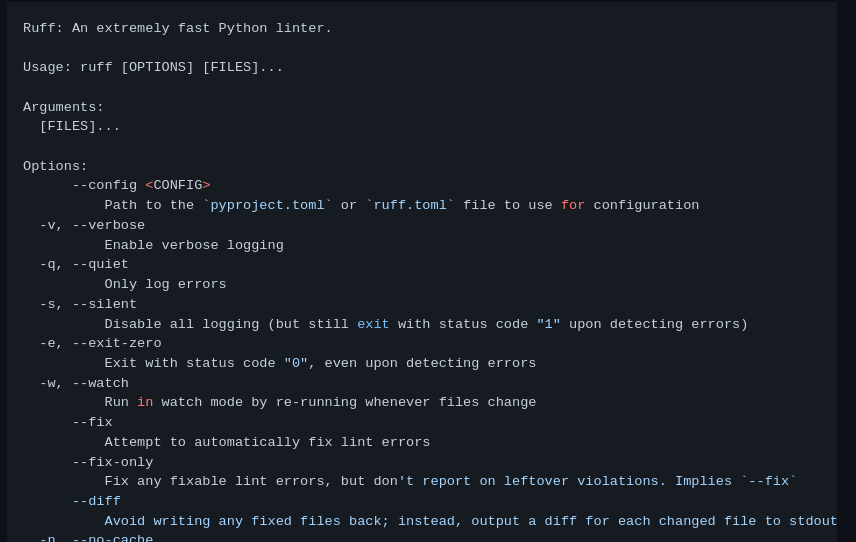
Ruff: An extremely fast Python linter.
|
||||
|
||||
Usage: ruff [OPTIONS] [FILES]...
|
||||
@@ -767,10 +767,12 @@ For more, see [flake8-bandit](https://pypi.org/project/flake8-bandit/4.1.1/) on
|
||||
| S102 | ExecUsed | Use of `exec` detected | |
|
||||
| S103 | BadFilePermissions | `os.chmod` setting a permissive mask `0o777` on file or directory | |
|
||||
| S104 | HardcodedBindAllInterfaces | Possible binding to all interfaces | |
|
||||
| S105 | HardcodedPasswordString | Possible hardcoded password: `"..."` | |
|
||||
| S106 | HardcodedPasswordFuncArg | Possible hardcoded password: `"..."` | |
|
||||
| S107 | HardcodedPasswordDefault | Possible hardcoded password: `"..."` | |
|
||||
| S108 | HardcodedTempFile | Probable insecure usage of temp file/directory: `"..."` | |
|
||||
| S105 | HardcodedPasswordString | Possible hardcoded password: "..." | |
|
||||
| S106 | HardcodedPasswordFuncArg | Possible hardcoded password: "..." | |
|
||||
| S107 | HardcodedPasswordDefault | Possible hardcoded password: "..." | |
|
||||
| S108 | HardcodedTempFile | Probable insecure usage of temporary file or directory: "..." | |
|
||||
| S324 | HashlibInsecureHashFunction | Probable use of insecure hash functions in `hashlib`: "..." | |
|
||||
| S506 | UnsafeYAMLLoad | Probable use of unsafe `yaml.load`. Allows instantiation of arbitrary objects. Consider `yaml.safe_load`. | |
|
||||
|
||||
### flake8-blind-except (BLE)
|
||||
|
||||
@@ -965,6 +967,7 @@ For more, see [flake8-simplify](https://pypi.org/project/flake8-simplify/0.19.3/
|
||||
|
||||
| Code | Name | Message | Fix |
|
||||
| ---- | ---- | ------- | --- |
|
||||
| SIM101 | DuplicateIsinstanceCall | Multiple `isinstance` calls for `...`, merge into a single call | 🛠 |
|
||||
| SIM102 | NestedIfStatements | Use a single `if` statement instead of nested `if` statements | |
|
||||
| SIM105 | UseContextlibSuppress | Use `contextlib.suppress(...)` instead of try-except-pass | |
|
||||
| SIM107 | ReturnInTryExceptFinally | Don't use `return` in `try`/`except` and `finally` | |
|
||||
@@ -2459,9 +2462,10 @@ the `extend_aliases` option.
|
||||
|
||||
```toml
|
||||
[tool.ruff.flake8-import-conventions]
|
||||
[tool.ruff.flake8-import-conventions.aliases]
|
||||
# Declare the default aliases.
|
||||
altair = "alt"
|
||||
matplotlib.pyplot = "plt"
|
||||
"matplotlib.pyplot" = "plt"
|
||||
numpy = "np"
|
||||
pandas = "pd"
|
||||
seaborn = "sns"
|
||||
@@ -2482,6 +2486,7 @@ will be added to the `aliases` mapping.
|
||||
|
||||
```toml
|
||||
[tool.ruff.flake8-import-conventions]
|
||||
[tool.ruff.flake8-import-conventions.extend-aliases]
|
||||
# Declare a custom alias for the `matplotlib` module.
|
||||
"dask.dataframe" = "dd"
|
||||
```
|
||||
|
||||
4
flake8_to_ruff/Cargo.lock
generated
4
flake8_to_ruff/Cargo.lock
generated
@@ -771,7 +771,7 @@ checksum = "0ce7134b9999ecaf8bcd65542e436736ef32ddca1b3e06094cb6ec5755203b80"
|
||||
|
||||
[[package]]
|
||||
name = "flake8_to_ruff"
|
||||
version = "0.0.211"
|
||||
version = "0.0.212"
|
||||
dependencies = [
|
||||
"anyhow",
|
||||
"clap",
|
||||
@@ -1975,7 +1975,7 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "ruff"
|
||||
version = "0.0.211"
|
||||
version = "0.0.212"
|
||||
dependencies = [
|
||||
"anyhow",
|
||||
"bincode",
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[package]
|
||||
name = "flake8-to-ruff"
|
||||
version = "0.0.211-dev.0"
|
||||
version = "0.0.212-dev.0"
|
||||
edition = "2021"
|
||||
|
||||
[lib]
|
||||
|
||||
@@ -7,7 +7,7 @@ use ruff::flake8_pytest_style::types::{
|
||||
use ruff::flake8_quotes::settings::Quote;
|
||||
use ruff::flake8_tidy_imports::settings::Strictness;
|
||||
use ruff::pydocstyle::settings::Convention;
|
||||
use ruff::registry_gen::CheckCodePrefix;
|
||||
use ruff::registry::CheckCodePrefix;
|
||||
use ruff::settings::options::Options;
|
||||
use ruff::settings::pyproject::Pyproject;
|
||||
use ruff::{
|
||||
@@ -345,7 +345,7 @@ mod tests {
|
||||
|
||||
use anyhow::Result;
|
||||
use ruff::pydocstyle::settings::Convention;
|
||||
use ruff::registry_gen::CheckCodePrefix;
|
||||
use ruff::registry::CheckCodePrefix;
|
||||
use ruff::settings::options::Options;
|
||||
use ruff::settings::pyproject::Pyproject;
|
||||
use ruff::{flake8_quotes, pydocstyle};
|
||||
|
||||
@@ -3,8 +3,7 @@ use std::str::FromStr;
|
||||
use anyhow::{bail, Result};
|
||||
use once_cell::sync::Lazy;
|
||||
use regex::Regex;
|
||||
use ruff::registry::PREFIX_REDIRECTS;
|
||||
use ruff::registry_gen::CheckCodePrefix;
|
||||
use ruff::registry::{CheckCodePrefix, PREFIX_REDIRECTS};
|
||||
use ruff::settings::types::PatternPrefixPair;
|
||||
use rustc_hash::FxHashMap;
|
||||
|
||||
@@ -128,7 +127,7 @@ fn tokenize_files_to_codes_mapping(value: &str) -> Vec<Token> {
|
||||
if mat.start() == 0 {
|
||||
tokens.push(Token {
|
||||
token_name,
|
||||
src: mat.as_str().to_string().trim().to_string(),
|
||||
src: mat.as_str().trim().to_string(),
|
||||
});
|
||||
i += mat.end();
|
||||
break;
|
||||
@@ -201,7 +200,7 @@ pub fn collect_per_file_ignores(
|
||||
#[cfg(test)]
|
||||
mod tests {
|
||||
use anyhow::Result;
|
||||
use ruff::registry_gen::CheckCodePrefix;
|
||||
use ruff::registry::CheckCodePrefix;
|
||||
use ruff::settings::types::PatternPrefixPair;
|
||||
|
||||
use crate::parser::{parse_files_to_codes_mapping, parse_prefix_codes, parse_strings};
|
||||
|
||||
@@ -3,7 +3,7 @@ use std::fmt;
|
||||
use std::str::FromStr;
|
||||
|
||||
use anyhow::anyhow;
|
||||
use ruff::registry_gen::CheckCodePrefix;
|
||||
use ruff::registry::CheckCodePrefix;
|
||||
|
||||
#[derive(Clone, Ord, PartialOrd, Eq, PartialEq)]
|
||||
pub enum Plugin {
|
||||
|
||||
@@ -4,7 +4,7 @@ build-backend = "maturin"
|
||||
|
||||
[project]
|
||||
name = "ruff"
|
||||
version = "0.0.211"
|
||||
version = "0.0.212"
|
||||
description = "An extremely fast Python linter, written in Rust."
|
||||
authors = [
|
||||
{ name = "Charlie Marsh", email = "charlie.r.marsh@gmail.com" },
|
||||
|
||||
52
resources/test/fixtures/flake8_bandit/S324.py
vendored
Normal file
52
resources/test/fixtures/flake8_bandit/S324.py
vendored
Normal file
@@ -0,0 +1,52 @@
|
||||
import hashlib
|
||||
from hashlib import new as hashlib_new
|
||||
from hashlib import sha1 as hashlib_sha1
|
||||
|
||||
# Invalid
|
||||
|
||||
hashlib.new('md5')
|
||||
|
||||
hashlib.new('md4', b'test')
|
||||
|
||||
hashlib.new(name='md5', data=b'test')
|
||||
|
||||
hashlib.new('MD4', data=b'test')
|
||||
|
||||
hashlib.new('sha1')
|
||||
|
||||
hashlib.new('sha1', data=b'test')
|
||||
|
||||
hashlib.new('sha', data=b'test')
|
||||
|
||||
hashlib.new(name='SHA', data=b'test')
|
||||
|
||||
hashlib.sha(data=b'test')
|
||||
|
||||
hashlib.md5()
|
||||
|
||||
hashlib_new('sha1')
|
||||
|
||||
hashlib_sha1('sha1')
|
||||
|
||||
# usedforsecurity arg only available in Python 3.9+
|
||||
hashlib.new('sha1', usedforsecurity=True)
|
||||
|
||||
# Valid
|
||||
|
||||
hashlib.new('sha256')
|
||||
|
||||
hashlib.new('SHA512')
|
||||
|
||||
hashlib.sha256(data=b'test')
|
||||
|
||||
# usedforsecurity arg only available in Python 3.9+
|
||||
hashlib_new(name='sha1', usedforsecurity=False)
|
||||
|
||||
# usedforsecurity arg only available in Python 3.9+
|
||||
hashlib_sha1(name='sha1', usedforsecurity=False)
|
||||
|
||||
# usedforsecurity arg only available in Python 3.9+
|
||||
hashlib.md4(usedforsecurity=False)
|
||||
|
||||
# usedforsecurity arg only available in Python 3.9+
|
||||
hashlib.new(name='sha256', usedforsecurity=False)
|
||||
31
resources/test/fixtures/flake8_bandit/S506.py
vendored
Normal file
31
resources/test/fixtures/flake8_bandit/S506.py
vendored
Normal file
@@ -0,0 +1,31 @@
|
||||
import json
|
||||
import yaml
|
||||
from yaml import CSafeLoader
|
||||
from yaml import SafeLoader
|
||||
from yaml import SafeLoader as NewSafeLoader
|
||||
|
||||
|
||||
def test_yaml_load():
|
||||
ystr = yaml.dump({"a": 1, "b": 2, "c": 3})
|
||||
y = yaml.load(ystr)
|
||||
yaml.dump(y)
|
||||
try:
|
||||
y = yaml.load(ystr, Loader=yaml.CSafeLoader)
|
||||
except AttributeError:
|
||||
# CSafeLoader only exists if you build yaml with LibYAML
|
||||
y = yaml.load(ystr, Loader=yaml.SafeLoader)
|
||||
|
||||
|
||||
def test_json_load():
|
||||
# no issue should be found
|
||||
j = json.load("{}")
|
||||
|
||||
|
||||
yaml.load("{}", Loader=yaml.Loader)
|
||||
|
||||
# no issue should be found
|
||||
yaml.load("{}", SafeLoader)
|
||||
yaml.load("{}", yaml.SafeLoader)
|
||||
yaml.load("{}", CSafeLoader)
|
||||
yaml.load("{}", yaml.CSafeLoader)
|
||||
yaml.load("{}", NewSafeLoader)
|
||||
23
resources/test/fixtures/flake8_simplify/SIM101.py
vendored
Normal file
23
resources/test/fixtures/flake8_simplify/SIM101.py
vendored
Normal file
@@ -0,0 +1,23 @@
|
||||
if isinstance(a, int) or isinstance(a, float): # SIM101
|
||||
pass
|
||||
|
||||
if isinstance(a, (int, float)) or isinstance(a, bool): # SIM101
|
||||
pass
|
||||
|
||||
if isinstance(a, int) or isinstance(a, float) or isinstance(b, bool): # SIM101
|
||||
pass
|
||||
|
||||
if isinstance(b, bool) or isinstance(a, int) or isinstance(a, float): # SIM101
|
||||
pass
|
||||
|
||||
if isinstance(a, int) or isinstance(b, bool) or isinstance(a, float): # SIM101
|
||||
pass
|
||||
|
||||
if (isinstance(a, int) or isinstance(a, float)) and isinstance(b, bool): # SIM101
|
||||
pass
|
||||
|
||||
if isinstance(a, int) and isinstance(b, bool) or isinstance(a, float):
|
||||
pass
|
||||
|
||||
if isinstance(a, bool) or isinstance(b, str):
|
||||
pass
|
||||
10
resources/test/fixtures/pyupgrade/UP028_1.py
vendored
10
resources/test/fixtures/pyupgrade/UP028_1.py
vendored
@@ -111,3 +111,13 @@ def f():
|
||||
class C:
|
||||
def __init__(self):
|
||||
print(x)
|
||||
|
||||
|
||||
def f():
|
||||
for x in y:
|
||||
yield x, x + 1
|
||||
|
||||
|
||||
def f():
|
||||
for x, y in z:
|
||||
yield x, y, x + y
|
||||
|
||||
@@ -927,9 +927,16 @@
|
||||
"S106",
|
||||
"S107",
|
||||
"S108",
|
||||
"S3",
|
||||
"S32",
|
||||
"S324",
|
||||
"S5",
|
||||
"S50",
|
||||
"S506",
|
||||
"SIM",
|
||||
"SIM1",
|
||||
"SIM10",
|
||||
"SIM101",
|
||||
"SIM102",
|
||||
"SIM105",
|
||||
"SIM107",
|
||||
|
||||
@@ -1,12 +1,11 @@
|
||||
[package]
|
||||
name = "ruff_dev"
|
||||
version = "0.0.211"
|
||||
version = "0.0.212"
|
||||
edition = "2021"
|
||||
|
||||
[dependencies]
|
||||
anyhow = { version = "1.0.66" }
|
||||
clap = { version = "4.0.1", features = ["derive"] }
|
||||
codegen = { version = "0.2.0" }
|
||||
itertools = { version = "0.10.5" }
|
||||
libcst = { git = "https://github.com/charliermarsh/LibCST", rev = "f2f0b7a487a8725d161fe8b3ed73a6758b21e177" }
|
||||
once_cell = { version = "1.16.0" }
|
||||
|
||||
@@ -3,10 +3,7 @@
|
||||
use anyhow::Result;
|
||||
use clap::Args;
|
||||
|
||||
use crate::{
|
||||
generate_check_code_prefix, generate_cli_help, generate_json_schema, generate_options,
|
||||
generate_rules_table,
|
||||
};
|
||||
use crate::{generate_cli_help, generate_json_schema, generate_options, generate_rules_table};
|
||||
|
||||
#[derive(Args)]
|
||||
pub struct Cli {
|
||||
@@ -16,9 +13,6 @@ pub struct Cli {
|
||||
}
|
||||
|
||||
pub fn main(cli: &Cli) -> Result<()> {
|
||||
generate_check_code_prefix::main(&generate_check_code_prefix::Cli {
|
||||
dry_run: cli.dry_run,
|
||||
})?;
|
||||
generate_json_schema::main(&generate_json_schema::Cli {
|
||||
dry_run: cli.dry_run,
|
||||
})?;
|
||||
|
||||
@@ -1,221 +0,0 @@
|
||||
//! Generate the `CheckCodePrefix` enum.
|
||||
|
||||
use std::collections::{BTreeMap, BTreeSet};
|
||||
use std::fs;
|
||||
use std::io::Write;
|
||||
use std::path::PathBuf;
|
||||
use std::process::{Command, Output, Stdio};
|
||||
|
||||
use anyhow::{ensure, Result};
|
||||
use clap::Parser;
|
||||
use codegen::{Scope, Type, Variant};
|
||||
use itertools::Itertools;
|
||||
use ruff::registry::{CheckCode, PREFIX_REDIRECTS};
|
||||
use strum::IntoEnumIterator;
|
||||
|
||||
const ALL: &str = "ALL";
|
||||
|
||||
#[derive(Parser)]
|
||||
#[command(author, version, about, long_about = None)]
|
||||
pub struct Cli {
|
||||
/// Write the generated source code to stdout (rather than to
|
||||
/// `src/registry_gen.rs`).
|
||||
#[arg(long)]
|
||||
pub(crate) dry_run: bool,
|
||||
}
|
||||
|
||||
pub fn main(cli: &Cli) -> Result<()> {
|
||||
// Build up a map from prefix to matching CheckCodes.
|
||||
let mut prefix_to_codes: BTreeMap<String, BTreeSet<CheckCode>> = BTreeMap::default();
|
||||
for check_code in CheckCode::iter() {
|
||||
let code_str: String = check_code.as_ref().to_string();
|
||||
let code_prefix_len = code_str
|
||||
.chars()
|
||||
.take_while(|char| char.is_alphabetic())
|
||||
.count();
|
||||
let code_suffix_len = code_str.len() - code_prefix_len;
|
||||
for i in 0..=code_suffix_len {
|
||||
let prefix = code_str[..code_prefix_len + i].to_string();
|
||||
prefix_to_codes
|
||||
.entry(prefix)
|
||||
.or_default()
|
||||
.insert(check_code.clone());
|
||||
}
|
||||
prefix_to_codes
|
||||
.entry(ALL.to_string())
|
||||
.or_default()
|
||||
.insert(check_code.clone());
|
||||
}
|
||||
|
||||
// Add any prefix aliases (e.g., "U" to "UP").
|
||||
for (alias, check_code) in PREFIX_REDIRECTS.iter() {
|
||||
prefix_to_codes.insert(
|
||||
(*alias).to_string(),
|
||||
prefix_to_codes
|
||||
.get(&check_code.as_ref().to_string())
|
||||
.unwrap_or_else(|| panic!("Unknown CheckCode: {alias:?}"))
|
||||
.clone(),
|
||||
);
|
||||
}
|
||||
|
||||
let mut scope = Scope::new();
|
||||
|
||||
// Create the `CheckCodePrefix` definition.
|
||||
let mut gen = scope
|
||||
.new_enum("CheckCodePrefix")
|
||||
.vis("pub")
|
||||
.derive("EnumString")
|
||||
.derive("AsRefStr")
|
||||
.derive("Debug")
|
||||
.derive("PartialEq")
|
||||
.derive("Eq")
|
||||
.derive("PartialOrd")
|
||||
.derive("Ord")
|
||||
.derive("Clone")
|
||||
.derive("Serialize")
|
||||
.derive("Deserialize")
|
||||
.derive("JsonSchema");
|
||||
for prefix in prefix_to_codes.keys() {
|
||||
gen = gen.push_variant(Variant::new(prefix.to_string()));
|
||||
}
|
||||
|
||||
// Create the `SuffixLength` definition.
|
||||
scope
|
||||
.new_enum("SuffixLength")
|
||||
.vis("pub")
|
||||
.derive("PartialEq")
|
||||
.derive("Eq")
|
||||
.derive("PartialOrd")
|
||||
.derive("Ord")
|
||||
.push_variant(Variant::new("None"))
|
||||
.push_variant(Variant::new("Zero"))
|
||||
.push_variant(Variant::new("One"))
|
||||
.push_variant(Variant::new("Two"))
|
||||
.push_variant(Variant::new("Three"))
|
||||
.push_variant(Variant::new("Four"));
|
||||
|
||||
// Create the `match` statement, to map from definition to relevant codes.
|
||||
let mut gen = scope
|
||||
.new_impl("CheckCodePrefix")
|
||||
.new_fn("codes")
|
||||
.arg_ref_self()
|
||||
.ret(Type::new("Vec<CheckCode>"))
|
||||
.vis("pub")
|
||||
.line("#[allow(clippy::match_same_arms)]")
|
||||
.line("match self {");
|
||||
for (prefix, codes) in &prefix_to_codes {
|
||||
if let Some(target) = PREFIX_REDIRECTS.get(&prefix.as_str()) {
|
||||
gen = gen.line(format!(
|
||||
"CheckCodePrefix::{prefix} => {{ one_time_warning!(\"{{}}{{}} {{}}\", \
|
||||
\"warning\".yellow().bold(), \":\".bold(), \"`{}` has been remapped to \
|
||||
`{}`\".bold()); \n vec![{}] }}",
|
||||
prefix,
|
||||
target.as_ref(),
|
||||
codes
|
||||
.iter()
|
||||
.map(|code| format!("CheckCode::{}", code.as_ref()))
|
||||
.join(", ")
|
||||
));
|
||||
} else {
|
||||
gen = gen.line(format!(
|
||||
"CheckCodePrefix::{prefix} => vec![{}],",
|
||||
codes
|
||||
.iter()
|
||||
.map(|code| format!("CheckCode::{}", code.as_ref()))
|
||||
.join(", ")
|
||||
));
|
||||
}
|
||||
}
|
||||
gen.line("}");
|
||||
|
||||
// Create the `match` statement, to map from definition to specificity.
|
||||
let mut gen = scope
|
||||
.new_impl("CheckCodePrefix")
|
||||
.new_fn("specificity")
|
||||
.arg_ref_self()
|
||||
.ret(Type::new("SuffixLength"))
|
||||
.vis("pub")
|
||||
.line("#[allow(clippy::match_same_arms)]")
|
||||
.line("match self {");
|
||||
for prefix in prefix_to_codes.keys() {
|
||||
let specificity = if prefix == "ALL" {
|
||||
"None"
|
||||
} else {
|
||||
let num_numeric = prefix.chars().filter(|char| char.is_numeric()).count();
|
||||
match num_numeric {
|
||||
0 => "Zero",
|
||||
1 => "One",
|
||||
2 => "Two",
|
||||
3 => "Three",
|
||||
4 => "Four",
|
||||
_ => panic!("Invalid prefix: {prefix}"),
|
||||
}
|
||||
};
|
||||
gen = gen.line(format!(
|
||||
"CheckCodePrefix::{prefix} => SuffixLength::{specificity},"
|
||||
));
|
||||
}
|
||||
gen.line("}");
|
||||
|
||||
// Construct the output contents.
|
||||
let mut output = String::new();
|
||||
output
|
||||
.push_str("//! File automatically generated by `examples/generate_check_code_prefix.rs`.");
|
||||
output.push('\n');
|
||||
output.push('\n');
|
||||
output.push_str("use colored::Colorize;");
|
||||
output.push('\n');
|
||||
output.push_str("use schemars::JsonSchema;");
|
||||
output.push('\n');
|
||||
output.push_str("use serde::{Deserialize, Serialize};");
|
||||
output.push('\n');
|
||||
output.push_str("use strum_macros::{AsRefStr, EnumString};");
|
||||
output.push('\n');
|
||||
output.push('\n');
|
||||
output.push_str("use crate::registry::CheckCode;");
|
||||
output.push('\n');
|
||||
output.push_str("use crate::one_time_warning;");
|
||||
output.push('\n');
|
||||
output.push('\n');
|
||||
output.push_str(&scope.to_string());
|
||||
output.push('\n');
|
||||
output.push('\n');
|
||||
|
||||
// Add the list of output categories (not generated).
|
||||
output.push_str("pub const CATEGORIES: &[CheckCodePrefix] = &[");
|
||||
output.push('\n');
|
||||
for prefix in prefix_to_codes.keys() {
|
||||
if prefix.chars().all(char::is_alphabetic)
|
||||
&& !PREFIX_REDIRECTS.contains_key(&prefix.as_str())
|
||||
{
|
||||
output.push_str(&format!("CheckCodePrefix::{prefix},"));
|
||||
output.push('\n');
|
||||
}
|
||||
}
|
||||
output.push_str("];");
|
||||
output.push('\n');
|
||||
output.push('\n');
|
||||
|
||||
let rustfmt = Command::new("rustfmt")
|
||||
.stdin(Stdio::piped())
|
||||
.stdout(Stdio::piped())
|
||||
.spawn()?;
|
||||
write!(rustfmt.stdin.as_ref().unwrap(), "{output}")?;
|
||||
let Output { status, stdout, .. } = rustfmt.wait_with_output()?;
|
||||
ensure!(status.success(), "rustfmt failed with {status}");
|
||||
|
||||
// Write the output to `src/registry_gen.rs` (or stdout).
|
||||
if cli.dry_run {
|
||||
println!("{}", String::from_utf8(stdout)?);
|
||||
} else {
|
||||
let file = PathBuf::from(env!("CARGO_MANIFEST_DIR"))
|
||||
.parent()
|
||||
.expect("Failed to find root directory")
|
||||
.join("src/registry_gen.rs");
|
||||
if fs::read(&file).map_or(true, |old| old != stdout) {
|
||||
fs::write(&file, stdout)?;
|
||||
}
|
||||
}
|
||||
|
||||
Ok(())
|
||||
}
|
||||
@@ -28,7 +28,7 @@ pub fn main(cli: &Cli) -> Result<()> {
|
||||
print!("{output}");
|
||||
} else {
|
||||
replace_readme_section(
|
||||
&format!("```shell\n{output}\n```\n"),
|
||||
&format!("```\n{output}\n```\n"),
|
||||
HELP_BEGIN_PRAGMA,
|
||||
HELP_END_PRAGMA,
|
||||
)?;
|
||||
|
||||
@@ -12,7 +12,6 @@
|
||||
)]
|
||||
|
||||
pub mod generate_all;
|
||||
pub mod generate_check_code_prefix;
|
||||
pub mod generate_cli_help;
|
||||
pub mod generate_json_schema;
|
||||
pub mod generate_options;
|
||||
|
||||
@@ -14,8 +14,8 @@
|
||||
use anyhow::Result;
|
||||
use clap::{Parser, Subcommand};
|
||||
use ruff_dev::{
|
||||
generate_all, generate_check_code_prefix, generate_cli_help, generate_json_schema,
|
||||
generate_options, generate_rules_table, print_ast, print_cst, print_tokens, round_trip,
|
||||
generate_all, generate_cli_help, generate_json_schema, generate_options, generate_rules_table,
|
||||
print_ast, print_cst, print_tokens, round_trip,
|
||||
};
|
||||
|
||||
#[derive(Parser)]
|
||||
@@ -30,8 +30,6 @@ struct Cli {
|
||||
enum Commands {
|
||||
/// Run all code and documentation generation steps.
|
||||
GenerateAll(generate_all::Cli),
|
||||
/// Generate the `CheckCodePrefix` enum.
|
||||
GenerateCheckCodePrefix(generate_check_code_prefix::Cli),
|
||||
/// Generate JSON schema for the TOML configuration file.
|
||||
GenerateJSONSchema(generate_json_schema::Cli),
|
||||
/// Generate a Markdown-compatible table of supported lint rules.
|
||||
@@ -54,7 +52,6 @@ fn main() -> Result<()> {
|
||||
let cli = Cli::parse();
|
||||
match &cli.command {
|
||||
Commands::GenerateAll(args) => generate_all::main(args)?,
|
||||
Commands::GenerateCheckCodePrefix(args) => generate_check_code_prefix::main(args)?,
|
||||
Commands::GenerateJSONSchema(args) => generate_json_schema::main(args)?,
|
||||
Commands::GenerateRulesTable(args) => generate_rules_table::main(args)?,
|
||||
Commands::GenerateOptions(args) => generate_options::main(args)?,
|
||||
|
||||
@@ -1,12 +1,13 @@
|
||||
[package]
|
||||
name = "ruff_macros"
|
||||
version = "0.0.211"
|
||||
version = "0.0.212"
|
||||
edition = "2021"
|
||||
|
||||
[lib]
|
||||
proc-macro = true
|
||||
|
||||
[dependencies]
|
||||
once_cell = { version = "1.17.0" }
|
||||
proc-macro2 = { version = "1.0.47" }
|
||||
quote = { version = "1.0.21" }
|
||||
syn = { version = "1.0.103", features = ["derive", "parsing"] }
|
||||
|
||||
289
ruff_macros/src/check_code_prefix.rs
Normal file
289
ruff_macros/src/check_code_prefix.rs
Normal file
@@ -0,0 +1,289 @@
|
||||
use std::collections::{BTreeMap, BTreeSet, HashMap};
|
||||
|
||||
use once_cell::sync::Lazy;
|
||||
use proc_macro2::Span;
|
||||
use quote::quote;
|
||||
use syn::punctuated::Punctuated;
|
||||
use syn::token::Comma;
|
||||
use syn::{DataEnum, DeriveInput, Ident, Variant};
|
||||
|
||||
const ALL: &str = "ALL";
|
||||
|
||||
/// A hash map from deprecated `CheckCodePrefix` to latest `CheckCodePrefix`.
|
||||
pub static PREFIX_REDIRECTS: Lazy<HashMap<&'static str, &'static str>> = Lazy::new(|| {
|
||||
HashMap::from_iter([
|
||||
// TODO(charlie): Remove by 2023-01-01.
|
||||
("U001", "UP001"),
|
||||
("U003", "UP003"),
|
||||
("U004", "UP004"),
|
||||
("U005", "UP005"),
|
||||
("U006", "UP006"),
|
||||
("U007", "UP007"),
|
||||
("U008", "UP008"),
|
||||
("U009", "UP009"),
|
||||
("U010", "UP010"),
|
||||
("U011", "UP011"),
|
||||
("U012", "UP012"),
|
||||
("U013", "UP013"),
|
||||
("U014", "UP014"),
|
||||
("U015", "UP015"),
|
||||
("U016", "UP016"),
|
||||
("U017", "UP017"),
|
||||
("U019", "UP019"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("I252", "TID252"),
|
||||
("M001", "RUF100"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("PDV002", "PD002"),
|
||||
("PDV003", "PD003"),
|
||||
("PDV004", "PD004"),
|
||||
("PDV007", "PD007"),
|
||||
("PDV008", "PD008"),
|
||||
("PDV009", "PD009"),
|
||||
("PDV010", "PD010"),
|
||||
("PDV011", "PD011"),
|
||||
("PDV012", "PD012"),
|
||||
("PDV013", "PD013"),
|
||||
("PDV015", "PD015"),
|
||||
("PDV901", "PD901"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("R501", "RET501"),
|
||||
("R502", "RET502"),
|
||||
("R503", "RET503"),
|
||||
("R504", "RET504"),
|
||||
("R505", "RET505"),
|
||||
("R506", "RET506"),
|
||||
("R507", "RET507"),
|
||||
("R508", "RET508"),
|
||||
("IC001", "ICN001"),
|
||||
("IC002", "ICN001"),
|
||||
("IC003", "ICN001"),
|
||||
("IC004", "ICN001"),
|
||||
// TODO(charlie): Remove by 2023-01-01.
|
||||
("U", "UP"),
|
||||
("U0", "UP0"),
|
||||
("U00", "UP00"),
|
||||
("U01", "UP01"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("I2", "TID2"),
|
||||
("I25", "TID25"),
|
||||
("M", "RUF100"),
|
||||
("M0", "RUF100"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("PDV", "PD"),
|
||||
("PDV0", "PD0"),
|
||||
("PDV01", "PD01"),
|
||||
("PDV9", "PD9"),
|
||||
("PDV90", "PD90"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("R", "RET"),
|
||||
("R5", "RET5"),
|
||||
("R50", "RET50"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("IC", "ICN"),
|
||||
("IC0", "ICN0"),
|
||||
])
|
||||
});
|
||||
|
||||
pub fn derive_impl(input: DeriveInput) -> syn::Result<proc_macro2::TokenStream> {
|
||||
let DeriveInput { ident, data, .. } = input;
|
||||
let syn::Data::Enum(DataEnum { variants, .. }) = data else {
|
||||
return Err(syn::Error::new(
|
||||
ident.span(),
|
||||
"Can only derive `CheckCodePrefix` from enums.",
|
||||
));
|
||||
};
|
||||
|
||||
let prefix_ident = Ident::new(&format!("{ident}Prefix"), ident.span());
|
||||
let prefix = expand(&ident, &prefix_ident, &variants);
|
||||
let expanded = quote! {
|
||||
#[derive(PartialEq, Eq, PartialOrd, Ord)]
|
||||
pub enum SuffixLength {
|
||||
None,
|
||||
Zero,
|
||||
One,
|
||||
Two,
|
||||
Three,
|
||||
Four,
|
||||
}
|
||||
|
||||
#prefix
|
||||
};
|
||||
Ok(expanded)
|
||||
}
|
||||
|
||||
fn expand(
|
||||
ident: &Ident,
|
||||
prefix_ident: &Ident,
|
||||
variants: &Punctuated<Variant, Comma>,
|
||||
) -> proc_macro2::TokenStream {
|
||||
// Build up a map from prefix to matching CheckCodes.
|
||||
let mut prefix_to_codes: BTreeMap<Ident, BTreeSet<String>> = BTreeMap::default();
|
||||
for variant in variants {
|
||||
let span = variant.ident.span();
|
||||
let code_str = variant.ident.to_string();
|
||||
let code_prefix_len = code_str
|
||||
.chars()
|
||||
.take_while(|char| char.is_alphabetic())
|
||||
.count();
|
||||
let code_suffix_len = code_str.len() - code_prefix_len;
|
||||
for i in 0..=code_suffix_len {
|
||||
let prefix = code_str[..code_prefix_len + i].to_string();
|
||||
prefix_to_codes
|
||||
.entry(Ident::new(&prefix, span))
|
||||
.or_default()
|
||||
.insert(code_str.clone());
|
||||
}
|
||||
prefix_to_codes
|
||||
.entry(Ident::new(ALL, span))
|
||||
.or_default()
|
||||
.insert(code_str.clone());
|
||||
}
|
||||
|
||||
// Add any prefix aliases (e.g., "U" to "UP").
|
||||
for (alias, check_code) in PREFIX_REDIRECTS.iter() {
|
||||
prefix_to_codes.insert(
|
||||
Ident::new(alias, Span::call_site()),
|
||||
prefix_to_codes
|
||||
.get(&Ident::new(check_code, Span::call_site()))
|
||||
.unwrap_or_else(|| panic!("Unknown CheckCode: {alias:?}"))
|
||||
.clone(),
|
||||
);
|
||||
}
|
||||
|
||||
let prefix_variants = prefix_to_codes.keys().map(|prefix| {
|
||||
quote! {
|
||||
#prefix
|
||||
}
|
||||
});
|
||||
|
||||
let prefix_impl = generate_impls(ident, prefix_ident, &prefix_to_codes);
|
||||
|
||||
let prefix_redirects = PREFIX_REDIRECTS.iter().map(|(alias, check_code)| {
|
||||
let code = Ident::new(check_code, Span::call_site());
|
||||
quote! {
|
||||
(#alias, #prefix_ident::#code)
|
||||
}
|
||||
});
|
||||
|
||||
quote! {
|
||||
#[derive(
|
||||
::strum_macros::EnumString,
|
||||
::strum_macros::AsRefStr,
|
||||
Debug,
|
||||
PartialEq,
|
||||
Eq,
|
||||
PartialOrd,
|
||||
Ord,
|
||||
Clone,
|
||||
::serde::Serialize,
|
||||
::serde::Deserialize,
|
||||
::schemars::JsonSchema,
|
||||
)]
|
||||
pub enum #prefix_ident {
|
||||
#(#prefix_variants,)*
|
||||
}
|
||||
|
||||
#prefix_impl
|
||||
|
||||
/// A hash map from deprecated `CheckCodePrefix` to latest `CheckCodePrefix`.
|
||||
pub static PREFIX_REDIRECTS: ::once_cell::sync::Lazy<::rustc_hash::FxHashMap<&'static str, #prefix_ident>> = ::once_cell::sync::Lazy::new(|| {
|
||||
::rustc_hash::FxHashMap::from_iter([
|
||||
#(#prefix_redirects),*
|
||||
])
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
fn generate_impls(
|
||||
ident: &Ident,
|
||||
prefix_ident: &Ident,
|
||||
prefix_to_codes: &BTreeMap<Ident, BTreeSet<String>>,
|
||||
) -> proc_macro2::TokenStream {
|
||||
let codes_match_arms = prefix_to_codes.iter().map(|(prefix, codes)| {
|
||||
let codes = codes.iter().map(|code| {
|
||||
let code = Ident::new(code, Span::call_site());
|
||||
quote! {
|
||||
#ident::#code
|
||||
}
|
||||
});
|
||||
let prefix_str = prefix.to_string();
|
||||
if let Some(target) = PREFIX_REDIRECTS.get(prefix_str.as_str()) {
|
||||
quote! {
|
||||
#prefix_ident::#prefix => {
|
||||
crate::one_time_warning!(
|
||||
"{}{} {}",
|
||||
"warning".yellow().bold(),
|
||||
":".bold(),
|
||||
format!("`{}` has been remapped to `{}`", #prefix_str, #target).bold()
|
||||
);
|
||||
vec![#(#codes),*]
|
||||
}
|
||||
}
|
||||
} else {
|
||||
quote! {
|
||||
#prefix_ident::#prefix => vec![#(#codes),*],
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
let specificity_match_arms = prefix_to_codes.keys().map(|prefix| {
|
||||
if *prefix == ALL {
|
||||
quote! {
|
||||
#prefix_ident::#prefix => SuffixLength::None,
|
||||
}
|
||||
} else {
|
||||
let num_numeric = prefix
|
||||
.to_string()
|
||||
.chars()
|
||||
.filter(|char| char.is_numeric())
|
||||
.count();
|
||||
let suffix_len = match num_numeric {
|
||||
0 => quote! { SuffixLength::Zero },
|
||||
1 => quote! { SuffixLength::One },
|
||||
2 => quote! { SuffixLength::Two },
|
||||
3 => quote! { SuffixLength::Three },
|
||||
4 => quote! { SuffixLength::Four },
|
||||
_ => panic!("Invalid prefix: {prefix}"),
|
||||
};
|
||||
quote! {
|
||||
#prefix_ident::#prefix => #suffix_len,
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
let categories = prefix_to_codes.keys().map(|prefix| {
|
||||
let prefix_str = prefix.to_string();
|
||||
if prefix_str.chars().all(char::is_alphabetic)
|
||||
&& !PREFIX_REDIRECTS.contains_key(&prefix_str.as_str())
|
||||
{
|
||||
quote! {
|
||||
#prefix_ident::#prefix,
|
||||
}
|
||||
} else {
|
||||
quote! {}
|
||||
}
|
||||
});
|
||||
|
||||
quote! {
|
||||
impl #prefix_ident {
|
||||
pub fn codes(&self) -> Vec<#ident> {
|
||||
use colored::Colorize;
|
||||
|
||||
#[allow(clippy::match_same_arms)]
|
||||
match self {
|
||||
#(#codes_match_arms)*
|
||||
}
|
||||
}
|
||||
|
||||
pub fn specificity(&self) -> SuffixLength {
|
||||
#[allow(clippy::match_same_arms)]
|
||||
match self {
|
||||
#(#specificity_match_arms)*
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
pub const CATEGORIES: &[#prefix_ident] = &[#(#categories)*];
|
||||
}
|
||||
}
|
||||
203
ruff_macros/src/config.rs
Normal file
203
ruff_macros/src/config.rs
Normal file
@@ -0,0 +1,203 @@
|
||||
use quote::{quote, quote_spanned};
|
||||
use syn::parse::{Parse, ParseStream};
|
||||
use syn::spanned::Spanned;
|
||||
use syn::token::Comma;
|
||||
use syn::{
|
||||
AngleBracketedGenericArguments, Attribute, Data, DataStruct, DeriveInput, Field, Fields, Lit,
|
||||
LitStr, Path, PathArguments, PathSegment, Token, Type, TypePath,
|
||||
};
|
||||
|
||||
pub fn derive_impl(input: DeriveInput) -> syn::Result<proc_macro2::TokenStream> {
|
||||
let DeriveInput { ident, data, .. } = input;
|
||||
|
||||
match data {
|
||||
Data::Struct(DataStruct {
|
||||
fields: Fields::Named(fields),
|
||||
..
|
||||
}) => {
|
||||
let mut output = vec![];
|
||||
|
||||
for field in fields.named.iter() {
|
||||
let docs: Vec<&Attribute> = field
|
||||
.attrs
|
||||
.iter()
|
||||
.filter(|attr| attr.path.is_ident("doc"))
|
||||
.collect();
|
||||
|
||||
if docs.is_empty() {
|
||||
return Err(syn::Error::new(
|
||||
field.span(),
|
||||
"Missing documentation for field",
|
||||
));
|
||||
}
|
||||
|
||||
if let Some(attr) = field.attrs.iter().find(|attr| attr.path.is_ident("option")) {
|
||||
output.push(handle_option(field, attr, docs)?);
|
||||
};
|
||||
|
||||
if field
|
||||
.attrs
|
||||
.iter()
|
||||
.any(|attr| attr.path.is_ident("option_group"))
|
||||
{
|
||||
output.push(handle_option_group(field)?);
|
||||
};
|
||||
}
|
||||
|
||||
Ok(quote! {
|
||||
use crate::settings::options_base::{OptionEntry, OptionField, OptionGroup, ConfigurationOptions};
|
||||
|
||||
#[automatically_derived]
|
||||
impl ConfigurationOptions for #ident {
|
||||
fn get_available_options() -> Vec<OptionEntry> {
|
||||
vec![#(#output),*]
|
||||
}
|
||||
}
|
||||
})
|
||||
}
|
||||
_ => Err(syn::Error::new(
|
||||
ident.span(),
|
||||
"Can only derive ConfigurationOptions from structs with named fields.",
|
||||
)),
|
||||
}
|
||||
}
|
||||
|
||||
/// For a field with type `Option<Foobar>` where `Foobar` itself is a struct
|
||||
/// deriving `ConfigurationOptions`, create code that calls retrieves options
|
||||
/// from that group: `Foobar::get_available_options()`
|
||||
fn handle_option_group(field: &Field) -> syn::Result<proc_macro2::TokenStream> {
|
||||
let ident = field
|
||||
.ident
|
||||
.as_ref()
|
||||
.expect("Expected to handle named fields");
|
||||
|
||||
match &field.ty {
|
||||
Type::Path(TypePath {
|
||||
path: Path { segments, .. },
|
||||
..
|
||||
}) => match segments.first() {
|
||||
Some(PathSegment {
|
||||
ident: type_ident,
|
||||
arguments:
|
||||
PathArguments::AngleBracketed(AngleBracketedGenericArguments { args, .. }),
|
||||
..
|
||||
}) if type_ident == "Option" => {
|
||||
let path = &args[0];
|
||||
let kebab_name = LitStr::new(&ident.to_string().replace('_', "-"), ident.span());
|
||||
|
||||
Ok(quote_spanned!(
|
||||
ident.span() => OptionEntry::Group(OptionGroup {
|
||||
name: #kebab_name,
|
||||
fields: #path::get_available_options(),
|
||||
})
|
||||
))
|
||||
}
|
||||
_ => Err(syn::Error::new(
|
||||
ident.span(),
|
||||
"Expected `Option<_>` as type.",
|
||||
)),
|
||||
},
|
||||
_ => Err(syn::Error::new(ident.span(), "Expected type.")),
|
||||
}
|
||||
}
|
||||
|
||||
/// Parse a `doc` attribute into it a string literal.
|
||||
fn parse_doc(doc: &Attribute) -> syn::Result<String> {
|
||||
let doc = doc
|
||||
.parse_meta()
|
||||
.map_err(|e| syn::Error::new(doc.span(), e))?;
|
||||
|
||||
match doc {
|
||||
syn::Meta::NameValue(syn::MetaNameValue {
|
||||
lit: Lit::Str(lit_str),
|
||||
..
|
||||
}) => Ok(lit_str.value()),
|
||||
_ => Err(syn::Error::new(doc.span(), "Expected doc attribute.")),
|
||||
}
|
||||
}
|
||||
|
||||
/// Parse an `#[option(doc="...", default="...", value_type="...",
|
||||
/// example="...")]` attribute and return data in the form of an `OptionField`.
|
||||
fn handle_option(
|
||||
field: &Field,
|
||||
attr: &Attribute,
|
||||
docs: Vec<&Attribute>,
|
||||
) -> syn::Result<proc_macro2::TokenStream> {
|
||||
// Convert the list of `doc` attributes into a single string.
|
||||
let doc = textwrap::dedent(
|
||||
&docs
|
||||
.into_iter()
|
||||
.map(parse_doc)
|
||||
.collect::<syn::Result<Vec<_>>>()?
|
||||
.join("\n"),
|
||||
)
|
||||
.trim_matches('\n')
|
||||
.to_string();
|
||||
|
||||
let ident = field
|
||||
.ident
|
||||
.as_ref()
|
||||
.expect("Expected to handle named fields");
|
||||
|
||||
let FieldAttributes {
|
||||
default,
|
||||
value_type,
|
||||
example,
|
||||
..
|
||||
} = attr.parse_args::<FieldAttributes>()?;
|
||||
let kebab_name = LitStr::new(&ident.to_string().replace('_', "-"), ident.span());
|
||||
|
||||
Ok(quote_spanned!(
|
||||
ident.span() => OptionEntry::Field(OptionField {
|
||||
name: #kebab_name,
|
||||
doc: &#doc,
|
||||
default: &#default,
|
||||
value_type: &#value_type,
|
||||
example: &#example,
|
||||
})
|
||||
))
|
||||
}
|
||||
|
||||
#[derive(Debug)]
|
||||
struct FieldAttributes {
|
||||
default: String,
|
||||
value_type: String,
|
||||
example: String,
|
||||
}
|
||||
|
||||
impl Parse for FieldAttributes {
|
||||
fn parse(input: ParseStream) -> syn::Result<Self> {
|
||||
let default = _parse_key_value(input, "default")?;
|
||||
input.parse::<Comma>()?;
|
||||
let value_type = _parse_key_value(input, "value_type")?;
|
||||
input.parse::<Comma>()?;
|
||||
let example = _parse_key_value(input, "example")?;
|
||||
if !input.is_empty() {
|
||||
input.parse::<Comma>()?;
|
||||
}
|
||||
|
||||
Ok(FieldAttributes {
|
||||
default,
|
||||
value_type,
|
||||
example: textwrap::dedent(&example).trim_matches('\n').to_string(),
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
fn _parse_key_value(input: ParseStream, name: &str) -> syn::Result<String> {
|
||||
let ident: proc_macro2::Ident = input.parse()?;
|
||||
if ident != name {
|
||||
return Err(syn::Error::new(
|
||||
ident.span(),
|
||||
format!("Expected `{name}` name"),
|
||||
));
|
||||
}
|
||||
|
||||
input.parse::<Token![=]>()?;
|
||||
let value: Lit = input.parse()?;
|
||||
|
||||
match &value {
|
||||
Lit::Str(v) => Ok(v.value()),
|
||||
_ => Err(syn::Error::new(value.span(), "Expected literal string")),
|
||||
}
|
||||
}
|
||||
@@ -11,215 +11,25 @@
|
||||
clippy::too_many_lines
|
||||
)]
|
||||
|
||||
use quote::{quote, quote_spanned};
|
||||
use syn::parse::{Parse, ParseStream};
|
||||
use syn::spanned::Spanned;
|
||||
use syn::token::Comma;
|
||||
use syn::{
|
||||
parse_macro_input, AngleBracketedGenericArguments, Attribute, Data, DataStruct, DeriveInput,
|
||||
Field, Fields, Lit, LitStr, Path, PathArguments, PathSegment, Token, Type, TypePath,
|
||||
};
|
||||
use syn::{parse_macro_input, DeriveInput};
|
||||
|
||||
mod check_code_prefix;
|
||||
mod config;
|
||||
|
||||
#[proc_macro_derive(ConfigurationOptions, attributes(option, doc, option_group))]
|
||||
pub fn derive(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
|
||||
pub fn derive_config(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
|
||||
let input = parse_macro_input!(input as DeriveInput);
|
||||
|
||||
derive_impl(input)
|
||||
config::derive_impl(input)
|
||||
.unwrap_or_else(syn::Error::into_compile_error)
|
||||
.into()
|
||||
}
|
||||
|
||||
fn derive_impl(input: DeriveInput) -> syn::Result<proc_macro2::TokenStream> {
|
||||
let DeriveInput { ident, data, .. } = input;
|
||||
#[proc_macro_derive(CheckCodePrefix)]
|
||||
pub fn derive_check_code_prefix(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
|
||||
let input = parse_macro_input!(input as DeriveInput);
|
||||
|
||||
match data {
|
||||
Data::Struct(DataStruct {
|
||||
fields: Fields::Named(fields),
|
||||
..
|
||||
}) => {
|
||||
let mut output = vec![];
|
||||
|
||||
for field in fields.named.iter() {
|
||||
let docs: Vec<&Attribute> = field
|
||||
.attrs
|
||||
.iter()
|
||||
.filter(|attr| attr.path.is_ident("doc"))
|
||||
.collect();
|
||||
|
||||
if docs.is_empty() {
|
||||
return Err(syn::Error::new(
|
||||
field.span(),
|
||||
"Missing documentation for field",
|
||||
));
|
||||
}
|
||||
|
||||
if let Some(attr) = field.attrs.iter().find(|attr| attr.path.is_ident("option")) {
|
||||
output.push(handle_option(field, attr, docs)?);
|
||||
};
|
||||
|
||||
if field
|
||||
.attrs
|
||||
.iter()
|
||||
.any(|attr| attr.path.is_ident("option_group"))
|
||||
{
|
||||
output.push(handle_option_group(field)?);
|
||||
};
|
||||
}
|
||||
|
||||
Ok(quote! {
|
||||
use crate::settings::options_base::{OptionEntry, OptionField, OptionGroup, ConfigurationOptions};
|
||||
|
||||
#[automatically_derived]
|
||||
impl ConfigurationOptions for #ident {
|
||||
fn get_available_options() -> Vec<OptionEntry> {
|
||||
vec![#(#output),*]
|
||||
}
|
||||
}
|
||||
})
|
||||
}
|
||||
_ => Err(syn::Error::new(
|
||||
ident.span(),
|
||||
"Can only derive ConfigurationOptions from structs with named fields.",
|
||||
)),
|
||||
}
|
||||
}
|
||||
|
||||
/// For a field with type `Option<Foobar>` where `Foobar` itself is a struct
|
||||
/// deriving `ConfigurationOptions`, create code that calls retrieves options
|
||||
/// from that group: `Foobar::get_available_options()`
|
||||
fn handle_option_group(field: &Field) -> syn::Result<proc_macro2::TokenStream> {
|
||||
let ident = field
|
||||
.ident
|
||||
.as_ref()
|
||||
.expect("Expected to handle named fields");
|
||||
|
||||
match &field.ty {
|
||||
Type::Path(TypePath {
|
||||
path: Path { segments, .. },
|
||||
..
|
||||
}) => match segments.first() {
|
||||
Some(PathSegment {
|
||||
ident: type_ident,
|
||||
arguments:
|
||||
PathArguments::AngleBracketed(AngleBracketedGenericArguments { args, .. }),
|
||||
..
|
||||
}) if type_ident == "Option" => {
|
||||
let path = &args[0];
|
||||
let kebab_name = LitStr::new(&ident.to_string().replace('_', "-"), ident.span());
|
||||
|
||||
Ok(quote_spanned!(
|
||||
ident.span() => OptionEntry::Group(OptionGroup {
|
||||
name: #kebab_name,
|
||||
fields: #path::get_available_options(),
|
||||
})
|
||||
))
|
||||
}
|
||||
_ => Err(syn::Error::new(
|
||||
ident.span(),
|
||||
"Expected `Option<_>` as type.",
|
||||
)),
|
||||
},
|
||||
_ => Err(syn::Error::new(ident.span(), "Expected type.")),
|
||||
}
|
||||
}
|
||||
|
||||
/// Parse a `doc` attribute into it a string literal.
|
||||
fn parse_doc(doc: &Attribute) -> syn::Result<String> {
|
||||
let doc = doc
|
||||
.parse_meta()
|
||||
.map_err(|e| syn::Error::new(doc.span(), e))?;
|
||||
|
||||
match doc {
|
||||
syn::Meta::NameValue(syn::MetaNameValue {
|
||||
lit: Lit::Str(lit_str),
|
||||
..
|
||||
}) => Ok(lit_str.value()),
|
||||
_ => Err(syn::Error::new(doc.span(), "Expected doc attribute.")),
|
||||
}
|
||||
}
|
||||
|
||||
/// Parse an `#[option(doc="...", default="...", value_type="...",
|
||||
/// example="...")]` attribute and return data in the form of an `OptionField`.
|
||||
fn handle_option(
|
||||
field: &Field,
|
||||
attr: &Attribute,
|
||||
docs: Vec<&Attribute>,
|
||||
) -> syn::Result<proc_macro2::TokenStream> {
|
||||
// Convert the list of `doc` attributes into a single string.
|
||||
let doc = textwrap::dedent(
|
||||
&docs
|
||||
.into_iter()
|
||||
.map(parse_doc)
|
||||
.collect::<syn::Result<Vec<_>>>()?
|
||||
.join("\n"),
|
||||
)
|
||||
.trim_matches('\n')
|
||||
.to_string();
|
||||
|
||||
let ident = field
|
||||
.ident
|
||||
.as_ref()
|
||||
.expect("Expected to handle named fields");
|
||||
|
||||
let FieldAttributes {
|
||||
default,
|
||||
value_type,
|
||||
example,
|
||||
..
|
||||
} = attr.parse_args::<FieldAttributes>()?;
|
||||
let kebab_name = LitStr::new(&ident.to_string().replace('_', "-"), ident.span());
|
||||
|
||||
Ok(quote_spanned!(
|
||||
ident.span() => OptionEntry::Field(OptionField {
|
||||
name: #kebab_name,
|
||||
doc: &#doc,
|
||||
default: &#default,
|
||||
value_type: &#value_type,
|
||||
example: &#example,
|
||||
})
|
||||
))
|
||||
}
|
||||
|
||||
#[derive(Debug)]
|
||||
struct FieldAttributes {
|
||||
default: String,
|
||||
value_type: String,
|
||||
example: String,
|
||||
}
|
||||
|
||||
impl Parse for FieldAttributes {
|
||||
fn parse(input: ParseStream) -> syn::Result<Self> {
|
||||
let default = _parse_key_value(input, "default")?;
|
||||
input.parse::<Comma>()?;
|
||||
let value_type = _parse_key_value(input, "value_type")?;
|
||||
input.parse::<Comma>()?;
|
||||
let example = _parse_key_value(input, "example")?;
|
||||
if !input.is_empty() {
|
||||
input.parse::<Comma>()?;
|
||||
}
|
||||
|
||||
Ok(FieldAttributes {
|
||||
default,
|
||||
value_type,
|
||||
example: textwrap::dedent(&example).trim_matches('\n').to_string(),
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
fn _parse_key_value(input: ParseStream, name: &str) -> syn::Result<String> {
|
||||
let ident: proc_macro2::Ident = input.parse()?;
|
||||
if ident != name {
|
||||
return Err(syn::Error::new(
|
||||
ident.span(),
|
||||
format!("Expected `{name}` name"),
|
||||
));
|
||||
}
|
||||
|
||||
input.parse::<Token![=]>()?;
|
||||
let value: Lit = input.parse()?;
|
||||
|
||||
match &value {
|
||||
Lit::Str(v) => Ok(v.value()),
|
||||
_ => Err(syn::Error::new(value.span(), "Expected literal string")),
|
||||
}
|
||||
check_code_prefix::derive_impl(input)
|
||||
.unwrap_or_else(syn::Error::into_compile_error)
|
||||
.into()
|
||||
}
|
||||
|
||||
@@ -213,23 +213,6 @@ pub fn is_constant_non_singleton(expr: &Expr) -> bool {
|
||||
is_constant(expr) && !is_singleton(expr)
|
||||
}
|
||||
|
||||
/// Return `true` if an `Expr` is not a reference to a variable (or something
|
||||
/// that could resolve to a variable, like a function call).
|
||||
pub fn is_non_variable(expr: &Expr) -> bool {
|
||||
matches!(
|
||||
expr.node,
|
||||
ExprKind::Constant { .. }
|
||||
| ExprKind::Tuple { .. }
|
||||
| ExprKind::List { .. }
|
||||
| ExprKind::Set { .. }
|
||||
| ExprKind::Dict { .. }
|
||||
| ExprKind::SetComp { .. }
|
||||
| ExprKind::ListComp { .. }
|
||||
| ExprKind::DictComp { .. }
|
||||
| ExprKind::GeneratorExp { .. }
|
||||
)
|
||||
}
|
||||
|
||||
/// Return the `Keyword` with the given name, if it's present in the list of
|
||||
/// `Keyword` arguments.
|
||||
pub fn find_keyword<'a>(keywords: &'a [Keyword], keyword_name: &str) -> Option<&'a Keyword> {
|
||||
@@ -316,7 +299,7 @@ pub fn is_super_call_with_arguments(func: &Expr, args: &[Expr]) -> bool {
|
||||
}
|
||||
|
||||
/// Format the module name for a relative import.
|
||||
pub fn format_import_from(level: Option<&usize>, module: Option<&String>) -> String {
|
||||
pub fn format_import_from(level: Option<&usize>, module: Option<&str>) -> String {
|
||||
let mut module_name = String::with_capacity(16);
|
||||
if let Some(level) = level {
|
||||
for _ in 0..*level {
|
||||
@@ -582,7 +565,7 @@ pub struct SimpleCallArgs<'a> {
|
||||
}
|
||||
|
||||
impl<'a> SimpleCallArgs<'a> {
|
||||
pub fn new(args: &'a Vec<Expr>, keywords: &'a Vec<Keyword>) -> Self {
|
||||
pub fn new(args: &'a [Expr], keywords: &'a [Keyword]) -> Self {
|
||||
let mut result = SimpleCallArgs::default();
|
||||
|
||||
for arg in args {
|
||||
|
||||
@@ -191,13 +191,18 @@ impl<'a> Checker<'a> {
|
||||
&& match_call_path(call_path, "typing_extensions", target, &self.from_imports))
|
||||
}
|
||||
|
||||
/// Return `true` if `member` is bound as a builtin.
|
||||
pub fn is_builtin(&self, member: &str) -> bool {
|
||||
/// Return the current `Binding` for a given `name`.
|
||||
pub fn find_binding(&self, member: &str) -> Option<&Binding> {
|
||||
self.current_scopes()
|
||||
.find_map(|scope| scope.values.get(member))
|
||||
.map_or(false, |index| {
|
||||
matches!(self.bindings[*index].kind, BindingKind::Builtin)
|
||||
})
|
||||
.map(|index| &self.bindings[*index])
|
||||
}
|
||||
|
||||
/// Return `true` if `member` is bound as a builtin.
|
||||
pub fn is_builtin(&self, member: &str) -> bool {
|
||||
self.find_binding(member).map_or(false, |binding| {
|
||||
matches!(binding.kind, BindingKind::Builtin)
|
||||
})
|
||||
}
|
||||
|
||||
/// Return `true` if a `CheckCode` is disabled by a `noqa` directive.
|
||||
@@ -926,9 +931,11 @@ where
|
||||
}
|
||||
|
||||
if self.settings.enabled.contains(&CheckCode::PT013) {
|
||||
if let Some(check) =
|
||||
flake8_pytest_style::plugins::import_from(stmt, module, level)
|
||||
{
|
||||
if let Some(check) = flake8_pytest_style::plugins::import_from(
|
||||
stmt,
|
||||
module.as_deref(),
|
||||
level.as_ref(),
|
||||
) {
|
||||
self.add_check(check);
|
||||
}
|
||||
}
|
||||
@@ -992,7 +999,7 @@ where
|
||||
self.add_check(Check::new(
|
||||
CheckKind::ImportStarNotPermitted(helpers::format_import_from(
|
||||
level.as_ref(),
|
||||
module.as_ref(),
|
||||
module.as_deref(),
|
||||
)),
|
||||
Range::from_located(stmt),
|
||||
));
|
||||
@@ -1003,7 +1010,7 @@ where
|
||||
self.add_check(Check::new(
|
||||
CheckKind::ImportStarUsed(helpers::format_import_from(
|
||||
level.as_ref(),
|
||||
module.as_ref(),
|
||||
module.as_deref(),
|
||||
)),
|
||||
Range::from_located(stmt),
|
||||
));
|
||||
@@ -1069,7 +1076,7 @@ where
|
||||
if self.settings.enabled.contains(&CheckCode::T100) {
|
||||
if let Some(check) = flake8_debugger::checks::debugger_import(
|
||||
stmt,
|
||||
module.as_ref().map(String::as_str),
|
||||
module.as_deref(),
|
||||
&alias.node.name,
|
||||
) {
|
||||
self.add_check(check);
|
||||
@@ -1727,10 +1734,30 @@ where
|
||||
}
|
||||
}
|
||||
// Avoid flagging on non-DataFrames (e.g., `{"a": 1}.values`).
|
||||
if helpers::is_non_variable(value) {
|
||||
continue;
|
||||
if pandas_vet::helpers::is_dataframe_candidate(value) {
|
||||
// If the target is a named variable, avoid triggering on
|
||||
// irrelevant bindings (like imports).
|
||||
if let ExprKind::Name { id, .. } = &value.node {
|
||||
if self.find_binding(id).map_or(true, |binding| {
|
||||
matches!(
|
||||
binding.kind,
|
||||
BindingKind::Builtin
|
||||
| BindingKind::ClassDefinition
|
||||
| BindingKind::FunctionDefinition
|
||||
| BindingKind::Export(..)
|
||||
| BindingKind::FutureImportation
|
||||
| BindingKind::StarImportation(..)
|
||||
| BindingKind::Importation(..)
|
||||
| BindingKind::FromImportation(..)
|
||||
| BindingKind::SubmoduleImportation(..)
|
||||
)
|
||||
}) {
|
||||
continue;
|
||||
}
|
||||
}
|
||||
|
||||
self.add_check(Check::new(code.kind(), Range::from_located(expr)));
|
||||
}
|
||||
self.add_check(Check::new(code.kind(), Range::from_located(expr)));
|
||||
};
|
||||
}
|
||||
}
|
||||
@@ -1896,11 +1923,33 @@ where
|
||||
self.add_check(check);
|
||||
}
|
||||
}
|
||||
if self.settings.enabled.contains(&CheckCode::S506) {
|
||||
if let Some(check) = flake8_bandit::checks::unsafe_yaml_load(
|
||||
func,
|
||||
args,
|
||||
keywords,
|
||||
&self.from_imports,
|
||||
&self.import_aliases,
|
||||
) {
|
||||
self.add_check(check);
|
||||
}
|
||||
}
|
||||
if self.settings.enabled.contains(&CheckCode::S106) {
|
||||
self.add_checks(
|
||||
flake8_bandit::checks::hardcoded_password_func_arg(keywords).into_iter(),
|
||||
);
|
||||
}
|
||||
if self.settings.enabled.contains(&CheckCode::S324) {
|
||||
if let Some(check) = flake8_bandit::checks::hashlib_insecure_hash_functions(
|
||||
func,
|
||||
args,
|
||||
keywords,
|
||||
&self.from_imports,
|
||||
&self.import_aliases,
|
||||
) {
|
||||
self.add_check(check);
|
||||
}
|
||||
}
|
||||
|
||||
// flake8-comprehensions
|
||||
if self.settings.enabled.contains(&CheckCode::C400) {
|
||||
@@ -2136,9 +2185,41 @@ where
|
||||
(CheckCode::PD013, "stack"),
|
||||
] {
|
||||
if self.settings.enabled.contains(&code) {
|
||||
if let ExprKind::Attribute { attr, .. } = &func.node {
|
||||
if let ExprKind::Attribute { value, attr, .. } = &func.node {
|
||||
if attr == name {
|
||||
self.add_check(Check::new(code.kind(), Range::from_located(func)));
|
||||
if pandas_vet::helpers::is_dataframe_candidate(value) {
|
||||
// If the target is a named variable, avoid triggering on
|
||||
// irrelevant bindings (like non-Pandas imports).
|
||||
if let ExprKind::Name { id, .. } = &value.node {
|
||||
if self.find_binding(id).map_or(true, |binding| {
|
||||
if let BindingKind::Importation(.., module) =
|
||||
&binding.kind
|
||||
{
|
||||
module != "pandas"
|
||||
} else {
|
||||
matches!(
|
||||
binding.kind,
|
||||
BindingKind::Builtin
|
||||
| BindingKind::ClassDefinition
|
||||
| BindingKind::FunctionDefinition
|
||||
| BindingKind::Export(..)
|
||||
| BindingKind::FutureImportation
|
||||
| BindingKind::StarImportation(..)
|
||||
| BindingKind::Importation(..)
|
||||
| BindingKind::FromImportation(..)
|
||||
| BindingKind::SubmoduleImportation(..)
|
||||
)
|
||||
}
|
||||
}) {
|
||||
continue;
|
||||
}
|
||||
}
|
||||
|
||||
self.add_check(Check::new(
|
||||
code.kind(),
|
||||
Range::from_located(func),
|
||||
));
|
||||
}
|
||||
};
|
||||
}
|
||||
}
|
||||
@@ -2555,7 +2636,7 @@ where
|
||||
}
|
||||
}
|
||||
if self.settings.enabled.contains(&CheckCode::UP025) {
|
||||
pyupgrade::plugins::rewrite_unicode_literal(self, expr, kind);
|
||||
pyupgrade::plugins::rewrite_unicode_literal(self, expr, kind.as_deref());
|
||||
}
|
||||
}
|
||||
ExprKind::Lambda { args, body, .. } => {
|
||||
@@ -2625,6 +2706,9 @@ where
|
||||
if self.settings.enabled.contains(&CheckCode::PLR1701) {
|
||||
pylint::plugins::merge_isinstance(self, expr, op, values);
|
||||
}
|
||||
if self.settings.enabled.contains(&CheckCode::SIM101) {
|
||||
flake8_simplify::plugins::duplicate_isinstance_call(self, expr);
|
||||
}
|
||||
if self.settings.enabled.contains(&CheckCode::SIM220) {
|
||||
flake8_simplify::plugins::a_and_not_a(self, expr);
|
||||
}
|
||||
@@ -2890,7 +2974,7 @@ where
|
||||
flake8_blind_except::plugins::blind_except(
|
||||
self,
|
||||
type_.as_deref(),
|
||||
name.as_ref().map(String::as_str),
|
||||
name.as_deref(),
|
||||
body,
|
||||
);
|
||||
}
|
||||
@@ -3354,7 +3438,7 @@ impl<'a> Checker<'a> {
|
||||
if let BindingKind::StarImportation(level, module) = &binding.kind {
|
||||
from_list.push(helpers::format_import_from(
|
||||
level.as_ref(),
|
||||
module.as_ref(),
|
||||
module.as_deref(),
|
||||
));
|
||||
}
|
||||
}
|
||||
@@ -3835,7 +3919,7 @@ impl<'a> Checker<'a> {
|
||||
if let BindingKind::StarImportation(level, module) = &binding.kind {
|
||||
from_list.push(helpers::format_import_from(
|
||||
level.as_ref(),
|
||||
module.as_ref(),
|
||||
module.as_deref(),
|
||||
));
|
||||
}
|
||||
}
|
||||
@@ -3860,7 +3944,7 @@ impl<'a> Checker<'a> {
|
||||
if self.settings.enabled.contains(&CheckCode::F401) {
|
||||
// Collect all unused imports by location. (Multiple unused imports at the same
|
||||
// location indicates an `import from`.)
|
||||
type UnusedImport<'a> = (&'a String, &'a Range);
|
||||
type UnusedImport<'a> = (&'a str, &'a Range);
|
||||
type BindingContext<'a, 'b> =
|
||||
(&'a RefEquality<'b, Stmt>, Option<&'a RefEquality<'b, Stmt>>);
|
||||
|
||||
@@ -3932,9 +4016,7 @@ impl<'a> Checker<'a> {
|
||||
let deleted: Vec<&Stmt> =
|
||||
self.deletions.iter().map(|node| node.0).collect();
|
||||
match autofix::helpers::remove_unused_imports(
|
||||
unused_imports
|
||||
.iter()
|
||||
.map(|(full_name, _)| full_name.as_str()),
|
||||
unused_imports.iter().map(|(full_name, _)| *full_name),
|
||||
child,
|
||||
parent,
|
||||
&deleted,
|
||||
@@ -3980,7 +4062,7 @@ impl<'a> Checker<'a> {
|
||||
let multiple = unused_imports.len() > 1;
|
||||
for (full_name, range) in unused_imports {
|
||||
let mut check = Check::new(
|
||||
CheckKind::UnusedImport(full_name.clone(), ignore_init, multiple),
|
||||
CheckKind::UnusedImport(full_name.to_string(), ignore_init, multiple),
|
||||
*range,
|
||||
);
|
||||
if matches!(child.node, StmtKind::ImportFrom { .. })
|
||||
|
||||
@@ -6,8 +6,7 @@ use rustc_hash::FxHashMap;
|
||||
|
||||
use crate::fs;
|
||||
use crate::logging::LogLevel;
|
||||
use crate::registry::CheckCode;
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
use crate::registry::{CheckCode, CheckCodePrefix};
|
||||
use crate::settings::types::{
|
||||
FilePattern, PatternPrefixPair, PerFileIgnore, PythonVersion, SerializationFormat,
|
||||
};
|
||||
|
||||
@@ -86,8 +86,8 @@ fn get_int_value(expr: &Expr) -> Option<u16> {
|
||||
/// S103
|
||||
pub fn bad_file_permissions(
|
||||
func: &Expr,
|
||||
args: &Vec<Expr>,
|
||||
keywords: &Vec<Keyword>,
|
||||
args: &[Expr],
|
||||
keywords: &[Keyword],
|
||||
from_imports: &FxHashMap<&str, FxHashSet<&str>>,
|
||||
import_aliases: &FxHashMap<&str, &str>,
|
||||
) -> Option<Check> {
|
||||
|
||||
@@ -42,7 +42,7 @@ pub fn compare_to_hardcoded_password_string(left: &Expr, comparators: &[Expr]) -
|
||||
}
|
||||
|
||||
/// S105
|
||||
pub fn assign_hardcoded_password_string(value: &Expr, targets: &Vec<Expr>) -> Option<Check> {
|
||||
pub fn assign_hardcoded_password_string(value: &Expr, targets: &[Expr]) -> Option<Check> {
|
||||
if let Some(string) = string_literal(value) {
|
||||
for target in targets {
|
||||
if is_password_target(target) {
|
||||
|
||||
66
src/flake8_bandit/checks/hashlib_insecure_hash_functions.rs
Normal file
66
src/flake8_bandit/checks/hashlib_insecure_hash_functions.rs
Normal file
@@ -0,0 +1,66 @@
|
||||
use rustc_hash::{FxHashMap, FxHashSet};
|
||||
use rustpython_ast::{Constant, Expr, ExprKind, Keyword};
|
||||
|
||||
use crate::ast::helpers::{match_module_member, SimpleCallArgs};
|
||||
use crate::ast::types::Range;
|
||||
use crate::flake8_bandit::helpers::string_literal;
|
||||
use crate::registry::{Check, CheckKind};
|
||||
|
||||
const WEAK_HASHES: [&str; 4] = ["md4", "md5", "sha", "sha1"];
|
||||
|
||||
fn is_used_for_security(call_args: &SimpleCallArgs) -> bool {
|
||||
match call_args.get_argument("usedforsecurity", None) {
|
||||
Some(expr) => !matches!(
|
||||
&expr.node,
|
||||
ExprKind::Constant {
|
||||
value: Constant::Bool(false),
|
||||
..
|
||||
}
|
||||
),
|
||||
_ => true,
|
||||
}
|
||||
}
|
||||
|
||||
/// S324
|
||||
pub fn hashlib_insecure_hash_functions(
|
||||
func: &Expr,
|
||||
args: &[Expr],
|
||||
keywords: &[Keyword],
|
||||
from_imports: &FxHashMap<&str, FxHashSet<&str>>,
|
||||
import_aliases: &FxHashMap<&str, &str>,
|
||||
) -> Option<Check> {
|
||||
if match_module_member(func, "hashlib", "new", from_imports, import_aliases) {
|
||||
let call_args = SimpleCallArgs::new(args, keywords);
|
||||
|
||||
if !is_used_for_security(&call_args) {
|
||||
return None;
|
||||
}
|
||||
|
||||
if let Some(name_arg) = call_args.get_argument("name", Some(0)) {
|
||||
let hash_func_name = string_literal(name_arg)?;
|
||||
|
||||
if WEAK_HASHES.contains(&hash_func_name.to_lowercase().as_str()) {
|
||||
return Some(Check::new(
|
||||
CheckKind::HashlibInsecureHashFunction(hash_func_name.to_string()),
|
||||
Range::from_located(name_arg),
|
||||
));
|
||||
}
|
||||
}
|
||||
} else {
|
||||
for func_name in &WEAK_HASHES {
|
||||
if match_module_member(func, "hashlib", func_name, from_imports, import_aliases) {
|
||||
let call_args = SimpleCallArgs::new(args, keywords);
|
||||
|
||||
if !is_used_for_security(&call_args) {
|
||||
return None;
|
||||
}
|
||||
|
||||
return Some(Check::new(
|
||||
CheckKind::HashlibInsecureHashFunction((*func_name).to_string()),
|
||||
Range::from_located(func),
|
||||
));
|
||||
}
|
||||
}
|
||||
}
|
||||
None
|
||||
}
|
||||
@@ -8,6 +8,8 @@ pub use hardcoded_password_string::{
|
||||
assign_hardcoded_password_string, compare_to_hardcoded_password_string,
|
||||
};
|
||||
pub use hardcoded_tmp_directory::hardcoded_tmp_directory;
|
||||
pub use hashlib_insecure_hash_functions::hashlib_insecure_hash_functions;
|
||||
pub use unsafe_yaml_load::unsafe_yaml_load;
|
||||
|
||||
mod assert_used;
|
||||
mod bad_file_permissions;
|
||||
@@ -17,3 +19,5 @@ mod hardcoded_password_default;
|
||||
mod hardcoded_password_func_arg;
|
||||
mod hardcoded_password_string;
|
||||
mod hardcoded_tmp_directory;
|
||||
mod hashlib_insecure_hash_functions;
|
||||
mod unsafe_yaml_load;
|
||||
|
||||
50
src/flake8_bandit/checks/unsafe_yaml_load.rs
Normal file
50
src/flake8_bandit/checks/unsafe_yaml_load.rs
Normal file
@@ -0,0 +1,50 @@
|
||||
use rustc_hash::{FxHashMap, FxHashSet};
|
||||
use rustpython_ast::{Expr, ExprKind, Keyword};
|
||||
|
||||
use crate::ast::helpers::{match_module_member, SimpleCallArgs};
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::{Check, CheckKind};
|
||||
|
||||
/// S506
|
||||
pub fn unsafe_yaml_load(
|
||||
func: &Expr,
|
||||
args: &[Expr],
|
||||
keywords: &[Keyword],
|
||||
from_imports: &FxHashMap<&str, FxHashSet<&str>>,
|
||||
import_aliases: &FxHashMap<&str, &str>,
|
||||
) -> Option<Check> {
|
||||
if match_module_member(func, "yaml", "load", from_imports, import_aliases) {
|
||||
let call_args = SimpleCallArgs::new(args, keywords);
|
||||
if let Some(loader_arg) = call_args.get_argument("Loader", Some(1)) {
|
||||
if !match_module_member(
|
||||
loader_arg,
|
||||
"yaml",
|
||||
"SafeLoader",
|
||||
from_imports,
|
||||
import_aliases,
|
||||
) && !match_module_member(
|
||||
loader_arg,
|
||||
"yaml",
|
||||
"CSafeLoader",
|
||||
from_imports,
|
||||
import_aliases,
|
||||
) {
|
||||
let loader = match &loader_arg.node {
|
||||
ExprKind::Attribute { attr, .. } => Some(attr.to_string()),
|
||||
ExprKind::Name { id, .. } => Some(id.to_string()),
|
||||
_ => None,
|
||||
};
|
||||
return Some(Check::new(
|
||||
CheckKind::UnsafeYAMLLoad(loader),
|
||||
Range::from_located(loader_arg),
|
||||
));
|
||||
}
|
||||
} else {
|
||||
return Some(Check::new(
|
||||
CheckKind::UnsafeYAMLLoad(None),
|
||||
Range::from_located(func),
|
||||
));
|
||||
}
|
||||
}
|
||||
None
|
||||
}
|
||||
@@ -21,6 +21,8 @@ mod tests {
|
||||
#[test_case(CheckCode::S106, Path::new("S106.py"); "S106")]
|
||||
#[test_case(CheckCode::S107, Path::new("S107.py"); "S107")]
|
||||
#[test_case(CheckCode::S108, Path::new("S108.py"); "S108")]
|
||||
#[test_case(CheckCode::S324, Path::new("S324.py"); "S324")]
|
||||
#[test_case(CheckCode::S506, Path::new("S506.py"); "S506")]
|
||||
fn checks(check_code: CheckCode, path: &Path) -> Result<()> {
|
||||
let snapshot = format!("{}_{}", check_code.as_ref(), path.to_string_lossy());
|
||||
let checks = test_path(
|
||||
|
||||
@@ -0,0 +1,135 @@
|
||||
---
|
||||
source: src/flake8_bandit/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: md5
|
||||
location:
|
||||
row: 7
|
||||
column: 12
|
||||
end_location:
|
||||
row: 7
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: md4
|
||||
location:
|
||||
row: 9
|
||||
column: 12
|
||||
end_location:
|
||||
row: 9
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: md5
|
||||
location:
|
||||
row: 11
|
||||
column: 17
|
||||
end_location:
|
||||
row: 11
|
||||
column: 22
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: MD4
|
||||
location:
|
||||
row: 13
|
||||
column: 12
|
||||
end_location:
|
||||
row: 13
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha1
|
||||
location:
|
||||
row: 15
|
||||
column: 12
|
||||
end_location:
|
||||
row: 15
|
||||
column: 18
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha1
|
||||
location:
|
||||
row: 17
|
||||
column: 12
|
||||
end_location:
|
||||
row: 17
|
||||
column: 18
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha
|
||||
location:
|
||||
row: 19
|
||||
column: 12
|
||||
end_location:
|
||||
row: 19
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: SHA
|
||||
location:
|
||||
row: 21
|
||||
column: 17
|
||||
end_location:
|
||||
row: 21
|
||||
column: 22
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha
|
||||
location:
|
||||
row: 23
|
||||
column: 0
|
||||
end_location:
|
||||
row: 23
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: md5
|
||||
location:
|
||||
row: 25
|
||||
column: 0
|
||||
end_location:
|
||||
row: 25
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha1
|
||||
location:
|
||||
row: 27
|
||||
column: 12
|
||||
end_location:
|
||||
row: 27
|
||||
column: 18
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha1
|
||||
location:
|
||||
row: 29
|
||||
column: 0
|
||||
end_location:
|
||||
row: 29
|
||||
column: 12
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha1
|
||||
location:
|
||||
row: 32
|
||||
column: 12
|
||||
end_location:
|
||||
row: 32
|
||||
column: 18
|
||||
fix: ~
|
||||
parent: ~
|
||||
|
||||
@@ -0,0 +1,25 @@
|
||||
---
|
||||
source: src/flake8_bandit/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind:
|
||||
UnsafeYAMLLoad: ~
|
||||
location:
|
||||
row: 10
|
||||
column: 8
|
||||
end_location:
|
||||
row: 10
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
UnsafeYAMLLoad: Loader
|
||||
location:
|
||||
row: 24
|
||||
column: 23
|
||||
end_location:
|
||||
row: 24
|
||||
column: 34
|
||||
fix: ~
|
||||
parent: ~
|
||||
|
||||
@@ -29,9 +29,10 @@ pub struct Options {
|
||||
default = r#"{"altair": "alt", "matplotlib.pyplot": "plt", "numpy": "np", "pandas": "pd", "seaborn": "sns"}"#,
|
||||
value_type = "FxHashMap<String, String>",
|
||||
example = r#"
|
||||
[tool.ruff.flake8-import-conventions.aliases]
|
||||
# Declare the default aliases.
|
||||
altair = "alt"
|
||||
matplotlib.pyplot = "plt"
|
||||
"matplotlib.pyplot" = "plt"
|
||||
numpy = "np"
|
||||
pandas = "pd"
|
||||
seaborn = "sns"
|
||||
@@ -44,6 +45,7 @@ pub struct Options {
|
||||
default = r#"{}"#,
|
||||
value_type = "FxHashMap<String, String>",
|
||||
example = r#"
|
||||
[tool.ruff.flake8-import-conventions.extend-aliases]
|
||||
# Declare a custom alias for the `matplotlib` module.
|
||||
"dask.dataframe" = "dd"
|
||||
"#
|
||||
|
||||
@@ -6,7 +6,7 @@ use crate::ast::types::Range;
|
||||
use crate::checkers::ast::Checker;
|
||||
use crate::registry::{Check, CheckKind};
|
||||
|
||||
pub fn fail_call(checker: &mut Checker, call: &Expr, args: &Vec<Expr>, keywords: &Vec<Keyword>) {
|
||||
pub fn fail_call(checker: &mut Checker, call: &Expr, args: &[Expr], keywords: &[Keyword]) {
|
||||
if is_pytest_fail(call, checker) {
|
||||
let call_args = SimpleCallArgs::new(args, keywords);
|
||||
let msg = call_args.get_argument("msg", Some(0));
|
||||
|
||||
@@ -25,8 +25,8 @@ pub fn import(import_from: &Stmt, name: &str, asname: Option<&str>) -> Option<Ch
|
||||
/// PT013
|
||||
pub fn import_from(
|
||||
import_from: &Stmt,
|
||||
module: &Option<String>,
|
||||
level: &Option<usize>,
|
||||
module: Option<&str>,
|
||||
level: Option<&usize>,
|
||||
) -> Option<Check> {
|
||||
// If level is not zero or module is none, return
|
||||
if let Some(level) = level {
|
||||
|
||||
@@ -52,8 +52,8 @@ where
|
||||
|
||||
fn check_patch_call(
|
||||
call: &Expr,
|
||||
args: &Vec<Expr>,
|
||||
keywords: &Vec<Keyword>,
|
||||
args: &[Expr],
|
||||
keywords: &[Keyword],
|
||||
new_arg_number: usize,
|
||||
) -> Option<Check> {
|
||||
let simple_args = SimpleCallArgs::new(args, keywords);
|
||||
@@ -81,7 +81,7 @@ fn check_patch_call(
|
||||
None
|
||||
}
|
||||
|
||||
pub fn patch_with_lambda(call: &Expr, args: &Vec<Expr>, keywords: &Vec<Keyword>) -> Option<Check> {
|
||||
pub fn patch_with_lambda(call: &Expr, args: &[Expr], keywords: &[Keyword]) -> Option<Check> {
|
||||
if let Some(call_path) = compose_call_path(call) {
|
||||
if PATCH_NAMES.contains(&call_path.as_str()) {
|
||||
check_patch_call(call, args, keywords, 1)
|
||||
|
||||
@@ -18,7 +18,7 @@ fn is_pytest_raises(
|
||||
match_module_member(func, "pytest", "raises", from_imports, import_aliases)
|
||||
}
|
||||
|
||||
fn is_non_trivial_with_body(body: &Vec<Stmt>) -> bool {
|
||||
fn is_non_trivial_with_body(body: &[Stmt]) -> bool {
|
||||
if body.len() > 1 {
|
||||
true
|
||||
} else if let Some(first_body_stmt) = body.first() {
|
||||
@@ -28,7 +28,7 @@ fn is_non_trivial_with_body(body: &Vec<Stmt>) -> bool {
|
||||
}
|
||||
}
|
||||
|
||||
pub fn raises_call(checker: &mut Checker, func: &Expr, args: &Vec<Expr>, keywords: &Vec<Keyword>) {
|
||||
pub fn raises_call(checker: &mut Checker, func: &Expr, args: &[Expr], keywords: &[Keyword]) {
|
||||
if is_pytest_raises(func, &checker.from_imports, &checker.import_aliases) {
|
||||
if checker.settings.enabled.contains(&CheckCode::PT010) {
|
||||
if args.is_empty() && keywords.is_empty() {
|
||||
@@ -57,7 +57,7 @@ pub fn raises_call(checker: &mut Checker, func: &Expr, args: &Vec<Expr>, keyword
|
||||
}
|
||||
}
|
||||
|
||||
pub fn complex_raises(checker: &mut Checker, stmt: &Stmt, items: &[Withitem], body: &Vec<Stmt>) {
|
||||
pub fn complex_raises(checker: &mut Checker, stmt: &Stmt, items: &[Withitem], body: &[Stmt]) {
|
||||
let mut is_too_complex = false;
|
||||
|
||||
let raises_called = items.iter().any(|item| match &item.context_expr.node {
|
||||
|
||||
@@ -62,7 +62,7 @@ impl<'a> Visitor<'a> for ReturnVisitor<'a> {
|
||||
StmtKind::Global { names } | StmtKind::Nonlocal { names } => {
|
||||
self.stack
|
||||
.non_locals
|
||||
.extend(names.iter().map(std::string::String::as_str));
|
||||
.extend(names.iter().map(String::as_str));
|
||||
}
|
||||
StmtKind::FunctionDef { .. } | StmtKind::AsyncFunctionDef { .. } => {
|
||||
// Don't recurse.
|
||||
|
||||
@@ -12,6 +12,7 @@ mod tests {
|
||||
use crate::registry::CheckCode;
|
||||
use crate::settings;
|
||||
|
||||
#[test_case(CheckCode::SIM101, Path::new("SIM101.py"); "SIM101")]
|
||||
#[test_case(CheckCode::SIM102, Path::new("SIM102.py"); "SIM102")]
|
||||
#[test_case(CheckCode::SIM105, Path::new("SIM105.py"); "SIM105")]
|
||||
#[test_case(CheckCode::SIM107, Path::new("SIM107.py"); "SIM107")]
|
||||
|
||||
@@ -1,10 +1,18 @@
|
||||
use rustpython_ast::{Boolop, Constant, Expr, ExprKind, Unaryop};
|
||||
use std::iter;
|
||||
|
||||
use itertools::Either::{Left, Right};
|
||||
use rustc_hash::FxHashMap;
|
||||
use rustpython_ast::{Boolop, Constant, Expr, ExprContext, ExprKind, Unaryop};
|
||||
|
||||
use crate::ast::helpers::create_expr;
|
||||
use crate::ast::types::Range;
|
||||
use crate::autofix::Fix;
|
||||
use crate::checkers::ast::Checker;
|
||||
use crate::registry::{Check, CheckCode, CheckKind};
|
||||
use crate::source_code_generator::SourceCodeGenerator;
|
||||
use crate::source_code_style::SourceCodeStyleDetector;
|
||||
|
||||
/// Return `true` if two `Expr` instances are equivalent names.
|
||||
fn is_same_expr<'a>(a: &'a Expr, b: &'a Expr) -> Option<&'a str> {
|
||||
if let (ExprKind::Name { id: a, .. }, ExprKind::Name { id: b, .. }) = (&a.node, &b.node) {
|
||||
if a == b {
|
||||
@@ -14,6 +22,131 @@ fn is_same_expr<'a>(a: &'a Expr, b: &'a Expr) -> Option<&'a str> {
|
||||
None
|
||||
}
|
||||
|
||||
/// Generate source code from an `Expr`.
|
||||
fn to_source(expr: &Expr, stylist: &SourceCodeStyleDetector) -> String {
|
||||
let mut generator = SourceCodeGenerator::new(
|
||||
stylist.indentation(),
|
||||
stylist.quote(),
|
||||
stylist.line_ending(),
|
||||
);
|
||||
generator.unparse_expr(expr, 0);
|
||||
generator.generate().unwrap()
|
||||
}
|
||||
|
||||
/// SIM101
|
||||
pub fn duplicate_isinstance_call(checker: &mut Checker, expr: &Expr) {
|
||||
let ExprKind::BoolOp { op: Boolop::Or, values } = &expr.node else {
|
||||
return;
|
||||
};
|
||||
|
||||
// Locate duplicate `isinstance` calls, represented as a map from argument name
|
||||
// to indices of the relevant `Expr` instances in `values`.
|
||||
let mut duplicates = FxHashMap::default();
|
||||
for (index, call) in values.iter().enumerate() {
|
||||
// Verify that this is an `isinstance` call.
|
||||
let ExprKind::Call { func, args, keywords } = &call.node else {
|
||||
continue;
|
||||
};
|
||||
if args.len() != 2 {
|
||||
continue;
|
||||
}
|
||||
if !keywords.is_empty() {
|
||||
continue;
|
||||
}
|
||||
let ExprKind::Name { id: func_name, .. } = &func.node else {
|
||||
continue;
|
||||
};
|
||||
if func_name != "isinstance" {
|
||||
continue;
|
||||
}
|
||||
|
||||
// Collect the name of the argument.
|
||||
let ExprKind::Name { id: arg_name, .. } = &args[0].node else {
|
||||
continue;
|
||||
};
|
||||
duplicates
|
||||
.entry(arg_name.as_str())
|
||||
.or_insert_with(Vec::new)
|
||||
.push(index);
|
||||
}
|
||||
|
||||
// Generate a `Check` for each duplicate.
|
||||
for (arg_name, indices) in duplicates {
|
||||
if indices.len() > 1 {
|
||||
let mut check = Check::new(
|
||||
CheckKind::DuplicateIsinstanceCall(arg_name.to_string()),
|
||||
Range::from_located(expr),
|
||||
);
|
||||
if checker.patch(&CheckCode::SIM101) {
|
||||
// Grab the types used in each duplicate `isinstance` call.
|
||||
let types: Vec<&Expr> = indices
|
||||
.iter()
|
||||
.map(|index| &values[*index])
|
||||
.map(|expr| {
|
||||
let ExprKind::Call { args, ..} = &expr.node else {
|
||||
unreachable!("Indices should only contain `isinstance` calls")
|
||||
};
|
||||
args.get(1).expect("`isinstance` should have two arguments")
|
||||
})
|
||||
.collect();
|
||||
|
||||
// Generate a single `isinstance` call.
|
||||
let call = create_expr(ExprKind::Call {
|
||||
func: Box::new(create_expr(ExprKind::Name {
|
||||
id: "isinstance".to_string(),
|
||||
ctx: ExprContext::Load,
|
||||
})),
|
||||
args: vec![
|
||||
create_expr(ExprKind::Name {
|
||||
id: arg_name.to_string(),
|
||||
ctx: ExprContext::Load,
|
||||
}),
|
||||
create_expr(ExprKind::Tuple {
|
||||
// Flatten all the types used across the `isinstance` calls.
|
||||
elts: types
|
||||
.iter()
|
||||
.flat_map(|value| {
|
||||
if let ExprKind::Tuple { elts, .. } = &value.node {
|
||||
Left(elts.iter())
|
||||
} else {
|
||||
Right(iter::once(*value))
|
||||
}
|
||||
})
|
||||
.map(Clone::clone)
|
||||
.collect(),
|
||||
ctx: ExprContext::Load,
|
||||
}),
|
||||
],
|
||||
keywords: vec![],
|
||||
});
|
||||
|
||||
// Generate the combined `BoolOp`.
|
||||
let bool_op = create_expr(ExprKind::BoolOp {
|
||||
op: Boolop::Or,
|
||||
values: iter::once(call)
|
||||
.chain(
|
||||
values
|
||||
.iter()
|
||||
.enumerate()
|
||||
.filter(|(index, _)| !indices.contains(index))
|
||||
.map(|(_, elt)| elt.clone()),
|
||||
)
|
||||
.collect(),
|
||||
});
|
||||
|
||||
// Populate the `Fix`. Replace the _entire_ `BoolOp`. Note that if we have
|
||||
// multiple duplicates, the fixes will conflict.
|
||||
check.amend(Fix::replacement(
|
||||
to_source(&bool_op, checker.style),
|
||||
expr.location,
|
||||
expr.end_location.unwrap(),
|
||||
));
|
||||
}
|
||||
checker.add_check(check);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/// SIM220
|
||||
pub fn a_and_not_a(checker: &mut Checker, expr: &Expr) {
|
||||
let ExprKind::BoolOp { op: Boolop::And, values, } = &expr.node else {
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
pub use ast_bool_op::{a_and_not_a, a_or_not_a, and_false, or_true};
|
||||
pub use ast_bool_op::{a_and_not_a, a_or_not_a, and_false, duplicate_isinstance_call, or_true};
|
||||
pub use ast_for::convert_loop_to_any_all;
|
||||
pub use ast_if::nested_if_statements;
|
||||
pub use ast_with::multiple_with_statements;
|
||||
|
||||
@@ -0,0 +1,107 @@
|
||||
---
|
||||
source: src/flake8_simplify/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind:
|
||||
DuplicateIsinstanceCall: a
|
||||
location:
|
||||
row: 1
|
||||
column: 3
|
||||
end_location:
|
||||
row: 1
|
||||
column: 45
|
||||
fix:
|
||||
content: "isinstance(a, (int, float))"
|
||||
location:
|
||||
row: 1
|
||||
column: 3
|
||||
end_location:
|
||||
row: 1
|
||||
column: 45
|
||||
parent: ~
|
||||
- kind:
|
||||
DuplicateIsinstanceCall: a
|
||||
location:
|
||||
row: 4
|
||||
column: 3
|
||||
end_location:
|
||||
row: 4
|
||||
column: 53
|
||||
fix:
|
||||
content: "isinstance(a, (int, float, bool))"
|
||||
location:
|
||||
row: 4
|
||||
column: 3
|
||||
end_location:
|
||||
row: 4
|
||||
column: 53
|
||||
parent: ~
|
||||
- kind:
|
||||
DuplicateIsinstanceCall: a
|
||||
location:
|
||||
row: 7
|
||||
column: 3
|
||||
end_location:
|
||||
row: 7
|
||||
column: 68
|
||||
fix:
|
||||
content: "isinstance(a, (int, float)) or isinstance(b, bool)"
|
||||
location:
|
||||
row: 7
|
||||
column: 3
|
||||
end_location:
|
||||
row: 7
|
||||
column: 68
|
||||
parent: ~
|
||||
- kind:
|
||||
DuplicateIsinstanceCall: a
|
||||
location:
|
||||
row: 10
|
||||
column: 3
|
||||
end_location:
|
||||
row: 10
|
||||
column: 68
|
||||
fix:
|
||||
content: "isinstance(a, (int, float)) or isinstance(b, bool)"
|
||||
location:
|
||||
row: 10
|
||||
column: 3
|
||||
end_location:
|
||||
row: 10
|
||||
column: 68
|
||||
parent: ~
|
||||
- kind:
|
||||
DuplicateIsinstanceCall: a
|
||||
location:
|
||||
row: 13
|
||||
column: 3
|
||||
end_location:
|
||||
row: 13
|
||||
column: 68
|
||||
fix:
|
||||
content: "isinstance(a, (int, float)) or isinstance(b, bool)"
|
||||
location:
|
||||
row: 13
|
||||
column: 3
|
||||
end_location:
|
||||
row: 13
|
||||
column: 68
|
||||
parent: ~
|
||||
- kind:
|
||||
DuplicateIsinstanceCall: a
|
||||
location:
|
||||
row: 16
|
||||
column: 4
|
||||
end_location:
|
||||
row: 16
|
||||
column: 46
|
||||
fix:
|
||||
content: "isinstance(a, (int, float))"
|
||||
location:
|
||||
row: 16
|
||||
column: 4
|
||||
end_location:
|
||||
row: 16
|
||||
column: 46
|
||||
parent: ~
|
||||
|
||||
@@ -33,7 +33,7 @@ pub mod types;
|
||||
#[derive(Debug)]
|
||||
pub struct AnnotatedAliasData<'a> {
|
||||
pub name: &'a str,
|
||||
pub asname: Option<&'a String>,
|
||||
pub asname: Option<&'a str>,
|
||||
pub atop: Vec<Comment<'a>>,
|
||||
pub inline: Vec<Comment<'a>>,
|
||||
}
|
||||
@@ -46,7 +46,7 @@ pub enum AnnotatedImport<'a> {
|
||||
inline: Vec<Comment<'a>>,
|
||||
},
|
||||
ImportFrom {
|
||||
module: Option<&'a String>,
|
||||
module: Option<&'a str>,
|
||||
names: Vec<AnnotatedAliasData<'a>>,
|
||||
level: Option<&'a usize>,
|
||||
atop: Vec<Comment<'a>>,
|
||||
@@ -87,7 +87,7 @@ fn annotate_imports<'a>(
|
||||
.iter()
|
||||
.map(|alias| AliasData {
|
||||
name: &alias.node.name,
|
||||
asname: alias.node.asname.as_ref(),
|
||||
asname: alias.node.asname.as_deref(),
|
||||
})
|
||||
.collect(),
|
||||
atop,
|
||||
@@ -145,14 +145,14 @@ fn annotate_imports<'a>(
|
||||
|
||||
aliases.push(AnnotatedAliasData {
|
||||
name: &alias.node.name,
|
||||
asname: alias.node.asname.as_ref(),
|
||||
asname: alias.node.asname.as_deref(),
|
||||
atop: alias_atop,
|
||||
inline: alias_inline,
|
||||
});
|
||||
}
|
||||
|
||||
annotated.push(AnnotatedImport::ImportFrom {
|
||||
module: module.as_ref(),
|
||||
module: module.as_deref(),
|
||||
names: aliases,
|
||||
level: level.as_ref(),
|
||||
trailing_comma: if split_on_trailing_comma {
|
||||
|
||||
@@ -18,14 +18,14 @@ impl Default for TrailingComma {
|
||||
|
||||
#[derive(Debug, Hash, Ord, PartialOrd, Eq, PartialEq, Clone)]
|
||||
pub struct ImportFromData<'a> {
|
||||
pub module: Option<&'a String>,
|
||||
pub module: Option<&'a str>,
|
||||
pub level: Option<&'a usize>,
|
||||
}
|
||||
|
||||
#[derive(Debug, Hash, Ord, PartialOrd, Eq, PartialEq)]
|
||||
pub struct AliasData<'a> {
|
||||
pub name: &'a str,
|
||||
pub asname: Option<&'a String>,
|
||||
pub asname: Option<&'a str>,
|
||||
}
|
||||
|
||||
#[derive(Debug, Default, Clone)]
|
||||
|
||||
@@ -66,7 +66,6 @@ mod pylint;
|
||||
mod python;
|
||||
mod pyupgrade;
|
||||
pub mod registry;
|
||||
pub mod registry_gen;
|
||||
pub mod resolver;
|
||||
mod ruff;
|
||||
mod rustpython_helpers;
|
||||
|
||||
@@ -6,8 +6,7 @@ use serde::Serialize;
|
||||
use wasm_bindgen::prelude::*;
|
||||
|
||||
use crate::linter::check_path;
|
||||
use crate::registry::CheckCode;
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
use crate::registry::{CheckCode, CheckCodePrefix};
|
||||
use crate::rustpython_helpers::tokenize;
|
||||
use crate::settings::configuration::Configuration;
|
||||
use crate::settings::options::Options;
|
||||
|
||||
18
src/pandas_vet/helpers.rs
Normal file
18
src/pandas_vet/helpers.rs
Normal file
@@ -0,0 +1,18 @@
|
||||
use rustpython_ast::{Expr, ExprKind};
|
||||
|
||||
/// Return `true` if an `Expr` _could_ be a `DataFrame`. This rules out
|
||||
/// obviously-wrong cases, like constants and literals.
|
||||
pub fn is_dataframe_candidate(expr: &Expr) -> bool {
|
||||
!matches!(
|
||||
expr.node,
|
||||
ExprKind::Constant { .. }
|
||||
| ExprKind::Tuple { .. }
|
||||
| ExprKind::List { .. }
|
||||
| ExprKind::Set { .. }
|
||||
| ExprKind::Dict { .. }
|
||||
| ExprKind::SetComp { .. }
|
||||
| ExprKind::ListComp { .. }
|
||||
| ExprKind::DictComp { .. }
|
||||
| ExprKind::GeneratorExp { .. }
|
||||
)
|
||||
}
|
||||
@@ -1,4 +1,5 @@
|
||||
pub mod checks;
|
||||
pub mod helpers;
|
||||
|
||||
#[cfg(test)]
|
||||
mod tests {
|
||||
@@ -10,8 +11,7 @@ mod tests {
|
||||
use textwrap::dedent;
|
||||
|
||||
use crate::linter::check_path;
|
||||
use crate::registry::CheckCode;
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
use crate::registry::{CheckCode, CheckCodePrefix};
|
||||
use crate::settings::flags;
|
||||
use crate::source_code_locator::SourceCodeLocator;
|
||||
use crate::source_code_style::SourceCodeStyleDetector;
|
||||
@@ -48,64 +48,201 @@ mod tests {
|
||||
Ok(())
|
||||
}
|
||||
|
||||
#[test_case("df.drop(['a'], axis=1, inplace=False)", &[]; "PD002_pass")]
|
||||
#[test_case("df.drop(['a'], axis=1, inplace=True)", &[CheckCode::PD002]; "PD002_fail")]
|
||||
#[test_case("nas = pd.isna(val)", &[]; "PD003_pass")]
|
||||
#[test_case("nulls = pd.isnull(val)", &[CheckCode::PD003]; "PD003_fail")]
|
||||
#[test_case("print('bah humbug')", &[]; "PD003_allows_other_calls")]
|
||||
#[test_case("not_nas = pd.notna(val)", &[]; "PD004_pass")]
|
||||
#[test_case("not_nulls = pd.notnull(val)", &[CheckCode::PD004]; "PD004_fail")]
|
||||
#[test_case("new_df = df.loc['d':, 'A':'C']", &[]; "PD007_pass_loc")]
|
||||
#[test_case("new_df = df.iloc[[1, 3, 5], [1, 3]]", &[]; "PD007_pass_iloc")]
|
||||
#[test_case("s = df.ix[[0, 2], 'A']", &[CheckCode::PD007]; "PD007_fail")]
|
||||
#[test_case("index = df.loc[:, ['B', 'A']]", &[]; "PD008_pass")]
|
||||
#[test_case("index = df.at[:, ['B', 'A']]", &[CheckCode::PD008]; "PD008_fail")]
|
||||
#[test_case("index = df.iloc[:, 1:3]", &[]; "PD009_pass")]
|
||||
#[test_case("index = df.iat[:, 1:3]", &[CheckCode::PD009]; "PD009_fail")]
|
||||
#[test_case(r#"table = df.pivot_table(
|
||||
df,
|
||||
values='D',
|
||||
index=['A', 'B'],
|
||||
columns=['C'],
|
||||
aggfunc=np.sum,
|
||||
fill_value=0
|
||||
)
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
x.drop(['a'], axis=1, inplace=False)
|
||||
"#, &[]; "PD002_pass")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
x.drop(['a'], axis=1, inplace=True)
|
||||
"#, &[CheckCode::PD002]; "PD002_fail")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
nas = pd.isna(val)
|
||||
"#, &[]; "PD003_pass")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
nulls = pd.isnull(val)
|
||||
"#, &[CheckCode::PD003]; "PD003_fail")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
print('bah humbug')
|
||||
"#, &[]; "PD003_allows_other_calls")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
not_nas = pd.notna(val)
|
||||
"#, &[]; "PD004_pass")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
not_nulls = pd.notnull(val)
|
||||
"#, &[CheckCode::PD004]; "PD004_fail")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
new_x = x.loc['d':, 'A':'C']
|
||||
"#, &[]; "PD007_pass_loc")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
new_x = x.iloc[[1, 3, 5], [1, 3]]
|
||||
"#, &[]; "PD007_pass_iloc")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
y = x.ix[[0, 2], 'A']
|
||||
"#, &[CheckCode::PD007]; "PD007_fail")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
index = x.loc[:, ['B', 'A']]
|
||||
"#, &[]; "PD008_pass")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
index = x.at[:, ['B', 'A']]
|
||||
"#, &[CheckCode::PD008]; "PD008_fail")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
index = x.iloc[:, 1:3]
|
||||
"#, &[]; "PD009_pass")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
index = x.iat[:, 1:3]
|
||||
"#, &[CheckCode::PD009]; "PD009_fail")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
table = x.pivot_table(
|
||||
x,
|
||||
values='D',
|
||||
index=['A', 'B'],
|
||||
columns=['C'],
|
||||
aggfunc=np.sum,
|
||||
fill_value=0
|
||||
)
|
||||
"#, &[]; "PD010_pass")]
|
||||
#[test_case(r#"table = pd.pivot(
|
||||
df,
|
||||
index='foo',
|
||||
columns='bar',
|
||||
values='baz'
|
||||
)
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
table = pd.pivot(
|
||||
x,
|
||||
index='foo',
|
||||
columns='bar',
|
||||
values='baz'
|
||||
)
|
||||
"#, &[CheckCode::PD010]; "PD010_fail_pivot")]
|
||||
#[test_case("result = df.to_array()", &[]; "PD011_pass_to_array")]
|
||||
#[test_case("result = df.array", &[]; "PD011_pass_array")]
|
||||
#[test_case("result = df.values", &[CheckCode::PD011]; "PD011_fail_values")]
|
||||
#[test_case("result = df.values()", &[]; "PD011_pass_values_call")]
|
||||
#[test_case("result = {}.values", &[]; "PD011_pass_values_dict")]
|
||||
#[test_case("result = values", &[]; "PD011_pass_node_name")]
|
||||
#[test_case("employees = pd.read_csv(input_file)", &[]; "PD012_pass_read_csv")]
|
||||
#[test_case("employees = pd.read_table(input_file)", &[CheckCode::PD012]; "PD012_fail_read_table")]
|
||||
#[test_case("employees = read_table", &[]; "PD012_node_Name_pass")]
|
||||
#[test_case(r#"table = df.melt(
|
||||
id_vars='airline',
|
||||
value_vars=['ATL', 'DEN', 'DFW'],
|
||||
value_name='airline delay'
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
result = x.to_array()
|
||||
"#, &[]; "PD011_pass_to_array")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
result = x.array
|
||||
"#, &[]; "PD011_pass_array")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
result = x.values
|
||||
"#, &[CheckCode::PD011]; "PD011_fail_values")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
result = x.values()
|
||||
"#, &[]; "PD011_pass_values_call")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
result = {}.values
|
||||
"#, &[]; "PD011_pass_values_dict")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
result = pd.values
|
||||
"#, &[]; "PD011_pass_values_import")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
result = x.values
|
||||
"#, &[]; "PD011_pass_values_unbound")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
result = values
|
||||
"#, &[]; "PD011_pass_node_name")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
employees = pd.read_csv(input_file)
|
||||
"#, &[]; "PD012_pass_read_csv")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
employees = pd.read_table(input_file)
|
||||
"#, &[CheckCode::PD012]; "PD012_fail_read_table")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
employees = read_table
|
||||
"#, &[]; "PD012_node_Name_pass")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
y = x.melt(
|
||||
id_vars='airline',
|
||||
value_vars=['ATL', 'DEN', 'DFW'],
|
||||
value_name='airline delay'
|
||||
)
|
||||
"#, &[]; "PD013_pass")]
|
||||
#[test_case("table = df.stack(level=-1, dropna=True)", &[CheckCode::PD013]; "PD013_fail_stack")]
|
||||
#[test_case("df1.merge(df2)", &[]; "PD015_pass_merge_on_dataframe")]
|
||||
#[test_case("df1.merge(df2, 'inner')", &[]; "PD015_pass_merge_on_dataframe_with_multiple_args")]
|
||||
#[test_case("pd.merge(df1, df2)", &[CheckCode::PD015]; "PD015_fail_merge_on_pandas_object")]
|
||||
#[test_case(r#"
|
||||
import numpy as np
|
||||
arrays = [np.random.randn(3, 4) for _ in range(10)]
|
||||
np.stack(arrays, axis=0).shape
|
||||
"#, &[]; "PD013_pass_numpy")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
y = x.stack(level=-1, dropna=True)
|
||||
"#, &[]; "PD013_pass_unbound")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
y = x.stack(level=-1, dropna=True)
|
||||
"#, &[CheckCode::PD013]; "PD013_fail_stack")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
pd.stack(
|
||||
"#, &[]; "PD015_pass_merge_on_dataframe")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
y = pd.DataFrame()
|
||||
x.merge(y, 'inner')
|
||||
"#, &[]; "PD015_pass_merge_on_dataframe_with_multiple_args")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
x = pd.DataFrame()
|
||||
y = pd.DataFrame()
|
||||
pd.merge(x, y)
|
||||
"#, &[CheckCode::PD015]; "PD015_fail_merge_on_pandas_object")]
|
||||
#[test_case(
|
||||
"pd.to_datetime(timestamp * 10 ** 9).strftime('%Y-%m-%d %H:%M:%S.%f')",
|
||||
&[];
|
||||
"PD015_pass_other_pd_function"
|
||||
)]
|
||||
#[test_case("employees = pd.DataFrame(employee_dict)", &[]; "PD901_pass_non_df")]
|
||||
#[test_case("employees_df = pd.DataFrame(employee_dict)", &[]; "PD901_pass_part_df")]
|
||||
#[test_case("my_function(df=data)", &[]; "PD901_pass_df_param")]
|
||||
#[test_case("df = pd.DataFrame()", &[CheckCode::PD901]; "PD901_fail_df_var")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
employees = pd.DataFrame(employee_dict)
|
||||
"#, &[]; "PD901_pass_non_df")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
employees_df = pd.DataFrame(employee_dict)
|
||||
"#, &[]; "PD901_pass_part_df")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
my_function(df=data)
|
||||
"#, &[]; "PD901_pass_df_param")]
|
||||
#[test_case(r#"
|
||||
import pandas as pd
|
||||
df = pd.DataFrame()
|
||||
"#, &[CheckCode::PD901]; "PD901_fail_df_var")]
|
||||
fn test_pandas_vet(code: &str, expected: &[CheckCode]) -> Result<()> {
|
||||
check_code(code, expected)?;
|
||||
Ok(())
|
||||
|
||||
@@ -303,7 +303,7 @@ impl<'a> Printer<'a> {
|
||||
}
|
||||
}
|
||||
|
||||
fn group_messages_by_filename(messages: &Vec<Message>) -> BTreeMap<&String, Vec<&Message>> {
|
||||
fn group_messages_by_filename(messages: &[Message]) -> BTreeMap<&String, Vec<&Message>> {
|
||||
let mut grouped_messages = BTreeMap::default();
|
||||
for message in messages {
|
||||
grouped_messages
|
||||
|
||||
@@ -1413,24 +1413,56 @@ fn missing_args(checker: &mut Checker, docstring: &Docstring, docstrings_args: &
|
||||
|
||||
// See: `GOOGLE_ARGS_REGEX` in `pydocstyle/checker.py`.
|
||||
static GOOGLE_ARGS_REGEX: Lazy<Regex> =
|
||||
Lazy::new(|| Regex::new(r"^\s*(\*?\*?\w+)\s*(\(.*?\))?\s*:.+").unwrap());
|
||||
Lazy::new(|| Regex::new(r"^\s*(\*?\*?\w+)\s*(\(.*?\))?\s*:\n?\s*.+").unwrap());
|
||||
|
||||
fn args_section(checker: &mut Checker, docstring: &Docstring, context: &SectionContext) {
|
||||
let mut matches = Vec::new();
|
||||
for line in context.following_lines {
|
||||
if let Some(captures) = GOOGLE_ARGS_REGEX.captures(line) {
|
||||
matches.push(captures);
|
||||
if context.following_lines.is_empty() {
|
||||
missing_args(checker, docstring, &FxHashSet::default());
|
||||
return;
|
||||
}
|
||||
|
||||
// Normalize leading whitespace, by removing any lines with less indentation
|
||||
// than the first.
|
||||
let leading_space = whitespace::leading_space(context.following_lines[0]);
|
||||
let relevant_lines = context
|
||||
.following_lines
|
||||
.iter()
|
||||
.filter(|line| line.starts_with(leading_space) || line.is_empty())
|
||||
.join("\n");
|
||||
let args_content = textwrap::dedent(&relevant_lines);
|
||||
|
||||
// Reformat each section.
|
||||
let mut args_sections: Vec<String> = vec![];
|
||||
for line in args_content.trim().lines() {
|
||||
if line.chars().next().map_or(true, char::is_whitespace) {
|
||||
// This is a continuation of the documentation for the previous parameter,
|
||||
// because it starts with whitespace.
|
||||
if let Some(last) = args_sections.last_mut() {
|
||||
last.push_str(line);
|
||||
last.push('\n');
|
||||
}
|
||||
} else {
|
||||
// This line is the start of documentation for the next parameter, because it
|
||||
// doesn't start with any whitespace.
|
||||
let mut line = line.to_string();
|
||||
line.push('\n');
|
||||
args_sections.push(line);
|
||||
}
|
||||
}
|
||||
|
||||
missing_args(
|
||||
checker,
|
||||
docstring,
|
||||
&matches
|
||||
.iter()
|
||||
.filter_map(|captures| captures.get(1).map(|arg_name| arg_name.as_str()))
|
||||
.collect(),
|
||||
);
|
||||
// Extract the argument name from each section.
|
||||
let mut matches = Vec::new();
|
||||
for section in &args_sections {
|
||||
if let Some(captures) = GOOGLE_ARGS_REGEX.captures(section) {
|
||||
matches.push(captures);
|
||||
}
|
||||
}
|
||||
let docstrings_args = matches
|
||||
.iter()
|
||||
.filter_map(|captures| captures.get(1).map(|arg_name| arg_name.as_str()))
|
||||
.collect();
|
||||
|
||||
missing_args(checker, docstring, &docstrings_args);
|
||||
}
|
||||
|
||||
fn parameters_section(checker: &mut Checker, docstring: &Docstring, context: &SectionContext) {
|
||||
|
||||
@@ -4,7 +4,7 @@ use ruff_macros::ConfigurationOptions;
|
||||
use schemars::JsonSchema;
|
||||
use serde::{Deserialize, Serialize};
|
||||
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
use crate::registry::CheckCodePrefix;
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq, Serialize, Deserialize, Hash, JsonSchema)]
|
||||
#[serde(deny_unknown_fields, rename_all = "kebab-case")]
|
||||
|
||||
@@ -75,18 +75,6 @@ expression: checks
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
DocumentAllArguments:
|
||||
- skip
|
||||
- verbose
|
||||
location:
|
||||
row: 370
|
||||
column: 4
|
||||
end_location:
|
||||
row: 382
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
DocumentAllArguments:
|
||||
- y
|
||||
|
||||
@@ -16,7 +16,6 @@ expression: checks
|
||||
parent: ~
|
||||
- kind:
|
||||
DocumentAllArguments:
|
||||
- x
|
||||
- y
|
||||
- z
|
||||
location:
|
||||
@@ -29,7 +28,6 @@ expression: checks
|
||||
parent: ~
|
||||
- kind:
|
||||
DocumentAllArguments:
|
||||
- x
|
||||
- y
|
||||
- z
|
||||
location:
|
||||
|
||||
@@ -4,7 +4,6 @@ expression: checks
|
||||
---
|
||||
- kind:
|
||||
DocumentAllArguments:
|
||||
- x
|
||||
- y
|
||||
- z
|
||||
location:
|
||||
|
||||
@@ -132,7 +132,7 @@ pub fn default_except_not_last(
|
||||
#[derive(Debug, PartialEq)]
|
||||
enum DictionaryKey<'a> {
|
||||
Constant(&'a Constant),
|
||||
Variable(&'a String),
|
||||
Variable(&'a str),
|
||||
}
|
||||
|
||||
fn convert_to_value(expr: &Expr) -> Option<DictionaryKey> {
|
||||
|
||||
@@ -16,8 +16,7 @@ mod tests {
|
||||
use textwrap::dedent;
|
||||
|
||||
use crate::linter::{check_path, test_path};
|
||||
use crate::registry::CheckCode;
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
use crate::registry::{CheckCode, CheckCodePrefix};
|
||||
use crate::settings::flags;
|
||||
use crate::source_code_locator::SourceCodeLocator;
|
||||
use crate::source_code_style::SourceCodeStyleDetector;
|
||||
|
||||
@@ -6,7 +6,7 @@ use crate::checkers::ast::Checker;
|
||||
use crate::registry::{Check, CheckKind};
|
||||
|
||||
/// UP025
|
||||
pub fn rewrite_unicode_literal(checker: &mut Checker, expr: &Expr, kind: &Option<String>) {
|
||||
pub fn rewrite_unicode_literal(checker: &mut Checker, expr: &Expr, kind: Option<&str>) {
|
||||
if let Some(const_kind) = kind {
|
||||
if const_kind.to_lowercase() == "u" {
|
||||
let mut check = Check::new(CheckKind::RewriteUnicodeLiteral, Range::from_located(expr));
|
||||
|
||||
@@ -8,11 +8,25 @@ use crate::autofix::Fix;
|
||||
use crate::checkers::ast::Checker;
|
||||
use crate::registry::{Check, CheckKind};
|
||||
|
||||
/// Return `true` if the two expressions are equivalent, and consistent solely
|
||||
/// of tuples and names.
|
||||
fn is_same_expr(a: &Expr, b: &Expr) -> bool {
|
||||
match (&a.node, &b.node) {
|
||||
(ExprKind::Name { id: a, .. }, ExprKind::Name { id: b, .. }) => a == b,
|
||||
(ExprKind::Tuple { elts: a, .. }, ExprKind::Tuple { elts: b, .. }) => {
|
||||
a.len() == b.len() && a.iter().zip(b).all(|(a, b)| is_same_expr(a, b))
|
||||
}
|
||||
_ => false,
|
||||
}
|
||||
}
|
||||
|
||||
/// Collect all named variables in an expression consisting solely of tuples and
|
||||
/// names.
|
||||
fn collect_names(expr: &Expr) -> Vec<&str> {
|
||||
match &expr.node {
|
||||
ExprKind::Name { id, .. } => vec![id],
|
||||
ExprKind::Tuple { elts, .. } => elts.iter().flat_map(collect_names).collect(),
|
||||
_ => vec![],
|
||||
_ => unreachable!("Expected: ExprKind::Name | ExprKind::Tuple"),
|
||||
}
|
||||
}
|
||||
|
||||
@@ -51,13 +65,12 @@ impl<'a> Visitor<'a> for YieldFromVisitor<'a> {
|
||||
let body = &body[0];
|
||||
if let StmtKind::Expr { value } = &body.node {
|
||||
if let ExprKind::Yield { value: Some(value) } = &value.node {
|
||||
let names = collect_names(target);
|
||||
if names == collect_names(value) {
|
||||
if is_same_expr(target, value) {
|
||||
self.yields.push(YieldFrom {
|
||||
stmt,
|
||||
body,
|
||||
iter,
|
||||
names,
|
||||
names: collect_names(target),
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
@@ -34,7 +34,7 @@ fn is_utf8_encoding_arg(arg: &Expr) -> bool {
|
||||
}
|
||||
}
|
||||
|
||||
fn is_default_encode(args: &Vec<Expr>, kwargs: &Vec<Keyword>) -> bool {
|
||||
fn is_default_encode(args: &[Expr], kwargs: &[Keyword]) -> bool {
|
||||
match (args.len(), kwargs.len()) {
|
||||
// .encode()
|
||||
(0, 0) => true,
|
||||
@@ -106,8 +106,8 @@ pub fn unnecessary_encode_utf8(
|
||||
checker: &mut Checker,
|
||||
expr: &Expr,
|
||||
func: &Expr,
|
||||
args: &Vec<Expr>,
|
||||
kwargs: &Vec<Keyword>,
|
||||
args: &[Expr],
|
||||
kwargs: &[Keyword],
|
||||
) {
|
||||
let Some(variable) = match_encoded_variable(func) else {
|
||||
return;
|
||||
|
||||
@@ -73,7 +73,7 @@ pub fn unnecessary_future_import(checker: &mut Checker, stmt: &Stmt, names: &[Lo
|
||||
.map(|alias| format!("__future__.{}", alias.node.name))
|
||||
.collect();
|
||||
match autofix::helpers::remove_unused_imports(
|
||||
unused_imports.iter().map(std::string::String::as_str),
|
||||
unused_imports.iter().map(String::as_str),
|
||||
defined_by.0,
|
||||
defined_in.map(|node| node.0),
|
||||
&deleted,
|
||||
|
||||
125
src/registry.rs
125
src/registry.rs
@@ -4,6 +4,7 @@ use std::fmt;
|
||||
|
||||
use itertools::Itertools;
|
||||
use once_cell::sync::Lazy;
|
||||
use ruff_macros::CheckCodePrefix;
|
||||
use rustc_hash::FxHashMap;
|
||||
use rustpython_ast::Cmpop;
|
||||
use rustpython_parser::ast::Location;
|
||||
@@ -19,10 +20,10 @@ use crate::flake8_pytest_style::types::{
|
||||
use crate::flake8_quotes::settings::Quote;
|
||||
use crate::flake8_tidy_imports::settings::Strictness;
|
||||
use crate::pyupgrade::types::Primitive;
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
|
||||
#[derive(
|
||||
AsRefStr,
|
||||
CheckCodePrefix,
|
||||
EnumIter,
|
||||
EnumString,
|
||||
Debug,
|
||||
@@ -217,6 +218,7 @@ pub enum CheckCode {
|
||||
YTT302,
|
||||
YTT303,
|
||||
// flake8-simplify
|
||||
SIM101,
|
||||
SIM102,
|
||||
SIM105,
|
||||
SIM107,
|
||||
@@ -333,6 +335,8 @@ pub enum CheckCode {
|
||||
S106,
|
||||
S107,
|
||||
S108,
|
||||
S324,
|
||||
S506,
|
||||
// flake8-boolean-trap
|
||||
FBT001,
|
||||
FBT002,
|
||||
@@ -956,6 +960,7 @@ pub enum CheckKind {
|
||||
SysVersionCmpStr10,
|
||||
SysVersionSlice1Referenced,
|
||||
// flake8-simplify
|
||||
DuplicateIsinstanceCall(String),
|
||||
AAndNotA(String),
|
||||
AOrNotA(String),
|
||||
AndFalse,
|
||||
@@ -1072,6 +1077,8 @@ pub enum CheckKind {
|
||||
HardcodedPasswordFuncArg(String),
|
||||
HardcodedPasswordDefault(String),
|
||||
HardcodedTempFile(String),
|
||||
HashlibInsecureHashFunction(String),
|
||||
UnsafeYAMLLoad(Option<String>),
|
||||
// mccabe
|
||||
FunctionIsTooComplex(String, usize),
|
||||
// flake8-boolean-trap
|
||||
@@ -1395,6 +1402,7 @@ impl CheckCode {
|
||||
// flake8-blind-except
|
||||
CheckCode::BLE001 => CheckKind::BlindExcept("Exception".to_string()),
|
||||
// flake8-simplify
|
||||
CheckCode::SIM101 => CheckKind::DuplicateIsinstanceCall("...".to_string()),
|
||||
CheckCode::SIM102 => CheckKind::NestedIfStatements,
|
||||
CheckCode::SIM105 => CheckKind::UseContextlibSuppress("...".to_string()),
|
||||
CheckCode::SIM107 => CheckKind::ReturnInTryExceptFinally,
|
||||
@@ -1534,6 +1542,8 @@ impl CheckCode {
|
||||
CheckCode::S106 => CheckKind::HardcodedPasswordFuncArg("...".to_string()),
|
||||
CheckCode::S107 => CheckKind::HardcodedPasswordDefault("...".to_string()),
|
||||
CheckCode::S108 => CheckKind::HardcodedTempFile("...".to_string()),
|
||||
CheckCode::S324 => CheckKind::HashlibInsecureHashFunction("...".to_string()),
|
||||
CheckCode::S506 => CheckKind::UnsafeYAMLLoad(None),
|
||||
// mccabe
|
||||
CheckCode::C901 => CheckKind::FunctionIsTooComplex("...".to_string(), 10),
|
||||
// flake8-boolean-trap
|
||||
@@ -1936,7 +1946,10 @@ impl CheckCode {
|
||||
CheckCode::S106 => CheckCategory::Flake8Bandit,
|
||||
CheckCode::S107 => CheckCategory::Flake8Bandit,
|
||||
CheckCode::S108 => CheckCategory::Flake8Bandit,
|
||||
CheckCode::S324 => CheckCategory::Flake8Bandit,
|
||||
CheckCode::S506 => CheckCategory::Flake8Bandit,
|
||||
// flake8-simplify
|
||||
CheckCode::SIM101 => CheckCategory::Flake8Simplify,
|
||||
CheckCode::SIM102 => CheckCategory::Flake8Simplify,
|
||||
CheckCode::SIM105 => CheckCategory::Flake8Simplify,
|
||||
CheckCode::SIM107 => CheckCategory::Flake8Simplify,
|
||||
@@ -2195,6 +2208,7 @@ impl CheckKind {
|
||||
CheckKind::SysVersionCmpStr10 => &CheckCode::YTT302,
|
||||
CheckKind::SysVersionSlice1Referenced => &CheckCode::YTT303,
|
||||
// flake8-simplify
|
||||
CheckKind::DuplicateIsinstanceCall(..) => &CheckCode::SIM101,
|
||||
CheckKind::AAndNotA(..) => &CheckCode::SIM220,
|
||||
CheckKind::AOrNotA(..) => &CheckCode::SIM221,
|
||||
CheckKind::AndFalse => &CheckCode::SIM223,
|
||||
@@ -2311,6 +2325,8 @@ impl CheckKind {
|
||||
CheckKind::HardcodedPasswordFuncArg(..) => &CheckCode::S106,
|
||||
CheckKind::HardcodedPasswordDefault(..) => &CheckCode::S107,
|
||||
CheckKind::HardcodedTempFile(..) => &CheckCode::S108,
|
||||
CheckKind::HashlibInsecureHashFunction(..) => &CheckCode::S324,
|
||||
CheckKind::UnsafeYAMLLoad(..) => &CheckCode::S506,
|
||||
// mccabe
|
||||
CheckKind::FunctionIsTooComplex(..) => &CheckCode::C901,
|
||||
// flake8-boolean-trap
|
||||
@@ -2961,6 +2977,9 @@ impl CheckKind {
|
||||
"`sys.version[:1]` referenced (python10), use `sys.version_info`".to_string()
|
||||
}
|
||||
// flake8-simplify
|
||||
CheckKind::DuplicateIsinstanceCall(name) => {
|
||||
format!("Multiple `isinstance` calls for `{name}`, merge into a single call")
|
||||
}
|
||||
CheckKind::UseContextlibSuppress(exception) => {
|
||||
format!("Use `contextlib.suppress({exception})` instead of try-except-pass")
|
||||
}
|
||||
@@ -3254,17 +3273,31 @@ impl CheckKind {
|
||||
CheckKind::HardcodedPasswordString(string)
|
||||
| CheckKind::HardcodedPasswordFuncArg(string)
|
||||
| CheckKind::HardcodedPasswordDefault(string) => {
|
||||
format!(
|
||||
"Possible hardcoded password: `\"{}\"`",
|
||||
string.escape_debug()
|
||||
)
|
||||
format!("Possible hardcoded password: \"{}\"", string.escape_debug())
|
||||
}
|
||||
CheckKind::HardcodedTempFile(string) => {
|
||||
format!(
|
||||
"Probable insecure usage of temp file/directory: `\"{}\"`",
|
||||
"Probable insecure usage of temporary file or directory: \"{}\"",
|
||||
string.escape_debug()
|
||||
)
|
||||
}
|
||||
CheckKind::HashlibInsecureHashFunction(string) => {
|
||||
format!(
|
||||
"Probable use of insecure hash functions in `hashlib`: \"{}\"",
|
||||
string.escape_debug()
|
||||
)
|
||||
}
|
||||
CheckKind::UnsafeYAMLLoad(loader) => match loader {
|
||||
Some(name) => {
|
||||
format!(
|
||||
"Probable use of unsafe loader `{name}` with `yaml.load`. Allows \
|
||||
instantiation of arbitrary objects. Consider `yaml.safe_load`."
|
||||
)
|
||||
}
|
||||
None => "Probable use of unsafe `yaml.load`. Allows instantiation of arbitrary \
|
||||
objects. Consider `yaml.safe_load`."
|
||||
.to_string(),
|
||||
},
|
||||
// flake8-blind-except
|
||||
CheckKind::BlindExcept(name) => format!("Do not catch blind exception: `{name}`"),
|
||||
// mccabe
|
||||
@@ -3616,6 +3649,7 @@ impl CheckKind {
|
||||
| CheckKind::DoNotAssignLambda(..)
|
||||
| CheckKind::DupeClassFieldDefinitions(..)
|
||||
| CheckKind::DuplicateHandlerException(..)
|
||||
| CheckKind::DuplicateIsinstanceCall(..)
|
||||
| CheckKind::EndsInPeriod
|
||||
| CheckKind::EndsInPunctuation
|
||||
| CheckKind::FStringMissingPlaceholders
|
||||
@@ -3753,6 +3787,9 @@ impl CheckKind {
|
||||
Some(format!("Remove duplicate field definition for `{name}`"))
|
||||
}
|
||||
CheckKind::DuplicateHandlerException(..) => Some("De-duplicate exceptions".to_string()),
|
||||
CheckKind::DuplicateIsinstanceCall(name) => {
|
||||
Some(format!("Merge `isinstance` calls for `{name}`"))
|
||||
}
|
||||
CheckKind::EndsInPeriod => Some("Add period".to_string()),
|
||||
CheckKind::EndsInPunctuation => Some("Add closing punctuation".to_string()),
|
||||
CheckKind::ExtraneousScopeFunction => Some("Remove `scope=` argument".to_string()),
|
||||
@@ -4026,82 +4063,6 @@ pub const INCOMPATIBLE_CODES: &[(CheckCode, CheckCode, &str)] = &[(
|
||||
Consider adding `D203` to `ignore`.",
|
||||
)];
|
||||
|
||||
/// A hash map from deprecated `CheckCodePrefix` to latest `CheckCodePrefix`.
|
||||
pub static PREFIX_REDIRECTS: Lazy<FxHashMap<&'static str, CheckCodePrefix>> = Lazy::new(|| {
|
||||
FxHashMap::from_iter([
|
||||
// TODO(charlie): Remove by 2023-01-01.
|
||||
("U001", CheckCodePrefix::UP001),
|
||||
("U003", CheckCodePrefix::UP003),
|
||||
("U004", CheckCodePrefix::UP004),
|
||||
("U005", CheckCodePrefix::UP005),
|
||||
("U006", CheckCodePrefix::UP006),
|
||||
("U007", CheckCodePrefix::UP007),
|
||||
("U008", CheckCodePrefix::UP008),
|
||||
("U009", CheckCodePrefix::UP009),
|
||||
("U010", CheckCodePrefix::UP010),
|
||||
("U011", CheckCodePrefix::UP011),
|
||||
("U012", CheckCodePrefix::UP012),
|
||||
("U013", CheckCodePrefix::UP013),
|
||||
("U014", CheckCodePrefix::UP014),
|
||||
("U015", CheckCodePrefix::UP015),
|
||||
("U016", CheckCodePrefix::UP016),
|
||||
("U017", CheckCodePrefix::UP017),
|
||||
("U019", CheckCodePrefix::UP019),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("I252", CheckCodePrefix::TID252),
|
||||
("M001", CheckCodePrefix::RUF100),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("PDV002", CheckCodePrefix::PD002),
|
||||
("PDV003", CheckCodePrefix::PD003),
|
||||
("PDV004", CheckCodePrefix::PD004),
|
||||
("PDV007", CheckCodePrefix::PD007),
|
||||
("PDV008", CheckCodePrefix::PD008),
|
||||
("PDV009", CheckCodePrefix::PD009),
|
||||
("PDV010", CheckCodePrefix::PD010),
|
||||
("PDV011", CheckCodePrefix::PD011),
|
||||
("PDV012", CheckCodePrefix::PD012),
|
||||
("PDV013", CheckCodePrefix::PD013),
|
||||
("PDV015", CheckCodePrefix::PD015),
|
||||
("PDV901", CheckCodePrefix::PD901),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("R501", CheckCodePrefix::RET501),
|
||||
("R502", CheckCodePrefix::RET502),
|
||||
("R503", CheckCodePrefix::RET503),
|
||||
("R504", CheckCodePrefix::RET504),
|
||||
("R505", CheckCodePrefix::RET505),
|
||||
("R506", CheckCodePrefix::RET506),
|
||||
("R507", CheckCodePrefix::RET507),
|
||||
("R508", CheckCodePrefix::RET508),
|
||||
("IC001", CheckCodePrefix::ICN001),
|
||||
("IC002", CheckCodePrefix::ICN001),
|
||||
("IC003", CheckCodePrefix::ICN001),
|
||||
("IC004", CheckCodePrefix::ICN001),
|
||||
// TODO(charlie): Remove by 2023-01-01.
|
||||
("U", CheckCodePrefix::UP),
|
||||
("U0", CheckCodePrefix::UP0),
|
||||
("U00", CheckCodePrefix::UP00),
|
||||
("U01", CheckCodePrefix::UP01),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("I2", CheckCodePrefix::TID2),
|
||||
("I25", CheckCodePrefix::TID25),
|
||||
("M", CheckCodePrefix::RUF100),
|
||||
("M0", CheckCodePrefix::RUF100),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("PDV", CheckCodePrefix::PD),
|
||||
("PDV0", CheckCodePrefix::PD0),
|
||||
("PDV01", CheckCodePrefix::PD01),
|
||||
("PDV9", CheckCodePrefix::PD9),
|
||||
("PDV90", CheckCodePrefix::PD90),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("R", CheckCodePrefix::RET),
|
||||
("R5", CheckCodePrefix::RET5),
|
||||
("R50", CheckCodePrefix::RET50),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("IC", CheckCodePrefix::ICN),
|
||||
("IC0", CheckCodePrefix::ICN0),
|
||||
])
|
||||
});
|
||||
|
||||
/// A hash map from deprecated to latest `CheckCode`.
|
||||
pub static CODE_REDIRECTS: Lazy<FxHashMap<&'static str, CheckCode>> = Lazy::new(|| {
|
||||
FxHashMap::from_iter([
|
||||
|
||||
3797
src/registry_gen.rs
3797
src/registry_gen.rs
File diff suppressed because it is too large
Load Diff
@@ -13,7 +13,7 @@ use shellexpand;
|
||||
use shellexpand::LookupError;
|
||||
|
||||
use crate::cli::{collect_per_file_ignores, Overrides};
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
use crate::registry::CheckCodePrefix;
|
||||
use crate::settings::options::Options;
|
||||
use crate::settings::pyproject::load_options;
|
||||
use crate::settings::types::{
|
||||
|
||||
@@ -17,8 +17,7 @@ use regex::Regex;
|
||||
use rustc_hash::FxHashSet;
|
||||
|
||||
use crate::cache::cache_dir;
|
||||
use crate::registry::{CheckCode, INCOMPATIBLE_CODES};
|
||||
use crate::registry_gen::{CheckCodePrefix, SuffixLength, CATEGORIES};
|
||||
use crate::registry::{CheckCode, CheckCodePrefix, SuffixLength, CATEGORIES, INCOMPATIBLE_CODES};
|
||||
use crate::settings::configuration::Configuration;
|
||||
use crate::settings::types::{
|
||||
FilePattern, PerFileIgnore, PythonVersion, SerializationFormat, Version,
|
||||
@@ -471,8 +470,7 @@ fn validate_enabled(enabled: FxHashSet<CheckCode>) -> FxHashSet<CheckCode> {
|
||||
mod tests {
|
||||
use rustc_hash::FxHashSet;
|
||||
|
||||
use crate::registry::CheckCode;
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
use crate::registry::{CheckCode, CheckCodePrefix};
|
||||
use crate::settings::{resolve_codes, CheckCodeSpec};
|
||||
|
||||
#[test]
|
||||
|
||||
@@ -5,7 +5,7 @@ use rustc_hash::FxHashMap;
|
||||
use schemars::JsonSchema;
|
||||
use serde::{Deserialize, Serialize};
|
||||
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
use crate::registry::CheckCodePrefix;
|
||||
use crate::settings::types::{PythonVersion, SerializationFormat, Version};
|
||||
use crate::{
|
||||
flake8_annotations, flake8_bandit, flake8_bugbear, flake8_errmsg, flake8_import_conventions,
|
||||
|
||||
@@ -131,7 +131,7 @@ mod tests {
|
||||
|
||||
use crate::flake8_quotes::settings::Quote;
|
||||
use crate::flake8_tidy_imports::settings::{BannedApi, Strictness};
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
use crate::registry::CheckCodePrefix;
|
||||
use crate::settings::pyproject::{
|
||||
find_settings_toml, parse_pyproject_toml, Options, Pyproject, Tools,
|
||||
};
|
||||
|
||||
@@ -12,8 +12,7 @@ use schemars::JsonSchema;
|
||||
use serde::{de, Deserialize, Deserializer, Serialize};
|
||||
|
||||
use crate::fs;
|
||||
use crate::registry::CheckCode;
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
use crate::registry::{CheckCode, CheckCodePrefix};
|
||||
|
||||
#[derive(
|
||||
Clone, Copy, Debug, PartialOrd, Ord, PartialEq, Eq, Serialize, Deserialize, Hash, JsonSchema,
|
||||
|
||||
Reference in New Issue
Block a user