Compare commits
80 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
0152814a00 | ||
|
|
0b3fab256b | ||
|
|
212ce4d331 | ||
|
|
491b1e4968 | ||
|
|
8b01b53d89 | ||
|
|
f9a5867d3e | ||
|
|
4149627f19 | ||
|
|
7d24146df7 | ||
|
|
1c6ef3666c | ||
|
|
16d933fcf5 | ||
|
|
a9cc56b2ac | ||
|
|
4de6c26ff9 | ||
|
|
98856e05d6 | ||
|
|
edf46c06d0 | ||
|
|
9cfce61f36 | ||
|
|
bdb9a4d1a7 | ||
|
|
82e0c0ced6 | ||
|
|
6a723b50c7 | ||
|
|
6208eb7bbf | ||
|
|
43db446dfa | ||
|
|
3c8fdbf107 | ||
|
|
54fb47ea6a | ||
|
|
efadfeda96 | ||
|
|
90198f7563 | ||
|
|
15084dff9d | ||
|
|
eea1379a74 | ||
|
|
3e80c0d43e | ||
|
|
76a366e05a | ||
|
|
07f72990a9 | ||
|
|
402feffe85 | ||
|
|
5cdd7ccdb8 | ||
|
|
f1c3ebfe0f | ||
|
|
c7e4e41a7a | ||
|
|
311a823a4a | ||
|
|
8c836aeecf | ||
|
|
3abd205f94 | ||
|
|
0527fb9335 | ||
|
|
d5256f89b6 | ||
|
|
3f84746d66 | ||
|
|
c39f687fca | ||
|
|
dd35e724dd | ||
|
|
43599a9e78 | ||
|
|
53ed52dc59 | ||
|
|
24999019e0 | ||
|
|
12d2526edb | ||
|
|
81b812d94c | ||
|
|
9409b49ea2 | ||
|
|
1392170dbf | ||
|
|
0a940b3cb4 | ||
|
|
6aba43a9b0 | ||
|
|
8a3a6a901a | ||
|
|
18a301a214 | ||
|
|
53157bc634 | ||
|
|
76a9dc61f0 | ||
|
|
16d7e13c72 | ||
|
|
5ed58ae595 | ||
|
|
cecd4b166c | ||
|
|
4ddcdd02d6 | ||
|
|
43575da537 | ||
|
|
fe67a0d239 | ||
|
|
8caa73df6a | ||
|
|
ee4cae97d5 | ||
|
|
2e3787adff | ||
|
|
81b211d1b7 | ||
|
|
1ad72261f1 | ||
|
|
914287d31b | ||
|
|
75bb6ad456 | ||
|
|
04111da3f3 | ||
|
|
2464cf6fe9 | ||
|
|
d34e6c02a1 | ||
|
|
e6611c4830 | ||
|
|
2d23b1ae69 | ||
|
|
5eb03d5e09 | ||
|
|
9f8ef1737e | ||
|
|
1991d618a3 | ||
|
|
2045b739a9 | ||
|
|
53e3dd8548 | ||
|
|
78c9056173 | ||
|
|
8d56e412ef | ||
|
|
3400be18a6 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
34
CONTRIBUTING.md → .github/CONTRIBUTING.md
vendored
34
CONTRIBUTING.md → .github/CONTRIBUTING.md
vendored
@@ -56,33 +56,35 @@ prior to merging.
|
||||
|
||||
There are four phases to adding a new lint rule:
|
||||
|
||||
1. Define the rule in `src/registry.rs`.
|
||||
2. Define the _logic_ for triggering the rule in `src/checkers/ast.rs` (for AST-based checks),
|
||||
1. Define the violation in `src/violations.rs` (e.g., `ModuleImportNotAtTopOfFile`).
|
||||
2. Map the violation to a code in `src/registry.rs` (e.g., `E402`).
|
||||
3. Define the _logic_ for triggering the violation in `src/checkers/ast.rs` (for AST-based checks),
|
||||
`src/checkers/tokens.rs` (for token-based checks), or `src/checkers/lines.rs` (for text-based checks).
|
||||
3. Add a test fixture.
|
||||
4. Update the generated files (documentation and generated code).
|
||||
4. Add a test fixture.
|
||||
5. Update the generated files (documentation and generated code).
|
||||
|
||||
To define the rule, open up `src/registry.rs`. You'll need to define both a `CheckCode` and
|
||||
`CheckKind`. As an example, you can grep for `E402` and `ModuleImportNotAtTopOfFile`, and follow the
|
||||
pattern implemented therein.
|
||||
To define the violation, open up `src/violations.rs`, and define a new struct using the
|
||||
`define_violation!` macro. There are plenty of examples in that file, so feel free to pattern-match
|
||||
against the existing structs.
|
||||
|
||||
To trigger the rule, you'll likely want to augment the logic in `src/checkers/ast.rs`, which defines
|
||||
the Python AST visitor, responsible for iterating over the abstract syntax tree and collecting
|
||||
lint-rule violations as it goes. If you need to inspect the AST, you can run
|
||||
`cargo +nightly dev print-ast` with a Python file. Grep for the `Check::new` invocations to
|
||||
understand how other, similar rules are implemented.
|
||||
To trigger the violation, you'll likely want to augment the logic in `src/checkers/ast.rs`, which
|
||||
defines the Python AST visitor, responsible for iterating over the abstract syntax tree and
|
||||
collecting diagnostics as it goes.
|
||||
|
||||
If you need to inspect the AST, you can run `cargo +nightly dev print-ast` with a Python file. Grep
|
||||
for the `Check::new` invocations to understand how other, similar rules are implemented.
|
||||
|
||||
To add a test fixture, create a file under `resources/test/fixtures/[plugin-name]`, named to match
|
||||
the `CheckCode` you defined earlier (e.g., `E402.py`). This file should contain a variety of
|
||||
the code you defined earlier (e.g., `E402.py`). This file should contain a variety of
|
||||
violations and non-violations designed to evaluate and demonstrate the behavior of your lint rule.
|
||||
|
||||
Run `cargo +nightly dev generate-all` to generate the code for your new fixture. Then run Ruff
|
||||
locally with (e.g.) `cargo run resources/test/fixtures/pycodestyle/E402.py --no-cache --select E402`.
|
||||
|
||||
Once you're satisfied with the output, codify the behavior as a snapshot test by adding a new
|
||||
`test_case` macro in the relevant `src/[plugin-name]/mod.rs` file. Then, run `cargo test`. Your
|
||||
test will fail, but you'll be prompted to follow-up with `cargo insta review`. Accept the generated
|
||||
snapshot, then commit the snapshot file alongside the rest of your changes.
|
||||
`test_case` macro in the relevant `src/[plugin-name]/mod.rs` file. Then, run `cargo test --all`.
|
||||
Your test will fail, but you'll be prompted to follow-up with `cargo insta review`. Accept the
|
||||
generated snapshot, then commit the snapshot file alongside the rest of your changes.
|
||||
|
||||
Finally, regenerate the documentation and generated code with `cargo +nightly dev generate-all`.
|
||||
|
||||
10
.github/ISSUE_TEMPLATE.md
vendored
Normal file
10
.github/ISSUE_TEMPLATE.md
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
<!--
|
||||
Thank you for taking the time to report an issue! We're glad to have you involved with Ruff.
|
||||
|
||||
If you're filing a bug report, please consider including the following information:
|
||||
|
||||
- A minimal code snippet that reproduces the bug.
|
||||
- The command you invoked (e.g., `ruff /path/to/file.py --fix`), ideally including the `--isolated` flag.
|
||||
- The current Ruff settings (any relevant sections from your `pyproject.toml`).
|
||||
- The current Ruff version (`ruff --version`).
|
||||
-->
|
||||
3
.github/workflows/ci.yaml
vendored
3
.github/workflows/ci.yaml
vendored
@@ -42,9 +42,8 @@ jobs:
|
||||
- run: cargo build --all --release
|
||||
- run: ./target/release/ruff_dev generate-all
|
||||
- run: git diff --quiet README.md || echo "::error file=README.md::This file is outdated. Run 'cargo +nightly dev generate-all'."
|
||||
- run: git diff --quiet src/registry_gen.rs || echo "::error file=src/registry_gen.rs::This file is outdated. Run 'cargo +nightly dev generate-all'."
|
||||
- run: git diff --quiet ruff.schema.json || echo "::error file=ruff.schema.json::This file is outdated. Run 'cargo +nightly dev generate-all'."
|
||||
- run: git diff --exit-code -- README.md src/registry_gen.rs ruff.schema.json
|
||||
- run: git diff --exit-code -- README.md ruff.schema.json
|
||||
|
||||
cargo-fmt:
|
||||
name: "cargo fmt"
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
repos:
|
||||
- repo: https://github.com/charliermarsh/ruff-pre-commit
|
||||
rev: v0.0.211
|
||||
rev: v0.0.215
|
||||
hooks:
|
||||
- id: ruff
|
||||
|
||||
|
||||
63
Cargo.lock
generated
63
Cargo.lock
generated
@@ -367,15 +367,6 @@ dependencies = [
|
||||
"winapi",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "codegen"
|
||||
version = "0.2.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "ff61280aed771c3070e7dcc9e050c66f1eb1e3b96431ba66f9f74641d02fc41d"
|
||||
dependencies = [
|
||||
"indexmap",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "codespan-reporting"
|
||||
version = "0.11.1"
|
||||
@@ -744,7 +735,7 @@ checksum = "0ce7134b9999ecaf8bcd65542e436736ef32ddca1b3e06094cb6ec5755203b80"
|
||||
|
||||
[[package]]
|
||||
name = "flake8-to-ruff"
|
||||
version = "0.0.211-dev.0"
|
||||
version = "0.0.215-dev.0"
|
||||
dependencies = [
|
||||
"anyhow",
|
||||
"clap 4.0.32",
|
||||
@@ -757,7 +748,7 @@ dependencies = [
|
||||
"serde_json",
|
||||
"strum",
|
||||
"strum_macros",
|
||||
"toml",
|
||||
"toml_edit",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
@@ -1294,6 +1285,15 @@ dependencies = [
|
||||
"version_check",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "nom8"
|
||||
version = "0.2.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "ae01545c9c7fc4486ab7debaf2aad7003ac19431791868fb2e8066df97fad2f8"
|
||||
dependencies = [
|
||||
"memchr",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "notify"
|
||||
version = "5.0.0"
|
||||
@@ -1365,9 +1365,9 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "once_cell"
|
||||
version = "1.16.0"
|
||||
version = "1.17.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "86f0b0d4bf799edbc74508c1e8bf170ff5f41238e5f8225603ca7caaae2b7860"
|
||||
checksum = "6f61fba1741ea2b3d6a1e3178721804bb716a68a6aeba1149b5d52e3d464ea66"
|
||||
|
||||
[[package]]
|
||||
name = "oorandom"
|
||||
@@ -1873,7 +1873,7 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "ruff"
|
||||
version = "0.0.211"
|
||||
version = "0.0.215"
|
||||
dependencies = [
|
||||
"annotate-snippets 0.9.1",
|
||||
"anyhow",
|
||||
@@ -1931,7 +1931,7 @@ dependencies = [
|
||||
"test-case",
|
||||
"textwrap",
|
||||
"titlecase",
|
||||
"toml",
|
||||
"toml_edit",
|
||||
"update-informer",
|
||||
"ureq",
|
||||
"walkdir",
|
||||
@@ -1941,11 +1941,10 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "ruff_dev"
|
||||
version = "0.0.211"
|
||||
version = "0.0.215"
|
||||
dependencies = [
|
||||
"anyhow",
|
||||
"clap 4.0.32",
|
||||
"codegen",
|
||||
"itertools",
|
||||
"libcst",
|
||||
"once_cell",
|
||||
@@ -1962,8 +1961,9 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "ruff_macros"
|
||||
version = "0.0.211"
|
||||
version = "0.0.215"
|
||||
dependencies = [
|
||||
"once_cell",
|
||||
"proc-macro2",
|
||||
"quote",
|
||||
"syn",
|
||||
@@ -2005,7 +2005,7 @@ dependencies = [
|
||||
[[package]]
|
||||
name = "rustpython-ast"
|
||||
version = "0.1.0"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=4d53c7cb27c0379adf8b51c4d3d0d2174f41d590#4d53c7cb27c0379adf8b51c4d3d0d2174f41d590"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=d532160333ffeb6dbeca2c2728c2391cd1e53b7f#d532160333ffeb6dbeca2c2728c2391cd1e53b7f"
|
||||
dependencies = [
|
||||
"num-bigint",
|
||||
"rustpython-common",
|
||||
@@ -2015,7 +2015,7 @@ dependencies = [
|
||||
[[package]]
|
||||
name = "rustpython-common"
|
||||
version = "0.0.0"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=4d53c7cb27c0379adf8b51c4d3d0d2174f41d590#4d53c7cb27c0379adf8b51c4d3d0d2174f41d590"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=d532160333ffeb6dbeca2c2728c2391cd1e53b7f#d532160333ffeb6dbeca2c2728c2391cd1e53b7f"
|
||||
dependencies = [
|
||||
"ascii",
|
||||
"bitflags",
|
||||
@@ -2040,7 +2040,7 @@ dependencies = [
|
||||
[[package]]
|
||||
name = "rustpython-compiler-core"
|
||||
version = "0.1.2"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=4d53c7cb27c0379adf8b51c4d3d0d2174f41d590#4d53c7cb27c0379adf8b51c4d3d0d2174f41d590"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=d532160333ffeb6dbeca2c2728c2391cd1e53b7f#d532160333ffeb6dbeca2c2728c2391cd1e53b7f"
|
||||
dependencies = [
|
||||
"bincode",
|
||||
"bitflags",
|
||||
@@ -2057,7 +2057,7 @@ dependencies = [
|
||||
[[package]]
|
||||
name = "rustpython-parser"
|
||||
version = "0.1.2"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=4d53c7cb27c0379adf8b51c4d3d0d2174f41d590#4d53c7cb27c0379adf8b51c4d3d0d2174f41d590"
|
||||
source = "git+https://github.com/RustPython/RustPython.git?rev=d532160333ffeb6dbeca2c2728c2391cd1e53b7f#d532160333ffeb6dbeca2c2728c2391cd1e53b7f"
|
||||
dependencies = [
|
||||
"ahash",
|
||||
"anyhow",
|
||||
@@ -2496,14 +2496,27 @@ dependencies = [
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "toml"
|
||||
version = "0.5.10"
|
||||
name = "toml_datetime"
|
||||
version = "0.5.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "1333c76748e868a4d9d1017b5ab53171dfd095f70c712fdb4653a406547f598f"
|
||||
checksum = "808b51e57d0ef8f71115d8f3a01e7d3750d01c79cac4b3eda910f4389fdf92fd"
|
||||
dependencies = [
|
||||
"serde",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "toml_edit"
|
||||
version = "0.17.1"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "a34cc558345efd7e88b9eda9626df2138b80bb46a7606f695e751c892bc7dac6"
|
||||
dependencies = [
|
||||
"indexmap",
|
||||
"itertools",
|
||||
"nom8",
|
||||
"serde",
|
||||
"toml_datetime",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "twox-hash"
|
||||
version = "1.6.3"
|
||||
|
||||
14
Cargo.toml
14
Cargo.toml
@@ -6,7 +6,7 @@ members = [
|
||||
|
||||
[package]
|
||||
name = "ruff"
|
||||
version = "0.0.211"
|
||||
version = "0.0.215"
|
||||
authors = ["Charlie Marsh <charlie.r.marsh@gmail.com>"]
|
||||
edition = "2021"
|
||||
rust-version = "1.65.0"
|
||||
@@ -29,7 +29,7 @@ bitflags = { version = "1.3.2" }
|
||||
cachedir = { version = "0.3.0" }
|
||||
cfg-if = { version = "1.0.0" }
|
||||
chrono = { version = "0.4.21", default-features = false, features = ["clock"] }
|
||||
clap = { version = "4.0.1", features = ["derive"] }
|
||||
clap = { version = "4.0.1", features = ["derive", "env"] }
|
||||
clap_complete_command = { version = "0.4.0" }
|
||||
colored = { version = "2.0.0" }
|
||||
dirs = { version = "4.0.0" }
|
||||
@@ -51,11 +51,11 @@ path-absolutize = { version = "3.0.14", features = ["once_cell_cache", "use_unix
|
||||
quick-junit = { version = "0.3.2" }
|
||||
regex = { version = "1.6.0" }
|
||||
ropey = { version = "1.5.0", features = ["cr_lines", "simd"], default-features = false }
|
||||
ruff_macros = { version = "0.0.211", path = "ruff_macros" }
|
||||
ruff_macros = { version = "0.0.215", path = "ruff_macros" }
|
||||
rustc-hash = { version = "1.1.0" }
|
||||
rustpython-ast = { features = ["unparse"], git = "https://github.com/RustPython/RustPython.git", rev = "4d53c7cb27c0379adf8b51c4d3d0d2174f41d590" }
|
||||
rustpython-common = { git = "https://github.com/RustPython/RustPython.git", rev = "4d53c7cb27c0379adf8b51c4d3d0d2174f41d590" }
|
||||
rustpython-parser = { features = ["lalrpop"], git = "https://github.com/RustPython/RustPython.git", rev = "4d53c7cb27c0379adf8b51c4d3d0d2174f41d590" }
|
||||
rustpython-ast = { features = ["unparse"], git = "https://github.com/RustPython/RustPython.git", rev = "d532160333ffeb6dbeca2c2728c2391cd1e53b7f" }
|
||||
rustpython-common = { git = "https://github.com/RustPython/RustPython.git", rev = "d532160333ffeb6dbeca2c2728c2391cd1e53b7f" }
|
||||
rustpython-parser = { features = ["lalrpop"], git = "https://github.com/RustPython/RustPython.git", rev = "d532160333ffeb6dbeca2c2728c2391cd1e53b7f" }
|
||||
schemars = { version = "0.8.11" }
|
||||
semver = { version = "1.0.16" }
|
||||
serde = { version = "1.0.147", features = ["derive"] }
|
||||
@@ -66,7 +66,7 @@ strum = { version = "0.24.1", features = ["strum_macros"] }
|
||||
strum_macros = { version = "0.24.3" }
|
||||
textwrap = { version = "0.16.0" }
|
||||
titlecase = { version = "2.2.1" }
|
||||
toml = { version = "0.5.9" }
|
||||
toml_edit = { version = "0.17.1", features = ["easy"] }
|
||||
walkdir = { version = "2.3.2" }
|
||||
|
||||
[target.'cfg(not(target_family = "wasm"))'.dependencies]
|
||||
|
||||
61
README.md
61
README.md
@@ -1,6 +1,6 @@
|
||||
# Ruff
|
||||
|
||||
[](https://github.com/charliermarsh/ruff)
|
||||
[](https://github.com/charliermarsh/ruff)
|
||||
[](https://pypi.python.org/pypi/ruff)
|
||||
[](https://pypi.python.org/pypi/ruff)
|
||||
[](https://pypi.python.org/pypi/ruff)
|
||||
@@ -180,7 +180,7 @@ Ruff also works with [pre-commit](https://pre-commit.com):
|
||||
```yaml
|
||||
- repo: https://github.com/charliermarsh/ruff-pre-commit
|
||||
# Ruff version.
|
||||
rev: 'v0.0.211'
|
||||
rev: 'v0.0.215'
|
||||
hooks:
|
||||
- id: ruff
|
||||
# Respect `exclude` and `extend-exclude` settings.
|
||||
@@ -312,7 +312,7 @@ ruff path/to/code/ --select F401 --select F403
|
||||
See `ruff --help` for more:
|
||||
|
||||
<!-- Begin auto-generated cli help. -->
|
||||
```shell
|
||||
```
|
||||
Ruff: An extremely fast Python linter.
|
||||
|
||||
Usage: ruff [OPTIONS] [FILES]...
|
||||
@@ -341,6 +341,8 @@ Options:
|
||||
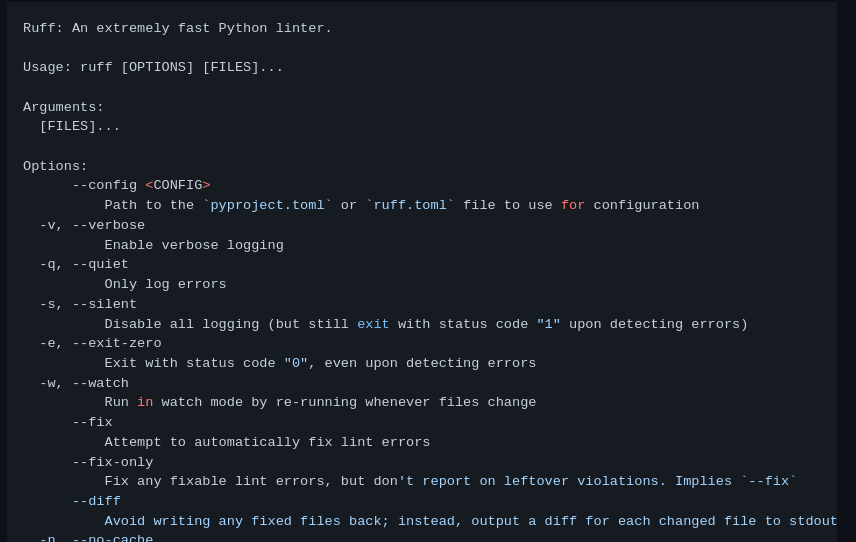
Avoid writing any fixed files back; instead, output a diff for each changed file to stdout
|
||||
-n, --no-cache
|
||||
Disable cache reads
|
||||
--isolated
|
||||
Ignore all configuration files
|
||||
--select <SELECT>
|
||||
Comma-separated list of error codes to enable (or ALL, to enable all checks)
|
||||
--extend-select <EXTEND_SELECT>
|
||||
@@ -360,11 +362,11 @@ Options:
|
||||
--per-file-ignores <PER_FILE_IGNORES>
|
||||
List of mappings from file pattern to code to exclude
|
||||
--format <FORMAT>
|
||||
Output serialization format for error messages [possible values: text, json, junit, grouped, github, gitlab]
|
||||
Output serialization format for error messages [env: RUFF_FORMAT=] [possible values: text, json, junit, grouped, github, gitlab]
|
||||
--stdin-filename <STDIN_FILENAME>
|
||||
The name of the file when passing it through stdin
|
||||
--cache-dir <CACHE_DIR>
|
||||
Path to the cache directory
|
||||
Path to the cache directory [env: RUFF_CACHE_DIR=]
|
||||
--show-source
|
||||
Show violations with source code
|
||||
--respect-gitignore
|
||||
@@ -551,8 +553,8 @@ For more, see [Pyflakes](https://pypi.org/project/pyflakes/2.5.0/) on PyPI.
|
||||
| F524 | StringDotFormatMissingArguments | '...'.format(...) is missing argument(s) for placeholder(s): ... | |
|
||||
| F525 | StringDotFormatMixingAutomatic | '...'.format(...) mixes automatic and manual numbering | |
|
||||
| F541 | FStringMissingPlaceholders | f-string without any placeholders | 🛠 |
|
||||
| F601 | MultiValueRepeatedKeyLiteral | Dictionary key literal repeated | |
|
||||
| F602 | MultiValueRepeatedKeyVariable | Dictionary key `...` repeated | |
|
||||
| F601 | MultiValueRepeatedKeyLiteral | Dictionary key literal `...` repeated | 🛠 |
|
||||
| F602 | MultiValueRepeatedKeyVariable | Dictionary key `...` repeated | 🛠 |
|
||||
| F621 | ExpressionsInStarAssignment | Too many expressions in star-unpacking assignment | |
|
||||
| F622 | TwoStarredExpressions | Two starred expressions in assignment | |
|
||||
| F631 | AssertTuple | Assert test is a non-empty tuple, which is always `True` | |
|
||||
@@ -569,7 +571,7 @@ For more, see [Pyflakes](https://pypi.org/project/pyflakes/2.5.0/) on PyPI.
|
||||
| F821 | UndefinedName | Undefined name `...` | |
|
||||
| F822 | UndefinedExport | Undefined name `...` in `__all__` | |
|
||||
| F823 | UndefinedLocal | Local variable `...` referenced before assignment | |
|
||||
| F841 | UnusedVariable | Local variable `...` is assigned to but never used | |
|
||||
| F841 | UnusedVariable | Local variable `...` is assigned to but never used | 🛠 |
|
||||
| F842 | UnusedAnnotation | Local variable `...` is annotated but never used | |
|
||||
| F901 | RaiseNotImplemented | `raise NotImplemented` should be `raise NotImplementedError` | 🛠 |
|
||||
|
||||
@@ -632,7 +634,7 @@ For more, see [pydocstyle](https://pypi.org/project/pydocstyle/6.1.1/) on PyPI.
|
||||
| D202 | NoBlankLineAfterFunction | No blank lines allowed after function docstring (found 1) | 🛠 |
|
||||
| D203 | OneBlankLineBeforeClass | 1 blank line required before class docstring | 🛠 |
|
||||
| D204 | OneBlankLineAfterClass | 1 blank line required after class docstring | 🛠 |
|
||||
| D205 | BlankLineAfterSummary | 1 blank line required between summary line and description | 🛠 |
|
||||
| D205 | BlankLineAfterSummary | 1 blank line required between summary line and description (found 2) | 🛠 |
|
||||
| D206 | IndentWithSpaces | Docstring should be indented with spaces, not tabs | |
|
||||
| D207 | NoUnderIndentation | Docstring is under-indented | 🛠 |
|
||||
| D208 | NoOverIndentation | Docstring is over-indented | 🛠 |
|
||||
@@ -767,10 +769,14 @@ For more, see [flake8-bandit](https://pypi.org/project/flake8-bandit/4.1.1/) on
|
||||
| S102 | ExecUsed | Use of `exec` detected | |
|
||||
| S103 | BadFilePermissions | `os.chmod` setting a permissive mask `0o777` on file or directory | |
|
||||
| S104 | HardcodedBindAllInterfaces | Possible binding to all interfaces | |
|
||||
| S105 | HardcodedPasswordString | Possible hardcoded password: `"..."` | |
|
||||
| S106 | HardcodedPasswordFuncArg | Possible hardcoded password: `"..."` | |
|
||||
| S107 | HardcodedPasswordDefault | Possible hardcoded password: `"..."` | |
|
||||
| S108 | HardcodedTempFile | Probable insecure usage of temp file/directory: `"..."` | |
|
||||
| S105 | HardcodedPasswordString | Possible hardcoded password: "..." | |
|
||||
| S106 | HardcodedPasswordFuncArg | Possible hardcoded password: "..." | |
|
||||
| S107 | HardcodedPasswordDefault | Possible hardcoded password: "..." | |
|
||||
| S108 | HardcodedTempFile | Probable insecure usage of temporary file or directory: "..." | |
|
||||
| S113 | RequestWithoutTimeout | Probable use of requests call without timeout | |
|
||||
| S324 | HashlibInsecureHashFunction | Probable use of insecure hash functions in `hashlib`: "..." | |
|
||||
| S501 | RequestWithNoCertValidation | Probable use of `...` call with `verify=False` disabling SSL certificate checks | |
|
||||
| S506 | UnsafeYAMLLoad | Probable use of unsafe `yaml.load`. Allows instantiation of arbitrary objects. Consider `yaml.safe_load`. | |
|
||||
|
||||
### flake8-blind-except (BLE)
|
||||
|
||||
@@ -914,20 +920,20 @@ For more, see [flake8-pytest-style](https://pypi.org/project/flake8-pytest-style
|
||||
| PT005 | IncorrectFixtureNameUnderscore | Fixture `...` returns a value, remove leading underscore | |
|
||||
| PT006 | ParametrizeNamesWrongType | Wrong name(s) type in `@pytest.mark.parametrize`, expected `tuple` | 🛠 |
|
||||
| PT007 | ParametrizeValuesWrongType | Wrong values type in `@pytest.mark.parametrize` expected `list` of `tuple` | |
|
||||
| PT008 | PatchWithLambda | Use `return_value=` instead of patching with lambda | |
|
||||
| PT009 | UnittestAssertion | Use a regular assert instead of unittest-style '...' | |
|
||||
| PT008 | PatchWithLambda | Use `return_value=` instead of patching with `lambda` | |
|
||||
| PT009 | UnittestAssertion | Use a regular `assert` instead of unittest-style `...` | 🛠 |
|
||||
| PT010 | RaisesWithoutException | set the expected exception in `pytest.raises()` | |
|
||||
| PT011 | RaisesTooBroad | `pytest.raises(...)` is too broad, set the `match` parameter or use a more specific exception | |
|
||||
| PT012 | RaisesWithMultipleStatements | `pytest.raises()` block should contain a single simple statement | |
|
||||
| PT013 | IncorrectPytestImport | Found incorrect import of pytest, use simple `import pytest` instead | |
|
||||
| PT015 | AssertAlwaysFalse | Assertion always fails, replace with `pytest.fail()` | |
|
||||
| PT016 | FailWithoutMessage | No message passed to `pytest.fail()` | |
|
||||
| PT017 | AssertInExcept | Found assertion on exception ... in except block, use pytest.raises() instead | |
|
||||
| PT017 | AssertInExcept | Found assertion on exception `...` in except block, use `pytest.raises()` instead | |
|
||||
| PT018 | CompositeAssertion | Assertion should be broken down into multiple parts | |
|
||||
| PT019 | FixtureParamWithoutValue | Fixture ... without value is injected as parameter, use @pytest.mark.usefixtures instead | |
|
||||
| PT019 | FixtureParamWithoutValue | Fixture `...` without value is injected as parameter, use `@pytest.mark.usefixtures` instead | |
|
||||
| PT020 | DeprecatedYieldFixture | `@pytest.yield_fixture` is deprecated, use `@pytest.fixture` | |
|
||||
| PT021 | FixtureFinalizerCallback | Use `yield` instead of `request.addfinalizer` | |
|
||||
| PT022 | UselessYieldFixture | No teardown in fixture ..., use `return` instead of `yield` | 🛠 |
|
||||
| PT022 | UselessYieldFixture | No teardown in fixture `...`, use `return` instead of `yield` | 🛠 |
|
||||
| PT023 | IncorrectMarkParenthesesStyle | Use `@pytest.mark....` over `@pytest.mark....()` | 🛠 |
|
||||
| PT024 | UnnecessaryAsyncioMarkOnFixture | `pytest.mark.asyncio` is unnecessary for fixtures | |
|
||||
| PT025 | ErroneousUseFixturesOnFixture | `pytest.mark.usefixtures` has no effect on fixtures | |
|
||||
@@ -965,13 +971,23 @@ For more, see [flake8-simplify](https://pypi.org/project/flake8-simplify/0.19.3/
|
||||
|
||||
| Code | Name | Message | Fix |
|
||||
| ---- | ---- | ------- | --- |
|
||||
| SIM101 | DuplicateIsinstanceCall | Multiple `isinstance` calls for `...`, merge into a single call | 🛠 |
|
||||
| SIM102 | NestedIfStatements | Use a single `if` statement instead of nested `if` statements | |
|
||||
| SIM103 | ReturnBoolConditionDirectly | Return the condition `...` directly | 🛠 |
|
||||
| SIM105 | UseContextlibSuppress | Use `contextlib.suppress(...)` instead of try-except-pass | |
|
||||
| SIM107 | ReturnInTryExceptFinally | Don't use `return` in `try`/`except` and `finally` | |
|
||||
| SIM108 | UseTernaryOperator | Use ternary operator `...` instead of if-else-block | 🛠 |
|
||||
| SIM109 | CompareWithTuple | Use `value in (..., ...)` instead of `value == ... or value == ...` | 🛠 |
|
||||
| SIM110 | ConvertLoopToAny | Use `return any(x for x in y)` instead of `for` loop | 🛠 |
|
||||
| SIM111 | ConvertLoopToAll | Use `return all(x for x in y)` instead of `for` loop | 🛠 |
|
||||
| SIM117 | MultipleWithStatements | Use a single `with` statement with multiple contexts instead of nested `with` statements | |
|
||||
| SIM118 | KeyInDict | Use `key in dict` instead of `key in dict.keys()` | 🛠 |
|
||||
| SIM201 | NegateEqualOp | Use `left != right` instead of `not left == right` | 🛠 |
|
||||
| SIM202 | NegateNotEqualOp | Use `left == right` instead of `not left != right` | 🛠 |
|
||||
| SIM208 | DoubleNegation | Use `expr` instead of `not (not expr)` | 🛠 |
|
||||
| SIM210 | IfExprWithTrueFalse | Use `bool(expr)` instead of `True if expr else False` | 🛠 |
|
||||
| SIM211 | IfExprWithFalseTrue | Use `not expr` instead of `False if expr else True` | 🛠 |
|
||||
| SIM212 | IfExprWithTwistedArms | Use `b if b else a` instead of `a if not b else b` | 🛠 |
|
||||
| SIM220 | AAndNotA | Use `False` instead of `... and not ...` | 🛠 |
|
||||
| SIM221 | AOrNotA | Use `True` instead of `... or not ...` | 🛠 |
|
||||
| SIM222 | OrTrue | Use `True` instead of `... or True` | 🛠 |
|
||||
@@ -1317,8 +1333,9 @@ jobs:
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install ruff
|
||||
# Include `--format=github` to enable automatic inline annotations.
|
||||
- name: Run Ruff
|
||||
run: ruff .
|
||||
run: ruff --format=github .
|
||||
```
|
||||
|
||||
## FAQ
|
||||
@@ -2459,9 +2476,10 @@ the `extend_aliases` option.
|
||||
|
||||
```toml
|
||||
[tool.ruff.flake8-import-conventions]
|
||||
[tool.ruff.flake8-import-conventions.aliases]
|
||||
# Declare the default aliases.
|
||||
altair = "alt"
|
||||
matplotlib.pyplot = "plt"
|
||||
"matplotlib.pyplot" = "plt"
|
||||
numpy = "np"
|
||||
pandas = "pd"
|
||||
seaborn = "sns"
|
||||
@@ -2482,6 +2500,7 @@ will be added to the `aliases` mapping.
|
||||
|
||||
```toml
|
||||
[tool.ruff.flake8-import-conventions]
|
||||
[tool.ruff.flake8-import-conventions.extend-aliases]
|
||||
# Declare a custom alias for the `matplotlib` module.
|
||||
"dask.dataframe" = "dd"
|
||||
```
|
||||
@@ -3111,4 +3130,4 @@ MIT
|
||||
## Contributing
|
||||
|
||||
Contributions are welcome and hugely appreciated. To get started, check out the
|
||||
[contributing guidelines](https://github.com/charliermarsh/ruff/blob/main/CONTRIBUTING.md).
|
||||
[contributing guidelines](https://github.com/charliermarsh/ruff/blob/main/.github/CONTRIBUTING.md).
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
{
|
||||
"label": "",
|
||||
"message": "Ruff",
|
||||
"logoSvg": "<svg xmlns=\"http://www.w3.org/2000/svg\" width=\"128\" height=\"128\"><path d=\"M115.36 61.84 70.22 50.49 114.45 2.4a1.222 1.222 0 0 0-1.54-1.87L12.3 61.98c-.41.25-.64.72-.57 1.2.06.48.4.87.87 1.01l45.07 13.25-44.29 48.16c-.42.46-.44 1.15-.04 1.61.24.29.58.44.94.44.22 0 .45-.06.65-.19l100.78-63.41c.42-.26.64-.75.56-1.22-.08-.49-.43-.88-.91-.99z\" style=\"fill:#fcc21b\"/></svg>",
|
||||
"logoWidth": 10,
|
||||
"labelColor": "grey",
|
||||
"color": "#E15759"
|
||||
"label": "",
|
||||
"message": "Ruff",
|
||||
"logoSvg": "<svg xmlns=\"http://www.w3.org/2000/svg\" width=\"128\" height=\"128\"><path d=\"M115.36 61.84 70.22 50.49 114.45 2.4a1.222 1.222 0 0 0-1.54-1.87L12.3 61.98c-.41.25-.64.72-.57 1.2.06.48.4.87.87 1.01l45.07 13.25-44.29 48.16c-.42.46-.44 1.15-.04 1.61.24.29.58.44.94.44.22 0 .45-.06.65-.19l100.78-63.41c.42-.26.64-.75.56-1.22-.08-.49-.43-.88-.91-.99z\" style=\"fill:#fcc21b\"/></svg>",
|
||||
"logoWidth": 10,
|
||||
"labelColor": "grey",
|
||||
"color": "#E15759"
|
||||
}
|
||||
|
||||
8
assets/badge/v1.json
Normal file
8
assets/badge/v1.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "",
|
||||
"message": "Ruff",
|
||||
"logoSvg": "<svg xmlns=\"http://www.w3.org/2000/svg\" width=\"109\" height=\"132\" fill=\"none\"><g filter=\"url(#a)\"><path fill=\"#FCC21B\" d=\"m103.642 61.492-45.14-11.35 44.23-48.09a1.222 1.222 0 0 0-1.54-1.87L.582 61.632c-.41.25-.64.72-.57 1.2.06.48.4.87.87 1.01l45.07 13.25-44.29 48.16c-.42.46-.44 1.15-.04 1.61.24.29.58.44.94.44.22 0 .45-.06.65-.19l100.78-63.41c.42-.26.64-.75.56-1.22-.08-.49-.43-.88-.91-.99Z\"/></g><defs><filter id=\"a\" width=\"108.569\" height=\"131.302\" x=\"0\" y=\"0\" color-interpolation-filters=\"sRGB\" filterUnits=\"userSpaceOnUse\"><feFlood flood-opacity=\"0\" result=\"BackgroundImageFix\"/><feColorMatrix in=\"SourceAlpha\" result=\"hardAlpha\" values=\"0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 127 0\"/><feOffset dx=\"4\" dy=\"4\"/><feComposite in2=\"hardAlpha\" operator=\"out\"/><feColorMatrix values=\"0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0\"/><feBlend in2=\"BackgroundImageFix\" result=\"effect1_dropShadow_7_4\"/><feBlend in=\"SourceGraphic\" in2=\"effect1_dropShadow_7_4\" result=\"shape\"/></filter></defs></svg>",
|
||||
"logoWidth": 10,
|
||||
"labelColor": "grey",
|
||||
"color": "#E15759"
|
||||
}
|
||||
4
flake8_to_ruff/Cargo.lock
generated
4
flake8_to_ruff/Cargo.lock
generated
@@ -771,7 +771,7 @@ checksum = "0ce7134b9999ecaf8bcd65542e436736ef32ddca1b3e06094cb6ec5755203b80"
|
||||
|
||||
[[package]]
|
||||
name = "flake8_to_ruff"
|
||||
version = "0.0.211"
|
||||
version = "0.0.215"
|
||||
dependencies = [
|
||||
"anyhow",
|
||||
"clap",
|
||||
@@ -1975,7 +1975,7 @@ dependencies = [
|
||||
|
||||
[[package]]
|
||||
name = "ruff"
|
||||
version = "0.0.211"
|
||||
version = "0.0.215"
|
||||
dependencies = [
|
||||
"anyhow",
|
||||
"bincode",
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[package]
|
||||
name = "flake8-to-ruff"
|
||||
version = "0.0.211-dev.0"
|
||||
version = "0.0.215-dev.0"
|
||||
edition = "2021"
|
||||
|
||||
[lib]
|
||||
@@ -18,7 +18,7 @@ serde = { version = "1.0.147", features = ["derive"] }
|
||||
serde_json = { version = "1.0.87" }
|
||||
strum = { version = "0.24.1", features = ["strum_macros"] }
|
||||
strum_macros = { version = "0.24.3" }
|
||||
toml = { version = "0.5.9" }
|
||||
toml_edit = { version = "0.17.1", features = ["easy"] }
|
||||
|
||||
[dev-dependencies]
|
||||
|
||||
|
||||
@@ -26,7 +26,7 @@ struct Pyproject {
|
||||
|
||||
pub fn parse_black_options<P: AsRef<Path>>(path: P) -> Result<Option<Black>> {
|
||||
let contents = std::fs::read_to_string(path)?;
|
||||
Ok(toml::from_str::<Pyproject>(&contents)?
|
||||
Ok(toml_edit::easy::from_str::<Pyproject>(&contents)?
|
||||
.tool
|
||||
.and_then(|tool| tool.black))
|
||||
}
|
||||
|
||||
@@ -7,7 +7,7 @@ use ruff::flake8_pytest_style::types::{
|
||||
use ruff::flake8_quotes::settings::Quote;
|
||||
use ruff::flake8_tidy_imports::settings::Strictness;
|
||||
use ruff::pydocstyle::settings::Convention;
|
||||
use ruff::registry_gen::CheckCodePrefix;
|
||||
use ruff::registry::CheckCodePrefix;
|
||||
use ruff::settings::options::Options;
|
||||
use ruff::settings::pyproject::Pyproject;
|
||||
use ruff::{
|
||||
@@ -345,7 +345,7 @@ mod tests {
|
||||
|
||||
use anyhow::Result;
|
||||
use ruff::pydocstyle::settings::Convention;
|
||||
use ruff::registry_gen::CheckCodePrefix;
|
||||
use ruff::registry::CheckCodePrefix;
|
||||
use ruff::settings::options::Options;
|
||||
use ruff::settings::pyproject::Pyproject;
|
||||
use ruff::{flake8_quotes, pydocstyle};
|
||||
|
||||
@@ -10,6 +10,7 @@
|
||||
clippy::similar_names,
|
||||
clippy::too_many_lines
|
||||
)]
|
||||
#![forbid(unsafe_code)]
|
||||
|
||||
pub mod black;
|
||||
pub mod converter;
|
||||
|
||||
@@ -11,6 +11,7 @@
|
||||
clippy::similar_names,
|
||||
clippy::too_many_lines
|
||||
)]
|
||||
#![forbid(unsafe_code)]
|
||||
|
||||
use std::path::PathBuf;
|
||||
|
||||
@@ -57,7 +58,7 @@ fn main() -> Result<()> {
|
||||
|
||||
// Create Ruff's pyproject.toml section.
|
||||
let pyproject = converter::convert(&config, black.as_ref(), cli.plugin)?;
|
||||
println!("{}", toml::to_string_pretty(&pyproject)?);
|
||||
println!("{}", toml_edit::easy::to_string_pretty(&pyproject)?);
|
||||
|
||||
Ok(())
|
||||
}
|
||||
|
||||
@@ -3,8 +3,7 @@ use std::str::FromStr;
|
||||
use anyhow::{bail, Result};
|
||||
use once_cell::sync::Lazy;
|
||||
use regex::Regex;
|
||||
use ruff::registry::PREFIX_REDIRECTS;
|
||||
use ruff::registry_gen::CheckCodePrefix;
|
||||
use ruff::registry::{CheckCodePrefix, PREFIX_REDIRECTS};
|
||||
use ruff::settings::types::PatternPrefixPair;
|
||||
use rustc_hash::FxHashMap;
|
||||
|
||||
@@ -128,7 +127,7 @@ fn tokenize_files_to_codes_mapping(value: &str) -> Vec<Token> {
|
||||
if mat.start() == 0 {
|
||||
tokens.push(Token {
|
||||
token_name,
|
||||
src: mat.as_str().to_string().trim().to_string(),
|
||||
src: mat.as_str().trim().to_string(),
|
||||
});
|
||||
i += mat.end();
|
||||
break;
|
||||
@@ -201,7 +200,7 @@ pub fn collect_per_file_ignores(
|
||||
#[cfg(test)]
|
||||
mod tests {
|
||||
use anyhow::Result;
|
||||
use ruff::registry_gen::CheckCodePrefix;
|
||||
use ruff::registry::CheckCodePrefix;
|
||||
use ruff::settings::types::PatternPrefixPair;
|
||||
|
||||
use crate::parser::{parse_files_to_codes_mapping, parse_prefix_codes, parse_strings};
|
||||
|
||||
@@ -3,7 +3,7 @@ use std::fmt;
|
||||
use std::str::FromStr;
|
||||
|
||||
use anyhow::anyhow;
|
||||
use ruff::registry_gen::CheckCodePrefix;
|
||||
use ruff::registry::CheckCodePrefix;
|
||||
|
||||
#[derive(Clone, Ord, PartialOrd, Eq, PartialEq)]
|
||||
pub enum Plugin {
|
||||
|
||||
@@ -4,7 +4,7 @@ build-backend = "maturin"
|
||||
|
||||
[project]
|
||||
name = "ruff"
|
||||
version = "0.0.211"
|
||||
version = "0.0.215"
|
||||
description = "An extremely fast Python linter, written in Rust."
|
||||
authors = [
|
||||
{ name = "Charlie Marsh", email = "charlie.r.marsh@gmail.com" },
|
||||
|
||||
23
resources/test/fixtures/flake8_bandit/S113.py
vendored
Normal file
23
resources/test/fixtures/flake8_bandit/S113.py
vendored
Normal file
@@ -0,0 +1,23 @@
|
||||
import requests
|
||||
|
||||
requests.get('https://gmail.com')
|
||||
requests.get('https://gmail.com', timeout=None)
|
||||
requests.get('https://gmail.com', timeout=5)
|
||||
requests.post('https://gmail.com')
|
||||
requests.post('https://gmail.com', timeout=None)
|
||||
requests.post('https://gmail.com', timeout=5)
|
||||
requests.put('https://gmail.com')
|
||||
requests.put('https://gmail.com', timeout=None)
|
||||
requests.put('https://gmail.com', timeout=5)
|
||||
requests.delete('https://gmail.com')
|
||||
requests.delete('https://gmail.com', timeout=None)
|
||||
requests.delete('https://gmail.com', timeout=5)
|
||||
requests.patch('https://gmail.com')
|
||||
requests.patch('https://gmail.com', timeout=None)
|
||||
requests.patch('https://gmail.com', timeout=5)
|
||||
requests.options('https://gmail.com')
|
||||
requests.options('https://gmail.com', timeout=None)
|
||||
requests.options('https://gmail.com', timeout=5)
|
||||
requests.head('https://gmail.com')
|
||||
requests.head('https://gmail.com', timeout=None)
|
||||
requests.head('https://gmail.com', timeout=5)
|
||||
52
resources/test/fixtures/flake8_bandit/S324.py
vendored
Normal file
52
resources/test/fixtures/flake8_bandit/S324.py
vendored
Normal file
@@ -0,0 +1,52 @@
|
||||
import hashlib
|
||||
from hashlib import new as hashlib_new
|
||||
from hashlib import sha1 as hashlib_sha1
|
||||
|
||||
# Invalid
|
||||
|
||||
hashlib.new('md5')
|
||||
|
||||
hashlib.new('md4', b'test')
|
||||
|
||||
hashlib.new(name='md5', data=b'test')
|
||||
|
||||
hashlib.new('MD4', data=b'test')
|
||||
|
||||
hashlib.new('sha1')
|
||||
|
||||
hashlib.new('sha1', data=b'test')
|
||||
|
||||
hashlib.new('sha', data=b'test')
|
||||
|
||||
hashlib.new(name='SHA', data=b'test')
|
||||
|
||||
hashlib.sha(data=b'test')
|
||||
|
||||
hashlib.md5()
|
||||
|
||||
hashlib_new('sha1')
|
||||
|
||||
hashlib_sha1('sha1')
|
||||
|
||||
# usedforsecurity arg only available in Python 3.9+
|
||||
hashlib.new('sha1', usedforsecurity=True)
|
||||
|
||||
# Valid
|
||||
|
||||
hashlib.new('sha256')
|
||||
|
||||
hashlib.new('SHA512')
|
||||
|
||||
hashlib.sha256(data=b'test')
|
||||
|
||||
# usedforsecurity arg only available in Python 3.9+
|
||||
hashlib_new(name='sha1', usedforsecurity=False)
|
||||
|
||||
# usedforsecurity arg only available in Python 3.9+
|
||||
hashlib_sha1(name='sha1', usedforsecurity=False)
|
||||
|
||||
# usedforsecurity arg only available in Python 3.9+
|
||||
hashlib.md4(usedforsecurity=False)
|
||||
|
||||
# usedforsecurity arg only available in Python 3.9+
|
||||
hashlib.new(name='sha256', usedforsecurity=False)
|
||||
40
resources/test/fixtures/flake8_bandit/S501.py
vendored
Normal file
40
resources/test/fixtures/flake8_bandit/S501.py
vendored
Normal file
@@ -0,0 +1,40 @@
|
||||
import httpx
|
||||
import requests
|
||||
|
||||
requests.get('https://gmail.com', timeout=30, verify=True)
|
||||
requests.get('https://gmail.com', timeout=30, verify=False)
|
||||
requests.post('https://gmail.com', timeout=30, verify=True)
|
||||
requests.post('https://gmail.com', timeout=30, verify=False)
|
||||
requests.put('https://gmail.com', timeout=30, verify=True)
|
||||
requests.put('https://gmail.com', timeout=30, verify=False)
|
||||
requests.delete('https://gmail.com', timeout=30, verify=True)
|
||||
requests.delete('https://gmail.com', timeout=30, verify=False)
|
||||
requests.patch('https://gmail.com', timeout=30, verify=True)
|
||||
requests.patch('https://gmail.com', timeout=30, verify=False)
|
||||
requests.options('https://gmail.com', timeout=30, verify=True)
|
||||
requests.options('https://gmail.com', timeout=30, verify=False)
|
||||
requests.head('https://gmail.com', timeout=30, verify=True)
|
||||
requests.head('https://gmail.com', timeout=30, verify=False)
|
||||
|
||||
httpx.request('GET', 'https://gmail.com', verify=True)
|
||||
httpx.request('GET', 'https://gmail.com', verify=False)
|
||||
httpx.get('https://gmail.com', verify=True)
|
||||
httpx.get('https://gmail.com', verify=False)
|
||||
httpx.options('https://gmail.com', verify=True)
|
||||
httpx.options('https://gmail.com', verify=False)
|
||||
httpx.head('https://gmail.com', verify=True)
|
||||
httpx.head('https://gmail.com', verify=False)
|
||||
httpx.post('https://gmail.com', verify=True)
|
||||
httpx.post('https://gmail.com', verify=False)
|
||||
httpx.put('https://gmail.com', verify=True)
|
||||
httpx.put('https://gmail.com', verify=False)
|
||||
httpx.patch('https://gmail.com', verify=True)
|
||||
httpx.patch('https://gmail.com', verify=False)
|
||||
httpx.delete('https://gmail.com', verify=True)
|
||||
httpx.delete('https://gmail.com', verify=False)
|
||||
httpx.stream('https://gmail.com', verify=True)
|
||||
httpx.stream('https://gmail.com', verify=False)
|
||||
httpx.Client()
|
||||
httpx.Client(verify=False)
|
||||
httpx.AsyncClient()
|
||||
httpx.AsyncClient(verify=False)
|
||||
31
resources/test/fixtures/flake8_bandit/S506.py
vendored
Normal file
31
resources/test/fixtures/flake8_bandit/S506.py
vendored
Normal file
@@ -0,0 +1,31 @@
|
||||
import json
|
||||
import yaml
|
||||
from yaml import CSafeLoader
|
||||
from yaml import SafeLoader
|
||||
from yaml import SafeLoader as NewSafeLoader
|
||||
|
||||
|
||||
def test_yaml_load():
|
||||
ystr = yaml.dump({"a": 1, "b": 2, "c": 3})
|
||||
y = yaml.load(ystr)
|
||||
yaml.dump(y)
|
||||
try:
|
||||
y = yaml.load(ystr, Loader=yaml.CSafeLoader)
|
||||
except AttributeError:
|
||||
# CSafeLoader only exists if you build yaml with LibYAML
|
||||
y = yaml.load(ystr, Loader=yaml.SafeLoader)
|
||||
|
||||
|
||||
def test_json_load():
|
||||
# no issue should be found
|
||||
j = json.load("{}")
|
||||
|
||||
|
||||
yaml.load("{}", Loader=yaml.Loader)
|
||||
|
||||
# no issue should be found
|
||||
yaml.load("{}", SafeLoader)
|
||||
yaml.load("{}", yaml.SafeLoader)
|
||||
yaml.load("{}", CSafeLoader)
|
||||
yaml.load("{}", yaml.CSafeLoader)
|
||||
yaml.load("{}", NewSafeLoader)
|
||||
@@ -1,9 +1,76 @@
|
||||
import pytest
|
||||
import unittest
|
||||
|
||||
|
||||
def test_xxx():
|
||||
assert 1 == 1 # OK no parameters
|
||||
class Test(unittest.TestCase):
|
||||
def test_xxx(self):
|
||||
assert 1 == 1 # OK no parameters
|
||||
|
||||
def test_assert_true(self):
|
||||
expr = 1
|
||||
msg = "Must be True"
|
||||
self.assertTrue(expr) # Error
|
||||
self.assertTrue(expr=expr) # Error
|
||||
self.assertTrue(expr, msg) # Error
|
||||
self.assertTrue(expr=expr, msg=msg) # Error
|
||||
self.assertTrue(msg=msg, expr=expr) # Error
|
||||
self.assertTrue(*(expr, msg)) # Error, unfixable
|
||||
self.assertTrue(**{"expr": expr, "msg": msg}) # Error, unfixable
|
||||
self.assertTrue(msg=msg, expr=expr, unexpected_arg=False) # Error, unfixable
|
||||
self.assertTrue(msg=msg) # Error, unfixable
|
||||
|
||||
def test_xxx():
|
||||
self.assertEqual(1, 1) # Error
|
||||
def test_assert_false(self):
|
||||
self.assertFalse(True) # Error
|
||||
|
||||
def test_assert_equal(self):
|
||||
self.assertEqual(1, 2) # Error
|
||||
|
||||
def test_assert_not_equal(self):
|
||||
self.assertNotEqual(1, 1) # Error
|
||||
|
||||
def test_assert_greater(self):
|
||||
self.assertGreater(1, 2) # Error
|
||||
|
||||
def test_assert_greater_equal(self):
|
||||
self.assertGreaterEqual(1, 2) # Error
|
||||
|
||||
def test_assert_less(self):
|
||||
self.assertLess(2, 1) # Error
|
||||
|
||||
def test_assert_less_equal(self):
|
||||
self.assertLessEqual(1, 2) # Error
|
||||
|
||||
def test_assert_in(self):
|
||||
self.assertIn(1, [2, 3]) # Error
|
||||
|
||||
def test_assert_not_in(self):
|
||||
self.assertNotIn(2, [2, 3]) # Error
|
||||
|
||||
def test_assert_is_none(self):
|
||||
self.assertIsNone(0) # Error
|
||||
|
||||
def test_assert_is_not_none(self):
|
||||
self.assertIsNotNone(0) # Error
|
||||
|
||||
def test_assert_is(self):
|
||||
self.assertIs([], []) # Error
|
||||
|
||||
def test_assert_is_not(self):
|
||||
self.assertIsNot(1, 1) # Error
|
||||
|
||||
def test_assert_is_instance(self):
|
||||
self.assertIsInstance(1, str) # Error
|
||||
|
||||
def test_assert_is_not_instance(self):
|
||||
self.assertNotIsInstance(1, int) # Error
|
||||
|
||||
def test_assert_regex(self):
|
||||
self.assertRegex("abc", r"def") # Error
|
||||
|
||||
def test_assert_not_regex(self):
|
||||
self.assertNotRegex("abc", r"abc") # Error
|
||||
|
||||
def test_assert_regexp_matches(self):
|
||||
self.assertRegexpMatches("abc", r"def") # Error
|
||||
|
||||
def test_assert_not_regexp_matches(self):
|
||||
self.assertNotRegex("abc", r"abc") # Error
|
||||
|
||||
23
resources/test/fixtures/flake8_simplify/SIM101.py
vendored
Normal file
23
resources/test/fixtures/flake8_simplify/SIM101.py
vendored
Normal file
@@ -0,0 +1,23 @@
|
||||
if isinstance(a, int) or isinstance(a, float): # SIM101
|
||||
pass
|
||||
|
||||
if isinstance(a, (int, float)) or isinstance(a, bool): # SIM101
|
||||
pass
|
||||
|
||||
if isinstance(a, int) or isinstance(a, float) or isinstance(b, bool): # SIM101
|
||||
pass
|
||||
|
||||
if isinstance(b, bool) or isinstance(a, int) or isinstance(a, float): # SIM101
|
||||
pass
|
||||
|
||||
if isinstance(a, int) or isinstance(b, bool) or isinstance(a, float): # SIM101
|
||||
pass
|
||||
|
||||
if (isinstance(a, int) or isinstance(a, float)) and isinstance(b, bool): # SIM101
|
||||
pass
|
||||
|
||||
if isinstance(a, int) and isinstance(b, bool) or isinstance(a, float):
|
||||
pass
|
||||
|
||||
if isinstance(a, bool) or isinstance(b, str):
|
||||
pass
|
||||
20
resources/test/fixtures/flake8_simplify/SIM103.py
vendored
Normal file
20
resources/test/fixtures/flake8_simplify/SIM103.py
vendored
Normal file
@@ -0,0 +1,20 @@
|
||||
def f():
|
||||
if a: # SIM103
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
def f():
|
||||
if a: # OK
|
||||
foo()
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
def f():
|
||||
if a: # OK
|
||||
return "foo"
|
||||
else:
|
||||
return False
|
||||
31
resources/test/fixtures/flake8_simplify/SIM108.py
vendored
Normal file
31
resources/test/fixtures/flake8_simplify/SIM108.py
vendored
Normal file
@@ -0,0 +1,31 @@
|
||||
# Bad
|
||||
if a:
|
||||
b = c
|
||||
else:
|
||||
b = d
|
||||
|
||||
# Good
|
||||
b = c if a else d
|
||||
|
||||
# https://github.com/MartinThoma/flake8-simplify/issues/115
|
||||
if a:
|
||||
b = c
|
||||
elif c:
|
||||
b = a
|
||||
else:
|
||||
b = d
|
||||
|
||||
if True:
|
||||
pass
|
||||
elif a:
|
||||
b = 1
|
||||
else:
|
||||
b = 2
|
||||
|
||||
if True:
|
||||
pass
|
||||
else:
|
||||
if a:
|
||||
b = 1
|
||||
else:
|
||||
b = 2
|
||||
7
resources/test/fixtures/flake8_simplify/SIM109.py
vendored
Normal file
7
resources/test/fixtures/flake8_simplify/SIM109.py
vendored
Normal file
@@ -0,0 +1,7 @@
|
||||
# Bad
|
||||
if a == b or a == c:
|
||||
d
|
||||
|
||||
# Good
|
||||
if a in (b, c):
|
||||
d
|
||||
17
resources/test/fixtures/flake8_simplify/SIM201.py
vendored
Normal file
17
resources/test/fixtures/flake8_simplify/SIM201.py
vendored
Normal file
@@ -0,0 +1,17 @@
|
||||
if not a == b: # SIM201
|
||||
pass
|
||||
|
||||
if not a == (b + c): # SIM201
|
||||
pass
|
||||
|
||||
if not (a + b) == c: # SIM201
|
||||
pass
|
||||
|
||||
if not a != b: # OK
|
||||
pass
|
||||
|
||||
if a == b: # OK
|
||||
pass
|
||||
|
||||
if not a == b: # OK
|
||||
raise ValueError()
|
||||
14
resources/test/fixtures/flake8_simplify/SIM202.py
vendored
Normal file
14
resources/test/fixtures/flake8_simplify/SIM202.py
vendored
Normal file
@@ -0,0 +1,14 @@
|
||||
if not a != b: # SIM202
|
||||
pass
|
||||
|
||||
if not a != (b + c): # SIM202
|
||||
pass
|
||||
|
||||
if not (a + b) != c: # SIM202
|
||||
pass
|
||||
|
||||
if not a == b: # OK
|
||||
pass
|
||||
|
||||
if a != b: # OK
|
||||
pass
|
||||
14
resources/test/fixtures/flake8_simplify/SIM208.py
vendored
Normal file
14
resources/test/fixtures/flake8_simplify/SIM208.py
vendored
Normal file
@@ -0,0 +1,14 @@
|
||||
if not (not a): # SIM208
|
||||
pass
|
||||
|
||||
if not (not (a == b)): # SIM208
|
||||
pass
|
||||
|
||||
if not a: # OK
|
||||
pass
|
||||
|
||||
if not a == b: # OK
|
||||
pass
|
||||
|
||||
if not a != b: # OK
|
||||
pass
|
||||
7
resources/test/fixtures/flake8_simplify/SIM210.py
vendored
Normal file
7
resources/test/fixtures/flake8_simplify/SIM210.py
vendored
Normal file
@@ -0,0 +1,7 @@
|
||||
a = True if b else False # SIM210
|
||||
|
||||
a = True if b != c else False # SIM210
|
||||
|
||||
a = True if b + c else False # SIM210
|
||||
|
||||
a = False if b else True # OK
|
||||
7
resources/test/fixtures/flake8_simplify/SIM211.py
vendored
Normal file
7
resources/test/fixtures/flake8_simplify/SIM211.py
vendored
Normal file
@@ -0,0 +1,7 @@
|
||||
a = False if b else True # SIM211
|
||||
|
||||
a = False if b != c else True # SIM211
|
||||
|
||||
a = False if b + c else True # SIM211
|
||||
|
||||
a = True if b else False # OK
|
||||
7
resources/test/fixtures/flake8_simplify/SIM212.py
vendored
Normal file
7
resources/test/fixtures/flake8_simplify/SIM212.py
vendored
Normal file
@@ -0,0 +1,7 @@
|
||||
c = b if not a else a # SIM212
|
||||
|
||||
c = b + c if not a else a # SIM212
|
||||
|
||||
c = b if not x else a # OK
|
||||
|
||||
c = a if a else b # OK
|
||||
28
resources/test/fixtures/isort/skip.py
vendored
28
resources/test/fixtures/isort/skip.py
vendored
@@ -1,10 +1,20 @@
|
||||
# isort: off
|
||||
import sys
|
||||
import os
|
||||
import collections
|
||||
# isort: on
|
||||
def f():
|
||||
# isort: off
|
||||
import sys
|
||||
import os
|
||||
import collections
|
||||
# isort: on
|
||||
|
||||
import sys
|
||||
import os # isort: skip
|
||||
import collections
|
||||
import abc
|
||||
|
||||
def f():
|
||||
import sys
|
||||
import os # isort: skip
|
||||
import collections
|
||||
import abc
|
||||
|
||||
|
||||
def f():
|
||||
import sys
|
||||
import os # isort:skip
|
||||
import collections
|
||||
import abc
|
||||
|
||||
7
resources/test/fixtures/isort/split.py
vendored
7
resources/test/fixtures/isort/split.py
vendored
@@ -3,7 +3,10 @@ import f
|
||||
|
||||
# isort: split
|
||||
|
||||
import a
|
||||
import b
|
||||
import c
|
||||
import d
|
||||
|
||||
# isort: split
|
||||
|
||||
import a
|
||||
import b
|
||||
|
||||
2
resources/test/fixtures/pycodestyle/E999.py
vendored
2
resources/test/fixtures/pycodestyle/E999.py
vendored
@@ -1,2 +1,4 @@
|
||||
|
||||
def x():
|
||||
|
||||
|
||||
|
||||
38
resources/test/fixtures/pyflakes/F601.py
vendored
38
resources/test/fixtures/pyflakes/F601.py
vendored
@@ -10,3 +10,41 @@ x = {
|
||||
b"123": 1,
|
||||
b"123": 4,
|
||||
}
|
||||
|
||||
x = {
|
||||
"a": 1,
|
||||
"a": 2,
|
||||
"a": 3,
|
||||
"a": 3,
|
||||
}
|
||||
|
||||
x = {
|
||||
"a": 1,
|
||||
"a": 2,
|
||||
"a": 3,
|
||||
"a": 3,
|
||||
"a": 4,
|
||||
}
|
||||
|
||||
x = {
|
||||
"a": 1,
|
||||
"a": 1,
|
||||
"a": 2,
|
||||
"a": 3,
|
||||
"a": 4,
|
||||
}
|
||||
|
||||
x = {
|
||||
a: 1,
|
||||
"a": 1,
|
||||
a: 1,
|
||||
"a": 2,
|
||||
a: 2,
|
||||
"a": 3,
|
||||
a: 3,
|
||||
"a": 3,
|
||||
a: 4,
|
||||
}
|
||||
|
||||
x = {"a": 1, "a": 1}
|
||||
x = {"a": 1, "b": 2, "a": 1}
|
||||
|
||||
38
resources/test/fixtures/pyflakes/F602.py
vendored
38
resources/test/fixtures/pyflakes/F602.py
vendored
@@ -5,3 +5,41 @@ x = {
|
||||
a: 2,
|
||||
b: 3,
|
||||
}
|
||||
|
||||
x = {
|
||||
a: 1,
|
||||
a: 2,
|
||||
a: 3,
|
||||
a: 3,
|
||||
}
|
||||
|
||||
x = {
|
||||
a: 1,
|
||||
a: 2,
|
||||
a: 3,
|
||||
a: 3,
|
||||
a: 4,
|
||||
}
|
||||
|
||||
x = {
|
||||
a: 1,
|
||||
a: 1,
|
||||
a: 2,
|
||||
a: 3,
|
||||
a: 4,
|
||||
}
|
||||
|
||||
x = {
|
||||
a: 1,
|
||||
"a": 1,
|
||||
a: 1,
|
||||
"a": 2,
|
||||
a: 2,
|
||||
"a": 3,
|
||||
a: 3,
|
||||
"a": 3,
|
||||
a: 4,
|
||||
}
|
||||
|
||||
x = {a: 1, a: 1}
|
||||
x = {a: 1, b: 2, a: 1}
|
||||
|
||||
46
resources/test/fixtures/pyflakes/F841_3.py
vendored
Normal file
46
resources/test/fixtures/pyflakes/F841_3.py
vendored
Normal file
@@ -0,0 +1,46 @@
|
||||
"""Test case for autofixing F841 violations."""
|
||||
|
||||
|
||||
def f():
|
||||
x = 1
|
||||
y = 2
|
||||
|
||||
z = 3
|
||||
print(z)
|
||||
|
||||
|
||||
def f():
|
||||
x: int = 1
|
||||
y: int = 2
|
||||
|
||||
z: int = 3
|
||||
print(z)
|
||||
|
||||
|
||||
def f():
|
||||
with foo() as x1:
|
||||
pass
|
||||
|
||||
with foo() as (x2, y2):
|
||||
pass
|
||||
|
||||
with (foo() as x3, foo() as y3, foo() as z3):
|
||||
pass
|
||||
|
||||
|
||||
def f():
|
||||
(x1, y1) = (1, 2)
|
||||
(x2, y2) = coords2 = (1, 2)
|
||||
coords3 = (x3, y3) = (1, 2)
|
||||
|
||||
|
||||
def f():
|
||||
try:
|
||||
1 / 0
|
||||
except ValueError as x1:
|
||||
pass
|
||||
|
||||
try:
|
||||
1 / 0
|
||||
except (ValueError, ZeroDivisionError) as x2:
|
||||
pass
|
||||
10
resources/test/fixtures/pyupgrade/UP028_1.py
vendored
10
resources/test/fixtures/pyupgrade/UP028_1.py
vendored
@@ -111,3 +111,13 @@ def f():
|
||||
class C:
|
||||
def __init__(self):
|
||||
print(x)
|
||||
|
||||
|
||||
def f():
|
||||
for x in y:
|
||||
yield x, x + 1
|
||||
|
||||
|
||||
def f():
|
||||
for x, y in z:
|
||||
yield x, y, x + y
|
||||
|
||||
@@ -927,18 +927,39 @@
|
||||
"S106",
|
||||
"S107",
|
||||
"S108",
|
||||
"S11",
|
||||
"S113",
|
||||
"S3",
|
||||
"S32",
|
||||
"S324",
|
||||
"S5",
|
||||
"S50",
|
||||
"S501",
|
||||
"S506",
|
||||
"SIM",
|
||||
"SIM1",
|
||||
"SIM10",
|
||||
"SIM101",
|
||||
"SIM102",
|
||||
"SIM103",
|
||||
"SIM105",
|
||||
"SIM107",
|
||||
"SIM108",
|
||||
"SIM109",
|
||||
"SIM11",
|
||||
"SIM110",
|
||||
"SIM111",
|
||||
"SIM117",
|
||||
"SIM118",
|
||||
"SIM2",
|
||||
"SIM20",
|
||||
"SIM201",
|
||||
"SIM202",
|
||||
"SIM208",
|
||||
"SIM21",
|
||||
"SIM210",
|
||||
"SIM211",
|
||||
"SIM212",
|
||||
"SIM22",
|
||||
"SIM220",
|
||||
"SIM221",
|
||||
|
||||
@@ -1,19 +1,18 @@
|
||||
[package]
|
||||
name = "ruff_dev"
|
||||
version = "0.0.211"
|
||||
version = "0.0.215"
|
||||
edition = "2021"
|
||||
|
||||
[dependencies]
|
||||
anyhow = { version = "1.0.66" }
|
||||
clap = { version = "4.0.1", features = ["derive"] }
|
||||
codegen = { version = "0.2.0" }
|
||||
itertools = { version = "0.10.5" }
|
||||
libcst = { git = "https://github.com/charliermarsh/LibCST", rev = "f2f0b7a487a8725d161fe8b3ed73a6758b21e177" }
|
||||
once_cell = { version = "1.16.0" }
|
||||
ruff = { path = ".." }
|
||||
rustpython-ast = { features = ["unparse"], git = "https://github.com/RustPython/RustPython.git", rev = "4d53c7cb27c0379adf8b51c4d3d0d2174f41d590" }
|
||||
rustpython-common = { git = "https://github.com/RustPython/RustPython.git", rev = "4d53c7cb27c0379adf8b51c4d3d0d2174f41d590" }
|
||||
rustpython-parser = { features = ["lalrpop"], git = "https://github.com/RustPython/RustPython.git", rev = "4d53c7cb27c0379adf8b51c4d3d0d2174f41d590" }
|
||||
rustpython-ast = { features = ["unparse"], git = "https://github.com/RustPython/RustPython.git", rev = "d532160333ffeb6dbeca2c2728c2391cd1e53b7f" }
|
||||
rustpython-common = { git = "https://github.com/RustPython/RustPython.git", rev = "d532160333ffeb6dbeca2c2728c2391cd1e53b7f" }
|
||||
rustpython-parser = { features = ["lalrpop"], git = "https://github.com/RustPython/RustPython.git", rev = "d532160333ffeb6dbeca2c2728c2391cd1e53b7f" }
|
||||
schemars = { version = "0.8.11" }
|
||||
serde_json = {version="1.0.91"}
|
||||
strum = { version = "0.24.1", features = ["strum_macros"] }
|
||||
|
||||
@@ -3,10 +3,7 @@
|
||||
use anyhow::Result;
|
||||
use clap::Args;
|
||||
|
||||
use crate::{
|
||||
generate_check_code_prefix, generate_cli_help, generate_json_schema, generate_options,
|
||||
generate_rules_table,
|
||||
};
|
||||
use crate::{generate_cli_help, generate_json_schema, generate_options, generate_rules_table};
|
||||
|
||||
#[derive(Args)]
|
||||
pub struct Cli {
|
||||
@@ -16,9 +13,6 @@ pub struct Cli {
|
||||
}
|
||||
|
||||
pub fn main(cli: &Cli) -> Result<()> {
|
||||
generate_check_code_prefix::main(&generate_check_code_prefix::Cli {
|
||||
dry_run: cli.dry_run,
|
||||
})?;
|
||||
generate_json_schema::main(&generate_json_schema::Cli {
|
||||
dry_run: cli.dry_run,
|
||||
})?;
|
||||
|
||||
@@ -1,221 +0,0 @@
|
||||
//! Generate the `CheckCodePrefix` enum.
|
||||
|
||||
use std::collections::{BTreeMap, BTreeSet};
|
||||
use std::fs;
|
||||
use std::io::Write;
|
||||
use std::path::PathBuf;
|
||||
use std::process::{Command, Output, Stdio};
|
||||
|
||||
use anyhow::{ensure, Result};
|
||||
use clap::Parser;
|
||||
use codegen::{Scope, Type, Variant};
|
||||
use itertools::Itertools;
|
||||
use ruff::registry::{CheckCode, PREFIX_REDIRECTS};
|
||||
use strum::IntoEnumIterator;
|
||||
|
||||
const ALL: &str = "ALL";
|
||||
|
||||
#[derive(Parser)]
|
||||
#[command(author, version, about, long_about = None)]
|
||||
pub struct Cli {
|
||||
/// Write the generated source code to stdout (rather than to
|
||||
/// `src/registry_gen.rs`).
|
||||
#[arg(long)]
|
||||
pub(crate) dry_run: bool,
|
||||
}
|
||||
|
||||
pub fn main(cli: &Cli) -> Result<()> {
|
||||
// Build up a map from prefix to matching CheckCodes.
|
||||
let mut prefix_to_codes: BTreeMap<String, BTreeSet<CheckCode>> = BTreeMap::default();
|
||||
for check_code in CheckCode::iter() {
|
||||
let code_str: String = check_code.as_ref().to_string();
|
||||
let code_prefix_len = code_str
|
||||
.chars()
|
||||
.take_while(|char| char.is_alphabetic())
|
||||
.count();
|
||||
let code_suffix_len = code_str.len() - code_prefix_len;
|
||||
for i in 0..=code_suffix_len {
|
||||
let prefix = code_str[..code_prefix_len + i].to_string();
|
||||
prefix_to_codes
|
||||
.entry(prefix)
|
||||
.or_default()
|
||||
.insert(check_code.clone());
|
||||
}
|
||||
prefix_to_codes
|
||||
.entry(ALL.to_string())
|
||||
.or_default()
|
||||
.insert(check_code.clone());
|
||||
}
|
||||
|
||||
// Add any prefix aliases (e.g., "U" to "UP").
|
||||
for (alias, check_code) in PREFIX_REDIRECTS.iter() {
|
||||
prefix_to_codes.insert(
|
||||
(*alias).to_string(),
|
||||
prefix_to_codes
|
||||
.get(&check_code.as_ref().to_string())
|
||||
.unwrap_or_else(|| panic!("Unknown CheckCode: {alias:?}"))
|
||||
.clone(),
|
||||
);
|
||||
}
|
||||
|
||||
let mut scope = Scope::new();
|
||||
|
||||
// Create the `CheckCodePrefix` definition.
|
||||
let mut gen = scope
|
||||
.new_enum("CheckCodePrefix")
|
||||
.vis("pub")
|
||||
.derive("EnumString")
|
||||
.derive("AsRefStr")
|
||||
.derive("Debug")
|
||||
.derive("PartialEq")
|
||||
.derive("Eq")
|
||||
.derive("PartialOrd")
|
||||
.derive("Ord")
|
||||
.derive("Clone")
|
||||
.derive("Serialize")
|
||||
.derive("Deserialize")
|
||||
.derive("JsonSchema");
|
||||
for prefix in prefix_to_codes.keys() {
|
||||
gen = gen.push_variant(Variant::new(prefix.to_string()));
|
||||
}
|
||||
|
||||
// Create the `SuffixLength` definition.
|
||||
scope
|
||||
.new_enum("SuffixLength")
|
||||
.vis("pub")
|
||||
.derive("PartialEq")
|
||||
.derive("Eq")
|
||||
.derive("PartialOrd")
|
||||
.derive("Ord")
|
||||
.push_variant(Variant::new("None"))
|
||||
.push_variant(Variant::new("Zero"))
|
||||
.push_variant(Variant::new("One"))
|
||||
.push_variant(Variant::new("Two"))
|
||||
.push_variant(Variant::new("Three"))
|
||||
.push_variant(Variant::new("Four"));
|
||||
|
||||
// Create the `match` statement, to map from definition to relevant codes.
|
||||
let mut gen = scope
|
||||
.new_impl("CheckCodePrefix")
|
||||
.new_fn("codes")
|
||||
.arg_ref_self()
|
||||
.ret(Type::new("Vec<CheckCode>"))
|
||||
.vis("pub")
|
||||
.line("#[allow(clippy::match_same_arms)]")
|
||||
.line("match self {");
|
||||
for (prefix, codes) in &prefix_to_codes {
|
||||
if let Some(target) = PREFIX_REDIRECTS.get(&prefix.as_str()) {
|
||||
gen = gen.line(format!(
|
||||
"CheckCodePrefix::{prefix} => {{ one_time_warning!(\"{{}}{{}} {{}}\", \
|
||||
\"warning\".yellow().bold(), \":\".bold(), \"`{}` has been remapped to \
|
||||
`{}`\".bold()); \n vec![{}] }}",
|
||||
prefix,
|
||||
target.as_ref(),
|
||||
codes
|
||||
.iter()
|
||||
.map(|code| format!("CheckCode::{}", code.as_ref()))
|
||||
.join(", ")
|
||||
));
|
||||
} else {
|
||||
gen = gen.line(format!(
|
||||
"CheckCodePrefix::{prefix} => vec![{}],",
|
||||
codes
|
||||
.iter()
|
||||
.map(|code| format!("CheckCode::{}", code.as_ref()))
|
||||
.join(", ")
|
||||
));
|
||||
}
|
||||
}
|
||||
gen.line("}");
|
||||
|
||||
// Create the `match` statement, to map from definition to specificity.
|
||||
let mut gen = scope
|
||||
.new_impl("CheckCodePrefix")
|
||||
.new_fn("specificity")
|
||||
.arg_ref_self()
|
||||
.ret(Type::new("SuffixLength"))
|
||||
.vis("pub")
|
||||
.line("#[allow(clippy::match_same_arms)]")
|
||||
.line("match self {");
|
||||
for prefix in prefix_to_codes.keys() {
|
||||
let specificity = if prefix == "ALL" {
|
||||
"None"
|
||||
} else {
|
||||
let num_numeric = prefix.chars().filter(|char| char.is_numeric()).count();
|
||||
match num_numeric {
|
||||
0 => "Zero",
|
||||
1 => "One",
|
||||
2 => "Two",
|
||||
3 => "Three",
|
||||
4 => "Four",
|
||||
_ => panic!("Invalid prefix: {prefix}"),
|
||||
}
|
||||
};
|
||||
gen = gen.line(format!(
|
||||
"CheckCodePrefix::{prefix} => SuffixLength::{specificity},"
|
||||
));
|
||||
}
|
||||
gen.line("}");
|
||||
|
||||
// Construct the output contents.
|
||||
let mut output = String::new();
|
||||
output
|
||||
.push_str("//! File automatically generated by `examples/generate_check_code_prefix.rs`.");
|
||||
output.push('\n');
|
||||
output.push('\n');
|
||||
output.push_str("use colored::Colorize;");
|
||||
output.push('\n');
|
||||
output.push_str("use schemars::JsonSchema;");
|
||||
output.push('\n');
|
||||
output.push_str("use serde::{Deserialize, Serialize};");
|
||||
output.push('\n');
|
||||
output.push_str("use strum_macros::{AsRefStr, EnumString};");
|
||||
output.push('\n');
|
||||
output.push('\n');
|
||||
output.push_str("use crate::registry::CheckCode;");
|
||||
output.push('\n');
|
||||
output.push_str("use crate::one_time_warning;");
|
||||
output.push('\n');
|
||||
output.push('\n');
|
||||
output.push_str(&scope.to_string());
|
||||
output.push('\n');
|
||||
output.push('\n');
|
||||
|
||||
// Add the list of output categories (not generated).
|
||||
output.push_str("pub const CATEGORIES: &[CheckCodePrefix] = &[");
|
||||
output.push('\n');
|
||||
for prefix in prefix_to_codes.keys() {
|
||||
if prefix.chars().all(char::is_alphabetic)
|
||||
&& !PREFIX_REDIRECTS.contains_key(&prefix.as_str())
|
||||
{
|
||||
output.push_str(&format!("CheckCodePrefix::{prefix},"));
|
||||
output.push('\n');
|
||||
}
|
||||
}
|
||||
output.push_str("];");
|
||||
output.push('\n');
|
||||
output.push('\n');
|
||||
|
||||
let rustfmt = Command::new("rustfmt")
|
||||
.stdin(Stdio::piped())
|
||||
.stdout(Stdio::piped())
|
||||
.spawn()?;
|
||||
write!(rustfmt.stdin.as_ref().unwrap(), "{output}")?;
|
||||
let Output { status, stdout, .. } = rustfmt.wait_with_output()?;
|
||||
ensure!(status.success(), "rustfmt failed with {status}");
|
||||
|
||||
// Write the output to `src/registry_gen.rs` (or stdout).
|
||||
if cli.dry_run {
|
||||
println!("{}", String::from_utf8(stdout)?);
|
||||
} else {
|
||||
let file = PathBuf::from(env!("CARGO_MANIFEST_DIR"))
|
||||
.parent()
|
||||
.expect("Failed to find root directory")
|
||||
.join("src/registry_gen.rs");
|
||||
if fs::read(&file).map_or(true, |old| old != stdout) {
|
||||
fs::write(&file, stdout)?;
|
||||
}
|
||||
}
|
||||
|
||||
Ok(())
|
||||
}
|
||||
@@ -28,7 +28,7 @@ pub fn main(cli: &Cli) -> Result<()> {
|
||||
print!("{output}");
|
||||
} else {
|
||||
replace_readme_section(
|
||||
&format!("```shell\n{output}\n```\n"),
|
||||
&format!("```\n{output}\n```\n"),
|
||||
HELP_BEGIN_PRAGMA,
|
||||
HELP_END_PRAGMA,
|
||||
)?;
|
||||
|
||||
@@ -10,9 +10,9 @@
|
||||
clippy::similar_names,
|
||||
clippy::too_many_lines
|
||||
)]
|
||||
#![forbid(unsafe_code)]
|
||||
|
||||
pub mod generate_all;
|
||||
pub mod generate_check_code_prefix;
|
||||
pub mod generate_cli_help;
|
||||
pub mod generate_json_schema;
|
||||
pub mod generate_options;
|
||||
|
||||
@@ -10,12 +10,13 @@
|
||||
clippy::similar_names,
|
||||
clippy::too_many_lines
|
||||
)]
|
||||
#![forbid(unsafe_code)]
|
||||
|
||||
use anyhow::Result;
|
||||
use clap::{Parser, Subcommand};
|
||||
use ruff_dev::{
|
||||
generate_all, generate_check_code_prefix, generate_cli_help, generate_json_schema,
|
||||
generate_options, generate_rules_table, print_ast, print_cst, print_tokens, round_trip,
|
||||
generate_all, generate_cli_help, generate_json_schema, generate_options, generate_rules_table,
|
||||
print_ast, print_cst, print_tokens, round_trip,
|
||||
};
|
||||
|
||||
#[derive(Parser)]
|
||||
@@ -30,8 +31,6 @@ struct Cli {
|
||||
enum Commands {
|
||||
/// Run all code and documentation generation steps.
|
||||
GenerateAll(generate_all::Cli),
|
||||
/// Generate the `CheckCodePrefix` enum.
|
||||
GenerateCheckCodePrefix(generate_check_code_prefix::Cli),
|
||||
/// Generate JSON schema for the TOML configuration file.
|
||||
GenerateJSONSchema(generate_json_schema::Cli),
|
||||
/// Generate a Markdown-compatible table of supported lint rules.
|
||||
@@ -54,7 +53,6 @@ fn main() -> Result<()> {
|
||||
let cli = Cli::parse();
|
||||
match &cli.command {
|
||||
Commands::GenerateAll(args) => generate_all::main(args)?,
|
||||
Commands::GenerateCheckCodePrefix(args) => generate_check_code_prefix::main(args)?,
|
||||
Commands::GenerateJSONSchema(args) => generate_json_schema::main(args)?,
|
||||
Commands::GenerateRulesTable(args) => generate_rules_table::main(args)?,
|
||||
Commands::GenerateOptions(args) => generate_options::main(args)?,
|
||||
|
||||
@@ -22,12 +22,8 @@ pub fn main(cli: &Cli) -> Result<()> {
|
||||
let python_ast = parser::parse_program(&contents, &cli.file.to_string_lossy())?;
|
||||
let locator = SourceCodeLocator::new(&contents);
|
||||
let stylist = SourceCodeStyleDetector::from_contents(&contents, &locator);
|
||||
let mut generator = SourceCodeGenerator::new(
|
||||
stylist.indentation(),
|
||||
stylist.quote(),
|
||||
stylist.line_ending(),
|
||||
);
|
||||
let mut generator: SourceCodeGenerator = (&stylist).into();
|
||||
generator.unparse_suite(&python_ast);
|
||||
println!("{}", generator.generate()?);
|
||||
println!("{}", generator.generate());
|
||||
Ok(())
|
||||
}
|
||||
|
||||
@@ -1,12 +1,13 @@
|
||||
[package]
|
||||
name = "ruff_macros"
|
||||
version = "0.0.211"
|
||||
version = "0.0.215"
|
||||
edition = "2021"
|
||||
|
||||
[lib]
|
||||
proc-macro = true
|
||||
|
||||
[dependencies]
|
||||
once_cell = { version = "1.17.0" }
|
||||
proc-macro2 = { version = "1.0.47" }
|
||||
quote = { version = "1.0.21" }
|
||||
syn = { version = "1.0.103", features = ["derive", "parsing"] }
|
||||
|
||||
289
ruff_macros/src/check_code_prefix.rs
Normal file
289
ruff_macros/src/check_code_prefix.rs
Normal file
@@ -0,0 +1,289 @@
|
||||
use std::collections::{BTreeMap, BTreeSet, HashMap};
|
||||
|
||||
use once_cell::sync::Lazy;
|
||||
use proc_macro2::Span;
|
||||
use quote::quote;
|
||||
use syn::punctuated::Punctuated;
|
||||
use syn::token::Comma;
|
||||
use syn::{DataEnum, DeriveInput, Ident, Variant};
|
||||
|
||||
const ALL: &str = "ALL";
|
||||
|
||||
/// A hash map from deprecated `CheckCodePrefix` to latest `CheckCodePrefix`.
|
||||
pub static PREFIX_REDIRECTS: Lazy<HashMap<&'static str, &'static str>> = Lazy::new(|| {
|
||||
HashMap::from_iter([
|
||||
// TODO(charlie): Remove by 2023-01-01.
|
||||
("U001", "UP001"),
|
||||
("U003", "UP003"),
|
||||
("U004", "UP004"),
|
||||
("U005", "UP005"),
|
||||
("U006", "UP006"),
|
||||
("U007", "UP007"),
|
||||
("U008", "UP008"),
|
||||
("U009", "UP009"),
|
||||
("U010", "UP010"),
|
||||
("U011", "UP011"),
|
||||
("U012", "UP012"),
|
||||
("U013", "UP013"),
|
||||
("U014", "UP014"),
|
||||
("U015", "UP015"),
|
||||
("U016", "UP016"),
|
||||
("U017", "UP017"),
|
||||
("U019", "UP019"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("I252", "TID252"),
|
||||
("M001", "RUF100"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("PDV002", "PD002"),
|
||||
("PDV003", "PD003"),
|
||||
("PDV004", "PD004"),
|
||||
("PDV007", "PD007"),
|
||||
("PDV008", "PD008"),
|
||||
("PDV009", "PD009"),
|
||||
("PDV010", "PD010"),
|
||||
("PDV011", "PD011"),
|
||||
("PDV012", "PD012"),
|
||||
("PDV013", "PD013"),
|
||||
("PDV015", "PD015"),
|
||||
("PDV901", "PD901"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("R501", "RET501"),
|
||||
("R502", "RET502"),
|
||||
("R503", "RET503"),
|
||||
("R504", "RET504"),
|
||||
("R505", "RET505"),
|
||||
("R506", "RET506"),
|
||||
("R507", "RET507"),
|
||||
("R508", "RET508"),
|
||||
("IC001", "ICN001"),
|
||||
("IC002", "ICN001"),
|
||||
("IC003", "ICN001"),
|
||||
("IC004", "ICN001"),
|
||||
// TODO(charlie): Remove by 2023-01-01.
|
||||
("U", "UP"),
|
||||
("U0", "UP0"),
|
||||
("U00", "UP00"),
|
||||
("U01", "UP01"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("I2", "TID2"),
|
||||
("I25", "TID25"),
|
||||
("M", "RUF100"),
|
||||
("M0", "RUF100"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("PDV", "PD"),
|
||||
("PDV0", "PD0"),
|
||||
("PDV01", "PD01"),
|
||||
("PDV9", "PD9"),
|
||||
("PDV90", "PD90"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("R", "RET"),
|
||||
("R5", "RET5"),
|
||||
("R50", "RET50"),
|
||||
// TODO(charlie): Remove by 2023-02-01.
|
||||
("IC", "ICN"),
|
||||
("IC0", "ICN0"),
|
||||
])
|
||||
});
|
||||
|
||||
pub fn derive_impl(input: DeriveInput) -> syn::Result<proc_macro2::TokenStream> {
|
||||
let DeriveInput { ident, data, .. } = input;
|
||||
let syn::Data::Enum(DataEnum { variants, .. }) = data else {
|
||||
return Err(syn::Error::new(
|
||||
ident.span(),
|
||||
"Can only derive `CheckCodePrefix` from enums.",
|
||||
));
|
||||
};
|
||||
|
||||
let prefix_ident = Ident::new(&format!("{ident}Prefix"), ident.span());
|
||||
let prefix = expand(&ident, &prefix_ident, &variants);
|
||||
let expanded = quote! {
|
||||
#[derive(PartialEq, Eq, PartialOrd, Ord)]
|
||||
pub enum SuffixLength {
|
||||
None,
|
||||
Zero,
|
||||
One,
|
||||
Two,
|
||||
Three,
|
||||
Four,
|
||||
}
|
||||
|
||||
#prefix
|
||||
};
|
||||
Ok(expanded)
|
||||
}
|
||||
|
||||
fn expand(
|
||||
ident: &Ident,
|
||||
prefix_ident: &Ident,
|
||||
variants: &Punctuated<Variant, Comma>,
|
||||
) -> proc_macro2::TokenStream {
|
||||
// Build up a map from prefix to matching CheckCodes.
|
||||
let mut prefix_to_codes: BTreeMap<Ident, BTreeSet<String>> = BTreeMap::default();
|
||||
for variant in variants {
|
||||
let span = variant.ident.span();
|
||||
let code_str = variant.ident.to_string();
|
||||
let code_prefix_len = code_str
|
||||
.chars()
|
||||
.take_while(|char| char.is_alphabetic())
|
||||
.count();
|
||||
let code_suffix_len = code_str.len() - code_prefix_len;
|
||||
for i in 0..=code_suffix_len {
|
||||
let prefix = code_str[..code_prefix_len + i].to_string();
|
||||
prefix_to_codes
|
||||
.entry(Ident::new(&prefix, span))
|
||||
.or_default()
|
||||
.insert(code_str.clone());
|
||||
}
|
||||
prefix_to_codes
|
||||
.entry(Ident::new(ALL, span))
|
||||
.or_default()
|
||||
.insert(code_str.clone());
|
||||
}
|
||||
|
||||
// Add any prefix aliases (e.g., "U" to "UP").
|
||||
for (alias, check_code) in PREFIX_REDIRECTS.iter() {
|
||||
prefix_to_codes.insert(
|
||||
Ident::new(alias, Span::call_site()),
|
||||
prefix_to_codes
|
||||
.get(&Ident::new(check_code, Span::call_site()))
|
||||
.unwrap_or_else(|| panic!("Unknown CheckCode: {alias:?}"))
|
||||
.clone(),
|
||||
);
|
||||
}
|
||||
|
||||
let prefix_variants = prefix_to_codes.keys().map(|prefix| {
|
||||
quote! {
|
||||
#prefix
|
||||
}
|
||||
});
|
||||
|
||||
let prefix_impl = generate_impls(ident, prefix_ident, &prefix_to_codes);
|
||||
|
||||
let prefix_redirects = PREFIX_REDIRECTS.iter().map(|(alias, check_code)| {
|
||||
let code = Ident::new(check_code, Span::call_site());
|
||||
quote! {
|
||||
(#alias, #prefix_ident::#code)
|
||||
}
|
||||
});
|
||||
|
||||
quote! {
|
||||
#[derive(
|
||||
::strum_macros::EnumString,
|
||||
::strum_macros::AsRefStr,
|
||||
Debug,
|
||||
PartialEq,
|
||||
Eq,
|
||||
PartialOrd,
|
||||
Ord,
|
||||
Clone,
|
||||
::serde::Serialize,
|
||||
::serde::Deserialize,
|
||||
::schemars::JsonSchema,
|
||||
)]
|
||||
pub enum #prefix_ident {
|
||||
#(#prefix_variants,)*
|
||||
}
|
||||
|
||||
#prefix_impl
|
||||
|
||||
/// A hash map from deprecated `CheckCodePrefix` to latest `CheckCodePrefix`.
|
||||
pub static PREFIX_REDIRECTS: ::once_cell::sync::Lazy<::rustc_hash::FxHashMap<&'static str, #prefix_ident>> = ::once_cell::sync::Lazy::new(|| {
|
||||
::rustc_hash::FxHashMap::from_iter([
|
||||
#(#prefix_redirects),*
|
||||
])
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
fn generate_impls(
|
||||
ident: &Ident,
|
||||
prefix_ident: &Ident,
|
||||
prefix_to_codes: &BTreeMap<Ident, BTreeSet<String>>,
|
||||
) -> proc_macro2::TokenStream {
|
||||
let codes_match_arms = prefix_to_codes.iter().map(|(prefix, codes)| {
|
||||
let codes = codes.iter().map(|code| {
|
||||
let code = Ident::new(code, Span::call_site());
|
||||
quote! {
|
||||
#ident::#code
|
||||
}
|
||||
});
|
||||
let prefix_str = prefix.to_string();
|
||||
if let Some(target) = PREFIX_REDIRECTS.get(prefix_str.as_str()) {
|
||||
quote! {
|
||||
#prefix_ident::#prefix => {
|
||||
crate::one_time_warning!(
|
||||
"{}{} {}",
|
||||
"warning".yellow().bold(),
|
||||
":".bold(),
|
||||
format!("`{}` has been remapped to `{}`", #prefix_str, #target).bold()
|
||||
);
|
||||
vec![#(#codes),*]
|
||||
}
|
||||
}
|
||||
} else {
|
||||
quote! {
|
||||
#prefix_ident::#prefix => vec![#(#codes),*],
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
let specificity_match_arms = prefix_to_codes.keys().map(|prefix| {
|
||||
if *prefix == ALL {
|
||||
quote! {
|
||||
#prefix_ident::#prefix => SuffixLength::None,
|
||||
}
|
||||
} else {
|
||||
let num_numeric = prefix
|
||||
.to_string()
|
||||
.chars()
|
||||
.filter(|char| char.is_numeric())
|
||||
.count();
|
||||
let suffix_len = match num_numeric {
|
||||
0 => quote! { SuffixLength::Zero },
|
||||
1 => quote! { SuffixLength::One },
|
||||
2 => quote! { SuffixLength::Two },
|
||||
3 => quote! { SuffixLength::Three },
|
||||
4 => quote! { SuffixLength::Four },
|
||||
_ => panic!("Invalid prefix: {prefix}"),
|
||||
};
|
||||
quote! {
|
||||
#prefix_ident::#prefix => #suffix_len,
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
let categories = prefix_to_codes.keys().map(|prefix| {
|
||||
let prefix_str = prefix.to_string();
|
||||
if prefix_str.chars().all(char::is_alphabetic)
|
||||
&& !PREFIX_REDIRECTS.contains_key(&prefix_str.as_str())
|
||||
{
|
||||
quote! {
|
||||
#prefix_ident::#prefix,
|
||||
}
|
||||
} else {
|
||||
quote! {}
|
||||
}
|
||||
});
|
||||
|
||||
quote! {
|
||||
impl #prefix_ident {
|
||||
pub fn codes(&self) -> Vec<#ident> {
|
||||
use colored::Colorize;
|
||||
|
||||
#[allow(clippy::match_same_arms)]
|
||||
match self {
|
||||
#(#codes_match_arms)*
|
||||
}
|
||||
}
|
||||
|
||||
pub fn specificity(&self) -> SuffixLength {
|
||||
#[allow(clippy::match_same_arms)]
|
||||
match self {
|
||||
#(#specificity_match_arms)*
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
pub const CATEGORIES: &[#prefix_ident] = &[#(#categories)*];
|
||||
}
|
||||
}
|
||||
203
ruff_macros/src/config.rs
Normal file
203
ruff_macros/src/config.rs
Normal file
@@ -0,0 +1,203 @@
|
||||
use quote::{quote, quote_spanned};
|
||||
use syn::parse::{Parse, ParseStream};
|
||||
use syn::spanned::Spanned;
|
||||
use syn::token::Comma;
|
||||
use syn::{
|
||||
AngleBracketedGenericArguments, Attribute, Data, DataStruct, DeriveInput, Field, Fields, Lit,
|
||||
LitStr, Path, PathArguments, PathSegment, Token, Type, TypePath,
|
||||
};
|
||||
|
||||
pub fn derive_impl(input: DeriveInput) -> syn::Result<proc_macro2::TokenStream> {
|
||||
let DeriveInput { ident, data, .. } = input;
|
||||
|
||||
match data {
|
||||
Data::Struct(DataStruct {
|
||||
fields: Fields::Named(fields),
|
||||
..
|
||||
}) => {
|
||||
let mut output = vec![];
|
||||
|
||||
for field in fields.named.iter() {
|
||||
let docs: Vec<&Attribute> = field
|
||||
.attrs
|
||||
.iter()
|
||||
.filter(|attr| attr.path.is_ident("doc"))
|
||||
.collect();
|
||||
|
||||
if docs.is_empty() {
|
||||
return Err(syn::Error::new(
|
||||
field.span(),
|
||||
"Missing documentation for field",
|
||||
));
|
||||
}
|
||||
|
||||
if let Some(attr) = field.attrs.iter().find(|attr| attr.path.is_ident("option")) {
|
||||
output.push(handle_option(field, attr, docs)?);
|
||||
};
|
||||
|
||||
if field
|
||||
.attrs
|
||||
.iter()
|
||||
.any(|attr| attr.path.is_ident("option_group"))
|
||||
{
|
||||
output.push(handle_option_group(field)?);
|
||||
};
|
||||
}
|
||||
|
||||
Ok(quote! {
|
||||
use crate::settings::options_base::{OptionEntry, OptionField, OptionGroup, ConfigurationOptions};
|
||||
|
||||
#[automatically_derived]
|
||||
impl ConfigurationOptions for #ident {
|
||||
fn get_available_options() -> Vec<OptionEntry> {
|
||||
vec![#(#output),*]
|
||||
}
|
||||
}
|
||||
})
|
||||
}
|
||||
_ => Err(syn::Error::new(
|
||||
ident.span(),
|
||||
"Can only derive ConfigurationOptions from structs with named fields.",
|
||||
)),
|
||||
}
|
||||
}
|
||||
|
||||
/// For a field with type `Option<Foobar>` where `Foobar` itself is a struct
|
||||
/// deriving `ConfigurationOptions`, create code that calls retrieves options
|
||||
/// from that group: `Foobar::get_available_options()`
|
||||
fn handle_option_group(field: &Field) -> syn::Result<proc_macro2::TokenStream> {
|
||||
let ident = field
|
||||
.ident
|
||||
.as_ref()
|
||||
.expect("Expected to handle named fields");
|
||||
|
||||
match &field.ty {
|
||||
Type::Path(TypePath {
|
||||
path: Path { segments, .. },
|
||||
..
|
||||
}) => match segments.first() {
|
||||
Some(PathSegment {
|
||||
ident: type_ident,
|
||||
arguments:
|
||||
PathArguments::AngleBracketed(AngleBracketedGenericArguments { args, .. }),
|
||||
..
|
||||
}) if type_ident == "Option" => {
|
||||
let path = &args[0];
|
||||
let kebab_name = LitStr::new(&ident.to_string().replace('_', "-"), ident.span());
|
||||
|
||||
Ok(quote_spanned!(
|
||||
ident.span() => OptionEntry::Group(OptionGroup {
|
||||
name: #kebab_name,
|
||||
fields: #path::get_available_options(),
|
||||
})
|
||||
))
|
||||
}
|
||||
_ => Err(syn::Error::new(
|
||||
ident.span(),
|
||||
"Expected `Option<_>` as type.",
|
||||
)),
|
||||
},
|
||||
_ => Err(syn::Error::new(ident.span(), "Expected type.")),
|
||||
}
|
||||
}
|
||||
|
||||
/// Parse a `doc` attribute into it a string literal.
|
||||
fn parse_doc(doc: &Attribute) -> syn::Result<String> {
|
||||
let doc = doc
|
||||
.parse_meta()
|
||||
.map_err(|e| syn::Error::new(doc.span(), e))?;
|
||||
|
||||
match doc {
|
||||
syn::Meta::NameValue(syn::MetaNameValue {
|
||||
lit: Lit::Str(lit_str),
|
||||
..
|
||||
}) => Ok(lit_str.value()),
|
||||
_ => Err(syn::Error::new(doc.span(), "Expected doc attribute.")),
|
||||
}
|
||||
}
|
||||
|
||||
/// Parse an `#[option(doc="...", default="...", value_type="...",
|
||||
/// example="...")]` attribute and return data in the form of an `OptionField`.
|
||||
fn handle_option(
|
||||
field: &Field,
|
||||
attr: &Attribute,
|
||||
docs: Vec<&Attribute>,
|
||||
) -> syn::Result<proc_macro2::TokenStream> {
|
||||
// Convert the list of `doc` attributes into a single string.
|
||||
let doc = textwrap::dedent(
|
||||
&docs
|
||||
.into_iter()
|
||||
.map(parse_doc)
|
||||
.collect::<syn::Result<Vec<_>>>()?
|
||||
.join("\n"),
|
||||
)
|
||||
.trim_matches('\n')
|
||||
.to_string();
|
||||
|
||||
let ident = field
|
||||
.ident
|
||||
.as_ref()
|
||||
.expect("Expected to handle named fields");
|
||||
|
||||
let FieldAttributes {
|
||||
default,
|
||||
value_type,
|
||||
example,
|
||||
..
|
||||
} = attr.parse_args::<FieldAttributes>()?;
|
||||
let kebab_name = LitStr::new(&ident.to_string().replace('_', "-"), ident.span());
|
||||
|
||||
Ok(quote_spanned!(
|
||||
ident.span() => OptionEntry::Field(OptionField {
|
||||
name: #kebab_name,
|
||||
doc: &#doc,
|
||||
default: &#default,
|
||||
value_type: &#value_type,
|
||||
example: &#example,
|
||||
})
|
||||
))
|
||||
}
|
||||
|
||||
#[derive(Debug)]
|
||||
struct FieldAttributes {
|
||||
default: String,
|
||||
value_type: String,
|
||||
example: String,
|
||||
}
|
||||
|
||||
impl Parse for FieldAttributes {
|
||||
fn parse(input: ParseStream) -> syn::Result<Self> {
|
||||
let default = _parse_key_value(input, "default")?;
|
||||
input.parse::<Comma>()?;
|
||||
let value_type = _parse_key_value(input, "value_type")?;
|
||||
input.parse::<Comma>()?;
|
||||
let example = _parse_key_value(input, "example")?;
|
||||
if !input.is_empty() {
|
||||
input.parse::<Comma>()?;
|
||||
}
|
||||
|
||||
Ok(FieldAttributes {
|
||||
default,
|
||||
value_type,
|
||||
example: textwrap::dedent(&example).trim_matches('\n').to_string(),
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
fn _parse_key_value(input: ParseStream, name: &str) -> syn::Result<String> {
|
||||
let ident: proc_macro2::Ident = input.parse()?;
|
||||
if ident != name {
|
||||
return Err(syn::Error::new(
|
||||
ident.span(),
|
||||
format!("Expected `{name}` name"),
|
||||
));
|
||||
}
|
||||
|
||||
input.parse::<Token![=]>()?;
|
||||
let value: Lit = input.parse()?;
|
||||
|
||||
match &value {
|
||||
Lit::Str(v) => Ok(v.value()),
|
||||
_ => Err(syn::Error::new(value.span(), "Expected literal string")),
|
||||
}
|
||||
}
|
||||
@@ -10,216 +10,27 @@
|
||||
clippy::similar_names,
|
||||
clippy::too_many_lines
|
||||
)]
|
||||
#![forbid(unsafe_code)]
|
||||
|
||||
use quote::{quote, quote_spanned};
|
||||
use syn::parse::{Parse, ParseStream};
|
||||
use syn::spanned::Spanned;
|
||||
use syn::token::Comma;
|
||||
use syn::{
|
||||
parse_macro_input, AngleBracketedGenericArguments, Attribute, Data, DataStruct, DeriveInput,
|
||||
Field, Fields, Lit, LitStr, Path, PathArguments, PathSegment, Token, Type, TypePath,
|
||||
};
|
||||
use syn::{parse_macro_input, DeriveInput};
|
||||
|
||||
mod check_code_prefix;
|
||||
mod config;
|
||||
|
||||
#[proc_macro_derive(ConfigurationOptions, attributes(option, doc, option_group))]
|
||||
pub fn derive(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
|
||||
pub fn derive_config(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
|
||||
let input = parse_macro_input!(input as DeriveInput);
|
||||
|
||||
derive_impl(input)
|
||||
config::derive_impl(input)
|
||||
.unwrap_or_else(syn::Error::into_compile_error)
|
||||
.into()
|
||||
}
|
||||
|
||||
fn derive_impl(input: DeriveInput) -> syn::Result<proc_macro2::TokenStream> {
|
||||
let DeriveInput { ident, data, .. } = input;
|
||||
#[proc_macro_derive(CheckCodePrefix)]
|
||||
pub fn derive_check_code_prefix(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
|
||||
let input = parse_macro_input!(input as DeriveInput);
|
||||
|
||||
match data {
|
||||
Data::Struct(DataStruct {
|
||||
fields: Fields::Named(fields),
|
||||
..
|
||||
}) => {
|
||||
let mut output = vec![];
|
||||
|
||||
for field in fields.named.iter() {
|
||||
let docs: Vec<&Attribute> = field
|
||||
.attrs
|
||||
.iter()
|
||||
.filter(|attr| attr.path.is_ident("doc"))
|
||||
.collect();
|
||||
|
||||
if docs.is_empty() {
|
||||
return Err(syn::Error::new(
|
||||
field.span(),
|
||||
"Missing documentation for field",
|
||||
));
|
||||
}
|
||||
|
||||
if let Some(attr) = field.attrs.iter().find(|attr| attr.path.is_ident("option")) {
|
||||
output.push(handle_option(field, attr, docs)?);
|
||||
};
|
||||
|
||||
if field
|
||||
.attrs
|
||||
.iter()
|
||||
.any(|attr| attr.path.is_ident("option_group"))
|
||||
{
|
||||
output.push(handle_option_group(field)?);
|
||||
};
|
||||
}
|
||||
|
||||
Ok(quote! {
|
||||
use crate::settings::options_base::{OptionEntry, OptionField, OptionGroup, ConfigurationOptions};
|
||||
|
||||
#[automatically_derived]
|
||||
impl ConfigurationOptions for #ident {
|
||||
fn get_available_options() -> Vec<OptionEntry> {
|
||||
vec![#(#output),*]
|
||||
}
|
||||
}
|
||||
})
|
||||
}
|
||||
_ => Err(syn::Error::new(
|
||||
ident.span(),
|
||||
"Can only derive ConfigurationOptions from structs with named fields.",
|
||||
)),
|
||||
}
|
||||
}
|
||||
|
||||
/// For a field with type `Option<Foobar>` where `Foobar` itself is a struct
|
||||
/// deriving `ConfigurationOptions`, create code that calls retrieves options
|
||||
/// from that group: `Foobar::get_available_options()`
|
||||
fn handle_option_group(field: &Field) -> syn::Result<proc_macro2::TokenStream> {
|
||||
let ident = field
|
||||
.ident
|
||||
.as_ref()
|
||||
.expect("Expected to handle named fields");
|
||||
|
||||
match &field.ty {
|
||||
Type::Path(TypePath {
|
||||
path: Path { segments, .. },
|
||||
..
|
||||
}) => match segments.first() {
|
||||
Some(PathSegment {
|
||||
ident: type_ident,
|
||||
arguments:
|
||||
PathArguments::AngleBracketed(AngleBracketedGenericArguments { args, .. }),
|
||||
..
|
||||
}) if type_ident == "Option" => {
|
||||
let path = &args[0];
|
||||
let kebab_name = LitStr::new(&ident.to_string().replace('_', "-"), ident.span());
|
||||
|
||||
Ok(quote_spanned!(
|
||||
ident.span() => OptionEntry::Group(OptionGroup {
|
||||
name: #kebab_name,
|
||||
fields: #path::get_available_options(),
|
||||
})
|
||||
))
|
||||
}
|
||||
_ => Err(syn::Error::new(
|
||||
ident.span(),
|
||||
"Expected `Option<_>` as type.",
|
||||
)),
|
||||
},
|
||||
_ => Err(syn::Error::new(ident.span(), "Expected type.")),
|
||||
}
|
||||
}
|
||||
|
||||
/// Parse a `doc` attribute into it a string literal.
|
||||
fn parse_doc(doc: &Attribute) -> syn::Result<String> {
|
||||
let doc = doc
|
||||
.parse_meta()
|
||||
.map_err(|e| syn::Error::new(doc.span(), e))?;
|
||||
|
||||
match doc {
|
||||
syn::Meta::NameValue(syn::MetaNameValue {
|
||||
lit: Lit::Str(lit_str),
|
||||
..
|
||||
}) => Ok(lit_str.value()),
|
||||
_ => Err(syn::Error::new(doc.span(), "Expected doc attribute.")),
|
||||
}
|
||||
}
|
||||
|
||||
/// Parse an `#[option(doc="...", default="...", value_type="...",
|
||||
/// example="...")]` attribute and return data in the form of an `OptionField`.
|
||||
fn handle_option(
|
||||
field: &Field,
|
||||
attr: &Attribute,
|
||||
docs: Vec<&Attribute>,
|
||||
) -> syn::Result<proc_macro2::TokenStream> {
|
||||
// Convert the list of `doc` attributes into a single string.
|
||||
let doc = textwrap::dedent(
|
||||
&docs
|
||||
.into_iter()
|
||||
.map(parse_doc)
|
||||
.collect::<syn::Result<Vec<_>>>()?
|
||||
.join("\n"),
|
||||
)
|
||||
.trim_matches('\n')
|
||||
.to_string();
|
||||
|
||||
let ident = field
|
||||
.ident
|
||||
.as_ref()
|
||||
.expect("Expected to handle named fields");
|
||||
|
||||
let FieldAttributes {
|
||||
default,
|
||||
value_type,
|
||||
example,
|
||||
..
|
||||
} = attr.parse_args::<FieldAttributes>()?;
|
||||
let kebab_name = LitStr::new(&ident.to_string().replace('_', "-"), ident.span());
|
||||
|
||||
Ok(quote_spanned!(
|
||||
ident.span() => OptionEntry::Field(OptionField {
|
||||
name: #kebab_name,
|
||||
doc: &#doc,
|
||||
default: &#default,
|
||||
value_type: &#value_type,
|
||||
example: &#example,
|
||||
})
|
||||
))
|
||||
}
|
||||
|
||||
#[derive(Debug)]
|
||||
struct FieldAttributes {
|
||||
default: String,
|
||||
value_type: String,
|
||||
example: String,
|
||||
}
|
||||
|
||||
impl Parse for FieldAttributes {
|
||||
fn parse(input: ParseStream) -> syn::Result<Self> {
|
||||
let default = _parse_key_value(input, "default")?;
|
||||
input.parse::<Comma>()?;
|
||||
let value_type = _parse_key_value(input, "value_type")?;
|
||||
input.parse::<Comma>()?;
|
||||
let example = _parse_key_value(input, "example")?;
|
||||
if !input.is_empty() {
|
||||
input.parse::<Comma>()?;
|
||||
}
|
||||
|
||||
Ok(FieldAttributes {
|
||||
default,
|
||||
value_type,
|
||||
example: textwrap::dedent(&example).trim_matches('\n').to_string(),
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
fn _parse_key_value(input: ParseStream, name: &str) -> syn::Result<String> {
|
||||
let ident: proc_macro2::Ident = input.parse()?;
|
||||
if ident != name {
|
||||
return Err(syn::Error::new(
|
||||
ident.span(),
|
||||
format!("Expected `{name}` name"),
|
||||
));
|
||||
}
|
||||
|
||||
input.parse::<Token![=]>()?;
|
||||
let value: Lit = input.parse()?;
|
||||
|
||||
match &value {
|
||||
Lit::Str(v) => Ok(v.value()),
|
||||
_ => Err(syn::Error::new(value.span(), "Expected literal string")),
|
||||
}
|
||||
check_code_prefix::derive_impl(input)
|
||||
.unwrap_or_else(syn::Error::into_compile_error)
|
||||
.into()
|
||||
}
|
||||
|
||||
@@ -52,8 +52,8 @@ fn common_ancestor<'a>(
|
||||
}
|
||||
|
||||
/// Return the alternative branches for a given node.
|
||||
fn alternatives<'a>(node: &'a RefEquality<'a, Stmt>) -> Vec<Vec<RefEquality<'a, Stmt>>> {
|
||||
match &node.0.node {
|
||||
fn alternatives<'a>(stmt: &'a RefEquality<'a, Stmt>) -> Vec<Vec<RefEquality<'a, Stmt>>> {
|
||||
match &stmt.node {
|
||||
StmtKind::If { body, .. } => vec![body.iter().map(RefEquality).collect()],
|
||||
StmtKind::Try {
|
||||
body,
|
||||
@@ -71,16 +71,16 @@ fn alternatives<'a>(node: &'a RefEquality<'a, Stmt>) -> Vec<Vec<RefEquality<'a,
|
||||
}
|
||||
}
|
||||
|
||||
/// Return `true` if `node` is a descendent of any of the nodes in `ancestors`.
|
||||
/// Return `true` if `stmt` is a descendent of any of the nodes in `ancestors`.
|
||||
fn descendant_of<'a>(
|
||||
node: &RefEquality<'a, Stmt>,
|
||||
stmt: &RefEquality<'a, Stmt>,
|
||||
ancestors: &[RefEquality<'a, Stmt>],
|
||||
stop: &RefEquality<'a, Stmt>,
|
||||
depths: &FxHashMap<RefEquality<'a, Stmt>, usize>,
|
||||
child_to_parent: &FxHashMap<RefEquality<'a, Stmt>, RefEquality<'a, Stmt>>,
|
||||
) -> bool {
|
||||
ancestors.iter().any(|ancestor| {
|
||||
common_ancestor(node, ancestor, Some(stop), depths, child_to_parent).is_some()
|
||||
common_ancestor(stmt, ancestor, Some(stop), depths, child_to_parent).is_some()
|
||||
})
|
||||
}
|
||||
|
||||
|
||||
524
src/ast/comparable.rs
Normal file
524
src/ast/comparable.rs
Normal file
@@ -0,0 +1,524 @@
|
||||
//! An equivalent object hierarchy to the `Expr` hierarchy, but with the ability
|
||||
//! to compare expressions for equality (via `Eq` and `Hash`).
|
||||
|
||||
use num_bigint::BigInt;
|
||||
use rustpython_ast::{
|
||||
Arg, Arguments, Boolop, Cmpop, Comprehension, Constant, Expr, ExprContext, ExprKind, Keyword,
|
||||
Operator, Unaryop,
|
||||
};
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Hash)]
|
||||
pub enum ComparableExprContext {
|
||||
Load,
|
||||
Store,
|
||||
Del,
|
||||
}
|
||||
|
||||
impl From<&ExprContext> for ComparableExprContext {
|
||||
fn from(ctx: &ExprContext) -> Self {
|
||||
match ctx {
|
||||
ExprContext::Load => Self::Load,
|
||||
ExprContext::Store => Self::Store,
|
||||
ExprContext::Del => Self::Del,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Hash)]
|
||||
pub enum ComparableBoolop {
|
||||
And,
|
||||
Or,
|
||||
}
|
||||
|
||||
impl From<&Boolop> for ComparableBoolop {
|
||||
fn from(op: &Boolop) -> Self {
|
||||
match op {
|
||||
Boolop::And => Self::And,
|
||||
Boolop::Or => Self::Or,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Hash)]
|
||||
pub enum ComparableOperator {
|
||||
Add,
|
||||
Sub,
|
||||
Mult,
|
||||
MatMult,
|
||||
Div,
|
||||
Mod,
|
||||
Pow,
|
||||
LShift,
|
||||
RShift,
|
||||
BitOr,
|
||||
BitXor,
|
||||
BitAnd,
|
||||
FloorDiv,
|
||||
}
|
||||
|
||||
impl From<&Operator> for ComparableOperator {
|
||||
fn from(op: &Operator) -> Self {
|
||||
match op {
|
||||
Operator::Add => Self::Add,
|
||||
Operator::Sub => Self::Sub,
|
||||
Operator::Mult => Self::Mult,
|
||||
Operator::MatMult => Self::MatMult,
|
||||
Operator::Div => Self::Div,
|
||||
Operator::Mod => Self::Mod,
|
||||
Operator::Pow => Self::Pow,
|
||||
Operator::LShift => Self::LShift,
|
||||
Operator::RShift => Self::RShift,
|
||||
Operator::BitOr => Self::BitOr,
|
||||
Operator::BitXor => Self::BitXor,
|
||||
Operator::BitAnd => Self::BitAnd,
|
||||
Operator::FloorDiv => Self::FloorDiv,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Hash)]
|
||||
pub enum ComparableUnaryop {
|
||||
Invert,
|
||||
Not,
|
||||
UAdd,
|
||||
USub,
|
||||
}
|
||||
|
||||
impl From<&Unaryop> for ComparableUnaryop {
|
||||
fn from(op: &Unaryop) -> Self {
|
||||
match op {
|
||||
Unaryop::Invert => Self::Invert,
|
||||
Unaryop::Not => Self::Not,
|
||||
Unaryop::UAdd => Self::UAdd,
|
||||
Unaryop::USub => Self::USub,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Hash)]
|
||||
pub enum ComparableCmpop {
|
||||
Eq,
|
||||
NotEq,
|
||||
Lt,
|
||||
LtE,
|
||||
Gt,
|
||||
GtE,
|
||||
Is,
|
||||
IsNot,
|
||||
In,
|
||||
NotIn,
|
||||
}
|
||||
|
||||
impl From<&Cmpop> for ComparableCmpop {
|
||||
fn from(op: &Cmpop) -> Self {
|
||||
match op {
|
||||
Cmpop::Eq => Self::Eq,
|
||||
Cmpop::NotEq => Self::NotEq,
|
||||
Cmpop::Lt => Self::Lt,
|
||||
Cmpop::LtE => Self::LtE,
|
||||
Cmpop::Gt => Self::Gt,
|
||||
Cmpop::GtE => Self::GtE,
|
||||
Cmpop::Is => Self::Is,
|
||||
Cmpop::IsNot => Self::IsNot,
|
||||
Cmpop::In => Self::In,
|
||||
Cmpop::NotIn => Self::NotIn,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Hash)]
|
||||
pub enum ComparableConstant<'a> {
|
||||
None,
|
||||
Bool(&'a bool),
|
||||
Str(&'a str),
|
||||
Bytes(&'a [u8]),
|
||||
Int(&'a BigInt),
|
||||
Tuple(Vec<ComparableConstant<'a>>),
|
||||
Float(u64),
|
||||
Complex { real: u64, imag: u64 },
|
||||
Ellipsis,
|
||||
}
|
||||
|
||||
impl<'a> From<&'a Constant> for ComparableConstant<'a> {
|
||||
fn from(constant: &'a Constant) -> Self {
|
||||
match constant {
|
||||
Constant::None => Self::None,
|
||||
Constant::Bool(value) => Self::Bool(value),
|
||||
Constant::Str(value) => Self::Str(value),
|
||||
Constant::Bytes(value) => Self::Bytes(value),
|
||||
Constant::Int(value) => Self::Int(value),
|
||||
Constant::Tuple(value) => {
|
||||
Self::Tuple(value.iter().map(std::convert::Into::into).collect())
|
||||
}
|
||||
Constant::Float(value) => Self::Float(value.to_bits()),
|
||||
Constant::Complex { real, imag } => Self::Complex {
|
||||
real: real.to_bits(),
|
||||
imag: imag.to_bits(),
|
||||
},
|
||||
Constant::Ellipsis => Self::Ellipsis,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Hash)]
|
||||
pub struct ComparableArguments<'a> {
|
||||
pub posonlyargs: Vec<ComparableArg<'a>>,
|
||||
pub args: Vec<ComparableArg<'a>>,
|
||||
pub vararg: Option<ComparableArg<'a>>,
|
||||
pub kwonlyargs: Vec<ComparableArg<'a>>,
|
||||
pub kw_defaults: Vec<ComparableExpr<'a>>,
|
||||
pub kwarg: Option<ComparableArg<'a>>,
|
||||
pub defaults: Vec<ComparableExpr<'a>>,
|
||||
}
|
||||
|
||||
impl<'a> From<&'a Arguments> for ComparableArguments<'a> {
|
||||
fn from(arguments: &'a Arguments) -> Self {
|
||||
Self {
|
||||
posonlyargs: arguments
|
||||
.posonlyargs
|
||||
.iter()
|
||||
.map(std::convert::Into::into)
|
||||
.collect(),
|
||||
args: arguments
|
||||
.args
|
||||
.iter()
|
||||
.map(std::convert::Into::into)
|
||||
.collect(),
|
||||
vararg: arguments.vararg.as_ref().map(std::convert::Into::into),
|
||||
kwonlyargs: arguments
|
||||
.kwonlyargs
|
||||
.iter()
|
||||
.map(std::convert::Into::into)
|
||||
.collect(),
|
||||
kw_defaults: arguments
|
||||
.kw_defaults
|
||||
.iter()
|
||||
.map(std::convert::Into::into)
|
||||
.collect(),
|
||||
kwarg: arguments.vararg.as_ref().map(std::convert::Into::into),
|
||||
defaults: arguments
|
||||
.defaults
|
||||
.iter()
|
||||
.map(std::convert::Into::into)
|
||||
.collect(),
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
impl<'a> From<&'a Box<Arg>> for ComparableArg<'a> {
|
||||
fn from(arg: &'a Box<Arg>) -> Self {
|
||||
(&**arg).into()
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Hash)]
|
||||
pub struct ComparableArg<'a> {
|
||||
pub arg: &'a str,
|
||||
pub annotation: Option<Box<ComparableExpr<'a>>>,
|
||||
pub type_comment: Option<&'a str>,
|
||||
}
|
||||
|
||||
impl<'a> From<&'a Arg> for ComparableArg<'a> {
|
||||
fn from(arg: &'a Arg) -> Self {
|
||||
Self {
|
||||
arg: &arg.node.arg,
|
||||
annotation: arg.node.annotation.as_ref().map(std::convert::Into::into),
|
||||
type_comment: arg.node.type_comment.as_deref(),
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Hash)]
|
||||
pub struct ComparableKeyword<'a> {
|
||||
pub arg: Option<&'a str>,
|
||||
pub value: ComparableExpr<'a>,
|
||||
}
|
||||
|
||||
impl<'a> From<&'a Keyword> for ComparableKeyword<'a> {
|
||||
fn from(keyword: &'a Keyword) -> Self {
|
||||
Self {
|
||||
arg: keyword.node.arg.as_deref(),
|
||||
value: (&keyword.node.value).into(),
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Hash)]
|
||||
pub struct ComparableComprehension<'a> {
|
||||
pub target: ComparableExpr<'a>,
|
||||
pub iter: ComparableExpr<'a>,
|
||||
pub ifs: Vec<ComparableExpr<'a>>,
|
||||
pub is_async: &'a usize,
|
||||
}
|
||||
|
||||
impl<'a> From<&'a Comprehension> for ComparableComprehension<'a> {
|
||||
fn from(comprehension: &'a Comprehension) -> Self {
|
||||
Self {
|
||||
target: (&comprehension.target).into(),
|
||||
iter: (&comprehension.iter).into(),
|
||||
ifs: comprehension
|
||||
.ifs
|
||||
.iter()
|
||||
.map(std::convert::Into::into)
|
||||
.collect(),
|
||||
is_async: &comprehension.is_async,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Hash)]
|
||||
pub enum ComparableExpr<'a> {
|
||||
BoolOp {
|
||||
op: ComparableBoolop,
|
||||
values: Vec<ComparableExpr<'a>>,
|
||||
},
|
||||
NamedExpr {
|
||||
target: Box<ComparableExpr<'a>>,
|
||||
value: Box<ComparableExpr<'a>>,
|
||||
},
|
||||
BinOp {
|
||||
left: Box<ComparableExpr<'a>>,
|
||||
op: ComparableOperator,
|
||||
right: Box<ComparableExpr<'a>>,
|
||||
},
|
||||
UnaryOp {
|
||||
op: ComparableUnaryop,
|
||||
operand: Box<ComparableExpr<'a>>,
|
||||
},
|
||||
Lambda {
|
||||
args: ComparableArguments<'a>,
|
||||
body: Box<ComparableExpr<'a>>,
|
||||
},
|
||||
IfExp {
|
||||
test: Box<ComparableExpr<'a>>,
|
||||
body: Box<ComparableExpr<'a>>,
|
||||
orelse: Box<ComparableExpr<'a>>,
|
||||
},
|
||||
Dict {
|
||||
keys: Vec<ComparableExpr<'a>>,
|
||||
values: Vec<ComparableExpr<'a>>,
|
||||
},
|
||||
Set {
|
||||
elts: Vec<ComparableExpr<'a>>,
|
||||
},
|
||||
ListComp {
|
||||
elt: Box<ComparableExpr<'a>>,
|
||||
generators: Vec<ComparableComprehension<'a>>,
|
||||
},
|
||||
SetComp {
|
||||
elt: Box<ComparableExpr<'a>>,
|
||||
generators: Vec<ComparableComprehension<'a>>,
|
||||
},
|
||||
DictComp {
|
||||
key: Box<ComparableExpr<'a>>,
|
||||
value: Box<ComparableExpr<'a>>,
|
||||
generators: Vec<ComparableComprehension<'a>>,
|
||||
},
|
||||
GeneratorExp {
|
||||
elt: Box<ComparableExpr<'a>>,
|
||||
generators: Vec<ComparableComprehension<'a>>,
|
||||
},
|
||||
Await {
|
||||
value: Box<ComparableExpr<'a>>,
|
||||
},
|
||||
Yield {
|
||||
value: Option<Box<ComparableExpr<'a>>>,
|
||||
},
|
||||
YieldFrom {
|
||||
value: Box<ComparableExpr<'a>>,
|
||||
},
|
||||
Compare {
|
||||
left: Box<ComparableExpr<'a>>,
|
||||
ops: Vec<ComparableCmpop>,
|
||||
comparators: Vec<ComparableExpr<'a>>,
|
||||
},
|
||||
Call {
|
||||
func: Box<ComparableExpr<'a>>,
|
||||
args: Vec<ComparableExpr<'a>>,
|
||||
keywords: Vec<ComparableKeyword<'a>>,
|
||||
},
|
||||
FormattedValue {
|
||||
value: Box<ComparableExpr<'a>>,
|
||||
conversion: &'a usize,
|
||||
format_spec: Option<Box<ComparableExpr<'a>>>,
|
||||
},
|
||||
JoinedStr {
|
||||
values: Vec<ComparableExpr<'a>>,
|
||||
},
|
||||
Constant {
|
||||
value: ComparableConstant<'a>,
|
||||
kind: Option<&'a str>,
|
||||
},
|
||||
Attribute {
|
||||
value: Box<ComparableExpr<'a>>,
|
||||
attr: &'a str,
|
||||
ctx: ComparableExprContext,
|
||||
},
|
||||
Subscript {
|
||||
value: Box<ComparableExpr<'a>>,
|
||||
slice: Box<ComparableExpr<'a>>,
|
||||
ctx: ComparableExprContext,
|
||||
},
|
||||
Starred {
|
||||
value: Box<ComparableExpr<'a>>,
|
||||
ctx: ComparableExprContext,
|
||||
},
|
||||
Name {
|
||||
id: &'a str,
|
||||
ctx: ComparableExprContext,
|
||||
},
|
||||
List {
|
||||
elts: Vec<ComparableExpr<'a>>,
|
||||
ctx: ComparableExprContext,
|
||||
},
|
||||
Tuple {
|
||||
elts: Vec<ComparableExpr<'a>>,
|
||||
ctx: ComparableExprContext,
|
||||
},
|
||||
Slice {
|
||||
lower: Option<Box<ComparableExpr<'a>>>,
|
||||
upper: Option<Box<ComparableExpr<'a>>>,
|
||||
step: Option<Box<ComparableExpr<'a>>>,
|
||||
},
|
||||
}
|
||||
|
||||
impl<'a> From<&'a Box<Expr>> for Box<ComparableExpr<'a>> {
|
||||
fn from(expr: &'a Box<Expr>) -> Self {
|
||||
Box::new((&**expr).into())
|
||||
}
|
||||
}
|
||||
|
||||
impl<'a> From<&'a Expr> for ComparableExpr<'a> {
|
||||
fn from(expr: &'a Expr) -> Self {
|
||||
match &expr.node {
|
||||
ExprKind::BoolOp { op, values } => Self::BoolOp {
|
||||
op: op.into(),
|
||||
values: values.iter().map(std::convert::Into::into).collect(),
|
||||
},
|
||||
ExprKind::NamedExpr { target, value } => Self::NamedExpr {
|
||||
target: target.into(),
|
||||
value: value.into(),
|
||||
},
|
||||
ExprKind::BinOp { left, op, right } => Self::BinOp {
|
||||
left: left.into(),
|
||||
op: op.into(),
|
||||
right: right.into(),
|
||||
},
|
||||
ExprKind::UnaryOp { op, operand } => Self::UnaryOp {
|
||||
op: op.into(),
|
||||
operand: operand.into(),
|
||||
},
|
||||
ExprKind::Lambda { args, body } => Self::Lambda {
|
||||
args: (&**args).into(),
|
||||
body: body.into(),
|
||||
},
|
||||
ExprKind::IfExp { test, body, orelse } => Self::IfExp {
|
||||
test: test.into(),
|
||||
body: body.into(),
|
||||
orelse: orelse.into(),
|
||||
},
|
||||
ExprKind::Dict { keys, values } => Self::Dict {
|
||||
keys: keys.iter().map(std::convert::Into::into).collect(),
|
||||
values: values.iter().map(std::convert::Into::into).collect(),
|
||||
},
|
||||
ExprKind::Set { elts } => Self::Set {
|
||||
elts: elts.iter().map(std::convert::Into::into).collect(),
|
||||
},
|
||||
ExprKind::ListComp { elt, generators } => Self::ListComp {
|
||||
elt: elt.into(),
|
||||
generators: generators.iter().map(std::convert::Into::into).collect(),
|
||||
},
|
||||
ExprKind::SetComp { elt, generators } => Self::SetComp {
|
||||
elt: elt.into(),
|
||||
generators: generators.iter().map(std::convert::Into::into).collect(),
|
||||
},
|
||||
ExprKind::DictComp {
|
||||
key,
|
||||
value,
|
||||
generators,
|
||||
} => Self::DictComp {
|
||||
key: key.into(),
|
||||
value: value.into(),
|
||||
generators: generators.iter().map(std::convert::Into::into).collect(),
|
||||
},
|
||||
ExprKind::GeneratorExp { elt, generators } => Self::GeneratorExp {
|
||||
elt: elt.into(),
|
||||
generators: generators.iter().map(std::convert::Into::into).collect(),
|
||||
},
|
||||
ExprKind::Await { value } => Self::Await {
|
||||
value: value.into(),
|
||||
},
|
||||
ExprKind::Yield { value } => Self::Yield {
|
||||
value: value.as_ref().map(std::convert::Into::into),
|
||||
},
|
||||
ExprKind::YieldFrom { value } => Self::YieldFrom {
|
||||
value: value.into(),
|
||||
},
|
||||
ExprKind::Compare {
|
||||
left,
|
||||
ops,
|
||||
comparators,
|
||||
} => Self::Compare {
|
||||
left: left.into(),
|
||||
ops: ops.iter().map(std::convert::Into::into).collect(),
|
||||
comparators: comparators.iter().map(std::convert::Into::into).collect(),
|
||||
},
|
||||
ExprKind::Call {
|
||||
func,
|
||||
args,
|
||||
keywords,
|
||||
} => Self::Call {
|
||||
func: func.into(),
|
||||
args: args.iter().map(std::convert::Into::into).collect(),
|
||||
keywords: keywords.iter().map(std::convert::Into::into).collect(),
|
||||
},
|
||||
ExprKind::FormattedValue {
|
||||
value,
|
||||
conversion,
|
||||
format_spec,
|
||||
} => Self::FormattedValue {
|
||||
value: value.into(),
|
||||
conversion,
|
||||
format_spec: format_spec.as_ref().map(std::convert::Into::into),
|
||||
},
|
||||
ExprKind::JoinedStr { values } => Self::JoinedStr {
|
||||
values: values.iter().map(std::convert::Into::into).collect(),
|
||||
},
|
||||
ExprKind::Constant { value, kind } => Self::Constant {
|
||||
value: value.into(),
|
||||
kind: kind.as_ref().map(String::as_str),
|
||||
},
|
||||
ExprKind::Attribute { value, attr, ctx } => Self::Attribute {
|
||||
value: value.into(),
|
||||
attr,
|
||||
ctx: ctx.into(),
|
||||
},
|
||||
ExprKind::Subscript { value, slice, ctx } => Self::Subscript {
|
||||
value: value.into(),
|
||||
slice: slice.into(),
|
||||
ctx: ctx.into(),
|
||||
},
|
||||
ExprKind::Starred { value, ctx } => Self::Starred {
|
||||
value: value.into(),
|
||||
ctx: ctx.into(),
|
||||
},
|
||||
ExprKind::Name { id, ctx } => Self::Name {
|
||||
id,
|
||||
ctx: ctx.into(),
|
||||
},
|
||||
ExprKind::List { elts, ctx } => Self::List {
|
||||
elts: elts.iter().map(std::convert::Into::into).collect(),
|
||||
ctx: ctx.into(),
|
||||
},
|
||||
ExprKind::Tuple { elts, ctx } => Self::Tuple {
|
||||
elts: elts.iter().map(std::convert::Into::into).collect(),
|
||||
ctx: ctx.into(),
|
||||
},
|
||||
ExprKind::Slice { lower, upper, step } => Self::Slice {
|
||||
lower: lower.as_ref().map(std::convert::Into::into),
|
||||
upper: upper.as_ref().map(std::convert::Into::into),
|
||||
step: step.as_ref().map(std::convert::Into::into),
|
||||
},
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -11,7 +11,9 @@ use rustpython_parser::lexer;
|
||||
use rustpython_parser::lexer::Tok;
|
||||
use rustpython_parser::token::StringKind;
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::ast::types::{Binding, BindingKind, Range};
|
||||
use crate::source_code_generator::SourceCodeGenerator;
|
||||
use crate::source_code_style::SourceCodeStyleDetector;
|
||||
use crate::SourceCodeLocator;
|
||||
|
||||
/// Create an `Expr` with default location from an `ExprKind`.
|
||||
@@ -24,6 +26,20 @@ pub fn create_stmt(node: StmtKind) -> Stmt {
|
||||
Stmt::new(Location::default(), Location::default(), node)
|
||||
}
|
||||
|
||||
/// Generate source code from an `Expr`.
|
||||
pub fn unparse_expr(expr: &Expr, stylist: &SourceCodeStyleDetector) -> String {
|
||||
let mut generator: SourceCodeGenerator = stylist.into();
|
||||
generator.unparse_expr(expr, 0);
|
||||
generator.generate()
|
||||
}
|
||||
|
||||
/// Generate source code from an `Stmt`.
|
||||
pub fn unparse_stmt(stmt: &Stmt, stylist: &SourceCodeStyleDetector) -> String {
|
||||
let mut generator: SourceCodeGenerator = stylist.into();
|
||||
generator.unparse_stmt(stmt);
|
||||
generator.generate()
|
||||
}
|
||||
|
||||
fn collect_call_path_inner<'a>(expr: &'a Expr, parts: &mut Vec<&'a str>) {
|
||||
match &expr.node {
|
||||
ExprKind::Call { func, .. } => {
|
||||
@@ -213,23 +229,6 @@ pub fn is_constant_non_singleton(expr: &Expr) -> bool {
|
||||
is_constant(expr) && !is_singleton(expr)
|
||||
}
|
||||
|
||||
/// Return `true` if an `Expr` is not a reference to a variable (or something
|
||||
/// that could resolve to a variable, like a function call).
|
||||
pub fn is_non_variable(expr: &Expr) -> bool {
|
||||
matches!(
|
||||
expr.node,
|
||||
ExprKind::Constant { .. }
|
||||
| ExprKind::Tuple { .. }
|
||||
| ExprKind::List { .. }
|
||||
| ExprKind::Set { .. }
|
||||
| ExprKind::Dict { .. }
|
||||
| ExprKind::SetComp { .. }
|
||||
| ExprKind::ListComp { .. }
|
||||
| ExprKind::DictComp { .. }
|
||||
| ExprKind::GeneratorExp { .. }
|
||||
)
|
||||
}
|
||||
|
||||
/// Return the `Keyword` with the given name, if it's present in the list of
|
||||
/// `Keyword` arguments.
|
||||
pub fn find_keyword<'a>(keywords: &'a [Keyword], keyword_name: &str) -> Option<&'a Keyword> {
|
||||
@@ -316,7 +315,7 @@ pub fn is_super_call_with_arguments(func: &Expr, args: &[Expr]) -> bool {
|
||||
}
|
||||
|
||||
/// Format the module name for a relative import.
|
||||
pub fn format_import_from(level: Option<&usize>, module: Option<&String>) -> String {
|
||||
pub fn format_import_from(level: Option<&usize>, module: Option<&str>) -> String {
|
||||
let mut module_name = String::with_capacity(16);
|
||||
if let Some(level) = level {
|
||||
for _ in 0..*level {
|
||||
@@ -407,6 +406,22 @@ pub fn identifier_range(stmt: &Stmt, locator: &SourceCodeLocator) -> Range {
|
||||
Range::from_located(stmt)
|
||||
}
|
||||
|
||||
/// Like `identifier_range`, but accepts a `Binding`.
|
||||
pub fn binding_range(binding: &Binding, locator: &SourceCodeLocator) -> Range {
|
||||
if matches!(
|
||||
binding.kind,
|
||||
BindingKind::ClassDefinition | BindingKind::FunctionDefinition
|
||||
) {
|
||||
if let Some(source) = &binding.source {
|
||||
identifier_range(source, locator)
|
||||
} else {
|
||||
binding.range
|
||||
}
|
||||
} else {
|
||||
binding.range
|
||||
}
|
||||
}
|
||||
|
||||
// Return the ranges of `Name` tokens within a specified node.
|
||||
pub fn find_names<T>(located: &Located<T>, locator: &SourceCodeLocator) -> Vec<Range> {
|
||||
let contents = locator.slice_source_code_range(&Range::from_located(located));
|
||||
@@ -555,7 +570,7 @@ pub fn preceded_by_continuation(stmt: &Stmt, locator: &SourceCodeLocator) -> boo
|
||||
Location::new(stmt.location.row(), 0),
|
||||
);
|
||||
let line = locator.slice_source_code_range(&range);
|
||||
if line.trim().ends_with('\\') {
|
||||
if line.trim_end().ends_with('\\') {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
@@ -582,7 +597,7 @@ pub struct SimpleCallArgs<'a> {
|
||||
}
|
||||
|
||||
impl<'a> SimpleCallArgs<'a> {
|
||||
pub fn new(args: &'a Vec<Expr>, keywords: &'a Vec<Keyword>) -> Self {
|
||||
pub fn new(args: &'a [Expr], keywords: &'a [Keyword]) -> Self {
|
||||
let mut result = SimpleCallArgs::default();
|
||||
|
||||
for arg in args {
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
pub mod branch_detection;
|
||||
pub mod cast;
|
||||
pub mod comparable;
|
||||
pub mod function_type;
|
||||
pub mod helpers;
|
||||
pub mod operations;
|
||||
|
||||
@@ -120,7 +120,7 @@ pub fn on_conditional_branch<'a>(parents: &mut impl Iterator<Item = &'a Stmt>) -
|
||||
}
|
||||
|
||||
/// Check if a node is in a nested block.
|
||||
pub fn in_nested_block<'a>(parents: &mut impl Iterator<Item = &'a Stmt>) -> bool {
|
||||
pub fn in_nested_block<'a>(mut parents: impl Iterator<Item = &'a Stmt>) -> bool {
|
||||
parents.any(|parent| {
|
||||
matches!(
|
||||
parent.node,
|
||||
@@ -212,7 +212,7 @@ pub fn is_unpacking_assignment(parent: &Stmt, child: &Expr) -> bool {
|
||||
ExprKind::Set { .. } | ExprKind::List { .. } | ExprKind::Tuple { .. }
|
||||
);
|
||||
// In `(a, b) = coords = (1, 2)`, `(a, b)` and `coords` are the targets, and
|
||||
// `(a, b`) is a tuple. (We use "tuple" as a placeholder for any
|
||||
// `(a, b)` is a tuple. (We use "tuple" as a placeholder for any
|
||||
// unpackable expression.)
|
||||
let targets_are_tuples = targets.iter().all(|item| {
|
||||
matches!(
|
||||
|
||||
@@ -1,3 +1,4 @@
|
||||
use std::ops::Deref;
|
||||
use std::sync::atomic::{AtomicUsize, Ordering};
|
||||
|
||||
use rustc_hash::FxHashMap;
|
||||
@@ -215,3 +216,23 @@ impl<'a, 'b, T> PartialEq<RefEquality<'b, T>> for RefEquality<'a, T> {
|
||||
}
|
||||
|
||||
impl<'a, T> Eq for RefEquality<'a, T> {}
|
||||
|
||||
impl<'a, T> Deref for RefEquality<'a, T> {
|
||||
type Target = T;
|
||||
|
||||
fn deref(&self) -> &T {
|
||||
self.0
|
||||
}
|
||||
}
|
||||
|
||||
impl<'a> From<&RefEquality<'a, Stmt>> for &'a Stmt {
|
||||
fn from(r: &RefEquality<'a, Stmt>) -> Self {
|
||||
r.0
|
||||
}
|
||||
}
|
||||
|
||||
impl<'a> From<&RefEquality<'a, Expr>> for &'a Expr {
|
||||
fn from(r: &RefEquality<'a, Expr>) -> Self {
|
||||
r.0
|
||||
}
|
||||
}
|
||||
|
||||
18
src/cache.rs
18
src/cache.rs
@@ -1,6 +1,5 @@
|
||||
use std::collections::hash_map::DefaultHasher;
|
||||
use std::fs;
|
||||
use std::fs::{create_dir_all, File, Metadata};
|
||||
use std::hash::{Hash, Hasher};
|
||||
use std::io::Write;
|
||||
use std::path::{Path, PathBuf};
|
||||
@@ -8,16 +7,15 @@ use std::path::{Path, PathBuf};
|
||||
use anyhow::Result;
|
||||
use filetime::FileTime;
|
||||
use log::error;
|
||||
use once_cell::sync::Lazy;
|
||||
use path_absolutize::Absolutize;
|
||||
use serde::{Deserialize, Serialize};
|
||||
|
||||
use crate::message::Message;
|
||||
use crate::settings::{flags, Settings};
|
||||
|
||||
pub const CACHE_DIR_NAME: &str = ".ruff_cache";
|
||||
|
||||
const CARGO_PKG_VERSION: &str = env!("CARGO_PKG_VERSION");
|
||||
static CACHE_DIR: Lazy<Option<String>> = Lazy::new(|| std::env::var("RUFF_CACHE_DIR").ok());
|
||||
pub const DEFAULT_CACHE_DIR_NAME: &str = ".ruff_cache";
|
||||
|
||||
#[derive(Serialize, Deserialize)]
|
||||
struct CacheMetadata {
|
||||
@@ -39,9 +37,7 @@ struct CheckResult {
|
||||
/// Return the cache directory for a given project root. Defers to the
|
||||
/// `RUFF_CACHE_DIR` environment variable, if set.
|
||||
pub fn cache_dir(project_root: &Path) -> PathBuf {
|
||||
CACHE_DIR
|
||||
.as_ref()
|
||||
.map_or_else(|| project_root.join(DEFAULT_CACHE_DIR_NAME), PathBuf::from)
|
||||
project_root.join(CACHE_DIR_NAME)
|
||||
}
|
||||
|
||||
fn content_dir() -> &'static Path {
|
||||
@@ -60,7 +56,7 @@ fn cache_key<P: AsRef<Path>>(path: P, settings: &Settings, autofix: flags::Autof
|
||||
/// Initialize the cache at the specified `Path`.
|
||||
pub fn init(path: &Path) -> Result<()> {
|
||||
// Create the cache directories.
|
||||
create_dir_all(path.join(content_dir()))?;
|
||||
fs::create_dir_all(path.join(content_dir()))?;
|
||||
|
||||
// Add the CACHEDIR.TAG.
|
||||
if !cachedir::is_tagged(path)? {
|
||||
@@ -70,7 +66,7 @@ pub fn init(path: &Path) -> Result<()> {
|
||||
// Add the .gitignore.
|
||||
let gitignore_path = path.join(".gitignore");
|
||||
if !gitignore_path.exists() {
|
||||
let mut file = File::create(gitignore_path)?;
|
||||
let mut file = fs::File::create(gitignore_path)?;
|
||||
file.write_all(b"*")?;
|
||||
}
|
||||
|
||||
@@ -91,7 +87,7 @@ fn read_sync(cache_dir: &Path, key: u64) -> Result<Vec<u8>, std::io::Error> {
|
||||
/// Get a value from the cache.
|
||||
pub fn get<P: AsRef<Path>>(
|
||||
path: P,
|
||||
metadata: &Metadata,
|
||||
metadata: &fs::Metadata,
|
||||
settings: &Settings,
|
||||
autofix: flags::Autofix,
|
||||
) -> Option<Vec<Message>> {
|
||||
@@ -115,7 +111,7 @@ pub fn get<P: AsRef<Path>>(
|
||||
/// Set a value in the cache.
|
||||
pub fn set<P: AsRef<Path>>(
|
||||
path: P,
|
||||
metadata: &Metadata,
|
||||
metadata: &fs::Metadata,
|
||||
settings: &Settings,
|
||||
autofix: flags::Autofix,
|
||||
messages: &[Message],
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -7,10 +7,10 @@ use rustpython_parser::ast::Location;
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::autofix::Fix;
|
||||
use crate::noqa;
|
||||
use crate::noqa::{is_file_exempt, Directive};
|
||||
use crate::registry::{Check, CheckCode, CheckKind, UnusedCodes, CODE_REDIRECTS};
|
||||
use crate::settings::{flags, Settings};
|
||||
use crate::{noqa, violations};
|
||||
|
||||
pub fn check_noqa(
|
||||
checks: &mut Vec<Check>,
|
||||
@@ -42,7 +42,7 @@ pub fn check_noqa(
|
||||
|
||||
// Remove any ignored checks.
|
||||
for (index, check) in checks.iter().enumerate() {
|
||||
if check.kind == CheckKind::BlanketNOQA {
|
||||
if matches!(check.kind, CheckKind::BlanketNOQA(..)) {
|
||||
continue;
|
||||
}
|
||||
|
||||
@@ -101,7 +101,7 @@ pub fn check_noqa(
|
||||
Directive::All(spaces, start, end) => {
|
||||
if matches.is_empty() {
|
||||
let mut check = Check::new(
|
||||
CheckKind::UnusedNOQA(None),
|
||||
violations::UnusedNOQA(None),
|
||||
Range::new(Location::new(row + 1, start), Location::new(row + 1, end)),
|
||||
);
|
||||
if matches!(autofix, flags::Autofix::Enabled)
|
||||
@@ -152,7 +152,7 @@ pub fn check_noqa(
|
||||
&& unmatched_codes.is_empty())
|
||||
{
|
||||
let mut check = Check::new(
|
||||
CheckKind::UnusedNOQA(Some(UnusedCodes {
|
||||
violations::UnusedNOQA(Some(UnusedCodes {
|
||||
disabled: disabled_codes
|
||||
.iter()
|
||||
.map(|code| (*code).to_string())
|
||||
|
||||
@@ -39,7 +39,7 @@ pub fn check_tokens(
|
||||
|
||||
// RUF001, RUF002, RUF003
|
||||
if enforce_ambiguous_unicode_character {
|
||||
if matches!(tok, Tok::String { .. } | Tok::Comment) {
|
||||
if matches!(tok, Tok::String { .. } | Tok::Comment(_)) {
|
||||
checks.extend(ruff::checks::ambiguous_unicode_character(
|
||||
locator,
|
||||
start,
|
||||
@@ -78,7 +78,7 @@ pub fn check_tokens(
|
||||
|
||||
// eradicate
|
||||
if enforce_commented_out_code {
|
||||
if matches!(tok, Tok::Comment) {
|
||||
if matches!(tok, Tok::Comment(_)) {
|
||||
if let Some(check) =
|
||||
eradicate::checks::commented_out_code(locator, start, end, settings, autofix)
|
||||
{
|
||||
|
||||
14
src/cli.rs
14
src/cli.rs
@@ -6,8 +6,7 @@ use rustc_hash::FxHashMap;
|
||||
|
||||
use crate::fs;
|
||||
use crate::logging::LogLevel;
|
||||
use crate::registry::CheckCode;
|
||||
use crate::registry_gen::CheckCodePrefix;
|
||||
use crate::registry::{CheckCode, CheckCodePrefix};
|
||||
use crate::settings::types::{
|
||||
FilePattern, PatternPrefixPair, PerFileIgnore, PythonVersion, SerializationFormat,
|
||||
};
|
||||
@@ -21,7 +20,7 @@ pub struct Cli {
|
||||
pub files: Vec<PathBuf>,
|
||||
/// Path to the `pyproject.toml` or `ruff.toml` file to use for
|
||||
/// configuration.
|
||||
#[arg(long)]
|
||||
#[arg(long, conflicts_with = "isolated")]
|
||||
pub config: Option<PathBuf>,
|
||||
/// Enable verbose logging.
|
||||
#[arg(short, long, group = "verbosity")]
|
||||
@@ -57,6 +56,9 @@ pub struct Cli {
|
||||
/// Disable cache reads.
|
||||
#[arg(short, long)]
|
||||
pub no_cache: bool,
|
||||
/// Ignore all configuration files.
|
||||
#[arg(long, conflicts_with = "config")]
|
||||
pub isolated: bool,
|
||||
/// Comma-separated list of error codes to enable (or ALL, to enable all
|
||||
/// checks).
|
||||
#[arg(long, value_delimiter = ',')]
|
||||
@@ -91,13 +93,13 @@ pub struct Cli {
|
||||
#[arg(long, value_delimiter = ',')]
|
||||
pub per_file_ignores: Option<Vec<PatternPrefixPair>>,
|
||||
/// Output serialization format for error messages.
|
||||
#[arg(long, value_enum)]
|
||||
#[arg(long, value_enum, env = "RUFF_FORMAT")]
|
||||
pub format: Option<SerializationFormat>,
|
||||
/// The name of the file when passing it through stdin.
|
||||
#[arg(long)]
|
||||
pub stdin_filename: Option<PathBuf>,
|
||||
/// Path to the cache directory.
|
||||
#[arg(long)]
|
||||
#[arg(long, env = "RUFF_CACHE_DIR")]
|
||||
pub cache_dir: Option<PathBuf>,
|
||||
/// Show violations with source code.
|
||||
#[arg(long, overrides_with("no_show_source"))]
|
||||
@@ -241,6 +243,7 @@ impl Cli {
|
||||
explain: self.explain,
|
||||
files: self.files,
|
||||
generate_shell_completion: self.generate_shell_completion,
|
||||
isolated: self.isolated,
|
||||
no_cache: self.no_cache,
|
||||
quiet: self.quiet,
|
||||
show_files: self.show_files,
|
||||
@@ -302,6 +305,7 @@ pub struct Arguments {
|
||||
pub explain: Option<CheckCode>,
|
||||
pub files: Vec<PathBuf>,
|
||||
pub generate_shell_completion: Option<clap_complete_command::Shell>,
|
||||
pub isolated: bool,
|
||||
pub no_cache: bool,
|
||||
pub quiet: bool,
|
||||
pub show_files: bool,
|
||||
|
||||
@@ -16,17 +16,17 @@ use serde::Serialize;
|
||||
use walkdir::WalkDir;
|
||||
|
||||
use crate::autofix::fixer;
|
||||
use crate::cache::DEFAULT_CACHE_DIR_NAME;
|
||||
use crate::cache::CACHE_DIR_NAME;
|
||||
use crate::cli::Overrides;
|
||||
use crate::iterators::par_iter;
|
||||
use crate::linter::{add_noqa_to_path, lint_path, lint_stdin, Diagnostics};
|
||||
use crate::logging::LogLevel;
|
||||
use crate::message::Message;
|
||||
use crate::registry::{CheckCode, CheckKind};
|
||||
use crate::registry::CheckCode;
|
||||
use crate::resolver::{FileDiscovery, PyprojectDiscovery};
|
||||
use crate::settings::flags;
|
||||
use crate::settings::types::SerializationFormat;
|
||||
use crate::{cache, fs, one_time_warning, packages, resolver};
|
||||
use crate::{cache, fs, one_time_warning, packages, resolver, violations};
|
||||
|
||||
/// Run the linter over a collection of files.
|
||||
pub fn run(
|
||||
@@ -119,7 +119,7 @@ pub fn run(
|
||||
let settings = resolver.resolve(path, pyproject_strategy);
|
||||
if settings.enabled.contains(&CheckCode::E902) {
|
||||
Diagnostics::new(vec![Message {
|
||||
kind: CheckKind::IOError(message),
|
||||
kind: violations::IOError(message).into(),
|
||||
location: Location::default(),
|
||||
end_location: Location::default(),
|
||||
fix: None,
|
||||
@@ -340,10 +340,10 @@ pub fn explain(code: &CheckCode, format: &SerializationFormat) -> Result<()> {
|
||||
pub fn clean(level: &LogLevel) -> Result<()> {
|
||||
for entry in WalkDir::new(&*path_dedot::CWD)
|
||||
.into_iter()
|
||||
.filter_map(std::result::Result::ok)
|
||||
.filter_map(Result::ok)
|
||||
.filter(|entry| entry.file_type().is_dir())
|
||||
{
|
||||
let cache = entry.path().join(DEFAULT_CACHE_DIR_NAME);
|
||||
let cache = entry.path().join(CACHE_DIR_NAME);
|
||||
if cache.is_dir() {
|
||||
if level >= &LogLevel::Default {
|
||||
eprintln!("Removing cache at: {}", fs::relativize_path(&cache).bold());
|
||||
|
||||
@@ -5,9 +5,8 @@ use nohash_hasher::{IntMap, IntSet};
|
||||
use rustpython_ast::Location;
|
||||
use rustpython_parser::lexer::{LexResult, Tok};
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::LintSource;
|
||||
use crate::{Settings, SourceCodeLocator};
|
||||
use crate::Settings;
|
||||
|
||||
bitflags! {
|
||||
pub struct Flags: u32 {
|
||||
@@ -42,11 +41,7 @@ pub struct Directives {
|
||||
pub isort: IsortDirectives,
|
||||
}
|
||||
|
||||
pub fn extract_directives(
|
||||
lxr: &[LexResult],
|
||||
locator: &SourceCodeLocator,
|
||||
flags: Flags,
|
||||
) -> Directives {
|
||||
pub fn extract_directives(lxr: &[LexResult], flags: Flags) -> Directives {
|
||||
Directives {
|
||||
commented_lines: extract_commented_lines(lxr),
|
||||
noqa_line_for: if flags.contains(Flags::NOQA) {
|
||||
@@ -55,7 +50,7 @@ pub fn extract_directives(
|
||||
IntMap::default()
|
||||
},
|
||||
isort: if flags.contains(Flags::ISORT) {
|
||||
extract_isort_directives(lxr, locator)
|
||||
extract_isort_directives(lxr)
|
||||
} else {
|
||||
IsortDirectives::default()
|
||||
},
|
||||
@@ -65,7 +60,7 @@ pub fn extract_directives(
|
||||
pub fn extract_commented_lines(lxr: &[LexResult]) -> Vec<usize> {
|
||||
let mut commented_lines = Vec::new();
|
||||
for (start, tok, ..) in lxr.iter().flatten() {
|
||||
if matches!(tok, Tok::Comment) {
|
||||
if matches!(tok, Tok::Comment(_)) {
|
||||
commented_lines.push(start.row());
|
||||
}
|
||||
}
|
||||
@@ -91,7 +86,7 @@ pub fn extract_noqa_line_for(lxr: &[LexResult]) -> IntMap<usize, usize> {
|
||||
}
|
||||
|
||||
/// Extract a set of lines over which to disable isort.
|
||||
pub fn extract_isort_directives(lxr: &[LexResult], locator: &SourceCodeLocator) -> IsortDirectives {
|
||||
pub fn extract_isort_directives(lxr: &[LexResult]) -> IsortDirectives {
|
||||
let mut exclusions: IntSet<usize> = IntSet::default();
|
||||
let mut splits: Vec<usize> = Vec::default();
|
||||
let mut skip_file: bool = false;
|
||||
@@ -105,16 +100,17 @@ pub fn extract_isort_directives(lxr: &[LexResult], locator: &SourceCodeLocator)
|
||||
continue;
|
||||
}
|
||||
|
||||
if !matches!(tok, Tok::Comment) {
|
||||
let Tok::Comment(comment_text) = tok else {
|
||||
continue;
|
||||
}
|
||||
|
||||
// TODO(charlie): Modify RustPython to include the comment text in the token.
|
||||
let comment_text = locator.slice_source_code_range(&Range::new(start, end));
|
||||
};
|
||||
|
||||
// `isort` allows for `# isort: skip` and `# isort: skip_file` to include or
|
||||
// omit a space after the colon. The remaining action comments are
|
||||
// required to include the space, and must appear on their own lines.
|
||||
let comment_text = comment_text.trim_end();
|
||||
if comment_text == "# isort: split" {
|
||||
splits.push(start.row());
|
||||
} else if comment_text == "# isort: skip_file" {
|
||||
} else if comment_text == "# isort: skip_file" || comment_text == "# isort:skip_file" {
|
||||
skip_file = true;
|
||||
} else if off.is_some() {
|
||||
if comment_text == "# isort: on" {
|
||||
@@ -126,13 +122,14 @@ pub fn extract_isort_directives(lxr: &[LexResult], locator: &SourceCodeLocator)
|
||||
off = None;
|
||||
}
|
||||
} else {
|
||||
if comment_text.contains("isort: skip") {
|
||||
if comment_text.contains("isort: skip") || comment_text.contains("isort:skip") {
|
||||
exclusions.insert(start.row());
|
||||
} else if comment_text == "# isort: off" {
|
||||
off = Some(start);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if skip_file {
|
||||
// Enforce `isort: skip_file`.
|
||||
if let Some(end) = last {
|
||||
@@ -158,7 +155,6 @@ mod tests {
|
||||
use rustpython_parser::lexer::LexResult;
|
||||
|
||||
use crate::directives::{extract_isort_directives, extract_noqa_line_for};
|
||||
use crate::SourceCodeLocator;
|
||||
|
||||
#[test]
|
||||
fn noqa_extraction() {
|
||||
@@ -246,11 +242,7 @@ z = x + 1",
|
||||
y = 2
|
||||
z = x + 1";
|
||||
let lxr: Vec<LexResult> = lexer::make_tokenizer(contents).collect();
|
||||
let locator = SourceCodeLocator::new(contents);
|
||||
assert_eq!(
|
||||
extract_isort_directives(&lxr, &locator).exclusions,
|
||||
IntSet::default()
|
||||
);
|
||||
assert_eq!(extract_isort_directives(&lxr).exclusions, IntSet::default());
|
||||
|
||||
let contents = "# isort: off
|
||||
x = 1
|
||||
@@ -258,9 +250,8 @@ y = 2
|
||||
# isort: on
|
||||
z = x + 1";
|
||||
let lxr: Vec<LexResult> = lexer::make_tokenizer(contents).collect();
|
||||
let locator = SourceCodeLocator::new(contents);
|
||||
assert_eq!(
|
||||
extract_isort_directives(&lxr, &locator).exclusions,
|
||||
extract_isort_directives(&lxr).exclusions,
|
||||
IntSet::from_iter([2, 3, 4])
|
||||
);
|
||||
|
||||
@@ -272,9 +263,8 @@ y = 2
|
||||
z = x + 1
|
||||
# isort: on";
|
||||
let lxr: Vec<LexResult> = lexer::make_tokenizer(contents).collect();
|
||||
let locator = SourceCodeLocator::new(contents);
|
||||
assert_eq!(
|
||||
extract_isort_directives(&lxr, &locator).exclusions,
|
||||
extract_isort_directives(&lxr).exclusions,
|
||||
IntSet::from_iter([2, 3, 4, 5])
|
||||
);
|
||||
|
||||
@@ -283,9 +273,8 @@ x = 1
|
||||
y = 2
|
||||
z = x + 1";
|
||||
let lxr: Vec<LexResult> = lexer::make_tokenizer(contents).collect();
|
||||
let locator = SourceCodeLocator::new(contents);
|
||||
assert_eq!(
|
||||
extract_isort_directives(&lxr, &locator).exclusions,
|
||||
extract_isort_directives(&lxr).exclusions,
|
||||
IntSet::from_iter([2, 3, 4])
|
||||
);
|
||||
|
||||
@@ -294,9 +283,8 @@ x = 1
|
||||
y = 2
|
||||
z = x + 1";
|
||||
let lxr: Vec<LexResult> = lexer::make_tokenizer(contents).collect();
|
||||
let locator = SourceCodeLocator::new(contents);
|
||||
assert_eq!(
|
||||
extract_isort_directives(&lxr, &locator).exclusions,
|
||||
extract_isort_directives(&lxr).exclusions,
|
||||
IntSet::from_iter([1, 2, 3, 4])
|
||||
);
|
||||
|
||||
@@ -307,9 +295,8 @@ y = 2
|
||||
# isort: skip_file
|
||||
z = x + 1";
|
||||
let lxr: Vec<LexResult> = lexer::make_tokenizer(contents).collect();
|
||||
let locator = SourceCodeLocator::new(contents);
|
||||
assert_eq!(
|
||||
extract_isort_directives(&lxr, &locator).exclusions,
|
||||
extract_isort_directives(&lxr).exclusions,
|
||||
IntSet::from_iter([1, 2, 3, 4, 5, 6])
|
||||
);
|
||||
}
|
||||
@@ -320,25 +307,19 @@ z = x + 1";
|
||||
y = 2
|
||||
z = x + 1";
|
||||
let lxr: Vec<LexResult> = lexer::make_tokenizer(contents).collect();
|
||||
let locator = SourceCodeLocator::new(contents);
|
||||
assert_eq!(
|
||||
extract_isort_directives(&lxr, &locator).splits,
|
||||
Vec::<usize>::new()
|
||||
);
|
||||
assert_eq!(extract_isort_directives(&lxr).splits, Vec::<usize>::new());
|
||||
|
||||
let contents = "x = 1
|
||||
y = 2
|
||||
# isort: split
|
||||
z = x + 1";
|
||||
let lxr: Vec<LexResult> = lexer::make_tokenizer(contents).collect();
|
||||
let locator = SourceCodeLocator::new(contents);
|
||||
assert_eq!(extract_isort_directives(&lxr, &locator).splits, vec![3]);
|
||||
assert_eq!(extract_isort_directives(&lxr).splits, vec![3]);
|
||||
|
||||
let contents = "x = 1
|
||||
y = 2 # isort: split
|
||||
z = x + 1";
|
||||
let lxr: Vec<LexResult> = lexer::make_tokenizer(contents).collect();
|
||||
let locator = SourceCodeLocator::new(contents);
|
||||
assert_eq!(extract_isort_directives(&lxr, &locator).splits, vec![2]);
|
||||
assert_eq!(extract_isort_directives(&lxr).splits, vec![2]);
|
||||
}
|
||||
}
|
||||
|
||||
@@ -3,9 +3,9 @@ use rustpython_ast::Location;
|
||||
use crate::ast::types::Range;
|
||||
use crate::autofix::Fix;
|
||||
use crate::eradicate::detection::comment_contains_code;
|
||||
use crate::registry::{CheckCode, CheckKind};
|
||||
use crate::registry::CheckCode;
|
||||
use crate::settings::flags;
|
||||
use crate::{Check, Settings, SourceCodeLocator};
|
||||
use crate::{violations, Check, Settings, SourceCodeLocator};
|
||||
|
||||
fn is_standalone_comment(line: &str) -> bool {
|
||||
for char in line.chars() {
|
||||
@@ -32,7 +32,7 @@ pub fn commented_out_code(
|
||||
|
||||
// Verify that the comment is on its own line, and that it contains code.
|
||||
if is_standalone_comment(&line) && comment_contains_code(&line, &settings.task_tags[..]) {
|
||||
let mut check = Check::new(CheckKind::CommentedOutCode, Range::new(start, end));
|
||||
let mut check = Check::new(violations::CommentedOutCode, Range::new(start, end));
|
||||
if matches!(autofix, flags::Autofix::Enabled)
|
||||
&& settings.fixable.contains(&CheckCode::ERA001)
|
||||
{
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/eradicate/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: CommentedOutCode
|
||||
- kind:
|
||||
CommentedOutCode: ~
|
||||
location:
|
||||
row: 1
|
||||
column: 0
|
||||
@@ -18,7 +19,8 @@ expression: checks
|
||||
row: 2
|
||||
column: 0
|
||||
parent: ~
|
||||
- kind: CommentedOutCode
|
||||
- kind:
|
||||
CommentedOutCode: ~
|
||||
location:
|
||||
row: 2
|
||||
column: 0
|
||||
@@ -34,7 +36,8 @@ expression: checks
|
||||
row: 3
|
||||
column: 0
|
||||
parent: ~
|
||||
- kind: CommentedOutCode
|
||||
- kind:
|
||||
CommentedOutCode: ~
|
||||
location:
|
||||
row: 3
|
||||
column: 0
|
||||
@@ -50,7 +53,8 @@ expression: checks
|
||||
row: 4
|
||||
column: 0
|
||||
parent: ~
|
||||
- kind: CommentedOutCode
|
||||
- kind:
|
||||
CommentedOutCode: ~
|
||||
location:
|
||||
row: 5
|
||||
column: 0
|
||||
@@ -66,7 +70,8 @@ expression: checks
|
||||
row: 6
|
||||
column: 0
|
||||
parent: ~
|
||||
- kind: CommentedOutCode
|
||||
- kind:
|
||||
CommentedOutCode: ~
|
||||
location:
|
||||
row: 12
|
||||
column: 4
|
||||
|
||||
@@ -4,7 +4,8 @@ use rustpython_ast::{Cmpop, Constant, Expr, ExprKind, Located};
|
||||
use crate::ast::helpers::match_module_member;
|
||||
use crate::ast::types::Range;
|
||||
use crate::checkers::ast::Checker;
|
||||
use crate::registry::{Check, CheckCode, CheckKind};
|
||||
use crate::registry::{Check, CheckCode};
|
||||
use crate::violations;
|
||||
|
||||
fn is_sys(checker: &Checker, expr: &Expr, target: &str) -> bool {
|
||||
match_module_member(
|
||||
@@ -34,15 +35,15 @@ pub fn subscript(checker: &mut Checker, value: &Expr, slice: &Expr) {
|
||||
if *i == BigInt::from(1)
|
||||
&& checker.settings.enabled.contains(&CheckCode::YTT303)
|
||||
{
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::SysVersionSlice1Referenced,
|
||||
checker.checks.push(Check::new(
|
||||
violations::SysVersionSlice1Referenced,
|
||||
Range::from_located(value),
|
||||
));
|
||||
} else if *i == BigInt::from(3)
|
||||
&& checker.settings.enabled.contains(&CheckCode::YTT101)
|
||||
{
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::SysVersionSlice3Referenced,
|
||||
checker.checks.push(Check::new(
|
||||
violations::SysVersionSlice3Referenced,
|
||||
Range::from_located(value),
|
||||
));
|
||||
}
|
||||
@@ -54,15 +55,15 @@ pub fn subscript(checker: &mut Checker, value: &Expr, slice: &Expr) {
|
||||
..
|
||||
} => {
|
||||
if *i == BigInt::from(2) && checker.settings.enabled.contains(&CheckCode::YTT102) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::SysVersion2Referenced,
|
||||
checker.checks.push(Check::new(
|
||||
violations::SysVersion2Referenced,
|
||||
Range::from_located(value),
|
||||
));
|
||||
} else if *i == BigInt::from(0)
|
||||
&& checker.settings.enabled.contains(&CheckCode::YTT301)
|
||||
{
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::SysVersion0Referenced,
|
||||
checker.checks.push(Check::new(
|
||||
violations::SysVersion0Referenced,
|
||||
Range::from_located(value),
|
||||
));
|
||||
}
|
||||
@@ -98,8 +99,8 @@ pub fn compare(checker: &mut Checker, left: &Expr, ops: &[Cmpop], comparators: &
|
||||
if *n == BigInt::from(3)
|
||||
&& checker.settings.enabled.contains(&CheckCode::YTT201)
|
||||
{
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::SysVersionInfo0Eq3Referenced,
|
||||
checker.checks.push(Check::new(
|
||||
violations::SysVersionInfo0Eq3Referenced,
|
||||
Range::from_located(left),
|
||||
));
|
||||
}
|
||||
@@ -118,8 +119,8 @@ pub fn compare(checker: &mut Checker, left: &Expr, ops: &[Cmpop], comparators: &
|
||||
) = (ops, comparators)
|
||||
{
|
||||
if checker.settings.enabled.contains(&CheckCode::YTT203) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::SysVersionInfo1CmpInt,
|
||||
checker.checks.push(Check::new(
|
||||
violations::SysVersionInfo1CmpInt,
|
||||
Range::from_located(left),
|
||||
));
|
||||
}
|
||||
@@ -144,8 +145,8 @@ pub fn compare(checker: &mut Checker, left: &Expr, ops: &[Cmpop], comparators: &
|
||||
) = (ops, comparators)
|
||||
{
|
||||
if checker.settings.enabled.contains(&CheckCode::YTT204) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::SysVersionInfoMinorCmpInt,
|
||||
checker.checks.push(Check::new(
|
||||
violations::SysVersionInfoMinorCmpInt,
|
||||
Range::from_located(left),
|
||||
));
|
||||
}
|
||||
@@ -170,14 +171,14 @@ pub fn compare(checker: &mut Checker, left: &Expr, ops: &[Cmpop], comparators: &
|
||||
{
|
||||
if s.len() == 1 {
|
||||
if checker.settings.enabled.contains(&CheckCode::YTT302) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::SysVersionCmpStr10,
|
||||
checker.checks.push(Check::new(
|
||||
violations::SysVersionCmpStr10,
|
||||
Range::from_located(left),
|
||||
));
|
||||
}
|
||||
} else if checker.settings.enabled.contains(&CheckCode::YTT103) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::SysVersionCmpStr3,
|
||||
checker.checks.push(Check::new(
|
||||
violations::SysVersionCmpStr3,
|
||||
Range::from_located(left),
|
||||
));
|
||||
}
|
||||
@@ -194,8 +195,8 @@ pub fn name_or_attribute(checker: &mut Checker, expr: &Expr) {
|
||||
&checker.from_imports,
|
||||
&checker.import_aliases,
|
||||
) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::SixPY3Referenced,
|
||||
checker.checks.push(Check::new(
|
||||
violations::SixPY3Referenced,
|
||||
Range::from_located(expr),
|
||||
));
|
||||
}
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_2020/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: SysVersionSlice3Referenced
|
||||
- kind:
|
||||
SysVersionSlice3Referenced: ~
|
||||
location:
|
||||
row: 6
|
||||
column: 6
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionSlice3Referenced
|
||||
- kind:
|
||||
SysVersionSlice3Referenced: ~
|
||||
location:
|
||||
row: 7
|
||||
column: 6
|
||||
@@ -20,7 +22,8 @@ expression: checks
|
||||
column: 13
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionSlice3Referenced
|
||||
- kind:
|
||||
SysVersionSlice3Referenced: ~
|
||||
location:
|
||||
row: 8
|
||||
column: 6
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_2020/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: SysVersion2Referenced
|
||||
- kind:
|
||||
SysVersion2Referenced: ~
|
||||
location:
|
||||
row: 4
|
||||
column: 11
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 22
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersion2Referenced
|
||||
- kind:
|
||||
SysVersion2Referenced: ~
|
||||
location:
|
||||
row: 5
|
||||
column: 11
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_2020/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: SysVersionCmpStr3
|
||||
- kind:
|
||||
SysVersionCmpStr3: ~
|
||||
location:
|
||||
row: 4
|
||||
column: 0
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 7
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionCmpStr3
|
||||
- kind:
|
||||
SysVersionCmpStr3: ~
|
||||
location:
|
||||
row: 5
|
||||
column: 0
|
||||
@@ -20,7 +22,8 @@ expression: checks
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionCmpStr3
|
||||
- kind:
|
||||
SysVersionCmpStr3: ~
|
||||
location:
|
||||
row: 6
|
||||
column: 0
|
||||
@@ -29,7 +32,8 @@ expression: checks
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionCmpStr3
|
||||
- kind:
|
||||
SysVersionCmpStr3: ~
|
||||
location:
|
||||
row: 7
|
||||
column: 0
|
||||
@@ -38,7 +42,8 @@ expression: checks
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionCmpStr3
|
||||
- kind:
|
||||
SysVersionCmpStr3: ~
|
||||
location:
|
||||
row: 8
|
||||
column: 0
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_2020/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: SysVersionInfo0Eq3Referenced
|
||||
- kind:
|
||||
SysVersionInfo0Eq3Referenced: ~
|
||||
location:
|
||||
row: 7
|
||||
column: 6
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 25
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionInfo0Eq3Referenced
|
||||
- kind:
|
||||
SysVersionInfo0Eq3Referenced: ~
|
||||
location:
|
||||
row: 8
|
||||
column: 6
|
||||
@@ -20,7 +22,8 @@ expression: checks
|
||||
column: 21
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionInfo0Eq3Referenced
|
||||
- kind:
|
||||
SysVersionInfo0Eq3Referenced: ~
|
||||
location:
|
||||
row: 9
|
||||
column: 6
|
||||
@@ -29,7 +32,8 @@ expression: checks
|
||||
column: 25
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionInfo0Eq3Referenced
|
||||
- kind:
|
||||
SysVersionInfo0Eq3Referenced: ~
|
||||
location:
|
||||
row: 10
|
||||
column: 6
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_2020/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: SixPY3Referenced
|
||||
- kind:
|
||||
SixPY3Referenced: ~
|
||||
location:
|
||||
row: 4
|
||||
column: 3
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 10
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SixPY3Referenced
|
||||
- kind:
|
||||
SixPY3Referenced: ~
|
||||
location:
|
||||
row: 6
|
||||
column: 3
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_2020/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: SysVersionInfo1CmpInt
|
||||
- kind:
|
||||
SysVersionInfo1CmpInt: ~
|
||||
location:
|
||||
row: 4
|
||||
column: 0
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 19
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionInfo1CmpInt
|
||||
- kind:
|
||||
SysVersionInfo1CmpInt: ~
|
||||
location:
|
||||
row: 5
|
||||
column: 0
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_2020/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: SysVersionInfoMinorCmpInt
|
||||
- kind:
|
||||
SysVersionInfoMinorCmpInt: ~
|
||||
location:
|
||||
row: 4
|
||||
column: 0
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 22
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionInfoMinorCmpInt
|
||||
- kind:
|
||||
SysVersionInfoMinorCmpInt: ~
|
||||
location:
|
||||
row: 5
|
||||
column: 0
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_2020/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: SysVersion0Referenced
|
||||
- kind:
|
||||
SysVersion0Referenced: ~
|
||||
location:
|
||||
row: 4
|
||||
column: 11
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 22
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersion0Referenced
|
||||
- kind:
|
||||
SysVersion0Referenced: ~
|
||||
location:
|
||||
row: 5
|
||||
column: 11
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_2020/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: SysVersionCmpStr10
|
||||
- kind:
|
||||
SysVersionCmpStr10: ~
|
||||
location:
|
||||
row: 4
|
||||
column: 0
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 7
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionCmpStr10
|
||||
- kind:
|
||||
SysVersionCmpStr10: ~
|
||||
location:
|
||||
row: 5
|
||||
column: 0
|
||||
@@ -20,7 +22,8 @@ expression: checks
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionCmpStr10
|
||||
- kind:
|
||||
SysVersionCmpStr10: ~
|
||||
location:
|
||||
row: 6
|
||||
column: 0
|
||||
@@ -29,7 +32,8 @@ expression: checks
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionCmpStr10
|
||||
- kind:
|
||||
SysVersionCmpStr10: ~
|
||||
location:
|
||||
row: 7
|
||||
column: 0
|
||||
@@ -38,7 +42,8 @@ expression: checks
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionCmpStr10
|
||||
- kind:
|
||||
SysVersionCmpStr10: ~
|
||||
location:
|
||||
row: 8
|
||||
column: 0
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_2020/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: SysVersionSlice1Referenced
|
||||
- kind:
|
||||
SysVersionSlice1Referenced: ~
|
||||
location:
|
||||
row: 4
|
||||
column: 6
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: SysVersionSlice1Referenced
|
||||
- kind:
|
||||
SysVersionSlice1Referenced: ~
|
||||
location:
|
||||
row: 5
|
||||
column: 6
|
||||
|
||||
@@ -8,9 +8,9 @@ use crate::checkers::ast::Checker;
|
||||
use crate::docstrings::definition::{Definition, DefinitionKind};
|
||||
use crate::flake8_annotations::fixes;
|
||||
use crate::flake8_annotations::helpers::match_function_def;
|
||||
use crate::registry::{CheckCode, CheckKind};
|
||||
use crate::registry::CheckCode;
|
||||
use crate::visibility::Visibility;
|
||||
use crate::{visibility, Check};
|
||||
use crate::{violations, visibility, Check};
|
||||
|
||||
#[derive(Default)]
|
||||
struct ReturnStatementVisitor<'a> {
|
||||
@@ -57,8 +57,8 @@ where
|
||||
F: FnOnce() -> String,
|
||||
{
|
||||
if checker.match_typing_expr(annotation, "Any") {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::DynamicallyTypedExpression(func()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::DynamicallyTypedExpression(func()),
|
||||
Range::from_located(annotation),
|
||||
));
|
||||
};
|
||||
@@ -93,8 +93,8 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
&& checker.settings.dummy_variable_rgx.is_match(&arg.node.arg))
|
||||
{
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN001) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingTypeFunctionArgument(arg.node.arg.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingTypeFunctionArgument(arg.node.arg.to_string()),
|
||||
Range::from_located(arg),
|
||||
));
|
||||
}
|
||||
@@ -116,8 +116,8 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
&& checker.settings.dummy_variable_rgx.is_match(&arg.node.arg))
|
||||
{
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN002) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingTypeArgs(arg.node.arg.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingTypeArgs(arg.node.arg.to_string()),
|
||||
Range::from_located(arg),
|
||||
));
|
||||
}
|
||||
@@ -139,8 +139,8 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
&& checker.settings.dummy_variable_rgx.is_match(&arg.node.arg))
|
||||
{
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN003) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingTypeKwargs(arg.node.arg.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingTypeKwargs(arg.node.arg.to_string()),
|
||||
Range::from_located(arg),
|
||||
));
|
||||
}
|
||||
@@ -165,16 +165,16 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
match visibility {
|
||||
Visibility::Public => {
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN201) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingReturnTypePublicFunction(name.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingReturnTypePublicFunction(name.to_string()),
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
));
|
||||
}
|
||||
}
|
||||
Visibility::Private => {
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN202) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingReturnTypePrivateFunction(name.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingReturnTypePrivateFunction(name.to_string()),
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
));
|
||||
}
|
||||
@@ -211,8 +211,8 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
&& checker.settings.dummy_variable_rgx.is_match(&arg.node.arg))
|
||||
{
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN001) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingTypeFunctionArgument(arg.node.arg.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingTypeFunctionArgument(arg.node.arg.to_string()),
|
||||
Range::from_located(arg),
|
||||
));
|
||||
}
|
||||
@@ -235,8 +235,8 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
&& checker.settings.dummy_variable_rgx.is_match(&arg.node.arg))
|
||||
{
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN002) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingTypeArgs(arg.node.arg.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingTypeArgs(arg.node.arg.to_string()),
|
||||
Range::from_located(arg),
|
||||
));
|
||||
}
|
||||
@@ -259,8 +259,8 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
&& checker.settings.dummy_variable_rgx.is_match(&arg.node.arg))
|
||||
{
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN003) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingTypeKwargs(arg.node.arg.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingTypeKwargs(arg.node.arg.to_string()),
|
||||
Range::from_located(arg),
|
||||
));
|
||||
}
|
||||
@@ -274,15 +274,15 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
if arg.node.annotation.is_none() {
|
||||
if visibility::is_classmethod(checker, cast::decorator_list(stmt)) {
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN102) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingTypeCls(arg.node.arg.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingTypeCls(arg.node.arg.to_string()),
|
||||
Range::from_located(arg),
|
||||
));
|
||||
}
|
||||
} else {
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN101) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingTypeSelf(arg.node.arg.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingTypeSelf(arg.node.arg.to_string()),
|
||||
Range::from_located(arg),
|
||||
));
|
||||
}
|
||||
@@ -307,15 +307,15 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
|
||||
if visibility::is_classmethod(checker, cast::decorator_list(stmt)) {
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN206) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingReturnTypeClassMethod(name.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingReturnTypeClassMethod(name.to_string()),
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
));
|
||||
}
|
||||
} else if visibility::is_staticmethod(checker, cast::decorator_list(stmt)) {
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN205) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingReturnTypeStaticMethod(name.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingReturnTypeStaticMethod(name.to_string()),
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
));
|
||||
}
|
||||
@@ -327,7 +327,7 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
&& has_any_typed_arg)
|
||||
{
|
||||
let mut check = Check::new(
|
||||
CheckKind::MissingReturnTypeSpecialMethod(name.to_string()),
|
||||
violations::MissingReturnTypeSpecialMethod(name.to_string()),
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
);
|
||||
if checker.patch(check.kind.code()) {
|
||||
@@ -338,13 +338,13 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
Err(e) => error!("Failed to generate fix: {e}"),
|
||||
}
|
||||
}
|
||||
checker.add_check(check);
|
||||
checker.checks.push(check);
|
||||
}
|
||||
}
|
||||
} else if visibility::is_magic(stmt) {
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN204) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingReturnTypeSpecialMethod(name.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingReturnTypeSpecialMethod(name.to_string()),
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
));
|
||||
}
|
||||
@@ -352,16 +352,16 @@ pub fn definition(checker: &mut Checker, definition: &Definition, visibility: &V
|
||||
match visibility {
|
||||
Visibility::Public => {
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN201) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingReturnTypePublicFunction(name.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingReturnTypePublicFunction(name.to_string()),
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
));
|
||||
}
|
||||
}
|
||||
Visibility::Private => {
|
||||
if checker.settings.enabled.contains(&CheckCode::ANN202) {
|
||||
checker.add_check(Check::new(
|
||||
CheckKind::MissingReturnTypePrivateFunction(name.to_string()),
|
||||
checker.checks.push(Check::new(
|
||||
violations::MissingReturnTypePrivateFunction(name.to_string()),
|
||||
helpers::identifier_range(stmt, checker.locator),
|
||||
));
|
||||
}
|
||||
|
||||
@@ -1,9 +1,10 @@
|
||||
use rustpython_ast::{Located, StmtKind};
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::{Check, CheckKind};
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
/// S101
|
||||
pub fn assert_used(stmt: &Located<StmtKind>) -> Check {
|
||||
Check::new(CheckKind::AssertUsed, Range::from_located(stmt))
|
||||
Check::new(violations::AssertUsed, Range::from_located(stmt))
|
||||
}
|
||||
|
||||
@@ -5,7 +5,8 @@ use rustpython_ast::{Constant, Expr, ExprKind, Keyword, Operator};
|
||||
|
||||
use crate::ast::helpers::{compose_call_path, match_module_member, SimpleCallArgs};
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::{Check, CheckKind};
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
const WRITE_WORLD: u16 = 0o2;
|
||||
const EXECUTE_GROUP: u16 = 0o10;
|
||||
@@ -86,8 +87,8 @@ fn get_int_value(expr: &Expr) -> Option<u16> {
|
||||
/// S103
|
||||
pub fn bad_file_permissions(
|
||||
func: &Expr,
|
||||
args: &Vec<Expr>,
|
||||
keywords: &Vec<Keyword>,
|
||||
args: &[Expr],
|
||||
keywords: &[Keyword],
|
||||
from_imports: &FxHashMap<&str, FxHashSet<&str>>,
|
||||
import_aliases: &FxHashMap<&str, &str>,
|
||||
) -> Option<Check> {
|
||||
@@ -97,7 +98,7 @@ pub fn bad_file_permissions(
|
||||
if let Some(int_value) = get_int_value(mode_arg) {
|
||||
if (int_value & WRITE_WORLD > 0) || (int_value & EXECUTE_GROUP > 0) {
|
||||
return Some(Check::new(
|
||||
CheckKind::BadFilePermissions(int_value),
|
||||
violations::BadFilePermissions(int_value),
|
||||
Range::from_located(mode_arg),
|
||||
));
|
||||
}
|
||||
|
||||
@@ -1,7 +1,8 @@
|
||||
use rustpython_ast::{Expr, ExprKind};
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::{Check, CheckKind};
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
/// S102
|
||||
pub fn exec_used(expr: &Expr, func: &Expr) -> Option<Check> {
|
||||
@@ -11,5 +12,5 @@ pub fn exec_used(expr: &Expr, func: &Expr) -> Option<Check> {
|
||||
if id != "exec" {
|
||||
return None;
|
||||
}
|
||||
Some(Check::new(CheckKind::ExecUsed, Range::from_located(expr)))
|
||||
Some(Check::new(violations::ExecUsed, Range::from_located(expr)))
|
||||
}
|
||||
|
||||
@@ -1,10 +1,11 @@
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::{Check, CheckKind};
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
/// S104
|
||||
pub fn hardcoded_bind_all_interfaces(value: &str, range: &Range) -> Option<Check> {
|
||||
if value == "0.0.0.0" {
|
||||
Some(Check::new(CheckKind::HardcodedBindAllInterfaces, *range))
|
||||
Some(Check::new(violations::HardcodedBindAllInterfaces, *range))
|
||||
} else {
|
||||
None
|
||||
}
|
||||
|
||||
@@ -2,7 +2,8 @@ use rustpython_ast::{ArgData, Arguments, Expr, Located};
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::flake8_bandit::helpers::{matches_password_name, string_literal};
|
||||
use crate::registry::{Check, CheckKind};
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
fn check_password_kwarg(arg: &Located<ArgData>, default: &Expr) -> Option<Check> {
|
||||
let string = string_literal(default)?;
|
||||
@@ -11,7 +12,7 @@ fn check_password_kwarg(arg: &Located<ArgData>, default: &Expr) -> Option<Check>
|
||||
return None;
|
||||
}
|
||||
Some(Check::new(
|
||||
CheckKind::HardcodedPasswordDefault(string.to_string()),
|
||||
violations::HardcodedPasswordDefault(string.to_string()),
|
||||
Range::from_located(default),
|
||||
))
|
||||
}
|
||||
|
||||
@@ -2,7 +2,8 @@ use rustpython_ast::Keyword;
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::flake8_bandit::helpers::{matches_password_name, string_literal};
|
||||
use crate::registry::{Check, CheckKind};
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
/// S106
|
||||
pub fn hardcoded_password_func_arg(keywords: &[Keyword]) -> Vec<Check> {
|
||||
@@ -15,7 +16,7 @@ pub fn hardcoded_password_func_arg(keywords: &[Keyword]) -> Vec<Check> {
|
||||
return None;
|
||||
}
|
||||
Some(Check::new(
|
||||
CheckKind::HardcodedPasswordFuncArg(string.to_string()),
|
||||
violations::HardcodedPasswordFuncArg(string.to_string()),
|
||||
Range::from_located(keyword),
|
||||
))
|
||||
})
|
||||
|
||||
@@ -2,7 +2,8 @@ use rustpython_ast::{Constant, Expr, ExprKind};
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::flake8_bandit::helpers::{matches_password_name, string_literal};
|
||||
use crate::registry::{Check, CheckKind};
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
fn is_password_target(target: &Expr) -> bool {
|
||||
let target_name = match &target.node {
|
||||
@@ -34,7 +35,7 @@ pub fn compare_to_hardcoded_password_string(left: &Expr, comparators: &[Expr]) -
|
||||
return None;
|
||||
}
|
||||
Some(Check::new(
|
||||
CheckKind::HardcodedPasswordString(string.to_string()),
|
||||
violations::HardcodedPasswordString(string.to_string()),
|
||||
Range::from_located(comp),
|
||||
))
|
||||
})
|
||||
@@ -42,12 +43,12 @@ pub fn compare_to_hardcoded_password_string(left: &Expr, comparators: &[Expr]) -
|
||||
}
|
||||
|
||||
/// S105
|
||||
pub fn assign_hardcoded_password_string(value: &Expr, targets: &Vec<Expr>) -> Option<Check> {
|
||||
pub fn assign_hardcoded_password_string(value: &Expr, targets: &[Expr]) -> Option<Check> {
|
||||
if let Some(string) = string_literal(value) {
|
||||
for target in targets {
|
||||
if is_password_target(target) {
|
||||
return Some(Check::new(
|
||||
CheckKind::HardcodedPasswordString(string.to_string()),
|
||||
violations::HardcodedPasswordString(string.to_string()),
|
||||
Range::from_located(value),
|
||||
));
|
||||
}
|
||||
|
||||
@@ -1,13 +1,14 @@
|
||||
use rustpython_ast::Expr;
|
||||
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::{Check, CheckKind};
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
/// S108
|
||||
pub fn hardcoded_tmp_directory(expr: &Expr, value: &str, prefixes: &[String]) -> Option<Check> {
|
||||
if prefixes.iter().any(|prefix| value.starts_with(prefix)) {
|
||||
Some(Check::new(
|
||||
CheckKind::HardcodedTempFile(value.to_string()),
|
||||
violations::HardcodedTempFile(value.to_string()),
|
||||
Range::from_located(expr),
|
||||
))
|
||||
} else {
|
||||
|
||||
67
src/flake8_bandit/checks/hashlib_insecure_hash_functions.rs
Normal file
67
src/flake8_bandit/checks/hashlib_insecure_hash_functions.rs
Normal file
@@ -0,0 +1,67 @@
|
||||
use rustc_hash::{FxHashMap, FxHashSet};
|
||||
use rustpython_ast::{Constant, Expr, ExprKind, Keyword};
|
||||
|
||||
use crate::ast::helpers::{match_module_member, SimpleCallArgs};
|
||||
use crate::ast::types::Range;
|
||||
use crate::flake8_bandit::helpers::string_literal;
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
const WEAK_HASHES: [&str; 4] = ["md4", "md5", "sha", "sha1"];
|
||||
|
||||
fn is_used_for_security(call_args: &SimpleCallArgs) -> bool {
|
||||
match call_args.get_argument("usedforsecurity", None) {
|
||||
Some(expr) => !matches!(
|
||||
&expr.node,
|
||||
ExprKind::Constant {
|
||||
value: Constant::Bool(false),
|
||||
..
|
||||
}
|
||||
),
|
||||
_ => true,
|
||||
}
|
||||
}
|
||||
|
||||
/// S324
|
||||
pub fn hashlib_insecure_hash_functions(
|
||||
func: &Expr,
|
||||
args: &[Expr],
|
||||
keywords: &[Keyword],
|
||||
from_imports: &FxHashMap<&str, FxHashSet<&str>>,
|
||||
import_aliases: &FxHashMap<&str, &str>,
|
||||
) -> Option<Check> {
|
||||
if match_module_member(func, "hashlib", "new", from_imports, import_aliases) {
|
||||
let call_args = SimpleCallArgs::new(args, keywords);
|
||||
|
||||
if !is_used_for_security(&call_args) {
|
||||
return None;
|
||||
}
|
||||
|
||||
if let Some(name_arg) = call_args.get_argument("name", Some(0)) {
|
||||
let hash_func_name = string_literal(name_arg)?;
|
||||
|
||||
if WEAK_HASHES.contains(&hash_func_name.to_lowercase().as_str()) {
|
||||
return Some(Check::new(
|
||||
violations::HashlibInsecureHashFunction(hash_func_name.to_string()),
|
||||
Range::from_located(name_arg),
|
||||
));
|
||||
}
|
||||
}
|
||||
} else {
|
||||
for func_name in &WEAK_HASHES {
|
||||
if match_module_member(func, "hashlib", func_name, from_imports, import_aliases) {
|
||||
let call_args = SimpleCallArgs::new(args, keywords);
|
||||
|
||||
if !is_used_for_security(&call_args) {
|
||||
return None;
|
||||
}
|
||||
|
||||
return Some(Check::new(
|
||||
violations::HashlibInsecureHashFunction((*func_name).to_string()),
|
||||
Range::from_located(func),
|
||||
));
|
||||
}
|
||||
}
|
||||
}
|
||||
None
|
||||
}
|
||||
@@ -8,6 +8,10 @@ pub use hardcoded_password_string::{
|
||||
assign_hardcoded_password_string, compare_to_hardcoded_password_string,
|
||||
};
|
||||
pub use hardcoded_tmp_directory::hardcoded_tmp_directory;
|
||||
pub use hashlib_insecure_hash_functions::hashlib_insecure_hash_functions;
|
||||
pub use request_with_no_cert_validation::request_with_no_cert_validation;
|
||||
pub use request_without_timeout::request_without_timeout;
|
||||
pub use unsafe_yaml_load::unsafe_yaml_load;
|
||||
|
||||
mod assert_used;
|
||||
mod bad_file_permissions;
|
||||
@@ -17,3 +21,7 @@ mod hardcoded_password_default;
|
||||
mod hardcoded_password_func_arg;
|
||||
mod hardcoded_password_string;
|
||||
mod hardcoded_tmp_directory;
|
||||
mod hashlib_insecure_hash_functions;
|
||||
mod request_with_no_cert_validation;
|
||||
mod request_without_timeout;
|
||||
mod unsafe_yaml_load;
|
||||
|
||||
70
src/flake8_bandit/checks/request_with_no_cert_validation.rs
Normal file
70
src/flake8_bandit/checks/request_with_no_cert_validation.rs
Normal file
@@ -0,0 +1,70 @@
|
||||
use rustc_hash::{FxHashMap, FxHashSet};
|
||||
use rustpython_ast::{Expr, ExprKind, Keyword};
|
||||
use rustpython_parser::ast::Constant;
|
||||
|
||||
use crate::ast::helpers::{collect_call_paths, dealias_call_path, match_call_path, SimpleCallArgs};
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
const REQUESTS_HTTP_VERBS: [&str; 7] = ["get", "options", "head", "post", "put", "patch", "delete"];
|
||||
const HTTPX_METHODS: [&str; 11] = [
|
||||
"get",
|
||||
"options",
|
||||
"head",
|
||||
"post",
|
||||
"put",
|
||||
"patch",
|
||||
"delete",
|
||||
"request",
|
||||
"stream",
|
||||
"Client",
|
||||
"AsyncClient",
|
||||
];
|
||||
|
||||
/// S501
|
||||
pub fn request_with_no_cert_validation(
|
||||
func: &Expr,
|
||||
args: &[Expr],
|
||||
keywords: &[Keyword],
|
||||
from_imports: &FxHashMap<&str, FxHashSet<&str>>,
|
||||
import_aliases: &FxHashMap<&str, &str>,
|
||||
) -> Option<Check> {
|
||||
let call_path = dealias_call_path(collect_call_paths(func), import_aliases);
|
||||
let call_args = SimpleCallArgs::new(args, keywords);
|
||||
|
||||
for func_name in &REQUESTS_HTTP_VERBS {
|
||||
if match_call_path(&call_path, "requests", func_name, from_imports) {
|
||||
if let Some(verify_arg) = call_args.get_argument("verify", None) {
|
||||
if let ExprKind::Constant {
|
||||
value: Constant::Bool(false),
|
||||
..
|
||||
} = &verify_arg.node
|
||||
{
|
||||
return Some(Check::new(
|
||||
violations::RequestWithNoCertValidation("requests".to_string()),
|
||||
Range::from_located(verify_arg),
|
||||
));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
for func_name in &HTTPX_METHODS {
|
||||
if match_call_path(&call_path, "httpx", func_name, from_imports) {
|
||||
if let Some(verify_arg) = call_args.get_argument("verify", None) {
|
||||
if let ExprKind::Constant {
|
||||
value: Constant::Bool(false),
|
||||
..
|
||||
} = &verify_arg.node
|
||||
{
|
||||
return Some(Check::new(
|
||||
violations::RequestWithNoCertValidation("httpx".to_string()),
|
||||
Range::from_located(verify_arg),
|
||||
));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
None
|
||||
}
|
||||
46
src/flake8_bandit/checks/request_without_timeout.rs
Normal file
46
src/flake8_bandit/checks/request_without_timeout.rs
Normal file
@@ -0,0 +1,46 @@
|
||||
use rustc_hash::{FxHashMap, FxHashSet};
|
||||
use rustpython_ast::{Expr, ExprKind, Keyword};
|
||||
use rustpython_parser::ast::Constant;
|
||||
|
||||
use crate::ast::helpers::{collect_call_paths, dealias_call_path, match_call_path, SimpleCallArgs};
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
const HTTP_VERBS: [&str; 7] = ["get", "options", "head", "post", "put", "patch", "delete"];
|
||||
|
||||
/// S113
|
||||
pub fn request_without_timeout(
|
||||
func: &Expr,
|
||||
args: &[Expr],
|
||||
keywords: &[Keyword],
|
||||
from_imports: &FxHashMap<&str, FxHashSet<&str>>,
|
||||
import_aliases: &FxHashMap<&str, &str>,
|
||||
) -> Option<Check> {
|
||||
let call_path = dealias_call_path(collect_call_paths(func), import_aliases);
|
||||
for func_name in &HTTP_VERBS {
|
||||
if match_call_path(&call_path, "requests", func_name, from_imports) {
|
||||
let call_args = SimpleCallArgs::new(args, keywords);
|
||||
if let Some(timeout_arg) = call_args.get_argument("timeout", None) {
|
||||
if let Some(timeout) = match &timeout_arg.node {
|
||||
ExprKind::Constant {
|
||||
value: value @ Constant::None,
|
||||
..
|
||||
} => Some(value.to_string()),
|
||||
_ => None,
|
||||
} {
|
||||
return Some(Check::new(
|
||||
violations::RequestWithoutTimeout(Some(timeout)),
|
||||
Range::from_located(timeout_arg),
|
||||
));
|
||||
}
|
||||
} else {
|
||||
return Some(Check::new(
|
||||
violations::RequestWithoutTimeout(None),
|
||||
Range::from_located(func),
|
||||
));
|
||||
}
|
||||
}
|
||||
}
|
||||
None
|
||||
}
|
||||
51
src/flake8_bandit/checks/unsafe_yaml_load.rs
Normal file
51
src/flake8_bandit/checks/unsafe_yaml_load.rs
Normal file
@@ -0,0 +1,51 @@
|
||||
use rustc_hash::{FxHashMap, FxHashSet};
|
||||
use rustpython_ast::{Expr, ExprKind, Keyword};
|
||||
|
||||
use crate::ast::helpers::{match_module_member, SimpleCallArgs};
|
||||
use crate::ast::types::Range;
|
||||
use crate::registry::Check;
|
||||
use crate::violations;
|
||||
|
||||
/// S506
|
||||
pub fn unsafe_yaml_load(
|
||||
func: &Expr,
|
||||
args: &[Expr],
|
||||
keywords: &[Keyword],
|
||||
from_imports: &FxHashMap<&str, FxHashSet<&str>>,
|
||||
import_aliases: &FxHashMap<&str, &str>,
|
||||
) -> Option<Check> {
|
||||
if match_module_member(func, "yaml", "load", from_imports, import_aliases) {
|
||||
let call_args = SimpleCallArgs::new(args, keywords);
|
||||
if let Some(loader_arg) = call_args.get_argument("Loader", Some(1)) {
|
||||
if !match_module_member(
|
||||
loader_arg,
|
||||
"yaml",
|
||||
"SafeLoader",
|
||||
from_imports,
|
||||
import_aliases,
|
||||
) && !match_module_member(
|
||||
loader_arg,
|
||||
"yaml",
|
||||
"CSafeLoader",
|
||||
from_imports,
|
||||
import_aliases,
|
||||
) {
|
||||
let loader = match &loader_arg.node {
|
||||
ExprKind::Attribute { attr, .. } => Some(attr.to_string()),
|
||||
ExprKind::Name { id, .. } => Some(id.to_string()),
|
||||
_ => None,
|
||||
};
|
||||
return Some(Check::new(
|
||||
violations::UnsafeYAMLLoad(loader),
|
||||
Range::from_located(loader_arg),
|
||||
));
|
||||
}
|
||||
} else {
|
||||
return Some(Check::new(
|
||||
violations::UnsafeYAMLLoad(None),
|
||||
Range::from_located(func),
|
||||
));
|
||||
}
|
||||
}
|
||||
None
|
||||
}
|
||||
@@ -21,6 +21,10 @@ mod tests {
|
||||
#[test_case(CheckCode::S106, Path::new("S106.py"); "S106")]
|
||||
#[test_case(CheckCode::S107, Path::new("S107.py"); "S107")]
|
||||
#[test_case(CheckCode::S108, Path::new("S108.py"); "S108")]
|
||||
#[test_case(CheckCode::S113, Path::new("S113.py"); "S113")]
|
||||
#[test_case(CheckCode::S324, Path::new("S324.py"); "S324")]
|
||||
#[test_case(CheckCode::S501, Path::new("S501.py"); "S501")]
|
||||
#[test_case(CheckCode::S506, Path::new("S506.py"); "S506")]
|
||||
fn checks(check_code: CheckCode, path: &Path) -> Result<()> {
|
||||
let snapshot = format!("{}_{}", check_code.as_ref(), path.to_string_lossy());
|
||||
let checks = test_path(
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_bandit/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: AssertUsed
|
||||
- kind:
|
||||
AssertUsed: ~
|
||||
location:
|
||||
row: 2
|
||||
column: 0
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: AssertUsed
|
||||
- kind:
|
||||
AssertUsed: ~
|
||||
location:
|
||||
row: 8
|
||||
column: 4
|
||||
@@ -20,7 +22,8 @@ expression: checks
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: AssertUsed
|
||||
- kind:
|
||||
AssertUsed: ~
|
||||
location:
|
||||
row: 11
|
||||
column: 4
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_bandit/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: ExecUsed
|
||||
- kind:
|
||||
ExecUsed: ~
|
||||
location:
|
||||
row: 3
|
||||
column: 4
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: ExecUsed
|
||||
- kind:
|
||||
ExecUsed: ~
|
||||
location:
|
||||
row: 5
|
||||
column: 0
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
source: src/flake8_bandit/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind: HardcodedBindAllInterfaces
|
||||
- kind:
|
||||
HardcodedBindAllInterfaces: ~
|
||||
location:
|
||||
row: 9
|
||||
column: 0
|
||||
@@ -11,7 +12,8 @@ expression: checks
|
||||
column: 9
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: HardcodedBindAllInterfaces
|
||||
- kind:
|
||||
HardcodedBindAllInterfaces: ~
|
||||
location:
|
||||
row: 10
|
||||
column: 0
|
||||
@@ -20,7 +22,8 @@ expression: checks
|
||||
column: 9
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: HardcodedBindAllInterfaces
|
||||
- kind:
|
||||
HardcodedBindAllInterfaces: ~
|
||||
location:
|
||||
row: 14
|
||||
column: 5
|
||||
@@ -29,7 +32,8 @@ expression: checks
|
||||
column: 14
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind: HardcodedBindAllInterfaces
|
||||
- kind:
|
||||
HardcodedBindAllInterfaces: ~
|
||||
location:
|
||||
row: 18
|
||||
column: 8
|
||||
|
||||
@@ -0,0 +1,145 @@
|
||||
---
|
||||
source: src/flake8_bandit/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind:
|
||||
RequestWithoutTimeout: ~
|
||||
location:
|
||||
row: 3
|
||||
column: 0
|
||||
end_location:
|
||||
row: 3
|
||||
column: 12
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: None
|
||||
location:
|
||||
row: 4
|
||||
column: 42
|
||||
end_location:
|
||||
row: 4
|
||||
column: 46
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: ~
|
||||
location:
|
||||
row: 6
|
||||
column: 0
|
||||
end_location:
|
||||
row: 6
|
||||
column: 13
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: None
|
||||
location:
|
||||
row: 7
|
||||
column: 43
|
||||
end_location:
|
||||
row: 7
|
||||
column: 47
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: ~
|
||||
location:
|
||||
row: 9
|
||||
column: 0
|
||||
end_location:
|
||||
row: 9
|
||||
column: 12
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: None
|
||||
location:
|
||||
row: 10
|
||||
column: 42
|
||||
end_location:
|
||||
row: 10
|
||||
column: 46
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: ~
|
||||
location:
|
||||
row: 12
|
||||
column: 0
|
||||
end_location:
|
||||
row: 12
|
||||
column: 15
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: None
|
||||
location:
|
||||
row: 13
|
||||
column: 45
|
||||
end_location:
|
||||
row: 13
|
||||
column: 49
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: ~
|
||||
location:
|
||||
row: 15
|
||||
column: 0
|
||||
end_location:
|
||||
row: 15
|
||||
column: 14
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: None
|
||||
location:
|
||||
row: 16
|
||||
column: 44
|
||||
end_location:
|
||||
row: 16
|
||||
column: 48
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: ~
|
||||
location:
|
||||
row: 18
|
||||
column: 0
|
||||
end_location:
|
||||
row: 18
|
||||
column: 16
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: None
|
||||
location:
|
||||
row: 19
|
||||
column: 46
|
||||
end_location:
|
||||
row: 19
|
||||
column: 50
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: ~
|
||||
location:
|
||||
row: 21
|
||||
column: 0
|
||||
end_location:
|
||||
row: 21
|
||||
column: 13
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithoutTimeout: None
|
||||
location:
|
||||
row: 22
|
||||
column: 43
|
||||
end_location:
|
||||
row: 22
|
||||
column: 47
|
||||
fix: ~
|
||||
parent: ~
|
||||
|
||||
@@ -0,0 +1,135 @@
|
||||
---
|
||||
source: src/flake8_bandit/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: md5
|
||||
location:
|
||||
row: 7
|
||||
column: 12
|
||||
end_location:
|
||||
row: 7
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: md4
|
||||
location:
|
||||
row: 9
|
||||
column: 12
|
||||
end_location:
|
||||
row: 9
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: md5
|
||||
location:
|
||||
row: 11
|
||||
column: 17
|
||||
end_location:
|
||||
row: 11
|
||||
column: 22
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: MD4
|
||||
location:
|
||||
row: 13
|
||||
column: 12
|
||||
end_location:
|
||||
row: 13
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha1
|
||||
location:
|
||||
row: 15
|
||||
column: 12
|
||||
end_location:
|
||||
row: 15
|
||||
column: 18
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha1
|
||||
location:
|
||||
row: 17
|
||||
column: 12
|
||||
end_location:
|
||||
row: 17
|
||||
column: 18
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha
|
||||
location:
|
||||
row: 19
|
||||
column: 12
|
||||
end_location:
|
||||
row: 19
|
||||
column: 17
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: SHA
|
||||
location:
|
||||
row: 21
|
||||
column: 17
|
||||
end_location:
|
||||
row: 21
|
||||
column: 22
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha
|
||||
location:
|
||||
row: 23
|
||||
column: 0
|
||||
end_location:
|
||||
row: 23
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: md5
|
||||
location:
|
||||
row: 25
|
||||
column: 0
|
||||
end_location:
|
||||
row: 25
|
||||
column: 11
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha1
|
||||
location:
|
||||
row: 27
|
||||
column: 12
|
||||
end_location:
|
||||
row: 27
|
||||
column: 18
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha1
|
||||
location:
|
||||
row: 29
|
||||
column: 0
|
||||
end_location:
|
||||
row: 29
|
||||
column: 12
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
HashlibInsecureHashFunction: sha1
|
||||
location:
|
||||
row: 32
|
||||
column: 12
|
||||
end_location:
|
||||
row: 32
|
||||
column: 18
|
||||
fix: ~
|
||||
parent: ~
|
||||
|
||||
@@ -0,0 +1,185 @@
|
||||
---
|
||||
source: src/flake8_bandit/mod.rs
|
||||
expression: checks
|
||||
---
|
||||
- kind:
|
||||
RequestWithNoCertValidation: requests
|
||||
location:
|
||||
row: 5
|
||||
column: 53
|
||||
end_location:
|
||||
row: 5
|
||||
column: 58
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: requests
|
||||
location:
|
||||
row: 7
|
||||
column: 54
|
||||
end_location:
|
||||
row: 7
|
||||
column: 59
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: requests
|
||||
location:
|
||||
row: 9
|
||||
column: 53
|
||||
end_location:
|
||||
row: 9
|
||||
column: 58
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: requests
|
||||
location:
|
||||
row: 11
|
||||
column: 56
|
||||
end_location:
|
||||
row: 11
|
||||
column: 61
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: requests
|
||||
location:
|
||||
row: 13
|
||||
column: 55
|
||||
end_location:
|
||||
row: 13
|
||||
column: 60
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: requests
|
||||
location:
|
||||
row: 15
|
||||
column: 57
|
||||
end_location:
|
||||
row: 15
|
||||
column: 62
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: requests
|
||||
location:
|
||||
row: 17
|
||||
column: 54
|
||||
end_location:
|
||||
row: 17
|
||||
column: 59
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: httpx
|
||||
location:
|
||||
row: 20
|
||||
column: 49
|
||||
end_location:
|
||||
row: 20
|
||||
column: 54
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: httpx
|
||||
location:
|
||||
row: 22
|
||||
column: 38
|
||||
end_location:
|
||||
row: 22
|
||||
column: 43
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: httpx
|
||||
location:
|
||||
row: 24
|
||||
column: 42
|
||||
end_location:
|
||||
row: 24
|
||||
column: 47
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: httpx
|
||||
location:
|
||||
row: 26
|
||||
column: 39
|
||||
end_location:
|
||||
row: 26
|
||||
column: 44
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: httpx
|
||||
location:
|
||||
row: 28
|
||||
column: 39
|
||||
end_location:
|
||||
row: 28
|
||||
column: 44
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: httpx
|
||||
location:
|
||||
row: 30
|
||||
column: 38
|
||||
end_location:
|
||||
row: 30
|
||||
column: 43
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: httpx
|
||||
location:
|
||||
row: 32
|
||||
column: 40
|
||||
end_location:
|
||||
row: 32
|
||||
column: 45
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: httpx
|
||||
location:
|
||||
row: 34
|
||||
column: 41
|
||||
end_location:
|
||||
row: 34
|
||||
column: 46
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: httpx
|
||||
location:
|
||||
row: 36
|
||||
column: 41
|
||||
end_location:
|
||||
row: 36
|
||||
column: 46
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: httpx
|
||||
location:
|
||||
row: 38
|
||||
column: 20
|
||||
end_location:
|
||||
row: 38
|
||||
column: 25
|
||||
fix: ~
|
||||
parent: ~
|
||||
- kind:
|
||||
RequestWithNoCertValidation: httpx
|
||||
location:
|
||||
row: 40
|
||||
column: 25
|
||||
end_location:
|
||||
row: 40
|
||||
column: 30
|
||||
fix: ~
|
||||
parent: ~
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user