## Summary
By taking a purely syntactic approach to the problem of trivial
initializer calls we can supress `x: T = T()`, `x: T = x.y.T()` and `x:
MyNewType = MyNewType(0)` but still display `x: T[U] = T()`.
The place where we drop a ball is this does not compose with our
analysis for supressing `x = (0, "hello")` as `x = (0, T())` and `x =
(T(), T())` will still get inlay hints (I don't think this is a huge
deal).
* fixes https://github.com/astral-sh/ty/issues/1516
## Test Plan
Existing snapshots cover this well.
## Summary
If you pass a non-tuple to `Annotated`, we end up running inference on
it twice. I _think_ the only case here is `Annotated[]`, where we insert
a (fake) empty `Name` node in the slice.
Closes https://github.com/astral-sh/ty/issues/1801.
## Summary
Increase our SQLAlchemy test coverage to make sure we understand
`Session.scalar`, `Session.scalars`, `Session.execute` (and their async
equivalents), as well as `Result.tuples`, `Result.one_or_none`,
`Row._tuple`.
## Summary
This PR adds the possibility to write mdtests that specify external
dependencies in a `project` section of TOML blocks. For example, here is
a test that makes sure that we understand Pydantic's dataclass-transform
setup:
````markdown
```toml
[environment]
python-version = "3.12"
python-platform = "linux"
[project]
dependencies = ["pydantic==2.12.2"]
```
```py
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
user = User(id=1, name="Alice")
reveal_type(user.id) # revealed: int
reveal_type(user.name) # revealed: str
# error: [missing-argument] "No argument provided for required parameter
`name`"
invalid_user = User(id=2)
```
````
## How?
Using the `python-version` and the `dependencies` fields from the
Markdown section, we generate a `pyproject.toml` file, write it to a
temporary directory, and use `uv sync` to install the dependencies into
a virtual environment. We then copy the Python source files from that
venv's `site-packages` folder to a corresponding directory structure in
the in-memory filesystem. Finally, we configure the search paths
accordingly, and run the mdtest as usual.
I fully understand that there are valid concerns here:
* Doesn't this require network access? (yes, it does)
* Is this fast enough? (`uv` caching makes this almost unnoticeable,
actually)
* Is this deterministic? ~~(probably not, package resolution can depend
on the platform you're on)~~ (yes, hopefully)
For this reason, this first version is opt-in, locally. ~~We don't even
run these tests in CI (even though they worked fine in a previous
iteration of this PR).~~ You need to set `MDTEST_EXTERNAL=1`, or use the
new `-e/--enable-external` command line option of the `mdtest.py`
runner. For example:
```bash
# Skip mdtests with external dependencies (default):
uv run crates/ty_python_semantic/mdtest.py
# Run all mdtests, including those with external dependencies:
uv run crates/ty_python_semantic/mdtest.py -e
# Only run the `pydantic` tests. Use `-e` to make sure it is not skipped:
uv run crates/ty_python_semantic/mdtest.py -e pydantic
```
## Why?
I believe that this can be a useful addition to our testing strategy,
which lies somewhere between ecosystem tests and normal mdtests.
Ecosystem tests cover much more code, but they have the disadvantage
that we only see second- or third-order effects via diagnostic diffs. If
we unexpectedly gain or lose type coverage somewhere, we might not even
notice (assuming the gradual guarantee holds, and ecosystem code is
mostly correct). Another disadvantage of ecosystem checks is that they
only test checked-in code that is usually correct. However, we also want
to test what happens on wrong code, like the code that is momentarily
written in an editor, before fixing it. On the other end of the spectrum
we have normal mdtests, which have the disadvantage that they do not
reflect the reality of complex real-world code. We experience this
whenever we're surprised by an ecosystem report on a PR.
That said, these tests should not be seen as a replacement for either of
these things. For example, we should still strive to write detailed
self-contained mdtests for user-reported issues. But we might use this
new layer for regression tests, or simply as a debugging tool. It can
also serve as a tool to document our support for popular third-party
libraries.
## Test Plan
* I've been locally using this for a couple of weeks now.
* `uv run crates/ty_python_semantic/mdtest.py -e`
## Summary
As-is, a single-element tuple gets destructured via:
```rust
let arguments = if let ast::Expr::Tuple(tuple) = slice {
&*tuple.elts
} else {
std::slice::from_ref(slice)
};
```
But then, because it's a single element, we call
`infer_annotation_expression_impl`, passing in the tuple, rather than
the first element.
Closes https://github.com/astral-sh/ty/issues/1793.
Closes https://github.com/astral-sh/ty/issues/1768.
---------
Co-authored-by: Claude Opus 4.5 <noreply@anthropic.com>
This PR adds the same `minimal-size` profile as `uv` repo workspace has
```toml
# Profile to build a minimally sized binary for uv-build
[profile.minimal-size]
inherits = "release"
opt-level = "z"
# This will still show a panic message, we only skip the unwind
panic = "abort"
codegen-units = 1
```
but removes its `panic = "abort"` setting
- As discussed in #21825
Compared to the ones pre-built via `uv tool install`, this builds 35%
smaller ruff and 24% smaller ty binaries
(as measured
[here](https://github.com/lmmx/just-pre-commit/blob/master/refresh_binaries.sh))
## Summary
Closes: https://github.com/astral-sh/ty/issues/157
This PR adds support for the following capabilities involving a
`ParamSpec` type variable:
- Representing `P.args` and `P.kwargs` in the type system
- Matching against a callable containing `P` to create a type mapping
- Specializing `P` against the stored parameters
The value of a `ParamSpec` type variable is being represented using
`CallableType` with a `CallableTypeKind::ParamSpecValue` variant. This
`CallableTypeKind` is expanded from the existing `is_function_like`
boolean flag. An `enum` is used as these variants are mutually
exclusive.
For context, an initial iteration made an attempt to expand the
`Specialization` to use `TypeOrParameters` enum that represents that a
type variable can specialize into either a `Type` or `Parameters` but
that increased the complexity of the code as all downstream usages would
need to handle both the variants appropriately. Additionally, we'd have
also need to establish an invariant that a regular type variable always
maps to a `Type` while a paramspec type variable always maps to a
`Parameters`.
I've intentionally left out checking and raising diagnostics when the
`ParamSpec` type variable and it's components are not being used
correctly to avoid scope increase and it can easily be done as a
follow-up. This would also include the scoping rules which I don't think
a regular type variable implements either.
## Test Plan
Add new mdtest cases and update existing test cases.
Ran this branch on pyx, no new diagnostics.
### Ecosystem analysis
There's a case where in an annotated assignment like:
```py
type CustomType[P] = Callable[...]
def value[**P](...): ...
def another[**P](...):
target: CustomType[P] = value
```
The type of `value` is a callable and it has a paramspec that's bound to
`value`, `CustomType` is a type alias that's a callable and `P` that's
used in it's specialization is bound to `another`. Now, ty infers the
type of `target` same as `value` and does not use the declared type
`CustomType[P]`. [This is the
assignment](0980b9d9ab/src/async_utils/gen_transform.py (L108))
that I'm referring to which then leads to error in downstream usage.
Pyright and mypy does seem to use the declared type.
There are multiple diagnostics in `dd-trace-py` that requires support
for `cls`.
I'm seeing `Divergent` type for an example like which ~~I'm not sure
why, I'll look into it tomorrow~~ is because of a cycle as mentioned in
https://github.com/astral-sh/ty/issues/1729#issuecomment-3612279974:
```py
from typing import Callable
def decorator[**P](c: Callable[P, int]) -> Callable[P, str]: ...
@decorator
def func(a: int) -> int: ...
# ((a: int) -> str) | ((a: Divergent) -> str)
reveal_type(func)
```
I ~~need to look into why are the parameters not being specialized
through multiple decorators in the following code~~ think this is also
because of the cycle mentioned in
https://github.com/astral-sh/ty/issues/1729#issuecomment-3612279974 and
the fact that we don't support `staticmethod` properly:
```py
from contextlib import contextmanager
class Foo:
@staticmethod
@contextmanager
def method(x: int):
yield
foo = Foo()
# ty: Revealed type: `() -> _GeneratorContextManager[Unknown, None, None]` [revealed-type]
reveal_type(foo.method)
```
There's some issue related to `Protocol` that are generic over a
`ParamSpec` in `starlette` which might be related to
https://github.com/astral-sh/ty/issues/1635 but I'm not sure. Here's a
minimal example to reproduce:
<details><summary>Code snippet:</summary>
<p>
```py
from collections.abc import Awaitable, Callable, MutableMapping
from typing import Any, Callable, ParamSpec, Protocol
P = ParamSpec("P")
Scope = MutableMapping[str, Any]
Message = MutableMapping[str, Any]
Receive = Callable[[], Awaitable[Message]]
Send = Callable[[Message], Awaitable[None]]
ASGIApp = Callable[[Scope, Receive, Send], Awaitable[None]]
_Scope = Any
_Receive = Callable[[], Awaitable[Any]]
_Send = Callable[[Any], Awaitable[None]]
# Since `starlette.types.ASGIApp` type differs from `ASGIApplication` from `asgiref`
# we need to define a more permissive version of ASGIApp that doesn't cause type errors.
_ASGIApp = Callable[[_Scope, _Receive, _Send], Awaitable[None]]
class _MiddlewareFactory(Protocol[P]):
def __call__(
self, app: _ASGIApp, *args: P.args, **kwargs: P.kwargs
) -> _ASGIApp: ...
class Middleware:
def __init__(
self, factory: _MiddlewareFactory[P], *args: P.args, **kwargs: P.kwargs
) -> None:
self.factory = factory
self.args = args
self.kwargs = kwargs
class ServerErrorMiddleware:
def __init__(
self,
app: ASGIApp,
value: int | None = None,
flag: bool = False,
) -> None:
self.app = app
self.value = value
self.flag = flag
async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None: ...
# ty: Argument to bound method `__init__` is incorrect: Expected `_MiddlewareFactory[(...)]`, found `<class 'ServerErrorMiddleware'>` [invalid-argument-type]
Middleware(ServerErrorMiddleware, value=500, flag=True)
```
</p>
</details>
### Conformance analysis
> ```diff
> -constructors_callable.py:36:13: info[revealed-type] Revealed type:
`(...) -> Unknown`
> +constructors_callable.py:36:13: info[revealed-type] Revealed type:
`(x: int) -> Unknown`
> ```
Requires return type inference i.e.,
https://github.com/astral-sh/ruff/pull/21551
> ```diff
> +constructors_callable.py:194:16: error[invalid-argument-type]
Argument is incorrect: Expected `list[T@__init__]`, found `list[Unknown
| str]`
> +constructors_callable.py:194:22: error[invalid-argument-type]
Argument is incorrect: Expected `list[T@__init__]`, found `list[Unknown
| str]`
> +constructors_callable.py:195:4: error[invalid-argument-type] Argument
is incorrect: Expected `list[T@__init__]`, found `list[Unknown | int]`
> +constructors_callable.py:195:9: error[invalid-argument-type] Argument
is incorrect: Expected `list[T@__init__]`, found `list[Unknown | str]`
> ```
I might need to look into why this is happening...
> ```diff
> +generics_defaults.py:79:1: error[type-assertion-failure] Type
`type[Class_ParamSpec[(str, int, /)]]` does not match asserted type
`<class 'Class_ParamSpec'>`
> ```
which is on the following code
```py
DefaultP = ParamSpec("DefaultP", default=[str, int])
class Class_ParamSpec(Generic[DefaultP]): ...
assert_type(Class_ParamSpec, type[Class_ParamSpec[str, int]])
```
It's occurring because there's no equivalence relationship defined
between `ClassLiteral` and `KnownInstanceType::TypeGenericAlias` which
is what these types are.
Everything else looks good to me!
When converting a class (whether specialized or not) into a `Callable`
type, we should carry through any generic context that the constructor
has. This includes both the generic context of the class itself (if it's
generic) and of the constructor methods (if they are separately
generic).
To help test this, this also updates the `generic_context` extension
function to work on `Callable` types and unions; and adds a new
`into_callable` extension function that works just like
`CallableTypeOf`, but on value forms instead of type forms.
Pulled this out of #21551 for separate review.
## Summary
Closes https://github.com/astral-sh/ty/issues/957
As explained in https://github.com/astral-sh/ty/issues/957, literal
union types for recursively defined values can be widened early to
speed up the convergence of fixed-point iterations.
This PR achieves this by embedding a marker in `UnionType` that
distinguishes whether a value is recursively defined.
This also allows us to identify values that are not recursively
defined, so I've increased the limit on the number of elements in a
literal union type for such values.
Edit: while this PR doesn't provide the significant performance
improvement initially hoped for, it does have the benefit of allowing
the number of elements in a literal union to be raised above the salsa
limit, and indeed mypy_primer results revealed that a literal union of
220 elements was actually being used.
## Test Plan
`call/union.md` has been updated
Fixes https://github.com/astral-sh/ty/issues/1587
## Summary
Perform cycle normalization on typevar bounds and constraints (similar
to how it was already done for typevar defaults) in order to ensure
convergence in cyclic cases.
There might be another fix here that could avoid the cycle in many more
cases, where we don't eagerly evaluate typevar bounds/constraints on
explicit specialization, but just accept the given specialization and
later evaluate to see whether we need to emit a diagnostic on it. But
the current fix here is sufficient to solve the problem and matches the
patterns we use to ensure cycle convergence elsewhere, so it seems good
for now; left a TODO for the other idea.
This fix is sufficient to make us not panic, but not sufficient to get
the semantics fully correct; see the TODOs in the tests. I have ideas
for fixing that as well, but it seems worth at least getting this in to
fix the panic.
## Test Plan
Test that previously panicked now does not.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
This makes auto-import include modules in suggestions.
In this initial implementation, we permit this to include submodules as
well. This is in contrast to what we do in `import ...` completions.
It's easy to change this behavior, but I think it'd be interesting to
run with this for now to see how well it works.
The existing importer functionality always required
an import request with a module and a member in that
module. But we want to be able to insert import statements
for a module itself and not any members in the module.
This is basically changing `member: &str` to an
`Option<&str>` and fixing the fallout in a way that
makes sense for module-only imports.
I think changes to this value are generally noise. It's hard to tell
what it means and it isn't especially actionable. We already have an
eval running in CI for completion ranking, so I don't think it's
terribly important to care about ranking here in e2e tests _generally_.
A completion lacking a module reference doesn't necessarily mean that
the symbol is defined within the current module. I believe the intent
here is that it means that no import is required to use it.
These are all improvements here with one slight regression on
`reveal_type` ranking. The previous completions offered were:
```
$ cargo r -q -p ty_completion_eval show-one ty-extensions-lower-stdlib
ENOTRECOVERABLE (module: errno)
REG_WHOLE_HIVE_VOLATILE (module: winreg)
SQLITE_NOTICE_RECOVER_WAL (module: _sqlite3)
SupportsGetItemViewable (module: _typeshed)
removeHandler (module: unittest.signals)
reveal_mro (module: ty_extensions)
reveal_protocol_interface (module: ty_extensions)
reveal_type (module: typing) (*, 8/10)
_remove_original_values (module: _osx_support)
_remove_universal_flags (module: _osx_support)
-----
found 10 completions
```
And now they are:
```
$ cargo r -q -p ty_completion_eval show-one ty-extensions-lower-stdlib
ENOTRECOVERABLE (module: errno)
REG_WHOLE_HIVE_VOLATILE (module: winreg)
SQLITE_NOTICE_RECOVER_WAL (module: sqlite3)
SQLITE_NOTICE_RECOVER_WAL (module: sqlite3.dbapi2)
removeHandler (module: unittest)
removeHandler (module: unittest.signals)
reveal_mro (module: ty_extensions)
reveal_protocol_interface (module: ty_extensions)
reveal_type (module: typing) (*, 9/9)
-----
found 9 completions
```
Some completions were removed (because they are now considered
unexported) and some were added (likely do to better re-export support).
This particular case probably warrants more special attention anyway.
So I think this is fine. (It's only a one-ranking regression.)
This applies recursively. So if *any* component of a module name starts
with a `_`, then symbols from that module are excluded from auto-import.
The exception is when it's a module within first party code. Then we
want to include it in auto-import.
Note that the `Deprecated` symbols from `importlib.metadata` are no
longer offered because 1) `importlib.metadata` defined `__all__` and 2)
the `Deprecated` symbols aren't in it. These seem to not be a part of
its public API according to the docs, so this seems right to me.
This commit (mostly) re-implements the support for `__all__` in
ty-proper, but inside the auto-import AST scanner.
When `__all__` isn't present in a module, we fall back to conventions to
determine whether a symbol is exported or not:
https://docs.python.org/3/library/index.html
However, in keeping with current practice for non-auto-import
completions, we continue to provide sunder and dunder names as
re-exports.
When `__all__` is present, we respect it strictly. That is, a symbol is
exported *if and only if* it's in `__all__`. This is somewhat stricter
than pylance seemingly is. I felt like it was a good idea to start here,
and we can relax it based on user demand (perhaps through a setting).
This simplifies the existing visitor by DRYing it up slightly.
We also add tests for the existing functionality. In particular,
we want to add support for re-export conventions, and that
warrants more careful testing.
## Summary
I realized we don't really test `DefinitionKind::ImportFromSubmodule` in
the IDE at all, so here's a bunch of them, just recording our current
behaviour.
## Test Plan
*stares at the camera*
## Summary
I have no idea what I'm doing with the fix (all the interesting stuff is
in the second commit).
The basic problem is the compiler emits the diagnostic:
```
x: "foobar"
^^^^^^
```
Which the suppression code-action hands the end of to `Tokens::after`
which then panics because that function panics if handed an offset that
is in the middle of a token.
Fixes https://github.com/astral-sh/ty/issues/1748
## Test Plan
Many tests added (only the e2e test matters).
## Summary
This makes an importing file a required argument to module resolution,
and if the fast-path cached query fails to resolve the module, take the
slow-path uncached (could be cached if we want)
`desperately_resolve_module` which will walk up from the importing file
until it finds a `pyproject.toml` (arbitrary decision, we could try
every ancestor directory), at which point it takes one last desperate
attempt to use that directory as a search-path. We do not continue
walking up once we've found a `pyproject.toml` (arbitrary decision, we
could keep going up).
Running locally, this fixes every broken-for-workspace-reasons import in
pyx's workspace!
* Fixes https://github.com/astral-sh/ty/issues/1539
* Improves https://github.com/astral-sh/ty/issues/839
## Test Plan
The workspace tests see a huge improvement on most absolute imports.
Fixes https://github.com/astral-sh/ty/issues/1716.
## Test plan
I added a corpus snippet that causes us to panic on `main` (I tested by
running `cargo run -p ty_python_semantic --test=corpus` without the fix
applied).
## Summary
This PR re-implements [return-in-generator
(B901)](https://docs.astral.sh/ruff/rules/return-in-generator/#return-in-generator-b901)
for async generators as a semantic syntax error. This is not a syntax
error for sync generators, so we'll need to preserve both the lint rule
and the syntax error in this case.
It also updates B901 and the new implementation to catch cases where the
generator's `yield` or `yield from` expression is part of another
statement, as in:
```py
def foo():
return (yield)
```
These were previously not caught because we only looked for
`Stmt::Expr(Expr::Yield)` in `visit_stmt` instead of visiting `yield`
expressions directly. I think this modification is within the spirit of
the rule and safe to try out since the rule is in preview.
## Test Plan
<!-- How was it tested? -->
I have written tests as directed in #17412
---------
Signed-off-by: 11happy <soni5happy@gmail.com>
Signed-off-by: 11happy <bhuminjaysoni@gmail.com>
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
Star-imports can not just affect the state of symbols that they pull in,
they can also affect the state of members that are associated with those
symbols. For example, if `obj.attr` was previously narrowed from `int |
None` to `int`, and a star-import now overwrites `obj`, then the
narrowing on `obj.attr` should be "reset".
This PR keeps track of the state of associated members during star
imports and properly models the flow of their corresponding state
through the control flow structure that we artificially create for
star-imports.
See [this
comment](https://github.com/astral-sh/ty/issues/1355#issuecomment-3607125005)
for an explanation why this caused ty to see certain `asyncio` symbols
as not being accessible on Python 3.14.
closes https://github.com/astral-sh/ty/issues/1355
## Ecosystem impact
```diff
async-utils (https://github.com/mikeshardmind/async-utils)
- src/async_utils/bg_loop.py:115:31: error[invalid-argument-type] Argument to bound method `set_task_factory` is incorrect: Expected `_TaskFactory | None`, found `def eager_task_factory[_T_co](loop: AbstractEventLoop | None, coro: Coroutine[Any, Any, _T_co@eager_task_factory], *, name: str | None = None, context: Context | None = None) -> Task[_T_co@eager_task_factory]`
- Found 30 diagnostics
+ Found 29 diagnostics
mitmproxy (https://github.com/mitmproxy/mitmproxy)
+ mitmproxy/utils/asyncio_utils.py:96:60: warning[unused-ignore-comment] Unused blanket `type: ignore` directive
- test/conftest.py:37:31: error[invalid-argument-type] Argument to bound method `set_task_factory` is incorrect: Expected `_TaskFactory | None`, found `def eager_task_factory[_T_co](loop: AbstractEventLoop | None, coro: Coroutine[Any, Any, _T_co@eager_task_factory], *, name: str | None = None, context: Context | None = None) -> Task[_T_co@eager_task_factory]`
```
All of these seem to be correct, they give us a different type for
`asyncio` symbols that are now imported from different
`sys.version_info` branches (where we previously failed to recognize
some of these as statically true/false).
```diff
dd-trace-py (https://github.com/DataDog/dd-trace-py)
- ddtrace/contrib/internal/asyncio/patch.py:39:12: error[invalid-argument-type] Argument to function `unwrap` is incorrect: Expected `WrappedFunction`, found `def create_task[_T](self, coro: Coroutine[Any, Any, _T@create_task] | Generator[Any, None, _T@create_task], *, name: object = None) -> Task[_T@create_task]`
+ ddtrace/contrib/internal/asyncio/patch.py:39:12: error[invalid-argument-type] Argument to function `unwrap` is incorrect: Expected `WrappedFunction`, found `def create_task[_T](self, coro: Generator[Any, None, _T@create_task] | Coroutine[Any, Any, _T@create_task], *, name: object = None) -> Task[_T@create_task]`
```
Similar, but only results in a diagnostic change.
## Test Plan
Added a regression test
This fixes a non-determinism that we were seeing in the constraint set
tests in https://github.com/astral-sh/ruff/pull/21715.
In this test, we create the following constraint set, and then try to
create a specialization from it:
```
(T@constrained_by_gradual_list = list[Base])
∨
(Bottom[list[Any]] ≤ T@constrained_by_gradual_list ≤ Top[list[Any]])
```
That is, `T` is either specifically `list[Base]`, or it's any `list`.
Our current heuristics say that, absent other restrictions, we should
specialize `T` to the more specific type (`list[Base]`).
In the correct test output, we end up creating a BDD that looks like
this:
```
(T@constrained_by_gradual_list = list[Base])
┡━₁ always
└─₀ (Bottom[list[Any]] ≤ T@constrained_by_gradual_list ≤ Top[list[Any]])
┡━₁ always
└─₀ never
```
In the incorrect output, the BDD looks like this:
```
(Bottom[list[Any]] ≤ T@constrained_by_gradual_list ≤ Top[list[Any]])
┡━₁ always
└─₀ never
```
The difference is the ordering of the two individual constraints. Both
constraints appear in the first BDD, but the second BDD only contains `T
is any list`. If we were to force the second BDD to contain both
constraints, it would look like this:
```
(Bottom[list[Any]] ≤ T@constrained_by_gradual_list ≤ Top[list[Any]])
┡━₁ always
└─₀ (T@constrained_by_gradual_list = list[Base])
┡━₁ always
└─₀ never
```
This is the standard shape for an OR of two constraints. However! Those
two constraints are not independent of each other! If `T` is
specifically `list[Base]`, then it's definitely also "any `list`". From
that, we can infer the contrapositive: that if `T` is not any list, then
it cannot be `list[Base]` specifically. When we encounter impossible
situations like that, we prune that path in the BDD, and treat it as
`false`. That rewrites the second BDD to the following:
```
(Bottom[list[Any]] ≤ T@constrained_by_gradual_list ≤ Top[list[Any]])
┡━₁ always
└─₀ (T@constrained_by_gradual_list = list[Base])
┡━₁ never <-- IMPOSSIBLE, rewritten to never
└─₀ never
```
We then would see that that BDD node is redundant, since both of its
outgoing edges point at the `never` node. Our BDDs are _reduced_, which
means we have to remove that redundant node, resulting in the BDD we saw
above:
```
(Bottom[list[Any]] ≤ T@constrained_by_gradual_list ≤ Top[list[Any]])
┡━₁ always
└─₀ never <-- redundant node removed
```
The end result is that we were "forgetting" about the `T = list[Base]`
constraint, but only for some BDD variable orderings.
To fix this, I'm leaning in to the fact that our BDDs really do need to
"remember" all of the constraints that they were created with. Some
combinations might not be possible, but we now have the sequent map,
which is quite good at detecting and pruning those.
So now our BDDs are _quasi-reduced_, which just means that redundant
nodes are allowed. (At first I was worried that allowing redundant nodes
would be an unsound "fix the glitch". But it turns out they're real!
[This](https://ieeexplore.ieee.org/abstract/document/130209) is the
paper that introduces them, though it's very difficult to read. Knuth
mentions them in §7.1.4 of
[TAOCP](https://course.khoury.northeastern.edu/csu690/ssl/bdd-knuth.pdf),
and [this paper](https://par.nsf.gov/servlets/purl/10128966) has a nice
short summary of them in §2.)
While we're here, I've added a bunch of `debug` and `trace` level log
messages to the constraint set implementation. I was getting tired of
having to add these by hands over and over. To enable them, just set
`TY_LOG` in your environment, e.g.
```sh
env TY_LOG=ty_python_semantic::types::constraints::SequentMap=trace ty check ...
```
[Note, this has an `internal` label because are still not using
`specialize_constrained` in anything user-facing yet.]
## Summary
For a type alias like the one below, where `UnknownClass` is something
with a dynamic type, we previously lost track of the fact that this
dynamic type was explicitly specialized *with a type variable*. If that
alias is then later explicitly specialized itself (`MyAlias[int]`), we
would miscount the number of legacy type variables and emit a
`invalid-type-arguments` diagnostic
([playground](https://play.ty.dev/886ae6cc-86c3-4304-a365-510d29211f85)).
```py
T = TypeVar("T")
MyAlias: TypeAlias = UnknownClass[T] | None
```
The solution implemented here is not pretty, but we can hopefully get
rid of it via https://github.com/astral-sh/ty/issues/1711. Also, once we
properly support `ParamSpec` and `Concatenate`, we should be able to
remove some of this code.
This addresses many of the `invalid-type-arguments` false-positives in
https://github.com/astral-sh/ty/issues/1685. With this change, there are
still some diagnostics of this type left. Instead of implementing even
more (rather sophisticated) workarounds for these cases as well, it
might be much easier to wait for full `ParamSpec`/`Concatenate` support
and then try again.
A disadvantage of this implementation is that we lose track of some
`@Todo` types and replace them with `Unknown`. We could spend more
effort and try to preserve them, but I'm unsure if this is the best use
of our time right now.
## Test Plan
New Markdown tests.
## Summary
Implement default-specialization of generic type aliases (implicit or
PEP-613) if they are used in a type expression without an explicit
specialization.
closes https://github.com/astral-sh/ty/issues/1690
## Typing conformance
```diff
-generics_defaults_specialization.py:26:5: error[type-assertion-failure] Type `SomethingWithNoDefaults[int, str]` does not match asserted type `SomethingWithNoDefaults[int, DefaultStrT]`
```
That's exactly what we want ✔️
All other tests in this file pass as well, with the exception of this
assertion, which is just wrong (at least according to our
interpretation, `type[Bar] != <class 'Bar'>`). I checked that we do
correctly default-specialize the type parameter which is not displayed
in the diagnostic that we raise.
```py
class Bar(SubclassMe[int, DefaultStrT]): ...
assert_type(Bar, type[Bar[str]]) # ty: Type `type[Bar[str]]` does not match asserted type `<class 'Bar'>`
```
## Ecosystem impact
Looks like I should have included this last week 😎
## Test Plan
Updated pre-existing tests and add a few new ones.
This adds a new `suppression` module to the `ruff_linter` crate, similar
to the suppression
module for ty, to parse comments for ruff suppression directives, such
as `# ruff: disable[CODE]`.
## Summary
Fixes#21750 and a related bug in `PLE1142`. We were not properly
considering generators to be valid `await` contexts, which caused the
`F704` issue. One of the tests I added for this also uncovered an issue
in `PLE1142` for comprehensions nested within async generators because
we were only checking the current scope rather than traversing the
nested context.
## Test Plan
Both of these rules are implemented as semantic syntax errors, so I
added tests (and fixes) in both Ruff and ty.
In the following example, there are two occurrences of `typing.Self`,
one for `Foo.foo` and one for `Bar.bar`:
```py
from typing import Self, reveal_type
class Foo[T]:
def foo(self: Self) -> T:
raise NotImplementedError
class Bar:
def bar(self: Self, x: Foo[Self]):
# SHOULD BE: bound method Foo[Self@bar].foo() -> Self@bar
# revealed: bound method Foo[Self@bar].foo() -> Foo[Self@bar]
reveal_type(x.foo)
def f[U: Bar](x: Foo[U]):
# revealed: bound method Foo[U@f].foo() -> U@f
reveal_type(x.foo)
```
When accessing a bound method, we replace any occurrences of `Self` with
the bound `self` type.
We were doing this correctly for the second reveal. We would first apply
the specialization, getting `(self: Self@foo) -> U@F` as the signature
of `x.foo`. We would then bind the `self` parameter, substituting
`Self@foo` with `Foo[U@F]` as part of that. The return type was already
specialized to `U@F`, so that substitution had no further affect on the
type that we revealed.
In the first reveal, we would follow the same process, but we confused
the two occurrences of `Self`. We would first apply the specialization,
getting `(self: Self@foo) -> Self@bar` as the method signature. We would
then try to bind the `self` parameter, substituting `Self@foo` with
`Foo[Self@bar]`. However, because we didn't distinguish the two separate
`Self`s, and applied the substitution to the return type as well as to
the `self` parameter.
The fix is to track which particular `Self` we're trying to substitute
when applying the type mapping.
Fixes https://github.com/astral-sh/ty/issues/1713
Here are a bunch of (variously failing and passing) mdtests that reflect
the kinds of issues people encounter when running ty over an entire
workspace without sufficient hand-holding (especially because in the IDE
it is unclear *how* to provide that hand-holding).
The `Display` implementation for constraint sets is brittle, and
deserves a rethink. But later! It's perfectly fine for printf debugging;
we just shouldn't be writing mdtests that depend on any particular
rendering details. Most of these tests can be replaced with an
equivalence check that actually validates that the _behavior_ of two
constraint sets are identical.
## Summary
Fixes false positives in SIM222 and SIM223 where truthiness was
incorrectly assumed for `tuple(x)`, `list(x)`, `set(x)` when `x` is not
iterable.
Fixes#21473.
## Problem
`Truthiness::from_expr` recursively called itself on arguments to
iterable initializers (`tuple`, `list`, `set`) without checking if the
argument is iterable, causing false positives for cases like `tuple(0)
or True` and `tuple("") or True`.
## Approach
Added `is_definitely_not_iterable` helper and updated
`Truthiness::from_expr` to return `Unknown` for non-iterable arguments
(numbers, booleans, None) and string literals when called with iterable
initializers, preventing incorrect truthiness assumptions.
## Test Plan
Added test cases to `SIM222.py` and `SIM223.py` for `tuple("")`,
`tuple(0)`, `tuple(1)`, `tuple(False)`, and `tuple(None)` with `or True`
and `and False` patterns.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
## Summary
Marks fixes as unsafe when they change return types (`None` → `Path`,
`str`/`bytes` → `Path`, `str` → `Path`), except when the call is a
top-level expression.
Fixes#21431.
## Problem
Fixes for `os.rename`, `os.replace`, `os.getcwd`/`os.getcwdb`, and
`os.readlink` were marked safe despite changing return types, which can
break code that uses the return value.
## Approach
Added `is_top_level_expression_call` helper to detect when a call is a
top-level expression (return value unused). Updated
`check_os_pathlib_two_arg_calls` and `check_os_pathlib_single_arg_calls`
to mark fixes as unsafe unless the call is a top-level expression.
Updated PTH109 to use the helper for applicability determination.
## Test Plan
Updated snapshots for `preview_full_name.py`, `preview_import_as.py`,
`preview_import_from.py`, and `preview_import_from_as.py` to reflect
unsafe markers.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
Previously, the code action to do auto-import on a pre-existing symbol
assumed that the auto-importer would always generate an import
statement. But sometimes an import statement already exists.
A good example of this is the following snippet:
```
import warnings
@deprecated
def myfunc(): pass
```
Specifically, `deprecated` exists in `warnings` but isn't currently
imported. A code action to fix this could feasibly do two
transformations here. One is:
```
import warnings
@warnings.deprecated
def myfunc(): pass
```
Another is:
```
from warnings import deprecated
import warnings
@deprecated
def myfunc(): pass
```
The existing auto-import infrastructure chooses the former, since it
reuses a pre-existing import statement. But this PR chooses the latter
for the case of a code action. I'm not 100% sure this is the correct
choice, but it seems to defer more strongly to what the user has typed.
That is, that they want to use it unqualified because it's what has been
typed. So we should add the necessary import statement to make that
work.
Fixesastral-sh/ty#1668
This works by adding a third module resolution mode that lets the caller
opt into _some_ shadowing of modules that is otherwise not allowed (for
`typing` and `typing_extensions`).
Fixesastral-sh/ty#1658
## Summary
If you manage to create an `typing.GenericAlias` instance without us
knowing how that was created, then we don't know what to do with this in
a type annotation. So it's better to be explicit and show an error
instead of failing silently with a `@Todo` type.
## Test Plan
* New Markdown tests
* Zero ecosystem impact
## Summary
We had tests for this already, but they used generic classes that were
bivariant in their type parameter, and so this case wasn't captured.
closes https://github.com/astral-sh/ty/issues/1702
## Test Plan
Updated Markdown tests
## Summary
These projects from `mypy_primer` were missing from both `good.txt` and
`bad.txt` for some reason. I thought about writing a script that would
verify that `good.txt` + `bad.txt` = `mypy_primer.projects`, but that's
not completely trivial since there are projects like `cpython` only
appear once in `good.txt`. Given that we can hopefully soon get rid of
both of these files (and always run on all projects), it's probably not
worth the effort. We are usually notified of all `mypy_primer` changes.
## Test Plan
CI on this PR
## Summary
The exact behavior around what's allowed vs. disallowed was partly
detected through trial and error in the runtime.
I was a little confused by [this
comment](https://github.com/python/cpython/pull/129352) that says
"`NamedTuple` subclasses cannot be inherited from" because in practice
that doesn't appear to error at runtime.
Closes [#1683](https://github.com/astral-sh/ty/issues/1683).
## Summary
This is another small refactor for
https://github.com/astral-sh/ruff/pull/21445 that splits the single
`paramspec.md` into `generics/legacy/paramspec.md` and
`generics/pep695/paramspec.md`.
## Test Plan
Make sure that all mdtests pass.
## Summary
Add support for generic PEP 613 type aliases and generic implicit type
aliases:
```py
from typing import TypeVar
T = TypeVar("T")
ListOrSet = list[T] | set[T]
def _(xs: ListOrSet[int]):
reveal_type(xs) # list[int] | set[int]
```
closes https://github.com/astral-sh/ty/issues/1643
closes https://github.com/astral-sh/ty/issues/1629
closes https://github.com/astral-sh/ty/issues/1596
closes https://github.com/astral-sh/ty/issues/573
closes https://github.com/astral-sh/ty/issues/221
## Typing conformance
```diff
-aliases_explicit.py:52:5: error[type-assertion-failure] Type `list[int]` does not match asserted type `@Todo(specialized generic alias in type expression)`
-aliases_explicit.py:53:5: error[type-assertion-failure] Type `tuple[str, ...] | list[str]` does not match asserted type `@Todo(Generic specialization of types.UnionType)`
-aliases_explicit.py:54:5: error[type-assertion-failure] Type `tuple[int, int, int, str]` does not match asserted type `@Todo(specialized generic alias in type expression)`
-aliases_explicit.py:56:5: error[type-assertion-failure] Type `(int, str, /) -> str` does not match asserted type `@Todo(Generic specialization of typing.Callable)`
-aliases_explicit.py:59:5: error[type-assertion-failure] Type `int | str | None | list[list[int]]` does not match asserted type `int | str | None | list[@Todo(specialized generic alias in type expression)]`
```
New true negatives ✔️
```diff
+aliases_explicit.py:41:36: error[invalid-type-arguments] Too many type arguments: expected 1, got 2
-aliases_explicit.py:57:5: error[type-assertion-failure] Type `(int, str, str, /) -> None` does not match asserted type `@Todo(Generic specialization of typing.Callable)`
+aliases_explicit.py:57:5: error[type-assertion-failure] Type `(int, str, str, /) -> None` does not match asserted type `(...) -> Unknown`
```
These require `ParamSpec`
```diff
+aliases_explicit.py:67:24: error[invalid-type-arguments] Too many type arguments: expected 0, got 1
+aliases_explicit.py:68:24: error[invalid-type-arguments] Too many type arguments: expected 0, got 1
+aliases_explicit.py:69:29: error[invalid-type-arguments] Too many type arguments: expected 1, got 2
+aliases_explicit.py:70:29: error[invalid-type-arguments] Too many type arguments: expected 1, got 2
+aliases_explicit.py:71:29: error[invalid-type-arguments] Too many type arguments: expected 1, got 2
+aliases_explicit.py:102:20: error[invalid-type-arguments] Too many type arguments: expected 0, got 1
```
New true positives ✔️
```diff
-aliases_implicit.py:63:5: error[type-assertion-failure] Type `list[int]` does not match asserted type `@Todo(specialized generic alias in type expression)`
-aliases_implicit.py:64:5: error[type-assertion-failure] Type `tuple[str, ...] | list[str]` does not match asserted type `@Todo(Generic specialization of types.UnionType)`
-aliases_implicit.py:65:5: error[type-assertion-failure] Type `tuple[int, int, int, str]` does not match asserted type `@Todo(specialized generic alias in type expression)`
-aliases_implicit.py:67:5: error[type-assertion-failure] Type `(int, str, /) -> str` does not match asserted type `@Todo(Generic specialization of typing.Callable)`
-aliases_implicit.py:70:5: error[type-assertion-failure] Type `int | str | None | list[list[int]]` does not match asserted type `int | str | None | list[@Todo(specialized generic alias in type expression)]`
-aliases_implicit.py:71:5: error[type-assertion-failure] Type `list[bool]` does not match asserted type `@Todo(specialized generic alias in type expression)`
```
New true negatives ✔️
```diff
+aliases_implicit.py:54:36: error[invalid-type-arguments] Too many type arguments: expected 1, got 2
-aliases_implicit.py:68:5: error[type-assertion-failure] Type `(int, str, str, /) -> None` does not match asserted type `@Todo(Generic specialization of typing.Callable)`
+aliases_implicit.py:68:5: error[type-assertion-failure] Type `(int, str, str, /) -> None` does not match asserted type `(...) -> Unknown`
```
These require `ParamSpec`
```diff
+aliases_implicit.py:76:24: error[invalid-type-arguments] Too many type arguments: expected 0, got 1
+aliases_implicit.py:77:24: error[invalid-type-arguments] Too many type arguments: expected 0, got 1
+aliases_implicit.py:78:29: error[invalid-type-arguments] Too many type arguments: expected 1, got 2
+aliases_implicit.py:79:29: error[invalid-type-arguments] Too many type arguments: expected 1, got 2
+aliases_implicit.py:80:29: error[invalid-type-arguments] Too many type arguments: expected 1, got 2
+aliases_implicit.py:81:25: error[invalid-type-arguments] Type `str` is not assignable to upper bound `int | float` of type variable `TFloat@GoodTypeAlias12`
+aliases_implicit.py:135:20: error[invalid-type-arguments] Too many type arguments: expected 0, got 1
```
New true positives ✔️
```diff
+callables_annotation.py:172:19: error[invalid-type-arguments] Too many type arguments: expected 0, got 1
+callables_annotation.py:175:19: error[invalid-type-arguments] Too many type arguments: expected 0, got 1
+callables_annotation.py:188:25: error[invalid-type-arguments] Too many type arguments: expected 0, got 1
+callables_annotation.py:189:25: error[invalid-type-arguments] Too many type arguments: expected 0, got 1
```
These require `ParamSpec` and `Concatenate`.
```diff
-generics_defaults_specialization.py:26:5: error[type-assertion-failure] Type `SomethingWithNoDefaults[int, str]` does not match asserted type `SomethingWithNoDefaults[int, typing.TypeVar]`
+generics_defaults_specialization.py:26:5: error[type-assertion-failure] Type `SomethingWithNoDefaults[int, str]` does not match asserted type `SomethingWithNoDefaults[int, DefaultStrT]`
```
Favorable diagnostic change ✔️
```diff
-generics_defaults_specialization.py:27:5: error[type-assertion-failure] Type `SomethingWithNoDefaults[int, bool]` does not match asserted type `@Todo(specialized generic alias in type expression)`
```
New true negative ✔️
```diff
-generics_defaults_specialization.py:30:1: error[non-subscriptable] Cannot subscript object of type `<class 'SomethingWithNoDefaults[int, typing.TypeVar]'>` with no `__class_getitem__` method
+generics_defaults_specialization.py:30:15: error[invalid-type-arguments] Too many type arguments: expected between 0 and 1, got 2
```
Correct new diagnostic ✔️
```diff
-generics_variance.py:175:25: error[non-subscriptable] Cannot subscript object of type `<class 'Contra[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:175:35: error[non-subscriptable] Cannot subscript object of type `<class 'Co[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:179:29: error[non-subscriptable] Cannot subscript object of type `<class 'Contra[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:179:39: error[non-subscriptable] Cannot subscript object of type `<class 'Contra[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:183:21: error[non-subscriptable] Cannot subscript object of type `<class 'Co[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:183:27: error[non-subscriptable] Cannot subscript object of type `<class 'Co[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:187:25: error[non-subscriptable] Cannot subscript object of type `<class 'Co[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:187:31: error[non-subscriptable] Cannot subscript object of type `<class 'Contra[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:191:33: error[non-subscriptable] Cannot subscript object of type `<class 'Contra[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:191:43: error[non-subscriptable] Cannot subscript object of type `<class 'Co[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:191:49: error[non-subscriptable] Cannot subscript object of type `<class 'Contra[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:196:5: error[non-subscriptable] Cannot subscript object of type `<class 'Contra[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:196:15: error[non-subscriptable] Cannot subscript object of type `<class 'Contra[typing.TypeVar]'>` with no `__class_getitem__` method
-generics_variance.py:196:25: error[non-subscriptable] Cannot subscript object of type `<class 'Contra[typing.TypeVar]'>` with no `__class_getitem__` method
```
One of these should apparently be an error, but not of this kind, so
this is good ✔️
```diff
-specialtypes_type.py:152:16: error[invalid-type-form] `typing.TypeVar` is not a generic class
-specialtypes_type.py:156:16: error[invalid-type-form] `typing.TypeVar` is not a generic class
```
Good, those were false positives. ✔️
I skipped the analysis for everything involving `TypeVarTuple`.
## Ecosystem impact
**[Full report with detailed
diff](https://david-generic-implicit-alias.ecosystem-663.pages.dev/diff)**
Previous iterations of this PR showed all kinds of problems. In it's
current state, I do not see any large systematic problems, but it is
hard to tell with 5k diagnostic changes.
## Performance
* There is a huge 4x regression in `colour-science/colour`, related to
[this large
file](https://github.com/colour-science/colour/blob/develop/colour/io/luts/tests/test_lut.py)
with [many assignments of hard-coded arrays (lists of lists) to
`np.NDArray`
types](83e754c8b6/colour/io/luts/tests/test_lut.py (L701-L781))
that we now understand. We now take ~2 seconds to check this file, so
definitely not great, but maybe acceptable for now.
## Test Plan
Updated and new Markdown tests
## Summary
This is a bugfix for subtyping of `type[Any]` / `type[T]` and protocols.
## Test Plan
Regression test that will only be really meaningful once
https://github.com/astral-sh/ruff/pull/21553 lands.
## Summary
**This is the final goto-targets with missing
goto-definition/declaration implementations!
You can now theoretically click on all the user-defined names in all the
syntax. 🎉**
This adds:
* goto definition/declaration on patterns/typevars
* find-references/rename on patterns/typevars
* fixes syntax highlighting of `*rest` patterns
This notably *does not* add:
* goto-type for patterns/typevars
* hover for patterns/typevars (because that's just goto-type for names)
Also I realized we were at the precipice of one of the great GotoTarget
sins being resolved, and so I made import aliases also resolve to a
ResolvedDefinition. This removes a ton of cruft and prevents further
backsliding.
Note however that import aliases are, in general, completely jacked up
when it comes to find-references/renames (both before and after this
PR). Previously you could try to rename an import alias and it just
wouldn't do anything. With this change we instead refuse to even let you
try to rename it.
Sorting out why import aliases are jacked up is an ongoing thing I hope
to handle in a followup.
## Test Plan
You'll surely not regret checking in 86 snapshot tests
## Summary
* Fixes https://github.com/astral-sh/ty/issues/1650
* Part of https://github.com/astral-sh/ty/issues/1610
We now handle:
* `.. warning::` (and friends) by bolding the line and rendering the
block as normal (non-code) text
* `.. code::` (and friends) by treating it the same as `::` (fully
deleted if seen, introduce a code block)
* `.. code:: lang` (and friends) by letting it set the language on the
codefence
* `.. versionchanged:: 1.2.3` (and friends) by rendering it like
`warning` but with the version included and italicized
* `.. dsfsdf-unknown:: (lang)` by assuming it's the same as `.. code::
(lang)`
## Test Plan
Snapshots added/updated. I also deleted a bunch of useless checks on
plaintext rendering. It's important for some edge-case tests but not for
the vast majority of tests.
## Summary
This PR adds a new `db` parameter to `Parameters::new` for
https://github.com/astral-sh/ruff/pull/21445. This change creates a
large diff so thought to split it out as it's just a mechanical change.
The `Parameters::new` method not only creates the `Parameters` but also
analyses the parameters to check what kind it is. For `ParamSpec`
support, it's going to require the `db` to check whether the annotated
type is `ParamSpec` or not. For the current set of parameters that isn't
required because it's only checking whether it's dynamic or not which
doesn't require `db`.
## Summary
Pulls in an ecosystem-analyzer change with a few updates to the diff
report:
* Breakdown of added/removed/changed diagnostics by project
* Option to filter diagnostics by project
* Small button to copy a file path to the clipboard
* `(-R +A ~C)` indicators in the filter dropdowns (removed, added,
changed)
* More concise layout, less scrolling
## Test Plan
Tested on https://github.com/astral-sh/ruff/pull/21553 =>
https://david-generic-implicit-alias.ecosystem-663.pages.dev/diff
## Summary
Originally I planned to feed this in as a `fix` but I realized that we
probably don't want to be trying to resolve import suggestions while
we're doing type inference. Thus I implemented this as a fallback when
there's no fixes on a diagnostic, which can use the full lsp machinery.
Fixes https://github.com/astral-sh/ty/issues/1552
## Test Plan
Works in the IDE, added some e2e tests.
## Summary
Previously if an explicit specialization failed (e.g. wrong number of
type arguments or violates an upper bound) we just inferred `Unknown`
for the entire type. This actually caused us to panic on an a case of a
recursive upper bound with invalid specialization; the upper bound would
oscillate indefinitely in fixpoint iteration between `Unknown` and the
given specialization. This could be fixed with a cycle recovery
function, but in this case there's a simpler fix: if we infer
`C[Unknown]` instead of `Unknown` for an invalid attempt to specialize
`C`, that allows fixpoint iteration to quickly converge, as well as
giving a more precise type inference.
Other type checkers actually just go with the attempted specialization
even if it's invalid. So if `C` has a type parameter with upper bound
`int`, and you say `C[str]`, they'll emit a diagnostic but just go with
`C[str]`. Even weirder, if `C` has a single type parameter and you say
`C[str, bytes]`, they'll just go with `C[str]` as the type. I'm not
convinced by this approach; it seems odd to have specializations
floating around that explicitly violate the declared upper bound, or in
the latter case aren't even the specialization the annotation requested.
I prefer `C[Unknown]` for this case.
Fixing this revealed an issue with `collections.namedtuple`, which
returns `type[tuple[Any, ...]]`. Due to
https://github.com/astral-sh/ty/issues/1649 we consider that to be an
invalid specialization. So previously we returned `Unknown`; after this
PR it would be `type[tuple[Unknown]]`, leading to more false positives
from our lack of functional namedtuple support. To avoid that I added an
explicit Todo type for functional namedtuples for now.
## Test Plan
Added and updated mdtests.
The conformance suite changes have to do with `ParamSpec`, so no
meaningful signal there.
The ecosystem changes appear to be the expected effects of having more
precise type information (including occurrences of known issues such as
https://github.com/astral-sh/ty/issues/1495 ). Most effects are just
changes to types in diagnostics.
## Summary
Lots of Ruff rules encourage you to make changes that might then cause
ty to start complaining about Liskov violations. Most of these Ruff
rules already refrain from complaining about a method if they see that
the method is decorated with `@override`, but this usually isn't
documented. This PR updates the docs of many Ruff rules to note that
they refrain from complaining about `@override`-decorated methods, and
also adds a similar note to the ty `invalid-method-override`
documentation.
Helps with
https://github.com/astral-sh/ty/issues/1644#issuecomment-3581663859
## Test Plan
- `uvx prek run -a` locally
- CI on this PR
## Summary
This PR updates the explicit specialization logic to avoid using the
call machinery.
Previously, the logic would use the call machinery by converting the
list of type variables into a `Binding` with a single `Signature` where
all the type variables are positional-only parameters with bounds and
constraints as the annotated type and the default type as the default
parameter value. This has the advantage that it doesn't need to
implement any specific logic but the disadvantages are subpar diagnostic
messages as it would use the ones specific to a function call. But, an
important disadvantage is that the kind of type variable is lost in this
translation which becomes important in #21445 where a `ParamSpec` can
specialize into a list of types which is provided using list literal.
For example,
```py
class Foo[T, **P]: ...
Foo[int, [int, str]]
```
This PR converts the logic to use a simple loop using `zip_longest` as
all type variables and their corresponding type argument maps on a 1-1
basis. They cannot be specified using keyword argument either e.g.,
`dict[_VT=str, _KT=int]` is invalid.
This PR also makes an initial attempt to improve the diagnostic message
to specifically target the specialization part by using words like "type
argument" instead of just "argument" and including information like the
type variable, bounds, and constraints. Further improvements can be made
by highlighting the type variable definition or the bounds / constraints
as a sub-diagnostic but I'm going to leave that as a follow-up.
## Test Plan
Update messages in existing test cases.
## Summary
This caused "deterministic but chaotic" ordering of some intersection
types in diagnostics. When calling a union, we infer the argument type
once per matching parameter type, intersecting the inferred types for
the argument expression, and we did that in an unpredictable order.
We do need a hashset here for de-duplication. Sometimes we call large
unions where the type for a given parameter is the same across the
union, we should infer the argument once per parameter type, not once
per union element. So use an `FxIndexSet` instead of an `FxHashSet`.
## Test Plan
With this change, switching between `main` and
https://github.com/astral-sh/ruff/pull/21646 no longer changes the
ordering of the intersection type in the test in
cca3a8045d
## Summary
The reference to the pre-commit hook inside the tutorial was to the
legacy alias `ruff` instead of the current `ruff-check`.
Ref: https://github.com/astral-sh/ruff-pre-commit/pull/124
## Test Plan
Not applicable.
## Summary
Derived from #17371Fixesastral-sh/ty#256
Fixes https://github.com/astral-sh/ty/issues/1415
Fixes https://github.com/astral-sh/ty/issues/1433
Fixes https://github.com/astral-sh/ty/issues/1524
Properly handles any kind of recursive inference and prevents panics.
---
Let me explain techniques for converging fixed-point iterations during
recursive type inference.
There are two types of type inference that naively don't converge
(causing salsa to panic): divergent type inference and oscillating type
inference.
### Divergent type inference
Divergent type inference occurs when eagerly expanding a recursive type.
A typical example is this:
```python
class C:
def f(self, other: "C"):
self.x = (other.x, 1)
reveal_type(C().x) # revealed: Unknown | tuple[Unknown | tuple[Unknown | tuple[..., Literal[1]], Literal[1]], Literal[1]]
```
To solve this problem, we have already introduced `Divergent` types
(https://github.com/astral-sh/ruff/pull/20312). `Divergent` types are
treated as a kind of dynamic type [^1].
```python
Unknown | tuple[Unknown | tuple[Unknown | tuple[..., Literal[1]], Literal[1]], Literal[1]]
=> Unknown | tuple[Divergent, Literal[1]]
```
When a query function that returns a type enters a cycle, it sets
`Divergent` as the cycle initial value (instead of `Never`). Then, in
the cycle recovery function, it reduces the nesting of types containing
`Divergent` to converge.
```python
0th: Divergent
1st: Unknown | tuple[Divergent, Literal[1]]
2nd: Unknown | tuple[Unknown | tuple[Divergent, Literal[1]], Literal[1]]
=> Unknown | tuple[Divergent, Literal[1]]
```
Each cycle recovery function for each query should operate only on the
`Divergent` type originating from that query.
For this reason, while `Divergent` appears the same as `Any` to the
user, it internally carries some information: the location where the
cycle occurred. Previously, we roughly identified this by having the
scope where the cycle occurred, but with the update to salsa, functions
that create cycle initial values can now receive a `salsa::Id`
(https://github.com/salsa-rs/salsa/pull/1012). This is an opaque ID that
uniquely identifies the cycle head (the query that is the starting point
for the fixed-point iteration). `Divergent` now has this `salsa::Id`.
### Oscillating type inference
Now, another thing to consider is oscillating type inference.
Oscillating type inference arises from the fact that monotonicity is
broken. Monotonicity here means that for a query function, if it enters
a cycle, the calculation must start from a "bottom value" and progress
towards the final result with each cycle. Monotonicity breaks down in
type systems that have features like overloading and overriding.
```python
class Base:
def flip(self) -> "Sub":
return Sub()
class Sub(Base):
def flip(self) -> "Base":
return Base()
class C:
def __init__(self, x: Sub):
self.x = x
def replace_with(self, other: "C"):
self.x = other.x.flip()
reveal_type(C(Sub()).x)
```
Naive fixed-point iteration results in `Divergent -> Sub -> Base -> Sub
-> ...`, which oscillates forever without diverging or converging. To
address this, the salsa API has been modified so that the cycle recovery
function receives the value of the previous cycle
(https://github.com/salsa-rs/salsa/pull/1012).
The cycle recovery function returns the union type of the current cycle
and the previous cycle. In the above example, the result type for each
cycle is `Divergent -> Sub -> Base (= Sub | Base) -> Base`, which
converges.
The final result of oscillating type inference does not contain
`Divergent` because `Divergent` that appears in a union type can be
removed, as is clear from the expansion. This simplification is
performed at the same time as nesting reduction.
```
T | Divergent = T | (T | (T | ...)) = T
```
[^1]: In theory, it may be possible to strictly treat types containing
`Divergent` types as recursive types, but we probably shouldn't go that
deep yet. (AFAIK, there are no PEPs that specify how to handle
implicitly recursive types that aren't named by type aliases)
## Performance analysis
A happy side effect of this PR is that we've observed widespread
performance improvements!
This is likely due to the removal of the `ITERATIONS_BEFORE_FALLBACK`
and max-specialization depth trick
(https://github.com/astral-sh/ty/issues/1433,
https://github.com/astral-sh/ty/issues/1415), which means we reach a
fixed point much sooner.
## Ecosystem analysis
The changes look good overall.
You may notice changes in the converged values for recursive types,
this is because the way recursive types are normalized has been changed.
Previously, types containing `Divergent` types were normalized by
replacing them with the `Divergent` type itself, but in this PR, types
with a nesting level of 2 or more that contain `Divergent` types are
normalized by replacing them with a type with a nesting level of 1. This
means that information about the non-divergent parts of recursive types
is no longer lost.
```python
# previous
tuple[tuple[Divergent, int], int] => Divergent
# now
tuple[tuple[Divergent, int], int] => tuple[Divergent, int]
```
The false positive error introduced in this PR occurs in class
definitions with self-referential base classes, such as the one below.
```python
from typing_extensions import Generic, TypeVar
T = TypeVar("T")
U = TypeVar("U")
class Base2(Generic[T, U]): ...
# TODO: no error
# error: [unsupported-base] "Unsupported class base with type `<class 'Base2[Sub2, U@Sub2]'> | <class 'Base2[Sub2[Unknown], U@Sub2]'>`"
class Sub2(Base2["Sub2", U]): ...
```
This is due to the lack of support for unions of MROs, or because cyclic
legacy generic types are not inferred as generic types early in the
query cycle.
## Test Plan
All samples listed in astral-sh/ty#256 are tested and passed without any
panic!
## Acknowledgments
Thanks to @MichaReiser for working on bug fixes and improvements to
salsa for this PR. @carljm also contributed early on to the discussion
of the query convergence mechanism proposed in this PR.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
We now use the type context for a lot of things, so re-inferring without
type context actually makes diagnostics more confusing (in most cases).
Autocomplete suggestions were not suppressed correctly during
some variable bindings if the parameter name was currently
matching a keyword. E.g. `def f(foo<CURSOR>` was handled
correctly but not `def f(in<CURSOR>`.
Previously we extracted the entire token as the query
independently of the cursor position. By not doing that
you avoid having to do special range handling
to figure out the start position of the current token.
It's likely also more intuitive from a user perspective
to only consider characters left of the cursor when
suggesting autocompletions.
## Summary
The implementation here is to just record the idents of these statements
in `scopes_by_expression` (which already supported idents but only ones
that happened to appear in expressions), so that `definitions_for_name`
Just Works.
goto-type (and therefore hover) notably does not work on these
statements because the typechecker does not record info for them. I am
tempted to just introduce `type_for_name` which runs
`definitions_for_name` to find other expressions and queries the
inferred type... but that's a bit whack because it won't be the computed
type at the right point in the code. It probably wouldn't be
particularly expensive to just compute/record the type at those nodes,
as if they were a load, because global/nonlocal is so scarce?
## Test Plan
Snapshot tests added/re-enabled.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Don't allow edits of some more invalid syntax types.
## Test Plan
Add a test for `x = Literal['a']` (similar) to show we don't allow
edits.
Fixes https://github.com/astral-sh/ty/issues/1009
## Summary
This adds support for:
* semantic-tokens (syntax highlighting)
* goto-type **(partially implemented, but want to land as-is)**
* goto-declaration
* goto-definition (falls out of goto-declaration)
* hover **(limited by goto-type)**
* find-references
* rename-references (falls out of find-references)
There are 3 major things being introduced here:
* `TypeInferenceBuilder::string_annotations` is a `FxHashSet` of exprs
which were determined to be string annotations during inference. It's
bubbled up in `extras` to hopefully minimize the overhead as in most
contexts it's empty.
* Very happy to hear if this is too hacky and if I should do something
better, but it's IMO important that we get an authoritative answer on
whether something is a string annotation or not.
* `SemanticModel::enter_string_annotation` checks if the expr was marked
by `TypeInferenceBuilder::string_annotations` and then parses the subast
and produces a sub-SemanticModel that sets
`SemanticModel::in_string_annotation_expr`. This expr will be used by
the model whenever we need to query e.g. the scope of the current
expression (otherwise the code will constantly panic as the subast nodes
are not in the current File's AST)
* This hazard consequently encouraged me to refactor a bunch of code to
replace uses of file/db with SemanticModel to minimize hazards (it is no
longer as safe to randomly materialize a SemanticModel in the middle of
analysis, you need to thread through the one you have in case it has
`in_string_annotation_expr` set).
* `GotoTarget::StringAnnotationSubexpr` (and a semantic-tokens impl)
which involves invoking `SemanticModel::enter_string_annotation` before
invoking the same kind of subroutine a normal expression would.
* goto-type (and consequently displaying the type in hover) is the main
hole here, because we can only get the type iff the string annotation is
the entire subexpression (i.e. we can get the type of `"int"` but not
the parts of `"int | str"`). This is shippable IMO.
## Test Plan
Messed around in IDE, wrote a ton of tests.
## Summary
This PR adds a code action to remove unused ignore comments.
This PR also includes some infrastructure boilerplate to set up code
actions in the editor:
* Extend `snapshot-diagnostics` to render fixes
* Render fixes when using `--output-format=full`
* Hook up edits and the code action request in the LSP
* Add the `Unnecessary` tag to `unused-ignore-comment` diagnostics
* Group multiple unused codes into a single diagnostic
The same fix can be used on the CLI once we add `ty fix`
Note: `unused-ignore-comment` is currently disabled by default.
https://github.com/user-attachments/assets/f9e21087-3513-4156-85d7-a90b1a7a3489
## Summary
Building on https://github.com/astral-sh/ruff/pull/21436.
There's nothing conceptually more complicated about this, it just
requires its own set of tests and its own subdiagnostic hint.
I also uncovered another inconsistency between mypy/pyright/pyrefly,
which is fun. In this case, I suggest we go with pyright's behaviour.
## Test Plan
mdtests/snapshots
## Summary
This PR sets up CI jobs to run ty from the `main` branch on the files
and subdirectories in our `scripts` directory
## Test Plan
Both these commands pass for me locally:
- `uv run --project=./scripts cargo run -p ty check --project=./scripts`
- `uv run --project=./scripts/ty_benchmark cargo run -p ty check
--project=./scripts/ty_benchmark`
## Summary
For something like this:
```py
from typing import Callable
def my_lossy_decorator(fn: Callable[..., int]) -> Callable[..., int]:
return fn
class MyClass:
@my_lossy_decorator
def method(self) -> int:
return 42
```
we will currently infer the type of `MyClass.method` as a function-like
`Callable`, but we will infer the type of `MyClass().method` as a
`Callable` that is _not_ function-like. That's because a `CallableType`
currently "forgets" whether it was function-like or not during the
`bound_self` transformation:
a57e291311/crates/ty_python_semantic/src/types.rs (L10985-L10987)
This seems incorrect, and it's quite different to what we do when
binding the `self` parameter of `FunctionLiteral` types: `BoundMethod`
types are all seen as subtypes of function-like `Callable` supertypes --
here's `BoundMethodType::into_callable_type`:
a57e291311/crates/ty_python_semantic/src/types.rs (L10844-L10860)
The bug here is also causing lots of false positives in the ecosystem
report on https://github.com/astral-sh/ruff/pull/21611: a decorated
method on a subclass is currently not seen as validly overriding an
undecorated method with the same signature on a superclass, because the
undecorated superclass method is seen as function-like after binding
`self` whereas the decorated subclass method is not.
Fixing the bug required adding a new API in `protocol_class.rs`, because
it turns out that for our purposes in protocol subtyping/assignability,
we really do want a callable type to forget its function-like-ness when
binding `self`.
I initially tried out this change without changing anything in
`protocol_class.rs`. However, it resulted in many ecosystem false
positives and new false positives on the typing conformance test suite.
This is because it would mean that no protocol with a `__call__` method
would ever be seen as a subtype of a `Callable` type, since the
`__call__` method on the protocol would be seen as being function-like
whereas the `Callable` type would not be seen as function-like.
## Test Plan
Added an mdtest that fails on `main`
Before, we would collapse any constraint of the form `Never ≤ T ≤
object` down to the "always true" constraint set. This is correct in
terms of BDD semantics, but loses information, since "not constraining a
typevar at all" is different than "constraining a typevar to take on any
type". Once we get to specialization inference, we should fall back on
the typevar's default for the former, but not for the latter.
This is much easier to support now that we have a sequent map, since we
need to treat `¬(Never ≤ T ≤ object)` as being impossible, and prune it
when we walk through BDD paths, just like we do for other impossible
combinations.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Resolves
https://github.com/astral-sh/ty/issues/317#issuecomment-3567398107.
I can't get the auto import working great.
I haven't added many places where we specify that the type display is
invalid syntax.
## Test Plan
Nothing yet
This patch updates our protocol assignability checks to substitute for
any occurrences of `typing.Self` in method signatures, replacing it with
the class being checked for assignability against the protocol.
This requires a new helper method on signatures, `apply_self`, which
substitutes occurrences of `typing.Self` _without_ binding the `self`
parameter.
We also update the `try_upcast_to_callable` method. Before, it would
return a `Type`, since certain types upcast to a _union_ of callables,
not to a single callable. However, even in that case, we know that every
element of the union is a callable. We now return a vector of
`CallableType`. (Actually a smallvec to handle the most common case of a
single callable; and wrapped in a new type so that we can provide helper
methods.) If there is more than one element in the result, it represents
a union of callables. This lets callers get at the `CallableType`
instances in a more type-safe way. (This makes it easier for our
protocol checking code to call the new `apply_self` helper.) We also
provide an `into_type` method so that callers that really do want a
`Type` can get the original result easily.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
This only applies to items that have a type associated with them. That
is, things that are already in scope. For items that don't have a type
associated with them (i.e., suggestions from auto-import), we still
suggest them since we can't know if they're appropriate or not. It's not
quite clear on how best to improve here for the auto-import case. (Short
of, say, asking for the type of each such symbol. But the performance
implications of that aren't known yet.)
Note that because of auto-import, we were still suggesting
`NotImplemented` even though astral-sh/ty#1262 specifically cites it as
the motivating example that we *shouldn't* suggest. This was occuring
because auto-import was including symbols from the `builtins` module,
even though those are actually already in scope. So this PR also gets
rid of those suggestions from auto-import.
Overall, this means that, at least, `raise NotImpl` won't suggest
`NotImplemented`.
Fixesastral-sh/ty#1262
## Summary
Fixes https://github.com/astral-sh/ty/issues/1620. #20909 added hints if
you do something like this and your Python version is set to 3.10 or
lower:
```py
import typing
typing.LiteralString
```
And we also have hints if you try to do something like this and your
Python version is set too low:
```py
from stdlib_module import new_submodule
```
But we don't currently have any subdiagnostic hint if you do something
like _this_ and your Python version is set too low:
```py
from typing import LiteralString
```
This PR adds that hint!
## Test Plan
snapshots
---------
Co-authored-by: Aria Desires <aria.desires@gmail.com>
## Summary
This PR adds a failing mdtest for the panic in
https://github.com/astral-sh/ty/issues/1587. The added snippet currently
panics with this query stacktrace:
```
error[panic]: Panicked at /Users/alexw/.cargo/git/checkouts/salsa-e6f3bb7c2a062968/17bc55d/src/function/execute.rs:321:21 when checking `/Users/alexw/dev/ruff/foo.py`: `ClassLiteral < 'db >::explicit_bases_(Id(4c09)): execute: too many cycle iterations`
info: This indicates a bug in ty.
info: If you could open an issue at https://github.com/astral-sh/ty/issues/new?title=%5Bpanic%5D, we'd be very appreciative!
info: Platform: macos aarch64
info: Version: ruff/0.14.5+105 (d24c891a4 2025-11-22)
info: Args: ["target/debug/ty", "check", "foo.py", "--python-version=3.14"]
info: run with `RUST_BACKTRACE=1` environment variable to show the full backtrace information
info: query stacktrace:
0: cached_protocol_interface(Id(6805))
at crates/ty_python_semantic/src/types/protocol_class.rs:795
1: is_equivalent_to_object_inner(Id(8003))
at crates/ty_python_semantic/src/types/instance.rs:667
2: infer_deferred_types(Id(1406))
at crates/ty_python_semantic/src/types/infer.rs:140
cycle heads: infer_definition_types(Id(140b)) -> iteration = 200, TypeVarInstance < 'db >::lazy_bound_(Id(5802)) -> iteration = 200
3: TypeVarInstance < 'db >::lazy_bound_(Id(5803))
at crates/ty_python_semantic/src/types.rs:8827
4: infer_definition_types(Id(140c))
at crates/ty_python_semantic/src/types/infer.rs:94
5: infer_deferred_types(Id(1405))
at crates/ty_python_semantic/src/types/infer.rs:140
6: TypeVarInstance < 'db >::lazy_bound_(Id(5802))
at crates/ty_python_semantic/src/types.rs:8827
7: infer_definition_types(Id(140b))
at crates/ty_python_semantic/src/types/infer.rs:94
8: infer_scope_types(Id(1000))
at crates/ty_python_semantic/src/types/infer.rs:70
9: check_file_impl(Id(c00))
at crates/ty_project/src/lib.rs:535
```
It's not totally clear to me how to fix this or to what extent it might
be a bug in our `Protocol` internals rather than a bug in our `TypeVar`
internals. (It's sort of interesting that we're trying to evaluate the
upper bound of any `TypeVar`s here!) @carljm suggested that it would be
a good idea to add a failing mdtest in the meantime to document the
panic, which I agree with.
## Test Plan
I verified that we panic on this snippet, and that the test fails if I
remove the `expect-panic` assertion or if I change the asserted error
message.
I experimented with ways of minimizing the snippet further, but I think
any further minimization takes the snippet further away from something a
user would actually be likely to write -- so I think is probably
counterproductive. The failing test added in this PR isn't unreasonable
code at the end of the day; I've seen Python like it in the wild.
## Summary
Fixes a panic when parsing IPython escape commands with `Help` kind
(`?`) in expression contexts. The parser now reports an error instead of
panicking.
Fixes#21465.
## Problem
The parser panicked with `unreachable!()` in
`parse_ipython_escape_command_expression` when encountering escape
commands with `Help` kind (`?`) in expression contexts, where only
`Magic` (`%`) and `Shell` (`!`) are allowed.
## Approach
Replaced the `unreachable!()` panic with error handling that adds a
`ParseErrorType::OtherError` and continues parsing, returning a valid
AST node with the error attached.
## Test Plan
Added `test_ipython_escape_command_in_with_statement` and
`test_ipython_help_escape_command_as_expression` to verify the fix.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| actions/checkout | action | digest | `ff7abcd` -> `c2d88d3` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0Mi4xNi4xIiwidXBkYXRlZEluVmVyIjoiNDIuMTYuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
---------
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [clap](https://redirect.github.com/clap-rs/clap) |
workspace.dependencies | patch | `4.5.51` -> `4.5.53` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>clap-rs/clap (clap)</summary>
###
[`v4.5.53`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4553---2025-11-19)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.52...v4.5.53)
##### Features
- Add `default_values_if`, `default_values_ifs`
###
[`v4.5.52`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4552---2025-11-17)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.51...v4.5.52)
##### Fixes
- Don't panic when `args_conflicts_with_subcommands` conflicts with an
`ArgGroup`
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0Mi4xNi4xIiwidXBkYXRlZEluVmVyIjoiNDIuMTYuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [indexmap](https://redirect.github.com/indexmap-rs/indexmap) |
workspace.dependencies | patch | `2.12.0` -> `2.12.1` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>indexmap-rs/indexmap (indexmap)</summary>
###
[`v2.12.1`](https://redirect.github.com/indexmap-rs/indexmap/blob/HEAD/RELEASES.md#2121-2025-11-20)
[Compare
Source](https://redirect.github.com/indexmap-rs/indexmap/compare/2.12.0...2.12.1)
- Simplified a lot of internals using `hashbrown`'s new bucket API.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0Mi4xNi4xIiwidXBkYXRlZEluVmVyIjoiNDIuMTYuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [syn](https://redirect.github.com/dtolnay/syn) |
workspace.dependencies | patch | `2.0.110` -> `2.0.111` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/syn (syn)</summary>
###
[`v2.0.111`](https://redirect.github.com/dtolnay/syn/releases/tag/2.0.111)
[Compare
Source](https://redirect.github.com/dtolnay/syn/compare/2.0.110...2.0.111)
- Allow first argument of `braced!`, `bracketed!`, `parenthesized!` to
be an otherwise unused variable
([#​1946](https://redirect.github.com/dtolnay/syn/issues/1946))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0Mi4xNi4xIiwidXBkYXRlZEluVmVyIjoiNDIuMTYuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
* Fixes https://github.com/astral-sh/ty/issues/1011
* Also fixes the fact that we didn't handle `.x` properly *at all* in
hover/goto
It turns out all of our import handling completely ignored the `level`
(number of relative `.`'s) in a `from ..x.y import z` statement. It was
nice seeing how much my understanding of `ty` has improved -- previously
this would have all been opaque to me but now it was just, completely
glaring and blatant.
Fixing this required refactoring all the import code to take the
importing file into consideration. I ended up refactoring a bunch of
code to pass around/require `SemanticModel` more, as it's the natural
API for resolving this kind of import (it actually had an API for this
that was just... dead code, whoops!).
## Summary
As reported in #19757:
While attempting ISC003 autofix for an expression with explicit string
concatenation, with either operand being a string literal that wraps
across multiple lines (in parentheses) - it resulted in generating a fix
which caused runtime error.
Example:
```
_ = "abc" + (
"def"
"ghi"
)
```
was being auto-fixed to:
```
_ = "abc" (
"def"
"ghi"
)
```
which raised `TypeError: 'str' object is not callable`
This commit makes changes to just report diagnostic - no autofix in such
cases.
Fixes#19757.
## Test Plan
Added example scenarios in
`crates/ruff_linter/resources/test/fixtures/flake8_implicit_str_concat/ISC.py`.
Signed-off-by: Prakhar Pratyush <prakhar1144@gmail.com>
## Summary
Fixes the PLE1141 (`dict-iter-missing-items`) rule to allow fixes for
empty dictionaries unless they have type annotations indicating 2-tuple
keys. Previously, the fix was incorrectly suppressed for all empty dicts
due to vacuous truth in the `all()` function.
Fixes#21289
## Problem Analysis
The `is_dict_key_tuple_with_two_elements` function was designed to
suppress the fix when a dictionary's keys are all 2-tuples, as unpacking
tuple keys directly would change runtime behavior.
However, for empty dictionaries, `iter_keys()` returns an empty
iterator, and `all()` on an empty iterator returns `true` (vacuous
truth). This caused the function to incorrectly suppress fixes for empty
dicts, even when there was no indication that future keys would be
2-tuples.
## Approach
1. **Detect empty dictionaries**: Added a check to identify when a dict
literal has no keys.
2. **Handle annotated empty dicts**: For empty dicts with type
annotations:
- Parse the annotation to check if it's `dict[tuple[T1, T2], ...]` where
the tuple has exactly 2 elements
- Support both PEP 484 (`typing.Dict`, `typing.Tuple`) and PEP 585
(`dict`, `tuple`) syntax
- If tuple keys are detected, suppress the fix (correct behavior)
- Otherwise, allow the fix
3. **Handle unannotated empty dicts**: For empty dicts without
annotations, allow the fix since there's no indication that keys will be
2-tuples.
4. **Preserve existing behavior**: For non-empty dicts, the original
logic is unchanged - check if all existing keys are 2-tuples.
The implementation includes helper functions:
- `is_annotation_dict_with_tuple_keys()`: Checks if a type annotation
specifies dict with tuple keys
- `is_tuple_type_with_two_elements()`: Checks if a type expression
represents a 2-tuple
Test cases were added to verify:
- Empty dict without annotation triggers the error
- Empty dict with `dict[tuple[int, str], bool]` suppresses the error
- Empty dict with `dict[str, int]` triggers the error
- Existing tests remain unchanged
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
PR #21549 introduced a subtle overflow bug that seemed impossible, but
can empirically happen. This PR fixes it by saturating to zero.
I did try to write a regression test for this, but couldn't manage it.
Instead, I'll attach before-and-after screen recordings.
These were added to try to make it clearer that assignability checks
will eventually return more detailed answers than true or false.
However, the constraint set display rendering is still more brittle than
I'd like it to be, and it's more trouble than it's worth to keep them
updated with semantically identically but textually different edits. The
`static_assert`s are sufficient to check correctness, and we can always
add `reveal_type` when needed for further debugging.
## Summary
Extends the `used-dummy-variable` rule
([RUF052](https://docs.astral.sh/ruff/rules/used-dummy-variable/)) to
detect dummy variables that are used within list comprehensions, dict
comprehensions, set comprehensions, and generator expressions, not just
regular for loops and function assignments.
### Problem
Previously, RUF052 only flagged dummy variables (variables with leading
underscores) that were used in function scopes via assignments or
regular for loops. It missed cases where dummy variables were used
within comprehensions:
```python
def example():
my_list = [{"foo": 1}, {"foo": 2}]
# These were not detected before:
[_item["foo"] for _item in my_list] # Should warn: _item is used
{_item["key"]: _item["val"] for _item in my_list} # Should warn: _item is used
(_item["foo"] for _item in my_list) # Should warn: _item is used
```
### Solution
- Extended scope checking to include all generator scopes () with any
(list/dict/set comprehensions and generator expressions)
`ScopeKind::Generator``GeneratorKind`
- Added support for bindings, which cover loop variables in both regular
for loops and comprehensions `BindingKind::LoopVar`
- Refactored the scope validation logic for better readability with a
descriptive variable `is_allowed_scope`
[ISSUE](https://github.com/astral-sh/ruff/issues/19732)
## Test Plan
```bash
cargo test
```
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
Statements such as `def foo(p<CURSOR>`,
`def foo[T<CURSOR>` and `for foo<CURSOR>`
should not generate any suggestions as these
cases are introducing new names.
If it's not possible to determine that suggestions should be omitted
using token matching in an easy way, we turn
to traversing the AST to determine the context.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes https://github.com/astral-sh/ty/issues/1563
It keeps using the existing token matching pattern for the easy cases
(nothing typed and most recent token is a definition token) and
fallbacks to AST traveral for the slightly more difficult cases where
token matching becomes difficult and error prone.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
New test cases and sanity-checking in the ty playground
<!-- How was it tested? -->
## Summary
This introduces a very bad and naive
python-docstring-flavoured-reStructuredText to github-flavor-markdown
translator. The main goal is to try to preserve a lot of the formatting
and plaintext, progressively enhance the content when we find things we
know about, and escape the text when we find things that might get
corrupt.
Previously I'd broken this out into rendering each different format, but
with this approach you don't really need to?
## Test Plan
Lots of snapshot tests, also messed around in some random stdlib
modules.
This commit essentially does away of all our old heuristic and piecemeal
code for detecting different kinds of import statements. Instead, we
offer one single state machine that does everything. This on its own
fixes a few bugs. For example, `import collections.abc, unico<CURSOR>`
would previously offer global scope completions instead of module
completions.
For the most part though, this commit is a refactoring that preserves
parity. In the next commit, we'll add support for completions on
relative imports.
This is a small refactor that helps centralize the
logic for how we gather, convert and possibly filter
completions.
Some of this logic was spread out before, which
motivated this refactor. Moreover, as part of other
refactoring, I found myself chaffing against the
lack of this abstraction.
Refs https://github.com/astral-sh/ty/issues/544
## Summary
Takes a more incremental approach to PEP 613 type alias support (vs
https://github.com/astral-sh/ruff/pull/20107). Instead of eagerly
inferring the RHS of a PEP 613 type alias as a type expression, infer it
as a value expression, just like we do for implicit type aliases, taking
advantage of the same support for e.g. unions and other type special
forms.
The main reason I'm following this path instead of the one in
https://github.com/astral-sh/ruff/pull/20107 is that we've realized that
people do sometimes use PEP 613 type aliases as values, not just as
types (because they are just a normal runtime assignment, unlike PEP 695
type aliases which create an opaque `TypeAliasType`).
This PR doesn't yet provide full support for recursive type aliases
(they don't panic, but they just fall back to `Unknown` at the recursion
point). This is future work.
## Test Plan
Added mdtests.
Many new ecosystem diagnostics, mostly because we
understand new types in lots of places.
Conformance suite changes are correct.
Performance regression is due to understanding lots of new
types; nothing we do in this PR is inherently expensive.
This is a very conservative minimal implementation of applying overloads
to resolve a callable-type-being-called down to a single function
signature on hover. If we ever encounter a situation where the answer
doesn't simplify down to a single function call, we bail out to preserve
prettier printing of non-raw-Signatures.
The resulting Signatures are still a bit bare, I'm going to try to
improve that in a followup to improve our Signature printing in general.
Fixes https://github.com/astral-sh/ty/issues/73
As far as I know this change is largely non-functional, largely because
of https://github.com/astral-sh/ty/issues/1601
It's possible some of these like `Type::KnownInstance` produce something
useful sometimes. `LiteralString` is a new introduction, although its
goto-type jumps to `str` which is a bit sad (considering that part of
the SpecialForm discourse for now).
Also wrt the generics testing followup: turns out the snapshot tests
were full of those already.
## Summary
Eagerly evaluate the elements of a PEP 604 union in value position (e.g.
`IntOrStr = int | str`) as type expressions and store the result (the
corresponding `Type::Union` if all elements are valid type expressions,
or the first encountered `InvalidTypeExpressionError`) on the
`UnionTypeInstance`, such that the `Type::Union(…)` does not need to be
recomputed every time the implicit type alias is used in a type
annotation.
This might lead to performance improvements for large unions, but is
also necessary for correctness, because the elements of the union might
refer to type variables that need to be looked up in the scope of the
type alias, not at the usage site.
## Test Plan
New Markdown tests
This PR generalizes the signature_help system's SignatureWriter which
could get the subspans of function parameters.
We now have TypeDetailsWriter which is threaded between type's display
implementations via a new `fmt_detailed` method that many of the Display
types now have.
With this information we can properly add goto-type targets to our inlay
hints. This also lays groundwork for any future "I want to render a type
but get spans" work.
Also a ton of lifetimes are introduced to avoid things getting conflated
with `'db`.
This PR is broken up into a series of commits:
* Generalizing `SignatureWriter` to `TypeDetailsWriter`, but not using
it anywhere else. This commit was confirmed to be a non-functional
change (no test results changed)
* Introducing `fmt_detailed` everywhere to thread through
`TypeDetailsWriter` and annotate various spans as "being" a given Type
-- this is also where I had to reckon with a ton of erroneous `&'db
self`. This commit was also confirmed to be a non-functional change.
* Finally, actually using the results for goto-type on inlay hints!
* Regenerating snapshots, fixups, etc.
#21414 added the ability to create a specialization from a constraint
set. It handled mutually constrained typevars just fine, e.g. given `T ≤
int ∧ U = T` we can infer `T = int, U = int`.
But it didn't handle _nested_ constraints correctly, e.g. `T ≤ int ∧ U =
list[T]`. Now we do! This requires doing a fixed-point "apply the
specialization to itself" step to propagate the assignments of any
nested typevars, and then a cycle detection check to make sure we don't
have an infinite expansion in the specialization.
This gets at an interesting nuance in our constraint set structure that
@sharkdp has asked about before. Constraint sets are BDDs, and each
internal node represents an _individual constraint_, of the form `lower
≤ T ≤ upper`. `lower` and `upper` are allowed to be other typevars, but
only if they appear "later" in the arbitary ordering that we establish
over typevars. The main purpose of this is to avoid infinite expansion
for mutually constrained typevars.
However, that restriction doesn't help us here, because only applies
when `lower` and `upper` _are_ typevars, not when they _contain_
typevars. That distinction is important, since it means the restriction
does not affect our expressiveness: we can always rewrite `Never ≤ T ≤
U` (a constraint on `T`) into `T ≤ U ≤ object` (a constraint on `U`).
The same is not true of `Never ≤ T ≤ list[U]` — there is no "inverse" of
`list` that we could apply to both sides to transform this into a
constraint on a bare `U`.
## Summary
Updated `S508` (snmp-insecure-version) and `S509`
(snmp-weak-cryptography) rules to support both old and new PySNMP API
module paths. Previously, these rules only detected the old API path
`pysnmp.hlapi.*`, but now they correctly detect all PySNMP API variants
including `pysnmp.hlapi.asyncio.*`, `pysnmp.hlapi.v1arch.*`,
`pysnmp.hlapi.v3arch.*`, and `pysnmp.hlapi.auth.*`.
Fixes#21364
## Problem Analysis
The `S508` and `S509` rules used exact pattern matching on qualified
names:
- `S509` only matched `["pysnmp", "hlapi", "UsmUserData"]`
- `S508` only matched `["pysnmp", "hlapi", "CommunityData"]`
This meant that newer PySNMP API paths were not detected, such as:
- `pysnmp.hlapi.asyncio.UsmUserData`
- `pysnmp.hlapi.v3arch.asyncio.UsmUserData`
- `pysnmp.hlapi.v3arch.asyncio.auth.UsmUserData`
- `pysnmp.hlapi.auth.UsmUserData`
- Similar variants for `CommunityData` in `S508`
Additionally, the old API path `pysnmp.hlapi.auth.*` was also missing
from both rules.
## Approach
Instead of exact pattern matching, both rules now check if:
1. The qualified name starts with `["pysnmp", "hlapi"]`
2. The qualified name ends with the target class name (`"UsmUserData"`
for `S509`, `"CommunityData"` for `S508`)
This flexible approach matches all PySNMP API paths without hardcoding
each variant, making the rules more maintainable and future-proof.
## Test Plan
Added comprehensive test cases to both `S508.py` and `S509.py` test
files covering:
- New API paths: `pysnmp.hlapi.asyncio.*`, `pysnmp.hlapi.v1arch.*`,
`pysnmp.hlapi.v3arch.*`
- Old API path: `pysnmp.hlapi.auth.*`
- Both insecure and secure usage patterns
All existing tests pass, and new snapshot tests were added and accepted.
Manual verification confirms both rules correctly detect all PySNMP API
variants.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
## Summary
Fixes https://github.com/astral-sh/ty/issues/1571.
I realised I was overcomplicating things when I described what we should
do in that issue description. The simplest thing to do here is just to
special-case call expressions and short-circuit the call-binding
machinery entirely if we see it's `NotImplemented` being called. It
doesn't really matter if the subdiagnostic doesn't fire when a union is
called and one element of the union is `NotImplemented` -- the
subdiagnostic doesn't need to be exhaustive; it's just to help people in
some common cases.
## Test Plan
Added snapshots
## Summary
The `.expect()` call here:
5dd56264fb/crates/ty_python_semantic/src/types/instance.rs (L816-L827)
is the direct cause of the panic in
https://github.com/astral-sh/ty/issues/1587. This patch gets rid of the
panic by refactoring our `Protocol` enum so that the
`Protocol::FromClass` variant holds a `ProtocolClass` instance rather
than a `ClassType` instance (all the `.expect()` call was doing was
attempting to convert form a `ClassType` to a `ProtocolClass`).
I hoped that this would provide a fix for
https://github.com/astral-sh/ty/issues/1587, but we still panic on the
provided reproducible examples in that issue even with this PR.
Nonetheless, I think this PR is a worthwhile change to make because:
- It's probably slightly more efficient this way (we no longer have to
re-verify that the wrapped class in a `Protocol::FromClass()` variant is
a protocol class every time we want to access its interface)
- It's nice to get rid of `.expect()` calls where possible, and this one
seems definitely unnecessary
- The _new_ panic message on this PR branch makes it much clearer what
the underlying cause of the bug in
https://github.com/astral-sh/ty/issues/1587 is:
<details>
<summary>New panic message</summary>
```
error[panic]: Panicked at
/Users/alexw/.cargo/git/checkouts/salsa-e6f3bb7c2a062968/a885bb4/src/function/execute.rs:321:21
when checking `/Users/alexw/dev/ruff/foo.py`: `ClassLiteral < 'db
>::explicit_bases_(Id(4c09)): execute: too many cycle iterations`
info: This indicates a bug in ty.
info: If you could open an issue at
https://github.com/astral-sh/ty/issues/new?title=%5Bpanic%5D, we'd be
very appreciative!
info: Platform: macos aarch64
info: Version: ruff/0.14.5+60 (18a14bfaf 2025-11-19)
info: Args: ["target/debug/ty", "check", "foo.py",
"--python-version=3.14"]
info: run with `RUST_BACKTRACE=1` environment variable to show the full
backtrace information
info: query stacktrace:
0: cached_protocol_interface(Id(6805))
at crates/ty_python_semantic/src/types/protocol_class.rs:790
1: is_equivalent_to_object_inner(Id(8003))
at crates/ty_python_semantic/src/types/instance.rs:667
2: infer_deferred_types(Id(1409))
at crates/ty_python_semantic/src/types/infer.rs:141
cycle heads: infer_definition_types(Id(140b)) -> iteration = 200,
TypeVarInstance < 'db >::lazy_bound_(Id(5803)) -> iteration = 200
3: TypeVarInstance < 'db >::lazy_bound_(Id(5802))
at crates/ty_python_semantic/src/types.rs:8734
4: infer_definition_types(Id(140c))
at crates/ty_python_semantic/src/types/infer.rs:94
5: infer_deferred_types(Id(140a))
at crates/ty_python_semantic/src/types/infer.rs:141
6: TypeVarInstance < 'db >::lazy_bound_(Id(5803))
at crates/ty_python_semantic/src/types.rs:8734
7: infer_definition_types(Id(140b))
at crates/ty_python_semantic/src/types/infer.rs:94
8: infer_scope_types(Id(1000))
at crates/ty_python_semantic/src/types/infer.rs:70
9: check_file_impl(Id(c00))
at crates/ty_project/src/lib.rs:535
Found 1 diagnostic
WARN A fatal error occurred while checking some files. Not all project
files were analyzed. See the diagnostics list above for details.
```
</details>
## Test Plan
All existing tests pass.
This patch lets us create specializations from a constraint set. The
constraint encodes the restrictions on which types each typevar can
specialize to. Given a generic context and a constraint set, we iterate
through all of the generic context's typevars. For each typevar, we
abstract the constraint set so that it only mentions the typevar in
question (propagating derived facts if needed). We then find the "best
representative type" for the typevar given the abstracted constraint
set.
When considering the BDD structure of the abstracted constraint set,
each path from the BDD root to the `true` terminal represents one way
that the constraint set can be satisfied. (This is also one of the
clauses in the DNF representation of the constraint set's boolean
formula.) Each of those paths is the conjunction of the individual
constraints of each internal node that we traverse as we walk that path,
giving a single lower/upper bound for the path. We use the upper bound
as the "best" (i.e. "closest to `object`") type for that path.
If there are multiple paths in the BDD, they technically represent
independent possible specializations. If there's a single specialization
that satisfies all of them, we will return that as the specialization.
If not, then the constraint set is ambiguous. (This happens most often
with constrained typevars.) We could in the future turn _each_ of the
paths into separate specializations, but it's not clear what we would do
with that, so instead we just report the ambiguity as a specialization
failure.
We were previously normalizing the upper and lower bounds of each
constraint when constructing constraint sets. Like in #21463, this was
for conflated reasons: It made constraint set displays nicer, since we
wouldn't render multiple constraints with obviously equivalent bounds.
(Think `T ≤ A & B` and `T ≤ B & A`) But it was also useful for
correctness, since prior to #21463 we were (trying to) add the full
transitive closure to a constraint set's BDD, and normalization gave a
useful reduction in the number of nodes in a typical BDD.
Now that we don't store the transitive closure explicitly, that second
reason is no longer relevant. Our sequent map can store that full
transitive closure much more efficiently than the expanded BDD would
have. This helps fix some false positives on #20933, where we're seeing
some (incorrect, need to be fixed, but ideally not blocking this effort)
assignability failures between a type and its normalization.
Normalization is still useful for display purposes, and so we do
normalize the upper/lower bounds before building up our display
representation of a constraint set BDD.
---------
Co-authored-by: David Peter <sharkdp@users.noreply.github.com>
We're seeing flaky test failures on macos, which seems to be caused by
different Salsa ID orderings on the different platforms. Constraint set
BDDs order their internal nodes based on the Salsa IDs of the interned
typevar structs, and we had some code that depended on variable ordering
in an unexpected way.
This patch definitely fixes the macos test failure on #21414, and
hopefully fixes it on #21436, too.
## Summary
Add a set of comprehensive tests for generic implicit type aliases to
illustrate the current behavior with many flavors of `@Todo` types and
false positive diagnostics.
The tests are partially based on the typing conformance suite, and the
expected behavior has been checked against other type checkers.
## Summary
Get rid of the catch-all todo type from subscripting a base type we
haven't implemented handling for yet in a type expression, and turn it
into a diagnostic instead.
Handle a few more cases explicitly, to avoid false positives from the
above change:
1. Subscripting any dynamic type (not just a todo type) in a type
expression should just result in that same dynamic type. This is
important for gradual guarantee, and matches other type checkers.
2. Subscripting a generic alias may be an error or not, depending
whether the specialization itself contains typevars. Don't try to handle
this yet (it should be handled in a later PR for specializing generic
non-PEP695 type aliases), just use a dedicated todo type for it.
3. Add a temporary todo branch to avoid false positives from string PEP
613 type aliases. This can be removed in the next PR, with PEP 613 type
alias support.
## Test Plan
Adjusted mdtests, ecosystem.
All new diagnostics in conformance suite are supposed to be diagnostics,
so this PR is a strict improvement there.
New diagnostics in the ecosystem are surfacing cases where we already
don't understand an annotation, but now we emit a diagnostic about it.
They are mostly intentional choices. Analysis of particular cases:
* `attrs`, `bokeh`, `django-stubs`, `dulwich`, `ibis`, `kornia`,
`mitmproxy`, `mongo-python-driver`, `mypy`, `pandas`, `poetry`,
`prefect`, `pydantic`, `pytest`, `scrapy`, `trio`, `werkzeug`, and
`xarray` are all cases where under `from __future__ import annotations`
or Python 3.14 deferred-annotations semantics, we follow normal
name-scoping rules, whereas some other type checkers prefer global names
over local names. This means we don't like it if e.g. you have a class
with a method or attribute named `type` or `tuple`, and you also try to
use `type` or `tuple` in method/attribute annotations of that class.
This PR isn't changing those semantics, just revealing them in more
cases where previously we just silently fell back to `Unknown`. I think
failing with a diagnostic (so authors can alias names as needed to avoid
relying on scoping rules that differ between type checkers) is better
than failing silently here.
* `beartype` assumes we support `TypeForm` (because it only supports
mypy and pyright, it uses `if MYPY:` to hide the `TypeForm` from mypy,
and pyright supports `TypeForm`), and we don't yet.
* `graphql-core` likes to use a `try: ... except ImportError: ...`
pattern for importing special forms from `typing` with fallback to
`typing_extensions`, instead of using `sys.version_info` checks. We
don't handle this well when type checking under an older Python version
(where the import from `typing` is not found); we see the imported name
as of type e.g. `Unknown | SpecialFormType(...)`, and because of the
union with `Unknown` we fail to handle it as the special form type. Mypy
and pyright also don't seem to support this pattern. They don't complain
about subscripting such special forms, but they do silently fail to
treat them as the desired special form. Again here, if we are going to
fail I'd rather fail with a diagnostic rather than silently.
* `ibis` is [trying to
use](https://github.com/ibis-project/ibis/blob/main/ibis/common/collections.py#L372)
`frozendict: type[FrozenDict]` as a way to create a "type alias" to
`FrozenDict`, but this is wrong: that means `frozendict:
type[FrozenDict[Any, Any]]`.
* `mypy` has some errors due to the fact that type-checking `typing.pyi`
itself (without knowing that it's the real `typing.pyi`) doesn't work
very well.
* `mypy-protobuf` imports some types from the protobufs library that end
up unioned with `Unknown` for some reason, and so we don't allow
explicit-specialization of them. Depending on the reason they end up
unioned with `Unknown`, we might want to better support this? But it's
orthogonal to this PR -- we aren't failing any worse here, just alerting
the author that we didn't understand their annotation.
* `pwndbg` has unresolved references due to star-importing from a
dependency that isn't installed, and uses un-imported names like `Dict`
in annotation expressions. Some of the unresolved references were hidden
by
https://github.com/astral-sh/ruff/blob/main/crates/ty_python_semantic/src/types/infer/builder.rs#L7223-L7228
when some annotations previously resolved to a Todo type that no longer
do.
Summary
--
This PR wires up the `Diagnostic::set_documentation_url` method from
#21502 to Ruff's lint diagnostics. This enables the links for the full
and concise output formats without any other changes.
I considered also including the URLs for the grouped and pylint output
formats, but the grouped format is still in `ruff_linter` instead of
`ruff_db`, so we'd have to export some additional functionality to wire
it up with `fmt_with_hyperlink`; and the pylint format doesn't currently
render with color, so I think it might actually be machine readable
rather than human readable?
The other ouput formats (json, json-lines, junit, github, gitlab,
rdjson, azure, sarif) seem more clearly not to need the links.
Test Plan
--
I guess you can't see my cursor or the browser opening, but it works for
lint rules, which have links, and doesn't include a link for syntax
errors, which don't have valid links.

Closes#11216
Essentially the approach is to implement `Format` for a new struct
`FormatClause` which is just a clause header _and_ its body. We then
have the information we need to see whether there is a skip suppression
comment on the last child in the body and it all fits on one line.
This saga began with a regression in how we handle constraint sets where
a typevar is constrained by another typevar, which #21068 first added
support for:
```py
def mutually_constrained[T, U]():
# If [T = U ∧ U ≤ int], then [T ≤ int] must be true as well.
given_int = ConstraintSet.range(U, T, U) & ConstraintSet.range(Never, U, int)
static_assert(given_int.implies_subtype_of(T, int))
```
While working on #21414, I saw a regression in this test, which was
strange, since that PR has nothing to do with this logic! The issue is
that something in that PR made us instantiate the typevars `T` and `U`
in a different order, giving them differently ordered salsa IDs. And
importantly, we use these salsa IDs to define the variable ordering that
is used in our constraint set BDDs. This showed that our "mutually
constrained" logic only worked for one of the two possible orderings.
(We can — and now do — test this in a brute-force way by copy/pasting
the test with both typevar orderings.)
The underlying bug was in our `ConstraintSet::simplify_and_domain`
method. It would correctly detect `(U ≤ T ≤ U) ∧ (U ≤ int)`, because
those two constraints affect different typevars, and from that, infer `T
≤ int`. But it wouldn't detect the equivalent pattern in `(T ≤ U ≤ T) ∧
(U ≤ int)`, since those constraints affect the same typevar. At first I
tried adding that as yet more pattern-match logic in the ever-growing
`simplify_and_domain` method. But doing so caused other tests to start
failing.
At that point, I realized that `simplify_and_domain` had gotten to the
point where it was trying to do too much, and for conflicting consumers.
It was first written as part of our display logic, where the goal is to
remove redundant information from a BDD to make its string rendering
simpler. But we also started using it to add "derived facts" to a BDD. A
derived fact is a constraint that doesn't appear in the BDD directly,
but which we can still infer to be true. Our failing test relies on
derived facts — being able to infer that `T ≤ int` even though that
particular constraint doesn't appear in the original BDD. Before,
`simplify_and_domain` would trace through all of the constraints in a
BDD, figure out the full set of derived facts, and _add those derived
facts_ to the BDD structure. This is brittle, because those derived
facts are not universally true! In our example, `T ≤ int` only holds
along the BDD paths where both `T = U` and `U ≤ int`. Other paths will
test the negations of those constraints, and on those, we _shouldn't_
infer `T ≤ int`. In theory it's possible (and we were trying) to use BDD
operators to express that dependency...but that runs afoul of how we
were simultaneously trying to _remove_ information to make our displays
simpler.
So, I ripped off the band-aid. `simplify_and_domain` is now _only_ used
for display purposes. I have not touched it at all, except to remove
some logic that is definitely not used by our `Display` impl. Otherwise,
I did not want to touch that house of cards for now, since the display
logic is not load-bearing for any type inference logic.
For all non-display callers, we have a new **_sequent map_** data type,
which tracks exactly the same derived information. But it does so (a)
without trying to remove anything from the BDD, and (b) lazily, without
updating the BDD structure.
So the end result is that all of the tests (including the new
regressions) pass, via a more efficient (and hopefully better
structured/documented) implementation, at the cost of hanging onto a
pile of display-related tech debt that we'll want to clean up at some
point.
## Summary
This is another attempt at https://github.com/astral-sh/ruff/pull/21410
that fixes https://github.com/astral-sh/ruff/issues/19226.
@MichaReiser helped me get something working in a very helpful pairing
session. I pushed one additional commit moving the comments back from
leading comments to trailing comments, which I think retains more of the
input formatting.
I was inspired by Dylan's PR (#21185) to make one of these tables:
<table>
<thead>
<tr>
<th scope="col">Input</th>
<th scope="col">Main</th>
<th scope="col">PR</th>
</tr>
</thead>
<tbody>
<tr>
<td><pre lang="python">
if (
not
# comment
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa +
bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
):
pass
</pre></td>
<td><pre lang="python">
if (
# comment
not aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
+ bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
):
pass
</pre></td>
<td><pre lang="python">
if (
not
# comment
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
+ bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
):
pass
</pre></td>
</tr>
<tr>
<td><pre lang="python">
if (
# unary comment
not
# operand comment
(
# comment
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
+ bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
)
):
pass
</pre></td>
<td><pre lang="python">
if (
# unary comment
# operand comment
not (
# comment
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
+ bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
)
):
pass
</pre></td>
<td><pre lang="python">
if (
# unary comment
not
# operand comment
(
# comment
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
+ bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
)
):
pass
</pre></td>
</tr>
<tr>
<td><pre lang="python">
if (
not # comment
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
+ bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
):
pass
</pre></td>
<td><pre lang="python">
if ( # comment
not aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
+ bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
):
pass
</pre></td>
<td><pre lang="python">
if (
not aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa # comment
+ bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
):
pass
</pre></td>
</tr>
</tbody>
</table>
hopefully it helps even though the snippets are much wider here.
The two main differences are (1) that we now retain own-line comments
between the unary operator and its operand instead of moving these to
leading comments on the operator itself, and (2) that we move
end-of-line comments between the operator and operand to dangling
end-of-line comments on the operand (the last example in the table).
## Test Plan
Existing tests, plus new ones based on the issue. As I noted below, I
also ran the output from main on the unary.py file back through this
branch to check that we don't reformat code from main. This made me feel
a bit better about not preview-gating the changes in this PR.
```shell
> git show main:crates/ruff_python_formatter/resources/test/fixtures/ruff/expression/unary.py | ruff format - | ./target/debug/ruff format --diff -
> echo $?
0
```
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Takayuki Maeda <takoyaki0316@gmail.com>
## Summary
This PR proposes that we add a new `set_concise_message` functionality
to our `Diagnostic` construction API. When used, the concise message
that is otherwise auto-generated from the main diagnostic message and
the primary annotation will be overwritten with the custom message.
To understand why this is desirable, let's look at the `invalid-key`
diagnostic. This is how I *want* the full diagnostic to look like:
<img width="620" height="282" alt="image"
src="https://github.com/user-attachments/assets/3bf70f52-9d9f-4817-bc16-fb0ebf7c2113"
/>
However, without the change in this PR, the concise message would have
the following form:
```
error[invalid-key]: Unknown key "Age" for TypedDict `Person`: Unknown key "Age" - did you mean "age"?
```
This duplication is why the full `invalid-key` diagnostic used a main
diagnostic message that is only "Invalid key for TypedDict `Person`", to
make that bearable:
```
error[invalid-key] Invalid key for TypedDict `Person`: Unknown key "Age" - did you mean "age"?
```
This is still less than ideal, *and* we had to make the "full"
diagnostic worse. With the new API here, we have to make no such
compromises. We need to do slightly more work (provide one additional
custom-designed message), but we get to keep the "full" diagnostic that
we actually want, and we can make the concise message more terse and
readable:
```
error[invalid-key] Unknown key "Age" for TypedDict `Person` - did you mean "age"?
```
Similar problems exist for other diagnostics as well (I really want this
for https://github.com/astral-sh/ruff/pull/21476). In this PR, I only
changed `invalid-key` and `type-assertion-failure`.
The PR here is somewhat related to the discussion in
https://github.com/astral-sh/ty/issues/1418, but note that we are
solving a problem that is unrelated to sub-diagnostics.
## Test Plan
Updated tests
## Summary
Add support for `Callable` special forms in implicit type aliases.
## Typing conformance
Four new tests are passing
## Ecosystem impact
* All of the `invalid-type-form` errors are from libraries that use
`mypy_extensions` and do something like `Callable[[NamedArg("x", str)],
int]`.
* A handful of new false positives because we do not support generic
specializations of implicit type aliases, yet. But other
* Everything else looks like true positives or known limitations
## Test Plan
New Markdown tests.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#21389
Avoid RUF012 false positives when reassigning a ClassVar
## Test Plan
<!-- How was it tested? -->
Added the new reassignment scenario to
`crates/ruff_linter/resources/test/fixtures/ruff/RUF012.py`.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
Constraint sets can now track subtyping/assignability/etc of generic
callables correctly. For instance:
```py
def identity[T](t: T) -> T:
return t
constraints = ConstraintSet.always()
static_assert(constraints.implies_subtype_of(TypeOf[identity], Callable[[int], int]))
static_assert(constraints.implies_subtype_of(TypeOf[identity], Callable[[str], str]))
```
A generic callable can be considered an intersection of all of its
possible specializations, and an assignability check with an
intersection as the lhs side succeeds of _any_ of the intersected types
satisfies the check. Put another way, if someone expects to receive any
function with a signature of `(int) -> int`, we can give them
`identity`.
Note that the corresponding check using `is_subtype_of` directly does
not yet work, since #20093 has not yet hooked up the core typing
relationship logic to use constraint sets:
```py
# These currently fail
static_assert(is_subtype_of(TypeOf[identity], Callable[[int], int]))
static_assert(is_subtype_of(TypeOf[identity], Callable[[str], str]))
```
To do this, we add a new _existential quantification_ operation on
constraint sets. This takes in a list of typevars and _removes_ those
typevars from the constraint set. Conceptually, we return a new
constraint set that evaluates to `true` when there was _any_ assignment
of the removed typevars that caused the old constraint set to evaluate
to `true`.
When comparing a generic constraint set, we add its typevars to the
`inferable` set, and figure out whatever constraints would allow any
specialization to satisfy the check. We then use the new existential
quantification operator to remove those new typevars, since the caller
doesn't (and shouldn't) know anything about them.
---------
Co-authored-by: David Peter <sharkdp@users.noreply.github.com>
Closes#19350
This fixes a syntax error caused by formatting. However, the new tests reveal that there are some cases where formatting attributes with certain comments behaves strangely, both before and after this PR, so some more polish may be in order.
For example, without parentheses around the value, and both before and after this PR, we have:
```python
# unformatted
variable = (
something # a comment
.first_method("some string")
)
# formatted
variable = something.first_method("some string") # a comment
```
which is probably not where the comment ought to go.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Partially addresses https://github.com/astral-sh/ty/issues/1562
Only suggest the keyword "as" in import statements when the user have
written `import foo a<CURSOR>` or `from foo import bar a<CURSOR>` as no
other suggestion makes sense here.
Re-uses the existing pattern for incomplete `import from` statements to
determine incomplete import alias statements and make the suggestions
more sane in those cases.
There was a potential suggestion from @BurntSushi in
https://github.com/astral-sh/ty/issues/1562#issue-3626853513 to move the
handling of import statements into one unified state machine but I acted
on the side of caution and fixed this with already established patterns,
pending a potential bigger re-write down the line.
## Test Plan
Added new tests and checked that it behaved reasonable in the
playground.
<!-- How was it tested? -->
Running `eglot-format` in buffers not managed by Eglot causes a
`jsonrpc-error` in Emacs 30. It may also display a
`documentFormattingProvider` warning when the server does not support
formatting. Add checks for both.
This PR attempts to improve the placement of own-line comments between
branches in the setting where the comment is more indented than the
preceding node.
There are two main changes.
### First change: Preceding node has leading content
If the preceding node has leading content, we now regard the comment as
automatically _less_ indented than the preceding node, and format
accordingly.
For example,
```python
if True: preceding_node
# leading on `else`, not trailing on `preceding_node`
else: ...
```
This is more compatible with `black`, although there is a (presumably
very uncommon) edge case:
```python
if True:
this;that
# leading on `else`, but trailing in `black`
else: ...
```
I'm sort of okay with this - presumably if one wanted a comment for
those semi-colon separated statements, one should have put it _above_
them, and one wanted a comment only for `that` then it ought to have
been on the same line?
### Second change: searching for last child in body
While searching for the (recursively) last child in the body of the
preceding _branch_, we implicitly assumed that the preceding node had to
have a body to begin the recursion. But actually, in the base case, the
preceding node _is_ the last child in the body of the preceding branch.
So, for example:
```python
if True:
something
last_child_but_no_body
# leading on else for `main` but trailing in this PR
else: ...
```
### More examples
The table below is an attempt to summarize the changes in behavior. The
rows alternate between an example snippet with `while` and the same
example with `if` - in the former case we do _not_ have an `else` node
and in the latter we do.
Notice that:
1. On `main` our handling of `if` vs. `while` is not consistent, whereas
it is consistent in the present PR
2. We disagree with `black` in all cases except that last example on
`main`, but agree in all cases for the present PR (though see above for
a wonky edge case where we disagree).
<table>
<tr>
<th>Original
</th>
<th><code>main</code> </th>
<th>This
PR </th>
<th><code>black</code> </th>
</tr>
<tr>
<td>
<pre lang="python">
while True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
while True:
pass
else:
# comment
pass
</pre>
</td>
<td>
<pre lang="python">
while True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
while True:
pass
# comment
else:
pass
</pre>
</td>
</tr>
<tr>
<td>
<pre lang="python">
if True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
if True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
if True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
if True:
pass
# comment
else:
pass
</pre>
</td>
</tr>
<tr>
<td>
<pre lang="python">
while True: pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
while True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
while True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
while True:
pass
# comment
else:
pass
</pre>
</td>
</tr>
<tr>
<td>
<pre lang="python">
if True: pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
if True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
if True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
if True:
pass
# comment
else:
pass
</pre>
</td>
</tr>
<tr>
<td>
<pre lang="python">
while True: pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
while True:
pass
else:
# comment
pass
</pre>
</td>
<td>
<pre lang="python">
while True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
while True:
pass
# comment
else:
pass
</pre>
</td>
</tr>
<tr>
<td>
<pre lang="python">
if True: pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
if True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
if True:
pass
# comment
else:
pass
</pre>
</td>
<td>
<pre lang="python">
if True:
pass
# comment
else:
pass
</pre>
</td>
</tr>
</table>
## Summary
Follow up from https://github.com/astral-sh/ruff/pull/21411. Again,
there are more things that could be improved here (like the diagnostics
for `lists`, or extending what we have for `dict` to `OrderedDict` etc),
but that will have to be postponed.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [get-size2](https://redirect.github.com/bircni/get-size2) |
workspace.dependencies | patch | `0.7.1` -> `0.7.2` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>bircni/get-size2 (get-size2)</summary>
###
[`v0.7.2`](https://redirect.github.com/bircni/get-size2/blob/HEAD/CHANGELOG.md#072---2025-11-13)
[Compare
Source](https://redirect.github.com/bircni/get-size2/compare/0.7.1...0.7.2)
##### Documentation
- Update docs with correct links -
([b234d70](b234d70ece))
- Nicolas
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS4xNzMuMSIsInVwZGF0ZWRJblZlciI6IjQxLjE3My4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [indicatif](https://redirect.github.com/console-rs/indicatif) |
workspace.dependencies | patch | `0.18.2` -> `0.18.3` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>console-rs/indicatif (indicatif)</summary>
###
[`v0.18.3`](https://redirect.github.com/console-rs/indicatif/releases/tag/0.18.3)
[Compare
Source](https://redirect.github.com/console-rs/indicatif/compare/0.18.2...0.18.3)
#### What's Changed
- Add ProgressBar::set\_elapsed by
[@​sunshowers](https://redirect.github.com/sunshowers) in
[#​742](https://redirect.github.com/console-rs/indicatif/pull/742)
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS4xNzMuMSIsInVwZGF0ZWRJblZlciI6IjQxLjE3My4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [quick-junit](https://redirect.github.com/nextest-rs/quick-junit) |
workspace.dependencies | patch | `0.5.1` -> `0.5.2` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>nextest-rs/quick-junit (quick-junit)</summary>
###
[`v0.5.2`](https://redirect.github.com/nextest-rs/quick-junit/blob/HEAD/CHANGELOG.md#052---2025-11-10)
[Compare
Source](https://redirect.github.com/nextest-rs/quick-junit/compare/quick-junit-0.5.1...quick-junit-0.5.2)
##### Added
- A long-requested feature: deserialization support for reports! The new
deserializer has undergone fuzzing and property-based testing, and it is
known to work with JUnit reports generated by quick-junit. The
deserializer should work with JUnit reports generated by other tools as
well. If it doesn't, fixes are welcome.
- The new `proptest` feature allows for generation of arbitrary
`Report`s.
##### Updated
Internal dependency update: `quick-xml` updated to 0.38.3.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS4xNzMuMSIsInVwZGF0ZWRJblZlciI6IjQxLjE3My4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
We previously only allowed models to overwrite the
`{eq,order,kw_only,frozen}_defaults` of the dataclass-transformer, but
all other standard-dataclass parameters should be equally supported with
the same behavior.
## Test Plan
Added regression tests.
## Summary
Not a high-priority task... but it _is_ a weekend :P
This PR improves our diagnostics for invalid exceptions. Specifically:
- We now give a special-cased ``help: Did you mean
`NotImplementedError`` subdiagnostic for `except NotImplemented`, `raise
NotImplemented` and `raise <EXCEPTION> from NotImplemented`
- If the user catches a tuple of exceptions (`except (foo, bar, baz):`)
and multiple elements in the tuple are invalid, we now collect these
into a single diagnostic rather than emitting a separate diagnostic for
each tuple element
- The explanation of why the `except`/`raise` was invalid ("must be a
`BaseException` instance or `BaseException` subclass", etc.) is
relegated to a subdiagnostic. This makes the top-level diagnostic
summary much more concise.
## Test Plan
Lots of snapshots. And here's some screenshots:
<details>
<summary>Screenshots</summary>
<img width="1770" height="1520" alt="image"
src="https://github.com/user-attachments/assets/7f27fd61-c74d-4ddf-ad97-ea4fd24d06fd"
/>
<img width="1916" height="1392" alt="image"
src="https://github.com/user-attachments/assets/83e5027c-8798-48a6-a0ec-1babfc134000"
/>
<img width="1696" height="588" alt="image"
src="https://github.com/user-attachments/assets/1bc16048-6eb4-4dfa-9ace-dd271074530f"
/>
</details>
Summary
--
I was firing up the fuzzer tonight and hit an assertion error here. We
now build with the `profiling` profile, so we need to use that
executable too.
This hasn't affected CI because we always set the `--test-executable`.
Test Plan
--
Ran the script again with the same arguments on this branch
## Summary
Allow metaclass-based and baseclass-based dataclass-transformers to
overwrite the default behavior using class arguments:
```py
class Person(Model, order=True):
# ...
```
## Conformance tests
Four new tests passing!
## Test Plan
New Markdown tests
This PR updates the constraint implication type relationship to work on
compound types as well. (A compound type is a non-atomic type, like
`list[T]`.)
The goal of constraint implication is to check whether the requirements
of a constraint imply that a particular subtyping relationship holds.
Before, we were only checking atomic typevars. That would let us verify
that the constraint set `T ≤ bool` implies that `T` is always a subtype
of `int`. (In this case, the lhs of the subtyping check, `T`, is an
atomic typevar.)
But we weren't recursing into compound types, to look for nested
occurrences of typevars. That means that we weren't able to see that `T
≤ bool` implies that `Covariant[T]` is always a subtype of
`Covariant[int]`.
Doing this recursion means that we have to carry the constraint set
along with us as we recurse into types as part of `has_relation_to`, by
adding constraint implication as a new `TypeRelation` variant. (Before
it was just a method on `ConstraintSet`.)
---------
Co-authored-by: David Peter <sharkdp@users.noreply.github.com>
## Summary
Currently our diagnostic only covers the range of the thing being
subscripted:
<img width="1702" height="312" alt="image"
src="https://github.com/user-attachments/assets/7e630431-e846-46ca-93c1-139f11aaba11"
/>
But it should probably cover the _whole_ subscript expression (arguably
the more "incorrect" bit is the `["foo"]` part of this expression, not
the `x` part of this expression!)
## Test Plan
Added a snapshot
Co-authored-by: Brent Westbrook
<36778786+ntBre@users.noreply.github.com>
## Summary
Extends literal promotion to apply to any generic method, as opposed to
only generic class constructors. This PR also improves our literal
promotion heuristics to only promote literals in non-covariant position
in the return type, and avoid promotion if the literal is present in
non-covariant position in any argument type.
Resolves https://github.com/astral-sh/ty/issues/1357.
## Summary
- Always restore the previous `deferred_state` after parsing a type
expression: we don't want that state leaking out into other contexts
where we shouldn't be deferring expression inference
- Always defer the right-hand-side of a PEP-613 type alias in a stub
file, allowing for forward references on the right-hand side of `T:
TypeAlias = X | Y` in a stub file
Addresses @carljm's review in
https://github.com/astral-sh/ruff/pull/21401#discussion_r2524260153
## Test Plan
I added a regression test for a regression that the first version of
this PR introduced (we need to make sure the r.h.s. of a PEP-613
`TypeAlias`es is always deferred in a stub file)
## Summary
We currently fail to account for the type context when inferring generic
classes constructed with `__new__`, or synthesized `__init__` for
dataclasses.
There are a few places in Python where it is known that new names are
being introduced and thus we probably shouldn't offer completions. We
already handle this today for things like `class <CURSOR>` and `def
<CURSOR>`. But we didn't handle `as <CURSOR>`, which can appear in
`import`, `with`, `except` and `match` statements. Indeed, these are
exactly the 4 cases where the `as` keyword can occur. So we look for the
presence of `as` and suppress completions based on that.
While we're here, we also make the implementation a bit more robust with
respect to suppressing completions when the user hasn't typed anything.
Namely, previously, we'd still offer completions in a `class <CURSOR>`
context. But it looks like LSP clients (at least, VS Code) doesn't ask
for completions here, so we were "saved" incidentally. This PR detects
this case and suppresses completions there so we don't rely on LSP
client behavior to handle that case correctly.
Fixesastral-sh/ty#1287
## Summary
Infer the first argument `type` inside `Annotated[type, …]` as a type
expression. This allows us to support stringified annotations inside
`Annotated`.
## Ecosystem
* The removed diagnostic on `prefect` shows that we now understand the
`State.data` type annotation in
`src/prefect/client/schemas/objects.py:230`, which uses a stringified
annotation in `Annoated`. The other diagnostics are downstream changes
that result from this, it seems to be a commonly used data type.
* `artigraph` does something like `Annotated[cast(Any,
field_info.annotation), *field_info.metadata]` which I'm not sure we
need to allow? It's unfortunate since this is probably supported at
runtime, but it seems reasonable that they need to add a `# type:
ignore` for that.
* `pydantic` uses something like `Annotated[(self.annotation,
*self.metadata)]` but adds a `# type: ignore`
## Test Plan
New Markdown test
## Summary
Typeshed has a (fake) `__getattr__` method on `types.ModuleType` with a
return type of `Any`. We ignore this method when accessing attributes on
module *literals*, but with this PR, we respect this method when dealing
with `ModuleType` itself. That is, we allow arbitrary attribute accesses
on instances of `types.ModuleType`. This is useful because dynamic
import mechanisms such as `importlib.import_module` use `ModuleType` as
a return type.
closes https://github.com/astral-sh/ty/issues/1346
## Ecosystem
Massive reduction in diagnostics. The few new diagnostics are true
positives.
## Test Plan
Added regression test.
## Summary
Add synthetic members to completions on dataclasses and dataclass
instances.
Also, while we're at it, add support for `__weakref__` and
`__match_args__`.
closes https://github.com/astral-sh/ty/issues/1542
## Test Plan
New Markdown tests
## Summary
Support various legacy `typing` special forms (`List`, `Dict`, …) in
implicit type aliases.
## Ecosystem impact
A lot of true positives (e.g. on `alerta`)!
## Test Plan
New Markdown tests
## Summary
Support `type[…]` in implicit type aliases, for example:
```py
SubclassOfInt = type[int]
reveal_type(SubclassOfInt) # GenericAlias
def _(subclass_of_int: SubclassOfInt):
reveal_type(subclass_of_int) # type[int]
```
part of https://github.com/astral-sh/ty/issues/221
## Typing conformance
```diff
-specialtypes_type.py:138:5: error[type-assertion-failure] Argument does not have asserted type `type[Any]`
-specialtypes_type.py:140:5: error[type-assertion-failure] Argument does not have asserted type `type[Any]`
```
Two new tests passing ✔️
```diff
-specialtypes_type.py:146:1: error[unresolved-attribute] Object of type `GenericAlias` has no attribute `unknown`
```
An `TA4.unknown` attribute on a PEP 613 alias (`TA4: TypeAlias =
type[Any]`) is being accessed, and the conformance suite expects this to
be an error. Since we currently use the inferred type for these type
aliases (and possibly in the future as well), we treat this as a direct
access of the attribute on `type[Any]`, which falls back to an access on
`Any` itself, which succeeds. 🔴
```
+specialtypes_type.py:152:16: error[invalid-type-form] `typing.TypeVar` is not a generic class
+specialtypes_type.py:156:16: error[invalid-type-form] `typing.TypeVar` is not a generic class
```
New errors because we don't handle `T = TypeVar("T"); MyType = type[T];
MyType[T]` yet. Support for this is being tracked in
https://github.com/astral-sh/ty/issues/221🔴
## Ecosystem impact
Looks mostly good, a few known problems.
## Test Plan
New Markdown tests
## Summary
Allow users of `mdtest.py` to press enter to rerun all mdtests without
recompiling (thanks @AlexWaygood).
I swear I tried three other approaches (including a fully async version)
before I settled on this solution. It is indeed silly, but works just
fine.
## Test Plan
Interactive playing around
## Summary
Further improve subscript assignment diagnostics, especially for
`dict`s:
```py
config: dict[str, int] = {}
config["retries"] = "three"
```
<img width="1276" height="274" alt="image"
src="https://github.com/user-attachments/assets/9762c733-8d1c-4a57-8c8a-99825071dc7d"
/>
I have many more ideas, but this looks like a reasonable first step.
Thank you @AlexWaygood for some of the suggestions here.
## Test Plan
Update tests
## Summary
This change to the mdtest runner makes it easy to run on a subset of
tests/files. For example:
```
▶ uv run crates/ty_python_semantic/mdtest.py implicit
running 1 test
test mdtest__implicit_type_aliases ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 281 filtered out; finished in 0.83s
Ready to watch for changes...
```
Subsequent changes to either that test file or the Rust source code will
also only rerun the `implicit_type_aliases` test.
Multiple arguments can be provided, and filters can either be partial
file paths (`loops/for.md`, `loops/for`, `for`) or mangled test names
(`loops_for`):
```
▶ uv run crates/ty_python_semantic/mdtest.py implicit binary/union
running 2 tests
test mdtest__binary_unions ... ok
test mdtest__implicit_type_aliases ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 280 filtered out; finished in 0.85s
Ready to watch for changes...
```
## Test Plan
Tested it interactively for a while
## Summary
This PR renames the `CallableBinding::matching_overload_index` field to
`CallableBinding::matching_overload_after_parameter_matching` to clarify
the main use case of this field which is to surface type checking errors
on the matching overloads directly instead of using the
`no-matching-overload` diagnostic. This can only happen after parameter
matching as following steps could filter out this overload which should
then result in `no-matching-overload` diagnostic.
Callers should use the `matching_overload_index` _method_ to get the
matching overloads.
## Summary
We synthesize a (potentially large) set of `__setitem__` overloads for
every item in a `TypedDict`. Previously, validation of subscript
assignments on `TypedDict`s relied on actually calling `__setitem__`
with the provided key and value types, which implied that we needed to
do the full overload call evaluation for this large set of overloads.
This PR improves the performance of subscript assignment checks on
`TypedDict`s by validating the assignment directly instead of calling
`__setitem__`.
This PR also adds better handling for assignments to subscripts on union
and intersection types (but does not attempt to make it perfect). It
achieves this by distributing the check over unions and intersections,
instead of calling `__setitem__` on the union/intersection directly. We
already do something similar when validating *attribute* assignments.
## Ecosystem impact
* A lot of diagnostics change their rule type, and/or split into
multiple diagnostics. The new version is more verbose, but easier to
understand, in my opinion
* Almost all of the invalid-key diagnostics come from pydantic, and they
should all go away (including many more) when we implement
https://github.com/astral-sh/ty/issues/1479
* Everything else looks correct to me. There may be some new diagnostics
due to the fact that we now check intersections.
## Test Plan
New Markdown tests.
## Summary
cf. https://github.com/astral-sh/ruff/pull/20962
In the following code, `foo` in the comprehension was not reported as
unresolved:
```python
# error: [unresolved-reference] "Name `foo` used when not defined"
foo
foo = [
# no error!
# revealed: Divergent
reveal_type(x) for _ in () for x in [foo]
]
baz = [
# error: [unresolved-reference] "Name `baz` used when not defined"
# revealed: Unknown
reveal_type(x) for _ in () for x in [baz]
]
```
In fact, this is a more serious bug than it looks: for `foo`,
[`explicit_global_symbol` is
called](6cc3393ccd/crates/ty_python_semantic/src/types/infer/builder.rs (L8052)),
causing a symbol that should actually be `Undefined` to be reported as
being of type `Divergent`.
This PR fixes this bug. As a result, the code in
`mdtest/regression/pr_20962_comprehension_panics.md` no longer panics.
## Test Plan
`corpus\cyclic_symbol_in_comprehension.py` is added.
New tests are added in `mdtest/comprehensions/basic.md`.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Added the PyScripter IDE to the list of "Who is using Ruff?".
PyScripter is a popular python IDE that is using ruff for code
diagnostics, fixes and code formatting.
## Summary
Fixes#21393
Now the rule checks if the index variable is initialized as an `int`
type rather than only flagging if the index variable is initialized to
`0`. I used `ResolvedPythonType` to check if the index variable is an
`int` type.
## Test Plan
Updated snapshot test for `SIM113`.
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
Add (snapshot) tests for subscript assignment diagnostics. This is
mainly intended to establish a baseline before I hope to improve some of
these messages.
## Summary
Add support for `typing.Union` in implicit type aliases / in value
position.
## Typing conformance tests
Two new tests are passing
## Ecosystem impact
* The 2k new `invalid-key` diagnostics on pydantic are caused by
https://github.com/astral-sh/ty/issues/1479#issuecomment-3513854645.
* Everything else I've checked is either a known limitation (often
related to type narrowing, because union types are often narrowed down
to a subset of options), or a true positive.
## Test Plan
New Markdown tests
I don't know why, but it always takes me an eternity to find the failing
project name a few lines below in the output. So I'm suggesting we just
add the project name to the assertion message.
## Summary
Fix https://github.com/astral-sh/ty/issues/664
This PR adds support for storing attributes in comprehension scopes (any
eager scope.)
For example in the following code we infer type of `z` correctly:
```py
class C:
def __init__(self):
[None for self.z in range(1)]
reveal_type(C().z) # previously [unresolved-attribute] but now shows Unknown | int
```
The fix works by adjusting the following logics:
To identify if an attriute is an assignment to self or cls we need to
check the scope is a method. To allow comprehension scopes here we skip
any eager scope in the check.
Also at this stage the code checks if self or the first method argument
is shadowed by another binding that eager scope to prevent this:
```py
class D:
g: int
class C:
def __init__(self):
[[None for self.g in range(1)] for self in [D()]]
reveal_type(C().g) # [unresolved-attribute]
```
When determining scopes that attributes might be defined after
collecting all the methods of the class the code also returns any
decendant scope that is eager and only has eager parents until the
method scope.
When checking reachability of a attribute definition if the attribute is
defined in an eager scope we use the reachability of the first non eager
scope which must be a method. This allows attributes to be marked as
reachable and be seen.
There are also which I didn't add support for:
```py
class C:
def __init__(self):
def f():
[None for self.z in range(1)]
f()
reveal_type(C().z) # [unresolved-attribute]
```
In the above example we will not even return the comprehension scope as
an attribute scope because there is a non eager scope (`f` function)
between the comprehension and the `__init__` method
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
It looks like VS Code does this forcefully. As in, I don't think we can
override it. It also seems like a plausibly good idea. But by us doing
it too, it makes our completion evaluation framework match real world
conditions. (To the extent that "VS Code" and "real world conditions"
are the same. Which... they aren't. But it's close, since VS Code is so
popular.)
This should round out the rest of the set. I think I had hesitated doing
this before because some of these don't make sense in every context. But
I think identifying the correct context for every keyword could be quite
difficult. And at the very least, I think offering these at least as a
choice---even if they aren't always correct---is better than not doing
it at all.
## Summary
Fixes https://github.com/astral-sh/ty/issues/1409
This PR allows `Final` instance attributes to be initialized in
`__init__` methods, as mandated by the Python typing specification (PEP
591). Previously, ty incorrectly prevented this initialization, causing
false positive errors.
The fix checks if we're inside an `__init__` method before rejecting
Final attribute assignments, allowing assignments during
instance initialization while still preventing reassignment elsewhere.
## Test Plan
- Added new test coverage in `final.md` for the reported issue with
`Self` annotations
- Updated existing tests that were incorrectly expecting errors
- All 278 mdtest tests pass
- Manually tested with real-world code examples
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Fixes https://github.com/astral-sh/ty/issues/1487
This one is a true extension of non-standard semantics, and is therefore
a certified Hot Take we might conclude is simply a Bad Take (let's see
what ecosystem tests say...).
By resolving `.` and the LHS of the from import during semantic
indexing, we can check if the LHS is a submodule of `.`, and handle
`from whatever.thispackage.x.y import z` exactly like we do `from .x.y
import z`.
Fixes https://github.com/astral-sh/ty/issues/1484
This manifested as an error when inferring the type of a PEP-695 generic
class via its constructor parameters:
```py
class D[T, U]:
@overload
def __init__(self: "D[str, U]", u: U) -> None: ...
@overload
def __init__(self, t: T, u: U) -> None: ...
def __init__(self, *args) -> None: ...
# revealed: D[Unknown, str]
# SHOULD BE: D[str, str]
reveal_type(D("string"))
```
This manifested because `D` is inferred to be bivariant in both `T` and
`U`. We weren't seeing this in the equivalent example for legacy
typevars, since those default to invariant. (This issue also showed up
for _covariant_ typevars, so this issue was not limited to bivariance.)
The underlying cause was because of a heuristic that we have in our
current constraint solver, which attempts to handle situations like
this:
```py
def f[T](t: T | None): ...
f(None)
```
Here, the `None` argument matches the non-typevar union element, so this
argument should not add any constraints on what `T` can specialize to.
Our previous heuristic would check for this by seeing if the argument
type is a subtype of the parameter annotation as a whole — even if it
isn't a union! That would cause us to erroneously ignore the `self`
parameter in our constructor call, since bivariant classes are
equivalent to each other, regardless of their specializations.
The quick fix is to move this heuristic "down a level", so that we only
apply it when the parameter annotation is a union. This heuristic should
go away completely 🤞 with the new constraint solver.
This loses any ability to have "per-function" implicit submodule
imports, to avoid the "ok but now we need per-scope imports" and "ok but
this should actually introduce a global that only exists during this
function" problems. A simple and clean implementation with no weird
corners.
Fixes https://github.com/astral-sh/ty/issues/1482
This rips out the previous implementation in favour of a new
implementation with 3 rules:
- **froms are locals**: a `from..import` can only define locals, it does
not have global
side-effects. Specifically any submodule attribute `a` that's implicitly
introduced by either
`from .a import b` or `from . import a as b` (in an `__init__.py(i)`) is
a local and not a
global. If you do such an import at the top of a file you won't notice
this. However if you do
such an import in a function, that means it will only be function-scoped
(so you'll need to do
it in every function that wants to access it, making your code less
sensitive to execution
order).
- **first from first serve**: only the *first* `from..import` in an
`__init__.py(i)` that imports a
particular direct submodule of the current package introduces that
submodule as a local.
Subsequent imports of the submodule will not introduce that local. This
reflects the fact that
in actual python only the first import of a submodule (in the entire
execution of the program)
introduces it as an attribute of the package. By "first" we mean "the
first time in this scope
(or any parent scope)". This pairs well with the fact that we are
specifically introducing a
local (as long as you don't accidentally shadow or overwrite the local).
- **dot re-exports**: `from . import a` in an `__init__.pyi` is
considered a re-export of `a`
(equivalent to `from . import a as a`). This is required to properly
handle many stubs in the
wild. Currently it must be *exactly* `from . import ...`.
This implementation is intentionally limited/conservative (notably,
often requiring a from import to be relative). I'm going to file a ton
of followups for improvements so that their impact can be evaluated
separately.
Fixes https://github.com/astral-sh/ty/issues/133
## Summary
Fixed RUF065 (`logging-eager-conversion`) to only flag `str()` calls
when they perform a simple conversion that can be safely removed. The
rule now ignores `str()` calls with no arguments, multiple arguments,
starred arguments, or keyword unpacking, preventing false positives.
Fixes#21315
## Problem Analysis
The RUF065 rule was incorrectly flagging all `str()` calls in logging
statements, even when `str()` was performing actual conversion work
beyond simple type coercion. Specifically, the rule flagged:
- `str()` with no arguments - which returns an empty string
- `str(b"data", "utf-8")` with multiple arguments - which performs
encoding conversion
- `str(*args)` with starred arguments - which unpacks arguments
- `str(**kwargs)` with keyword unpacking - which passes keyword
arguments
These cases cannot be safely removed because `str()` is doing meaningful
work (encoding conversion, argument unpacking, etc.), not just redundant
type conversion.
The root cause was that the rule only checked if the function was
`str()` without validating the call signature. It didn't distinguish
between simple `str(value)` conversions (which can be removed) and more
complex `str()` calls that perform actual work.
## Approach
The fix adds validation to the `str()` detection logic in
`logging_eager_conversion.rs`:
1. **Check argument count**: Only flag `str()` calls with exactly one
positional argument (`str_call_args.args.len() == 1`)
2. **Check for starred arguments**: Ensure the single argument is not
starred (`!str_call_args.args[0].is_starred_expr()`)
3. **Check for keyword arguments**: Ensure there are no keyword
arguments (`str_call_args.keywords.is_empty()`)
This ensures the rule only flags cases like `str(value)` where `str()`
is truly redundant and can be removed, while ignoring cases where
`str()` performs actual conversion work.
The fix maintains backward compatibility - all existing valid test cases
continue to be flagged correctly, while the new edge cases are properly
ignored.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
It's everyone's favourite language corner case!
Also having kicked the tires on it, I'm pretty happy to call this (in
conjunction with #21367):
Fixes https://github.com/astral-sh/ty/issues/494
There's cases where you can make noisy Literal hints appear, so we can
always iterate on it, but this handles like, 98% of the cases in the
wild, which is great.
---------
Co-authored-by: David Peter <sharkdp@users.noreply.github.com>
I'm not 100% sold on this implementation, but it's a strict improvement
and it adds a ton of snapshot tests for future iteration.
Part of https://github.com/astral-sh/ty/issues/494
## Summary
Fixes FURB105 (`print-empty-string`) to detect empty f-strings in
addition to regular empty strings. Previously, the rule only flagged
`print("")` but missed `print(f"")`. This fix ensures both cases are
detected and can be automatically fixed.
Fixes#21346
## Problem Analysis
The FURB105 rule checks for unnecessary empty strings passed to
`print()` calls. The `is_empty_string` helper function was only checking
for `Expr::StringLiteral` with empty values, but did not handle
`Expr::FString` (f-strings). As a result, `print(f"")` was not being
flagged as a violation, even though it's semantically equivalent to
`print("")` and should be simplified to `print()`.
The issue occurred because the function used a `matches!` macro that
only checked for string literals:
```rust
fn is_empty_string(expr: &Expr) -> bool {
matches!(
expr,
Expr::StringLiteral(ast::ExprStringLiteral { value, .. }) if value.is_empty()
)
}
```
## Approach
1. **Import the helper function**: Added `is_empty_f_string` to the
imports from `ruff_python_ast::helpers`, which already provides logic to
detect empty f-strings.
2. **Update `is_empty_string` function**: Changed the implementation
from a `matches!` macro to a `match` expression that handles both string
literals and f-strings:
```rust
fn is_empty_string(expr: &Expr) -> bool {
match expr {
Expr::StringLiteral(ast::ExprStringLiteral { value, .. }) =>
value.is_empty(),
Expr::FString(f_string) => is_empty_f_string(f_string),
_ => false,
}
}
```
The fix leverages the existing `is_empty_f_string` helper function which
properly handles the complexity of f-strings, including nested f-strings
and interpolated expressions. This ensures the detection is accurate and
consistent with how empty strings are detected elsewhere in the
codebase.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Resolves https://github.com/astral-sh/ty/issues/1494
## Test Plan
Add a test showing if we are in `from <name> <name> ` we provide the
keyword completion "import"
This elides the following inlay hints:
```py
foo([x=]x)
foo([x=]y.x)
foo([x=]x[0])
foo([x=]x(...))
# composes to complex situations
foo([x=]y.x(..)[0])
```
Fixes https://github.com/astral-sh/ty/issues/1514
Summary
--
Fixes#21360 by using the union of names instead of overwriting them, as
Micha suggested originally on #21104.
This avoids overwriting the `n` name in the `Subscript` by the empty set
of names visited in the nested OR pattern before visiting the other arm
of the outer OR pattern.
Test Plan
--
A new inline test case taken from the issue
Summary
--
This PR adds a new section to CONTRIBUTING.md describing the expected
contents of the PR summary and test plan, using the ecosystem report,
and communicating the status of a PR.
This seemed like a pretty good place to insert this in the document, at
the end of the advice on preparing actual code changes, but I'm
certainly open to other suggestions about both the content and
placement.
Test Plan
--
Future PRs :)
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Detect usages of implicit `self` in property getters, which allows us to
treat their signature as being generic.
closes https://github.com/astral-sh/ty/issues/1502
## Typing conformance
Two new type assertions that are succeeding.
## Ecosystem results
Mostly look good. There are a few new false positives related to a bug
with constrained typevars that is unrelated to the work here. I reported
this as https://github.com/astral-sh/ty/issues/1503.
## Test Plan
Added regression tests.
## Summary
Add support for `Optional` and `Annotated` in implicit type aliases
part of https://github.com/astral-sh/ty/issues/221
## Typing conformance changes
New expected diagnostics.
## Ecosystem
A lot of true positives, some known limitations unrelated to this PR.
## Test Plan
New Markdown tests
## Summary
This PR adds extra validation for `isinstance()` and `issubclass()`
calls that use `UnionType` instances for their second argument.
According to typeshed's annotations, any `UnionType` is accepted for the
second argument, but this isn't true at runtime: at runtime, all
elements in the `UnionType` must either be class objects or be `None` in
order for the `isinstance()` or `issubclass()` call to reliably succeed:
```pycon
% uvx python3.14
Python 3.14.0 (main, Oct 10 2025, 12:54:13) [Clang 20.1.4 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from typing import LiteralString
>>> import types
>>> type(LiteralString | int) is types.UnionType
True
>>> isinstance(42, LiteralString | int)
Traceback (most recent call last):
File "<python-input-5>", line 1, in <module>
isinstance(42, LiteralString | int)
~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/alexw/Library/Application Support/uv/python/cpython-3.14.0-macos-aarch64-none/lib/python3.14/typing.py", line 559, in __instancecheck__
raise TypeError(f"{self} cannot be used with isinstance()")
TypeError: typing.LiteralString cannot be used with isinstance()
```
## Test Plan
Added mdtests/snapshots
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[cargo-bins/cargo-binstall](https://redirect.github.com/cargo-bins/cargo-binstall)
| action | patch | `v1.15.10` -> `v1.15.11` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>cargo-bins/cargo-binstall (cargo-bins/cargo-binstall)</summary>
###
[`v1.15.11`](https://redirect.github.com/cargo-bins/cargo-binstall/releases/tag/v1.15.11)
[Compare
Source](https://redirect.github.com/cargo-bins/cargo-binstall/compare/v1.15.10...v1.15.11)
*Binstall is a tool to fetch and install Rust-based executables as
binaries. It aims to be a drop-in replacement for `cargo install` in
most cases. Install it today with `cargo install cargo-binstall`, from
the binaries below, or if you already have it, upgrade with `cargo
binstall cargo-binstall`.*
##### In this release:
- Fix binstalk-downloader cannot decode some zip files on macos (x64 and
arm64) platforms
([#​2049](https://redirect.github.com/cargo-bins/cargo-binstall/issues/2049)
[#​2362](https://redirect.github.com/cargo-bins/cargo-binstall/issues/2362))
- Fix grammer in `HELP.md` and `--help` output
([#​2357](https://redirect.github.com/cargo-bins/cargo-binstall/issues/2357)
[#​2359](https://redirect.github.com/cargo-bins/cargo-binstall/issues/2359))
- Update documentation link in Cargo.toml
([#​2355](https://redirect.github.com/cargo-bins/cargo-binstall/issues/2355))
##### Other changes:
- Upgrade dependencies
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS4xNTkuNCIsInVwZGF0ZWRJblZlciI6IjQxLjE1OS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [jiff](https://redirect.github.com/BurntSushi/jiff) |
workspace.dependencies | patch | `0.2.15` -> `0.2.16` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>BurntSushi/jiff (jiff)</summary>
###
[`v0.2.16`](https://redirect.github.com/BurntSushi/jiff/blob/HEAD/CHANGELOG.md#0216-2025-11-07)
[Compare
Source](https://redirect.github.com/BurntSushi/jiff/compare/0.2.15...0.2.16)
\===================
This release contains a number of enhancements and bug fixes that have
accrued
over the last few months. Most are small polishes. A couple of the bug
fixes
apply to panics that could occur when parsing invalid `TZ` strings or
invalid
`strptime` format strings.
Also, parsing into a `Span` should now be much faster (for both the ISO
8601
and "friendly" duration formats).
Enhancements:
- [#​298](https://redirect.github.com/BurntSushi/jiff/issues/298):
Add Serde helpers for (de)serializing `std::time::Duration` values.
- [#​396](https://redirect.github.com/BurntSushi/jiff/issues/396):
Add `Sub` and `Add` trait implementations for `Zoned` (in addition to
the
already existing trait implementations for `&Zoned`).
- [#​397](https://redirect.github.com/BurntSushi/jiff/pull/397):
Add `BrokenDownTime::set_meridiem` and ensure it overrides the hour when
formatting.
- [#​409](https://redirect.github.com/BurntSushi/jiff/pull/409):
Switch dependency on `serde` to `serde_core`. This should help speed up
compilation times in some cases.
- [#​430](https://redirect.github.com/BurntSushi/jiff/pull/430):
Add new `Zoned::series` API, making it consistent with the same API on
other
datetime types.
- [#​432](https://redirect.github.com/BurntSushi/jiff/pull/432):
When `lenient` mode is enabled for `strftime`, Jiff will no longer error
when
the formatting string contains invalid UTF-8.
- [#​432](https://redirect.github.com/BurntSushi/jiff/pull/432):
Formatting of `%y` and `%g` no longer fails based on the specific year
value.
- [#​432](https://redirect.github.com/BurntSushi/jiff/pull/432):
Parsing of `%s` is now a bit more consistent with other fields.
Moreover,
`BrokenDownTime::{to_timestamp,to_zoned}` will now prefer timestamps
parsed
with `%s` over any other fields that have been parsed.
- [#​433](https://redirect.github.com/BurntSushi/jiff/pull/433):
Allow parsing just a `%s` into a `Zoned` via the `Etc/Unknown` time
zone.
Bug fixes:
- [#​386](https://redirect.github.com/BurntSushi/jiff/issues/386):
Fix a bug where `2087-12-31T23:00:00Z` in the `Africa/Casablanca` time
zone
could not be round-tripped (because its offset was calculated
incorrectly as
a result of not handling "permanent DST" POSIX time zones).
- [#​407](https://redirect.github.com/BurntSushi/jiff/issues/407):
Fix a panic that occurred when parsing an empty string as a POSIX time
zone.
- [#​410](https://redirect.github.com/BurntSushi/jiff/issues/410):
Fix a panic that could occur when parsing `%:` via `strptime` APIs.
- [#​414](https://redirect.github.com/BurntSushi/jiff/pull/414):
Update some parts of the documentation to indicate that
`TimeZone::unknown()`
is a fallback for `TimeZone::system()` (instead of the `jiff 0.1`
behavior of
using `TimeZone::UTC`).
- [#​423](https://redirect.github.com/BurntSushi/jiff/issues/423):
Fix a panicking bug when reading malformed TZif data.
- [#​426](https://redirect.github.com/BurntSushi/jiff/issues/426):
Fix a panicking bug when parsing century (`%C`) via `strptime`.
- [#​445](https://redirect.github.com/BurntSushi/jiff/pull/445):
Fixed bugs with parsing durations like `-9223372036854775808s`
and `-PT9223372036854775808S`.
Performance:
- [#​445](https://redirect.github.com/BurntSushi/jiff/pull/445):
Parsing into `Span` or `SignedDuration` is now a fair bit faster in some
cases.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS4xNTkuNCIsInVwZGF0ZWRJblZlciI6IjQxLjE1OS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
Fixed FURB101 (`read-whole-file`) to handle annotated assignments.
Previously, the rule would detect violations in code like `contents: str
= f.read()` but fail to generate a fix. Now it correctly generates fixes
that preserve type annotations (e.g., `contents: str =
Path("file.txt").read_text(encoding="utf-8")`).
Fixes#21274
## Problem Analysis
The FURB101 rule was only checking for `Stmt::Assign` statements when
determining whether a fix could be applied. When encountering annotated
assignments (`Stmt::AnnAssign`) like `contents: str = f.read()`, the
rule would:
1. Correctly detect the violation (the diagnostic was reported)
2. Fail to generate a fix because:
- The `visit_expr` method only matched `Stmt::Assign`, not
`Stmt::AnnAssign`
- The `generate_fix` function only accepted `Stmt::Assign` in its body
validation
- The replacement code generation didn't account for type annotations
This occurred because Python's AST represents annotated assignments as a
different node type (`StmtAnnAssign`) with separate fields for the
target, annotation, and value, unlike regular assignments which use a
list of targets.
## Approach
The fix extends the rule to handle both assignment types:
1. **Updated `visit_expr` method**: Now matches both `Stmt::Assign` and
`Stmt::AnnAssign`, extracting:
- Variable name from the target expression
- Type annotation code (when present) using the code generator
2. **Updated `generate_fix` function**:
- Added `annotation: Option<String>` parameter to accept annotation code
- Updated body validation to accept both `Stmt::Assign` and
`Stmt::AnnAssign`
- Modified replacement code generation to preserve annotations: `{var}:
{annotation} = {binding}({filename_code}).{suggestion}`
3. **Added test case**: Added an annotated assignment test case to
verify the fix works correctly.
The implementation maintains backward compatibility with regular
assignments while adding support for annotated assignments, ensuring
type annotations are preserved in the generated fixes.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
We have lots of `TypeVisitor`s that end up having very similar
`visit_type` implementations. This PR consolidates some of the code for
these so that there's less repetition and duplication.
When checking whether a constraint set is satisfied, if a typevar has a
non-fully-static upper bound or constraint, we are free to choose any
materialization that makes the check succeed.
In non-inferable positions, we have to show that the constraint set is
satisfied for all valid specializations, so it's best to choose the most
restrictive materialization, since that minimizes the set of valid
specializations that have to pass.
In inferable positions, we only have to show that the constraint set is
satisfied for _some_ valid specializations, so it's best to choose the
most permissive materialization, since that maximizes our chances of
finding a specialization that passes.
Summary
--
These rules are themselves in preview, so we don't need the additional
preview checks on the fixes or the separate preview tests. This has
confused me in a couple of reviews of changes to the fixes.
Test Plan
--
Existing tests, with the fixes previously only shown in the preview
tests now in the "non-preview" tests.
## Summary
Add support for `Literal` types in implicit type aliases.
part of https://github.com/astral-sh/ty/issues/221
## Ecosystem analysis
This looks good to me, true positives and known problems.
## Test Plan
New Markdown tests.
## Summary
This PR adds support for understanding the legacy definition and PEP 695
definition for `ParamSpec`.
This is still very initial and doesn't really implement any of the
semantics.
Part of https://github.com/astral-sh/ty/issues/157
## Test Plan
Add mdtest cases.
## Ecosystem analysis
Most of the diagnostics in `starlette` are due to the fact that ty now
understands `ParamSpec` is not a `Todo` type, so the assignability check
fails. The code looks something like:
```py
class _MiddlewareFactory(Protocol[P]):
def __call__(self, app: ASGIApp, /, *args: P.args, **kwargs: P.kwargs) -> ASGIApp: ... # pragma: no cover
class Middleware:
def __init__(
self,
cls: _MiddlewareFactory[P],
*args: P.args,
**kwargs: P.kwargs,
) -> None:
self.cls = cls
self.args = args
self.kwargs = kwargs
# ty complains that `ServerErrorMiddleware` is not assignable to `_MiddlewareFactory[P]`
Middleware(ServerErrorMiddleware, handler=error_handler, debug=debug)
```
There are multiple diagnostics where there's an attribute access on the
`Wrapped` object of `functools` which Pyright also raises:
```py
from functools import wraps
def my_decorator(f):
@wraps(f)
def wrapper(*args, **kwds):
return f(*args, **kwds)
# Pyright: Cannot access attribute "__signature__" for class "_Wrapped[..., Unknown, ..., Unknown]"
Attribute "__signature__" is unknown [reportAttributeAccessIssue]
# ty: Object of type `_Wrapped[Unknown, Unknown, Unknown, Unknown]` has no attribute `__signature__` [unresolved-attribute]
wrapper.__signature__
return wrapper
```
There are additional diagnostics that is due to the assignability checks
failing because ty now infers the `ParamSpec` instead of using the
`Todo` type which would always succeed. This results in a few
`no-matching-overload` diagnostics because the assignability checks
fail.
There are a few diagnostics related to
https://github.com/astral-sh/ty/issues/491 where there's a variable
which is either a bound method or a variable that's annotated with
`Callable` that doesn't contain the instance as the first parameter.
Another set of (valid) diagnostics are where the code hasn't provided
all the type variables. ty is now raising diagnostics for these because
we include `ParamSpec` type variable in the signature. For example,
`staticmethod[Any]` which contains two type variables.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Closes https://github.com/astral-sh/ty/issues/989
There are various situations where users expect the Python packages
installed in the same environment as ty itself to be considered during
type checking. A minimal example would look like:
```
uv venv my-env
uv pip install my-env ty httpx
echo "import httpx" > foo.py
./my-env/bin/ty check foo.py
```
or
```
uv tool install ty --with httpx
echo "import httpx" > foo.py
ty check foo.py
```
While these are a bit contrived, there are real-world situations where a
user would expect a similar behavior to work. Notably, all of the other
type checkers consider their own environment when determining search
paths (though I'll admit that I have not verified when they choose not
to do this).
One common situation where users are encountering this today is with
`uvx --with-requirements script.py ty check script.py` — which is
currently our "best" recommendation for type checking a PEP 723 script,
but it doesn't work.
Of the options discussed in
https://github.com/astral-sh/ty/issues/989#issuecomment-3307417985, I've
chosen (2) as our criteria for including ty's environment in the search
paths.
- If no virtual environment is discovered, we will always include ty's
environment.
- If a `.venv` is discovered in the working directory, we will _prepend_
ty's environment to the search paths. The dependencies in ty's
environment (e.g., from `uvx --with`) will take precedence.
- If a virtual environment is active, e.g., `VIRTUAL_ENV` (i.e.,
including conda prefixes) is set, we will not include ty's environment.
The reason we need to special case the `.venv` case is that we both
1. Recommend `uvx ty` today as a way to check your project
2. Want to enable `uvx --with <...> ty`
And I don't want (2) to break when you _happen_ to be in a project
(i.e., if we only included ty's environment when _no_ environment is
found) and don't want to remove support for (1).
I think long-term, I want to make `uvx <cmd>` layer the environment on
_top_ of the project environment (in uv), which would obviate the need
for this change when you're using uv. However, that change is breaking
and I think users will expect this behavior in contexts where they're
not using uv, so I think we should handle it in ty regardless.
I've opted not to include the environment if it's non-virtual (i.e., a
system environment) for now. It seems better to start by being more
restrictive. I left a comment in the code.
## Test Plan
I did some manual testing with the initial commit, then subsequently
added some unit tests.
```
❯ echo "import httpx" > example.py
❯ uvx --with httpx ty check example.py
Installed 8 packages in 19ms
error[unresolved-import]: Cannot resolve imported module `httpx`
--> foo/example.py:1:8
|
1 | import httpx
| ^^^^^
|
info: Searched in the following paths during module resolution:
info: 1. /Users/zb/workspace/ty/python (first-party code)
info: 2. /Users/zb/workspace/ty (first-party code)
info: 3. vendored://stdlib (stdlib typeshed stubs vendored by ty)
info: make sure your Python environment is properly configured: https://docs.astral.sh/ty/modules/#python-environment
info: rule `unresolved-import` is enabled by default
Found 1 diagnostic
❯ uvx --from . --with httpx ty check example.py
All checks passed!
```
```
❯ uv init --script foo.py
Initialized script at `foo.py`
❯ uv add --script foo.py httpx
warning: The Python request from `.python-version` resolved to Python 3.13.8, which is incompatible with the script's Python requirement: `>=3.14`
Updated `foo.py`
❯ echo "import httpx" >> foo.py
❯ uvx --with-requirements foo.py ty check foo.py
error[unresolved-import]: Cannot resolve imported module `httpx`
--> foo.py:15:8
|
13 | if __name__ == "__main__":
14 | main()
15 | import httpx
| ^^^^^
|
info: Searched in the following paths during module resolution:
info: 1. /Users/zb/workspace/ty/python (first-party code)
info: 2. /Users/zb/workspace/ty (first-party code)
info: 3. vendored://stdlib (stdlib typeshed stubs vendored by ty)
info: make sure your Python environment is properly configured: https://docs.astral.sh/ty/modules/#python-environment
info: rule `unresolved-import` is enabled by default
Found 1 diagnostic
❯ uvx --from . --with-requirements foo.py ty check foo.py
All checks passed!
```
Notice we do not include ty's environment if `VIRTUAL_ENV` is set
```
❯ VIRTUAL_ENV=.venv uvx --with httpx ty check foo/example.py
error[unresolved-import]: Cannot resolve imported module `httpx`
--> foo/example.py:1:8
|
1 | import httpx
| ^^^^^
|
info: Searched in the following paths during module resolution:
info: 1. /Users/zb/workspace/ty/python (first-party code)
info: 2. /Users/zb/workspace/ty (first-party code)
info: 3. vendored://stdlib (stdlib typeshed stubs vendored by ty)
info: 4. /Users/zb/workspace/ty/.venv/lib/python3.13/site-packages (site-packages)
info: make sure your Python environment is properly configured: https://docs.astral.sh/ty/modules/#python-environment
info: rule `unresolved-import` is enabled by default
Found 1 diagnostic
```
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Since 4c4ddc8c29, ruff uses the `WalkBuilder::current_dir` API
[introduced in `ignore` version
0.4.24](https://diff.rs/ignore/0.4.23/0.4.24/src%2Fwalk.rs), so it
should explicitly depend on this minimum version.
See also https://github.com/astral-sh/ruff/pull/20979.
## Test Plan
<!-- How was it tested? -->
Source inspection verifies this version is necessary; no additional
testing is required since `Cargo.lock` already has (at least) this
version.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Raised by @AlexWaygood.
We previously did not favour imported symbols, when we probably
should've
## Test Plan
Add test showing that we favour imported symbol even if it is
alphabetically after other symbols that are builtin.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR ports PLE0117 as a semantic syntax error.
## Test Plan
<!-- How was it tested? -->
Tests previously written
---------
Signed-off-by: 11happy <soni5happy@gmail.com>
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
This PR carries over some of the `has_relation_to` logic for comparing a
typevar with itself. A typevar will specialize to the same type if it's
mentioned multiple times, so it is always assignable to and a subtype of
itself. (Note that typevars can only specialize to fully static types.)
This is also true when the typevar appears in a union on the right-hand
side, or in an intersection on the left-hand side. Similarly, a typevar
is always disjoint from its negation, so when a negated typevar appears
on the left-hand side, the constraint set is never satisfiable.
(Eventually this will allow us to remove the corresponding clauses from
`has_relation_to`, but that can't happen until more of #20093 lands.)
## Summary
Splitting this one out from https://github.com/astral-sh/ruff/pull/21210. This is also something that should be made obselete by the new constraint solver, but is easy enough to fix now.
## Summary
Fixes FURB157 false negative where `Decimal("_-1")` was not flagged as
verbose when underscores precede the sign character. This fixes#21186.
## Problem Analysis
The `verbose-decimal-constructor` (FURB157) rule failed to detect
verbose `Decimal` constructors when the sign character (`+` or `-`) was
preceded by underscores. For example, `Decimal("_-1")` was not flagged,
even though it can be simplified to `Decimal(-1)`.
The bug occurred because the rule checked for the sign character at the
start of the string before stripping leading underscores. According to
Python's `Decimal` parser behavior (as documented in CPython's
`_pydecimal.py`), underscores are removed before parsing the sign. The
rule's logic didn't match this behavior, causing a false negative for
cases like `"_-1"` where the underscore came before the sign.
This was a regression introduced in version 0.14.3, as these cases were
correctly flagged in version 0.14.2.
## Approach
The fix updates the sign extraction logic to:
1. Strip leading underscores first (matching Python's Decimal parser
behavior)
2. Extract the sign from the underscore-stripped string
3. Preserve the string after the sign for normalization purposes
This ensures that cases like `Decimal("_-1")`, `Decimal("_+1")`, and
`Decimal("_-1_000")` are correctly detected and flagged. The
normalization logic was also updated to use the string after the sign
(without underscores) to avoid double signs in the replacement output.
## Summary
Allow values of type `None` in type expressions. The [typing
spec](https://typing.python.org/en/latest/spec/annotations.html#type-and-annotation-expressions)
could be more explicit on whether this is actually allowed or not, but
it seems relatively harmless and does help in some use cases like:
```py
try:
from module import MyClass
except ImportError:
MyClass = None # ty: ignore
def f(m: MyClass):
pass
```
## Test Plan
Updated tests, ecosystem check.
## Summary
This reduces the walltime benchmarks from 15m to 10m, and we should see an even bigger improvement once build caching kicks in, so I think it's worth the downsides.
Summary
--
This PR fixes#17796 by taking the approach mentioned in
https://github.com/astral-sh/ruff/issues/17796#issuecomment-2847943862
of simply recursing into the `MatchAs` patterns when checking if we need
parentheses. This allows us to reuse the parentheses in the inner
pattern before also breaking the `MatchAs` pattern itself:
```diff
match class_pattern:
case Class(xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx) as capture:
pass
- case (
- Class(xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx) as capture
- ):
+ case Class(
+ xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
+ ) as capture:
pass
- case (
- Class(
- xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
- ) as capture
- ):
+ case Class(
+ xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
+ ) as capture:
pass
case (
Class(
@@ -685,13 +683,11 @@
match sequence_pattern_brackets:
case [xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx] as capture:
pass
- case (
- [xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx] as capture
- ):
+ case [
+ xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
+ ] as capture:
pass
- case (
- [
- xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
- ] as capture
- ):
+ case [
+ xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
+ ] as capture:
pass
```
I haven't really resolved the question of whether or not it's okay
always to recurse, but I'm hoping the ecosystem check on this PR might
shed some light on that.
Test Plan
--
New tests based on the issue and then reviewing the ecosystem check here
## Summary
A lot of the bidirectional inference work relies on `dict` not being
assignable to `TypedDict`, so I think it makes sense to add this before
fully implementing https://github.com/astral-sh/ty/issues/1387.
## Summary
Add support for implicit type aliases that use PEP 604 unions:
```py
IntOrStr = int | str
reveal_type(IntOrStr) # UnionType
def _(int_or_str: IntOrStr):
reveal_type(int_or_str) # int | str
```
## Typing conformance
The changes are either removed false positives, or new diagnostics due
to known limitations unrelated to this PR.
## Ecosystem impact
Spot checked, a mix of true positives and known limitations.
## Test Plan
New Markdown tests.
Fixes https://github.com/astral-sh/ty/issues/1053
## Summary
Other type checkers prioritize a submodule over a package `__getattr__`
in `from mod import sub`, even though the runtime precedence is the
other direction. In effect, this is making an implicit assumption that a
module `__getattr__` will not handle (that is, will raise
`AttributeError`) for names that are also actual submodules, rather than
shadowing them. In practice this seems like a realistic assumption in
the ecosystem? Or at least the ecosystem has adapted to it, and we need
to adapt this precedence also, for ecosystem compatibility.
The implementation is a bit ugly, precisely because it departs from the
runtime semantics, and our implementation is oriented toward modeling
runtime semantics accurately. That is, `__getattr__` is modeled within
the member-lookup code, so it's hard to split "member lookup result from
module `__getattr__`" apart from other member lookup results. I did this
via a synthetic `TypeQualifier::FROM_MODULE_GETATTR` that we attach to a
type resulting from a member lookup, which isn't beautiful but it works
well and doesn't introduce inefficiency (e.g. redundant member lookups).
## Test Plan
Updated mdtests.
Also added a related mdtest formalizing our support for a module
`__getattr__` that is explicitly annotated to accept a limited set of
names. In principle this could be an alternative (more explicit) way to
handle the precedence problem without departing from runtime semantics,
if the ecosystem would adopt it.
### Ecosystem analysis
Lots of removed diagnostics which are an improvement because we now
infer the expected submodule.
Added diagnostics are mostly unrelated issues surfaced now because we
previously had an earlier attribute error resulting in `Unknown`; now we
correctly resolve the module so that earlier attribute error goes away,
we get an actual type instead of `Unknown`, and that triggers a new
error.
In scipy and sklearn, the module `__getattr__` which we were respecting
previously is un-annotated so returned a forgiving `Unknown`; now we
correctly see the actual module, which reveals some cases of
https://github.com/astral-sh/ty/issues/133 that were previously hidden
(`scipy/optimize/__init__.py` [imports `from
._tnc`](eff82ca575/scipy/optimize/__init__.py (L429)).)
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
* extend AIR301 to include deprecated argument `concurrency` in
`airflow....DAG`
## Test Plan
<!-- How was it tested? -->
update the existing test fixture in the first commit and then reorganize
in the second one
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Resolves https://github.com/astral-sh/ty/issues/1464
We sort the completions before we add the unimported ones, meaning that
imported completions show up before unimported ones.
This is also spoken about in
https://github.com/astral-sh/ty/issues/1274, and this is probably a
duplicate of that.
@AlexWaygood mentions this
[here](https://github.com/astral-sh/ty/issues/1274#issuecomment-3345942698)
too.
## Test Plan
Add a test showing even if an unimported completion "should"
(alphabetically before) come first, we favor the imported one.
Summary
--
This code has been unused since #14233 but not detected by clippy I
guess. This should help to remove the temptation to use the set
comparison again like I suggested in #21144. And we shouldn't do the set
comparison because of #13802, which #14233 fixed.
Test Plan
--
Existing tests
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[globset](https://redirect.github.com/BurntSushi/ripgrep/tree/master/crates/globset)
([source](https://redirect.github.com/BurntSushi/ripgrep/tree/HEAD/crates/globset))
| workspace.dependencies | patch | `0.4.17` -> `0.4.18` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>BurntSushi/ripgrep (globset)</summary>
###
[`v0.4.18`](https://redirect.github.com/BurntSushi/ripgrep/compare/globset-0.4.17...globset-0.4.18)
[Compare
Source](https://redirect.github.com/BurntSushi/ripgrep/compare/globset-0.4.17...globset-0.4.18)
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS4xNTkuNCIsInVwZGF0ZWRJblZlciI6IjQxLjE1OS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [aho-corasick](https://redirect.github.com/BurntSushi/aho-corasick) |
workspace.dependencies | patch | `1.1.3` -> `1.1.4` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>BurntSushi/aho-corasick (aho-corasick)</summary>
###
[`v1.1.4`](https://redirect.github.com/BurntSushi/aho-corasick/compare/1.1.3...1.1.4)
[Compare
Source](https://redirect.github.com/BurntSushi/aho-corasick/compare/1.1.3...1.1.4)
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS4xNTkuNCIsInVwZGF0ZWRJblZlciI6IjQxLjE1OS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Fixes https://github.com/astral-sh/ty/issues/1368
## Summary
Add support for patterns like this, where a type alias to a literal type
(or union of literal types) is used to subscript `typing.Literal`:
```py
type MyAlias = Literal[1]
def _(x: Literal[MyAlias]): ...
```
This shows up in the ecosystem report for PEP 613 type alias support.
One interesting case is an alias to `bool` or an enum type. `bool` is an
equivalent type to `Literal[True, False]`, which is a union of literal
types. Similarly an enum type `E` is also equivalent to a union of its
member literal types. Since (for explicit type aliases) we infer the RHS
directly as a type expression, this makes it difficult for us to
distinguish between `bool` and `Literal[True, False]`, so we allow
either one to (or an alias to either one) to appear inside `Literal`,
where other type checkers allow only the latter.
I think for implicit type aliases it may be simpler to support only
types derived from actually subscripting `typing.Literal`, though, so I
didn't make a TODO-comment commitment here.
## Test Plan
Added mdtests, including TODO-filled tests for PEP 613 and implicit type
aliases.
### Conformance suite
All changes here are positive -- we now emit errors on lines that should
be errors. This is a side effect of the new implementation, not the
primary purpose of this PR, but it's still a positive change.
### Ecosystem
Eliminates one ecosystem false positive, where a PEP 695 type alias for
a union of literal types is used to subscript `typing.Literal`.
## Summary
There have been some larger-scale updates to the conformance suite since
we introduced our CI job, so it seems sensible to bump the version of
the conformance suite to the latest state.
## Test plan
This is a bit awkward to test. Here is the diff of running ty on the
conformance suite before and after this bump. I filtered out line/column
information (`sed -re 's/\.py:[0-9]+:[0-9]+:/.py/'`) to avoid spurious
changes from content that has simply been moved around.
```diff
1,2c1
< fatal[panic] Panicked at /home/shark/.cargo/git/checkouts/salsa-e6f3bb7c2a062968/cdd0b85/src/function/execute.rs:419:17 when checking `/home/shark/typing/conformance/tests/aliases_typealiastype.py`: `infer_definition_types(Id(1a99c)): execute: too many cycle iterations`
< src/type_checker.py error[unresolved-import] Cannot resolve imported module `tqdm`
---
> fatal[panic] Panicked at /home/shark/.cargo/git/checkouts/salsa-e6f3bb7c2a062968/cdd0b85/src/function/execute.rs:419:17 when checking `/home/shark/typing/conformance/tests/aliases_typealiastype.py`: `infer_definition_types(Id(6e4c)): execute: too many cycle iterations`
205,206d203
< tests/constructors_call_metaclass.py error[type-assertion-failure] Argument does not have asserted type `Never`
< tests/constructors_call_metaclass.py error[missing-argument] No argument provided for required parameter `x` of function `__new__`
268a266,273
> tests/dataclasses_match_args.py error[type-assertion-failure] Argument does not have asserted type `tuple[Literal["x"]]`
> tests/dataclasses_match_args.py error[unresolved-attribute] Class `DC1` has no attribute `__match_args__`
> tests/dataclasses_match_args.py error[type-assertion-failure] Argument does not have asserted type `tuple[Literal["x"]]`
> tests/dataclasses_match_args.py error[unresolved-attribute] Class `DC2` has no attribute `__match_args__`
> tests/dataclasses_match_args.py error[type-assertion-failure] Argument does not have asserted type `tuple[Literal["x"]]`
> tests/dataclasses_match_args.py error[unresolved-attribute] Class `DC3` has no attribute `__match_args__`
> tests/dataclasses_match_args.py error[unresolved-attribute] Class `DC4` has no attribute `__match_args__`
> tests/dataclasses_match_args.py error[type-assertion-failure] Argument does not have asserted type `tuple[()]`
339a345
> tests/directives_assert_type.py error[type-assertion-failure] Argument does not have asserted type `Any`
424a431
> tests/generics_defaults.py error[type-assertion-failure] Argument does not have asserted type `Any`
520a528,529
> tests/generics_syntax_infer_variance.py error[invalid-return-type] Function always implicitly returns `None`, which is not assignable to return type `T@ShouldBeCovariant2 | Sequence[T@ShouldBeCovariant2]`
> tests/generics_syntax_infer_variance.py error[invalid-return-type] Function always implicitly returns `None`, which is not assignable to return type `int`
711a721
> tests/namedtuples_define_class.py error[too-many-positional-arguments] Too many positional arguments: expected 3, got 4
795d804
< tests/protocols_explicit.py error[invalid-attribute-access] Cannot assign to ClassVar `cm1` from an instance of type `Self@__init__`
822,823d830
< tests/qualifiers_annotated.py error[invalid-syntax] named expression cannot be used within a type annotation
< tests/qualifiers_annotated.py error[invalid-syntax] await expression cannot be used within a type annotation
922a930,953
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `Movie`: Unknown key "novel_adaptation"
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `Movie`: Unknown key "year"
> tests/typeddicts_extra_items.py error[type-assertion-failure] Argument does not have asserted type `bool`
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `Movie`: Unknown key "novel_adaptation"
> tests/typeddicts_extra_items.py error[invalid-argument-type] Invalid argument to key "year" with declared type `int` on TypedDict `InheritedMovie`: value of type `None`
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `InheritedMovie`: Unknown key "other_extra_key"
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `MovieEI`: Unknown key "year"
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `MovieExtraInt`: Unknown key "year"
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `MovieExtraStr`: Unknown key "description"
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `MovieExtraInt`: Unknown key "year"
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `NonClosedMovie`: Unknown key "year"
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `ExtraMovie`: Unknown key "year"
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `ExtraMovie`: Unknown key "language"
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `ClosedMovie`: Unknown key "year"
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `MovieExtraStr`: Unknown key "summary"
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `MovieExtraInt`: Unknown key "year"
> tests/typeddicts_extra_items.py error[invalid-assignment] Object of type `dict[Unknown | str, Unknown | str | int]` is not assignable to `Mapping[str, int]`
> tests/typeddicts_extra_items.py error[type-assertion-failure] Argument does not have asserted type `list[tuple[str, int | str]]`
> tests/typeddicts_extra_items.py error[type-assertion-failure] Argument does not have asserted type `list[int | str]`
> tests/typeddicts_extra_items.py error[unresolved-attribute] Object of type `IntDict` has no attribute `clear`
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `IntDictWithNum`: Unknown key "bar" - did you mean "num"?
> tests/typeddicts_extra_items.py error[type-assertion-failure] Argument does not have asserted type `tuple[str, int]`
> tests/typeddicts_extra_items.py error[invalid-key] Cannot access `IntDictWithNum` with a key of type `str`. Only string literals are allowed as keys on TypedDicts.
> tests/typeddicts_extra_items.py error[invalid-key] Invalid key for TypedDict `IntDictWithNum` of type `str`
950c981
< Found 949 diagnostics
---
> Found 980 diagnostics
```
## Summary
Adds type inference for list/dict/set comprehensions, including
bidirectional inference:
```py
reveal_type({k: v for k, v in [("a", 1), ("b", 2)]}) # dict[Unknown | str, Unknown | int]
squares: list[int | None] = [x for x in range(10)]
reveal_type(squares) # list[int | None]
```
## Ecosystem impact
I did spot check the changes and most of them seem like known
limitations or true positives. Without proper bidirectional inference,
we saw a lot of false positives.
## Test Plan
New Markdown tests
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
@BurntSushi provided some feedback in #21146 so i address it here.
Summary
--
This is a first step toward fixing #9745. After reviewing our open
issues and several Black issues and PRs, I personally found the function
case the most compelling, especially with very long argument lists:
```py
def func(
self,
arg1: int,
arg2: bool,
arg3: bool,
arg4: float,
arg5: bool,
) -> tuple[...]:
if arg2 and arg3:
raise ValueError
```
or many annotations:
```py
def function(
self, data: torch.Tensor | tuple[torch.Tensor, ...], other_argument: int
) -> torch.Tensor | tuple[torch.Tensor, ...]:
do_something(data)
return something
```
I think docstrings help the situation substantially both because syntax
highlighting will usually give a very clear separation between the
annotations and the docstring and because we already allow a blank line
_after_ the docstring:
```py
def function(
self, data: torch.Tensor | tuple[torch.Tensor, ...], other_argument: int
) -> torch.Tensor | tuple[torch.Tensor, ...]:
"""
A function doing something.
And a longer description of the things it does.
"""
do_something(data)
return something
```
There are still other comments on #9745, such as [this one] with 9
upvotes, where users specifically request blank lines in all block
types, or at least including conditionals and loops. I'm sympathetic to
that case as well, even if personally I don't find an [example] like
this:
```py
if blah:
# Do some stuff that is logically related
data = get_data()
# Do some different stuff that is logically related
results = calculate_results()
return results
```
to be much more readable than:
```py
if blah:
# Do some stuff that is logically related
data = get_data()
# Do some different stuff that is logically related
results = calculate_results()
return results
```
I'm probably just used to the latter from the formatters I've used, but
I do prefer it. I also think that functions are the least susceptible to
the accidental introduction of a newline after refactoring described in
Micha's [comment] on #8893.
I actually considered further restricting this change to functions with
multiline headers. I don't think very short functions like:
```py
def foo():
return 1
```
benefit nearly as much from the allowed newline, but I just went with
any function without a docstring for now. I guess a marginal case like:
```py
def foo(a_long_parameter: ALongType, b_long_parameter: BLongType) -> CLongType:
return 1
```
might be a good argument for not restricting it.
I caused a couple of syntax errors before adding special handling for
the ellipsis-only case, so I suspect that there are some other
interesting edge cases that may need to be handled better.
Test Plan
--
Existing tests, plus a few simple new ones. As noted above, I suspect
that we may need a few more for edge cases I haven't considered.
[this one]:
https://github.com/astral-sh/ruff/issues/9745#issuecomment-2876771400
[example]:
https://github.com/psf/black/issues/902#issuecomment-1562154809
[comment]:
https://github.com/astral-sh/ruff/issues/8893#issuecomment-1867259744
## Summary
Discussion with @ibraheemdev clarified that
https://github.com/astral-sh/ruff/pull/21168 was incorrect. In a case of
failed inference of a dict literal as a `TypedDict`, we should store the
context-less inferred type of the dict literal as the type of the dict
literal expression itself; the fallback to declared type should happen
at the level of the overall assignment definition.
The reason the latter isn't working yet is because currently we
(wrongly) consider a homogeneous dict type as assignable to a
`TypedDict`, so we don't actually consider the assignment itself as
failed. So the "bug" I observed (and tried to fix) will naturally be
fixed by implementing TypedDict assignability rules.
Rollback https://github.com/astral-sh/ruff/pull/21168 except for the
tests, and modify the tests to include TODOs as needed.
## Test Plan
Updated mdtests.
The parser currently uses single quotes to wrap tokens. This is
inconsistent with the rest of ruff/ty, which use backticks.
For example, see the inconsistent diagnostics produced in this simple
example: https://play.ty.dev/0a9d6eab-6599-4a1d-8e40-032091f7f50f
Consistently wrapping tokens in backticks produces uniform diagnostics.
Following the style decision of #723, in #2889 some quotes were already
switched into backticks.
This is also in line with Rust's guide on diagnostics
(https://rustc-dev-guide.rust-lang.org/diagnostics.html#diagnostic-structure):
> When code or an identifier must appear in a message or label, it
should be surrounded with backticks
## Summary
In general, when we have an invalid assignment (inferred assigned type
is not assignable to declared type), we fall back to inferring the
declared type, since the declared type is a more explicit declaration of
the programmer's intent. This also maintains the invariant that our
inferred type for a name is always assignable to the declared type for
that same name. For example:
```py
x: str = 1
reveal_type(x) # revealed: str
```
We weren't following this pattern for dictionary literals inferred (via
type context) as a typed dictionary; if the literal was not valid for
the annotated TypedDict type, we would just fall back to the normal
inferred type of the dict literal, effectively ignoring the annotation,
and resulting in inferred type not assignable to declared type.
## Test Plan
Added mdtest assertions.
## Summary
The solver is currently order-dependent, and will choose a supertype
over the exact type if it appears earlier in the list of constraints. We
could be smarter and try to choose the most precise subtype, but I
imagine this is something the new constraint solver will fix anyways,
and this fixes the issue showing up on
https://github.com/astral-sh/ruff/pull/21070.
This PR adds a new `satisfied_by_all_typevar` method, which implements
one of the final steps of actually using these dang constraint sets.
Constraint sets exist to help us check assignability and subtyping of
types in the presence of typevars. We construct a constraint set
describing the conditions under which assignability holds between the
two types. Then we check whether that constraint set is satisfied for
the valid specializations of the relevant typevars (which is this new
method).
We also add a new `ty_extensions.ConstraintSet` method so that we can
test this method's behavior in mdtests, before hooking it up to the rest
of the specialization inference machinery.
## Summary
We currently perform a subtyping check instead of the intended subclass
check (and the subtyping check is confusingly named `is_subclass_of`).
This showed up in https://github.com/astral-sh/ruff/pull/21070.
## Summary
Before this PR, we would emit diagnostics like "Invalid key access" for
a TypedDict literal with invalid key, which doesn't make sense since
there's no "access" in that case. This PR just adjusts the wording to be
more general, and adjusts the documentation of the lint rule too.
I noticed this in the playground and thought it would be a quick fix. As
usual, it turned out to be a bit more subtle than I expected, but for
now I chose to punt on the complexity. We may ultimately want to have
different rules for invalid subscript vs invalid TypedDict literal,
because an invalid key in a TypedDict literal is low severity: it's a
typo detector, but not actually a type error. But then there's another
wrinkle there: if the TypedDict is `closed=True`, then it _is_ a type
error. So would we want to separate the open and closed cases into
separate rules, too? I decided to leave this as a question for future.
If we wanted to use separate rules, or use specific wording for each
case instead of the generalized wording I chose here, that would also
involve a bit of extra work to distinguish the cases, since we use a
generic set of functions for reporting these errors.
## Test Plan
Added and updated mdtests.
This is a second take at the implicit imports approach, allowing `from .
import submodule` in an `__init__.pyi` to create the
`mypackage.submodule` attribute everyhere.
This implementation operates inside of the
available_submodule_attributes subsystem instead of as a re-export rule.
The upside of this is we are no longer purely syntactic, and absolute
from imports that happen to target submodules work (an intentional
discussed deviation from pyright which demands a relative from import).
Also we don't re-export functions or classes.
The downside(?) of this is star imports no longer see these attributes
(this may be either good or bad. I believe it's not a huge lift to make
it work with star imports but it's some non-trivial reworking).
I've also intentionally made `import mypackage.submodule` not trigger
this rule although it's trivial to change that.
I've tried to cover as many relevant cases as possible for discussion in
the new test file I've added (there are some random overlaps with
existing tests but trying to add them piecemeal felt confusing and
weird, so I just made a dedicated file for this extension to the rules).
Fixes https://github.com/astral-sh/ty/issues/133
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
## Summary
Fixes https://github.com/astral-sh/ty/issues/1427
This PR fixes a regression introduced in alpha.24 where non-dataclass
children of generic dataclasses lost generic type parameter information
during `__init__` synthesis.
The issue occurred because when looking up inherited members in the MRO,
the child class's `inherited_generic_context` was correctly passed down,
but `own_synthesized_member()` (which synthesizes dataclass `__init__`
methods) didn't accept this parameter. It only used
`self.inherited_generic_context(db)`, which returned the parent's
context instead of the child's.
The fix threads the child's generic context through to the synthesis
logic, allowing proper generic type inference for inherited dataclass
constructors.
## Test Plan
- Added regression test for non-dataclass inheriting from generic
dataclass
- Verified the exact repro case from the issue now works
- All 277 mdtest tests passing
- Clippy clean
- Manually verified with Python runtime, mypy, and pyright - all accept
this code pattern
## Verification
Tested against multiple type checkers:
- ✅ Python runtime: Code works correctly
- ✅ mypy: No issues found
- ✅ pyright: 0 errors, 0 warnings
- ✅ ty alpha.23: Worked (before regression)
- ❌ ty alpha.24: Regression
- ✅ ty with this fix: Works correctly
---------
Co-authored-by: Claude <noreply@anthropic.com>
Co-authored-by: David Peter <mail@david-peter.de>
It's possible for a constraint to mention two typevars. For instance, in
the body of
```py
def f[S: int, T: S](): ...
```
the baseline constraint set would be `(T ≤ S) ∧ (S ≤ int)`. That is, `S`
must specialize to some subtype of `int`, and `T` must specialize to a
subtype of the type that `S` specializes to.
This PR updates the new "constraint implication" relationship from
#21010 to work on these kinds of constraint sets. For instance, in the
example above, we should be able to see that `T ≤ int` must always hold:
```py
def f[S, T]():
constraints = ConstraintSet.range(Never, S, int) & ConstraintSet.range(Never, T, S)
static_assert(constraints.implies_subtype_of(T, int)) # now succeeds!
```
This did not require major changes to the implementation of
`implies_subtype_of`. That method already relies on how our `simplify`
and `domain` methods expand a constraint set to include the transitive
closure of the constraints that it mentions, and to mark certain
combinations of constraints as impossible. Previously, that transitive
closure logic only looked at pairs of constraints that constrain the
same typevar. (For instance, to notice that `(T ≤ bool) ∧ ¬(T ≤ int)` is
impossible.)
Now we also look at pairs of constraints that constraint different
typevars, if one of the constraints is bound by the other — that is,
pairs of the form `T ≤ S` and `S ≤ something`, or `S ≤ T` and `something
≤ S`. In those cases, transitivity lets us add a new derived constraint
that `T ≤ something` or `something ≤ T`, respectively. Having done that,
our existing `implies_subtype_of` logic finds and takes into account
that derived constraint.
Summary
--
Fixes#21121 by upgrading `RuntimeEvaluated` annotations like
`dataclasses.KW_ONLY` to `RuntimeRequired`. We already had special
handling for
`TypingOnly` annotations in this context but not `RuntimeEvaluated`.
Combining
that with the `future-annotations` setting, which allowed ignoring the
`RuntimeEvaluated` flag, led to the reported bug where we would try to
move
`KW_ONLY` into a `TYPE_CHECKING` block.
Test Plan
--
A new test based on the issue
## Summary
We weren't correctly modeling it as a `staticmethod` in all cases,
leading us to incorrectly infer that the `cls` argument would be bound
if it was accessed on an instance (rather than the class object).
## Test Plan
Added mdtests that fail on `main`. The primer output also looks good!
## Summary
Fixes#21101 by storing the child visitor's names in the parent visitor.
This makes sure that `visitor.names` on line 1818 isn't empty after we
visit a nested OR pattern.
## Test Plan
New inline test cases derived from the issue,
[playground](https://play.ruff.rs/7b6439ac-ee8f-4593-9a3e-c2aa34a595d0)
## Summary
Adds proper type narrowing and reachability analysis for matching on
non-inferable type variables bound to enums. For example:
```py
from enum import Enum
class Answer(Enum):
NO = 0
YES = 1
def is_yes(self) -> bool: # no error here!
match self:
case Answer.YES:
return True
case Answer.NO:
return False
```
closes https://github.com/astral-sh/ty/issues/1404
## Test Plan
Added regression tests
## Summary
We previously didn't understand `range` and wrote these custom
`IntIterable`/`IntIterator` classes for tests. We can now remove them
and make the tests shorter in some places.
## Summary
Infer a type of unannotated `self` parameters in decorated methods /
properties.
closes https://github.com/astral-sh/ty/issues/1448
## Test Plan
Existing tests, some new tests.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixed the incorrect import example in the "correct exmaple"
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
🤷
<!-- How was it tested? -->
Note that this doesn't change the evaluation results unfortunately.
In particular, prior to this fix, the correct result was ranked above
the redundant result. Our MRR-based evaluation doesn't care about
anything below the rank of the correct answer, and so this change isn't
reflected in our evaluation.
Fixesastral-sh/ty#1445
The status quo grew organically and didn't do well when one wanted to
mix and match different settings to generate a snapshot.
This does a small refactor to use more of a builder to generate
snapshots.
This fixes a bug where the `import module` part of a completion for
unimported candidates would be missing. This makes it especially
confusing because the user can't tell where the symbol is coming from,
and there is no hint that an `import` statement will be inserted.
Previously, we were using [`CompletionItemLabelDetails`] to render the
`import module` part of the suggestion. But this is only supported in
clients that support version 3.17 (or newer) of the LSP specification.
It turns out that this support isn't widespread yet. In particular,
Heliex doesn't seem to support "label details."
To fix this, we take a [cue from rust-analyzer][rust-analyzer-details].
We detect if the client supports "label details," and if so, use it.
Otherwise, we push the `import module` text into the completion label
itself.
Fixes https://github.com/astral-sh/ruff/pull/20439#issuecomment-3313689568
[`CompletionItemLabelDetails`]: https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#completionItemLabelDetails
[rust-analyzer-details]: 5d905576d4/crates/rust-analyzer/src/lsp/to_proto.rs (L391-L404)
This PR updates the mdtests that test how our generics solver interacts
with our new constraint set implementation. Because the rendering of a
constraint set can get long, this standardizes on putting the `revealed`
assertion on a separate line. We also add a `static_assert` test for
each constraint set to verify that they are all coerced into simple
`bool`s correctly.
This is a pure reformatting (not even a refactoring!) that changes no
behavior. I've pulled it out of #20093 to reduce the amount of effort
that will be required to review that PR.
We have several functions in `ty_extensions` for testing our constraint
set implementation. This PR refactors those functions so that they are
all methods of the `ConstraintSet` class, rather than being standalone
top-level functions. 🎩 to @sharkdp for pointing out that
`KnownBoundMethod` gives us what we need to implement that!
This PR adds the new **_constraint implication_** relationship between
types, aka `is_subtype_of_given`, which tests whether one type is a
subtype of another _assuming that the constraints in a particular
constraint set hold_.
For concrete types, constraint implication is exactly the same as
subtyping. (A concrete type is any fully static type that is not a
typevar. It can _contain_ a typevar, though — `list[T]` is considered
concrete.)
The interesting case is typevars. The other typing relationships (TODO:
will) all "punt" on the question when considering a typevar, by
translating the desired relationship into a constraint set. At some
point, though, we need to resolve a constraint set; at that point, we
can no longer punt on the question. Unlike with concrete types, the
answer will depend on the constraint set that we are considering.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR refactors semantic error tests in each seperate file
## Test Plan
<!-- How was it tested? -->
## CC
- @ntBre
---------
Signed-off-by: 11happy <soni5happy@gmail.com>
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
Summary
--
Fixes#19550
This PR copies our non-watch diagnostic rendering code into
`Printer::write_continuously` in preview mode, allowing it to use
whatever output format is passed in.
I initially marked this as also fixing #19552, but I guess that's not
true currently but will be true once this is stabilized and we can
remove the warning.
Test Plan
--
Existing tests, but I don't think we have any `watch` tests, so some
manual testing as well. The default with just `ruff check --watch` is
still `concise`, adding just `--preview` still gives the `full` output,
and then specifying any other output format works, with JSON as one
example:
<img width="695" height="719" alt="Screenshot 2025-10-27 at 9 21 41 AM"
src="https://github.com/user-attachments/assets/98957911-d216-4fc4-8b6c-22c56c963b3f"
/>
When formatting clause headers for clauses that are not their own node,
like an `else` clause or `finally` clause, we begin searching for the
keyword at the end of the previous statement. However, if the previous
statement ended in a semicolon this caused a panic because we only
expected trivia between the end of the last statement and the keyword.
This PR adjusts the starting point of our search for the keyword to
begin after the optional semicolon in these cases.
Closes#21065
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Add docstring sections which were missing from the numpy list as pointed
out here #20923. For now these are only the official sections as
documented
[here](https://numpydoc.readthedocs.io/en/latest/format.html#sections).
## Test Plan
Added a test case for DOC102
## Summary
Fixes#20973 (`docstring-extraneous-exception`) false positive when
exceptions mentioned in docstrings are caught and explicitly re-raised
using `raise e` or `raise e from None`.
## Problem Analysis
The DOC502 rule was incorrectly flagging exceptions mentioned in
docstrings as "not explicitly raised" when they were actually being
explicitly re-raised through exception variables bound in `except`
clauses.
**Root Cause**: The `BodyVisitor` in `check_docstring.rs` only checked
for direct exception references (like `raise OSError()`) but didn't
recognize when a variable bound to an exception in an `except` clause
was being re-raised.
**Example of the bug**:
```python
def f():
"""Do nothing.
Raises
------
OSError
If the OS errors.
"""
try:
pass
except OSError as e:
raise e # This was incorrectly flagged as not explicitly raising OSError
```
The issue occurred because `resolve_qualified_name(e)` couldn't resolve
the variable `e` to a qualified exception name, since `e` is just a
variable binding, not a direct reference to an exception class.
## Approach
Modified the `BodyVisitor` in
`crates/ruff_linter/src/rules/pydoclint/rules/check_docstring.rs` to:
1. **Track exception variable bindings**: Added `exception_variables`
field to map exception variable names to their exception types within
`except` clauses
2. **Enhanced raise statement detection**: Updated `visit_stmt` to check
if a `raise` statement uses a variable name that's bound to an exception
in the current `except` clause
3. **Proper scope management**: Clear exception variable mappings when
leaving `except` handlers to prevent cross-contamination
**Key changes**:
- Added `exception_variables: FxHashMap<&'a str, QualifiedName<'a>>` to
track variable-to-exception mappings
- Enhanced `visit_except_handler` to store exception variable bindings
when entering `except` clauses
- Modified `visit_stmt` to check for variable-based re-raising: `raise
e` → lookup `e` in `exception_variables`
- Clear mappings when exiting `except` handlers to maintain proper scope
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
That PR title might be a bit inscrutable.
Consider the two constraints `T ≤ bool` and `T ≤ int`. Since `bool ≤
int`, by transitivity `T ≤ bool` implies `T ≤ int`. (Every type that is
a subtype of `bool` is necessarily also a subtype of `int`.) That means
that `T ≤ bool ∧ T ≰ int` is an impossible combination of constraints,
and is therefore not a valid input to any BDD. We say that that
assignment is not in the _domain_ of the BDD.
The implication `T ≤ bool → T ≤ int` can be rewritten as `T ≰ bool ∨ T ≤
int`. (That's the definition of implication.) If we construct that
constraint set in an mdtest, we should get a constraint set that is
always satisfiable. Previously, that constraint set would correctly
_display_ as `always`, but a `static_assert` on it would fail.
The underlying cause is that our `is_always_satisfied` method would only
test if the BDD was the `AlwaysTrue` terminal node. `T ≰ bool ∨ T ≤ int`
does not simplify that far, because we purposefully keep around those
constraints in the BDD structure so that it's easier to compare against
other BDDs that reference those constraints.
To fix this, we need a more nuanced definition of "always satisfied".
Instead of evaluating to `true` for _every_ input, we only need it to
evaluate to `true` for every _valid_ input — that is, every input in its
domain.
## Summary
implement pylint rule stop-iteration-return / R1708
## Test Plan
<!-- How was it tested? -->
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
* Extend `airflow.models.Param` to include `airflow.models.param.Param`
case and include both `airflow.models.param.ParamDict` and
`airflow.models.param.DagParam` and their `airflow.models.` counter part
## Test Plan
<!-- How was it tested? -->
update the text fixture accordingly and reorganize them in the third
commit
Summary
--
Inspired by #20859, this PR adds the version a rule was added, and the
file and line where it was defined, to `ViolationMetadata`. The file and
line just use the standard `file!` and `line!` macros, while the more
interesting version field uses a new `violation_metadata` attribute
parsed by our `ViolationMetadata` derive macro.
I moved the commit modifying all of the rule files to the end, so it
should be a lot easier to review by omitting that one.
As a curiosity and a bit of a sanity check, I also plotted the rule
numbers over time:
<img width="640" height="480" alt="image"
src="https://github.com/user-attachments/assets/75b0b5cc-3521-4d40-a395-8807e6f4925f"
/>
I think this looks pretty reasonable and avoids some of the artifacts
the earlier versions of the script ran into, such as the `rule`
sub-command not being available or `--explain` requiring a file
argument.
<details><summary>Script and summary data</summary>
```shell
gawk --csv '
NR > 1 {
split($2, a, ".")
major = a[1]; minor = a[2]; micro = a[3]
# sum the number of rules added per minor version
versions[minor] += 1
}
END {
tot = 0
for (i = 0; i <= 14; i++) {
tot += versions[i]
print i, tot
}
}
' ruff_rules_metadata.csv > summary.dat
```
```
0 696
1 768
2 778
3 803
4 822
5 848
6 855
7 865
8 893
9 915
10 916
11 924
12 929
13 932
14 933
```
</details>
Test Plan
--
I built and viewed the documentation locally, and it looks pretty good!
<img width="1466" height="676" alt="image"
src="https://github.com/user-attachments/assets/5e227df4-7294-4d12-bdaa-31cac4e9ad5c"
/>
The spacing seems a bit awkward following the `h1` at the top, so I'm
wondering if this might look nicer as a footer in Ruff. The links work
well too:
- [v0.0.271](https://github.com/astral-sh/ruff/releases/tag/v0.0.271)
- [Related
issues](https://github.com/astral-sh/ruff/issues?q=sort%3Aupdated-desc%20is%3Aissue%20is%3Aopen%20airflow-variable-name-task-id-mismatch)
- [View
source](https://github.com/astral-sh/ruff/blob/main/crates%2Fruff_linter%2Fsrc%2Frules%2Fairflow%2Frules%2Ftask_variable_name.rs#L34)
The last one even works on `main` now since it points to the
`derive(ViolationMetadata)` line.
In terms of binary size, this branch is a bit bigger than main with
38,654,520 bytes compared to 38,635,728 (+20 KB). I guess that's not
_too_ much of an increase, but I wanted to check since we're generating
a lot more code with macros.
---------
Co-authored-by: GiGaGon <107241144+MeGaGiGaGon@users.noreply.github.com>
## Summary
Infer a type of `Self` for unannotated `self` parameters in methods of
classes.
part of https://github.com/astral-sh/ty/issues/159
closes https://github.com/astral-sh/ty/issues/1081
## Conformance tests changes
```diff
+enums_member_values.py:85:9: error[invalid-assignment] Object of type `int` is not assignable to attribute `_value_` of type `str`
```
A true positive ✔️
```diff
-generics_self_advanced.py:35:9: error[type-assertion-failure] Argument does not have asserted type `Self@method2`
-generics_self_basic.py:14:9: error[type-assertion-failure] Argument does not have asserted type `Self@set_scale
```
Two false positives going away ✔️
```diff
+generics_syntax_infer_variance.py:82:9: error[invalid-assignment] Cannot assign to final attribute `x` on type `Self@__init__`
```
This looks like a true positive to me, even if it's not marked with `#
E` ✔️
```diff
+protocols_explicit.py:56:9: error[invalid-assignment] Object of type `tuple[int, int, str]` is not assignable to attribute `rgb` of type `tuple[int, int, int]`
```
True positive ✔️
```
+protocols_explicit.py:85:9: error[invalid-attribute-access] Cannot assign to ClassVar `cm1` from an instance of type `Self@__init__`
```
This looks like a true positive to me, even if it's not marked with `#
E`. But this is consistent with our understanding of `ClassVar`, I
think. ✔️
```py
+qualifiers_final_annotation.py:52:9: error[invalid-assignment] Cannot assign to final attribute `ID4` on type `Self@__init__`
+qualifiers_final_annotation.py:65:9: error[invalid-assignment] Cannot assign to final attribute `ID7` on type `Self@method1`
```
New true positives ✔️
```py
+qualifiers_final_annotation.py:52:9: error[invalid-assignment] Cannot assign to final attribute `ID4` on type `Self@__init__`
+qualifiers_final_annotation.py:57:13: error[invalid-assignment] Cannot assign to final attribute `ID6` on type `Self@__init__`
+qualifiers_final_annotation.py:59:13: error[invalid-assignment] Cannot assign to final attribute `ID6` on type `Self@__init__`
```
This is a new false positive, but that's a pre-existing issue on main
(if you annotate with `Self`):
https://play.ty.dev/3ee1c56d-7e13-43bb-811a-7a81e236e6ab❌ => reported
as https://github.com/astral-sh/ty/issues/1409
## Ecosystem
* There are 5931 new `unresolved-attribute` and 3292 new
`possibly-missing-attribute` attribute errors, way too many to look at
all of them. I randomly sampled 15 of these errors and found:
* 13 instances where there was simply no such attribute that we could
plausibly see. Sometimes [I didn't find it
anywhere](8644d886c6/openlibrary/plugins/openlibrary/tests/test_listapi.py (L33)).
Sometimes it was set externally on the object. Sometimes there was some
[`setattr` dynamicness going
on](a49f6b927d/setuptools/wheel.py (L88-L94)).
I would consider all of them to be true positives.
* 1 instance where [attribute was set on `obj` in
`__new__`](9e87b44fd4/sympy/tensor/array/array_comprehension.py (L45C1-L45C36)),
which we don't support yet
* 1 instance [where the attribute was defined via `__slots__`
](e250ec0fc8/lib/spack/spack/vendor/pyrsistent/_pdeque.py (L48C5-L48C14))
* I see 44 instances [of the false positive
above](https://github.com/astral-sh/ty/issues/1409) with `Final`
instance attributes being set in `__init__`. I don't think this should
block this PR.
## Test Plan
New Markdown tests.
---------
Co-authored-by: Shaygan Hooshyari <sh.hooshyari@gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#21017
Taught UP032’s parenthesize check to ignore underscores when inspecting
decimal integer literals so the converter emits `f"{(1_2).real}"`
instead of invalid syntax.
## Test Plan
Added test cases to UP032_2.py.
<!-- How was it tested? -->
## Summary
Also bumps `cargo dist` to 0.30, and moves us
back to the upstream copy of `dist` now that
the latest version has integrated our fork's
patches.
## Test Plan
See what happens in CI 🙂
---------
Signed-off-by: William Woodruff <william@astral.sh>
This PR adds another useful simplification when rendering constraint
sets: `T = int` instead of `T = int ∧ T ≠ str`. (The "smaller"
constraint `T = int` implies the "larger" constraint `T ≠ str`.
Constraint set clauses are intersections, and if one constraint in a
clause implies another, we can throw away the "larger" constraint.)
While we're here, we also normalize the bounds of a constraint, so that
we equate e.g. `T ≤ int | str` with `T ≤ str | int`, and change the
ordering of BDD variables so that all constraints with the same typevar
are ordered adjacent to each other.
Lastly, we also add a new `display_graph` helper method that prints out
the full graph structure of a BDD.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Fall back to `C[Divergent]` if we are trying to specialize `C[T]` with a
type that itself already contains deeply nested specialized generic
classes. This is a way to prevent infinite recursion for cases like
`self.x = [self.x]` where type inference for the implicit instance
attribute would not converge.
closes https://github.com/astral-sh/ty/issues/1383
closes https://github.com/astral-sh/ty/issues/837
## Test Plan
Regression tests.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#18778
Prevent SIM911 from triggering when zip() is called on .keys()/.values()
that take any positional or keyword arguments, so Ruff
never suggests the lossy rewrite.
## Test Plan
<!-- How was it tested? -->
Added a test case to SIM911.py.
## Summary
I spun this out from #21005 because I thought it might be helpful
separately. It just renders a nice `Diagnostic` for syntax errors
pointing to the source of the error. This seemed a bit more helpful to
me than just the byte offset when working on #21005, and we had most of
the code around after #20443 anyway.
## Test Plan
This doesn't actually affect any passing tests, but here's an example of
the additional output I got when I broke the spacing after the `in`
token:
```
error[internal-error]: Expected 'in', found name
--> /home/brent/astral/ruff/crates/ruff_python_formatter/resources/test/fixtures/black/cases/cantfit.py:50:79
|
48 | need_more_to_make_the_line_long_enough,
49 | )
50 | del ([], name_1, name_2), [(), [], name_4, name_3], name_1[[name_2 for name_1 inname_0]]
| ^^^^^^^^
51 | del ()
|
```
I just appended this to the other existing output for now.
This is an alternative to #21012 that more narrowly handles this logic
in the stub-mapping machinery rather than pervasively allowing us to
identify cached files as typeshed stubs. Much of the logic is the same
(pulling the logic out of ty_server so it can be reused).
I don't have a good sense for if one approach is "better" or "worse" in
terms of like, semantics and Weird Bugs that this can cause. This one is
just "less spooky in its broad consequences" and "less muddying of
separation of concerns" and puts the extra logic on a much colder path.
I won't be surprised if one day the previous implementation needs to be
revisited for its more sweeping effects but for now this is good.
Fixes https://github.com/astral-sh/ty/issues/1054
## Summary
We currently panic in the seemingly rare case where the type of a
default value of a parameter depends on the callable itself:
```py
class C:
def f(self: C):
self.x = lambda a=self.x: a
```
Types of default values are only used for display reasons, and it's
unclear if we even want to track them (or if we should rather track the
actual value). So it didn't seem to me that we should spend a lot of
effort (and runtime) trying to achieve a theoretically correct type here
(which would be infinite).
Instead, we simply replace *nested* default types with `Unknown`, i.e.
only if the type of the default value is a callable itself.
closes https://github.com/astral-sh/ty/issues/1402
## Test Plan
Regression tests
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR implements a new semantic syntax error where name is parameter &
global.
## Test Plan
<!-- How was it tested? -->
I have written inline test as directed in #17412
---------
Signed-off-by: 11happy <soni5happy@gmail.com>
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
Only run the "pull types" test after performing the "actual" mdtest. We
observed that the order matters. There is currently one mdtest which
panics when checked in the CLI or the playground. With this change, it
also panics in the mdtest suite.
reopens https://github.com/astral-sh/ty/issues/837?
## Summary
Implement handling of ellipsis (`...`) defaults in the `FAST002` autofix
to correctly differentiate between required and optional parameters in
FastAPI route definitions.
Previously, the autofix did not properly handle cases where parameters
used `...` as a default value (to indicate required parameters). This
could lead to incorrect transformations when applying the autofix.
This change updates the `FAST002` autofix logic to:
- Correctly recognize `...` as a valid FastAPI required default.
- Preserve the semantics of required parameters while still applying
other autofix improvements.
- Avoid incorrectly substituting or removing ellipsis defaults.
Fixes https://github.com/astral-sh/ruff/issues/20800
## Test Plan
Added a new test fixture at:
```crates/ruff_linter/resources/test/fixtures/fastapi/FAST002_2.py```
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#20941
Skip autofix for keyword and __debug__ path params
## Test Plan
<!-- How was it tested? -->
I added two test cases to
crates/ruff_linter/resources/test/fixtures/fastapi/FAST003.py.
Closes#20997
This will _decrease_ the number of diagnostics emitted for
[zip-without-explicit-strict
(B905)](https://docs.astral.sh/ruff/rules/zip-without-explicit-strict/#zip-without-explicit-strict-b905),
since previously it triggered on any `zip` call no matter the number of
arguments. It may _increase_ the number of diagnostics for
[map-without-explicit-strict
(B912)](https://docs.astral.sh/ruff/rules/map-without-explicit-strict/#map-without-explicit-strict-b912)
since it will now trigger on a single starred argument where before it
would not. However, the latter rule is in `preview` so this is
acceptable.
Note - we do not need to make any changes to
[batched-without-explicit-strict
(B911)](https://docs.astral.sh/ruff/rules/batched-without-explicit-strict/#batched-without-explicit-strict-b911)
since that just takes a single iterable.
I am doing this in one PR rather than two because we should keep the
behavior of these rules consistent with one another.
For review: apologies for the unreadability of the snapshot for `B905`.
Unfortunately I saw no way of keeping a small diff and a correct fixture
(the fixture labeled a whole block as `# Error` whereas now several in
the block became `# Ok`).Probably simplest to just view the actual
snapshot - it's relatively small.
## Summary
Make rules `INT001`, `INT002`, and `INT003` also
* trigger on qualified names when we're sure the calls are calls to the
`gettext` module. For example
```python
from gettext import gettext as foo
foo(f"{'bar'}") # very certain that this is a call to a real `gettext`
function => worth linting
```
* trigger on `builtins` bindings
```python
from builtins, gettext
gettext.install("...") # binds `gettext.gettext` to `builtins._`
builtins.__dict__["_"] = ... # also a common pattern
_(f"{'bar'}") # should therefore also be linted
```
Fixes: https://github.com/astral-sh/ruff/issues/19028
## Test Plan
Tests have been added to all three rules.
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
Summary
--
This PR fixes the issue I added in #20867 and noticed in #20930. Cases
like this
cause an error on any Python version:
```py
f"{1:""}"
```
which gave me a false sense of security before. Cases like this are
still
invalid only before 3.12 and weren't flagged after the changes in
#20867:
```py
f'{1: abcd "{'aa'}" }'
# ^ reused quote
f'{1: abcd "{"\n"}" }'
# ^ backslash
```
I didn't recognize these as nested interpolations that also need to be
checked
for invalid expressions, so filtering out the whole format spec wasn't
quite
right. And `elements.interpolations()` only iterates over the outermost
interpolations, not the nested ones.
There's basically no code change in this PR, I just moved the existing
check
from `parse_interpolated_string`, which parses the entire string, to
`parse_interpolated_element`. This kind of seems more natural anyway and
avoids
having to try to recursively visit nested elements after the fact in
`parse_interpolated_string`. So viewing the diff with something like
```
git diff --color-moved --ignore-space-change --color-moved-ws=allow-indentation-change main
```
should make this more clear.
Test Plan
--
New tests
## Summary
More dogfooding of our own tools.
I didn't touch the build-binaries workflow (it's scary) or the
publish-docs workflow (which doesn't run on PRs) or the ruff-lsp job in
the ci.yaml workflow (ruff-lsp is deprecated; it doesn't seem worth
making changes there).
## Test Plan
CI on this PR
## Summary
- Type checkers (and type-checker authors) think in terms of types, but
I think most Python users think in terms of values. Rather than saying
that a _type_ `X` "has no attribute `foo`" (which I think sounds strange
to many users), say that "an object of type `X` has no attribute `foo`"
- Special-case certain types so that the diagnostic messages read more
like normal English: rather than saying "Type `<class 'Foo'>` has no
attribute `bar`" or "Object of type `<class 'Foo'>` has no attribute
`bar`", just say "Class `Foo` has no attribute `bar`"
## Test Plan
Mdtests and snapshots updated
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR implements semantic syntax error where alternative patterns bind
different names
## Test Plan
<!-- How was it tested? -->
I have written inline tests as directed in #17412
---------
Signed-off-by: 11happy <soni5happy@gmail.com>
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
Same as https://github.com/astral-sh/ty/pull/1391:
> Last time I ran this script, due to what I assume was a `npm` version
mismatch, the `package-lock.json` file was updated while running `npm
install` in the `schemastore`. Due to the use of `git commit -a`, it was
accidentally included in the commit for the semi-automated schemastore
PR. The solution here is to only add the actual file that we want to
commit.
## Summary
Derived from #20900
Implement `VarianceInferable` for `KnownInstanceType` (especially for
`KnownInstanceType::TypeAliasType`).
The variance of a type alias matches its value type. In normal usage,
type aliases are expanded to value types, so the variance of a type
alias can be obtained without implementing this. However, for example,
if we want to display the variance when hovering over a type alias, we
need to be able to obtain the variance of the type alias itself (cf.
#20900).
## Test Plan
I couldn't come up with a way to test this in mdtest, so I'm testing it
in a test submodule at the end of `types.rs`.
I also added a test to `mdtest/generics/pep695/variance.md`, but it
passes without the changes in this PR.
## Summary
Fixes#20774 by tracking whether an `InterpolatedStringState` element is
nested inside of another interpolated element. This feels like kind of a
naive fix, so I'm welcome to other ideas. But it resolves the problem in
the issue and clears up the syntax error in the black compatibility
test, without affecting many other cases.
The other affected case is actually interesting too because the
[input](96b156303b/crates/ruff_python_formatter/resources/test/fixtures/ruff/expression/fstring.py (L707))
is invalid, but the previous quote selection fixed the invalid syntax:
```pycon
Python 3.11.13 (main, Sep 2 2025, 14:20:25) [Clang 20.1.4 ] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> f'{1: abcd "{'aa'}" }' # input
File "<stdin>", line 1
f'{1: abcd "{'aa'}" }'
^^
SyntaxError: f-string: expecting '}'
>>> f'{1: abcd "{"aa"}" }' # old output
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: Invalid format specifier ' abcd "aa" ' for object of type 'int'
>>> f'{1: abcd "{'aa'}" }' # new output
File "<stdin>", line 1
f'{1: abcd "{'aa'}" }'
^^
SyntaxError: f-string: expecting '}'
```
We now preserve the invalid syntax in the input.
Unfortunately, this also seems to be another edge case I didn't consider
in https://github.com/astral-sh/ruff/pull/20867 because we don't flag
this as a syntax error after 0.14.1:
<details><summary>Shell output</summary>
<p>
```
> uvx ruff@0.14.0 check --ignore ALL --target-version py311 - <<EOF
f'{1: abcd "{'aa'}" }'
EOF
invalid-syntax: Cannot reuse outer quote character in f-strings on Python 3.11 (syntax was added in Python 3.12)
--> -:1:14
|
1 | f'{1: abcd "{'aa'}" }'
| ^
|
Found 1 error.
> uvx ruff@0.14.1 check --ignore ALL --target-version py311 - <<EOF
f'{1: abcd "{'aa'}" }'
EOF
All checks passed!
> uvx python@3.11 -m ast <<EOF
f'{1: abcd "{'aa'}" }'
EOF
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "/home/brent/.local/share/uv/python/cpython-3.11.13-linux-x86_64-gnu/lib/python3.11/ast.py", line 1752, in <module>
main()
File "/home/brent/.local/share/uv/python/cpython-3.11.13-linux-x86_64-gnu/lib/python3.11/ast.py", line 1748, in main
tree = parse(source, args.infile.name, args.mode, type_comments=args.no_type_comments)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/brent/.local/share/uv/python/cpython-3.11.13-linux-x86_64-gnu/lib/python3.11/ast.py", line 50, in parse
return compile(source, filename, mode, flags,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<stdin>", line 1
f'{1: abcd "{'aa'}" }'
^^
SyntaxError: f-string: expecting '}'
```
</p>
</details>
I assumed that was the same `ParseError` as the one caused by
`f"{1:""}"`, but this is a nested interpolation inside of the format
spec.
## Test Plan
New test copied from the black compatibility test. I guess this is a
duplicate now, I started working on this branch before the new black
tests were imported, so I could delete the separate test in our fixtures
if that's preferable.
## Summary
Support `dataclass_transform` when used on a (base) class.
## Typing conformance
* The changes in `dataclasses_transform_class.py` look good, just a few
mistakes due to missing `alias` support.
* I didn't look closely at the changes in
`dataclasses_transform_converter.py` since we don't support `converter`
yet.
## Ecosystem impact
The impact looks huge, but it's concentrated on a single project (ibis).
Their setup looks more or less like this:
* the real `Annotatable`:
d7083c2c96/ibis/common/grounds.py (L100-L101)
* the real `DataType`:
d7083c2c96/ibis/expr/datatypes/core.py (L161-L179)
* the real `Array`:
d7083c2c96/ibis/expr/datatypes/core.py (L1003-L1006)
```py
from typing import dataclass_transform
@dataclass_transform()
class Annotatable:
pass
class DataType(Annotatable):
nullable: bool = True
class Array[T](DataType):
value_type: T
```
They expect something like `Array([1, 2])` to work, but ty, pyright,
mypy, and pyrefly would all expect there to be a first argument for the
`nullable` field on `DataType`. I don't really understand on what
grounds they expect the `nullable` field to be excluded from the
signature, but this seems to be the main reason for the new diagnostics
here. Not sure if related, but it looks like their typing setup is not
really complete
(https://github.com/ibis-project/ibis/issues/6844#issuecomment-1868274770,
this thread also mentions `dataclass_transform`).
## Test Plan
Update pre-existing tests.
Detect legacy namespace packages and treat them like namespace packages
when looking them up as the *parent* of the module we're interested in.
In all other cases treat them like a regular package.
(This PR is coauthored by @MichaReiser in a shared coding session)
Fixes https://github.com/astral-sh/ty/issues/838
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Prefer the declared type for collection literals, e.g.,
```py
x: list[Any] = [1, "2", (3,)]
reveal_type(x) # list[Any]
```
This solves a large part of https://github.com/astral-sh/ty/issues/136
for invariant generics, where respecting the declared type is a lot more
important. It also means that annotated dict literals with `dict[_,
Any]` is a way out of https://github.com/astral-sh/ty/issues/1248.
We have to track whether a typevar appears in a position where it's
inferable or not. In a non-inferable position (in the body of the
generic class or function that binds it), assignability must hold for
every possible specialization of the typevar. In an inferable position,
it only needs to hold for _some_ specialization.
https://github.com/astral-sh/ruff/pull/20093 is working on using
constraint sets to model assignability of typevars, and the constraint
sets that we produce will be the same for inferable vs non-inferable
typevars; what changes is what we _compare_ that constraint set to. (For
a non-inferable typevar, the constraint set must equal the set of valid
specializations; for an inferable typevar, it must not be `never`.)
When I first added support for tracking inferable vs non-inferable
typevars, it seemed like it would be easiest to have separate `Type`
variants for each. The alternative (which lines up with the Δ set in
[POPL15](https://doi.org/10.1145/2676726.2676991)) would be to
explicitly plumb through a list of inferable typevars through our type
property methods. That seemed cumbersome.
In retrospect, that was the wrong decision. We've had to jump through
hoops to translate types between the inferable and non-inferable
variants, which has been quite brittle. Combined with the original point
above, that much of the assignability logic will become more identical
between inferable and non-inferable, there is less justification for the
two `Type` variants. And plumbing an extra `inferable` parameter through
all of these methods turns out to not be as bad as I anticipated.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Use the declared type of variables as type context for the RHS of assignment expressions, e.g.,
```py
x: list[int | str]
x = [1]
reveal_type(x) # revealed: list[int | str]
```
## Summary
Ignore the type context when specializing a generic call if it leads to
an unnecessarily wide return type. For example, [the example mentioned
here](https://github.com/astral-sh/ruff/pull/20796#issuecomment-3403319536)
works as expected after this change:
```py
def id[T](x: T) -> T:
return x
def _(i: int):
x: int | None = id(i)
y: int | None = i
reveal_type(x) # revealed: int
reveal_type(y) # revealed: int
```
I also added extended our usage of `filter_disjoint_elements` to tuple
and typed-dict inference, which resolves
https://github.com/astral-sh/ty/issues/1266.
## Summary
Add support for the `field_specifiers` parameter on
`dataclass_transform` decorator calls.
closes https://github.com/astral-sh/ty/issues/1068
## Conformance test results
All true positives ✔️
## Ecosystem analysis
* `trio`: this is the kind of change that I would expect from this PR.
The code makes use of a dataclass `Outcome` with a `_unwrapped: bool =
attr.ib(default=False, eq=False, init=False)` field that is excluded
from the `__init__` signature, so we now see a bunch of
constructor-call-related errors going away.
* `home-assistant/core`: They have a `domain: str = attr.ib(init=False,
repr=False)` field and then use
```py
@domain.default
def _domain_default(self) -> str:
# …
```
This accesses the `default` attribute on `dataclasses.Field[…]` with a
type of `default: _T | Literal[_MISSING_TYPE.MISSING]`, so we get those
"Object of type `_MISSING_TYPE` is not callable" errors. I don't really
understand how that is supposed to work. Even if `_MISSING_TYPE` would
be absent from that union, what does this try to call? pyright also
issues an error and it doesn't seem to work at runtime? So this looks
like a true positive?
* `attrs`: Similar here. There are some new diagnostics on code that
tries to access `.validator` on a field. This *does* work at runtime,
but I'm not sure how that is supposed to type-check (without a [custom
plugin](2c6c395935/mypy/plugins/attrs.py (L575-L602))).
pyright errors on this as well.
* A handful of new false positives because we don't support `alias` yet
## Test Plan
Updated tests.
Summary
--
This PR unifies the two different ways Ruff and ty construct syntax
errors. Ruff has been storing the primary message in the diagnostic
itself, while ty attached the message to the primary annotation:
```
> ruff check try.py
invalid-syntax: name capture `x` makes remaining patterns unreachable
--> try.py:2:10
|
1 | match 42:
2 | case x: ...
| ^
3 | case y: ...
|
Found 1 error.
> uvx ty check try.py
WARN ty is pre-release software and not ready for production use. Expect to encounter bugs, missing features, and fatal errors.
Checking ------------------------------------------------------------ 1/1 files
error[invalid-syntax]
--> try.py:2:10
|
1 | match 42:
2 | case x: ...
| ^ name capture `x` makes remaining patterns unreachable
3 | case y: ...
|
Found 1 diagnostic
```
I think there are benefits to both approaches, and I do like ty's
version, but I feel like we should pick one (and it might help with
#20901 eventually). I slightly prefer Ruff's version, so I went with
that. Hopefully this isn't too controversial, but I'm happy to close
this if it is.
Note that this shouldn't change any other diagnostic formats in ty
because
[`Diagnostic::primary_message`](98d27c4128/crates/ruff_db/src/diagnostic/mod.rs (L177))
was already falling back to the primary annotation message if the
diagnostic message was empty. As a result, I think this change will
partially resolve the FIXME therein.
Test Plan
--
Existing tests with updated snapshots
This is the ultra-minimal implementation of
* https://github.com/astral-sh/ty/issues/296
that was previously discussed as a good starting point. In particular we
don't actually bother trying to figure out the exact python versions,
but we still mention "hey btw for No Reason At All... you're on python
3.10" when you try to access something that has a definition rooted in
the stdlib that we believe exists sometimes.
This is a drive-by improvement that I stumbled backwards into while
looking into
* https://github.com/astral-sh/ty/issues/296
I was writing some simple tests for "thing not in old version of stdlib"
diagnostics and checked what was added in 3.14, and saw
`compression.zstd` and to my surprise discovered that `import
compression.zstd` and `from compression import zstd` had completely
different quality diagnostics.
This is because `compression` and `compression.zstd` were *both*
introduced in 3.14, and so per VERSIONS policy only an entry for
`compression` was added, and so we don't actually have any definite info
on `compression.zstd` and give up on producing a diagnostic. However the
`from compression import zstd` form fails on looking up `compression`
and we *do* have an exact match for that, so it gets a better
diagnostic!
(aside: I have now learned about the VERSIONS format and I *really* wish
they would just enumerate all the submodules but, oh well!)
The fix is, when handling an import failure, if we fail to find an exact
match *we requery with the parent module*. In cases like
`compression.zstd` this lets us at least identify that, hey, not even
`compression` exists, and luckily that fixes the whole issue. In cases
where the parent module and submodule were introduced at different times
then we may discover that the parent module is in-range and that's fine,
we don't produce the richer stdlib diagnostic.
## Summary
`dataclasses.field` and field-specifier functions of commonly used
libraries like `pydantic`, `attrs`, and `SQLAlchemy` all return the
default type for the field (or `Any`) instead of an actual `Field`
instance, even if this is not what happens at runtime. Let's make use of
this fact and assume that *all* field specifiers return the type of the
default value of the field.
For standard dataclasses, this leads to more or less the same outcome
(see test diff for details), but this change is important for 3rd party
dataclass-transformers.
## Test Plan
Tested the consequences of this change on the field-specifiers branch as
well.
## Summary
Resolves https://github.com/astral-sh/ty/issues/1349.
Fix match statement value patterns to use equality comparison semantics
instead of incorrectly narrowing to literal types directly. Value
patterns use equality for matching, and equality can be overridden, so
we can't always narrow to the matched literal.
## Test Plan
Updated match.md with corrected expected types and an additional example
with explanation
---------
Co-authored-by: David Peter <mail@david-peter.de>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR implements `F702`
https://docs.astral.sh/ruff/rules/continue-outside-loop/ as semantic
syntax error.
## Test Plan
<!-- How was it tested? -->
Tests are already previously written in F702
---------
Signed-off-by: 11happy <soni5happy@gmail.com>
## Summary
Part of astral-sh/ty#1341
The following changes will be made to `Place`.
* Introduce `TypeOrigin`
* `Place::Type` -> `Place::Defined`
* `Place::Unbound` -> `Place::Undefined`
* `Boundness` -> `Definedness`
`TypeOrigin::Declared`+`Definedness::PossiblyUndefined` are patterns
that weren't considered before, but this PR doesn't address them yet,
only refactors.
## Test Plan
Refactoring
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
`airflow.datasets.DatasetEvent` has been removed in 3 but `AssetEvent`
might be added in the future
## Test Plan
<!-- How was it tested? -->
update the test fixture and reorg in the second commit
Summary
--
Fixes#20844 by refining the unsupported syntax error check for [PEP
701]
f-strings before Python 3.12 to allow backslash escapes and escaped
outer quotes
in the format spec part of f-strings. These are only disallowed within
the
f-string expression part on earlier versions. Using the examples from
the PR:
```pycon
>>> f"{1:\x64}"
'1'
>>> f"{1:\"d\"}"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: Invalid format specifier '"d"' for object of type 'int'
```
Note that the second case is a runtime error, but this is actually
avoidable if
you override `__format__`, so despite being pretty weird, this could
actually be
a valid use case.
```pycon
>>> class C:
... def __format__(*args, **kwargs): return "<C>"
...
>>> f"{C():\"d\"}"
'<C>'
```
At first I thought narrowing the range we check to exclude the format
spec would
only work for escapes, but it turns out that cases like `f"{1:""}"` are
already
covered by an existing `ParseError`, so we can just narrow the range of
both our
escape and quote checks.
Our comment check also seems to be working correctly because it's based
on the
actual tokens. A case like
[this](https://play.ruff.rs/9f1c2ff2-cd8e-4ad7-9f40-56c0a524209f):
```python
f"""{1:# }"""
```
doesn't include a comment token, instead the `#` is part of an
`InterpolatedStringLiteralElement`.
Test Plan
--
New inline parser tests
[PEP 701]: https://peps.python.org/pep-0701/
A large part of the diff on #20677 just involves threading a new
`inferable` parameter through all of the type property methods. In the
interests of making that PR easier to review, I've pulled that bit out
into here, so that it can be reviewed in isolation. This should be a
pure refactoring, with no logic changes or behavioral changes.
## Summary
I considered making a dedicated cargo profile for these, but the
`profiling` profile basically made all the modifications to `release`
that I would have also made.
## Test Plan
CI on this PR
## Summary
Fixed a typo. It should be "or", not "of". Both `.pop()` and `next()` on
an empty collection will raise `IndexError`, not "`[0]` of the `pop()`
function"
## Test Plan
n/a
Summary
--
This PR implements the black preview style from
https://github.com/psf/black/pull/4720. As of Python 3.14, you're
allowed to omit the parentheses around groups of exceptions, as long as
there's no `as` binding:
**3.13**
```pycon
Python 3.13.4 (main, Jun 4 2025, 17:37:06) [Clang 20.1.4 ] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> try: ...
... except (Exception, BaseException): ...
...
Ellipsis
>>> try: ...
... except Exception, BaseException: ...
...
File "<python-input-1>", line 2
except Exception, BaseException: ...
^^^^^^^^^^^^^^^^^^^^^^^^
SyntaxError: multiple exception types must be parenthesized
```
**3.14**
```pycon
Python 3.14.0rc2 (main, Sep 2 2025, 14:20:56) [Clang 20.1.4 ] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> try: ...
... except Exception, BaseException: ...
...
Ellipsis
>>> try: ...
... except (Exception, BaseException): ...
...
Ellipsis
>>> try: ...
... except Exception, BaseException as e: ...
...
File "<python-input-2>", line 2
except Exception, BaseException as e: ...
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
SyntaxError: multiple exception types must be parenthesized when using 'as'
```
I think this ended up being pretty straightforward, at least once Micha
showed me where to start :)
Test Plan
--
New tests
At first I thought we were deviating from black in how we handle
comments within the exception type tuple, but I think this applies to
how we format all tuples, not specifically with the new preview style.
Summary
--
```shell
git clone git@github.com:psf/black.git ../other/black
crates/ruff_python_formatter/resources/test/fixtures/import_black_tests.py ../other/black
```
Then ran our tests and accepted the snapshots
I had to make a small fix to our tuple normalization logic for `del`
statements
in the second commit, otherwise the tests were panicking at a changed
AST. I
think the new implementation is closer to the intention described in the
nearby
comment anyway, though.
The first commit adds the new Python, settings, and `.expect` files, the
next three commits make some small
fixes to help get the tests running, and then the fifth commit accepts
all but one of the new snapshots. The last commit includes the new
unsupported syntax error for one f-string example, tracked in #20774.
Test Plan
--
Newly imported tests. I went through all of the new snapshots and added
review comments below. I think they're all expected, except a few cases
I wasn't 100% sure about.
## Summary
If a function is decorated with a decorator that returns a union of
`Callable`s, also treat it as a union of function-like `Callable`s.
Labeling as `internal`, since the previous change has not been released
yet.
## Test Plan
New regression test.
## Summary
Rename "unwrapping" methods on `Type` from e.g.
`Type::into_class_literal` to `Type::as_class_literal`. I personally
find that name more intuitive, since no transformation of any kind is
happening. We are just unwrapping from certain enum variants. An
alternative would be `try_as_class_literal`, which would follow the
[`strum` naming
scheme](https://docs.rs/strum/latest/strum/derive.EnumTryAs.html), but
is slightly longer.
Also rename `Type::into_callable` to `Type::try_upcast_to_callable`.
Note that I intentionally kept names like
`FunctionType::into_callable_type`, because those return `CallableType`,
not `Option<Type<…>>`.
## Test Plan
Pure refactoring
As part of #20598, we added `is_identical_to` methods to
`TypeVarInstance` and `BoundTypeVarInstance`, which compare when two
typevar instances refer to "the same" underlying typevar, even if we
have forced their lazy bounds/constraints as part of marking typevars as
inferable. (Doing so results in a different salsa interned struct ID,
since we've changed the contents of the `bounds_or_constraints` field.)
It turns out that marking typevars as inferable is not the only way that
we might force lazy bounds/constraints; it also happens when we
materialize a type containing a typevar. This surfaced as ecosystem
report failures on #20677.
That means that we need a more long-term fix to this problem.
(`is_identical_to`, and its underlying `original` field, were meant to
be a temporary fix until we removed the `MarkTypeVarsInferable` type
mapping.)
This PR extracts out a separate type (`TypeVarIdentity`) that only
includes the fields that actually inform whether two typevars are "the
same". All other properties of the typevar (default, bounds/constraints,
etc) still live in `TypeVarInstance`. Call sites that care about typevar
identity can now either store just `TypeVarIdentity` (if they never need
access to those other properties), or continue to store
`TypeVarInstance` but pull out its `identity` when performing those "are
they the same typevar" comparisons. (All of this also applies
respectively to `BoundTypeVar{Identity,Instance}`.) In particular,
constraint sets now work on `BoundTypeVarIdentity`, and generic contexts
still _store_ a `BoundTypeVarInstance` (since we might need access to
defaults when specializing), but are keyed on `BoundTypeVarIdentity`.
Generic classes are not allowed to bind or reference a typevar from an
enclosing scope:
```py
def f[T](x: T, y: T) -> None:
class Ok[S]: ...
# error: [invalid-generic-class]
class Bad1[T]: ...
# error: [invalid-generic-class]
class Bad2(Iterable[T]): ...
class C[T]:
class Ok1[S]: ...
# error: [invalid-generic-class]
class Bad1[T]: ...
# error: [invalid-generic-class]
class Bad2(Iterable[T]): ...
```
It does not matter if the class uses PEP 695 or legacy syntax. It does
not matter if the enclosing scope is a generic class or function. The
generic class cannot even _reference_ an enclosing typevar in its base
class list.
This PR adds diagnostics for these cases.
In addition, the PR adds better fallback behavior for generic classes
that violate this rule: any enclosing typevars are not included in the
class's generic context. (That ensures that we don't inadvertently try
to infer specializations for those typevars in places where we
shouldn't.) The `dulwich` ecosystem project has [examples of
this](d912eaaffd/dulwich/config.py (L251))
that were causing new false positives on #20677.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR implements https://docs.astral.sh/ruff/rules/break-outside-loop/
(F701) as a semantic syntax error.
## Test Plan
<!-- How was it tested? -->
---------
Signed-off-by: 11happy <soni5happy@gmail.com>
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
## Summary
Treat `Callable`s as bound-method descriptors if `Callable` is the
return type of a decorator that is applied to a function definition. See
the [rendered version of the new test
file](https://github.com/astral-sh/ruff/blob/david/callables-as-descriptors/crates/ty_python_semantic/resources/mdtest/call/callables_as_descriptors.md)
for the full description of this new heuristic.
I could imagine that we want to treat `Callable`s as bound-method
descriptors in other cases as well, but this seems like a step in the
right direction. I am planning to add other "use cases" from
https://github.com/astral-sh/ty/issues/491 to this test suite.
partially addresses https://github.com/astral-sh/ty/issues/491
closes https://github.com/astral-sh/ty/issues/1333
## Ecosystem impact
All positive
* 2961 removed `unsupported-operator` diagnostics on `sympy`, which was
one of the main motivations for implementing this change
* 37 removed `missing-argument` diagnostics, and no added call-error
diagnostics, which is an indicator that this heuristic shouldn't cause
many false positives
* A few removed `possibly-missing-attribute` diagnostics when accessing
attributes like `__name__` on decorated functions. The two added
`unused-ignore-comment` diagnostics are also cases of this.
* One new `invalid-assignment` diagnostic on `dd-trace-py`, which looks
suspicious, but only because our `invalid-assignment` diagnostics are
not great. This is actually a "Implicit shadowing of function"
diagnostic that hides behind the `invalid-assignment` diagnostic,
because a module-global function is being patched through a
`module.func` attribute assignment.
## Test Plan
New Markdown tests.
This PR resolves the issue noticed in
https://github.com/astral-sh/ruff/pull/20777#discussion_r2417233227.
Namely, cases like this were being flagged as syntax errors despite
being perfectly valid on Python 3.8:
```pycon
Python 3.8.20 (default, Oct 2 2024, 16:34:12)
[Clang 18.1.8 ] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> with (open("foo.txt", "w")): ...
...
Ellipsis
>>> with (open("foo.txt", "w")) as f: print(f)
...
<_io.TextIOWrapper name='foo.txt' mode='w' encoding='UTF-8'>
```
The second of these was already allowed but not the first:
```shell
> ruff check --target-version py38 --ignore ALL - <<EOF
with (open("foo.txt", "w")): ...
with (open("foo.txt", "w")) as f: print(f)
EOF
invalid-syntax: Cannot use parentheses within a `with` statement on Python 3.8 (syntax was added in Python 3.9)
--> -:1:6
|
1 | with (open("foo.txt", "w")): ...
| ^
2 | with (open("foo.txt", "w")) as f: print(f)
|
Found 1 error.
```
There was some discussion of related cases in
https://github.com/astral-sh/ruff/pull/16523#discussion_r1984657793, but
it seems I overlooked the single-element case when flagging tuples. As
suggested in the other thread, we can just check if there's more than
one element or a trailing comma, which will cause the tuple parsing on
<=3.8 and avoid the false positives.
## Summary
Based on the suggestion in
https://github.com/astral-sh/ruff/issues/20774#issuecomment-3383153511,
I added rendering of unsupported syntax errors in our `format` test.
In support of this, I added a `DummyFileResolver` type to `ruff_db` to
pass to `DisplayDiagnostics::new` (first commit). Another option would
obviously be implementing this directly in the fixtures, but we'd have
to import a `NotebookIndex` somehow; either by depending directly on
`ruff_notebook` or re-exporting it from `ruff_db`. I thought it might be
convenient elsewhere to have a dummy resolver, for example in the
parser, where we currently have a separate rendering pipeline
[copied](https://github.com/astral-sh/ruff/blob/main/crates/ruff_python_parser/tests/fixtures.rs#L321)
from our old rendering code in `ruff_linter`. I also briefly tried
implementing a `TestDb` in the formatter since I noticed the
`ruff_python_formatter::db` module, but that was turning into a lot more
code than the dummy resolver.
We could also push this a bit further if we wanted. I didn't add the new
snapshots to the black compatibility tests or to the preview snapshots,
for example. I thought it was kind of noisy enough (and helpful enough)
already, though. We could also use a shorter diagnostic format, but the
full output seems most useful once we accept this initial large batch of
changes.
## Test Plan
I went through the baseline snapshots pretty quickly, but they all
looked reasonable to me, with one exception I noted below. I also tested
that the case from #20774 produces a new unsupported syntax error.
## Summary
Move the `class_member` function to the `member` module. This allows us
to move the `member` module into the `types` module and to reduce the
visibility of its contents to `pub(super)`. The drawback is that we need
to make `place::place_by_id` public.
## Test Plan
Pure refactoring.
## Summary
When accessing an (instance) attribute on a given class, we were
previously traversing its MRO, and building a union of types (if the
attribute was available on multiple classes in the MRO) until we found a
*definitely bound* symbol. The idea was that possibly unbound symbols in
a subclass might only partially shadow the underlying base class
attribute.
This behavior was problematic for two reasons:
* if the attribute was definitely bound on a class (e.g. `self.x =
None`), we would have stopped iterating, even if there might be a `x:
str | None` declaration in a base class (the bug reported in
https://github.com/astral-sh/ty/issues/1067).
* if the attribute originated from an implicit instance attribute
assignment (e.g. `self.x = 1` in method `Sub.foo`), we might stop
looking and miss another implicit instance attribute assignment in a
base class method (e.g. `self.x = 2` in method `Base.bar`).
With this fix, we still iterate the MRO of the class, but we only stop
iterating if we find a *definitely declared* symbol. In this case, we
only return the declared attribute type. Otherwise, we keep building a
union of inferred attribute types.
The implementation here seemed to be the easiest fix for
https://github.com/astral-sh/ty/issues/1067 that also kept the ecosystem
impact low (the changes that I see all look correct). However, as the
Markdown tests show, there are other things to fix in this area. For
example, we should do a similar thing for *class attributes*. This is
more involved, though (affects many different areas and probably
involves a change to our descriptor protocol implementation), so I'd
like to postpone this to a follow-up.
closes https://github.com/astral-sh/ty/issues/1067
## Test Plan
Updated Markdown tests, including a regression test for
https://github.com/astral-sh/ty/issues/1067.
## Summary
Implements bidirectional type inference using function return type
annotations.
This PR was originally proposed to solve astral-sh/ty#1167, but this
does not fully resolve it on its own.
Additionally, I believe we need to allow dataclasses to generate their
own `__new__` methods, [use constructor return types for
inference](5844c0103d/crates/ty_python_semantic/src/types.rs (L5326-L5328)),
and a mechanism to discard type narrowing like `& ~AlwaysFalsy` if
necessary (at a more general level than this PR).
## Test Plan
`mdtest/bidirectional.md` is added.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Ibraheem Ahmed <ibraheem@ibraheem.ca>
## Summary
Resolves#19384.
- Distinguishes more clearly between `date` and `datetime` objects.
- Uniformly links to the relevant Python docs from rules in this
category.
I've tried to be clearer, but there's still a contradiction in the rules
as written: we say "use timezone-aware objects", but `date`s are
inherently timezone-naive.
Also, the full docs don't always match the error message: for instance,
in [DTZ012](https://docs.astral.sh/ruff/rules/call-date-fromtimestamp/),
the example says to use:
```python
datetime.datetime.fromtimestamp(946684800, tz=datetime.UTC)
```
while `fix_title` returns "Use `datetime.datetime.fromtimestamp(ts,
tz=...)**.date()**` instead".
I have left this as it was for now.
## Test Plan
Ran `mkdocs` locally and inspected result.
## Summary
Adds a set of basic new tests corresponding to open points in
https://github.com/astral-sh/ty/issues/1327, to document the state of
support for `dataclass_transform`.
## Summary
Type annotations are deferred by default starting with Python 3.14. No
`from __future__ import annotations` import is necessary.
## Test Plan
New Markdown test
## Summary
Simplify and fix the implementation of
`ty_extensions.CallableTypeOf[..]`.
closes https://github.com/astral-sh/ty/issues/1331
## Test Plan
Added regression test.
## Summary
The original autofix for G004 was quietly dropping everything but the
f-string components of any implicit concatenation sequence; this
addresses that.
Side note: It looks like `f_strings` is a bit risky to use (since it
implicitly skips non-f-string parts); use iter and include implicitly
concatenated pieces. We should consider if it's worth having
(convenience vs. bit risky).
## Test Plan
```
cargo test -p ruff_linter
```
Backtest (run new testcases against previous implementation):
```
git checkout HEAD^ crates/ruff_linter/src/rules/flake8_logging_format/rules/logging_call.rs
cargot test -p ruff_linter
```
## Summary
This allows us to handle self-referential bounds/constraints/defaults
without panicking.
Handles more cases from https://github.com/astral-sh/ty/issues/256
This also changes the way we infer the types of legacy TypeVars. Rather
than understanding a constructor call to `typing[_extension].TypeVar`
inside of any (arbitrarily nested) expression, and having to use a
special `assigned_to` field of the semantic index to try to best-effort
figure out what name the typevar was assigned to, we instead understand
the creation of a legacy `TypeVar` only in the supported syntactic
position (RHS of a simple un-annotated assignment with one target). In
any other position, we just infer it as creating an opaque instance of
`typing.TypeVar`. (This behavior matches all other type checkers.)
So we now special-case TypeVar creation in `TypeInferenceBuilder`, as a
special case of an assignment definition, rather than deeper inside call
binding. This does mean we re-implement slightly more of
argument-parsing, but in practice this is minimal and easy to handle
correctly.
This is easier to implement if we also make the RHS of a simple (no
unpacking) one-target assignment statement no longer a standalone
expression. Which is fine to do, because simple one-target assignments
don't need to infer the RHS more than once. This is a bonus performance
(0-3% across various projects) and significant memory-usage win, since
most assignment statements are simple one-target assignment statements,
meaning we now create many fewer standalone-expression salsa
ingredients.
This change does mean that inference of manually-constructed
`TypeAliasType` instances can no longer find its Definition in
`assigned_to`, which regresses go-to-definition for these aliases. In a
future PR, `TypeAliasType` will receive the same treatment that
`TypeVar` did in this PR (moving its special-case inference into
`TypeInferenceBuilder` and supporting it only in the correct syntactic
position, and lazily inferring its value type to support recursion),
which will also fix the go-to-definition regression. (I decided a
temporary edge-case regression is better in this case than doubling the
size of this PR.)
This PR also tightens up and fixes various aspects of the validation of
`TypeVar` creation, as seen in the tests.
We still (for now) treat all typevars as instances of `typing.TypeVar`,
even if they were created using `typing_extensions.TypeVar`. This means
we'll wrongly error on e.g. `T.__default__` on Python 3.11, even if `T`
is a `typing_extensions.TypeVar` instance at runtime. We share this
wrong behavior with both mypy and pyrefly. It will be easier to fix
after we pull in https://github.com/python/typeshed/pull/14840.
There are some issues that showed up here with typevar identity and
`MarkTypeVarsInferable`; the fix here (using the new `original` field
and `is_identical_to` methods on `BoundTypeVarInstance` and
`TypeVarInstance`) is a bit kludgy, but it can go away when we eliminate
`MarkTypeVarsInferable`.
## Test Plan
Added and updated mdtests.
### Conformance suite impact
The impact here is all positive:
* We now correctly error on a legacy TypeVar with exactly one constraint
type given.
* We now correctly error on a legacy TypeVar with both an upper bound
and constraints specified.
### Ecosystem impact
Basically none; in the setuptools case we just issue slightly different
errors on an invalid TypeVar definition, due to the modified validation
code.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Avoid literal promotion when a literal type annotation is provided, e.g.,
```py
x: list[Literal[1]] = [1]
```
Resolves https://github.com/astral-sh/ty/issues/1198. This does not fix
issue https://github.com/astral-sh/ty/issues/1284, but it does make it
more relevant because after this change, it is possible to directly
instantiate a generic type with a literal specialization.
## Summary
Respect parameters such as `frozen_default` for metaclass-based
`@dataclass_transformer` models.
Related to: https://github.com/astral-sh/ty/issues/1260
## Typing conformance changes
Those are all correct (new true positives)
## Test Plan
New Markdown tests
## Summary
- Add support for eq, kw_only, and frozen parameter overrides in
@dataclass_transform
- Previously only order parameter override was supported
- Update test documentation to reflect fixed behavior
- Resolves issue where kw_only_default and frozen_default could not be
overridden
closes https://github.com/astral-sh/ty/issues/1260
## Test Plan
New Markdown tests
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
Two stable property tests are currently failing on `main`, following
f054b8a55e
(of course, I only thought to run the property tests again around 30
minutes _after_ landing that PR...). The issue is quite subtle, and took
me an annoying amount of time to pin down: we're matching over `(self,
other)` in `Type::is_disjoint_from_impl`, but `other` here is shadowed
by the binding in the `match` branch, which means that the wrong key is
inserted into the cache of the `IsDisjointFrom` cycle detector:
f054b8a55e/crates/ty_python_semantic/src/types.rs (L2408-L2435)
This PR fixes that issue, and also adds a few `Debug` implementations to
our cycle detectors, so that issues like this are easier to debug in the
future.
I'm adding the `internal` label, as this fixes a bug that hasn't yet
appeared in any released version of ty, so it doesn't deserve its own
changelog entry.
## Test Plan
`QUICKCHECK_TESTS=1000000 cargo test --release -p ty_python_semantic --
--ignored types::property_tests::stable` now once again passes on `main`
I considered adding new mdtests as well, but the examples that the
property tests were throwing at me all seemed _quite_ obscure and
somewhat unlikely to occur in the real world. I don't think it's worth
it.
## Summary
Even disambiguating classes using their fully qualified names is not
enough for some diagnostics. We've seen real-world examples in the
ecosystem (and https://github.com/astral-sh/ruff/pull/20368 introduces
some more!) where two types can be different, but can still have the
same fully qualified name. In these cases, our disambiguation machinery
needs to print the file path and line number of the class in order to
disambiguate classes with similar names in our diagnostics.
Helps with https://github.com/astral-sh/ty/issues/1306
## Test Plan
Mdtests
## Summary
This adds a couple of new test cases related to
https://github.com/astral-sh/ty/issues/1067 and beyond that. For now,
they are just documenting the current (problematic) behavior. Since the
topic has some subtleties, I'd like to merge this prior to the actual
bugfix(es) in order to evaluate the changes in an easier way.
## Summary
The `types` module currently re-exports a lot of functions and data
types from `types::ide_support`. One of these is called `Member`, a name
that is overloaded several times already. And I'd like to add one more
`Member` struct soon. Making the whole `ide_support` module public seems
cleaner to me, anyway.
## Test Plan
Pure refactoring.
This is still early days, but I hope the framework introduced here makes
it very easy to add new truth data. Truth data should be seen as a form
of regression test for non-ideal ranking of completion suggestions.
I think it would help to read `crates/ty_completion_eval/README.md`
first to get an idea of what you're reviewing.
## Summary
We have the following test in `protocols.md`:
```py
class HasX(Protocol):
x: int
# […]
class Foo:
x: int
# […]
class FooBool(Foo):
x: bool
static_assert(not is_subtype_of(FooBool, HasX))
static_assert(not is_assignable_to(FooBool, HasX))
```
If `Foo` was indeed intended to be a base class of `FooBool`, then `x:
bool` should be reported as a Liskov violation. And then it's a matter
of definition whether or not these assertions should hold true or not
(should the incorrect override take precedence or not?). So it looks to
me like this is just an oversight, probably a copy-paste error from
another test right before it, where `FooSub` is indeed intended to be a
subclass of `Foo`.
I am fixing this because this test started to fail on a branch of mine
that changes how attribute lookup in inheritance chains works.
## Summary
Fixes [astral-sh/ty#1307](https://github.com/astral-sh/ty/issues/1307)
Unions with length <= 5 are unaffected to minimize test churn
Unions with length > 5 will only display the first 3 elements + "...
omitted x union elements"
Here "length" is defined as the number of elements after condensation to
literals
Edit: we no longer truncate in revel case.
Before:
> info: Attempted to call union type `(def f1() -> int) | (def f2(name:
str) -> int) | (def f3(a: int, b: int) -> int) | (def f4[T](x: T@f4) ->
int) | Literal[5] | (Overload[() -> None, (x: str) -> str]) |
(Overload[() -> None, (x: str, y: str) -> str]) | PossiblyNotCallable`
After:
> info: Attempted to call union type `(def f1() -> int) | (def f2(name:
str) -> int) | (def f3(a: int, b: int) -> int) | ... omitted 5 union
elements`
The below comparisons are outdated, but left here as a reference.
Before:
```reveal_type(x) # revealed: Literal[1, 2] | A | B | C | D | E | F | G```
```reveal_type(x) # revealed: Result1A | Result1B | Result2A | Result2B
| Result3 | Result4```
After:
```reveal_type(x) # revealed: Literal[1, 2] | A | B | ... omitted 5 union elements```
```reveal_type(x) # revealed: Result1A | Result1B | Result2A | ...
omitted 3 union elements```
This formatting is consistent with
`crates/ty_python_semantic/src/types/call/bind.rs` line 2992
## Test Plan
Cosmetic only, covered and verified by changes in mdtest
## Summary
Bump the latest supported Python version of ty to 3.14 and updates some
references from 3.13 to 3.14.
This also fixes a bug with `dataclasses.field` on 3.14 (which adds a new
keyword-only parameter to that function, breaking our previously naive
matching on the parameter structure of that function).
## Test Plan
A `ty check` on a file with template strings (without any further
configuration) doesn't raise errors anymore.
## Summary
Typevar attributes (bound/constraints/default) can be either lazily
evaluated or eagerly evaluated. Currently they are lazily evaluated for
PEP 695 typevars, and eager for legacy and synthetic typevars.
https://github.com/astral-sh/ruff/pull/20598 will make them lazy also
for legacy typevars, and the ecosystem report on that PR surfaced the
issue fixed here (because legacy typevars are much more common in the
ecosystem than PEP 695 typevars.)
Applying a transform to a typevar (normalization, materialization, or
mark-inferable) will reify all lazy attributes and create a new typevar
with eager attributes. In terms of Salsa identity, this transformed
typevar will be considered different from the original typevar, whether
or not the attributes were actually transformed.
In general, this is not a problem, since all typevars in a given generic
context will be transformed, or not, together.
The exception to this was implicit-self vs explicit Self annotations.
The typevar we created for implicit self was created initially using
inferable typevars, whereas an explicit Self annotation is initially
non-inferable, then transformed via mark-inferable when accessed as part
of a function signature. If the containing class (which becomes the
upper bound of `Self`) is generic, and has e.g. a lazily-evaluated
default, then the explicit-Self annotation will reify that default in
the upper bound, and the implicit-self would not, leading them to be
treated as different typevars, and causing us to fail to solve a call to
a method such as `def method(self) -> Self` correctly.
The fix here is to treat implicit-self more like explicit-Self,
initially creating it as non-inferable and then using the mark-inferable
transform on it. This is less efficient, but restores the invariant that
all typevars in a given generic context are transformed together, or
not, fixing the bug.
In the improved-constraint-solver work, the separation of typevars into
"inferable" and "non-inferable" is expected to disappear, along with the
mark-inferable transform, which would render both this bug and the fix
moot. So this fix is really just temporary until that lands.
There is a performance regression, but not a huge one: 1-2% on most
projects, 5% on one outlier. This seems acceptable, given that it should
be fully recovered by removing the mark-inferable transform.
## Test Plan
Added mdtests that failed before this change.
Resolves https://github.com/astral-sh/ruff/issues/20694
This PR updates the `zip_without_explicit_strict` and
`map_without_explicit_strict` rules so their fixes are always marked
unsafe, following Brent's guidance that adding `strict=False` can
silently preserve buggy behaviour when inputs differ. The fix safety
docs now spell out that reasoning, the applicability drops to `Unsafe`,
and the snapshots were refreshed so Ruff clearly warns users before
applying the edit.
This PR adds a specialization inference special case that lets us handle
the following examples better:
```py
def f[T](t: T | None) -> T: ...
def g[T](t: T | int | None) -> T | int: ...
def _(x: str | None):
reveal_type(f(x)) # revealed: str (previously str | None)
def _(y: str | int | None):
reveal_type(g(x)) # revealed: str | int (previously str | int | None)
```
We already have a special case for when the formal is a union where one
element is a typevar, but it maps the entire actual type to the typevar
(as you can see in the "previously" results above).
The new special case kicks in when the actual is also a union. Now, we
filter out any actual union elements that are already subtypes of the
formal, and only bind whatever types remain to the typevar. (The `|
None` pattern appears quite often in the ecosystem results, but it's
more general and works with any number of non-typevar union elements.)
The new constraint solver should handle this case as well, but it's
worth adding this heuristic now with the old solver because it
eliminates some false positives from the ecosystem report, and makes the
ecosystem report less noisy on the other constraint solver PRs.
Summary
--
Closes#19467 and also removes the warning about using Python 3.14
without
preview enabled.
I also bumped `PythonVersion::default` to 3.9 because it reaches EOL
this month,
but we could also defer that for now if we wanted.
The first three commits are related to the `latest` bump to 3.14; the
fourth commit
bumps the default to 3.10.
Note that this PR also bumps the default Python version for ty to 3.10
because
there was a test asserting that it stays in sync with
`ast::PythonVersion`.
Test Plan
--
Existing tests
I spot-checked the ecosystem report, and I believe these are all
expected. Inbits doesn't specify a target Python version, so I guess
we're applying the default. UP007, UP035, and UP045 all use the new
default value to emit new diagnostics.
Resolves a crash when attempting to format code like:
```
from x import (a as # whatever
b)
```
Reworks the way comments are associated with nodes when parsing modules,
so that all possible comment positions can be retained and reproduced during
formatting.
Overall follows Black's formatting style for multi-line import statements.
Fixes issue #19138
## Summary
`infer_method_information` was previously calling
`ClassLiteral::to_class_type`, which uses the default-specialization of
a generic class. This specialized `ClassType` was later only used if the
class was non-generic, making the specialization irrelevant. The
implementation was still a bit confusing, so this PR proposes a way to
avoid turning the class literal into a `ClassType`.
## Summary
Fixes#20700
`else` and `elif` blocks could previously be deleted when applying a fix
for this rule. If an `else` or `elif` branch is detected the rule will
not trigger. So now the rule will only flag if it is safe.
## Summary
Use the type annotation of function parameters as bidirectional type
context when inferring the argument expression. For example, the
following example now type-checks:
```py
class TD(TypedDict):
x: int
def f(_: TD): ...
f({ "x": 1 })
```
Part of https://github.com/astral-sh/ty/issues/168.
We add an `inherited_generic_context` to the constructors of a generic
class. That lets us infer specializations of the class when invoking the
constructor. The constructor might itself be generic, in which case we
have to merge the list of typevars that we are willing to infer in the
constructor call.
Before we did that by tracking the two (and their specializations)
separately, with distinct `Option` fields/parameters. This PR updates
our call binding logic such that any given function call has _one_
optional generic context that we're willing to infer a specialization
for. If needed, we use the existing `GenericContext::merge` method to
create a new combined generic context for when the class and constructor
are both generic. This simplifies the call binding code considerably,
and is no more complex in the constructor call logic.
We also have a heuristic that we will promote any literals in the
specialized types of a generic class, but we don't promote literals in
the specialized types of the function itself. To handle this, we now
track this `should_promote_literals` property within `GenericContext`.
And moreover, we track this separately for each typevar, instead of a
single property for the generic context as a whole, so that we can
correctly merge the generic context of a constructor method (where the
option should be `false`) with the inherited generic context of its
containing class (where the option should be `true`).
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
The union `T | U` can be validly simplified to `U` iff:
1. `T` is a subtype of `U` OR
2. `T` is equivalent to `U` OR
3. `U` is a union and contains a type that is equivalent to `T` OR
4. `T` is an intersection and contains a type that is equivalent to `U`
(In practice, the only situation in which 2, 3 or 4 would be true when
(1) was not true would be if `T` or `U` is a dynamic type.)
Currently we achieve these simplifications in the union builder by doing
something along the lines of `t.is_subtype_of(db, u) ||
t.is_equivalent_to_(db, u) ||
t.into_intersection().is_some_and(|intersection|
intersection.positive(db).contains(&u)) ||
u.into_union().is_some_and(|union| union.elements(db).contains(&t))`.
But this is both slow and misses some cases (it doesn't simplify the
union `Any | (Unknown & ~None)` to `Any`, for example). We can improve
the consistency and performance of our union simplifications by adding a
third type relation that sits in between `TypeRelation::Subtyping` and
`TypeRelation::Assignability`: `TypeRelation::UnionSimplification`.
This change leads to simpler, more user-friendly types due to the more
consistent simplification. It also lead to a pretty huge performance
improvement!
## Test Plan
Existing tests, plus some new ones.
## Summary
Resolves#20004
The implementation now supports guaranteed-mutable expressions in the
following cases:
- Tuple literals with mutable elements (supporting deep nesting)
- Generator expressions
- Named expressions (walrus operator) containing mutable components
Preserves original formatting for assignment value:
```python
# Test case
def f5(x=([1, ])):
print(x)
```
```python
# Fix before
def f5(x=(None)):
if x is None:
x = [1]
print(x)
```
```python
# Fix after
def f5(x=None):
if x is None:
x = ([1, ])
print(x)
```
The expansion of detected expressions and the new fixes gated behind
previews.
## Test Plan
- Added B006_9.py with a bunch of test cases
- Generated snapshots
---------
Co-authored-by: Igor Drokin <drokinii1017@gmail.com>
Co-authored-by: dylwil3 <dylwil3@gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
#19990 didn't completely fix the base vs. child conda environment
distinction, since it detected slightly different behavior than what I
usually see in conda. E.g., I see something like the following:
```
(didn't yet activate conda, but base is active)
➜ printenv | grep CONDA
CONDA_PYTHON_EXE=/opt/anaconda3/bin/python
CONDA_PREFIX=/opt/anaconda3
CONDA_DEFAULT_ENV=base
CONDA_EXE=/opt/anaconda3/bin/conda
CONDA_SHLVL=1
CONDA_PROMPT_MODIFIER=(base)
(activating conda)
➜ conda activate test
(test is an active conda environment)
❯ printenv | grep CONDA
CONDA_PREFIX=/opt/anaconda3/envs/test
CONDA_PYTHON_EXE=/opt/anaconda3/bin/python
CONDA_SHLVL=2
CONDA_PREFIX_1=/opt/anaconda3
CONDA_DEFAULT_ENV=test
CONDA_PROMPT_MODIFIER=(test)
CONDA_EXE=/opt/anaconda3/bin/conda
```
But the current behavior looks for `CONDA_DEFAULT_ENV =
basename(CONDA_PREFIX)` for the base environment instead of the child
environment, where we actually see this equality.
This pull request fixes that and updates the tests correspondingly.
## Test Plan
I updated the existing tests with the new behavior. Let me know if you
want more tests. Note: It shouldn't be necessary to test for the case
where we have `conda/envs/base`, since one should not be able to create
such an environment (one with the name of `CONDA_DEFAULT_ENV`).
---------
Co-authored-by: Aria Desires <aria.desires@gmail.com>
Resolves https://github.com/astral-sh/ruff/issues/20512
This PR expands FA102’s preview coverage to flag every
PEP 585-compatible API that breaks without from `from __future__ import
annotations`, including `collections.abc`. The rule now treats asyncio
futures, pathlib-style queues, weakref containers, shelve proxies, and
the full `collections.abc` family as generics once preview mode is
enabled.
Stable behavior is unchanged; the broader matching runs behind
`is_future_required_preview_generics_enabled`, letting us vet the new
diagnostics before marking them as stable.
I've also added a snapshot test that covers all of the newly supported
types.
Check out
https://docs.python.org/3/library/stdtypes.html#standard-generic-classes
for a list of commonly used PEP 585-compatible APIs.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#20655
- Guard `argfile::expand_args_from` with contextual error handling so
missing @file arguments surface a friendly failure instead of panicking.
- Extract existing stderr reporting into `report_error` for reuse on
both CLI parsing failures and runtime errors.
## Test Plan
<!-- How was it tested? -->
Add a regression test to integration_test.rs.
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#19837
Track quote usage across the joiner and parts to choose a safe f-string
quote or skip the fix when both appear.
## Test Plan
<!-- How was it tested? -->
Add regression coverage to FLY002.py
Previously, we would always add `/{*filepath}` as our wildcard to match
descendant paths. But when the root is just `/` (as it can be in tests,
weird environments or in the ty playground), this causes a double `/`
and inhibits most descendant matches.
The regression test added in this commit fails without this fix.
Specifically, it panics because it can't find a file root for
`/project`.
Fixes#1277
This has the effect of emitting tracing events via `log`
whenever there isn't an active tracing subscriber present.
This makes it so `ty_wasm` logs tracing messages to the
JavaScript console automatically (via our use of `console_log`).
## Summary
closes: https://github.com/astral-sh/ty/issues/247
This PR adds support for variadic arguments to overload call evaluation.
This basically boils down to making sure that the overloads are not
filtered out incorrectly during the step 5 in the overload call
evaluation algorithm. For context, the step 5 tries to filter out the
remaining overloads after finding an overload where the materialization
of argument types are assignable to the parameter types.
The issue with the previous implementation was that it wouldn't unpack
the variadic argument and wouldn't consider the many-to-one (multiple
arguments mapping to a single variadic parameter) correctly. This PR
fixes that.
## Test Plan
Update existing test cases and resolve the TODOs.
## Summary
Currently we do not emit an error on this code:
```py
from ty_extensions import Not
def f[T](x: T, y: Not[T]) -> T:
x = y
return x
```
But we should do! `~T` should never be assignable to `T`.
This fixes a small regression introduced in
14fe1228e7 (diff-8049ab5af787dba29daa389bbe2b691560c15461ef536f122b1beab112a4b48aR1443-R1446),
where a branch that previously returned `false` was replaced with a
branch that returns `C::always_satisfiable` -- the opposite of what it
used to be! The regression occurred because we didn't have any tests for
this -- so I added some tests in this PR that fail on `main`. I only
spotted the problem because I was going through the code of
`has_relation_to_impl` with a fine toothcomb for
https://github.com/astral-sh/ruff/pull/20602😄
## Summary
Quoting from the newly added comment:
Module-level globals can be mutated externally. A `MY_CONSTANT = 1`
global might be changed to `"some string"` from code outside of the
module that we're looking at, and so from a gradual-guarantee
perspective, it makes sense to infer a type of `Literal[1] | Unknown`
for global symbols. This allows the code that does the mutation to type
check correctly, and for code that uses the global, it accurately
reflects the lack of knowledge about the type.
External modifications (or modifications through `global` statements)
that would require a wider type are relatively rare. From a practical
perspective, we can therefore achieve a better user experience by
trusting the inferred type. Users who need the external mutation to work
can always annotate the global with the wider type. And everyone else
benefits from more precise type inference.
I initially implemented this by applying literal promotion to the type
of the unannotated module globals (as suggested in
https://github.com/astral-sh/ty/issues/1069), but the ecosystem impact
showed a lot of problems (https://github.com/astral-sh/ruff/pull/20643).
I fixed/patched some of these problems, but this PR seems like a good
first step, and it seems sensible to apply the literal promotion change
in a second step that can be evaluated separately.
closes https://github.com/astral-sh/ty/issues/1069
## Ecosystem impact
This seems like an (unexpectedly large) net positive with 650 fewer
diagnostics overall.. even though this change will certainly catch more
true positives.
* There are 666 removed `type-assertion-failure` diagnostics, where we
were previously used the correct type already, but removing the
`Unknown` now leads to an "exact" match.
* 1464 of the 1805 total new diagnostics are `unresolved-attribute`
errors, most (1365) of which were previously
`possibly-missing-attribute` errors. So they could also be counted as
"changed" diagnostics.
* For code that uses constants like
```py
IS_PYTHON_AT_LEAST_3_10 = sys.version_info >= (3, 10)
```
where we would have previously inferred a type of `Literal[True/False] |
Unknown`, removing the `Unknown` now allows us to do reachability
analysis on branches that use these constants, and so we get a lot of
favorable ecosystem changes because of that.
* There is code like the following, where we previously emitted
`conflicting-argument-forms` diagnostics on calls to the aliased
`assert_type`, because its type was `Unknown | def …` (and the call to
`Unknown` "used" the type form argument in a non type-form way):
```py
if sys.version_info >= (3, 11):
import typing
assert_type = typing.assert_type
else:
import typing_extensions
assert_type = typing_extensions.assert_type
```
* ~100 new `invalid-argument-type` false positives, due to missing
`**kwargs` support (https://github.com/astral-sh/ty/issues/247)
## Typing conformance
```diff
+protocols_modules.py:25:1: error[invalid-assignment] Object of type `<module '_protocols_modules1'>` is not assignable to `Options1`
```
This diagnostic should apparently not be there, but it looks like we
also fail other tests in that file, so it seems to be a limitation that
was previously hidden by `Unknown` somehow.
## Test Plan
Updated tests and relatively thorough ecosystem analysis.
## Summary
Reformulation of the public symbol type inference test suite to use
class scopes instead of module scopes. This is in preparation for an
upcoming change to module-global scopes (#20664).
## Test Plan
Updated tests
This doesn't seem to be flaky in the sense of tests failing
non-deterministically, but they are flaky in the sense of unrelated
changes causing testing failures from the clauses of a constraint set
being rendered in different orders. This flakiness is because we're
using Salsa IDs to determine the order in which typevars appear in a
constraint set BDD, and those IDs are assigned non-deterministically.
The fix is ham-fisted but effective: sort the constraints in each
clause, and the clauses in each set, as part of the rendering process.
Constraint sets are only rendered in our test cases, so we don't need to
over-optimize this.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Since we are trying to import both `AutoImport` and `SourceModuleMoved`,
the previous naming was not as descriptive. Renaming it to `Rename`
better reflects the intention.
## Test Plan
<!-- How was it tested? -->
no functionality change
## Summary
This PR uses the new `Diagnostic` type for rendering formatter
diagnostics. This allows the formatter to inherit all of the output
formats already implemented in the linter and ty. For example, here's
the new `full` output format, with the formatting diff displayed using
the same infrastructure as the linter:
<img width="592" height="364" alt="image"
src="https://github.com/user-attachments/assets/6d09817d-3f27-4960-aa8b-41ba47fb4dc0"
/>
<details><summary>Resolved TODOs</summary>
<p>
~~There are several limitiations/todos here still, especially around the
`OutputFormat` type~~:
- [x] A few literal `todo!`s for the remaining `OutputFormat`s without
matching `DiagnosticFormat`s
- [x] The default output format is `full` instead of something more
concise like the current output
- [x] Some of the output formats (namely JSON) have information that
doesn't make much sense for these diagnostics
The first of these is definitely resolved, and I think the other two are
as well, based on discussion on the design document. In brief, we're
okay inheriting the default `OutputFormat` and can separate the global
option into `lint.output-format` and `format.output-format` in the
future, if needed; and we're okay including redundant information in the
non-human-readable output formats.
My last major concern is with the performance of the new code, as
discussed in the `Benchmarks` section below.
A smaller question is whether we should use `Diagnostic`s for formatting
errors too. I think the answer to this is yes, in line with changes
we're making in the linter too. I still need to implement that here.
</p>
</details>
<details><summary>Benchmarks</summary>
<p>
The values in the table are from a large benchmark on the CPython 3.10
code
base, which involves checking 2011 files, 1872 of which need to be
reformatted.
`stable` corresponds to the same code used on `main`, while
`preview-full` and
`preview-concise` use the new `Diagnostic` code gated behind `--preview`
for the
`full` and `concise` output formats, respectively. `stable-diff` uses
the
`--diff` to compare the two diff rendering approaches. See the full
hyperfine
command below for more details. For a sense of scale, the `stable`
output format
produces 1873 lines on stdout, compared to 855,278 for `preview-full`
and
857,798 for `stable-diff`.
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|:------------------|--------------:|---------:|---------:|-------------:|
| `stable` | 201.2 ± 6.8 | 192.9 | 220.6 | 1.00 |
| `preview-full` | 9113.2 ± 31.2 | 9076.1 | 9152.0 | 45.29 ± 1.54 |
| `preview-concise` | 214.2 ± 1.4 | 212.0 | 217.6 | 1.06 ± 0.04 |
| `stable-diff` | 3308.6 ± 20.2 | 3278.6 | 3341.8 | 16.44 ± 0.56 |
In summary, the `preview-concise` diagnostics are ~6% slower than the
stable
output format, increasing the average runtime from 201.2 ms to 214.2 ms.
The
`full` preview diagnostics are much more expensive, taking over 9113.2
ms to
complete, which is ~3x more expensive even than the stable diffs
produced by the
`--diff` flag.
My main takeaways here are:
1. Rendering `Edit`s is much more expensive than rendering the diffs
from `--diff`
2. Constructing `Edit`s actually isn't too bad
### Constructing `Edit`s
I also took a closer look at `Edit` construction by modifying the code
and
repeating the `preview-concise` benchmark and found that the main issue
is
constructing a `SourceFile` for use in the `Edit` rendering. Commenting
out the
`Edit` construction itself has basically no effect:
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|:----------|------------:|---------:|---------:|------------:|
| `stable` | 197.5 ± 1.6 | 195.0 | 200.3 | 1.00 |
| `no-edit` | 208.9 ± 2.2 | 204.8 | 212.2 | 1.06 ± 0.01 |
However, also omitting the source text from the `SourceFile`
construction
resolves the slowdown compared to `stable`. So it seems that copying the
full
source text into a `SourceFile` is the main cause of the slowdown for
non-`full`
diagnostics.
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|:-----------------|------------:|---------:|---------:|------------:|
| `stable` | 202.4 ± 2.9 | 197.6 | 207.9 | 1.00 |
| `no-source-text` | 202.7 ± 3.3 | 196.3 | 209.1 | 1.00 ± 0.02 |
### Rendering diffs
The main difference between `stable-diff` and `preview-full` seems to be
the diffing strategy we use from `similar`. Both versions use the same
algorithm, but in the existing
[`CodeDiff`](https://github.com/astral-sh/ruff/blob/main/crates/ruff_linter/src/source_kind.rs#L259)
rendering for the `--diff` flag, we only do line-level diffing, whereas
for `Diagnostic`s we use `TextDiff::iter_inline_changes` to highlight
word-level changes too. Skipping the word diff for `Diagnostic`s closes
most of the gap:
| Command | Mean [s] | Min [s] | Max [s] | Relative |
|:---|---:|---:|---:|---:|
| `stable-diff` | 3.323 ± 0.015 | 3.297 | 3.341 | 1.00 |
| `preview-full` | 3.654 ± 0.019 | 3.618 | 3.682 | 1.10 ± 0.01 |
(In some repeated runs, I've seen as small as a ~5% difference, down
from 10% in the table)
This doesn't actually change any of our snapshots, but it would
obviously change the rendered result in a terminal since we wouldn't
highlight the specific words that changed within a line.
Another much smaller change that we can try is removing the deadline
from the `iter_inline_changes` call. It looks like there's a fair amount
of overhead from the default 500 ms deadline for computing these, and
using `iter_inline_changes(op, None)` (`None` for the optional deadline
argument) improves the runtime quite a bit:
| Command | Mean [s] | Min [s] | Max [s] | Relative |
|:---|---:|---:|---:|---:|
| `stable-diff` | 3.322 ± 0.013 | 3.298 | 3.341 | 1.00 |
| `preview-full` | 5.296 ± 0.030 | 5.251 | 5.366 | 1.59 ± 0.01 |
<hr>
<details><summary>hyperfine command</summary>
```shell
cargo build --release --bin ruff && hyperfine --ignore-failure --warmup 10 --export-markdown /tmp/table.md \
-n stable -n preview-full -n preview-concise -n stable-diff \
"./target/release/ruff format --check ./crates/ruff_linter/resources/test/cpython/ --no-cache" \
"./target/release/ruff format --check ./crates/ruff_linter/resources/test/cpython/ --no-cache --preview --output-format=full" \
"./target/release/ruff format --check ./crates/ruff_linter/resources/test/cpython/ --no-cache --preview --output-format=concise" \
"./target/release/ruff format --check ./crates/ruff_linter/resources/test/cpython/ --no-cache --diff"
```
</details>
</p>
</details>
## Test Plan
Some new CLI tests and manual testing
## Summary
Not sure if this was the original intention, but it looks to me like the
previous `Type::literal_promotion_type` was more of an implementation
detail for the actual operation of promoting all literals in a
possibly-nested position of a type.
This is not a pure refactor, as I'm technically changing the behavior
for that protocols diagnostic message suggestion.
## Test Plan
New Markdown test
## Summary
Add two simple tests that we recently discussed with @dcreager. They
demonstrate that the `TypeMapping::MarkTypeVarsInferable` operation
really does need to keep track of the binding context.
## Test Plan
Made sure that those tests fail if we create
`TypeMapping::MarkTypeVarsInferable(None)`s everywhere.
This PR ensures that we always put `./src` before `.` in our list of
first-party search paths. This better emulates the fact that at runtime,
the module name of a file `src/foo.py` would almost certainly be `foo`
rather than `src.foo`.
I wondered if fixing this might fix
https://github.com/astral-sh/ruff/pull/20603#issuecomment-3345317444. It
seems like that's not the case, but it also seems like it leads to
better diagnostics because we report much more intuitive module names to
the user in our error messages -- so, it's probably a good change
anyway.
## Summary
Modify the (external) signature of instance methods such that the first
parameter uses `Self` unless it is explicitly annotated. This allows us
to correctly type-check more code, and allows us to infer correct return
types for many functions that return `Self`. For example:
```py
from pathlib import Path
from datetime import datetime, timedelta
reveal_type(Path(".config") / ".ty") # now Path, previously Unknown
def _(dt: datetime, delta: timedelta):
reveal_type(dt - delta) # now datetime, previously Unknown
```
part of https://github.com/astral-sh/ty/issues/159
## Performance
I ran benchmarks locally on `attrs`, `freqtrade` and `colour`, the
projects with the largest regressions on CodSpeed. I see much smaller
effects locally, but can definitely reproduce the regression on `attrs`.
From looking at the profiling results (on Codspeed), it seems that we
simply do more type inference work, which seems plausible, given that we
now understand much more return types (of many stdlib functions). In
particular, whenever a function uses an implicit `self` and returns
`Self` (without mentioning `Self` anywhere else in its signature), we
will now infer the correct type, whereas we would previously return
`Unknown`. This also means that we need to invoke the generics solver in
more cases. Comparing half a million lines of log output on attrs, I can
see that we do 5% more "work" (number of lines in the log), and have a
lot more `apply_specialization` events (7108 vs 4304). On freqtrade, I
see similar numbers for `apply_specialization` (11360 vs 5138 calls).
Given these results, I'm not sure if it's generally worth doing more
performance work, especially since none of the code modifications
themselves seem to be likely candidates for regressions.
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|:---|---:|---:|---:|---:|
| `./ty_main check /home/shark/ecosystem/attrs` | 92.6 ± 3.6 | 85.9 |
102.6 | 1.00 |
| `./ty_self check /home/shark/ecosystem/attrs` | 101.7 ± 3.5 | 96.9 |
113.8 | 1.10 ± 0.06 |
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|:---|---:|---:|---:|---:|
| `./ty_main check /home/shark/ecosystem/freqtrade` | 599.0 ± 20.2 |
568.2 | 627.5 | 1.00 |
| `./ty_self check /home/shark/ecosystem/freqtrade` | 607.9 ± 11.5 |
594.9 | 626.4 | 1.01 ± 0.04 |
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|:---|---:|---:|---:|---:|
| `./ty_main check /home/shark/ecosystem/colour` | 423.9 ± 17.9 | 394.6
| 447.4 | 1.00 |
| `./ty_self check /home/shark/ecosystem/colour` | 426.9 ± 24.9 | 373.8
| 456.6 | 1.01 ± 0.07 |
## Test Plan
New Markdown tests
## Ecosystem report
* apprise: ~300 new diagnostics related to problematic stubs in apprise
😩
* attrs: a new true positive, since [this
function](4e2c89c823/tests/test_make.py (L2135))
is missing a `@staticmethod`?
* Some legitimate true positives
* sympy: lots of new `invalid-operator` false positives in [matrix
multiplication](cf9f4b6805/sympy/matrices/matrixbase.py (L3267-L3269))
due to our limited understanding of [generic `Callable[[Callable[[T1,
T2], T3]], Callable[[T1, T2], T3]]` "identity"
types](cf9f4b6805/sympy/core/decorators.py (L83-L84))
of decorators. This is not related to type-of-self.
## Typing conformance results
The changes are all correct, except for
```diff
+generics_self_usage.py:50:5: error[invalid-assignment] Object of type `def foo(self) -> int` is not assignable to `(typing.Self, /) -> int`
```
which is related to an assignability problem involving type variables on
both sides:
```py
class CallableAttribute:
def foo(self) -> int:
return 0
bar: Callable[[Self], int] = foo # <- we currently error on this assignment
```
---------
Co-authored-by: Shaygan Hooshyari <sh.hooshyari@gmail.com>
## Summary
Addresses
https://github.com/astral-sh/ruff/pull/20443#discussion_r2381237640 by
factoring out the `match` on the ruff output format in a way that should
be reusable by the formatter.
I didn't think this was going to work at first, but the fact that the
config holds options that apply only to certain output formats works in
our favor here. We can set up a single config for all of the output
formats and then use `try_from` to convert the `OutputFormat` to a
`DiagnosticFormat` later.
## Test Plan
Existing tests, plus a few new ones to make sure relocating the
`SHOW_FIX_SUMMARY` rendering worked, that was untested before. I deleted
a bunch of test code along with the `text` module, but I believe all of
it is now well-covered by the `full` and `concise` tests in `ruff_db`.
I also merged this branch into
https://github.com/astral-sh/ruff/pull/20443 locally and made sure that
the API actually helps. `render_diagnostics` dropped in perfectly and
passed the tests there too.
## Summary
Pull in a small upstream change
(6ce3a60957),
because some type check times were close to the previous limits, which
prevents us from seeing diagnostics diffs (in case they run into a
timeout).
`TypeMapping` is no longer cow-shaped.
Before, `TypeMapping` defined a `to_owned` method, which would make an
owned copy of the type mapping. This let us apply type mappings to
function literals lazily. The primary part of a function that you have
to apply the type mapping to is its signature. The hypothesis was that
doing this lazily would prevent us from constructing the signature of a
function just to apply a type mapping; if you never ended up needed the
updated function signature, that would be extraneous work.
But looking at the CI for this PR, it looks like that hypothesis is
wrong! And this definitely cleans up the code quite a bit. It also means
that over time we can consider replacing all of these `TypeMapping` enum
variants with separate `TypeTransformer` impls.
---------
Co-authored-by: David Peter <mail@david-peter.de>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR addresses #20570 . In the example, the correct usage had a
bug/issue where in the except block after logging exception, None was
getting returned, which made the linters flag out the code. So adding an
empty raise solves the issue.
## Test Plan
Tested it by building the doc locally.
## Summary
Fixes a bug observed by @AlexWaygood where `C[Any] <: C[object]` should
hold for a class that is covariant in its type parameter (and similar
subtyping relations involving dynamic types for other variance
configurations).
## Test Plan
New and updated Markdown tests
While working on #20093, I kept running into test failures due to
constraint sets not simplifying as much as they could, and therefore not
being easily testable against "always true" and "always false".
This PR updates our constraint set representation to use BDDs. Because
BDDs are reduced and ordered, they are canonical — equivalent boolean
formulas are represented by the same interned BDD node.
That said, there is a wrinkle, in that the "variables" that we use in
these BDDs — the individual constraints like `Lower ≤ T ≤ Upper` are not
always independent of each other.
As an example, given types `A ≤ B ≤ C ≤ D` and a typevar `T`, the
constraints `A ≤ T ≤ C` and `B ≤ T ≤ D` "overlap" — their intersection
is non-empty. So we should be able to simplify
```
(A ≤ T ≤ C) ∧ (B ≤ T ≤ D) == (B ≤ T ≤ C)
```
That's not a simplification that the BDD structure can perform itself,
since those three constraints are modeled as separate BDD variables, and
are therefore "opaque" to the BDD algorithms.
That means we need to perform this kind of simplification ourselves. We
look at pairs of constraints that appear in a BDD and see if they can be
simplified relative to each other, and if so, replace the pair with the
simplification. A large part of the toil of getting this PR to work was
identifying all of those patterns and getting that substitution logic
correct.
With this new representation, all existing tests pass, as well as some
new ones that represent test failures that were occuring on #20093.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Follow up on #20495. The improvement suggested by @AlexWaygood cannot be
applied as-is since the `argument_matches` vector is indexed by argument
number, while the two boolean vectors are indexed by parameter number.
Still coalescing the latter two saves one allocation.
I guess I missed these in #20007, but I found them today while grepping
for something else. `Option::unwrap` has been const since 1.83, so we
can use it here and avoid some unsafe code.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR implements
https://docs.astral.sh/ruff/rules/future-feature-not-defined/ (F407) as
a semantic syntax error.
## Test Plan
<!-- How was it tested? -->
I have written inline tests as directed in #17412
---------
Signed-off-by: 11happy <soni5happy@gmail.com>
Summary
--
Fixes#20536 by linking between the isort options `case-sensitive` and
`order-by-type`. The latter takes precedence over the former, so it
seems good to clarify this somewhere.
I tweaked the wording slightly, but this is otherwise based on the patch
from @SkylerWittman in
https://github.com/astral-sh/ruff/issues/20536#issuecomment-3326097324
(thank you!)
Test Plan
--
N/a
---------
Co-authored-by: Skyler Wittman <skyler.wittman@gmail.com>
Co-authored-by: Micha Reiser <micha@reiser.io>
Summary
--
This fixes a bug pointed out in #20560 where one of the `pylint`
settings wasn't used in its `Display` implementation.
Test Plan
--
Existing tests with updated snapshots
## Summary
Improve the SIM105 rule message to prevent user confusion about how to
properly use `contextlib.suppress`.
The previous message "Replace with `contextlib.suppress(ValueError)`"
was ambiguous and led users to incorrectly use
`contextlib.suppress(ValueError)` as a statement inside except blocks
instead of replacing the entire try-except-pass block with `with
contextlib.suppress(ValueError):`.
This change makes the message more explicit:
- **Before**: `"Use \`contextlib.suppress({exception})\` instead of
\`try\`-\`except\`-\`pass\`"`
- **After**: `"Replace \`try\`-\`except\`-\`pass\` block with \`with
contextlib.suppress({exception})\`"`
The fix title is also updated to be more specific:
- **Before**: `"Replace with \`contextlib.suppress({exception})\`"`
- **After**: `"Replace \`try\`-\`except\`-\`pass\` with \`with
contextlib.suppress({exception})\`"`
Fixes#20462
## Test Plan
- ✅ All existing SIM105 tests pass with updated snapshots
- ✅ Cargo clippy passes without warnings
- ✅ Full test suite passes
- ✅ The new messages clearly indicate that the entire try-except-pass
block should be replaced with a `with` statement, preventing the misuse
described in the issue
---------
Co-authored-by: Giovani Moutinho <e@mgiovani.dev>
## Summary
Closes: https://github.com/astral-sh/ty/issues/551
This PR adds support for step 4 of the overload call evaluation
algorithm which states that:
> If the argument list is compatible with two or more overloads,
determine whether one or more of the overloads has a variadic parameter
(either `*args` or `**kwargs`) that maps to a corresponding argument
that supplies an indeterminate number of positional or keyword
arguments. If so, eliminate overloads that do not have a variadic
parameter.
And, with that, the overload call evaluation algorithm has been
implemented completely end to end as stated in the typing spec.
## Test Plan
Expand the overload call test suite.
Summary
--
This reduces the page size of GraphQL queries
(https://github.com/zanieb/rooster/pull/85), hopefully helping with some
of the 502s we've been hitting.
Test Plan
--
I ran the release script, and it succeeded after failing several times
on the old rooster version.
## Summary
Generate a timing diff across the whole ecosystem and deploy it to
CloudFlare pages. The timing information is collected already, we just
need to create and upload the HTML report.
The timing results are just based on a single run. No statistical
analysis across multiple runs or similar is performed. This means that
results can be noisy, as can be seen on this PR, where we see slowdowns
up to 1.26× and speedups down to 0.89×, even though the change should be
neutral. Across all projects, these random events cancel out and we see
an average factor of 1.01×. So I think this feature can still be
interesting, given that it comes "for free". We just need to keep in
mind that it will be noisy, and shouldn't read too much into these
results.
## Test Plan
CI run on this PR (see the new *timing results* link).
## Summary
This removes a hack in the protocol satisfiability check that was
previously needed to work around missing assignability-modeling of
inferable type variables. Assignability of type variables is not
implemented fully, but some recent changes allow us to remove that hack
with limited impact on the ecosystem (and the test suite). The change in
the typing conformance test is favorable.
## Test Plan
* Adapted Markdown tests
* Made sure that this change works in combination with
https://github.com/astral-sh/ruff/pull/20517
## Summary
Closes: https://github.com/astral-sh/ty/issues/1236
This PR fixes a bug where the variadic argument wouldn't match against
the variadic parameter in certain scenarios.
This was happening because I didn't realize that the `all_elements`
iterator wouldn't keep on returning the variable element (which is
correct, I just didn't realize it back then).
I don't think we can use the `resize` method here because we don't know
how many parameters this variadic argument is matching against as this
is where the actual parameter matching occurs.
## Test Plan
Expand test cases to consider a few more combinations of arguments and
parameters which are variadic.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
First contribution so please let me know if I've made a mistake
anywhere. This was aimed to fix#19982, it adds the isolation level to
PYI021 to in the same style as the PIE790 rule.
fixes: #19982
## Test Plan
<!-- How was it tested? -->
I added a case to the PYI021.pyi file where the two rules are present as
there wasn't a case with them both interacting, using the minimal
reproducible example that @ntBre created on the issue (I think I got the
`# ERROR` markings wrong, so please let me know how to fix that if I
did).
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR implements
https://docs.astral.sh/ruff/rules/multiple-starred-expressions/ as a
semantic syntax error
## Test Plan
I have added inline tests as directed in #17412
---------
Signed-off-by: 11happy <soni5happy@gmail.com>
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
Fixes https://github.com/astral-sh/ty/issues/1242
From finding references with the LSP, `FileResolver::path` is only
called once, in `UnifiedFile::path`, so I went through those references,
and it looked safe to make this change in every case. Most of the
references are in the various output formats, where we inherited the
absolute vs relative path decision from Ruff. Two other uses are as
fallbacks if converting a relativized path to a string fails. Finally,
we use the path for sorting and in `UnifiedFile::relative_path`.
## Test Plan
Existing tests, with snapshots updated to show absolute paths (in the
`TestDb` this just added a `/` in front of the file names). I also
updated the GitLab CLI test to set the `CI_PROJECT_DIR` environment
variable and ran a test in GitLab CI:
<img width="613" height="114" alt="image"
src="https://github.com/user-attachments/assets/8ab81dba-54fd-4a24-9110-77ef89293cff"
/>
- Adds test cases exercising file selection by extension with
`--preview` enabled and disabled.
- Adds `INCLUDE_PREVIEW` with file patterns including `*.pyw`.
- In global preview mode, default configuration selects patterns from
`INCLUDE_PREVIEW`.
- Manually tested ruff server with local vscode for both formatting and
linting of a `.pyw` file.
Closes https://github.com/astral-sh/ruff/issues/13246
## Summary
This applies the trick that we use for `builtins.open` to similar
functions that have the same problem. The reason is that the problem
would otherwise become even more pronounced once we add understanding of
the implicit type of `self` parameters, because then something like
`(base_path / "test.bin").open("rb")` also leads to a wrong return type
and can result in false positives.
## Test Plan
New Markdown tests
## Summary
I found this bug while working on #20528.
The minimum reproducible code is:
```python
from __future__ import annotations
from typing import NamedTuple
from ty_extensions import is_disjoint_from, static_assert
class Path(NamedTuple):
prev: Path | None
key: str
static_assert(not is_disjoint_from(Path, Path))
```
A stack overflow occurs when a nominal instance type inherits from
`NamedTuple` and is defined recursively.
This PR fixes this bug.
## Test Plan
mdtest updated
## Summary
Adds a new rule to find and report use of `os.path` or `pathlib.Path` in
async functions.
Issue: #8451
## Test Plan
Using `cargo insta test`
### Summary
This PR includes two changes, both of which are necessary to resolve
https://github.com/astral-sh/ty/issues/1196:
* For a generic class `C[T]`, we previously used `C[Unknown]` as the
upper bound of the `Self` type variable. There were two problems with
this. For one, when `Self` appeared in contravariant position, we would
materialize its upper bound to `Bottom[C[Unknown]]` (which might
simplify to `C[Never]` if `C` is covariant in `T`) when accessing
methods on `Top[C[Unknown]]`. This would result in `invalid-argument`
errors on the `self` parameter. Also, using an upper bound of
`C[Unknown]` would mean that inside methods, references to `T` would be
treated as `Unknown`. This could lead to false negatives. To fix this,
we now use `C[T]` (with a "nested" typevar) as the upper bound for
`Self` on `C[T]`.
* In order to make this work, we needed to allow assignability/subtyping
of inferable typevars to other types, since we now check assignability
of e.g. `C[int]` to `C[T]` (when checking assignability to the upper
bound of `Self`) when calling an instance-method on `C[int]` whose
`self` parameter is annotated as `self: Self` (or implicitly `Self`,
following https://github.com/astral-sh/ruff/pull/18007).
closes https://github.com/astral-sh/ty/issues/1196
closes https://github.com/astral-sh/ty/issues/1208
### Test Plan
Regression tests for both issues.
## Summary
@ibraheemdev notes this example failed
```py
from typing import Callable
class X:
...
def f(callable: Callable[[], X]) -> X:
return callable()
x = f(X)
```
Resolves https://github.com/astral-sh/ty/issues/1210
The issue was that we set the `Self` to the class type instead of the
instance type of the class.
## Test Plan
Fix tests in `is_subtype_of.md`
## Summary
Previous error:
```
▶ cargo shear
Analyzing /home/shark/ruff
ruff_diagnostics -- crates/ruff_diagnostics/Cargo.toml:
get-size2
ruff_index -- crates/ruff_index/Cargo.toml:
get-size2
ruff_source_file -- crates/ruff_source_file/Cargo.toml:
get-size2
ruff_text_size -- crates/ruff_text_size/Cargo.toml:
get-size2
ty_ide -- crates/ty_ide/Cargo.toml:
get-size2
ty_project -- crates/ty_project/Cargo.toml:
get-size2
cargo-shear may have detected unused dependencies incorrectly due to its limitations.
They can be ignored by adding the crate name to the package's Cargo.toml:
[package.metadata.cargo-shear]
ignored = ["crate-name"]
or in the workspace Cargo.toml:
[workspace.metadata.cargo-shear]
ignored = ["crate-name"]
```
## Summary
Fixes https://github.com/astral-sh/ty/issues/1218.
This bug doesn't currently cause us any real-world issues, because we
don't yet understand the signatures typeshed gives us for `isinstance()`
and `issubclass()` (typeshed's annotations there use PEP-613 type
aliases). #20107 demonstrates that this will start causing us issues as
soon as we add support for PEP-613 aliases, however, so it makes sense
to fix it now.
## Test Plan
Added mdtests
Coming soon: The Renovate bot (GitHub App) will be renamed to Mend. PRs
from Renovate will soon appear from 'Mend'. Learn more
[here](https://redirect.github.com/renovatebot/renovate/discussions/37842).
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[wasm-bindgen-test](https://redirect.github.com/wasm-bindgen/wasm-bindgen)
| workspace.dependencies | patch | `0.3.51` -> `0.3.53` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45Ny4xMCIsInVwZGF0ZWRJblZlciI6IjQxLjk3LjEwIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Coming soon: The Renovate bot (GitHub App) will be renamed to Mend. PRs
from Renovate will soon appear from 'Mend'. Learn more
[here](https://redirect.github.com/renovatebot/renovate/discussions/37842).
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [clap](https://redirect.github.com/clap-rs/clap) |
workspace.dependencies | patch | `4.5.47` -> `4.5.48` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>clap-rs/clap (clap)</summary>
###
[`v4.5.48`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4548---2025-09-19)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.47...v4.5.48)
##### Documentation
- Add a new CLI Concepts document as another way of framing clap
- Expand the `typed_derive` cookbook entry
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45Ny4xMCIsInVwZGF0ZWRJblZlciI6IjQxLjk3LjEwIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Coming soon: The Renovate bot (GitHub App) will be renamed to Mend. PRs
from Renovate will soon appear from 'Mend'. Learn more
[here](https://redirect.github.com/renovatebot/renovate/discussions/37842).
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [serde_with](https://redirect.github.com/jonasbb/serde_with) |
workspace.dependencies | patch | `3.14.0` -> `3.14.1` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>jonasbb/serde_with (serde_with)</summary>
###
[`v3.14.1`](https://redirect.github.com/jonasbb/serde_with/releases/tag/v3.14.1):
serde_with v3.14.1
[Compare
Source](https://redirect.github.com/jonasbb/serde_with/compare/v3.14.0...v3.14.1)
##### Fixed
- Show macro expansion in the docs.rs generated rustdoc.
Since macros are used to generate trait implementations, this is useful
to understand the exact generated code.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45Ny4xMCIsInVwZGF0ZWRJblZlciI6IjQxLjk3LjEwIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Coming soon: The Renovate bot (GitHub App) will be renamed to Mend. PRs
from Renovate will soon appear from 'Mend'. Learn more
[here](https://redirect.github.com/renovatebot/renovate/discussions/37842).
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [ordermap](https://redirect.github.com/indexmap-rs/ordermap) |
workspace.dependencies | patch | `0.5.10` -> `0.5.12` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>indexmap-rs/ordermap (ordermap)</summary>
###
[`v0.5.12`](https://redirect.github.com/indexmap-rs/ordermap/blob/HEAD/RELEASES.md#0512-2025-09-15)
[Compare
Source](https://redirect.github.com/indexmap-rs/ordermap/compare/0.5.11...0.5.12)
- Make the minimum `serde` version only apply when "serde" is enabled.
###
[`v0.5.11`](https://redirect.github.com/indexmap-rs/ordermap/blob/HEAD/RELEASES.md#0511-2025-09-15)
[Compare
Source](https://redirect.github.com/indexmap-rs/ordermap/compare/0.5.10...0.5.11)
- Switched the "serde" feature to depend on `serde_core`, improving
build
parallelism in cases where other dependents have enabled "serde/derive".
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45Ny4xMCIsInVwZGF0ZWRJblZlciI6IjQxLjk3LjEwIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#12734
I have started with simply checking if any arguments that are providing
extra values to the log message are calls to `str` or `repr`, as
suggested in the linked issue. There was a concern that this could cause
false positives and the check should be more explicit. I am happy to
look into that if I have some further examples to work with.
If this is the accepted solution then there are more cases to add to the
test and it should possibly also do test for the same behavior via the
`extra` keyword.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
I have added a new test case and python file to flake8_logging_format
with examples of this anti-pattern.
<!-- How was it tested? -->
## Summary
Fixes#20440
Fix B004 to skip invalid hasattr/getattr calls
- Add argument validation for `hasattr` and `getattr`
- Skip B004 rule when function calls have invalid argument patterns
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#20035, fixes#19395
This is for deduplicating input paths to avoid processing the same file
multiple times.
This is my first contribution, so I'm sorry if I miss something. Please
tell me if this is needed for this feature.
## Test Plan
<!-- How was it tested? -->
I just added a test `find_python_files_deduplicated` in
eee1020e32/crates/ruff_workspace/src/resolver.rs (L1017)
. This pull request adds changes to `WalkPythonFilesState::finish`,
which is used in `python_files_in_path`, so they affect some commands
such as `analyze`, `format`, `check` and so on. I will add snapshot
tests for them if necessary.
I’ve already confirmed that the same thing happens with ruff check as
well.
```
$ echo "x = 1" > example/foo.py
$ uvx ruff check example example/foo.py
I002 [*] Missing required import: `from __future__ import annotations`
--> /path/to/example/foo.py:1:1
help: Insert required import: `from __future__ import annotations`
I002 [*] Missing required import: `from __future__ import annotations`
--> /path/to/example/foo.py:1:1
help: Insert required import: `from __future__ import annotations`
Found 2 errors.
[*] 2 fixable with the `--fix` option.
```
## Summary
Implements new rule `B912` that requires the `strict=` argument for
`map(...)` calls with two or more iterables on Python 3.14+, following
the same pattern as `B905` for `zip()`.
Closes#20057
---------
Co-authored-by: dylwil3 <dylwil3@gmail.com>
Coming soon: The Renovate bot (GitHub App) will be renamed to Mend. PRs
from Renovate will soon appear from 'Mend'. Learn more
[here](https://redirect.github.com/renovatebot/renovate/discussions/37842).
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [hashbrown](https://redirect.github.com/rust-lang/hashbrown) |
workspace.dependencies | minor | `0.15.0` -> `0.16.0` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>rust-lang/hashbrown (hashbrown)</summary>
###
[`v0.16.0`](https://redirect.github.com/rust-lang/hashbrown/blob/HEAD/CHANGELOG.md#0160---2025-08-28)
[Compare
Source](https://redirect.github.com/rust-lang/hashbrown/compare/v0.15.5...v0.16.0)
##### Changed
- Bump foldhash, the default hasher, to 0.2.0.
- Replaced `DefaultHashBuilder` with a newtype wrapper around `foldhash`
instead
of re-exporting it directly.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45Ny4xMCIsInVwZGF0ZWRJblZlciI6IjQxLjk3LjEwIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
---------
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: David Peter <mail@david-peter.de>
Co-authored-by: Ibraheem Ahmed <ibraheem@ibraheem.ca>
Now that imports are actually inserted, this should give us some
valuable dog-fooding experience.
Note that we don't currently do any ranking on completions, so until
that is improved, even in-scope completions could suffer. With that
said, this shouldn't have any impact at all in several scenarios (like
completions for attributes on objects).
We don't attempt to fix these yet. I think there are bigger fish to fry.
I came up with these based on this discussion:
https://github.com/astral-sh/ruff/pull/20439#discussion_r2357769518
Here's one example:
```
if ...:
from foo import MAGIC
else:
from bar import MAGIC
MAG<CURSOR>
```
Now in this example, completions will include `MAGIC` from the local
scope. That is, auto-import is involved with that completion. But at
present, auto-import will suggest importing `foo` and `bar` because we
haven't de-duplicated completions yet. Which is fine.
Here's another example:
```
if ...:
import foo as fubar
else:
import bar as fubar
MAG<CURSOR>
```
Now here, there is no `MAGIC` symbol in scope. So auto-import is in
play. Let's assume that the user selects `MAGIC` from `foo` in this
example. (`bar` also has `MAGIC`.)
Since we currently ignore the declaration site for symbols with
multiple possible bindings, the importer today doesn't know that
`fubar` _could_ contain `MAGIC`. But even if it did, what would we do
with that information? Should we do this?
```
if ...:
import foo as fubar
from foo import MAGIC
else:
import bar as fubar
MAGIC
```
Or could we reason that `bar` also has `MAGIC`?
```
if ...:
import foo as fubar
else:
import bar as fubar
fubar.MAGIC
```
But if we did that, we're making an assumption of user intent, since
they *selected* `foo.MAGIC` but not `bar.MAGIC`.
Anyway, I don't think we need to settle on an answer today, but I
wanted to capture some of these tricky cases in tests at the very
least.
## Summary
This PR adds support for unpacking `**kwargs` argument.
This can be matched against any standard (positional or keyword),
keyword-only, or keyword variadic parameter that haven't been matched
yet.
This PR also takes care of special casing `TypedDict` because the key
names and the corresponding value type is known, so we can be more
precise in our matching and type checking step. In the future, this
special casing would be extended to include `ParamSpec` as well.
Part of astral-sh/ty#247
## Test Plan
Add test cases for various scenarios.
Makes ⌘-T file search ignore snapshot files, so you can actually fuzzy
match "ruff cache" to "ruff/src/cache.rs" without looking/scrolling past
dozens of snapshot files in the search results.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Resolves#20033
## Test Plan
unit tests added to the new split function, existing snapshot test
updated.
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#19887
- flynt(FLY002): When joining only string constants, upgrade raw
single-quoted strings to raw triple-quoted if the resulting
content contains a newline.
- Choose a safe triple-quote delimiter by switching to the opposite
quote style if the preferred triple appears inside the
content.
- Update FLY002 snapshot to include the `\n'.join([r'line1','line2'])`
case.
## Test Plan
I've added one test case to FLY002.py.
<!-- How was it tested? -->
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#20255
Mark single-item-membership-test fixes as always unsafe
- Always set `Applicability::Unsafe` for FURB171 fixes
- Update “Fix safety” docs to reflect always-unsafe behavior
- Expand tests (not in, nested set/frozenset, commented args)
## Test Plan
<!-- How was it tested? -->
I have added new test cases to
`crates/ruff_linter/resources/test/fixtures/refurb/FURB171_0.py` and
`crates/ruff_linter/resources/test/fixtures/refurb/FURB171_1.py`.
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
This seems to be more consistent with how other LSPs work (like
`rust-analyzer`), and also I think is more consistent with how
`CompletionItem.detail` is itself rendered. Namely, in VS Code, it
is right-aligned. And it's also where we put the type signature.
But `CompletionItemLabelDetails.detail` is left-aligned where as
`CompletionItemLabelDetails.description` is right-aligned. So let's
swap them such that type signatures go in the latter and not the
former.
This also adds a space before the module name and contextualizes
it with `(import <name>)` to help aide the end user in figuring out
selecting the completion will do.
Fixes#1200
## Summary
This change reduces MD test compilation time from 6s to 3s on my laptop.
We don't need to build the unit tests and the corpus tests when we're
only interested in Markdown-based tests.
## Test Plan
local benchmarks
## Summary
Part of https://github.com/astral-sh/ty/issues/168. Infer more precise types for collection literals (currently, only `list` and `set`). For example,
```py
x = [1, 2, 3] # revealed: list[Unknown | int]
y: list[int] = [1, 2, 3] # revealed: list[int]
```
This could easily be extended to `dict` literals, but I am intentionally limiting scope for now.
Fixes: https://github.com/astral-sh/ty/issues/1173
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR will change the logic of binding Self type variables to bind
self to the immediate function that it's used on.
Since we are binding `self` to methods and not the class itself we need
to ensure that we bind self consistently.
The fix is to traverse scopes containing the self and find the first
function inside a class and use that function to bind the typevar for
self.
If no such scope is found we fallback to the normal behavior. Using Self
outside of a class scope is not legal anyway.
## Test Plan
Added a new mdtest.
Checked the diagnostics that are not emitted anymore in [primer
results](https://github.com/astral-sh/ruff/pull/20366#issuecomment-3289411424).
It looks good altough I don't completely understand what was wrong
before.
---------
Co-authored-by: Douglas Creager <dcreager@dcreager.net>
This is somewhat inspired by a similar abstraction in
`ruff_linter`. The main idea is to create an importer once
for a module that you want to add imports to. And then call
`import` to generate an edit for each symbol you want to
add.
I haven't done any performance profiling here yet. I don't
know if it will be a bottleneck. In particular, I do expect
`Importer::import` (but not `Importer::new`) to get called
many times for a single completion request when auto-import
is enabled. Particularly in projects with a lot of unimported
symbols. Because I don't know the perf impact, I didn't do
any premature optimization here. But there are surely some
low hanging fruit if this does prove to be a problem.
New tests make up a big portion of the diff here. I tried to
think of a bunch of different cases, although I'm sure there
are more.
This rejiggers some stuff in the main completions entrypoint
in `ty_ide`. A more refined `Completion` type is defined
with more information. In particular, to support auto-import,
we now include a module name and an "edit" for inserting an
import.
This also rolls the old "detailed completion" into the new
completion type. Previously, we were relying on the completion
type for `ty_python_semantic`. But `ty_ide` is really the code
that owns completions.
Note that this code doesn't build as-is. The next commit will
add the importer used here in `add_unimported_completions`.
Based on how this API is currently implemented, this doesn't
really cost us anything. But it gives us access to more
information about where the symbol is defined.
I think this is a better home for it. This way, `ty_ide`
more clearly owns how the "kind" of a completion is computed.
In particular, it is computed differently for things where
we know its type versus unimported symbols.
In the course of writing the "add an import" implementation,
I realized that we needed to know which symbols were in scope
and how they were defined. This was necessary to be able to
determine how to add a new import in a way that (minimally)
does not conflict with existing symbols.
I'm not sure that this is fully correct (especially for
symbol bindings) and it's unclear to me in which cases a
definition site will be missing. But this seems to work for
some of the basic cases that I tried.
The names of the submodules returned should be *complete*. This
is the contract of `Module::name`. However, we were previously
only returning the basename of the submodule.
This can already be accomplished via a `From` impl (and indeed,
that's how this is implemented). But in a generic context, the
turbo-fishing that needs to be applied is quite annoying.
Basically, given a `from module import name1, name2, ...` statement,
we'd like to be able to insert another name in that list.
This new `Insertion::existing_import` API provides such
functionality. There isn't much to it, although we are careful
to try and avoid inserting nonsense for import statements
that are already invalid.
This refactors the importer abstraction to use a shared
`Insertion`. This is mostly just moving some code around
with some slight tweaks.
The plan here is to keep the rest of the importing code
in `ruff_linter` and then write something ty-specific on
top of `Insertion`. This ends up sharing some code, but
not as much as would be ideal. In particular, the
`ruff_linter` imported is pretty tightly coupled with
ruff's semantic model. So to share the code, we'd need to
abstract over that.
## Summary
This PR wires up the GitHub output format moved to `ruff_db` in #20320
to the ty CLI.
It's a bit smaller than the GitLab version (#20155) because some of the
helpers were already in place, but I did factor out a few
`DisplayDiagnosticConfig` constructor calls in Ruff. I also exposed the
`GithubRenderer` and a wrapper `DisplayGithubDiagnostics` type because
we needed a way to configure the program name displayed in the GitHub
diagnostics. This was previously hard-coded to `Ruff`:
<img width="675" height="247" alt="image"
src="https://github.com/user-attachments/assets/592da860-d2f5-4abd-bc5a-66071d742509"
/>
Another option would be to drop the program name in the output format,
but I think it can be helpful in workflows with multiple programs
emitting annotations (such as Ruff and ty!)
## Test Plan
New CLI test, and a manual test with `--config 'terminal.output-format =
"github"'`
## Summary
Catch infinite recursion in binary-compare inference.
Fixes the stack overflow in `graphql-core` in mypy-primer.
## Test Plan
Added two tests that stack-overflowed before this PR.
## Summary
Use `Type::Divergent` to short-circuit diverging types in type
expressions. This avoids panicking in a wide variety of cases of
recursive type expressions.
Avoids many panics (but not yet all -- I'll be tracking down the rest)
from https://github.com/astral-sh/ty/issues/256 by falling back to
Divergent. For many of these recursive type aliases, we'd like to
support them properly (i.e. really understand the recursive nature of
the type, not just fall back to Divergent) but that will be future work.
This switches `Type::has_divergent_type` from using `any_over_type` to a
custom set of visit methods, because `any_over_type` visits more than we
need to visit, and exercises some lazy attributes of type, causing
significantly more work. This change means this diff doesn't regress
perf; it even reclaims some of the perf regression from
https://github.com/astral-sh/ruff/pull/20333.
## Test Plan
Added mdtest for recursive type alias that panics on main.
Verified that we can now type-check `packaging` (and projects depending
on it) without panic; this will allow moving a number of mypy-primer
projects from `bad.txt` to `good.txt` in a subsequent PR.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR implements F406
https://docs.astral.sh/ruff/rules/undefined-local-with-nested-import-star-usage/
as a semantic syntax error
## Test Plan
I have written inline tests as directed in #17412
---------
Signed-off-by: 11happy <soni5happy@gmail.com>
- Convert panics to diagnostics with id `Panic`, severity `Fatal`, and
the error as the diagnostic message, annotated with a `Span` with empty
code block and no range.
- Updates the post-linting message diagnostic handling to track the
maximum severity seen, and then prints the "report a bug in ruff"
message only if the max severity was `Fatal`
This depends on the sorting changes since it creates diagnostics with no
range specified.
Previously, we used a very fine-grained representation for individual
constraints: each constraint was _either_ a range constraint, a
not-equivalent constraint, or an incomparable constraint. These three
pieces are enough to represent all of the "real" constraints we need to
create — range constraints and their negation.
However, it meant that we weren't picking up as many chances to simplify
constraint sets as we could. Our simplification logic depends on being
able to look at _pairs_ of constraints or clauses to see if they
simplify relative to each other. With our fine-grained representation,
we could easily encounter situations that we should have been able to
simplify, but that would require looking at three or more individual
constraints.
For instance, negating a range constraint would produce:
```
¬(Base ≤ T ≤ Super) = ((T ≤ Base) ∧ (T ≠ Base)) ∨ (T ≁ Base) ∨
((Super ≤ T) ∧ (T ≠ Super)) ∨ (T ≁ Super)
```
That is, `T` must be (strictly) less than `Base`, (strictly) greater
than `Super`, or incomparable to either.
If we tried to union those back together, we should get `always`, since
`x ∨ ¬x` should always be true, no matter what `x` is. But instead we
would get:
```
(Base ≤ T ≤ Super) ∨ ((T ≤ Base) ∧ (T ≠ Base)) ∨ (T ≁ Base) ∨ ((Super ≤ T) ∧ (T ≠
Super)) ∨ (T ≁ Super)
```
Nothing would simplify relative to each other, because we'd have to look
at all five union elements to see that together they do in fact combine
to `always`.
The fine-grained representation was nice, because it made it easier to
[work out the math](https://dcreager.net/theory/constraints/) for
intersections and unions of each kind of constraint. But being able to
simplify is more important, since the example above comes up immediately
in #20093 when trying to handle constrained typevars.
The fix in this PR is to go back to a more coarse-grained
representation, where each individual constraint consists of a positive
range (which might be `always` / `Never ≤ T ≤ object`), and zero or more
negative ranges. The intuition is to think of a constraint as a region
of the type space (representable as a range) with zero or more "holes"
removed from it.
With this representation, negating a range constraint produces:
```
¬(Base ≤ T ≤ Super) = (always ∧ ¬(Base ≤ T ≤ Super))
```
(That looks trivial, because it is! We just move the positive range to
the negative side.)
The math is not that much harder than before, because there are only
three combinations to consider (each for intersection and union) —
though the fact that there can be multiple holes in a constraint does
require some nested loops. But the mdtest suite gives me confidence that
this is not introducing any new issues, and it definitely removes a
troublesome TODO.
(As an aside, this change also means that we are back to having each
clause contain no more than one individual constraint for any typevar.
This turned out to be important, because part of our simplification
logic was also depending on that!)
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This mainly removes an internal inconsistency, where we didn't remove
the `Self` type variable when eagerly binding `Self` to an instance
type. It has no observable effect, apparently.
builds on top of https://github.com/astral-sh/ruff/pull/20328
## Test Plan
None
## Summary
Fixes https://github.com/astral-sh/ty/issues/1161
Include `NamedTupleFallback` members in `NamedTuple` instance
completions.
- Augment instance attribute completions when completing on NamedTuple
instances by merging members from
`_typeshed._type_checker_internals.NamedTupleFallback`
## Test Plan
Adds a minimal completion test `namedtuple_fallback_instance_methods`
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
This project was [recently removed from
mypy_primer](https://github.com/astral-sh/ruff/pull/20378), so we need
to remove it from `good.txt` in order for ecosystem-analyzer to work
correctly.
## Test Plan
Run mypy_primer and ecosystem-analyzer on this branch.
## Summary
https://github.com/astral-sh/ruff/pull/20165 added a lot of false
positives around calls to `builtins.open()`, because our missing support
for PEP-613 type aliases means that we don't understand typeshed's
overloads for `builtins.open()` at all yet, and therefore always select
the first overload. This didn't use to matter very much, but now that we
have a much stricter implementation of protocol assignability/subtyping
it matters a lot, because most of the stdlib functions dealing with I/O
(`pickle`, `marshal`, `io`, `json`, etc.) are annotated in typeshed as
taking in protocols of some kind.
In lieu of full PEP-613 support, which is blocked on various things and
might not land in time for our next alpha release, this PR adds some
temporary special-casing for `builtins.open()` to avoid the false
positives. We just infer `Todo` for anything that isn't meant to match
typeshed's first `open()` overload. This should be easy to rip out again
once we have proper support for PEP-613 type aliases, which hopefully
should be pretty soon!
## Test Plan
Added an mdtest
## Summary
Fixes https://github.com/astral-sh/ty/issues/377.
We were treating any function as being assignable to any callback
protocol, because we were trying to figure out a type's `Callable`
supertype by looking up the `__call__` attribute on the type's
meta-type. But a function-literal's meta-type is `types.FunctionType`,
and `types.FunctionType.__call__` is `(...) -> Any`, which is not very
helpful!
While working on this PR, I also realised that assignability between
class-literals and callback protocols was somewhat broken too, so I
fixed that at the same time.
## Test Plan
Added mdtests
## Summary
Resolves#20266
Definition of the frozen dataclass attribute can be instantiation of a
nested frozen dataclass as well as a non-nested one.
### Problem explanation
The `function_call_in_dataclass_default` function is invoked during the
"defined scope" stage, after all scopes have been processed. At this
point, the semantic references the top-level scope. When
`SemanticModel::lookup_attribute` executes, it searches for bindings in
the top-level module scope rather than the class scope, resulting in an
error.
To solve this issue, the lookup should be evaluated through the class
scope.
## Test Plan
- Added test case from issue
Co-authored-by: Igor Drokin <drokinii1017@gmail.com>
## Summary
Fixes#19842
Prevent infinite loop with I002 and UP026
- Implement isort-aware handling for UP026 (deprecated mock import):
- Add CLI integration tests in crates/ruff/tests/lint.rs:
## Test Plan
I have added two integration tests
`pyupgrade_up026_respects_isort_required_import_fix` and
`pyupgrade_up026_respects_isort_required_import_from_fix` in
`crates/ruff/tests/lint.rs`.
## Summary
This looks like it should fix the errors that we've been seeing in sympy
in recent mypy-primer runs.
## Test Plan
I wasn't able to reproduce the sympy failures locally; it looks like
there is probably a dependency on the order in which files are checked.
So I don't have a minimal reproducible example, and wasn't able to add a
test :/ Obviously I would be happier if we could commit a regression
test here, but since the change is straightforward and clearly
desirable, I'm not sure how many hours it's worth trying to track it
down.
Mypy-primer is still failing in CI on this PR, because it fails on the
"old" ty commit already (i.e. on main). But it passes [on a no-op PR
stacked on top of this](https://github.com/astral-sh/ruff/pull/20370),
which strongly suggests this PR fixes the problem.
## Summary
Resolves#20282
Makes the rule fix always unsafe, because the replacement may not be
semantically equivalent to the original expression, potentially changing
the behavior of the code.
Updated docstring with examples.
## Test Plan
- Added two tests from issue and regenerated the snapshot
---------
Co-authored-by: Igor Drokin <drokinii1017@gmail.com>
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
Fixes#20204
Recognize t-strings, generators, and lambdas in RUF016
- Accept boolean literals as valid index and slice bounds.
- Add TString, Generator, and Lambda to `CheckableExprType`.
- Expand RUF016.py fixture and update snapshots accordingly.
Our token-based rules and `noqa` extraction used an `Indexer` that kept
track of f-string ranges but not t-strings. We've updated the `Indexer`
and downstream uses thereof to handle both f-strings and t-strings.
Most of the diff is renaming and adding tests.
Note that much of the "new" logic gets to be naive because the lexer has
already ensured that f and t-string "starts" are paired with their
respective "ends", even amidst nesting and so on.
Finally: one could imagine wanting to know if a given interpolated
string range corresponds to an f-string or a t-string, but I didn't find
a place where we actually needed this.
Closes#20310
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR adds support for building loongarch64 binaries in CI. As such
support has been merged in uv (astral-sh/uv#15387) it's time to consider
adding it to ruff.
Please note that as Ubuntu is not yet available for loongarch64, I have
elected to use a Debian Trixie container maintained by community
members. In addition, as Debian's pip does not allow installing modules
system-wide, I have modified the workflow to install additional modules
in a virtual environment.
Since the workflow is shared between all targets, the only way to handle
this difference (between Debian and Ubuntu) is just to install pip in a
venv for all targets. If there is a better (and less intrusive) way to
work around this, please let me know.
## Test Plan
Tests are included in CI and the loongarch64 artifacts built in [this
workflow](https://github.com/SkyBird233/ruff/actions/runs/17640270032/job/50125471548)
has been smoke tested.
## Summary
This PR addresses an issue for a variadic argument when involved in
argument type expansion of overload call evaluation.
The issue is that the expansion of the variadic argument could result in
argument list of different arity. For example, in `*args: tuple[int] |
tuple[int, str]`, the expansion would lead to the variadic argument
being unpacked into 1 and 2 element respectively. This means that the
parameter matching that was performed initially isn't sufficient and
each expanded argument list would need to redo the parameter matching
again.
This is currently done by redoing the parameter matching directly,
maintaining the state of argument forms (and the conflicting forms), and
updating the `Bindings` values if it changes.
Closes: astral-sh/ty#735
## Test Plan
Update existing mdtest.
This PR removes the `Constraints` trait. We removed the `bool`
implementation several weeks back, and are using `ConstraintSet`
everywhere. There have been discussions about trying to include the
reason for an assignability failure as part of the result, but that
there are no concrete plans to do so soon, and it's not clear that we'll
need the `Constraints` trait to do that. (We can ideally just update the
`ConstraintSet` type directly.)
In the meantime, this just complicates the code for no good reason.
This PR is a pure refactoring, and contains no behavioral changes.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This is the GitHub analog to #20117. This PR prepares to add a GitHub
output format to ty by moving the implementation from `ruff_linter` to
`ruff_db`. Hopefully this one is a bit easier to review
commit-by-commit. Almost all of the refactoring this time is in the
first commit, then the second commit adds the new `OutputFormat` variant
and moves the file into `ruff_db`. The third commit is just a small
touch up to use a private method that accommodates ty files so that we
can run the tests and update/move the snapshots.
I had to push a fourth commit to fix and test diagnostics without a
span/file.
## Test Plan
Existing tests
Previously, `Type::object` would find the definition of the `object`
class in typeshed, load that in (to produce a `ClassLiteral` and
`ClassType`), and then create a `NominalInstance` of that class.
It's possible that we are using a typeshed that doesn't define `object`.
We will not be able to do much useful work with that kind of typeshed,
but it's still a possibility that we have to support at least without
panicking. Previously, we would handle this situation by falling back on
`Unknown`.
In most cases, that's a perfectly fine fallback! But `object` is also
our top type — the type of all values. `Unknown` is _not_ an acceptable
stand-in for the top type.
This PR adds a new `NominalInstance` variant for "instances of
`object`". Unlike other nominal instances, we do not need to load in
`object`'s `ClassType` to instantiate this variant. We will use this new
variant even when the current typeshed does not define an `object`
class, ensuring that we have a fully static representation of our top
type at all times.
There are several operations that need access to a nominal instance's
class, and for this new `object` variant we load it lazily only when
it's needed. That means this operation is now fallible, since this is
where the "typeshed doesn't define `object`" failure shows up.
This new approach also has the benefit of avoiding some salsa cycles
that were cropping up while I was debugging #20093, since the new
constraint set representation was trying to instantiate `Type::object`
while in the middle of processing its definition in typeshed. Cycle
handling was kicking in correctly and returning the `Unknown` fallback
mentioned above. But the constraint set implementation depends on
`Type::object` being a distinct and fully static type, highlighting that
this is a correctness fix, not just an optimization fix.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Use `Type::Divergent` to avoid "too many iterations" panic on an
infinitely-nested tuple in an implicit instance attribute.
The regression here is from checking all tuple elements to see if they
contain a Divergent type. It's 5% on one project, 1% on another, and
zero on the rest. I spent some time looking into eliminating this
regression by tracking a flag on inference results to note if they could
possibly contain any Divergent type, but this doesn't really work --
there are too many different ways a type containing a Divergent type
could enter an inference result. Still thinking about whether there are
other ways to reduce this. One option is if we see certain kinds of
non-atomic types that are commonly expensive to check for Divergent, we
could make `has_divergent_type` a Salsa query on those types.
## Test Plan
Added mdtest.
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
The debug representation isn't as useful as calling `.display(db)`, but
it's still kind-of annoying when `dbg!()` calls don't compile locally
due to the compiler not being able to guarantee that an object of type
`impl Constraints` implements `Debug`
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#20235
• Fix `RUF102` to properly handle rule redirects when validating noqa
codes
• Update `code_is_valid` to check redirect targets before determining
validity
• Add test case for rule redirects (TCH002 in this case)
## Test Plan
<!-- How was it tested? -->
I have added a test case for rule redirects to
`crates/ruff_linter/resources/test/fixtures/ruff/RUF102.py`.
## Summary
`CallableTypeOf[bound_method]` would previously bind `self` to the
bound method type itself, instead of binding it to the instance type
stored inside the bound method type.
## Test Plan
Added regression test
This PR adds a new `ty_extensions.ConstraintSet` class, which is used to
expose constraint sets to our mdtest framework. This lets us write a
large collection of unit tests that exercise the invariants and rewrite
rules of our constraint set implementation.
As part of this, `is_assignable_to` and friends are updated to return a
`ConstraintSet` instead of a `bool`, and we implement
`ConstraintSet.__bool__` to return when a constraint set is always
satisfied. That lets us still use
`static_assert(is_assignable_to(...))`, since the assertion will coerce
the constraint set to a bool, and also lets us
`reveal_type(is_assignable_to(...))` to see more detail about
whether/when the two types are assignable. That lets us get rid of
`reveal_when_assignable_to` and friends, since they are now redundant
with the expanded capabilities of `is_assignable_to`.
## Summary
When adding an enum literal `E = Literal[Color.RED]` to a union which
already contained a subtype of that enum literal(!), we were previously
not simplifying the union correctly. My assumption is that our property
tests didn't catch that earlier, because the only possible non-trivial
subytpe of an enum literal that I can think of is `Any & E`. And in
order for that to be detected by the property tests, it would have to
randomly generate `Any & E | E` and then also compare that with `E` on
the other side (in an equivalence test, or the subtyping-antisymmetry
test).
closes https://github.com/astral-sh/ty/issues/1155
## Test Plan
* Added a regression test.
* I also ran the property tests for a while, but probably not for two
months worth of daily CI runs.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Closes#18349
After this change:
- All deprecated rules are deselected by default
- They are only selected if the user specifically selects them by code,
e.g. `--select UP038`
- Thus, `--select ALL --select UP --select UP0` won't select the
deprecated rule UP038
- Documented the change in version policy. From now on, deprecating a
rule should increase the minor version
## Test Plan
Integration tests in "integration_tests.rs"
Also tested with a temporary test package:
```
~> ../../ruff/target/debug/ruff.exe check --select UP038
warning: Rule `UP038` is deprecated and will be removed in a future release.
warning: Detected debug build without --no-cache.
UP038 Use `X | Y` in `isinstance` call instead of `(X, Y)`
--> main.py:2:11
|
1 | def main():
2 | print(isinstance(25, (str, int)))
| ^^^^^^^^^^^^^^^^^^^^^^^^^^
|
help: Convert to `X | Y`
Found 1 error.
No fixes available (1 hidden fix can be enabled with the `--unsafe-fixes` option).
~> ../../ruff/target/debug/ruff.exe check --select UP03
warning: Detected debug build without --no-cache.
All checks passed!
~> ../../ruff/target/debug/ruff.exe check --select UP0
warning: Detected debug build without --no-cache.
All checks passed!
~> ../../ruff/target/debug/ruff.exe check --select UP
warning: Detected debug build without --no-cache.
All checks passed!
~> ../../ruff/target/debug/ruff.exe check --select ALL
# warnings and errors, but because of other errors, UP038 was deselected
```
- **Stabilize `airflow3-suggested-update` (`AIR311`)**
- **Stabilize `airflow3-suggested-to-move-to-provider` (`AIR312`)**
- **Stabilize `airflow3-removal` (`AIR301`)**
- **Stabilize `airflow3-moved-to-provider` (`AIR302`)**
- **Stabilize `airflow-dag-no-schedule-argument` (`AIR002`)**
I put this all in one PR to make it easier to double check with @Lee-W
before we merge this. I also made a few minor documentation changes and
updated one error message that I want to make sure are okay. But for the
most part this just moves the rules from `RuleGroup::Preview` to
`RuleGroup::Stable`!
Fixes#17749
This stabilizes the behavior introduced in #16565 which (roughly) tries
to match an import like `import a.b.c` to an actual directory path
`a/b/c` in order to label it as first-party, rather than simply looking
for a directory `a`.
Mainly this affects the sorting of imports in the presence of namespace
packages, but a few other rules are affected as well.
This one has been a bit contentious in the past. It usually uncovers
~700 ecosystem hits. See:
- https://github.com/astral-sh/ruff/pull/16657
- https://github.com/astral-sh/ruff/issues/16690
But I think there's consensus that it's okay to merge as-is. We'd love
an
autofix since it's so common, but we can't reliably tell what a user
meant. The
pattern is ambiguous after all 😆
This is the first rule that actually needed its test case relocated, but
the
docs looked good.
## Summary
This PR Removes deprecated UP038 as per instructed in #18727closes#18727
## Test Plan
I have run tests non of them failing
One Question i have is do we have to document that UP038 is removed?
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
closes#7710
## Test Plan
It is is removal so i don't think we have to add tests otherwise i have
followed test plan mentioned in contributing.md
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
In #11115 we moved from defaulting to $HOME/Library/Application Support
to $XDG_HOME on macOS and added a deprecation warning if we find files
in the old location. So this PR removes the warning
closes#19145
## Test Plan
Ran `cargo test`
Summary
--
Rule and test/snapshot updated, the docs look good
My one hesitation here is that we could hold off stabilizing the rule
until its fix is also ready for stabilization, but this is also the only
preview PTH rule, so I think it's okay to stabilize the rule and later
(probably in the next minor release) stabilize the fixes together.
The tests looked good. For the docs, I added a `## See also` section
pointing to
the closely-related F841 (unused-variable) and the corresponding section
to F841
pointing back to RUF059. It seems like you'd probably want both of these
active
or at least to know about the other when reading the docs.
The constraint representation that we added in #19997 was subtly wrong,
in that it didn't correctly model that type assignability is a _partial_
order — it's possible for two types to be incomparable, with neither a
subtype of the other. That means the negation of a constraint like `T ≤
t` (typevar `T` must be a subtype of `t`) is **_not_** `t < T`, but
rather `t < T ∨ T ≁ t` (using ≁ to mean "not comparable to").
That means we need to update our constraint representation to be an
enum, so that we can track both _range_ constraints (upper/lower bound
on the typevar), and these new _incomparable_ constraints.
Since we need an enum now, that also lets us simplify how we were
modeling range constraints. Before, we let the lower/upper bounds be
either open (<) or closed (≤). Now, range constraints are always closed,
and we add a third kind of constraint for _not equivalent_ (≠). We can
translate an open upper bound `T < t` into `T ≤ t ∧ T ≠ t`.
We already had the logic for doing adding _clauses_ to a _set_ by doing
a pairwise simplification. We copy that over to where we add
_constraints_ to a _clause_. To calculate the intersection or union of
two constraints, the new enum representation makes it easy to break down
all of the possibilities into a small number of cases: intersect range
with range, intersect range with not-equivalent, etc. I've done the math
[here](https://dcreager.net/theory/constraints/) to show that the
simplifications for each of these cases is correct.
## Summary
Resolves#19357
Skip UP008 diagnostic for `builtins.super(P, self)` calls when
`__class__` is not referenced locally, preventing incorrect fixes.
**Note:** I haven't found concrete information about which cases
`__class__` will be loaded into the scope. Let me know if anyone has
references, it would be useful to enhance the implementation. I did a
lot of tests to determine when `__class__` is loaded. Considered
sources:
1. [Python doc
super](https://docs.python.org/3/library/functions.html#super)
2. [Python doc classes](https://docs.python.org/3/tutorial/classes.html)
3. [pep-3135](https://peps.python.org/pep-3135/#specification)
As I understand it, Python will inject at runtime into local scope a
`__class__` variable if it detects references to `super` or `__class__`.
This allows calling `super()` and passing appropriate parameters.
However, the compiler doesn't do the same for `builtins.super`, so we
need to somehow introduce `__class__` into the local scope.
I figured out `__class__` will be in scope with valid value when two
conditions are met:
1. `super` or `__class__` names have been loaded within function scope
4. `__class__` is not overridden.
I think my solution isn't elegant, so I would be appreciate a detailed
review.
## Test Plan
Added 19 test cases, updated snapshots.
---------
Co-authored-by: Igor Drokin <drokinii1017@gmail.com>
- Renames functions to drop `expect_` from names.
- Make functions return `Option<LineColumn>` to appropriately signal
when range is not available.
- Update existing consumers to use `unwrap_or_default()`. Uncertain if
there are better fallback behaviors for individual consumers.
This adds a new `backend: internal | uv` option to the LSP
`FormatOptions` allowing users to perform document and range formatting
operations though uv. The idea here is to prototype a solution for users
to transition to a `uv format` command without encountering version
mismatches (and consequently, formatting differences) between the LSP's
version of `ruff` and uv's version of `ruff`.
The primarily alternative to this would be to use uv to discover the
`ruff` version used to start the LSP in the first place. However, this
would increase the scope of a minimal `uv format` command beyond "run a
formatter", and raise larger questions about how uv should be used to
coordinate toolchain discovery. I think those are good things to
explore, but I'm hesitant to let them block a `uv format`
implementation. Another downside of using uv to discover `ruff`, is that
it needs to be implemented _outside_ the LSP; e.g., we'd need to change
the instructions on how to run the LSP and implement it in each editor
integration, like the VS Code plugin.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
Specifically, the [`if_not_else`] lint will sometimes flag
code to change the order of `if` and `else` bodies if this
would allow a `!` to be removed. While perhaps tasteful in
some cases, there are many cases in my experience where this
bows to other competing concerns that impact readability.
(Such as the relative sizes of the `if` and `else` bodies,
or perhaps an ordering that just makes the code flow in a
more natural way.)
[`if_not_else`]: https://rust-lang.github.io/rust-clippy/master/index.html#/if_not_else
## Summary
This is a follow-up to https://github.com/astral-sh/ruff/pull/19321.
Now lazy snapshots are updated to take into account new bindings on
every symbol reassignment.
```python
def outer(x: A | None):
if x is None:
x = A()
reveal_type(x) # revealed: A
def inner() -> None:
# lazy snapshot: {x: A}
reveal_type(x) # revealed: A
inner()
def outer() -> None:
x = None
x = 1
def inner() -> None:
# lazy snapshot: {x: Literal[1]} -> {x: Literal[1, 2]}
reveal_type(x) # revealed: Literal[1, 2]
inner()
x = 2
```
Closesastral-sh/ty#559.
## Test Plan
Some TODOs in `public_types.md` now work properly.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Adds support for generic PEP695 type aliases, e.g.,
```python
type A[T] = T
reveal_type(A[int]) # A[int]
```
Resolves https://github.com/astral-sh/ty/issues/677.
## Summary
Support cases like the following, where we need the generic context to
include both `Self` and `T` (not just `T`):
```py
from typing import Self
class C:
def method[T](self: Self, arg: T): ...
C().method(1)
```
closes https://github.com/astral-sh/ty/issues/1131
## Test Plan
Added regression test
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Noticed this was not escaped when writing a project that parses the
result of `ruff rule --outputformat json`. This is visible here:
<https://docs.astral.sh/ruff/rules/mixed-case-variable-in-global-scope/#why-is-this-bad>
## Test Plan
documentation only
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
Pr #11919 changed the fuzz build from `taiki-e/install-action` to
`cargo-bins/cargo-binstall` for necessary reasons of version selection.
But it left the `with:` parameter, which the `binstall` action does not
support. As a result, all workflow runs are showing a warning:
> Unexpected input(s) `'tool'`, valid inputs are `['']`
Eliminate the warning by removing the `with` parameter.
## Test Plan
Run CI, determine that the "cargo fuzz build" step no longer includes an
Annotation showing the warning message (quoted above).
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [bitflags](https://redirect.github.com/bitflags/bitflags) |
workspace.dependencies | patch | `2.9.3` -> `2.9.4` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>bitflags/bitflags (bitflags)</summary>
###
[`v2.9.4`](https://redirect.github.com/bitflags/bitflags/blob/HEAD/CHANGELOG.md#294)
[Compare
Source](https://redirect.github.com/bitflags/bitflags/compare/2.9.3...2.9.4)
#### What's Changed
- Add Cargo features to readme by
[@​KodrAus](https://redirect.github.com/KodrAus) in
[#​460](https://redirect.github.com/bitflags/bitflags/pull/460)
**Full Changelog**:
<https://github.com/bitflags/bitflags/compare/2.9.3...2.9.4>
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45MS4xIiwidXBkYXRlZEluVmVyIjoiNDEuOTEuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [clap](https://redirect.github.com/clap-rs/clap) |
workspace.dependencies | patch | `4.5.46` -> `4.5.47` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>clap-rs/clap (clap)</summary>
###
[`v4.5.47`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4547---2025-09-02)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.46...v4.5.47)
##### Features
- Added `impl FromArgMatches for ()`
- Added `impl Args for ()`
- Added `impl Subcommand for ()`
- Added `impl FromArgMatches for Infallible`
- Added `impl Subcommand for Infallible`
##### Fixes
- *(derive)* Update runtime error text to match `clap`
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45MS4xIiwidXBkYXRlZEluVmVyIjoiNDEuOTEuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[wasm-bindgen-test](https://redirect.github.com/wasm-bindgen/wasm-bindgen)
| workspace.dependencies | patch | `0.3.50` -> `0.3.51` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45MS4xIiwidXBkYXRlZEluVmVyIjoiNDEuOTEuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [log](https://redirect.github.com/rust-lang/log) |
workspace.dependencies | patch | `0.4.27` -> `0.4.28` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>rust-lang/log (log)</summary>
###
[`v0.4.28`](https://redirect.github.com/rust-lang/log/blob/HEAD/CHANGELOG.md#0428---2025-09-02)
[Compare
Source](https://redirect.github.com/rust-lang/log/compare/0.4.27...0.4.28)
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45MS4xIiwidXBkYXRlZEluVmVyIjoiNDEuOTEuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
The sub-checks for assignability and subtyping of materializations
performed in `has_relation_in_invariant_position` and
`is_subtype_in_invariant_position` need to propagate the
`HasRelationToVisitor`, or we can stack overflow.
A side effect of this change is that we also propagate the
`ConstraintSet` through, rather than using `C::from_bool`, which I think
may also become important for correctness in cases involving type
variables (though it isn't testable yet, since we aren't yet actually
creating constraints other than always-true and always-false.)
## Test Plan
Added mdtest (derived from code found in pydantic) which
stack-overflowed before this PR.
With this change incorporated, pydantic now checks successfully on my
draft PR for PEP 613 TypeAlias support.
Now that https://github.com/astral-sh/ruff/pull/20263 is merged, we can
update mypy_primer and add the new `egglog-python` project to
`good.txt`. The ecosystem-analyzer run shows that we now add 1,356
diagnostics (where we had over 5,000 previously, due to the unsupported
project layout).
## Summary
I felt it was safer to add the `python` folder *in addition* to a
possibly-existing `src` folder, even though the `src` folder only
contains Rust code for `maturin`-based projects. There might be
non-maturin projects where a `python` folder exists for other reasons,
next to a normal `src` layout.
closes https://github.com/astral-sh/ty/issues/1120
## Test Plan
Tested locally on the egglog-python project.
## Summary
Add backreferences to the original item declaration in TypedDict
diagnostics.
Thanks to @AlexWaygood for the suggestion.
## Test Plan
Updated snapshots
## Summary
An annotated assignment `name: annotation` without a right-hand side was
previously not covered by the range returned from
`DefinitionKind::full_range`, because we did expand the range to include
the right-hand side (if there was one), but failed to include the
annotation.
## Test Plan
Updated snapshot tests
## Summary
Add support for `typing.ReadOnly` as a type qualifier to mark
`TypedDict` fields as being read-only. If you try to mutate them, you
get a new diagnostic:
<img width="787" height="234" alt="image"
src="https://github.com/user-attachments/assets/f62fddf9-4961-4bcd-ad1c-747043ebe5ff"
/>
## Test Plan
* New Markdown tests
* The typing conformance changes are all correct. There are some false
negatives, but those are related to the missing support for the
functional form of `TypedDict`, or to overriding of fields via
inheritance. Both of these topics are tracked in
https://github.com/astral-sh/ty/issues/154
Closesastral-sh/ty#456. Part of astral-sh/ty#994.
After all the foundational work, this is only a small change, but let's
see if it exposes any unresolved issues.
## Summary
Part of astral-sh/ty#994. The goal of this PR was to add correct
behavior for attribute access on the top and bottom materializations.
This is necessary for the end goal of using the top materialization for
narrowing generics (`isinstance(x, list)`): we want methods like
`x.append` to work correctly in that case.
It turned out to be convenient to represent materialization as a
TypeMapping, so it can be stashed in the `type_mappings` list of a
function object. This also allowed me to remove most concrete
`materialize` methods, since they usually just delegate to the subparts
of the type, the same as other type mappings. That is why the net effect
of this PR is to remove a few hundred lines.
## Test Plan
I added a few more tests. Much of this PR is refactoring and covered by
existing tests.
## Followups
Assigning to attributes of top materializations is not yet covered. This
seems less important so I'd like to defer it.
I noticed that the `materialize` implementation of `Parameters` was
wrong; it did the same for the top and bottom materializations. This PR
makes the bottom materialization slightly more reasonable, but
implementing this correctly will require extending the struct.
## Summary
Two minor cleanups:
- Return `Option<ClassType>` rather than `Option<ClassLiteral>` from
`TypeInferenceBuilder::class_context_of_current_method`. Now that
`ClassType::is_protocol` exists as a method as well as
`ClassLiteral::is_protocol`, this simplifies most of the call-sites of
the `class_context_of_current_method()` method.
- Make more use of the `MethodDecorator::try_from_fn_type` method in
`class.rs`. Under the hood, this method uses the new methods
`FunctionType::is_classmethod()` and `FunctionType::is_staticmethod()`
that @sharkdp recently added, so it gets the semantics more precisely
correct than the code it's replacing in `infer.rs` (by accounting for
implicit staticmethods/classmethods as well as explicit ones). By using
these methods we can delete some code elsewhere (the
`FunctionDecorators::from_decorator_types()` constructor)
## Test Plan
Existing tests
## Summary
A small set of additional tests for `TypedDict` that I wrote while going
through the spec. Note that this certainly doesn't make the test suite
exhaustive (see remaining open points in the updated list here:
https://github.com/astral-sh/ty/issues/154).
## Summary
Per
https://github.com/astral-sh/ruff/issues/20191#issuecomment-3251131478,
this PR restructures the license file to draw a distinction between
projects from which we've (e.g.) drawn source code and projects whose
rules we've implemented but have otherwise not reused or adapted source
code from, which are credited in the README. While I was here, I also
sorted the list.
This PR adds two new `ty_extensions` functions,
`reveal_when_assignable_to` and `reveal_when_subtype_of`. These are
closely related to the existing `is_assignable_to` and `is_subtype_of`,
but instead of returning when the property (always) holds, it produces a
diagnostic that describes _when_ the property holds. (This will let us
construct mdtests that print out constraints that are not always true or
always false — though we don't currently have any instances of those.)
I did not replace _every_ occurrence of the `is_property` variants in
the mdtest suite, instead focusing on the generics-related tests where
it will be important to see the full detail of the constraint sets.
As part of this, I also updated the mdtest harness to accept the shorter
`# revealed:` assertion format for more than just `reveal_type`, and
updated the existing uses of `reveal_protocol_interface` to take
advantage of this.
## Summary
Pull this out of https://github.com/astral-sh/ruff/pull/18473 as an
isolated change to make sure it has no adverse effects.
The wrong behavior is observable on `main` for something like
```py
class C:
def __new__(cls) -> "C":
cls.x = 1
C.x # previously: Attribute `x` can only be accessed on instances
# now: Type `<class 'C'>` has no attribute `x`
```
where we currently treat `x` as an *instance* attribute (because we
consider `__new__` to be a normal function and `cls` to be the "self"
attribute). With this PR, we do not consider `x` to be an attribute,
neither on the class nor on instances of `C`. If this turns out to be an
important feature, we should add it intentionally, instead of
accidentally.
## Test Plan
Ecosystem checks.
## Summary
I'm trying to reduce code complexity for
[RustPython](https://github.com/RustPython/RustPython), we have this
file:
056795eed4/compiler/codegen/src/unparse.rs
which can be replaced entirely by `ruff_python_codegen::Generator`.
Unfortunately we can not create an instance of `Generator` easily,
because `Indentation` is not exported at
cda376afe0/crates/ruff_python_codegen/src/lib.rs (L3)
I have managed to bypass this restriction by doing:
```rust
let contents = r"x = 1";
let module = ruff_python_parser::parse_module(contents).unwrap();
let stylist = ruff_python_codegen::Stylist::from_tokens(module.tokens(), contents);
stylist.indentation()
```
But ideally I'd rather use:
```rust
ruff_python_codegen::Indentation::default()
```
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [tracing-subscriber](https://tokio.rs)
([source](https://redirect.github.com/tokio-rs/tracing)) |
workspace.dependencies | patch | `0.3.19` -> `0.3.20` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
### GitHub Vulnerability Alerts
####
[CVE-2025-58160](https://redirect.github.com/tokio-rs/tracing/security/advisories/GHSA-xwfj-jgwm-7wp5)
### Impact
Previous versions of tracing-subscriber were vulnerable to ANSI escape
sequence injection attacks. Untrusted user input containing ANSI escape
sequences could be injected into terminal output when logged,
potentially allowing attackers to:
- Manipulate terminal title bars
- Clear screens or modify terminal display
- Potentially mislead users through terminal manipulation
In isolation, impact is minimal, however security issues have been found
in terminal emulators that enabled an attacker to use ANSI escape
sequences via logs to exploit vulnerabilities in the terminal emulator.
### Patches
`tracing-subscriber` version 0.3.20 fixes this vulnerability by escaping
ANSI control characters in when writing events to destinations that may
be printed to the terminal.
### Workarounds
Avoid printing logs to terminal emulators without escaping ANSI control
sequences.
### References
https://www.packetlabs.net/posts/weaponizing-ansi-escape-sequences/
### Acknowledgments
We would like to thank [zefr0x](http://github.com/zefr0x) who
responsibly reported the issue at `security@tokio.rs`.
If you believe you have found a security vulnerability in any tokio-rs
project, please email us at `security@tokio.rs`.
---
### Release Notes
<details>
<summary>tokio-rs/tracing (tracing-subscriber)</summary>
###
[`v0.3.20`](https://redirect.github.com/tokio-rs/tracing/releases/tag/tracing-subscriber-0.3.20):
tracing-subscriber 0.3.20
[Compare
Source](https://redirect.github.com/tokio-rs/tracing/compare/tracing-subscriber-0.3.19...tracing-subscriber-0.3.20)
**Security Fix**: ANSI Escape Sequence Injection (CVE-TBD)
#### Impact
Previous versions of tracing-subscriber were vulnerable to ANSI escape
sequence injection attacks. Untrusted user input containing ANSI escape
sequences could be injected into terminal output when logged,
potentially allowing attackers to:
- Manipulate terminal title bars
- Clear screens or modify terminal display
- Potentially mislead users through terminal manipulation
In isolation, impact is minimal, however security issues have been found
in terminal emulators that enabled an attacker to use ANSI escape
sequences via logs to exploit vulnerabilities in the terminal emulator.
#### Solution
Version 0.3.20 fixes this vulnerability by escaping ANSI control
characters in when writing events to destinations that may be printed to
the terminal.
#### Affected Versions
All versions of tracing-subscriber prior to 0.3.20 are affected by this
vulnerability.
#### Recommendations
Immediate Action Required: We recommend upgrading to tracing-subscriber
0.3.20 immediately, especially if your application:
- Logs user-provided input (form data, HTTP headers, query parameters,
etc.)
- Runs in environments where terminal output is displayed to users
#### Migration
This is a patch release with no breaking API changes. Simply update your
Cargo.toml:
```toml
[dependencies]
tracing-subscriber = "0.3.20"
```
#### Acknowledgments
We would like to thank [zefr0x](http://github.com/zefr0x) who
responsibly reported the issue at `security@tokio.rs`.
If you believe you have found a security vulnerability in any tokio-rs
project, please email us at `security@tokio.rs`.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "" (UTC), Automerge - At any time (no
schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS44Mi43IiwidXBkYXRlZEluVmVyIjoiNDEuODIuNyIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiLCJzZWN1cml0eSJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
### Why
Removal should be grouped into the same category. It doesn't matter
whether it's from a provider or not (and the only case we used to have
was not anyway).
`ProviderReplacement` is used to indicate that we have a replacement and
we might need to install an extra Python package to cater to it.
### What
Move `airflow.operators.postgres_operator.Mapping` from AIR302 to AIR301
and get rid of `ProviderReplace::None`
## Test Plan
<!-- How was it tested? -->
Update the test fixtures accordingly in the first commit and reorganize
them in the second commit
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
update the argument `datasets` as `assets`
## Test Plan
<!-- How was it tested? -->
update fixture accordingly
It's almost certainly bad juju to show literally every single possible
symbol when completions are requested but there is nothing typed yet.
Moreover, since there are so many symbols, it is likely beneficial to
try and winnow them down before sending them to the client.
This change tries to extract text that has been typed and then uses
that as a query to listing all available symbols.
Instead of waiting to land auto-import until it is "ready
for users," it'd be nicer to get incremental progress merged
to `main`. By making it an experimental opt-in, we avoid making
the default completion experience worse but permit developers
and motivated users to try it.
This re-works the `all_symbols` based added previously to work across
all modules available, and not just what is directly in the workspace.
Note that we always pass an empty string as a query, which makes the
results always empty. We'll fix this in a subsequent commit.
This is to facilitate recursive traversal of all modules in an
environment. This way, we can keep asking for submodules.
This also simplifies how this is used in completions, and probably makes
it faster. Namely, since we return the `Module` itself, callers don't
need to invoke the full module resolver just to get the module type.
Note that this doesn't include namespace packages. (Which were
previously not supported in `Module::all_submodules`.) Given how they
can be spread out across multiple search paths, they will likely require
special consideration here.
This is similar to a change made in the "list top-level modules"
implementation that had been masked by poor Salsa failure modes.
Basically, if we can't find a root here, it *must* be a bug. And if we
just silently skip over it, we risk voiding Salsa's purity contract,
leading to more difficult to debug panics.
This did cause one test to fail, but only because the test wasn't
properly setting up roots.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
### What
Change the message from "DAG should have an explicit `schedule`
argument" to "`DAG` or `@dag` should have an explicit `schedule`
argument"
### Why
We're trying to get rid of the idea that DAG in airflow was Directed
acyclic graph. Thus, change it to refer to the class `DAG` or the
decorator `@dag` might help a bit.
## Test Plan
<!-- How was it tested? -->
update the test fixtures accordly
## Summary
This wires up the GitLab output format moved into `ruff_db` in
https://github.com/astral-sh/ruff/pull/20117 to the ty CLI.
While I was here, I made one unrelated change to the CLI docs. Clap was
rendering the escapes around the `\[default\]` brackets for the `full`
output, so I just switched those to parentheses:
```
--output-format <OUTPUT_FORMAT>
The format to use for printing diagnostic messages
Possible values:
- full: Print diagnostics verbosely, with context and helpful hints \[default\]
- concise: Print diagnostics concisely, one per line
- gitlab: Print diagnostics in the JSON format expected by GitLab Code Quality reports
```
## Test Plan
New CLI test, and a manual test with `--config 'terminal.output-format =
"gitlab"'` to make sure this works as a configuration option too. I also
tried piping the output through jq to make sure it's at least valid JSON
## Summary
We already have `mypy_primer` running in debug mode, so this should
provide some additional coverage, and allows us produce reasonable
timing results.
## Test Plan
CI run on this PR
This introduces `GotoTarget::Call` that represents the kind of
ambiguous/overloaded click of a callable-being-called:
```py
x = mymodule.MyClass(1, 2)
^^^^^^^
```
This is equivalent to `GotoTarget::Expression` for the same span but
enriched
with information about the actual callable implementation.
That is, if you click on `MyClass` in `MyClass()` it is *both* a
reference to the class and to the initializer of the class. Therefore
it would be ideal for goto-* and docstrings to be some intelligent
merging of both the class and the initializer.
In particular the callable-implementation (initializer) is prioritized
over the callable-itself (class) so when showing docstrings we will
preferentially show the docs of the initializer if it exists, and then
fallback to the docs of the class.
For goto-definition/goto-declaration we will yield both the class and
the initializer, requiring you to pick which you want (this is perhaps
needlessly pedantic but...).
Fixes https://github.com/astral-sh/ty/issues/898
Fixes https://github.com/astral-sh/ty/issues/1010
I decided to split out the addition of these tests from other PRs so
that it's easier to follow changes to the LSP's function call handling.
I'm not particularly concerned with whether the results produced by
these tests are "good" or "bad" in this PR, I'm just establishing a
baseline.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [rui314/setup-mold](https://redirect.github.com/rui314/setup-mold) |
action | digest | `7344740` -> `725a879` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45MS4xIiwidXBkYXRlZEluVmVyIjoiNDEuOTEuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [camino](https://redirect.github.com/camino-rs/camino) |
workspace.dependencies | patch | `1.1.11` -> `1.1.12` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>camino-rs/camino (camino)</summary>
###
[`v1.1.12`](https://redirect.github.com/camino-rs/camino/blob/HEAD/CHANGELOG.md#1112---2025-08-26)
[Compare
Source](https://redirect.github.com/camino-rs/camino/compare/camino-1.1.11...camino-1.1.12)
##### Added
- `Utf8PathBuf::from_os_string` and `Utf8Path::from_os_str` conversions.
- `TryFrom<OsString> for Utf8PathBuf` and `TryFrom<&OsStr> for
&Utf8Path` conversions.
Thanks to [BenjaminBrienen](https://redirect.github.com/BenjaminBrienen)
for your first contribution!
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45MS4xIiwidXBkYXRlZEluVmVyIjoiNDEuOTEuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [clap](https://redirect.github.com/clap-rs/clap) |
workspace.dependencies | patch | `4.5.45` -> `4.5.46` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>clap-rs/clap (clap)</summary>
###
[`v4.5.46`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4546---2025-08-26)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.45...v4.5.46)
##### Features
- Expose `StyledStr::push_str`
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45MS4xIiwidXBkYXRlZEluVmVyIjoiNDEuOTEuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [mimalloc](https://redirect.github.com/purpleprotocol/mimalloc_rust) |
workspace.dependencies | patch | `0.1.47` -> `0.1.48` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>purpleprotocol/mimalloc_rust (mimalloc)</summary>
###
[`v0.1.48`](https://redirect.github.com/purpleprotocol/mimalloc_rust/releases/tag/v0.1.48):
Version 0.1.48
[Compare
Source](https://redirect.github.com/purpleprotocol/mimalloc_rust/compare/v0.1.47...v0.1.48)
##### Changes
- Mimalloc `v3` feature flag. (credits
[@​gschulze](https://redirect.github.com/gschulze)).
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS45MS4xIiwidXBkYXRlZEluVmVyIjoiNDEuOTEuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
Thread visitors through the rest of `apply_type_mapping`: callable and
protocol types.
## Test Plan
Added mdtest that previously stack overflowed.
## Summary
We have the ability to defer type inference of some parts of
definitions, so as to allow us to create a type that may need to be
recursively referenced in those other parts of the definition.
We also have the ability to do type inference in a context where all
name resolution should be deferred (that is, names should be looked up
from all-reachable-definitions rather than from the location of use.)
This is used for all annotations in stubs, or if `from __future__ import
annotations` is active.
Previous to this PR, these two concepts were linked: deferred-inference
always implied deferred-name-resolution, though we also supported
deferred-name-resolution without deferred-inference, via
`DeferredExpressionState`.
For the upcoming `typing.TypeAlias` support, I will defer inference of
the entire RHS of the alias (so as to support cycles), but that doesn't
imply deferred name resolution; at runtime, the RHS of a name annotated
as `typing.TypeAlias` is executed eagerly.
So this PR fully de-couples the two concepts, instead explicitly setting
the `DeferredExpressionState` in those cases where we should defer name
resolution.
It also fixes a long-standing related bug, where we were deferring name
resolution of all names in class bases, if any of the class bases
contained a stringified annotation.
## Test Plan
Added test that failed before this PR.
## Summary
Fuzzer seed 208 seems to be timing out all fuzzer runs on PRs today.
This has happened on multiple unrelated PRs, as well as on an initial
version of this PR that made a comment-only change in ty and didn't skip
any seeds, so the timeout appears to be consistent in CI, on ty main
branch, as of today, but it started happening due to some change in a
factor outside ty; not sure what.
I checked the code generated for seed 208 locally, and it takes about
30s to check on current ty main branch. This is slow for a fuzzer seed,
but shouldn't be slow enough to make it time out after 20min in CI (even
accounting for GH runners being slower than my laptop.)
I tried to bisect the slowness of checking that code locally, but I
didn't go back far enough to find the change that made it slow. In fact
it seems like it became significantly faster in the last few days (on an
older checkout I had to stop it after several minutes.) So whatever the
cause of the slowness, it's not a recent change in ty.
I don't want to rabbit-hole on this right now (fuzzer-discovered issues
are lower-priority than real-world-code issues), and need a working CI,
so skip this seed for now until we can investigate it.
## Test Plan
CI. This PR contains a no-op (comment) change in ty, so that the fuzz
test is triggered in CI and we can verify it now works (as well as
verify, on the previous commit, that the fuzzer job is timing out on
that seed, even with just a no-op change in ty.)
Reverts astral-sh/ruff#20156. As @sharkdp noted in his post-merge
review, there were several issues with that PR that I didn't spot before
merging — but I'm out for four days now, and would rather not leave
things in an inconsistent state for that long. I'll revisit this on
Wednesday.
## Summary
These projects all check successfully now.
(Pandas still takes 9s, as the comment in `bad.txt` said, but I don't
think this is slow enough to exclude it; mypy-primer overall still runs
in 4 minutes, faster than e.g. the test suite on Windows.)
## Test Plan
mypy-primer CI.
## Summary
This error is about assigning to attributes rather than reading
attributes, so I think `invalid-assignment` makes more sense than
`invalid-attribute-access`
## Test Plan
existing mdtests updated
## Summary
In `is_disjoint_from_impl`, we should unpack type aliases before we
check `TypedDict`. This change probably doesn't have any visible effect
until we have a more discriminating implementation of disjointness for
`TypedDict`, but making the change now can avoid some confusion/bugs in
future.
In `type_ordering.rs`, we should order `TypedDict` near more similar
types, and leave Union/Intersection together at the end of the list.
This is not necessary for correctness, but it's more consistent and it
could have saved me some confusion trying to figure out why I was only
getting an unreachable panic when my code example included a `TypedDict`
type.
## Test Plan
None besides existing tests.
## Summary
Now that we have `Type::TypeAlias`, which can wrap a union, and the
possibility of unions including non-unpacked type aliases (which is
necessary to support recursive type aliases), we can no longer assume in
`UnionType::normalized_impl` that normalizing each element of an
existing union will result in a set of elements that we can order and
then place raw into `UnionType` to create a normalized union. It's now
possible for those elements to themselves include union types (unpacked
from an alias). So instead, we need to feed those elements into the full
`UnionBuilder` (with alias-unpacking turned on) to flatten/normalize
them, and then order them.
## Test Plan
Added mdtest.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR fixes#7352 by exposing the `show_fix_diff` option used in our
snapshot tests in the CLI. As the issue suggests, we plan to make this
the default output format in the future, so this is added to the `full`
output format in preview for now.
This turned out to be pretty straightforward. I just used our existing
`Applicability` settings to determine whether or not to print the diff.
The snapshot differences are because we now set
`Applicability::DisplayOnly` for our snapshot tests. This
`Applicability` is also used to determine whether or not the fix icon
(`[*]`) is rendered, so this is now shown for display-only fixes in our
snapshots. This was already the case previously, but we were only
setting `Applicability::Unsafe` in these tests and ignoring the
`Applicability` when rendering fix diffs. CLI users can't enable
display-only fixes, so this is only a test change for now, but this
should work smoothly if we decide to expose a `--display-only-fixes`
flag or similar in the future.
I also deleted the `PrinterFlags::SHOW_FIX_DIFF` flag. This was
completely unused before, and it seemed less confusing just to delete it
than to enable it in the right place and check it along with the
`OutputFormat` and `preview`.
## Test Plan
I only added one CLI test for now. I'm kind of assuming that we have
decent coverage of the cases where this shouldn't be firing, especially
the `output_format` CLI test, which shows that this definitely doesn't
affect non-preview `full` output. I'm happy to add more tests with
different combinations of options, if we're worried about any in
particular. I did try `--diff` and `--preview` and a few other
combinations manually.
And here's a screenshot using our trusty UP049 example from the design
discussion confirming that all the colors and other formatting still
look as expected:
<img width="786" height="629" alt="image"
src="https://github.com/user-attachments/assets/94e408bc-af7b-4573-b546-a5ceac2620f2"
/>
And one with an unsafe fix to see the footer:
<img width="782" height="367" alt="image"
src="https://github.com/user-attachments/assets/bbb29e47-310b-4293-b2c2-cc7aee3baff4"
/>
## Related issues and PR
- https://github.com/astral-sh/ruff/issues/7352
- https://github.com/astral-sh/ruff/pull/12595
- https://github.com/astral-sh/ruff/issues/12598
- https://github.com/astral-sh/ruff/issues/12599
- https://github.com/astral-sh/ruff/issues/12600
I think we could probably close all of these issues now. I think we've
either resolved or avoided most of them, and if we encounter them again
with the new output format, it would probably make sense to open new
ones anyway.
## Summary
This PR fixes various TODOs around overload call when a variadic
argument is used.
The reason this bug existed is because the specialization wouldn't
account for unpacking the type of the variadic argument.
This is fixed by expanding `MatchedArgument` to contain the type of that
argument _only_ when it is a variadic argument. The reason is that
there's a split for when the argument type is inferred -- the
non-variadic arguments are inferred using `infer_argument_types` _after_
parameter matching while the variadic argument type is inferred _during_
the parameter matching. And, the `MatchedArgument` is populated _during_
parameter matching which means the unpacking would need to happen during
parameter matching.
This split seems a bit inconsistent but I don't want to spend a lot of
time on trying to merge them such that all argument type inference
happens in a single place. I might look into it while adding support for
`**kwargs`.
## Test Plan
Update existing tests by resolving the todos.
The ecosystem changes looks correct to me except for the `slice` call
but it seems that it's unrelated to this PR as we infer `slice[Any, Any,
Any]` for a `slice(1, 2, 3)` call on `main` as well
([playground](https://play.ty.dev/9eacce00-c7d5-4dd5-a932-4265cb2bb4f6)).
This PR adds an implementation of constraint sets.
An individual constraint restricts the specialization of a single
typevar to be within a particular lower and upper bound: the typevar can
only specialize to types that are a supertype of the lower bound, and a
subtype of the upper bound. (Note that lower and upper bounds are fully
static; we take the bottom and top materializations of the bounds to
remove any gradual forms if needed.) Either bound can be “closed” (where
the bound is a valid specialization), or “open” (where it is not).
You can then build up more complex constraint sets using union,
intersection, and negation operations. We use a disjunctive normal form
(DNF) representation, just like we do for types: a _constraint set_ is
the union of zero or more _clauses_, each of which is the intersection
of zero or more individual constraints. Note that the constraint set
that contains no clauses is never satisfiable (`⋃ {} = 0`); and the
constraint set that contains a single clause, which contains no
constraints, is always satisfiable (`⋃ {⋂ {}} = 1`).
One thing to note is that this PR does not change the logic of the
actual assignability checks, and in particular, we still aren't ever
trying to create an "individual constraint" that constrains a typevar.
Technically we're still operating only on `bool`s, since we only ever
instantiate `C::always_satisfiable` (i.e., `true`) and
`C::unsatisfiable` (i.e., `false`) in the `has_relation_to` methods. So
if you thought that #19838 introduced an unnecessarily complex stand-in
for `bool`, well here you go, this one is worse! (But still seemingly
not yielding a performance regression!) The next PR in this series,
#20093, is where we will actually create some non-trivial constraint
sets and use them in anger.
That said, the PR does go ahead and update the assignability checks to
use the new `ConstraintSet` type instead of `bool`. That part is fairly
straightforward since we had already updated the assignability checks to
use the `Constraints` trait; we just have to actively choose a different
impl type. (For the `is_whatever` variants, which still return a `bool`,
we have to convert the constraint set, but the explicit
`is_always_satisfiable` calls serve as nice documentation of our
intent.)
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
This pull request fixes the bug described in issue
[#19153](https://github.com/astral-sh/ruff/issues/19153).
The issue occurred when `PERF403` incorrectly flagged cases involving
tuple unpacking in a for loop. For example:
```python
def f():
v = {}
for (o, p), x in [("op", "x")]:
v[x] = o, p
```
This code was wrongly suggested to be rewritten into a dictionary
comprehension, which changes the semantics.
Changes in this PR:
Updated the `PERF403` rule to correctly handle tuple unpacking in loop
targets.
Added regression tests to ensure this case (and similar ones) are no
longer flagged incorrectly.
Why:
This ensures that `PERF403` only triggers when a dictionary
comprehension is semantically equivalent to the original loop,
preventing false positives.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
This is a variant of #20076 that moves some complexity out of
`apply_type_mapping_impl` in `generics.rs`. The tradeoff is that now
every place that applies `TypeMapping::Specialization` must take care to
call `.materialize()` afterwards. (A previous version of this didn't
work because I had missed a spot where I had to call `.materialize()`.)
@carljm as asked in
https://github.com/astral-sh/ruff/pull/20076#discussion_r2305385298 .
## Summary
Adds new rule to catch use of builtins `input()` in async functions.
Issue #8451
## Test Plan
New snapshosts in `ASYNC250.py` with `cargo insta test`.
## Summary
Resolves https://github.com/astral-sh/ty/issues/1103
## Test Plan
Edited `crates/ty_python_semantic/resources/mdtest/literal/boolean.md`
with:
```
# Boolean literals
```python
reveal_type(True) # revealed: Literal[False]
reveal_type(False) # revealed: Literal[False]
```
Ran `cargo test -p ty_python_semantic --test mdtest -- mdtest__literal_boolean`
And we get a test failure:
```
running 1 test
test mdtest__literal_boolean ... FAILED
failures:
---- mdtest__literal_boolean stdout ----
boolean.md - Boolean literals (c336e1af3d538acd)
crates/ty_python_semantic/resources/mdtest/literal/boolean.md:4
unmatched assertion: revealed: Literal[False]
crates/ty_python_semantic/resources/mdtest/literal/boolean.md:4
unexpected error: 13 [revealed-type] "Revealed type: `Literal[True]`"
To rerun this specific test, set the environment variable:
MDTEST_TEST_FILTER='boolean.md - Boolean literals (c336e1af3d538acd)'
MDTEST_TEST_FILTER='boolean.md - Boolean literals (c336e1af3d538acd)'
cargo test -p ty_python_semantic --test mdtest --
mdtest__literal_boolean
--------------------------------------------------
thread 'mdtest__literal_boolean' panicked at
crates/ty_test/src/lib.rs:138:5:
Some tests failed.
note: run with `RUST_BACKTRACE=1` environment variable to display a
backtrace
failures:
mdtest__literal_boolean
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 263
filtered out; finished in 0.18s
error: test failed, to rerun pass `-p ty_python_semantic --test mdtest`
```
As expected.
And when i checkout main and keep the same mdtest file all tests pass (as the repro).
## Summary
I spun this off from #19919 to separate the rendering code change and
snapshot updates from the (much smaller) changes to expose this in the
CLI. I grouped all of the `ruff_linter` snapshot changes in the final
commit in an effort to make this easier to review. The code changes are
in [this
range](619395eb41).
I went through all of the snapshots, albeit fairly quickly, and they all
looked correct to me. In the last few commits I was trying to resolve an
existing issue in the alignment of the line number separator:
73720c73be/crates/ruff_linter/src/rules/flake8_comprehensions/snapshots/ruff_linter__rules__flake8_comprehensions__tests__C409_C409.py.snap (L87-L89)
In the snapshot above on `main`, you can see that a double-digit line
number at the end of the context lines for a snippet was causing a
misalignment with the other separators. That's now resolved. The one
downside is that this can lead to a mismatch with the diagnostic above:
```
C409 [*] Unnecessary list literal passed to `tuple()` (rewrite as a tuple literal)
--> C409.py:4:6
|
2 | t2 = tuple([1, 2])
3 | t3 = tuple((1, 2))
4 | t4 = tuple([
| ______^
5 | | 1,
6 | | 2
7 | | ])
| |__^
8 | t5 = tuple(
9 | (1, 2)
|
help: Rewrite as a tuple literal
1 | t1 = tuple([])
2 | t2 = tuple([1, 2])
3 | t3 = tuple((1, 2))
- t4 = tuple([
4 + t4 = (
5 | 1,
6 | 2
- ])
7 + )
8 | t5 = tuple(
9 | (1, 2)
10 | )
note: This is an unsafe fix and may remove comments or change runtime behavior
```
But I don't think we can avoid that without really reworking this
rendering to make the diagnostic and diff rendering aware of each other.
Anyway, this should only happen in relatively rare cases where the
diagnostic is near a digit boundary and also near a context boundary.
Most of our diagnostics line up nicely.
Another potential downside of the new rendering format is its handling
of long stretches of `+` or `-` lines:
```
help: Replace with `Literal[...] | None`
21 | ...
22 |
23 |
- def func6(arg1: Literal[
- "hello",
- None # Comment 1
- , "world"
- ]):
24 + def func6(arg1: Literal["hello", "world"] | None):
25 | ...
26 |
27 |
note: This is an unsafe fix and may remove comments or change runtime behavior
```
To me it just seems a little hard to tell what's going on with just a
long streak of `-`-prefixed lines. I saw an even more exaggerated
example at some point, but I think this is also fairly rare. Most of the
snapshots seem more like the examples we looked at on Discord with
plenty of `|` lines and pairs of `+` and `-` lines.
## Test Plan
Existing tests plus one new test in `ruff_db` to isolate a line
separator alignment issue
## Summary
Decrease the maximum number of literals in a union before we collapse to
the supertype. The better fix for this will be
https://github.com/astral-sh/ty/issues/957, but it is very tempting to
solve this for now by simply decreasing the limit by one, to get below
the salsa limit of 200.
closes https://github.com/astral-sh/ty/issues/660
## Test Plan
Added a regression test that would previously lead to a "too many cycle
iterations" panic.
## Summary
With this PR, we stop performing boundness analysis for implicit
instance attributes:
```py
class C:
def __init__(self):
if False:
self.x = 1
C().x # would previously show an error, with this PR we pretend the attribute exists
```
This PR is potentially just a temporary measure until we find a better
fix. But I have already invested a lot of time trying to find the root
cause of https://github.com/astral-sh/ty/issues/758 (and [this
example](https://github.com/astral-sh/ty/issues/758#issuecomment-3206108262),
which I'm not entirely sure is related) and I still don't understand
what is going on. This PR fixes the performance problems in both of
these problems (in a rather crude way).
The impact of the proposed change on the ecosystem is small, and the
three new diagnostics are arguably true positives (previously hidden
because we considered the code unreachable, based on e.g. `assert`ions
that depended on implicit instance attributes). So this seems like a
reasonable fix for now.
Note that we still support cases like these:
```py
class D:
if False: # or any other expression that statically evaluates to `False`
x: int = 1
D().x # still an error
class E:
if False: # or any other expression that statically evaluates to `False`
def f(self):
self.x = 1
E().x # still an error
```
closes https://github.com/astral-sh/ty/issues/758
## Test Plan
Updated tests, benchmark results
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#19664
Fix allowed unused imports matching for top-level modules.
I've simply replaced `from_dotted_name` with `user_defined`. Since
QualifiedName for imports is created in
crates/ruff_python_semantic/src/imports.rs, I guess it's acceptable to
use `user_defined` here. Please tell me if there is better way.
0c5089ed9e/crates/ruff_python_semantic/src/imports.rs (L62)
## Test Plan
<!-- How was it tested? -->
I've added a snapshot test
`f401_allowed_unused_imports_top_level_module`.
## Summary
This PR is a first step toward adding a GitLab output format to ty. It
converts the `GitlabEmitter` from `ruff_linter` to a `GitlabRenderer` in
`ruff_db` and updates its implementation to handle non-Ruff files and
diagnostics without primary spans. I tried to break up the changes here
so that they're easy to review commit-by-commit, or at least in groups
of commits:
- [preparatory changes in-place in `ruff_linter` and a `ruff_db`
skeleton](0761b73a61)
- [moving the code over with no implementation changes mixed
in](0761b73a61..8f909ea0bb)
- [tidying up the code now in
`ruff_db`](9f047c4f9f..e5e217fcd6)
This wasn't strictly necessary, but I also added some `Serialize`
structs instead of calling `json!` to make it a little clearer that we
weren't modifying the schema (e4c4bee35d).
I plan to follow this up with a separate PR exposing this output format
in the ty CLI, which should be quite straightforward.
## Test Plan
Existing tests, especially the two that show up in the diff as renamed
nearly without changes
## Summary
closes https://github.com/astral-sh/ty/issues/692
If the expression (or any child expressions) is not definitely bound the
reachability constraint evaluation is determined as ambiguous.
This fixes the infinite cycles panic in the following code:
```py
from typing import Literal
class Toggle:
def __init__(self: "Toggle"):
if not self.x:
self.x: Literal[True] = True
```
Credit of this solution is for David.
## Test Plan
- Added a test case with too many cycle iterations panic.
- Previous tests.
---------
Co-authored-by: David Peter <mail@david-peter.de>
Part of #994. This adds a new field to the Specialization struct to
record when we're dealing with the top or bottom materialization of an
invariant generic. It also implements subtyping and assignability for
these objects.
Next planned steps after this is done are to implement other operations
on top/bottom materializations; probably attribute access is an
important one.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Adds new rule to find and report use of `httpx.Client` in synchronous
functions.
See issue #8451
## Test Plan
New snapshots for `ASYNC212.py` with `cargo insta test`.
There are some situations that we have a confusing diagnostics due to
identical class names.
## Class with same name from different modules
```python
import pandas
import polars
df: pandas.DataFrame = polars.DataFrame()
```
This yields the following error:
**Actual:**
error: [invalid-assignment] "Object of type `DataFrame` is not
assignable to `DataFrame`"
**Expected**:
error: [invalid-assignment] "Object of type `polars.DataFrame` is not
assignable to `pandas.DataFrame`"
## Nested classes
```python
from enum import Enum
class A:
class B(Enum):
ACTIVE = "active"
INACTIVE = "inactive"
class C:
class B(Enum):
ACTIVE = "active"
INACTIVE = "inactive"
```
**Actual**:
error: [invalid-assignment] "Object of type `Literal[B.ACTIVE]` is not
assignable to `B`"
**Expected**:
error: [invalid-assignment] "Object of type
`Literal[my_module.C.B.ACTIVE]` is not assignable to `my_module.A.B`"
## Solution
In this MR we added an heuristics to detect when to use a fully
qualified name:
- There is an invalid assignment and;
- They are two different classes and;
- They have the same name
The fully qualified name always includes:
- module name
- nested classes name
- actual class name
There was no `QualifiedDisplay` so I had to implement it from scratch.
I'm very new to the codebase, so I might have done things inefficiently,
so I appreciate feedback.
Should we pre-compute the fully qualified name or do it on demand?
## Not implemented
### Function-local classes
Should we approach this in a different PR?
**Example**:
```python
# t.py
from __future__ import annotations
def function() -> A:
class A:
pass
return A()
class A:
pass
a: A = function()
```
#### mypy
```console
t.py:8: error: Incompatible return value type (got "t.A@5", expected "t.A") [return-value]
```
From my testing the 5 in `A@5` comes from the like number.
#### ty
```console
error[invalid-return-type]: Return type does not match returned value
--> t.py:4:19
|
4 | def function() -> A:
| - Expected `A` because of return type
5 | class A:
6 | pass
7 |
8 | return A()
| ^^^ expected `A`, found `A`
|
info: rule `invalid-return-type` is enabled by default
```
Fixes https://github.com/astral-sh/ty/issues/848
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
While looking at some logging output that I added to
`ReachabilityConstraintBuilder::add_and_constraint` in order to debug
https://github.com/astral-sh/ty/issues/1091, I noticed that it seemed to
suggest that the TDD was built in an imbalanced way for code like the
following, where we have a sequence of non-nested `if` conditions:
```py
def f(t1, t2, t3, t4, …):
x = 0
if t1:
x = 1
if t2:
x = 2
if t3:
x = 3
if t4:
x = 4
…
```
To understand this a bit better, I added some code to the
`ReachabilityConstraintBuilder` to render the resulting TDD. On `main`,
we get a tree that looks like the following, where you can see a pattern
of N sub-trees that grow linearly with N (number of `if` statements).
This results in an overall tree structure that has N² nodes (see graph
below):
<img alt="normal order"
src="https://github.com/user-attachments/assets/aab40ce9-e82a-4fcd-823a-811f05f15f66"
/>
If we zoom in to one of these subgraphs, we can see what the problem is.
When we add new constraints that represent combinations like `t1 AND ~t2
AND ~t3 AND t4 AND …`, they start with the evaluation of "early"
conditions (`t1`, `t2`, …). This means that we have to create new
subgraphs for each new `if` condition because there is little sharing
with the previous structure. We evaluate the Boolean condition in a
right-associative way: `t1 AND (~t2 AND (~t3 AND t4)))`:
<img width="500" align="center"
src="https://github.com/user-attachments/assets/31ea7182-9e00-4975-83df-d980464f545d"
/>
If we change the ordering of TDD atoms, we can change that to a
left-associative evaluation: `(((t1 AND ~t2) AND ~t3) AND t4) …`. This
means that we can re-use previous subgraphs `(t1 AND ~t2)`, which
results in a much more compact graph structure overall (note how "late"
conditions are now at the top, and "early" conditions are further down
in the graph):
<img alt="reverse order"
src="https://github.com/user-attachments/assets/96a6b7c1-3d35-4192-a917-0b2d24c6b144"
/>
If we count the number of TDD nodes for a growing number if `if`
statements, we can see that this change results in a slower growth. It's
worth noting that the growth is still superlinear, though:
<img width="800" height="600" alt="plot"
src="https://github.com/user-attachments/assets/22e8394f-e74e-4a9e-9687-0d41f94f2303"
/>
On the actual code from the referenced ticket (the `t_main.py` file
reduced to its main function, with the main function limited to 2000
lines instead of 11000 to allow the version on `main` to run to
completion), the effect is much more dramatic. Instead of 26 million TDD
nodes (`main`), we now only create 250 thousand (this branch), which is
slightly less than 1%.
The change in this PR allows us to build the semantic index and
type-check the problematic `t_main.py` file in
https://github.com/astral-sh/ty/issues/1091 in 9 seconds. This is still
not great, but an obvious improvement compared to running out of memory
after *minutes* of execution.
An open question remains whether this change is beneficial for all kinds
of code patterns, or just this linear sequence of `if` statements. It
does not seem unreasonable to think that referring to "earlier"
conditions is generally a good idea, but I learned from Doug that it's
generally not possible to find a TDD-construction heuristic that is
non-pathological for all kinds of inputs. Fortunately, it seems like
this change here results in performance improvements across *all of our
benchmarks*, which should increase the confidence in this change:
| Benchmark | Improvement |
|---------------------|-------------------------|
| hydra-zen | +13% |
| DateType | +5% |
| sympy (walltime) | +4% |
| attrs | +4% |
| pydantic (walltime) | +2% |
| pandas (walltime) | +2% |
| altair (walltime) | +2% |
| static-frame | +2% |
| anyio | +1% |
| freqtrade | +1% |
| colour-science | +1% |
| tanjun | +1% |
closes https://github.com/astral-sh/ty/issues/1091
---------
Co-authored-by: Douglas Creager <dcreager@dcreager.net>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Extend the following rules.
### AIR311
* `airflow.sensors.base.BaseSensorOperator` →
airflow.sdk.bases.sensor.BaseSensorOperator`
* `airflow.sensors.base.PokeReturnValue` →
airflow.sdk.bases.sensor.PokeReturnValue`
* `airflow.sensors.base.poke_mode_only` →
airflow.sdk.bases.sensor.poke_mode_only`
* `airflow.decorators.base.DecoratedOperator` →
airflow.sdk.bases.decorator.DecoratedOperator`
* `airflow.models.param.Param` → airflow.sdk.definitions.param.Param`
* `airflow.decorators.base.DecoratedMappedOperator` →
`airflow.sdk.bases.decorator.DecoratedMappedOperator`
* `airflow.decorators.base.DecoratedOperator` →
`airflow.sdk.bases.decorator.DecoratedOperator`
* `airflow.decorators.base.TaskDecorator` →
`airflow.sdk.bases.decorator.TaskDecorator`
* `airflow.decorators.base.get_unique_task_id` →
`airflow.sdk.bases.decorator.get_unique_task_id`
* `airflow.decorators.base.task_decorator_factory` →
`airflow.sdk.bases.decorator.task_decorator_factory`
### AIR312
* `airflow.sensors.bash.BashSensor` →
`airflow.providers.standard.sensor.bash.BashSensor`
* `airflow.sensors.python.PythonSensor` →
`airflow.providers.standard.sensors.python.PythonSensor`
## Test Plan
<!-- How was it tested? -->
update the test fixture accordingly in the second commit and reorg in
the third
## Summary
Properly preserve type qualifiers when accessing attributes on unions
and intersections. This is a prerequisite for
https://github.com/astral-sh/ruff/pull/19579.
Also fix a completely wrong implementation of
`map_with_boundness_and_qualifiers`. It now closely follows
`map_with_boundness` (just above).
## Test Plan
I thought about it, but didn't find any easy way to test this. This only
affected `Type::member`. Things like validation of attribute writes
(where type qualifiers like `ClassVar` and `Final` are important) were
already handling things correctly.
## Summary
Add a subtly different test case for recursive PEP 695 type aliases,
which does require that we relax our union simplification, so we don't
eagerly unpack aliases from user-provided union annotations.
## Test Plan
Added mdtest.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Part of https://github.com/astral-sh/ruff/pull/20100 |
https://github.com/astral-sh/ruff/pull/20100#issuecomment-3225349156
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes https://github.com/astral-sh/ruff/issues/20088
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
`cargo nextest run flake8_use_pathlib`
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Part of #20009 (i forgot to delete it in this PR)
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
Closes#19302
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
This adds an auto-fix for `Logging statement uses f-string` Ruff G004,
so users don't have to resolve it manually.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
I ran the auto-fixes on a Python file locally and and it worked as
expected.
<!-- How was it tested? -->
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
Summary
--
This PR aims to resolve (or help to resolve) #18442 and #19357 by
encoding the CPython semantics around the `__class__` cell in our
semantic model. Namely,
> `__class__` is an implicit closure reference created by the compiler
if any methods in a class body refer to either `__class__` or super.
from the Python
[docs](https://docs.python.org/3/reference/datamodel.html#creating-the-class-object).
As noted in the variant docs by @AlexWaygood, we don't fully model this
behavior, opting always to create the `__class__` cell binding in a new
`ScopeKind::DunderClassCell` around each method definition, without
checking if any method in the class body actually refers to `__class__`
or `super`.
As such, this PR fixes#18442 but not #19357.
Test Plan
--
Existing tests, plus the tests from #19783, which now pass without any
rule-specific code.
Note that we opted not to alter the behavior of F841 here because
flagging `__class__` in these cases still seems helpful. See the
discussion in
https://github.com/astral-sh/ruff/pull/20048#discussion_r2296252395 and
in the test comments for more information.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Mikko Leppänen <mleppan23@gmail.com>
## Summary
D413 in this section was incorrectly linking to D410.
I haven't checked if this issue happens anywhere else in the docs.
## Test Plan
Look at docs
## Summary
Our internal inlay hints structure (`ty_ide::InlayHint`) now more
closely resembles `lsp_types::InlayHint`.
This mainly allows us to convert to `lsp_types::InlayHint` with less
hassle, but it also allows us to manage the different parts of the inlay
hint better, which in the future will allow us to implement features
like goto on the type part of the type inlay hint.
It also really isn't important to store a specific `Type` instance in
the `InlayHintContent`. So we remove this and use `InlayHintLabel`
instead which just shows the representation of the type (along with
other information).
We see a similar structure used in rust-analyzer too.
## Summary
This has been here for awhile (since our initial PEP 695 type alias
support) but isn't really correct. The right-hand-side of a PEP 695 type
alias is a distinct scope, and we don't mark it as an "eager" nested
scope, so it automatically gets "deferred" resolution of names from
outer scopes (just like a nested function). Thus it's
redundant/unnecessary for us to use `DeferredExpressionState::Deferred`
for resolving that RHS expression -- that's for deferring resolution of
individual names within a scope. Using it here causes us to wrongly
ignore applicable outer-scope narrowing.
## Test Plan
Added mdtest that failed before this PR (the second snippet -- the first
snippet always passed.)
## Summary
As noted in a code TODO, our `Diff` rendering code previously didn't
have any
special handling for notebooks. This was particularly obvious when the
diffs
were rendered right next to the corresponding diagnostic because the
diagnostic
used cell-based line numbers, while the diff was still using line
numbers from
the concatenated source. This PR updates the diff rendering to handle
notebooks
too.
The main improvements shown in the example below are:
- Line numbers are now remapped to be relative to their cell
- Context lines from other cells are suppressed
```
error[unused-import][*]: `math` imported but unused
--> notebook.ipynb:cell 2:2:8
|
1 | # cell 2
2 | import math
| ^^^^
3 |
4 | print('hello world')
|
help: Remove unused import: `math`
ℹ Safe fix
1 1 | # cell 2
2 |-import math
3 2 |
4 3 | print('hello world')
```
I tried a few different approaches here before finally just splitting
the notebook into separate text ranges by cell and diffing each one
separately. It seems to work and passes all of our tests, but I don't
know if it's actually enforced anywhere that a single edit doesn't span
cells. Such an edit would silently be dropped right now since it would
fail the `contains_range` check. I also feel like I may have overlooked
an existing way to partition a file into cells like this.
## Test Plan
Existing notebook tests, plus a new one in `ruff_db`
## Summary
Implement validation for `TypedDict` constructor calls and dictionary
literal assignments, including support for `total=False` and proper
field management.
Also add support for `Required` and `NotRequired` type qualifiers in
`TypedDict` classes, along with proper inheritance behavior and the
`total=` parameter.
Support both constructor calls and dict literal syntax
part of https://github.com/astral-sh/ty/issues/154
### Basic Required Field Validation
```py
class Person(TypedDict):
name: str
age: int | None
# Error: Missing required field 'name' in TypedDict `Person` constructor
incomplete = Person(age=25)
# Error: Invalid argument to key "name" with declared type `str` on TypedDict `Person`
wrong_type = Person(name=123, age=25)
# Error: Invalid key access on TypedDict `Person`: Unknown key "extra"
extra_field = Person(name="Bob", age=25, extra=True)
```
<img width="773" height="191" alt="Screenshot 2025-08-07 at 17 59 22"
src="https://github.com/user-attachments/assets/79076d98-e85f-4495-93d6-a731aa72a5c9"
/>
### Support for `total=False`
```py
class OptionalPerson(TypedDict, total=False):
name: str
age: int | None
# All valid - all fields are optional with total=False
charlie = OptionalPerson()
david = OptionalPerson(name="David")
emily = OptionalPerson(age=30)
frank = OptionalPerson(name="Frank", age=25)
# But type validation and extra fields still apply
invalid_type = OptionalPerson(name=123) # Error: Invalid argument type
invalid_extra = OptionalPerson(extra=True) # Error: Invalid key access
```
### Dictionary Literal Validation
```py
# Type checking works for both constructors and dict literals
person: Person = {"name": "Alice", "age": 30}
reveal_type(person["name"]) # revealed: str
reveal_type(person["age"]) # revealed: int | None
# Error: Invalid key access on TypedDict `Person`: Unknown key "non_existing"
reveal_type(person["non_existing"]) # revealed: Unknown
```
### `Required`, `NotRequired`, `total`
```python
from typing import TypedDict
from typing_extensions import Required, NotRequired
class PartialUser(TypedDict, total=False):
name: Required[str] # Required despite total=False
age: int # Optional due to total=False
email: NotRequired[str] # Explicitly optional (redundant)
class User(TypedDict):
name: Required[str] # Explicitly required (redundant)
age: int # Required due to total=True
bio: NotRequired[str] # Optional despite total=True
# Valid constructions
partial = PartialUser(name="Alice") # name required, age optional
full = User(name="Bob", age=25) # name and age required, bio optional
# Inheritance maintains original field requirements
class Employee(PartialUser):
department: str # Required (new field)
# name: still Required (inherited)
# age: still optional (inherited)
emp = Employee(name="Charlie", department="Engineering") # ✅
Employee(department="Engineering") # ❌
e: Employee = {"age": 1} # ❌
```
<img width="898" height="683" alt="Screenshot 2025-08-11 at 22 02 57"
src="https://github.com/user-attachments/assets/4c1b18cd-cb2e-493a-a948-51589d121738"
/>
## Implementation
The implementation reuses existing validation logic done in
https://github.com/astral-sh/ruff/pull/19782
### ℹ️ Why I did NOT synthesize an `__init__` for `TypedDict`:
`TypedDict` inherits `dict.__init__(self, *args, **kwargs)` that accepts
all arguments.
The type resolution system finds this inherited signature **before**
looking for synthesized members.
So `own_synthesized_member()` is never called because a signature
already exists.
To force synthesis, you'd have to override Python’s inheritance
mechanism, which would break compatibility with the existing ecosystem.
This is why I went with ad-hoc validation. IMO it's the only viable
approach that respects Python’s
inheritance semantics while providing the required validation.
### Refacto of `Field`
**Before:**
```rust
struct Field<'db> {
declared_ty: Type<'db>,
default_ty: Option<Type<'db>>, // NamedTuple and dataclass only
init_only: bool, // dataclass only
init: bool, // dataclass only
is_required: Option<bool>, // TypedDict only
}
```
**After:**
```rust
struct Field<'db> {
declared_ty: Type<'db>,
kind: FieldKind<'db>,
}
enum FieldKind<'db> {
NamedTuple { default_ty: Option<Type<'db>> },
Dataclass { default_ty: Option<Type<'db>>, init_only: bool, init: bool },
TypedDict { is_required: bool },
}
```
## Test Plan
Updated Markdown tests
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
This PR limits the argument type expansion size for an overload call
evaluation to 512.
The limit chosen is arbitrary but I've taken the 256 limit from Pyright
into account and bumped it x2 to start with.
Initially, I actually started out by trying to refactor the entire
argument type expansion to be lazy. Currently, expanding a single
argument at any position eagerly creates the combination (argument
lists) and returns that (`Vec<CallArguments>`) but I thought we could
make it lazier by converting the return type of `expand` from
`Iterator<Item = Vec<CallArguments>>` to `Iterator<Item = Iterator<Item
= CallArguments>>` but that's proving to be difficult to implement
mainly because we **need** to maintain the previous expansion to
generate the next expansion which is the main reason to use
`std::iter::successors` in the first place.
Another approach would be to eagerly expand all the argument types and
then use the `combinations` from `itertools` to generate the
combinations but we would need to find the "boundary" between arguments
lists produced from expanding argument at position 1 and position 2
because that's important for the algorithm.
Closes: https://github.com/astral-sh/ty/issues/868
## Test Plan
Add test case to demonstrate the limit along with the diagnostic
snapshot stating that the limit has been reached.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| actions/checkout | action | digest | `08c6903` -> `ff7abcd` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS44Mi43IiwidXBkYXRlZEluVmVyIjoiNDEuODIuNyIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
---------
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[regex-automata](https://redirect.github.com/rust-lang/regex/tree/master/regex-automata)
([source](https://redirect.github.com/rust-lang/regex)) |
workspace.dependencies | patch | `0.4.9` -> `0.4.10` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>rust-lang/regex (regex-automata)</summary>
###
[`v0.4.10`](https://redirect.github.com/rust-lang/regex/compare/regex-automata-0.4.9...regex-automata-0.4.10)
[Compare
Source](https://redirect.github.com/rust-lang/regex/compare/regex-automata-0.4.9...regex-automata-0.4.10)
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS44Mi43IiwidXBkYXRlZEluVmVyIjoiNDEuODIuNyIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [regex](https://redirect.github.com/rust-lang/regex) |
workspace.dependencies | patch | `1.11.1` -> `1.11.2` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>rust-lang/regex (regex)</summary>
###
[`v1.11.2`](https://redirect.github.com/rust-lang/regex/blob/HEAD/CHANGELOG.md#1112-2025-08-24)
[Compare
Source](https://redirect.github.com/rust-lang/regex/compare/1.11.1...1.11.2)
\===================
This is a new patch release of `regex` with some minor fixes. A larger
number
of typo or lint fix patches were merged. Also, we now finally recommend
using
`std::sync::LazyLock`.
Improvements:
- [BUG
#​1217](https://redirect.github.com/rust-lang/regex/issues/1217):
Switch recommendation from `once_cell` to `std::sync::LazyLock`.
- [BUG
#​1225](https://redirect.github.com/rust-lang/regex/issues/1225):
Add `DFA::set_prefilter` to `regex-automata`.
Bug fixes:
- [BUG
#​1165](https://redirect.github.com/rust-lang/regex/pull/1150):
Remove `std` dependency from `perf-literal-multisubstring` crate
feature.
- [BUG
#​1165](https://redirect.github.com/rust-lang/regex/pull/1165):
Clarify the meaning of `(?R)$` in the documentation.
- [BUG
#​1281](https://redirect.github.com/rust-lang/regex/pull/1281):
Remove `fuzz/` and `record/` directories from published crate on
crates.io.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS44Mi43IiwidXBkYXRlZEluVmVyIjoiNDEuODIuNyIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[tracing-indicatif](https://redirect.github.com/emersonford/tracing-indicatif)
| workspace.dependencies | patch | `0.3.12` -> `0.3.13` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>emersonford/tracing-indicatif (tracing-indicatif)</summary>
###
[`v0.3.13`](https://redirect.github.com/emersonford/tracing-indicatif/blob/HEAD/CHANGELOG.md#0313---2025-08-15)
[Compare
Source](https://redirect.github.com/emersonford/tracing-indicatif/compare/0.3.12...0.3.13)
- eliminate panics on internal lock poison
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS44Mi43IiwidXBkYXRlZEluVmVyIjoiNDEuODIuNyIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Part of astral-sh/ty#994
## Summary
Add new special forms to `ty_extensions`, `Top[T]` and `Bottom[T]`.
Remove `ty_extensions.top_materialization` and
`ty_extensions.bottom_materialization`.
## Test Plan
Converted the existing `materialization.md` mdtest to the new syntax.
Added some tests for invalid use of the new special form.
In effect, we make the Salsa query aspect keyed only on whether we want
global symbols. We move everything else (hierarchical and querying) to
an aggregate step *after* the query.
This was a somewhat involved change since we want to return a flattened
list from visiting the source while also preserving enough information
to reform the symbols into a hierarchical structure that the LSP
expects. But I think overall the API has gotten simpler and we encode
more invariants into the type system. (For example, previously you got a
runtime assertion if you tried to provide a query string while enabling
hierarchical mode. But now that's prevented by construction.)
Basically, this splits the implementation into two pieces:
the first piece does the traversal and finds *all* symbols
across the workspace. The second piece does filtering based
on a user provided query string. Only the first piece is
cached by Salsa.
This brings warm "workspace symbols" requests down from
500-600ms to 100-200ms.
While this doesn't typically matter, when ty returns a very
large list of symbols, this can have an impact. Specifically,
when searching `async` in home-assistant, this gets times
closer to 500ms versus closer to 600ms before this change.
It looks like an overall ~50ms improvement (so around 10%),
but variance is all over the place and I didn't do any
statistical tests.
But this does make intuitive sense. Previously, we were
allocating intermediate strings, doing UTF-8 decoding and
consulting Unicode casing tables. Now we're just doing what
is likely a single DFA scan. In effect, we front load all
of the Unicode junk into regex compilation.
There is a small amount of subtlety to this matching routine,
and it could be implemented in a faster way. So let's right some
tests for what we have to ensure we don't break anything when
we optimize it.
## Summary
Looks like an oversight at some point that led to two identical globals,
the one in `ty_project` just calls `ty_python_semantic::register_lints`.
## Summary
Removes the `module_ptr` field from `AstNodeRef` in release mode, and
change `NodeIndex` to a `NonZeroU32` to reduce the size of
`Option<AstNodeRef<_>>` fields.
I believe CI runs in debug mode, so this won't show up in the memory
report, but this reduces memory by ~2% in release mode.
## Summary
Previously we held off from doing this because we weren't sure that it
was worth the added complexity cost. But our code has changed in the
months since we made that initial decision, and I think the structure of
the code is such that it no longer really leads to much added complexity
to add precise inference when unpacking a string literal or a bytes
literal.
The improved inference we gain from this has real benefits to users (see
the mypy_primer report), and this PR doesn't appear to have a
performance impact.
## Test plan
mdtests
## Summary
We use the `System` abstraction in ty to abstract away the host/system
on which ty runs.
This has a few benefits:
* Tests can run in full isolation using a memory system (that uses an
in-memory file system)
* The LSP has a custom implementation where `read_to_string` returns the
content as seen by the editor (e.g. unsaved changes) instead of always
returning the content as it is stored on disk
* We don't require any file system polyfills for wasm in the browser
However, it does require extra care that we don't accidentally use
`std::fs` or `std::env` (etc.) methods in ty's code base (which is very
easy).
This PR sets up Clippy and disallows the most common methods, instead
pointing users towards the corresponding `System` methods.
The setup is a bit awkward because clippy doesn't support inheriting
configurations. That means, a crate can only override the entire
workspace configuration or not at all.
The approach taken in this PR is:
* Configure the disallowed methods at the workspace level
* Allow `disallowed_methods` at the workspace level
* Enable the lint at the crate level using the warn attribute (in code)
The obvious downside is that it won't work if we ever want to disallow
other methods, but we can figure that out once we reach that point.
What about false positives: Just add an `allow` and move on with your
life :) This isn't something that we have to enforce strictly; the goal
is to catch accidental misuse.
## Test Plan
Clippy found a place where we incorrectly used `std::fs::read_to_string`
Adds a method to `TStringValue` to detect whether the t-string is empty
_as an iterable_. Note the subtlety here that, unlike f-strings, an
empty t-string is still truthy (i.e. `bool(t"")==True`).
Closes#19951
## Summary
Rename `TypeAliasType::Bare` to `TypeAliasType::ManualPEP695`, and
`BareTypeAliasType` to `ManualPEP695TypeAliasType`.
Why?
Both existing variants of `TypeAliasType` are specific to features added
in PEP 695 (which introduced both the `type` statement and
`types.TypeAliasType`), so it doesn't make sense to name one with the
name `PEP695` and not the other.
A "bare" type alias, in my mind, is a legacy type alias like `IntOrStr =
int | str`, which is "bare" in that there is nothing at all
distinguishing it as a type alias. I will want to use the "bare" name
for this variant, in a future PR.
The renamed variant here describes a type alias created with `IntOrStr =
types.TypeAliasType("IntOrStr", int | str)`, which is not "bare", it's
just "manually" instantiated instead of using the `type` statement
syntax sugar. (This is useful when using the `typing_extensions`
backport of `TypeAliasType` on older Python versions.)
## Test Plan
Pure rename, existing tests pass.
## Summary
This PR fixes https://github.com/astral-sh/ty/issues/1071
The core issue is that `CallableType` is a salsa interned but
`Signature` (which `CallableType` stores) ignores the `Definition` in
its `Eq` and `Hash` implementation.
This PR tries to simplest fix by removing the custom `Eq` and `Hash`
implementation. The main downside of this fix is that it can increase
memory usage because `CallableType`s that are equal except for their
`Definition` are now interned separately.
The alternative is to remove `Definition` from `CallableType` and
instead, call `bindings` directly on the callee (call_expression.func).
However, this would require
addressing the TODO
here
39ee71c2a5/crates/ty_python_semantic/src/types.rs (L4582-L4586)
This might probably be worth addressing anyway, but is the more involved
fix. That's why I opted for removing the custom `Eq` implementation.
We already "ignore" the definition during normalization, thank's to
Alex's work in https://github.com/astral-sh/ruff/pull/19615
## Test Plan
https://github.com/user-attachments/assets/248d1cb1-12fd-4441-adab-b7e0866d23eb
While implementing similar logic for initializers I noticed that this
code appeared to be walking the ancestors in the wrong direction, and so
if you have nested function calls it would always grab the outermost one
instead of the closest-ancestor.
The four copies of the test are because there's something really evil in
our caching that can't seem to be demonstrated in our cursor testing
framework, which I'm filing a followup for.
Summary
--
This is a preparatory PR in support of #19919. It moves our `Diff`
rendering code from `ruff_linter` to `ruff_db`, where we have direct
access to the `DiagnosticStylesheet` used by our other diagnostic
rendering code. As shown by the tests, this shouldn't cause any visible
changes. The colors aren't exactly the same, as I note in a TODO
comment, but I don't think there's any existing way to see those, even
in tests.
The `Diff` implementation is mostly unchanged. I just switched from a
Ruff-specific `SourceFile` to a `DiagnosticSource` (removing an
`expect_ruff_source_file` call) and updated the `LineStyle` struct and
other styling calls to use `fmt_styled` and our existing stylesheet.
In support of these changes, I added three styles to our stylesheet:
`insertion` and `deletion` for the corresponding diff operations, and
`underline`, which apparently we _can_ use, as I hoped on Discord. This
isn't supported in all terminals, though. It worked in ghostty but not
in st for me.
I moved the `calculate_print_width` function from the now-deleted
`diff.rs` to a method on `OneIndexed`, where it was available everywhere
we needed it. I'm not sure if that's desirable, or if my other changes
to the function are either (using `ilog10` instead of a loop). This does
make it `const` and slightly simplifies things in my opinion, but I'm
happy to revert it if preferred.
I also inlined a version of `show_nonprinting` from the
`ShowNonprinting` trait in `ruff_linter`:
f4be05a83b/crates/ruff_linter/src/text_helpers.rs (L3-L5)
This trait is now only used in `source_kind.rs`, so I'm not sure it's
worth having the trait or the macro-generated implementation (which is
only called once). This is obviously closely related to our unprintable
character handling in diagnostic rendering, but the usage seems
different enough not to try to combine them.
f4be05a83b/crates/ruff_db/src/diagnostic/render.rs (L990-L998)
We could also move the trait to another crate where we can use it in
`ruff_db` instead of inlining here, of course.
Finally, this PR makes `TextEmitter` a very thin wrapper around a
`DisplayDiagnosticsConfig`. It's still used in a few places, though,
unlike the other emitters we've replaced, so I figured it was worth
keeping around. It's a pretty nice API for setting all of the options on
the config and then passing that along to a `DisplayDiagnostics`.
Test Plan
--
Existing snapshot tests with diffs
"Why would you do this? This looks like you just replaced `bool` with an
overly complex trait"
Yes that's correct!
This should be a no-op refactoring. It replaces all of the logic in our
assignability, subtyping, equivalence, and disjointness methods to work
over an arbitrary `Constraints` trait instead of only working on `bool`.
The methods that `Constraints` provides looks very much like what we get
from `bool`. But soon we will add a new impl of this trait, and some new
methods, that let us express "fuzzy" constraints that aren't always true
or false. (In particular, a constraint will express the upper and lower
bounds of the allowed specializations of a typevar.)
Even once we have that, most of the operations that we perform on
constraint sets will be the usual boolean operations, just on sets.
(`false` becomes empty/never; `true` becomes universe/always; `or`
becomes union; `and` becomes intersection; `not` becomes negation.) So
it's helpful to have this separate PR to refactor how we invoke those
operations without introducing the new functionality yet.
Note that we also have translations of `Option::is_some_and` and
`is_none_or`, and of `Iterator::any` and `all`, and that the `and`,
`or`, `when_any`, and `when_all` methods are meant to short-circuit,
just like the corresponding boolean operations. For constraint sets,
that depends on being able to implement the `is_always` and `is_never`
trait methods.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Part of: https://github.com/astral-sh/ty/issues/868
This PR adds a heuristic to avoid argument type expansion if it's going
to eventually lead to no matching overload.
This is done by checking whether the non-expandable argument types are
assignable to the corresponding annotated parameter type. If one of them
is not assignable to all of the remaining overloads, then argument type
expansion isn't going to help.
## Test Plan
Add mdtest that would otherwise take a long time because of the number
of arguments that it would need to expand (30).
This is a fairly simple but effective way to add docstrings to like 95%
of completions from initial experimentation.
Fixes https://github.com/astral-sh/ty/issues/1036
Although ironically this approach *does not* work specifically for
`print` and I haven't looked into why.
## Summary
Resolves#19561
Fixes the [unnecessary-future-import
(UP010)](https://docs.astral.sh/ruff/rules/unnecessary-future-import/)
rule to correctly identify when imported __future__ modules are actually
used in the code, preventing false positives.
I assume there is no way to check usage in `analyze::statements`,
because we don't have any usage bindings for imports. To determine
unused imports, we have to fully scan the file to create bindings and
then check usage, similar to [unused-import
(F401)](https://docs.astral.sh/ruff/rules/unused-import/#unused-import-f401).
So, `Rule::UnnecessaryFutureImport` was moved from the
`analyze::statements` to the `analyze::deferred_scopes` stage. This
caused the need to change the logic of future import handling to a
bindings-based approach.
Also, the diagnostic report was changed.
Before
```
|
1 | from __future__ import nested_scopes, generators
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ UP010
```
after
```
|
1 | from __future__ import nested_scopes, generators
| ^^^^^^^^^^^^^ UP010
```
I believe this is the correct way, because `generators` may be used, but
`nested_scopes` is not.
### Special case
I've found out about some specific case.
```python
from __future__ import nested_scopes
nested_scopes = 1
```
Here we can treat `nested_scopes` as an unused import because the
variable `nested_scopes` shadows it and we can safely remove the future
import (my fix does it).
But
[F401](https://docs.astral.sh/ruff/rules/unused-import/#unused-import-f401)
not triggered for such case
([sandbox](https://play.ruff.rs/296d9c7e-0f02-4659-b0c0-78cc21f3de76))
```
from foo import print_function
print_function = 1
```
In my mind, `print_function` here is an unused import and should be
deleted (my IDE highlight it). What do you think?
## Test Plan
Added test cases and snapshots:
- Split test file into separate _0 and _1 files for appropriate checks.
- Added test cases to verify fixes when future module are used.
---------
Co-authored-by: Igor Drokin <drokinii1017@gmail.com>
This commit corrects the type checker's behavior when handling
`dataclass_transform` decorators that don't explicitly specify
`field_specifiers`. According to [PEP 681 (Data Class
Transforms)](https://peps.python.org/pep-0681/#dataclass-transform-parameters),
when `field_specifiers` is not provided, it defaults to an empty tuple,
meaning no field specifiers are supported and
`dataclasses.field`/`dataclasses.Field` calls should be ignored.
Fixes https://github.com/astral-sh/ty/issues/980
This basically splits `list_modules` into a higher level "aggregation"
routine and a lower level "get modules for one search path" routine.
This permits Salsa to cache the lower level components, e.g., many
search paths refer to directories that rarely change. This saves us
interaction with the system.
This did require a fair bit of surgery in terms of being careful about
adding file roots. Namely, now that we rely even more on file roots
existing for correct handling of cache invalidation, there were several
spots in our code that needed to be updated to add roots (that we
weren't previously doing). This feels Not Great, and it would be better
if we had some kind of abstraction that handled this for us. But it
isn't clear to me at this time what that looks like.
This ensures there is some level of consistency between the APIs.
This did require exposing a couple more things on `Module` for good
error messages. This also motivated a switch to an interned struct
instead of a tracked struct. This ensures that `list_modules` and
`resolve_modules` reuse the same `Module` values when the inputs are the
same.
Ref https://github.com/astral-sh/ruff/pull/19883#discussion_r2272520194
This makes `import <CURSOR>` and `from <CURSOR>` completions work.
This also makes `import os.<CURSOR>` and `from os.<CURSOR>`
completions work. In this case, we are careful to only offer
submodule completions.
These tests were added as a regression check that a panic
didn't occur. So we were asserting a bit more than necessary.
In particular, these will soon return completions for modules,
which creates large snapshots that we don't need.
So modify these to just check there is sensible output that
doesn't panic.
The actual implementation wasn't too bad. It's not long
but pretty fiddly. I copied over the tests from the existing
module resolver and adapted them to work with this API. Then
I added a number of my own tests as well.
Previously, if the module was just `foo-stubs`, we'd skip over
stripping the `-stubs` suffix which would lead to us returning
`None`.
This function is now a little convoluted and could be simpler
if we did an intermediate allocation. But I kept the iterative
approach and added a special case to handle `foo-stubs`.
These tests capture existing behavior.
I added these when I stumbled upon what I thought was an
oddity: we prioritize `foo.pyi` over `foo.py`, but
prioritize `foo/__init__.py` over `foo.pyi`.
(I plan to investigate this more closely in follow-up
work. Particularly, to look at other type checkers. It
seems like we may want to change this to always prioritize
stubs.)
This is a port of the logic in https://github.com/astral-sh/uv/pull/7691
The basic idea is we use CONDA_DEFAULT_ENV as a signal for whether
CONDA_PREFIX is just the ambient system conda install, or the user has
explicitly activated a custom one. If the former, then the conda is
treated like a system install (having lowest priority). If the latter,
the conda is treated like an activated venv (having priority over
everything but an Actual activated venv).
Fixes https://github.com/astral-sh/ty/issues/611
## Summary
Closes: https://github.com/astral-sh/ty/issues/669
(This turned out to be simpler that I thought :))
## Test Plan
Update existing test cases.
### Ecosystem report
Most of them are basically because ty has now started inferring more
precise types for the return type to an overloaded call and a lot of the
types are defined using type aliases, here's some examples:
<details><summary>Details</summary>
<p>
> attrs (https://github.com/python-attrs/attrs)
> + tests/test_make.py:146:14: error[unresolved-attribute] Type
`Literal[42]` has no attribute `default`
> - Found 555 diagnostics
> + Found 556 diagnostics
This is accurate now that we infer the type as `Literal[42]` instead of
`Unknown` (Pyright infers it as `int`)
> optuna (https://github.com/optuna/optuna)
> + optuna/_gp/search_space.py:181:53: error[invalid-argument-type]
Argument to function `_round_one_normalized_param` is incorrect:
Expected `tuple[int | float, int | float]`, found `tuple[Unknown |
ndarray[Unknown, <class 'float'>], Unknown | ndarray[Unknown, <class
'float'>]]`
> + optuna/_gp/search_space.py:181:83: error[invalid-argument-type]
Argument to function `_round_one_normalized_param` is incorrect:
Expected `int | float`, found `Unknown | ndarray[Unknown, <class
'float'>]`
> + tests/gp_tests/test_search_space.py:109:13:
error[invalid-argument-type] Argument to function
`_unnormalize_one_param` is incorrect: Expected `tuple[int | float, int
| float]`, found `Unknown | ndarray[Unknown, <class 'float'>]`
> + tests/gp_tests/test_search_space.py:110:13:
error[invalid-argument-type] Argument to function
`_unnormalize_one_param` is incorrect: Expected `int | float`, found
`Unknown | ndarray[Unknown, <class 'float'>]`
> - Found 559 diagnostics
> + Found 563 diagnostics
Same as above where ty is now inferring a more precise type like
`Unknown | ndarray[tuple[int, int], <class 'float'>]` instead of just
`Unknown` as before
> jinja (https://github.com/pallets/jinja)
> + src/jinja2/bccache.py:298:39: error[invalid-argument-type] Argument
to bound method `write_bytecode` is incorrect: Expected `IO[bytes]`,
found `_TemporaryFileWrapper[str]`
> - Found 186 diagnostics
> + Found 187 diagnostics
This requires support for type aliases to match the correct overload.
> hydra-zen (https://github.com/mit-ll-responsible-ai/hydra-zen)
> + src/hydra_zen/wrapper/_implementations.py:945:16:
error[invalid-return-type] Return type does not match returned value:
expected `DataClass_ | type[@Todo(type[T] for protocols)] | ListConfig |
DictConfig`, found `@Todo(unsupported type[X] special form) | (((...) ->
Any) & dict[Unknown, Unknown]) | (DataClass_ & dict[Unknown, Unknown]) |
dict[Any, Any] | (ListConfig & dict[Unknown, Unknown]) | (DictConfig &
dict[Unknown, Unknown]) | (((...) -> Any) & list[Unknown]) | (DataClass_
& list[Unknown]) | list[Any] | (ListConfig & list[Unknown]) |
(DictConfig & list[Unknown])`
> + tests/annotations/behaviors.py:60:28: error[call-non-callable]
Object of type `Path` is not callable
> + tests/annotations/behaviors.py:64:21: error[call-non-callable]
Object of type `Path` is not callable
> + tests/annotations/declarations.py:167:17: error[call-non-callable]
Object of type `Path` is not callable
> + tests/annotations/declarations.py:524:17:
error[unresolved-attribute] Type `<class 'int'>` has no attribute
`_target_`
> - Found 561 diagnostics
> + Found 566 diagnostics
Same as above, this requires support for type aliases to match the
correct overload.
> paasta (https://github.com/yelp/paasta)
> + paasta_tools/utils.py:4188:19: warning[redundant-cast] Value is
already of type `list[str]`
> - Found 888 diagnostics
> + Found 889 diagnostics
This is correct.
> colour (https://github.com/colour-science/colour)
> + colour/plotting/diagrams.py:448:13: error[invalid-argument-type]
Argument to bound method `__init__` is incorrect: Expected
`Sequence[@Todo(Support for `typing.TypeAlias`)]`, found
`ndarray[tuple[int, int, int], dtype[Unknown]]`
> + colour/plotting/diagrams.py:462:13: error[invalid-argument-type]
Argument to bound method `__init__` is incorrect: Expected
`Sequence[@Todo(Support for `typing.TypeAlias`)]`, found
`ndarray[tuple[int, int, int], dtype[Unknown]]`
> + colour/plotting/models.py:419:13: error[invalid-argument-type]
Argument to bound method `__init__` is incorrect: Expected
`Sequence[@Todo(Support for `typing.TypeAlias`)]`, found
`ndarray[tuple[int, int, int], dtype[Unknown]]`
> + colour/plotting/temperature.py:230:9: error[invalid-argument-type]
Argument to bound method `__init__` is incorrect: Expected
`Sequence[@Todo(Support for `typing.TypeAlias`)]`, found
`ndarray[tuple[int, int, int], dtype[Unknown]]`
> + colour/plotting/temperature.py:474:13: error[invalid-argument-type]
Argument to bound method `__init__` is incorrect: Expected
`Sequence[@Todo(Support for `typing.TypeAlias`)]`, found
`ndarray[tuple[int, int, int], dtype[Unknown]]`
> + colour/plotting/temperature.py:495:17: error[invalid-argument-type]
Argument to bound method `__init__` is incorrect: Expected
`Sequence[@Todo(Support for `typing.TypeAlias`)]`, found
`ndarray[tuple[int, int, int], dtype[Unknown]]`
> + colour/plotting/temperature.py:513:13: error[invalid-argument-type]
Argument to bound method `text` is incorrect: Expected `int | float`,
found `ndarray[@Todo(Support for `typing.TypeAlias`), dtype[Unknown]]`
> + colour/plotting/temperature.py:514:13: error[invalid-argument-type]
Argument to bound method `text` is incorrect: Expected `int | float`,
found `ndarray[@Todo(Support for `typing.TypeAlias`), dtype[Unknown]]`
> - Found 480 diagnostics
> + Found 488 diagnostics
Most of them are correct except for the last two diagnostics which I'm
not sure
what's happening, it's trying to index into an `np.ndarray` type (which
is
inferred correctly) but I think it might be picking up an incorrect
overload
for the `__getitem__` method.
Scipy's diagnostics also requires support for type alises to pick the
correct overload.
</p>
</details>
In implementing partial stubs I had observed that this continue in the
namespace package code seemed erroneous since the same continue for
partial stubs didn't work. Unfortunately I wasn't confident enough to
push on that hunch. Fortunately I remembered that hunch to make this an
easy fix.
The issue with the continue is that it bails out of the current
search-path without testing any .py files. This breaks when for example
`google` and `google-stubs`/`types-google` are both in the same
site-packages dir -- failing to find a module in `types-google` has us
completely skip over `google`!
Fixes https://github.com/astral-sh/ty/issues/520
fix https://github.com/astral-sh/ty/issues/1047
## Summary
This PR fixes how `KW_ONLY` is applied in dataclasses. Previously, the
sentinel leaked into subclasses and incorrectly marked their fields as
keyword-only; now it only affects fields declared in the same class.
```py
from dataclasses import dataclass, KW_ONLY
@dataclass
class D:
x: int
_: KW_ONLY
y: str
@dataclass
class E(D):
z: bytes
# This should work: x=1 (positional), z=b"foo" (positional), y="foo" (keyword-only)
E(1, b"foo", y="foo")
reveal_type(E.__init__) # revealed: (self: E, x: int, z: bytes, *, y: str) -> None
```
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
mdtests
Requires some iteration, but this includes the most tedious part --
threading a new concept of DisplaySettings through every type display
impl. Currently it only holds a boolean for multiline, but in the future
it could also take other things like "render to markdown" or "here's
your base indent if you make a newline".
For types which have exposed display functions I've left the old
signature as a compatibility polyfill to avoid having to audit
everywhere that prints types right off the bat (notably I originally
tried doing multiline functions unconditionally and a ton of things
churned that clearly weren't ready for multi-line (diagnostics).
The only real use of this API in this PR is to multiline render function
types in hovers, which is the highest impact (see snapshot changes).
Fixes https://github.com/astral-sh/ty/issues/1000
This change rejiggers how we register globs for file watching with the
LSP client. Previously, we registered a few globs like `**/*.py`,
`**/pyproject.toml` and more. There were two problems with this
approach.
Firstly, it only watches files within the project root. Search paths may
be outside the project root. Such as virtualenv directory.
Secondly, there is variation on how tools interact with virtual
environments. In the case of uv, depending on its link mode, we might
not get any file change notifications after running `uv add foo` or
`uv remove foo`.
To remedy this, we instead just list for file change notifications on
all files for all search paths. This simplifies the globs we use, but
does potentially increase the number of notifications we'll get.
However, given the somewhat simplistic interface supported by the LSP
protocol, I think this is unavoidable (unless we used our own file
watcher, which has its own considerably downsides). Moreover, this is
seemingly consistent with how `ty check --watch` works.
This also required moving file watcher registration to *after*
workspaces are initialized, or else we don't know what the right search
paths are.
This change is in service of #19883, which in order for cache
invalidation to work right, the LSP client needs to send notifications
whenever a dependency is added or removed. This change should make that
possible.
I tried this patch with #19883 in addition to my work to activate Salsa
caching, and everything seems to work as I'd expect. That is,
completions no longer show stale results after a dependency is added or
removed.
## Summary
Fixes https://github.com/astral-sh/ty/issues/1046
We special-case iteration of certain types because they may have a more
detailed tuple-spec. Now that type aliases are a distinct type variant,
we need to handle them as well.
I don't love that `Type::TypeAlias` means we have to remember to add a
case for it basically anywhere we are special-casing a certain kind of
type, but at the moment I don't have a better plan. It's another
argument for avoiding fallback cases in `Type` matches, which we usually
prefer; I've updated this match statement to be comprehensive.
## Test Plan
Added mdtest.
Summary
--
I thought this might warrant a small blog-style writeup, especially
since we already got a question about it (#19966), but I'm happy to
switch back to a one-liner under `### Other changes` if preferred.
I'll copy whatever we add here to the release notes too.
Do we need a note at the top about the late addition?
`Type::TypeVar` now distinguishes whether the typevar in question is
inferable or not.
A typevar is _not inferable_ inside the body of the generic class or
function that binds it:
```py
def f[T](t: T) -> T:
return t
```
The infered type of `t` in the function body is `TypeVar(T,
NotInferable)`. This represents how e.g. assignability checks need to be
valid for all possible specializations of the typevar. Most of the
existing assignability/etc logic only applies to non-inferable typevars.
Outside of the function body, the typevar is _inferable_:
```py
f(4)
```
Here, the parameter type of `f` is `TypeVar(T, Inferable)`. This
represents how e.g. assignability doesn't need to hold for _all_
specializations; instead, we need to find the constraints under which
this specific assignability check holds.
This is in support of starting to perform specialization inference _as
part of_ performing the assignability check at the call site.
In the [[POPL2015][]] paper, this concept is called _monomorphic_ /
_polymorphic_, but I thought _non-inferable_ / _inferable_ would be
clearer for us.
Depends on #19784
[POPL2015]: https://doi.org/10.1145/2676726.2676991
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
**Stacked on top of #19849; diff will include that PR until it is
merged.**
---
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
As part of #19849, I noticed this fix could be implemented.
## Test Plan
Tests added based on CPython behaviour.
## Summary
This PR adds a new lint, `invalid-await`, for all sorts of reasons why
an object may not be `await`able, as discussed in astral-sh/ty#919.
Precisely, `__await__` is guarded against being missing, possibly
unbound, or improperly defined (expects additional arguments or doesn't
return an iterator).
Of course, diagnostics need to be fine-tuned. If `__await__` cannot be
called with no extra arguments, it indicates an error (or a quirk?) in
the method signature, not at the call site. Without any doubt, such an
object is not `Awaitable`, but I feel like talking about arguments for
an *implicit* call is a bit leaky.
I didn't reference any actual diagnostic messages in the lint
definition, because I want to hear feedback first.
Also, there's no mention of the actual required method signature for
`__await__` anywhere in the docs. The only reference I had is the
`typing` stub. I basically ended up linking `[Awaitable]` to ["must
implement
`__await__`"](https://docs.python.org/3/library/collections.abc.html#collections.abc.Awaitable),
which is insufficient on its own.
## Test Plan
The following code was tested:
```python
import asyncio
import typing
class Awaitable:
def __await__(self) -> typing.Generator[typing.Any, None, int]:
yield None
return 5
class NoDunderMethod:
pass
class InvalidAwaitArgs:
def __await__(self, value: int) -> int:
return value
class InvalidAwaitReturn:
def __await__(self) -> int:
return 5
class InvalidAwaitReturnImplicit:
def __await__(self):
pass
async def main() -> None:
result = await Awaitable() # valid
result = await NoDunderMethod() # `__await__` is missing
result = await InvalidAwaitReturn() # `__await__` returns `int`, which is not a valid iterator
result = await InvalidAwaitArgs() # `__await__` expects additional arguments and cannot be called implicitly
result = await InvalidAwaitReturnImplicit() # `__await__` returns `Unknown`, which is not a valid iterator
asyncio.run(main())
```
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This PR renames `ty.inlayHints.functionArgumentNames` to
`ty.inlayHints.callArgumentNames` which would contain both function
calls and class initialization calls i.e., it represents a generic call
expression.
## Summary
This PR changes the default of `ty.inlayHints.*` settings to `true`.
I somehow missed this in my initial PR.
This is marked as `internal` because it's not yet released.
## Summary
For PEP 695 generic functions and classes, there is an extra "type
params scope" (a child of the outer scope, and wrapping the body scope)
in which the type parameters are defined; class bases and function
parameter/return annotations are resolved in that type-params scope.
This PR fixes some longstanding bugs in how we resolve name loads from
inside these PEP 695 type parameter scopes, and also defers type
inference of PEP 695 typevar bounds/constraints/default, so we can
handle cycles without panicking.
We were previously treating these type-param scopes as lazy nested
scopes, which is wrong. In fact they are eager nested scopes; the class
`C` here inherits `int`, not `str`, and previously we got that wrong:
```py
Base = int
class C[T](Base): ...
Base = str
```
But certain syntactic positions within type param scopes (typevar
bounds/constraints/defaults) are lazy at runtime, and we should use
deferred name resolution for them. This also means they can have cycles;
in order to handle that without panicking in type inference, we need to
actually defer their type inference until after we have constructed the
`TypeVarInstance`.
PEP 695 does specify that typevar bounds and constraints cannot be
generic, and that typevar defaults can only reference prior typevars,
not later ones. This reduces the scope of (valid from the type-system
perspective) cycles somewhat, although cycles are still possible (e.g.
`class C[T: list[C]]`). And this is a type-system-only restriction; from
the runtime perspective an "invalid" case like `class C[T: T]` actually
works fine.
I debated whether to implement the PEP 695 restrictions as a way to
avoid some cycles up-front, but I ended up deciding against that; I'd
rather model the runtime name-resolution semantics accurately, and
implement the PEP 695 restrictions as a separate diagnostic on top.
(This PR doesn't yet implement those diagnostics, thus some `# TODO:
error` in the added tests.)
Introducing the possibility of cyclic typevars made typevar display
potentially stack overflow. For now I've handled this by simply removing
typevar details (bounds/constraints/default) from typevar display. This
impacts display of two kinds of types. If you `reveal_type(T)` on an
unbound `T` you now get just `typing.TypeVar` instead of
`typing.TypeVar("T", ...)` where `...` is the bound/constraints/default.
This matches pyright and mypy; pyrefly uses `type[TypeVar[T]]` which
seems a bit confusing, but does include the name. (We could easily
include the name without cycle issues, if there's a syntax we like for
that.)
It also means that displaying a generic function type like `def f[T:
int](x: T) -> T: ...` now displays as `f[T](x: T) -> T` instead of `f[T:
int](x: T) -> T`. This matches pyright and pyrefly; mypy does include
bound/constraints/defaults of typevars in function/callable type
display. If we wanted to add this, we would either need to thread a
visitor through all the type display code, or add a `decycle` type
transformation that replaced recursive reoccurrence of a type with a
marker.
## Test Plan
Added mdtests and modified existing tests to improve their correctness.
After this PR, there's only a single remaining py-fuzzer seed in the
0-500 range that panics! (Before this PR, there were 10; the fuzzer
likes to generate cyclic PEP 695 syntax.)
## Ecosystem report
It's all just the changes to `TypeVar` display.
This PR adds a type tag to the `CycleDetector` visitor (and its
aliases).
There are some places where we implement e.g. an equivalence check by
making a disjointness check. Both `is_equivalent_to` and
`is_disjoint_from` use a `PairVisitor` to handle cycles, but they should
not use the same visitor. I was finding it tedious to remember when it
was appropriate to pass on a visitor and when not to. This adds a
`PhantomData` type tag to ensure that we can't pass on one method's
visitor to a different method.
For `has_relation` and `apply_type_mapping`, we have an existing type
that we can use as the tag. For the other methods, I've added empty
structs (`Normalized`, `IsDisjointFrom`, `IsEquivalentTo`) to use as
tags.
## Summary
- Refactored `BLE001` logic for clarity and minor speed-up.
- Improved documentation and comments (previously, `BLE001` docs claimed
it catches bare `except:`s, but it doesn't).
- Fixed a false-positive bug with `from None` cause:
```python
# somefile.py
try:
pass
except BaseException as e:
raise e from None
```
### main branch
```
somefile.py:3:8: BLE001 Do not catch blind exception: `BaseException`
|
1 | try:
2 | pass
3 | except BaseException as e:
| ^^^^^^^^^^^^^ BLE001
4 | raise e from None
|
Found 1 error.
```
### this change
```cargo run -p ruff -- check somefile.py --no-cache --select=BLE001```
```
All checks passed!
```
## Test Plan
- Added a test case to cover `raise X from Y` clause
- Added a test case to cover `raise X from None` clause
This also reintroduces the `ResolvedDefinition::Module` variant because
reverse-engineering it in several places is a bit confusing. In an ideal
world we wouldn't have `ResolvedDefinition::FileWithRange` as it kinda
kills the ability to do richer analysis, so I want to chip away at its
scope wherever I can (currently it's used to point at asname parts of
import statements when doing `ImportAliasResolution::PreserveAliases`,
and also keyword arguments).
This also makes a kind of odd change to allow a hover to *only* produce
a docstring. This works around an oddity where hovering over a module
name in an import fails to resolve to a `ty` even though hovering over
uses of that imported name *does*.
The two fixed tests reflect the two interesting cases here.
## Summary
Fixes#19881. While I was here, I also made a couple of related tweaks
to the output format. First, we don't need to strip the `SyntaxError: `
prefix anymore since that's not added directly to the diagnostic message
after #19644. Second, we can use `secondary_code_or_id` to fall back on
the lint ID for syntax errors, which changes the `check_name` from
`syntax-error` to `invalid-syntax`. And then the main change requested
in the issue, prepending the `check_name` to the description.
## Test Plan
Existing tests and a new screenshot from GitLab:
<img width="362" height="113" alt="image"
src="https://github.com/user-attachments/assets/97654ad4-a639-4489-8c90-8661c7355097"
/>
This PR has several components:
* Introduce a Docstring String wrapper type that has render_plaintext
and render_markdown methods, to force docstring handlers to pick a
rendering format
* Implement [PEP-257](https://peps.python.org/pep-0257/) docstring
trimming for it
* The markdown rendering just renders the content in a plaintext
codeblock for now (followup work)
* Introduce a `DefinitionsOrTargets` type representing the partial
evaluation of `GotoTarget::get_definition_targets` to ideally stop at
getting `ResolvedDefinitions`
* Add `declaration_targets`, `definition_targets`, and `docstring`
methods to `DefinitionsOrTargets` for the 3 usecases we have for this
operation
* `docstring` is of course the key addition here, it uses the same basic
logic that `signature_help` was using: first check the goto-declaration
for docstrings, then check the goto-definition for docstrings.
* Refactor `signature_help` to use the new APIs instead of implementing
it itself
* Not fixed in this PR: an issue I found where `signature_help` will
erroneously cache docs between functions that have the same type (hover
docs don't have this bug)
* A handful of new tests and additions to tests to add docstrings in
various places and see which get caught
Examples of it working with stdlib, third party, and local definitions:
<img width="597" height="120" alt="Screenshot 2025-08-12 at 2 13 55 PM"
src="https://github.com/user-attachments/assets/eae54efd-882e-4b50-b5b4-721595224232"
/>
<img width="598" height="281" alt="Screenshot 2025-08-12 at 2 14 06 PM"
src="https://github.com/user-attachments/assets/5c9740d5-a06b-4c22-9349-da6eb9a9ba5a"
/>
<img width="327" height="180" alt="Screenshot 2025-08-12 at 2 14 18 PM"
src="https://github.com/user-attachments/assets/3b5647b9-2cdd-4c5b-bb7d-da23bff1bcb5"
/>
Notably modules don't work yet (followup work):
<img width="224" height="83" alt="Screenshot 2025-08-12 at 2 14 37 PM"
src="https://github.com/user-attachments/assets/7e9dcb70-a10e-46d9-a85c-9fe52c3b7e7b"
/>
Notably we don't show docs for an item if you hover its actual
definition (followup work, but also, not the most important):
<img width="324" height="69" alt="Screenshot 2025-08-12 at 2 16 54 PM"
src="https://github.com/user-attachments/assets/d4ddcdd8-c3fc-4120-ac93-cefdf57933b4"
/>
## Summary
A [passing
comment](https://github.com/astral-sh/ruff/pull/19711#issuecomment-3169312014)
led me to explore why we didn't report a class attribute as possibly
unbound if it was a method and defined in two different conditional
branches.
I found that the reason was because of our handling of "conflicting
declarations" in `place_from_declarations`. It returned a `Result` which
would be `Err` in case of conflicting declarations.
But we only actually care about conflicting declarations when we are
actually doing type inference on that scope and might emit a diagnostic
about it. And in all cases (including that one), we want to otherwise
proceed with the union of the declared types, as if there was no
conflict.
In several cases we were failing to handle the union of declared types
in the same way as a normal declared type if there was a declared-types
conflict. The `Result` return type made this mistake really easy to
make, as we'd match on e.g. `Ok(Place::Type(...))` and do one thing,
then match on `Err(...)` and do another, even though really both of
those cases should be handled the same.
This PR refactors `place_from_declarations` to instead return a struct
which always represents the declared type we should use in the same way,
as well as carrying the conflicting declared types, if any. This struct
has a method to allow us to explicitly ignore the declared-types
conflict (which is what we want in most cases), as well as a method to
get the declared type and the conflict information, in the case where we
want to emit a diagnostic on the conflict.
## Test Plan
Existing CI; added a test showing that we now understand a
multiply-conditionally-defined method as possibly-unbound.
This does trigger issues on a couple new fuzzer seeds, but the issues
are just new instances of an already-known (and rarely occurring)
problem which I already plan to address in a future PR, so I think it's
OK to land as-is.
I happened to build this initially on top of
https://github.com/astral-sh/ruff/pull/19711, which adds invalid-await
diagnostics, so I also updated some invalid-syntax tests to not await on
an invalid type, since the purpose of those tests is to check the
syntactic location of the `await`, not the validity of the awaited type.
Summary
--
To take advantage of the new diagnostics, we need to update our caching
model to include all of the information supported by `ruff_db`'s
diagnostic type. Instead of trying to serialize all of this information,
Micha suggested simply not caching files with diagnostics, like we
already do for files with syntax errors. This PR is an attempt at that
approach.
This has the added benefit of trimming down our `Rule` derives since
this was the last place the `FromStr`/`strum_macros::EnumString`
implementation was used, as well as the (de)serialization macros and
`CacheKey`.
Test Plan
--
Existing tests, with their input updated not to include a diagnostic,
plus a new test showing that files with lint diagnostics are not cached.
Benchmarks
--
In addition to tests, we wanted to check that this doesn't degrade
performance too much. I posted part of this new analysis in
https://github.com/astral-sh/ruff/issues/18198#issuecomment-3175048672,
but I'll duplicate it here. In short, there's not much difference
between `main` and this branch for projects with few diagnostics
(`home-assistant`, `airflow`), as expected. The difference for projects
with many diagnostics (`cpython`) is quite a bit bigger (~300 ms vs ~220
ms), but most projects that run ruff regularly are likely to have very
few diagnostics, so this may not be a problem practically.
I guess GitHub isn't really rendering this as I intended, but the extra
separator line is meant to separate the benchmarks on `main` (above the
line) from this branch (below the line).
| Command | Mean [ms] | Min [ms] | Max [ms] |
|:--------------------------------------------------------------|----------:|---------:|---------:|
| `ruff check cpython --no-cache --isolated --exit-zero` | 322.0 | 317.5
| 326.2 |
| `ruff check cpython --isolated --exit-zero` | 217.3 | 209.8 | 237.9 |
| `ruff check home-assistant --no-cache --isolated --exit-zero` | 279.5
| 277.0 | 283.6 |
| `ruff check home-assistant --isolated --exit-zero` | 37.2 | 35.7 |
40.6 |
| `ruff check airflow --no-cache --isolated --exit-zero` | 133.1 | 130.4
| 146.4 |
| `ruff check airflow --isolated --exit-zero` | 34.7 | 32.9 | 41.6 |
|:--------------------------------------------------------------|----------:|---------:|---------:|
| `ruff check cpython --no-cache --isolated --exit-zero` | 330.1 | 324.5
| 333.6 |
| `ruff check cpython --isolated --exit-zero` | 309.2 | 306.1 | 314.7 |
| `ruff check home-assistant --no-cache --isolated --exit-zero` | 288.6
| 279.4 | 302.3 |
| `ruff check home-assistant --isolated --exit-zero` | 39.8 | 36.9 |
42.4 |
| `ruff check airflow --no-cache --isolated --exit-zero` | 134.5 | 131.3
| 140.6 |
| `ruff check airflow --isolated --exit-zero` | 39.1 | 37.2 | 44.3 |
I had Claude adapt one of the
[scripts](https://github.com/sharkdp/hyperfine/blob/master/scripts/plot_whisker.py)
from the hyperfine repo to make this plot, so it's not quite perfect,
but maybe it's still useful. The table is probably more reliable for
close comparisons. I'll put more details about the benchmarks below for
the sake of future reproducibility.
<img width="4472" height="2368" alt="image"
src="https://github.com/user-attachments/assets/1c42d13e-818a-44e7-b34c-247340a936d7"
/>
<details><summary>Benchmark details</summary>
<p>
The versions of each project:
- CPython: 6322edd260e8cad4b09636e05ddfb794a96a0451, the 3.10 branch
from the contributing docs
- `home-assistant`: 5585376b406f099fb29a970b160877b57e5efcb0
- `airflow`: 29a1cb0cfde9d99b1774571688ed86cb60123896
The last two are just the main branches at the time I cloned the repos.
I don't think our Ruff config should be applied since I used
`--isolated`, but these are cloned into my copy of Ruff at
`crates/ruff_linter/resources/test`, and I trimmed the
`./target/release/` prefix from each of the commands, but these are
builds of Ruff in release mode.
And here's the script with the `hyperfine` invocation:
```shell
#!/bin/bash
cargo build --release --bin ruff
# git clone --depth 1 https://github.com/home-assistant/core crates/ruff_linter/resources/test/home-assistant
# git clone --depth 1 https://github.com/apache/airflow crates/ruff_linter/resources/test/airflow
bin=./target/release/ruff
resources=./crates/ruff_linter/resources/test
cpython=$resources/cpython
home_assistant=$resources/home-assistant
airflow=$resources/airflow
base=${1:-bench}
hyperfine --warmup 10 --export-json $base.json --export-markdown $base.md \
"$bin check $cpython --no-cache --isolated --exit-zero" \
"$bin check $cpython --isolated --exit-zero" \
"$bin check $home_assistant --no-cache --isolated --exit-zero" \
"$bin check $home_assistant --isolated --exit-zero" \
"$bin check $airflow --no-cache --isolated --exit-zero" \
"$bin check $airflow --isolated --exit-zero"
```
I ran this once on `main` (`baseline` in the graph, top half of the
table) and once on this branch (`nocache` and bottom of the table).
</p>
</details>
## Summary
Support recursive type aliases by adding a `Type::TypeAlias` type
variant, which allows referring to a type alias directly as a type
without eagerly unpacking it to its value.
We still unpack type aliases when they are added to intersections and
unions, so that we can simplify the intersection/union appropriately
based on the unpacked value of the type alias.
This introduces new possible recursive types, and so also requires
expanding our usage of recursion-detecting visitors in Type methods. The
use of these visitors is still not fully comprehensive in this PR, and
will require further expansion to support recursion in more kinds of
types (I already have further work on this locally), but I think it may
be better to do this incrementally in multiple PRs.
## Test Plan
Added some recursive type-alias tests and made them pass.
## Summary
After https://github.com/astral-sh/ruff/pull/19871, I realized that now
that we are passing around shared references to `CycleDetector`
visitors, we can now also simplify the `visit` callback signature; we
don't need to smuggle a single visitor reference through it anymore.
This is a pretty minor simplification, and it doesn't really make
anything shorter since I typically used a very short name (`v`) for the
smuggled reference, but I think it reduces cognitive overhead in reading
these `visit` usages; the extra variable would likely be confusing
otherwise for a reader.
## Test Plan
Existing CI.
## Summary
Type visitors are conceptually immutable, they just internally track the
types they've seen (and some maintain a cache of results.) Passing
around mutable visitors everywhere can get us into borrow-checker
trouble in some cases, where we need to recursively pass along the
visitor inside more than one closure with non-disjoint lifetime.
Use interior mutability (via `RefCell` and `Cell`) inside the visitors
instead, to allow us to pass around shared references.
## Test Plan
Existing tests.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Add "airflow.secrets.cache.SecretCache" →
"airflow.sdk.cache.SecretCache" rule
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
---------
Co-authored-by: Wei Lee <weilee.rx@gmail.com>
Summary
--
This fixes a regression caused by the BOM handling in #19806. Most
diagnostics already account for the BOM in their ranges, but those that
use `TextRange::default` to mean the beginning of the file do not,
causing an underflow in `RenderableAnnotation::new` when subtracting the
BOM-shifted `snippet_start` from the annotation range.
I ran into this when trying to run benchmarks on CPython in preparation
for caching work. The file `cpython/Lib/test/bad_coding2.py` was causing
a crash because it had a default-range `I002` diagnostic, with a BOM.
7cc3f1ebe9/crates/ruff_linter/src/rules/isort/rules/add_required_imports.rs (L122-L126)
The fix here is just to saturate to zero instead of panicking. I
considered adding a `TextRange::saturating_sub` method, but I wasn't
sure it was worth it for this one use. I'm happy to do that if
preferred, though.
Saturating seemed easier than shifting the affected annotations over,
but that could be another solution.
Test Plan
--
A new `ruff_db` test that reproduced the issue and manual testing
against the CPython file mentioned above
## Summary
This is a follow-up to
https://github.com/astral-sh/ruff/pull/19415#discussion_r2263456740 to
remove some unused code. As Micha noticed,
`GroupedEmitter::with_show_source` was only used in local unit tests[^1]
and was safe to remove. This allowed deleting `MessageCodeFrame` and a
lot more helper code previously shared with the `full` output format.
I also moved some other code from `text.rs` and `message/mod.rs` into
`grouped.rs` that is now only used for the `grouped` format. With a
little refactoring of the `concise` rendering logic in `ruff_db`, we
could probably remove `RuleCodeAndBody` too. The only difference I see
from the `concise` output is whether we print the filename next to the
row and column or not:
```shell
> ruff check --output-format concise
try.py:1:8: F401 [*] `math` imported but unused
> ruff check --output-format grouped
try.py:
1:8 F401 [*] `math` imported but unused
```
But I didn't try to do that here.
## Test Plan
Existing tests, with the source code no longer displayed. I also deleted
one test, as it was now a duplicate of the `default` test.
[^1]: "Local unit tests" as opposed to all of our linter snapshot tests,
as is the case for `TextEmitter::with_show_fix_diff`. We also want to
expose that to users eventually
(https://github.com/astral-sh/ruff/issues/7352), which I don't believe
is the case for the `grouped` format.
The [minimal
reproduction](https://gist.github.com/dcreager/fc53c59b30d7ce71d478dcb2c1c56444)
of https://github.com/astral-sh/ty/issues/948 is an example of a class
with implicit attributes whose types end up depending on themselves. Our
existing cycle detection for `infer_expression_types` is usually enough
to handle this situation correctly, but when there are very many of
these implicit attributes, we get a combinatorial explosion of running
time and memory usage.
Adding a separate cycle handler for `ClassLiteral::implicit_attribute`
lets us catch and recover from this situation earlier.
Closes https://github.com/astral-sh/ty/issues/948
The stub mapper wasn't being passed into this codepath. It is now being
used. A previously messed up test result I intentionally checked in was
subsequently fixed.
by using essentially the same logic for system site-packages, on the
assumption that system site-packages are always a subdir of the stdlib
we were looking for.
fix https://github.com/astral-sh/ty/issues/943
## Summary
Add module-level `__getattr__` support for ty's type checker, fixing
issue https://github.com/astral-sh/ty/issues/943.
Module-level `__getattr__` functions ([PEP
562](https://peps.python.org/pep-0562/)) are now respected when
resolving dynamic attributes, matching the behavior of mypy and pyright.
## Implementation
Thanks @sharkdp for the guidance in
https://github.com/astral-sh/ty/issues/943#issuecomment-3157566579
- Adds module-specific `__getattr__` resolution in
`ModuleLiteral.static_member()`
- Maintains proper attribute precedence: explicit attributes >
submodules > `__getattr__`
## Test Plan
- New mdtest covering basic functionality, type annotations, attribute
precedence, and edge cases
(run ```cargo nextest run -p ty_python_semantic
mdtest__import_module_getattr```)
- All new tests pass, verifying `__getattr__` is called correctly and
returns proper types
- Existing test suite passes, ensuring no regressions introduced
## Summary
This PR switches the `full` output format in Ruff over to use the
rendering code
in `ruff_db`. As proposed in the design doc, this involves a lot of
changes to the snapshot output.
I also had to comment out this assertion with a TODO to replace it after
https://github.com/astral-sh/ruff/issues/19688 because many of Ruff's
"file-level" annotations aren't actually file-level. They just happen to
occur at the start of the file, especially in tests with very short
snippets.
529d81daca/crates/ruff_annotate_snippets/src/renderer/display_list.rs (L1204-L1208)
I broke up the snapshot commits at the end into several blocks, but I
don't think it's enough to help with review. The first few (notebooks,
syntax errors, and test rules) are small enough to look at, but I
couldn't really think of other categories beyond that. I'm happy to
break those up or pick out specific examples beyond what I have below,
if that would help.
The minimal code changes are in this
[range](abd28f1e77),
with the snapshot commits following. Moving the `FullRenderer` and
updating the `EmitterFlags` aren't strictly necessary either. I even
dropped the renderer commit this morning but figured it made sense to
keep it since we have the `full` module for tests. I don't feel strongly
either way.
## Test Plan
I did actually click through all 1700 snapshots individually instead of
accepting them all at once, although I moved through them quickly. There
are a
few main categories:
### Lint diagnostics
```diff
-unused.py:8:19: F401 [*] `pathlib` imported but unused
+F401 [*] `pathlib` imported but unused
+ --> unused.py:8:19
|
7 | # Unused, _not_ marked as required (due to the alias).
8 | import pathlib as non_alias
- | ^^^^^^^^^ F401
+ | ^^^^^^^^^
9 |
10 | # Unused, marked as required.
|
- = help: Remove unused import: `pathlib`
+help: Remove unused import: `pathlib`
```
- The filename and line numbers are moved to the second line
- The second noqa code next to the underline is removed
### Syntax errors
These are much like the above.
```diff
- -:1:16: invalid-syntax: Expected one or more symbol names after import
+ invalid-syntax: Expected one or more symbol names after import
+ --> -:1:16
|
1 | from foo import
| ^
```
One thing I noticed while reviewing some of these, but I don't think is
strictly syntax-error-related, is that some of the new diagnostics have
a little less context after the error. I don't think this is a problem,
but it's one small discrepancy I hadn't noticed before. Here's a minor
example:
```diff
-syntax_errors.py:1:15: invalid-syntax: Expected one or more symbol names after import
+invalid-syntax: Expected one or more symbol names after import
+ --> syntax_errors.py:1:15
|
1 | from os import
| ^
2 |
3 | if call(foo
-4 | def bar():
|
```
And one of the biggest examples:
```diff
-E30_syntax_error.py:18:11: invalid-syntax: Expected ')', found newline
+invalid-syntax: Expected ')', found newline
+ --> E30_syntax_error.py:18:11
|
16 | pass
17 |
18 | foo = Foo(
| ^
-19 |
-20 |
-21 | def top(
|
```
Similarly, a few of the lint diagnostics showed that the cut indicator
calculation for overly long lines is also slightly different, but I
think that's okay too.
### Full-file diagnostics
```diff
-comment.py:1:1: I002 [*] Missing required import: `from __future__ import annotations`
+I002 [*] Missing required import: `from __future__ import annotations`
+--> comment.py:1:1
+help: Insert required import: `from __future__ import annotations`
+
```
As noted above, these will be much more rare after #19688 too. This case
isn't a true full-file diagnostic and will render a snippet in the
future, but you can see that we're now rendering the help message that
would have been discarded before. In contrast, this is a true full-file
diagnostic and should still look like this after #19688:
```diff
-__init__.py:1:1: A005 Module `logging` shadows a Python standard-library module
+A005 Module `logging` shadows a Python standard-library module
+--> __init__.py:1:1
```
### Jupyter notebooks
There's nothing particularly different about these, just showing off the
cell index again.
```diff
- Jupyter.ipynb:cell 3:1:7: F821 Undefined name `x`
+ F821 Undefined name `x`
+ --> Jupyter.ipynb:cell 3:1:7
|
1 | print(x)
- | ^ F821
+ | ^
|
```
## Summary
Fixes the remaining range reporting differences between the `ruff_db`
diagnostic rendering and Ruff's existing rendering, as noted in
https://github.com/astral-sh/ruff/pull/19415#issuecomment-3160525595.
This PR is structured as a series of three pairs. The first commit in
each pair adds a test showing the previous behavior, followed by a fix
and the updated snapshot. It's quite a small PR, but that might be
helpful just for the contrast.
You can also look at [this
range](052e656c6c..c3ea51030d)
of commits from #19415 to see the impact on real Ruff diagnostics. I
spun these commits out of that PR.
## Test Plan
New `ruff_db` tests
PLE2513 --fix changes ESC and SUB to uppercase hexadecimal values such
as \x1B while the formatter changes them to lowercase \x1b
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
## Summary
This is a small refactor to update the server to send a single request
to perform registrations and unregistrations of dynamic capabilities.
## Test Plan
Existing E2E test cases pass, add a new test case to verify multiple
registrations.
## Summary
Reported in:
https://github.com/astral-sh/ruff/pull/19795#issuecomment-3161981945
If a root expression is reassigned, narrowing on the member should be
invalidated, but there was an oversight in the current implementation.
This PR fixes that, and also removes some unnecessary handling.
## Test Plan
New tests cases in `narrow/conditionals/nested.md`.
## Summary
This PR adds a new `ty.inlayHints.variableTypes` server setting to
configure ty to include / exclude inlay hints at variable position.
Currently, we only support inlay hints at this position so this option
basically translates to enabling / disabling inlay hints for now :)
The VS Code extension PR is
https://github.com/astral-sh/ty-vscode/pull/112.
closes: astral-sh/ty#472
## Test Plan
Add E2E tests.
## Summary
This PR is a follow-up from https://github.com/astral-sh/ruff/pull/19551
and adds a new `ty.experimental.rename` setting to conditionally
register for the rename capability. The complementary PR in ty VS Code
extension is https://github.com/astral-sh/ty-vscode/pull/111.
This is done using dynamic registration after the settings have been
resolved. The experimental group is part of the global settings because
they're applied for all workspaces that are managed by the client.
## Test Plan
Add E2E tests.
In VS Code, with the following setting:
```json
{
"ty.experimental.rename": "true",
"python.languageServer": "None"
}
```
I get the relevant log entry:
```
2025-08-07 16:05:40.598709000 DEBUG client_response{id=3 method="client/registerCapability"}: Registered rename capability
```
And, I'm able to rename a symbol. Once I set it to `false`, then I can
see this log entry:
```
2025-08-07 16:08:39.027876000 DEBUG Rename capability is disabled in the client settings
```
And, I don't see the "Rename Symbol" open in the VS Code dropdown.
https://github.com/user-attachments/assets/501659df-ba96-4252-bf51-6f22acb4920b
This PR adds support for the "rename" language server feature. It builds
upon existing functionality used for "go to references".
The "rename" feature involves two language server requests. The first is
a "prepare rename" request that determines whether renaming should be
possible for the identifier at the current offset. The second is a
"rename" request that returns a list of file ranges where the rename
should be applied.
Care must be taken when attempting to rename symbols that span files,
especially if the symbols are defined in files that are not part of the
project. We don't want to modify code in the user's Python environment
or in the vendored stub files.
I found a few bugs in the "go to references" feature when implementing
"rename", and those bug fixes are included in this PR.
---------
Co-authored-by: UnboundVariable <unbound@gmail.com>
## Summary
As per our naming scheme (at least for callable types) this should
return a `BoundMethodType`, or be renamed, but it makes more sense to
change the return type.
I also ensure `ClassType.into_callable` returns a `Type::Callable` in
the changed branch.
Ideally we could return a `CallableType` from these `into_callable`
functions (and rename to `into_callable_type` but because of unions we
cannot do this.
## Summary
Validates writes to `TypedDict` keys, for example:
```py
class Person(TypedDict):
name: str
age: int | None
def f(person: Person):
person["naem"] = "Alice" # error: [invalid-key]
person["age"] = "42" # error: [invalid-assignment]
```
The new specialized `invalid-assignment` diagnostic looks like this:
<img width="1160" height="279" alt="image"
src="https://github.com/user-attachments/assets/51259455-3501-4829-a84e-df26ff90bd89"
/>
## Ecosystem analysis
As far as I can tell, all true positives!
There are some extremely long diagnostic messages. We should truncate
our display of overload sets somehow.
## Test Plan
New Markdown tests
## Summary
When seeing a failed test like
```bash
is_subtype_of.md - Subtype relation - Callable - Class literals - Classes with `__new_… (1e9782853227c019)
crates/ty_python_semantic/resources/mdtest/type_properties/is_subtype_of.md:1810 unexpected error: [unresolved-reference] "Name `Aa` used when not defined"
To rerun this specific test, set the environment variable: MDTEST_TEST_FILTER='is_subtype_of.md - Subtype relation - Callable - Class literals - Classes with `__new_… (1e9782853227c019)'
MDTEST_TEST_FILTER='is_subtype_of.md - Subtype relation - Callable - Class literals - Classes with `__new_… (1e9782853227c019)' cargo test -p ty_python_semantic --test mdtest -- mdtest__type_properties_is_subtype_of
```
running the following now works
```bash
MDTEST_TEST_FILTER='is_subtype_of.md - Subtype relation - Callable - Class literals - Classes with `__new_… (1e9782853227c019)' cargo test -p ty_python_semantic --test mdtest -- mdtest__type_properties_is_subtype_of
```
## Test Plan
Do we have tests for the test runner? :)
This fixes our logic for binding a legacy typevar with its binding
context. (To recap, a legacy typevar starts out "unbound" when it is
first created, and each time it's used in a generic class or function,
we "bind" it with the corresponding `Definition`.)
We treat `typing.Self` the same as a legacy typevar, and so we apply
this binding logic to it too. Before, we were using the enclosing class
as its binding context. But that's not correct — it's the method where
`typing.Self` is used that binds the typevar. (Each invocation of the
method will find a new specialization of `Self` based on the specific
instance type containing the invoked method.)
This required plumbing through some additional state to the
`in_type_expression` method.
This also revealed that we weren't handling `Self`-typed instance
attributes correctly (but were coincidentally not getting the expected
false positive diagnostics).
## Summary
Disallow `typing.TypedDict` in type expressions.
Related reference: https://github.com/python/mypy/issues/11030
## Test Plan
New Markdown tests, checked ecosystem and conformance test impact.
## Summary
This PR updates the client settings handling to recognize unknown
options provided by the user and show a warning popup along with a
warning log message.
## Test Plan
Add E2E tests.
## Summary
This PR implements support for providing LSP client settings.
The complementary PR in the ty VS Code extension:
astral-sh/ty-vscode#106.
Notes for the previous iteration of this PR is in
https://github.com/astral-sh/ruff/pull/19614#issuecomment-3136477864
(click on "Details").
Specifically, this PR splits the client settings into 3 distinct groups.
Keep in mind that these groups are not visible to the user, they're
merely an implementation detail. The groups are:
1. `GlobalOptions` - these are the options that are global to the
language server and will be the same for all the workspaces that are
handled by the server
2. `WorkspaceOptions` - these are the options that are specific to a
workspace and will be applied only when running any logic for that
workspace
3. `InitializationOptions` - these are the options that can be specified
during initialization
The initialization options are a superset that contains both the global
and workspace options flattened into a 1-dimensional structure. This
means that the user can specify any and all fields present in
`GlobalOptions` and `WorkspaceOptions` in the initialization options in
addition to the fields that are _specific_ to initialization options.
From the current set of available settings, following are only available
during initialization because they are required at that time, are static
during the runtime of the server and changing their values require a
restart to take effect:
- `logLevel`
- `logFile`
And, following are available under `GlobalOptions`:
- `diagnosticMode`
And, following under `WorkspaceOptions`:
- `disableLanguageServices`
- `pythonExtension` (Python environment information that is populated by
the ty VS Code extension)
### `workspace/configuration`
This request allows server to ask the client for configuration to a
specific workspace. But, this is only supported by the client that has
the `workspace.configuration` client capability set to `true`. What to
do for clients that don't support pulling configurations?
In that case, the settings needs to be provided in the initialization
options and updating the values of those settings can only be done by
restarting the server. With the way this is implemented, this means that
if the client does not support pulling workspace configuration then
there's no way to specify settings specific to a workspace. Earlier,
this would've been possible by providing an array of client options with
an additional field which specifies which workspace the options belong
to but that adds complexity and clients that actually do not support
`workspace/configuration` would usually not support multiple workspaces
either.
Now, for the clients that do support this, the server will initiate the
request to get the configuration for all the workspaces at the start of
the server. Once the server receives these options, it will resolve them
for each workspace as follows:
1. Combine the client options sent during initialization with the
options specific to the workspace creating the final client options
that's specific to this workspace
2. Create a global options by combining the global options from (1) for
all workspaces which in turn will also combine the global options sent
during initialization
The global options are resolved into the global settings and are
available on the `Session` which is initialized with the default global
settings. The workspace options are resolved into the workspace settings
and are available on the respective `Workspace`.
The `SessionSnapshot` contains the global settings while the document
snapshot contains the workspace settings. We could add the global
settings to the document snapshot but that's currently not needed.
### Document diagnostic dynamic registration
Currently, the document diagnostic server capability is created based on
the `diagnosticMode` sent during initialization. But, that wouldn't
provide us with the complete picture. This means the server needs to
defer registering the document diagnostic capability at a later point
once the settings have been resolved.
This is done using dynamic registration for clients that support it. For
clients that do not support dynamic registration for document diagnostic
capability, the server advertises itself as always supporting workspace
diagnostics and work done progress token.
This dynamic registration now allows us to change the server capability
for workspace diagnostics based on the resolved `diagnosticMode` value.
In the future, once `workspace/didChangeConfiguration` is supported, we
can avoid the server restart when users have changed any client
settings.
## Test Plan
Add integration tests and recorded videos on the user experience in
various editors:
### VS Code
For VS Code users, the settings experience is unchanged because the
extension defines it's own interface on how the user can specify the
server setting. This means everything is under the `ty.*` namespace as
usual.
https://github.com/user-attachments/assets/c2e5ba5c-7617-406e-a09d-e397ce9c3b93
### Zed
For Zed, the settings experience has changed. Users can specify settings
during initialization:
```json
{
"lsp": {
"ty": {
"initialization_options": {
"logLevel": "debug",
"logFile": "~/.cache/ty.log",
"diagnosticMode": "workspace",
"disableLanguageServices": true
}
},
}
}
```
Or, can specify the options under the `settings` key:
```json
{
"lsp": {
"ty": {
"settings": {
"ty": {
"diagnosticMode": "openFilesOnly",
"disableLanguageServices": true
}
},
"initialization_options": {
"logLevel": "debug",
"logFile": "~/.cache/ty.log"
}
},
}
}
```
The `logLevel` and `logFile` setting still needs to go under the
initialization options because they're required by the server during
initialization.
We can remove the nesting of the settings under the "ty" namespace by
updating the return type of
db9ea0cdfd/src/tychecker.rs (L45-L49)
to be wrapped inside `ty` directly so that users can avoid doing the
double nesting.
There's one issue here which is that if the `diagnosticMode` is
specified in both the initialization option and settings key, then the
resolution is a bit different - if either of them is set to be
`workspace`, then it wins which means that in the following
configuration, the diagnostic mode is `workspace`:
```json
{
"lsp": {
"ty": {
"settings": {
"ty": {
"diagnosticMode": "openFilesOnly"
}
},
"initialization_options": {
"diagnosticMode": "workspace"
}
},
}
}
```
This behavior is mainly a result of combining global options from
various workspace configuration results. Users should not be able to
provide global options in multiple workspaces but that restriction
cannot be done on the server side. The ty VS Code extension restricts
these global settings to only be set in the user settings and not in
workspace settings but we do not control extensions in other editors.
https://github.com/user-attachments/assets/8e2d6c09-18e6-49e5-ab78-6cf942fe1255
### Neovim
Same as in Zed.
### Other
Other editors that do not support `workspace/configuration`, the users
would need to provide the server settings during initialization.
## Summary
This PR improves the `is_safe_mutable_class` function in `infer.rs` in
several ways:
- It uses `KnownClass::to_instance()` for all "safe mutable classes".
Previously, we were using `SpecialFormType::instance_fallback()` for
some variants -- I'm not totally sure why. Switching to
`KnownClass::to_instance()` for all "safe mutable classes" fixes a
number of TODOs in the `assignment.md` mdtest suite
- Rather than eagerly calling `.to_instance(db)` on all "safe mutable
classes" every time `is_safe_mutable_class` is called, we now only call
it lazily on each element, allowing us to short-circuit more
effectively.
- I removed the entry entirely for `TypedDict` from the list of "safe
mutable classes", as it's not correct.
`SpecialFormType::TypedDict.instance_fallback(db)` just returns an
instance type representing "any instance of `typing._SpecialForm`",
which I don't think was the intent of this code. No tests fail as a
result of removing this entry, as we already check separately whether an
object is an inhabitant of a `TypedDict` type (and consider that object
safe-mutable if so!).
## Test Plan
mdtests updated
## Summary
This PR adds type inference for key-based access on `TypedDict`s and a
new diagnostic for invalid subscript accesses:
```py
class Person(TypedDict):
name: str
age: int | None
alice = Person(name="Alice", age=25)
reveal_type(alice["name"]) # revealed: str
reveal_type(alice["age"]) # revealed: int | None
alice["naem"] # Unknown key "naem" - did you mean "name"?
```
## Test Plan
Updated Markdown tests
## Summary
This PR remaps ranges in Jupyter notebooks from simple `row:column`
indices in the concatenated source code to `cell:row:col` to match
Ruff's output. This is probably not a likely change to land upstream in
`annotate-snippets`, but I didn't see a good way around it.
The remapping logic is taken nearly verbatim from here:
cd6bf1457d/crates/ruff_linter/src/message/text.rs (L212-L222)
## Test Plan
New `full` rendering test for a notebook
I was mainly focused on Ruff, but in local tests this also works for ty:
```
error[invalid-assignment]: Object of type `Literal[1]` is not assignable to `str`
--> Untitled.ipynb:cell 1:3:1
|
1 | import math
2 |
3 | x: str = 1
| ^
|
info: rule `invalid-assignment` is enabled by default
error[invalid-assignment]: Object of type `Literal[1]` is not assignable to `str`
--> Untitled.ipynb:cell 2:3:1
|
1 | import math
2 |
3 | x: str = 1
| ^
|
info: rule `invalid-assignment` is enabled by default
```
This isn't a duplicate diagnostic, just an unimaginative example:
```py
# cell 1
import math
x: str = 1
# cell 2
import math
x: str = 1
```
Summary
--
This is the other commit I wanted to spin off from #19415, currently
stacked on #19644.
This PR suppresses blank snippets for empty ranges at the very beginning
of a file, and for empty ranges in non-existent files. Ruff includes
empty ranges for IO errors, for example.
f4e93b6335/crates/ruff_linter/src/message/text.rs (L100-L110)
The diagnostics now look like this (new snapshot test):
```
error[test-diagnostic]: main diagnostic message
--> example.py:1:1
```
Instead of [^*]
```
error[test-diagnostic]: main diagnostic message
--> example.py:1:1
|
|
```
Test Plan
--
A new `ruff_db` test showing the expected output format
[^*]: This doesn't correspond precisely to the example in the PR because
of some details of the diagnostic builder helper methods in `ruff_db`,
but you can see another example in the current version of the summary in
#19415.
Summary
--
Fixes a snapshot test failure I saw in #19653 locally and in Windows CI
by
padding the hex ID to 16 digits to match the regex in
`filter_result_id`.
78e5fe0a51/crates/ty_server/tests/e2e/pull_diagnostics.rs (L380-L384)
Test Plan
--
I applied this to the branch from #19653 locally and saw that the tests
now
pass. I couldn't reproduce this failure directly on `main` or this
branch,
though.
## Summary
This PR is a spin-off from https://github.com/astral-sh/ruff/pull/19415.
It enables replacing the severity and lint name in a ty-style
diagnostic:
```
error[unused-import]: `os` imported but unused
```
with the noqa code and optional fix availability icon for a Ruff
diagnostic:
```
F401 [*] `os` imported but unused
F821 Undefined name `a`
```
or nothing at all for a Ruff syntax error:
```
SyntaxError: Expected one or more symbol names after import
```
Ruff adds the `SyntaxError` prefix to these messages manually.
Initially (d912458), I just passed a `hide_severity` flag through a
bunch of calls to get it into `annotate-snippets`, but after looking at
it again today, I think reusing the `None` severity/level gave a nicer
result. As I note in a lengthy code comment, I think all of this code
should be temporary and reverted when Ruff gets real severities, so
hopefully it's okay if it feels a little hacky.
I think the main visible downside of this approach is that we can't
style the asterisk in the fix availabilty icon in cyan, as in Ruff's
current output. It's part of the message in this PR and any styling gets
overwritten in `annotate-snippets`.
<img width="400" height="342" alt="image"
src="https://github.com/user-attachments/assets/57542ec9-a81c-4a01-91c7-bd6d7ec99f99"
/>
Hmm, I guess reusing `Level::None` also means the `F401` isn't red
anymore. Maybe my initial approach was better after all. In any case,
the rest of the PR should be basically the same, it just depends how we
want to toggle the severity.
## Test Plan
New `ruff_db` tests. These snapshots should be compared to the two tests
just above them (`hide_severity_output` vs `output` and
`hide_severity_syntax_errors` against `syntax_errors`).
## Summary
Use `$GITHUB_SHA` (the merged state of `feature` + `main` branch)
instead of `{{ github.event.pull_request.head.sha }}` (just the latest
`feature` commit) for building the "new" version of `ty` in the typing
conformance workflow.
## Test Plan
None.
## Summary
This PR fixes a few inaccuracies in attribute access on `TypedDict`s. It
also changes the return type of `type(person)` to `type[dict[str,
object]]` if `person: Person` is an inhabitant of a `TypedDict`
`Person`. We still use `type[Person]` as the *meta type* of Person,
however (see reasoning
[here](https://github.com/astral-sh/ruff/pull/19733#discussion_r2253297926)).
## Test Plan
Updated Markdown tests.
## Summary
This PR adds a new `Type::TypedDict` variant. Before this PR, we treated
`TypedDict`-based types as dynamic Todo-types, and I originally planned
to make this change a no-op. And we do in fact still treat that new
variant similar to a dynamic type when it comes to type properties such
as assignability and subtyping. But then I somehow tricked myself into
implementing some of the things correctly, so here we are. The two main
behavioral changes are: (1) we now also detect generic `TypedDict`s,
which removes a few false positives in the ecosystem, and (2) we now
support *attribute* access (not key-based indexing!) on these types,
i.e. we infer proper types for something like
`MyTypedDict.__required_keys__`. Nothing exciting yet, but gets the
infrastructure into place.
Note that with this PR, the type of (the type) `MyTypedDict` itself is
still represented as a `Type::ClassLiteral` or `Type::GenericAlias` (in
case `MyTypedDict` is generic). Only inhabitants of `MyTypedDict`
(instances of `dict` at runtime) are represented by `Type::TypedDict`.
We may want to revisit this decision in the future, if this turns out to
be too error-prone. Right now, we need to use `.is_typed_dict(db)` in
all the right places to distinguish between actual (generic) classes and
`TypedDict`s. But so far, it seemed unnecessary to add additional `Type`
variants for these as well.
part of https://github.com/astral-sh/ty/issues/154
## Ecosystem impact
The new diagnostics on `cloud-init` look like true positives to me.
## Test Plan
Updated and new Markdown tests
## Summary
This is a follow-up to #19321.
Narrowing constraints introduced in a class scope were not applied even
when they can be applied in lazy nested scopes. This PR fixes so that
they are now applied.
Conversely, there were cases where narrowing constraints were being
applied in places where they should not, so it is also fixed.
## Test Plan
Some TODOs in `narrow/conditionals/nested.md` are now work correctly.
## Summary
This is a follow-up to #19321.
If we try to access a class variable before it is defined, the variable
is looked up in the global scope, rather than in any enclosing scopes.
Closes https://github.com/astral-sh/ty/issues/875.
## Test Plan
New tests in `narrow/conditionals/nested.md`.
## Summary
This PR enhances the `BLE001` rule to correctly detect blind exception
handling in tuple exceptions. Previously, the rule only checked single
exception types, but Python allows catching multiple exceptions using
tuples like `except (Exception, ValueError):`.
## Test Plan
It fails the following (whereas the main branch does not):
```bash
cargo run -p ruff -- check somefile.py --no-cache --select=BLE001
```
```python
# somefile.py
try:
1/0
except (ValueError, Exception) as e:
print(e)
```
```
somefile.py:3:21: BLE001 Do not catch blind exception: `Exception`
|
1 | try:
2 | 1/0
3 | except (ValueError, Exception) as e:
| ^^^^^^^^^ BLE001
4 | print(e)
|
Found 1 error.
```
## Summary
Support `as` patterns in reachability analysis:
```py
from typing import assert_never
def f(subject: str | int):
match subject:
case int() as x:
pass
case str():
pass
case _:
assert_never(subject) # would previously emit an error
```
Note that we still don't support inferring correct types for the bound
name (`x`).
Closes https://github.com/astral-sh/ty/issues/928
## Test Plan
New Markdown tests
## Summary
This PR reduces the virality of some of the `Todo` types in
`infer_tuple_type_expression`. Rather than inferring `Todo`, we instead
infer `tuple[Todo, ...]`. This reflects the fact that whatever the
contents of the slice in a `tuple[]` type expression, we would always
infer some kind of tuple type as the result of the type expression. Any
tuple type should be assignable to `tuple[Todo, ...]`, so this shouldn't
introduce any new false positives; this can be seen in the ecosystem
report.
As a result of the change, we are now able to enforce in the signature
of `Type::infer_tuple_type_expression` that it returns an
`Option<TupleType<'db>>`, which is more strongly typed and expresses
clearly the invariant that a tuple type expression should always be
inferred as a `tuple` type. To enable this, it was necessary to refactor
several `TupleType` constructors in `tuple.rs` so that they return
`Option<TupleType>` rather than `Type`; this means that callers of these
constructor functions are now free to either propagate the
`Option<TupleType<'db>>` or convert it to a `Type<'db>`.
## Test Plan
Mdtests updated.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [notify](https://redirect.github.com/notify-rs/notify) |
workspace.dependencies | minor | `8.1.0` -> `8.2.0` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>notify-rs/notify (notify)</summary>
###
[`v8.2.0`](https://redirect.github.com/notify-rs/notify/blob/HEAD/CHANGELOG.md#notify-820-2025-08-03)
[Compare
Source](https://redirect.github.com/notify-rs/notify/compare/notify-8.1.0...notify-8.2.0)
- FEATURE: notify user if inotify's `max_user_watches` has been reached
[#​698]
- FIX: `INotifyWatcher` ignore events with unknown watch descriptors
(instead of `EventMask::Q_OVERFLOW`) [#​700]
[#​698]: https://redirect.github.com/notify-rs/notify/pull/698
[#​700]: https://redirect.github.com/notify-rs/notify/pull/700
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS41MS4xIiwidXBkYXRlZEluVmVyIjoiNDEuNTEuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[cargo-bins/cargo-binstall](https://redirect.github.com/cargo-bins/cargo-binstall)
| action | patch | `v1.14.2` -> `v1.14.3` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>cargo-bins/cargo-binstall (cargo-bins/cargo-binstall)</summary>
###
[`v1.14.3`](https://redirect.github.com/cargo-bins/cargo-binstall/releases/tag/v1.14.3)
[Compare
Source](https://redirect.github.com/cargo-bins/cargo-binstall/compare/v1.14.2...v1.14.3)
*Binstall is a tool to fetch and install Rust-based executables as
binaries. It aims to be a drop-in replacement for `cargo install` in
most cases. Install it today with `cargo install cargo-binstall`, from
the binaries below, or if you already have it, upgrade with `cargo
binstall cargo-binstall`.*
##### In this release:
- Fix race condition in target detections
([#​2238](https://redirect.github.com/cargo-bins/cargo-binstall/issues/2238))
##### Other changes:
- Upgrade dependencies
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS41MS4xIiwidXBkYXRlZEluVmVyIjoiNDEuNTEuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [serde_json](https://redirect.github.com/serde-rs/json) |
workspace.dependencies | patch | `1.0.141` -> `1.0.142` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>serde-rs/json (serde_json)</summary>
###
[`v1.0.142`](https://redirect.github.com/serde-rs/json/releases/tag/v1.0.142)
[Compare
Source](https://redirect.github.com/serde-rs/json/compare/v1.0.141...v1.0.142)
- impl Default for \&Value
([#​1265](https://redirect.github.com/serde-rs/json/issues/1265),
thanks [@​aatifsyed](https://redirect.github.com/aatifsyed))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS41MS4xIiwidXBkYXRlZEluVmVyIjoiNDEuNTEuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
When splitting triple-quoted, raw strings one has to take care before attempting to make each item have single-quotes.
Fixes#19577
---------
Co-authored-by: dylwil3 <dylwil3@gmail.com>
This is subtle, and the root cause became more apparent with #19604,
since we now have many more cases of superclasses and subclasses using
different typevars. The issue is easiest to see in the following:
```py
class C[T]:
def __init__(self, t: T) -> None: ...
class D[U](C[T]):
pass
reveal_type(C(1)) # revealed: C[int]
reveal_type(D(1)) # should be: D[int]
```
When instantiating a generic class, the `__init__` method inherits the
generic context of that class. This lets our call binding machinery
infer a specialization for that context.
Prior to this PR, the instantiation of `C` worked just fine. Its
`__init__` method would inherit the `[T]` generic context, and we would
infer `{T = int}` as the specialization based on the argument
parameters.
It didn't work for `D`. The issue is that the `__init__` method was
inheriting the generic context of the class where `__init__` was defined
(here, `C` and `[T]`). At the call site, we would then infer `{T = int}`
as the specialization — but that wouldn't help us specialize `D[U]`,
since `D` does not have `T` in its generic context!
Instead, the `__init__` method should inherit the generic context of the
class that we are performing the lookup on (here, `D` and `[U]`). That
lets us correctly infer `{U = int}` as the specialization, which we can
successfully apply to `D[U]`.
(Note that `__init__` refers to `C`'s typevars in its signature, but
that's okay; our member lookup logic already applies the `T = U`
specialization when returning a member of `C` while performing a lookup
on `D`, transforming its signature from `(Self, T) -> None` to `(Self,
U) -> None`.)
Closes https://github.com/astral-sh/ty/issues/588
This PR introduces a few related changes:
- We now keep track of each time a legacy typevar is bound in a
different generic context (e.g. class, function), and internally create
a new `TypeVarInstance` for each usage. This means the rest of the code
can now assume that salsa-equivalent `TypeVarInstance`s refer to the
same typevar, even taking into account that legacy typevars can be used
more than once.
- We also go ahead and track the binding context of PEP 695 typevars.
That's _much_ easier to track since we have the binding context right
there during type inference.
- With that in place, we can now include the name of the binding context
when rendering typevars (e.g. `T@f` instead of `T`)
## Summary
Adds an initial set of tests based on the highest-priority items in
https://github.com/astral-sh/ty/issues/154. This is certainly not yet
exhaustive (required/non-required, `total`, and other things are
missing), but will be useful to measure progress on this feature.
## Test Plan
Checked intended behavior against runtime and other type checkers.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [unnecessary-from-float
(FURB164)](https://docs.astral.sh/ruff/rules/unnecessary-from-float/#unnecessary-from-float-furb164)'s
example error out-of-the-box.
[Old example](https://play.ruff.rs/807ef72f-9671-408d-87ab-8b8bad65b33f)
```py
Decimal.from_float(4.2)
Decimal.from_float(float("inf"))
Fraction.from_float(4.2)
Fraction.from_decimal(Decimal("4.2"))
```
[New example](https://play.ruff.rs/303680d1-8a68-4b6c-a5fd-d79c56eb0f88)
```py
from decimal import Decimal
from fractions import Fraction
Decimal.from_float(4.2)
Decimal.from_float(float("inf"))
Fraction.from_float(4.2)
Fraction.from_decimal(Decimal("4.2"))
```
The "Use instead" section also had imports added, and one of the fixed
examples was slightly wrong and needed modification.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
## Summary
Adds validation to subscript assignment expressions.
```py
class Foo: ...
class Bar:
__setattr__ = None
class Baz:
def __setitem__(self, index: str, value: int) -> None:
pass
# We now emit a diagnostic on these statements
Foo()[1] = 2
Bar()[1] = 2
Baz()[1] = 2
```
Also improves error messages on invalid `__getitem__` expressions
## Test Plan
Update mdtests and add more to `subscript/instance.md`
---------
Co-authored-by: David Peter <sharkdp@users.noreply.github.com>
Co-authored-by: David Peter <mail@david-peter.de>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [meta-class-abc-meta
(FURB180)](https://docs.astral.sh/ruff/rules/meta-class-abc-meta/#meta-class-abc-meta-furb180)'s
example error out-of-the-box.
[Old example](https://play.ruff.rs/6beca1be-45cd-4e5a-aafa-6a0584c10d64)
```py
class C(metaclass=ABCMeta):
pass
```
[New example](https://play.ruff.rs/bbad34da-bf07-44e6-9f34-53337e8f57d4)
```py
import abc
class C(metaclass=abc.ABCMeta):
pass
```
The "Use instead" section as also modified similarly.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
## Summary
Fixes#18729 and fixes#16802
## Test Plan
Manually verified via CLI that Ruff no longer enters an infinite loop by
running:
```sh
echo 1 | ruff --isolated check - --select I002,UP010 --fix
```
with `required-imports = ["from __future__ import generator_stop"]` set
in the config, confirming “All checks passed!” and no snapshots were
generated.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
Summary
--
Fixes#19640. I'm not sure these are the exact fixes we really want, but
I
reproduced the issue in a 32-bit Docker container and tracked down the
causes,
so I figured I'd open a PR.
As I commented on the issue, the `goto_references` test depends on the
iteration
order of the files in an `FxHashSet` in `Indexed`. In this case, we can
just
sort the output in test code.
Similarly, the tuple case depended on the order of overloads inserted in
an
`FxHashMap`. `FxIndexMap` seemed like a convenient drop-in replacement,
but I
don't know if that will have other detrimental effects. I did have to
change the
assertion for the tuple test, but I think it should now be stable across
architectures.
Test Plan
--
Running the tests in the aforementioned Docker container
Issue: https://github.com/astral-sh/ruff/issues/19498
## Summary
[missing-required-import](https://docs.astral.sh/ruff/rules/missing-required-import/)
inserts the missing import on the line immediately following the last
line of the docstring. However, if the dosctring is immediately followed
by a continuation token (i.e. backslash) then this leads to a syntax
error because Python interprets the docstring and the inserted import to
be on the same line.
The proposed solution in this PR is to check if the first token after a
file docstring is a continuation character, and if so, to advance an
additional line before inserting the missing import.
## Test Plan
Added a unit test, and the following example was verified manually:
Given this simple test Python file:
```python
"Hello, World!"\
print(__doc__)
```
and this ruff linting configuration in the `pyproject.toml` file:
```toml
[tool.ruff.lint]
select = ["I"]
[tool.ruff.lint.isort]
required-imports = ["import sys"]
```
Without the changes in this PR, the ruff linter would try to insert the
missing import in line 2, resulting in a syntax error, and report the
following:
`error: Fix introduced a syntax error. Reverting all changes.`
With the changes in this PR, ruff correctly advances one more line
before adding the missing import, resulting in the following output:
```python
"Hello, World!"\
import sys
print(__doc__)
```
---------
Co-authored-by: Jim Hoekstra <jim.hoekstra@pacmed.nl>
## Summary
This PR improves our generics solver such that we are able to solve the
`TypeVar` in this snippet to `int | str` (the union of the elements in
the heterogeneous tuple) by upcasting the heterogeneous tuple to its
pure-homogeneous-tuple supertype:
```py
def f[T](x: tuple[T, ...]) -> T:
return x[0]
def g(x: tuple[int, str]):
reveal_type(f(x))
```
## Test Plan
Mdtests. Some TODOs remain in the mdtest regarding solving `TypeVar`s
for mixed tuples, but I think this PR on its own is a significant step
forward for our generics solver when it comes to tuple types.
---------
Co-authored-by: Douglas Creager <dcreager@dcreager.net>
## Summary
Add support for `async for` loops and async iterables.
part of https://github.com/astral-sh/ty/issues/151
## Ecosystem impact
```diff
- boostedblob/listing.py:445:54: warning[unused-ignore-comment] Unused blanket `type: ignore` directive
```
This is correct. We now find a true positive in the `# type: ignore`'d
code.
All of the other ecosystem hits are of the type
```diff
trio (https://github.com/python-trio/trio)
+ src/trio/_core/_tests/test_guest_mode.py:532:24: error[not-iterable] Object of type `MemorySendChannel[int] | MemoryReceiveChannel[int]` may not be iterable
```
The message is correct, because only `MemoryReceiveChannel` has an
`__aiter__` method, but `MemorySendChannel` does not. What's not correct
is our inferred type here. It should be `MemoryReceiveChannel[int]`, not
the union of the two. This is due to missing unpacking support for tuple
subclasses, which @AlexWaygood is working on. I don't think this should
block merging this PR, because those wrong types are already there,
without this PR.
## Test Plan
New Markdown tests and snapshot tests for diagnostics.
## Summary
I was a bit stuck on some snapshot differences I was seeing in #19415,
but @BurntSushi pointed out that `annotate-snippets` already normalizes
tabs on its own, which was very helpful! Instead of applying this change
directly to the other branch, I wanted to try applying it in
`ruff_linter` first. This should very slightly reduce the number of
changes in #19415 proper.
It looks like `annotate-snippets` always expands a tab to four spaces,
whereas I think we were aligning to tab stops:
```diff
6 | spam(ham[1], { eggs: 2})
7 | #: E201:1:6
- 8 | spam( ham[1], {eggs: 2})
- | ^^^ E201
+ 8 | spam( ham[1], {eggs: 2})
+ | ^^^^ E201
```
```diff
61 | #: E203:2:15 E702:2:16
62 | if x == 4:
-63 | print(x, y) ; x, y = y, x
- | ^ E203
+63 | print(x, y) ; x, y = y, x
+ | ^^^^ E203
```
```diff
E27.py:15:6: E271 [*] Multiple spaces after keyword
|
-13 | True and False
+13 | True and False
14 | #: E271
15 | a and b
| ^^ E271
```
I don't think this is too bad and has the major benefit of allowing us
to pass the non-tab-expanded range to `annotate-snippets` in #19415,
where it's also displayed in the header. Ruff doesn't have this problem
currently because it uses its own concise diagnostic output as the
header for full diagnostics, where the pre-expansion range is used
directly.
## Test Plan
Existing tests with a few snapshot updates
## Summary
- Add support for the return types of `async` functions
- Add type inference for `await` expressions
- Add support for `async with` / async context managers
- Add support for `yield from` expressions
This PR is generally lacking proper error handling in some cases (e.g.
illegal `__await__` attributes). I'm planning to work on this in a
follow-up.
part of https://github.com/astral-sh/ty/issues/151
closes https://github.com/astral-sh/ty/issues/736
## Ecosystem
There are a lot of true positives on `prefect` which look similar to:
```diff
prefect (https://github.com/PrefectHQ/prefect)
+ src/integrations/prefect-aws/tests/workers/test_ecs_worker.py:406:12: error[unresolved-attribute] Type `str` has no attribute `status_code`
```
This is due to a wrong return type annotation
[here](e926b8c4c1/src/integrations/prefect-aws/tests/workers/test_ecs_worker.py (L355-L391)).
```diff
mitmproxy (https://github.com/mitmproxy/mitmproxy)
+ test/mitmproxy/addons/test_clientplayback.py:18:1: error[invalid-argument-type] Argument to function `asynccontextmanager` is incorrect: Expected `(...) -> AsyncIterator[Unknown]`, found `def tcp_server(handle_conn, **server_args) -> Unknown | tuple[str, int]`
```
[This](a4d794c59a/test/mitmproxy/addons/test_clientplayback.py (L18-L19))
is a true positive. That function should return
`AsyncIterator[Address]`, not `Address`.
I looked through almost all of the other new diagnostics and they all
look like known problems or true positives.
## Typing conformance
The typing conformance diff looks good.
## Test Plan
New Markdown tests
Summary
--
This partially reverts commit 13634ff433
after issues in the release today.
Test Plan
--
```shell
uv build --sdist
tar -tzf dist/ruff-0.12.6.tar.gz | grep ruff-0.12.6/LICENSE
```
which finds the license now.
Summary
--
This PR adds a `Checker::context` method that returns the underlying
`LintContext` to unify `Candidate::into_diagnostic` and
`Candidate::report_diagnostic` in our ambiguous Unicode character
checks. This avoids some duplication and also avoids collecting a `Vec`
of `Candidate`s only to iterate over it later.
Test Plan
--
Existing tests
## Summary
Fixes#19385.
Based on [unnecessary-placeholder
(PIE790)](https://docs.astral.sh/ruff/rules/unnecessary-placeholder/)
behavior, [ellipsis-in-non-empty-class-body
(PYI013)](https://docs.astral.sh/ruff/rules/ellipsis-in-non-empty-class-body/)
now safely preserve inline comment on ellipsis removal.
## Test Plan
A new test class was added:
```python
class NonEmptyChildWithInlineComment:
value: int
... # preserve me
```
with the following expected fix:
```python
class NonEmptyChildWithInlineComment:
value: int
# preserve me
```
The diagram is written in the Dot language, which can
be converted to SVG (or any other image) by GraphViz.
I thought it was a good idea to write this down in
preparation for adding routines that list modules.
Code reuse is likely to be difficult and I wanted to
be sure I understood how it worked.
I mostly just did this because the long string literals were annoying
me. And these can make rustfmt give up on formatting.
I also re-flowed some long comment lines while I was here.
I'm not sure if this used to be used elsewhere, but it no longer is.
And it looks like an internal-only helper function, so just un-export
it.
And note that `ModuleNameIngredient` is also un-exported, so this
function isn't really usable outside of its defining module anyway.
Summary
--
I noticed while reviewing #19390 that in `check_tokens` we were still
passing
around an extra `LinterSettings`, despite all of the same functions also
receiving a `LintContext` with its own settings.
This PR adds the `LintContext::settings` method and calls that instead
of using
the separate `LinterSettings`.
Test Plan
--
Existing tests
## Summary
Resolves#19531
I've implemented a check to determine whether the for_stmt target is
declared as global or nonlocal. I believe we should skip the rule in all
such cases, since variables declared this way are intended for use
outside the loop scope, making value changes expected behavior.
## Test Plan
Added two test cases for global and nonlocal variable to snapshot.
This PR improves the "signature help" language server feature in two
ways:
1. It adds support for the recently-introduced "stub mapper" which maps
symbol declarations within stubs to their implementation counterparts.
This allows the signature help to display docstrings from the original
implementation.
2. It incorporates a more robust fix to a bug that was addressed in a
[previous PR](https://github.com/astral-sh/ruff/pull/19542). It also
adds more comprehensive tests to cover this case.
Co-authored-by: UnboundVariable <unbound@gmail.com>
This eliminates the panic reported in
https://github.com/astral-sh/ty/issues/909, though it doesn't address
the underlying cause, which is that we aren't yet checking the types of
the fields of a protocol when checking whether a class implements the
protocol. And in particular, if a class explictly opts out of iteration
via
```py
class NotIterable:
__iter__ = None
```
we currently treat that as "having an `__iter__`" member, and therefore
implementing `Iterable`.
Note that the assumption that was in the comment before is still
correct: call binding will have already checked that the argument
satisfies `Iterable`, and so it shouldn't be an error to iterate over
said argument. But arguably, the new logic in this PR is a better way to
discharge that assumption — instead of panicking if we happen to be
wrong, fall back on an unknown iteration result.
## Summary
Fixes#18844
I'm not too sure if the solution is as simple as the way I implemented
it, but I'm curious to see if we are covering all cases correctly here.
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
As a follow-up to #18949 (suggested
[here](https://github.com/astral-sh/ruff/pull/18949#pullrequestreview-2998417889)),
this PR implements auto-fix logic for `PLC0207`.
## Test Plan
<!-- How was it tested? -->
Existing tests pass, with updates to the snapshot so that it expects the
new output that comes along with the auto-fix.
## Summary
Split the "Generator functions" tests into two parts. The first part
(synchronous) refers to a function called `i` from a function `i2`. But
`i` is later redeclared in the asynchronous part, which was probably not
intended.
## Summary
Declare licenses using only these two fields, as per PEP 639:
* `license`: SPDX license expression consisting of one or more license
identifiers
* `license-files`: list of license file glob patterns
Supported by maturin ≥ 1.9.0:
https://www.maturin.rs/changelog.html
## Test Plan
N/A
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[astral-sh/ruff-pre-commit](https://redirect.github.com/astral-sh/ruff-pre-commit)
| repository | patch | `v0.12.4` -> `v0.12.5` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
Note: The `pre-commit` manager in Renovate is not supported by the
`pre-commit` maintainers or community. Please do not report any problems
there, instead [create a Discussion in the Renovate
repository](https://redirect.github.com/renovatebot/renovate/discussions/new)
if you have any questions.
---
### Release Notes
<details>
<summary>astral-sh/ruff-pre-commit (astral-sh/ruff-pre-commit)</summary>
###
[`v0.12.5`](https://redirect.github.com/astral-sh/ruff-pre-commit/releases/tag/v0.12.5)
[Compare
Source](https://redirect.github.com/astral-sh/ruff-pre-commit/compare/v0.12.4...v0.12.5)
See: https://github.com/astral-sh/ruff/releases/tag/0.12.5
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS40MC4wIiwidXBkYXRlZEluVmVyIjoiNDEuNDAuMCIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[cargo-bins/cargo-binstall](https://redirect.github.com/cargo-bins/cargo-binstall)
| action | patch | `v1.14.1` -> `v1.14.2` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>cargo-bins/cargo-binstall (cargo-bins/cargo-binstall)</summary>
###
[`v1.14.2`](https://redirect.github.com/cargo-bins/cargo-binstall/releases/tag/v1.14.2)
[Compare
Source](https://redirect.github.com/cargo-bins/cargo-binstall/compare/v1.14.1...v1.14.2)
*Binstall is a tool to fetch and install Rust-based executables as
binaries. It aims to be a drop-in replacement for `cargo install` in
most cases. Install it today with `cargo install cargo-binstall`, from
the binaries below, or if you already have it, upgrade with `cargo
binstall cargo-binstall`.*
##### In this release:
- Upgrade dependencies
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS40MC4wIiwidXBkYXRlZEluVmVyIjoiNDEuNDAuMCIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [criterion](https://bheisler.github.io/criterion.rs/book/index.html)
([source](https://redirect.github.com/bheisler/criterion.rs)) |
workspace.dependencies | minor | `0.6.0` -> `0.7.0` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>bheisler/criterion.rs (criterion)</summary>
###
[`v0.7.0`](https://redirect.github.com/bheisler/criterion.rs/blob/HEAD/CHANGELOG.md#070---2025-07-25)
[Compare
Source](https://redirect.github.com/bheisler/criterion.rs/compare/0.6.0...0.7.0)
- Bump version of criterion-plot to align dependencies.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS40MC4wIiwidXBkYXRlZEluVmVyIjoiNDEuNDAuMCIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
Follow-up to https://github.com/astral-sh/ruff/pull/19556, this PR adds
the workflow that computes the diagnostic diff which the workflow
introduced in the linked PR will add as a comment.
This workflow is similar to the [ty ecosystem-analyzer
workflow](d781a6ab3f/.github/workflows/ty-ecosystem-analyzer.yaml).
Closes: astral-sh/ty#212
## Test Plan
1. Initially there's no diff to show
2. This
[commit](d0db9937df)
comments out a rule which updates the comment with the diff
3. Later, that commit is reverted and the diff goes away
Use the comment history to look at the diff output where the order of
the history corresponds to the steps mentioned above in reverse order
i.e., the edit in the middle will contain the diff output:
<img width="1082" height="313" alt="Screenshot 2025-07-25 at 21 09 26"
src="https://github.com/user-attachments/assets/6aceb60c-1987-4b9a-9063-e3999844f035"
/>
As of [this cpython PR](https://github.com/python/cpython/pull/135996),
it is not allowed to concatenate t-strings with non-t-strings,
implicitly or explicitly. Expressions such as `"foo" t"{bar}"` are now
syntax errors.
This PR updates some AST nodes and parsing to reflect this change.
The structural change is that `TStringPart` is no longer needed, since,
as in the case of `BytesStringLiteral`, the only possibilities are that
we have a single `TString` or a vector of such (representing an implicit
concatenation of t-strings). This removes a level of nesting from many
AST expressions (which is what all the snapshot changes reflect), and
simplifies some logic in the implementation of visitors, for example.
The other change of note is in the parser. When we meet an implicit
concatenation of string-like literals, we now count the number of
t-string literals. If these do not exhaust the total number of
implicitly concatenated pieces, then we emit a syntax error. To recover
from this syntax error, we encode any t-string pieces as _invalid_
string literals (which means we flag them as invalid, record their
range, and record the value as `""`). Note that if at least one of the
pieces is an f-string we prefer to parse the entire string as an
f-string; otherwise we parse it as a string.
This logic is exactly the same as how we currently treat
`BytesStringLiteral` parsing and error recovery - and carries with it
the same pros and cons.
Finally, note that I have not implemented any changes in the
implementation of the formatter. As far as I can tell, none are needed.
I did change a few of the fixtures so that we are always concatenating
t-strings with t-strings.
This PR adds support for the "selection range" language server feature.
This feature was recently requested by a ty user in [this feature
request](https://github.com/astral-sh/ty/issues/882).
This feature allows a client to implement "smart selection expansion"
based on the structure of the parse tree. For example, if you type
"shift-ctrl-right-arrow" in VS Code, the current selection will be
expanded to include the parent AST node. Conversely,
"shift-ctrl-left-arrow" shrinks the selection.
We will probably need to tune the granularity of selection expansion
based on user feedback. The initial implementation includes most AST
nodes, but users may find this to be too fine-grained. We have the
option of skipping some AST nodes that are not as meaningful when
editing code.
Co-authored-by: UnboundVariable <unbound@gmail.com>
We now correctly exclude legacy typevars from enclosing scopes when
constructing the generic context for a generic function.
more detail:
A function is generic if it refers to legacy typevars in its signature:
```py
from typing import TypeVar
T = TypeVar("T")
def f(t: T) -> T:
return t
```
Generic functions are allowed to appear inside of other generic
contexts. When they do, they can refer to the typevars of those
enclosing generic contexts, and that should not rebind the typevar:
```py
from typing import TypeVar, Generic
T = TypeVar("T")
U = TypeVar("U")
class C(Generic[T]):
@staticmethod
def method(t: T, u: U) -> None: ...
# revealed: def method(t: int, u: U) -> None
reveal_type(C[int].method)
```
This substitution was already being performed correctly, but we were
also still including the enclosing legacy typevars in the method's own
generic context, which can be seen via `ty_extensions.generic_context`
(which has been updated to work on generic functions and methods):
```py
from ty_extensions import generic_context
# before: tuple[T, U]
# after: tuple[U]
reveal_type(generic_context(C[int].method))
```
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Changing `BLE001` (blind-except) so that it does not flag `except`
clauses which include `logging.critical(..., exc_info=True)`.
## Test Plan
It passes the following (whereas the `main` branch does not):
```sh
$ cargo run -p ruff -- check somefile.py --no-cache --select=BLE001
```
```python
# somefile.py
import logging
try:
print("Hello world!")
except Exception:
logging.critical("Did not run.", exc_info=True)
```
Related: https://github.com/astral-sh/ruff/issues/19519
Small rewording to indicate that core development is done but that we
may add breaking changes.
Feel free to bikeshed!
Test:
```console
❯ echo "t''" | cargo run -p ruff -- check --no-cache --isolated --target-version py314 -
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/ruff check --no-cache --isolated --target-version py314 -`
warning: Support for Python 3.14 is in preview and may undergo breaking changes. Enable `preview` to remove this warning.
All checks passed!
```
This PR adds support for "document symbols" and "workspace symbols"
language server features. Most of the logic to implement these features
is shared.
The "document symbols" feature returns a list of all symbols within a
specified source file. Clients can specify whether they want a flat or
hierarchical list. Document symbols are typically presented by a client
in an "outline" form. Here's what this looks like in VS Code, for
example.
<img width="240" height="249" alt="image"
src="https://github.com/user-attachments/assets/82b11f4f-32ec-4165-ba01-d6496ad13bdf"
/>
The "workspace symbols" feature returns a list of all symbols across the
entire workspace that match some user-supplied query string. This allows
the user to quickly find and navigate to any symbol within their code.
<img width="450" height="134" alt="image"
src="https://github.com/user-attachments/assets/aac131e0-9464-4adf-8a6c-829da028c759"
/>
---------
Co-authored-by: UnboundVariable <unbound@gmail.com>
Summary
--
I looked at other uses of `TextEmitter`, and I think this should be the
only one affected by this. The other integration tests must work
properly since they're run with `assert_cmd_snapshot!`, which I assume
triggers the `SHOULD_COLORIZE` case, and the `cfg!(test)` check will
work for uses in `ruff_linter`.
4a4dc38b5b/crates/ruff_linter/src/message/text.rs (L36-L44)
Alternatively, we could probably move this to a CLI test instead.
Test Plan
--
`cargo test -p ruff`, which was failing on `main` with color codes in
the output before this
## Summary
We currently infer a `@Todo` type whenever we access an attribute on an
intersection type with negative components. This can happen very
naturally. Consequently, this `@Todo` type is rather pervasive and hides
a lot of true positives that ty could otherwise detect:
```py
class Foo:
attr: int = 1
def _(f: Foo | None):
if f:
reveal_type(f) # Foo & ~AlwaysFalsy
reveal_type(f.attr) # now: int, previously: @Todo
```
The changeset here proposes to handle member access on these
intersection types by simply ignoring all negative contributions. This
is not always ideal: a negative contribution like `~<Protocol with
members 'attr'>` could be a hint that `.attr` should not be accessible
on the full intersection type. The behavior can certainly be improved in
the future, but this seems like a reasonable initial step to get rid of
this unnecessary `@Todo` type.
## Ecosystem analysis
There are quite a few changes here. I spot-checked them and found one
bug where attribute access on pure negation types (`~P == object & ~P`)
would not allow attributes on `object` to be accessed. After that was
fixed, I only see true positives and known problems. The fact that a lot
of `unused-ignore-comment` diagnostics go away are also evidence for the
fact that this touches a sensitive area, where static analysis clashes
with dynamically adding attributes to objects:
```py
… # type: ignore # Runtime attribute access
```
## Test Plan
Updated tests.
## Summary
Add basic support for `dataclasses.field`:
* remove fields with `init=False` from the signature of the synthesized
`__init__` method
* infer correct default value types from `default` or `default_factory`
arguments
```py
from dataclasses import dataclass, field
def default_roles() -> list[str]:
return ["user"]
@dataclass
class Member:
name: str
roles: list[str] = field(default_factory=default_roles)
tag: str | None = field(default=None, init=False)
# revealed: (self: Member, name: str, roles: list[str] = list[str]) -> None
reveal_type(Member.__init__)
```
Support for `kw_only` has **not** been added.
part of https://github.com/astral-sh/ty/issues/111
## Test Plan
New Markdown tests
This PR adds support for the "document highlights" language server
feature.
This feature allows a client to highlight all instances of a selected
name within a document. Without this feature, editors perform
highlighting based on a simple text match. This adds semantic knowledge.
The implementation of this feature largely overlaps that of the
recently-added "references" feature. This PR refactors the existing
"references.rs" module, separating out the functionality and tests that
are specific to the other language feature into a "goto_references.rs"
module. The "references.rs" module now contains the functionality that
is common to "goto references", "document highlights" and "rename"
(which is not yet implemented).
As part of this PR, I also created a new `ReferenceTarget` type which is
similar to the existing `NavigationTarget` type but better suited for
references. This idea was suggested by @MichaReiser in [this code review
feedback](https://github.com/astral-sh/ruff/pull/19475#discussion_r2224061006)
from a previous PR. Notably, this new type contains a field that
specifies the "kind" of the reference (read, write or other). This
"kind" is needed for the document highlights feature.
Before: all textual instances of `foo` are highlighted
<img width="156" height="126" alt="Screenshot 2025-07-23 at 12 51 09 PM"
src="https://github.com/user-attachments/assets/37ccdb2f-d48a-473d-89d5-8e89cb6c394e"
/>
After: only semantic matches are highlighted
<img width="164" height="157" alt="Screenshot 2025-07-23 at 12 52 05 PM"
src="https://github.com/user-attachments/assets/2efadadd-4691-4815-af04-b031e74c81b7"
/>
---------
Co-authored-by: UnboundVariable <unbound@gmail.com>
## Summary
Expand cases in which ruff can offer a fix for `RUF039` (some of which
are unsafe).
While turning `"\n"` (== `\n`) into `r"\n"` (== `\\n`) is not equivalent
at run-time, it's still functionally equivalent to do so in the context
of [regex
patterns](https://docs.python.org/3/library/re.html#regular-expression-syntax)
as they themselves interpret the escape sequence. Therefore, an unsafe
fix can be offered.
Further, this PR also makes ruff offer fixes for byte string literals,
not only strings literals as before.
## Test Plan
Tests for all escape sequences have been added.
## Related
Closes: https://github.com/astral-sh/ruff/issues/16713
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
I saw that this creates a lot of false positives in the ecosystem, and
it seemed to be relatively easy to add basic support for this.
Some preliminary work on this was done by @InSyncWithFoo — thank you.
part of https://github.com/astral-sh/ty/issues/111
## Ecosystem analysis
The results look good.
## Test Plan
New Markdown tests
---------
Co-authored-by: InSync <insyncwithfoo@gmail.com>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
The generated fix for `RUF033` would cause a syntax error for named
expressions as parameter defaults.
```python
from dataclasses import InitVar, dataclass
@dataclass
class Foo:
def __post_init__(self, bar: int = (x := 1)) -> None:
pass
```
would be turned into
```python
from dataclasses import InitVar, dataclass
@dataclass
class Foo:
x: InitVar[int] = x := 1
def __post_init__(self, bar: int = (x := 1)) -> None:
pass
```
instead of the syntactically correct
```python
# ...
x: InitVar[int] = (x := 1)
# ...
```
## Test Plan
Test reproducer (plus some extra tests) have been added to the test
suite.
## Related
Fixes: https://github.com/astral-sh/ruff/issues/18950
## Summary
A couple of months ago now
(https://github.com/astral-sh/ruff-pre-commit/pull/124) we changed the
hook ID from just `ruff` to `ruff-check` to mirror `ruff-format`. I
noticed the `ruff (legacy alias)` when running pre-commit on the release
today and realized we should probably update.
## Test Plan
Commit on this PR:
```shell
> git commit -m "Update pre-commit hook name"
check for merge conflicts................................................Passed
Validate pyproject.toml..............................(no files to check)Skipped
mdformat.............................................(no files to check)Skipped
markdownlint-fix.....................................(no files to check)Skipped
blacken-docs.........................................(no files to check)Skipped
typos....................................................................Passed
cargo fmt............................................(no files to check)Skipped
ruff format..........................................(no files to check)Skipped
ruff check...........................................(no files to check)Skipped <--
prettier.................................................................Passed
zizmor...............................................(no files to check)Skipped
Validate GitHub Workflows............................(no files to check)Skipped
shellcheck...........................................(no files to check)Skipped
```
Compared to the release branch:
```shell
> pre-commit run
...
cargo fmt............................................(no files to check)Skipped
ruff format..........................................(no files to check)Skipped
ruff (legacy alias)..................................(no files to check)Skipped
...
```
This PR updates our iterator protocol machinery to return a tuple spec
describing the elements that are returned, instead of a type. That
allows us to track heterogeneous iterators more precisely, and
consolidates the logic in unpacking and splatting, which are the two
places where we can take advantage of that more precise information.
(Other iterator consumers, like `for` loops, have to collapse the
iterated elements down to a single type regardless, and we provide a new
helper method on `TupleSpec` to perform that summarization.)
## Summary
Implements proper reachability analysis and — in effect — exhaustiveness
checking for `match` statements. This allows us to check the following
code without any errors (leads to *"can implicitly return `None`"* on
`main`):
```py
from enum import Enum, auto
class Color(Enum):
RED = auto()
GREEN = auto()
BLUE = auto()
def hex(color: Color) -> str:
match color:
case Color.RED:
return "#ff0000"
case Color.GREEN:
return "#00ff00"
case Color.BLUE:
return "#0000ff"
```
Note that code like this already worked fine if there was a
`assert_never(color)` statement in a catch-all case, because we would
then consider that `assert_never` call terminal. But now this also works
without the wildcard case. Adding a member to the enum would still lead
to an error here, if that case would not be handled in `hex`.
What needed to happen to support this is a new way of evaluating match
pattern constraints. Previously, we would simply compare the type of the
subject expression against the patterns. For the last case here, the
subject type would still be `Color` and the value type would be
`Literal[Color.BLUE]`, so we would infer an ambiguous truthiness.
Now, before we compare the subject type against the pattern, we first
generate a union type that corresponds to the set of all values that
would have *definitely been matched* by previous patterns. Then, we
build a "narrowed" subject type by computing `subject_type &
~already_matched_type`, and compare *that* against the pattern type. For
the example here, `already_matched_type = Literal[Color.RED] |
Literal[Color.GREEN]`, and so we have a narrowed subject type of `Color
& ~(Literal[Color.RED] | Literal[Color.GREEN]) = Literal[Color.BLUE]`,
which allows us to infer a reachability of `AlwaysTrue`.
<details>
<summary>A note on negated reachability constraints</summary>
It might seem that we now perform duplicate work, because we also record
*negated* reachability constraints. But that is still important for
cases like the following (and possibly also for more realistic
scenarios):
```py
from typing import Literal
def _(x: int | str):
match x:
case None:
pass # never reachable
case _:
y = 1
y
```
</details>
closes https://github.com/astral-sh/ty/issues/99
## Test Plan
* I verified that this solves all examples from the linked ticket (the
first example needs a PEP 695 type alias, because we don't support
legacy type aliases yet)
* Verified that the ecosystem changes are all because of removed false
positives
* Updated tests
## Summary
I noticed that our type narrowing and reachability analysis was
incorrect for class patterns that are not irrefutable. The test cases
below compare the old and the new behavior:
```py
from dataclasses import dataclass
@dataclass
class Point:
x: int
y: int
class Other: ...
def _(target: Point):
y = 1
match target:
case Point(0, 0):
y = 2
case Point(x=0, y=1):
y = 3
case Point(x=1, y=0):
y = 4
reveal_type(y) # revealed: Literal[1, 2, 3, 4] (previously: Literal[2])
def _(target: Point | Other):
match target:
case Point(0, 0):
reveal_type(target) # revealed: Point
case Point(x=0, y=1):
reveal_type(target) # revealed: Point (previously: Never)
case Point(x=1, y=0):
reveal_type(target) # revealed: Point (previously: Never)
case Other():
reveal_type(target) # revealed: Other (previously: Other & ~Point)
```
## Test Plan
New Markdown test
## Summary
This PR moves most of the work of rendering concise diagnostics in Ruff
into `ruff_db`, where the code is shared with ty. To accomplish this
without breaking backwards compatibility in Ruff, there are two main
changes on the `ruff_db`/ty side:
- Added the logic from Ruff for remapping notebook line numbers to cells
- Reordered the fields in the diagnostic to match Ruff and rustc
```text
# old
error[invalid-assignment] try.py:3:1: Object of type `Literal[1]` is not
assignable to `str`
# new
try.py:3:1: error[invalid-assignment]: Object of type `Literal[1]` is
not assignable to `str`
```
I don't think the notebook change failed any tests on its own, and only
a handful of snaphots changed in ty after reordering the fields, but
this will obviously affect any other uses of the concise format, outside
of tests, too.
The other big change should only affect Ruff:
- Added three new `DisplayDiagnosticConfig` options
Micha and I hoped that we could get by with one option
(`hide_severity`), but Ruff also toggles `show_fix_status` itself,
independently (there are cases where we want neither severity nor the
fix status), and during the implementation I realized we also needed
access to an `Applicability`. The main goal here is to suppress the
severity (`error` above) because ruff only uses the `error` severity and
to use the secondary/noqa code instead of the line name
(`invalid-assignment` above).
```text
# ty - same as "new" above
try.py:3:1: error[invalid-assignment]: Object of type `Literal[1]` is
not assignable to `str`
# ruff
try.py:3:1: RUF123 [*] Object of type `Literal[1]` is not assignable to
`str`
```
This part of the concise diagnostic is actually shared with the `full`
output format in Ruff, but with the settings above, there are no
snapshot changes to either format.
## Test Plan
Existing tests with the handful of updates mentioned above, as well as
some new tests in the `concise` module.
Also this PR. Swapping the fields might have broken mypy_primer, unless
it occasionally times out on its own.
I also ran this script in the root of my Ruff checkout, which also has
CPython in it:
```shell
flags=(--isolated --no-cache --no-respect-gitignore --output-format concise .)
diff <(target/release/ruff check ${flags[@]} 2> /dev/null) \
<(ruff check ${flags[@]} 2> /dev/null)
```
This yielded an expected diff due to some t-string error changes on main
since 0.12.4:
```diff
33622c33622
< crates/ruff_python_parser/resources/inline/err/f_string_lambda_without_parentheses.py:1:15: SyntaxError: Expected an element of or the end of the f-string
---
> crates/ruff_python_parser/resources/inline/err/f_string_lambda_without_parentheses.py:1:15: SyntaxError: Expected an f-string or t-string element or the end of the f-string or t-string
33742c33742
< crates/ruff_python_parser/resources/inline/err/implicitly_concatenated_unterminated_string_multiline.py:4:1: SyntaxError: Expected an element of or the end of the f-string
---
> crates/ruff_python_parser/resources/inline/err/implicitly_concatenated_unterminated_string_multiline.py:4:1: SyntaxError: Expected an f-string or t-string element or the end of the f-string or t-string
34131c34131
< crates/ruff_python_parser/resources/inline/err/t_string_lambda_without_parentheses.py:2:15: SyntaxError: Expected an element of or the end of the t-string
---
> crates/ruff_python_parser/resources/inline/err/t_string_lambda_without_parentheses.py:2:15: SyntaxError: Expected an f-string or t-string element or the end of the f-string or t-string
```
So modulo color, the results are identical on 38,186 errors in our test
suite and CPython 3.10.
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
We previously didn't recognize `Literal[Color.RED]` as single-valued, if
the enum also derived from `str` or `int`:
```py
from enum import Enum
class Color(str, Enum):
RED = "red"
GREEN = "green"
BLUE = "blue"
def _(color: Color):
if color == Color.RED:
reveal_type(color) # previously: Color, now: Literal[Color.RED]
```
The reason for that was that `int` and `str` have "custom" `__eq__` and
`__ne__` implementations that return `bool`. We do not treat enum
literals from classes with custom `__eq__` and `__ne__` implementations
as single-valued, but of course we know that `int.__eq__` and
`str.__eq__` are well-behaved.
## Test Plan
New Markdown tests.
This makes caching of submodules independent of whether `Module`
is itself a Salsa ingredient. In fact, this makes the work done in
the prior commit superfluous. But we're possibly keeping it as an
ingredient for now since it's a bit of a tedious change and we might
need it in the near future.
Ref https://github.com/astral-sh/ruff/pull/19495#pullrequestreview-3045736715
## Summary
Add more precise type inference for a limited set of `isinstance(…)`
calls, i.e. return `Literal[True]` if we can be sure that this is the
correct result. This improves exhaustiveness checking / reachability
analysis for if-elif-else chains with `isinstance` checks. For example:
```py
def is_number(x: int | str) -> bool: # no "can implicitly return `None` error here anymore
if isinstance(x, int):
return True
elif isinstance(x, str):
return False
# code here is now detected as being unreachable
```
This PR also adds a new test suite for exhaustiveness checking.
## Test Plan
New Markdown tests
### Ecosystem analysis
The removed diagnostics look good. There's [one
case](f52c4f1afd/torchvision/io/video_reader.py (L125-L143))
where a "true positive" is removed in unreachable code. `src` is
annotated as being of type `str`, but there is an `elif isinstance(src,
bytes)` branch, which we now detect as unreachable. And so the
diagnostic inside that branch is silenced. I don't think this is a
problem, especially once we have a "graying out" feature, or a lint that
warns about unreachable code.
## Summary
Fixes https://github.com/astral-sh/ty/issues/874
Labeling this as `internal`, since we haven't released the
enum-expansion feature.
## Test Plan
New Markdown tests
## Summary
Closes: astral-sh/ty#88
This PR implements an initial version of a mock language server that can
be used to write e2e tests using the real server running in the
background.
The way it works is that you'd use the `TestServerBuilder` to help
construct the `TestServer` with the setup data. This could be the
workspace folders, populating the file and it's content in the memory
file system, setting the right client capabilities to make the server
respond correctly, etc. This can be expanded as we write more test
cases.
There are still a few things to follow-up on:
- ~In the `Drop` implementation, we should assert that there are no
pending notification, request and responses from the server that the
test code hasn't handled yet~ Implemented in [`afd1f82`
(#19391)](afd1f82bde)
- Reduce the setup boilerplate in any way we can
- Improve the final assertion, currently I'm just snapshotting the final
output
## Test Plan
Written a few test cases.
## Summary
This PR implements the following section from the [typing spec on
enums](https://typing.python.org/en/latest/spec/enums.html#enum-definition):
> Enum classes can also be defined using a subclass of `enum.Enum` **or
any class that uses `enum.EnumType` (or a subclass thereof) as a
metaclass**. Note that `enum.EnumType` was named `enum.EnumMeta` prior
to Python 3.11.
part of https://github.com/astral-sh/ty/issues/183
## Test Plan
New Markdown tests
This PR updates our call binding logic to handle splatted arguments.
Complicating matters is that we have separated call bind analysis into
two phases: parameter matching and type checking. Parameter matching
looks at the arity of the function signature and call site, and assigns
arguments to parameters. Importantly, we don't yet know the type of each
argument! This is needed so that we can decide whether to infer the type
of each argument as a type form or value form, depending on the
requirements of the parameter that the argument was matched to.
This is an issue when splatting an argument, since we need to know how
many elements the splatted argument contains to know how many positional
parameters to match it against. And to know how many elements the
splatted argument has, we need to know its type.
To get around this, we now make the assumption that splatted arguments
can only be used with value-form parameters. (If you end up splatting an
argument into a type-form parameter, we will silently pass in its
value-form type instead.) That allows us to preemptively infer the
(value-form) type of any splatted argument, so that we have its arity
available during parameter matching. We defer inference of non-splatted
arguments until after parameter matching has finished, as before.
We reuse a lot of the new tuple machinery to make this happen — in
particular resizing the tuple spec representing the number of arguments
passed in with the tuple length representing the number of parameters
the splat was matched with.
This work also shows that we might need to change how we are performing
argument expansion during overload resolution. At the moment, when we
expand parameters, we assume that each argument will still be matched to
the same parameters as before, and only retry the type-checking phase.
With splatted arguments, this is no longer the case, since the inferred
arity of each union element might be different than the arity of the
union as a whole, which can affect how many parameters the splatted
argument is matched to. See the regression test case in
`mdtest/call/function.md` for more details.
Summary
--
I've been noticing this failure in the formatter ecosystem check and
decided to
look into it. We fail to parse the
[notebook](https://github.com/openai/openai-cookbook/blob/main/examples/mcp/databricks_mcp_cookbook.ipynb)
because some of the `code` cells
have non-Python code in them. `ruff format` only reports one of these,
corresponding to a shell snippet, but `ruff check` emits some additional
errors
about JS code later in the file too:
```
databricks_mcp_cookbook.ipynb:cell 21:1:11: SyntaxError: Simple statements must be separated by newlines or semicolons
databricks_mcp_cookbook.ipynb:cell 21:1:19: SyntaxError: Simple statements must be separated by newlines or semicolons
databricks_mcp_cookbook.ipynb:cell 21:1:50: SyntaxError: Simple statements must be separated by newlines or semicolons
databricks_mcp_cookbook.ipynb:cell 30:4:7: SyntaxError: Simple statements must be separated by newlines or semicolons
databricks_mcp_cookbook.ipynb:cell 30:4:41: E703 Statement ends with an unnecessary semicolon
databricks_mcp_cookbook.ipynb:cell 30:5:14: SyntaxError: Expected ':', found '{'
databricks_mcp_cookbook.ipynb:cell 30:6:9: SyntaxError: Expected ',', found '{'
databricks_mcp_cookbook.ipynb:cell 30:6:25: SyntaxError: Expected ',', found '='
databricks_mcp_cookbook.ipynb:cell 30:6:46: SyntaxError: Expected ',', found ';'
databricks_mcp_cookbook.ipynb:cell 30:6:47: SyntaxError: Expected '}', found newline
databricks_mcp_cookbook.ipynb:cell 30:7:1: SyntaxError: Unexpected indentation
databricks_mcp_cookbook.ipynb:cell 30:7:13: SyntaxError: Expected ':', found 'break'
databricks_mcp_cookbook.ipynb:cell 30:7:18: E703 Statement ends with an unnecessary semicolon
databricks_mcp_cookbook.ipynb:cell 30:8:28: SyntaxError: Simple statements must be separated by newlines or semicolons
databricks_mcp_cookbook.ipynb:cell 30:8:55: E703 Statement ends with an unnecessary semicolon
databricks_mcp_cookbook.ipynb:cell 30:9:18: SyntaxError: Expected an expression
databricks_mcp_cookbook.ipynb:cell 30:10:11: SyntaxError: Expected ',', found name
databricks_mcp_cookbook.ipynb:cell 30:10:16: SyntaxError: Expected ',', found '='
databricks_mcp_cookbook.ipynb:cell 30:10:22: SyntaxError: Expected ',', found name
databricks_mcp_cookbook.ipynb:cell 30:10:24: SyntaxError: Expected ',', found ';'
databricks_mcp_cookbook.ipynb:cell 30:11:27: SyntaxError: Expected ',', found '='
databricks_mcp_cookbook.ipynb:cell 30:11:34: SyntaxError: Expected ',', found name
databricks_mcp_cookbook.ipynb:cell 30:11:48: SyntaxError: Expected ',', found ';'
databricks_mcp_cookbook.ipynb:cell 30:11:49: SyntaxError: Expected '}', found NonLogicalNewline
databricks_mcp_cookbook.ipynb:cell 30:12:1: SyntaxError: Unexpected indentation
databricks_mcp_cookbook.ipynb:cell 30:12:16: E703 Statement ends with an unnecessary semicolon
databricks_mcp_cookbook.ipynb:cell 30:13:3: SyntaxError: Expected a statement
databricks_mcp_cookbook.ipynb:cell 30:13:4: SyntaxError: Expected a statement
databricks_mcp_cookbook.ipynb:cell 30:13:5: SyntaxError: Expected a statement
databricks_mcp_cookbook.ipynb:cell 30:13:5: E703 Statement ends with an unnecessary semicolon
databricks_mcp_cookbook.ipynb:cell 30:13:6: SyntaxError: Expected a statement
databricks_mcp_cookbook.ipynb:cell 30:14:1: SyntaxError: Expected a statement
databricks_mcp_cookbook.ipynb:cell 30:14:2: SyntaxError: Expected a statement
```
Test Plan
--
This PR
## Summary
Infer the correct type in a scenario like this:
```py
class Color(Enum):
RED = 1
GREEN = 2
BLUE = 3
for color in Color:
reveal_type(color) # revealed: Color
```
We should eventually support this out-of-the-box when
https://github.com/astral-sh/ty/issues/501 is implemented. For this
reason, @AlexWaygood would prefer to keep things as they are (we
currently infer `Unknown`, so false positives seem unlikely). But it
seemed relatively easy to support, so I'm opening this for discussion.
part of https://github.com/astral-sh/ty/issues/183
## Test Plan
Adapted existing test.
## Ecosystem analysis
```diff
- warning[unused-ignore-comment] rotkehlchen/chain/aggregator.py:591:82: Unused blanket `type: ignore` directive
```
This `unused-ignore-comment` goes away due to a new true positive.
## Summary
Fixes pull-types panics for illegal annotations like
`Literal[object[index]]`.
Originally reported by @AlexWaygood
## Test Plan
* Verified that this caused panics in the playground, when typing (and
potentially hovering over) `x: Literal[obj[0]]`.
* Added a regression test
Summary
--
This PR tweaks Ruff's internal usage of the new diagnostic model to more
closely
match the intended use, as I understand it. Specifically, it moves the
fix/help
suggestion from the primary annotation's message to a subdiagnostic. In
turn, it
adds the secondary/noqa code as the new primary annotation message. As
shown in
the new `ruff_db` tests, this more closely mirrors Ruff's current
diagnostic
output.
I also added `Severity::Help` to render the fix suggestion with a
`help:` prefix
instead of `info:`.
These changes don't have any external impact now but should help a bit
with #19415.
Test Plan
--
New full output format tests in `ruff_db`
Rendered Diagnostics
--
Full diagnostic output from `annotate-snippets` in this PR:
```
error[unused-import]: `os` imported but unused
--> fib.py:1:8
|
1 | import os
| ^^
|
help: Remove unused import: `os`
```
Current Ruff output for the same code:
```
fib.py:1:8: F401 [*] `os` imported but unused
|
1 | import os
| ^^ F401
|
= help: Remove unused import: `os`
```
Proposed final output after #19415:
```
F401 [*] `os` imported but unused
--> fib.py:1:8
|
1 | import os
| ^^
|
help: Remove unused import: `os`
```
These are slightly updated from
https://github.com/astral-sh/ruff/pull/19464#issuecomment-3097377634
below to remove the extra noqa codes in the primary annotation messages
for the first and third cases.
This implements mapping of definitions in stubs to definitions in the
"real" implementation using the approach described in
https://github.com/astral-sh/ty/issues/788#issuecomment-3097000287
I've tested this with goto-definition in vscode with code that uses
`colorama` and `types-colorama`.
Notably this implementation does not add support for stub-mapping stdlib
modules, which can be done as an essentially orthogonal followup in the
implementation of `resolve_real_module`.
Part of https://github.com/astral-sh/ty/issues/788
## Summary
It was faster to implement this then to write the ticket: Disallow
`ClassVar` annotations almost everywhere outside of class body scopes.
## Test Plan
New Markdown tests
## Summary
Disallow `Final` in function parameter- and return-type annotations.
[Typing
spec](https://typing.python.org/en/latest/spec/qualifiers.html#uppercase-final):
> `Final` may only be used in assignments or variable annotations. Using
it in any other position is an error. In particular, `Final` can’t be
used in annotations for function arguments
## Test Plan
Updated MD test
## Summary
Exclusions in Git pathspecs [are not
order-sensitive](https://css-tricks.com/git-pathspecs-and-how-to-use-them/#aa-exclude):
> After all other pathspecs have been resolved, all pathspecs with an
exclude signature are resolved and then removed from the returned paths.
This means that we can't write chains like we had here before to exclude
Markdown file changes *unless* they are in
`crates/ty_python_semantic/resources/mdtest`. This doesn't work. The
exclude pattern will just overwrite the second pattern and all Markdown
changes will be excluded:
```bash
':!**/*.md' \
':crates/ty_python_semantic/resources/mdtest/**/*.md' \
```
The configuration we had here before meant that tests wouldn't run on
MD-test only PRs, see e.g. https://github.com/astral-sh/ruff/pull/19476.
So here, I'm proposing to remove the broad `:!**/*.md` pattern. We can
always add more fine-grained exclusion patterns, if that's needed. The
`docs` folder is already excluded.
## Test Plan
Tested with local `git diff` invocations.
I noticed that the semantic token implementation was not handling
identifiers in a few cases. This adds support for identifiers that
appear in `except`, `case`, `nonlocal`, and `global` statements.
Co-authored-by: UnboundVariable <unbound@gmail.com>
This is a follow-on to #19410 that further reduces the memory usage of
our reachability constraints. When finishing the building of a use-def
map, we walk through all of the "final" states and mark only those
reachability constraints as "used". We then throw away the interior TDD
nodes of any reachability constraints that weren't marked as used.
(This helps because we build up quite a few intermediate TDD nodes when
constructing complex reachability constraints. These nodes can never be
accessed if they were _only_ used as an intermediate TDD node. The
marking step ensures that we keep any nodes that ended up being referred
to in some accessible use-def map state.)
## Summary
Adds proper type inference for implicit instance attributes that are
declared with a "bare" `Final` and adds `invalid-assignment` diagnostics
for all implicit instance attributes that are declared `Final` or
`Final[…]`.
## Test Plan
New and updated MD tests.
## Ecosystem analysis
```diff
pytest (https://github.com/pytest-dev/pytest)
+ error[invalid-return-type] src/_pytest/fixtures.py:1662:24: Return type does not match returned value: expected `Scope`, found `Scope | (Unknown & ~None & ~((...) -> object) & ~str) | (((str, Config, /) -> Unknown) & ~((...) -> object) & ~str) | (Unknown & ~str)
```
The definition of the `scope` attribute is [here](
5f99385635/src/_pytest/fixtures.py (L1020-L1028)).
Looks like this is a new false positive due to missing `TypeAlias`
support that is surfaced here because we now infer a more precise type
for `FixtureDef._scope`.
## Summary
Implement expansion of enums into unions of enum literals (and the
reverse operation). For the enum below, this allows us to understand
that `Color = Literal[Color.RED, Color.GREEN, Color.BLUE]`, or that
`Color & ~Literal[Color.RED] = Literal[Color.GREEN, Color.BLUE]`. This
helps in exhaustiveness checking, which is why we see some removed
`assert_never` false positives. And since exhaustiveness checking also
helps with understanding terminal control flow, we also see a few
removed `invalid-return-type` and `possibly-unresolved-reference` false
positives. This PR also adds expansion of enums in overload resolution
and type narrowing constructs.
```py
from enum import Enum
from typing_extensions import Literal, assert_never
from ty_extensions import Intersection, Not, static_assert, is_equivalent_to
class Color(Enum):
RED = 1
GREEN = 2
BLUE = 3
type Red = Literal[Color.RED]
type Green = Literal[Color.GREEN]
type Blue = Literal[Color.BLUE]
static_assert(is_equivalent_to(Red | Green | Blue, Color))
static_assert(is_equivalent_to(Intersection[Color, Not[Red]], Green | Blue))
def color_name(color: Color) -> str: # no error here (we detect that this can not implicitly return None)
if color is Color.RED:
return "Red"
elif color is Color.GREEN:
return "Green"
elif color is Color.BLUE:
return "Blue"
else:
assert_never(color) # no error here
```
## Performance
I avoided an initial regression here for large enums, but the
`UnionBuilder` and `IntersectionBuilder` parts can certainly still be
optimized. We might want to use the same technique that we also use for
unions of other literals. I didn't see any problems in our benchmarks so
far, so this is not included yet.
## Test Plan
Many new Markdown tests
## Summary
Emit errors for the following assignments:
```py
class C:
CLASS_LEVEL_CONSTANT: Final[int] = 1
C.CLASS_LEVEL_CONSTANT = 2
C().CLASS_LEVEL_CONSTANT = 2
```
## Test Plan
Updated and new MD tests
Parsing the (invalid) expression `f"{\t"i}"` caused a panic because the
`TStringMiddle` character was "unreachable" due the way the parser
recovered from the line continuation (it ate the t-string start).
The cause of the issue is as follows:
The parser begins parsing the f-string and expects to see a list of
objects, essentially alternating between _interpolated elements_ and
ordinary strings. It is happy to see the first left brace, but then
there is a lexical error caused by the line-continuation character. So
instead of the parser seeing a list of elements with just one member, it
sees a list that starts like this:
- Interpolated element with an invalid token, stored as a `Name`
- Something else built from tokens beginning with `TStringStart` and
`TStringMiddle`
When it sees the `TStringStart` error recovery says "that's a list
element I don't know what to do with, let's skip it". When it sees
`TStringMiddle` it says "oh, that looks like the middle of _some
interpolated string_ so let's try to parse it as one of the literal
elements of my `FString`". Unfortunately, the function being used to
parse individual list elements thinks (arguably correctly) that it's not
possible to have a `TStringMiddle` sitting in your `FString`, and hits
`unreachable`.
Two potential ways (among many) to solve this issue are:
1. Allow a `TStringMiddle` as a valid "literal" part of an f-string
during parsing (with the hope/understanding that this would only occur
in an invalid context)
2. Skip the `TStringMiddle` as an "unexpected/invalid list item" in the
same way that we skipped `TStringStart`.
I have opted for the second approach since it seems somehow more morally
correct, even though it loses more information. To implement this, the
recovery context needs to know whether we are in an f-string or t-string
- hence the changes to that enum. As a bonus we get slightly more
specific error messages in some cases.
Closes#18860
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Closes#18739
## Test Plan
<!-- How was it tested? -->
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
This PR extends the "go to declaration" and "go to definition"
functionality to support import statements — both standard imports and
"from" import forms.
---------
Co-authored-by: UnboundVariable <unbound@gmail.com>
* [x] basic handling
* [x] parse and discover `@warnings.deprecated` attributes
* [x] associate them with function definitions
* [x] associate them with class definitions
* [x] add a new "deprecated" diagnostic
* [x] ensure diagnostic is styled appropriately for LSPs
(DiagnosticTag::Deprecated)
* [x] functions
* [x] fire on calls
* [x] fire on arbitrary references
* [x] classes
* [x] fire on initializers
* [x] fire on arbitrary references
* [x] methods
* [x] fire on calls
* [x] fire on arbitrary references
* [ ] overloads
* [ ] fire on calls
* [ ] fire on arbitrary references(??? maybe not ???)
* [ ] only fire if the actual selected overload is deprecated
* [ ] dunder desugarring (warn on deprecated `__add__` if `+` is
invoked)
* [ ] alias supression? (don't warn on uses of variables that deprecated
items were assigned to)
* [ ] import logic
* [x] fire on imports of deprecated items
* [ ] suppress subsequent diagnostics if the import diagnostic fired (is
this handled by alias supression?)
* [x] fire on all qualified references (`module.mydeprecated`)
* [x] fire on all references that depend on a `*` import
Fixes https://github.com/astral-sh/ty/issues/153
Fixes https://github.com/astral-sh/ty/issues/769.
**Updated:** The preferred approach here is to keep the SemanticIndex
simple (`del` of any name marks that name "bound" in the current scope)
and to move complexity to type inference (free variable resolution stops
when it finds a binding, unless that binding is declared `nonlocal`). As
part of this change, free variable resolution will now union the types
it finds as it walks in enclosing scopes. This approach is still
incomplete, because it doesn't consider inner scopes or sibling scopes,
but it improves the common case.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
This PR builds upon #19371. It addresses a few additional code review
suggestions and adds support for attribute accesses (expressions of the
form `x.y`) and keyword arguments within call expressions.
---------
Co-authored-by: UnboundVariable <unbound@gmail.com>
This change makes it so we aren't doing a directory traversal every time
we ask for completions from a module. Specifically, submodules that
aren't attributes of their parent module can only be discovered by
looking at the directory tree. But we want to avoid doing a directory
scan unless we think there are changes.
To make this work, this change does a little bit of surgery to
`FileRoot`. Previously, a `FileRoot` was only used for library search
paths. Its revision was bumped whenever a file in that tree was added,
deleted or even modified (to support the discovery of `pth` files and
changes to its contents). This generally seems fine since these are
presumably dependency paths that shouldn't change frequently.
In this change, we add a `FileRoot` for the project. But having the
`FileRoot`'s revision bumped for every change in the project makes
caching based on that `FileRoot` rather ineffective. That is, cache
invalidation will occur too aggressively. To the point that there is
little point in adding caching in the first place. To mitigate this, a
`FileRoot`'s revision is only bumped on a change to a child file's
contents when the `FileRoot` is a `LibrarySearchPath`. Otherwise, we
only bump the revision when a file is created or added.
The effect is that, at least in VS Code, when a new module is added or
removed, this change is picked up and the cache is properly invalidated.
Other LSP clients with worse support for file watching (which seems to
be the case for the CoC vim plugin that I use) don't work as well. Here,
the cache is less likely to be invalidated which might cause completions
to have stale results. Unless there's an obvious way to fix or improve
this, I propose punting on improvements here for now.
## Summary
This PR updates the server to keep track of open files both system and
virtual files.
This is done by updating the project by adding the file in the open file
set in `didOpen` notification and removing it in `didClose`
notification.
This does mean that for workspace diagnostics, ty will only check open
files because the behavior of different diagnostic builder is to first
check `is_file_open` and only add diagnostics for open files. So, this
required updating the `is_file_open` model to be `should_check_file`
model which validates whether the file needs to be checked based on the
`CheckMode`. If the check mode is open files only then it will check
whether the file is open. If it's all files then it'll return `true` by
default.
Closes: astral-sh/ty#619
## Test Plan
### Before
There are two files in the project: `__init__.py` and `diagnostics.py`.
In the video, I'm demonstrating the old behavior where making changes to
the (open) `diagnostics.py` file results in re-parsing the file:
https://github.com/user-attachments/assets/c2ac0ecd-9c77-42af-a924-c3744b146045
### After
Same setup as above.
In the video, I'm demonstrating the new behavior where making changes to
the (open) `diagnostics.py` file doesn't result in re-parting the file:
https://github.com/user-attachments/assets/7b82fe92-f330-44c7-b527-c841c4545f8f
Summary
--
This PR moves the JUnit output format to the new rendering
infrastructure. As I
mention in a TODO in the code, there's some code that will be shared
with the
`grouped` output format. Hopefully I'll have that PR up too by the time
this one
is reviewed.
Test Plan
--
Existing tests moved to `ruff_db`
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
This PR is changes how `reveal_type` determines what type to reveal, in
a way that should be a no-op to most callers.
Previously, we would reveal the type of the first parameter, _after_ all
of the call binding machinery had done its work. This includes inferring
the specialization of a generic function, and then applying that
specialization to all parameter and argument types, which is relevant
since the typeshed definition of `reveal_type` is generic:
```pyi
def reveal_type(obj: _T, /) -> _T: ...
```
Normally this does not matter, since we infer `_T = [arg type]` and
apply that to the parameter type, yielding `[arg type]`. But applying
that specialization also simplifies the argument type, which makes
`reveal_type` less useful as a debugging aid when we want to see the
actual, raw, unsimplified argument type.
With this patch, we now grab the original unmodified argument type and
reveal that instead.
In addition to making the debugging aid example work, this also makes
our `reveal_type` implementation more robust to custom typeshed
definitions, such as
```py
def reveal_type(obj: Any) -> Any: ...
```
(That custom definition is probably not what anyone would want, since
you wouldn't be able to depend on the return type being equivalent to
the argument type, but still)
## Summary
This PR updates the `ResolvedClientCapabilities` to be represented as
`bitflags`. This allows us to remove the `Arc` as the type becomes copy.
Additionally, this PR also fixed the goto definition and declaration
code to use the `textDocument.definition.linkSupport` and
`textDocument.declaration.linkSupport` client capability.
This PR also removes the unused client capabilities which are
`code_action_deferred_edit_resolution`, `apply_edit`, and
`document_changes` which are all related to auto-fix ability.
This PR implements "go to definition" and "go to declaration"
functionality for name nodes only. Future PRs will add support for
attributes, module names in import statements, keyword argument names,
etc.
This PR:
* Registers a declaration and definition request handler for the
language server.
* Splits out the `goto_type_definition` into its own module. The `goto`
module contains functionality that is common to `goto_type_definition`,
`goto_declaration` and `goto_definition`.
* Roughs in a new module `stub_mapping` that is not yet implemented. It
will be responsible for mapping a definition in a stub file to its
corresponding definition(s) in an implementation (source) file.
* Adds a new IDE support function `definitions_for_name` that collects
all of the definitions associated with a name and resolves any imports
(recursively) to find the original definitions associated with that
name.
* Adds a new `VisibleAncestorsIter` stuct that iterates up the scope
hierarchy but skips scopes that are not visible to starting scope.
---------
Co-authored-by: UnboundVariable <unbound@gmail.com>
## Summary
Resolves https://github.com/astral-sh/ty/issues/339
Supports having a blank function body inside `if TYPE_CHECKING` block or
in the elif or else of a `if not TYPE_CHECKING` block.
```py
if TYPE_CHECKING:
def foo() -> int: ...
if not TYPE_CHECKING: ...
else:
def bar() -> int: ...
```
## Test Plan
Update `function/return_type.md`
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Fixes#19076
An attempt at fixing #19076 where the rule could change program behavior
by incorrectly converting from_float/from_decimal method calls to
constructor calls.
The fix implements argument validation using Ruff's existing type
inference system (`ResolvedPythonType`, `typing::is_int`,
`typing::is_float`) to determine when conversions are actually safe,
adds logic to detect invalid method calls (wrong argument counts,
incorrect keyword names) and suppress fixes for them, and changes the
default fix applicability from `Safe` to `Unsafe` with safe fixes only
offered when the argument type is known to be compatible and no
problematic keywords are used.
One uncertainty is whether the type inference catches all possible edge
cases in complex codebases, but the new approach is significantly more
conservative and safer than the previous implementation.
## Test Plan
I updated the existing test fixtures with edge cases from the issue and
manually verified behavior with temporary test files for
valid/unsafe/invalid scenarios.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
This is a follow-up to https://github.com/astral-sh/ruff/pull/19344 that
improves the error formatting slightly. For example with this program:
```py
def f():
global foo, bar
```
Before we printed:
```
1 | def f():
2 | global foo, bar
| ^^^^^^^^^^^^^^^ `foo` has no declarations or bindings in the global scope
...
1 | def f():
2 | global foo, bar
| ^^^^^^^^^^^^^^^ `bar` has no declarations or bindings in the global scope
```
Now we print:
```
1 | def f():
2 | global foo, bar
| ^^^ `foo` has no declarations or bindings in the global scope
...
1 | def f():
2 | global foo, bar
| ^^^ `bar` has no declarations or bindings in the global scope
```
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Previously this worked if there was also a binding in the same scope as
the `global` declaration (probably almost always the case), but CPython
doesn't require this.
This change surfaced an error in an existing test, where a global
variable was only ever declared and bound using the `global` keyword,
and never mentioned explicitly in the global scope. @AlexWaygood
suggested we probably want to keep that requirement, so I'm adding an a
new test for that on top of fixing the failing test.
## Summary
Add a new `Type::EnumLiteral(…)` variant and infer this type for member
accesses on enums.
**Example**: No more `@Todo` types here:
```py
from enum import Enum
class Answer(Enum):
YES = 1
NO = 2
def is_yes(self) -> bool:
return self == Answer.YES
reveal_type(Answer.YES) # revealed: Literal[Answer.YES]
reveal_type(Answer.YES == Answer.NO) # revealed: Literal[False]
reveal_type(Answer.YES.is_yes()) # revealed: bool
```
## Test Plan
* Many new Markdown tests for the new type variant
* Added enum literal types to property tests, ran property tests
## Ecosystem analysis
Summary:
Lots of false positives removed. All of the new diagnostics are
either new true positives (the majority) or known problems. Click for
detailed analysis</summary>
Details:
```diff
AutoSplit (https://github.com/Toufool/AutoSplit)
+ error[call-non-callable] src/capture_method/__init__.py:137:9: Method `__getitem__` of type `bound method CaptureMethodDict.__getitem__(key: Never, /) -> type[CaptureMethodBase]` is not callable on object of type `CaptureMethodDict`
+ error[call-non-callable] src/capture_method/__init__.py:147:9: Method `__getitem__` of type `bound method CaptureMethodDict.__getitem__(key: Never, /) -> type[CaptureMethodBase]` is not callable on object of type `CaptureMethodDict`
+ error[call-non-callable] src/capture_method/__init__.py:148:1: Method `__getitem__` of type `bound method CaptureMethodDict.__getitem__(key: Never, /) -> type[CaptureMethodBase]` is not callable on object of type `CaptureMethodDict`
```
New true positives. That `__getitem__` method is apparently annotated
with `Never` to prevent developers from using it.
```diff
dd-trace-py (https://github.com/DataDog/dd-trace-py)
+ error[invalid-assignment] ddtrace/vendor/psutil/_common.py:29:5: Object of type `None` is not assignable to `Literal[AddressFamily.AF_INET6]`
+ error[invalid-assignment] ddtrace/vendor/psutil/_common.py:33:5: Object of type `None` is not assignable to `Literal[AddressFamily.AF_UNIX]`
```
Arguably true positives:
e0a772c28b/ddtrace/vendor/psutil/_common.py (L29)
```diff
ignite (https://github.com/pytorch/ignite)
+ error[invalid-argument-type] tests/ignite/engine/test_custom_events.py:190:34: Argument to bound method `__call__` is incorrect: Expected `((...) -> Unknown) | None`, found `Literal["123"]`
+ error[invalid-argument-type] tests/ignite/engine/test_custom_events.py:220:37: Argument to function `default_event_filter` is incorrect: Expected `Engine`, found `None`
+ error[invalid-argument-type] tests/ignite/engine/test_custom_events.py:220:43: Argument to function `default_event_filter` is incorrect: Expected `int`, found `None`
+ error[call-non-callable] tests/ignite/engine/test_custom_events.py:561:9: Object of type `CustomEvents` is not callable
+ error[invalid-argument-type] tests/ignite/metrics/test_frequency.py:50:38: Argument to bound method `attach` is incorrect: Expected `Events`, found `CallableEventWithFilter`
```
All true positives. Some of them are inside `pytest.raises(TypeError,
…)` blocks 🙃
```diff
meson (https://github.com/mesonbuild/meson)
+ error[invalid-argument-type] unittests/internaltests.py:243:51: Argument to bound method `__init__` is incorrect: Expected `bool`, found `Literal[MachineChoice.HOST]`
+ error[invalid-argument-type] unittests/internaltests.py:271:51: Argument to bound method `__init__` is incorrect: Expected `bool`, found `Literal[MachineChoice.HOST]`
```
New true positives. Enum literals can not be assigned to `bool`, even if
their value types are `0` and `1`.
```diff
poetry (https://github.com/python-poetry/poetry)
+ error[invalid-assignment] src/poetry/console/exceptions.py:101:5: Object of type `Literal[""]` is not assignable to `InitVar[str]`
```
New false positive, missing support for `InitVar`.
```diff
prefect (https://github.com/PrefectHQ/prefect)
+ error[invalid-argument-type] src/integrations/prefect-dask/tests/test_task_runners.py:193:17: Argument is incorrect: Expected `StateType`, found `Literal[StateType.COMPLETED]`
```
This is confusing. There are two definitions
([one](74d8cd93ee/src/prefect/client/schemas/objects.py (L89-L100)),
[two](https://github.com/PrefectHQ/prefect/blob/main/src/prefect/server/schemas/states.py#L40))
of the `StateType` enum. Here, we're trying to assign one to the other.
I don't think that should be allowed, so this is a true positive (?).
```diff
python-htmlgen (https://github.com/srittau/python-htmlgen)
+ error[invalid-assignment] test_htmlgen/form.py:51:9: Object of type `str` is not assignable to attribute `autocomplete` of type `Autocomplete | None`
+ error[invalid-assignment] test_htmlgen/video.py:38:9: Object of type `str` is not assignable to attribute `preload` of type `Preload | None`
```
True positives. [The stubs are
wrong](01e3b911ac/htmlgen/form.pyi (L8-L10)).
These should not contain type annotations, but rather just `OFF = ...`.
```diff
rotki (https://github.com/rotki/rotki)
+ error[invalid-argument-type] rotkehlchen/tests/unit/test_serialization.py:62:30: Argument to bound method `deserialize` is incorrect: Expected `str`, found `Literal[15]`
```
New true positive.
```diff
vision (https://github.com/pytorch/vision)
+ error[unresolved-attribute] test/test_extended_models.py:302:17: Type `type[WeightsEnum]` has no attribute `DEFAULT`
+ error[unresolved-attribute] test/test_extended_models.py:302:58: Type `type[WeightsEnum]` has no attribute `DEFAULT`
```
Also new true positives. No `DEFAULT` member exists on `WeightsEnum`.
The initial implementation of `infer_nonlocal` landed in
https://github.com/astral-sh/ruff/pull/19112 fails to report an error
for this example:
```py
x = 1
def f():
# This is only a usage of `x`, not a definition. It shouldn't be
# enough to make the `nonlocal` statement below allowed.
print(x)
def g():
nonlocal x
```
Fix this by continuing to walk enclosing scopes when the place we've
found isn't bound, declared, or `nonlocal`.
We previously had separate `CallArguments` and `CallArgumentTypes` types
in support of our two-phase call binding logic. `CallArguments` would
store only the arity/kind of each argument (positional, keyword,
variadic, etc). We then performed parameter matching using only this
arity/kind information, and then infered the type of each argument,
placing the result of this second phase into a new `CallArgumentTypes`.
In #18996, we will need to infer the types of splatted arguments
_before_ performing parameter matching, since we need to know the
argument type to accurately infer its length, which informs how many
parameters the splatted argument is matched against.
That makes this separation of Rust types no longer useful. This PR
merges everything back into a single `CallArguments`. In the case where
we are performing two-phase call binding, the types will be initialized
to `None`, and updated to the actual argument type during the second
`check_types` phase.
_[This is a refactoring in support of fixing the merge conflicts on
#18996. I've pulled this out into a separate PR to make it easier to
review in isolation.]_
Summary
--
This is a very simple output format, the only decision is what to do if
the file
is missing from the diagnostic. For now, I opted to `unwrap_or_default`
both the
path and the `OneIndexed` row number, giving `:1: main diagnostic
message` in
the test without a file.
Another quirk here is that the path is relativized. I just pasted in the
`relativize_path` and `get_cwd` implementations from `ruff_linter::fs`
for now,
but maybe there's a better place for them.
I didn't see any details about why this needs to be relativized in the
original
[issue](https://github.com/astral-sh/ruff/issues/1953),
[PR](https://github.com/astral-sh/ruff/pull/1995), or in the pylint
[docs](https://flake8.pycqa.org/en/latest/internal/formatters.html#pylint-formatter),
but it did change the results of the CLI integration test when I tried
deleting
it. I haven't been able to reproduce that in the CLI, though, so it may
only
happen with `Command::current_dir`.
Test Plan
--
Tests ported from `ruff_linter` and a new test for the case with no file
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Another output format like #19133. This is the
[reviewdog](https://github.com/reviewdog/reviewdog) output format, which
is somewhat similar to regular JSON. Like #19270, in the first commit I
converted from using `json!` to `Serialize` structs, then in the second
commit I moved the module to `ruff_db`.
The reviewdog
[schema](320a8e73a9/proto/rdf/jsonschema/DiagnosticResult.json)
seems a bit more flexible than our JSON schema, so I'm not sure if we
need any preview checks here. I'll flag the places I wasn't sure about
as review comments.
## Test Plan
New tests in `rdjson.rs`, ported from the old `rjdson.rs` module, as
well as the new CLI output tests.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR removes the `ConnectionInitializer` and inlines the
`initialize_start` and `initialize_finish` calls.
The main benefit of this is that it will allow us to use
[`Connection::memory`](https://docs.rs/lsp-server/latest/lsp_server/struct.Connection.html#method.memory)
in the mock server. That method returns two `Connection` where one of
them will represent the client side connection and the other will be
sent to the `Server::new` call to be used by the server. This way the
mock client can send notifications and requests to mimic the editor.
## Test Plan
I tested out the initialization process and checked that the initialized
result contains the server capabilities and server info.
## Summary
Adds a new workflow that generates an ecosystem report of all
diagnostics and publishes it to Cloudflare pages.
## Test Plan
Not yet tested.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972Fixes#14346
This PR makes [bidirectional-unicode
(PLE2502)](https://docs.astral.sh/ruff/rules/bidirectional-unicode/#bidirectional-unicode-ple2502)'s
example error out-of-the-box, by converting it to use one of the test
cases. The documentation in general is also updated to replace
"bidirectional unicode character" with "bidirectional formatting
character", as those are the only ones checked for, and the "unicode"
suffix is redundant. The new example section looks like this:
<img width="1074" height="264" alt="image"
src="https://github.com/user-attachments/assets/cc1d2cb4-b590-4f20-a4d2-15b744872cdd"
/>
The "References" section link is also updated to reflect the rule's
actual behavior.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR fixes#7172 by suppressing the fixes for
[docstring-missing-returns
(DOC201)](https://docs.astral.sh/ruff/rules/docstring-missing-returns/#docstring-missing-returns-doc201)
/ [docstring-extraneous-returns
(DOC202)](https://docs.astral.sh/ruff/rules/docstring-extraneous-returns/#docstring-extraneous-returns-doc202)
if there is a surrounding line continuation character `\` that would
make the fix cause a syntax error.
To do this, the lints are changed from `AlwaysFixableViolation` to
`Violation` with `FixAvailability::Sometimes`.
In the case of `DOC201`, the fix is not given if the non-break line ends
in a line continuation character `\`. Note that lines are iterated in
reverse from the docstring to the function definition.
In the case of `DOC202`, the fix is not given if the docstring ends with
a line continuation character `\`.
## Test Plan
<!-- How was it tested? -->
Added a test case.
## Summary
Part of #18972
This PR makes [for-loop-writes
(FURB122)](https://docs.astral.sh/ruff/rules/for-loop-writes/#for-loop-writes-furb122)'s
example error out-of-the-box. I also had to re-name the second case's
variables to get both to raise at the same time, I suspect because of
limitations in ruff's current semantic model. New names subject to
bikeshedding, I just went with the least effort `_b` for binary suffix.
[Old example](https://play.ruff.rs/19e8e47a-8058-4013-aef5-e9b5eab65962)
```py
with Path("file").open("w") as f:
for line in lines:
f.write(line)
with Path("file").open("wb") as f:
for line in lines:
f.write(line.encode())
```
[New example](https://play.ruff.rs/e96b00e5-3c63-47c3-996d-dace420dd711)
```py
from pathlib import Path
with Path("file").open("w") as f:
for line in lines:
f.write(line)
with Path("file").open("wb") as f_b:
for line_b in lines_b:
f_b.write(line_b.encode())
```
The "Use instead" section was also modified similarly.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Part of #18972
This PR makes
[implicit-cwd(FURB177)](https://docs.astral.sh/ruff/rules/implicit-cwd/)'s
example error out-of-the-box.
[Old example](https://play.ruff.rs/a0bef229-9626-426f-867f-55cb95ee64d8)
```python
cwd = Path().resolve()
```
[New example](https://play.ruff.rs/bdbea4af-e276-4603-a1b6-88757dfaa399)
```python
from pathlib import Path
cwd = Path().resolve()
```
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
## Summary
Previously, the virtual files were being added to the default database
that's present on the session. This is wrong because the default
database is for any files that don't belong to any project i.e., they're
outside of any projects managed by the server. Virtual files are neither
part of the project nor it is outside the projects. This was not the
intention as in the initial version, virtual files were being added to
the only project database managed by the server.
This PR fixes this by reverting back to the original behavior where
virtual files will be added to the only project database present. When
support for multiple workspace and project is added, this will require
updating (https://github.com/astral-sh/ty/issues/794).
This is required for #19264 because workspace diagnostics doesn't check
the default project database yet. Ideally, the default db should be
checked as well.
The implementation of this PR means that virtual files are now being
included for workspace diagnostics but it doesn't work completely e.g.,
if I save an untitled file the diagnostics disappears but it doesn't
appear back for the (now) saved file on disk as shown in the following
video demonstration:
https://github.com/user-attachments/assets/123e8d20-1e95-4c7d-b7eb-eb65be8c476e
## Summary
This PR removes the `FileLookupError` as it's not really required. The
original intention was that this would be returned from the `.file`
lookup to the different handlers but we've since moved the logic of
"lookup file and add trace message if file unavailable with the reason"
under the `file_ok` method which all of the handlers use.
Basically, we weren't quite using `Type::member` in every case
correctly. Specifically, this example from @sharkdp:
```
class Meta(type):
@property
def meta_attr(self) -> int:
return 0
class C(metaclass=Meta): ...
C.<CURSOR>
```
While we would return `C.meta_attr` here, we were claiming its type was
`property`. But its type should be `int`.
Ref https://github.com/astral-sh/ruff/pull/19216#discussion_r2197065241
## Summary
Adds a way to list all members of an `Enum` and implements almost all of
the mechanisms by which members are distinguished from non-members
([spec](https://typing.python.org/en/latest/spec/enums.html#defining-members)).
This has no effect on actual enums, so far.
## Test Plan
New Markdown tests using `ty_extensions.enum_members`.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[astral-sh/ruff-pre-commit](https://redirect.github.com/astral-sh/ruff-pre-commit)
| repository | patch | `v0.12.2` -> `v0.12.3` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
Note: The `pre-commit` manager in Renovate is not supported by the
`pre-commit` maintainers or community. Please do not report any problems
there, instead [create a Discussion in the Renovate
repository](https://redirect.github.com/renovatebot/renovate/discussions/new)
if you have any questions.
---
### Release Notes
<details>
<summary>astral-sh/ruff-pre-commit (astral-sh/ruff-pre-commit)</summary>
###
[`v0.12.3`](https://redirect.github.com/astral-sh/ruff-pre-commit/releases/tag/v0.12.3)
[Compare
Source](https://redirect.github.com/astral-sh/ruff-pre-commit/compare/v0.12.2...v0.12.3)
See: https://github.com/astral-sh/ruff/releases/tag/0.12.3
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS4yMy4yIiwidXBkYXRlZEluVmVyIjoiNDEuMjMuMiIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [non-pep695-type-alias
(UP040)](https://docs.astral.sh/ruff/rules/non-pep695-type-alias/#non-pep695-type-alias-up040)'s
example error out-of-the-box.
[Old example](https://play.ruff.rs/6beca1be-45cd-4e5a-aafa-6a0584c10d64)
```py
ListOfInt: TypeAlias = list[int]
PositiveInt = TypeAliasType("PositiveInt", Annotated[int, Gt(0)])
```
[New example](https://play.ruff.rs/bbad34da-bf07-44e6-9f34-53337e8f57d4)
```py
from typing import Annotated, TypeAlias, TypeAliasType
from annotated_types import Gt
ListOfInt: TypeAlias = list[int]
PositiveInt = TypeAliasType("PositiveInt", Annotated[int, Gt(0)])
```
Imports were also added to the "Use instead" section.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [timeout-error-alias
(UP041)](https://docs.astral.sh/ruff/rules/timeout-error-alias/#timeout-error-alias-up041)'s
example error out-of-the-box.
[Old example](https://play.ruff.rs/87e20352-d80a-46ec-98a2-6f6ea700438b)
```py
raise asyncio.TimeoutError
```
[New example](https://play.ruff.rs/d3b95557-46a2-4856-bd71-30d5f3f5ca44)
```py
import asyncio
raise asyncio.TimeoutError
```
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
## Summary
This was originally stacked on #19129, but some of the changes I made
for JSON also impacted the Azure format, so I went ahead and combined
them. The main changes here are:
- Implementing `FileResolver` for Ruff's `EmitterContext`
- Adding `FileResolver::notebook_index` and `FileResolver::is_notebook`
methods
- Adding a `DisplayDiagnostics` (with an "s") type for rendering a group
of diagnostics at once
- Adding `Azure`, `Json`, and `JsonLines` as new `DiagnosticFormat`s
I tried a couple of alternatives to the `FileResolver::notebook` methods
like passing down the `NotebookIndex` separately and trying to reparse a
`Notebook` from Ruff's `SourceFile`. The latter seemed promising, but
the `SourceFile` only stores the concatenated plain text of the
notebook, not the re-parsable JSON. I guess the current version is just
a variation on passing the `NotebookIndex`, but at least we can reuse
the existing `resolver` argument. I think a lot of this can be cleaned
up once Ruff has its own actual file resolver.
As suggested, I also tried deleting the corresponding `Emitter` files in
`ruff_linter`, but it doesn't look like git was able to follow this as a
rename. It did, however, track that the tests were moved, so the
snapshots should be easy to review.
## Test Plan
Existing Ruff tests ported to tests in `ruff_db`. I think some other
existing ruff tests also cover parts of this refactor.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR fixes a bug that didn't return a response to the client if the
document snapshotting failed.
This is resolved by making sure that the server always creates the
document snapshot and embed the any failures inside the snapshot.
Closes: astral-sh/ty#798
## Test Plan
Using the test case as described in the linked issue:
https://github.com/user-attachments/assets/f32833f8-03e5-4641-8c7f-2a536fe2e270
While we did previously support submodule completions via our
`all_members` API, that only works when submodules are attributes of
their parent module. For example, `os.path`. But that didn't work when
the submodule was not an attribute of its parent. For example,
`http.client`. To make the latter work, we read the directory of the
parent module to discover its submodules.
This is mostly just holding a zip file in the right way
to simulate reading a directory. We want this to be able
to discover sub-modules for completions.
## Summary
See https://github.com/astral-sh/ruff/pull/19133#discussion_r2198413586
for recent discussion. This PR moves to using structs for the types in
our JSON output format instead of the `json!` macro.
I didn't rename any of the `message` references because that should be
handled when rebasing #19133 onto this.
My plan for handling the `preview` behavior with the new diagnostics is
to use a wrapper enum. Something like:
```rust
#[derive(Serialize)]
#[serde(untagged)]
pub(crate) enum JsonDiagnostic<'a> {
Old(OldJsonDiagnostic<'a>),
}
#[derive(Serialize)]
pub(crate) struct OldJsonDiagnostic<'a> {
// ...
}
```
Initially I thought I could use a `&dyn Serialize` for the affected
fields, but I see that `Serialize` isn't dyn-compatible in testing this
now.
## Test Plan
Existing tests. One quirk of the new types is that their fields are in
alphabetical order. I guess `json!` sorts the fields alphabetically? The
tests were failing before I sorted the struct fields.
## Other formats
It looks like the `rdjson`, `sarif`, and `gitlab` formats also use
`json!`, so if we decide to merge this, I can do something similar for
those before moving them to the new diagnostic format.
This PR includes:
* Implemented core signature help logic
* Added new docstring method on Definition that returns a docstring for
function and class definitions
* Modified the display code for Signature that allows a signature string
to be broken into text ranges that correspond to each parameter in the
signature
* Augmented Signature struct so it can track the Definition for a
signature when available; this allows us to find the docstring
associated with the signature
* Added utility functions for parsing parameter documentation from three
popular docstring formats (Google, NumPy and reST)
* Implemented tests for all of the above
"Signature help" is displayed by an editor when you are typing a
function call expression. It is typically triggered when you type an
open parenthesis. The language server provides information about the
target function's signature (or multiple signatures), documentation, and
parameters.
Here is how this appears:

---------
Co-authored-by: UnboundVariable <unbound@gmail.com>
Co-authored-by: Micha Reiser <micha@reiser.io>
Summary
--
I spun this off from #19133 to be sure to get an accurate baseline
before modifying any of the formats. I picked the code snippet to
include a lint diagnostic with a fix, one without a fix, and one syntax
error. I'm happy to expand it if there are any other kinds we want to
test.
I initially passed `CONTENT` on stdin, but I was a bit surprised to
notice that some of our output formats include an absolute path to the
file. I switched to a `TempDir` to use the `tempdir_filter`.
Test Plan
--
New CLI tests
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR is the same as #17656.
I accidentally deleted the branch of that PR, so I'm creating a new one.
Fixes#14052
## Test Plan
Add regression tests
<!-- How was it tested? -->
## Summary
We noticed that all files get reparsed when workspace diagnostics are
enabled.
I realised that this is because `check_file_impl` access the parsed
module but itself isn't a salsa query.
This pr makes `check_file_impl` a salsa query, so that we only access
the `parsed_module` when the file actually changed. I decided to remove
the salsa query from `check_types` because most functions it calls are
salsa queries itself and having both `check_types` and `check_file` as
salsa querise has the downside that we double cache the diagnostics.
## Test Plan
**Before**
```
2025-07-10 12:54:16.620766000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c0c))}: File `/Users/micha/astral/test/yaml/yaml-stubs/__init__.pyi` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.621942000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c13))}: File `/Users/micha/astral/test/ignore2 2/nested-repository/main.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.622107000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c09))}: File `/Users/micha/astral/test/notebook.ipynb` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.622357000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c04))}: File `/Users/micha/astral/test/no-trailing.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.622634000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c02))}: File `/Users/micha/astral/test/simple.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.623056000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c07))}: File `/Users/micha/astral/test/open/more.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.623254000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c11))}: File `/Users/micha/astral/test/ignore-bug/backend/src/subdir/log/some_logging_lib.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.623450000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c0f))}: File `/Users/micha/astral/test/yaml/tomllib/__init__.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.624599000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c05))}: File `/Users/micha/astral/test/create.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.624784000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c00))}: File `/Users/micha/astral/test/lib.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.624911000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c0a))}: File `/Users/micha/astral/test/sub/test.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.625032000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c12))}: File `/Users/micha/astral/test/ignore2/nested-repository/main.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.625101000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c08))}: File `/Users/micha/astral/test/open/test.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.625227000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c03))}: File `/Users/micha/astral/test/pseudocode_with_bom.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.625353000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c0b))}: File `/Users/micha/astral/test/yaml/yaml-stubs/loader.pyi` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.625543000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c01))}: File `/Users/micha/astral/test/test_trailing.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.625616000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c0d))}: File `/Users/micha/astral/test/yaml/tomllib/_re.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.625667000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c06))}: File `/Users/micha/astral/test/yaml/main.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.625779000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c10))}: File `/Users/micha/astral/test/yaml/tomllib/_types.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.627526000 WARN request{id=19 method="workspace/diagnostic"}:Project::check:check_file{file=file(Id(c0e))}: File `/Users/micha/astral/test/yaml/tomllib/_parser.py` was reparsed after being collected in the current Salsa revision
2025-07-10 12:54:16.627959000 DEBUG request{id=19 method="workspace/diagnostic"}:Project::check: Checking all files took 0.007s
```
Now, no more logs regarding reparsing
## Summary
Pulls in two fixes and a performance optimization:
- Fix a bug with the Markdown table formatting.
- Combine the two `analyze` commands into a single `diff` command. This
means we only need to set up the projects once, which is faster and also
avoids a race condition where projects could change between the two
`analyze` runs.
## Summary
Changes the ecosystem-analyzer workflow to deploy the diff to Cloudflare
pages and post a link in the PR. Also adds a summary statistics to that
PR comment.
## Test Plan
The comment below:
https://github.com/astral-sh/ruff/pull/19234#issuecomment-3053205937. I
previously had some dummy changes on this PR to see a non-zero diff. And
I didn't reapply the label after I reverted that change, such that it's
still visible for reviewers.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Add Capital One to Who's Using Ruff (README)
Also thanks for the fantastic project!
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [suspicious-httpoxy-import
(S412)](https://docs.astral.sh/ruff/rules/suspicious-httpoxy-import/#suspicious-httpoxy-import-s412)'s
example error out-of-the-box. Since the checked imports are classes
instead of modules, the example isn't valid. See #19009 for more details
```
PS ~>py -c "import wsgiref.handlers.CGIHandler"
Traceback (most recent call last):
File "<string>", line 1, in <module>
import wsgiref.handlers.CGIHandler
ModuleNotFoundError: No module named 'wsgiref.handlers.CGIHandler'; 'wsgiref.handlers' is not a package
PS ~>py -c "from wsgiref.handlers import CGIHandler"
PS ~>
```
[Old example](https://play.ruff.rs/bf48c901-6a46-4795-ba1d-c6af79d5c96e)
```py
import wsgiref.handlers.CGIHandler
```
[New example](https://play.ruff.rs/1f0e1e60-1f0f-484a-9a17-2d0290a68f2a)
```py
from wsgiref.handlers import CGIHandler
```
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [docstring-missing-exception
(DOC501)](https://docs.astral.sh/ruff/rules/docstring-missing-exception/#docstring-missing-exception-doc501)'s
example error out-of-the-box. Since the exceptions in the function body
need to undergo name resolution to figure out if one of them is
`NotImplementedError`, `DOC501` won't lint if the raised name is not
defined. This could be considered a limitation, but should be fine since
`F821` already covers undefined names. I did discover a different edge
case, but it's not relevant to the example.
[Old example](https://play.ruff.rs/d213e87d-e5c7-49d8-a908-931f61f06055)
```py
def calculate_speed(distance: float, time: float) -> float:
"""Calculate speed as distance divided by time.
Args:
distance: Distance traveled.
time: Time spent traveling.
Returns:
Speed as distance divided by time.
"""
try:
return distance / time
except ZeroDivisionError as exc:
raise FasterThanLightError from exc
```
[New example](https://play.ruff.rs/cb41e0b7-b950-4fa0-842d-cecab9c8e842)
```py
class FasterThanLightError(ArithmeticError): ...
def calculate_speed(distance: float, time: float) -> float:
"""Calculate speed as distance divided by time.
Args:
distance: Distance traveled.
time: Time spent traveling.
Returns:
Speed as distance divided by time.
"""
try:
return distance / time
except ZeroDivisionError as exc:
raise FasterThanLightError from exc
```
The "Use instead" section was also updated similarly.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
This makes use of the new `Type` field on `Completion` to figure out the
"kind" of a `Completion`.
The mapping here is perhaps a little suspect for some cases.
Closesastral-sh/ty#775
Since we generally need (so far) to get the type information of each
suggestion to figure out its boundness anyway, we might as well expose
it here. Completions want to use this information to enhance the
metadata on each suggestion for a more pleasant user experience.
For the most part, this was pretty straight-forward. The most exciting
part was in computing the types for instance attributes. I'm not 100%
sure it's correct or is the best way to do it.
This commit doesn't change any behavior, but makes it so `all_members`
returns a `Vec<Member>` instead of `Vec<Name>`, where a `Member`
contains a `Name`. This gives us an expansion point to include other
data (such as the type of the `Name`).
## Summary
Change `ClassLiteral.into_callable` to also look for `__init__` functions
of type `Type::Callable` (such as synthesized `__init__` functions of
dataclasses).
Fixes https://github.com/astral-sh/ty/issues/760
## Test Plan
Add subtype test
---------
Co-authored-by: David Peter <mail@david-peter.de>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fix#18383 by updating the documentation and error message to explain
that users should use `rsplit` in order to access the last element of
the result with `maxsplit=1`
## Test Plan
<!-- How was it tested? -->
Only documentation and an error message was changed. As such, snapshots
were updated to reflect the new error message. With this change, all
existing tests pass.
## Summary
Emit a diagnostic when a `Final`-qualified symbol is modified. This
first iteration only works for name targets. Tests with TODO comments
were added for attribute assignments as well.
related ticket: https://github.com/astral-sh/ty/issues/158
## Ecosystem impact
Correctly identified [modification of a `Final`
symbol](7b4164a5f2/sphinx/__init__.py (L44))
(behind a `# type: ignore`):
```diff
- warning[unused-ignore-comment] sphinx/__init__.py:44:56: Unused blanket `type: ignore` directive
```
And the same
[here](5471a37e82/src/trio/_core/_run.py (L128)):
```diff
- warning[unused-ignore-comment] src/trio/_core/_run.py:128:45: Unused blanket `type: ignore` directive
```
## Test Plan
New Markdown tests
This is the trivial first part of
https://github.com/astral-sh/ty/issues/613
Ideally we should surface these elsewhere, but this is definitely Not
the place to surface them.
## Summary
Fixes a bug where conditionally defined dataclass fields were previously
ignored.
Thanks to @lipefree for reporting this.
## Test Plan
New Markdown tests
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [indentation-with-invalid-multiple-comment
(E114)](https://docs.astral.sh/ruff/rules/indentation-with-invalid-multiple-comment/#indentation-with-invalid-multiple-comment-e114)'s
example not raise a syntax error by adding a 4 space indented `...`. The
example still gave `E114` without this, but adding the `...` both makes
the change in indentation of the comment clearer, and makes it not give
a `SyntaxError`.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [multiple-spaces-before-keyword
(E272)](https://docs.astral.sh/ruff/rules/multiple-spaces-before-keyword/#multiple-spaces-before-keyword-e272)'s
example error out-of-the-box. Since `True` is also a keyword, the old
example raises `E271` instead.
[Old example](https://play.ruff.rs/23ec3774-5038-471c-be3f-1c1e36f85cbb)
```py
True and False
```
[New example](https://play.ruff.rs/d77432e2-fd99-4db2-9cd0-bc08675c0aca)
```py
x and y
```
The "Use instead" section was also updated similarly.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
## Summary
This PR addresses some additional feedback on #19053:
- Renaming the `syntax_error` methods to `invalid_syntax` to match the
lint id
- Moving the standalone `diagnostic_from_violation` function to
`Violation::into_diagnostic`
- Removing the `Ord` and `PartialOrd` implementations from `Diagnostic`
in favor of `Diagnostic::start_ordering`
## Test Plan
Existing tests
## Additional Follow-ups
Besides these, I also put the following comments on my todo list, but
they seemed like they might be big enough to have their own PRs:
- [Use `LintId::IOError` for IO
errors](https://github.com/astral-sh/ruff/pull/19053#discussion_r2189425922)
- [Move `Fix` and
`Edit`](https://github.com/astral-sh/ruff/pull/19053#discussion_r2189448647)
- [Avoid so many
unwraps](https://github.com/astral-sh/ruff/pull/19053#discussion_r2189465980)
## Summary
Related:
- https://github.com/astral-sh/ty/issues/111
- https://github.com/astral-sh/ruff/pull/17974#discussion_r2108527106
Previously, when validating an attribute assignment, a `__setattr__`
call check was only done if the attribute wasn't found as either a class
member or instance member
This PR changes the `__setattr__` call check to be attempted first,
prior to the "[normal
mechanism](https://docs.python.org/3/reference/datamodel.html#object.__setattr__)",
as a defined `__setattr__` should take precedence over setting an
attribute on the instance dictionary directly.
if the return type of `__setattr__` is `Never`, an `invalid-assignment`
diagnostic is emitted
Once this is merged, a subsequent PR will synthesize a `__setattr__`
method with a `Never` return type for frozen dataclasses.
## Test Plan
Existing tests + mypy_primer
---------
Co-authored-by: David Peter <mail@david-peter.de>
This PR implements a basic semantic token provider for ty's language
server. This allows for more accurate semantic highlighting / coloring
within editors that support this LSP functionality.
Here are screen shots that show how code appears in VS Code using the
"rainbow" theme both before and after this change.


The token types and modifier tags in this implementation largely mirror
those used in Microsoft's default language server for Python.
The implementation supports two LSP interfaces. The first provides
semantic tokens for an entire document, and the second returns semantic
tokens for a requested range within a document.
The PR includes unit tests. It also includes comments that document
known limitations and areas for future improvements.
---------
Co-authored-by: UnboundVariable <unbound@gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [if-else-block-instead-of-dict-lookup
(SIM116)](https://docs.astral.sh/ruff/rules/if-else-block-instead-of-dict-lookup/#if-else-block-instead-of-dict-lookup-sim116)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/718f17ee-fbe2-4520-97c6-153bc0f4502d)
```py
if x == 1:
return "Hello"
elif x == 2:
return "Goodbye"
else:
return "Goodnight"
```
[New example](https://play.ruff.rs/8a9b47b4-da46-4a50-8576-362cdd707cee)
```py
def find_phrase(x):
if x == 1:
return "Hello"
elif x == 2:
return "Goodbye"
elif x == 3:
return "Good morning"
else:
return "Goodnight"
```
The "Use instead" section was also updated to reflect the new case. I
also changed it to use an intermediary variable since I find the `return
<long dict>.get` very ugly and hard to read.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [invalid-pathlib-with-suffix
(PTH210)](https://docs.astral.sh/ruff/rules/invalid-pathlib-with-suffix/#invalid-pathlib-with-suffix-pth210)'s
example error out-of-the-box.
[Old example](https://play.ruff.rs/d45720cc-fd08-4443-820f-b3bc9756ac59)
```py
path.with_suffix("py")
```
[New example](https://play.ruff.rs/4103669e-19c5-464a-a3fb-6e7d190ce5fd)
```py
from pathlib import Path
path = Path()
path.with_suffix("py")
```
The "Use instead" section was also modified similarly.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Part of #2331 |
[#18763](https://github.com/astral-sh/ruff/pull/18763#issuecomment-2988340436)
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
update snapshots
<!-- How was it tested? -->
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
I noticed this while working on #18972. If the string targeted by
[quoted-type-alias
(TC008)](https://docs.astral.sh/ruff/rules/quoted-type-alias/#quoted-type-alias-tc008)
is a multiline string, the fix would introduce a syntax error. This PR
fixes that by adding parenthesis around the resulting replacement if the
string contained any newline characters (`\n`, `\r`) if it doesn't
already have parenthesis outside `("""...""")` or inside `"""(...)"""`
the annotation.
Failing examples:
https://play.ruff.rs/8793eb95-860a-4bb3-9cbc-6a042fee2946
```
PS D:\rust_projects\ruff> Get-Content issue.py
```
```py
from typing import TypeAlias
OptInt: TypeAlias = """int
| None"""
type OptInt = """int
| None"""
```
```
PS D:\rust_projects\ruff> uvx ruff check issue.py --isolated --select TC008 --fix --diff --preview
```
```
error: Fix introduced a syntax error. Reverting all changes.
This indicates a bug in Ruff. If you could open an issue at:
https://github.com/astral-sh/ruff/issues/new?title=%5BFix%20error%5D
...quoting the contents of `issue.py`, the rule codes TC008, along with the `pyproject.toml` settings and executed command, we'd be very appreciative!
```
This PR also makes the example error out-of-the-box for #18972
Old example: https://play.ruff.rs/f6cd5adb-7f9b-444d-bb3e-8c045241d93e
```py
OptInt: TypeAlias = "int | None"
```
New example: https://play.ruff.rs/906c1056-72c0-4777-b70b-2114eb9e6eaf
```py
from typing import TypeAlias
OptInt: TypeAlias = "int | None"
```
The import was also added to the "Use instead" section.
## Test Plan
<!-- How was it tested? -->
Added multiple test cases
## Summary
Part of #18972
Both in one PR since they are in the same file
No playground links since the playground does not support rules that
only apply to PYI files
PYI007
---
This PR makes [unrecognized-platform-check
(PYI007)](https://docs.astral.sh/ruff/rules/unrecognized-platform-check/#unrecognized-platform-check-pyi007)'s
example error out-of-the-box
Old example:
```
PS ~\Desktop\New_folder\ruff>echo @"
```
```py
if sys.platform.startswith("linux"):
# Linux specific definitions
...
else:
# Posix specific definitions
...
```
```
"@ | uvx ruff check --isolated --preview --select PYI007 --stdin-filename "test.pyi" -
```
```
All checks passed!
```
New example:
```
PS ~\Desktop\New_folder\ruff>echo @"
```
```py
import sys
if sys.platform is "linux":
# Linux specific definitions
...
else:
# Posix specific definitions
...
```
```
"@ | uvx ruff check --isolated --preview --select PYI007 --stdin-filename "test.pyi" -
```
```snap
test.pyi:3:4: PYI007 Unrecognized `sys.platform` check
|
1 | import sys
2 |
3 | if sys.platform is "linux":
| ^^^^^^^^^^^^^^^^^^^^^^^ PYI007
4 | # Linux specific definitions
5 | ...
|
Found 1 error.
```
Imports were also added to the "use instead" section
> [!NOTE]
> `PYI007` is really hard to trigger, it's only specifically in the case
of a comparison where the operator is not `!=` or `==`. The original
example raises [complex-if-statement-in-stub
(PYI002)](https://docs.astral.sh/ruff/rules/complex-if-statement-in-stub/#complex-if-statement-in-stub-pyi002)
with or without the `import sys`
PYI008
---
This PR makes [unrecognized-platform-name
(PYI008)](https://docs.astral.sh/ruff/rules/unrecognized-platform-name/#unrecognized-platform-name-pyi008)'s
example error out-of-the-box
Old example:
```
PS ~\Desktop\New_folder\ruff>echo @"
```
```py
if sys.platform == "linus": ...
```
```
"@ | uvx ruff check --isolated --preview --select PYI008 --stdin-filename "test.pyi" -
```
```
All checks passed!
```
New example:
```
PS ~\Desktop\New_folder\ruff>echo @"
```
```py
import sys
if sys.platform == "linus": ...
```
```
"@ | uvx ruff check --isolated --preview --select PYI008 --stdin-filename "test.pyi" -
```
```snap
test.pyi:3:20: PYI008 Unrecognized platform `linus`
|
1 | import sys
2 |
3 | if sys.platform == "linus": ...
| ^^^^^^^ PYI008
|
Found 1 error.
```
Imports were also added to the "use instead" section
> [!NOTE]
> The original example raises `PYI002` instead
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
This PR addresses the post-merge review comments from
https://github.com/astral-sh/ruff/pull/19041, specifically it:
- Rename `WorkspaceSnapshot` to `SessionSnapshot`
- Rename `take_workspace_snapshot` to `take_session_snapshot`
- Rename `take_snapshot` to `take_document_snapshot`
- Move `AssertUnwindSafe` closer to the `catch_unwind` call which
requires the assertion
## Summary
It was recently clarified in the [typing
spec](https://typing.python.org/en/latest/spec/class-compat.html#classvar)
that bare `ClassVar` annotations are allowed. For annotated assignments
with a right hand side value, the spec requires type checkers to infer
the type as something "to which [the] value is assignable". For a value
of `2`, the spec suggests `int`, `Literal[2]`, or `Any` as examples.
Here, we choose `Unknown | Literal[2]` instead, conforming with out
usual treatment of attribute types.
closes https://github.com/astral-sh/ty/issues/211
## Summary
I played with those numbers a bit locally and `sample_size=3,
sample_count=8` seemed like a rather stable setup. This means a single
sample consistents of 3 iterations of checking pydantic multithreaded.
And this is repeated 8 times for statistics. A single check took ~300 ms
previously on the runners, so this should only take 7 s.
## Summary
This PR implements the following pieces of `Protocol` semantics:
1. A protocol with a method member that does not have a fully static
signature should not be considered fully static. I.e., this protocol is
not fully static because `Foo.x` has no return type; we previously
incorrectly considered that it was:
```py
class Foo(Protocol):
def f(self): ...
```
2. Two protocols `P1` and `P2`, both with method members `x`, should be
considered equivalent if the signature of `P1.x` is equivalent to the
signature of `P2.x`. Currently we do not recognize this.
Implementing these semantics requires distinguishing between method
members and non-method members. The stored type of a method member must
be eagerly upcast to a `Callable` type when collecting the protocol's
interface: doing otherwise would mean that it would be hard to implement
equivalence of protocols even in the face of differently ordered unions,
since the two equivalent protocols would have different Salsa IDs even
when normalized.
The semantics implemented by this PR are that we consider something a
method member if:
1. It is accessible on the class itself; and
2. It is a function-like callable: a callable type that also has a
`__get__` method, meaning it can be used as a method when accessed on
instances.
Note that the spec has complicated things to say about classmethod
members and staticmethod members. These semantics are not implemented by
this PR; they are all deferred for now.
The infrastructure added in this PR fixes bugs in its own right, but
also lays the groundwork for implementing subtyping and assignability
rules for method members of protocols. A (currently failing) test is
added to verify this.
## Test Plan
mdtests
## Summary
Infer the type of symbols with a `Final` qualifier as their
right-hand-side inferred type:
```py
x: Final = 1
y: Final[int] = 1
def _():
reveal_type(x) # previously: Unknown, now: Literal[1]
reveal_type(y) # int, same as before
```
Part of https://github.com/astral-sh/ty/issues/158
## Ecosystem analysis
### aiohttp
```diff
aiohttp (https://github.com/aio-libs/aiohttp)
+ error[invalid-argument-type] aiohttp/compression_utils.py:131:54: Argument to bound method `__init__` is incorrect: Expected `ZLibBackendProtocol`, found `<module 'zlib'>`
```
This code [creates a
protocol](a83597fa88/aiohttp/compression_utils.py (L52-L77))
that looks like
```pyi
class ZLibBackendProtocol(Protocol):
Z_FULL_FLUSH: int
Z_SYNC_FLUSH: int
# more fields…
```
It then [tries to
assign](a83597fa88/aiohttp/compression_utils.py (L131))
the module literal `zlib` to that protocol. Howefer, in typeshed, these
`zlib` members are annotated like this:
```pyi
Z_FULL_FLUSH: Final = 3
Z_SYNC_FLUSH: Final = 2
```
With the proposed change here, we now infer these as `Literal[3]` /
`Literal[2]`. Since protocol members have to be assignable both ways
(invariance), we do not consider `zlib` assignable to this protocol
anymore.
That seems rather unfortunate. Not sure who is to blame here? That
`ZLibBackendProtocol` protocol should probably not annotate the members
with `int`, given that `typeshed` doesn't use an explicit annotation
here either? But what should they do instead? Annotate those fields with
`Any`?
Or is it another case where we should consider literal-widening?
FYI @AlexWaygood
### cloud-init
```diff
cloud-init (https://github.com/canonical/cloud-init)
+ error[invalid-argument-type] tests/unittests/sources/test_smartos.py:575:32: Argument to function `oct` is incorrect: Expected `SupportsIndex`, found `int | float`
+ error[invalid-argument-type] tests/unittests/sources/test_smartos.py:593:32: Argument to function `oct` is incorrect: Expected `SupportsIndex`, found `int | float`
+ error[invalid-argument-type] tests/unittests/sources/test_smartos.py:647:35: Argument to function `oct` is incorrect: Expected `SupportsIndex`, found `int | float`
```
New false positives on expressions like
`oct(os.stat(legacy_script_f)[stat.ST_MODE])`. We now correctly infer
`stat.ST_MODE` as `Literal[1]`, because in typeshed, it is annotated as
`ST_MODE: Final = 0`. `os.stat` returns a `stat_result` which is a tuple
subclass. Accessing it at index 0 should return an `int`, but we
currently return `int | float`, presumably due to missing support for
tuple subclasses (FYI @AlexWaygood):
```pyi
class stat_result(structseq[float], tuple[int, int, int, int, int, int, int, float, float, float]):
```
In terms of `typing.Final`, things are working as expected here.
### pywin-32
Many new false positives similar to:
```diff
pywin32 (https://github.com/mhammond/pywin32)
+ error[invalid-argument-type] Pythonwin/pywin/docking/DockingBar.py:288:55: Argument to function `LoadCursor` is incorrect: Expected `PyResourceId`, found `Literal[32645]`
```
The line in question calls `win32api.LoadCursor(0, win32con.IDC_ARROW)`.
The `win32con.IDC_ARROW` symbol is annotated as [`IDC_ARROW: Final =
32512` in
typeshed](2408c028f4/stubs/pywin32/win32/lib/win32con.pyi (L594)),
but
[`LoadCursor`](2408c028f4/stubs/pywin32/win32/win32api.pyi (L197))
expects a
[`PyResourceId`](2408c028f4/stubs/pywin32/_win32typing.pyi (L1252)),
which is an empty class. So.. this seems like a true positive to me,
unless that typeshed annotation of `IDC_ARROW` is meant to imply that
the type should be `Unknown`/`Any`?
### streamlit
```diff
streamlit (https://github.com/streamlit/streamlit)
+ error[invalid-argument-type] lib/streamlit/string_util.py:163:37: Argument to bound method `translate` is incorrect: Expected `bytes`, found `bytearray`
```
This looks like a true positive? The code calls `inp.translate(None,
TEXTCHARS)`. `inp` is `bytes`, and `TEXTCHARS` is:
```py
TEXTCHARS: Final = bytearray(
{7, 8, 9, 10, 12, 13, 27} | set(range(0x20, 0x100)) - {0x7F}
)
```
~~We now infer this as `bytearray`, but `bytes.translate` [expects
`bytes` for its `delete`
parameter](2408c028f4/stdlib/builtins.pyi (L710)).
This seems to work at runtime, so maybe the typeshed annotation is
wrong?~~ (Edit: this is now fixed in typeshed)
```pycon
>>> b"abc".translate(None, bytearray(b"b"))
b'ac'
```
## rotki
```diff
+ error[invalid-return-type] rotkehlchen/chain/ethereum/modules/yearn/decoder.py:412:13: Return type does not match returned value: expected `dict[Unknown, str]`, found `dict[Unknown, Literal["yearn-v1", "yearn-v2"]]`
```
The code in question looks like
```py
def addresses_to_counterparties(self) -> dict[ChecksumEvmAddress, str]:
return dict.fromkeys(self.vaults, CPT_BEEFY_FINANCE)
```
where `CPT_BEEFY_FINANCE: Final = 'beefy_finance'. We previously
inferred the value type of the returned `dict` as `Unknown`, and now we
infer it as `Literal["beefy_finance"]`, which does not match the
annotated return type because `dict` is invariant in the value type.
```diff
+ error[invalid-argument-type] rotkehlchen/tests/unit/decoders/test_curve.py:249:9: Argument is incorrect: Expected `int`, found `FVal`
```
There are true positives that were previously silenced through the
`Unknown`.
## Test Plan
New Markdown tests
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [notify](https://redirect.github.com/notify-rs/notify) |
workspace.dependencies | minor | `8.0.0` -> `8.1.0` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>notify-rs/notify (notify)</summary>
###
[`v8.1.0`](https://redirect.github.com/notify-rs/notify/blob/HEAD/CHANGELOG.md#notify-810-2025-07-03)
[Compare
Source](https://redirect.github.com/notify-rs/notify/compare/notify-8.0.0...notify-8.1.0)
- FEATURE: added support for the [`flume`](https://docs.rs/flume) crate
- FIX: kqueue-backend: do not double unwatch top-level directory when
recursively unwatching
\[[#​683](https://redirect.github.com/notify-rs/notify/issues/683)]
- FIX: Return the crate error `PathNotFound` instead bubbling up the
std::io error
\[[#​685](https://redirect.github.com/notify-rs/notify/issues/685)]
- FIX: fix server hangs when trashing folders on Windows
\[[#​674](https://redirect.github.com/notify-rs/notify/issues/674)]
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MS4xNy4yIiwidXBkYXRlZEluVmVyIjoiNDEuMTcuMiIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
The [`DateType`](https://github.com/glyph/DateType) library has some
very large protocols in it. Currently we type-check it quite quickly,
but the current version of https://github.com/astral-sh/ruff/pull/18659
makes our execution time on this library pathologically slow. That PR
doesn't seem to have a big impact on any of our current benchmarks,
however, so it seems we have some missing coverage in this area; I
therefore propose that we add `DateType` as a benchmark.
Currently the benchmark runs pretty quickly (about half the runtime of
attrs, which is our fastest real-world benchmark currently), and the
library has 0 third-party dependencies, so the benchmark is quick to
setup.
## Test Plan
`cargo bench -p ruff_benchmark --bench=ty`
## Summary
`ty` does not understand that calls to functions which have been
annotated as having a return type of `Never` / `NoReturn` are terminal.
This PR fixes that, by adding new reachability constraints when call
expressions are seen. If the call expression evaluates to `Never`, the
code following it will be considered to be unreachable. Note that, for
adding these constraints, we only consider call expressions at the
statement level, and that too only inside function scopes. This is
because otherwise, the number of such constraints becomes too high, and
evaluating them later on during type inference results in a major
performance degradation.
Fixes https://github.com/astral-sh/ty/issues/180
## Test Plan
New mdtests.
## Ecosystem changes
This PR removes the following false-positives:
- "Function can implicitly return `None`, which is not assignable to
...".
- "Name `foo` used when possibly not defind" - because the branch in
which it is not defined has a `NoReturn` call, or when `foo` was
imported in a `try`, and the except had a `NoReturn` call.
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
Per @ntBre in https://github.com/astral-sh/ruff/pull/19111, it would be
a good idea to make the tests no longer have these syntax errors, so
this PR updates the tests and snapshots.
`B031` gave me a lot of trouble since the ending test of declaring a
function named `groupby` makes it so that inside other functions, it's
unclear which `groupby` is referred to since it depends on when the
function is called. To fix it I made each function have it's own `from
itertools import groupby` so there's no more ambiguity.
## Summary
From me and @ntBre's discussion in #19111.
This PR makes these two examples into valid code, since they previously
had `F701`-`F707` syntax errors. `SIM110` was already fixed in a
different PR, I just forgot to pull.
## Summary
Was just playing around with this, there's definitely more to do with
this function, but it seems like maybe a better option than having so
many arms in has_relation_to for (_, Callable).
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This PR is a collaboration with @AlexWaygood from our pairing session
last Friday.
The main goal here is removing `ruff_linter::message::OldDiagnostic` in
favor of
using `ruff_db::diagnostic::Diagnostic` directly. This involved a few
major steps:
- Transferring the fields
- Transferring the methods and trait implementations, where possible
- Converting some constructor methods to free functions
- Moving the `SecondaryCode` struct
- Updating the method names
I'm hoping that some of the methods, especially those in the
`expect_ruff_*`
family, won't be necessary long-term, but I avoided trying to replace
them
entirely for now to keep the already-large diff a bit smaller.
### Related refactors
Alex and I noticed a few refactoring opportunities while looking at the
code,
specifically the very similar implementations for
`create_parse_diagnostic`,
`create_unsupported_syntax_diagnostic`, and
`create_semantic_syntax_diagnostic`.
We combined these into a single generic function, which I then copied
into
`ruff_linter::message` with some small changes and a TODO to combine
them in the
future.
I also deleted the `DisplayParseErrorType` and `TruncateAtNewline` types
for
reporting parse errors. These were added in #4124, I believe to work
around the
error messages from LALRPOP. Removing these didn't affect any tests, so
I think
they were unnecessary now that we fully control the error messages from
the
parser.
On a more minor note, I factored out some calls to the
`OldDiagnostic::filename`
(now `Diagnostic::expect_ruff_filename`) function to avoid repeatedly
allocating
`String`s in some places.
### Snapshot changes
The `show_statistics_syntax_errors` integration test changed because the
`OldDiagnostic::name` method used `syntax-error` instead of
`invalid-syntax`
like in ty. I think this (`--statistics`) is one of the only places we
actually
use this name for syntax errors, so I hope this is okay. An alternative
is to
use `syntax-error` in ty too.
The other snapshot changes are from removing this code, as discussed on
[Discord](https://discord.com/channels/1039017663004942429/1228460843033821285/1388252408848847069):
34052a1185/crates/ruff_linter/src/message/mod.rs (L128-L135)
I think both of these are technically breaking changes, but they only
affect
syntax errors and are very narrow in scope, while also pretty
substantially
simplifying the refactor, so I hope they're okay to include in a patch
release.
## Test plan
Existing tests, with the adjustments mentioned above
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
This implements filtering of private symbols from stub files based on
type information as discussed in
https://github.com/astral-sh/ruff/pull/19102. It extends the previous
implementation to apply to all stub files, instead of just the
`builtins` module, and uses type information to retain private names
that are may be relevant at runtime.
Summary
--
Closes#19014 by identifying more `field` functions from `attrs`. We
already detected these when imported from `attrs` but not the `attr`
module from the same package. These functions are identical to the
`attrs` versions:
```pycon
>>> import attrs, attr
>>> attrs.field is attr.field
True
>>> attrs.Factory is attr.Factory
True
>>>
```
Test Plan
--
Regression tests based on the issue
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [pytest-incorrect-mark-parentheses-style
(PT023)](https://docs.astral.sh/ruff/rules/pytest-incorrect-mark-parentheses-style/#pytest-incorrect-mark-parentheses-style-pt023)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/48989153-6d4a-493a-a287-07f330f270bc)
```py
import pytest
@pytest.mark.foo
def test_something(): ...
```
[New example](https://play.ruff.rs/741f4d19-4607-4777-a77e-4ea6c62845e1)
```py
import pytest
@pytest.mark.foo()
def test_something(): ...
```
This just swaps the parenthesis in the "Example" and "Use instead"
sections since the default configuration is no parenthesis
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [pytest-warns-too-broad
(PT030)](https://docs.astral.sh/ruff/rules/pytest-warns-too-broad/#pytest-warns-too-broad-pt030)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/2296ae7e-c775-427a-a020-6fb25321f3f7)
```py
import pytest
def test_foo():
with pytest.warns(RuntimeWarning):
...
# empty string is also an error
with pytest.warns(RuntimeWarning, match=""):
...
```
[New example](https://play.ruff.rs/af35a482-1c2f-47ee-aff3-ff1e9fa447de)
```py
import pytest
def test_foo():
with pytest.warns(Warning):
...
# empty string is also an error
with pytest.warns(Warning, match=""):
...
```
`RuntimeWarning` is not in the default
[warns-require-match-for](https://docs.astral.sh/ruff/settings/#lint_flake8-pytest-style_warns-require-match-for)
list, while `Warning` is. The "Use instead" section was also updated
similarly
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [avoidable-escaped-quote
(Q003)](https://docs.astral.sh/ruff/rules/avoidable-escaped-quote/#avoidable-escaped-quote-q003)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/fb319d0f-8016-46a1-b6bb-42b1b054feea)
```py
foo = 'bar\'s'
```
[New example](https://play.ruff.rs/d9626561-0646-448f-9282-3f0691b90831)
```py
foo = "bar\"s"
```
The original example got overwritten by `Q000`, since double quotes is
the default config. The quotes were also switched in the "Use instead"
section.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [enumerate-for-loop
(SIM113)](https://docs.astral.sh/ruff/rules/enumerate-for-loop/#enumerate-for-loop-sim113)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/a6ef6fec-eb6b-477c-a962-616f0b8e1491)
```py
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(f"{i + 1}. {fruit}")
i += 1
```
[New example](https://play.ruff.rs/1811d608-1aa0-45d8-96dc-18105e74b8cc)
```py
fruits = ["apple", "banana", "cherry"]
i = 0
for fruit in fruits:
print(f"{i + 1}. {fruit}")
i += 1
```
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [enumerate-for-loop [if-else-block-instead-of-dict-get
(SIM401)](https://docs.astral.sh/ruff/rules/if-else-block-instead-of-dict-get/#if-else-block-instead-of-dict-get-sim401)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/635629eb-7146-45a8-9e0c-4a0aa9446ded)
```py
if "bar" in foo:
value = foo["bar"]
else:
value = 0
```
[New example](https://play.ruff.rs/a1227ec9-05c2-4a22-800d-c76cb7abe249)
```py
foo = {}
if "bar" in foo:
value = foo["bar"]
else:
value = 0
```
The "Use instead" section was also updated similarly.
The docs for `SIM401` also has another section on the preview ternary
version, but it does not seem to check that the variable is a dict
(bug?) https://play.ruff.rs/c0feada8-a7fe-43f7-b57e-c10520fdcdca
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [reimplemented-builtin
(SIM110)](https://docs.astral.sh/ruff/rules/reimplemented-builtin/#reimplemented-builtin-sim110)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/1c192e8b-13f8-4f07-8c35-9dcd516a4a02)
```py
for item in iterable:
if predicate(item):
return True
return False
```
[New example](https://play.ruff.rs/f77393ad-20b1-436f-a872-d3bccec7c829)
```py
def foo():
for item in iterable:
if predicate(item):
return True
return False
```
The "Use instead" section was also updated to reflect the change.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
The benchmark is currently very noisy (± 10%). This leads to codspeed
reports on PRs, because we often exceed the trigger threshold. This is
confusing to ty contributors who are not aware about the flakiness.
Let's disable it for now.
## Summary
This PR adds initial support for workspace diagnostics in the ty server.
Reference spec:
https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#workspace_diagnostic
This is currently implemented via the **pull diagnostics method** which
was added in the current version (3.17) and the server advertises it via
the `diagnosticProvider.workspaceDiagnostics` server capability.
**Note:** This might be a bit confusing but a workspace diagnostics is
not for a single workspace but for all the workspaces that the server
handles. These are the ones that the server received during
initialization. Currently, the ty server doesn't support multiple
workspaces so this capability is also limited to provide diagnostics
only for a single workspace (the first one if the client provided
multiple).
A new `ty.diagnosticMode` server setting is added which can be either
`workspace` (for workspace diagnostics) or `openFilesOnly` (for checking
only open files) (default). This is same as
`python.analysis.diagnosticMode` that Pyright / Pylance utilizes. In the
future, we could use the value under `python.*` namespace as fallback to
improve the experience on user side to avoid setting the value multiple
times.
Part of: astral-sh/ty#81
## Test Plan
This capability was introduced in the current LSP version (~3 years) and
the way it's implemented by various clients are a bit different. I've
provided notes on what I've noticed and what would need to be done on
our side to further improve the experience.
### VS Code
VS Code sends the `workspace/diagnostic` requests every ~2 second:
```
[Trace - 12:12:32 PM] Sending request 'workspace/diagnostic - (403)'.
[Trace - 12:12:32 PM] Received response 'workspace/diagnostic - (403)' in 2ms.
[Trace - 12:12:34 PM] Sending request 'workspace/diagnostic - (404)'.
[Trace - 12:12:34 PM] Received response 'workspace/diagnostic - (404)' in 2ms.
[Trace - 12:12:36 PM] Sending request 'workspace/diagnostic - (405)'.
[Trace - 12:12:36 PM] Received response 'workspace/diagnostic - (405)' in 2ms.
[Trace - 12:12:38 PM] Sending request 'workspace/diagnostic - (406)'.
[Trace - 12:12:38 PM] Received response 'workspace/diagnostic - (406)' in 3ms.
[Trace - 12:12:40 PM] Sending request 'workspace/diagnostic - (407)'.
[Trace - 12:12:40 PM] Received response 'workspace/diagnostic - (407)' in 2ms.
...
```
I couldn't really find any resource that explains this behavior. But,
this does mean that we'd need to implement the caching layer via the
previous result ids sooner. This will allow the server to avoid sending
all the diagnostics on every request and instead just send a response
stating that the diagnostics hasn't changed yet. This could possibly be
achieved by using the salsa ID.
If we switch from workspace diagnostics to open-files diagnostics, the
server would send the diagnostics only via the `textDocument/diagnostic`
endpoint. Here, when a document containing the diagnostic is closed, the
server would send a publish diagnostics notification with an empty list
of diagnostics to clear the diagnostics from that document. The issue is
the VS Code doesn't seem to be clearing the diagnostics in this case
even though it receives the notification. (I'm going to open an issue on
VS Code side for this today.)
https://github.com/user-attachments/assets/b0c0833d-386c-49f5-8a15-0ac9133e15ed
### Zed
Zed's implementation works by refreshing the workspace diagnostics
whenever the content of the documents are changed. This seems like a
very reasonable behavior and I was a bit surprised that VS Code didn't
use this heuristic.
https://github.com/user-attachments/assets/71c7b546-7970-434a-9ba0-4fa620647f6c
### Neovim
Neovim only recently added support for workspace diagnostics
(https://github.com/neovim/neovim/pull/34262, merged ~3 weeks ago) so
it's only available on nightly versions.
The initial support is limited and requires fetching the workspace
diagnostics manually as demonstrated in the video. It doesn't support
refreshing the workspace diagnostics either, so that would need to be
done manually as well. I'm assuming that these are just a temporary
limitation and will be implemented before the stable release.
https://github.com/user-attachments/assets/25b4a0e5-9833-4877-88ad-279904fffaf9
## Summary
This PR adds a new trait to support running a request in the background.
Currently, there exists a `BackgroundDocumentRequestHandler` trait which
is similar but is scoped to a specific document (file in an editor
context). The new trait `BackgroundRequestHandler` is not tied to a
specific document nor a specific project but it's for the entire
workspace.
This is added to support running workspace wide requests like computing
the [workspace
diagnostics](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#workspace_diagnostic)
or [workspace
symbols](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#workspace_symbol).
**Note:** There's a slight difference with what a "workspace" means
between the server and ty. Currently, there's a 1-1 relationship between
a workspace in an editor and the project database corresponding to that
workspace in ty but this could change in the future when Micha adds
support for multiple workspaces or multi-root workspaces.
The data that would be required by the request handler (based on
implementing workspace diagnostics) is the list of databases
(`ProjectDatabse`) corresponding to the projects in the workspace and
the index (`Index`) that contains the open documents. The
`WorkspaceSnapshot` represents this and is passed to the handler similar
to `DocumentSnapshot`.
## Test Plan
This is used in implementing the workspace diagnostics which is where
this is tested.
## Summary
Part of https://github.com/astral-sh/ty/issues/129
There were previously some false positives here.
## Test Plan
Updated `is_subtype_of.md` and `is_assignable_to.md`
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [snake-case-type-alias
(PYI042)](https://docs.astral.sh/ruff/rules/snake-case-type-alias/#snake-case-type-alias-pyi042)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/8fafec81-2228-4ffe-81e8-1989b724cb47)
```py
type_alias_name: TypeAlias = int
```
[New example](https://play.ruff.rs/b396746c-e6d2-423c-bc13-01a533bb0747)
```py
from typing import TypeAlias
type_alias_name: TypeAlias = int
```
Imports were also added to the "use instead" section.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This fixes the docs for [expressions-in-star-assignment
(F621)](https://docs.astral.sh/ruff/rules/expressions-in-star-assignment/#expressions-in-star-assignment-f621)
having a backslash `\` before the left shifts `<<`. I'm not sure why
this happened in the first place, as the docstring looks fine, but
putting the `<<` inside a code block fixes it. I was not able to track
down the source of the issue either. The only other rule with a `<<` is
[missing-whitespace-around-bitwise-or-shift-operator
(E227)](https://docs.astral.sh/ruff/rules/missing-whitespace-around-bitwise-or-shift-operator/#missing-whitespace-around-bitwise-or-shift-operator-e227),
which already has it in a code block.
Old docs page:

> In Python 3, no more than 1 \\<< 8 assignments are allowed before a
starred expression, and no more than 1 \\<< 24 expressions are allowed
after a starred expression.
New docs page:

> In Python 3, no more than `1 << 8` assignments are allowed before a
starred expression, and no more than `1 << 24` expressions are allowed
after a starred expression.
## Test Plan
<!-- How was it tested? -->
N/A, no tests/functionality affected.
## Summary
Allow declared-only class-level attributes to be accessed on the class:
```py
class C:
attr: int
C.attr # this is now allowed
```
closes https://github.com/astral-sh/ty/issues/384
closes https://github.com/astral-sh/ty/issues/553
## Ecosystem analysis
* We see many removed `unresolved-attribute` false-positives for code
that makes use of sqlalchemy, as expected (see changes for `prefect`)
* We see many removed `call-non-callable` false-positives for uses of
`pytest.skip` and similar, as expected
* Most new diagnostics seem to be related to cases like the following,
where we previously inferred `int` for `Derived().x`, but now we infer
`int | None`. I think this should be a
conflicting-declarations/bad-override error anyway? The new behavior may
even be preferred here?
```py
class Base:
x: int | None
class Derived(Base):
def __init__(self):
self.x: int = 1
```
## Summary
The motivation of `ScopedExpressionId` was that we have an expression
identifier that's local to a scope and, therefore, unlikely to change if
a user makes changes in another scope. A local identifier like this has
the advantage that query results may remain unchanged even if other
parts of the file change, which in turn allows Salsa to short-circuit
dependent queries.
However, I noticed that we aren't using `ScopedExpressionId` in a place
where it's important that the identifier is local. It's main use is
inside `infer` which we always run for the entire file. The one
exception to this is `Unpack` but unpack runs as part of `infer`.
Edit: The above isn't entirely correct. We used ScopedExpressionId in
TypeInference which is a query result. Now using ExpressionNodeKey does
mean that a change to the AST invalidates most if not all TypeInference
results of a single file. Salsa then has to run all dependent queries to
see if they're affected by this change even if the change was local to
another scope.
If this locality proves to be important I suggest that we create two
queries on top of TypeInference: one that returns the expression map
which is mainly used in the linter and type inference and a second that
returns all remaining fields. This should give us a similar optimization
at a much lower cost
I also considered remove `ScopedUseId` but I believe that one is still
useful because using `ExpressionNodeKey` for it instead would mean that
all `UseDefMap` change when a single AST node changes. Whether this is
important is something difficult to assess. I'm simply not familiar
enough with the `UseDefMap`. If the locality doesn't matter for the
`UseDefMap`, then a similar change could be made and `bindings_by_use`
could be changed to an `FxHashMap<UseId, Bindings>` where `UseId` is a
thin wrapper around `NodeKey`.
Closes https://github.com/astral-sh/ty/issues/721
## Summary
This PR updates Salsa to pull in Ibraheem's multithreading improvements (https://github.com/salsa-rs/salsa/pull/921).
## Performance
A small regression for single-threaded benchmarks is expected because
papaya is slightly slower than a `Mutex<FxHashMap>` in the uncontested
case (~10%). However, this shouldn't matter as much in practice because:
1. Salsa has a fast-path when only using 1 DB instance which is the
common case in production. This fast-path is not impacted by the changes
but we measure the slow paths in our benchmarks (because we use multiple
db instances)
2. Fixing the 10x slowdown for the congested case (multi threading)
outweights the downsides of a 10% perf regression for single threaded
use cases, especially considering that ty is heavily multi threaded.
## Test Plan
`cargo test`
## Summary
Extracts the vendored typeshed stubs lazily and caches them on the local
filesystem to support go-to in the LSP.
Resolves https://github.com/astral-sh/ty/issues/77.
## Summary
This PR makes the necessary changes to the server that it can request
configurations from the client using the `configuration` request.
This PR doesn't make use of the request yet. It only sets up the
foundation (mainly the coordination between client and server)
so that future PRs could pull specific settings.
I plan to use this for pulling the Python environment from the Python
extension.
Deno does something very similar to this.
## Test Plan
Tested that diagnostics are still shown.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [duplicate-literal-member
(PYI062)](https://docs.astral.sh/ruff/rules/duplicate-literal-member/#duplicate-literal-member-pyi062)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/6b00b41c-c1c5-4421-873d-fc2a143e7337)
```py
foo: Literal["a", "b", "a"]
```
[New example](https://play.ruff.rs/1aea839b-9ae8-4848-bb83-2637e1a68ce4)
```py
from typing import Literal
foo: Literal["a", "b", "a"]
```
Imports were also added to the "use instead" section.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
Follow-up to https://github.com/astral-sh/ruff/pull/19083, also log the
target names like `ty_python_semantic::module_resolver::resolver` in
`2025-07-02 10:12:20.188697000 DEBUG
ty_python_semantic::module_resolver::resolver: Adding first-party search
path '/Users/dhruv/playground/ty_server'` at trace level.
## Summary
I hoped this might fix the latest stack overflows on
https://github.com/astral-sh/ruff/pull/18659... it doesn't look like it
does, but these changes seem like they're probably correct anyway...?
## Test Plan
<!-- How was it tested? -->
https://github.com/ankitects/anki/pull/4119
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Add Anki to Who's Using Ruff (README)
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR fixes#19047 / the [isinstance-type-none
(FURB168)](https://docs.astral.sh/ruff/rules/isinstance-type-none/#isinstance-type-none-furb168)
tuple false positive by adding a check if the tuple is empty to the
code. I also noticed there was another false positive with the other
tuple check in the same function, so I fixed it the same way.
`Union[()]` is invalid at runtime with `TypeError: Cannot take a Union
of no types.`, but it is accepted by `basedpyright`
[playground](https://basedpyright.com/?pythonVersion=3.8&typeCheckingMode=all&code=GYJw9gtgBALgngBwJYDsDmUkQWEMoCqKSYKAsAFAgCmAbtQIYA2A%2BvAtQBREkoDanAJQBdQUA)
and is equivalent to `Never`, so I fixed it anyways. I'm getting on a
side tangent here, but it looks like MyPy doesn't accept it, and ty
[playground](https://play.ty.dev/c2c468b6-38e4-4dd9-a9fa-0276e843e395)
gives `@Todo`.
## Test Plan
<!-- How was it tested? -->
Added two test cases for the two false positives.
[playground](https://play.ruff.rs/a53afc21-9a1d-4b9b-9346-abfbeabeb449)
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [datetime-min-max
(DTZ901)](https://docs.astral.sh/ruff/rules/datetime-min-max/#datetime-min-max-dtz901)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/c1202727-1a18-4d3f-92a4-334ede07ed3e)
```py
datetime.max
```
[New example](https://play.ruff.rs/af2c76aa-9beb-46bc-8e27-faf53ecdbe8c)
```py
import datetime
datetime.datetime.max
```
I also added imports to the problem demonstration and use instead.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
## Summary
Remove a hack in control flow modeling that was treating `return`
statements at the end of function bodies in a special way (basically
considering the state *just before* the `return` statement as the
end-of-scope state). This is not needed anymore now that #18750 has been
merged.
In order to make this work, we now use *all reachable bindings* for
purposes of finding implicit instance attribute assignments as well as
for deferred lookups of symbols. Both would otherwise be affected by
this change:
```py
def C:
def f(self):
self.x = 1 # a reachable binding that is not visible at the end of the scope
return
```
```py
def f():
class X: ... # a reachable binding that is not visible at the end of the scope
x: "X" = X() # deferred use of `X`
return
```
Implicit instance attributes also required another change. We previously
kept track of possibly-unbound instance attributes in some cases, but we
now give up on that completely and always consider *implicit* instance
attributes to be bound if we see a reachable binding in a reachable
method. The previous behavior was somewhat inconsistent anyway because
we also do not consider attributes possibly-unbound in other scenarios:
we do not (and can not) keep track of whether or not methods are called
that define these attributes.
closes https://github.com/astral-sh/ty/issues/711
## Ecosystem analysis
I think this looks very positive!
* We see an unsurprising drop in `possibly-unbound-attribute`
diagnostics (599), mostly for classes that define attributes in `try …
except` blocks, `for` loops, or `if … else: raise …` constructs. There
might obviously also be true positives that got removed, but the vast
majority should be false positives.
* There is also a drop in `possibly-unresolved-reference` /
`unresolved-reference` diagnostics (279+13) from the change to deferred
lookups.
* Some `invalid-type-form` false positives got resolved (13), because we
can now properly look up the names in the annotations.
* There are some new *true* positives in `attrs`, since we understand
the `Attribute` annotation that was previously inferred as `Unknown`
because of a re-assignment after the class definition.
## Test Plan
The existing attributes.md test suite has sufficient coverage here.
## Summary
Temporarily modify `UseDefMapBuilder::reachability` for star imports in
order for new definitions to pick up the right reachability. This was
already working for `UseDefMapBuilder::place_states`, but not for
`UseDefMapBuilder::reachable_definitions`.
closes https://github.com/astral-sh/ty/issues/728
## Test Plan
Regression test
## Summary
Evaluate `TYPE_CHECKING` to `ALWAYS_TRUE` and `not TYPE_CHECKING` to
`ALWAYS_FALSE` during semantic index building. This is a follow-up to
https://github.com/astral-sh/ruff/pull/18998 and is in principle just a
performance optimization. We see some (favorable) ecosystem changes
because we can eliminate definitely-unreachable branches early now and
retain narrowing constraints without solving
https://github.com/astral-sh/ty/issues/690 first.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [get-size2](https://redirect.github.com/bircni/get-size2) |
workspace.dependencies | patch | `0.5.0` -> `0.5.1` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>bircni/get-size2 (get-size2)</summary>
###
[`v0.5.1`](https://redirect.github.com/bircni/get-size2/blob/HEAD/CHANGELOG.md#051---2025-06-25)
[Compare
Source](https://redirect.github.com/bircni/get-size2/compare/0.5.0...0.5.1)
##### Bug Fixes
- correctly determine size for enums
([#​24](https://redirect.github.com/bircni/get-size2/issues/24)) -
([3c5bd18](3c5bd18cac))
- Nicolas
##### Miscellaneous Chores
- add top-level `heap_size` function
([#​25](https://redirect.github.com/bircni/get-size2/issues/25)) -
([f3b5e6e](f3b5e6e38c))
- Ibraheem Ahmed
##### Build
- update to newer cargo-verset to set dependency version automatically -
([b1154e4](b1154e4572))
- Nicolas
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MC42Mi4xIiwidXBkYXRlZEluVmVyIjoiNDAuNjIuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Gates all uses of `get-size2` behind the feature `get-size` in the crate
`ruff_python_ast`. Also requires that `ruff_text_size` is pulled in with
the feature `get-size` enabled if we enable the same-named feature for
`ruff_python_ast`.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Make `UP045` ignore `Optional[NamedTuple]` as `NamedTuple` is a function
(not a proper type). Rewriting it to `NamedTuple | None` breaks at
runtime. While type checkers currently accept `NamedTuple` as a type,
they arguably shouldn't. Therefore, we outright ignore it and don't
touch or lint on it.
For a more detailed discussion, see the linked issue.
## Test Plan
Added examples to the existing tests.
## Related Issues
Fixes: https://github.com/astral-sh/ruff/issues/18619
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [call-date-today
(DTZ011)](https://docs.astral.sh/ruff/rules/call-date-today/#call-date-today-dtz011)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/b42d6aef-7777-4b3b-9f96-19132000b765)
```py
import datetime
datetime.datetime.today()
```
[New example](https://play.ruff.rs/8577c3c1-cfa8-425b-b1e1-4c53b2a48375)
```py
import datetime
datetime.date.today()
```
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [no-explicit-stacklevel
(B028)](https://docs.astral.sh/ruff/rules/no-explicit-stacklevel/#no-explicit-stacklevel-b028)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/1ee80aec-2d6e-4a3f-8e98-da82b6a9f544)
```py
warnings.warn("This is a warning")
```
[New example](https://play.ruff.rs/343593aa-38a0-4d76-a32b-5abd0a4306cc)
```py
import warnings
warnings.warn("This is a warning")
```
Imports were also added to the "use instead" section
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [batched-without-explicit-strict
(B911)](https://docs.astral.sh/ruff/rules/batched-without-explicit-strict/#batched-without-explicit-strict-b911)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/a897d96b-0749-4291-8a62-dfd4caf290a0)
```py
itertools.batched(iterable, n)
```
[New example](https://play.ruff.rs/1c1e0ab7-014c-4dc2-abed-c2cb6cd01f70)
```py
import itertools
itertools.batched(iterable, n)
```
Imports were also added to the "use instead" sections
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
## Summary
This just replaces one temporary solution to recursive protocols (the
`SelfReference` mechanism) with another one (track seen types when
recursively descending in `normalize` and replace recursive references
with `Any`). But this temporary solution can handle mutually-recursive
types, not just self-referential ones, and it's sufficient for the
primer ecosystem and some other projects we are testing on to no longer
stack overflow.
The follow-up here will be to properly handle these self-references
instead of replacing them with `Any`.
We will also eventually need cycle detection on more recursive-descent
type transformations and tests.
## Test Plan
Existing tests (including recursive-protocol tests) and primer.
Added mdtest for mutually-recursive protocols that stack-overflowed
before this PR.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR fixes rule C420's fix. The fix replaces `{...}` with
`dict....(...)`. Therefore, if there is any identifier or such right
before the fix, the fix will fuse that previous token with `dict...`.
The example in the issue is
```python
0 or{x: None for x in "x"}
# gets "fixed" to
0 ordict.fromkeys(iterable)
```
## Related Issues
Fixes: https://github.com/astral-sh/ruff/issues/18599
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#18908
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
As discussed on Slack, there was an issue with the walltime metrics with
`divan`. The issue was fixed with the latest version of `cargo-codspeed`
and `codpseed-divan-compat`:
https://github.com/CodSpeedHQ/codspeed-rust/releases/tag/v3.0.0.
This PR updates all crates related to CodSpeed. A performance increase
of the following benchmarks is expected, as now the correct metric will
be used.
```
crates/ruff_benchmark/benches/ty_walltime.rs::multithreaded[pydantic]
crates/ruff_benchmark/benches/ty_walltime.rs::small[altair]
crates/ruff_benchmark/benches/ty_walltime.rs::small[freqtrade]
crates/ruff_benchmark/benches/ty_walltime.rs::small[pydantic]
crates/ruff_benchmark/benches/ty_walltime.rs::small[tanjun]
```
Once this is merged, we will update the historic data of the affected
benchmark on the CodSpeed UI, so that no false positives will appear.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [airflow3-moved-to-provider
(AIR302)](https://docs.astral.sh/ruff/rules/airflow3-moved-to-provider/#airflow3-moved-to-provider-air302)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/1026c008-57bc-4330-93b9-141444f2a611)
```py
from airflow.auth.managers.fab.fab_auth_manage import FabAuthManager
```
[New example](https://play.ruff.rs/b690e809-a81d-4265-9fde-1494caa0b7fd)
```py
from airflow.auth.managers.fab.fab_auth_manager import FabAuthManager
fab_auth_manager_app = FabAuthManager().get_fastapi_app()
```
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Mark `UP008`'s fix safe if it won't delete comments.
## Relevant Issues
Fixes: https://github.com/astral-sh/ruff/issues/18533
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #18972
This PR makes [flask-debug-true
(S201)](https://docs.astral.sh/ruff/rules/flask-debug-true/#flask-debug-true-s201)'s
example error out-of-the-box
[Old example](https://play.ruff.rs/d5e1a013-1107-4223-9094-0e8393ad3c64)
```py
import flask
app = Flask()
app.run(debug=True)
```
[New example](https://play.ruff.rs/c4aebd2c-0448-4471-8bad-3e38ace68367)
```py
from flask import Flask
app = Flask()
app.run(debug=True)
```
Imports were also added to the `Use instead:` section to make it valid
code out-of-the-box.
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
## Summary
Simplifies literal `True` and `False` conditions to `ALWAYS_TRUE` /
`ALWAYS_FALSE` during semantic index building. This allows us to eagerly
evaluate more constraints, which should help with performance (looks
like there is a tiny 1% improvement in instrumented benchmarks), but
also allows us to eliminate definitely-unreachable branches in
control-flow merging. This can lead to better type inference in some
cases because it allows us to retain narrowing constraints without
solving https://github.com/astral-sh/ty/issues/690 first:
```py
def _(c: int | None):
if c is None:
assert False
reveal_type(c) # int, previously: int | None
```
closes https://github.com/astral-sh/ty/issues/713
## Test Plan
* Regression test for https://github.com/astral-sh/ty/issues/713
* Made sure that all ecosystem diffs trace back to removed false
positives
## Summary
This PR adds diagnostic for invalid binary operators in type
expressions. It should close https://github.com/astral-sh/ty/issues/706
if merged.
Please feel free to suggest better wordings for the diagnostic message.
## Test Plan
I modified `mdtest/annotations/invalid.md` and added a test for each
binary operator, and fixed tests that was broken by the new diagnostic.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [astral-sh/setup-uv](https://redirect.github.com/astral-sh/setup-uv) |
action | patch | `v6.3.0` -> `v6.3.1` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>astral-sh/setup-uv (astral-sh/setup-uv)</summary>
###
[`v6.3.1`](https://redirect.github.com/astral-sh/setup-uv/releases/tag/v6.3.1):
🌈 Do not warn when version not in manifest-file
[Compare
Source](https://redirect.github.com/astral-sh/setup-uv/compare/v6.3.0...v6.3.1)
##### Changes
This is a hotfix to change the warning messages that a version could not
be found in the local manifest-file to info level.
A `setup-uv` release contains a version-manifest.json file with infos in
all available `uv` releases. When a new `uv` version is released this is
not contained in this file until the file gets updated and a new
`setup-uv` release is made.
We will overhaul this process in the future but for now the spamming of
warnings is removed.
##### 🐛 Bug fixes
- Do not warn when version not in manifest-file
[@​eifinger](https://redirect.github.com/eifinger)
([#​462](https://redirect.github.com/astral-sh/setup-uv/issues/462))
##### 🧰 Maintenance
- chore: update known versions for 0.7.14
@​[github-actions\[bot\]](https://redirect.github.com/apps/github-actions)
([#​459](https://redirect.github.com/astral-sh/setup-uv/issues/459))
- Revert "Set expected cache dir drive to C: on windows
([#​451](https://redirect.github.com/astral-sh/setup-uv/issues/451))"
[@​eifinger](https://redirect.github.com/eifinger)
([#​460](https://redirect.github.com/astral-sh/setup-uv/issues/460))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MC42Mi4xIiwidXBkYXRlZEluVmVyIjoiNDAuNjIuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [clearscreen](https://redirect.github.com/watchexec/clearscreen) |
workspace.dependencies | patch | `4.0.1` -> `4.0.2` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>watchexec/clearscreen (clearscreen)</summary>
###
[`v4.0.2`](https://redirect.github.com/watchexec/clearscreen/blob/HEAD/CHANGELOG.md#v402-2025-06-25)
[Compare
Source](https://redirect.github.com/watchexec/clearscreen/compare/v4.0.1...v4.0.2)
- **Deps:** Upgrade which from 7.0.2 to 8.0.0
([#​34](https://redirect.github.com/watchexec/clearscreen/issues/34))
-
([09bc029](09bc0299f4))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MC42Mi4xIiwidXBkYXRlZEluVmVyIjoiNDAuNjIuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [ordermap](https://redirect.github.com/indexmap-rs/ordermap) |
workspace.dependencies | patch | `0.5.7` -> `0.5.8` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>indexmap-rs/ordermap (ordermap)</summary>
###
[`v0.5.8`](https://redirect.github.com/indexmap-rs/ordermap/blob/HEAD/RELEASES.md#058-2025-06-26)
[Compare
Source](https://redirect.github.com/indexmap-rs/ordermap/compare/0.5.7...0.5.8)
- Added `extract_if` methods to `OrderMap` and `OrderSet`, similar to
the
methods for `HashMap` and `HashSet` with ranges like `Vec::extract_if`.
- Added more `#[track_caller]` annotations to functions that may panic.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MC42Mi4xIiwidXBkYXRlZEluVmVyIjoiNDAuNjIuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [indexmap](https://redirect.github.com/indexmap-rs/indexmap) |
workspace.dependencies | minor | `2.9.0` -> `2.10.0` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>indexmap-rs/indexmap (indexmap)</summary>
###
[`v2.10.0`](https://redirect.github.com/indexmap-rs/indexmap/blob/HEAD/RELEASES.md#2100-2025-06-26)
[Compare
Source](https://redirect.github.com/indexmap-rs/indexmap/compare/2.9.0...2.10.0)
- Added `extract_if` methods to `IndexMap` and `IndexSet`, similar to
the
methods for `HashMap` and `HashSet` with ranges like `Vec::extract_if`.
- Added more `#[track_caller]` annotations to functions that may panic.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiI0MC42Mi4xIiwidXBkYXRlZEluVmVyIjoiNDAuNjIuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
Print the [new salsa memory usage
dumps](https://github.com/astral-sh/ruff/pull/18928) in mypy primer CI
runs to help us catch memory regressions. The numbers are rounded to the
nearest power of 1.1 (about a 5% threshold between buckets) to avoid overly sensitive diffs.
This PR extracts a lot of the complex logic in the `match_parameters`
and `check_types` methods of our call binding machinery into separate
helper types. This is setup for #18996, which will update this logic to
handle variadic arguments. To do so, it is helpful to have the
per-argument logic extracted into a method that we can call repeatedly
for each _element_ of a variadic argument.
This should be a pure refactoring, with no behavioral changes.
This PR updates our unpacking assignment logic to use the new tuple
machinery. As a result, we can now unpack variable-length tuples
correctly.
As part of this, the `TupleSpec` classes have been renamed to `Tuple`,
and can now contain any element (Rust) type, not just `Type<'db>`. The
unpacker uses a tuple of `UnionBuilder`s to maintain the types that will
be assigned to each target, as we iterate through potentially many union
elements on the rhs. We also add a new consuming iterator for tuples,
and update the `all_elements` methods to wrap the result in an enum
(similar to `itertools::Position`) letting you know which part of the
tuple each element appears in. I also added a new
`UnionBuilder::try_build`, which lets you specify a different fallback
type if the union contains no elements.
## Summary
Ensure that we correctly infer calls such as `tuple((1, 2))`,
`tuple(range(42))`, etc. Ensure that we emit errors on invalid calls
such as `tuple[int, str]()`.
## Test Plan
Mdtests
## Summary
Under preview 🧪 I've expanded rule `PYI016` to also flag type
union duplicates containing `None` and `Optional`.
## Test Plan
Examples/tests have been added. I've made sure that the existing
examples did not change unless preview is enabled.
## Relevant Issues
* https://github.com/astral-sh/ruff/issues/18508 (discussing
introducing/extending a rule to flag `Optional[None]`)
* https://github.com/astral-sh/ruff/issues/18546 (where I discussed this
addition with @AlexWaygood)
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
## Summary
I think this should be the last step before combining `OldDiagnostic`
and `ruff_db::Diagnostic`. We can't store a `NoqaCode` on
`ruff_db::Diagnostic`, so I converted the `noqa_code` field to an
`Option<String>` and then propagated this change to all of the callers.
I tried to use `&str` everywhere it was possible, so I think the
remaining `to_string` calls are necessary. I spent some time trying to
convert _everything_ to `&str` but ran into lifetime issues, especially
in the `FixTable`. Maybe we can take another look at that if it causes a
performance regression, but hopefully these paths aren't too hot. We
also avoid some `to_string` calls, so it might even out a bit too.
## Test Plan
Existing tests
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Most of the work here was doing some light refactoring to facilitate
sensible testing. That is, we don't want to list every builtin included
in most tests, so we add some structure to the completion type returned.
Tests can now filter based on whether a completion is a builtin or not.
Otherwise, builtins are found using the existing infrastructure for
`object.attr` completions (where we hard-code the module name
`builtins`).
I did consider changing the sort order based on whether a completion
suggestion was a builtin or not. In particular, it seemed like it might
be a good idea to sort builtins after other scope based completions,
but before the dunder and sunder attributes. Namely, it seems likely
that there is an inverse correlation between the size of a scope and
the likelihood of an item in that scope being used at any given point.
So it *might* be a good idea to prioritize the likelier candidates in
the completions returned.
Additionally, the number of items introduced by adding builtins is quite
large. So I wondered whether mixing them in with everything else would
become too noisy.
However, it's not totally clear to me that this is the right thing to
do. Right now, I feel like there is a very obvious lexicographic
ordering that makes "finding" the right suggestion to activate
potentially easier than if the ranking mechanism is less clear.
(Technically, the dunder and sunder attributes are not sorted
lexicographically, but I'd put forward that most folks don't have an
intuitive understanding of where `_` ranks lexicographically with
respect to "regular" letters. Moreover, since dunder and sunder
attributes are all grouped together, I think the ordering here ends up
being very obvious after even a quick glance.)
## Summary
Setting `TY_MEMORY_REPORT=full` will generate and print a memory usage
report to the CLI after a `ty check` run:
```
=======SALSA STRUCTS=======
`Definition` metadata=7.24MB fields=17.38MB count=181062
`Expression` metadata=4.45MB fields=5.94MB count=92804
`member_lookup_with_policy_::interned_arguments` metadata=1.97MB fields=2.25MB count=35176
...
=======SALSA QUERIES=======
`File -> ty_python_semantic::semantic_index::SemanticIndex`
metadata=11.46MB fields=88.86MB count=1638
`Definition -> ty_python_semantic::types::infer::TypeInference`
metadata=24.52MB fields=86.68MB count=146018
`File -> ruff_db::parsed::ParsedModule`
metadata=0.12MB fields=69.06MB count=1642
...
=======SALSA SUMMARY=======
TOTAL MEMORY USAGE: 577.61MB
struct metadata = 29.00MB
struct fields = 35.68MB
memo metadata = 103.87MB
memo fields = 409.06MB
```
Eventually, we should integrate these numbers into CI in some form. The
one limitation currently is that heap allocations in salsa structs (e.g.
interned values) are not tracked, but memoized values should have full
coverage. We may also want a peak memory usage counter (that accounts
for non-salsa memory), but that is relatively simple to profile manually
(e.g. `time -v ty check`) and would require a compile-time option to
avoid runtime overhead.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR also supresses the fix if the assignment expression target
shadows one of the lambda's parameters.
Fixes#18675
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Add regression tests.
<!-- How was it tested? -->
## Summary
Part of #15584
This PR adds a fix safety section to [fast-api-non-annotated-dependency
(FAST002)](https://docs.astral.sh/ruff/rules/fast-api-non-annotated-dependency/#fast-api-non-annotated-dependency-fast002).
It also re-words the availability section since I found it confusing.
The lint/fix was added in #11579 as always unsafe.
No reasoning is given in the original PR/code as to why this was chosen.
Example of why the fix is unsafe:
https://play.ruff.rs/3bd0566e-1ef6-4cec-ae34-3b07cd308155
```py
from fastapi import Depends, FastAPI, Query
app = FastAPI()
# Fix will remove the parameter default value
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
# Fix will delete comment and change default parameter value
@app.get("/items/")
async def read_items_1(q: str = Query( # This comment will be deleted
default="rick")):
return q
```
After fixing both instances of `FAST002`:
```py
from fastapi import Depends, FastAPI, Query
from typing import Annotated
app = FastAPI()
# Fix will remove the parameter default value
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
# Fix will delete comment and change default parameter value
@app.get("/items/")
async def read_items_1(q: Annotated[str, Query()] = "rick"):
return q
```
It turns out that astral-sh/ty#18692 also fixedastral-sh/ty#203. This
PR adds a regression test for it. (Locally, I "unfixed" the bug and
confirmed that this is actually a regression test.)
Fixesastral-sh/ty#203
It turns out that `annotate-snippets` doesn't do a great job of
consistently handling tabs. The intent of the implementation is clearly
to expand tabs into 4 ASCII whitespace characters. But there are a few
places where the column computation wasn't taking this expansion into
account. In particular, the `unicode-width` crate returns `None` for a
`\t` input, and `annotate-snippets` would in turn treat this as either
zero columns or one column. Both are wrong.
In patching this, it caused one of the existing `annotate-snippets`
tests to fail. I spent a fair bit of time on it trying to fix it before
coming to the conclusion that the test itself was wrong. In particular,
the annotation ranges are 4 bytes off. However, when the range was
wrong, the buggy code was rendering the example as intended since `\t`
characters were treated as taking up zero columns of space. Now that
they are correctly computed as taking up 4 columns of space, the offsets
of the test needed to be adjusted.
Fixes#670
## Summary
Adds a new micro-benchmark as a regression test for
https://github.com/astral-sh/ty/issues/627.
## Test Plan
Ran the benchmark on the parent commit of
89d915a1e3,
and verified that it took > 1s, while it takes ~10 ms after the fix.
## Summary
Format conflicting declared types as
```
`str`, `int` and `bytes`
```
Thanks to @AlexWaygood for the initial draft.
@dcreager, looking forward to your one-character follow-up PR.
## Summary
This PR includes a behavioral change to how we infer types for public
uses of symbols within a module. Where we would previously use the type
that a use at the end of the scope would see, we now consider all
reachable bindings and union the results:
```py
x = None
def f():
reveal_type(x) # previously `Unknown | Literal[1]`, now `Unknown | None | Literal[1]`
f()
x = 1
f()
```
This helps especially in cases where the the end of the scope is not
reachable:
```py
def outer(x: int):
def inner():
reveal_type(x) # previously `Unknown`, now `int`
raise ValueError
```
This PR also proposes to skip the boundness analysis of public uses.
This is consistent with the "all reachable bindings" strategy, because
the implicit `x = <unbound>` binding is also always reachable, and we
would have to emit "possibly-unresolved" diagnostics for every public
use otherwise. Changing this behavior allows common use-cases like the
following to type check without any errors:
```py
def outer(flag: bool):
if flag:
x = 1
def inner():
print(x) # previously: possibly-unresolved-reference, now: no error
```
closes https://github.com/astral-sh/ty/issues/210
closes https://github.com/astral-sh/ty/issues/607
closes https://github.com/astral-sh/ty/issues/699
## Follow up
It is now possible to resolve the following TODO, but I would like to do
that as a follow-up, because it requires some changes to how we treat
implicit attribute assignments, which could result in ecosystem changes
that I'd like to see separately.
315fb0f3da/crates/ty_python_semantic/src/semantic_index/builder.rs (L1095-L1117)
## Ecosystem analysis
[**Full report**](https://shark.fish/diff-public-types.html)
* This change obviously removes a lot of `possibly-unresolved-reference`
diagnostics (7818) because we do not analyze boundness for public uses
of symbols inside modules anymore.
* As the primary goal here, this change also removes a lot of
false-positive `unresolved-reference` diagnostics (231) in scenarios
like this:
```py
def _(flag: bool):
if flag:
x = 1
def inner():
x
raise
```
* This change also introduces some new false positives for cases like:
```py
def _():
x = None
x = "test"
def inner():
x.upper() # Attribute `upper` on type `Unknown | None | Literal["test"]`
is possibly unbound
```
We have test cases for these situations and it's plausible that we can
improve this in a follow-up.
## Test Plan
New Markdown tests
## Summary
This function is huge, and hugely indented. This PR breaks most of it
out into two helper functions: `KnownFunction::check_call()` and
`KnownClass::check_call`.
My immediate motivation is that we need to add yet more special cases to
this function in order to properly handle `tuple` instantiations and
instantiations of tuple subclasses. But I really don't relish the
thought of doing that with the function's current structure 😆
## Test Plan
Existing tests all pass. No new ones are added; this is a pure refactor
that should have no functional change.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Here's the part that was split out of #18906. I wanted to move these
into the rule files since the rest of the rules in
`deferred_scope`/`statement` have that same structure of implementations
being in the rule definition file. It also resolves the dilemma of where
to put the comment, at least for these rules.
## Test Plan
<!-- How was it tested? -->
N/A, no test/functionality affected
Summary
--
Closes#18849 by adding a `## Known issues` section describing the
potential performance issues when fixing nested iterables. I also
deleted the comment check since the fix is already unsafe and added a
note to the `## Fix safety` docs.
Test Plan
--
Existing tests, updated to allow a fix when comments are present since
the fix is already unsafe.
Summary
--
This PR resolves the easiest part of
https://github.com/astral-sh/ruff/issues/18502 by adding an autofix that
just adds
`from __future__ import annotations` at the top of the file, in the same
way
as FA102, which already has an identical unsafe fix.
Test Plan
--
Existing snapshots, updated to add the fixes.
## Summary
Add type narrowing inside comprehensions:
```py
def _(xs: list[int | None]):
[reveal_type(x) for x in xs if x is not None] # revealed: int
```
closes https://github.com/astral-sh/ty/issues/680
## Test Plan
* New Markdown tests
* Made sure the example from https://github.com/astral-sh/ty/issues/680
now checks without errors
* Made sure that all removed ecosystem diagnostics were actually false
positives
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
From @ntBre
https://github.com/astral-sh/ruff/pull/18906#discussion_r2162843366 :
> This could be a good target for a follow-up PR, but we could fold
these `if checker.is_rule_enabled { checker.report_diagnostic` checks
into calls to `checker.report_diagnostic_if_enabled`. I didn't notice
these when adding that method.
>
> Also, the docs on `Checker::report_diagnostic_if_enabled` and
`LintContext::report_diagnostic_if_enabled` are outdated now that the
`Rule` conversion is basically free 😅
>
> No pressure to take on this refactor, just an idea if you're
interested!
This PR folds those calls. I also updated the doc comments by copying
from `report_diagnostic`.
Note: It seems odd to me that the doc comment for `Checker` says
`Diagnostic` while `LintContext` says `OldDiagnostic`, not sure if that
needs a bigger docs change to fix the inconsistency.
<details>
<summary>Python script to do the changes</summary>
This script assumes it is placed in the top level `ruff` directory (ie
next to `.git`/`crates`/`README.md`)
```py
import re
from copy import copy
from pathlib import Path
ruff_crates = Path(__file__).parent / "crates"
for path in ruff_crates.rglob("**/*.rs"):
with path.open(encoding="utf-8", newline="") as f:
original_content = f.read()
if "is_rule_enabled" not in original_content or "report_diagnostic" not in original_content:
continue
original_content_position = 0
changed_content = ""
for match in re.finditer(r"(?m)(?:^[ \n]*|(?<=(?P<else>else )))if[ \n]+checker[ \n]*\.is_rule_enabled\([ \n]*Rule::\w+[ \n]*\)[ \n]*{[ \n]*checker\.report_diagnostic\(", original_content):
# Content between last match and start of this one is unchanged
changed_content += original_content[original_content_position:match.start()]
# If this was an else if, a { needs to be added at the start
if match.group("else"):
changed_content += "{"
# This will result in bad formatting, but the precommit cargo format will handle it
changed_content += "checker.report_diagnostic_if_enabled("
# Depth tracking would fail if a string/comment included a { or }, but unlikely given the context
depth = 1
position = match.end()
while depth > 0:
if original_content[position] == "{":
depth += 1
if original_content[position] == "}":
depth -= 1
position += 1
# pos - 1 is the closing }
changed_content += original_content[match.end():position - 1]
# If this was an else if, a } needs to be added at the end
if match.group("else"):
changed_content += "}"
# Skip the closing }
original_content_position = position
if original_content[original_content_position] == "\n":
# If the } is followed by a \n, also skip it for better formatting
original_content_position += 1
# Add remaining content between last match and file end
changed_content += original_content[original_content_position:]
with path.open("w", encoding="utf-8", newline="") as f:
f.write(changed_content)
```
</details>
## Test Plan
<!-- How was it tested? -->
N/A, no tests/functionality affected.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
While making some of my other changes, I noticed some of the lints were
missing comments with their lint code/had the wrong numbered lint code.
These comments are super useful since they allow for very easily and
quickly finding the source code of a lint, so I decided to try and
normalize them.
Most of them were fairly straightforward, just adding a doc
comment/comment in the appropriate place.
I decided to make all of the `Pylint` rules have the `PL` prefix.
Previously it was split between no prefix and having prefix, but I
decided to normalize to with prefix since that's what's in the docs, and
the with prefix will show up on no prefix searches, while the reverse is
not true.
I also ran into a lot of rules with implementations in "non-standard"
places (where "standard" means inside a file matching the glob
`crates/ruff_linter/rules/*/rules/**/*.rs` and/or the same rule file
where the rule `struct`/`ViolationMetadata` is defined).
I decided to move all the implementations out of
`crates/ruff_linter/src/checkers/ast/analyze/deferred_scopes.rs` and
into their own files, since that is what the rest of the rules in
`deferred_scopes.rs` did, and those were just the outliers.
There were several rules which I did not end up moving, which you can
see as the extra paths I had to add to my python code besides the
"standard" glob. These rules are generally the error-type rules that
just wrap an error from the parser, and have very small
implementations/are very tightly linked to the module they are in, and
generally every rule of that type was implemented in module instead of
in the "standard" place.
Resolving that requires answering a question I don't think I'm equipped
to handle: Is the point of these comments to give quick access to the
rule definition/docs, or the rule implementation? For all the rules with
implementations in the "standard" location this isn't a problem, as they
are the same, but it is an issue for all of these error type rules. In
the end I chose to leave the implementations where they were, but I'm
not sure if that was the right choice.
<details>
<summary>Python script I wrote to find missing comments</summary>
This script assumes it is placed in the top level `ruff` directory (ie
next to `.git`/`crates`/`README.md`)
```py
import re
from copy import copy
from pathlib import Path
linter_to_code_prefix = {
"Airflow": "AIR",
"Eradicate": "ERA",
"FastApi": "FAST",
"Flake82020": "YTT",
"Flake8Annotations": "ANN",
"Flake8Async": "ASYNC",
"Flake8Bandit": "S",
"Flake8BlindExcept": "BLE",
"Flake8BooleanTrap": "FBT",
"Flake8Bugbear": "B",
"Flake8Builtins": "A",
"Flake8Commas": "COM",
"Flake8Comprehensions": "C4",
"Flake8Copyright": "CPY",
"Flake8Datetimez": "DTZ",
"Flake8Debugger": "T10",
"Flake8Django": "DJ",
"Flake8ErrMsg": "EM",
"Flake8Executable": "EXE",
"Flake8Fixme": "FIX",
"Flake8FutureAnnotations": "FA",
"Flake8GetText": "INT",
"Flake8ImplicitStrConcat": "ISC",
"Flake8ImportConventions": "ICN",
"Flake8Logging": "LOG",
"Flake8LoggingFormat": "G",
"Flake8NoPep420": "INP",
"Flake8Pie": "PIE",
"Flake8Print": "T20",
"Flake8Pyi": "PYI",
"Flake8PytestStyle": "PT",
"Flake8Quotes": "Q",
"Flake8Raise": "RSE",
"Flake8Return": "RET",
"Flake8Self": "SLF",
"Flake8Simplify": "SIM",
"Flake8Slots": "SLOT",
"Flake8TidyImports": "TID",
"Flake8Todos": "TD",
"Flake8TypeChecking": "TC",
"Flake8UnusedArguments": "ARG",
"Flake8UsePathlib": "PTH",
"Flynt": "FLY",
"Isort": "I",
"McCabe": "C90",
"Numpy": "NPY",
"PandasVet": "PD",
"PEP8Naming": "N",
"Perflint": "PERF",
"Pycodestyle": "",
"Pydoclint": "DOC",
"Pydocstyle": "D",
"Pyflakes": "F",
"PygrepHooks": "PGH",
"Pylint": "PL",
"Pyupgrade": "UP",
"Refurb": "FURB",
"Ruff": "RUF",
"Tryceratops": "TRY",
}
ruff = Path(__file__).parent / "crates"
ruff_linter = ruff / "ruff_linter" / "src"
code_to_rule_name = {}
with open(ruff_linter / "codes.rs") as codes_file:
for linter, code, rule_name in re.findall(
# The (?<! skips ruff test rules
# Only Preview|Stable rules are checked
r"(?<!#\[cfg\(any\(feature = \"test-rules\", test\)\)\]\n) \((\w+), \"(\w+)\"\) => \(RuleGroup::(?:Preview|Stable), [\w:]+::(\w+)\)",
codes_file.read(),
):
code_to_rule_name[linter_to_code_prefix[linter] + code] = (rule_name, [])
ruff_linter_rules = ruff_linter / "rules"
for rule_file_path in [
*ruff_linter_rules.rglob("*/rules/**/*.rs"),
ruff / "ruff_python_parser" / "src" / "semantic_errors.rs",
ruff_linter / "pyproject_toml.rs",
ruff_linter / "checkers" / "noqa.rs",
ruff_linter / "checkers" / "ast" / "mod.rs",
ruff_linter / "checkers" / "ast" / "analyze" / "unresolved_references.rs",
ruff_linter / "checkers" / "ast" / "analyze" / "expression.rs",
ruff_linter / "checkers" / "ast" / "analyze" / "statement.rs",
]:
with open(rule_file_path, encoding="utf-8") as f:
rule_file_content = f.read()
for code, (rule, _) in copy(code_to_rule_name).items():
if rule in rule_file_content:
if f"// {code}" in rule_file_content or f", {code}" in rule_file_content:
del code_to_rule_name[code]
else:
code_to_rule_name[code][1].append(rule_file_path)
for code, rule in code_to_rule_name.items():
print(code, rule[0])
for path in rule[1]:
print(path)
```
</details>
## Test Plan
<!-- How was it tested? -->
N/A, no tests/functionality affected.
## Summary
Having a recursive type method to check whether a type is fully static
is inefficient, unnecessary, and makes us overly strict about subtyping
relations.
It's inefficient because we end up re-walking the same types many times
to check for fully-static-ness.
It's unnecessary because we can check relations involving the dynamic
type appropriately, depending whether the relation is subtyping or
assignability.
We use the subtyping relation to simplify unions and intersections. We
can usefully consider that `S <: T` for gradual types also, as long as
it remains true that `S | T` is equivalent to `T` and `S & T` is
equivalent to `S`.
One conservative definition (implemented here) that satisfies this
requirement is that we consider `S <: T` if, for every possible pair of
materializations `S'` and `T'`, `S' <: T'`. Or put differently the top
materialization of `S` (`S+` -- the union of all possible
materializations of `S`) is a subtype of the bottom materialization of
`T` (`T-` -- the intersection of all possible materializations of `T`).
In the most basic cases we can usefully say that `Any <: object` and
that `Never <: Any`, and we can handle more complex cases inductively
from there.
This definition of subtyping for gradual subtypes is not reflexive
(`Any` is not a subtype of `Any`).
As a corollary, we also remove `is_gradual_equivalent_to` --
`is_equivalent_to` now has the meaning that `is_gradual_equivalent_to`
used to have. If necessary, we could restore an
`is_fully_static_equivalent_to` or similar (which would not do an
`is_fully_static` pre-check of the types, but would instead pass a
relation-kind enum down through a recursive equivalence check, similar
to `has_relation_to`), but so far this doesn't appear to be necessary.
Credit to @JelleZijlstra for the observation that `is_fully_static` is
unnecessary and overly restrictive on subtyping.
There is another possible definition of gradual subtyping: instead of
requiring that `S+ <: T-`, we could instead require that `S+ <: T+` and
`S- <: T-`. In other words, instead of requiring all materializations of
`S` to be a subtype of every materialization of `T`, we just require
that every materialization of `S` be a subtype of _some_ materialization
of `T`, and that every materialization of `T` be a supertype of some
materialization of `S`. This definition also preserves the core
invariant that `S <: T` implies that `S | T = T` and `S & T = S`, and it
restores reflexivity: under this definition, `Any` is a subtype of
`Any`, and for any equivalent types `S` and `T`, `S <: T` and `T <: S`.
But unfortunately, this definition breaks transitivity of subtyping,
because nominal subclasses in Python use assignability ("consistent
subtyping") to define acceptable overrides. This means that we may have
a class `A` with `def method(self) -> Any` and a subtype `B(A)` with
`def method(self) -> int`, since `int` is assignable to `Any`. This
means that if we have a protocol `P` with `def method(self) -> Any`, we
would have `B <: A` (from nominal subtyping) and `A <: P` (`Any` is a
subtype of `Any`), but not `B <: P` (`int` is not a subtype of `Any`).
Breaking transitivity of subtyping is not tenable, so we don't use this
definition of subtyping.
## Test Plan
Existing tests (modified in some cases to account for updated
semantics.)
Stable property tests pass at a million iterations:
`QUICKCHECK_TESTS=1000000 cargo test -p ty_python_semantic -- --ignored
types::property_tests::stable`
### Changes to property test type generation
Since we no longer have a method of categorizing built types as
fully-static or not-fully-static, I had to add a previously-discussed
feature to the property tests so that some tests can build types that
are known by construction to be fully static, because there are still
properties that only apply to fully-static types (for example,
reflexiveness of subtyping.)
## Changes to handling of `*args, **kwargs` signatures
This PR "discovered" that, once we allow non-fully-static types to
participate in subtyping under the above definitions, `(*args: Any,
**kwargs: Any) -> Any` is now a subtype of `() -> object`. This is true,
if we take a literal interpretation of the former signature: all
materializations of the parameters `*args: Any, **kwargs: Any` can
accept zero arguments, making the former signature a subtype of the
latter. But the spec actually says that `*args: Any, **kwargs: Any`
should be interpreted as equivalent to `...`, and that makes a
difference here: `(...) -> Any` is not a subtype of `() -> object`,
because (unlike a literal reading of `(*args: Any, **kwargs: Any)`),
`...` can materialize to _any_ signature, including a signature with
required positional arguments.
This matters for this PR because it makes the "any two types are both
assignable to their union" property test fail if we don't implement the
equivalence to `...`. Because `FunctionType.__call__` has the signature
`(*args: Any, **kwargs: Any) -> Any`, and if we take that at face value
it's a subtype of `() -> object`, making `FunctionType` a subtype of `()
-> object)` -- but then a function with a required argument is also a
subtype of `FunctionType`, but not a subtype of `() -> object`. So I
went ahead and implemented the equivalence to `...` in this PR.
## Ecosystem analysis
* Most of the ecosystem report are cases of improved union/intersection
simplification. For example, we can now simplify a union like `bool |
(bool & Unknown) | Unknown` to simply `bool | Unknown`, because we can
now observe that every possible materialization of `bool & Unknown` is
still a subtype of `bool` (whereas before we would set aside `bool &
Unknown` as a not-fully-static type.) This is clearly an improvement.
* The `possibly-unresolved-reference` errors in sockeye, pymongo,
ignite, scrapy and others are true positives for conditional imports
that were formerly silenced by bogus conflicting-declarations (which we
currently don't issue a diagnostic for), because we considered two
different declarations of `Unknown` to be conflicting (we used
`is_equivalent_to` not `is_gradual_equivalent_to`). In this PR that
distinction disappears and all equivalence is gradual, so a declaration
of `Unknown` no longer conflicts with a declaration of `Unknown`, which
then results in us surfacing the possibly-unbound error.
* We will now issue "redundant cast" for casting from a typevar with a
gradual bound to the same typevar (the hydra-zen diagnostic). This seems
like an improvement.
* The new diagnostics in bandersnatch are interesting. For some reason
primer in CI seems to be checking bandersnatch on Python 3.10 (not yet
sure why; this doesn't happen when I run it locally). But bandersnatch
uses `enum.StrEnum`, which doesn't exist on 3.10. That makes the `class
SimpleDigest(StrEnum)` a class that inherits from `Unknown` (and
bypasses our current TODO handling for accessing attributes on enum
classes, since we don't recognize it as an enum class at all). This PR
improves our understanding of assignability to classes that inherit from
`Any` / `Unknown`, and we now recognize that a string literal is not
assignable to a class inheriting `Any` or `Unknown`.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
I saw the smallest typo while familiarizing myself with the playground,
it bothered me so much I just had to make a PR for it 😂
## Summary
This PR expands PGH005 to also check for AsyncMock methods in the same
vein. E.g., currently `assert mock.not_called` is linted. This PR adds
the corresponding async assertions `assert mock.not_awaited()`.
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
/closes #2331
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
update snapshots
<!-- How was it tested? -->
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
This commit does a small refactor to combine the file and
cursor offset into a single type. I think this makes it
clearer that even if there are multiple files in the cursor
test, this one in particular corresponds to the file that
contains the `<CURSOR>` marker.
This doesn't change any functionality of the cursor tests, but does
re-arrange the code a bit. Firstly, it's now in a builder. And secondly,
there's an API to add multiple files to the test (but exactly one must
have a `<CURSOR>` marker).
We achieve this by setting the "sort text" field of every completion.
Since we are trying to be smart about the order, we want the client to
respect our order.
Prior to this change, VS Code was re-sorting completions in
lexicographic order. This in turn resulted in dunder attributes
appearing before "normal" attributes.
## Summary
This PR removes the last two places we were using `NoqaCode::rule` in
`linter.rs` (see
https://github.com/astral-sh/ruff/pull/18391#discussion_r2154637329 and
https://github.com/astral-sh/ruff/pull/18391#discussion_r2154649726) by
checking whether fixes are actually desired before adding them to a
`DiagnosticGuard`. I implemented this by storing a `Violation`'s `Rule`
on the `DiagnosticGuard` so that we could check if it was enabled in the
embedded `LinterSettings` when trying to set a fix.
All of the corresponding `set_fix` methods on `OldDiagnostic` were now
unused (except in tests where I just set `.fix` directly), so I moved
these to the guard instead of keeping both sets.
The very last place where we were using `NoqaCode::rule` was in the
cache. I just reverted this to parsing the `Rule` from the name. I had
forgotten to update the comment there anyway. Hopefully this doesn't
cause too much of a perf hit.
In terms of binary size, we're back down almost to where `main` was two
days ago
(https://github.com/astral-sh/ruff/pull/18391#discussion_r2155034320):
```
41,559,344 bytes for main 2 days ago
41,669,840 bytes for #18391
41,653,760 bytes for main now (after #18391 merged)
41,602,224 bytes for this branch
```
Only 43 kb up, but that shouldn't all be me this time :)
## Test Plan
Existing tests and benchmarks on this PR
## Summary
I tried running `py-fuzzer` using executables in the current working
directory, but that failed with:
```
▶ uvx --from ./python/py-fuzzer --reinstall fuzz --test-executable ./ty_feature --bin=ty --baseline-executable ./ty_main --only-new-bugs 0-500
Usage: fuzz [-h] [--only-new-bugs] [--quiet] [--test-executable TEST_EXECUTABLE] [--baseline-executable BASELINE_EXECUTABLE] --bin {ruff,ty} seeds [seeds ...]
fuzz: error: Bad argument passed to `--baseline-executable`: no such file or executable PosixPath('ty_main')
"Bad argument passed to `--baseline-executable`: no such file or executable PosixPath('ty_main')"
```
Using `.absolute()` on the `Path` fixes this.
## Test Plan
Successful `py-fuzzer` run with the invocation above.
## Summary
Ref:
https://github.com/astral-sh/ruff/issues/14820#issuecomment-2996690681
This PR fixes a bug where virtual paths or any paths that doesn't exists
on the file system weren't being considered for checking inclusion /
exclusion. This was because the logic used `file_path` which returns
`None` for those path. This PR fixes that by using the
`virtual_file_path` method that returns a `Path` corresponding to the
actual file on disk or any kind of virtual path.
This should ideally just fix the above linked issue by way of excluding
the documents representing the interactive window because they aren't in
the inclusion set. It failed only on Windows previously because the file
path construction would fail and then Ruff would default to including
all the files.
## Test Plan
On my machine, the `.interactive` paths are always excluded so I'm using
the inclusion set instead:
```json
{
"ruff.nativeServer": "on",
"ruff.path": ["/Users/dhruv/work/astral/ruff/target/debug/ruff"],
"ruff.configuration": {
"extend-include": ["*.interactive"]
}
}
```
The diagnostics are shown for both the file paths and the interactive
window:
<img width="1727" alt="Screenshot 2025-06-24 at 14 56 40"
src="https://github.com/user-attachments/assets/d36af96a-777e-4367-8acf-4d9c9014d025"
/>
And, the logs:
```
2025-06-24 14:56:26.478275000 DEBUG notification{method="notebookDocument/didChange"}: Included path via `extend-include`: /Interactive-1.interactive
```
And, when using `ruff.exclude` via:
```json
{
"ruff.exclude": ["*.interactive"]
}
```
With logs:
```
2025-06-24 14:58:41.117743000 DEBUG notification{method="notebookDocument/didChange"}: Ignored path via `exclude`: /Interactive-1.interactive
```
## Summary
Previously, the checks for implicit attribute assignments didn't
properly account for method decorators. This PR fixes that by:
- Adding a decorator check in `implicit_instance_attribute`. This allows
it to filter out methods with mismatching decorators when analyzing
attribute assignments.
- Adding attribute search for implicit class attributes: if an attribute
can't be found directly in the class body, the
`ClassLiteral::own_class_member` function will now search in
classmethods.
- Adding `staticmethod`: it has been added into `KnownClass` and
together with the new decorator check, it will no longer expose
attributes when the assignment target name is the same as the first
method name.
If accepted, it should fix https://github.com/astral-sh/ty/issues/205
and https://github.com/astral-sh/ty/issues/207.
## Test Plan
This is tested with existing mdtest suites and is able to get most of
the TODO marks for implicit assignments in classmethods and
staticmethods removed.
However, there's one specific test case I failed to figure out how to
correctly resolve:
b279508bdc/crates/ty_python_semantic/resources/mdtest/attributes.md (L754-L755)
I tried to add `instance_member().is_unbound()` check in this [else
branch](b279508bdc/crates/ty_python_semantic/src/types/infer.rs (L3299-L3301))
but it causes tests with class attributes defined in class body to fail.
While it's possible to implicitly add `ClassVar` to qualifiers to make
this assignment fail and keep everything else passing, it doesn't feel
like the right solution.
## Summary
This PR fixesastral-sh/ty#185 by avoiding to infer the value expression
for an unpacking.
This is done simply by only inferring the value expression in a
non-unpacking branch for assignment statement, for statement, with
statement and comprehensions.
This is a simpler alternative to
https://github.com/astral-sh/ruff/pull/18890 which I only realized in
hindsight! Ideally, the solution would to consider the "unpack" as it's
own region and do all of the inference of every expressions involved in
an unpacking inside the unpack query and then merge the results in the
outer query. This would require access to the `Unpack` ingredient which
is stored on the `Definition`. And, this would require create the said
`Definition`s for all attributes and subscript expressions. It does
simplify the target inference logic by streamlining it into a single
`infer_target` method instead of the `infer_target`/`infer_target_impl`
split.
Additionally, #18890 also solves a couple of TODOs around raising errors
around attribute / subscript assignment.
## Test Plan
Update the existing test, go through a couple of ecosystem diagnostic.
## Summary
Resolves#18165
Added pattern `["sys", "version_info", "major"]` to the existing matches
for `sys.version_info` to ensure consistent handling of both the base
object and its major version attribute.
## Test Plan
`cargo nextest run` and `cargo insta test`
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
/closes #17424
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
## Summary
Note this modifies the diagnostics a bit. Previously performing
subscript access on something like `NotSubscriptable1 |
NotSubscriptable2` would report the full type as not being
subscriptable:
```
[non-subscriptable] "Cannot subscript object of type `NotSubscriptable1 | NotSubscriptable2` with no `__getitem__` method"
```
Now each erroneous constituent has a separate error:
```
[non-subscriptable] "Cannot subscript object of type `NotSubscriptable2` with no `__getitem__` method"
[non-subscriptable] "Cannot subscript object of type `NotSubscriptable1` with no `__getitem__` method"
```
Closes https://github.com/astral-sh/ty/issues/625
## Test Plan
mdtest
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
There were two main challenges in this PR.
The first was mostly just figuring out how to get the symbols
corresponding to `module`. It turns out that we do this in a couple
of places in ty already, but through different means. In one approach,
we use [`exported_names`]. In another approach, we get a `Type`
corresponding to the module. We take the latter approach here, which is
consistent with how we do completions elsewhere. (I looked into
factoring this logic out into its own function, but it ended up being
pretty constrained. e.g., There's only one other place where we want to
go from `ast::StmtImportFrom` to a module `Type`, and that code also
wants the module name.)
The second challenge was recognizing the `from module import <CURSOR>`
pattern in the code. I initially started with some fixed token patterns
to get a proof of concept working. But I ended up switching to mini
state machine over tokens. I looked at the parser for `StmtImportFrom`
to determine what kinds of tokens we can expect.
[`exported_names`]:
23a3b6ef23/crates/ty_python_semantic/src/semantic_index/re_exports.rs (L47)
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
The fix would create a syntax error if there wasn't a space between the
`in` keyword and the following expression.
For example:
```python
for country, stars in(zip)(flag_stars.keys(), flag_stars.values()):...
```
I also noticed that the tests for `SIM911` were note being run, so I
fixed that.
Fixes#18776
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Add regression test
<!-- How was it tested? -->
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR fixes `PLC2801` autofix creating a syntax error due to lack of
padding if it is directly after a keyword.
Fixes https://github.com/astral-sh/ruff/issues/18813
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Add regression test
<!-- How was it tested? -->
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #15584
This adds a `Fix safety` section to [useless-object-inheritance
(UP004)](https://docs.astral.sh/ruff/rules/useless-object-inheritance/#useless-object-inheritance-up004)
I could not track down the original PR as this rule is so old it has
gone through several large ruff refactors.
No reasoning is given on the unsafety in the PR/code.
The unsafety is determined here:
f24e650dfd/crates/ruff_linter/src/rules/pyupgrade/rules/useless_class_metaclass_type.rs (L76-L80)
Unsafe fix demonstration:
[playground](https://play.ruff.rs/12b24eb4-d7a5-4ae0-93bb-492d64967ae3)
```py
class A( # will be deleted
object
):
...
```
## Test Plan
<!-- How was it tested? -->
N/A, no tests/functionality affected
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #15584
This adds a `Fix safety` section to [unnecessary-future-import
(UP010)](https://docs.astral.sh/ruff/rules/unnecessary-future-import/#unnecessary-future-import-up010)
The unsafety is determined here:
d9266284df/crates/ruff_linter/src/rules/pyupgrade/rules/unnecessary_future_import.rs (L128-L132)
Unsafe code example:
[playground](https://play.ruff.rs/c07d8c41-9ab8-4b86-805b-8cf482d450d9)
```py
from __future__ import (print_function,# ...
__annotations__) # ...
```
Edit: It looks like there was already a PR for this, #17490, but I
missed it since they said `UP029` instead of `UP010` :/
## Test Plan
<!-- How was it tested? -->
N/A, no tests/functionality affected
## Summary
Fixes `analyze.direction` to use kebab-case for the variant names.
Fixes https://github.com/astral-sh/ruff/issues/18887
## Test Plan
Created a `ruff.toml` and tested that both `dependents` and `Dependents`
were accepted
## Summary
As far as I can tell, the two existing tests did the exact same thing.
Remove the redundant test, and add tests for all combinations of
declared/not-declared and local/"public" use of the name.
Proposing this as a separate PR before the behavior might change via
https://github.com/astral-sh/ruff/pull/18750
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
I've also found another bug while fixing this, where the diagnostic
would not trigger if the `len` call argument variable was shadowed. This
fixed a few false negatives in the test cases.
Example:
```python
fruits = []
fruits = []
if len(fruits): # comment
...
```
Fixes#18811Fixes#18812
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Add regression test
<!-- How was it tested? -->
---------
Co-authored-by: Charlie Marsh <crmarsh416@gmail.com>
## Summary
The code in the `Variable` branch of
`VariableLengthTupleSpec::has_relation_to` made the incorrect assumption
that if you zip two possibly-different-length iterators together and
iterate over the resulting zip iterator, the original two iterators will
only have their common elements consumed. But in fact, the zip iterator
detects that it is done when it receives a `None` from one iterator and
`Some()` element from the other iterator, which means that it consumes
one additional element from the longer iterator. This meant that we
failed to detect mismatched types on this extra consumed element,
because we never compared it to the variable type of the other tuple.
Use `zip_longest` from itertools as an alternative, which allows us to
combine all the handling into just two `zip_longest`, one for prefixes
and one for suffixes.
Marking this PR internal since it fixes a bug in a commit that wasn't
released yet.
## Test Plan
Added mdtests that failed before this fix and pass after it.
## Summary
Fixes https://github.com/astral-sh/ty/issues/640. If a user passes
`--python=<some-virtual-environment>/bin/python`, we must avoid
canonicalizing the path until we've traversed upwards to find the
`sys.prefix` directory (`<some-virtual-environment>`). On Unix systems,
`<sys.prefix>/bin/python` is often a symlink to a system interpreter; if
we resolve the symlink too easily then we'll add the system
interpreter's `site-packages` directory as a search path rather than the
virtual environment's directory.
## Test Plan
I added an integration test to
`crates/ty/tests/cli/python_environment.rs` which fails on `main`. I
also manually tested locally that running `cargo run -p ty check foo.py
--python=.venv/bin/python -vv` now prints this log to the terminal
```
2025-06-20 18:35:24.57702 DEBUG Resolved site-packages directories for this virtual environment are: SitePackagesPaths({"/Users/alexw/dev/ruff/.venv/lib/python3.13/site-packages"})
```
Whereas it previously resolved `site-packages` to my system
intallation's `site-packages` directory
We already had support for homogeneous tuples (`tuple[int, ...]`). This
PR extends this to also support mixed tuples (`tuple[str, str,
*tuple[int, ...], str str]`).
A mixed tuple consists of a fixed-length (possibly empty) prefix and
suffix, and a variable-length portion in the middle. Every element of
the variable-length portion must be of the same type. A homogeneous
tuple is then just a mixed tuple with an empty prefix and suffix.
The new data representation uses different Rust types for a fixed-length
(aka heterogeneous) tuple. Another option would have been to use the
`VariableLengthTuple` representation for all tuples, and to wrap the
"variable + suffix" portion in an `Option`. I don't think that would
simplify the method implementations much, though, since we would still
have a 2×2 case analysis for most of them.
One wrinkle is that the definition of the `tuple` class in the typeshed
has a single typevar, and canonically represents a homogeneous tuple.
When getting the class of a tuple instance, that means that we have to
summarize our detailed mixed tuple type information into its
"homogeneous supertype". (We were already doing this for heterogeneous
types.)
A similar thing happens when concatenating two mixed tuples: the
variable-length portion and suffix of the LHS, and the prefix and
variable-length portion of the RHS, all get unioned into the
variable-length portion of the result. The LHS prefix and RHS suffix
carry through unchanged.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
A little bit of cleanup for consistency's sake: we move all the helpers
modules to a consistent location, and update the import paths when
needed. In the case of `refurb` there were two helpers modules, so we
just merged them.
Happy to revert the last commit if people are okay with `super::super` I
just thought it looked a little silly.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Fix `PYI041`'s fix turning `None | int | None | float` into `None | None
| float`, which raises a `TypeError` when executed.
The fix consists of making sure that the merged super-type is inserted
where the first type that is merged was before.
## Test Plan
Tests have been expanded with examples from the issue.
## Related Issue
Fixes https://github.com/astral-sh/ruff/issues/18298
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes https://github.com/astral-sh/ruff/issues/18726 by also checking if
its a literal and not only that it is truthy. See also the first comment
in the issue.
It would have been nice to check for inheritance of BaseException but I
figured that is not possible yet...
## Test Plan
I added a few tests for valid input to exc_info
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
I noticed this since my code for finding missing safety fix sections
flagged it, there is a missing `/` causing part of the new changes to be
a normal comment instead of a doc comment
## Test Plan
<!-- How was it tested? -->
N/A, no functionality/tests affected
## Summary
Ignore `__init__.py` files in `useless-import-alias` (PLC0414).
See discussion in #18365 and #6294: we want to allow redundant aliases
in `__init__.py` files, as they're almost always intentional explicit
re-exports.
Closes#18365Closes#6294
---------
Co-authored-by: Dylan <dylwil3@gmail.com>
## Summary
This PR avoids one of the three calls to `NoqaCode::rule` from
https://github.com/astral-sh/ruff/pull/18391 by applying per-file
ignores in the `LintContext`. To help with this, it also replaces all
direct uses of `LinterSettings.rules.enabled` with a
`LintContext::enabled` (or `Checker::enabled`, which defers to its
context) method. There are still some direct accesses to
`settings.rules`, but as far as I can tell these are not in a part of
the code where we can really access a `LintContext`. I believe all of
the code reachable from `check_path`, where the replaced per-file ignore
code was, should be converted to the new methods.
## Test Plan
Existing tests, with a single snapshot updated for RUF100, which I think
actually shows a more accurate diagnostic message now.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
I also noticed that the tests for SIM911 were note being run, so I fixed
that.
Fixes#18777
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Add regression test
<!-- How was it tested? -->
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
While reading the docs I noticed this paragraph on `PERF401`. It was
added in the same PR that the bug with `:=` was fixed, #15050, but don't
know why it was added. The fix should already take care of adding the
parenthesis, so having this paragraph in the docs is just confusing
since it sounds like the user has to do something.
## Test Plan
<!-- How was it tested? -->
N/A, no tests/functionality affected
## Summary
Fixes false positives (and incorrect autofixes) in `nested-min-max`
(`PLW3301`) when the outer `min`/`max` call only has a single argument.
Previously the rule would flatten:
```python
min(min([2, 3], [4, 1]))
```
into `min([2, 3], [4, 1])`, changing the semantics. The rule now skips
any nested call when the outer call has only one positional argument.
The pylint fixture and snapshot were updated accordingly.
## Test Plan
Ran Ruff against the updated `nested_min_max.py` fixture:
```shell
cargo run -p ruff -- check crates/ruff_linter/resources/test/fixtures/pylint/nested_min_max.py --no-cache --select=PLW3301 --preview
```
to verify that `min(min([2, 3], [4, 1]))` and `max(max([2, 4], [3, 1]))`
are no longer flagged. Updated the fixture and snapshot; all other
existing warnings remain unchanged. The code compiles and the unit tests
pass.
---
This PR was generated by an AI system in collaboration with maintainers:
@carljm, @ntBre
Fixes#16163
---------
Signed-off-by: Gene Parmesan Thomas <201852096+gopoto@users.noreply.github.com>
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
Added `cls.__dict__.get('__annotations__')` check for Python 3.10+ and
Python < 3.10 with `typing-extensions` enabled.
Closes#17853
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Added `cls.__dict__.get('__annotations__')` check for Python 3.10+ and
Python < 3.10 with `typing-extensions` enabled.
## Test Plan
`cargo test`
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Adds a new ecosystem-analyzer workflow with a similar purpose to the
mypy-primer workflow. It creates a richer ecosystem diff report using
[ecosystem-analyzer](https://github.com/astral-sh/ecosystem-analyzer/)
([example
report](https://shark.fish/diff-attr-subscript-narrowing.html)). This is
still experimental and also quite a bit slower than mypy_primer, so I
chose to make this opt-in for now via a `ecosystem-analyzer` label. This
would give us a way to play with this while still evaluating if we
should further invest in this or not.
Advantages over the mypy_primer diff output:
- Interactive filtering of diagnostics
- Statistics overview which breaks down added/removed/changed
diagnostics across lint rules
- Has the concept of "changed" diagnostics, which makes it easier to
review changes where diagnostic messages have changed (along with other
changes).
- Compute diff based on old and new project-lists (`good.txt`). This
allows us to diff changes to the project list itself. This has caused
confusion in the past where we tried to add new projects to `good.txt`,
but then ran the `main`-branch version of ty on that new list (where the
bug was not yet fixed)
Disadvantages:
- The report currently needs to be downloaded from the workflow run, as
I don't know if we have a way of deploying HTML files like this
temporarily to some hosted infrastructure.
## Summary
Add support for `@staticmethod`s. Overall, the changes are very similar
to #16305.
#18587 will be dependent on this PR for a potential fix of
https://github.com/astral-sh/ty/issues/207.
mypy_primer will look bad since the new code allows ty to check more
code.
## Test Plan
Added new markdown tests. Please comment if there's any missing tests
that I should add in, thank you.
## Summary
This PR resolves the way diagnostics are reported for an invalid call to
an overloaded function.
If any of the steps in the overload call evaluation algorithm yields a
matching overload but it's type checking that failed, the
`no-matching-overload` diagnostic is incorrect because there is a
matching overload, it's the arguments passed that are invalid as per the
signature. So, this PR improves that by surfacing the diagnostics on the
matching overload directly.
It also provides additional context, specifically the matching overload
where this error occurred and other non-matching overloads. Consider the
following example:
```py
from typing import overload
@overload
def f() -> None: ...
@overload
def f(x: int) -> int: ...
@overload
def f(x: int, y: int) -> int: ...
def f(x: int | None = None, y: int | None = None) -> int | None:
return None
f("a")
```
We get:
<img width="857" alt="Screenshot 2025-06-18 at 11 07 10"
src="https://github.com/user-attachments/assets/8dbcaf13-2a74-4661-aa94-1225c9402ea6"
/>
## Test Plan
Update test cases, resolve existing todos and validate the updated
snapshots.
## Summary
Part of [#111](https://github.com/astral-sh/ty/issues/111).
After this change, dataclasses with two or more `KW_ONLY` field will be
reported as invalid. The duplicate fields will simply be ignored when
computing `__init__`'s signature.
## Test Plan
Markdown tests.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #15584
This PR adds a fix safety section to `PIE794`
I could not track down when this rule was initially implemented/made
unsafe due how old it could be + multiple large refactors to `ruff`.
There is no comment/reasoning in the code given for the unsafety.
Here is a code example demonstrating why it should be unsafe, since
removing any of the assignments would change program behavior
[playground](https://play.ruff.rs/01004644-4259-4449-a581-5007cd59846a)
```py
class A:
x = 1
x = 2
print(x)
class B:
x = print(3)
x = print(4)
class C:
x = [1,2,3]
y = x
x = y[1]
```
## Test Plan
<!-- How was it tested? -->
N/A, no tests affected.
---------
Co-authored-by: Dylan <dylwil3@gmail.com>
Essentially this PR ensures that when we do fixes like this:
```diff
- t"{set(f(x) for x in foo)}"
+ t"{ {f(x) for x in foo} }"
```
we are correctly adding whitespace around the braces.
This logic is already in place for f-strings and just needed to be
generalized to interpolated strings.
Summary
--
This PR unifies the remaining differences between `OldDiagnostic` and
`Message` (`OldDiagnostic` was only missing an optional `noqa_offset`
field) and
replaces `Message` with `OldDiagnostic`.
The biggest functional difference is that the combined `OldDiagnostic`
kind no
longer implements `AsRule` for an infallible conversion to `Rule`. This
was
pretty easy to work around with `is_some_and` and `is_none_or` in the
few places
it was needed. In `LintContext::report_diagnostic_if_enabled` we can
just use
the new `Violation::rule` method, which takes care of most cases.
Most of the interesting changes are in [this
range](8156992540)
before I started renaming.
Test Plan
--
Existing tests
Future Work
--
I think it's time to start shifting some of these fields to the new
`Diagnostic`
kind. I believe we want `Fix` for sure, but I'm less sure about the
others. We
may want to keep a thin wrapper type here anyway to implement a `rule`
method,
so we could leave some of these fields on that too.
## Summary
This PR avoids the `Vec::retain` call in `check_tokens` by checking if
rules are enabled as their diagnostics are constructed.
2a425e43fd/crates/ruff_linter/src/checkers/tokens.rs (L174-L176)
Since `LintContext::report_diagnostic_if_enabled` required a
`LinterSettings`, I added a `settings` field to the context itself
instead of trying to pass it everywhere. This also turned
`LogicalLinesContext` into a trivial wrapper around `LintContext`, so I
just removed it in favor of using `LintContext` directly too.
The diff is a bit smaller with whitespace hidden since many blocks got
moved into something like this:
```rust
if let Some(mut diagnostic) = context.report_diagnostic.enabled(...) {
// old code
}
```
## Test Plan
Existing tests
When I try to grep CPython with `__super__` I get 0 results:
```
(.venv) ~/Desktop/cpython main ✔
» ag __super__ .
```
That's how we can understand that the naming is not the best.
Summary
--
During the release today, I noticed that the changelog is finally too
long to
render at all on GitHub. This PR follows the same splitting procedure as
in
uv (astral-sh/uv#11510, astral-sh/uv#12099): first splitting the file
into one
per minor version, and then reversing the contents of each file to start
with
the breaking release (`changelogs/0.11.x.md` starts with 0.11.0 instead
of
0.11.13 as in the old changelog).
For the second part, I used
[`reverse-changelog.py`](https://github.com/astral-sh/uv/blob/main/scripts/reverse-changelog.py)
from the uv repo, so hopefully everything is correct. I spot-checked
0.7.0 at least.
This involved slightly more code changes than usual for a stabilization
- so maybe worth double-checking the logic!
I did verify by hand that the new stable behavior on the test fixture
matches the old preview behavior, even after the internal refactor.
Summary
--
Deprecates PD901 as part of #7710. I don't feel particularly strongly
about this one, though I have certainly used `df` as a dataframe name in
the past, just going through the open issues in the 0.12 milestone.
Test Plan
--
N/a
## Summary
- Stabilizes RUF058 (starmap-zip) rule by changing it from Preview to
Stable
- Migrates test cases from preview_rules to main rules function
- Updates snapshots accordingly and removes old preview snapshots
## Test plan
- ✅ Migrated tests from preview to main test function
- ✅ `make check` passes
- ✅ `make test` passes
- ✅ `make citest` passes (no leftover snapshots)
## Rule Documentation
- [Test
file](https://github.com/astral-sh/ruff/blob/main/crates/ruff_linter/src/rules/ruff/mod.rs#L103-L104)
- [Rule documentation](https://docs.astral.sh/ruff/rules/starmap-zip/)
## Summary
Stabilizes the UP049 rule (private-type-parameter) by moving it from
Preview to Stable.
UP049 detects and fixes the use of private type parameters (those with
leading underscores) in PEP 695 generic classes and functions.
## Test plan
- Verified that UP049 tests pass:
`crates/ruff_linter/src/rules/pyupgrade/mod.rs`
- Ran full test suite with `make test`
- Confirmed that no test migration was needed as UP049 was already in
the main `rules` test function
## Rule documentation
https://docs.astral.sh/ruff/rules/private-type-parameter/
Note that the preview behavior was not documented (shame on us!) so the
documentation was not modified.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
This PR stabilizes the FURB162 rule by moving it from preview to stable
status for the 0.12.0 release.
## Summary
- **Rule**: FURB162 (`fromisoformat-replace-z`)
- **Purpose**: Detects unnecessary timezone replacement operations when
calling `datetime.fromisoformat()`
- **Change**: Move from `RuleGroup::Preview` to `RuleGroup::Stable` in
`codes.rs`
## Verification Links
- **Tests**:
[refurb/mod.rs](https://github.com/astral-sh/ruff/blob/main/crates/ruff_linter/src/rules/refurb/mod.rs#L54)
- Confirms FURB162 has only standard tests, no preview-specific test
cases
- **Documentation**:
https://docs.astral.sh/ruff/rules/fromisoformat-replace-z/ - Current
documentation shows preview status that will be automatically updated
This PR stabilizes the RUF053 rule by moving it from preview to stable
status for the 0.12.0 release.
## Summary
- **Rule**: RUF053 (`class-with-mixed-type-vars`)
- **Purpose**: Detects classes that have both PEP 695 type parameter
lists while also inheriting from `typing.Generic`
- **Change**: Move from `RuleGroup::Preview` to `RuleGroup::Stable` in
`codes.rs` and migrate preview tests to stable tests
## Verification Links
- **Tests**:
[ruff/mod.rs](https://github.com/astral-sh/ruff/blob/main/crates/ruff_linter/src/rules/ruff/mod.rs#L98)
- Shows RUF053 moved from preview_rules to main rules test function
- **Documentation**:
https://docs.astral.sh/ruff/rules/class-with-mixed-type-vars/ - Current
documentation shows preview status that will be automatically updated
Note that the preview behavior was not documented (shame on us!) so the
documentation was not modified.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
## Summary
Closes: astral-sh/ty#552
This PR adds support for step 5 of the overload call evaluation
algorithm which specifies:
> For all arguments, determine whether all possible materializations of
the argument’s type are
> assignable to the corresponding parameter type for each of the
remaining overloads. If so,
> eliminate all of the subsequent remaining overloads.
The algorithm works in two parts:
1. Find out the participating parameter indexes. These are the
parameters that aren't gradual equivalent to one or more parameter types
at the same index in other overloads.
2. Loop over each overload and check whether that would be the _final_
overload for the argument types i.e., the remaining overloads will never
be matched against these argument types
For step 1, the participating parameter indexes are computed by just
comparing whether all the parameter types at the corresponding index for
all the overloads are **gradual equivalent**.
The step 2 of the algorithm used is described in [this
comment](https://github.com/astral-sh/ty/issues/552#issuecomment-2969165421).
## Test Plan
Update the overload call tests.
## Summary
This PR closesastral-sh/ty#164.
This PR introduces a basic type narrowing mechanism for
attribute/subscript expressions.
Member accesses, int literal subscripts, string literal subscripts are
supported (same as mypy and pyright).
## Test Plan
New test cases are added to `mdtest/narrow/complex_target.md`.
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
PR adding support for it in the VS Code extension:
https://github.com/astral-sh/ty-vscode/pull/36
This PR adds support for `python.ty.disableLanguageServices` to the ty
language server by accepting this as server setting.
This has the same issue as https://github.com/astral-sh/ty/issues/282 in
that it only works when configured globally. Fixing that requires
support for multiple workspaces in the server itself.
I also went ahead and did a similar refactor as the Ruff server to use
"Options" and "Settings" to keep the code consistent although the
combine functionality doesn't exists yet because workspace settings
isn't supported in the ty server.
## Test Plan
Refer to https://github.com/astral-sh/ty-vscode/pull/36 for the test
demo.
## Summary
* Completely removes the concept of visibility constraints. Reachability
constraints are now used to model the static visibility of bindings and
declarations. Reachability constraints are *much* easier to reason about
/ work with, since they are applied at the beginning of a branch, and
not applied retroactively. Removing the duplication between visibility
and reachability constraints also leads to major code simplifications
[^1]. For an overview of how the new constraint system works, see the
updated doc comment in `reachability_constraints.rs`.
* Fixes a [control-flow modeling bug
(panic)](https://github.com/astral-sh/ty/issues/365) involving `break`
statements in loops
* Fixes a [bug where](https://github.com/astral-sh/ty/issues/624) where
`elif` branches would have wrong reachability constraints
* Fixes a [bug where](https://github.com/astral-sh/ty/issues/648) code
after infinite loops would not be considered unreachble
* Fixes a panic on the `pywin32` ecosystem project, which we should be
able to move to `good.txt` once this has been merged.
* Removes some false positives in unreachable code because we infer
`Never` more often, due to the fact that reachability constraints now
apply retroactively to *all* active bindings, not just to bindings
inside a branch.
* As one example, this removes the `division-by-zero` diagnostic from
https://github.com/astral-sh/ty/issues/443 because we now infer `Never`
for the divisor.
* Supersedes and includes similar test changes as
https://github.com/astral-sh/ruff/pull/18392
closes https://github.com/astral-sh/ty/issues/365
closes https://github.com/astral-sh/ty/issues/624
closes https://github.com/astral-sh/ty/issues/642
closes https://github.com/astral-sh/ty/issues/648
## Benchmarks
Benchmarks on black, pandas, and sympy showed that this is neither a
performance improvement, nor a regression.
## Test Plan
Regression tests for:
- [x] https://github.com/astral-sh/ty/issues/365
- [x] https://github.com/astral-sh/ty/issues/624
- [x] https://github.com/astral-sh/ty/issues/642
- [x] https://github.com/astral-sh/ty/issues/648
[^1]: I'm afraid this is something that @carljm advocated for since the
beginning, and I'm not sure anymore why we have never seriously tried
this before. So I suggest we do *not* attempt to do a historical deep
dive to find out exactly why this ever became so complicated, and just
enjoy the fact that we eventually arrived here.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#18684
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Add regression test
<!-- How was it tested? -->
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
/closes #18639
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
update snapshots
<!-- How was it tested? -->
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
This PR aims to close#16605.
## Summary
This PR introduces a new rule (`RUF061`) that detects non-contextmanager
usage of `pytest.raises`, `pytest.warns`, and `pytest.deprecated_call`.
This pattern is discouraged and [was proposed in
flake8-pytest-style](https://github.com/m-burst/flake8-pytest-style/pull/332),
but the corresponding PR has been open for over a month without
activity.
Additionally, this PR provides an unsafe fix for simple cases where the
non-contextmanager form can be transformed into the context manager
form. Examples of supported patterns are listed in `RUF061_raises.py`,
`RUF061_warns.py`, and `RUF061_deprecated_call.py` test files.
The more complex case from the original issue (involving two separate
statements):
```python
excinfo = pytest.raises(ValueError, int, "hello")
assert excinfo.match("^invalid literal")
```
is getting fixed like this:
```python
with pytest.raises(ValueError) as excinfo:
int("hello")
assert excinfo.match("^invalid literal")
```
Putting match in the raises call requires multi-statement
transformation, which I am not sure how to implement.
## Test Plan
<!-- How was it tested? -->
New test files were added to cover various usages of the
non-contextmanager form of pytest.raises, warns, and deprecated_call.
Closes#18671
Note that while this has, I believe, always been invalid syntax, it was
reported as a different syntax error until Python 3.12:
Python 3.11:
```pycon
>>> x = 1
>>> f"{x! s}"
File "<stdin>", line 1
f"{x! s}"
^
SyntaxError: f-string: invalid conversion character: expected 's', 'r', or 'a'
```
Python 3.12:
```pycon
>>> x = 1
>>> f"{x! s}"
File "<stdin>", line 1
f"{x! s}"
^^^
SyntaxError: f-string: conversion type must come right after the exclamanation mark
```
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Solves #18257
## Test Plan
<!-- How was it tested? -->
Snapshots updated with some cases (negative, positive, mixed
annotations).
Summary
--
As @AlexWaygood noted on the 0.12 release blog post draft, the existing
example is a bit confusing. Either `**/*.py` or just `*.py`, as I went
with here, makes more sense, although the old version (`scripts/**.py`)
also worked when I tested it. However, this probably shouldn't be relied
upon since the [globset](https://docs.rs/globset/latest/globset/#syntax)
docs say:
> Using ** anywhere else is illegal
where "anywhere else" comes after the listing of the three valid
positions:
1. At the start of a pattern (`**/`)
2. At the end of a pattern (`/**`)
3. Or directly between two slashes (`/**/`)
I think the current version is luckily treated the same as a single `*`,
and the default globbing settings allow it to match subdirectories such
that the new example pattern will apply to the whole `scripts` tree in a
project like this:
```
.
├── README.md
├── pyproject.toml
├── scripts
│ ├── matching.py
│ └── sub
│ └── nested.py
└── src
└── main.py
```
Test Plan
--
Local testing of the new pattern, but the specifics of the pattern
aren't as important as having a more intuitive-looking/correct example.
Specifically, this PR reverts "Make completions an opt-in LSP feature
(#17921)",
corresponding to commit 51e2effd2d.
In practice, this means you don't need to opt into completions working
by enabling experimental features. i.e., I was able to remove this from
my LSP configuration:
```
"experimental": {
"completions": {
"enable": true
}
},
```
There's still a lot of work left to do to make completions awesome, but
I think it's in a state where it would be useful to get real user
feedback. It's also meaningfully using ty to provide completions that
use type information.
Ref astral-sh/ty#86
## Summary
Fixes https://github.com/astral-sh/ruff/issues/18628 by avoiding a fix
if there are "unknown" arguments, including any keyword arguments and
more than the expected 2 positional arguments.
I'm a bit on the fence here because it also seems reasonable to avoid a
diagnostic at all. Especially in the final test case I added (`not
my_dict.get(default=False)`), the hint suggesting to remove
`default=False` seems pretty misleading. At the same time, I guess the
diagnostic at least calls attention to the call site, which could help
to fix the missing argument bug too.
As I commented on the issue, I double-checked that keyword arguments are
invalid as far back as Python 3.8, even though the positional-only
marker was only added to the
[docs](https://docs.python.org/3.11/library/stdtypes.html#dict.get) in
3.12 (link is to 3.11, showing its absence).
## Test Plan
New tests derived from the bug report
## Stabilization
This was planned to be stabilized in 0.12, and the bug is less severe
than some others, but if there's nobody opposed, I will plan **not to
stabilize** this one for now.
## Summary
Part of [#117](https://github.com/astral-sh/ty/issues/117).
`TypeIs[]` is a special form that allows users to define their own
narrowing functions. Despite the syntax, `TypeIs` is not a generic and,
on its own, it is meaningless as a type.
[Officially](https://typing.python.org/en/latest/spec/narrowing.html#typeis),
a function annotated as returning a `TypeIs[T]` is a <i>type narrowing
function</i>, where `T` is called the <i>`TypeIs` return type</i>.
A `TypeIs[T]` may or may not be bound to a symbol. Only bound types have
narrowing effect:
```python
def f(v: object = object()) -> TypeIs[int]: ...
a: str = returns_str()
if reveal_type(f()): # Unbound: TypeIs[int]
reveal_type(a) # str
if reveal_type(f(a)): # Bound: TypeIs[a, int]
reveal_type(a) # str & int
```
Delayed usages of a bound type has no effect, however:
```python
b = f(a)
if b:
reveal_type(a) # str
```
A `TypeIs[T]` type:
* Is fully static when `T` is fully static.
* Is a singleton/single-valued when it is bound.
* Has exactly two runtime inhabitants when it is unbound: `True` and
`False`.
In other words, an unbound type have ambiguous truthiness.
It is possible to infer more precise truthiness for bound types;
however, that is not part of this change.
`TypeIs[T]` is a subtype of or otherwise assignable to `bool`. `TypeIs`
is invariant with respect to the `TypeIs` return type: `TypeIs[int]` is
neither a subtype nor a supertype of `TypeIs[bool]`. When ty sees a
function marked as returning `TypeIs[T]`, its `return`s will be checked
against `bool` instead. ty will also report such functions if they don't
accept a positional argument. Addtionally, a type narrowing function
call with no positional arguments (e.g., `f()` in the example above)
will be considered invalid.
## Test Plan
Markdown tests.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Consider the following example, which leads to a excessively large
runtime on `main`. The reason for this is the following. When inferring
types for `self.a`, we look up the `a` attribute on `C`. While looking
for implicit instance attributes, we go through every method and check
for `self.a = …` assignments. There are no such assignments here, but we
always have an implicit `self.a = <unbound>` binding at the beginning
over every method. This binding accumulates a complex visibility
constraint in `C.f`, due to the `isinstance` checks. While evaluating
that constraint, we need to infer the type of `self.b`. There's no
binding for `self.b` either, but there's also an implicit `self.b =
<unbound>` binding with the same complex visibility constraint
(involving `self.b` recursively). This leads to a combinatorial
explosion:
```py
class C:
def f(self: "C"):
if isinstance(self.a, str):
return
if isinstance(self.b, str):
return
if isinstance(self.b, str):
return
if isinstance(self.b, str):
return
# repeat 20 times
```
(note that the `self` parameter here is annotated explicitly because we
currently still infer `Unknown` for `self` otherwise)
The fix proposed here is rather simple: when there are no `self.name =
…` attribute assignments in a given method, we skip evaluating the
visibility constraint of the implicit `self.name = <unbound>` binding.
This should also generally help with performance, because that's a very
common case.
This is *not* a fix for cases where there *are* actual bindings in the
method. When we add `self.a = 1; self.b = 1` to that example above, we
still see that combinatorial explosion of runtime. I still think it's
worth to make this optimization, as it fixes the problems with `pandas`
and `sqlalchemy` reported by users. I will open a ticket to track that
separately.
closes https://github.com/astral-sh/ty/issues/627
closes https://github.com/astral-sh/ty/issues/641
## Test Plan
* Made sure that `ty` finishes quickly on the MREs in
https://github.com/astral-sh/ty/issues/627
* Made sure that `ty` finishes quickly on `pandas`
* Made sure that `ty` finishes quickly on `sqlalchemy`
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes false positive in B909 (`loop-iterator-mutation`) where mutations
inside return/break statements were incorrectly flagged as violations.
The fix adds tracking for when mutations occur within return/break
statements and excludes them from violation detection, as they don't
cause the iteration issues B909 is designed to prevent.
## Test Plan
- Added test cases covering the reported false positive scenarios to
`B909.py`
- Verified existing B909 tests continue to pass (no regressions)
- Ran `cargo test -p ruff_linter --lib flake8_bugbear` successfully
Fixes#18399
## Summary
Garbage collect ASTs once we are done checking a given file. Queries
with a cross-file dependency on the AST will reparse the file on demand.
This reduces ty's peak memory usage by ~20-30%.
The primary change of this PR is adding a `node_index` field to every
AST node, that is assigned by the parser. `ParsedModule` can use this to
create a flat index of AST nodes any time the file is parsed (or
reparsed). This allows `AstNodeRef` to simply index into the current
instance of the `ParsedModule`, instead of storing a pointer directly.
The indices are somewhat hackily (using an atomic integer) assigned by
the `parsed_module` query instead of by the parser directly. Assigning
the indices in source-order in the (recursive) parser turns out to be
difficult, and collecting the nodes during semantic indexing is
impossible as `SemanticIndex` does not hold onto a specific
`ParsedModuleRef`, which the pointers in the flat AST are tied to. This
means that we have to do an extra AST traversal to assign and collect
the nodes into a flat index, but the small performance impact (~3% on
cold runs) seems worth it for the memory savings.
Part of https://github.com/astral-sh/ty/issues/214.
## Summary
This PR closes https://github.com/astral-sh/ty/issues/238.
Since `DefinitionState::Deleted` was introduced in #18041, support for
the `del` statement (and deletion of except handler names) is
straightforward.
However, it is difficult to determine whether references to attributes
or subscripts are unresolved after they are deleted. This PR only
invalidates narrowing by assignment if the attribute or subscript is
deleted.
## Test Plan
`mdtest/del.md` is added.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Fixes https://github.com/astral-sh/ruff/issues/18612 by:
- Bailing out without a fix in the case of `*args`, which I don't think
we can fix reliably
- Using an `Edit::deletion` from `remove_argument` instead of an
`Edit::range_replacement` in the presence of unrecognized keyword
arguments
I thought we could always switch to the `Edit::deletion` approach
initially, but it caused problems when `maxlen` was passed positionally,
which we didn't have any existing tests for.
The replacement fix can easily delete comments, so I also marked the fix
unsafe in these cases and updated the docs accordingly.
## Test Plan
New test cases derived from the issue.
## Stabilization
These are pretty significant changes, much like those to PYI059 in
https://github.com/astral-sh/ruff/pull/18611 (and based a bit on the
implementation there!), so I think it probably makes sense to
un-stabilize this for the 0.12 release, but I'm open to other thoughts
there.
## Summary
This is to support https://github.com/astral-sh/ruff/pull/18607.
This PR adds support for generating the top materialization (or upper
bound materialization) and the bottom materialization (or lower bound
materialization) of a type. This is the most general and the most
specific form of the type which is fully static, respectively.
More concretely, `T'`, the top materialization of `T`, is the type `T`
with all occurrences
of dynamic type (`Any`, `Unknown`, `@Todo`) replaced as follows:
- In covariant position, it's replaced with `object`
- In contravariant position, it's replaced with `Never`
- In invariant position, it's replaced with an unresolved type variable
(For an invariant position, it should actually be replaced with an
existential type, but this is not currently representable in our type
system, so we use an unresolved type variable for now instead.)
The bottom materialization is implemented in the same way, except we
start out in "contravariant" position.
## Test Plan
Add test cases for various types.
## Summary
Minor documentation update to make `mypy_primer` instructions a bit more
verbose/helpful for running against a local branch
## Test Plan
N/A
This makes it work for a number of additional cases, like nested
attribute access and things like `[].<CURSOR>`.
The basic idea is that instead of selecting a covering node closest to a
leaf that contains the cursor, we walk up the tree as much as we can.
This lets us access the correct `ExprAttribute` node when performing
nested access.
This routine lets us climb up the AST tree when we find
a contiguous sequence of nodes that satisfy our predicate.
This will be useful for making things like `a.b.<CURSOR>`
work. That is, we don't want the `ExprAttribute` closest
to a leaf. We also don't always want the `ExprAttribute`
closest to the root. Rather, (I think) we want the
`ExprAttribute` closest to the root that has an unbroken
chain to the `ExprAttribute` closest to the leaf.
This commit doesn't change any functionality, but instead changes the
representation of `CoveringNode` to make the implementation simpler (as
well as planned future additions). By putting the found node last in the
list of ancestors (now just generically called `nodes`), we reduce the
amount of special case handling we need.
The downside is that the representation now allows invalid states (a
`CoveringNode` with no elements). But I think this is well mitigated by
encapsulation.
Summary
--
Updates the rule docs to explicitly state how cases like
`Decimal("0.1")` are handled (not affected) because the discussion of
"float casts" referring to values like `nan` and `inf` is otherwise a
bit confusing.
These changes are based on suggestions from @AlexWaygood on Notion, with
a slight adjustment to use 0.1 instead of 0.5 since it causes a more
immediate issue in the REPL:
```pycon
>>> from decimal import Decimal
>>> Decimal(0.5) == Decimal("0.5")
True
>>> Decimal(0.1) == Decimal("0.1")
False
```
Test plan
--
N/a
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Summary
--
This PR updates the docs for PLW1641 to place less emphasis on the
example of inheriting a parent class's `__hash__` implementation by both
reducing the length of the example and warning that it may be unsound in
general, as @AlexWaygood pointed out on Notion.
Test plan
--
Existing tests
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Fixes https://github.com/astral-sh/ruff/issues/18602 by:
1. Avoiding a fix when `*args` are present
2. Inserting the `Generic` base class right before the first keyword
argument, if one is present
In an intermediate commit, I also had special handling to avoid a fix in
the `**kwargs` case, but this is treated (roughly) as a normal keyword,
and I believe handling it properly falls out of the other keyword fix.
I also updated the `add_argument` utility function to insert new
arguments right before the keyword argument list instead of at the very
end of the argument list. This changed a couple of snapshots unrelated
to `PYI059`, but there shouldn't be any functional changes to other
rules because all other calls to `add_argument` were adding a keyword
argument anyway.
## Test Plan
Existing PYI059 cases, plus new tests based on the issue
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Closes https://github.com/astral-sh/ty/issues/577. Make global
`__debug__` a `bool` constant.
## Test Plan
Mdtest `global-constants.md` was created to check if resolved type was
`bool`.
---------
Co-authored-by: David Peter <mail@david-peter.de>
Summary
--
Fixes#18590 by adding parentheses around lambdas and if expressions in
`for` loop iterators for FURB122 and FURB142. I also updated the docs on
the helper function to reflect the part actually being parenthesized and
the new checks.
The `lambda` case actually causes a `TypeError` at runtime, but I think
it's still worth handling to avoid causing a syntax error.
```pycon
>>> s = set()
... for x in (1,) if True else (2,):
... s.add(-x)
... for x in lambda: 0:
... s.discard(-x)
...
Traceback (most recent call last):
File "<python-input-0>", line 4, in <module>
for x in lambda: 0:
^^^^^^^^^
TypeError: 'function' object is not iterable
```
Test Plan
--
New test cases based on the bug report
---------
Co-authored-by: Dylan <dylwil3@gmail.com>
## Summary
This PR fixes an error in the example Neovim configuration on [this
documentation
page](https://docs.astral.sh/ruff/editors/settings/#configuration).
The `configuration` block should be nested under `settings`, consistent
with other properties and as outlined
[here](https://docs.astral.sh/ruff/editors/setup/#neovim).
I encountered this issue when copying the example to configure ruff
integration in my neovim - the config didn’t work until I corrected the
nesting.
## Test Plan
- [x] Confirmed that the corrected configuration works in a real Neovim
+ Ruff setup
- [x] Verified that the updated configuration renders correctly in
MkDocs
<img width="382" alt="image"
src="https://github.com/user-attachments/assets/0722fb35-8ffa-4b10-90ba-c6e8417e40bf"
/>
## Summary
As the title says, this PR removes the `Message::to_rule` method by
replacing related uses of `Rule` with `NoqaCode` (or the rule's name in
the case of the cache). Where it seemed a `Rule` was really needed, we
convert back to the `Rule` by parsing either the rule name (with
`str::parse`) or the `NoqaCode` (with `Rule::from_code`).
I thought this was kind of like cheating and that it might not resolve
this part of Micha's
[comment](https://github.com/astral-sh/ruff/pull/18391#issuecomment-2933764275):
> because we can't add Rule to Diagnostic or **have it anywhere in our
shared rendering logic**
but after looking again, the only remaining `Rule` conversion in
rendering code is for the SARIF output format. The other two non-test
`Rule` conversions are for caching and writing a fix summary, which I
don't think fall into the shared rendering logic. That leaves the SARIF
format as the only real problem, but maybe we can delay that for now.
The motivation here is that we won't be able to store a `Rule` on the
new `Diagnostic` type, but we should be able to store a `NoqaCode`,
likely as a string.
## Test Plan
Existing tests
##
[Benchmarks](https://codspeed.io/astral-sh/ruff/branches/brent%2Fremove-to-rule)
Almost no perf regression, only -1% on
`linter/default-rules[large/dataset.py]`.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
https://github.com/astral-sh/ty/issues/214 will require a couple
invasive changes that I would like to get merged even before garbage
collection is fully implemented (to avoid rebasing):
- `ParsedModule` can no longer be dereferenced directly. Instead you
need to load a `ParsedModuleRef` to access the AST, which requires a
reference to the salsa database (as it may require re-parsing the AST if
it was collected).
- `AstNodeRef` can only be dereferenced with the `node` method, which
takes a reference to the `ParsedModuleRef`. This allows us to encode the
fact that ASTs do not live as long as the database and may be collected
as soon a given instance of a `ParsedModuleRef` is dropped. There are a
number of places where we currently merge the `'db` and `'ast`
lifetimes, so this requires giving some types/functions two separate
lifetime parameters.
## Summary
This is a spin-off from
https://github.com/astral-sh/ruff/pull/18447#discussion_r2125844669 to
avoid using `Message::noqa_code` to differentiate between lints and
syntax errors. I went through all of the calls on `main` and on the
branch from #18447, and the instance in `ruff_server` noted in the
linked comment was actually the primary place where this was being done.
Other calls to `noqa_code` are typically some variation of
`message.noqa_code().map_or(String::new, format!(...))`, with the major
exception of the gitlab output format:
a120610b5b/crates/ruff_linter/src/message/gitlab.rs (L93-L105)
which obviously assumes that `None` means syntax error. A simple fix
here would be to use `message.name()` for `check_name` instead of the
noqa code, but I'm not sure how breaking that would be. This could just
be:
```rust
let description = message.body();
let description = description.strip_prefix("SyntaxError: ").unwrap_or(description).to_string();
let check_name = message.name();
```
In that case. This sounds reasonable based on the [Code Quality report
format](https://docs.gitlab.com/ci/testing/code_quality/#code-quality-report-format)
docs:
> | Name | Type | Description|
> |-----|-----|----|
> |`check_name` | String | A unique name representing the check, or
rule, associated with this violation. |
## Test Plan
Existing tests
## Summary
Fixes https://github.com/astral-sh/ty/issues/556.
On Windows, system installations have different layouts to virtual
environments. In Windows virtual environments, the Python executable is
found at `<sys.prefix>/Scripts/python.exe`. But in Windows system
installations, the Python executable is found at
`<sys.prefix>/python.exe`. That means that Windows users were able to
point to Python executables inside virtual environments with the
`--python` flag, but they weren't able to point to Python executables
inside system installations.
This PR fixes that issue. It also makes a couple of other changes:
- Nearly all `sys.prefix` resolution is moved inside `site_packages.rs`.
That was the original design of the `site-packages` resolution logic,
but features implemented since the initial implementation have added
some resolution and validation to `resolver.rs` inside the module
resolver. That means that we've ended up with a somewhat confusing code
structure and a situation where several checks are unnecessarily
duplicated between the two modules.
- I noticed that we had quite bad error messages if you e.g. pointed to
a path that didn't exist on disk with `--python` (we just gave a
somewhat impenetrable message saying that we "failed to canonicalize"
the path). I improved the error messages here and added CLI tests for
`--python` and the `environment.python` configuration setting.
## Test Plan
- Existing tests pass
- Added new CLI tests
- I manually checked that virtual-environment discovery still works if
no configuration is given
- Micha did some manual testing to check that pointing `--python` to a
system-installation executable now works on Windows
## Summary
This PR partially solves https://github.com/astral-sh/ty/issues/164
(derived from #17643).
Currently, the definitions we manage are limited to those for simple
name (symbol) targets, but we expand this to track definitions for
attribute and subscript targets as well.
This was originally planned as part of the work in #17643, but the
changes are significant, so I made it a separate PR.
After merging this PR, I will reflect this changes in #17643.
There is still some incomplete work remaining, but the basic features
have been implemented, so I am publishing it as a draft PR.
Here is the TODO list (there may be more to come):
* [x] Complete rewrite and refactoring of documentation (removing
`Symbol` and replacing it with `Place`)
* [x] More thorough testing
* [x] Consolidation of duplicated code (maybe we can consolidate the
handling related to name, attribute, and subscript)
This PR replaces the current `Symbol` API with the `Place` API, which is
a concept that includes attributes and subscripts (the term is borrowed
from Rust).
## Test Plan
`mdtest/narrow/assignment.md` is added.
---------
Co-authored-by: David Peter <sharkdp@users.noreply.github.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This optimizes some of the logic added in
https://github.com/astral-sh/ruff/pull/18444. In general, we only
calculate information for subdiagnostics if we know we'll actually emit
the diagnostic. The check to see whether we'll emit the diagnostic is
work we'll definitely have to do whereas the the work to gather
information for a subdiagnostic isn't work we necessarily have to do if
the diagnostic isn't going to be emitted at all.
This PR makes us lazier about gathering the information we need for the
subdiagnostic, and moves all the subdiagnostic logic into one function
rather than having some `unresolved-reference` subdiagnostic logic in
`infer.rs` and some in `diagnostic.rs`.
## Test Plan
`cargo test -p ty_python_semantic`
## Summary
As well as excluding a hardcoded set of special attributes, CPython at
runtime also excludes any attributes or declarations starting with
`_abc_` from the set of members that make up a protocol interface. I
missed this in my initial implementation.
This is a bit of a CPython implementation detail, but I do think it's
important that we try to model the runtime as best we can here. The
closer we are to the runtime behaviour, the closer we come to sound
behaviour when narrowing types from `isinstance()` checks against
runtime-checkable protocols (for example)
## Test Plan
Extended an existing mdtest
## Summary
Closes https://github.com/astral-sh/ty/issues/502.
In the following example:
```py
class Foo:
x: int
def method(self):
y = x
```
The user may intended to use `y = self.x` in `method`.
This is now added as a subdiagnostic in the following form :
`info: An attribute with the same name as 'x' is defined, consider using
'self.x'`
## Test Plan
Added mdtest with snapshot diagnostics.
## Summary
Previously, all symbols where provided as possible completions. In an
example like the following, both `foo` and `f` were suggested as
completions, because `f` itself is a symbol.
```py
foo = 1
f<CURSOR>
```
Similarly, in the following example, `hidden_symbol` was suggested, even
though it is not statically visible:
```py
if 1 + 2 != 3:
hidden_symbol = 1
hidden_<CURSOR>
```
With the change suggested here, we only use statically visible
declarations and bindings as a source for completions.
## Test Plan
- Updated snapshot tests
- New test for statically hidden definitions
- Added test for star import
## Summary
Part of astral-sh/ty#104, closes: astral-sh/ty#468
This PR implements the argument type expansion which is step 3 of the
overload call evaluation algorithm.
Specifically, this step needs to be taken if type checking resolves to
no matching overload and there are argument types that can be expanded.
## Test Plan
Add new test cases.
## Ecosystem analysis
This PR removes 174 `no-matching-overload` false positives -- I looked
at a lot of them and they all are false positives.
One thing that I'm not able to understand is that in
2b7e3adf27/sphinx/ext/autodoc/preserve_defaults.py (L179)
the inferred type of `value` is `str | None` by ty and Pyright, which is
correct, but it's only ty that raises `invalid-argument-type` error
while Pyright doesn't. The constructor method of `DefaultValue` has
declared type of `str` which is invalid.
There are few cases of false positives resulting due to the fact that ty
doesn't implement narrowing on attribute expressions.
## Summary
An issue seen here https://github.com/astral-sh/ty/issues/500
The `__init__` method of dataclasses had no inherited generic context,
so we could not infer the type of an instance from a constructor call
with generics
## Test Plan
Add tests to classes.md` in generics folder
## Summary
Part of https://github.com/astral-sh/ty/issues/111
Using `dataclass` as a function, instead of as a decorator did not work
as expected prior to this.
Fix that by modifying the dataclass overload's return type.
## Test Plan
New mdtests, fixing the existing TODO.
This updates our representation of functions to more closely match our
representation of classes.
The new `OverloadLiteral` and `FunctionLiteral` classes represent a
function definition in the AST. If a function is generic, this is
unspecialized. `FunctionType` has been updated to represent a function
type, which is specialized if the function is generic. (These names are
chosen to match `ClassLiteral` and `ClassType` on the class side.)
This PR does not add a separate `Type` variant for `FunctionLiteral`.
Maybe we should? Possibly as a follow-on PR?
Part of https://github.com/astral-sh/ty/issues/462
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Follow-up from #18401, I was looking at whether that would fix the issue
at https://github.com/astral-sh/ty/issues/247#issuecomment-2917656676
and it didn't, which made me realize that the PR only inferred `list[T]`
when the value type was tuple but it could be other types as well.
This PR fixes the actual issue by inferring `list[T]` for the non-tuple
type case.
## Test Plan
Add test cases for starred expression involved with non-tuple type. I
also added a few test cases for list type and list literal.
I also verified that the example in the linked issue comment works:
```py
def _(line: str):
a, b, *c = line.split(maxsplit=2)
c.pop()
```
## Summary
Came across this while debugging some ecosystem changes in
https://github.com/astral-sh/ruff/pull/18347. I think the meta-type of a
typevar-annotated variable should be equal to `type`, not `<class
'object'>`.
## Test Plan
New Markdown tests.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
/closes #18387
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
update snapshots
<!-- How was it tested? -->
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
https://github.com/astral-sh/ruff/issues/18387#issuecomment-2923039331
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
update snapshots
<!-- How was it tested? -->
## Summary
I struggled to make ruff_organize_imports work and then I found out I
missed the key note about conform.nvim before because it was put in the
Vim section wrongly! So I refined them both.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Mark `FURB180`'s fix as unsafe if the class already has base classes.
This is because the base classes might validate the other base classes
(like `typing.Protocol` does) or otherwise alter runtime behavior if
more base classes are added.
## Test Plan
The existing snapshot test covers this case already.
## References
Partially addresses https://github.com/astral-sh/ruff/issues/13307 (left
out way to permit certain exceptions)
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Closes#17226.
This PR updates the `FAST003` rule to correctly handle [FastAPI class
dependencies](https://fastapi.tiangolo.com/tutorial/dependencies/classes-as-dependencies/).
Specifically, if a path parameter is declared in either:
- a `pydantic.BaseModel` used as a dependency, or
- the `__init__` method of a class used as a dependency,
then `FAST003` will no longer incorrectly report it as unused.
FastAPI allows a shortcut when using annotated class dependencies -
`Depends` can be called without arguments, e.g.:
```python
class MyParams(BaseModel):
my_id: int
@router.get("/{my_id}")
def get_id(params: Annotated[MyParams, Depends()]): ...
```
This PR ensures that such usage is properly supported by the linter.
Note: Support for dataclasses is not included in this PR. Let me know if
you’d like it to be added.
## Test Plan
Added relevant test cases to the `FAST003.py` fixture.
## Summary
This currently doesn't work because the benchmark changes the working
directory. Also updates the process name to make it easier to compare
two local ty binaries.
This PR implements template strings (t-strings) in the parser and
formatter for Ruff.
Minimal changes necessary to compile were made in other parts of the code (e.g. ty, the linter, etc.). These will be covered properly in follow-up PRs.
## Summary
Allow a typevar to be callable if it is bound to a callable type, or
constrained to callable types.
I spent some time digging into why this support didn't fall out
naturally, and ultimately the reason is that we look up `__call__` on
the meta type (since its a dunder), and our implementation of
`Type::to_meta_type` for `Type::Callable` does not return a type with
`__call__`.
A more general solution here would be to have `Type::to_meta_type` for
`Type::Callable` synthesize a protocol with `__call__` and return an
intersection with that protocol (since for a type to be callable, we
know its meta-type must have `__call__`). That solution could in
principle also replace the special-case handling of `Type::Callable`
itself, here in `Type::bindings`. But that more general approach would
also be slower, and our protocol support isn't quite ready for that yet,
and handling this directly in `Type::bindings` is really not bad.
Fixes https://github.com/astral-sh/ty/issues/480
## Test Plan
Added mdtests.
This PR adds initial support for listing all attributes of
an object. It is exposed through a new `all_members`
routine in `ty_extensions`, which is in turn used to test
the functionality.
The purpose of listing all members is for code
completion. That is, given a `object.<CURSOR>`, we
would like to list all available attributes on
`object`.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Follow up on https://github.com/astral-sh/ruff/pull/18093 and apply it
to AIR312
## Test Plan
<!-- How was it tested? -->
The existing test fixtures have been updated
Summary
--
This is the last main difference between the `OldDiagnostic` and
`Message`
types, so attaching a `SourceFile` to `OldDiagnostic` should make
combining the
two types almost trivial.
Initially I updated the remaining rules without access to a `Checker` to
take a
`&SourceFile` directly, but after Micha's suggestion in
https://github.com/astral-sh/ruff/pull/18356#discussion_r2113281552, I
updated all of these calls to take a
`LintContext` instead. This new type is a thin wrapper around a
`RefCell<Vec<OldDiagnostic>>`
and a `SourceFile` and now has the `report_diagnostic` method returning
a `DiagnosticGuard` instead of `Checker`.
This allows the same `Drop`-based implementation to be used in cases
without a `Checker` and also avoids a lot of intermediate allocations of
`Vec<OldDiagnostic>`s.
`Checker` now also contains a `LintContext`, which it defers to for its
`report_diagnostic` methods, which I preserved for convenience.
Test Plan
--
Existing tests
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Follow up on https://github.com/astral-sh/ruff/pull/18093 and apply it
to AIR311
---
Rules fixed
* `airflow.models.datasets.expand_alias_to_datasets` →
`airflow.models.asset.expand_alias_to_assets`
* `airflow.models.baseoperatorlink.BaseOperatorLink` →
`airflow.sdk.BaseOperatorLink`
## Test Plan
<!-- How was it tested? -->
The existing test fixtures have been updated
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Follow up on https://github.com/astral-sh/ruff/pull/18093 and apply it
to AIR301
## Test Plan
<!-- How was it tested? -->
The existing test fixtures have been updated
## Summary
- Convert tests demonstrating our resilience to malformed/absent
`version` fields in `pyvenf.cfg` files to mdtests. Also make them more
expansive.
- Convert the regression test I added in
https://github.com/astral-sh/ruff/pull/18157 to an mdtest
- Add comments next to unit tests that cannot be converted to mdtests
(but where it's not obvious why they can't) so I don't have to do this
exercise again 😄
- In `site_packages.rs`, factor out the logic for figuring out where we
expect the system-installation `site-packages` to be. Currently we have
the same logic twice.
## Test Plan
`cargo test -p ty_python_semantic`
## Summary
This change was based on a mis-reading of a comment in typeshed, and a
wrong assumption about what was causing a test failure in a prior PR.
Reverting it doesn't cause any tests to fail.
## Test Plan
Existing tests.
## Summary
Resolves [#513](https://github.com/astral-sh/ty/issues/513).
Callable types are now considered to be disjoint from nominal instance
types where:
* The class is `@final`, and
* Its `__call__` either does not exist or is not assignable to `(...) ->
Unknown`.
## Test Plan
Markdown tests.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Partially implement https://github.com/astral-sh/ty/issues/538,
```py
from pathlib import Path
def setup_test_project(registry_name: str, registry_url: str, project_dir: str) -> Path:
pyproject_file = Path(project_dir) / "pyproject.toml"
pyproject_file.write_text("...", encoding="utf-8")
```
As no return statement is defined in the function `setup_test_project`
with annotated return type `Path`, we provide the following diagnosis :
- error[invalid-return-type]: Function **always** implicitly returns
`None`, which is not assignable to return type `Path`
with a subdiagnostic :
- note: Consider changing your return annotation to `-> None` or adding a `return` statement
## Test Plan
mdtests with snapshots to capture the subdiagnostic. I have to mention
that existing snapshots were modified since they now fall in this
category.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Add utility functions `generate_import_edit` and
`generate_remove_and_runtime_import_edit` to generate the fix needed for
the airflow rules.
1. `generate_import_edit` is for the cases where the member name has
changed. (e.g., `airflow.datasts.Dataset` to `airflow.sdk.Asset`) It's
just extracted from the original logic
2. `generate_remove_and_runtime_import_edit` is for cases where the
member name has not changed. (e.g.,
`airflow.operators.pig_operator.PigOperator` to
`airflow.providers.apache.pig.hooks.pig.PigCliHook`) This is newly
introduced. As it introduced runtime import, I mark it as an unsafe fix.
Under the hook, it tried to find the original import statement, remove
it, and add a new import fix
---
* rules fix
* `airflow.sensors.external_task_sensor.ExternalTaskSensorLink` →
`airflow.providers.standard.sensors.external_task.ExternalDagLink`
## Test Plan
<!-- How was it tested? -->
The existing test fixtures have been updated
Summary
--
It's a bit late in the refactoring process, but I think there are still
a couple of PRs left before getting rid of this type entirely, so I
thought it would still be worth doing.
This PR is just a quick rename with no other changes.
Test Plan
--
Existing tests
## Summary
Adds coverage of using set(...) in addition to `{...} in
SingleItemMembershipTest.
Fixes#15792
(and replaces the old PR #15793)
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Updated unit test and snapshot.
Steps to reproduce are in the issue linked above.
<!-- How was it tested? -->
Previously, completions were based on just returning every identifier
parsed in the current Python file. In this commit, we change it to
identify an expression under the cursor and then return all symbols
available to the scope containing that expression.
This is still returning too much, and also, in some cases, not enough.
Namely, it doesn't really take the specific context into account other
than scope. But this does improve on the status quo. For example:
def foo(): ...
def bar():
def fast(): ...
def foofoo(): ...
f<CURSOR>
When asking for completions here, the LSP will no longer include `fast`
as a possible completion in this context.
Ref https://github.com/astral-sh/ty/issues/86
This is analogous to the existing `Tokens::after` method. Its
implementation is almost identical.
We plan to use this for looking at the tokens immediately before the
cursor when fetching completions.
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#18231
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Snapshot tests
<!-- How was it tested? -->
## Summary
Implements `use-maxsplit-arg` (`PLC0207`)
https://pylint.readthedocs.io/en/latest/user_guide/messages/convention/use-maxsplit-arg.html
> Emitted when accessing only the first or last element of str.split().
The first and last element can be accessed by using str.split(sep,
maxsplit=1)[0] or str.rsplit(sep, maxsplit=1)[-1] instead.
This is part of https://github.com/astral-sh/ruff/issues/970
## Test Plan
`cargo test`
Additionally compared Ruff output to Pylint:
```
pylint --disable=all --enable=use-maxsplit-arg crates/ruff_linter/resources/test/fixtures/pylint/missing_maxsplit_arg.py
cargo run -p ruff -- check crates/ruff_linter/resources/test/fixtures/pylint/missing_maxsplit_arg.py --no-cache --select PLC0207
```
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
## Summary
This PR add the `fix safety` section for rule `B006` in
`mutable_argument_default.rs` for #15584
When applying this rule for fixes, certain changes may alter the
original logical behavior. For example:
before:
```python
def cache(x, storage=[]):
storage.append(x)
return storage
print(cache(1)) # [1]
print(cache(2)) # [1, 2]
```
after:
```python
def cache(x, storage=[]):
storage.append(x)
return storage
print(cache(1)) # [1]
print(cache(2)) # [2]
```
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#18353
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
Snapshot tests
There were many fields in `Signature` and friends that really had more
to do with how a signature was being _used_ — how it was looked up,
details about an individual call site, etc. Those fields more properly
belong in `Bindings` and friends.
This is a pure refactoring, and should not affect any tests or ecosystem
projects.
I started on this journey in support of
https://github.com/astral-sh/ty/issues/462. It seemed worth pulling out
as a separate PR.
One major concrete benefit of this refactoring is that we can now use
`CallableSignature` directly in `CallableType`. (We can't use
`CallableSignature` directly in that `Type` variant because signatures
are not currently interned.)
Summary
--
This PR adds a `DiagnosticGuard` type to ruff that is adapted from the
`DiagnosticGuard` and `LintDiagnosticGuard` types from ty. This guard is
returned by `Checker::report_diagnostic` and derefs to a
`ruff_diagnostics::Diagnostic` (`OldDiagnostic`), allowing methods like
`OldDiagnostic::set_fix` to be called on the result. On `Drop` the
`DiagnosticGuard` pushes its contained `OldDiagnostic` to the `Checker`.
The main motivation for this is to make a following PR adding a
`SourceFile` to each diagnostic easier. For every rule where a `Checker`
is available, this will now only require modifying
`Checker::report_diagnostic` rather than all the rules.
In the few cases where we need to create a diagnostic before we know if
we actually want to emit it, there is a `DiagnosticGuard::defuse`
method, which consumes the guard without emitting the diagnostic. I was
able to restructure about half of the rules that naively called this to
avoid calling it, but a handful of rules still need it.
One of the fairly common patterns where `defuse` was needed initially
was something like
```rust
let diagnostic = Diagnostic::new(DiagnosticKind, range);
if !checker.enabled(diagnostic.rule()) {
return;
}
```
So I also added a `Checker::checked_report_diagnostic` method that
handles this check internally. That helped to avoid some additional
`defuse` calls. The name is a bit repetitive, so I'm definitely open to
suggestions there. I included a warning against using it in the docs
since, as we've seen, the conversion from a diagnostic to a rule is
actually pretty expensive.
Test Plan
--
Existing tests
## Summary
We create `Callable` types for synthesized functions like the `__init__`
method of a dataclass. These generated functions are real functions
though, with descriptor-like behavior. That is, they can bind `self`
when accessed on an instance. This was modeled incorrectly so far.
## Test Plan
Updated tests
## Summary
I don't think we're ever going to add any `KnownInstanceType` variants
that evaluate to `False` in a boolean context; the
`KnownInstanceType::bool()` method just seems like unnecessary
complexity.
## Test Plan
`cargo test -p ty_python_semantic`
# Summary
Adds a subdiagnostic hint in the following scenario where a
synchronous `with` is used with an async context manager:
```py
class Manager:
async def __aenter__(self): ...
async def __aexit__(self, *args): ...
# error: [invalid-context-manager] "Object of type `Manager` cannot be used with `with` because it does not implement `__enter__` and `__exit__`"
# note: Objects of type `Manager` *can* be used as async context managers
# note: Consider using `async with` here
with Manager():
...
```
closes https://github.com/astral-sh/ty/issues/508
## Test Plan
New MD snapshot tests
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
fixesastral-sh/ty#366
## Test Plan
* Added panic corpus regression tests
* I also wrote a hover regression test (see below), but decided not to
include it. The corpus tests are much more "effective" at finding these
types of errors, since they exhaustively check all expressions for
types.
<details>
```rs
#[test]
fn hover_regression_test_366() {
let test = cursor_test(
r#"
from ty_extensions import Intersection
class A: ...
class B: ...
def _(x: Intersection[A,<CURSOR> B]):
pass
"#,
);
assert_snapshot!(test.hover(), @r"
A & B
---------------------------------------------
```text
A & B
```
---------------------------------------------
info[hover]: Hovered content is
--> main.py:7:31
|
5 | class B: ...
6 |
7 | def _(x: Intersection[A, B]):
| ^^-^
| | |
| | Cursor offset
| source
8 | pass
|
");
}
```
</details>
## Summary
The playground default settings set the `division-by-zero` rule severity
to `error`. This slightly confusing because `division-by-zero` is now
disabled by default. I am assuming that we have a `rules` section in
there to make it easier for users to customize those settings (in
addition to what the JSON schema gives us).
Here, I'm proposing a different default rule-set (`"undefined-reveal":
"ignore"`) that I would personally find more helpful for the playground,
since we're using it so frequently for MREs that often involve some
`reveal_type` calls.
## Summary
The previous `try_call_dunder_with_policy` API was a bit of a footgun
since you needed to pass `NO_INSTANCE_FALLBACK` in *addition* to other
policies that you wanted for the member lookup. Implicit calls to dunder
methods never access instance members though, so we can do this
implicitly in `try_call_dunder_with_policy`.
No functional changes.
## Summary
`Type::member_lookup_with_policy` now falls back to calling
`__getattribute__` when a member cannot be found as a second fallback
after `__getattr__`.
closes https://github.com/astral-sh/ty/issues/441
## Test Plan
Added markdown tests.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
This should address a problem that came up while working on
https://github.com/astral-sh/ruff/pull/18280. When looking up an
attribute (typically a dunder method) with the `MRO_NO_OBJECT_FALLBACK`
policy, the attribute is first looked up on the meta type. If the meta
type happens to be `type`, we go through the following branch in
`find_name_in_mro_with_policy`:
97ff015c88/crates/ty_python_semantic/src/types.rs (L2565-L2573)
The problem is that we now look up the attribute on `object` *directly*
(instead of just having `object` in the MRO). In this case,
`MRO_NO_OBJECT_FALLBACK` has no effect in `class_member_from_mro`:
c3feb8ce27/crates/ty_python_semantic/src/types/class.rs (L1081-L1082)
So instead, we need to explicitly respect the `MRO_NO_OBJECT_FALLBACK`
policy here by returning `Symbol::Unbound`.
## Test Plan
Added new Markdown tests that explain the ecosystem changes that we
observe.
## Summary
Fix a bug that involved writes to attributes on union/intersection types
that included modules as elements.
This is a prerequisite to avoid some ecosystem false positives in
https://github.com/astral-sh/ruff/pull/18312
## Test Plan
Added regression test
## Summary
This PR moves the diagnostics API for the language server out from the
request handler module to the diagnostics API module.
This is in preparation to add support for publishing diagnostics.
## Summary
Resolves https://github.com/astral-sh/ty/issues/485.
`infer_binary_intersection_type_comparison()` now checks for all
positive members before concluding that an operation is unsupported for
a given intersection type.
## Test Plan
Markdown tests.
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
This is a practice I followed on previous projects. Should hopefully
further help developers who want to update the documentation.
The big downside is that it's annoying to see this *as a user of the
documentation* if you don't open the Markdown file in the browser. But
I'd argue that those files don't really follow the original Markdown
spirit anyway with all the inline HTML.
## Summary
This is something I wrote a few months ago, and continued to update from
time to time. It was mostly written for my own education. I found a few
bugs while writing it at the time (there are still one or two TODOs in
the test assertions that are probably bugs). Our other tests are fairly
comprehensive, but they are usually structured around a certain
functionality or operation (subtyping, assignability, narrowing). The
idea here was to focus on individual *types and their properties*.
closes#197 (added `JustFloat` and `JustComplex` to `ty_extensions`).
## Summary
Fix remaining `knot.toml` reference and replace it with `ty.toml`. This
change was probably still in flight while we renamed things.
## Test Plan
Added a second assertion which ensures that the config file has any
effect.
## Summary
It doesn't seem to be necessary for our generics implementation to carry
the `GenericContext` in the `ClassBase` variants. Removing it simplifies
the code, fixes many TODOs about `Generic` or `Protocol` appearing
multiple times in MROs when each should only appear at most once, and
allows us to more accurately detect runtime errors that occur due to
`Generic` or `Protocol` appearing multiple times in a class's bases.
In order to remove the `GenericContext` from the `ClassBase` variant, it
turns out to be necessary to emulate
`typing._GenericAlias.__mro_entries__`, or we end up with a large number
of false-positive `inconsistent-mro` errors. This PR therefore also does
that.
Lastly, this PR fixes the inferred MROs of PEP-695 generic classes,
which implicitly inherit from `Generic` even if they have no explicit
bases.
## Test Plan
mdtests
## Summary
Fix some issues with subtying/assignability for instances vs callables.
We need to look up dunders on the class, not the instance, and we should
limit our logic here to delegating to the type of `__call__`, so it
doesn't get out of sync with the calls we allow.
Also, we were just entirely missing assignability handling for
`__call__` implemented as anything other than a normal bound method
(though we had it for subtyping.)
A first step towards considering what else we want to change in
https://github.com/astral-sh/ty/issues/491
## Test Plan
mdtests
---------
Co-authored-by: med <medioqrity@gmail.com>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Division works differently in Python than in Rust. If the result is
negative and there is a remainder, the division rounds down (instead of
towards zero). The remainder needs to be adjusted to compensate so that
`(lhs // rhs) * rhs + (lhs % rhs) == lhs`.
Fixesastral-sh/ty#481.
## Summary
Make sure that the following definitions all lead to the same outcome
(bug originally noticed by @AlexWaygood)
```py
from typing import ClassVar
class Descriptor:
def __get__(self, instance, owner) -> int:
return 42
class C:
a: ClassVar[Descriptor]
b: Descriptor = Descriptor()
c: ClassVar[Descriptor] = Descriptor()
reveal_type(C().a) # revealed: int (previously: int | Descriptor)
reveal_type(C().b) # revealed: int
reveal_type(C().c) # revealed: int
```
## Test Plan
New Markdown tests
## Summary
I think `division-by-zero` is a low-value diagnostic in general; most
real division-by-zero errors (especially those that are less obvious to
the human eye) will occur on values typed as `int`, in which case we
don't issue the diagnostic anyway. Mypy and pyright do not emit this
diagnostic.
Currently the diagnostic is prone to false positives because a) we do
not silence it in unreachable code, and b) we do not implement narrowing
of literals from inequality checks. We will probably fix (a) regardless,
but (b) is low priority apart from division-by-zero.
I think we have many more important things to do and should not allow
false positives on a low-value diagnostic to be a distraction. Not
opposed to re-enabling this diagnostic in future when we can prioritize
reducing its false positives.
References https://github.com/astral-sh/ty/issues/443
## Test Plan
Existing tests.
## Summary
This PR updates the language server to avoid panicking when there are
multiple workspace folders passed during initialization. The server
currently picks up the first workspace folder and provides a warning and
a log message.
## Test Plan
<img width="1724" alt="Screenshot 2025-05-17 at 11 43 09"
src="https://github.com/user-attachments/assets/1a7ddbc3-198d-4191-a28f-9b69321e8f99"
/>
## Summary
Resolves [#461](https://github.com/astral-sh/ty/issues/461).
ty was hardcoded to infer `BytesLiteral` types for integer indexing into
`BytesLiteral`. It will now infer `IntLiteral` types instead.
## Test Plan
Markdown tests.
Summary
--
I thought that emitting multiple diagnostics at once would be difficult
to port to a diagnostic construction model closer to ty's
`InferContext::report_lint`, so as a first step toward that, this PR
removes `Checker::report_diagnostics`.
In many cases I was able to do some related refactoring to avoid
allocating a `Vec<Diagnostic>` at all, often by adding a `Checker` field
to a `Visitor` or by passing a `Checker` instead of a `&mut
Vec<Diagnostic>`.
In other cases, I had to fall back on something like
```rust
for diagnostic in diagnostics {
checker.report_diagnostic(diagnostic);
}
```
which I guess is a bit worse than the `extend` call in
`report_diagnostics`, but hopefully it won't make too much of a
difference.
I'm still not quite sure what to do with the remaining loop cases. The
two main use cases for collecting a sequence of diagnostics before
emitting any of them are:
1. Applying a single `Fix` to a group of diagnostics
2. Avoiding an earlier diagnostic if something goes wrong later
I was hoping we could get away with just a `DiagnosticGuard` that
reported a `Diagnostic` on drop, but I guess we will still need a
`DiagnosticGuardBuilder` that can be collected in these cases and
produce a `DiagnosticGuard` once we know we actually want the
diagnostics.
Test Plan
--
Existing tests
Closes https://github.com/astral-sh/ty/issues/453.
## Summary
Add an additional info diagnostic to `unresolved-import` check to hint
to users that they should make sure their Python environment is properly
configured for ty, linking them to the corresponding doc. This
diagnostic is only shown when an import is not relative, e.g., `import
maturin` not `import .maturin`.
## Test Plan
Updated snapshots with new info message and reran tests.
The PR add the `fix safety` section for rule `SIM110` (#15584 )
### Unsafe Fix Example
```python
def predicate(item):
global called
called += 1
if called == 1:
# after first call we change the method
def new_predicate(_): return False
globals()['predicate'] = new_predicate
return True
def foo():
for item in range(10):
if predicate(item):
return True
return False
def foo_gen():
return any(predicate(item) for item in range(10))
called = 0
print(foo()) # true – returns immediately on first call
called = 0
print(foo_gen()) # false – second call uses new `predicate`
```
### Note
I notice that
[here](46be305ad2/crates/ruff_linter/src/rules/flake8_simplify/rules/reimplemented_builtin.rs (L60))
we have two rules, `SIM110` & `SIM111`. The second one seems not anymore
active. Should I delete `SIM111`?
This implements the stopgap approach described in
https://github.com/astral-sh/ty/issues/336#issuecomment-2880532213 for
handling literal types in generic class specializations.
With this approach, we will promote any literal to its instance type,
but _only_ when inferring a generic class specialization from a
constructor call:
```py
class C[T]:
def __init__(self, x: T) -> None: ...
reveal_type(C("string")) # revealed: C[str]
```
If you specialize the class explicitly, we still use whatever type you
provide, even if it's a literal:
```py
from typing import Literal
reveal_type(C[Literal[5]](5)) # revealed: C[Literal[5]]
```
And this doesn't apply at all to generic functions:
```py
def f[T](x: T) -> T:
return x
reveal_type(f(5)) # revealed: Literal[5]
```
---
As part of making this happen, we also generalize the `TypeMapping`
machinery. This provides a way to apply a function to type, returning a
new type. Complicating matters is that for function literals, we have to
apply the mapping lazily, since the function's signature is not created
until (and if) someone calls its `signature` method. That means we have
to stash away the mappings that we want to apply to the signatures
parameter/return annotations once we do create it. This requires some
minor `Cow` shenanigans to continue working for partial specializations.
This is a follow-on to #18155. For the example raised in
https://github.com/astral-sh/ty/issues/370:
```py
import tempfile
with tempfile.TemporaryDirectory() as tmp: ...
```
the new logic would notice that both overloads of `TemporaryDirectory`
match, and combine their specializations, resulting in an inferred type
of `str | bytes`.
This PR updates the logic to match our other handling of other calls,
where we only keep the _first_ matching overload. The result for this
example then becomes `str`, matching the runtime behavior. (We still do
not implement the full [overload resolution
algorithm](https://typing.python.org/en/latest/spec/overload.html#overload-call-evaluation)
from the spec.)
## Summary
Add a new diagnostic hint if you try to use PEP 604 `X | Y` union syntax
in a non-type-expression before 3.10.
closes https://github.com/astral-sh/ty/issues/437
## Test Plan
New snapshot test
## Summary
This PR unifies the ruff `Message` enum variants for syntax errors and
rule violations into a single `Message` struct consisting of a shared
`db::Diagnostic` and some additional, optional fields used for some rule
violations.
This version of `Message` is nearly a drop-in replacement for
`ruff_diagnostics::Diagnostic`, which is the next step I have in mind
for the refactor.
I think this is also a useful checkpoint because we could possibly add
some of these optional fields to the new `Diagnostic` type. I think
we've previously discussed wanting support for `Fix`es, but the other
fields seem less relevant, so we may just need to preserve the `Message`
wrapper for a bit longer.
## Test plan
Existing tests
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
* Remove the following rules
* name
* `airflow.auth.managers.base_auth_manager.is_authorized_dataset` →
`airflow.api_fastapi.auth.managers.base_auth_manager.is_authorized_asset`
*
`airflow.providers.fab.auth_manager.fab_auth_manager.is_authorized_dataset`
→
`airflow.providers.fab.auth_manager.fab_auth_manager.is_authorized_asset`
* Update the following rules
* name
* `airflow.models.baseoperatorlink.BaseOperatorLink` →
`airflow.sdk.BaseOperatorLink`
* `airflow.api_connexion.security.requires_access` → "Use
`airflow.api_fastapi.core_api.security.requires_access_*` instead`"
* `airflow.api_connexion.security.requires_access_dataset`→
`airflow.api_fastapi.core_api.security.requires_access_asset`
* `airflow.notifications.basenotifier.BaseNotifier` →
`airflow.sdk.bases.notifier.BaseNotifier`
* `airflow.www.auth.has_access` → None
* `airflow.www.auth.has_access_dataset` → None
* `airflow.www.utils.get_sensitive_variables_fields`→ None
* `airflow.www.utils.should_hide_value_for_key`→ None
* class attribute
* `airflow..sensors.weekday.DayOfWeekSensor`
* `use_task_execution_day` removed
*
`airflow.providers.amazon.aws.auth_manager.aws_auth_manager.AwsAuthManager`
* `is_authorized_dataset`
* Add the following rules
* class attribute
* `airflow.auth.managers.base_auth_manager.BaseAuthManager` |
`airflow.providers.fab.auth_manager.fab_auth_manager.FabAuthManager`
* name
* `airflow.auth.managers.base_auth_manager.BaseAuthManager` →
`airflow.api_fastapi.auth.managers.base_auth_manager.BaseAuthManager` *
`is_authorized_dataset` → `is_authorized_asset`
* refactor
* simplify unnecessary match with if else
* rename Replacement::Name as Replacement::AttrName
## Test Plan
<!-- How was it tested? -->
The test fixtures have been revised and updated.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
In the later development of Airflow 3.0, backward compatibility was not
added for some cases. Thus, the following rules are moved back to AIR302
* airflow.hooks.subprocess.SubprocessResult →
airflow.providers.standard.hooks.subprocess.SubprocessResult
* airflow.hooks.subprocess.working_directory →
airflow.providers.standard.hooks.subprocess.working_directory
* airflow.operators.datetime.target_times_as_dates →
airflow.providers.standard.operators.datetime.target_times_as_dates
* airflow.operators.trigger_dagrun.TriggerDagRunLink →
airflow.providers.standard.operators.trigger_dagrun.TriggerDagRunLink
* airflow.sensors.external_task.ExternalTaskSensorLink →
airflow.providers.standard.sensors.external_task.ExternalDagLink (**This
one contains a minor change**)
* airflow.sensors.time_delta.WaitSensor →
airflow.providers.standard.sensors.time_delta.WaitSensor
## Test Plan
<!-- How was it tested? -->
This primarily comes up with annotated `self` parameters in
constructors:
```py
class C[T]:
def __init__(self: C[int]): ...
```
Here, we want infer a specialization of `{T = int}` for a call that hits
this overload.
Normally when inferring a specialization of a function call, typevars
appear in the parameter annotations, and not in the argument types. In
this case, this is reversed: we need to verify that the `self` argument
(`C[T]`, as we have not yet completed specialization inference) is
assignable to the parameter type `C[int]`.
To do this, we simply look for a typevar/type in both directions when
performing inference, and apply the inferred specialization to argument
types as well as parameter types before verifying assignability.
As a wrinkle, this exposed that we were not checking
subtyping/assignability for function literals correctly. Our function
literal representation includes an optional specialization that should
be applied to the signature. Before, function literals were considered
subtypes of (assignable to) each other only if they were identical Salsa
objects. Two function literals with different specializations should
still be considered subtypes of (assignable to) each other if those
specializations result in the same function signature (typically because
the function doesn't use the typevars in the specialization).
Closes https://github.com/astral-sh/ty/issues/370
Closes https://github.com/astral-sh/ty/issues/100
Closes https://github.com/astral-sh/ty/issues/258
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
My editor runs `rustfmt` on save to format Rust code, not `cargo fmt`.
With our recent bump to the Rust 2024 edition, the formatting that
`rustfmt`/`cargo fmt` applies changed. Unfortunately, `rustfmt` and
`cargo fmt` have different behaviors for determining which edition to
use when formatting: `cargo fmt` looks for the Rust edition in
`Cargo.toml`, whereas `rustfmt` looks for it in `rustfmt.toml`. As a
result, whenever I save, I have to remember to manually run `cargo fmt`
before committing/pushing.
There is an open issue asking for `rustfmt` to also look at `Cargo.toml`
when it's present (https://github.com/rust-lang/rust.vim/issues/368),
but it seems like they "closed" that issue just by bumping the default
edition (six years ago, from 2015 to 2018).
In the meantime, this PR adds a `rustfmt.toml` file with our current
Rust edition so that both invocation have the same behavior. I don't
love that this duplicates information in `Cargo.toml`, but I've added a
reminder comment there to hopefully ensure that we bump the edition in
both places three years from now.
## Summary
Support direct uses of `typing.TypeAliasType`, as in:
```py
from typing import TypeAliasType
IntOrStr = TypeAliasType("IntOrStr", int | str)
def f(x: IntOrStr) -> None:
reveal_type(x) # revealed: int | str
```
closes https://github.com/astral-sh/ty/issues/392
## Ecosystem
The new false positive here:
```diff
+ error[invalid-type-form] altair/utils/core.py:49:53: The first argument to `Callable` must be either a list of types, ParamSpec, Concatenate, or `...`
```
comes from the fact that we infer the second argument as a type
expression now. We silence false positives for PEP695 `ParamSpec`s, but
not for `P = ParamSpec("P")` inside `Callable[P, ...]`.
## Test Plan
New Markdown tests
## Summary
just a minor nit followup to
https://github.com/astral-sh/ruff/pull/18010 -- put all the
non-`Visitor` methods of `SemanticIndexBuilder` in the same impl block
rather than having multiple impl blocks
## Test Plan
`cargo build`
Summary
--
I noticed these `cfg` directives while working on diagnostics. I think
it makes more sense to apply an `insta` filter in the test instead. I
copied this filter from a CLI test for the same rule.
Test Plan
--
Existing tests, especially Windows CI on this PR
## Summary
With this PR we now detect that x is always defined in `use`:
```py
if flag and (x := number):
use(x)
```
When outside if, it's still detected as possibly not defined
```py
flag and (x := number)
# error: [possibly-unresolved-reference]
use(x)
```
In order to achieve that, I had to find a way to get access to the
flow-snapshots of the boolean expression when analyzing the flow of the
if statement. I did it by special casing the visitor of boolean
expression to return flow control information, exporting two snapshots -
`maybe_short_circuit` and `no_short_circuit`. When indexing
boolean expression itself we must assume all possible flows, but when
it's inside if statement, we can be smarter than that.
## Test Plan
Fixed existing and added new mdtests.
I went through some of mypy primer results and they look fine
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Add various attributes to `NamedTuple` classes/instances that are
available at runtime.
closes https://github.com/astral-sh/ty/issues/417
## Test Plan
New Markdown tests
The PR add the `fix safety` section for rule `SIM210` (#15584 )
It is a little cheating, as the Fix safety section is copy/pasted by
#18086 as the problem is the same.
### Unsafe Fix Example
```python
class Foo():
def __eq__(self, other):
return 0
def foo():
return True if Foo() == 0 else False
def foo_fix():
return Foo() == 0
print(foo()) # False
print(foo_fix()) # 0
```
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#18107
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Snapshot tests
<!-- How was it tested? -->
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
`ProviderReplacement::Name` was designed back when we only wanted to do
linting. Now we also want to fix the user code. It would be easier for
us to replace them with better AutoImport struct.
## Test Plan
<!-- How was it tested? -->
The test fixture has been updated as some cases can now be fixed
## Summary
The PR adds an explicit check for `"__builtins__"` during name lookup,
similar to how `"__file__"` is implemented. The inferred type is
`Any`.
closes https://github.com/astral-sh/ty/issues/393
## Test Plan
Added a markdown test for `__builtins__`.
---------
Co-authored-by: David Peter <sharkdp@users.noreply.github.com>
This makes an easy tweak to allow our diagnostics for unmatched
overloads to apply to method calls. Previously, they only worked for
function calls.
There is at least one other case worth addressing too, namely, class
literals. e.g., `type()`. We had a diagnostic snapshot test case to
track it.
Closesastral-sh/ty#274
## Summary
Model that `type[C]` is always assignable to `type`, even if `C` is not
fully static.
closes https://github.com/astral-sh/ty/issues/312
## Test Plan
* New Markdown tests
* Property tests
## Summary
This PR deletes the `DiagnosticKind` type by inlining its three fields
(`name`, `body`, and `suggestion`) into three other diagnostic types:
`Diagnostic`, `DiagnosticMessage`, and `CacheMessage`.
Instead of deferring to an internal `DiagnosticKind`, both `Diagnostic`
and `DiagnosticMessage` now have their own macro-generated `AsRule`
implementations.
This should make both https://github.com/astral-sh/ruff/pull/18051 and
another follow-up PR changing the type of `name` on `CacheMessage`
easier since its type will be able to change separately from
`Diagnostic` and `DiagnosticMessage`.
## Test Plan
Existing tests
## Summary
Resolves [#290](https://github.com/astral-sh/ty/issues/290).
All arguments, synthesized or not, are now accounted for in
`too-many-positional-arguments`'s error message.
For example, consider this example:
```python
class C:
def foo(self): ...
C().foo(1) # !!!
```
Previously, ty would say:
> Too many positional arguments to bound method foo: expected 0, got 1
After this change, it will say:
> Too many positional arguments to bound method foo: expected 1, got 2
This is what Python itself does too:
```text
Traceback (most recent call last):
File "<python-input-0>", line 3, in <module>
C().foo()
~~~~~~~^^
TypeError: C.foo() takes 0 positional arguments but 1 was given
```
## Test Plan
Markdown tests.
## Summary
Nvim 0.11+ uses the builtin `vim.lsp.enable` and `vim.lsp.config` to
enable and configure LSP clients. This adds the new non legacy way of
configuring Nvim with `nvim-lspconfig` according to the upstream
documentation.
Update documentation for Nvim LSP configuration according to
`nvim-lspconfig` and Nvim 0.11+
## Test Plan
Tested locally on macOS with Nvim 0.11.1 and `nvim-lspconfig`
master/[ac1dfbe](ac1dfbe3b6).
The PR add the `fix safety` section for rule `SIM103` (#15584 )
### Unsafe Fix Example
```python
class Foo:
def __eq__(self, other):
return 1
def foo():
if Foo() == 1:
return True
return False
def foo_fix():
return Foo() == 1
print(foo()) # True
print(foo_fix()) # 1
```
### Note
I updated the code snippet example, because I thought it was cool to
have a correct example, i.e., that I can paste inside the playground and
it works :-)
Fixes#18069
<!--
Thank you for contributing to Ruff/ty! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title? (Please prefix
with `[ty]` for ty pull
requests.)
- Does this pull request include references to any relevant issues?
-->
## Summary
This PR addresses a bug in the `flake8-simplify` rule `SIM905`
(split-static-string) where `str.split(maxsplit=0)` and
`str.rsplit(maxsplit=0)` produced incorrect results for empty strings or
strings starting/ending with whitespace. The fix ensures that the
linting rule's suggested replacements now align with Python's native
behavior for these specific `maxsplit=0` scenarios.
## Test Plan
1. Added new test cases to the existing
`crates/ruff_linter/resources/test/fixtures/flake8_simplify/SIM905.py`
fixture to cover the scenarios described in issue #18069.
2. Ran `cargo test -p ruff_linter`.
3. Verified and accepted the updated snapshots for `SIM905.py` using
`cargo insta review`. The new snapshots confirm the corrected behavior
for `maxsplit=0`.
## Summary
This PR does the following:
1. Remove the symlinks from the `fuzz/` directory
2. Update `init-fuzzer.sh` script to create those symlinks
3. Update `fuzz/.gitignore` to ignore those corpus directories
## Test Plan
Initialize the fuzzer:
```sh
./fuzz/init-fuzzer.sh
```
And, run a fuzz target:
```sh
cargo +nightly fuzz run ruff_parse_simple -- -timeout=1 -only_ascii=1
```
The diagnostic now includes a pointer to the implementation definition
along with each possible overload.
This doesn't include information about *why* each overload failed. But
given the emphasis on concise output (since there can be *many*
unmatched overloads), it's not totally clear how to include that
additional information.
Fixes#274
These are, after all, specific to function types. The methods on `Type`
are more like conveniences that return something when the type *happens*
to be a function. But defining them on `FunctionType` itself makes it
easy to call them when you have a `FunctionType` instead of a `Type`.
I found the previous code somewhat harder to read. Namely, a `for`
loop was being used to encode "execute zero or one times, but not
more." Which is sometimes okay, but it seemed clearer to me to use
more explicit case analysis here.
This should have no behavioral changes.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Similiar to https://github.com/astral-sh/ruff/pull/17941.
`Replacement::Name` was designed for linting only. Now, we also want to
fix the user code. It would be easier to replace it with a better
AutoImport struct whenever possible.
On the other hand, `AIR301` and `AIR311` contain attribute changes that
can still use a struct like `Replacement::Name`. To reduce the
confusion, I also updated it as `Replacement::AttrName`
Some of the original `Replacement::Name` has been replaced as
`Replacement::Message` as they're not directly mapping and the message
has now been moved to `help`
## Test Plan
<!-- How was it tested? -->
The test fixtures have been updated
The PR add the `fix safety` section for rule `RUF007` (#15584 )
It seems that the fix was always marked as unsafe #14401
## Unsafety example
This first example is a little extreme. In fact, the class `Foo`
overrides the `__getitem__` method but in a very special, way. The
difference lies in the fact that `zip(letters, letters[1:])` call the
slice `letters[1:]` which is behaving weird in this case, while
`itertools.pairwise(letters)` call just `__getitem__(0), __getitem__(1),
...` and so on.
Note that the diagnostic is emitted: [playground](https://play.ruff.rs)
I don't know if we want to mention this problem, as there is a subtile
bug in the python implementation of `Foo` which make the rule unsafe.
```python
from dataclasses import dataclass
import itertools
@dataclass
class Foo:
letters: str
def __getitem__(self, index):
return self.letters[index] + "_foo"
letters = Foo("ABCD")
zip_ = zip(letters, letters[1:])
for a, b in zip_:
print(a, b) # A_foo B, B_foo C, C_foo D, D_foo _
pair = itertools.pairwise(letters)
for a, b in pair:
print(a, b) # A_foo B_foo, B_foo C_foo, C_foo D_foo
```
This other example is much probable.
here, `itertools.pairwise` was shadowed by a costume function
[(playground)](https://play.ruff.rs)
```python
from dataclasses import dataclass
from itertools import pairwise
def pairwise(a):
return []
letters = "ABCD"
zip_ = zip(letters, letters[1:])
print([(a, b) for a, b in zip_]) # [('A', 'B'), ('B', 'C'), ('C', 'D')]
pair = pairwise(letters)
print(pair) # []
```
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#17599.
## Test Plan
Snapshot tests.
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
Dunder methods are never looked up on instances. We do this implicitly
in `try_call_dunder`, but the corresponding flag was missing in the
instance-construction code where we use `member_lookup_with_policy`
directly.
fixes https://github.com/astral-sh/ty/issues/322
## Test Plan
Added regression test.
## Summary
This PR adds cycle handling for `infer_unpack_types` based on the
analysis in astral-sh/ty#364.
Fixes: astral-sh/ty#364
## Test Plan
Add a cycle handling test for unpacking in `cycle.md`
## Summary
Add a micro-benchmark for the code pattern observed in
https://github.com/astral-sh/ty/issues/362.
This currently takes around 1 second on my machine.
## Test Plan
```bash
cargo bench -p ruff_benchmark -- 'ty_micro\[many_tuple' --sample-size 10
```
Follows on from (and depends on)
https://github.com/astral-sh/ruff/pull/18021.
This updates our function specialization inference to infer type
mappings from parameters that are generic protocols.
For now, this only works when the argument _explicitly_ implements the
protocol by listing it as a base class. (We end up using exactly the
same logic as for generic classes in #18021.) For this to work with
classes that _implicitly_ implement the protocol, we will have to check
the types of the protocol members (which we are not currently doing), so
that we can infer the specialization of the protocol that the class
implements.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Understand that `__file__` is always set and a `str` when looked up as
an implicit global from a Python file we are type checking.
## Test Plan
mdtests
## Summary
Fix the lookup of `submodule`s in cases where the `parent` module has a
self-referential import like `from parent import submodule`. This allows
us to infer proper types for many symbols where we previously inferred
`Never`. This leads to many new false (and true) positives across the
ecosystem because the fact that we previously inferred `Never` shadowed
a lot of problems. For example, we inferred `Never` for `os.path`, which
is why we now see a lot of new diagnostics related to `os.path.abspath`
and similar.
```py
import os
reveal_type(os.path) # previously: Never, now: <module 'os.path'>
```
closes https://github.com/astral-sh/ty/issues/261
closes https://github.com/astral-sh/ty/issues/307
## Ecosystem analysis
```
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┓
┃ Diagnostic ID ┃ Severity ┃ Removed ┃ Added ┃ Net Change ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━┩
│ call-non-callable │ error │ 1 │ 5 │ +4 │
│ call-possibly-unbound-method │ warning │ 6 │ 26 │ +20 │
│ invalid-argument-type │ error │ 26 │ 94 │ +68 │
│ invalid-assignment │ error │ 18 │ 46 │ +28 │
│ invalid-context-manager │ error │ 9 │ 4 │ -5 │
│ invalid-raise │ error │ 1 │ 1 │ 0 │
│ invalid-return-type │ error │ 3 │ 20 │ +17 │
│ invalid-super-argument │ error │ 4 │ 0 │ -4 │
│ invalid-type-form │ error │ 573 │ 0 │ -573 │
│ missing-argument │ error │ 2 │ 10 │ +8 │
│ no-matching-overload │ error │ 0 │ 715 │ +715 │
│ non-subscriptable │ error │ 0 │ 35 │ +35 │
│ not-iterable │ error │ 6 │ 7 │ +1 │
│ possibly-unbound-attribute │ warning │ 14 │ 31 │ +17 │
│ possibly-unbound-import │ warning │ 13 │ 0 │ -13 │
│ possibly-unresolved-reference │ warning │ 0 │ 8 │ +8 │
│ redundant-cast │ warning │ 1 │ 0 │ -1 │
│ too-many-positional-arguments │ error │ 2 │ 0 │ -2 │
│ unknown-argument │ error │ 2 │ 0 │ -2 │
│ unresolved-attribute │ error │ 583 │ 304 │ -279 │
│ unresolved-import │ error │ 0 │ 96 │ +96 │
│ unsupported-operator │ error │ 0 │ 17 │ +17 │
│ unused-ignore-comment │ warning │ 29 │ 2 │ -27 │
├───────────────────────────────┼──────────┼─────────┼───────┼────────────┤
│ TOTAL │ │ 1293 │ 1421 │ +128 │
└───────────────────────────────┴──────────┴─────────┴───────┴────────────┘
Analysis complete. Found 23 unique diagnostic IDs.
Total diagnostics removed: 1293
Total diagnostics added: 1421
Net change: +128
```
* We see a lot of new errors (`no-matching-overload`) related to
`os.path.dirname` and other `os.path` operations because we infer `str |
None` for `__file__`, but many projects use something like
`os.path.dirname(__file__)`.
* We also see many new `unresolved-attribute` errors related to the fact
that we now infer proper module types for some imports (e.g. `import
kornia.augmentation as K`), but we don't allow implicit imports (e.g.
accessing `K.auto.operations` without also importing `K.auto`). See
https://github.com/astral-sh/ty/issues/133.
* Many false positive `invalid-type-form` are removed because we now
infer the correct type for some type expression instead of `Never`,
which is not valid in a type annotation/expression context.
## Test Plan
Added new Markdown tests
## Summary
If the user tries to use a new builtin on an old Python version, tell
them what Python version the builtin was added on, what our inferred
Python version is for their project, and what configuration settings
they can tweak to fix the error.
## Test Plan
Snapshots and screenshots:

First take on a contributing guide for `ty`. Lots of it is copied from
the existing Ruff contribution guide.
I've put this in Ruff repo, since I think a contributing guide belongs
where the code is. I also updated the Ruff contributing guide to link to
the `ty` one.
Once this is merged, we can also add a link from the `CONTRIBUTING.md`
in ty repo (which focuses on making contributions to things that are
actually in the ty repo), to this guide.
I also updated the pull request template to mention that it might be a
ty PR, and mention the `[ty]` PR title prefix.
Feel free to update/modify/merge this PR before I'm awake tomorrow.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
Co-authored-by: David Peter <mail@david-peter.de>
Fixes: https://github.com/astral-sh/ty/issues/92
## Summary
We currently get a `invalid-argument-type` error when using
`dataclass.fields` on a dataclass, because we do not synthesize the
`__dataclass_fields__` member.
This PR fixes this diagnostic.
Note that we do not yet model the `Field` type correctly. After that is
done, we can assign a more precise `tuple[Field, ...]` type to this new
member.
## Test Plan
New mdtest.
---------
Co-authored-by: David Peter <mail@david-peter.de>
This updates our function specialization inference to infer type
mappings from parameters that are generic aliases, e.g.:
```py
def f[T](x: list[T]) -> T: ...
reveal_type(f(["a", "b"])) # revealed: str
```
Though note that we're still inferring the type of list literals as
`list[Unknown]`, so for now we actually need something like the
following in our tests:
```py
def _(x: list[str]):
reveal_type(f(x)) # revealed: str
```
We were not inducting into instance types and subclass-of types when
looking for legacy typevars, nor when apply specializations.
This addresses
https://github.com/astral-sh/ruff/pull/17832#discussion_r2081502056
```py
from __future__ import annotations
from typing import TypeVar, Any, reveal_type
S = TypeVar("S")
class Foo[T]:
def method(self, other: Foo[S]) -> Foo[T | S]: ... # type: ignore[invalid-return-type]
def f(x: Foo[Any], y: Foo[Any]):
reveal_type(x.method(y)) # revealed: `Foo[Any | S]`, but should be `Foo[Any]`
```
We were not detecting that `S` made `method` generic, since we were not
finding it when searching the function signature for legacy typevars.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
If a try-catch block guards the names, we don't raise warnings. During
this change, I discovered that some of the replacement types were
missed. Thus, I extend the fix to types other than AutoImport as well
## Test Plan
<!-- How was it tested? -->
Test fixtures are added and updated.
## Summary
Updates the `--python` flag to accept Python executables in virtual
environments. Notably, we do not query the executable and it _must_ be
in a canonical location in a virtual environment. This is pretty naive,
but solves for the trivial case of `ty check --python .venv/bin/python3`
which will be a common mistake (and `ty check --python $(which python)`)
I explored this while trying to understand Python discovery in ty in
service of https://github.com/astral-sh/ty/issues/272, I'm not attached
to it, but figure it's worth sharing.
As an alternative, we can add more variants to the
`SearchPathValidationError` and just improve the _error_ message, i.e.,
by hinting that this looks like a virtual environment and suggesting the
concrete alternative path they should provide. We'll probably want to do
that for some other cases anyway (e.g., `3.13` as described in the
linked issue)
This functionality is also briefly mentioned in
https://github.com/astral-sh/ty/issues/193
Closes https://github.com/astral-sh/ty/issues/318
## Test Plan
e.g.,
```
uv run ty check --python .venv/bin/python3
```
needs test coverage still
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
The existing implementation of RUF060 (InEmptyCollection) is not
recursive, meaning that although set([]) results in an empty collection,
the existing code fails it because set is taking an argument.
The updated implementation allows set and frozenset to take empty
collection as positional argument (which results in empty
set/frozenset).
## Test Plan
Added test cases for recursive cases + updated snapshot (see RUF060.py).
---------
Co-authored-by: Marcus Näslund <marcus.naslund@kognity.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fixes#17776.
This PR also handles all other `PTH*` rules that don't support file
descriptors.
## Test Plan
<!-- How was it tested? -->
Update existing tests.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
We can only guarantee the safety of the autofix for number literals, all
other cases may change the runtime behaviour of the program or introduce
a syntax error. For the cases reported in the issue that would result in
a syntax error, I disabled the autofix.
Follow-up of #17661.
Fixes#16472.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Snapshot tests.
<!-- How was it tested? -->
Function literals have an optional specialization, which is applied to
the parameter/return type annotations lazily when the function's
signature is requested. We were previously only applying this
specialization to the final overload of an overloaded function.
This manifested most visibly for `list.__add__`, which has an overloaded
definition in the typeshed:
b398b83631/crates/ty_vendored/vendor/typeshed/stdlib/builtins.pyi (L1069-L1072)
Closes https://github.com/astral-sh/ty/issues/314
## Summary
I found this bug while working on #18041. The following code leads to
infinite recursion.
```python
from ty_extensions import is_disjoint_from, static_assert, TypeOf
class C:
@property
def prop(self) -> int:
return 1
static_assert(not is_disjoint_from(int, TypeOf[C.prop]))
```
The cause is a trivial missing binding in `is_disjoint_from`. This PR
fixes the bug and adds a test case (this is a simple fix and may not
require a new test case?).
## Test Plan
A new test case is added to
`mdtest/type_properties/is_disjoint_from.md`.
## Summary
Added version 3.14 to the script generating the `known_stdlib.rs` file.
Rebuilt the known stdlibs with latest version (2025.5.10) of [stdlibs
Python lib](https://pypi.org/project/stdlibs/) (which added support for
3.14.0b1).
_Note: Python 3.14 is now in [feature
freeze](https://peps.python.org/pep-0745/) so the modules in stdlib
should be stable._
_See also: #15506_
## Test Plan
The following command has been run. Using for tests the `compression`
module which been introduced with Python 3.14.
```sh
ruff check --no-cache --select I001 --target-version py314 --fix
```
With ruff 0.11.9:
```python
import base64
import datetime
import compression
print(base64, compression, datetime)
```
With this PR:
```python
import base64
import compression
import datetime
print(base64, compression, datetime)
```
## Summary
`KnownClass::Range`, `KnownInstanceType::Any` and `ClassBase::any()` are
no longer used or useful: all our tests pass with them removed.
`KnownModule::Abc` _is_ now used outside of tests, however, so I removed
the `#[allow(dead_code)]` branch above that variant.
## Test Plan
`cargo test -p ty_python_semantic`
Following #17991, removes some of
https://github.com/astral-sh/ruff/pull/17222 which is no longer strictly
necessary. I don't actually think it's that ugly to have around? no
strong feelings on retaining it or not.
Follow-up to https://github.com/astral-sh/ruff/pull/17991 ensuring we do
not allow detection of system environments when the origin is
`VIRTUAL_ENV` or a discovered `.venv` directory — i.e., those always
require a `pyvenv.cfg` file.
Adds test coverage for https://github.com/astral-sh/ruff/pull/17991,
which includes some minor refactoring of the virtual environment test
infrastructure.
I tried to minimize stylistic changes, but there are still a few because
I was a little confused by the setup. I could see this evolving more in
the future, as I don't think the existing model can capture all the test
coverage I'm looking for.
This adds basic support for non-virtual Python environments by accepting
a directory without a `pyvenv.cfg` which allows existing, subsequent
site-packages discovery logic to succeed. We can do better here in the
long-term, by adding more eager validation (for error messages) and
parsing the Python version from the discovered site-packages directory
(which isn't relevant yet, because we don't use the discovered Python
version from virtual environments as the default `--python-version` yet
either).
Related
- https://github.com/astral-sh/ty/issues/265
- https://github.com/astral-sh/ty/issues/193
You can review this commit by commit if it makes you happy.
I tested this manually; I think refactoring the test setup is going to
be a bit more invasive so I'll stack it on top (see
https://github.com/astral-sh/ruff/pull/17996).
```
❯ uv run ty check --python /Users/zb/.local/share/uv/python/cpython-3.10.17-macos-aarch64-none/ -vv example
2025-05-09 12:06:33.685911 DEBUG Version: 0.0.0-alpha.7 (f9c4c8999 2025-05-08)
2025-05-09 12:06:33.685987 DEBUG Architecture: aarch64, OS: macos, case-sensitive: case-insensitive
2025-05-09 12:06:33.686002 DEBUG Searching for a project in '/Users/zb/workspace/ty'
2025-05-09 12:06:33.686123 DEBUG Resolving requires-python constraint: `>=3.8`
2025-05-09 12:06:33.686129 DEBUG Resolved requires-python constraint to: 3.8
2025-05-09 12:06:33.686142 DEBUG Project without `tool.ty` section: '/Users/zb/workspace/ty'
2025-05-09 12:06:33.686147 DEBUG Searching for a user-level configuration at `/Users/zb/.config/ty/ty.toml`
2025-05-09 12:06:33.686156 INFO Defaulting to python-platform `darwin`
2025-05-09 12:06:33.68636 INFO Python version: Python 3.8, platform: darwin
2025-05-09 12:06:33.686375 DEBUG Adding first-party search path '/Users/zb/workspace/ty'
2025-05-09 12:06:33.68638 DEBUG Using vendored stdlib
2025-05-09 12:06:33.686634 DEBUG Discovering site-packages paths from sys-prefix `/Users/zb/.local/share/uv/python/cpython-3.10.17-macos-aarch64-none` (`--python` argument')
2025-05-09 12:06:33.686667 DEBUG Attempting to parse virtual environment metadata at '/Users/zb/.local/share/uv/python/cpython-3.10.17-macos-aarch64-none/pyvenv.cfg'
2025-05-09 12:06:33.686671 DEBUG Searching for site-packages directory in `sys.prefix` path `/Users/zb/.local/share/uv/python/cpython-3.10.17-macos-aarch64-none`
2025-05-09 12:06:33.686702 DEBUG Resolved site-packages directories for this environment are: ["/Users/zb/.local/share/uv/python/cpython-3.10.17-macos-aarch64-none/lib/python3.10/site-packages"]
2025-05-09 12:06:33.686706 DEBUG Adding site-packages search path '/Users/zb/.local/share/uv/python/cpython-3.10.17-macos-aarch64-none/lib/python3.10/site-packages'
...
❯ uv run ty check --python /tmp -vv example
2025-05-09 15:36:10.819416 DEBUG Version: 0.0.0-alpha.7 (f9c4c8999 2025-05-08)
2025-05-09 15:36:10.819708 DEBUG Architecture: aarch64, OS: macos, case-sensitive: case-insensitive
2025-05-09 15:36:10.820118 DEBUG Searching for a project in '/Users/zb/workspace/ty'
2025-05-09 15:36:10.821652 DEBUG Resolving requires-python constraint: `>=3.8`
2025-05-09 15:36:10.821667 DEBUG Resolved requires-python constraint to: 3.8
2025-05-09 15:36:10.8217 DEBUG Project without `tool.ty` section: '/Users/zb/workspace/ty'
2025-05-09 15:36:10.821888 DEBUG Searching for a user-level configuration at `/Users/zb/.config/ty/ty.toml`
2025-05-09 15:36:10.822072 INFO Defaulting to python-platform `darwin`
2025-05-09 15:36:10.822439 INFO Python version: Python 3.8, platform: darwin
2025-05-09 15:36:10.822773 DEBUG Adding first-party search path '/Users/zb/workspace/ty'
2025-05-09 15:36:10.822929 DEBUG Using vendored stdlib
2025-05-09 15:36:10.829872 DEBUG Discovering site-packages paths from sys-prefix `/tmp` (`--python` argument')
2025-05-09 15:36:10.829911 DEBUG Attempting to parse virtual environment metadata at '/private/tmp/pyvenv.cfg'
2025-05-09 15:36:10.829917 DEBUG Searching for site-packages directory in `sys.prefix` path `/private/tmp`
ty failed
Cause: Invalid search path settings
Cause: Failed to discover the site-packages directory: Failed to search the `lib` directory of the Python installation at `sys.prefix` path `/private/tmp` for `site-packages`
```
## Summary
Suppress false positives for uses of PEP-695 `ParamSpec` in `Callable`
annotations:
```py
from typing_extensions import Callable
def f[**P](c: Callable[P, int]):
pass
```
addresses a comment here:
https://github.com/astral-sh/ty/issues/157#issuecomment-2859284721
## Test Plan
Adapted Markdown tests
Summary
--
This should resolve the formatter ecosystem errors we've been seeing
lately. https://github.com/mesonbuild/meson-python/pull/728 added the
links, which I think are intentionally broken for testing purposes.
Test Plan
--
Ecosystem check on this PR
Re: #17526
## Summary
Add integration test for semantic syntax for `IrrefutableCasePattern`,
`SingleStarredAssignment`, `WriteToDebug`, and `InvalidExpression`.
## Notes
- Following @ntBre's suggestion, I will keep the test coming in batches
like this over the next few days in separate PRs to keep the review load
per PR manageable while also not spamming too many.
- I did not add a test for `del __debug__` which is one of the examples
in `crates/ruff_python_parser/src/semantic_errors.rs:1051`.
For python version `<= 3.8` there is no error and for `>=3.9` the error
is not `WriteToDebug` but `SyntaxError: cannot delete __debug__ on
Python 3.9 (syntax was removed in 3.9)`.
- The `blacken-docs` bypass is necessary because otherwise the test does
not pass pre-commit checks; but we want to check for this faulty syntax.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
This is a test.
Summary
--
This was suggested on Discord, I hope this is roughly what we had in
mind. I took the message from the ty README, but I'm more than happy to
update it. Otherwise I just tried to mimic the appearance of the `ruff
analyze graph` warning (although I'm realizing now the whole text is
bold for ruff).
Test Plan
--
New warnings in the CLI tests. I thought this might be undesirable but
it looks like uv did the same thing
(https://github.com/astral-sh/uv/pull/6166).

This makes one very simple change: we report all call binding
errors from each union variant.
This does result in duplicate-seeming diagnostics. For example,
when two union variants are invalid for the same reason.
## Summary
Adds a simple progress bar for the `ty check` CLI command. The style is
taken from uv, and like uv the bar is always shown - for smaller
projects it is fast enough that it isn't noticeable. We could
alternatively hide it completely based on some heuristic for the number
of files, or only show it after some amount of time.
I also disabled it when `--watch` is passed, cancelling inflight checks
was leading to zombie progress bars. I think we can fix this by using
[`MultiProgress`](https://docs.rs/indicatif/latest/indicatif/struct.MultiProgress.html)
and managing all the bars globally, but I left that out for now.
Resolves https://github.com/astral-sh/ty/issues/98.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
* `airflow.models.Connection` → `airflow.sdk.Connection`
* `airflow.models.Variable` → `airflow.sdk.Variable`
## Test Plan
<!-- How was it tested? -->
The test fixtures has been updated (see the first commit for easier
review)
This does a deeper removal of the `lint:` prefix by removing the
`DiagnosticId::as_str` method and replacing it with `as_concise_str`. We
remove the associated error type and simplify the `Display` impl for
`DiagnosticId` as well.
This turned out to catch a `lint:` that was still in the diagnostic
output: the part that says why a lint is enabled.
We just set the ID on the `Message` and it just does what we want in
this case. I think I didn't do this originally because I was trying to
preserve the existing rendering? I'm not sure. I might have just missed
this method.
In a subsequent commit, we're going to start using `annotate-snippets`'s
functionality for diagnostic IDs in the rendering. As part of doing
that, I wanted to remove this special casing of an empty message. I did
that independently to see what, if anything, would change. (The changes
look fine to me. They'll be tweaked again in the next commit along with
a bunch of others.)
## Summary
Use a self-reference "marker" ~~and fixpoint iteration~~ to solve the
stack overflow problems with recursive protocols. This is not pretty and
somewhat tedious, but seems to work fine. Much better than all my
fixpoint-iteration attempts anyway.
closes https://github.com/astral-sh/ty/issues/93
## Test Plan
New Markdown tests.
## Summary
Add cycle handling for `try_metaclass` and `pep695_generic_context`
queries, as well as adjusting the cycle handling for `try_mro` to ensure
that it short-circuits on cycles and won't grow MROs indefinitely.
This reduces the number of failing fuzzer seeds from 68 to 17. The
latter count includes fuzzer seeds 120, 160, and 335, all of which
previously panicked but now either hang or are very slow; I've
temporarily skipped those seeds in the fuzzer until I can dig into that
slowness further.
This also allows us to move some more ecosystem projects from `bad.txt`
to `good.txt`, which I've done in
https://github.com/astral-sh/ruff/pull/17903
## Test Plan
Added mdtests.
@AlexWaygood pointed out that the `SliceLiteral` type variant was
originally created to handle slices before we had generics.
https://github.com/astral-sh/ruff/pull/17927#discussion_r2078115787
Now that we _do_ have generics, we can use a specialization of the
`slice` builtin type for slice literals.
This depends on https://github.com/astral-sh/ruff/pull/17956, since we
need to make sure that all typevar defaults are fully substituted when
specializing `slice`.
It's possible for a typevar to list another typevar as its default
value:
```py
class C[T, U = T]: ...
```
When specializing this class, if a type isn't provided for `U`, we would
previously use the default as-is, leaving an unspecialized `T` typevar
in the specialization. Instead, we want to use what `T` is mapped to as
the type of `U`.
```py
reveal_type(C()) # revealed: C[Unknown, Unknown]
reveal_type(C[int]()) # revealed: C[int, int]
reveal_type(C[int, str]()) # revealed: C[int, str]
```
This is especially important for the `slice` built-in type.
## Summary
This PR is a first step toward integration of the new `Diagnostic` type
into ruff. There are two main changes:
- A new `UnifiedFile` enum wrapping `File` for red-knot and a
`SourceFile` for ruff
- ruff's `Message::SyntaxError` variant is now a `Diagnostic` instead of
a `SyntaxErrorMessage`
The second of these changes was mostly just a proof of concept for the
first, and it went pretty smoothly. Converting `DiagnosticMessage`s will
be most of the work in replacing `Message` entirely.
## Test Plan
Existing tests, which show no changes.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: Micha Reiser <micha@reiser.io>
Summary
--
This PR resolves both the typing-related and syntax error TODOs added in
#17563 by tracking a set of `global` bindings for each scope. As
discussed below, we avoid the additional AST traversal from ruff by
collecting `Name`s from `global` statements while building the semantic
index and emit a syntax error if the `Name` is already bound in the
current scope at the point of the `global` statement. This has the
downside of separating the error from the `SemanticSyntaxChecker`, but I
plan to explore using this approach in the `SemanticSyntaxChecker`
itself as a follow-up. It seems like this may be a better approach for
ruff as well.
Test Plan
--
Updated all of the related mdtests to remove the TODOs (and add quotes I
forgot on the messages).
There is one remaining TODO, but it requires `nonlocal` support, which
isn't even incorporated into the `SemanticSyntaxChecker` yet.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Fixes: astral-sh/ty#159
This PR adds support for using `Self` in methods.
When the type of an annotation is `TypingSelf` it is converted to a type
var based on:
https://typing.python.org/en/latest/spec/generics.html#self
I just skipped Protocols because it had more problems and the tests was
not useful.
Also I need to create a follow up PR that implicitly assumes `self`
argument has type `Self`.
In order to infer the type in the `in_type_expression` method I needed
to have scope id and semantic index available. I used the idea from
[this PR](https://github.com/astral-sh/ruff/pull/17589/files) to pass
additional context to this method.
Also I think in all places that `in_type_expression` is called we need
to have this context because `Self` can be there so I didn't split the
method into one version with context and one without.
## Test Plan
Added new tests from spec.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Carl Meyer <carl@astral.sh>
#17897 added variance handling for legacy typevars — but they were only
being considered when checking generic aliases of the same class:
```py
class A: ...
class B(A): ...
class C[T]: ...
static_assert(is_subtype_of(C[B], C[A]))
```
and not for generic subclasses:
```py
class D[U](C[U]): ...
static_assert(is_subtype_of(D[B], C[A]))
```
Now we check those too!
Closes https://github.com/astral-sh/ty/issues/101
Fixes#17867
## Summary
The CPython parser does not allow generator expressions which are the
sole arguments in an argument list to have a trailing comma.
With this change, we start flagging such instances.
## Test Plan
Added new inline tests.
## Summary
We now expect the client to send initialization options to opt-in to
experimental (but LSP-standardized) features, like completion support.
Specifically, the client should set `"experimental.completions.enable":
true`.
Closes https://github.com/astral-sh/ty/issues/74.
## Summary
This PR adds support for the `__all__` module variable.
Reference spec:
https://typing.python.org/en/latest/spec/distributing.html#library-interface-public-and-private-symbols
This PR adds a new `dunder_all_names` query that returns a set of
`Name`s defined in the `__all__` variable of the given `File`. The query
works by implementing the `StatementVisitor` and collects all the names
by recognizing the supported idioms as mentioned in the spec. Any idiom
that's not recognized are ignored.
The current implementation is minimum to what's required for us to
remove all the false positives that this is causing. Refer to the
"Follow-ups" section below to see what we can do next. I'll a open
separate issue to keep track of them.
Closes: astral-sh/ty#106Closes: astral-sh/ty#199
### Follow-ups
* Diagnostics:
* Add warning diagnostics for unrecognized `__all__` idioms, `__all__`
containing non-string element
* Add an error diagnostic for elements that are present in `__all__` but
not defined in the module. This could lead to runtime error
* Maybe we should return `<type>` instead of `Unknown | <type>` for
`module.__all__`. For example:
https://playknot.ruff.rs/2a6fe5d7-4e16-45b1-8ec3-d79f2d4ca894
* Mark a symbol that's mentioned in `__all__` as used otherwise it could
raise (possibly in the future) "unused-name" diagnostic
Supporting diagnostics will require that we update the return type of
the query to be something other than `Option<FxHashSet<Name>>`,
something that behaves like a result and provides a way to check whether
a name exists in `__all__`, loop over elements in `__all__`, loop over
the invalid elements, etc.
## Ecosystem analysis
The following are the maximum amount of diagnostics **removed** in the
ecosystem:
* "Type <module '...'> has no attribute ..."
* `collections.abc` - 14
* `numpy` - 35534
* `numpy.ma` - 296
* `numpy.char` - 37
* `numpy.testing` - 175
* `hashlib` - 311
* `scipy.fft` - 2
* `scipy.stats` - 38
* "Module '...' has no member ..."
* `collections.abc` - 85
* `numpy` - 508
* `numpy.testing` - 741
* `hashlib` - 36
* `scipy.stats` - 68
* `scipy.interpolate` - 7
* `scipy.signal` - 5
The following modules have dynamic `__all__` definition, so `ty` assumes
that `__all__` doesn't exists in that module:
* `scipy.stats`
(95a5d6ea8b/scipy/stats/__init__.py (L665))
* `scipy.interpolate`
(95a5d6ea8b/scipy/interpolate/__init__.py (L221))
* `scipy.signal` (indirectly via
95a5d6ea8b/scipy/signal/_signal_api.py (L30))
* `numpy.testing`
(de784cd6ee/numpy/testing/__init__.py (L16-L18))
~There's this one category of **false positives** that have been added:~
Fixed the false positives by also ignoring `__all__` from a module that
uses unrecognized idioms.
<details><summary>Details about the false postivie:</summary>
<p>
The `scipy.stats` module has dynamic `__all__` and it imports a bunch of
symbols via star imports. Some of those modules have a mix of valid and
invalid `__all__` idioms. For example, in
95a5d6ea8b/scipy/stats/distributions.py (L18-L24),
2 out of 4 `__all__` idioms are invalid but currently `ty` recognizes
two of them and says that the module has a `__all__` with 5 values. This
leads to around **2055** newly added false positives of the form:
```
Type <module 'scipy.stats'> has no attribute ...
```
I think the fix here is to completely ignore `__all__`, not only if
there are invalid elements in it, but also if there are unrecognized
idioms used in the module.
</p>
</details>
## Test Plan
Add a bunch of test cases using the new `ty_extensions.dunder_all_names`
function to extract a module's `__all__` names.
Update various test cases to remove false positives around `*` imports
and re-export convention.
Add new test cases for named import behavior as `*` imports covers all
of it already (thanks Alex!).
## Summary
Fixes#17541
Before this change, in the case of overloaded functions,
`@dataclass_transform` was detected only when applied to the
implementation, not the overloads.
However, the spec also allows this decorator to be applied to any of the
overloads as well.
With this PR, we start handling `@dataclass_transform`s applied to
overloads.
## Test Plan
Fixed existing TODOs in the test suite.
## Summary
This is sort of an anticlimactic resolution to #17863, but now that we
understand what the root cause for the stack overflows was, I think it's
fine to enable running on this project. See the linked ticket for the
full analysis.
closes#17863
## Test Plan
Ran lots of times locally and never observed a crash at worker thread
stack sizes > 8 MiB.
We now track the variance of each typevar, and obey the `covariant` and
`contravariant` parameters to the legacy `TypeVar` constructor. We still
don't yet infer variance for PEP-695 typevars or for the
`infer_variance` legacy constructor parameter.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
A recursive protocol like the following would previously lead to stack
overflows when attempting to create the union type for the `P | None`
member, because `UnionBuilder` checks if element types are fully static,
and the fully-static check on `P` would in turn list all members and
check whether all of them were fully static, leading to a cycle.
```py
from __future__ import annotations
from typing import Protocol
class P(Protocol):
parent: P | None
```
Here, we make the fully-static check on protocols a salsa query and add
fixpoint iteration, starting with `true` as the initial value (assume
that the recursive protocol is fully-static). If the recursive protocol
has any non-fully-static members, we still return `false` when
re-executing the query (see newly added tests).
closes#17861
## Test Plan
Added regression test
## Summary
Resolves#15502.
`ty generate-shell-completion` now works in a similar manner to `ruff
generate-shell-completion`.
## Test Plan
Manually:
<details>
```shell
$ cargo run --package ty generate-shell-completion nushell
module completions {
# An extremely fast Python type checker.
export extern ty [
--help(-h) # Print help
--version(-V) # Print version
]
# ...
}
export use completions *
```
</details>
@AlexWaygood discovered that even though we've been propagating
specializations to _parent_ base classes correctly, we haven't been
passing them on to _grandparent_ base classes:
https://github.com/astral-sh/ruff/pull/17832#issuecomment-2854360969
```py
class Bar[T]:
x: T
class Baz[T](Bar[T]): ...
class Spam[T](Baz[T]): ...
reveal_type(Spam[int]().x) # revealed: `T`, but should be `int`
```
This PR updates the MRO machinery to apply the current specialization
when starting to iterate the MRO of each base class.
## Summary
This PR partially addresses #16418 via the following:
- `LinterSettings::unresolved_python_version` is now a `TargetVersion`,
which is a thin wrapper around an `Option<PythonVersion>`
- `Checker::target_version` now calls `TargetVersion::linter_version`
internally, which in turn uses `unwrap_or_default` to preserve the
current default behavior
- Calls to the parser now call `TargetVersion::parser_version`, which
calls `unwrap_or_else(PythonVersion::latest)`
- The `Checker`'s implementation of
`SemanticSyntaxContext::python_version` also uses
`TargetVersion::parser_version` to use `PythonVersion::latest` for
semantic errors
In short, all lint rule behavior should be unchanged, but we default to
the latest Python version for the new syntax errors, which should
minimize confusing version-related syntax errors for users without a
version configured.
## Test Plan
Existing tests, which showed no changes (except for printing default
settings).
## Summary
Introducing a new rule based on discussions in #15732 and #15729 that
checks for unnecessary in with empty collections.
I called it in_empty_collection and gave the rule number RUF060.
Rule is in preview group.
e.g.,
```
❯ uv run -q -- ty -V
ty 0.0.0-alpha.4 (08881edba 2025-05-05)
❯ uv run -q -- ty --version
ty 0.0.0-alpha.4 (08881edba 2025-05-05)
```
Previously, this just displayed `ty 0.0.0` because it didn't use our
custom version implementation. We no longer have a short version —
matching the interface in uv. We could add a variant for it, if it seems
important to people. However, I think we found it more confusing than
not over there and didn't get any complaints about the change.
Closes https://github.com/astral-sh/ty/issues/54
Extends https://github.com/astral-sh/ruff/pull/17866, using
`dist-workspace.toml` as a source of truth for versions to enable
version retrieval in distributions that are not Git repositories (i.e.,
Python source distributions and source tarballs consumed by Linux
distros).
I retain the Git tag lookup from
https://github.com/astral-sh/ruff/pull/17866 as a fallback — it seems
harmless, but we could drop it to simplify things here.
I confirmed this works from the repository as well as Python source and
binary distributions:
```
❯ uv run --refresh-package ty --reinstall-package ty -q -- ty version
ty 0.0.1-alpha.1+5 (2eadc9e61 2025-05-05)
❯ uv build
...
❯ uvx --from ty@dist/ty-0.0.0a1.tar.gz --no-cache -q -- ty version
ty 0.0.1-alpha.1
❯ uvx --from ty@dist/ty-0.0.0a1-py3-none-macosx_11_0_arm64.whl -q -- ty version
ty 0.0.1-alpha.1
```
Requires https://github.com/astral-sh/ty/pull/36
cc @Gankra and @MichaReiser for review.
Currently, `ty version` pulls its information from the Ruff repository —
but we want this to pull from the repository in the directory _above_
when Ruff is a submodule.
I tested this in the `ty` repository after tagging an arbitrary commit:
```
❯ uv run --refresh-package ty --reinstall-package ty ty version
Built ty @ file:///Users/zb/workspace/ty
Uninstalled 1 package in 2ms
Installed 1 package in 1ms
ty 0.0.0+3 (34253b1d4 2025-05-05)
```
We also use the last Git tag as the source of truth for the version,
instead of the crate version. However, we'll need a way to set the
version for releases still, as the tag is published _after_ the build.
We can either tag early (without pushing the tag to the remote), or add
another environment variable. (**Note, this approach is changed in a
follow-up. See https://github.com/astral-sh/ruff/pull/17868**)
From this repository, the version will be `unknown`:
```
❯ cargo run -q --bin ty -- version
ty unknown
```
We could add special handling like... `ty unknown (ruff@...)` but I see
that as a secondary goal.
Closes https://github.com/astral-sh/ty/issues/5
The reviewer situation in this repository is unhinged, cc @Gankra and
@MichaReiser for review.
## Summary
This fixes some false positives that showed up in the primer diff for
https://github.com/astral-sh/ruff/pull/17832
## Test Plan
new mdtests added that fail with false-positive diagnostics on `main`
## Summary
This PR fixes#17595.
## Test Plan
New test cases are added to `mdtest/narrow/conditionals/nested.md`.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
If a typevar is declared as having a default, we shouldn't require a
type to be specified for that typevar when explicitly specializing a
generic class:
```py
class WithDefault[T, U = int]: ...
reveal_type(WithDefault[str]()) # revealed: WithDefault[str, int]
```
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Fixes
https://github.com/astral-sh/ruff/pull/17832#issuecomment-2851224968. We
had a comment that we did not need to apply specializations to generic
aliases, or to the bound `self` of a bound method, because they were
already specialized. But they might be specialized with a type variable,
which _does_ need to be specialized, in the case of a "multi-step"
specialization, such as:
```py
class LinkedList[T]: ...
class C[U]:
def method(self) -> LinkedList[U]:
return LinkedList[U]()
```
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
closes#17472
This is obviously just a band-aid solution to this problem (in that you
can always make your [pathological
inputs](28994edd82/sympy/polys/numberfields/resolvent_lookup.py)
bigger and it will still crash), but I think this is not an unreasonable
change — even if we add more sophisticated solutions later. I tried
using `stacker` as suggested by @MichaReiser, and it works. But it's
unclear where exactly would be the right place to put it, and even for
the `sympy` problem, we would need to add it both in the semantic index
builder AST traversal and in type inference. Increasing the default
stack size for worker threads, as proposed here, doesn't solve the
underlying problem (that there is a hard limit), but it is more
universal in the sense that it is not specific to large binary-operator
expression chains.
To determine a reasonable stack size, I created files that look like
*right associative*:
```py
from typing import reveal_type
total = (1 + (1 + (1 + (1 + (… + 1)))))
reveal_type(total)
```
*left associative*
```py
from typing import reveal_type
total = 1 + 1 + 1 + 1 + … + 1
reveal_type(total)
```
with a variable amount of operands (`N`). I then chose the stack size
large enough to still be able to handle cases that existing type
checkers can not:
```
right
N = 20: mypy takes ~ 1min
N = 350: pyright crashes with a stack overflow (mypy fails with "too many nested parentheses")
N = 800: ty(main) infers Literal[800] instantly
N = 1000: ty(main) crashes with "thread '<unknown>' has overflowed its stack"
N = 7000: ty(this branch) infers Literal[7000] instantly
N = 8000+: ty(this branch) crashes
left
N = 300: pyright emits "Maximum parse depth exceeded; break expression into smaller sub-expressions"
total is inferred as Unknown
N = 5500: mypy crashes with "INTERNAL ERROR"
N = 2500: ty(main) infers Literal[2500] instantly
N = 3000: ty(main) crashes with "thread '<unknown>' has overflowed its stack"
N = 22000: ty(this branch) infers Literal[22000] instantly
N = 23000+: ty(this branch) crashes
```
## Test Plan
New regression test.
This fixes cycle panics in several ecosystem projects (moved to
`good.txt` in a following PR
https://github.com/astral-sh/ruff/pull/17834 because our mypy-primer job
doesn't handle it well if we move projects to `good.txt` in the same PR
that fixes `ty` to handle them), as well as in the minimal case in the
added mdtest. It also fixes a number of panicking fuzzer seeds. It
doesn't appear to cause any regression in any ecosystem project or any
fuzzer seed.
The PR add the fix safety section for rule `RUF013`
(https://github.com/astral-sh/ruff/issues/15584 )
The fix was introduced here #4831
The rule as a lot of False Negative (as it is explained in the docs of
the rule).
The main reason because the fix is unsafe is that it could change code
generation tools behaviour, as in the example here:
```python
def generate_api_docs(func):
hints = get_type_hints(func)
for param, hint in hints.items():
if is_optional_type(hint):
print(f"Parameter '{param}' is optional")
else:
print(f"Parameter '{param}' is required")
# Before fix
def create_user(name: str, roles: list[str] = None):
pass
# After fix
def create_user(name: str, roles: Optional[list[str]] = None):
pass
# Generated docs would change from "roles is required" to "roles is optional"
```
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
Re: #17526
## Summary
Add test fixtures for `AwaitOutsideAsync` and
`AsyncComprehensionOutsideAsyncFunction` errors.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
This is a test.
<!-- How was it tested? -->
Re: #17526
## Summary
Add integration tests for Python Semantic Syntax for
`InvalidStarExpression`, `DuplicateMatchKey`, and
`DuplicateMatchClassAttribute`.
## Note
- Red knot integration tests for `DuplicateMatchKey` exist already in
line 89-101.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
This is a test.
<!-- How was it tested? -->
When attempting to determine whether `import foo.bar.baz` is a known
first-party import relative to [user-provided source
paths](https://docs.astral.sh/ruff/settings/#src), when `preview` is
enabled we now check that `SRC/foo/bar/baz` is a directory or
`SRC/foo/bar/baz.py` or `SRC/foo/bar/baz.pyi` exist.
Previously, we just checked the analogous thing for `SRC/foo`, but this
can be misleading in situations with disjoint namespace packages that
share a common base name (e.g. we may be working inside the namespace
package `foo.buzz` and importing `foo.bar` from elsewhere).
Supersedes #12987Closes#12984
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#17798
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Snapshot tests
<!-- How was it tested? -->
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Skip attribute check in try catch block (`AIR301`)
## Test Plan
<!-- How was it tested? -->
update
`crates/ruff_linter/resources/test/fixtures/airflow/AIR301_names_try.py`
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Remove `airflow.utils.dag_parsing_context.get_parsing_context` from
AIR301 as it has been moved to AIR311
## Test Plan
<!-- How was it tested? -->
the test fixture was updated in the previous PR
## Summary
When entering an `infer_expression_types` cycle from
`TypeInferenceBuilder::infer_standalone_expression`, we might get back a
`TypeInference::cycle_fallback(…)` that doesn't actually contain any new
types, but instead it contains a `cycle_fallback_type` which is set to
`Some(Type::Never)`. When calling `self.extend(…)`, we therefore don't
really pull in a type for the expression we're interested in. This
caused us to panic if we tried to call `self.expression_type(…)` after
`self.extend(…)`.
The proposed fix here is to retrieve that type from the nested
`TypeInferenceBuilder` directly, which will correctly fall back to
`cycle_fallback_type`.
## Details
I minimized the second example from #17792 a bit further and used this
example for debugging:
```py
from __future__ import annotations
class C: ...
def f(arg: C):
pass
x, _ = f(1)
assert x
```
This is self-referential because when we check the assignment statement
`x, _ = f(1)`, we need to look up the signature of `f`. Since evaluation
of annotations is deferred, we look up the public type of `C` for the
`arg` parameter. The public use of `C` is visibility-constraint by "`x`"
via the `assert` statement. While evaluating this constraint, we need to
look up the type of `x`, which in turn leads us back to the `x, _ =
f(1)` definition.
The reason why this only showed up in the relatively peculiar case with
unpack assignments is the code here:
78b4c3ccf1/crates/ty_python_semantic/src/types/infer.rs (L2709-L2718)
For a non-unpack assignment like `x = f(1)`, we would not try to infer
the right-hand side eagerly. Instead, we would enter a
`infer_definition_types` cycle that handles the situation correctly. For
unpack assignments, however, we try to infer the type of `value`
(`f(1)`) and therefore enter the cycle via `standalone_expression_type
=> infer_expression_type`.
closes#17792
## Test Plan
* New regression test
* Made sure that we can now run successfully on scipy => see #17850
This PR updates the semantic model for Python 3.14 by essentially
equating "run using Python 3.14" with "uses `from __future__ import
annotations`".
While this is not technically correct under the hood, it appears to be
correct for the purposes of our semantic model. That is: from the point
of view of deciding when to parse, bind, etc. annotations, these two
contexts behave the same. More generally these contexts behave the same
unless you are performing some kind of introspection like the following:
Without future import:
```pycon
>>> from annotationlib import get_annotations,Format
>>> def foo()->Bar:...
...
>>> get_annotations(foo,format=Format.FORWARDREF)
{'return': ForwardRef('Bar')}
>>> get_annotations(foo,format=Format.STRING)
{'return': 'Bar'}
>>> get_annotations(foo,format=Format.VALUE)
Traceback (most recent call last):
[...]
NameError: name 'Bar' is not defined
>>> get_annotations(foo)
Traceback (most recent call last):
[...]
NameError: name 'Bar' is not defined
```
With future import:
```
>>> from __future__ import annotations
>>> from annotationlib import get_annotations,Format
>>> def foo()->Bar:...
...
>>> get_annotations(foo,format=Format.FORWARDREF)
{'return': 'Bar'}
>>> get_annotations(foo,format=Format.STRING)
{'return': 'Bar'}
>>> get_annotations(foo,format=Format.VALUE)
{'return': 'Bar'}
>>> get_annotations(foo)
{'return': 'Bar'}
```
(Note: the result of the last call to `get_annotations` in these
examples relies on the fact that, as of this writing, the default value
for `format` is `Format.VALUE`).
If one day we support lint rules targeting code that introspects using
the new `annotationlib`, then it is possible we will need to revisit our
approximation.
Closes#15100
## Summary
Currently red-knot does not understand `Foo` and `Bar` here as being
equivalent:
```py
from typing import Protocol
class A: ...
class B: ...
class C: ...
class Foo(Protocol):
x: A | B | C
class Bar(Protocol):
x: B | A | C
```
Nor does it understand `A | B | Foo` as being equivalent to `Bar | B |
A`. This PR fixes that.
## Test Plan
new mdtest assertions added that fail on `main`
## Summary
Currently this assertion fails on `main`, because we do not synthesize a
`__call__` attribute for Callable types:
```py
from typing import Protocol, Callable
from knot_extensions import static_assert, is_assignable_to
class Foo(Protocol):
def __call__(self, x: int, /) -> str: ...
static_assert(is_assignable_to(Callable[[int], str], Foo))
```
This PR fixes that.
See previous discussion about this in
https://github.com/astral-sh/ruff/pull/16493#discussion_r1985098508 and
https://github.com/astral-sh/ruff/pull/17682#issuecomment-2839527750
## Test Plan
Existing mdtests updated; a couple of new ones added.
This adds support for legacy generic classes, which use a
`typing.Generic` base class, or which inherit from another generic class
that has been specialized with legacy typevars.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Quick follow-on to #17788. If there is no bound `self` parameter, we can
reuse the existing `CallArgument{,Type}s`, and we can use a straight
`Vec` instead of a `VecDeque`.
## Summary
Remove mutability in parameter types for a few functions such as
`with_self` and `try_call`. I tried the `Rc`-approach with cheap cloning
[suggest
here](https://github.com/astral-sh/ruff/pull/17733#discussion_r2068722860)
first, but it turns out we need a whole stack of prepended arguments
(there can be [both `self` *and*
`cls`](3cf44e401a/crates/red_knot_python_semantic/resources/mdtest/call/constructor.md (L113))),
and we would need the same construct not just for `CallArguments` but
also for `CallArgumentTypes`. At that point we're cloning `VecDeque`s
anyway, so the overhead of cloning the whole `VecDeque` with all
arguments didn't seem to justify the additional code complexity.
## Benchmarks
Benchmarks on tomllib, black, jinja, isort seem neutral.
## Summary
Add the ability to detect instance attribute assignments in class
methods that are generic.
This does not address the code duplication mentioned in #16928. I can
open a ticket for this after this has been merged.
closes#16928
## Test Plan
Added regression test.
This PR does the wiring necessary to respond to completion requests from
LSP clients.
As far as the actual completion results go, they are nearly about the
dumbest and simplest thing we can do: we simply return a de-duplicated
list of all identifiers from the current module.
Summary
--
Fixes#16598 by adding the `--python` flag to `ruff analyze graph`,
which adds a `PythonPath` to the `SearchPathSettings` for module
resolution. For the [albatross-virtual-workspace] example from the uv
repo, this updates the output from the initial issue:
```shell
> ruff analyze graph packages/albatross
{
"packages/albatross/check_installed_albatross.py": [
"packages/albatross/src/albatross/__init__.py"
],
"packages/albatross/src/albatross/__init__.py": []
}
```
To include both the the workspace `bird_feeder` import _and_ the
third-party `tqdm` import in the output:
```shell
> myruff analyze graph packages/albatross --python .venv
{
"packages/albatross/check_installed_albatross.py": [
"packages/albatross/src/albatross/__init__.py"
],
"packages/albatross/src/albatross/__init__.py": [
".venv/lib/python3.12/site-packages/tqdm/__init__.py",
"packages/bird-feeder/src/bird_feeder/__init__.py"
]
}
```
Note the hash in the uv link! I was temporarily very confused why my
local tests were showing an `iniconfig` import instead of `tqdm` until I
realized that the example has been updated on the uv main branch, which
I had locally.
Test Plan
--
A new integration test with a stripped down venv based on the
`albatross` example.
[albatross-virtual-workspace]:
aa629c4a54/scripts/workspaces/albatross-virtual-workspace
## Summary
Adds preliminary support for `NamedTuple`s, including:
* No false positives when constructing a `NamedTuple` object
* Correct signature for the synthesized `__new__` method, i.e. proper
checking of constructor calls
* A patched MRO (`NamedTuple` => `tuple`), mainly to make type inference
of named attributes possible, but also to better reflect the runtime
MRO.
All of this works:
```py
from typing import NamedTuple
class Person(NamedTuple):
id: int
name: str
age: int | None = None
alice = Person(1, "Alice", 42)
alice = Person(id=1, name="Alice", age=42)
reveal_type(alice.id) # revealed: int
reveal_type(alice.name) # revealed: str
reveal_type(alice.age) # revealed: int | None
# error: [missing-argument]
Person(3)
# error: [too-many-positional-arguments]
Person(3, "Eve", 99, "extra")
# error: [invalid-argument-type]
Person(id="3", name="Eve")
```
Not included:
* type inference for index-based access.
* support for the functional `MyTuple = NamedTuple("MyTuple", […])`
syntax
## Test Plan
New Markdown tests
## Ecosystem analysis
```
Diagnostic Analysis Report
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┓
┃ Diagnostic ID ┃ Severity ┃ Removed ┃ Added ┃ Net Change ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━┩
│ lint:call-non-callable │ error │ 0 │ 3 │ +3 │
│ lint:call-possibly-unbound-method │ warning │ 0 │ 4 │ +4 │
│ lint:invalid-argument-type │ error │ 0 │ 72 │ +72 │
│ lint:invalid-context-manager │ error │ 0 │ 2 │ +2 │
│ lint:invalid-return-type │ error │ 0 │ 2 │ +2 │
│ lint:missing-argument │ error │ 0 │ 46 │ +46 │
│ lint:no-matching-overload │ error │ 19121 │ 0 │ -19121 │
│ lint:not-iterable │ error │ 0 │ 6 │ +6 │
│ lint:possibly-unbound-attribute │ warning │ 13 │ 32 │ +19 │
│ lint:redundant-cast │ warning │ 0 │ 1 │ +1 │
│ lint:unresolved-attribute │ error │ 0 │ 10 │ +10 │
│ lint:unsupported-operator │ error │ 3 │ 9 │ +6 │
│ lint:unused-ignore-comment │ warning │ 15 │ 4 │ -11 │
├───────────────────────────────────┼──────────┼─────────┼───────┼────────────┤
│ TOTAL │ │ 19152 │ 191 │ -18961 │
└───────────────────────────────────┴──────────┴─────────┴───────┴────────────┘
Analysis complete. Found 13 unique diagnostic IDs.
Total diagnostics removed: 19152
Total diagnostics added: 191
Net change: -18961
```
I uploaded the ecosystem full diff (ignoring the 19k
`no-matching-overload` diagnostics)
[here](https://shark.fish/diff-namedtuple.html).
* There are some new `missing-argument` false positives which come from
the fact that named tuples are often created using unpacking as in
`MyNamedTuple(*fields)`, which we do not understand yet.
* There are some new `unresolved-attribute` false positives, because
methods like `_replace` are not available.
* Lots of the `invalid-argument-type` diagnostics look like true
positives
---------
Co-authored-by: Douglas Creager <dcreager@dcreager.net>
## Summary
This PR updates the existing overload matching methods to return an
iterator of all the matched overloads instead.
This would be useful once the overload call evaluation algorithm is
implemented which should provide an accurate picture of all the matched
overloads. The return type would then be picked from either the only
matched overload or the first overload from the ones that are matched.
In an earlier version of this PR, it tried to check if using an
intersection of return types from the matched overload would help reduce
the false positives but that's not enough. [This
comment](https://github.com/astral-sh/ruff/pull/17618#issuecomment-2842891696)
keep the ecosystem analysis for that change for prosperity.
> [!NOTE]
>
> The best way to review this PR is by hiding the whitespace changes
because there are two instances where a large match expression is
indented to be inside a loop over matching overlods
>
> <img width="1207" alt="Screenshot 2025-04-28 at 15 12 16"
src="https://github.com/user-attachments/assets/e06cbfa4-04fa-435f-84ef-4e5c3c5626d1"
/>
## Test Plan
Make sure existing test cases are unaffected and no ecosystem changes.
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This is not yet fixing anything as the names are not changed, but it
lays down the foundation for fixing.
## Test Plan
<!-- How was it tested? -->
the existing test fixture should already cover this change
## Summary
Part of #17412
Starred expressions cannot be used as values in assignment expressions.
Add a new semantic syntax error to catch such instances.
Note that we already have
`ParseErrorType::InvalidStarredExpressionUsage` to catch some starred
expression errors during parsing, but that does not cover top level
assignment expressions.
## Test Plan
- Added new inline tests for the new rule
- Found some examples marked as "valid" in existing tests (`_ = *data`),
which are not really valid (per this new rule) and updated them
- There was an existing inline test - `assign_stmt_invalid_value_expr`
which had instances of `*` expression which would be deemed invalid by
this new rule. Converted these to tuples, so that they do not trigger
this new rule.
## Summary
Model the lookup of `__new__` without going through
`Type::try_call_dunder`. The `__new__` method is only looked up on the
constructed type itself, not on the meta-type.
This now removes ~930 false positives across the ecosystem (vs 255 for
https://github.com/astral-sh/ruff/pull/17662). It introduces 30 new
false positives related to the construction of enums via something like
`Color = enum.Enum("Color", ["RED", "GREEN"])`. This is expected,
because we don't handle custom metaclass `__call__` methods. The fact
that we previously didn't emit diagnostics there was a coincidence (we
incorrectly called `EnumMeta.__new__`, and since we don't fully
understand its signature, that happened to work with `str`, `list`
arguments).
closes#17462
## Test Plan
Regression test
## Summary
Part of #15383.
As per the spec
(https://typing.python.org/en/latest/spec/overload.html#invalid-overload-definitions):
For `@staticmethod` and `@classmethod`:
> If one overload signature is decorated with `@staticmethod` or
`@classmethod`, all overload signatures must be similarly decorated. The
implementation, if present, must also have a consistent decorator. Type
checkers should report an error if these conditions are not met.
For `@final` and `@override`:
> If a `@final` or `@override` decorator is supplied for a function with
overloads, the decorator should be applied only to the overload
implementation if it is present. If an overload implementation isn’t
present (for example, in a stub file), the `@final` or `@override`
decorator should be applied only to the first overload. Type checkers
should enforce these rules and generate an error when they are violated.
If a `@final` or `@override` decorator follows these rules, a type
checker should treat the decorator as if it is present on all overloads.
## Test Plan
Update existing tests; add snapshots.
## Summary
As mentioned in the spec
(https://typing.python.org/en/latest/spec/overload.html#invalid-overload-definitions),
part of #15383:
> The `@overload`-decorated definitions must be followed by an overload
implementation, which does not include an `@overload` decorator. Type
checkers should report an error or warning if an implementation is
missing. Overload definitions within stub files, protocols, and on
abstract methods within abstract base classes are exempt from this
check.
## Test Plan
Remove TODOs from the test; create one diagnostic snapshot.
Re: #17526
## Summary
Adds tests to red knot and `linter.rs` for the semantic syntax.
Specifically add tests for `ReboundComprehensionVariable`,
`DuplicateTypeParameter`, and `MultipleCaseAssignment`.
Refactor the `test_async_comprehension_in_sync_comprehension` →
`test_semantic_error` to be more general for all semantic syntax test
cases.
## Test Plan
This is a test.
## Question
I'm happy to contribute more tests the coming days.
Should that happen here or should we merge this PR such that the
refactor `test_async_comprehension_in_sync_comprehension` →
`test_semantic_error` is available on main and others can chime in, too?
## Summary
Part of #15383, this PR adds the core infrastructure to check for
invalid overloads and adds a diagnostic to raise if there are < 2
overloads for a given definition.
### Design notes
The requirements to check the overloads are:
* Requires `FunctionType` which has the `to_overloaded` method
* The `FunctionType` **should** be for the function that is either the
implementation or the last overload if the implementation doesn't exists
* Avoid checking any `FunctionType` that are part of an overload chain
* Consider visibility constraints
This required a couple of iteration to make sure all of the above
requirements are fulfilled.
#### 1. Use a set to deduplicate
The logic would first collect all the `FunctionType` that are part of
the overload chain except for the implementation or the last overload if
the implementation doesn't exists. Then, when iterating over all the
function declarations within the scope, we'd avoid checking these
functions. But, this approach would fail to consider visibility
constraints as certain overloads _can_ be behind a version check. Those
aren't part of the overload chain but those aren't a separate overload
chain either.
<details><summary>Implementation:</summary>
<p>
```rs
fn check_overloaded_functions(&mut self) {
let function_definitions = || {
self.types
.declarations
.iter()
.filter_map(|(definition, ty)| {
// Filter out function literals that result from anything other than a function
// definition e.g., imports.
if let DefinitionKind::Function(function) = definition.kind(self.db()) {
ty.inner_type()
.into_function_literal()
.map(|ty| (ty, definition.symbol(self.db()), function.node()))
} else {
None
}
})
};
// A set of all the functions that are part of an overloaded function definition except for
// the implementation function and the last overload in case the implementation doesn't
// exists. This allows us to collect all the function definitions that needs to be skipped
// when checking for invalid overload usages.
let mut overloads: HashSet<FunctionType<'db>> = HashSet::default();
for (function, _) in function_definitions() {
let Some(overloaded) = function.to_overloaded(self.db()) else {
continue;
};
if overloaded.implementation.is_some() {
overloads.extend(overloaded.overloads.iter().copied());
} else if let Some((_, previous_overloads)) = overloaded.overloads.split_last() {
overloads.extend(previous_overloads.iter().copied());
}
}
for (function, function_node) in function_definitions() {
let Some(overloaded) = function.to_overloaded(self.db()) else {
continue;
};
if overloads.contains(&function) {
continue;
}
// At this point, the `function` variable is either the implementation function or the
// last overloaded function if the implementation doesn't exists.
if overloaded.overloads.len() < 2 {
if let Some(builder) = self
.context
.report_lint(&INVALID_OVERLOAD, &function_node.name)
{
let mut diagnostic = builder.into_diagnostic(format_args!(
"Function `{}` requires at least two overloads",
&function_node.name
));
if let Some(first_overload) = overloaded.overloads.first() {
diagnostic.annotate(
self.context
.secondary(first_overload.focus_range(self.db()))
.message(format_args!("Only one overload defined here")),
);
}
}
}
}
}
```
</p>
</details>
#### 2. Define a `predecessor` query
The `predecessor` query would return the previous `FunctionType` for the
given `FunctionType` i.e., the current logic would be extracted to be a
query instead. This could then be used to make sure that we're checking
the entire overload chain once. The way this would've been implemented
is to have a `to_overloaded` implementation which would take the root of
the overload chain instead of the leaf. But, this would require updates
to the use-def map to somehow be able to return the _following_
functions for a given definition.
#### 3. Create a successor link
This is what Pyrefly uses, we'd create a forward link between two
functions that are involved in an overload chain. This means that for a
given function, we can get the successor function. This could be used to
find the _leaf_ of the overload chain which can then be used with the
`to_overloaded` method to get the entire overload chain. But, this would
also require updating the use-def map to be able to "see" the
_following_ function.
### Implementation
This leads us to the final implementation that this PR implements which
is to consider the overloaded functions using:
* Collect all the **function symbols** that are defined **and** called
within the same file. This could potentially be an overloaded function
* Use the public bindings to get the leaf of the overload chain and use
that to get the entire overload chain via `to_overloaded` and perform
the check
This has a limitation that in case a function redefines an overload,
then that overload will not be checked. For example:
```py
from typing import overload
@overload
def f() -> None: ...
@overload
def f(x: int) -> int: ...
# The above overload will not be checked as the below function with the same name
# shadows it
def f(*args: int) -> int: ...
```
## Test Plan
Update existing mdtest and add snapshot diagnostics.
## Summary
@sharkdp and I realised in our 1:1 this morning that our control flow
for `assert` statements isn't quite accurate at the moment. Namely, for
something like this:
```py
def _(x: int | None):
assert x is None, reveal_type(x)
```
we currently reveal `None` for `x` here, but this is incorrect. In
actual fact, the `msg` expression of an `assert` statement (the
expression after the comma) will only be evaluated if the test (`x is
None`) evaluates to `False`. As such, we should be adding a constraint
of `~None` to `x` in the `msg` expression, which should simplify the
inferred type of `x` to `int` in that context (`(int | None) & ~None` ->
`int`).
## Test Plan
Mdtests added.
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
We were previously recording wrong reachability constraints for negative
branches. Instead of `[cond] AND (NOT [True])` below, we were recording
`[cond] AND (NOT ([cond] AND [True]))`, i.e. we were negating not just
the last predicate, but the `AND`-ed reachability constraint from last
clause. With this fix, we now record the correct constraints for the
example from #17723:
```py
def _(cond: bool):
if cond:
# reachability: [cond]
if True:
# reachability: [cond] AND [True]
pass
else:
# reachability: [cond] AND (NOT [True])
x
```
closes#17723
## Test Plan
* Regression test.
* Verified the ecosystem changes
## Summary
Part of #15383, this PR adds `is_equivalent_to` support for overloaded
callables.
This is mainly done by delegating it to the subtyping check in that two
types A and B are considered equivalent if A is a subtype of B and B is
a subtype of A.
## Test Plan
Add test cases for overloaded callables in `is_equivalent_to.md`
## Summary
Includes minor changes to the semantic type inference to help detect the
return type of function call.
Fixes#17691
## Test Plan
Snapshot tests
## Summary
Subtyping was already modeled, but assignability also needs an explicit
branch. Removes 921 ecosystem false positives.
## Test Plan
New Markdown tests.
We are currently representing type variables using a `KnownInstance`
variant, which wraps a `TypeVarInstance` that contains the information
about the typevar (name, bounds, constraints, default type). We were
previously only constructing that type for PEP 695 typevars. This PR
constructs that type for legacy typevars as well.
It also detects functions that are generic because they use legacy
typevars in their parameter list. With the existing logic for inferring
specializations of function calls (#17301), that means that we are
correctly detecting that the definition of `reveal_type` in the typeshed
is generic, and inferring the correct specialization of `_T` for each
call site.
This does not yet handle legacy generic classes; that will come in a
follow-on PR.
A small PR that just updates the various settings/configurations to
allow Python 3.14. At the moment selecting that target version will
have no impact compared to Python 3.13 - except that a warning
is emitted if the user does so with `preview` disabled.
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Apply auto fixes to cases where the names have changed in Airflow 3 in
AIR302 and split the huge test cases into different test cases based on
proivder
## Test Plan
<!-- How was it tested? -->
the test cases has been split into multiple for easier checking
Summary
--
This PR resolves https://github.com/astral-sh/ruff/issues/9761 by adding
a linter configuration option to disable
`typing_extensions` imports. As mentioned [here], it would be ideal if
we could
detect whether or not `typing_extensions` is available as a dependency
automatically, but this seems like a much easier fix in the meantime.
The default for the new option, `typing-extensions`, is `true`,
preserving the current behavior. Setting it to `false` will bail out of
the new
`Checker::typing_importer` method, which has been refactored from the
`Checker::import_from_typing` method in
https://github.com/astral-sh/ruff/pull/17340),
with `None`, which is then handled specially by each rule that calls it.
I considered some alternatives to a config option, such as checking if
`typing_extensions` has been imported or checking for a `TYPE_CHECKING`
block we could use, but I think defaulting to allowing
`typing_extensions` imports and allowing the user to disable this with
an option is both simple to implement and pretty intuitive.
[here]:
https://github.com/astral-sh/ruff/issues/9761#issuecomment-2790492853
Test Plan
--
New linter tests exercising several combinations of Python versions and
the new config option for PYI019. I also added tests for the other
affected rules, but only in the case where the new config option is
enabled. The rules' existing tests also cover the default case.
This is done in what appears to be the same way as Ruff: we get the CWD,
strip the prefix from the path if possible, and use that. If stripping
the prefix fails, then we print the full path as-is.
Fixes#17233
## Summary
Removes ~850 diagnostics related to assignability of callable types,
where the callable-being-assigned-to has a "Todo signature", which
should probably accept any left hand side callable/signature.
This PR promotes the fix applicability of [readlines-in-for
(FURB129)](https://docs.astral.sh/ruff/rules/readlines-in-for/#readlines-in-for-furb129)
to always safe.
In the original PR (https://github.com/astral-sh/ruff/pull/9880), the
author marked the rule as unsafe because Ruff's type inference couldn't
quite guarantee that we had an `IOBase` object in hand. Some false
positives were recorded in the test fixture. However, before the PR was
merged, Charlie added the necessary type inference and the false
positives went away.
According to the [Python
documentation](https://docs.python.org/3/library/io.html#io.IOBase), I
believe this fix is safe for any proper implementation of `IOBase`:
>[IOBase](https://docs.python.org/3/library/io.html#io.IOBase) (and its
subclasses) supports the iterator protocol, meaning that an
[IOBase](https://docs.python.org/3/library/io.html#io.IOBase) object can
be iterated over yielding the lines in a stream. Lines are defined
slightly differently depending on whether the stream is a binary stream
(yielding bytes), or a text stream (yielding character strings). See
[readline()](https://docs.python.org/3/library/io.html#io.IOBase.readline)
below.
and then in the [documentation for
`readlines`](https://docs.python.org/3/library/io.html#io.IOBase.readlines):
>Read and return a list of lines from the stream. hint can be specified
to control the number of lines read: no more lines will be read if the
total size (in bytes/characters) of all lines so far exceeds hint. [...]
>Note that it’s already possible to iterate on file objects using for
line in file: ... without calling file.readlines().
I believe that a careful reading of our [versioning
policy](https://docs.astral.sh/ruff/versioning/#version-changes)
requires that this change be deferred to a minor release - but please
correct me if I'm wrong!
This PR collects all behavior gated under preview into a new module
`ruff_linter::preview` that exposes functions like
`is_my_new_feature_enabled` - just as is done in the formatter crate.
## Summary
Do not emit errors when defining `TypedDict`s:
```py
from typing_extensions import TypedDict
# No error here
class Person(TypedDict):
name: str
age: int | None
# No error for this alternative syntax
Message = TypedDict("Message", {"id": int, "content": str})
```
## Ecosystem analysis
* Removes ~ 450 false positives for `TypedDict` definitions.
* Changes a few diagnostic messages.
* Adds a few (< 10) false positives, for example:
```diff
+ error[lint:unresolved-attribute]
/tmp/mypy_primer/projects/hydra-zen/src/hydra_zen/structured_configs/_utils.py:262:5:
Type `Literal[DataclassOptions]` has no attribute `__required_keys__`
+ error[lint:unresolved-attribute]
/tmp/mypy_primer/projects/hydra-zen/src/hydra_zen/structured_configs/_utils.py:262:42:
Type `Literal[DataclassOptions]` has no attribute `__optional_keys__`
```
* New true positive
4f8263cd7f/corporate/lib/remote_billing_util.py (L155-L157)
```diff
+ error[lint:invalid-assignment]
/tmp/mypy_primer/projects/zulip/corporate/lib/remote_billing_util.py:155:5:
Object of type `RemoteBillingIdentityDict | LegacyServerIdentityDict |
None` is not assignable to `LegacyServerIdentityDict | None`
```
## Test Plan
New Markdown tests
The PR add the `fix safety` section for rule `RUF027` (#15584 ).
Actually, I have an example of a false positive. Should I include it in
the` fix safety` section?
---------
Co-authored-by: Dylan <dylwil3@gmail.com>
The PR add the fix safety section for rule `FLY002` (#15584 )
The motivation for the content of the fix safety section is given by the
following example
```python
foo = 1
bar = [2, 3]
try:
result_join = " ".join((foo, bar))
print(f"Join result: {result_join}")
except TypeError as e:
print(f"Join error: {e}")
```
which print `Join error: sequence item 0: expected str instance, int
found`
But after the fix is applied, we have
```python
foo = 1
bar = [2, 3]
try:
result_join = f"{foo} {bar}"
print(f"Join result: {result_join}")
except TypeError as e:
print(f"Join error: {e}")
```
which print `Join result: 1 [2, 3]`
---------
Co-authored-by: dylwil3 <dylwil3@gmail.com>
## Summary
This PR add the `fix safety` section for rule `ASYNC116` in
`long_sleep_not_forever.rs` for #15584
---------
Co-authored-by: dylwil3 <dylwil3@gmail.com>
## Summary
I remember we discussed about adding this as a property tests so here I
am.
## Test Plan
```console
❯ QUICKCHECK_TESTS=10000000 cargo test --locked --release --package red_knot_python_semantic -- --ignored types::property_tests::stable::bottom_callable_is_subtype_of_all_fully_static_callable
Finished `release` profile [optimized] target(s) in 0.10s
Running unittests src/lib.rs (target/release/deps/red_knot_python_semantic-e41596ca2dbd0e98)
running 1 test
test types::property_tests::stable::bottom_callable_is_subtype_of_all_fully_static_callable ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 233 filtered out; finished in 30.91s
```
As discussed today, this is needed to handle legacy generic classes
without having to infer the types of the class's explicit bases eagerly
at class construction time. Pulling this out into a separate PR so
there's a smaller diff to review.
This also makes our representation of generic classes and functions more
consistent — before, we had separate Rust types and enum variants for
generic/non-generic classes, but a single type for generic functions.
Now we each a single (respective) type for each.
There were very few places we were differentiation between generic and
non-generic _class literals_, and these are handled now by calling the
(salsa cached) `generic_context` _accessor function_.
Note that _`ClassType`_ is still an enum with distinct variants for
non-generic classes and specialized generic classes.
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Add "airflow.operators.python.get_current_context" →
"airflow.sdk.get_current_context" rule
## Test Plan
<!-- How was it tested? -->
the test fixture has been updated accordingly
## Summary
Even though the original suggestion works, they've been removed in later
version and is no longer the best practices.
e.g., many sql realted operators have been removed and are now suggested
to use SQLExecuteQueryOperator instead
## Test Plan
The existing test fixtures have been updated
Previously, we could iterate over files in an unspecified order (via
`HashSet` iteration) and we could accumulate diagnostics from files in
an unspecified order (via parallelism).
Here, we change the status quo so that diagnostics collected from files
are sorted after checking is complete. For now, we sort by severity
(with higher severity diagnostics appearing first) and then by
diagnostic ID to give a stable ordering.
I'm not sure if this is the best ordering.
## Summary
After https://github.com/astral-sh/ruff/pull/17620 (which this PR is
based on), I was looking at other call sites of `Type::into_class_type`,
and I began to feel that _all_ of them were currently buggy due to
silently skipping unspecialized generic class literal types (though in
some cases the bug hadn't shown up yet because we don't understand
legacy generic classes from typeshed), and in every case they would be
better off if an unspecialized generic class literal were implicitly
specialized with the default specialization (which is the usual Python
typing semantics for an unspecialized reference to a generic class),
instead of silently skipped.
So I changed the method to implicitly apply the default specialization,
and added a test that previously failed for detecting metaclasses on an
unspecialized generic base.
I also renamed the method to `to_class_type`, because I feel we have a
strong naming convention where `Type::into_foo` is always a trivial
`const fn` that simply returns `Some()` if the type is of variant `Foo`
and `None` otherwise. Even the existing method (with it handling both
`GenericAlias` and `ClassLiteral`, and distinguishing kinds of
`ClassLiteral`) was stretching this convention, and the new version
definitely breaks that envelope.
## Test Plan
Added a test that failed before this PR.
## Summary
The `ClassLiteralType::inheritance_cycle` method is intended to detect
inheritance cycles that would result in cyclic MROs, emit a diagnostic,
and skip actually trying to create the cyclic MRO, falling back to an
"error" MRO instead with just `Unknown` and `object`.
This method didn't work properly for generic classes. It used
`fully_static_explicit_bases`, which filter-maps `explicit_bases` over
`Type::into_class_type`, which returns `None` for an unspecialized
generic class literal. So in a case like `class C[T](C): ...`, because
the explicit base is an unspecialized generic, we just skipped it, and
failed to detect the class as cyclically defined.
Instead, iterate directly over all `explicit_bases`, and explicitly
handle both the specialized (`GenericAlias`) and unspecialized
(`ClassLiteral`) cases, so that we check all bases and correctly detect
cyclic inheritance.
## Test Plan
Added mdtests.
Summary
--
While going through the syntax errors in [this comment], I was surprised
to see the error `name 'x' is assigned to before global declaration`,
which corresponds to [load-before-global-declaration (PLE0118)] and has
also been reimplemented as a syntax error (#17135). However, it looks
like neither of the implementations consider `global` declarations in
the top-level module scope, which is a syntax error in CPython:
```python
# try.py
x = None
global x
```
```shell
> python -m compileall -f try.py
Compiling 'try.py'...
*** File "try.py", line 2
global x
^^^^^^^^
SyntaxError: name 'x' is assigned to before global declaration
```
I'm not sure this is the best or most elegant solution, but it was a
quick fix that passed all of our tests.
Test Plan
--
New PLE0118 test case.
[this comment]:
https://github.com/astral-sh/ruff/issues/7633#issuecomment-1740424031
[load-before-global-declaration (PLE0118)]:
https://docs.astral.sh/ruff/rules/load-before-global-declaration/#load-before-global-declaration-ple0118
## Summary
Tracked structs have some issues with fixpoint iteration in Salsa, and
there's not actually any need for this to be tracked, it should be
interned like most of our type structs.
The removed comment was probably never correct (in that we could have
disambiguated sufficiently), and is definitely not relevant now that
`TypeVarInstance` also holds its `Definition`.
## Test Plan
Existing tests.
## Summary
This PR adds special-casing for `@final` and `@override` decorator for a
similar reason as https://github.com/astral-sh/ruff/pull/17591 to
support the invalid overload check.
Both `final` and `override` are identity functions which can be removed
once `TypeVar` support is added.
## Summary
As promised, this just adds a TODO comment to document something we
discussed today that should probably be improved at some point, but
isn't a priority right now (since it's an issue that in practice would
only affect generic classes with both `__init__` and `__new__` methods,
where some typevar is bound to `Unknown` in one and to some other type
in another.)
## Summary
Part of #17412
Add a new compile-time syntax error for detecting `nonlocal`
declarations at a module level.
## Test Plan
- Added new inline tests for the syntax error
- Updated existing tests for `nonlocal` statement parsing to be inside a
function scope
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
While adding semantic error support to red-knot, I noticed duplicate
diagnostics for code like this:
```py
# error: [invalid-syntax] "cannot use an asynchronous comprehension outside of an asynchronous function on Python 3.9 (syntax was added in 3.11)"
# error: [invalid-syntax] "`asynchronous comprehension` outside of an asynchronous function"
[reveal_type(x) async for x in AsyncIterable()]
```
Beyond the duplication, the first error message doesn't make much sense
because this syntax is _not_ allowed on Python 3.11 either.
To fix this, this PR renames the
`async-comprehension-outside-async-function` semantic syntax error to
`async-comprehension-in-sync-comprehension` and fixes the rule to avoid
applying outside of sync comprehensions at all.
## Test Plan
New linter test demonstrating the false positive. The mdtests from my red-knot
PR also reflect this change.
## Summary
This PR updates the `to_overloaded` method to use an iterative approach
instead of a recursive one.
Refer to
https://github.com/astral-sh/ruff/pull/17585#discussion_r2056804587 for
context.
The main benefit here is that it avoids calling the `to_overloaded`
function in a recursive manner which is a salsa query. So, this is a bit
hand wavy but we should also see less memory used because the cache will
only contain a single entry which should be the entire overload chain.
Previously, the recursive approach would mean that each of the function
involved in an overload chain would have a cache entry. This reduce in
memory shouldn't be too much and I haven't looked at the actual data for
it.
## Test Plan
Existing test cases should pass.
This mostly only improves things for incorrect arguments and for an
incorrect return type. It doesn't do much to improve the case where
`__bool__` isn't callable and leaves the union/other cases untouched
completely.
I picked this one because, at first glance, this _looked_ like a lower
hanging fruit. The conceptual improvement here is pretty
straight-forward: add annotations for relevant data. But it took me a
bit to figure out how to connect all of the pieces.
I wanted to use this method in other places, so I moved it
to what appears to be a God-type. I also made it slightly
more versatile: callers can ask for the entire parameter list
by omitting a specific parameter index.
## Summary
Historically we have avoided narrowing on `==` tests because in many
cases it's unsound, since subclasses of a type could compare equal to
who-knows-what. But there are a lot of types (literals and unions of
them, as well as some known instances like `None` -- single-valued
types) whose `__eq__` behavior we know, and which we can safely narrow
away based on equality comparisons.
This PR implements equality narrowing in the cases where it is sound.
The most elegant way to do this (and the way that is most in-line with
our approach up until now) would be to introduce new Type variants
`NeverEqualTo[...]` and `AlwaysEqualTo[...]`, and then implement all
type relations for those variants, narrow by intersection, and let union
and intersection simplification sort it all out. This is analogous to
our existing handling for `AlwaysFalse` and `AlwaysTrue`.
But I'm reluctant to add new `Type` variants for this, mostly because
they could end up un-simplified in some types and make types even more
complex. So let's try this approach, where we handle more of the
narrowing logic as a special case.
## Test Plan
Updated and added tests.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: Carl Meyer <carl@oddbird.net>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Another follow-up to the unions-of-large-literals optimization. Restore
the behavior that e.g. `Literal[""] | ~Literal[""]` collapses to
`object`.
## Test Plan
Added mdtests.
## Summary
This is required because otherwise the inferred type is not going to be
`Type::FunctionLiteral` but a todo type because we don't recognize
`TypeVar` yet:
```py
_FuncT = TypeVar("_FuncT", bound=Callable[..., Any])
def abstractmethod(funcobj: _FuncT) -> _FuncT: ...
```
This is mainly required to raise diagnostic when only some (and not all)
`@overload`-ed functions are decorated with `@abstractmethod`.
## Summary
This PR adds a new method `FunctionType::to_overloaded` which converts a
`FunctionType` into an `OverloadedFunction` which contains all the
`@overload`-ed `FunctionType` and the implementation `FunctionType` if
it exists.
There's a big caveat here (it's the way overloads work) which is that
this method can only "see" all the overloads that comes _before_ itself.
Consider the following example:
```py
from typing import overload
@overload
def foo() -> None: ...
@overload
def foo(x: int) -> int: ...
def foo(x: int | None) -> int | None:
return x
```
Here, when the `to_overloaded` method is invoked on the
1. first `foo` definition, it would only contain a single overload which
is itself and no implementation.
2. second `foo` definition, it would contain both overloads and still no
implementation
3. third `foo` definition, it would contain both overloads and the
implementation which is itself
### Usages
This method will be used in the logic for checking invalid overload
usages. It can also be used for #17541.
## Test Plan
Make sure that existing tests pass.
## Summary
This is a first step toward `global` support in red-knot (#15385). I
went through all the matches for `global` in the `mypy/test-data`
directory, but I didn't find anything too interesting that wasn't
already covered by @carljm's suggestions on Discord. I still pulled in a
couple of cases for a little extra variety. I also included a section
from the
[PLE0118](https://docs.astral.sh/ruff/rules/load-before-global-declaration/)
tests in ruff that will become syntax errors once #17463 is merged and
we handle `global` statements.
I don't think I figured out how to use `@Todo` properly, so please let
me know if I need to fix that. I hope this is a good start to the test
suite otherwise.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Status
--
This is a pretty minor change, but it was breaking a red-knot mdtest
until #17463 landed. Now this should close#11934 as the last syntax
error being tracked there!
Summary
--
Moves `Parser::validate_parameters` to
`SemanticSyntaxChecker::duplicate_parameter_name`.
Test Plan
--
Existing tests, with `## Errors` replaced with `## Semantic Syntax
Errors`.
We now handle generic constructor methods on generic classes correctly:
```py
class C[T]:
def __init__[S](self, t: T, s: S): ...
x = C(1, "str")
```
Here, constructing `C` requires us to infer a specialization for the
generic contexts of `C` and `__init__` at the same time.
At first I thought I would need to track the full stack of nested
generic contexts here (since the `[S]` context is nested within the
`[T]` context). But I think this is the only way that we might need to
specialize more than one generic context at once — in all other cases, a
containing generic context must be specialized before we get to a nested
one, and so we can just special-case this.
While we're here, we also construct the generic context for a generic
function lazily, when its signature is accessed, instead of eagerly when
inferring the function body.
## Summary
Model assignability of class instances with a `__call__` method to
`Callable` types. This should solve some false positives related to
`functools.partial` (yes, 1098 fewer diagnostics!).
Reference:
https://github.com/astral-sh/ruff/issues/17343#issuecomment-2824618483
## Test Plan
New Markdown tests.
## Summary
Many symbols in typeshed are defined without being declared. For
example:
```pyi
# builtins:
IOError = OSError
# types
LambdaType = FunctionType
NotImplementedType = _NotImplementedType
# typing
Text = str
# random
uniform = _inst.uniform
# optparse
make_option = Option
# all over the place:
_T = TypeVar("_T")
```
Here, we introduce a change that skips widening the public type of these
symbols (by unioning with `Unknown`).
fixes#17032
## Ecosystem analysis
This is difficult to analyze in detail, but I went over most changes and
it looks very favorable to me overall. The diff on the overall numbers
is:
```
errors: 1287 -> 859 (reduction by 428)
warnings: 45 -> 59 (increase by 14)
```
### Removed false positives
`invalid-base` examples:
```diff
- error[lint:invalid-base] /tmp/mypy_primer/projects/pip/src/pip/_vendor/rich/console.py:548:27: Invalid class base with type `Unknown | Literal[_local]` (all bases must be a class, `Any`, `Unknown` or `Todo`)
- error[lint:invalid-base] /tmp/mypy_primer/projects/tornado/tornado/iostream.py:84:25: Invalid class base with type `Unknown | Literal[OSError]` (all bases must be a class, `Any`, `Unknown` or `Todo`)
- error[lint:invalid-base] /tmp/mypy_primer/projects/mitmproxy/test/conftest.py:35:40: Invalid class base with type `Unknown | Literal[_UnixDefaultEventLoopPolicy]` (all bases must be a class, `Any`, `Unknown` or `Todo`)
```
`invalid-exception-caught` examples:
```diff
- error[lint:invalid-exception-caught] /tmp/mypy_primer/projects/cloud-init/cloudinit/cmd/status.py:334:16: Cannot catch object of type `Literal[ProcessExecutionError]` in an exception handler (must be a `BaseException` subclass or a tuple of `BaseException` subclasses)
- error[lint:invalid-exception-caught] /tmp/mypy_primer/projects/jinja/src/jinja2/loaders.py:537:16: Cannot catch object of type `Literal[TemplateNotFound]` in an exception handler (must be a `BaseException` subclass or a tuple of `BaseException` subclasses)
```
`unresolved-reference` examples
7a0265d36e/cloudinit/handlers/jinja_template.py (L120-L123)
(we now understand the `isinstance` narrowing)
```diff
- error[lint:unresolved-attribute] /tmp/mypy_primer/projects/cloud-init/cloudinit/handlers/jinja_template.py:123:16: Type `Exception` has no attribute `errno`
```
`unknown-argument` examples
https://github.com/hauntsaninja/boostedblob/blob/master/boostedblob/request.py#L53
```diff
- error[lint:unknown-argument] /tmp/mypy_primer/projects/boostedblob/boostedblob/request.py:53:17: Argument `connect` does not match any known parameter of bound method `__init__`
```
`unknown-argument`
There are a lot of `__init__`-related changes because we now understand
[`@attr.s`](3d42a6978a/src/attr/__init__.pyi (L387))
as a `@dataclass_transform` annotated symbol. For example:
```diff
- error[lint:unknown-argument] /tmp/mypy_primer/projects/attrs/tests/test_hooks.py:72:18: Argument `x` does not match any known parameter of bound method `__init__`
```
### New false positives
This can happen if a symbol that previously was inferred as `X |
Unknown` was assigned-to, but we don't yet understand the assignability
to `X`:
https://github.com/strawberry-graphql/strawberry/blob/main/strawberry/exceptions/handler.py#L90
```diff
+ error[lint:invalid-assignment] /tmp/mypy_primer/projects/strawberry/strawberry/exceptions/handler.py:90:9: Object of type `def strawberry_threading_exception_handler(args: tuple[type[BaseException], BaseException | None, TracebackType | None, Thread | None]) -> None` is not assignable to attribute `excepthook` of type `(_ExceptHookArgs, /) -> Any`
```
### New true positives
6bbb5519fe/tests/tracer/test_span.py (L714)
```diff
+ error[lint:invalid-argument-type] /tmp/mypy_primer/projects/dd-trace-py/tests/tracer/test_span.py:714:33: Argument to this function is incorrect: Expected `str`, found `Literal[b"\xf0\x9f\xa4\x94"]`
```
### Changed diagnostics
A lot of changed diagnostics because we now show `@Todo(Support for
`typing.TypeVar` instances in type expressions)` instead of `Unknown`
for all kinds of symbols that used a `_T = TypeVar("_T")` as a type. One
prominent example is the `list.__getitem__` method:
`builtins.pyi`:
```pyi
_T = TypeVar("_T") # previously `TypeVar | Unknown`, now just `TypeVar`
# …
class list(MutableSequence[_T]):
# …
@overload
def __getitem__(self, i: SupportsIndex, /) -> _T: ...
# …
```
which causes this change in diagnostics:
```py
xs = [1, 2]
reveal_type(xs[0]) # previously `Unknown`, now `@Todo(Support for `typing.TypeVar` instances in type expressions)`
```
## Test Plan
Updated Markdown tests
## Summary
Apply auto fixes to cases where the names have changed in Airflow 3
## Test Plan
Add `AIR301_names_fix.py` and `AIR301_provider_names_fix.py` test fixtures
This pull request fixes https://github.com/astral-sh/ruff/issues/17014
changes this
```python
from __future__ import annotations
flag1 = True
flag2 = True
if flag1 == True or flag2 == True:
pass
if flag1 == False and flag2 == False:
pass
flag3 = True
if flag1 == flag3 and (flag2 == False or flag3 == True): # Should become: if flag1==flag3 and (not flag2 or flag3)
pass
if flag1 == True and (flag2 == False or not flag3 == True): # Should become: if flag1 and (not flag2 or not flag3)
pass
if flag1 != True and (flag2 != False or not flag3 == True): # Should become: if not flag1 and (flag2 or not flag3)
pass
flag = True
while flag == True: # Should become: while flag
flag = False
flag = True
x = 5
if flag == True and x > 0: # Should become: if flag and x > 0
print("ok")
flag = True
result = "yes" if flag == True else "no" # Should become: result = "yes" if flag else "no"
x = flag == True < 5
x = (flag == True) == False < 5
```
to this
```python
from __future__ import annotations
flag1 = True
flag2 = True
if flag1 or flag2:
pass
if not flag1 and not flag2:
pass
flag3 = True
if flag1 == flag3 and (not flag2 or flag3): # Should become: if flag1 == flag3 and (not flag2 or flag3)
pass
if flag1 and (not flag2 or not flag3): # Should become: if flag1 and (not flag2 or not flag3)
pass
if not flag1 and (flag2 or not flag3): # Should become: if not flag1 and (flag2 or not flag3)
pass
flag = True
while flag: # Should become: while flag
flag = False
flag = True
x = 5
if flag and x > 0: # Should become: if flag and x > 0
print("ok")
flag = True
result = "yes" if flag else "no" # Should become: result = "yes" if flag else "no"
x = flag is True < 5
x = (flag) is False < 5
```
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
Summary
--
This PR extends semantic syntax error detection to red-knot. The main
changes here are:
1. Adding `SemanticSyntaxChecker` and `Vec<SemanticSyntaxError>` fields
to the `SemanticIndexBuilder`
2. Calling `SemanticSyntaxChecker::visit_stmt` and `visit_expr` in the
`SemanticIndexBuilder`'s `visit_stmt` and `visit_expr` methods
3. Implementing `SemanticSyntaxContext` for `SemanticIndexBuilder`
4. Adding new mdtests to test the context implementation and show
diagnostics
(3) is definitely the trickiest and required (I think) a minor addition
to the `SemanticIndexBuilder`. I tried to look around for existing code
performing the necessary checks, but I definitely could have missed
something or misused the existing code even when I found it.
There's still one TODO around `global` statement handling. I don't think
there's an existing way to look this up, but I'm happy to work on that
here or in a separate PR. This currently only affects detection of one
error (`LoadBeforeGlobalDeclaration` or
[PLE0118](https://docs.astral.sh/ruff/rules/load-before-global-declaration/)
in ruff), so it's not too big of a problem even if we leave the TODO.
Test Plan
--
New mdtests, as well as new errors for existing mdtests
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Allow (instances of) subclasses of `Any` and `Unknown` to be assignable
to (instances of) other classes, unless they are final. This allows us
to get rid of ~1000 false positives, mostly when mock-objects like
`unittest.mock.MagicMock` are assigned to various targets.
## Test Plan
Adapted and new Markdown tests.
## Summary
mypy_primer changes included here:
ebaa9fd27b..4c22d192a4
- Add strawberry as a `good.txt` project (was previously included in our
fork)
- Print Red Knot compilation errors to stderr (thanks @MichaReiser)
## Summary
We currently emit a diagnostic for code like the following:
```py
from typing import Any
# error: Invalid class base with type `GenericAlias` (all bases must be a class, `Any`, `Unknown` or `Todo`)
class C(tuple[Any, ...]): ...
```
The changeset here silences this diagnostic by recognizing instances of
`GenericAlias` in `ClassBase::try_from_type`, and inferring a `@Todo`
type for them. This is a change in preparation for #17557, because `C`
previously had `Unknown` in its MRO …
```py
reveal_type(C.__mro__) # tuple[Literal[C], Unknown, Literal[object]]
```
… which would cause us to think that `C` is assignable to everything.
The changeset also removes some false positive `invalid-base`
diagnostics across the ecosystem.
## Test Plan
Updated Markdown tests.
## Summary
Add parentheses to multi-element intersections, when displayed in a
context that's otherwise potentially ambiguous.
## Test Plan
Update mdtest files
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
#17451 was incomplete. `AlwaysFalsy` and `AlwaysTruthy` are not the only
two types that are super-types of some literals (of a given kind) and
not others. That set also includes intersections containing
`AlwaysTruthy` or `AlwaysFalsy`, and intersections containing literal
types of the same kind. Cover these cases as well.
Fixes#17478.
## Test Plan
Added mdtests.
`QUICKCHECK_TESTS=1000000 cargo test -p red_knot_python_semantic --
--ignored types::property_tests::stable` failed on both
`all_fully_static_type_pairs_are_subtypes_of_their_union` and
`all_type_pairs_are_assignable_to_their_union` prior to this PR, passes
after it.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
I gave up trying to do this one lint at a time and just (mostly)
mechanically translated this entire file in one go.
Generally the messages stay the same (with most moving from an
annotation message to the diagnostic's main message). I added a couple
of `info` sub-diagnostics where it seemed to be the obvious intent.
This finishes the migration for the `INVALID_ASSIGNMENT` lint.
Notice how I'm steadily losing steam in terms of actually improving the
diagnostics. This change is more mechanical, because taking the time to
revamp every diagnostic is a ton of effort. Probably future migrations
will be similar unless there are easy pickings.
We mostly keep things the same here, but the message has been moved from
the annotation to the diagnostic's top-line message. I think this is
perhaps a little worse, but some bigger improvements could be made here.
Indeed, we could perhaps even add a "fix" here.
This moves all INVALID_ASSIGNMENT lints related to unpacking over to the new
diagnostic model.
While we're here, we improve the diagnostic a bit by adding a secondary
annotation covering where the value is. We also split apart the original
singular message into one message for the diagnostic and the "expected
versus got" into annotation messages.
This tests the diagnostic rendering of a case that wasn't previously
covered by snapshots: when unpacking fails because there are too few
values, but where the left hand side can tolerate "N or more." In the
code, this is a distinct diagnostic, so we capture it here.
(Sorry about the diff here, but it made sense to rename the other
sections and that changes the name of the snapshot file.)
I believe this was an artifact of an older iteration of the diagnostic
reporting API. But this is strictly not necessary now, and indeed, might
even be annoying. It is okay, but perhaps looks a little odd, to do
`builder.into_diagnostic("...")` if you don't want to add anything else
to the diagnostic.
I suspect this will be used pretty frequently (I wanted it
immediately). And more practically, this avoids needing to
import `Annotation` to create it.
## Summary
A switch from 16 to 32 cores reduces the `mypy_primer` CI time from
3.5-4 min to 2.5-3 min. There's also a 64-core runner, but the 4 min ->
3 min change when doubling the cores once does suggest that it doesn't
parallelize *this* well.
## Summary
I ran red-knot on every project in mypy-primer. I moved every project
where red-knot ran to completion (fast enough, and mypy-primer could
handle its output) into `good.txt`, so it will run in our CI.
The remaining projects I left listed in `bad.txt`, with a comment
summarizing the failure mode (a few don't fail, they are just slow -- on
a debug build, at least -- or output too many diagnostics for
mypy-primer to handle.)
We will now run CI on 109 projects; 34 are left in `bad.txt`.
## Test Plan
CI on this PR!
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
Takes the `good.txt` changes from #17474, and removes the following
projects:
- arrow (not part of mypy_primer upstream)
- freqtrade, hydpy, ibis, pandera, xarray (saw panics locally, all
related to try_metaclass cycles)
Increases the mypy_primer CI run time to ~4 min.
## Test Plan
Three successful CI runs.
## Summary
`mypy_primer` is not deterministic (we pin `mypy_primer` itself, but
projects change over time and we just pull in the latest version). We've
also seen occasional panics being caught in `mypy_primer` runs, so this
is trying to make these CI failures more helpful.
## Summary
* Add initial support for `typing.dataclass_transform`
* Support decorating a function decorator with `@dataclass_transform(…)`
(used by `attrs`, `strawberry`)
* Support decorating a metaclass with `@dataclass_transform(…)` (used by
`pydantic`, but doesn't work yet, because we don't seem to model
`__new__` calls correctly?)
* *No* support yet for decorating base classes with
`@dataclass_transform(…)`. I haven't figured out how this even supposed
to work. And haven't seen it being used.
* Add `strawberry` as an ecosystem project, as it makes heavy use of
`@dataclass_transform`
## Test Plan
New Markdown tests
This is an implementation of the discussion from #16719.
This change will allow list function calls to be replaced with
comprehensions:
```python
result = list()
for i in range(3):
result.append(i + 1)
# becomes
result = [i + 1 for i in range(3)]
```
I added a new test to `PERF401.py` to verify that this fix will now work
for `list()`.
## Summary
This PR is a follow-up to #16852.
Instance variables bound in comprehensions are recorded, allowing type
inference to work correctly.
This required adding support for unpacking in comprehension which
resolves https://github.com/astral-sh/ruff/issues/15369.
## Test Plan
One TODO in `mdtest/attributes.md` is now resolved, and some new test
cases are added.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
If two types are gradually-equivalent, that means they share the same
set of possible materializations. There's no need to keep two such types
in the same union or intersection; we should simplify them.
Fixes https://github.com/astral-sh/ruff/issues/17465
The one downside here is that now we will simplify e.g. `Unknown |
Todo(...)` to just `Unknown`, if `Unknown` was added to the union first.
This is correct from a type perspective (they are equivalent types), but
it can mean we lose visibility into part of the cause for the type
inferring as unknown. I think this is OK, but if we think it's important
to avoid this, I can add a special case to try to preserve `Todo` over
`Unknown`, if we see them both in the same union or intersection.
## Test Plan
Added and updated mdtests.
## Summary
The long line of projects in `mypy_primer.yaml` is hard to work with
when adding projects or checking whether they are currently run. Use a
one-per-line text file instead.
## Test Plan
Ecosystem check on this PR.
## Summary
add fix safety section to replace_stdout_stderr and
super_call_with_parameters, for #15584
I checked the behavior and found that these two files could only
potentially delete the appended comments, so I submitted them as a PR.
The PR fixes#16457 .
Specifically, `FURB161` is marked safe, but the rule generates safe
fixes only in specific cases. Therefore, we attempt to mark the fix as
unsafe when we are not in one of these cases.
For instances, the fix is marked as aunsafe just in case of strings (as
pointed out in the issue). Let me know if I should change something.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
## Summary
Member lookup can be cyclic, with type inference of implicit members. A
sample case is shown in the added mdtest.
There's no clear way to handle such cases other than to fixpoint-iterate
the cycle.
Fixes#17457.
## Test Plan
Added test.
## Summary
This change adds an auto-fix for manual dict comprehensions. It also
copies many of the improvements from #13919 (and associated PRs fixing
issues with it), and moves some of the utility functions from
`manual_list_comprehension.rs` into a separate `helpers.rs` to be used
in both.
## Test Plan
I added a preview test case to showcase the new fix and added a test
case in `PERF403.py` to make sure lines with semicolons function. I
didn't yet make similar tests to the ones I added earlier to
`PERF401.py`, but the logic is the same, so it might be good to add
those to make sure they work.
You can now use subscript expressions in a type expression to explicitly
specialize generic classes, just like you could already do in value
expressions.
This still does not implement bidirectional checking, so a type
annotation on an assignment does not influence how we infer a
specialization for a (not explicitly specialized) constructor call. You
might get an `invalid-assignment` error if (a) we cannot infer a class
specialization from the constructor call (in which case you end up e.g.
trying to assign `C[Unknown]` to `C[int]`) or if (b) we can infer a
specialization, but it doesn't match the annotation.
Closes https://github.com/astral-sh/ruff/issues/17432
## Summary
There was some narrowing constraints not covered from the previous PR
```py
def _(x: object):
if (type(y := x)) is bool:
reveal_type(y) # revealed: bool
```
Also, refactored a bit
## Test Plan
Update type_api.md
In #17403 I added a comment asserting that all same-kind literal types
share all the same super-types. This is true, with two notable
exceptions: the types `AlwaysTruthy` and `AlwaysFalsy`. These two types
are super-types of some literal types within a given kind and not
others: `Literal[0]`, `Literal[""]`, and `Literal[b""]` inhabit
`AlwaysFalsy`, while other literals inhabit `AlwaysTruthy`.
This PR updates the literal-unions optimization to handle these types
correctly.
Fixes https://github.com/astral-sh/ruff/issues/17447
Verified locally that `QUICKCHECK_TESTS=100000 cargo test -p
red_knot_python_semantic -- --ignored types::property_tests::stable` now
passes again.
## Summary
Fixes#17147.
This was landed in #17149 and then reverted in #17335 because it caused
cycle panics in checking pybind11. #17456 fixed the cause of that panic.
## Test Plan
Add new narrow/assert.md test file
Co-authored-by: Matthew Mckee <matthewmckee04@yahoo.co.uk>
## Summary
We were over-conflating the conditions for deferred name resolution.
`from __future__ import annotations` defers annotations, but not class
bases. In stub files, class bases are also deferred. Modeling this
correctly also reduces likelihood of cycles in Python files using `from
__future__ import annotations` (since deferred resolution is inherently
cycle-prone). The same cycles are still possible in `.pyi` files, but
much less likely, since typically there isn't anything in a `pyi` file
that would cause an early return from a scope, or otherwise cause
visibility constraints to persist to end of scope. Usually there is only
code at module global scope and class scope, which can't have `return`
statements, and `raise` or `assert` statements in a stub file would be
very strange. (Technically according to the spec we'd be within our
rights to just forbid a whole bunch of syntax outright in a stub file,
but I kinda like minimizing unnecessary differences between the handling
of Python files and stub files.)
## Test Plan
Added mdtests.
## Summary
Part of #15383, this PR adds support for overloaded callables.
Typing spec: https://typing.python.org/en/latest/spec/overload.html
Specifically, it does the following:
1. Update the `FunctionType::signature` method to return signatures from
a possibly overloaded callable using a new `FunctionSignature` enum
2. Update `CallableType` to accommodate overloaded callable by updating
the inner type to `Box<[Signature]>`
3. Update the relation methods on `CallableType` with logic specific to
overloads
4. Update the display of callable type to display a list of signatures
enclosed by parenthesis
5. Update `CallableTypeOf` special form to recognize overloaded callable
6. Update subtyping, assignability and fully static check to account for
callables (equivalence is planned to be done as a follow-up)
For (2), it is required to be done in this PR because otherwise I'd need
to add some workaround for `into_callable_type` and I though it would be
best to include it in here.
For (2), another possible design would be convert `CallableType` in an
enum with two variants `CallableType::Single` and
`CallableType::Overload` but I decided to go with `Box<[Signature]>` for
now to (a) mirror it to be equivalent to `overload` field on
`CallableSignature` and (b) to avoid any refactor in this PR. This could
be done in a follow-up to better split the two kind of callables.
### Design
There were two main candidates on how to represent the overloaded
definition:
1. To include it in the existing infrastructure which is what this PR is
doing by recognizing all the signatures within the
`FunctionType::signature` method
2. To create a new `Overload` type variant
<details><summary>For context, this is what I had in mind with the new
type variant:</summary>
<p>
```rs
pub enum Type {
FunctionLiteral(FunctionType),
Overload(OverloadType),
BoundMethod(BoundMethodType),
...
}
pub struct OverloadType {
// FunctionLiteral or BoundMethod
overloads: Box<[Type]>,
// FunctionLiteral or BoundMethod
implementation: Option<Type>
}
pub struct BoundMethodType {
kind: BoundMethodKind,
self_instance: Type,
}
pub enum BoundMethodKind {
Function(FunctionType),
Overload(OverloadType),
}
```
</p>
</details>
The main reasons to choose (1) are the simplicity in the implementation,
reusing the existing infrastructure, avoiding any complications that the
new type variant has specifically around the different variants between
function and methods which would require the overload type to use `Type`
instead.
### Implementation
The core logic is how to collect all the overloaded functions. The way
this is done in this PR is by recording a **use** on the `Identifier`
node that represents the function name in the use-def map. This is then
used to fetch the previous symbol using the same name. This way the
signatures are going to be propagated from top to bottom (from first
overload to the final overload or the implementation) with each function
/ method. For example:
```py
from typing import overload
@overload
def foo(x: int) -> int: ...
@overload
def foo(x: str) -> str: ...
def foo(x: int | str) -> int | str:
return x
```
Here, each definition of `foo` knows about all the signatures that comes
before itself. So, the first overload would only see itself, the second
would see the first and itself and so on until the implementation or the
final overload.
This approach required some updates specifically recognizing
`Identifier` node to record the function use because it doesn't use
`ExprName`.
## Test Plan
Update existing test cases which were limited by the overload support
and add test cases for the following cases:
* Valid overloads as functions, methods, generics, version specific
* Invalid overloads as stated in
https://typing.python.org/en/latest/spec/overload.html#invalid-overload-definitions
(implementation will be done in a follow-up)
* Various relation: fully static, subtyping, and assignability (others
in a follow-up)
## Ecosystem changes
_WIP_
After going through the ecosystem changes (there are a lot!), here's
what I've found:
We need assignability check between a callable type and a class literal
because a lot of builtins are defined as classes in typeshed whose
constructor method is overloaded e.g., `map`, `sorted`, `list.sort`,
`max`, `min` with the `key` parameter, `collections.abc.defaultdict`,
etc. (https://github.com/astral-sh/ruff/issues/17343). This makes up
most of the ecosystem diff **roughly 70 diagnostics**. For example:
```py
from collections import defaultdict
# red-knot: No overload of bound method `__init__` matches arguments [lint:no-matching-overload]
defaultdict(int)
# red-knot: No overload of bound method `__init__` matches arguments [lint:no-matching-overload]
defaultdict(list)
class Foo:
def __init__(self, x: int):
self.x = x
# red-knot: No overload of function `__new__` matches arguments [lint:no-matching-overload]
map(Foo, ["a", "b", "c"])
```
Duplicate diagnostics in unpacking
(https://github.com/astral-sh/ruff/issues/16514) has **~16
diagnostics**.
Support for the `callable` builtin which requires `TypeIs` support. This
is **5 diagnostics**. For example:
```py
from typing import Any
def _(x: Any | None) -> None:
if callable(x):
# red-knot: `Any | None`
# Pyright: `(...) -> object`
# mypy: `Any`
# pyrefly: `(...) -> object`
reveal_type(x)
```
Narrowing on `assert` which has **11 diagnostics**. This is being worked
on in https://github.com/astral-sh/ruff/pull/17345. For example:
```py
import re
match = re.search("", "")
assert match
match.group() # error: [possibly-unbound-attribute]
```
Others:
* `Self`: 2
* Type aliases: 6
* Generics: 3
* Protocols: 13
* Unpacking in comprehension: 1
(https://github.com/astral-sh/ruff/pull/17396)
## Performance
Refer to
https://github.com/astral-sh/ruff/pull/17366#issuecomment-2814053046.
## Summary
Add more narrowing analysis for match statements:
* add narrowing constraints from guard expressions
* add negated constraints from previous predicates and guards to
subsequent cases
This PR doesn't address that guards can mutate your subject, and so
theoretically invalidate some of these narrowing constraints that you've
previously accumulated. Some prior art on this issue [here][mutable
guards].
[mutable guards]:
https://www.irif.fr/~scherer/research/mutable-patterns/mutable-patterns-mlworkshop2024-abstract.pdf
## Test Plan
Add some new tests, and update some existing ones
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#14866Fixes#17437
## Test Plan
Update mdtests in `narrow/`
## Summary
Prevent overcommit by using max 4 threads as intended.
Unintuitively, `.max()` returns the maximum value of `self` and the
argument (not limiting to the argument). To limit the value to 4, one
needs to use `.min()`.
https://doc.rust-lang.org/std/cmp/trait.Ord.html#method.max
## Summary
This PR extends version-related syntax error detection to red-knot. The
main changes here are:
1. Passing `ParseOptions` specifying a `PythonVersion` to parser calls
2. Adding a `python_version` method to the `Db` trait to make this
possible
3. Converting `UnsupportedSyntaxError`s to `Diagnostic`s
4. Updating existing mdtests to avoid unrelated syntax errors
My initial draft of (1) and (2) in #16090 instead tried passing a
`PythonVersion` down to every parser call, but @MichaReiser suggested
the `Db` approach instead
[here](https://github.com/astral-sh/ruff/pull/16090#discussion_r1969198407),
and I think it turned out much nicer.
All of the new `python_version` methods look like this:
```rust
fn python_version(&self) -> ruff_python_ast::PythonVersion {
Program::get(self).python_version(self)
}
```
with the exception of the `TestDb` in `ruff_db`, which hard-codes
`PythonVersion::latest()`.
## Test Plan
Existing mdtests, plus a new mdtest to see at least one of the new
diagnostics.
add fix safety section to docs for #15584, I'm new to ruff and not sure
if the content of this PR is correct, but I hope it can be helpful.
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
## Summary
part of: #15655
I tried generating the source order function using code generation. I
tried a simple approach, but it is not enough to generate all of them
this way.
There is one good thing, that most of the implementations are fine with
this. We only have a few that are not. So one benefit of this PR could
be it eliminates a lot of the code, hence changing the AST structure
will only leave a few places to be fixed.
The `source_order` field determines if a node requires a source order
implementation. If it’s empty it means source order does not visit
anything.
Initially I didn’t want to repeat the field names. But I found two
things:
- `ExprIf` statement unlike other statements does not have the fields
defined in source order. This and also some fields do not need to be
included in the visit. So we just need a way to determine order, and
determine presence.
- Relying on the fields sounds more complicated to me. Maybe another
solution is to add a new attribute `order` to each field? I'm open to
suggestions.
But anyway, except for the `ExprIf` we don't need to write the field
names in order. Just knowing what fields must be visited are enough.
Some nodes had a more complex visitor:
`ExprCompare` required zipping two fields.
`ExprBoolOp` required a match over the fields.
`FstringValue` required a match, I created a new walk_ function that
does the match. and used it in code generation. I don’t think this
provides real value. Because I mostly moved the code from one file to
another. I was tried it as an option. I prefer to leave it in the code
as before.
Some visitors visit a slice of items. Others visit a single element. I
put a check on this in code generation to see if the field requires a
for loop or not. I think better approach is to have a consistent style.
So we can by default loop over any field that is a sequence.
For field types `StringLiteralValue` and `BytesLiteralValue` the types
are not a sequence in toml definition. But they implement `iter` so they
are iterated over. So the code generation does not properly identify
this. So in the code I'm checking for their types.
## Test Plan
All the tests should pass without any changes.
I checked the generated code to make sure it's the same as old code. I'm
not sure if there's a test for the source order visitor.
## Summary
This changeset allows us to generate the signature of synthesized
`__init__` functions in dataclasses by analyzing the fields on the class
(and its superclasses). There are certain things that I have not yet
attempted to model in this PR, like `kw_only`,
[`dataclasses.KW_ONLY`](https://docs.python.org/3/library/dataclasses.html#dataclasses.KW_ONLY)
or functionality around
[`dataclasses.field`](https://docs.python.org/3/library/dataclasses.html#dataclasses.field).
ticket: https://github.com/astral-sh/ruff/issues/16651
## Ecosystem analysis
These two seem to depend on missing features in generics (see [relevant
code
here](9898ccbb78/tests/core/test_generics.py (L54))):
> ```diff
> + error[lint:unknown-argument]
/tmp/mypy_primer/projects/dacite/tests/core/test_generics.py:54:24:
Argument `x` does not match any known parameter
> + error[lint:unknown-argument]
/tmp/mypy_primer/projects/dacite/tests/core/test_generics.py:54:38:
Argument `y` does not match any known parameter
> ```
These two are true positives. See [relevant code
here](9898ccbb78/tests/core/test_config.py (L154-L161)).
> ```diff
> + error[lint:invalid-argument-type]
/tmp/mypy_primer/projects/dacite/tests/core/test_config.py:161:24:
Argument to this function is incorrect: Expected `int`, found
`Literal["test"]`
> + error[lint:invalid-argument-type]
/tmp/mypy_primer/projects/dacite/tests/core/test_config.py:172:24:
Argument to this function is incorrect: Expected `int | float`, found
`Literal["test"]`
> ```
This one depends on `**` unpacking of dictionaries, which we don't
support yet:
> ```diff
> + error[lint:missing-argument]
/tmp/mypy_primer/projects/mypy_primer/mypy_primer/globals.py:218:11: No
arguments provided for required parameters `new`, `old`, `repo`,
`type_checker`, `mypyc_compile_level`, `custom_typeshed_repo`,
`new_typeshed`, `old_typeshed`, `new_prepend_path`, `old_prepend_path`,
`additional_flags`, `project_selector`, `known_dependency_selector`,
`local_project`, `expected_success`, `project_date`, `shard_index`,
`num_shards`, `output`, `old_success`, `coverage`, `bisect`,
`bisect_output`, `validate_expected_success`,
`measure_project_runtimes`, `concurrency`, `base_dir`, `debug`, `clear`
> ```
## Test Plan
New Markdown tests.
## Summary
Support dataclasses with `order=True`:
```py
@dataclass(order=True)
class WithOrder:
x: int
WithOrder(1) < WithOrder(2) # no error
```
Also adds some additional tests to `dataclasses.md`.
ticket: #16651
## Test Plan
New Markdown tests
This PR adds **_very_** basic inference of generic typevars at call
sites. It does not bring in a full unification algorithm, and there are
a few TODOs in the test suite that are not discharged by this. But it
handles a good number of useful cases! And the PR does not add anything
that would go away with a more sophisticated constraint solver.
In short, we just look for typevars in the formal parameters, and assume
that the inferred type of the corresponding argument is what that
typevar should map to. If a typevar appears more than once, we union
together the corresponding argument types.
Cases we are not yet handling:
- We are not widening literals.
- We are not recursing into parameters that are themselves generic
aliases.
- We are not being very clever with parameters that are union types.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This is similar to https://github.com/astral-sh/ruff/pull/17095, it adds
assignability check for bound methods to callables.
## Test Plan
Add test cases to for assignability; specifically it uses gradual types
because otherwise it would just delegate to `is_subtype_of`.
## Summary
closes#16615
This PR includes:
- Introduces a new type: `Type::BoundSuper`
- Implements member lookup for `Type::BoundSuper`, resolving attributes
by traversing the MRO starting from the specified class
- Adds support for inferring appropriate arguments (`pivot_class` and
`owner`) for `super()` when it is used without arguments
When `super(..)` appears in code, it can be inferred into one of the
following:
- `Type::Unknown`: when a runtime error would occur (e.g. calling
`super()` out of method scope, or when parameter validation inside
`super` fails)
- `KnownClass::Super::to_instance()`: when the result is an *unbound
super object* or when a dynamic type is used as parameters (MRO
traversing is meaningless)
- `Type::BoundSuper`: the common case, representing a properly
constructed `super` instance that is ready for MRO traversal and
attribute resolution
### Terminology
Python defines the terms *bound super object* and *unbound super
object*.
An **unbound super object** is created when `super` is called with only
one argument (e.g.
`super(A)`). This object may later be bound via the `super.__get__`
method. However, this form is rarely used in practice.
A **bound super object** is created either by calling
`super(pivot_class, owner)` or by using the implicit form `super()`,
where both arguments are inferred from the context. This is the most
common usage.
### Follow-ups
- Add diagnostics for `super()` calls that would result in runtime
errors (marked as TODO)
- Add property tests for `Type::BoundSuper`
## Test Plan
- Added `mdtest/class/super.md`
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
* Extend the following AIR311 rules
* `airflow.io.path.ObjectStoragePath` → `airflow.sdk.ObjectStoragePath`
* `airflow.io.storage.attach` → `airflow.sdk.io.attach`
* `airflow.models.dag.DAG` → `airflow.sdk.DAG`
* `airflow.models.DAG` → `airflow.sdk.DAG`
* `airflow.decorators.dag` → `airflow.sdk.dag`
* `airflow.decorators.task` → `airflow.sdk.task`
* `airflow.decorators.task_group` → `airflow.sdk.task_group`
* `airflow.decorators.setup` → `airflow.sdk.setup`
* `airflow.decorators.teardown` → `airflow.sdk.teardown`
## Test Plan
<!-- How was it tested? -->
The test case has been added to the button of the existing test
fixtures, confirmed to be correct and later reorgnaized
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
As discussed in
https://github.com/astral-sh/ruff/issues/14626#issuecomment-2766146129,
we're to separate suggested changes from required changes.
The following symbols have been moved to AIR311 from AIR301. They still
work in Airflow 3.0, but they're suggested to be changed as they're
expected to be removed in a future version.
* arguments
* `airflow..DAG | dag`
* `sla_miss_callback`
* operators
* `sla`
* name
* `airflow.Dataset] | [airflow.datasets.Dataset` → `airflow.sdk.Asset`
* `airflow.datasets, rest @ ..`
* `DatasetAlias` → `airflow.sdk.AssetAlias`
* `DatasetAll` → `airflow.sdk.AssetAll`
* `DatasetAny` → `airflow.sdk.AssetAny`
* `expand_alias_to_datasets` → `airflow.sdk.expand_alias_to_assets`
* `metadata.Metadata` → `airflow.sdk.Metadata`
<!--airflow.models.baseoperator-->
* `airflow.models.baseoperator.chain` → `airflow.sdk.chain`
* `airflow.models.baseoperator.chain_linear` →
`airflow.sdk.chain_linear`
* `airflow.models.baseoperator.cross_downstream` →
`airflow.sdk.cross_downstream`
* `airflow.models.baseoperatorlink.BaseOperatorLink` →
`airflow.sdk.definitions.baseoperatorlink.BaseOperatorLink`
* `airflow.timetables, rest @ ..`
* `datasets.DatasetOrTimeSchedule` → *
`airflow.timetables.assets.AssetOrTimeSchedule`
* `airflow.utils, rest @ ..`
<!--airflow.utils.dag_parsing_context-->
* `dag_parsing_context.get_parsing_context` →
`airflow.sdk.get_parsing_context`
## Test Plan
<!-- How was it tested? -->
The test fixture has been updated acccordingly
## Summary
Until we optimize our full union/intersection representation to
efficiently handle large numbers of same-kind literal types "as a
block", set a fairly low limit on the size of unions of literals.
We will want to increase this limit once we've made the broader
efficiency improvement (tracked in
https://github.com/astral-sh/ruff/issues/17420).
## Test Plan
`cargo bench --bench red_knot`
## Summary
Now that we've made the large-unions benchmark fast, let's make it slow
again!
This adds a following operation (checking `len`) on the large union,
which is slow, even though building the large union is now fast. (This
is also observed in a real-world code sample.) It's slow because for
every element of the union, we fetch its `__len__` method and check it
for compatibility with `Sized`.
We can make this fast by extending the grouped-types approach, as
discussed in https://github.com/astral-sh/ruff/pull/17403, so that we
can do this `__len__` operation (which is identical for every literal
string) just once for all literal strings, instead of once per literal
string type in the union.
Until we do that, we can make this acceptably fast again for now by
setting a lowish limit on union size, which we can increase in the
future when we make it fast. This is what I'll do in the next PR.
## Test Plan
`cargo bench --bench red_knot`
## Summary
Special-case literal types in `UnionBuilder` to speed up building large
unions of literals.
This optimization is extremely effective at speeding up building even a
very large union (it improves the large-unions benchmark by 41x!). The
problem we can run into is that it is easy to then run into another
operation on the very large union (for instance, narrowing may add it to
an intersection, which then distributes it over the intersection) which
is still slow.
I think it is possible to avoid this by extending this optimized
"grouped" representation throughout not just `UnionBuilder`, but all of
our union and intersection representations. I have some work in this
direction, but rather than spending more time on it right now, I'd
rather just land this much, along with a limit on the size of these
unions (to avoid building really big unions quickly and then hitting
issues where they are used.)
## Test Plan
Existing tests and benchmarks.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Fixes incorrect negated type eq and ne assertions in
infer_binary_intersection_type_comparison
fixes#17360
## Test Plan
Remove and update some now incorrect tests
This reworks the assignability/subtyping relations a bit to handle
typevars better:
1. For the most part, types are not assignable to typevars, since
there's no guarantee what type the typevar will be specialized to.
2. An intersection is an exception, if it contains the typevar itself as
one of the positive elements. This should fall out from the other
clauses automatically, since a typevar is assignable to itself, and an
intersection is assignable to something if any positive element is
assignable to that something.
3. Constrained typevars are an exception, since they must be specialized
to _exactly_ one of the constraints, not to a _subtype_ of a constraint.
If a type is assignable to every constraint, then the type is also
assignable to the constrained typevar.
We already had a special case for (3), but the ordering of it relative
to the intersection clauses meant we weren't catching (2) correctly. To
fix this, we keep the special case for (3), but fall through to the
other match arms for non-constrained typevars and if the special case
isn't true for a constrained typevar.
Closes https://github.com/astral-sh/ruff/issues/17364
## Summary
This PR fixes a bug in the lexer specifically around line continuation
character at end of file.
The reason this was occurring is because the lexer wouldn't check for
EOL _after_ consuming the escaped newline but only if the EOL was right
after the line continuation character.
fixes: #17398
## Test Plan
Add tests for the scenarios where this should occur mainly (a) when the
state is `AfterNewline` and (b) when the state is `Other`.
## Summary
closes#17215
This PR adds regression tests for the following cycled queries:
- all_narrowing_constraints_for_expression
- all_negative_narrowing_constraints_for_expression
The following test files are included:
-
`red_knot_project/resources/test/corpus/cycle_narrowing_constraints.py`
-
`red_knot_project/resources/test/corpus/cycle_negative_narrowing_constraints.py`
These test names don't follow the existing naming convention based on
Cinder.
However, I’ve chosen these names to clearly reflect the regression
cases.
Let me know if you’d prefer to align more closely with the existing
Cinder-based style.
## Test Plan
```sh
git checkout 1a6a10b30
cargo test --package red_knot_project -- corpus
```
We weren't really using `chrono` for anything other than getting the
current time and formatting it for logs.
Unfortunately, this doesn't quite get us to a point where `chrono`
can be removed. From what I can tell, we're still bringing it via
[`tracing-subscriber`](https://docs.rs/tracing-subscriber/latest/tracing_subscriber/)
and
[`quick-junit`](https://docs.rs/quick-junit/latest/quick_junit/).
`tracing-subscriber` does have an
[issue open about Jiff](https://github.com/tokio-rs/tracing/discussions/3128),
but there's no movement on it.
Normally I'd suggest holding off on this since it doesn't get us all of
the way there and it would be better to avoid bringing in two datetime
libraries, but we are, it appears, already there. In particular,
`env_logger` brings in Jiff. So this PR doesn't really make anything
worse, but it does bring us closer to an all-Jiff world.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [bstr](https://redirect.github.com/BurntSushi/bstr) |
workspace.dependencies | minor | `1.11.3` -> `1.12.0` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>BurntSushi/bstr (bstr)</summary>
###
[`v1.12.0`](https://redirect.github.com/BurntSushi/bstr/compare/1.11.3...1.12.0)
[Compare
Source](https://redirect.github.com/BurntSushi/bstr/compare/1.11.3...1.12.0)
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMzguMCIsInVwZGF0ZWRJblZlciI6IjM5LjIzOC4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
Add very early support for dataclasses. This is mostly to make sure that
we do not emit false positives on dataclass construction, but it also
lies some foundations for future extensions.
This seems like a good initial step to merge to me, as it basically
removes all false positives on dataclass constructor calls. This allows
us to use the ecosystem checks for making sure we don't introduce new
false positives as we continue to work on dataclasses.
## Ecosystem analysis
I re-ran the mypy_primer evaluation of [the `__init__`
PR](https://github.com/astral-sh/ruff/pull/16512) locally with our
current mypy_primer version and project selection. It introduced 1597
new diagnostics. Filtering those by searching for `__init__` and
rejecting those that contain `invalid-argument-type` (those could not
possibly be solved by this PR) leaves 1281 diagnostics. The current
version of this PR removes 1171 diagnostics, which leaves 110
unaccounted for. I extracted the lint + file path for all of these
diagnostics and generated a diff (of diffs), to see which
`__init__`-diagnostics remain. I looked at a subset of these: There are
a lot of `SomeClass(*args)` calls where we don't understand the
unpacking yet (this is not even related to `__init__`). Some others are
related to `NamedTuple`, which we also don't support yet. And then there
are some errors related to `@attrs.define`-decorated classes, which
would probably require support for `dataclass_transform`, which I made
no attempt to include in this PR.
## Test Plan
New Markdown tests.
## Summary
* Partial #17238
* Flyby from discord discussion - `todo_type!` now statically checks for
no parens in the message to avoid issues between debug & release build
tests
## Test Plan
many mdtests are changing
## Summary
This PR moves all the relation methods from `CallableType` to
`Signature`.
The main reason for this is that `Signature` is going to be the common
denominator between normal and overloaded callables and the core logic
to check a certain relationship is going to just require the information
that would exists on `Signature`. For example, to check whether an
overloaded callable is a subtype of a normal callable, we need to check
whether _every_ overloaded signature is a subtype of the normal
callable's signature. This "every" logic would become part of the
`CallableType` and the core logic of checking the subtyping would exists
on `Signature`.
Summary
--
This PR implements detecting the use of `await` expressions outside of
async functions. This is a reimplementation of
[await-outside-async
(PLE1142)](https://docs.astral.sh/ruff/rules/await-outside-async/) as a
semantic syntax error.
Despite the rule name, PLE1142 also applies to `async for` and `async
with`, so these are covered here too.
Test Plan
--
Existing PLE1142 tests.
I also deleted more code from the `SemanticSyntaxCheckerVisitor` to
avoid changes in other parser tests.
## Summary
Allows us to establish that two literals do not have a subtype
relationship with each other, without having to fallback to a typeshed
Instance type, which is comparatively slow.
Improves the performance of the many-string-literals union benchmark by
5x.
## Test Plan
`cargo test -p red_knot_python_semantic` and `cargo bench --bench
red_knot`.
## Summary
Add a benchmark for a large-union case that currently has exponential
blow-up in execution time.
## Test Plan
`cargo bench --bench red_knot`
## Summary
Let the mypy_primer job fail if Red Knot panics or exits with code 2
(indicating an internal error).
Corresponding mypy_primer commit:
90808f4656
In addition, we may also want to make a successful mypy_primer run
required for merging?
## Test Plan
Made sure that mypy_primer exits with code 70 locally on panics, which
should result in a pipeline failure, since we only allow code 0 and 1 in
the pipeline here:
a4d7c6669b/.github/workflows/mypy_primer.yaml (L73)
## Summary
This is mainly a follow-up from
https://github.com/astral-sh/ruff/pull/17357 to use the
`concise_message` method for the red-knot server which I noticed
recently while testing the overload implementation.
This commit shuffles the reporting API around a little bit such that a
range is required, up front, when reporting a lint diagnostic. This in
turn enables us to make suppression checking eager.
In order to avoid callers needing to provide the range twice, we create
a primary annotation *without* a message inside the `Diagnostic`
encapsulated by the guard. We do this instead of requiring the message
up front because we're concerned about API complexity and the effort
involved in creating the message.
In order to provide a means of attaching a message to the primary
annotation, we expose a convenience API on `LintDiagnosticGuard` for
setting the message. This isn't generally possible for a `Diagnostic`,
but since a `LintDiagnosticGuard` knows how the `Diagnostic` was
constructed, we can offer this API correctly.
It strikes me that it might be easy to forget to attach a primary
annotation message, btu I think this the "least" bad failure mode. And
in particular, it should be somewhat obvious that it's missing once one
adds a snapshot test for how the diagnostic renders.
Otherwise, this API gives us the ability to eagerly check whether a
diagnostic should be reported with nearly minimal information. It also
shouldn't have any footguns since it guarantees that the primary
annotation is tied to the file in the typing context. And it keeps
things pretty simple: callers only need to provide what is actually
strictly necessary to make a diagnostic.
This will enable us to provide an API on `LintDiagnosticGuard` for
setting the primary annotation message. It will require an `unwrap()`,
but due to how `LintDiagnosticGuard` will build a `Diagnostic`, this
`unwrap()` will be guaranteed to succeed. (And it won't bubble out to
every user of `LintDiagnosticGuard`.)
This is the payoff from removing a bit of indirection. The types still
exist, but now callers don't need to do builder -> reporter ->
diagnostic. They can just conceptually think of it as builder ->
diagnostic.
We're going to make the guards deref to `Diagnostic` in order to remove
a layer of indirection in the reporter API. (Well, technically the layer
is not removed since the types still exist, but in actual _usage_ the
layer will be removed. We'll see how it shakes out in the next commit.)
This expands the set of types accepted for diagnostic messages. Instead
of only `std::fmt::Display` impls, we now *also* accept a concrete
`DiagnosticMessage`.
This will be useful to avoid unnecessary copies of every single
diagnostic message created via `InferContext::report_lint`. (I'll call
out how this helps in a subsequent commit.)
## Summary
Infer precise Boolean literal types for `str.startswith` calls where the
instance and the prefix are both string literals. This allows us to
understand `sys.platform.startswith(…)` branches.
## Test Plan
New Markdown tests
Summary
--
This PR reimplements [yield-outside-function
(F704)](https://docs.astral.sh/ruff/rules/yield-outside-function/) as a
semantic syntax error. Despite the name, this rule covers `yield from`
and `await` in addition to `yield`.
Test Plan
--
New linter tests, along with the existing F704 test.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
Summary
--
This PR replaces uses of version-dependent imports from `typing` or
`typing_extensions` with a centralized `Checker::import_from_typing`
method.
The idea here is to make the fix for #9761 (whatever it ends up being)
applicable to all of the rules performing similar checks.
Test Plan
--
Existing tests for the affected rules.
## Summary
For silencing `invalid-type-form` diagnostics in unreachable code, we
use the same approach that we use before and check the reachability that
we already record.
For silencing `invalid-bases`, we simply check if the type of the base
is `Never`. If so, we silence the diagnostic with the argument that the
class construction would never happen.
## Test Plan
Updated Markdown tests.
## Summary
Similar to what we did for `unresolved-reference` and
`unresolved-attribute`, we now also silence `unresolved-import`
diagnostics if the corresponding `import` statement is unreachable.
This addresses the (already closed) issue #17049.
## Test Plan
Adapted Markdown tests.
I added this accessor because tests want it, but we can also use it in
other places internally. It's a little nicer because it does the
`as_deref()` for you.
This finally completes the deletion of all old diagnostic types.
We do this by migrating the second (and last) use of secondary
diagnostic messages: to highlight the return type of a function
definition when its return value is inconsistent with the type.
Like the last diagnostic, we do actually change the message here a bit.
We don't need a sub-diagnostic here, and we can instead just add a
secondary annotation to highlight the return type.
This is the first use of the new `lint()` reporter.
I somewhat skipped a step here and also modified the actual diagnostic
message itself. The snapshots should tell the story.
We couldn't do this before because we had no way of differentiating
between "message for the diagnostic as a whole" and "message for a
specific code annotation." Now we can, so we can write more precise
messages based on the assumption that users are also seeing the code
snippet.
The downside here is that the actual message text can become quite vague
in the absence of the code snippet. This occurs, for example, with
concise diagnostic formatting. It's unclear if we should do anything
about it. I don't really see a way to make it better that doesn't
involve creating diagnostics with messages for each mode, which I think
would be a major PITA.
The upside is that this code gets a bit simpler, and we very
specifically avoid doing extra work if this specific lint is disabled.
This required a bit of surgery in the diagnostic matching and more
faffing about using a "concise" message from a diagnostic instead of
only printing the "primary" message.
In the new diagnostic data model, we really should have a main
diagnostic message *and* a primary span (with an optional message
attached to it) for every diagnostic.
In this commit, I try to make this true for the "revealed type"
diagnostic. Instead of the annotation saying both "revealed type is"
and also the revealed type itself, the annotation is now just the
revealed type and the main diagnostic message is "Revealed type."
I expect this may be controversial. I'm open to doing something
different. I tried to avoid redundancy, but maybe this is a special case
where we want the redundancy. I'm honestly not sure. I do *like* how it
looks with this commit, but I'm not working with Red Knot's type
checking daily, so my opinion doesn't count for much.
This did also require some tweaking to concise diagnostic formatting in
order to preserve the essential information.
This commit doesn't update every relevant snapshot. Just a few. I split
the rest out into the next commit.
... and replace it with use of `report()`.
Interestingly, this is the only instance of `report_diagnostic` used
directly, and thus anticipated to be the only instance of using
`report()`. If this ends up being a true single use method, we could
make it less generic and tailored specifically to "reveal type."
Two other things to note:
I left the "primary message" as empty. This avoids changing snapshots.
I address this in a subsequent commit.
The creation of a diagnostic here is a bit verbose/annoying. Certainly
more so than it was. This is somewhat expected since our diagnostic
model is more expressive and because we don't have a proc macro. I
avoided creating helpers for this case since there's only one use of
`report()`. But I expect to create helpers for the `lint()` case.
This is a surgical change that adds new `report()` and `lint()`
APIs to `InferContext`. These are intended to replace the existing
`report_*` APIs.
The comments should explain what these reporters are meant to do. For
the most part, this is "just" shuffling some code around. The actual
logic for determining whether a lint *should* be reported or not remains
unchanged and we don't make any changes to how a `Diagnostic` is
actually constructed (yet).
I initially tried to just use `LintReporter` and `DiagnosticReporter`
without the builder types, since I perceive the builder types to be an
annoying additional layer. But I found it also exceedingly annoying to
have to construct and provide the diagnostic message before you even
know if you are going to build the diagnostic. I also felt like this
could result in potentially unnecessary and costly querying in some
cases, although this is somewhat hand wavy. So I overall felt like the
builder route was the way to go. If the builders end up being super
annoying, we can probably add convenience APIs for common patterns to
paper over them.
## Summary
Basically just repeat the same thing that we did for
`unresolved-reference`, but now for attribute expressions.
We now also handle the case where the unresolved attribute (or the
unresolved reference) diagnostic originates from a stringified type
annotation.
And I made the evaluation of reachability constraints lazy (will only be
evaluated right before we are about to emit a diagnostic).
## Test Plan
New Markdown tests for stringified annotations.
I merged #17149 without checking the ecosystem results, and it still
caused a cycle panic in pybind11. Reverting for now until I fix that, so
we don't lose the ecosystem signal on other PRs.
This causes spurious query cycles.
This PR also includes an update to Salsa, which gives us db events on
cycle iteration, so we can write tests asserting the absence of a cycle.
Putting this up to confirm that it does what it should:
* undirty the release.yml by including action-commits in the config
* add persist-credentials=false hardening
## Summary
Track the reachability of nested scopes within their parent scopes. We
use this as an additional requirement for emitting
`unresolved-reference` diagnostics (and in the future,
`unresolved-attribute` and `unresolved-import`). This means that we only
emit `unresolved-reference` for a given use of a symbol if the use
itself is reachable (within its own scope), *and if the scope itself is
reachable*. For example, no diagnostic should be emitted for the use of
`x` here:
```py
if False:
x = 1
def f():
print(x) # this use of `x` is reachable inside the `f` scope,
# but the whole `f` scope is not reachable.
```
There are probably more fine-grained ways of solving this problem, but
they require a more sophisticated understanding of nested scopes (see
#15777, in particular
https://github.com/astral-sh/ruff/issues/15777#issuecomment-2788950267).
But it doesn't seem completely unreasonable to silence *this specific
kind of error* in unreachable scopes.
## Test Plan
Observed changes in reachability tests and ecosystem.
## Summary
Update Salsa to pull in https://github.com/salsa-rs/salsa/pull/788 which
fixes the, by now, famous *access to field whilst the value is being
initialized*.
This PR also re-enables all tests that previously triggered the panic.
## Test Plan
`cargo test`
## Summary
There is a new official URL for the typing documentation:
https://typing.python.org/
Change all https://typing.readthedocs.io/ links to use the new sub
domain, which is slightly shorter and looks more official.
## Test Plan
Tested to see if each and every new URL is accessible. I noticed that
some links go to https://typing.python.org/en/latest/source/stubs.html
which seems to be outdated, but that is a separate issue. The same page
shows up for the old URL.
## Summary
Based on the discussion in
https://github.com/astral-sh/ruff/pull/17298#discussion_r2033975460, we
decided to move the scope handling out of the `SemanticSyntaxChecker`
and into the `SemanticSyntaxContext` trait. This PR implements that
refactor by:
- Reverting all of the `Checkpoint` and `in_async_context` code in the
`SemanticSyntaxChecker`
- Adding four new methods to the `SemanticSyntaxContext` trait
- `in_async_context`: matches `SemanticModel::in_async_context` and only
detects the nearest enclosing function
- `in_sync_comprehension`: uses the new `is_async` tracking on
`Generator` scopes to detect any enclosing sync comprehension
- `in_module_scope`: reports whether we're at the top-level scope
- `in_notebook`: reports whether we're in a Jupyter notebook
- In-lining the `TestContext` directly into the
`SemanticSyntaxCheckerVisitor`
- This allows modifying the context as the visitor traverses the AST,
which wasn't possible before
One potential question here is "why not add a single method returning a
`Scope` or `Scopes` to the context?" The main reason is that the `Scope`
type is defined in the `ruff_python_semantic` crate, which is not
currently a dependency of the parser. It also doesn't appear to be used
in red-knot. So it seemed best to use these more granular methods
instead of trying to access `Scope` in `ruff_python_parser` (and
red-knot).
## Test Plan
Existing parser and linter tests.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
attribute check was missing in the previous implementation
e.g.
```python
from airflow.api.auth.backend import basic_auth
basic_auth.auth_current_user
```
This PR adds this kind of check.
## Test Plan
<!-- How was it tested? -->
The test case has been added to the button of the existing test
fixtures, confirmed to be correct and later reorgnaized
Summary
--
This PR extends the documentation of the `LoadBeforeGlobalDeclaration`
check to specify the behavior on versions of Python before 3.13. Namely,
on Python 3.12, the `else` clause of a `try` statement is visited before
the `except` handlers:
```pycon
Python 3.12.9 (main, Feb 12 2025, 14:50:50) [Clang 19.1.6 ] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> a = 10
>>> def g():
... try:
... 1 / 0
... except:
... a = 1
... else:
... global a
...
>>> def f():
... try:
... pass
... except:
... global a
... else:
... print(a)
...
File "<stdin>", line 5
SyntaxError: name 'a' is used prior to global declaration
```
The order is swapped on 3.13 (see
[CPython#111123](https://github.com/python/cpython/issues/111123)):
```pycon
Python 3.13.2 (main, Feb 5 2025, 08:05:21) [GCC 14.2.1 20250128] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> a = 10
... def g():
... try:
... 1 / 0
... except:
... a = 1
... else:
... global a
...
File "<python-input-0>", line 8
global a
^^^^^^^^
SyntaxError: name 'a' is assigned to before global declaration
>>> def f():
... try:
... pass
... except:
... global a
... else:
... print(a)
...
>>>
```
The current implementation of PLE0118 is correct for 3.13 but not 3.12:
[playground](https://play.ruff.rs/d7467ea6-f546-4a76-828f-8e6b800694c9)
(it flags the first case regardless of Python version).
We decided to maintain this incorrect diagnostic for Python versions
before 3.13 because the pre-3.13 behavior is very unintuitive and
confirmed to be a bug, although the bug fix was not backported to
earlier versions. This can lead to false positives and false negatives
for pre-3.13 code, but we also expect that to be very rare, as
demonstrated by the ecosystem check (before the version-dependent check
was reverted here).
Test Plan
--
N/a
This PR lets you explicitly specialize a generic class using a subscript
expression. It introduces three new Rust types for representing classes:
- `NonGenericClass`
- `GenericClass` (not specialized)
- `GenericAlias` (specialized)
and two enum wrappers:
- `ClassType` (a non-generic class or generic alias, represents a class
_type_ at runtime)
- `ClassLiteralType` (a non-generic class or generic class, represents a
class body in the AST)
We also add internal support for specializing callables, in particular
function literals. (That is, the internal `Type` representation now
attaches an optional specialization to a function literal.) This is used
in this PR for the methods of a generic class, but should also give us
most of what we need for specializing generic _functions_ (which this PR
does not yet tackle).
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
* Simplify match conditions in AIR301
* Fix
* `airflow.datasets.manager.DatasetManager` →
`airflow.assets.manager.AssetManager`
* `airflow.www.auth.has_access_dataset` →
`airflow.www.auth.has_access_dataset`
## Test Plan
<!-- How was it tested? -->
The test fixture has been updated accordingly
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
As discussed in
https://github.com/astral-sh/ruff/issues/14626#issuecomment-2766146129,
we're to separate suggested changes from required changes.
The following symbols has been moved to AIR312 from AIR302. They still
work in Airflow 3.0, but they're suggested to be changed as they're
expected to be removed in future version
```python
from airflow.hooks.filesystem import FSHook
from airflow.hooks.package_index import PackageIndexHook
from airflow.hooks.subprocess import (SubprocessHook, SubprocessResult, working_directory)
from airflow.operators.bash import BashOperator
from airflow.operators.datetime import BranchDateTimeOperator, target_times_as_dates
from airflow.operators.trigger_dagrun import TriggerDagRunLink, TriggerDagRunOperator
from airflow.operators.empty import EmptyOperator
from airflow.operators.latest_only import LatestOnlyOperator
from airflow.operators.python import (BranchPythonOperator, PythonOperator, PythonVirtualenvOperator, ShortCircuitOperator)
from airflow.operators.weekday import BranchDayOfWeekOperator
from airflow.sensors.date_time import DateTimeSensor, DateTimeSensorAsync
from airflow.sensors.external_task import ExternalTaskMarker, ExternalTaskSensor, ExternalTaskSensorLink
from airflow.sensors.filesystem import FileSensor
from airflow.sensors.time_sensor import TimeSensor, TimeSensorAsync
from airflow.sensors.time_delta import TimeDeltaSensor, TimeDeltaSensorAsync, WaitSensor
from airflow.sensors.weekday import DayOfWeekSensor
from airflow.triggers.external_task import DagStateTrigger, WorkflowTrigger
from airflow.triggers.file import FileTrigger
from airflow.triggers.temporal import DateTimeTrigger, TimeDeltaTrigger
```
## Test Plan
<!-- How was it tested? -->
The test fixture has been updated acccordingly
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
As discussed in https://github.com/astral-sh/ruff/issues/16983 and
"mitigate" said issue for the alpha.
This PR changes the default for `PythonPlatform` to be the current
platform rather than `all`.
I'm not sure if we should be as sophisticated as supporting `ios` and
`android` as defaults but it was easy...
## Test Plan
Updated Markdown tests.
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
This is a new test case that I don't know how to handle yet. It leads to
many false positives in `rich/tests/test_win32_console.py`, which does
something like:
```py
if sys.platform == "win32":
from windows_only_module import some_symbol
some_other_symbol = 1
def some_test_case():
use(some_symbol) # Red Knot: unresolved-reference
use(some_other_symbol) # Red Knot: unresolved-reference
```
Also adds a test for using unreachable symbols in type annotations or as
class bases.
## Summary
* Addresses #16511 for simple cases where only `__init__` method is
bound on class or doesn't exist at all.
* fixes a bug with argument counting in bound method diagnostics
Caveats:
* No handling of `__new__` or modified `__call__` on metaclass.
* This leads to a couple of false positive errors in tests
## Test Plan
- A couple new cases in mdtests
- cargo nextest run -p red_knot_python_semantic --no-fail-fast
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: David Peter <sharkdp@users.noreply.github.com>
This fix closes#16868
I noticed the issue is assigned, but the assignee appears to be actively
working on another pull request. I hope that’s okay!
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
As of Python 3.11.1, `enum.auto()` can be used in multiple assignments.
This pattern should not trigger non-unique-enums check.
Reference: [Python docs on
enum.auto()](https://docs.python.org/3/library/enum.html#enum.auto)
This fix updates the check logic to skip enum variant statements where
the right-hand side is a tuple containing a call to `enum.auto()`.
## Test Plan
<!-- How was it tested? -->
The added test case uses the example from the original issue. It
previously triggered a false positive, but now passes successfully.
Summary
--
Detect async comprehensions nested in sync comprehensions in async
functions before Python 3.11, when this was [changed].
The actual logic of this rule is very straightforward, but properly
tracking the async scopes took a bit of work. An alternative to the
current approach is to offload the `in_async_context` check into the
`SemanticSyntaxContext` trait, but that actually required much more
extensive changes to the `TestContext` and also to ruff's semantic
model, as you can see in the changes up to
31554b473507034735bd410760fde6341d54a050. This version has the benefit
of mostly centralizing the state tracking in `SemanticSyntaxChecker`,
although there was some subtlety around deferred function body traversal
that made the changes to `Checker` more intrusive too (hence the new
linter test).
The `Checkpoint` struct/system is obviously overkill for now since it's
only tracking a single `bool`, but I thought it might be more useful
later.
[changed]: https://github.com/python/cpython/issues/77527
Test Plan
--
New inline tests and a new linter integration test.
## Summary
### Improvement
Expand the following moved module into individual symbols.
* airflow.triggers.temporal
* airflow.triggers.file
* airflow.triggers.external_task
* airflow.hooks.subprocess
* airflow.hooks.package_index
* airflow.hooks.filesystem
* airflow.sensors.weekday
* airflow.sensors.time_delta
* airflow.sensors.time_sensor
* airflow.sensors.date_time
* airflow.operators.weekday
* airflow.operators.datetime
* airflow.operators.bash
This removes `Replacement::ImportPathMoved`.
## Fix
During the expansion, the following paths were also fixed
* airflow.sensors.s3_key_sensor.S3KeySensor →
airflow.providers.amazon.aws.sensors.S3KeySensor
* airflow.operators.sql.SQLThresholdCheckOperator →
airflow.providers.common.sql.operators.sql.SQLThresholdCheckOperator
* airflow.hooks.druid_hook.DruidDbApiHook →
airflow.providers.apache.druid.hooks.druid.DruidDbApiHook
* airflow.hooks.druid_hook.DruidHook →
airflow.providers.apache.druid.hooks.druid.DruidHook
* airflow.kubernetes.pod_generator.extend_object_field →
airflow.providers.cncf.kubernetes.pod_generator.extend_object_field
* airflow.kubernetes.pod_launcher.PodLauncher →
airflow.providers.cncf.kubernetes.pod_launcher_deprecated.PodLauncher
* airflow.kubernetes.pod_launcher.PodStatus →
airflow.providers.cncf.kubernetes.pod_launcher_deprecated.PodStatus
* airflow.kubernetes.pod_generator.PodDefaults →
airflow.providers.cncf.kubernetes.pod_generator.PodDefaults
* airflow.kubernetes.pod_launcher_deprecated.PodDefaults →
airflow.providers.cncf.kubernetes.pod_launcher_deprecated.PodDefaults
### Refactor
As many symbols are moved into the same module,
`SourceModuleMovedToProvider` is introduced for grouping similar logic
## Test Plan
Summary
--
This PR extends the checks in #17101 and #17282 to annotated assignments
after Python 3.13.
Currently stacked on #17282 to include `await`.
Test Plan
--
New inline tests. These are simpler than the other cases because there's
no place to put generics.
Summary
--
This PR extends the changes in #17101 to include `await` in the same
positions.
I also renamed the `valid_annotation_function` test to include `_py313`
and explicitly passed a Python version to contrast it with the `_py314`
version.
Test Plan
--
New test cases added to existing files.
## Summary
We already have partial "support" for `assert_never`, because it is
annotated as
```pyi
def assert_never(arg: Never, /) -> Never: ...
```
in typeshed. So we already emit a `invalid-argument-type` diagnostic if
the argument type to `assert_never` is not assignable to `Never`.
That is not enough, however. Gradual types like `Any`, `Unknown`,
`@Todo(…)` or `Any & int` can be assignable to `Never`. Which means that
we didn't issue any diagnostic in those cases.
Also, it seems like `assert_never` deserves a dedicated diagnostic
message, not just a generic "invalid argument type" error.
## Test Plan
New Markdown tests.
This fix closes#17026
## Summary
The check for the `PytestRaisesTooBroad` rule is now skipped if there is
a second positional argument present, which means `pytest.raises` is
used as a function.
## Test Plan
Tested on the example from the issue, which now passes the check.
```Python3
pytest.raises(Exception, func, *func_args, **func_kwargs).match("error message")
```
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Resolves#17289.
After this change, Red Knot will no longer show types on hover for
`None`, `...`, `True`, `False`, numbers, strings (but not f-strings),
and bytes literals.
## Test Plan
Unit tests.
## Summary
This implements a new approach to silencing `unresolved-reference`
diagnostics by keeping track of the reachability of each use of a
symbol. The changes merged in
https://github.com/astral-sh/ruff/pull/17169 are still needed for the
"Use of variable in nested function" test case, but that could also be
solved in another way eventually (see
https://github.com/astral-sh/ruff/issues/15777). We can use the same
technique to silence `unresolved-import` and `unresolved-attribute`
false-positives, but I think this could be merged in isolation.
## Test Plan
New Markdown tests, ecosystem tests
## Summary
The priority latency-sensitive is reserved for actions that need to run
immediately because they would otherwise block the user's action. An
example of this is a format request. VS code blocks the editor until the
save action is complete. That's why formatting a document is very
sensitive to delays and it's important that we always have a worker
thread available to run a format request *immediately*. Another example
are code completions, where it's important that they appear immediately
when the user types.
On the other hand, showing diagnostics, hover, or inlay hints has high
priority but users are used that the editor takes a few ms to compute
the overlay.
Computing this information can also be expensive (e.g. find all
references), blocking the worker for quiet some time (a few 100ms).
That's why it's important
that those requests don't clog the sensitive worker threads.
## Summary
This PR proposes to change the default example program in the
playground. I realize that this is somewhat underwhelming, but I found
it rather difficult to come up with something that circumvented missing
support for overloads/generics/self-type, while still looking like
(easy!) code that someone might actually write, and demonstrating some
Red Knot features. One thing that I wanted to capture was the experience
of adding type constraints to an untyped program. And I wanted something
that could be executed in the Playground once all errors are fixed.
Happy for any suggestions on what we could do instead. I had a lot of
different ideas, but always ran into one or another limitation. So I
guess we can also iterate on this as we add more features to Red Knot.
Try it here:
https://playknot.ruff.rs/8e3a96af-f35d-4488-840a-2abee6c0512d
```py
from typing import Literal
type Style = Literal["italic", "bold", "underline"]
# Add parameter annotations `line: str, word: str, style: Style` and a return
# type annotation `-> str` to see if you can find the mistakes in this program.
def with_style(line, word, style):
if style == "italic":
return line.replace(word, f"*{word}*")
elif style == "bold":
return line.replace(word, f"__{word}__")
position = line.find(word)
output = line + "\n"
output += " " * position
output += "-" * len(word)
print(with_style("Red Knot is a fast type checker for Python.", "fast", "underlined"))
```
closes https://github.com/astral-sh/ruff/issues/17267
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [clap](https://redirect.github.com/clap-rs/clap) |
workspace.dependencies | patch | `4.5.34` -> `4.5.35` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>clap-rs/clap (clap)</summary>
###
[`v4.5.35`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4535---2025-04-01)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.34...v4.5.35)
##### Fixes
- *(help)* Align positionals and flags when put in the same
`help_heading`
- *(help)* Don't leave space for shorts if there are none
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMjcuMyIsInVwZGF0ZWRJblZlciI6IjM5LjIyNy4zIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
---------
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Co-authored-by: Micha Reiser <micha@reiser.io>
Closes#17042
## Summary
This PR fixes the issue outlined in #17042 where RUF100 (unused-noqa)
fails to detect unused file-level noqa directives (`# ruff: noqa` or `#
ruff: noqa: {code}`).
The issue stems from two underlying causes:
1. For blanket file-level directives (`# ruff: noqa`), there's a
circular dependency: the directive exempts all rules including RUF100
itself, which prevents checking for usage. This isn't changed by this
PR. I would argue it is intendend behavior - a blanket `# ruff: noqa`
directive should exempt all rules including RUF100 itself.
2. For code-specific file-level directives (e.g. `# ruff: noqa: F841`),
the handling was missing in the `check_noqa` function. This is added in
this PR.
## Notes
- For file-level directives, the `matches` array is pre-populated with
the specified codes during parsing, unlike line-level directives which
only populate their `matches` array when actually suppressing
diagnostics. This difference requires the somewhat clunky handling of
both cases. I would appreciate guidance on a cleaner design :)
- A more fundamental solution would be to change how file-level
directives initialize the `matches` array in
`FileNoqaDirectives::extract()`, but that requires more substantial
changes as it breaks existing functionality. I suspect discussions in
#16483 are relevant for this.
## Test Plan
- Local verification
- Added a test case and fixture
## Summary
`**/*` only matches files in a subdirectory whereas `**` matches any
file at an arbitrary depth
> A trailing "/**" matches everything inside. For example, "abc/**"
matches all files inside directory "abc", relative to the location of
the .gitignore file, with infinite depth.
> A leading "**" followed by a slash means match in all directories. For
example, "**/foo" matches file or directory "foo" anywhere, the same as
pattern "foo". "**/foo/bar" matches file or directory "bar" anywhere
that is directly under directory "foo".
## Summary
Some of the migration rules has been changed during Airflow 3
development. The following are new AIR302 rules. Corresponding AIR301
has also been removed.
* airflow.sensors.external_task_sensor.ExternalTaskMarker →
airflow.providers.standard.sensors.external_task.ExternalTaskMarker
* airflow.sensors.external_task_sensor.ExternalTaskSensor →
airflow.providers.standard.sensors.external_task.ExternalTaskSensor
* airflow.sensors.external_task_sensor.ExternalTaskSensorLink →
airflow.providers.standard.sensors.external_task.ExternalTaskSensorLink
* airflow.sensors.time_delta_sensor.TimeDeltaSensor →
airflow.providers.standard.sensors.time_delta.TimeDeltaSensor
* airflow.operators.dagrun_operator.TriggerDagRunLink →
airflow.providers.standard.operators.trigger_dagrun.TriggerDagRunLink
* airflow.operators.dagrun_operator.TriggerDagRunOperator →
airflow.providers.standard.operators.trigger_dagrun.TriggerDagRunOperator
* airflow.operators.python_operator.BranchPythonOperator →
airflow.providers.standard.operators.python.BranchPythonOperator
* airflow.operators.python_operator.PythonOperator →
airflow.providers.standard.operators.python.PythonOperator
* airflow.operators.python_operator.PythonVirtualenvOperator →
airflow.providers.standard.operators.python.PythonVirtualenvOperator
* airflow.operators.python_operator.ShortCircuitOperator →
airflow.providers.standard.operators.python.ShortCircuitOperator
* airflow.operators.latest_only_operator.LatestOnlyOperator →
airflow.providers.standard.operators.latest_only.LatestOnlyOperator
* airflow.sensors.date_time_sensor.DateTimeSensor →
airflow.providers.standard.sensors.DateTimeSensor
* airflow.operators.email_operator.EmailOperator →
airflow.providers.smtp.operators.smtp.EmailOperator
* airflow.operators.email.EmailOperator →
airflow.providers.smtp.operators.smtp.EmailOperator
* airflow.operators.bash.BashOperator →
airflow.providers.standard.operators.bash.BashOperator
* airflow.operators.EmptyOperator →
airflow.providers.standard.operators.empty.EmptyOperator
closes: https://github.com/astral-sh/ruff/issues/17103
## Test Plan
The test fixture has been updated and checked after each change and
later reorganized in the latest commit
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Minor formatting tweak in the docs. Looks like the link is meant to be
italic (others "See XXXX" are), but the opening underscore isn't closed
so it's displayed in the rendered version:
https://docs.astral.sh/ruff/formatter/#philosophy

## Test Plan
<!-- How was it tested? -->
## Summary
This PR adds support for stub packages, except for partial stub packages
(a stub package is always considered non-partial).
I read the specification at
[typing.python.org/en/latest/spec/distributing.html#stub-only-packages](https://typing.python.org/en/latest/spec/distributing.html#stub-only-packages)
but I found it lacking some details, especially on how to handle
namespace packages or when the regular and stub packages disagree on
whether they're namespace packages. I tried to document my decisions in
the mdtests where the specification isn't clear and compared the
behavior to Pyright.
Mypy seems to only support stub packages in the venv folder. At least,
it never picked up my stub packages otherwise. I decided not to spend
too much time fighting mypyp, which is why I focused the comparison
around Pyright
Closes https://github.com/astral-sh/ruff/issues/16612
## Test plan
Added mdtests
## Summary
Some more edge cases that I thought of while working on integrating
knowledge of statically known branches into the `*`-import machinery
## Test Plan
`cargo test -p red_knot_python_semantic`
## Summary
Use more local `expect(dead_code)` suppressions instead of a global
`allow(dead_code)` in `lib.rs`.
Remove some methods that are either easy to add later, are less likely
to be needed for red knot, or it's unclear if we'd add it the same way
as in ruff.
## Summary
This PR does the following things:
- Fixes the `python` configuration setting for mdtest (added in
https://github.com/astral-sh/ruff/pull/17221) so that it expects a path
pointing to a venv's `sys.prefix` variable rather than the a path
pointing to the venv's `site-packages` subdirectory. This brings the
`python` setting in mdtest in sync with our CLI `--python` flag.
- Tweaks mdtest so that it automatically creates a valid `pyvenv.cfg`
file for you if you don't specify one. This makes it much more ergonomic
to write an mdtest with a custom `python` setting: red-knot will reject
a `python` setting that points to a directory that doesn't have a
`pyvenv.cfg` file in it
- Tweaks mdtest so that it doesn't check a custom `pyvenv.cfg` as Python
source code if you _do_ add a custom `pyvenv.cfg` file for your mock
virtual environment in an mdtest. (You get a lot of diagnostics about
Python syntax errors in the `pyvenv.cfg` file, otherwise!)
- Rewrites the test added in
https://github.com/astral-sh/ruff/pull/17178 as an mdtest, and deletes
the original test that was added in that PR
## Test Plan
I verified that the new mdtest fails if I revert the changes to
`resolver.rs` that were added in
https://github.com/astral-sh/ruff/pull/17178
## Summary
This PR extends the mdtest options to allow setting the
`environment.python` option.
## Test Plan
I let @AlexWaygood write a test and he'll tell me if it works 😆
## Summary
This PR fixes the cycle issue that was causing problems in the `support
super` PR.
### Affected queries
- `all_narrowing_constraints_for_expression`
- `all_negative_narrowing_constraints_for_expression`
--
Additionally, `bidict` and `werkzeug` have been added to the
project-selection list in `mypy_primer`.
This PR also addresses the panics that occurred while analyzing those
packages:
- `bidict`: panic triggered by
`all_narrowing_constraints_for_expression`
- `werkzeug`: panic triggered by
`all_negative_narrowing_constraints_for_expression`
I think the mypy-primer results for this PR can serve as sufficient test
:)
Summary
--
Updates `fuzz.py` to run with `--preview`, which should allow it to
catch semantic syntax errors.
Test Plan
--
@AlexWaygood and I temporarily made any named expression a semantic
syntax error and checked that this led to fuzzing errors. We also tested
that reverting the `--preview` addition did not show any errors.
We also ran the fuzzer on 500 seeds on `main` but didn't find any
issues, (un)fortunately.
Summary
--
This PR fixes the issue pointed out by @JelleZijlstra in
https://github.com/astral-sh/ruff/pull/17101#issuecomment-2777480204.
Namely, I conflated two very different errors from CPython:
```pycon
>>> def m[T](x: (yield from 1)): ...
File "<python-input-310>", line 1
def m[T](x: (yield from 1)): ...
^^^^^^^^^^^^
SyntaxError: yield expression cannot be used within the definition of a generic
>>> def m(x: (yield from 1)): ...
File "<python-input-311>", line 1
def m(x: (yield from 1)): ...
^^^^^^^^^^^^
SyntaxError: 'yield from' outside function
>>> def outer():
... def m(x: (yield from 1)): ...
...
>>>
```
I thought the second error was the same as the first, but `yield` (and
`yield from`) is actually valid in this position when inside a function
scope. The same is true for base classes, as pointed out in the original
comment.
We don't currently raise an error for `yield` outside of a function, but
that should be handled separately.
On the upside, this had the benefit of removing the
`InvalidExpressionPosition::BaseClass` variant and the
`allow_named_expr` field from the visitor because they were both no
longer used.
Test Plan
--
Updated inline tests.
Fixes: #17196
## Summary
Skipping these nodes for malformed type expressions would lead to
incorrect semantic state, which can in turn mean we emit false positives
for rules like `unused-variable`(`F841`)
## Test Plan
`cargo nextest run`
## Summary
This is a follow up to the goto type definition PR. Specifically, that
we want to avoid exposing too many semantic model internals publicly.
I want to get some feedback on the approach taken. I think it goes into
the right direction but I'm not super happy with it.
The basic idea is that we add a `Type::definition` method which does the
"goto type definition". The parts that I think make it awkward:
* We can't directly return `Definition` because we don't create a
`Definition` for modules (but we could?). Although I think it makes
sense to possibly have a more public wrapper type anyway?
* It doesn't handle unions and intersections. Mainly because not all
elements in an intersection may have a definition and we only want to
show a navigation target for intersections if there's only a single
positive element (besides maybe `Unknown`).
An alternative design or an addition to this design is to introduce a
`SemanticAnalysis(Db)` struct that has methods like
`type_definition(&self, type)` which explicitly exposes the methods we
want. I don't feel comfortable design this API yet because it's unclear
how fine granular it has to be (and if it is very fine granular,
directly using `Type` might be better after all)
## Test Plan
`cargo test`
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
Closes#17084
## Summary
This PR adds a new rule (RUF102) to detect and fix invalid rule codes in
`noqa` comments.
Invalid rule codes in `noqa` directives serve no purpose and may
indicate outdated code suppressions.
This extends the previous behaviour originating from
`crates/ruff_linter/src/noqa.rs` which would only emit a warnigs.
With this rule a `--fix` is available.
The rule:
1. Analyzes all `noqa` directives to identify invalid rule codes
2. Provides autofix functionality to:
- Remove the entire comment if all codes are invalid
- Remove only the invalid codes when mixed with valid codes
3. Preserves original comment formatting and whitespace where possible
Example cases:
- `# noqa: XYZ111` → Remove entire comment (keep empty line)
- `# noqa: XYZ222, XYZ333` → Remove entire comment (keep empty line)
- `# noqa: F401, INVALID123` → Keep only valid codes (`# noqa: F401`)
## Test Plan
- Added tests in
`crates/ruff_linter/resources/test/fixtures/ruff/RUF102.py` covering
different example cases.
<!-- How was it tested? -->
## Notes
- This does not handle cases where parsing fails. E.g. `# noqa:
NON_EXISTENT, ANOTHER_INVALID` causes a `LexicalError` and the
diagnostic is not propagated and we cannot handle the diagnostic. I am
also unsure what proper `fix` handling would be and making the user
aware we don't understand the codes is probably the best bet.
- The rule is added to the Preview rule group as it's a new addition
## Questions
- Should we remove the warnings, now that we have a rule?
- Is the current fix behavior appropriate for all cases, particularly
the handling of whitespace and line deletions?
- I'm new to the codebase; let me know if there are rule utilities which
could have used but didn't.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
For two non-disjoint types `P` and `Q`, the simplification of `(P | Q) &
~Q` is not `P`, but `P & ~Q`. In other words, the non-empty set `P & Q`
is also excluded from the type.
The same applies for a constrained typevar `[T: (P, Q)]`: `T & ~Q`
should simplify to `P & ~Q`, not just `P`.
Implementing this is actually purely a matter of removing code from the
constrained typevar simplification logic; we just need to not bother
removing the negations. If the negations are actually redundant (because
the constraint types are disjoint), normal intersection simplification
will already eliminate them (as shown in the added test.)
Summary
--
This PR detects the use of invalid syntax in annotation scopes,
including
`yield` and `yield from` expressions and named expressions. I combined a
few
different types of CPython errors here, but I think the resulting error
messages
still make sense and are even preferable to what CPython gives. For
example, we
report `yield expression cannot be used in a type annotation` for both
of these:
```pycon
>>> def f[T](x: (yield 1)): ...
File "<python-input-26>", line 1
def f[T](x: (yield 1)): ...
^^^^^^^
SyntaxError: yield expression cannot be used within the definition of a generic
>>> def foo() -> (yield x): ...
File "<python-input-28>", line 1
def foo() -> (yield x): ...
^^^^^^^
SyntaxError: 'yield' outside function
```
Fixes https://github.com/astral-sh/ruff/issues/11118.
Test Plan
--
New inline tests, along with some updates to existing tests.
Summary
--
Detects duplicate attributes in a `match` class pattern:
```python
match x:
case Class(x=1, x=2): ...
```
which are more analogous to the similar check for mapping patterns than
to the
multiple assignments rule.
I also realized that both this and the mapping check would only work on
top-level patterns, despite the possibility that they can be nested
inside other
patterns:
```python
match x:
case [{"x": 1, "x": 2}]: ... # false negative in the old version
```
and moved these checks into the recursive pattern visitor instead.
I also tidied up some of the names like the `multiple_case_assignment`
function
and the `MultipleCaseAssignmentVisitor`, which are now doing more than
checking
for multiple assignments.
Test Plan
--
New inline tests for both classes and mappings.
Summary
--
Fixes#17181. The cases being tested with multiple *keys* being equal
are actually a slightly different error, more like the error for
`MatchMapping` than like the other multiple assignment errors:
```pycon
>>> match x:
... case Class(x=x, x=x): ...
...
File "<python-input-249>", line 2
case Class(x=x, x=x): ...
^
SyntaxError: attribute name repeated in class pattern: x
>>> match x:
... case {"x": 1, "x": 2}: ...
...
File "<python-input-251>", line 2
case {"x": 1, "x": 2}: ...
^^^^^^^^^^^^^^^^
SyntaxError: mapping pattern checks duplicate key ('x')
>>> match x:
... case [x, x]: ...
...
File "<python-input-252>", line 2
case [x, x]: ...
^
SyntaxError: multiple assignments to name 'x' in pattern
```
This PR just stops the false positive reported in the issue, but I will
quickly follow it up with a new rule (or possibly combined with the
mapping rule) catching the repeated attributes separately.
Test Plan
--
New inline `test_ok` and updating the `test_err` cases to have duplicate
values instead of keys.
## Summary
It turns out that `a.` isn't a list format supported by rustdoc. I
changed the documentation to use `1.`, `2.` instead.
## Test Plan
`cargo clippy`
This adds a new `Type` variant for holding an instance of a typevar
inside of a generic function or class. We don't handle specializing the
typevars yet, but this should implement most of the typing rules for
inside the generic function/class, where we don't know yet which
specific type the typevar will be specialized to.
This PR does _not_ yet handle the constraint that multiple occurrences
of the typevar must be specialized to the _same_ time. (There is an
existing test case for this in `generics/functions.md` which is still
marked as TODO.)
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
I decided to disable the new
[`needless_continue`](https://rust-lang.github.io/rust-clippy/master/index.html#needless_continue)
rule because I often found the explicit `continue` more readable over an
empty block or having to invert the condition of an other branch.
## Test Plan
`cargo test`
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR changes the inferred type for symbols in unreachable sections of
code to `Never` (instead of reporting them as unbound), in order to
silence false positive diagnostics. See the lengthy comment in the code
for further details.
## Test Plan
- Updated Markdown tests.
- Manually verified a couple of ecosystem diagnostic changes.
## Summary
If a package in `site-packages` had this directory structure:
```py
# bar/__init__.py
from .a import A
# bar/a.py
class A: ...
```
then we would fail to resolve the `from .a import A` import _if_ (as is
usually the case!) the `site-packages` search path was located inside a
`.venv` directory that was a subdirectory of the project's first-party
search path. The reason for this is a bug in `file_to_module` in the
module resolver. In this loop, we would identify that
`/project_root/.venv/lib/python3.13/site-packages/foo/__init__.py` can
be turned into a path relative to the first-party search path
(`/project_root`):
6e2b8f9696/crates/red_knot_python_semantic/src/module_resolver/resolver.rs (L101-L110)
but we'd then try to turn the relative path
(.venv/lib/python3.13/site-packages/foo/__init__.py`) into a module
path, realise that it wasn't a valid module path... and therefore
immediately `break` out of the loop before trying any other search paths
(such as the `site-packages` search path).
This bug was originally reported on Discord by @MatthewMckee4.
## Test Plan
I added a unit test for `file_to_module` in `resolver.rs`, and an
integration test that shows we can now resolve the import correctly in
`infer.rs`.
Update to latest Salsa main branch, so as to get a baseline for
measuring the perf effect of https://github.com/salsa-rs/salsa/pull/786
on red-knot in isolation from other recent changes in Salsa main branch.
Summary
--
Detects duplicate literals in `match` mapping keys.
This PR also adds a `source` method to `SemanticSyntaxContext` to
display the duplicated key in the error message by slicing out its
range.
Test Plan
--
New inline tests.
Fixes#17164. Simply checking whether one type is gradually equivalent
to another is too simplistic here: `Any` is gradually equivalent to
`Todo`, but we should permit users to cast from `Todo` or `Unknown` to
`Any` without complaining about it. This changes our logic so that we
only complain about redundant casts if:
- the two types are exactly equal (when normalized) OR they are
equivalent (we'll still complain about `Any -> Any` casts, and about
`Any | str | int` -> `str | int | Any` casts, since their normalized
forms are exactly equal, even though the type is not fully static -- and
therefore does not participate in equivalence relations)
- AND the casted type does not contain `Todo`
We add support for `return` and `raise` statements in the control flow
graph: we simply add an edge to the terminal block, push the statements
to the current block, and proceed.
This implementation will have to be modified somewhat once we add
support for `try` statements - then we will need to check whether to
_defer_ the jump. But for now this will do!
Also in this PR: We fix the `unreachable` diagnostic range so that it
lumps together consecutive unreachable blocks.
## Summary
The existing signature for `str` calls had various problems, one of
which I noticed while looking at some ecosystem projects (`scrapy`,
added as a project to mypy_primer in this PR).
## Test Plan
- New tests for `str(…)` calls.
- Observed reduction of false positives in ecosystem checks
## Summary
Fixes a crash in the playground where it crashed with an "index out of
bounds" error in the `Diagnostic::to_range` call
after deleting content at the end of the file.
The root cause was that the playground uses `useDeferred` to avoid too
frequent `checkFile` calls (to get a smoother UX).
However, this has the problem that the rendered `diagnostics` can be
stable (from before the last change).
Rendering the diagnostics can then fail because the `toRange` call
queries the latest content and not the content
from when the diagnostics were created.
The fix is "easy" in the sense that we now eagerly perform the `toRange`
calls. This way, it doesn't matter
when the diagnostics are stale for a few ms.
This problem can only be observed on examples where Red Knot is "slow"
(takes more than ~16ms to check) because
only then does `useDeferred` "debounce" the `check` calls.
## Summary
A callable type is disjoint from other literal types. For example,
`Type::StringLiteral` must be an instance of exactly `str`, not a
subclass of `str`, and `str` is not callable. The same applies to other
literal types.
This should hopefully fix#17144, I couldn't produce any failures after
running property tests multiple times.
## Test Plan
Add test cases for disjointness check between callable and other literal
types.
Run property tests multiple times.
## Summary
Python `**` works differently to Rust `**`!
## Test Plan
Added an mdtest for various edge cases, and checked in the Python REPL
that we infer the correct type in all the new cases tested.
## Summary
This PR adds a CI job that causes GitHub to add annotations to a PR diff
when mdtest assertions fail. For example:
<details>
<summary>Screenshot</summary>

</details>
## Motivation
Debugging mdtest failures locally is currently a really nice experience:
- Errors are displayed with pretty colours, which makes them much more
readable
- If you run the test from inside an IDE, you can CTRL-click on a path
and jump directly to the line that had the failing assertion
- If you use
[`mdtest.py`](https://github.com/astral-sh/ruff/blob/main/crates/red_knot_python_semantic/mdtest.py),
you don't even need to recompile anything after changing an assertion in
an mdtest, amd the test results instantly live-update with each change
to the MarkDown file
Debugging mdtest failures in CI is much more unpleasant, however.
Sometimes an error message is just
> [static-assert-error] Argument evaluates to `False`
...which doesn't tell you very much unless you navigate to the line in
question that has the failing mdtest assertion. The line in question
might not even be touched by the PR, and even if it is, it can be hard
to find the line if the PR touches many files. Unlike locally, you can't
click on the error and jump straight to the line that contains the
failing assertion. You also don't get colourised output in CI
(https://github.com/astral-sh/ruff/issues/13939).
GitHub PR annotations should make it really easy to debug why mdtests
are failing on PRs, making PR review much easier.
## Test Plan
I opened a PR to my fork
[here](https://github.com/AlexWaygood/ruff/pull/11/files) with some
bogus changes to an mdtest to show what it looks like when there are
failures in CI and this job has been added. Scroll down to
`crates/red_knot_python_semantic/resources/mdtest/type_properties/is_equivalent_to.md`
on the "files changed" tab for that PR to see the annotations.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/17058.
Equivalent callable types were not understood as equivalent when they
appeared nested inside unions and intersections. This PR fixes that by
ensuring that `Callable` elements nested inside unions, intersections
and tuples have their representations normalized before one union type
is compared with another for equivalence, or before one intersection
type is compared with another for equivalence.
The normalizations applied to a `Callable` type are:
- the type of the default value is stripped from all parameters (only
whether the parameter _has_ a default value is relevant to whether one
`Callable` type is equivalent to another)
- The names of the parameters are stripped from positional-only
parameters, variadic parameters and keyword-variadic parameters
- Unions and intersections that are present (top-level or nested) inside
parameter annotations or return annotations are normalized.
Adding a `CallableType::normalized()` method also allows us to simplify
the implementation of `CallableType::is_equivalent_to()`.
### Should these normalizations be done eagerly as part of a
`CallableType` constructor?
I considered this. It's something that we could still consider doing in
the future; this PR doesn't rule it out as a possibility. However, I
didn't pursue it for now, for several reasons:
1. Our current `Display` implementation doesn't handle well the
possibility that a parameter might not have a name or an annotated type.
Callable types with parameters like this would be displayed as follows:
```py
(, ,) -> None: ...
```
That's fixable! It could easily become something like `(Unknown,
Unknown) -> None: ...`. But it also illustrates that we probably want to
retain the parameter names when displaying the signature of a `lambda`
function if you're hovering over a reference to the lambda in an IDE.
Currently we don't have a `LambdaType` struct for representing `lambda`
functions; if we wanted to eagerly normalize signatures when creating
`CallableType`s, we'd probably have to add a `LambdaType` struct so that
we would retain the full signature of a `lambda` function, rather than
representing it as an eagerly simplified `CallableType`.
2. In order to ensure that it's impossible to create `CallableType`s
without the parameters being normalized, I'd either have to create an
alternative `SimplifiedSignature` struct (which would duplicate a lot of
code), or move `CallableType` to a new module so that the only way of
constructing a `CallableType` instance would be via a constructor method
that performs the normalizations eagerly on the callable's signature.
Again, this isn't a dealbreaker, and I think it's still an option, but
it would be a lot of churn, and it didn't seem necessary for now. Doing
it this way, at least to start with, felt like it would create a diff
that's easier to review and felt like it would create fewer merge
conflicts for others.
## Test Plan
- Added a regression mdtest for
https://github.com/astral-sh/ruff/issues/17058
- Ran `QUICKCHECK_TESTS=1000000 cargo test --release -p
red_knot_python_semantic -- --ignored types::property_tests::stable`
## Summary
Add an initial set of tests that will eventually document our behavior
around unreachable code. In the last section of this suite, I argue why
we should never type check unreachable sections and never emit any
diagnostics in these sections.
## Summary
Following up the discussion in
https://github.com/astral-sh/ruff/issues/14626#issuecomment-2766548545,
we're to reorganize airflow rules. Before this discussion happens, we
combine required changes and suggested changes in to one single error
code.
This PR first rename the original error code to the new error code as we
discussed. We will gradually extract suggested changes out of AIR301 and
AIR302 to AIR311 and AIR312 in the following PRs
## Test Plan
Except for file, error code rename, the test case should work as it used
to be.
I initially split the lifetime out into three distinct lifetimes on
near-instinct because I moved the struct into the public API. But
because they are all shared borrows, and because there are no other APIs
on `DisplayDiagnostic` to access individual fields (and probably never
will be), it's probably fine to just specify one lifetime. Because of
subtyping, the one lifetime will be the shorter of the three.
There's also the point that `ruff_db` isn't _really_ a public API, since
it isn't a library that others depend on. So my instinct is probably a
bit off there.
## Summary
With this PR, we emit a diagnostic for this case where
previously didn't:
```py
from typing import Literal
def f(m: int, n: Literal[-1, 0, 1]):
# error: [division-by-zero] "Cannot divide object of type `int` by zero"
return m / n
```
## Test Plan
New Markdown test
## Summary
Add autofix infrastructure to `AIR302` name checks and use this logic to
fix`"airflow", "api_connexion", "security", "requires_access_dataset"`, `"airflow", "Dataset"` and `"airflow",
"datasets", "Dataset"`
## Test Plan
The existing test fixture reflects the update
## Summary
Closes#17112. Allows passing in string and list-of-strings literals
into `subprocess.run` (and related) calls without marking them as
untrusted input:
```py
import subprocess
subprocess.run("true")
# "instant" named expressions are also allowed
subprocess.run(c := "ls")
```
## Test Plan
Added test cases covering new behavior, passed with `cargo nextest run`.
## Summary
* ``airflow.auth.managers.base_auth_manager.is_authorized_dataset`` has
been moved to
``airflow.api_fastapi.auth.managers.base_auth_manager.is_authorized_asset``
in Airflow 3.0
* ``airflow.auth.managers.models.resource_details.DatasetDetails`` has
been moved to
``airflow.api_fastapi.auth.managers.models.resource_details.AssetDetails``
in Airflow 3.0
* Dag arguments `default_view` and `orientation` has been removed in
Airflow 3.0
* `airflow.models.baseoperatorlink.BaseOperatorLink` has been moved to
`airflow.sdk.definitions.baseoperatorlink.BaseOperatorLink` in Airflow
3.0
* ``airflow.notifications.basenotifier.BaseNotifier`` has been moved to
``airflow.sdk.BaseNotifier`` in Airflow 3.0
* ``airflow.utils.log.secrets_masker`` has been moved to
``airflow.sdk.execution_time.secrets_masker`` in Airflow 3.0
* ``airflow...DAG.allow_future_exec_dates`` has been removed in Airflow
3.0
* `airflow.utils.db.create_session` has een removed in Airflow 3.0
* `airflow.sensors.base_sensor_operator.BaseSensorOperator` has been
moved to `airflow.sdk.bases.sensor.BaseSensorOperator` removed Airflow
3.0
* `airflow.utils.file.TemporaryDirectory` has been removed in Airflow
3.0 and can be replaced by `tempfile.TemporaryDirectory`
* `airflow.utils.file.mkdirs` has been removed in Airflow 3.0 and can be
replaced by `pathlib.Path({path}).mkdir`
## Test Plan
Test fixture has been added for these changes
## Summary
Unlike other AIR3XX rules, this best practice can be applied to Airflow
1 and Airflow 2 as well. Thus, we think it might make sense for use to
move it to AIR002 so that the first number of the error align to Airflow
version as possible to reduce confusion
## Test Plan
the test fixture has been updated
It was already using this approach internally, so this is "just" a
matter of rejiggering the public API of `Diagnostic`.
We were previously writing directly to a `std::io::Write` since it was
thought that this worked better with the linear typing fakery. Namely,
it increased confidence that the diagnostic rendering was actually
written somewhere useful, instead of just being converted to a string
that could potentially get lost.
For reasons discussed in #17130, the linear type fakery was removed.
And so there is less of a reason to require a `std::io::Write`
implementation for diagnostic rendering. Indeed, this would sometimes
result in `unwrap()` calls when one wants to convert to a `String`.
## Summary
This PR adds Goto type definition to the playground, using the same
infrastructure as the LSP.
The main *challenge* with implementing this feature was that the editor
can now participate in which tab is open.
## Known limitations
The same as for the LSP. Most notably, navigating to types defined in
typeshed isn't supported.
## Test Plan
https://github.com/user-attachments/assets/22dad7c8-7ac7-463f-b066-5d5b2c45d1fe
This just adds an extra blank line. I think these tests were written
against the new renderer before it was used by Red Knot's `main`
function. Once I did that, I saw that it was missing a blank line, and
so I added it to match the status quo. But that means these snapshots
have become stale. So this commit updates them.
I put this in its own commit in case all of the information removed here
was controversial. But it *looks* stale to me. At the very least,
`TypeCheckDiagnostic` no longer exists, so that would need to be fixed.
And it doesn't really make sense to me (at this point) to make
`Diagnostic` a Salsa struct, particularly since we are keen on using it
in Ruff (at some point).
We do keep around `OldSecondaryDiagnosticMessage`, since that's part of
the Red Knot `InferContext` API. But it's a rather simple type, and
we'll be able to delete it entirely once `InferContext` exposes the new
`Diagnostic` type directly.
Since we aren't consuming `OldSecondaryDiagnosticMessage` any more, we
can now accept a slice instead of a vec. (Thanks Clippy.)
This replaces things like `TypeCheckDiagnostic` with the new Diagnostic`
type.
This is a "surgical" replacement where we retain the existing API of
of diagnostic reporting such that _most_ of Red Knot doesn't need to be
changed to support this update. But it will enable us to start using the
new diagnostic renderer and to delete the old renderer. It also paves
the path for exposing the new `Diagnostic` data model to the broader Red
Knot codebase.
Previously, this was only available in the old renderer.
To avoid regressions, we just copy it to the new renderer.
We don't bother with DRY because the old renderer will be
deleted very soon.
Now that we don't need to update the `printed` flag, this can just be an
immutable borrow.
(Arguably this should have been an immutable borrow even initially, but
I didn't want to introduce interior mutability without a more compelling
justification.)
The switch to `Arc` was done because Salsa sometimes requires cloning a
`Diagnostic` (or something that contains a `Diagnostic`). And so it
probably makes sense to make this cheap.
Since `Diagnostic` exposes a mutable API, we adopt "clone on write"
semantics. Although, it's more like, "clone on write when the `Arc` has
more than one reference." In the common case of creating a `Diagnostic`
and then immediately mutating it, no additional copies should be made
over the status quo.
We also drop the linear type fakery. Its interaction with Salsa is
somewhat awkward, and it has been suggested that there will be points
where diagnostics will be dropped unceremoniously without an opportunity
to tag them as having been ignored. Moreover, this machinery was added
out of "good sense" and isn't actually motivated by real world problems
with accidentally ignoring diagnostics. So that makes it easier, I
think, to just kick this out entirely instead of trying to find a way to
make it work.
This is temporary to scaffold the refactor.
The main idea is that we want to take the `InferContext` API,
*as it is*, and migrate that to the new diagnostic data model
*internally*. Then we can rip out the old stuff and iterate
on the API.
I did this mostly because it wasn't buying us much, and I'm
trying to simplify the public API of the types I'd like to
refactor in order to make the refactor simpler.
If we really want something like this, we can re-add it
later.
I removed this to see how much code was depending internally on the
`&[Arc<TypeCheckDiagnostic>]` representation. Thankfully, it was just
one place. So I just removed the `Deref` impl in favor of adding an
explicit `iter` method.
In general, I think using `Deref` for things like this is _somewhat_ of
an abuse. The tip-off is if there are `&self` or `&mut self` methods on
the type, then it's probably not a good candidate for `Deref`.
Summary
--
This PR reimplements
[load-before-global-declaration
(PLE0118)](https://docs.astral.sh/ruff/rules/load-before-global-declaration/)
as a semantic syntax error.
I added a `global` method to the `SemanticSyntaxContext` trait to make
this very easy, at least in ruff. Does red-knot have something similar?
If this approach will also work in red-knot, I think some of the other
PLE rules are also compile-time errors in CPython, PLE0117 in
particular. 0115 and 0116 also mention `SyntaxError`s in their docs, but
I haven't confirmed them in the REPL yet.
Test Plan
--
Existing linter tests for PLE0118. I think this actually can't be tested
very easily in an inline test because the `TestContext` doesn't have a
real way to track globals.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Summary
--
Fixes https://github.com/astral-sh/ruff/issues/16520 by flagging single,
starred expressions in `return`, `yield`, and
`for` statements.
I thought `yield from` would also be included here, but that error is
emitted by
the CPython parser:
```pycon
>>> ast.parse("def f(): yield from *x")
Traceback (most recent call last):
File "<python-input-214>", line 1, in <module>
ast.parse("def f(): yield from *x")
~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.13/ast.py", line 54, in parse
return compile(source, filename, mode, flags,
_feature_version=feature_version, optimize=optimize)
File "<unknown>", line 1
def f(): yield from *x
^
SyntaxError: invalid syntax
```
And we also already catch it in our parser.
Test Plan
--
New inline tests and updates to existing tests.
## Summary
Implement basic *Goto type definition* support for Red Knot's LSP.
This PR also builds the foundation for other LSP operations. E.g., Goto
definition, hover, etc., should be able to reuse some, if not most,
logic introduced in this PR.
The basic steps of resolving the type definitions are:
1. Find the closest token for the cursor offset. This is a bit more
subtle than I first anticipated because the cursor could be positioned
right between the callee and the `(` in `call(test)`, in which case we
want to resolve the type for `call`.
2. Find the node with the minimal range that fully encloses the token
found in 1. I somewhat suspect that 1 and 2 could be done at the same
time but it complicated things because we also need to compute the spine
(ancestor chain) for the node and there's no guarantee that the found
nodes have the same ancestors
3. Reduce the node found in 2. to a node that is a valid goto target.
This may require traversing upwards to e.g. find the closest expression.
4. Resolve the type for the goto target
5. Resolve the location for the type, return it to the LSP
## Design decisions
The current implementation navigates to the inferred type. I think this
is what we want because it means that it correctly accounts for
narrowing (in which case we want to go to the narrowed type because
that's the value's type at the given position). However, it does have
the downside that Goto type definition doesn't work whenever we infer `T
& Unknown` because intersection types aren't supported. I'm not sure
what to do about this specific case, other than maybe ignoring `Unkown`
in Goto type definition if the type is an intersection?
## Known limitations
* Types defined in the vendored typeshed aren't supported because the
client can't open files from the red knot binary (we can either
implement our own file protocol and handler OR extract the typeshed
files and point there). See
https://github.com/astral-sh/ruff/issues/17041
* Red Knot only exposes an API to get types for expressions and
definitions. However, there are many other nodes with identifiers that
can have a type (e.g. go to type of a globals statement, match patterns,
...). We can add support for those in separate PRs (after we figure out
how to query the types from the semantic model). See
https://github.com/astral-sh/ruff/issues/17113
* We should have a higher-level API for the LSP that doesn't directly
call semantic queries. I intentionally decided not to design that API
just yet.
## Test plan
https://github.com/user-attachments/assets/fa077297-a42d-4ec8-b71f-90c0802b4edb
Goto type definition on a union
<img width="1215" alt="Screenshot 2025-04-01 at 13 02 55"
src="https://github.com/user-attachments/assets/689cabcc-4a86-4a18-b14a-c56f56868085"
/>
Note: I recorded this using a custom typeshed path so that navigating to
builtins works.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
from https://github.com/astral-sh/ruff/pull/17034#discussion_r2024222525
This is a simple PR to fix the invalid behavior of `NotImplemented` on
Python >=3.10.
## Test Plan
I think it would be better if we could run mdtest across multiple Python
versions in GitHub Actions.
<!-- How was it tested? -->
---------
Co-authored-by: David Peter <sharkdp@users.noreply.github.com>
## Summary
Add support for decorators on function as well as support
for properties by adding special handling for `@property` and `@<name of
property>.setter`/`.getter` decorators.
closes https://github.com/astral-sh/ruff/issues/16987
## Ecosystem results
- ✔️ A lot of false positives are fixed by our new
understanding of properties
- 🔴 A bunch of new false positives (typically
`possibly-unbound-attribute` or `invalid-argument-type`) occur because
we currently do not perform type narrowing on attributes. And with the
new understanding of properties, this becomes even more relevant. In
many cases, the narrowing occurs through an assertion, so this is also
something that we need to implement to get rid of these false positives.
- 🔴 A few new false positives occur because we do not
understand generics, and therefore some calls to custom setters fail.
- 🔴 Similarly, some false positives occur because we do not
understand protocols yet.
- ✔️ Seems like a true positive to me. [The
setter](e624d8edfa/src/packaging/specifiers.py (L752-L754))
only accepts `bools`, but `None` is assigned in [this
line](e624d8edfa/tests/test_specifiers.py (L688)).
```
+ error[lint:invalid-assignment]
/tmp/mypy_primer/projects/packaging/tests/test_specifiers.py:688:9:
Invalid assignment to data descriptor attribute `prereleases` on type
`SpecifierSet` with custom `__set__` method
```
- ✔️ This is arguable also a true positive. The setter
[here](0c6c75644f/rich/table.py (L359-L363))
returns `Table`, but typeshed wants [setters to return
`None`](bf8d2a9912/stdlib/builtins.pyi (L1298)).
```
+ error[lint:invalid-argument-type]
/tmp/mypy_primer/projects/rich/rich/table.py:359:5: Object of type
`Literal[padding]` cannot be assigned to parameter 2 (`fset`) of bound
method `setter`; expected type `(Any, Any, /) -> None`
```
## Follow ups
- Fix the `@no_type_check` regression
- Implement class decorators
## Test Plan
New Markdown test suites for decorators and properties.
## Summary
Adds import `numpy.typing as npt` to `default in
flake8-import-conventions.aliases`
Resolves#17028
## Test Plan
Manually ran local ruff on the altered fixture and also ran `cargo test`
## Summary
Part of #15382, this PR adds property tests for callable types.
Specifically, this PR updates the property tests to generate an
arbitrary signature for a general callable type which includes:
* Arbitrary combination of parameter kinds in the correct order
* Arbitrary number of parameters
* Arbitrary optional types for annotation and return type
* Arbitrary parameter names (no duplicate names), optional for
positional-only parameters
## Test Plan
```
QUICKCHECK_TESTS=100000 cargo test -p red_knot_python_semantic -- --ignored types::property_tests::stable
```
Also, the commands in CI:
d72b4100a3/.github/workflows/daily_property_tests.yaml (L47-L52)
## Summary
Part of #15382, this PR adds support for disjointness between two
callable types. They are never disjoint because there exists a callable
type that's a subtype of all other callable types:
```py
(*args: object, **kwargs: object) -> Never
```
The `Never` is a subtype of every fully static type thus a callable type
that has the return type of `Never` means that it is a subtype of every
return type.
## Test Plan
Add test cases related to mixed parameter kinds, gradual form (`...`)
and `Never` type.
## Summary
Currently our `Type::Callable` wraps a four-variant `CallableType` enum.
But as time has gone on, I think we've found that the four variants in
`CallableType` are really more different to each other than they are
similar to each other:
- `GeneralCallableType` is a structural type describing all callable
types with a certain signature, but the other three types are "literal
types", more similar to the `FunctionLiteral` variant
- `GeneralCallableType` is not a singleton or a single-valued type, but
the other three are all single-valued types
(`WrapperDescriptorDunderGet` is even a singleton type)
- `GeneralCallableType` has (or should have) ambiguous truthiness, but
all possible inhabitants of the other three types are always truthy.
- As a structural type, `GeneralCallableType` can contain inner unions
and intersections that must be sorted in some contexts in our internal
model, but this is not true for the other three variants.
This PR flattens `Type::Callable` into four distinct `Type::` variants.
In the process, it fixes a number of latent bugs that were concealed by
the current architecture but are laid bare by the refactor. Unit tests
for these bugs are included in the PR.
## Summary
Currently if I run `uv run crates/red_knot_python_semantic/mdtest.py`
from the Ruff repo root, I get this output:
```
~/dev/ruff (main)⚡ % uv run crates/red_knot_python_semantic/mdtest.py
Ready to watch for changes...
```
...And I then have to make some spurious whitespace changes or something
to a test file in order to get the script to actually run mdtest. This
PR changes mdtest.py so that it does an initial run of all mdtests when
you invoke the script, and _then_ starts watching for changes in test
files/Rust code.
## Summary
This PR fixes a bug in callable subtyping to consider both the
positional and keyword form of the standard parameter in the supertype
when matching against variadic, keyword-only and keyword-variadic
parameter in the subtype.
This is done by collecting the unmatched standard parameters and then
checking them against the keyword-only / keyword-variadic parameters
after the positional loop.
## Test Plan
Add test cases.
## Summary
There are quite a few places we infer `Todo` types currently, and some
of them are nested somewhat deeply in type expressions. These can cause
spurious issues for the new `redundant-cast` diagnostics. We fixed all
the false positives we saw in the mypy_primer report before merging
https://github.com/astral-sh/ruff/pull/17100, but I think there are
still lots of places where we'd emit false positives due to this check
-- we currently don't run on that many projects at all in our
mypy_primer check:
d0c8eaa092/.github/workflows/mypy_primer.yaml (L71)
This PR fixes some more false positives from this diagnostic by making
the `Type::contains_todo()` method more expansive.
## Test Plan
I added a regression test which causes us to emit a spurious diagnostic
on `main`, but does not with this PR.
## Summary
In https://github.com/python/typeshed/pull/13520 the typeshed definition
of `typing.Any` was changed from `Any = object()` to `class Any: ...`.
Our automated typeshed updater pulled down this change in
https://github.com/astral-sh/ruff/pull/17106, with the consequence that
we no longer understand `Any`, which is... not good.
This PR gives us the ability to understand `Any` defined as a class
instead of `object()`. It doesn't remove our ability to understand the
old form. Perhaps at some point we'll want to remove it, but for now we
may as well support both old and new typeshed?
This also directly patches typeshed to use the new form of `Any`; this
is purely to work around our tests that no known class is inferred as
`Unknown`, which otherwise fail with the old typeshed and the changes in
this PR. (All other tests pass.) This patch to typeshed will shortly be
subsumed by https://github.com/astral-sh/ruff/pull/17106 anyway.
## Test Plan
Without the typeshed change in this PR, all tests pass except for the
two `known_class_doesnt_fallback_to_unknown_unexpectedly_*` tests (so we
still support the old form of defining `Any`). With the typeshed change
in this PR, all tests pass, so we now support the new form in a way that
is indistinguishable to our test suite from the old form. And
indistinguishable to the ecosystem check: after rebasing
https://github.com/astral-sh/ruff/pull/17106 on this PR, there's zero
ecosystem impact.
## Summary
I don't remember exactly when we made `Identifier` a node but it is now
considered a node (it implements `AnyNodeRef`, it has a range). However,
we never updated
the `SourceOrderVisitor` to visit identifiers because we never had a use
case for it and visiting new nodes can change how the formatter
associates comments (breaking change!).
This PR updates the `SourceOrderVisitor` to visit identifiers and
changes the formatter comment visitor to skip identifiers (updating the
visitor might be desired because it could help simplifying some comment
placement logic but this is out of scope for this PR).
## Test Plan
Tests, updated snapshot tests
## Summary
I noticed we were inferring `Todo` as the declared type for annotations
such as `x: tuple[list[int], list[int]]`. This PR reworks our annotation
parsing so that we instead infer `tuple[Todo, Todo]` for this
annotation, which is quite a bit more precise.
## Test Plan
Existing mdtest updated.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
Closes#16903
## Summary
Check if the current working directory exist. If not, provide an error
instead of panicking.
Fixed a stale comment in `resolve_default_files`.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
I added a test to the `resolve_files.rs`.
Manual testing follows steps of #16903 :
- Terminal 1
```bash
mkdir tmp
cd tmp
```
- Terminal 2
```bash
rm -rf tmp
```
- Terminal 1
```bash
ruff check
```
## Open Issues / Questions to Reviewer
All tests pass when executed with `cargo nextest run`.
However, with `cargo test` the parallelization makes the other tests
fail as we change the `pwd`.
Serial execution with `cargo test` seems to require [another dependency
or some
workarounds](https://stackoverflow.com/questions/51694017/how-can-i-avoid-running-some-tests-in-parallel).
Do you think an additional dependency or test complexity is worth
testing this small edge case, do you have another implementation idea,
or should i rather remove the test?
---
P.S.: I'm currently participating in a batch at the [Recurse
Center](https://www.recurse.com/) and would love to contribute more for
the next six weeks to improve my Rust. Let me know if you're open to
mentoring/reviewing and/or if you have specific areas where help would
be most valued.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
This PR contains the scaffolding for a new control flow graph
implementation, along with its application to the `unreachable` rule. At
the moment, the implementation is a maximal over-approximation: no
control flow is modeled and all statements are counted as reachable.
With each additional statement type we support, this approximation will
improve.
So this PR just contains:
- A `ControlFlowGraph` struct and builder
- Support for printing the flow graph as a Mermaid graph
- Snapshot tests for the actual graphs
- (a very bad!) reimplementation of `unreachable` using the new structs
- Snapshot tests for `unreachable`
# Instructions for Viewing Mermaid snapshots
Unfortunately I don't know how to convince GitHub to render the Mermaid
graphs in the snapshots. However, you can view these locally in VSCode
if you install an extension that supports Mermaid graphs in Markdown,
and then add this to your `settings.json`:
```json
"files.associations": {
"*.md.snap": "markdown",
}
```
## Summary
A few smaller editor improvements that felt worth pulling out of my
other feature PRs:
* Load the `Editor` lazily: This allows splitting the entire monaco
javascript into a separate async bundle, drastically reducing the size
of the `index.js`
* Fix the name of `to_range` and `text_range` to the more idiomatic js
names `toRange` and `textRange`
* Use one indexed values for `Position::line` and `Position::column`,
which is the same as monaco (reduces the need for `+1` and `-1`
operations spread all over the place)
* Preserve the editor state when navigating between tabs. This ensures
that selections are preserved even when switching between tabs.
* Stop the default handling of the `Enter` key press event when renaming
a file because it resulted in adding a newline in the editor
## Summary
This PR adds a new but so far empty and unused `red_knot_ide` crate.
This new crate's purpose is to implement IDE-specific functionality,
such as go to definition, hover, completion, etc., which are used by
both the LSP and the playground.
The crate itself doesn't depend on `lsptypes`. The idea is that the
facade crates (e.g., `red_knot_server`) convert external to internal
types.
Not only allows this to share the logic between server and playground,
it also ensures that the core functionality is easier to test because it
can be tested without needing a full LSP.
## Test Plan
`cargo build`
## Summary
Following up from earlier discussion on Discord, this PR adds logic to
flag casts as redundant when the inferred type of the expression is the
same as the target type. It should follow the semantics from
[mypy](https://github.com/python/mypy/pull/1705).
Example:
```python
def f() -> int:
return 10
# error: [redundant-cast] "Value is already of type `int`"
cast(int, f())
```
## Summary
Part of #13694
Seems there a bit more to cover regarding `in` and other types, but i
can cover them in different PRs
## Test Plan
Add `in.md` file in narrowing conditionals folder
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Rewrites the virtual env discovery to:
* Only use of `System` APIs, this ensures that the discovery will also
work when using a memory file system (testing or WASM)
* Don't traverse ancestor directories. We're not convinced that this is
necessary. Let's wait until someone shows us a use case where it is
needed
* Start from the project root and not from the current working
directory. This ensures that Red Knot picks up the right venv even when
using `knot --project ../other-dir`
## Test Plan
Existing tests, @ntBre tested that the `file_watching` tests no longer
pick up his virtual env in a parent directory
## Summary
In preparation for #17017, where we will need them to suppress new false
positives (once we understand the `ParamSpec.args`/`ParamSpec.kwargs`
properties).
## Test Plan
Tested on branch #17017
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
* Combine AIR302 matches
* Found a few errors. Will be fixed in another PR
## Test Plan
<!-- How was it tested? -->
This PR does not change anything. The existing testing fixture should
work as it used to be
## Summary
Disallow empty `todo_type!()`s without a custom message. They can lead
to spurious diffs in `mypy_primer` where the only thing that's changed
is the file/line information.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
* The following paths are wrong
* `airflow.providers.amazon.auth_manager.avp.entities` should be
`airflow.providers.amazon.aws.auth_manager.avp.entities`
* `["airflow", "datasets", "manager", "dataset_manager"]` should be
fixed as `airflow.assets.manager` but not
`airflow.assets.manager.asset_manager`
* `["airflow", "datasets.manager", "DatasetManager"]` should be `
["airflow", "datasets", "manager", "DatasetManager"]` instead
## Test Plan
<!-- How was it tested? -->
the test fixture is updated accordingly
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Improve AIR302 test cases
## Test Plan
<!-- How was it tested? -->
test fixtures have been updated accordingly
## Summary
A quick fix for how union/intersection member search ins performed in
Knot.
## Test Plan
* Added a dunder method call test for Union, which exhibits the error
* Also added an intersection error, but it is not triggering currently
due to `call` logic not being fully implemented for intersections.
---------
Co-authored-by: David Peter <mail@david-peter.de>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [clap](https://redirect.github.com/clap-rs/clap) |
workspace.dependencies | patch | `4.5.32` -> `4.5.34` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>clap-rs/clap (clap)</summary>
###
[`v4.5.34`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4534---2025-03-27)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.33...v4.5.34)
##### Fixes
- *(help)* Don't add extra blank lines with `flatten_help(true)` and
subcommands without arguments
###
[`v4.5.33`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4533---2025-03-26)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.32...v4.5.33)
##### Fixes
- *(error)* When showing the usage of a suggestion for an unknown
argument, don't show the group
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[actions/setup-python](https://redirect.github.com/actions/setup-python)
| action | digest | `4237552` -> `8d9ed9a` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [astral-sh/setup-uv](https://redirect.github.com/astral-sh/setup-uv) |
action | digest | `2269511` -> `0c5e2b8` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[taiki-e/install-action](https://redirect.github.com/taiki-e/install-action)
| action | digest | `914ac1e` -> `6aca1cf` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[webfactory/ssh-agent](https://redirect.github.com/webfactory/ssh-agent)
| action | patch | `v0.9.0` -> `v0.9.1` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>webfactory/ssh-agent (webfactory/ssh-agent)</summary>
###
[`v0.9.1`](https://redirect.github.com/webfactory/ssh-agent/blob/HEAD/CHANGELOG.md#v091-2024-03-17)
[Compare
Source](https://redirect.github.com/webfactory/ssh-agent/compare/v0.9.0...v0.9.1)
##### Fixed
- Fix path used to execute ssh-agent in cleanup.js to respect custom
paths set by input
([#​235](https://redirect.github.com/webfactory/ssh-agent/issues/235))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
Closes#16661
This PR includes two changes:
- `NotImplementedType` is now a member of `KnownClass`
- We skip `is_assignable_to` checks for `NotImplemented` when checking
return types
### Limitation
```py
def f(cond: bool) -> int:
return 1 if cond else NotImplemented
```
The implementation covers cases where `NotImplemented` appears inside a
`Union`.
However, for more complex types (ex. `Intersection`) it will not worked.
In my opinion, supporting such complexity is unnecessary at this point.
## Test Plan
Two `mdtest` files were updated:
- `mdtest/function/return_type.md`
- `mdtest/type_properties/is_singleton.md`
To test `KnownClass`, run:
```bash
cargo test -p red_knot_python_semantic -- types::class::
```
Summary
--
Detects starred assignment targets outside of tuples and lists like `*a
= (1,)`.
This PR only considers assignment statements. I also checked annotated
assigment statements, but these give a separate error that we already
catch, so I think they're okay not to consider:
```pycon
>>> *a: list[int] = []
File "<python-input-72>", line 1
*a: list[int] = []
^
SyntaxError: invalid syntax
```
Fixes#13759
Test Plan
--
New inline tests, plus a new `SemanticSyntaxError` for an existing
parser test. I also removed a now-invalid case from an otherwise-valid
test fixture.
The new semantic error leads to two errors for the case below:
```python
*foo() = 42
```
but this matches [pyright] too.
[pyright]: https://pyright-play.net/?code=FQMw9mAUCUAEC8sAsAmAUEA
Summary
--
Detect setting or deleting `__debug__`. Assigning to `__debug__` was a
`SyntaxError` on the earliest version I tested (3.8). Deleting
`__debug__` was made a `SyntaxError` in [BPO 45000], which said it was
resolved in Python 3.10. However, `del __debug__` was also a runtime
error (`NameError`) when I tested in Python 3.9.6, so I thought it was
worth including 3.9 in this check.
I don't think it was ever a *good* idea to try `del __debug__`, so I
think there's also an argument for not making this version-dependent at
all. That would only simplify the implementation very slightly, though.
[BPO 45000]: https://github.com/python/cpython/issues/89163
Test Plan
--
New inline tests. This also required adding a `PythonVersion` field to
the `TestContext` that could be taken from the inline `ParseOptions` and
making the version field on the options accessible.
Following
29573daef5,
it doesn't look to me like any of the pre-commit hooks run in CI here
are Rust-based:
- `cargo fmt` is Rust-based but it's explicitly skipped as part of this
job and run as a separate CI job:
93052331b0/.pre-commit-config.yaml (L124-L125)
- The `typos` hook is Rust-based, but according to
https://github.com/crate-ci/typos/blob/master/docs/pre-commit.md
pre-commit should install a built binary rather than building the binary
from source
As such, I think this step in the workflow is just taking up 15s of CI
time and not actually speeding up pre-commit at all
## Summary
This PR adds `as_<group>` methods to `AnyNodeRef` to e.g. convert an
`AnyNodeRef` to an `ExprRef`.
I need this for go to definition where the fallback is to test if
`AnyNodeRef` is an expression and then call `inferred_type` (listing
this mapping at every call site where we need to convert `AnyNodeRef` to
an `ExprRef` is a bit painful ;))
Split out from https://github.com/astral-sh/ruff/pull/16901
## Test Plan
`cargo test`
## Summary
We renamed the `PreorderVisitor` to `SourceOrderVisitor` a long time ago
but it seems that we missed to rename the `visit_preorder` functions to
`visit_source_order`.
This PR renames `visit_preorder` to `visit_source_order`
## Test Plan
`cargo test`
## Summary
This PR refactors the common logic for unpacking in assignment, for loops, and with items.
## Test Plan
Make sure existing tests pass.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#16744
Code from
bbf4f830b5/crates/uv-python/src/virtualenv.rs (L124-L144)
## Test Plan
Manual testing
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
From #16861, and the continuation of #16915.
This PR fixes the incorrect behavior of
`TypeInferenceBuilder::infer_name_load` in eager nested scopes.
And this PR closes#16341.
## Test Plan
New test cases are added in `annotations/deferred.md`.
## Summary
Part of #13694
Narrow in or-patterns by taking the type union of the type constraints
in each disjunct pattern.
## Test Plan
Add new tests to narrow/match.md
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Move the mypy_primer build to the depot runners to speed them up.
## Test Plan
Previous run of mypy_primer: 3m 49s
Run on this branch: 1m 38s
## Summary
Use a debug build instead of a release build in order to speed up
mypy_primer runs.
## Test Plan
Previous mypy_primer run: 5m 45s
mypy_primer run on this branch: 3m 49s
## Summary
Part of #13694
The implementation here was suspiciously straightforward so please lmk
if I missed something
Also some drive-by changes to DRY things up a bit
## Test Plan
Add new tests to narrow/match.md
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This PR adds some branches so that we infer `Todo` types for attribute
access on instances of `super()` and subtypes of `type[Enum]`. It reduces
false positives in the short term until we implement full support for
these features.
## Test Plan
New mdtests added + mypy_primer report
This is a well-typed codebase on which we only emit 23 diagnostics right
now, but which is highlighting some interesting issues. It uses some
modern syntactic features such as `match` statements that aren't used
much in other open-source projects in mypy_primer
## Summary
Fixes https://github.com/astral-sh/ruff/issues/17018
## Test Plan
I renamed a python file to `knot.toml` and verified that there are no
diagnostics. Renaming back the file to `*.py` brings back the
diagnostics
Monaco supports inferring the language based on the file's extension but
it doesn't seem to support `pyi`. I tried to patch up the python
language definition by adding `.pyi` to the language's `extension` array
but that didn't work. That's why I decided to patch up the language in
React.
## Summary
Capture both `stdout` and `stderr` in a single stream. This fixes
`reveal_type`, which prints to `stderr` by default.
## Test Plan
Tested with a simple `reveal_type(1)` example and got the output:
```
Runtime value is '1'
Runtime type is 'int'
```
## Summary
Resolves#16950 and [a 1.5-year-old TODO
comment](8d16a5c8c9/crates/ruff/src/diagnostics.rs (L380)).
After this change, a `pyproject.toml` will be linted the same as any
Python files would when passed via stdin.
## Test Plan
Integration tests.
## Summary
Mainly for partially fixing #16953
## Test Plan
Update is_subtype tests. And should maybe do these checks for many other
types (is subtype of object but object is not subtype)
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
Return the revealed-type from the monkey-patched `revale_type`
implementation to
preserve the identity behavior.
This PR also isolates different script runs by assigning a different
`globals` dict for each script-run. See
https://github.com/pyodide/pyodide/issues/703
Summary
--
This PR detects multiple assignments to the same name in `case` patterns
by recursively visiting each pattern.
Test Plan
--
New inline tests.
Summary
--
Detects irrefutable `match` cases before the final case using a modified
version
of the existing `Pattern::is_irrefutable` method from the AST crate. The
modified method helps to retrieve a more precise diagnostic range to
match what
Python 3.13 shows in the REPL.
Test Plan
--
New inline tests, as well as some updates to existing tests that had
irrefutable
patterns before the last block.
## Summary
`std::time::now` isn't available on `wasm32-unknown-unknown` but it is
used by `FileTime::now`.
This PR replaces the usages of `FileTime::now` with a target specific
helper function that we already had in the memory file system.
Fixes https://github.com/astral-sh/ruff/issues/16966
## Test Plan
Tested that the playground no longer crash when adding an extra-path
## Summary
Further work towards https://github.com/astral-sh/ruff/issues/14169.
We currently panic on encountering cyclic `*` imports. This is easily
fixed using fixpoint iteration.
## Test Plan
Added a test that panics on `main`, but passes with this PR
## Summary
As mentioned in
https://github.com/astral-sh/ruff/pull/16698#discussion_r2004920075,
part of #15382, this PR updates the `is_gradual_equivalent_to`
implementation between callable types to be similar to
`is_equivalent_to` and checks other attributes of parameters like name,
optionality, and parameter kind.
## Test Plan
Expand the existing test cases to consider other properties but not all
similar to how the tests are structured for subtyping and assignability.
## Summary
This PR adds initial support for `*` imports to red-knot. The approach
is to implement a standalone query, called from semantic indexing, that
visits the module referenced by the `*` import and collects all
global-scope public names that will be imported by the `*` import. The
`SemanticIndexBuilder` then adds separate definitions for each of these
names, all keyed to the same `ast::Alias` node that represents the `*`
import.
There are many pieces of `*`-import semantics that are still yet to be
done, even with this PR:
- This PR does not attempt to implement any of the semantics to do with
`__all__`. (If a module defines `__all__`, then only the symbols
included in `__all__` are imported, _not_ all public global-scope
symbols.
- With the logic implemented in this PR as it currently stands, we
sometimes incorrectly consider a symbol bound even though it is defined
in a branch that is statically known to be dead code, e.g. (assuming the
target Python version is set to 3.11):
```py
# a.py
import sys
if sys.version_info < (3, 10):
class Foo: ...
```
```py
# b.py
from a import *
print(Foo) # this is unbound at runtime on 3.11,
# but we currently consider it bound with the logic in this PR
```
Implementing these features is important, but is for now deferred to
followup PRs.
Many thanks to @ntBre, who contributed to this PR in a pairing session
on Friday!
## Test Plan
Assertions in existing mdtests are adjusted, and several new ones are
added.
## Summary
Default to 3.13 for good.
I incorrectly used `workspace.updateOptions` instead of `updateOptions`
where the latter has a fallback.
## Test Plan
```py
import os
import sys
reveal_type(sys.version_info.minor)
```
reveals 13 on initial page load
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [PyO3/maturin-action](https://redirect.github.com/PyO3/maturin-action)
| action | digest | `36db840` -> `22fe573` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
combine similar case condition in AIR302
## Test Plan
<!-- How was it tested? -->
nothing should be changed. existing test case should already cover it
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [astral-sh/setup-uv](https://redirect.github.com/astral-sh/setup-uv) |
action | digest | `f94ec6b` -> `2269511` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[taiki-e/install-action](https://redirect.github.com/taiki-e/install-action)
| action | digest | `2c41309` -> `914ac1e` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Summary
--
Fixes#16943 by checking if the tuple is not parenthesized before
emitting an error.
Test Plan
--
New inline test based on the initial report
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [actions/cache](https://redirect.github.com/actions/cache) | action |
digest | `d4323d4` -> `5a3ec84` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[actions/upload-artifact](https://redirect.github.com/actions/upload-artifact)
| action | digest | `4cec3d8` -> `ea165f8` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [tempfile](https://stebalien.com/projects/tempfile-rs/)
([source](https://redirect.github.com/Stebalien/tempfile)) |
workspace.dependencies | patch | `3.19.0` -> `3.19.1` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>Stebalien/tempfile (tempfile)</summary>
###
[`v3.19.1`](https://redirect.github.com/Stebalien/tempfile/blob/HEAD/CHANGELOG.md#3191)
[Compare
Source](https://redirect.github.com/Stebalien/tempfile/compare/v3.19.0...v3.19.1)
- Don't unlink temporary files immediately on Windows (fixes
[#​339](https://redirect.github.com/Stebalien/tempfile/issues/339)).
Unfortunately, this seemed to corrupt the file object (possibly a
Windows kernel bug) in rare cases and isn't strictly speaking necessary.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [mimalloc](https://redirect.github.com/purpleprotocol/mimalloc_rust) |
workspace.dependencies | patch | `0.1.43` -> `0.1.44` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>purpleprotocol/mimalloc_rust (mimalloc)</summary>
###
[`v0.1.44`](https://redirect.github.com/purpleprotocol/mimalloc_rust/releases/tag/v0.1.44):
Version 0.1.44
[Compare
Source](https://redirect.github.com/purpleprotocol/mimalloc_rust/compare/v0.1.43...v0.1.44)
##### Changes
- Mimalloc v2.2.2
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[actions/download-artifact](https://redirect.github.com/actions/download-artifact)
| action | digest | `cc20338` -> `95815c3` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [Swatinem/rust-cache](https://redirect.github.com/Swatinem/rust-cache)
| action | digest | `f0deed1` -> `9d47c6a` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjIwNy4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
Here I fix the last English spelling errors I could find in the repo.
Again, I am trying not to touch variable/function names, or anything
that might be misspelled in the API. The goal is to make this PR safe
and easy to merge.
## Test Plan
I have run all the unit tests. Though, again, all of the changes I make
here are to docs and docstrings. I make no code changes, which I believe
should greatly mitigate the testing concerns.
## Summary
Resolves#16895.
`abstractmethod` is now a `KnownFunction`. When a function is decorated
by `abstractmethod` or when the parent class inherits directly from
`Protocol`, `invalid-return-type` won't be emitted for that function.
## Test Plan
Markdown tests.
---------
Co-authored-by: Carl Meyer <carl@oddbird.net>
## Summary
Fixes#16912
Create a new type `DisplayMaybeParenthesizedType` that is now used in
Union and Intersection display
## Test Plan
Update callable annotations
## Summary
From #16861
This PR fixes the incorrect `ClassDef` handling of
`SemanticIndexBuilder::visit_stmt`, which fixes some of the incorrect
behavior of referencing the class itself in the class scope (a complete
fix requires a different fix, which will be done in the another PR).
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
This is a cleanup PR. I am fixing various English language spelling
errors. This is mostly in docs and docstrings.
## Test Plan
The usual CI tests were run. I tried to build the docs (though I had
some troubles there). The testing needs here are, I trust, very low
impact. (Though I would happily test more.)
## Summary
Log the origin of the sys path prefix. This should help with debugging
if someone doesn't understand
why Red Knot picks up a certain venv.
## Test Plan
Ran the CLI and tested that it logs the origin
## Summary
Part of #15382, this PR adds support for calling a variable that's
annotated with `typing.Callable`.
## Test Plan
Add test cases in a new `call/annotation.md` file.
## Summary
Part of #15382
This PR adds support for checking the assignability of two general
callable types.
This is built on top of #16804 by including the gradual parameters check
and accepting a function that performs the check between the two types.
## Test Plan
Update `is_assignable_to.md` with callable types section.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
When callables are displayed in unions, like:
```py
from typing import Callable
def foo(x: Callable[[], int] | None):
# red-knot: Revealed type is `() -> int | None` [revealed-type]
reveal_type(x)
```
This leaves the type rather ambiguous, to fix this we can add
parenthesis to callable type in union
Fixes#16893
## Test Plan
Update callable annotations tests
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes#16898
## Test Plan
Update test for lang mismatch panic
Summary
--
Detects duplicate type parameter names in function definitions, class
definitions, and type alias statements.
I also boxed the `type_params` field on `StmtTypeAlias` to make it
easier to
`match` with functions and classes. (That's the reason for the red-knot
code
owner review requests, sorry!)
Test Plan
--
New `ruff_python_syntax_errors` unit tests.
Fixes#11119.
## Summary
This PR implements the "greeter" approach for checking the AST for
syntax errors emitted by the CPython compiler. It introduces two main
infrastructural changes to support all of the compile-time errors:
1. Adds a new `semantic_errors` module to the parser crate with public
`SemanticSyntaxChecker` and `SemanticSyntaxError` types
2. Embeds a `SemanticSyntaxChecker` in the `ruff_linter::Checker` for
checking these errors in ruff
As a proof of concept, it also implements detection of two syntax
errors:
1. A reimplementation of
[`late-future-import`](https://docs.astral.sh/ruff/rules/late-future-import/)
(`F404`)
2. Detection of rebound comprehension iteration variables
(https://github.com/astral-sh/ruff/issues/14395)
## Test plan
Existing F404 tests, new inline tests in the `ruff_python_parser` crate,
and a linter CLI test showing an example of the `Message` output.
I also tested in VS Code, where `preview = false` and turning off syntax
errors both disable the new errors:

And on the playground, where `preview = false` also disables the errors:

Fixes#14395
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
I am one of the core developers of Airflow and working on the
"airflow.sdk"
package, and this updates the recommended replacments to the correct
user-facing imports.[^1]
cc @Lee-W @uranusjr
[^1]:
33f0f1d639/task-sdk/src/airflow/sdk/__init__.py (L68-L93)
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Hope and pray? 😉
I'm sure there are some snapshot files I'm supposed to fix first.
<!-- How was it tested? -->
## Summary
This PR removes false-positive diagnostics for `*` imports. Currently we
always emit a diagnostic for these statements unless the module we're
importing from has a symbol named `"*"` in its symbol table for the
global scope. (And if we were doing everything correctly, no module ever
would have a symbol named `"*"` in its global scope!)
The fix here is sort-of hacky and won't be what we'll want to do
long-term. However, I think it's useful to do this as a first step
since:
- It significantly reduces false positives when running on code that
uses `*` imports
- It "resets" the tests to a cleaner state with many fewer TODOs, making
it easier to see what the hard work is that's still to be done.
## Test Plan
`cargo test -p red_knot_python_semantic`
## Summary
This PR adds a suite of tests for wildcard (`*`) imports. The tests
nearly all fail for now, and those that don't, ahem, pass for the wrong
reasons...
I've tried to add TODO comments in all instances for places where we are
currently inferring the incorrect thing, incorrectly emitting a
diagnostic, or emitting a diagnostic with a bad error message.
## Test Plan
`cargo test -p red_knot_python_semantic`
This breaks up call binding into two phases:
- **_Matching parameters_** just looks at the names and kinds
(positional/keyword) of each formal and actual parameters, and matches
them up. Most of the current call binding errors happen during this
phase.
- Once we have matched up formal and actual parameters, we can **_infer
types_** of each actual parameter, and **_check_** that each one is
assignable to the corresponding formal parameter type.
As part of this, we add information to each formal parameter about
whether it is a type form or not. Once [PEP
747](https://peps.python.org/pep-0747/) is finalized, we can hook that
up to this internal type form representation. This replaces the
`ParameterExpectations` type, which did the same thing in a more ad hoc
way.
While we're here, we add a new fluent API for building `Parameter`s,
which makes our signature constructors a bit nicer to read. We also
eliminate a TODO where we were consuming types from the argument list
instead of the bound parameter list when evaluating our special-case
known functions.
Closes#15460
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This change continues to resolve#16071 (and continues the work started
in #16162). Specifically, this PR changes the code in the parser so that
it uses the `OperatorPrecedence` struct from `ruff_python_ast` instead
of its own version. This is part of an effort to get rid of the
redundant definitions of `OperatorPrecedence` throughout the codebase.
Note that this PR only makes this change for `ruff_python_parser` -- we
still want to make a similar change for the formatter (namely the
`OperatorPrecedence` defined in the expression part of the formatter,
the pattern one is different). I separated the work to keep the PRs
small and easily reviewable.
## Test Plan
Because this is an internal change, I didn't add any additional tests.
Existing tests do pass.
## Summary
Part of #15382
This PR adds support for checking the subtype relationship between the
two callable types.
The main source of reference used for implementation is
https://typing.python.org/en/latest/spec/callables.html#assignability-rules-for-callables.
The implementation is split into two phases:
1. Check all the positional parameters which includes positional-only,
standard (positional or keyword) and variadic kind
2. Collect all the keywords in a `HashMap` to do the keyword parameters
check via name lookup
For (1), there's a helper struct which is similar to `.zip_longest`
(from `itertools`) except that it allows control over one of the
iterator as that's required when processing a variadic parameter. This
is required because positional parameters needs to be checked as per
their position between the two callable types. The struct also keeps
track of the current iteration element because when the loop is exited
(to move on to the phase 2) the current iteration element would be
carried over to the phase 2 check.
This struct is internal to the `is_subtype_of` method as I don't think
it makes sense to expose it outside. It also allows me to use "self" and
"other" suffixed field names as that's only relevant in that context.
## Test Plan
Add extensive tests in markdown.
Converted all of the code snippets from
https://typing.python.org/en/latest/spec/callables.html#assignability-rules-for-callables
to use `knot_extensions.is_subtype_of` and verified the result.
## Summary
This PR checks whether two callable types are equivalent or not.
This is required because for an equivalence relationship, the default
value does not necessarily need to be the same but if the parameter in
one of the callable has a default value then the corresponding parameter
in the other callable should also have a default value. This is the main
reason a manual implementation is required.
And, as per https://typing.python.org/en/latest/spec/callables.html#id4,
the default _type_ doesn't participate in a subtype relationship, only
the optionality (required or not) participates. This means that the
following two callable types are equivalent:
```py
def f1(a: int = 1) -> None: ...
def f2(a: int = 2) -> None: ...
```
Additionally, the name of positional-only, variadic and keyword-variadic
are not required to be the same for an equivalence relation.
A potential solution to avoid the manual implementation would be to only
store whether a parameter has a default value or not but the type is
currently required to check for assignability.
## Test plan
Add tests for callable types in `is_equivalent_to.md`
## Summary
Catch some Instances, but raise type error for the rest of them
Fixes#16851
## Test Plan
Extend invalid.md in annotations
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Currently for something like `X = typing.Tuple[str, str]`, we infer the
value of `X` as `object`. That's because `Tuple` (like many of the
symbols in the typing module) is annotated as a `_SpecialForm` instance
in typeshed's stubs:
23382f5f8c/crates/red_knot_vendored/vendor/typeshed/stdlib/typing.pyi (L215)
and we don't understand implicit type aliases yet, and the stub for
`_SpecialForm.__getitem__` says it always returns `object`:
23382f5f8c/crates/red_knot_vendored/vendor/typeshed/stdlib/typing.pyi (L198-L200)
We have existing false positives in our test suite due to this:
23382f5f8c/crates/red_knot_python_semantic/resources/mdtest/annotations/annotated.md (L76-L78)
and it's causing _many_ new false positives in #16872, which tries to
make our annotation-expression parsing stricter in some ways.
This PR therefore adds some small special casing for `KnownInstanceType`
variants that fallback to `_SpecialForm`, so that these false positives
can be avoided.
## Test Plan
Existing mdtest altered.
Cc. @MatthewMckee4
Summary
--
Fixes#16874. I previously emitted a syntax error when starred
annotations were _allowed_ rather than when they were actually used.
This caused false positives for any starred parameter name because these
are allowed to have starred annotations but not required to. The fix is
to check if the annotation is actually starred after parsing it.
Test Plan
--
New inline parser tests derived from the initial report and more
examples from the comments, although I think the first case should cover
them all.
Summary
--
This updates the regex in `ruff-ecosystem` to catch syntax errors in an
effort to prevent bugs like #16874. This should catch `ParseError`s,
`UnsupportedSyntaxError`s, and the upcoming `SemanticSyntaxError`s.
Test Plan
--
I ran the ecosystem check locally comparing v0.11.0 and v0.11.1 and saw
a large number (2757!) of new syntax errors. I also manually tested the
regex on a few lines before that.
If we merge this before #16878, I'd expect to see that number decrease
substantially in that PR too, as another test.
## Summary
From #16641
The previous PR attempted to fix the errors presented in this PR, but as
discussed in the conversation, it was concluded that the approach was
undesirable and that further work would be needed to fix the errors with
a correct general solution.
In this PR, I instead add the test cases from the previous PR as TODOs,
as a starting point for future work.
## Test Plan
---------
Co-authored-by: Carl Meyer <carl@oddbird.net>
## Summary
Fixes#16744
Allows the cli to find a virtual environment from the VIRTUAL_ENV
environment variable if no `--python` is set
## Test Plan
Manual testing, of:
- Virtual environments explicitly activated using `source .venv/bin/activate`
- Virtual environments implicilty activated via `uv run`
- Broken virtual environments with no `pyvenv.cfg` file
`base.sha` appears to be the commit of the base branch when the pull
request was opened, not the base commit that's used to construct the
test merge commit — which can lead to incorrect "determine changes"
results where commits made to the base ref since the pull request are
opened are included in the results.
We use `git merge-base` to find the correct sha, as I don't think that
GitHub provides this. They provide `merge_commit_sha` but my
understanding is that is equivalent to the actual merge commit we're
testing in CI.
I tested this locally on an example pull request. I don't think it's
worth trying to reproduce a specific situation here.
---------
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
## Summary
This change follows up on the bug-fix requested in #16747 --
`ruff_python_ast::OperatorPrecedence` had an enum variant, `BitXorOr`,
which which gave the same precedence to the `|` and `^` operators. This
goes against [Python's documentation for operator
precedence](https://docs.python.org/3/reference/expressions.html#operator-precedence),
so this PR changes the code so that it's correct.
This is part of the overall effort to unify redundant definitions of
`OperatorPrecedence` throughout the codebase (#16071)
## Test Plan
Because this is an internal change, I only ran existing tests to ensure
nothing was broken.
The single flag `has_syntax_error` on `LinterResult` is replaced with
two (private) flags: `has_valid_syntax` and
`has_no_unsupported_syntax_errors`, which record whether there are
`ParseError`s or `UnsupportedSyntaxError`s, respectively. Only the
former is used to prevent a `FixAll` action.
An attempt has been made to make consistent the usage of the phrases
"valid syntax" (which seems to be used to refer only to _parser_ errors)
and "syntax error" (which refers to both _parser_ errors and
version-specific syntax errors).
Closes#16841
## Summary
Fixes#8191 by introducing `--exit-non-zero-on-format` to `ruff format`
which pretty much does what it says on the tin.
## Test Plan
Added a new test!
---------
Co-authored-by: Brent Westbrook <brentrwestbrook@gmail.com>
## Summary
This PR reworks `TypeInferenceBuilder::infer_type_expression()` so that
we emit diagnostics when encountering a list literal in a type
expression. The only place where a list literal is allowed in a type
expression is if it appears as the first argument to `Callable[]`, and
`Callable` is already heavily special-cased in our type-expression
parsing.
In order to ensure that list literals are _always_ allowed as the
_first_ argument to `Callabler` (but never allowed as the second, third,
etc. argument), I had to do some refactoring of our type-expression
parsing for `Callable` annotations.
## Test Plan
New mdtests added, and existing ones updated
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
fixes#15048
We want to handle more types from Type::KnownInstance
## Test Plan
Add tests for each type added explicitly in the match
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
These are just cosmetic changes, but I'm separating them out into a
standalone PR to make a branch I have stacked on top of this easier to
review
## Test Plan
Existing tests all pass
Summary
--
This PR updates `check_path` in the `ruff_linter` crate to return a
`Vec<Message>` instead of a `Vec<Diagnostic>`. The main motivation for
this is to make it easier to convert semantic syntax errors directly
into `Message`s rather than `Diagnostic`s in #16106. However, this also
has the benefit of keeping the preview check on unsupported syntax
errors in `check_path`, as suggested in
https://github.com/astral-sh/ruff/pull/16429#discussion_r1974748024.
All of the interesting changes are in the first commit. The second
commit just renames variables like `diagnostics` to `messages`, and the
third commit is a tiny import fix.
I also updated the `ExpandedMessage::location` field name, which caused
a few extra commits tidying up the playground code. I thought it was
nicely symmetric with `end_location`, but I'm happy to revert that too.
Test Plan
--
Existing tests. I also tested the playground and server manually.
## Summary
Part of #15382
This PR infers the return type `lambda` expression as `Unknown`. In the
future, it would be more useful to infer the expression type considering
the surrounding context (#16696).
## Test Plan
Update existing test cases from `@todo` to the (verified) return type.
## Summary
Previously, the `name` field was on `Parameter` which required it to be
always optional regardless of the parameter kind because a
`typing.Callable` signature does not have name for the parameters. This
is the case for positional-only parameters. This wasn't enforced at the
type level which meant that downstream usages would have to unwrap on
`name` even though it's guaranteed to be present.
This commit moves the `name` field from `Parameter` to the
`ParameterKind` variants and makes it optional only for
`ParameterKind::PositionalOnly` variant while required for all other
variants.
One change that's now required is that a `Callable` form using a gradual
form for parameter types (`...`) would have a default `args` and
`kwargs` name used for variadic and keyword-variadic parameter kind
respectively. This is also the case for invalid `Callable` type forms. I
think this is fine as names are not relevant in this context but happy
to make it optional even in variadic variants.
## Test Plan
No new tests; make sure existing tests are passing.
## Summary
Add error messages for invalid nodes in type expressions
Fixes#16816
## Test Plan
Extend annotations/invalid.md to handle these invalid AST nodes error
messages
## Summary
This PR adds a playground for Red Knot
[Screencast from 2024-08-14
10-33-54.webm](https://github.com/user-attachments/assets/ae81d85f-74a3-4ba6-bb61-4a871b622f05)
Sharing does work 😆 I just forgot to start wrangler.
It supports:
* Multiple files
* Showing the AST
* Showing the tokens
* Sharing
* Persistence to local storage
Future extensions:
* Configuration support: The `pyproject.toml` would *just* be another
file.
* Showing type information on hover
## Blockers
~~Salsa uses `catch_unwind` to break cycles, which Red Knot uses
extensively when inferring types in the standard library.
However, WASM (at least `wasm32-unknown-unknown`) doesn't support
`catch_unwind` today, so the playground always crashes when the type
inference encounters a cycle.~~
~~I created a discussion in the [salsa
zulip](https://salsa.zulipchat.com/#narrow/stream/333573-salsa-3.2E0/topic/WASM.20support)
to see if it would be possible to **not** use catch unwind to break
cycles.~~
~~[Rust tracking issue for WASM catch unwind
support](https://github.com/rust-lang/rust/issues/118168)~~
~~I tried to build the WASM with the nightly compiler option but ran
into problems because wasm-bindgen doesn't support WASM-exceptions. We
could try to write the binding code by hand.~~
~~Another alternative is to use `wasm32-unknown-emscripten` but it's
rather painful to build~~
## Summary
This PR detects the use of PEP 701 f-strings before 3.12. This one
sounded difficult and ended up being pretty easy, so I think there's a
good chance I've over-simplified things. However, from experimenting in
the Python REPL and checking with [pyright], I think this is correct.
pyright actually doesn't even flag the comment case, but Python does.
I also checked pyright's implementation for
[quotes](98dc4469cc/packages/pyright-internal/src/analyzer/checker.ts (L1379-L1398))
and
[escapes](98dc4469cc/packages/pyright-internal/src/analyzer/checker.ts (L1365-L1377))
and think I've approximated how they do it.
Python's error messages also point to the simple approach of these
characters simply not being allowed:
```pycon
Python 3.11.11 (main, Feb 12 2025, 14:51:05) [Clang 19.1.6 ] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> f'''multiline {
... expression # comment
... }'''
File "<stdin>", line 3
}'''
^
SyntaxError: f-string expression part cannot include '#'
>>> f'''{not a line \
... continuation}'''
File "<stdin>", line 2
continuation}'''
^
SyntaxError: f-string expression part cannot include a backslash
>>> f'hello {'world'}'
File "<stdin>", line 1
f'hello {'world'}'
^^^^^
SyntaxError: f-string: expecting '}'
```
And since escapes aren't allowed, I don't think there are any tricky
cases where nested quotes or comments can sneak in.
It's also slightly annoying that the error is repeated for every nested
quote character, but that also mirrors pyright, although they highlight
the whole nested string, which is a little nicer. However, their check
is in the analysis phase, so I don't think we have such easy access to
the quoted range, at least without adding another mini visitor.
## Test Plan
New inline tests
[pyright]:
https://pyright-play.net/?pythonVersion=3.11&strict=true&code=EYQw5gBAvBAmCWBjALgCgO4gHaygRgEoAoEaCAIgBpyiiBiCLAUwGdknYIBHAVwHt2LIgDMA5AFlwSCJhwAuCAG8IoMAG1Rs2KIC6EAL6iIxosbPmLlq5foRWiEAAcmERAAsQAJxAomnltY2wuSKogA6WKIAdABWfPBYqCAE%2BuSBVqbpWVm2iHwAtvlMWMgB2ekiolUAgq4FjgA2TAAeEMieSADWCsoV5qoaqrrGDJ5MiDz%2B8ABuLqosAIREhlXlaybrmyYMXsDw7V4AnoysyAmQ5SIhwYo3d9cheADUeKlv5O%2BpQA
## Summary
For now, `property_tests.rs` has grown larger and larger, making the
file difficult to read and maintain.
Although the code has been split, the test paths and full names remain
unchanged. There are no changes affecting test execution.
## Summary
This PR simplifies `IterationError` and `ContextManagerError` so that
they no longer "remember" what type it was that was (respectively) not
iterable or not valid as a context manager. Instead, the type that was
iterated over (or was used as a context manager) is passed back in when
calling the error struct's `report_diagnostic` method.
The motivations for this are:
- It significantly simplifies the code
- It reduces the size of these types on the stack
## Test Plan
`cargo test -p red_knot_python_semantic`
## Summary
This PR brings an optimization.
- `get_cached_db` no longer returns a `MutexGuard`; instead, it returns
a cloned database.
### `get_cached_db`
Previously, the `MutexGuard` was held inside the property test function
(defined in the macro), which prevented multiple property tests from
running in parallel. More specifically, the program could only test one
random test case at a time, which likely caused a significant
bottleneck.
On my local machine, running:
```
QUICKCHECK_TESTS=100000 cargo test --release -p red_knot_python_semantic -- --ignored stable
```
showed about **a 75% speedup** (from \~60s to \~15s).
Fixes#16751
## Summary
Previously, unsafe fixes were counted as "fixable" in
`Printer::write_statistics`, in contrast to the behaviour in
`Printer::write_once`. This changes the behaviour to align with
`write_once`, including them only if `--unsafe-fixes` is set.
We now also reuse `Printer::write_summary` to avoid duplicating the
logic for whether or not to report if there are hidden fixes.
## Test Plan
Existing tests modified to use an unsafe-fixable rule, and new ones
added to cover the case with `--unsafe-fixes`
## Summary
This is prep-work for the Red Knot playground. We'll have two
playgrounds, one for Red Knot and Ruff.
I want to share some components between the two, a "shared" NPM package
in a local workspace is a great fit for that.
I also want to share the dev dependencies and dev scripts. Again, NPM
workspaces are great for that.
This PR also sets up a CI workflow for the playground to prevent
surprises during the release.
## Test Plan
CI, local `npm install`, `npm start`, ...
I verified that the new CI step fails if there's a typescript or
formatting error.
* [Deployment test
run](https://github.com/astral-sh/ruff/actions/runs/13904914480/job/38905524353)
These should all be minor cosmetic changes. To summarize:
* In many cases, `-` was replaced with `^` for primary annotations.
This is because, previously, whether `-` or `^` was used depended
on the severity. But in the new data model, it's based on whether
the annotation is "primary" or not. We could of course change this
in whatever way we want, but I think we should roll with this for now.
* The "secondary messages" in the old API are rendered as
sub-diagnostics. This in turn results in a small change in the output
format, since previously, the secondary messages were represented as
just another snippet. We use sub-diagnostics because that's the intended
way to enforce relative ordering between messages within a diagnostic.
* The "info:" prefix used in some annotation messages has been dropped.
We could re-add this, but I think I like it better without this prefix.
I believe those 3 cover all of the snapshot changes here.
... and switch to the new one.
We do this switch by converting the old diagnostics to a
`Diagnostic`, and then rendering that.
This does not quite emit identical output. There are some
changes. They *could* be fixed to remain the same, but the
changes aren't obviously worse to me and I think the right
way to *improve* them is to move Red Knot to the new `Diagnostic`
API.
The next commit will have the snapshot changes.
In our existing diagnostics, our message is just the diagnostic
ID, and the message goes to the annotation. In reality, the
diagnostic can have its own message distinct from the optional
messages associated with an annotation.
In order to make the outputs match, we do a small tweak here:
when the main diagnostic message is empty, we drop the colon
after the diagnostic ID.
I expect that we'll want to rejigger this output format more
in the future, but for now this was a very simple change to
preserve the status quo.
When moving over to the new renderer, I noticed that it
was emitting an extra line terminator compared to the status
quo. This removes it by turning the line terminator into a
line delimiter between diagnostics.
Previously, unless you had some other configuration that impacts
ripgrep, `rg -tyaml uses:` would return zero results. After this
changes, it returns more of what you might expect.
This is because ripgrep ignores hidden files and directories by default.
But arguably, searching `.github` by default is probably what we want.
I do the same thing in ripgrep's repository:
de4baa1002/.ignore (L1)
This cleans up how we handle calling unions of types. #16568 adding a
three-level structure for callable signatures (`Signatures`,
`CallableSignature`, and `Signature`) to handle unions and overloads.
This PR updates the bindings side to mimic that structure. What used to
be called `CallOutcome` is now `Bindings`, and represents the result of
binding actual arguments against a possible union of callables.
`CallableBinding` is the result of binding a single, possibly
overloaded, callable type. `Binding` is the result of binding a single
overload.
While we're here, this also cleans up `CallError` greatly. It was
previously extracting error information from the bindings and storing it
in the error result. It is now a simple enum, carrying no data, that's
used as a status code to talk about whether the overall binding was
successful or not. We are now more consistent about walking the binding
itself to get detailed information about _how_ the binding was
unsucessful.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This PR fixes a bug in the check for fully static callable type where we
would skip unannotated parameter type.
## Test Plan
Add tests using the new `CallableTypeFromFunction` special form.
## Summary
The PPC64le wheel testing job spuriously failes due to some race when
installing python dependencies.
This is very annoying because it requires restarting the release process
over and over again until you're lucky and it passes.
This PR disables wheel testing on PPC64le
This is the same as we did in uv, see
https://github.com/astral-sh/uv/issues/11231
## Test Plan
The wheel test step was skipped in CI, see
https://github.com/astral-sh/ruff/actions/runs/13895143309/job/38874065160?pr=16793
but it still runs for other targets
## Summary
This is a re-creation of https://github.com/astral-sh/ruff/pull/16764 by
@mtshiba, which I closed meaning to immediately reopen (GitHub wasn't
updating the PR with the latest pushed changes), and which GitHub will
not allow me to reopen for some reason. Pasting the summary from that PR
below:
> From https://github.com/astral-sh/ruff/pull/16641
>
> As stated in this comment
(https://github.com/astral-sh/ruff/pull/16641#discussion_r1996153702),
the current ordering implementation for intersection types is incorrect.
So, I will introduce lexicographic ordering for intersection types.
## Test Plan
One property test stabilised (tested locally with
`QUICKCHECK_TESTS=2000000 cargo test --release -p
red_knot_python_semantic -- --ignored
types::property_tests::stable::negation_reverses_subtype_order`), and
existing mdtests that previously failed now pass.
Primarily-authored-by:
[mtshiba](https://github.com/astral-sh/ruff/commits?author=mtshiba)
---------
Co-authored-by: Shunsuke Shibayama <sbym1346@gmail.com>
## Summary
Use bash and `git diff` to determine which steps need to run.
We previously used the `changed-files` github actions but using `git`
directly seems simple enough.
All credit for the bash magic goes to @zanieb and @geofft. All I did was
replace the paths arguments.
## Test Plan
* [Linter only change](https://github.com/astral-sh/ruff/pull/16800):
See how the fuzzer and formatter steps, and the linter ecosystem checks
are skipped
* [Formatter only change](https://github.com/astral-sh/ruff/pull/16799):
See how the fuzzer and linter ecosystem checks are skipped
## Summary
A small followup to https://github.com/astral-sh/ruff/pull/16386. We now
tell the user exactly what it was about their decorator that constituted
invalid syntax on Python <3.9, and the range now highlights the specific
sub-expression that is invalid rather than highlighting the whole
decorator
## Test Plan
Inline snapshots are updated, and new ones are added.
## Summary
Stop flagging each invocation of `django.utils.safestring.mark_safe`
(also available at, `django.utils.html.mark_safe`) as an error.
Instead, allow string literals as valid uses for `mark_safe`.
Also, update the documentation, pointing at
`django.utils.html.format_html` for dynamic content generation use
cases.
Closes#16702
## Test Plan
I verified several possible uses, but string literals, are still
flagged.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR adds a new `--color` CLI option that controls whether the output
should be colorized or not.
This is implements part of
https://github.com/astral-sh/ruff/issues/16727 except that it doesn't
implement the persistent configuration support as initially proposed in
the CLI document. I realized, that having this as a persistent
configuration is somewhat awkward because we may end up writing tracing
logs **before** we loaded and resolved the settings. Arguably, it's
probably fine to color the output up to that point, but it feels like a
somewhat broken experience. That's why I decided not to add the
persistent configuration option for now.
## Test Plan
I tested this change manually by running Red Knot with `--color=always`,
`--color=never`, and `--color=auto` (or no argument) and verified that:
* The diagnostics are or aren't colored
* The tracing output is or isn't colored.
---------
Co-authored-by: David Peter <sharkdp@users.noreply.github.com>
## Summary
Another salsa upgrade.
The main motivation is to stay on a recent salsa version because there
are still a lot of breaking changes happening.
The most significant changes in this update:
* Salsa no longer derives `Debug` by default. It now requires
`interned(debug)` (or similar)
* This version ships the foundation for garbage collecting interned
values. However, this comes at the cost that queries now track which
interned values they created (or read). The micro benchmarks in the
salsa repo showed a significant perf regression. Will see if this also
visible in our benchmarks.
## Test Plan
`cargo test`
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [clap](https://redirect.github.com/clap-rs/clap) |
workspace.dependencies | patch | `4.5.31` -> `4.5.32` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>clap-rs/clap (clap)</summary>
###
[`v4.5.32`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4532---2025-03-10)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.31...v4.5.32)
##### Features
- Add `Error::remove`
##### Documentation
- *(cookbook)* Switch from `humantime` to `jiff`
- *(tutorial)* Better cover required vs optional
##### Internal
- Update `pulldown-cmark`
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDAuMCIsInVwZGF0ZWRJblZlciI6IjM5LjIwMC4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [quote](https://redirect.github.com/dtolnay/quote) |
workspace.dependencies | patch | `1.0.39` -> `1.0.40` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/quote (quote)</summary>
###
[`v1.0.40`](https://redirect.github.com/dtolnay/quote/releases/tag/1.0.40)
[Compare
Source](https://redirect.github.com/dtolnay/quote/compare/1.0.39...1.0.40)
- Optimize construction of lifetime tokens
([#​293](https://redirect.github.com/dtolnay/quote/issues/293),
thanks [@​aatifsyed](https://redirect.github.com/aatifsyed))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [x] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDAuMCIsInVwZGF0ZWRJblZlciI6IjM5LjIwMC4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [ordermap](https://redirect.github.com/indexmap-rs/ordermap) |
workspace.dependencies | patch | `0.5.5` -> `0.5.6` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>indexmap-rs/ordermap (ordermap)</summary>
###
[`v0.5.6`](https://redirect.github.com/indexmap-rs/ordermap/blob/HEAD/RELEASES.md#056-2025-03-10)
[Compare
Source](https://redirect.github.com/indexmap-rs/ordermap/compare/0.5.5...0.5.6)
- Added `ordermap_with_default!` and `orderset_with_default!` to be used
with
alternative hashers, especially when using the crate without `std`.
- Updated the `indexmap` dependency to version 2.8.0.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [x] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDAuMCIsInVwZGF0ZWRJblZlciI6IjM5LjIwMC4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[cloudflare/wrangler-action](https://redirect.github.com/cloudflare/wrangler-action)
| action | patch | `v3.14.0` -> `v3.14.1` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>cloudflare/wrangler-action
(cloudflare/wrangler-action)</summary>
###
[`v3.14.1`](https://redirect.github.com/cloudflare/wrangler-action/releases/tag/v3.14.1)
[Compare
Source](https://redirect.github.com/cloudflare/wrangler-action/compare/v3.14.0...v3.14.1)
##### Patch Changes
-
[#​358](https://redirect.github.com/cloudflare/wrangler-action/pull/358)
[`cd6314a`](cd6314a97b)
Thanks [@​penalosa](https://redirect.github.com/penalosa)! - Use
`secret bulk` instead of deprecated `secret:bulk` command
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [x] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDAuMCIsInVwZGF0ZWRJblZlciI6IjM5LjIwMC4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [env_logger](https://redirect.github.com/rust-cli/env_logger) |
workspace.dependencies | patch | `0.11.6` -> `0.11.7` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>rust-cli/env_logger (env_logger)</summary>
###
[`v0.11.7`](https://redirect.github.com/rust-cli/env_logger/blob/HEAD/CHANGELOG.md#0117---2025-03-10)
[Compare
Source](https://redirect.github.com/rust-cli/env_logger/compare/v0.11.6...v0.11.7)
##### Internal
- Replaced `humantime` with `jiff`
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [x] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDAuMCIsInVwZGF0ZWRJblZlciI6IjM5LjIwMC4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [indexmap](https://redirect.github.com/indexmap-rs/indexmap) |
workspace.dependencies | minor | `2.7.1` -> `2.8.0` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>indexmap-rs/indexmap (indexmap)</summary>
###
[`v2.8.0`](https://redirect.github.com/indexmap-rs/indexmap/blob/HEAD/RELEASES.md#280-2025-03-10)
[Compare
Source](https://redirect.github.com/indexmap-rs/indexmap/compare/2.7.1...2.8.0)
- Added `indexmap_with_default!` and `indexset_with_default!` to be used
with
alternative hashers, especially when using the crate without `std`.
- Implemented `PartialEq` between each `Slice` and `[]`/arrays.
- Removed the internal `rustc-rayon` feature and dependency.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [x] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4yMDAuMCIsInVwZGF0ZWRJblZlciI6IjM5LjIwMC4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
The intent here is that all actions should be pinned to an immutable SHA
(but that Renovate should annotate each SHA with the corresponding
SemVer version).
See https://github.com/astral-sh/uv/pull/12189
## Test plan
```
npx --yes --package renovate -- renovate-config-validator
npm warn deprecated inflight@1.0.6: This module is not supported, and leaks memory. Do not use it. Check out lru-cache if you want a good and tested way to coalesce async requests by a key value, which is much more comprehensive and powerful.
npm warn deprecated rimraf@2.4.5: Rimraf versions prior to v4 are no longer supported
npm warn deprecated boolean@3.2.0: Package no longer supported. Contact Support at https://www.npmjs.com/support for more info.
npm warn deprecated glob@6.0.4: Glob versions prior to v9 are no longer supported
INFO: Validating .github/renovate.json5
INFO: Config validated successfully
```
## Summary
tj-actions/changed-files no longer exists due to a malicious commit.
This PR removes it so that we can re-enable CI.
We can follow up with a proper replacement in a separate PR
Currently the red-knot LSP server emits any log messages of level `INFO`
or higher from non-red-knot crates. This makes its output quite verbose,
because Salsa emits an `INFO` level message every time it executes a
query. I use red-knot as LSP with neovim, and this spams the log file
quite a lot.
It seems like a better default to only emit `WARN` or higher messages
from non-red-knot sources.
I confirmed that this fixes the nvim LSP log spam.
## Summary
The ecosystem checks have proven useful so far, so I'm extending the
list a bit. My main selection criteria are:
- Few dependencies (we don't understand -stubs/-types packages yet)
- Fewer than 1000 diagnostics
- No panics
## Test Plan
Ran it locally. We now have ~2k diagnostics in total, across 12 projects
## Summary
Uses the `try_call_dunder` infrastructure for augmented assignment and
fixes the logic to work for types other than `Type::Instance(…)`. This
allows us to infer the correct type here:
```py
x = (1, 2)
x += (3, 4)
reveal_type(x) # revealed: tuple[Literal[1], Literal[2], Literal[3], Literal[4]]
```
Or in this (extremely weird) scenario:
```py
class Meta(type):
def __iadd__(cls, other: int) -> str:
return ""
class C(metaclass=Meta): ...
cls = C
cls += 1
reveal_type(cls) # revealed: str
```
Union and intersection handling could also be improved here, but I made
no attempt to do so in this PR.
## Test Plan
New MD tests
## Summary
A follow-up to https://github.com/astral-sh/ruff/pull/16705 which
documents various kinds of diagnostics that can appear when assigning to
an attribute.
## Test Plan
New snapshot tests.
## Summary
This PR implements the first part of
https://github.com/astral-sh/ruff/discussions/16440. It ensures that Red
Knot's module resolver is case sensitive on all systems.
This PR combines a few approaches:
1. It uses `canonicalize` on non-case-sensitive systems to get the real
casing of a path. This works for as long as no symlinks or mapped
network drives (the windows `E:\` is mapped to `\\server\share` thingy).
This is the same as what Pyright does
2. If 1. fails, fall back to recursively list the parent directory and
test if the path's file name matches the casing exactly as listed in by
list dir. This is the same approach as CPython takes in its module
resolver. The main downside is that it requires more syscalls because,
unlike CPython, we Red Knot needs to invalidate its caches if a file
name gets renamed (CPython assumes that the folders are immutable).
It's worth noting that the file watching test that I added that renames
`lib.py` to `Lib.py` currently doesn't pass on case-insensitive systems.
Making it pass requires some more involved changes to `Files`. I plan to
work on this next. There's the argument that landing this PR on its own
isn't worth it without this issue being addressed. I think it's still a
good step in the right direction even when some of the details on how
and where the path case sensitive comparison is implemented.
## Test plan
I added multiple integration tests (including a failing one). I tested
that the `case-sensitivity` detection works as expected on Windows,
MacOS and Linux and that the fast-paths are taken accordingly.
## Summary
This PR detects unparenthesized assignment expressions used in set
literals and comprehensions and in sequence indexes. The link to the
release notes in https://github.com/astral-sh/ruff/issues/6591 just has
this entry:
> * Assignment expressions can now be used unparenthesized within set
literals and set comprehensions, as well as in sequence indexes (but not
slices).
with no other information, so hopefully the test cases I came up with
cover all of the changes. I also tested these out in the Python REPL and
they actually worked in Python 3.9 too. I'm guessing this may be another
case that was "formally made part of the language spec in Python 3.10,
but usable -- and commonly used -- in Python >=3.9" as @AlexWaygood
added to the body of #6591 for context managers. So we may want to
change the version cutoff, but I've gone along with the release notes
for now.
## Test Plan
New inline parser tests and linter CLI tests.
We don't actually hook this up to anything in this PR, but we do
go to some trouble to granularly unit test it. The unit tests caught
plenty of bugs after I initially wrote down the implementation, so they
were very much worth it.
Closes#16506
Instead of hard-coding a specific context window,
it seemed prudent to make this configurable. That
makes it easier to test different context window
sizes as well.
I am not totally convinced that this is the right
place for this configuration. I could see the context
window size being a property of `Diagnostic` instead,
since we might want to change the context window
size based not just on some end user configuration,
but perhaps also the specific diagnostic.
But for now, I think it's fine for it to live here,
and all of the rendering logic doesn't care where
it lives. So it should be relatively easy to change
in the future.
This adds a new configuration knob to diagnostic rendering that, when
enabled, will make diagnostic rendering much more terse. Specifically,
it will guarantee that each diagnostic will only use one line.
This doesn't actually hook the concise output option up to anything.
We'll do that plumbing in the next commit.
Summary
--
This is closely related to (and stacked on)
https://github.com/astral-sh/ruff/pull/16544 and detects star
annotations in function definitions.
I initially called the variant `StarExpressionInAnnotation` to mirror
`StarExpressionInIndex`, but I realized it's not really a "star
expression" in this position and renamed it. `StarAnnotation` seems in
line with the PEP.
Test Plan
--
Two new inline tests. It looked like there was pretty good existing
coverage of this syntax, so I just added simple examples to test the
version cutoff.
## Summary
Follow-up release for Ruff v0.10 that now includes the following two
changes that we intended to ship but slipped:
* Changes to how the Python version is inferred when a `target-version`
is not specified (#16319)
* `blanket-noqa` (`PGH004`): Also detect blanked file-level noqa
comments (and not just line level comments).
## Test plan
I verified that the binary built on this branch respects the
`requires-python` setting
([logs](https://www.diffchecker.com/qyJWYi6W/), left: v0.10, right:
v0.11)
## Summary
This PR includes minor improvements to binary operation inference,
specifically for tuple concatenation.
### Before
```py
reveal_type((1, 2) + (3, 4)) # revealed: @Todo(return type of decorated function)
# If TODO is ignored, the revealed type would be `tuple[1|2|3|4, ...]`
```
The `builtins.tuple` type stub defines `__add__`, but it appears to only
work for homogeneous tuples. However, I think this limitation is not
ideal for many use cases.
### After
```py
reveal_type((1, 2) + (3, 4)) # revealed: tuple[Literal[1], Literal[2], Literal[3], Literal[4]]
```
## Test Plan
### Added
- `mdtest/binary/tuples.md`
### Affected
- `mdtest/slots.md` (a test have been moved out of the `False-Negative`
block.)
## Summary
This changeset adds proper support for assignments to attributes:
```py
obj.attr = value
```
In particular, the following new features are now available:
* We previously didn't raise any errors if you tried to assign to a
non-existing attribute `attr`. This is now fixed.
* If `type(obj).attr` is a data descriptor, we now call its `__set__`
method instead of trying to assign to the load-context type of
`obj.attr`, which can be different for data descriptors.
* An initial attempt was made to support unions and intersections, as
well as possibly-unbound situations. There are some remaining TODOs in
tests, but they only affect edge cases. Having nested diagnostics would
be one way that could help solve the remaining cases, I believe.
## Follow ups
The following things are planned as follow-ups:
- Write a test suite with snapshot diagnostics for various attribute
assignment errors
- Improve the diagnostics. An easy improvement would be to highlight the
right hand side of the assignment as a secondary span (with the rhs type
as additional information). Some other ideas are mentioned in TODO
comments in this PR.
- Improve the union/intersection/possible-unboundness handling
- Add support for calling custom `__setattr__` methods (see new false
positive in the ecosystem results)
## Ecosystem changes
Some changes are related to assignments on attributes with a custom
`__setattr__` method (see above). Since we didn't notice missing
attributes at all in store context previously, these are new.
The other changes are related to properties. We previously used their
read-context type to test the assignment. That results in weird error
messages, as we often see assignments to `self.property` and then we
think that those are instance attributes *and* descriptors, leading to
union types. Now we properly look them up on the meta type, see the
decorated function, and try to overwrite it with the new value (as we
don't understand decorators yet). Long story short: the errors are still
weird, we need to understand decorators to make them go away.
## Test Plan
New Markdown tests
Summary
--
This PR reuses a slightly modified version of the
`check_tuple_unpacking` method added for detecting unpacking in `return`
and `yield` statements to detect the same issue in the iterator clause
of `for` loops.
I ran into the same issue with a bare `for x in *rest: ...` example
(invalid even on Python 3.13) and added it as a comment on
https://github.com/astral-sh/ruff/issues/16520.
I considered just making this an additional `StarTupleKind` variant as
well, but this change was in a different version of Python, so I kept it
separate.
Test Plan
--
New inline tests.
There can be semi-cyclic inheritance patterns (e.g. recursive generics)
that are not technically inheritance cycles, but that can cause us to
hit Salsa query cycles in evaluating a type's MRO. Add fixed-point
handling to these MRO-related queries so we don't panic on these cycles.
The details of what queries we hit in what order in this case will
change as we implement support for generics, but ultimately we will
probably need cycle handling for all queries that can re-enter type
inference, otherwise we are susceptible to small changes in query
execution order causing panics.
Fixes#14333
Further reduces the panicking set of seeds in #14737
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Part of #15655
Replaced statement nodes with autogenerated ones. Reused the stuff we
introduced in #16285. Nothing except for copying the nodes to new
format.
## Test Plan
Tests run without any changes. Also moved the test that checks size of
AST nodes to `generated.rs` since all of the structs that it tests are
now there.
<!-- How was it tested? -->
## Summary
This PR stabilizes the behavior introduced in
https://github.com/astral-sh/ruff/pull/15985
The new behavior improves the inference of `str.strip` calls:
* before: The rule only considered calls on string or byte literals
(`"abcd".strip`)
* now: The rule also catches calls to `strip` on object where the type
is known to be a `str` or `bytes` (e.g. `a = "abc"; a.strip("//")`)
The new behavior shipped as part of Ruff 0.9.6 on the 10th of Feb which
is a little more than a month ago.
There have been now new issues or PRs related to the new behavior.
## Summary
This PR promotes the fix improvements for `PLR1714` that were introduced
in https://github.com/astral-sh/ruff/pull/14372/ to stable.
The improvement is that the fix now proposes to use a set if all
elements are hashable:
```
foo == "bar" or foo == "baz" or foo == "qux"
```
Gets fixed to
```py
foo in {"bar", "baz", "qux"}
```
where it previously always got fixed to a tuple.
The new fix was first released in ruff 0.8.0 (Nov last year). This is
not a breaking change. The change was preview gated only to get some
extra test coverage.
There are no open issues or PRs related to this changed fix behavior.
## Summary
This PR stabilizes the behavior changes introduced by
https://github.com/astral-sh/ruff/pull/13305 that were gated behind
preview.
The change is that `__new__` methods are now no longer flagged by
`invalid-first-argument-name-for-class-method` (`N804`) but instead by
`bad-staticmethod-argument` (`PLW0211`)
> __new__ methods are technically static methods, with cls as their
first argument. However, Ruff currently classifies them as classmethod,
which causes two issues:
## Test Plan
There have been no new issues or PRs related to `N804` or `PLW0211`
since the behavior change was released in Ruff 0.9.7 (about 3 weeks
ago).
This is a somewhat recent change but I don't think it's necessary to
leave this in preview for another 2 months. The main reason why it was
in preview
is that it is breaking, not because it is a risky change.
## Summary
This PR stabilizes the fix for `PYI018` introduced in
https://github.com/astral-sh/ruff/pull/15999/ (first released with Ruff
0.9.5 early February)
There are no known issues with the fix or open PRs.
## Summary
Deprecate `S320` because defusedxml has deprecated there `lxml` module
and `lxml` has been hardened since.
flake8-bandit has removed their implementation as well
(https://github.com/PyCQA/bandit/pull/1212).
Addresses https://github.com/astral-sh/ruff/issues/13707
## Test Plan
I verified that selecting `S320` prints a warning and fails if the
preview mode is enabled.
## Summary
This PR stabilizes the fixes improvements made in
https://github.com/astral-sh/ruff/pull/15562 (released with ruff 0.9.3
in mid January).
There's no open issue or PR related to the changed fix behavior.
This is not a breaking change. The fix was only gated behind preview to
get some more test coverage before releasing.
## Summary
This PR stabilizes the behavior change introduced in
https://github.com/astral-sh/ruff/pull/15872/
The diagnostic range is now the range of the redundant `mode` argument
where it previously was the range of the entire `open` call:
Before:
```
UP015.py:2:1: UP015 [*] Unnecessary mode argument
|
1 | open("foo", "U")
2 | open("foo", "Ur")
| ^^^^^^^^^^^^^^^^^ UP015
3 | open("foo", "Ub")
4 | open("foo", "rUb")
|
= help: Remove mode argument
```
Now:
```
UP015.py:2:13: UP015 [*] Unnecessary mode argument
|
1 | open("foo", "U")
2 | open("foo", "Ur")
| ^^^^ UP015
3 | open("foo", "Ub")
4 | open("foo", "rUb")
|
= help: Remove mode argument
```
This is a breaking change because it may require moving a `noqa` comment
onto a different line, e.g if you have
```py
open(
"foo",
"Ur",
) # noqa: UP015
```
Needs to be rewritten to
```py
open(
"foo",
"Ur", # noqa: UP015
)
```
There have been now new issues or PRs since the new preview behavior was
implemented. It first was released as part of Ruff 0.9.5 on the 5th of
Feb (a little more than a month ago)
## Test Plan
I reviewed the snapshot tests
## Summary
This PR stabilizes the preview behavior introduced in
https://github.com/astral-sh/ruff/pull/15719 to recognize all symbols
named `TYPE_CHECKING` as type-checking
checks in `if TYPE_CHECKING` conditions. This ensures compatibility with
mypy and pyright.
This PR also stabilizes the new behavior that removes `if 0:` and `if
False` to be no longer considered type checking blocks.
Since then, this syntax has been removed from the typing spec and was
only used for Python modules that don't have a `typing` module
([comment](https://github.com/astral-sh/ruff/pull/15719#issuecomment-2612787793)).
The preview behavior was first released with Ruff 0.9.5 (6th of
February), which was about a month ago. There are no open issues or PRs
for the changed behavior
## Test Plan
The snapshots for `SIM108` change because `SIM108` ignored type checking
blocks but it can no
simplify `if 0` or `if False` blocks again because they're no longer
considered type checking blocks.
The changes in the `TC005` snapshot or only due to that `if 0` and `if
False` are no longer recognized as type checking blocks
<!-- How was it tested? -->
## Summary
This PR stabilizes the preview behavior for `invalid-argument-name`
(`N803`)
to ignore argument names of functions decorated with `typing.override`
because
these methods are *out of the authors* control.
This behavior was introduced in
https://github.com/astral-sh/ruff/pull/15954
and released as part of Ruff 0.9.5 (6th of February).
There have been no new issues or PRs since this behavior change
(preview) was introduced.
## Summary
This PR stabilizes the preview behavior introduced in
https://github.com/astral-sh/ruff/pull/15905
The behavior change is that the rule now also recognizes `type(expr) is
type(None)` comparisons where `expr` isn't a name expression.
For example, the rule now detects `type(a.b) is type(None)` and suggests
rewriting the comparison to `a.b is None`.
The new behavior was introduced with Ruff 0.9.5 (6th of February), about
a month ago. There are no open issues or PRs related to this rule (or
behavior change).
## Summary
This PR stabilizes the new behavior introduced in
https://github.com/astral-sh/ruff/pull/14512 to also detect defalut
value arguemnts to `os.environ.get` that have an invalid type (not
`str`).
There's an upstream issue for this behavior change
https://github.com/pylint-dev/pylint/issues/10092 that was accepted and
a PR, but it hasn't been merged yet.
This behavior change was first shipped with Ruff 0.8.1 (Nov 22).
There has only be one PR since the new behavior was introduced but it
was unrelated to the scope increase
(https://github.com/astral-sh/ruff/pull/14841).
## Summary
This PR stabilizes the behavior change introduced in
https://github.com/astral-sh/ruff/pull/15542 to allow
for statements with an empty body in `pytest.raises` and `pytest.warns`
with statements.
This raised an error before but is now allowed:
```py
with pytest.raises(KeyError, match='unknown'):
async for _ in gpt.generate(gpt_request):
pass
```
The same applies to
```py
with pytest.raises(KeyError, match='unknown'):
async for _ in gpt.generate(gpt_request):
...
```
There have been now new issues or PRs related to PT012 or PT031 since
this behavior change was introduced in ruff 0.9.3 (January 23rd).
## Summary
This PR deprecates UP038. Using PEP 604 syntax in `isinstance` and
`issubclass` calls isn't a recommended pattern (or community agreed best
practice)
and it negatively impacts performance.
Resolves https://github.com/astral-sh/ruff/issues/7871
## Test Plan
I tested that selecting `UP038` results in a warning in no-preview mode
and an error in preview mode
Summary
--
Stabilizes TC006. The test was already in the right place.
Test Plan
--
No open issues or PRs. The last related [issue] was closed on
2025-02-09.
[issue]: https://github.com/astral-sh/ruff/issues/16037
Summary
--
Stabilizes S704, which is also being recoded from RUF035 in 0.10.
Test Plan
--
Existing tests with `PreviewMode` removed from the settings.
There was one issue closed on 2024-12-20 calling the rule noisy and
asking for a config option, but the option was added and then there were
no more issues or PRs.
Summary
--
Stabilizes DTZ901, renames the rule function to match the rule name,
removes the `preview_rules` test, and handles some nits in the docs
(mention `min` first to match the rule name too).
Test Plan
--
1 closed issue on 2024-11-12, 4 days after the rule was added. No issues
since
## Summary
Follow-up to #16677.
This change converts all unit tests (69 of them) in `noqa.rs` to use
inline snapshots instead. It extends the file by more than 1000 lines,
but the tests are now much easier to read and reason about.
## Test Plan
`cargo insta test`.
Summary
--
Stabilizes RUF041. The tests are already in the right place, and the
docs look good.
Test Plan
--
0 issues, 1 [PR] fixing nested literals and unions the day after the
rule was added. No changes since then
I wonder if the fix in that PR could be relevant for
https://github.com/astral-sh/ruff/pull/16639, where I noticed a
potential issue with `Union`. It could be unrelated, though.
[PR]: https://github.com/astral-sh/ruff/pull/14641
Summary
--
Stabilizes PTH210. Tests and docs looked good.
Test Plan
--
Mentioned in 1 open issue around Python 3.14 support (`"."` becomes a
valid suffix in 3.14). Otherwise no issues or PRs since 2024-12-12, 6
days after the rule was added.
## Summary
Follow-up to #16659.
This change adds tests for these three cases, which are (also) not
covered by existing tests:
* `# noqa: A` (lone incomplete code)
* `# noqa: A123, B` (complete codes, last one incomplete)
* `# noqa: A123B` (squashed codes, last one incomplete)
Summary
--
Stabilizes RUF051. The tests and docs looked good.
Test Plan
--
1 closed documentation issue from 4 days after the rule was added and 1
typo fix from the same day it was added, but no other issues or PRs.
Summary
--
Stabilizes LOG015. The tests and docs looked good.
Test Plan
--
1 closed documentation issue from 4 days after the rule was added, but
no other issues or PRs.
Summary
--
Stabilizes RUF048 and moves its test to the right place. The docs look
good.
Test Plan
--
0 closed or open issues. There was 1 [PR] related to an extension to the
rule, but it was closed without comment.
[PR]: https://github.com/astral-sh/ruff/pull/14701
Summary
--
Stabilizes RUF046 and moves its test to the right place. The docs look
good.
Test Plan
--
2 closed newline/whitespace issues from early January and 1 closed issue
about really being multiple rules, but otherwise no recent issues or
PRs.
# Summary
The goal of this PR is to address various issues around parsing
suppression comments by
1. Unifying the logic used to parse in-line (`# noqa`) and file-level
(`# ruff: noqa`) noqa comments
2. Recovering from certain errors and surfacing warnings in these cases
Closes#15682
Supersedes #12811
Addresses
https://github.com/astral-sh/ruff/pull/14229#discussion_r1835481018
Related: #14229 , #12809
## Summary
This PR changes the default value of
`lint.flake8-builtins.builtins-strict-checking` added in
https://github.com/astral-sh/ruff/pull/15951 from `true` to `false`.
This also allows simplifying the default option logic and removes the
dependence on preview mode.
https://github.com/astral-sh/ruff/issues/15399 was already closed by
#15951, but this change will finalize the behavior mentioned in
https://github.com/astral-sh/ruff/issues/15399#issuecomment-2587017147.
As an example, strict checking flags modules based on their last
component, so `utils/logging.py` triggers A005. Non-strict checking
checks the path to the module, so `utils/logging.py` is allowed (this is
the example and desired behavior from #15399 exactly) but a top-level
`logging.py` or `logging/__init__.py` is still disallowed.
## Test Plan
Existing tests from #15951 and #16006, with the snapshot updated in
`a005_module_shadowing_strict_default` to reflect the new default.
Summary
--
Stabilizes UP044, renames the module to match the rule name, and removes
the `PreviewMode` from the test settings.
Test Plan
--
2 closed issues in November, just after the rule was added, otherwise no
issues
Summary
--
Stabilizes SIM905 and adds a small addition to the docs. The test was
already in the right place.
Test Plan
--
No issues except 2 recent, general issues about whitespace
normalization.
## Summary
This PR stabilizes several preview-only behaviours for
`custom-typevar-for-self` (`PYI019`). Namely:
- A new, more accurate technique is now employed for detecting custom
TypeVars that are replaceable with `Self`. See
https://github.com/astral-sh/ruff/pull/15888 for details.
- The range of the diagnostic is now the full function header rather
than just the return annotation. (Previously, the rule only applied to
methods with return annotations, but this is no longer true due to the
changes in the first bullet point.)
- The fix is now available even when preview mode is not enabled.
## Test Plan
- Existing snapshots that do not have preview mode enabled are updated
- Preview-specific snapshots are removed
- I'll check the ecosystem report on this PR to verify everything's as
expected
Summary
--
Stabilizes PLC1802. The tests were already in the right place, and I
just tidied the docs a little bit.
Test Plan
--
1 issue closed 4 days after the rule was added, no other issues
Summary
--
Stabilizes PLW1507. The tests were already in the right place, and I
just tidied the docs a little bit.
Test Plan
--
1 issue from 2 weeks ago but just suggesting to mark the fix unsafe. The
shallow vs deep copy *does* change the program behavior, just usually in
a preferable way.
## Summary
Stabilizes FAST003, completing the group with FAST001 and FAST002.
## Test Plan
Last bug fix (false positive) was fixed on 2025-01-13, almost 2 months
ago.
The test case was already in the right place.
## Summary
Stabilizes C420 for the 0.10 release.
## Test Plan
No open issues or PRs (except a general issue about [string
normalization](https://github.com/astral-sh/ruff/issues/16579)). The
last (and only) false-negative bug fix was over a month ago.
The tests for this rule were already not on the `preview_rules` test, so
I just changed the `RuleGroup`. The documentation looked okay to me.
## Summary
Resolves#15368.
The following options have been renamed:
* `builtins-allowed-modules` → `allowed-modules`
* `builtins-ignorelist` → `ignorelist`
* `builtins-strict-checking` → `strict-checking`
To preserve compatibility, the old names are kept as Serde aliases.
## Test Plan
`cargo nextest run` and `cargo insta test`.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
`RUF035` has been backported into bandit as `S704` in this
[PR](https://github.com/PyCQA/bandit/pull/1225)
This moves the rule and its corresponding setting to the `flake8-bandit`
category
## Test Plan
`cargo nextest run`
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
For context, the initial implementation started out by sending a log
notification to the client to include this information in the client
channel. This is a bit ineffective because it doesn't allow the client
to display this information in a more obvious way. In addition to that,
it isn't obvious from a users perspective as to where the information is
being printed unless they actually open the output channel.
The change was to actually return this formatted string that contains
the information and let the client handle how it should display this
information. For example, in the Ruff VS Code extension we open a split
window and show this information which is similar to what rust-analyzer
does.
The notification request was kept as a precaution in case there are
users who are actually utilizing this way. If they exists, it should a
minority as it requires the user to actually dive into the code to
understand how to hook into this notification. With 0.10, we're removing
the old way as it only clobbers the output channel with a long message.
fixes: #16225
## Test Plan
Tested it out locally that the information is not being logged to the
output channel of VS Code.
## Summary
This PR stabilizies the fix for
https://github.com/astral-sh/ruff/issues/14001
We try to only make breaking formatting changes once a year. However,
the plan was to release this fix as part of Ruff 0.9 but I somehow
missed it when promoting all other formatter changes.
I think it's worth making an exception here considering that this is a
bug fix, it improves readability, and it should be rare
(very few files in a single project). Our version policy explicitly
allows breaking formatter changes in any minor release and the idea of
only making breaking formatter changes once a year is mainly to avoid
multiple releases throughout the year that introduce large formatter
changes
Closes https://github.com/astral-sh/ruff/issues/14001
## Test Plan
Updated snapshot
## Summary
Since Ruff changed to GitHub releases, tags are no longer annotated and
`git describe` no longer picks them up. Instead, it's necessary to also
search lightweight tags.
This changes fixes the `version` command to give more accurate
`last_tag`/`commits_since_last_tag` information. This only affects
development builds, as this information is not present in releases.
## Test Plan
Testing is a little tricky because this information changes on every
commit. Running manually on current `main` and my branch:
`main`:
```
# cargo run --bin ruff -- version --output-format=text
ruff 0.9.10+2547 (dd2313ab0 2025-03-12)
# cargo run --bin ruff -- version --output-format=json
{
"version": "0.9.10",
"commit_info": {
"short_commit_hash": "dd2313ab0",
"commit_hash": "dd2313ab0faea90abf66a75f1b5c388e728d9d0a",
"commit_date": "2025-03-12",
"last_tag": "v0.4.10",
"commits_since_last_tag": 2547
}
}
```
This PR:
```
# cargo run --bin ruff -- version --output-format=text
ruff 0.9.10+46 (11f39f616 2025-03-12)
# cargo run --bin ruff -- version --output-format=json
{
"version": "0.9.10",
"commit_info": {
"short_commit_hash": "11f39f616",
"commit_hash": "11f39f6166c3d7a521725b938a166659f64abb59",
"commit_date": "2025-03-12",
"last_tag": "0.9.10",
"commits_since_last_tag": 46
}
}
```
## Summary
This PR adds a new `CallableTypeFromFunction` special form to allow
extracting the abstract signature of a function literal i.e., convert a
`Type::Function` into a `Type::Callable` (`CallableType::General`).
This is done to support testing the `is_gradual_equivalent_to` type
relation specifically the case we want to make sure that a function that
has parameters with no annotations and does not have a return type
annotation is gradual equivalent to `Callable[[Any, Any, ...], Any]`
where the number of parameters should match between the function literal
and callable type.
Refer
https://github.com/astral-sh/ruff/pull/16634#discussion_r1989976692
### Bikeshedding
The name `CallableTypeFromFunction` is a bit too verbose. A possibly
alternative from Carl is `CallableTypeOf` but that would be similar to
`TypeOf` albeit with a limitation that the former only accepts function
literal types and errors on other types.
Some other alternatives:
* `FunctionSignature`
* `SignatureOf` (similar issues as `TypeOf`?)
* ...
## Test Plan
Update `type_api.md` with a new section that tests this special form,
both invalid and valid forms.
The red-knot CLI changed since the fuzzer script was added; update it to
work with current red-knot CLI.
Also add some notes on how to ensure local changes to the fuzzer script
are picked up.
## Summary
Add support for calling custom `__getattr__` methods in case an
attribute is not otherwise found. This allows us to get rid of many
ecosystem false positives where we previously emitted errors when
accessing attributes on `argparse.Namespace`.
closes#16614
## Test Plan
* New Markdown tests
* Observed expected ecosystem changes (the changes for `arrow` also look
fine, since the `Arrow` class has a custom [`__getattr__`
here](1d70d00919/arrow/arrow.py (L802-L815)))
Pulls in the latest Salsa main branch, which supports fixpoint
iteration, and uses it to handle all query cycles.
With this, we no longer need to skip any corpus files to avoid panics.
Latest perf results show a 6% incremental and 1% cold-check regression.
This is not a "no cycles" regression, as tomllib and typeshed do trigger
some definition cycles (previously handled by our old
`infer_definition_types` fallback to `Unknown`). We don't currently have
a benchmark we can use to measure the pure no-cycles regression, though
I expect there would still be some regression; the fixpoint iteration
feature in Salsa does add some overhead even for non-cyclic queries.
I think this regression is within the reasonable range for this feature.
We can do further optimization work later, but I don't think it's the
top priority right now. So going ahead and acknowledging the regression
on CodSpeed.
Mypy primer is happy, so this doesn't regress anything on our
currently-checked projects. I expect it probably unlocks adding a number
of new projects to our ecosystem check that previously would have
panicked.
Fixes#13792Fixes#14672
## Summary
Implements attribute access on intersection types, which didn't
previously work. For example:
```py
from typing import Any
class P: ...
class Q: ...
class A:
x: P = P()
class B:
x: Any = Q()
def _(obj: A):
if isinstance(obj, B):
reveal_type(obj.x) # revealed: P & Any
```
Refers to [this comment].
[this comment]:
https://github.com/astral-sh/ruff/pull/16416#discussion_r1985040363
## Test Plan
New Markdown tests
## Summary
Background - as a follow up to #16611 I noticed that there's a lot of
code duplicated between the `is_assignable_to` and `is_subtype_of`
functions and considered trying to merge them.
[A subtype and an assignable type are pretty much the
same](https://typing.python.org/en/latest/spec/concepts.html#the-assignable-to-or-consistent-subtyping-relation),
except that subtypes are by definition fully static, so I think we can
replace the whole of `is_subtype_of` with:
```
if !self.is_fully_static(db) || !target.is_fully_static(db) {
return false;
}
return self.is_assignable_to(target)
```
if we move all of the logic to is_assignable_to and delete duplicate
code. Then we can discuss if it even makes sense to have a separate
is_subtype_of function (I think the answer is yes since it's used by a
bunch of other places, but we may be able to basically rip out the
concept).
Anyways while playing with combining the functions I noticed is that the
handling of Intersections in `is_subtype_of` has a special case for two
intersections, which I didn't include in the last PR - rather I first
handled right hand intersections before left hand, which should properly
handle double intersections (hand-wavy explanation I can justify if
needed - (A & B & C) is assignable to (A & B) because the left is
assignable to both A and B, but none of A, B, or C is assignable to (A &
B)).
I took a look at what breaks if I remove the handling for double
intersections, and the reason it is needed is because is_disjoint does
not properly handle intersections with negative conditions (so instead
`is_subtype_of` basically implements the check correctly).
This PR adds support to is_disjoint for properly checking negative
branches, which also lets us simplify `is_subtype_of`, bringing it in
line with `is_assignable_to`
## Test Plan
Added a bunch of tests, most of which failed before this fix
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This is a pure restructuring of the `attributes.md` and
`descriptor_protocol.md` test suites. They have grown organically and I
didn't want to make major structural changes in my recent PR to keep the
diff clean.
## Summary
A follow up to address [this comment]:
> Similarly here, it might be a little more performant to have a single
`Type::instance()` branch with an inner match over `class.known()`
rather than having multiple branches with `if class.is_known()` guards
[this comment]:
https://github.com/astral-sh/ruff/pull/16416#discussion_r1985159037
## Summary
Properly handle binary operator inference for union types.
This fixes a bug I noticed while looking at ecosystem results. The MRE
version of it is this:
```py
def sub(x: float, y: float):
# Red Knot: Operator `-` is unsupported between objects of type `int | float` and `int | float`
return x - y
```
## Test Plan
- New Markdown tests.
- Expected diff in the ecosystem checks
## Summary
Part of #15382
This PR adds the check for whether a callable type is fully static or
not.
A callable type is fully static if all of the parameter types are fully
static _and_ the return type is fully static _and_ if it does not use
the gradual form (`...`) for its parameters.
## Test Plan
Update `is_fully_static.md` with callable types.
It seems that currently this test is grouped into either fully static or
not, I think it would be useful to split them up in groups like
callable, etc. I intentionally avoided that in this PR but I'll put up a
PR for an appropriate split.
Note: I've an explicit goal of updating the property tests with the new
callable types once all relations are implemented.
## Summary
This PR closes#16248.
If the return type of the function isn't assignable to the one
specified, an `invalid-return-type` error occurs.
I thought it would be better to report this as a different kind of error
than the `invalid-assignment` error, so I defined this as a new error.
## Test Plan
All type inconsistencies in the test cases have been replaced with
appropriate ones.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
This updates the `Signature` and `CallBinding` machinery to support
multiple overloads for a callable. This is currently only used for
`KnownFunction`s that we special-case in our type inference code. It
does **_not_** yet update the semantic index builder to handle
`@overload` decorators and construct a multi-signature `Overloads`
instance for real Python functions.
While I was here, I updated many of the `try_call` special cases to use
signatures (possibly overloaded ones now) and `bind_call` to check
parameter lists. We still need some of the mutator methods on
`OverloadBinding` for the special cases where we need to update return
types based on some Rust code.
## Summary
One of the motivations in https://github.com/astral-sh/ruff/pull/16428
for panicking when the `test` or `debug_assertions` features are enabled
and a lookup of a `KnownClass` fails is that we've had some latent bugs
in our code where certain variants have been silently falling back to
`Unknown` in every typeshed lookup without us realising. But that in
itself isn't a great motivation for panicking in
`KnownClass::to_instance()`, since we can fairly easily add some tests
that assert that we don't unexpectedly fallback to `Unknown` for any
`KnownClass` variant. This PR adds those tests.
## Test Plan
`cargo test -p red_knot_python_semantic`
## Summary
This mostly fixes#14899
My motivation was similar to the last comment by @sharkdp there. I ran
red_knot on a codebase and the most common error was patterns like this
failing:
```
def foo(x: str): ...
x: Any = ...
if isinstance(x, str):
foo(x) # Object of type `Any & str` cannot be assigned to parameter 1 (`x`) of function `foo`; expected type `str`
```
The desired behavior is pretty much to ignore Any/Unknown when resolving
intersection assignability - `Any & str` should be assignable to `str`,
and `str` should be assignable to `str & Any`
The fix is actually very similar to the existing code in
`is_subtype_of`, we need to correctly handle intersections on either
side, while being careful to handle dynamic types as desired.
This does not fix the second test case from that issue:
```
static_assert(is_assignable_to(Intersection[Unrelated, Any], Not[tuple[Unrelated, Any]]))
```
but that's misleading because the root cause there has nothing to do
with gradual types. I added a simpler test case that also fails:
```
static_assert(is_assignable_to(Unrelated, Not[tuple[Unrelated]]))
```
This is because we don't determine that Unrelated does not subclass from
tuple so we can't rule out this relation. If that logic is improved then
this fix should also handle the case of the intersection
## Test Plan
Added a bunch of is_assignable_to tests, most of which failed before
this fix.
## Summary
I noticed that the pipeline can succeed if there are problems with tool
installation or dependency resolution. This change makes sure that the
pipeline fails in these cases.
## Summary
Part of https://github.com/astral-sh/ruff/issues/15382
This PR adds support for inferring the `lambda` expression and return
the `CallableType`.
Currently, this is only limited to inferring the parameters and a todo
type for the return type.
For posterity, I tried using the `file_expression_type` to infer the
return type of lambda but it would always lead to cycle. The main reason
is that in `infer_parameter_definition`, the default expression is being
inferred using `file_expression_type`, which is correct, but it then
Take the following source code as an example:
```py
lambda x=1: x
```
Here's how the code will flow:
* `infer_scope_types` for the global scope
* `infer_lambda_expression`
* `infer_expression` for the default value `1`
* `file_expression_type` for the return type using the body expression.
This is because the body creates it's own scope
* `infer_scope_types` (lambda body scope)
* `infer_name_load` for the symbol `x` whose visible binding is the
lambda parameter `x`
* `infer_parameter_definition` for parameter `x`
* `file_expression_type` for the default value `1`
* `infer_scope_types` for the global scope because of the default
expression
This will then reach to `infer_definition` for the parameter `x` again
which then creates the cycle.
## Test Plan
Add tests around `lambda` expression inference.
## Summary
Add a new pipeline to comment on PRs if there is a mypy_primer diff
result.
## Test Plan
Not yet, I'm afraid I will have to merge this first to have the pipeline
available on main.
## Summary
This PR updates the migration guide to use the new `ruff.configuration`
settings update to provide a better experience.
### Preview
<details><summary>Migration page screenshot</summary>
<p>

</p>
</details>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [indoc](https://redirect.github.com/dtolnay/indoc) |
workspace.dependencies | patch | `2.0.5` -> `2.0.6` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/indoc (indoc)</summary>
###
[`v2.0.6`](https://redirect.github.com/dtolnay/indoc/releases/tag/2.0.6)
[Compare
Source](https://redirect.github.com/dtolnay/indoc/compare/2.0.5...2.0.6)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xODUuNCIsInVwZGF0ZWRJblZlciI6IjM5LjE4NS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [syn](https://redirect.github.com/dtolnay/syn) |
workspace.dependencies | patch | `2.0.98` -> `2.0.100` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/syn (syn)</summary>
###
[`v2.0.100`](https://redirect.github.com/dtolnay/syn/releases/tag/2.0.100)
[Compare
Source](https://redirect.github.com/dtolnay/syn/compare/2.0.99...2.0.100)
- Add `Visit::visit_token_stream`, `VisitMut::visit_token_stream_mut`,
`Fold::fold_token_stream` for processing TokenStream during syntax tree
traversals
([#​1852](https://redirect.github.com/dtolnay/syn/issues/1852))
###
[`v2.0.99`](https://redirect.github.com/dtolnay/syn/releases/tag/2.0.99)
[Compare
Source](https://redirect.github.com/dtolnay/syn/compare/2.0.98...2.0.99)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xODUuNCIsInVwZGF0ZWRJblZlciI6IjM5LjE4NS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [thiserror](https://redirect.github.com/dtolnay/thiserror) |
workspace.dependencies | patch | `2.0.11` -> `2.0.12` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/thiserror (thiserror)</summary>
###
[`v2.0.12`](https://redirect.github.com/dtolnay/thiserror/releases/tag/2.0.12)
[Compare
Source](https://redirect.github.com/dtolnay/thiserror/compare/2.0.11...2.0.12)
- Prevent elidable_lifetime_names pedantic clippy lint in generated impl
([#​413](https://redirect.github.com/dtolnay/thiserror/issues/413))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xODUuNCIsInVwZGF0ZWRJblZlciI6IjM5LjE4NS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [serde_json](https://redirect.github.com/serde-rs/json) |
workspace.dependencies | patch | `1.0.139` -> `1.0.140` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>serde-rs/json (serde_json)</summary>
###
[`v1.0.140`](https://redirect.github.com/serde-rs/json/releases/tag/v1.0.140)
[Compare
Source](https://redirect.github.com/serde-rs/json/compare/v1.0.139...v1.0.140)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xODUuNCIsInVwZGF0ZWRJblZlciI6IjM5LjE4NS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [quote](https://redirect.github.com/dtolnay/quote) |
workspace.dependencies | patch | `1.0.38` -> `1.0.39` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/quote (quote)</summary>
###
[`v1.0.39`](https://redirect.github.com/dtolnay/quote/releases/tag/1.0.39)
[Compare
Source](https://redirect.github.com/dtolnay/quote/compare/1.0.38...1.0.39)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xODUuNCIsInVwZGF0ZWRJblZlciI6IjM5LjE4NS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [serde](https://serde.rs)
([source](https://redirect.github.com/serde-rs/serde)) |
workspace.dependencies | patch | `1.0.218` -> `1.0.219` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>serde-rs/serde (serde)</summary>
###
[`v1.0.219`](https://redirect.github.com/serde-rs/serde/releases/tag/v1.0.219)
[Compare
Source](https://redirect.github.com/serde-rs/serde/compare/v1.0.218...v1.0.219)
- Prevent `absolute_paths` Clippy restriction being triggered inside
macro-generated code
([#​2906](https://redirect.github.com/serde-rs/serde/issues/2906),
thanks [@​davidzeng0](https://redirect.github.com/davidzeng0))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xODUuNCIsInVwZGF0ZWRJblZlciI6IjM5LjE4NS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [proc-macro2](https://redirect.github.com/dtolnay/proc-macro2) |
workspace.dependencies | patch | `1.0.93` -> `1.0.94` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/proc-macro2 (proc-macro2)</summary>
###
[`v1.0.94`](https://redirect.github.com/dtolnay/proc-macro2/releases/tag/1.0.94)
[Compare
Source](https://redirect.github.com/dtolnay/proc-macro2/compare/1.0.93...1.0.94)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xODUuNCIsInVwZGF0ZWRJblZlciI6IjM5LjE4NS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [anyhow](https://redirect.github.com/dtolnay/anyhow) |
workspace.dependencies | patch | `1.0.96` -> `1.0.97` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/anyhow (anyhow)</summary>
###
[`v1.0.97`](https://redirect.github.com/dtolnay/anyhow/releases/tag/1.0.97)
[Compare
Source](https://redirect.github.com/dtolnay/anyhow/compare/1.0.96...1.0.97)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xODUuNCIsInVwZGF0ZWRJblZlciI6IjM5LjE4NS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [unicode-ident](https://redirect.github.com/dtolnay/unicode-ident) |
workspace.dependencies | patch | `1.0.17` -> `1.0.18` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/unicode-ident (unicode-ident)</summary>
###
[`v1.0.18`](https://redirect.github.com/dtolnay/unicode-ident/releases/tag/1.0.18)
[Compare
Source](https://redirect.github.com/dtolnay/unicode-ident/compare/1.0.17...1.0.18)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xODUuNCIsInVwZGF0ZWRJblZlciI6IjM5LjE4NS40IiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
We currently fail to add the stubs for the `venv` stdlib module because
there is a `venv/` ignore pattern in the top-level `.gitignore` file.
## Test Plan
Ran the typeshed sync workflow manually once to see if the `venv/`
folder is now correctly added.
## Summary
Theoretically this should be slightly more performant, since the
`class.is_known()` calls each do a separate Salsa lookup, which we can
avoid if we do a single `match` on the value of `class.known()`. It also
ends up being two lines less code overall!
## Test Plan
`cargo test -p red_knot_python_semantic`
## Summary
Fixes#16566, fixes#16575
The semantics of `Type::class_member` changed in
https://github.com/astral-sh/ruff/pull/16416, but the property-test
infrastructure was not updated. That means that the property tests were
panicking on the second `expect_type` call here:
0361021863/crates/red_knot_python_semantic/src/types/property_tests.rs (L151-L158)
With the somewhat unhelpful message:
```
Expected a (possibly unbound) type, not an unbound symbol
```
Applying this patch, and then running `QUICKCHECK_TESTS=1000000 cargo
test --release -p red_knot_python_semantic -- --ignored
types::property_tests::stable::equivalent_to_is_reflexive` showed
clearly that it was no longer able to find _any_ methods on _any_
classes due to the change in semantics of `Type::class_member`:
```diff
--- a/crates/red_knot_python_semantic/src/types/property_tests.rs
+++ b/crates/red_knot_python_semantic/src/types/property_tests.rs
@@ -27,7 +27,7 @@
use std::sync::{Arc, Mutex, MutexGuard, OnceLock};
use crate::db::tests::{setup_db, TestDb};
-use crate::symbol::{builtins_symbol, known_module_symbol};
+use crate::symbol::{builtins_symbol, known_module_symbol, Symbol};
use crate::types::{
BoundMethodType, CallableType, IntersectionBuilder, KnownClass, KnownInstanceType,
SubclassOfType, TupleType, Type, UnionType,
@@ -150,10 +150,11 @@ impl Ty {
Ty::BuiltinsFunction(name) => builtins_symbol(db, name).symbol.expect_type(),
Ty::BuiltinsBoundMethod { class, method } => {
let builtins_class = builtins_symbol(db, class).symbol.expect_type();
- let function = builtins_class
- .class_member(db, method.into())
- .symbol
- .expect_type();
+ let Symbol::Type(function, ..) =
+ builtins_class.class_member(db, method.into()).symbol
+ else {
+ panic!("no method `{method}` on class `{class}`");
+ };
create_bound_method(db, function, builtins_class)
}
```
This PR updates the property-test infrastructure to use `Type::member`
rather than `Type::class_member`.
## Test Plan
- Ran `QUICKCHECK_TESTS=1000000 cargo test --release -p
red_knot_python_semantic -- --ignored types::property_tests::stable`
successfully
- Checked that there were no remaining uses of `Type::class_member` in
`property_tests.rs`
## Summary
Fixes a small nit of mine -- we are currently inconsistent in our
spelling between "metaclass" and "meta class", and between "meta type"
and "meta-type". This PR means that we consistently use "metaclass" and
"meta-type".
## Test Plan
`uvx pre-commit run -a`
## Summary
Part of https://github.com/astral-sh/ruff/issues/15382
This PR implements a general callable type that wraps around a
`Signature` and it uses that new type to represent `typing.Callable`.
It also implements `Display` support for `Callable`. The format is as:
```
([<arg name>][: <arg type>][ = <default type>], ...) -> <return type>
```
The `/` and `*` separators are added at the correct boundary for
positional-only and keyword-only parameters. Now, as `typing.Callable`
only has positional-only parameters, the rendered signature would be:
```py
Callable[[int, str], None]
# (int, str, /) -> None
```
The `/` separator represents that all the arguments are positional-only.
The relationship methods that check assignability, subtype relationship,
etc. are not yet implemented and will be done so as a follow-up.
## Test Plan
Add test cases for display support for `Signature` and various mdtest
for `typing.Callable`.
## Summary
Resolves#16365
Add support for unpacking `with` statement targets.
## Test Plan
Added some test cases, alike the ones added by #15058.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
* Attributes/method are now properly looked up on metaclasses, when
called on class objects
* We properly distinguish between data descriptors and non-data
descriptors (but we do not yet support them in store-context, i.e.
`obj.data_descr = …`)
* The descriptor protocol is now implemented in a single unified place
for instances, classes and dunder-calls. Unions and possibly-unbound
symbols are supported in all possible stages of the process by creating
union types as results.
* In general, the handling of "possibly-unbound" symbols has been
improved in a lot of places: meta-class attributes, attributes,
descriptors with possibly-unbound `__get__` methods, instance
attributes, …
* We keep track of type qualifiers in a lot more places. I anticipate
that this will be useful if we import e.g. `Final` symbols from other
modules (see relevant change to typing spec:
https://github.com/python/typing/pull/1937).
* Detection and special-casing of the `typing.Protocol` special form in
order to avoid lots of changes in the test suite due to new `@Todo`
types when looking up attributes on builtin types which have `Protocol`
in their MRO. We previously
looked up attributes in a wrong way, which is why this didn't come up
before.
closes#16367closes#15966
## Context
The way attribute lookup in `Type::member` worked before was simply
wrong (mostly my own fault). The whole instance-attribute lookup should
probably never have been integrated into `Type::member`. And the
`Type::static_member` function that I introduced in my last descriptor
PR was the wrong abstraction. It's kind of fascinating how far this
approach took us, but I am pretty confident that the new approach
proposed here is what we need to model this correctly.
There are three key pieces that are required to implement attribute
lookups:
- **`Type::class_member`**/**`Type::find_in_mro`**: The
`Type::find_in_mro` method that can look up attributes on class bodies
(and corresponding bases). This is a partial function on types, as it
can not be called on instance types like`Type::Instance(…)` or
`Type::IntLiteral(…)`. For this reason, we usually call it through
`Type::class_member`, which is essentially just
`type.to_meta_type().find_in_mro(…)` plus union/intersection handling.
- **`Type::instance_member`**: This new function is basically the
type-level equivalent to `obj.__dict__[name]` when called on
`Type::Instance(…)`. We use this to discover instance attributes such as
those that we see as declarations on class bodies or as (annotated)
assignments to `self.attr` in methods of a class.
- The implementation of the descriptor protocol. It works slightly
different for instances and for class objects, but it can be described
by the general framework:
- Call `type.class_member("attribute")` to look up "attribute" in the
MRO of the meta type of `type`. Call the resulting `Symbol` `meta_attr`
(even if it's unbound).
- Use `meta_attr.class_member("__get__")` to look up `__get__` on the
*meta type* of `meta_attr`. Call it with `__get__(meta_attr, self,
self.to_meta_type())`. If this fails (either the lookup or the call),
just proceed with `meta_attr`. Otherwise, replace `meta_attr` in the
following with the return type of `__get__`. In this step, we also probe
if a `__set__` or `__delete__` method exists and store it in
`meta_attr_kind` (can be either "data descriptor" or "normal attribute
or non-data descriptor").
- Compute a `fallback` type.
- For instances, we use `self.instance_member("attribute")`
- For class objects, we use `class_attr =
self.find_in_mro("attribute")`, and then try to invoke the descriptor
protocol on `class_attr`, i.e. we look up `__get__` on the meta type of
`class_attr` and call it with `__get__(class_attr, None, self)`. This
additional invocation of the descriptor protocol on the fallback type is
one major asymmetry in the otherwise universal descriptor protocol
implementation.
- Finally, we look at `meta_attr`, `meta_attr_kind` and `fallback`, and
handle various cases of (possible) unboundness of these symbols.
- If `meta_attr` is bound and a data descriptor, just return `meta_attr`
- If `meta_attr` is not a data descriptor, and `fallback` is bound, just
return `fallback`
- If `meta_attr` is not a data descriptor, and `fallback` is unbound,
return `meta_attr`
- Return unions of these three possibilities for partially-bound
symbols.
This allows us to handle class objects and instances within the same
framework. There is a minor additional detail where for instances, we do
not allow the fallback type (the instance attribute) to completely
shadow the non-data descriptor. We do this because we (currently) don't
want to pretend that we can statically infer that an instance attribute
is always set.
Dunder method calls can also be embedded into this framework. The only
thing that changes is that *there is no fallback type*. If a dunder
method is called on an instance, we do not fall back to instance
variables. If a dunder method is called on a class object, we only look
it up on the meta class, never on the class itself.
## Test Plan
New Markdown tests.
## Summary
This PR closes#15199.
The change I just made is to set all variables to type `Unknown` if
unpacking fails, but in some cases this may be excessive.
For example:
```py
a, b, c = "ab"
reveal_type(a) # Unknown, but it would be reasonable to think of it as LiteralString
reveal_type(c) # Unknown
```
```py
# Failed to unpack before the starred expression
(a, b, *c, d, e) = (1,)
reveal_type(a) # Unknown
reveal_type(b) # Unknown
...
# Failed to unpack after the starred expression
(a, b, *c, d, e) = (1, 2, 3)
reveal_type(a) # Unknown, but should it be Literal[1]?
reveal_type(b) # Unknown, but should it be Literal[2]?
reveal_type(c) # Todo
reveal_type(d) # Unknown
reveal_type(e) # Unknown
```
I will modify it if you think it would be better to make it a different
type than just `Unknown`.
## Test Plan
I have made appropriate modifications to the test cases affected by this
change, and also added some more test cases.
## Summary
This should give us better coverage for the unsupported syntax error
features and
increases our confidence that the formatter doesn't accidentially
introduce new unsupported
syntax errors.
A feature like this would have been very useful when working on f-string
formatting
where it took a lot of iteration to find all Python 3.11 or older
incompatibilities.
## Test Plan
I applied my changes on top of
https://github.com/astral-sh/ruff/pull/16523 and
removed the target version check in the with-statement formatting code.
As expected,
the integration tests now failed
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
If an mdtest fails, the error output will include an example command
that can be run to re-run just the failing test, e.g
```
To rerun this specific test, set the environment variable: MDTEST_TEST_FILTER="sync.md - With statements - Context manager with non-callable `__exit__` attribute"
MDTEST_TEST_FILTER="sync.md - With statements - Context manager with non-callable `__exit__` attribute" cargo test -p red_knot_python_semantic --test mdtest -- mdtest__with_sync
```
This is very helpful, but because we're printing the envvar value
surrounded in double-quotes, the bits between backticks in this example
get interpreted as a shell interpolation. When running this in zsh, for
example, I see
```console
❯ MDTEST_TEST_FILTER="sync.md - With statements - Context manager with non-callable `__exit__` attribute" cargo test -p red_knot_python_semantic --test mdtest -- mdtest__with_sync
zsh: command not found: __exit__
Compiling red_knot_python_semantic v0.0.0 (/home/ericmarkmartin/Development/ruff/crates/red_knot_python_semantic)
Compiling red_knot_test v0.0.0 (/home/ericmarkmartin/Development/ruff/crates/red_knot_test)
Finished `test` profile [unoptimized + debuginfo] target(s) in 6.09s
Running tests/mdtest.rs (target/debug/deps/mdtest-149b8f9d937e36bc)
running 1 test
test mdtest__with_sync ... ok
```
[^1]
This is a minor annoyance which we can solve by using single-quotes
instead of double-quotes for this string. To do so safely, we also
escape single-quotes possibly contained within the string.
There is a [shell-quote](https://github.com/allenap/shell-quote) crate,
which seems to handle all this escaping stuff for you but fixing this
issue perfectly isn't a big deal (if there are more things to escape we
can deal with it then), so adding a new dependency (even a dev one)
seemed overkill.
[^1]: The filter does still work---it turns out that the filter
`MDTEST_TEST_FILTER="sync.md - With statements - Context manager with
non-callable attribute"` (what you get after the failed interpolation)
is still good enough
## Test Plan
<!-- How was it tested? -->
I broke the ``## Context manager with non-callable `__exit__`
attribute`` test by deleting the error assertion, then successfully ran
the new command it printed out.
Summary
--
Unlike the other syntax errors detected so far, parenthesized keyword
arguments are only allowed *before* 3.8. It sounds like they were only
accidentally allowed before that [^1].
As an aside, you get a pretty confusing error from Python for this, so
it's nice that we can catch it:
```pycon
>>> def f(**kwargs): ...
... f((a)=1)
...
File "<python-input-0>", line 2
f((a)=1)
^^^
SyntaxError: expression cannot contain assignment, perhaps you meant "=="?
>>>
```
Test Plan
--
Inline tests.
[^1]: https://github.com/python/cpython/issues/78822
Summary
--
Checks for tuple unpacking in `return` and `yield` statements before
Python 3.8, as described [here].
Test Plan
--
Inline tests.
[here]: https://github.com/python/cpython/issues/76298
## Summary
- `Never` is callable
- `Never` is iterable
- Arbitrary attributes can be accessed on `Never`
Split out from #16416 that is going to be required.
## Test Plan
Tests for all properties above.
## Summary
This came up in https://github.com/astral-sh/ruff/issues/16477
It's not obvious from the D417 rule's documentation that it only checks
docstrings
with an arguments section. Functions without such a section aren't
checked.
This PR tries to make this clearer in the documentation.
## Summary
This PR introduces a new mdtest option `system` that can either be
`in-memory` or `os`
where `in-memory` is the default.
The motivation for supporting `os` is so that we can write OS/system
specific tests
with mdtests. Specifically, I want to write mdtests for the module
resolver,
testing that module resolution is case sensitive.
## Test Plan
I tested that the case-sensitive module resolver test start failing when
setting `system = "os"`
## Summary
Python's module resolver is case sensitive.
This PR adds mdtests that assert that our module resolution is case
sensitive.
The tests currently all pass because our in memory file system is case
sensitive.
I'll add support for using the real file system to the mdtest framework
in a separate PR.
This PR also adds support for specifying extra search paths to the
mdtest framework.
## Test Plan
The tests fail when running them using the real file system.
To kick off the work of supporting generics, this adds many new
(currently failing) tests, showing the behavior we plan to support.
This is still missing a lot! Not included:
- typevar tuples
- param specs
- variance
- `Self`
But it's a good start! We can add more failing tests for those once we
tackle these.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
This is split out of https://github.com/astral-sh/ruff/pull/14029, to
reduce the size of that PR, and to validate that this "fallback type"
support in `TypeInference` doesn't come with a performance cost. It also
improves the reliability and debuggability of our current (temporary)
cycle handling.
In order to recover from a cycle, we have to be able to construct a
"default" `TypeInference` where all expressions and definitions have
some "default" type. In our current cycle handling, this "default" type
is just unknown or a todo type. With fixpoint iteration, the "default"
type will be `Type::Never`, which is the "bottom" type that fixpoint
iteration starts from.
Since it would be costly (both in space and time) to actually enumerate
all expressions and definitions in a scope, just to insert the same
default type for all of them, instead we add an optional "missing type"
fallback to `TypeInference`, which (if set) is the fallback type for any
expression or definition which doesn't have an explicit type set.
With this change, cycles can no longer result in the dreaded "Missing
key" errors looking up the type of some expression.
... with supporting types. This is meant to give us a base to work with
in terms of our new diagnostic data model. I expect the representations
to be tweaked over time, but I think this is a decent start.
I would also like to add doctest examples, but I think it's better if we
wait until an initial version of the renderer is done for that.
This puts them out of the way so that they can hopefully be removed more
easily in the (near) future, and so that they don't get in the way of
the new types. This also makes the intent of the migration a bit clearer
in the code and hopefully results in less confusion.
This trait should eventually go away, so we rename it (and supporting
types) to make room for a new concrete `Diagnostic` type.
This commit is just the rename. In the next commit, we'll move it to a
different module.
Summary
--
Another simple one, just detect type parameter lists in functions
and classes. Like pyright, we don't emit a second diagnostic for
`type` alias statements, which were also introduced in 3.12.
Test Plan
--
Inline tests.
## Summary
This PR does a small refactor to avoid double
`symbol_table(...).symbol(...)` call to check for `__slots__` and
`TYPE_CHECKING`. It merges them into a single call.
I noticed this while looking at
https://github.com/astral-sh/ruff/pull/16468.
## Summary
This PR adds more features to #16468.
* Adds a new error rule `invalid-type-checking-constant`, which occurs
when we try to assign a value other than `False` to a user-defined
`TYPE_CHECKING` variable (it is possible to assign `...` in a stub
file).
* Allows annotated assignment to `TYPE_CHECKING`. Only types that
`False` can be assigned to are allowed. However, the type of
`TYPE_CHECKING` will be inferred to be `Literal[True]` regardless of
what the type is specified.
## Test plan
I ran the tests with `cargo test -p red_knot_python_semantic` and
confirmed that all tests passed.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Fixes https://github.com/astral-sh/ruff/issues/16476fixes: #11453
We format notebooks cell by cell. That means, that offsets in parse
errors are relative
to the cell and not the entire document. We didn't account for this fact
when emitting syntax errors for notebooks in the formatter.
This PR ensures that we correctly offset parse errors by the cell
location.
## Test Plan
Added test (it panicked before)
Summary
--
Detects the presence of a [PEP 696] type parameter default before Python
3.13.
Test Plan
--
New inline parser tests for type aliases, generic functions and generic
classes.
[PEP 696]: https://peps.python.org/pep-0696/#grammar-changes
Summary
--
This is a follow-up to #16446 to fix the diagnostic range to point to
the `*` like `pyright` does
(https://github.com/astral-sh/ruff/pull/16446#discussion_r1976900643).
Storing the range in the `ExceptClauseKind::Star` variant feels slightly
awkward, but we don't store the star itself anywhere on the
`ExceptHandler`. And we can't just take `ExceptHandler.start() +
"except".text_len()` because this code appears to be valid:
```python
try: ...
except * Error: ...
```
Test Plan
--
Existing tests.
## Summary
This PR closes#15722.
The change is that if the variable `TYPE_CHECKING` is defined/imported,
the type of the variable is interpreted as `Literal[True]` regardless of
what the value is.
This is compatible with the behavior of other type checkers (e.g. mypy,
pyright).
## Test Plan
I ran the tests with `cargo test -p red_knot_python_semantic` and
confirmed that all tests passed.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Summary
--
This is a follow up addressing the comments on #16425. As @dhruvmanila
pointed out, the naming is a bit tricky. I went with `has_no_errors` to
try to differentiate it from `is_valid`. It actually ends up negated in
most uses, so it would be more convenient to have `has_any_errors` or
`has_errors`, but I thought it would sound too much like the opposite of
`is_valid` in that case. I'm definitely open to suggestions here.
Test Plan
--
Existing tests.
## Summary
Resolves#16445.
`UP028` is now no longer always fixable: it will not offer a fix when at
least one `ExprName` target is bound to either a `global` or a
`nonlocal` declaration.
## Test Plan
`cargo nextest run` and `cargo insta test`.
## Summary
Fixes#9381. This PR fixes errors like
```
Cause: error parsing glob '/Users/me/project/{{cookiecutter.project_dirname}}/__pycache__': nested alternate groups are not allowed
```
caused by glob special characters in filenames like
`{{cookiecutter.project_dirname}}`. When the user is matching that
directory exactly, they can use the workaround given by
https://github.com/astral-sh/ruff/issues/7959#issuecomment-1764751734,
but that doesn't work for a nested config file with relative paths. For
example, the directory tree in the reproduction repo linked
[here](https://github.com/astral-sh/ruff/issues/9381#issuecomment-2677696408):
```
.
├── README.md
├── hello.py
├── pyproject.toml
├── uv.lock
└── {{cookiecutter.repo_name}}
├── main.py
├── pyproject.toml
└── tests
└── maintest.py
```
where the inner `pyproject.toml` contains a relative glob:
```toml
[tool.ruff.lint.per-file-ignores]
"tests/*" = ["F811"]
```
## Test Plan
A new CLI test in both the linter and formatter. The formatter test may
not be necessary because I didn't have to modify any additional code to
pass it, but the original report mentioned both `check` and `format`, so
I wanted to be sure both were fixed.
The PR addresses issue #16396 .
Specifically:
- If the exit statement contains a code keyword argument, it is
converted into a positional argument.
- If retrieving the code from the exit statement is not possible, a
violation is raised without suggesting a fix.
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
This PR adds support for an optional list of paths that should be
checked to `knot check`.
E.g. to only check the `src` directory
```sh
knot check src
```
The default is to check all files in the project but users can reduce
the included files by specifying one or multiple optional paths.
The main two challenges with adding this feature were:
* We now need to show an error when one of the provided paths doesn't
exist. That's why this PR now collects errors from the project file
indexing phase and adds them to the output diagnostics. The diagnostic
looks similar to ruffs (see CLI test)
* The CLI should pick up new files added to included folders. For
example, `knot check src --watch` should pick up new files that are
added to the `src` folder. This requires that we now filter the files
before adding them to the project. This is a good first step to
supporting `include` and `exclude`.
The PR makes two simplifications:
1. I didn't test the changes with case-insensitive file systems. We may
need to do some extra path normalization to support those well. See
https://github.com/astral-sh/ruff/issues/16400
2. Ideally, we'd accumulate the IO errors from the initial indexing
phase and subsequent incremental indexing operations. For example, we
should preserve the IO diagnostic for a non existing `test.py` if it was
specified as an explicit CLI argument until the file gets created and we
should show it again when the file gets deleted. However, this is
somewhat complicated because we'd need to track which files we revisited
(or were removed because the entire directory is gone). I considered
this too low a priority as it's worth dealing with right now.
The implementation doesn't support symlinks within the project but that
is the same as Ruff and is unchanged from before this PR.
Closes https://github.com/astral-sh/ruff/issues/14193
## Test Plan
Added CLI and file watching integration tests. Manually testing.
Split from F841 following discussion in #8884.
Fixes#8884.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Add a new rule for unused assignments in tuples. Remove similar behavior
from F841.
## Test Plan
Adapt F841 tests and move them over to the new rule.
<!-- How was it tested? -->
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[globset](https://redirect.github.com/BurntSushi/ripgrep/tree/master/crates/globset)
([source](https://redirect.github.com/BurntSushi/ripgrep/tree/HEAD/crates/globset))
| workspace.dependencies | patch | `0.4.15` -> `0.4.16` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNzYuMiIsInVwZGF0ZWRJblZlciI6IjM5LjE3Ni4yIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [clap](https://redirect.github.com/clap-rs/clap) |
workspace.dependencies | patch | `4.5.30` -> `4.5.31` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>clap-rs/clap (clap)</summary>
###
[`v4.5.31`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4531---2025-02-24)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.30...v4.5.31)
##### Features
- Add `ValueParserFactory` for `Saturating<T>`
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNzYuMiIsInVwZGF0ZWRJblZlciI6IjM5LjE3Ni4yIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [schemars](https://graham.cool/schemars/)
([source](https://redirect.github.com/GREsau/schemars)) |
workspace.dependencies | patch | `0.8.21` -> `0.8.22` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>GREsau/schemars (schemars)</summary>
###
[`v0.8.22`](https://redirect.github.com/GREsau/schemars/blob/HEAD/CHANGELOG.md#0822---2025-02-25)
[Compare
Source](https://redirect.github.com/GREsau/schemars/compare/v0.8.21...v0.8.22)
##### Fixed:
- Fix compatibility with rust 2024 edition
([https://github.com/GREsau/schemars/pull/378](https://redirect.github.com/GREsau/schemars/pull/378))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNzYuMiIsInVwZGF0ZWRJblZlciI6IjM5LjE3Ni4yIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [insta](https://insta.rs/)
([source](https://redirect.github.com/mitsuhiko/insta)) |
workspace.dependencies | patch | `1.42.1` -> `1.42.2` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>mitsuhiko/insta (insta)</summary>
###
[`v1.42.2`](https://redirect.github.com/mitsuhiko/insta/blob/HEAD/CHANGELOG.md#1422)
[Compare
Source](https://redirect.github.com/mitsuhiko/insta/compare/1.42.1...1.42.2)
- Support other indention characters than spaces in inline snapshots.
[#​679](https://redirect.github.com/mitsuhiko/insta/issues/679)
- Fix an issue where multiple targets with the same root would cause too
many pending snapshots to be reported.
[#​730](https://redirect.github.com/mitsuhiko/insta/issues/730)
- Hide `unseen` option in CLI, as it's pending deprecation.
[#​732](https://redirect.github.com/mitsuhiko/insta/issues/732)
- Stop `\t` and `\x1b` (ANSI color escape) from causing snapshots to be
escaped.
[#​715](https://redirect.github.com/mitsuhiko/insta/issues/715)
- Improved handling of inline snapshots within `allow_duplicates! { ..
}`.
[#​712](https://redirect.github.com/mitsuhiko/insta/issues/712)
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNzYuMiIsInVwZGF0ZWRJblZlciI6IjM5LjE3Ni4yIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
This PR is the first in a series derived from
https://github.com/astral-sh/ruff/pull/16308, each of which add support
for detecting one version-related syntax error from
https://github.com/astral-sh/ruff/issues/6591. This one should be
the largest because it also includes the addition of the
`Parser::add_unsupported_syntax_error` method
Otherwise I think the general structure will be the same for each syntax
error:
* Detecting the error in the parser
* Inline parser tests for the new error
* New ruff CLI tests for the new error
## Test Plan
As noted above, there are new inline parser tests, as well as new ruff
CLI
tests. Once https://github.com/astral-sh/ruff/pull/16379 is resolved,
there should also be new mdtests for red-knot,
but this PR does not currently include those.
Regardless of whether #16408 and #16311 pan out, this part is worth
pulling out as a separate PR.
Before, you had to define a new `IndexVec` index type for each type of
association list you wanted to create. Now there's a single index type
that's internal to the alist implementation, and you use `List<K, V>` to
store a handle to a particular list.
This also adds some property tests for the alist implementation.
## Summary
This PR updates the ordering of changelog sections to prioritize `bug`
label such that any PRs that has that label is categorized in "Bug
fixes" section in when generating the changelog irrespective of any
other labels present on the PR.
I think this works because I've seen PRs with both `server` and `bug` in
the "Server" section instead of the "Bug fixes" section. For example,
https://github.com/astral-sh/ruff/pull/16262 in
https://github.com/astral-sh/ruff/releases/tag/0.9.7.
On that note, this also changes the ordering such that any PR with both
`server` and `bug` labels are in the "Bug fixes" section instead of the
"Server" section. This is in line with how "Formatter" is done. I think
it makes sense to instead prefix the entries with "Formatter:" and
"Server:" if they're bug fixes. But, I'm happy to change this such that
any PRs with `formatter` and `server` labels are always in their own
section irrespective of other labels.
## Summary
This PR adds support for a pragma-style header for inline parser tests
containing JSON-serialized `ParseOptions`. For example,
```python
# parse_options: { "target-version": "3.9" }
match 2:
case 1:
pass
```
The line must start with `# parse_options: ` and then the rest of the
(trimmed) line is deserialized into `ParseOptions` used for parsing the
the test.
## Test Plan
Existing inline tests, plus two new inline tests for
`match-before-py310`.
---------
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
## Summary
As mentioned in
https://github.com/astral-sh/ruff/pull/16296#discussion_r1967047387
This PR updates the client settings resolver to notify the user if there
are any errors in the config using a very basic approach. In addition,
each error related to specific settings are logged.
This isn't the best approach because it can log the same message
multiple times when both workspace and global settings are provided and
they both are the same. This is the case for a single workspace VS Code
instance.
I do have some ideas on how to improve this and will explore them during
my free time (low priority):
* Avoid resolving the global settings multiple times as they're static
* Include the source of the setting (workspace or global?)
* Maybe use a struct (`ResolvedClientSettings` +
`Vec<ClientSettingsResolverError>`) instead to make unit testing easier
## Test Plan
Using:
```jsonc
{
"ruff.logLevel": "debug",
// Invalid settings
"ruff.configuration": "$RANDOM",
"ruff.lint.select": ["RUF000", "I001"],
"ruff.lint.extendSelect": ["B001", "B002"],
"ruff.lint.ignore": ["I999", "F401"]
}
```
The error logs:
```
2025-02-27 12:30:04.318736000 ERROR Failed to load settings from `configuration`: error looking key 'RANDOM' up: environment variable not found
2025-02-27 12:30:04.319196000 ERROR Failed to load settings from `configuration`: error looking key 'RANDOM' up: environment variable not found
2025-02-27 12:30:04.320549000 ERROR Unknown rule selectors found in `lint.select`: ["RUF000"]
2025-02-27 12:30:04.320669000 ERROR Unknown rule selectors found in `lint.extendSelect`: ["B001"]
2025-02-27 12:30:04.320764000 ERROR Unknown rule selectors found in `lint.ignore`: ["I999"]
```
Notification preview:
<img width="470" alt="Screenshot 2025-02-27 at 12 29 06 PM"
src="https://github.com/user-attachments/assets/61f41d5c-2558-46b3-a1ed-82114fd8ec22"
/>
## Summary
Closes: https://github.com/astral-sh/ruff/issues/16267
This change skips building the `index` in RuffSettingsIndex when the
configuration preference, in the editor settings, is set to
`editorOnly`. This is appropriate due to the fact that the indexes will
go unused as long as the configuration preference persists.
## Test Plan
I have tested this in VSCode and can confirm that we skip indexing when
`editorOnly` is set. Upon switching back to `editorFirst` or
`filesystemFirst` we index the settings as normal.
I don't seen any unit tests for setting indexing at the moment, but I am
happy to give it a shot if that is something we want.
We currently keep two separate pieces of state regarding the current
loop on `SemanticIndexBuilder`. One is an enum simply reflecting whether
we are currently inside a loop, and the other is the saved flow states
for `break` statements found in the current loop.
For adding loopy control flow, I'll need to add some additional loop
state (`continue` states, for example). Prepare for this by
consolidating our existing loop state into a single struct and
simplifying the API for pushing and popping a loop.
This is purely a refactor, so tests are not changed.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Resolves#16374.
`PLW0177` now also reports the pattern of a case branch if it is an
attribute access whose qualified name is that of either `np.nan` or
`math.nan`.
As the rule is in preview, the changes are not preview-gated.
## Test Plan
`cargo nextest run` and `cargo insta test`.
Minor follow-up to https://github.com/astral-sh/ruff/pull/16161
This `not_callable` flag wasn't functional, because it could never be
`false`. It was initialized to `true` and then only ever updated with
`|=`, which can never make it `false`.
Add a test that exercises the case where it _should_ be `false` (all of
the union elements are callable) but `bindings` is also empty (all union
elements have binding errors). Before this PR, the added test wrongly
emits a diagnostic that the union `Literal[f1] | Literal[f2]` is not
callable.
And add a test where a union call results in one binding error and one
not-callable error, where we currently give the wrong result (we show
only the binding error), with a TODO.
Also add TODO comments in a couple other tests where ideally we'd report
more than just one error out of a union call.
Also update the flag name to `all_errors_not_callable` to more clearly
indicate the semantics of the flag.
## Summary
Currently, the log messages emitted by the server includes multiple
information which isn't really required most of the time.
Here's the current format:
```
0.000755625s DEBUG main ruff_server::session::index::ruff_settings: Indexing settings for workspace: /Users/dhruv/playground/ruff
0.016334666s DEBUG ThreadId(10) ruff_server::session::index::ruff_settings: Ignored path via `exclude`: /Users/dhruv/playground/ruff/.vscode
0.019954541s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/playground/ruff
0.020160416s TRACE ruff:main notification{method="textDocument/didOpen"}: ruff_server::server::api: enter
0.020209625s TRACE ruff:worker:0 request{id=1 method="textDocument/diagnostic"}: ruff_server::server::api: enter
0.020228166s DEBUG ruff:worker:0 request{id=1 method="textDocument/diagnostic"}: ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/test.py
0.020359833s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
```
This PR updates the following:
* Uses current timestamp (same as red-knot) for all log levels instead
of the uptime value
* Includes the target and thread names only at the trace level
What this means is that the message is reduced to only important
information at DEBUG level:
```
2025-02-26 11:35:02.198375000 DEBUG Indexing settings for workspace: /Users/dhruv/playground/ruff
2025-02-26 11:35:02.209933000 DEBUG Ignored path via `exclude`: /Users/dhruv/playground/ruff/.vscode
2025-02-26 11:35:02.217165000 INFO Registering workspace: /Users/dhruv/playground/ruff
2025-02-26 11:35:02.217631000 DEBUG Included path via `include`: /Users/dhruv/playground/ruff/lsp/test.py
2025-02-26 11:35:02.217684000 INFO Configuration file watcher successfully registered
```
while still showing the other information (thread names and target) at
trace level:
```
2025-02-26 11:35:27.819617000 DEBUG main ruff_server::session::index::ruff_settings: Indexing settings for workspace: /Users/dhruv/playground/ruff
2025-02-26 11:35:27.830500000 DEBUG ThreadId(11) ruff_server::session::index::ruff_settings: Ignored path via `exclude`: /Users/dhruv/playground/ruff/.vscode
2025-02-26 11:35:27.837212000 INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/playground/ruff
2025-02-26 11:35:27.837714000 TRACE ruff:main notification{method="textDocument/didOpen"}: ruff_server::server::api: enter
2025-02-26 11:35:27.838019000 INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
2025-02-26 11:35:27.838084000 TRACE ruff:worker:1 request{id=1 method="textDocument/diagnostic"}: ruff_server::server::api: enter
2025-02-26 11:35:27.838205000 DEBUG ruff:worker:1 request{id=1 method="textDocument/diagnostic"}: ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/test.py
```
## Summary
[Internal design
document](https://www.notion.so/astral-sh/In-editor-settings-19e48797e1ca807fa8c2c91b689d9070?pvs=4)
This PR expands `ruff.configuration` to allow inline configuration
directly in the editor. For example:
```json
{
"ruff.configuration": {
"line-length": 100,
"lint": {
"unfixable": ["F401"],
"flake8-tidy-imports": {
"banned-api": {
"typing.TypedDict": {
"msg": "Use `typing_extensions.TypedDict` instead"
}
}
}
},
"format": {
"quote-style": "single"
}
}
}
```
This means that now `ruff.configuration` accepts either a path to
configuration file or the raw config itself. It's _mostly_ similar to
`--config` with one difference that's highlighted in the following
section. So, it can be said that the format of `ruff.configuration` when
provided the config map is same as the one on the [playground] [^1].
## Limitations
<details><summary><b>Casing (<code>kebab-case</code> v/s/
<code>camelCase</code>)</b></summary>
<p>
The config keys needs to be in `kebab-case` instead of `camelCase` which
is being used for other settings in the editor.
This could be a bit confusing. For example, the `line-length` option can
be set directly via an editor setting or can be configured via
`ruff.configuration`:
```json
{
"ruff.configuration": {
"line-length": 100
},
"ruff.lineLength": 120
}
```
#### Possible solution
We could use feature flag with [conditional
compilation](https://doc.rust-lang.org/reference/conditional-compilation.html#the-cfg_attr-attribute)
to indicate that when used in `ruff_server`, we need the `Options`
fields to be renamed as `camelCase` while for other crates it needs to
be renamed as `kebab-case`. But, this might not work very easily because
it will require wrapping the `Options` struct and create two structs in
which we'll have to add `#[cfg_attr(...)]` because otherwise `serde`
will complain:
```
error: duplicate serde attribute `rename_all`
--> crates/ruff_workspace/src/options.rs:43:38
|
43 | #[cfg_attr(feature = "editor", serde(rename_all = "camelCase"))]
| ^^^^^^^^^^
```
</p>
</details>
<details><summary><b>Nesting (flat v/s nested keys)</b></summary>
<p>
This is the major difference between `--config` flag on the command-line
v/s `ruff.configuration` and it makes it such that `ruff.configuration`
has same value format as [playground] [^1].
The config keys needs to be split up into keys which can result in
nested structure instead of flat structure:
So, the following **won't work**:
```json
{
"ruff.configuration": {
"format.quote-style": "single",
"lint.flake8-tidy-imports.banned-api.\"typing.TypedDict\".msg": "Use `typing_extensions.TypedDict` instead"
}
}
```
But, instead it would need to be split up like the following:
```json
{
"ruff.configuration": {
"format": {
"quote-style": "single"
},
"lint": {
"flake8-tidy-imports": {
"banned-api": {
"typing.TypedDict": {
"msg": "Use `typing_extensions.TypedDict` instead"
}
}
}
}
}
}
```
#### Possible solution (1)
The way we could solve this and make it same as `--config` would be to
add a manual logic of converting the JSON map into an equivalent TOML
string which would be then parsed into `Options`.
So, the following JSON map:
```json
{ "lint.flake8-tidy-imports": { "banned-api": {"\"typing.TypedDict\".msg": "Use typing_extensions.TypedDict instead"}}}
```
would need to be converted into the following TOML string:
```toml
lint.flake8-tidy-imports = { banned-api = { "typing.TypedDict".msg = "Use typing_extensions.TypedDict instead" } }
```
by recursively convering `"key": value` into `key = value` which is to
remove the quotes from key and replacing `:` with `=`.
#### Possible solution (2)
Another would be to just accept `Map<String, String>` strictly and
convert it into `key = value` and then parse it as a TOML string. This
would also match `--config` but quotes might become a nuisance because
JSON only allows double quotes and so it'll require escaping any inner
quotes or use single quotes.
</p>
</details>
## Test Plan
### VS Code
**Requires https://github.com/astral-sh/ruff-vscode/pull/702**
**`settings.json`**:
```json
{
"ruff.lint.extendSelect": ["TID"],
"ruff.configuration": {
"line-length": 50,
"format": {
"quote-style": "single"
},
"lint": {
"unfixable": ["F401"],
"flake8-tidy-imports": {
"banned-api": {
"typing.TypedDict": {
"msg": "Use `typing_extensions.TypedDict` instead"
}
}
}
}
}
}
```
Following video showcases me doing the following:
1. Check diagnostics that it includes `TID`
2. Run `Ruff: Fix all auto-fixable problems` to test `unfixable`
3. Run `Format: Document` to test `line-length` and `quote-style`
https://github.com/user-attachments/assets/0a38176f-3fb0-4960-a213-73b2ea5b1180
### Neovim
**`init.lua`**:
```lua
require('lspconfig').ruff.setup {
init_options = {
settings = {
lint = {
extendSelect = { 'TID' },
},
configuration = {
['line-length'] = 50,
format = {
['quote-style'] = 'single',
},
lint = {
unfixable = { 'F401' },
['flake8-tidy-imports'] = {
['banned-api'] = {
['typing.TypedDict'] = {
msg = 'Use typing_extensions.TypedDict instead',
},
},
},
},
},
},
},
}
```
Same steps as in the VS Code test:
https://github.com/user-attachments/assets/cfe49a9b-9a89-43d7-94f2-7f565d6e3c9d
## Documentation Preview
https://github.com/user-attachments/assets/e0062f58-6ec8-4e01-889d-fac76fd8b3c7
[playground]: https://play.ruff.rs
[^1]: This has one advantage that the value can be copy-pasted directly
into the playground
## Summary
This PR builds on the changes in #16220 to pass a target Python version
to the parser. It also adds the `Parser::unsupported_syntax_errors` field, which
collects version-related syntax errors while parsing. These syntax
errors are then turned into `Message`s in ruff (in preview mode).
This PR only detects one syntax error (`match` statement before Python
3.10), but it has been pretty quick to extend to several other simple
errors (see #16308 for example).
## Test Plan
The current tests are CLI tests in the linter crate, but these could be
supplemented with inline parser tests after #16357.
I also tested the display of these syntax errors in VS Code:


---------
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
In https://github.com/astral-sh/ruff/pull/16306#discussion_r1966290700,
@carljm pointed out that #16306 introduced a terminology problem, with
too many things called a "constraint". This is a follow-up PR that
renames `Constraint` to `Predicate` to hopefully clear things up a bit.
So now we have that:
- a _predicate_ is a Python expression that might influence type
inference
- a _narrowing constraint_ is a list of predicates that constraint the
type of a binding that is visible at a use
- a _visibility constraint_ is a ternary formula of predicates that
define whether a binding is visible or a statement is reachable
This is a pure renaming, with no behavioral changes.
## Summary
Model dunder-calls correctly (and in one single place), by implementing
this behavior (using `__getitem__` as an example).
```py
def getitem_desugared(obj: object, key: object) -> object:
getitem_callable = find_in_mro(type(obj), "__getitem__")
if hasattr(getitem_callable, "__get__"):
getitem_callable = getitem_callable.__get__(obj, type(obj))
return getitem_callable(key)
```
See the new `calls/dunder.md` test suite for more information. The new
behavior also needs much fewer lines of code (the diff is positive due
to new tests).
## Test Plan
New tests; fix TODOs in existing tests.
This PR adds an implementation of [association
lists](https://en.wikipedia.org/wiki/Association_list), and uses them to
replace the previous `BitSet`/`SmallVec` representation for narrowing
constraints.
An association list is a linked list of key/value pairs. We additionally
guarantee that the elements of an association list are sorted (by their
keys), and that they do not contain any entries with duplicate keys.
Association lists have fallen out of favor in recent decades, since you
often need operations that are inefficient on them. In particular,
looking up a random element by index is O(n), just like a linked list;
and looking up an element by key is also O(n), since you must do a
linear scan of the list to find the matching element. Luckily we don't
need either of those operations for narrowing constraints!
The typical implementation also suffers from poor cache locality and
high memory allocation overhead, since individual list cells are
typically allocated separately from the heap. We solve that last problem
by storing the cells of an association list in an `IndexVec` arena.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
I am working on a project that uses ruff linters' docs to generate a
fine-tuning dataset for LLMs.
To achieve this, I first ran the command `ruff rule --all
--output-format json` to retrieve all the rules. Then, I parsed the
explanation field to get these 3 consistent sections:
- `Why is this bad?`
- `What it does`
- `Example`
However, during the initial processing, I noticed that the markdown
headings are not that consistent. For instance:
- In most cases, `Use instead` appears as a normal paragraph within the
`Example` section, but in the file
`crates/ruff_linter/src/rules/flake8_bandit/rules/django_extra.rs` it is
a level-2 heading
- The heading "What it does**?**" is used in some places, while others
consistently use "What it does"
- There are 831 `Example` headings and 65 `Examples`. But all of them
only have one example case
This PR normalized these across all rules.
## Test Plan
CI are passed.
## Summary
Add a diagnostic if a pure instance variable is accessed on a class object. For example
```py
class C:
instance_only: str
def __init__(self):
self.instance_only = "a"
# error: Attribute `instance_only` can only be accessed on instances, not on the class object `Literal[C]` itself.
C.instance_only
```
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
This PR is another step in preparing to detect syntax errors in the
parser. It introduces the new `per-file-target-version` top-level
configuration option, which holds a mapping of compiled glob patterns to
Python versions. I intend to use the
`LinterSettings::resolve_target_version` method here to pass to the
parser:
f50849aeef/crates/ruff_linter/src/linter.rs (L491-L493)
## Test Plan
I added two new CLI tests to show that the `per-file-target-version` is
respected in both the formatter and the linter.
## Summary
Add support for `@classmethod`s.
```py
class C:
@classmethod
def f(cls, x: int) -> str:
return "a"
reveal_type(C.f(1)) # revealed: str
```
## Test Plan
New Markdown tests
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [clap](https://redirect.github.com/clap-rs/clap) |
workspace.dependencies | patch | `4.5.29` -> `4.5.30` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>clap-rs/clap (clap)</summary>
###
[`v4.5.30`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4530---2025-02-17)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.29...v4.5.30)
##### Fixes
- *(assert)* Allow `num_args(0..=1)` to be used with `SetTrue`
- *(assert)* Clean up rendering of `takes_values` assertions
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNzYuMiIsInVwZGF0ZWRJblZlciI6IjM5LjE3Ni4yIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [anyhow](https://redirect.github.com/dtolnay/anyhow) |
workspace.dependencies | patch | `1.0.95` -> `1.0.96` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/anyhow (anyhow)</summary>
###
[`v1.0.96`](https://redirect.github.com/dtolnay/anyhow/releases/tag/1.0.96)
[Compare
Source](https://redirect.github.com/dtolnay/anyhow/compare/1.0.95...1.0.96)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNzYuMiIsInVwZGF0ZWRJblZlciI6IjM5LjE3Ni4yIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [serde_json](https://redirect.github.com/serde-rs/json) |
workspace.dependencies | patch | `1.0.138` -> `1.0.139` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>serde-rs/json (serde_json)</summary>
###
[`v1.0.139`](https://redirect.github.com/serde-rs/json/releases/tag/v1.0.139)
[Compare
Source](https://redirect.github.com/serde-rs/json/compare/v1.0.138...v1.0.139)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNzYuMiIsInVwZGF0ZWRJblZlciI6IjM5LjE3Ni4yIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [log](https://redirect.github.com/rust-lang/log) |
workspace.dependencies | patch | `0.4.25` -> `0.4.26` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>rust-lang/log (log)</summary>
###
[`v0.4.26`](https://redirect.github.com/rust-lang/log/blob/HEAD/CHANGELOG.md#0426---2025-02-18)
[Compare
Source](https://redirect.github.com/rust-lang/log/compare/0.4.25...0.4.26)
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNzYuMiIsInVwZGF0ZWRJblZlciI6IjM5LjE3Ni4yIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [serde](https://serde.rs)
([source](https://redirect.github.com/serde-rs/serde)) |
workspace.dependencies | patch | `1.0.217` -> `1.0.218` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>serde-rs/serde (serde)</summary>
###
[`v1.0.218`](https://redirect.github.com/serde-rs/serde/releases/tag/v1.0.218)
[Compare
Source](https://redirect.github.com/serde-rs/serde/compare/v1.0.217...v1.0.218)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNzYuMiIsInVwZGF0ZWRJblZlciI6IjM5LjE3Ni4yIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [tempfile](https://stebalien.com/projects/tempfile-rs/)
([source](https://redirect.github.com/Stebalien/tempfile)) |
workspace.dependencies | patch | `3.17.0` -> `3.17.1` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>Stebalien/tempfile (tempfile)</summary>
###
[`v3.17.1`](https://redirect.github.com/Stebalien/tempfile/blob/HEAD/CHANGELOG.md#3171)
[Compare
Source](https://redirect.github.com/Stebalien/tempfile/compare/v3.17.0...v3.17.1)
- Fix build with `windows-sys` 0.52. Unfortunately, we have no CI for
older `windows-sys` versions at the moment...
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNzYuMiIsInVwZGF0ZWRJblZlciI6IjM5LjE3Ni4yIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [unicode-ident](https://redirect.github.com/dtolnay/unicode-ident) |
workspace.dependencies | patch | `1.0.16` -> `1.0.17` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/unicode-ident (unicode-ident)</summary>
###
[`v1.0.17`](https://redirect.github.com/dtolnay/unicode-ident/releases/tag/1.0.17)
[Compare
Source](https://redirect.github.com/dtolnay/unicode-ident/compare/1.0.16...1.0.17)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNzYuMiIsInVwZGF0ZWRJblZlciI6IjM5LjE3Ni4yIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
* Existing example did not include RawSQL() call like it should
* Also clarify the example a bit to make it clearer that the code is not
secure
## Test Plan
N/A, only documentation updated
## Summary
I spotted a minor mistake in my descriptor protocol implementation where
`C.descriptor` would pass the meta type (`type`) of the type of `C`
(`Literal[C]`) as the owner argument to `__get__`, instead of passing
`Literal[C]` directly.
## Test Plan
New test.
Two related changes. For context:
1. We were maintaining two separate arenas of `Constraint`s in each
use-def map. One was used for narrowing constraints, and the other for
visibility constraints. The visibility constraint arena was interned,
ensuring that we always used the same ID for any particular
`Constraint`. The narrowing constraint arena was not interned.
2. The TDD code relies on _all_ TDD nodes being interned and reduced.
This is an important requirement for TDDs to be a canonical form, which
allows us to use a single int comparison to test for "always true/false"
and to compare two TDDs for equivalence. But we also need to support an
individual `Constraint` having multiple values in a TDD evaluation (e.g.
to handle a `while` condition having different values the first time
it's evaluated vs later times). Previously, we handled that by
introducing a "copy" number, which was only there as a disambiguator, to
allow an interned, deduplicated constraint ID to appear in the TDD
formula multiple times.
A better way to handle (2) is to not intern the constraints in the
visibility constraint arena! The caller now gets to decide: if they add
a `Constraint` to the arena more than once, they get distinct
`ScopedConstraintId`s — which the TDD code will treat as distinct
variables, allowing them to take on different values in the ternary
function.
With that in place, we can then consolidate on a single (non-interned)
arena, which is shared for both narrowing and visibility constraints.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Resolves 3/4 requests in #16217:
- ✅ Remove not special methods: `__cmp__`, `__div__`, `__nonzero__`, and
`__unicode__`.
- ✅ Add special methods: `__next__`, `__buffer__`, `__class_getitem__`,
`__mro_entries__`, `__release_buffer__`, and `__subclasshook__`.
- ✅ Support positional-only arguments.
- ❌ Add support for module functions `__dir__` and `__getattr__`. As
mentioned in the issue the check is scoped for methods rather than
module functions. I am hesitant to expand the scope of this check
without a discussion.
## Test Plan
- Manually confirmed each example file from the issue functioned as
expected.
- Ran cargo nextest to ensure `unexpected_special_method_signature` test
still passed.
Fixes#16217.
## Summary
This is just a small refactor to move workspace related structs and impl
out from `server.rs` where `Server` is defined and into a new
`workspace.rs`.
Update to latest Salsa main branch. This provides a point of comparison
for the perf impact of fixpoint iteration, which is based on latest
Salsa main.
This requires an update to the locked version of our boxcar dep, since
Salsa now depends on a newer version of boxcar.
## Summary
This PR achieves the following:
* Add support for checking method calls, and inferring return types from
method calls. For example:
```py
reveal_type("abcde".find("abc")) # revealed: int
reveal_type("foo".encode(encoding="utf-8")) # revealed: bytes
"abcde".find(123) # error: [invalid-argument-type]
class C:
def f(self) -> int:
pass
reveal_type(C.f) # revealed: <function `f`>
reveal_type(C().f) # revealed: <bound method: `f` of `C`>
C.f() # error: [missing-argument]
reveal_type(C().f()) # revealed: int
```
* Implement the descriptor protocol, i.e. properly call the `__get__`
method when a descriptor object is accessed through a class object or an
instance of a class. For example:
```py
from typing import Literal
class Ten:
def __get__(self, instance: object, owner: type | None = None) ->
Literal[10]:
return 10
class C:
ten: Ten = Ten()
reveal_type(C.ten) # revealed: Literal[10]
reveal_type(C().ten) # revealed: Literal[10]
```
* Add support for member lookup on intersection types.
* Support type inference for `inspect.getattr_static(obj, attr)` calls.
This was mostly used as a debugging tool during development, but seems
more generally useful. It can be used to bypass the descriptor protocol.
For the example above:
```py
from inspect import getattr_static
reveal_type(getattr_static(C, "ten")) # revealed: Ten
```
* Add a new `Type::Callable(…)` variant with the following sub-variants:
* `Type::Callable(CallableType::BoundMethod(…))` — represents bound
method objects, e.g. `C().f` above
* `Type::Callable(CallableType::MethodWrapperDunderGet(…))` — represents
`f.__get__` where `f` is a function
* `Type::Callable(WrapperDescriptorDunderGet)` — represents
`FunctionType.__get__`
* Add new known classes:
* `types.MethodType`
* `types.MethodWrapperType`
* `types.WrapperDescriptorType`
* `builtins.range`
## Performance analysis
On this branch, we do more work. We need to do more call checking, since
we now check all method calls. We also need to do ~twice as many member
lookups, because we need to check if a `__get__` attribute exists on
accessed members.
A brief analysis on `tomllib` shows that we now call `Type::call` 1780
times, compared to 612 calls before.
## Limitations
* Data descriptors are not yet supported, i.e. we do not infer correct
types for descriptor attribute accesses in `Store` context and do not
check writes to descriptor attributes. I felt like this was something
that could be split out as a follow-up without risking a major
architectural change.
* We currently distinguish between `Type::member` (with descriptor
protocol) and `Type::static_member` (without descriptor protocol). The
former corresponds to `obj.attr`, the latter corresponds to
`getattr_static(obj, "attr")`. However, to model some details correctly,
we would also need to distinguish between a static member lookup *with*
and *without* instance variables. The lookup without instance variables
corresponds to `find_name_in_mro`
[here](https://docs.python.org/3/howto/descriptor.html#invocation-from-an-instance).
We currently approximate both using `member_static`, which leads to two
open TODOs. Changing this would be a larger refactoring of
`Type::own_instance_member`, so I chose to leave it out of this PR.
## Test Plan
* New `call/methods.md` test suite for method calls
* New tests in `descriptor_protocol.md`
* New `call/getattr_static.md` test suite for `inspect.getattr_static`
* Various updated tests
## Summary
This avoids looking up `__bool__` on class `bool` for every
`Type::Instance(bool).bool()` call. 1% performance win on cold cache, 4%
win on incremental performance.
This updates the `SymbolBindings` and `SymbolDeclarations` types to use
a single smallvec of live bindings/declarations, instead of splitting
that out into separate containers for each field.
I'm seeing an 11-13% `cargo bench` performance improvement with this
locally (for both cold and incremental). I'm interested to see if
Codspeed agrees!
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
A minor cleanup that breaks up a `HashMap` of an enum into separate
`HashMap`s for each variant. (These separate fields were already how
this cache was being described in the big comment at the top of the
file!)
This is a small tweak to avoid adding the callable `Type` on the error
value itself. Namely, it's always available regardless of the error, and
it's easy to pass it down explicitly to the diagnostic generating code.
It's likely that the other `CallBindingError` variants will also want
the callable `Type` to improve diagnostics too. This way, we don't have
to duplicate the `Type` on each variant. It's just available to all of
them.
Ref https://github.com/astral-sh/ruff/pull/16239#discussion_r1962352646
## Summary
Follow up on the discussion
[here](https://github.com/astral-sh/ruff/pull/16121#discussion_r1962973298).
Replace builtin classes with custom placeholder names, which should
hopefully make the tests a bit easier to understand.
I carefully renamed things one after the other, to make sure that there
is no functional change in the tests.
## Summary
This PR should help in
https://github.com/astral-sh/ruff-vscode/issues/676.
There are two issues that this is trying to fix all related to the way
shutdown should happen as per the protocol:
1. After the server handled the [shutdown
request](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#shutdown)
and while waiting for the exit notification:
> If a server receives requests after a shutdown request those requests
should error with `InvalidRequest`.
But, we raised an error and exited. This PR fixes it by entering a loop
which responds to any request during this period with `InvalidRequest`
2. If the server received an [exit
notification](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#exit)
but the shutdown request was never received, the server handled that by
logging and exiting with success but as per the spec:
> The server should exit with success code 0 if the shutdown request has
been received before; otherwise with error code 1.
So, this PR fixes that as well by raising an error in this case.
## Test Plan
I'm not sure how to go about testing this without using a mock server.
## Summary
This is part of the preparation for detecting syntax errors in the
parser from https://github.com/astral-sh/ruff/pull/16090/. As suggested
in [this
comment](https://github.com/astral-sh/ruff/pull/16090/#discussion_r1953084509),
I started working on a `ParseOptions` struct that could be stored in the
parser. For this initial refactor, I only made it hold the existing
`Mode` option, but for syntax errors, we will also need it to have a
`PythonVersion`. For that use case, I'm picturing something like a
`ParseOptions::with_python_version` method, so you can extend the
current calls to something like
```rust
ParseOptions::from(mode).with_python_version(settings.target_version)
```
But I thought it was worth adding `ParseOptions` alone without changing
any other behavior first.
Most of the diff is just updating call sites taking `Mode` to take
`ParseOptions::from(Mode)` or those taking `PySourceType`s to take
`ParseOptions::from(PySourceType)`. The interesting changes are in the
new `parser/options.rs` file and smaller parts of `parser/mod.rs` and
`ruff_python_parser/src/lib.rs`.
## Test Plan
Existing tests, this should not change any behavior.
We now resolve references in "eager" scopes correctly — using the
bindings and declarations that are visible at the point where the eager
scope is created, not the "public" type of the symbol (typically the
bindings visible at the end of the scope).
---------
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
This uses the refactoring and support for secondary diagnostic messages
to improve the diagnostic for "invalid argument type." The main
improvement here is that we show where the function being called is
defined, and annotate the span corresponding to the invalid parameter.
This is a small little hack to make the `Diagnostic` trait
capable of supporting attaching multiple spans.
This design should be considered transient. This was just the
quickest way that I could see to pass multiple spans through from
the type checker to the diagnostic renderer.
This commit has no behavioral changes.
This refactor moves the logic for turning a `D: Diagnostic` into
an `annotate_snippets::Message` into its own types. This would
ideally just be a function or something, but the `annotate-snippets`
types want borrowed data, and sometimes we need to produce owned
data. So we gather everything we need into our own types and then
spit it back out in the format that `annotate-snippets` wants.
This factor was motivated by wanting to render multiple snippets.
The logic for generating a code frame is complicated enough that
it's worth splitting out so that we can reuse it for other spans.
(Note that one should consider this prototype-level code. It is
unlikely to survive for long.)
It seems nothing is using it, and I'm not sure if it makes semantic
sense. Particularly if we want to support multiple ranges. One could
make an argument that this ought to correspond to the "primary"
range (which we should have), but I think such a concept is better
expressed as an explicit routine if possible.
## Summary
Resolves#15979.
The file explains what Red Knot is (a type checker), what state it is in
(not yet ready for user testing), what its goals ("extremely fast") and
non-goals (not a drop-in replacement for other type checkers) are as
well as what the crates contain.
## Test Plan
None.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Move class attribute (property, methods, variables) related cases in
AIR302_names to AIR302_class_attribute
## Test Plan
No functionality change. Test fixture is reogranized
Fixes false negative when slice bound uses length of string literal.
We were meant to check the following, for example. Given:
```python
text[:bound] if text.endswith(suffix) else text
```
We want to know whether:
- `suffix` is a string literal and `bound` is a number literal
- `suffix` is an expression and `bound` is
exactly `-len(suffix)` (as AST nodes, prior to evaluation.)
The issue is that negative number literals like `-10` are stored as
unary operators applied to a number literal in the AST. So when `suffix`
was a string literal but `bound` was `-len(suffix)` we were getting
caught in the match arm where `bound` needed to be a number. This is now
fixed with a guard.
Closes#16231
## Summary
This PR updates the formatter and linter to use the `PythonVersion`
struct from the `ruff_python_ast` crate internally. While this doesn't
remove the need for the `linter::PythonVersion` enum, it does remove the
`formatter::PythonVersion` enum and limits the use in the linter to
deserializing from CLI arguments and config files and moves most of the
remaining methods to the `ast::PythonVersion` struct.
## Test Plan
Existing tests, with some inputs and outputs updated to reflect the new
(de)serialization format. I think these are test-specific and shouldn't
affect any external (de)serialization.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR updates the `ruff.printDebugInformation` command to return the
info as string in the response. Currently, we send a `window/logMessage`
request with the info but that has the disadvantage that it's not
visible to the user directly.
What `rust-analyzer` does with it's `rust-analyzer/status` request which
returns it as a string which then the client can just display it in a
separate window. This is what I'm thinking of doing as well.
Other editors can also benefit from it by directly opening a temporary
file with this information that the user can see directly.
There are couple of options here:
1. Keep using the command, keep the log request and return the string
2. Keep using the command, remove the log request and return the string
3. Create a new request similar to `rust-analyzer/status` which returns
a string
This PR implements (1) but I'd want to move towards (2) and remove the
log request completely. We haven't advertised it as such so this would
only require updating the VS Code extension to handle it by opening a
new document with the debug content.
## Test plan
For VS Code, refer to https://github.com/astral-sh/ruff-vscode/pull/694.
For Neovim, one could do:
```lua
local function execute_ruff_command(command)
local client = vim.lsp.get_clients({
bufnr = vim.api.nvim_get_current_buf(),
name = name,
method = 'workspace/executeCommand',
})[1]
if not client then
return
end
client.request('workspace/executeCommand', {
command = command,
arguments = {
{ uri = vim.uri_from_bufnr(0) }
},
function(err, result)
if err then
-- log error
return
end
vim.print(result)
-- Or, open a new window with the `result` content
end
}
```
## Summary
Separate ImportPathMoved and ProviderName to avoid misusing (AIR303)
## Test Plan
only code arrangement is updated. existing test fixture should be not be
changed
## Summary
Related to https://github.com/astral-sh/ruff-vscode/pull/686, this PR
ignores handling source code actions for notebooks which are not
prefixed with `notebook`.
The main motivation is that the native server does not actually handle
it well which results in gibberish code. There's some context about this
in
https://github.com/astral-sh/ruff-vscode/issues/680#issuecomment-2647490812
and the following comments.
closes: https://github.com/astral-sh/ruff-vscode/issues/680
## Test Plan
Running a notebook with the following does nothing except log the
message:
```json
"notebook.codeActionsOnSave": {
"source.organizeImports.ruff": "explicit",
},
```
while, including the `notebook` code actions does make the edit (as
usual):
```json
"notebook.codeActionsOnSave": {
"notebook.source.organizeImports.ruff": "explicit"
},
```
## Summary
This PR does the following:
* Moves the following from `types.rs` in `symbol.rs`:
* `symbol`
* `global_symbol`
* `imported_symbol`
* `symbol_from_bindings`
* `symbol_from_declarations`
* `SymbolAndQualifiers`
* `SymbolFromDeclarationsResult`
* Moves the following from `stdlib.rs` in `symbol.rs` and removes
`stdlib.rs`:
* `known_module_symbol`
* `builtins_symbol`
* `typing_symbol` (only for tests)
* `typing_extensions_symbol`
* `builtins_module_scope`
* `core_module_scope`
* Add `symbol_from_bindings_impl` and `symbol_from_declarations_impl` to
keep `RequiresExplicitReExport` an implementation detail
* Make `declaration_type` a `pub(crate)` as it's required in
`symbol_from_declarations` (`binding_type` is already `pub(crate)`
The main motivation is to keep the implementation details private and
only expose an ergonomic API which uses sane defaults for various
scenario to avoid any mistakes from the caller. Refer to
https://github.com/astral-sh/ruff/pull/16133#discussion_r1955262772,
https://github.com/astral-sh/ruff/pull/16133#issue-2850146612 for
details.
## Summary
I did ran the NPM dev commands before merging
https://github.com/astral-sh/ruff/pull/16199 but I didn't notice that
one file got reformatted.
This PR formats the `index.css` with the now used Prettier version.
## Summary
This PR makes the following changes:
- It adjusts various callsites to use the new
`ast::StringLiteral::contents_range()` method that was introduced in
https://github.com/astral-sh/ruff/pull/16183. This is less verbose and
more type-safe than using the `ast::str::raw_contents()` helper
function.
- It adds a new `ast::ExprStringLiteral::as_unconcatenated_literal()`
helper method, and adjusts various callsites to use it. This addresses
@MichaReiser's review comment at
https://github.com/astral-sh/ruff/pull/16183#discussion_r1957334365.
There is no functional change here, but it helps readability to make it
clearer that we're differentiating between implicitly concatenated
strings and unconcatenated strings at various points.
- It renames the `StringLiteralValue::flags()` method to
`StringLiteralFlags::first_literal_flags()`. If you're dealing with an
implicitly concatenated string `string_node`,
`string_node.value.flags().closer_len()` could give an incorrect result;
this renaming makes it clearer that the `StringLiteralFlags` instance
returned by the method is only guaranteed to give accurate information
for the first `StringLiteral` contained in the `ExprStringLiteral` node.
- It deletes the unused `BytesLiteralValue::flags()` method. This seems
prone to misuse in the same way as `StringLiteralValue::flags()`: if
it's an implicitly concatenated bytestring, the `BytesLiteralFlags`
instance returned by the method would only give accurate information for
the first `BytesLiteral` in the bytestring.
## Test Plan
`cargo test`
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [tempfile](https://stebalien.com/projects/tempfile-rs/)
([source](https://redirect.github.com/Stebalien/tempfile)) |
workspace.dependencies | minor | `3.16.0` -> `3.17.0` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>Stebalien/tempfile (tempfile)</summary>
###
[`v3.17.0`](https://redirect.github.com/Stebalien/tempfile/blob/HEAD/CHANGELOG.md#3170)
[Compare
Source](https://redirect.github.com/Stebalien/tempfile/compare/v3.16.0...v3.17.0)
- Make sure to use absolute paths in when creating unnamed temporary
files (avoids a small race in the "immediate unlink" logic) and in
`Builder::make_in` (when creating temporary files of arbitrary types).
- Prevent a theoretical crash that could (maybe) happen when a temporary
file is created from a drop function run in a TLS destructor. Nobody has
actually reported a case of this happening in practice and I have been
unable to create this scenario in a test.
- When reseeding with `getrandom`, use platform (e.g., CPU) specific
randomness sources where possible.
- Clarify some documentation.
- Unlink unnamed temporary files on windows *immediately* when possible
instead of waiting for the handle to be closed. We open files with
"Unix" semantics, so this is generally possible.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNjcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjE2Ny4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
---------
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Co-authored-by: Micha Reiser <micha@reiser.io>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[cloudflare/wrangler-action](https://redirect.github.com/cloudflare/wrangler-action)
| action | minor | `v3.13.1` -> `v3.14.0` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>cloudflare/wrangler-action
(cloudflare/wrangler-action)</summary>
###
[`v3.14.0`](https://redirect.github.com/cloudflare/wrangler-action/releases/tag/v3.14.0)
[Compare
Source](https://redirect.github.com/cloudflare/wrangler-action/compare/v3.13.1...v3.14.0)
##### Minor Changes
-
[#​351](https://redirect.github.com/cloudflare/wrangler-action/pull/351)
[`4ff07f4`](4ff07f4310)
Thanks [@​Maximo-Guk](https://redirect.github.com/Maximo-Guk)! -
Use wrangler outputs for version upload and wrangler deploy
##### Patch Changes
-
[#​350](https://redirect.github.com/cloudflare/wrangler-action/pull/350)
[`e209094`](e209094e62)
Thanks [@​Maximo-Guk](https://redirect.github.com/Maximo-Guk)! -
Handle failures in createGitHubDeployment and createGitHubJobSummary
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNjcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjE2Ny4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [strum](https://redirect.github.com/Peternator7/strum) |
workspace.dependencies | patch | `0.27.0` -> `0.27.1` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>Peternator7/strum (strum)</summary>
###
[`v0.27.1`](https://redirect.github.com/Peternator7/strum/blob/HEAD/CHANGELOG.md#0271)
[Compare
Source](https://redirect.github.com/Peternator7/strum/compare/v0.27.0...v0.27.1)
- [#​414](https://redirect.github.com/Peternator7/strum/pull/414):
Fix docrs build error.
- [#​417](https://redirect.github.com/Peternator7/strum/pull/417):
Mention `parse_error_ty` and `parse_error_fn` that had been
left out of the docs accidentally.
-
[#​421](https://redirect.github.com/Peternator7/strum/pull/421)[#​331](https://redirect.github.com/Peternator7/strum/pull/331):
Implement
`#[strum(transparent)]` attribute on `IntoStaticStr`, `Display` and
`AsRefStr` that forwards the implmenentation to
the inner value. Note that for static strings, the inner value must be
convertible to an `&'static str`.
```rust
#[derive(strum::Display)]
enum SurveyResponse {
Yes,
No,
#[strum(transparent)]
Other(String)
}
fn main() {
let response = SurveyResponse::Other("It was good".into());
println!("Question: Did you have fun?");
println!("Answer: {}", response);
// prints: Answer: It was good
}
```
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNjcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjE2Ny4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [clap](https://redirect.github.com/clap-rs/clap) |
workspace.dependencies | patch | `4.5.28` -> `4.5.29` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>clap-rs/clap (clap)</summary>
###
[`v4.5.29`](https://redirect.github.com/clap-rs/clap/blob/HEAD/CHANGELOG.md#4529---2025-02-11)
[Compare
Source](https://redirect.github.com/clap-rs/clap/compare/v4.5.28...v4.5.29)
##### Fixes
- Change `ArgMatches::args_present` so not-present flags are considered
not-present (matching the documentation)
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNjcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjE2Ny4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [strum_macros](https://redirect.github.com/Peternator7/strum) |
workspace.dependencies | patch | `0.27.0` -> `0.27.1` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>Peternator7/strum (strum_macros)</summary>
###
[`v0.27.1`](https://redirect.github.com/Peternator7/strum/blob/HEAD/CHANGELOG.md#0271)
[Compare
Source](https://redirect.github.com/Peternator7/strum/compare/v0.27.0...v0.27.1)
- [#​414](https://redirect.github.com/Peternator7/strum/pull/414):
Fix docrs build error.
- [#​417](https://redirect.github.com/Peternator7/strum/pull/417):
Mention `parse_error_ty` and `parse_error_fn` that had been
left out of the docs accidentally.
-
[#​421](https://redirect.github.com/Peternator7/strum/pull/421)[#​331](https://redirect.github.com/Peternator7/strum/pull/331):
Implement
`#[strum(transparent)]` attribute on `IntoStaticStr`, `Display` and
`AsRefStr` that forwards the implmenentation to
the inner value. Note that for static strings, the inner value must be
convertible to an `&'static str`.
```rust
#[derive(strum::Display)]
enum SurveyResponse {
Yes,
No,
#[strum(transparent)]
Other(String)
}
fn main() {
let response = SurveyResponse::Other("It was good".into());
println!("Question: Did you have fun?");
println!("Answer: {}", response);
// prints: Answer: It was good
}
```
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNjcuMSIsInVwZGF0ZWRJblZlciI6IjM5LjE2Ny4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
On `main` we warn the user if there is an invalid noqa comment[^1] and
at least one of the following holds:
- There is at least one diagnostic
- A lint rule related to `noqa`s is enabled (e.g. `RUF100`)
This is probably strange behavior from the point of view of the user, so
we now show invalid `noqa`s even when there are no diagnostics.
Closes#12831
[^1]: For the current definition of "invalid noqa comment", which may be
expanded in #12811 . This PR is independent of loc. cit. in the sense
that the CLI warnings should be consistent, regardless of which `noqa`
comments are considered invalid.
## Summary
Fixes#16189.
Only `sys.breakpointhook` is flagged by the upstream linter:
007a745c86/pylint/checkers/stdlib.py (L38)
but I think it makes sense to flag
[`__breakpointhook__`](https://docs.python.org/3/library/sys.html#sys.__breakpointhook__)
too, as suggested in the issue because it
> contain[s] the original value of breakpointhook [...] in case [it
happens] to get replaced with broken or alternative objects.
## Test Plan
New T100 test cases
## Summary
Provides documentation about the FIPS compliant flag for Python hashlib
`usedforsecurity`
Fixes#16188
## Test Plan
* pre-commit hooks
---------
Co-authored-by: Brent Westbrook <36778786+ntBre@users.noreply.github.com>
## Summary
Running `cargo test -p red_knot_python_semantic` failed because of a
missing serde feature. This PR enables the `ruff_python_ast`'`s `serde`
if the crate's `serde` feature is enabled
## Test Plan
`cargo test -p red_knot_python_semantic` compiles again
When adjusting the existing tests, I aimed to avoid dealing with the
special case in other tests if it's not necessary to do so (that is,
avoid using `float` and `complex` as examples where we just need "some
type"), and keep the tests for the special case mostly collected in the
mdtest dedicated to that purpose.
Fixes https://github.com/astral-sh/ruff/issues/14932
## Summary
Added checks for subscript expressions on builtin classes as in FURB189.
The object is changed to use the collections objects and the types from
the subscript are kept.
Resolves#16130
> Note: Added some comments in the code explaining why
## Test Plan
- Added a subscript dict and list class to the test file.
- Tested locally to check that the symbols are changed and the types are
kept.
- No modifications changed on optional `str` values.
## Summary
This PR moves the `PythonVersion` struct from the
`red_knot_python_semantic` crate to the `ruff_python_ast` crate so that
it can be used more easily in the syntax error detection work. Compared
to that [prototype](https://github.com/astral-sh/ruff/pull/16090/) these
changes reduce us from 2 `PythonVersion` structs to 1.
This does not unify any of the `PythonVersion` *enums*, but I hope to
make some progress on that in a follow-up.
## Test Plan
Existing tests, this should not change any external behavior.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This change begins to resolve#16071 by moving the `OperatorPrecedence`
structs from the `ruff_python_linter` crate into `ruff_python_ast`. This
PR also implements `precedence()` methods on the `Expr` and `ExprRef`
enums.
## Test Plan
Since this change mainly shifts existing logic, I didn't add any
additional tests. Existing tests do pass.
## Summary
This PR refactors the symbol lookup APIs to better facilitate the
re-export implementation. Specifically,
* Add `module_type_symbol` which returns the `Symbol` that's a member of
`types.ModuleType`
* Rename `symbol` -> `symbol_impl`; add `symbol` which delegates to
`symbol_impl` with `RequireExplicitReExport::No`
* Update `global_symbol` to do `symbol_impl` -> fall back to
`module_type_symbol` and default to `RequireExplicitReExport::No`
* Add `imported_symbol` to do `symbol_impl` with
`RequireExplicitReExport` as `Yes` if the module is in a stub file else
`No`
* Update `known_module_symbol` to use `imported_symbol` with a fallback
to `module_type_symbol`
* Update `ModuleLiteralType::member` to use `imported_symbol` with a
custom fallback
We could potentially also update `symbol_from_declarations` and
`symbol_from_bindings` to avoid passing in the `RequireExplicitReExport`
as it would be always `No` if called directly. We could add
`symbol_from_declarations_impl` and `symbol_from_bindings_impl`.
Looking at the `_impl` functions, I think we should move all of these
symbol related logic into `symbol.rs` where `Symbol` is defined and the
`_impl` could be private while we expose the public APIs at the crate
level. This would also make the `RequireExplicitReExport` an
implementation detail and the caller doesn't need to worry about it.
This is an alternative implementation to #15848.
## Summary
This PR adds support for re-export conventions for imports for stub
files.
**How does this work?**
* Add a new flag on the `Import` and `ImportFrom` definitions to
indicate whether they're being exported or not
* Add a new enum to indicate whether the symbol lookup is happening
within the same file or is being queried from another file (e.g., an
import statement)
* When a `Symbol` is being queried, we'll skip the definitions that are
(a) coming from a stub file (b) external lookup and (c) check the
re-export flag on the definition
This implementation does not yet support `__all__` and `*` imports as
both are features that needs to be implemented independently.
closes: #14099closes: #15476
## Test Plan
Add test cases, update existing ones if required.
## Summary
Resolves#15859.
The rule now adds parentheses if the original call wraps an unary
expression and is:
* The left-hand side of a binary expression where the operator is `**`.
* The caller of a call expression.
* The subscripted of a subscript expression.
* The object of an attribute access.
The fix will also be marked as unsafe if there are any comments in its
range.
## Test Plan
`cargo nextest run` and `cargo insta test`.
## Summary
Follow-up to #16035.
`check_docs_formatted.py` will now report backtick-quoted shortcut links
in rule documentation. It uses a regular expression to find them. Such a
link:
* Starts with `[`, followed by <code>\`</code>, then a "name" sequence
of at least one non-backtick non-newline character, followed by another
<code>\`</code>, then ends with `]`.
* Is not followed by either a `[` or a `(`.
* Is not placed within a code block.
If the name is a known Ruff option name, that link is not considered a
violation.
## Test Plan
Manual.
## Summary
Rome Tools Playground was renamed to Biome Playground. The link was
replaced to the new website.
Resolves#16143
## Test Plan
- Checked the linked is accessible from the README
## Summary
Resolves#13294, follow-up to #13882.
At #13882, it was concluded that a fix should not be offered for raw
strings. This change implements that. The five rules in question are now
no longer always fixable.
## Test Plan
`cargo nextest run` and `cargo insta test`.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Follow-up to https://github.com/astral-sh/ruff/pull/15951 to update
* the options links in A005 to reference
`lint.flake8-builtins.builtins-strict-checking`
* the description of the rule to explain strict vs non-strict checking
* the option documentation to point back to the rule
For now, the only thing one can configure is whether color is enabled or
not. This avoids needing to ask the `colored` crate whether colors have
been globally enabled or disabled. And, more crucially, avoids the need
to _set_ this global flag for testing diagnostic output. Doing so can
have unintended consequences, as outlined in #16115.
Fixes#16115
## Summary
Add support for the `project.requires-python` field in `pyproject.toml`
files.
Fall back to the resolved lower bound of `project.requires-python` if
the `environment.python-version` field is `None` (or more accurately,
initialize `environment.python-version with `requires-python`'s lower
bound if left unspecified).
## UX design
There are two options on how we can handle the fallback to
`requires-python`'s lower bound:
1. Store the resolved lower bound in `environment.python-version` if
that field is `None` (Implemented in this PR)
2. Store the `requires-python` constraint separately.
There's no observed difference unless a user-level configuration (or any
other inherited configuration is used). Let's discuss it on the given
example
**User configuration**
```toml
[environment]
python-version = "3.10"
```
**Project configuration (`pyproject.toml`)**
```toml
[project]
name = "test"
requires-python = ">= 3.12"
[tool.knot]
# No environment table
```
The resolved version for 1. is 3.12 because the `requires-python`
constraint precedence takes precedence over the `python-version` in the
user configuration. 2. resolves to 3.10 because all `python-version`
constraints take precedence before falling back to `requires-python`.
Ruff implements 1. It's also the easier to implement and it does seem
intuitive to me that the more local `requires-python` constraint takes
precedence.
## Test plan
Added CLI and unit tests.
The PR addresses the issue #16040 .
---
The logic used into the rule is the following:
Suppose to have an expression of the form
```python
if a cmp b:
c = d
```
where `a`,` b`, `c` and `d` are Python obj and `cmp` one of `<`, `>`,
`<=`, `>=`.
Then:
- `if a=c and b=d`
- if `<=` fix with `a = max(b, a)`
- if `>=` fix with `a = min(b, a)`
- if `>` fix with `a = min(a, b)`
- if `<` fix with `a = max(a, b)`
- `if a=d and b=c`
- if `<=` fix with `b = min(a, b)`
- if `>=` fix with `b = max(a, b)`
- if `>` fix with `b = max(b, a)`
- if `<` fix with `b = min(b, a)`
- do nothing, i.e., we cannot fix this case.
---
In total we have 8 different and possible cases.
```
| Case | Expression | Fix |
|-------|------------------|---------------|
| 1 | if a >= b: a = b | a = min(b, a) |
| 2 | if a <= b: a = b | a = max(b, a) |
| 3 | if a <= b: b = a | b = min(a, b) |
| 4 | if a >= b: b = a | b = max(a, b) |
| 5 | if a > b: a = b | a = min(a, b) |
| 6 | if a < b: a = b | a = max(a, b) |
| 7 | if a < b: b = a | b = min(b, a) |
| 8 | if a > b: b = a | b = max(b, a) |
```
I added them in the tests.
Please double-check that I didn't make any mistakes. It's quite easy to
mix up > and <.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
After I was asked twice within the same day, I thought it would be a
good idea to write some *user facing* documentation that explains our
reasoning behind inferring `Unknown | T_inferred` for public uses of
undeclared symbols. This is a major deviation from the behavior of other
type checkers and it seems like a good practice to defend our choice
like this.
## Summary
* fix ImportPathMoved / ProviderName misuse
* oncrete names, such as `["airflow", "config_templates",
"default_celery", "DEFAULT_CELERY_CONFIG"]`, should use `ProviderName`.
In contrast, module paths like `"airflow", "operators", "weekday", ...`
should use `ImportPathMoved`. Misuse may lead to incorrect detection.
## Test Plan
update test fixture
This essentially makes it impossible to construct a `Diagnostic`
that has a `TextRange` but no `File`.
This is meant to be a precursor to multi-span support.
(Note that I consider this more of a prototyping-change and not
necessarily what this is going to look like longer term.)
Reviewers can probably review this PR as one big diff instead of
commit-by-commit.
## Summary
This is a follow up to
https://github.com/astral-sh/ruff/pull/15763#discussion_r1949681336
It reverts the change to using ptr equality for `AstNodeRef`s, which in
turn removes the `Eq`, `PartialEq`, and `Hash` implementations for
`AstNodeRef`s parametrized with AST nodes.
Cheap comparisons shouldn't be needed because the node field is
generally marked as `[#tracked]` and `#[no_eq]` and removing the
implementations even enforces that those
attributes are set on all `AstNodeRef` fields (which is good).
The only downside this has is that we technically wouldn't have to mark
the `Unpack::target` as `#[tracked]` because
the `target` field is accessed in every query accepting `Unpack` as an
argument.
Overall, enforcing the use of `#[tracked]` seems like a good trade off,
espacially considering that it's very likely that
we'd probably forget to mark the `Unpack::target` field as tracked if we
add a new `Unpack` query that doesn't access the target.
## Test Plan
`cargo test`
## Summary
Fixes#16007. The logic from the last fix for this (#9427) was
sufficient, it just wasn't being applied because `Attributes` sections
aren't expected to have nested sections. I just deleted the outer
conditional, which should hopefully fix this for all section types.
## Test Plan
New regression test, plus the existing D417 tests.
## Summary
Transition to using coarse-grained tracked structs (depends on
https://github.com/salsa-rs/salsa/pull/657). For now, this PR doesn't
add any `#[tracked]` fields, meaning that any changes cause the entire
struct to be invalidated. It also changes `AstNodeRef` to be
compared/hashed by pointer address, instead of performing a deep AST
comparison.
## Test Plan
This yields a 10-15% improvement on my machine (though weirdly some runs
were 5-10% without being flagged as inconsistent by criterion, is there
some non-determinism involved?). It's possible that some of this is
unrelated, I'll try applying the patch to the current salsa version to
make sure.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Resolves#16082.
`UP036` will now also take into consideration whether or not a micro
version number is set:
* If a third element doesn't exist, the existing logic is preserved.
* If it exists but is not an integer literal, the check will not be
reported.
* If it is an integer literal but doesn't fit into a `u8`, the check
will be reported as invalid.
* Otherwise, the compared version is determined to always be less than
the target version when:
* The target's minor version is smaller than that of the comparator, or
* The operator is `<`, the micro version is 0, and the two minor
versions compare equal.
As this is considered a bugfix, it is not preview-gated.
## Test Plan
`cargo nextest run` and `cargo insta test`.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
- Simplify unions with `object` to `object`.
- Add a new `Type::object(db)` constructor to abbreviate
`KnownClass::Object.to_instance(db)` in some places.
- Add a `Type::is_object` and `Class::is_object` function to make some
tests for a bit easier to read.
closes#16084
## Test Plan
New Markdown tests.
The index in subscript access like `d[*y]` will not be linted or
autofixed with parentheses, even when
`lint.ruff.parenthesize-tuple-in-subscript = true`.
Closes#16077
## Summary
This PR adds support for user-level configurations
(`~/.config/knot/knot.toml`) to Red Knot.
Red Knot will watch the user-level configuration file for changes but
only if it exists
when the process start. It doesn't watch for new configurations,
mainly to simplify things for now (it would require watching the entire
`.config` directory because the `knot` subfolder might not exist
either).
The new `ConfigurationFile` struct seems a bit overkill for now but I
plan to use it for
hierarchical configurations as well.
Red Knot uses the same strategy as uv and Ruff by using the etcetera
crate.
## Test Plan
Added CLI and file watching test
## Summary
This PR adds a new `user_configuration_directory` method to `System`. We
need it to resolve where to lookup a user-level `knot.toml`
configuration file.
The method belongs to `System` because not all platforms have a
convention of where to store such configuration files (e.g. wasm).
I refactored `TestSystem` to be a simple wrapper around an `Arc<dyn
System...>` and use the `System.as_any` method instead to cast it down
to an `InMemory` system. I also removed some `System` specific methods
from `InMemoryFileSystem`, they don't belong there.
This PR removes the `os` feature as a default feature from `ruff_db`.
Most crates depending on `ruff_db` don't need it because they only
depend on `System` or only depend on `os` for testing. This was
necessary to fix a compile error with `red_knot_wasm`
## Test Plan
I'll make use of the method in my next PR. So I guess we won't know if
it works before then but I copied the code from Ruff/uv, so I have high
confidence that it is correct.
`cargo test`
## Summary
This PR generalize the idea that we may want to emit diagnostics for
invalid or incompatible configuration values similar to how we already
do it for `rules`.
This PR introduces a new `Settings` struct that is similar to `Options`
but, unlike
`Options`, are fields have their default values filled in and they use a
representation optimized for reads.
The diagnostics created during loading the `Settings` are stored on the
`Project` so that we can emit them when calling `check`.
The motivation for this work is that it simplifies adding new settings.
That's also why I went ahead and added the `terminal.error-on-warning`
setting to demonstrate how new settings are added.
## Test Plan
Existing tests, new CLI test.
## Summary
Revert the v4 update for now until the codebase is updated
(https://github.com/astral-sh/ruff/pull/16069).
Update renovate config to disable updating it.
## Test Plan
```console
$ npx --yes --package renovate -- renovate-config-validator
(node:98977) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
INFO: Validating .github/renovate.json5
INFO: Config validated successfully
```
And run `npm run build` in the `playground/` directory.
This PR resolved#15772
Before PR:
```
def _(
this_is_fine: int = f(), # No error
this_is_not: list[int] = f() # B008: Do not perform function call `f` in argument defaults
): ...
@dataclass
class _:
this_is_not_fine: list[int] = f() # RUF009: Do not perform function call `f` in dataclass defaults
this_is_also_not: int = f() # RUF009: Do not perform function call `f` in dataclass defaults
```
After PR:
```
def _(
this_is_fine: int = f(), # No error
this_is_not: list[int] = f() # B008: Do not perform function call `f` in argument defaults
): ...
@dataclass
class _:
this_is_not_fine: list[int] = f() # RUF009: Do not perform function call `f` in dataclass defaults
this_is_fine: int = f()
```
## Summary
Follow-up to #15984.
Previously, `PLE1310` would only report when the object is a literal:
```python
'a'.strip('//') # error
foo = ''
foo.strip('//') # no error
```
After this change, objects whose type can be inferred to be either `str`
or `bytes` will also be reported in preview.
## Test Plan
`cargo nextest run` and `cargo insta test`.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [rustc-hash](https://redirect.github.com/rust-lang/rustc-hash) |
workspace.dependencies | patch | `2.1.0` -> `2.1.1` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>rust-lang/rustc-hash (rustc-hash)</summary>
###
[`v2.1.1`](https://redirect.github.com/rust-lang/rustc-hash/blob/HEAD/CHANGELOG.md#211)
[Compare
Source](https://redirect.github.com/rust-lang/rustc-hash/compare/v2.1.0...v2.1.1)
- Change the internal algorithm to better accomodate large hashmaps.
This mitigates a [regression with 2.0 in
rustc](https://redirect.github.com/rust-lang/rust/issues/135477).
See [PR#55](https://redirect.github.com/rust-lang/rustc-hash/pull/55)
for more details on the change (this PR was not merged).
This problem might be improved with changes to hashbrown in the future.
#### 2.1.0
- Implement `Clone` for `FxRandomState`
- Implement `Clone` for `FxSeededState`
- Use SPDX license expression in license field
#### 2.0.0
- Replace hash with faster and better finalized hash.
This replaces the previous "fxhash" algorithm originating in Firefox
with a custom hasher designed and implemented by Orson Peters
([`@orlp`](https://redirect.github.com/orlp)).
It was measured to have slightly better performance for rustc, has
better theoretical properties
and also includes a significantly better string hasher.
- Fix `no_std` builds
#### 1.2.0 (**YANKED**)
**Note: This version has been yanked due to issues with the `no_std`
feature!**
- Add a `FxBuildHasher` unit struct
- Improve documentation
- Add seed API for supplying custom seeds other than 0
- Add `FxRandomState` based on `rand` (behind the `rand` feature) for
random seeds
- Make many functions `const fn`
- Implement `Clone` for `FxHasher` struct
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNjQuMSIsInVwZGF0ZWRJblZlciI6IjM5LjE2NC4xIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
fixes: #16041
## Test Plan
Using the [project](https://github.com/bwcc-clan/polebot) in the linked
issue:
Notice how the project "polebot" is in the "play" directory which is
included in the `exclude` setting as:
```toml
exclude = ["play"]
```
**Before this fix**
```
DEBUG ruff:worker:0 ruff_server::resolve: Ignored path via `exclude`: /private/tmp/ruff-test/play/polebot/src/utils/log_tools.py
```
**After this fix**
```
DEBUG ruff:worker:2 ruff_server::resolve: Included path via `include`: /private/tmp/ruff-test/play/polebot/src/utils/log_tools.py
```
I also updated the same project to remove the "play" directory from the
`exclude` setting and made sure that anything under the `polebot/play`
directory is included:
```
DEBUG ruff:worker:4 ruff_server::resolve: Included path via `include`: /private/tmp/ruff-test/play/polebot/play/test.py
```
And, excluded when I add the directory back:
```
DEBUG ruff:worker:2 ruff_server::resolve: Ignored path via `exclude`: /private/tmp/ruff-test/play/polebot/play/test.py
```
## Summary
This PR refactors the `RuffSettings` struct to directly include the
resolved `Settings` instead of including the specific fields from it.
The server utilizes a lot of it already, so it makes sense to just
include the entire struct for simplicity.
### `Deref`
I implemented `Deref` on `RuffSettings` to return the `Settings` because
`RuffSettings` is now basically a wrapper around it with the config path
as the other field. This path field is only used for debugging
("printDebugInformation" command).
## Summary
This PR adds the configuration option
`lint.flake8-builtins.builtins-strict-checking`, which is used in A005
to determine whether the fully-qualified module name (relative to the
project root or source directories) should be checked instead of just
the final component as is currently the case.
As discussed in
https://github.com/astral-sh/ruff/issues/15399#issuecomment-2587017147,
the default value of the new option is `false` on preview, so modules
like `utils.logging` from the initial report are no longer flagged by
default. For non-preview the default is still strict checking.
## Test Plan
New A005 test module with the structure reported in #15399.
Fixes#15399
## Summary
Resolves#12321.
The physical-line-based `RUF054` checks for form feed characters that
are preceded by only tabs and spaces, but not any other characters,
including form feeds.
## Test Plan
`cargo nextest run` and `cargo insta test`.
## Summary
No functional change here; this is another simplification split out from
my outcome-refactor branch to reduce the diff there. This merges
`TypeInferenceBuilder::infer_name_load` and
`TypeInferenceBuilder::lookup_name`. This removes the need to have
extensive doc-comments about the purpose of
`TypeInferenceBuilder::lookup_name`, since the method only makes sense
when called from the specific context of
`TypeInferenceBuilder::infer_name_load`.
## Test Plan
`cargo test -p red_knot_python_semantic`
Fixes#16024
## Summary
This PR adds proper isolation for `UP049` fixes so that two type
parameters are not renamed to the same name, which would introduce
invalid syntax. E.g. for this:
```py
class Foo[_T, __T]: ...
```
we cannot apply two autofixes to the class, as that would produce
invalid syntax -- this:
```py
class Foo[T, T]: ...
```
The "isolation" here means that Ruff won't apply more than one fix to
the same type-parameter list in a single iteration of the loop it does
to apply all autofixes. This means that after the first autofix has been
done, the semantic model will have recalculated which variables are
available in the scope, meaning that the diagnostic for the second
parameter will be deemed unfixable since it collides with an existing
name in the same scope (the name we autofixed the first parameter to in
an earlier iteration of the autofix loop).
Cc. @ntBre, for interest!
## Test Plan
I added an integration test that reproduces the bug on `main`.
When suggesting a return type as a union in Python <=3.9, we now avoid a
`TypeError` by correctly suggesting syntax like `Union[int,str,None]`
instead of `Union[int | str | None]`.
## Summary
Follow-up to #16026.
Previously, the fix for this would be marked as unsafe, even though all
comments are preserved:
```python
# .pyi
T: TypeAlias = ( # Comment
int | str
)
```
Now it is safe: comments within the parenthesized range no longer affect
applicability.
## Test Plan
`cargo nextest run` and `cargo insta test`.
---------
Co-authored-by: Dylan <53534755+dylwil3@users.noreply.github.com>
## Summary
Resolves#15968.
Previously, these would be considered violations:
```python
b''.strip('//')
''.lstrip('//', foo = "bar")
```
...while these are not:
```python
b''.strip(b'//')
''.strip('\\b\\x08')
```
Ruff will now not report when the types of the object and that of the
argument mismatch, or when there are extra arguments.
## Test Plan
`cargo nextest run` and `cargo insta test`.
See #15951 for the original discussion and reviews. This is just the
first half of that PR (reaching parity with `flake8-builtins` without
adding any new configuration options) split out for nicer changelog
entries.
For posterity, here's a script for generating the module structure that
was useful for interactive testing and creating the table
[here](https://github.com/astral-sh/ruff/pull/15951#issuecomment-2640662041).
The results for this branch are the same as the `Strict` column there,
as expected.
```shell
mkdir abc collections foobar urlparse
for i in */
do
touch $i/__init__.py
done
cp -r abc foobar collections/.
cp -r abc collections foobar/.
touch ruff.toml
touch foobar/logging.py
```
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
This very large PR changes the field `.diagnostics` in the `Checker`
from a `Vec<Diagnostic>` to a `RefCell<Vec<Diagnostic>>`, adds methods
to push new diagnostics to this cell, and then removes unnecessary
mutability throughout all of our lint rule implementations.
Consequently, the compiler may now enforce what was, till now, the
_convention_ that the only changes to the `Checker` that can happen
during a lint are the addition of diagnostics[^1].
The PR is best reviewed commit-by-commit. I have tried to keep the large
commits limited to "bulk actions that you can easily see are performing
the same find/replace on a large number of files", and separate anything
ad-hoc or with larger diffs. Please let me know if there's anything else
I can do to make this easier to review!
Many thanks to [`ast-grep`](https://github.com/ast-grep/ast-grep),
[`helix`](https://github.com/helix-editor/helix), and good ol'
fashioned`git` magic, without which this PR would have taken the rest of
my natural life.
[^1]: And randomly also the seen variables violating `flake8-bugbear`?
## Summary
- Do not return `Option<Type<…>>` from `Unpacker::get`, but just `Type`.
Panic otherwise.
- Rename `Unpacker::get` to `Unpacker::expression_type`
## Summary
* Support assignments to attributes in more cases:
- assignments in `for` loops
- in unpacking assignments
* Add test for multi-target assignments
* Add tests for all other possible assignments to attributes that could
possibly occur (in decreasing order of likeliness):
- augmented attribute assignments
- attribute assignments in `with` statements
- attribute assignments in comprehensions
- Note: assignments to attributes in named expressions are not
syntactically allowed
closes#15962
## Test Plan
New Markdown tests
## Summary
This PR reverts the behavior changes from
https://github.com/astral-sh/ruff/pull/15990
But it isn't just a revert, it also:
* Adds a test covering this specific behavior
* Preserves the improvement to use `saturating_sub` in the package case
to avoid overflows in the case of invalid syntax
* Use `ancestors` instead of a `for` loop
## Test Plan
Added test
## Summary
Adds a JSON schema generation step for Red Knot. This PR doesn't yet add
a publishing step because it's still a bit early for that
## Test plan
I tested the schema in Zed, VS Code and PyCharm:
* PyCharm: You have to manually add a schema mapping (settings JSON
Schema Mappings)
* Zed and VS code support the inline schema specification
```toml
#:schema /Users/micha/astral/ruff/knot.schema.json
[environment]
extra-paths = []
[rules]
call-possibly-unbound-method = "error"
unknown-rule = "error"
# duplicate-base = "error"
```
```json
{
"$schema": "file:///Users/micha/astral/ruff/knot.schema.json",
"environment": {
"python-version": "3.13",
"python-platform": "linux2"
},
"rules": {
"unknown-rule": "error"
}
}
```
https://github.com/user-attachments/assets/a18fcd96-7cbe-4110-985b-9f1935584411
The Schema overall works but all editors have their own quirks:
* PyCharm: Hovering a name always shows the section description instead
of the description of the specific setting. But it's the same for other
settings in `pyproject.toml` files 🤷
* VS Code (JSON): Using the generated schema in a JSON file gives
exactly the experience I want
* VS Code (TOML):
* Properties with multiple possible values are repeated during
auto-completion without giving any hint how they're different. 
* The property description mushes together the description of the
property and the value, which looks sort of ridiculous. 
* Autocompletion and documentation hovering works (except the
limitations mentioned above)
* Zed:
* Very similar to VS Code with the exception that it uses the
description attribute to distinguish settings with multiple possible
values 
I don't think there's much we can do here other than hope (or help)
editors improve their auto completion. The same short comings also apply
to ruff, so this isn't something new. For now, I think this is good
enough
## Summary
Part of #15809 and #15876.
This change brings several bugfixes:
* The nested `map()` call in `list(map(lambda x: x, []))` where `list`
is overshadowed is now correctly reported.
* The call will no longer reported if:
* Any arguments given to `map()` are variadic.
* Any of the iterables contain a named expression.
## Test Plan
`cargo nextest run` and `cargo insta test`.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This change resolves#15814 to ensure that `SIM401` is only triggered on
known dictionary types. Before, the rule was getting triggered even on
types that _resemble_ a dictionary but are not actually a dictionary.
I did this using the `is_known_to_be_of_type_dict(...)` functionality.
The logic for this function was duplicated in a few spots, so I moved
the code to a central location, removed redundant definitions, and
updated existing calls to use the single definition of the function!
## Test Plan
Since this PR only modifies an existing rule, I made changes to the
existing test instead of adding new ones. I made sure that `SIM401` is
triggered on types that are clearly dictionaries and that it's not
triggered on a simple custom dictionary-like type (using a modified
version of [the code in the issue](#15814))
The additional changes to de-duplicate `is_known_to_be_of_type_dict`
don't break any existing tests -- I think this should be fine since the
logic remains the same (please let me know if you think otherwise, I'm
excited to get feedback and work towards a good fix 🙂).
---------
Co-authored-by: Junhson Jean-Baptiste <junhsonjb@naan.mynetworksettings.com>
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Resolves#15997.
Ruff used to introduce syntax errors while fixing these cases, but no
longer will:
```python
{"a": [], **{},}
# ^^^^ Removed, leaving two contiguous commas
{"a": [], **({})}
# ^^^^^ Removed, leaving a stray closing parentheses
```
Previously, the function would take a shortcut if the unpacked
dictionary is empty; now, both cases are handled using the same logic
introduced in #15394. This change slightly modifies that logic to also
remove the first comma following the dictionary, if and only if it is
empty.
## Test Plan
`cargo nextest run` and `cargo insta test`.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/15978
Even Better TOML doesn't support `allOf` well. In fact, it just crashes.
This PR works around this limitation by avoid using `allOf` in the
automatically
derived schema for the docstring formatting setting.
### Alternatives
schemars introduces `allOf` whenver it sees a `$ref` alongside other
object properties
because this is no longer valid according to Draft 7. We could replace
the
visitor performing the rewrite but I prefer not to because replacing
`allOf` with `oneOf`
is only valid for objects that don't have any other `oneOf` or `anyOf`
schema.
## Test Plan
https://github.com/user-attachments/assets/25d73b2a-fee1-4ba6-9ffe-869b2c3bc64e
## Summary
I noticed that the diagnostic range in specific unpacking assignments is
wrong. For this example
```py
a, b = 1
```
we previously got (see first commit):
```
error: lint:not-iterable
--> /src/mdtest_snippet.py:1:1
|
1 | a, b = 1
| ^^^^ Object of type `Literal[1]` is not iterable
|
```
and with this change, we get:
```
error: lint:not-iterable
--> /src/mdtest_snippet.py:1:8
|
1 | a, b = 1
| ^ Object of type `Literal[1]` is not iterable
|
```
## Test Plan
New snapshot tests.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/15989
Red Knot failed to resolve relative imports if the importing module is
located at a search path root.
The issue was that the module resolver returned an `Err(TooManyDots)` as
soon as the parent of the current module is `None` (which is the case
for a module at the search path root).
However, this is incorrect if a `tail` (a module name) exists.
Closes#15681
## Summary
This changes `analyze::typing::is_type_checking_block` to recognize all
symbols named "TYPE_CHECKING".
This matches the current behavior of mypy and pyright as well as
`flake8-type-checking`.
It also drops support for detecting `if False:` and `if 0:` as type
checking blocks. This used to be an option for
providing backwards compatibility with Python versions that did not have
a `typing` module, but has since
been removed from the typing spec and is no longer supported by any of
the mainstream type checkers.
## Test Plan
`cargo nextest run`
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
- Minor wording update
- Code improvement (thanks Alex)
- Removed all unnecessary filenames throughout our Markdown tests (two
new ones were added in the meantime)
- Minor rewording of the statically-known-branches introduction
This example from @sharkdp shows how terminal statements can appear in
statically known branches:
https://github.com/astral-sh/ruff/pull/15676#issuecomment-2618809716
```py
def _(cond: bool):
x = "a"
if cond:
x = "b"
if True:
return
reveal_type(x) # revealed: "a", "b"; should be "a"
```
We now use visibility constraints to track reachability, which allows us
to model this correctly. There are two related changes as a result:
- New bindings are not assumed to be visible; they inherit the current
"scope start" visibility, which effectively means that new bindings are
visible if/when the current flow is reachable
- When simplifying visibility constraints after branching control flow,
we only simplify if none of the intervening branches included a terminal
statement. That is, earlier unaffected bindings are only _actually_
unaffected if all branches make it to the merge point.
## Summary
Allow for literate style in Markdown tests and merge multiple (unnamed)
code blocks into a single embedded file.
closes#15941
## Test Plan
- Interactively made sure that error-lines were reported correctly in
multi-snippet sections.
This causes the diagnostic to highlight the actual unresovable import
instead of the entire `from ... import ...` statement.
While we're here, we expand the test coverage to cover all of the
possible ways that an `import` or a `from ... import` can fail.
Some considerations:
* The first commit in this PR adds a regression test for the current
behavior.
* This creates a new `mdtest/diagnostics` directory. Are folks cool
with this? I guess the idea is to put tests more devoted to diagnostics
than semantics in this directory. (Although I'm guessing there will
be some overlap.)
Fixes#15866
## Summary
This is a first step towards creating a test suite for
[descriptors](https://docs.python.org/3/howto/descriptor.html). It does
not (yet) aim to be exhaustive.
relevant ticket: #15966
## Test Plan
Compared desired behavior with the runtime behavior and the behavior of
existing type checkers.
---------
Co-authored-by: Mike Perlov <mishamsk@gmail.com>
This ties together everything from the previous commits.
Some interesting bits here are how the snapshot is generated
(where we include relevant info to make it easier to review
the snapshots) and also a tweak to how inline assertions are
processed.
This commit also includes some example snapshots just to get
a sense of what they look like. Follow-up work should add
more of these I think.
I split this out into a separate commit and put it here
so that reviewers can get a conceptual model of what the
code is doing before seeing the code. (Hopefully that helps.)
This makes it possible for callers to set where snapshots
should be stored. In general, I think we expect this to
always be set, since otherwise snapshots will end up in
`red_knot_test`, which is where the tests are actually run.
But that's overall counter-intuitive. This permits us to
store snapshots from mdtests alongside the mdtests themselves.
I found it useful to have the `&dyn Diagnostic` trait impl
specifically. I added `Arc<dyn Diagnostic>` for completeness.
(I do kind of wonder if we should be preferring `Arc<dyn ...>`
over something like `Box<dyn ...>` more generally, especially
for things with immutable APIs. It would make cloning cheap.)
This change was done to reduce snapshot churn. Previously,
if one added a new section to an Markdown test suite, then
the snapshots of all sections with unnamed files below it would
necessarily change because of the unnamed file count being
global to the test suite.
Instead, we track counts based on section. While adding new
unnamed files within a section will still change unnamed
files below it, I believe this will be less "churn" because
the snapshot will need to change anyway. Some churn is still
possible, e.g., if code blocks are re-ordered. But I think this
is an acceptable trade-off.
## Summary
Minor docs follow-up to #15862 to mention UP049 in the UP046 and UP047
`See also` sections. I wanted to mention it in UP040 too but realized it
didn't have a `See also` section, so I also added that, adapted from the
other two rules.
## Test Plan
cargo test
## Summary
The PR addresses the issue #15887
For two objects `a` and `b`, we ensure that the auto-fix and the
suggestion is of the form `a = min(a, b)` (or `a = max(a, b)`). This is
because we want to be consistent with the python implementation of the
methods: `min` and `max`. See the above issue for more details.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Resolves#15936.
The fixes will now attempt to preserve the original iterable's format
and quote it if necessary. For `FURB142`, comments within the fix range
will make it unsafe as well.
## Test Plan
`cargo nextest run` and `cargo insta test`.
## Summary
Resolves#15863.
In preview, diagnostic ranges will now be limited to that of the
argument. Rule documentation, variable names, error messages and fix
titles have all been modified to use "argument" consistently.
## Test Plan
`cargo nextest run` and `cargo insta test`.
## Summary
Resolves#15925.
`N803` now checks for functions instead of parameters. In preview mode,
if a method is decorated with `@override` and the current scope is that
of a class, it will be ignored.
## Test Plan
`cargo nextest run` and `cargo insta test`.
## Summary
Follow-up to #15779.
Prior to this change, non-name expressions are not reported at all:
```python
type(a.b) is type(None) # no error
```
This change enhances the rule so that such cases are also reported in
preview. Additionally:
* The fix will now be marked as unsafe if there are any comments within
its range.
* Error messages are slightly modified.
## Test Plan
`cargo nextest run` and `cargo insta test`.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Previously an error was emitted any time the configuration required both
an import of a module and an alias for that module. However, required
imports could themselves contain an alias, which may or may not agree
with the required alias.
To wit: requiring `import pandas as pd` does not conflict with the
`flake8-import-conventions.alias` config `{"pandas":"pd"}`.
This PR refines the check before throwing an error.
Closes#15911
## Summary
This PR adds `Type::call_bound` method for calls that should follow
descriptor protocol calling convention. The PR is intentionally shallow
in scope and only fixes#15672
Couple of obvious things that weren't done:
* Switch to `call_bound` everywhere it should be used
* Address the fact, that red_knot resolves `__bool__ = bool` as a Union,
which includes `Type::Dynamic` and hence fails to infer that the
truthiness is always false for such a class (I've added a todo comment
in mdtests)
* Doesn't try to invent a new type for descriptors, although I have a
gut feeling it may be more convenient in the end, instead of doing
method lookup each time like I did in `call_bound`
## Test Plan
* extended mdtests with 2 examples from the issue
* cargo neatest run
We now use ternary decision diagrams (TDDs) to represent visibility
constraints. A TDD is just like a BDD ([_binary_ decision
diagram](https://en.wikipedia.org/wiki/Binary_decision_diagram)), but
with "ambiguous" as an additional allowed value. Unlike the previous
representation, TDDs are strongly normalizing, so equivalent ternary
formulas are represented by exactly the same graph node, and can be
compared for equality in constant time.
We currently have a slight 1-3% performance regression with this in
place, according to local testing. However, we also have a _5× increase_
in performance for pathological cases, since we can now remove the
recursion limit when we evaluate visibility constraints.
As follow-on work, we are now closer to being able to remove the
`simplify_visibility_constraint` calls in the semantic index builder. In
the vast majority of cases, we now see (for instance) that the
visibility constraint after an `if` statement, for bindings of symbols
that weren't rebound in any branch, simplifies back to `true`. But there
are still some cases we generate constraints that are cyclic. With
fixed-point cycle support in salsa, or with some careful analysis of the
still-failing cases, we might be able to remove those.
## Summary
This is a new rule to implement the renaming of PEP 695 type parameters
with leading underscores after they have (presumably) been converted
from standalone type variables by either UP046 or UP047. Part of #15642.
I'm not 100% sure the fix is always safe, but I haven't come up with any
counterexamples yet. `Renamer` seems pretty precise, so I don't think
the usual issues with comments apply.
I initially tried writing this as a rule that receives a `Stmt` rather
than a `Binding`, but in that case the
`checker.semantic().current_scope()` was the global scope, rather than
the scope of the type parameters as I needed. Most of the other rules
using `Renamer` also used `Binding`s, but it does have the downside of
offering separate diagnostics for each parameter to rename.
## Test Plan
New snapshot tests for UP049 alone and the combination of UP046, UP049,
and PYI018.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
I experimented with [not trimming trailing newlines in code
snippets](https://github.com/astral-sh/ruff/pull/15926#discussion_r1940992090),
but since came to the conclusion that the current behavior is better
because otherwise, there is no way to write snippets without a trailing
newline at all. And when you copy the code from a Markdown snippet in
GitHub, you also don't get a trailing newline.
I was surprised to see some test failures when I played with this
though, and decided to make this test independent from this
implementation detail.
## Summary
Fix line number reporting in MDTest error messages.
## Test Plan
Introduced an error in a Markdown test and made sure that the line in
the error message matches.
## Summary
This is a follow-up to #15726, #15778, and #15794 to preserve the triple
quote and prefix flags in plain strings, bytestrings, and f-strings.
I also added a `StringLiteralFlags::without_triple_quotes` method to
avoid passing along triple quotes in rules like SIM905 where it might
not make sense, as discussed
[here](https://github.com/astral-sh/ruff/pull/15726#discussion_r1930532426).
## Test Plan
Existing tests, plus many new cases in the `generator::tests::quote`
test that should cover all combinations of quotes and prefixes, at least
for simple string bodies.
Closes#7799 when combined with #15694, #15726, #15778, and #15794.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Replaces our existing Markdown test parser with a fully hand-written
parser. I tried to fix this bug using the old approach and kept running
into problems. Eventually this seemed like the easier way. It's more
code (+50 lines, excluding the new test), but I hope it's relatively
straightforward to understand, compared to the complex interplay between
the byte-stream-manipulation and regex-parsing that we had before.
I did not really focus on performance, as the parsing time does not
dominate the test execution time, but this seems to be slightly faster
than what we had before (executing all MD tests; debug):
| Command | Mean [s] | Min [s] | Max [s] | Relative |
|:---|---:|---:|---:|---:|
| this branch | 2.775 ± 0.072 | 2.690 | 2.877 | 1.00 |
| `main` | 2.921 ± 0.034 | 2.865 | 2.967 | 1.05 ± 0.03 |
closes#15923
## Test Plan
One new regression test.
## Summary
Extend AIR302 with
* `airflow.operators.bash.BashOperator →
airflow.providers.standard.operators.bash.BashOperator`
* change existing rules `airflow.operators.bash_operator.BashOperator →
airflow.operators.bash.BashOperator` to
`airflow.operators.bash_operator.BashOperator →
airflow.providers.standard.operators.bash.BashOperator`
## Test Plan
a test fixture has been updated
## Summary
Resolves#15695, rework of #15704.
This change modifies the Mdtests framework so that:
* Paths must now be specified in a separate preceding line:
`````markdown
`a.py`:
```py
x = 1
```
`````
If the path of a file conflicts with its `lang`, an error will be
thrown.
* Configs are no longer accepted. The pattern still take them into
account, however, to avoid "Unterminated code block" errors.
* Unnamed files are now assigned unique, `lang`-respecting paths
automatically.
Additionally, all legacy usages have been updated.
## Test Plan
Unit tests and Markdown tests.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
This extracts some pure refactoring noise from
https://github.com/astral-sh/ruff/pull/15861. This changes the API for
creating and evaluating visibility constraints, but does not change how
they are respresented internally. There should be no behavioral or
performance changes in this PR.
Changes:
- Hide the internal representation isn't changed, so that we can make
changes to it in #15861.
- Add a separate builder type for visibility constraints. (With TDDs, we
will have some additional builder state that we can throw away once
we're done constructing.)
- Remove a layer of helper methods from `UseDefMapBuilder`, making
`SemanticIndexBuilder` responsible for constructing whatever visibility
constraints it needs.
## Summary
Add support for implicitly-defined instance attributes, i.e. support
type inference for cases like this:
```py
class C:
def __init__(self) -> None:
self.x: int = 1
self.y = None
reveal_type(C().x) # int
reveal_type(C().y) # Unknown | None
```
## Benchmarks
Codspeed reports no change in a cold-cache benchmark, and a -1%
regression in the incremental benchmark. On `black`'s `src` folder, I
don't see a statistically significant difference between the branches:
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|:---|---:|---:|---:|---:|
| `./red_knot_main check --project /home/shark/black/src` | 133.7 ± 9.5 | 126.7 | 164.7 | 1.01 ± 0.08 |
| `./red_knot_feature check --project /home/shark/black/src` | 132.2 ± 5.1 | 118.1 | 140.9 | 1.00 |
## Test Plan
Updated and new Markdown tests
## Summary
Given the following code:
```python
set(([x for x in range(5)]))
```
the current implementation of C403 results in
```python
{(x for x in range(5))}
```
which is a set containing a generator rather than the result of the
generator.
This change removes the extraneous parentheses so that the resulting
code is:
```python
{x for x in range(5)}
```
## Test Plan
`cargo nextest run` and `cargo insta test`
## Summary
Related to #15848, this PR adds the imports explicitly as we'll now flag
these symbols as undefined.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [imara-diff](https://redirect.github.com/pascalkuthe/imara-diff) |
workspace.dependencies | patch | `0.1.7` -> `0.1.8` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>pascalkuthe/imara-diff (imara-diff)</summary>
###
[`v0.1.8`](https://redirect.github.com/pascalkuthe/imara-diff/blob/HEAD/CHANGELOG.md#018---2025-2-1)
[Compare
Source](https://redirect.github.com/pascalkuthe/imara-diff/compare/v0.1.7...v0.1.8)
##### Changed
- update MSRV to 1.71
- drop ahash dependency in favour of hashbrowns default hasher
(foldhash)
##### Fixed
- incomplete documentation for sink and interner
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNDUuMCIsInVwZGF0ZWRJblZlciI6IjM5LjE0NS4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [serde_json](https://redirect.github.com/serde-rs/json) |
workspace.dependencies | patch | `1.0.137` -> `1.0.138` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>serde-rs/json (serde_json)</summary>
###
[`v1.0.138`](https://redirect.github.com/serde-rs/json/releases/tag/v1.0.138)
[Compare
Source](https://redirect.github.com/serde-rs/json/compare/v1.0.137...v1.0.138)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNDUuMCIsInVwZGF0ZWRJblZlciI6IjM5LjE0NS4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [syn](https://redirect.github.com/dtolnay/syn) |
workspace.dependencies | patch | `2.0.96` -> `2.0.98` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/syn (syn)</summary>
###
[`v2.0.98`](https://redirect.github.com/dtolnay/syn/releases/tag/2.0.98)
[Compare
Source](https://redirect.github.com/dtolnay/syn/compare/2.0.97...2.0.98)
- Allow lifetimes in function pointer return values in
`ParseStream::call` and `Punctuated` parsers
([#​1847](https://redirect.github.com/dtolnay/syn/issues/1847))
###
[`v2.0.97`](https://redirect.github.com/dtolnay/syn/releases/tag/2.0.97)
[Compare
Source](https://redirect.github.com/dtolnay/syn/compare/2.0.96...2.0.97)
- Documentation improvements
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNDUuMCIsInVwZGF0ZWRJblZlciI6IjM5LjE0NS4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [unicode-ident](https://redirect.github.com/dtolnay/unicode-ident) |
workspace.dependencies | patch | `1.0.15` -> `1.0.16` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>dtolnay/unicode-ident (unicode-ident)</summary>
###
[`v1.0.16`](https://redirect.github.com/dtolnay/unicode-ident/releases/tag/1.0.16)
[Compare
Source](https://redirect.github.com/dtolnay/unicode-ident/compare/1.0.15...1.0.16)
- Update `rand` dev dependency to 0.9
([#​29](https://redirect.github.com/dtolnay/unicode-ident/issues/29))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNDUuMCIsInVwZGF0ZWRJblZlciI6IjM5LjE0NS4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [tempfile](https://stebalien.com/projects/tempfile-rs/)
([source](https://redirect.github.com/Stebalien/tempfile)) |
workspace.dependencies | minor | `3.15.0` -> `3.16.0` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>Stebalien/tempfile (tempfile)</summary>
###
[`v3.16.0`](https://redirect.github.com/Stebalien/tempfile/blob/HEAD/CHANGELOG.md#3160)
[Compare
Source](https://redirect.github.com/Stebalien/tempfile/compare/v3.15.0...v3.16.0)
- Update `getrandom` to `0.3.0` (thanks to
[@​paolobarbolini](https://redirect.github.com/paolobarbolini)).
- Allow `windows-sys` versions `0.59.x` in addition to `0.59.0` (thanks
[@​ErichDonGubler](https://redirect.github.com/ErichDonGubler)).
- Improved security documentation (thanks to
[@​n0toose](https://redirect.github.com/n0toose) for collaborating
with me on this).
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS4xNDUuMCIsInVwZGF0ZWRJblZlciI6IjM5LjE0NS4wIiwidGFyZ2V0QnJhbmNoIjoibWFpbiIsImxhYmVscyI6WyJpbnRlcm5hbCJdfQ==-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This change does a simple swap of the existing renderer for one that
uses our vendored copy of `annotate-snippets`. We don't change anything
about the diagnostic data model, but this alone already makes
diagnostics look a lot nicer!
This mimics a simplification we have on the OR side, where we simplify
`A ∨ !A` to true. This requires changes to how we add `while` statements
to the semantic index, since we now need distinct
`VisibilityConstraint`s if we need to model evaluating a `Constraint`
multiple times at different points in the execution of the program.
Something Alex and I threw together during our 1:1 this morning. Allows
us to collect statistics on the prevalence of various types in a file,
most usefully TODO types or other dynamic types.
## Summary
This is a follow-up to #15565, tracked in #15642, to reuse the string
replacement logic from the other PEP 695 rules instead of the
`Generator`, which has the benefit of preserving more comments. However,
comments in some places are still dropped, so I added a check for this
and update the fix safety accordingly. I also added a `## Fix safety`
section to the docs to reflect this and the existing `isinstance`
caveat.
## Test Plan
Existing UP040 tests, plus some new cases.
## Summary
Resolves#10063 and follow-up to #15521.
The fix is now marked as unsafe if there are any comments within its
range. Tests are adapted from that of #15521.
## Test Plan
`cargo nextest run` and `cargo insta test`.
Both `list` and `dict` expect only a single positional argument. Giving
more positional arguments, or a keyword argument, is a `TypeError` and
neither the lint rule nor its fix make sense in that context.
Closes#15810
Builtin bindings are given a range of `0..0`, which causes strange
behavior when range checks are made at the top of the file. In this
case, the logic of the rule demands that the value of the dict
comprehension is not self-referential (i.e. it does not contain
definitions for any of the variables used within it). This logic was
confused by builtins which looked like they were defined "in the
comprehension", if the comprehension appeared at the top of the file.
Closes#15830
## Summary
This PR removes a trailing semicolon after an interface definition in
the custom TypeScript section of `ruff_wasm`. Currently, this semicolon
triggers the error "TS1036: Statements are not allowed in ambient
contexts" when including the file and compiling with e.g `tsc`.
## Test Plan
I made the change, ran `wasm-pack` and copied the generated directory
manually to my `node_modules` folder. I then compiled a file importing
`@astral-sh/ruff-wasm-web` again and confirmed that the compilation
error was gone.
If there is any `ParenthesizedWhitespace` (in the sense of LibCST) after
the function name `sorted` and before the arguments, then we must wrap
`sorted` with parentheses after removing the surrounding function.
Closes#15789
This PR uses the tokens of the parsed annotation available in the
`Checker`, instead of re-lexing (using `SimpleTokenizer`) the
annotation. This avoids some limitations of the `SimpleTokenizer`, such
as not being able to handle number and string literals.
Closes#15816 .
## Summary
Permits suspicious imports (the `S4` namespaced diagnostics) from stub
files.
Closes#15207.
## Test Plan
Added tests and ran `cargo nextest run`. The test files are copied from
the `.py` variants.
`FlowSnapshot` now tracks a `reachable` bool, which indicates whether we
have encountered a terminal statement on that control flow path. When
merging flow states together, we skip any that have been marked
unreachable. This ensures that bindings that can only be reached through
unreachable paths are not considered visible.
## Test Plan
The new mdtests failed (with incorrect `reveal_type` results, and
spurious `possibly-unresolved-reference` errors) before adding the new
visibility constraints.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This is another follow-up to #15726 and #15778, extending the
quote-preserving behavior to f-strings and deleting the now-unused
`Generator::quote` field.
## Details
I also made one unrelated change to `rules/flynt/helpers.rs` to remove a
`to_string` call for making a `Box<str>` and tweaked some arguments to
some of the `Generator::unparse_f_string` methods to make the code
easier to follow, in my opinion. Happy to revert especially the latter
of these if needed.
Unfortunately this still does not fix the issue in #9660, which appears
to be more of an escaping issue than a quote-preservation issue. After
#15726, the result is now `a = f'# {"".join([])}' if 1 else ""` instead
of `a = f"# {''.join([])}" if 1 else ""` (single quotes on the outside
now), but we still don't have the desired behavior of double quotes
everywhere on Python 3.12+. I added a test for this but split it off
into another branch since it ended up being unaddressed here, but my
`dbg!` statements showed the correct preferred quotes going into
[`UnicodeEscape::with_preferred_quote`](https://github.com/astral-sh/ruff/blob/main/crates/ruff_python_literal/src/escape.rs#L54).
## Test Plan
Existing rule and `Generator` tests.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Implements some of #14738, by adding support for 6 new patterns:
```py
re.search("abc", s) is None # ⇒ "abc" not in s
re.search("abc", s) is not None # ⇒ "abc" in s
re.match("abc", s) is None # ⇒ not s.startswith("abc")
re.match("abc", s) is not None # ⇒ s.startswith("abc")
re.fullmatch("abc", s) is None # ⇒ s != "abc"
re.fullmatch("abc", s) is not None # ⇒ s == "abc"
```
## Test Plan
```shell
cargo nextest run
cargo insta review
```
And ran the fix on my startup's repo.
## Note
One minor limitation here:
```py
if not re.match('abc', s) is None:
pass
```
will get fixed to this (technically correct, just not nice):
```py
if not not s.startswith('abc'):
pass
```
This seems fine given that Ruff has this covered: the initial code
should be caught by
[E714](https://docs.astral.sh/ruff/rules/not-is-test/) and the fixed
code should be caught by
[SIM208](https://docs.astral.sh/ruff/rules/double-negation/).
## Summary
When we discussed the plan on how to proceed with instance attributes,
we said that we should first extend our research into the behavior of
existing type checkers. The result of this research is summarized in the
newly added / modified tests in this PR. The TODO comments align with
existing behavior of other type checkers. If we deviate from the
behavior, it is described in a comment.
## Summary
Resolves#12717.
This change incorporates the logic added in #15588.
## Test Plan
`cargo nextest run` and `cargo insta test`.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
As promised in #15603 - the **highly** sophisticated change - adding
missing config docstrings that are used in command completions.
## Test Plan
I actually made a local change to emit all empty items and verified
there are none now, before opening the PR.
## Summary
This is a very closely related follow-up to #15726, adding the same
quote-preserving behavior to bytestrings. Only one rule (UP018) was
affected this time, and it was easy to mirror the plain string changes.
## Test Plan
Existing tests
## Summary
This is a first step toward fixing #7799 by using the quoting style
stored in the `flags` field on `ast::StringLiteral`s to select a quoting
style. This PR does not include support for f-strings or byte strings.
Several rules also needed small updates to pass along existing quoting
styles instead of using `StringLiteralFlags::default()`. The remaining
snapshot changes are intentional and should preserve the quotes from the
input strings.
## Test Plan
Existing tests with some accepted updates, plus a few new RUF055 tests
for raw strings.
---------
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
* feat
* add is_execute_method_inherits_from_airflow_operator for checking the
removed context key in the execute method
* refactor: rename
* is_airflow_task as is_airflow_task_function_def
* in_airflow_task as in_airflow_task_function_def
* removed_in_3 as airflow_3_removal_expr
* removed_in_3_function_def as airflow_3_removal_function_def
* test:
* reorganize test cases
## Test Plan
a test fixture has been updated
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
Not the most important feature, but hey... was marked as the good first
issue ;-) fixes#4551
Unfortunately, looks like clap only generates proper completions for
zsh, so this would not make any difference for bash/fish.
## Test Plan
- cargo nextest run
- manual test by sourcing completions and then triggering autocomplete:
```shell
misha@PandaBook ruff % source <(target/debug/ruff generate-shell-completion zsh)
misha@PandaBook ruff % target/debug/ruff config lin
line-length -- The line length to use when enforcing long-lines violations
lint -- Configures how Ruff checks your code.
lint.allowed-confusables -- A list of allowed 'confusable' Unicode characters to ignore
lint.dummy-variable-rgx -- A regular expression used to identify 'dummy' variables, or
lint.exclude -- A list of file patterns to exclude from linting in addition
lint.explicit-preview-rules -- Whether to require exact codes to select preview rules. Whe
lint.extend-fixable -- A list of rule codes or prefixes to consider fixable, in ad
lint.extend-ignore -- A list of rule codes or prefixes to ignore, in addition to
lint.extend-per-file-ignores -- A list of mappings from file pattern to rule codes or prefi
lint.extend-safe-fixes -- A list of rule codes or prefixes for which unsafe fixes sho
lint.extend-select -- A list of rule codes or prefixes to enable, in addition to
lint.extend-unsafe-fixes -- A list of rule codes or prefixes for which safe fixes shoul
lint.external -- A list of rule codes or prefixes that are unsupported by Ru
lint.fixable -- A list of rule codes or prefixes to consider fixable. By de
lint.flake8-annotations -- Print a list of available options
lint.flake8-annotations.allow-star-arg-any -- Whether to suppress `ANN401` for dynamically typed `*args`
...
```
- check command help
```shell
❯ target/debug/ruff config -h
List or describe the available configuration options
Usage: ruff config [OPTIONS] [OPTION]
Arguments:
[OPTION] Config key to show
Options:
--output-format <OUTPUT_FORMAT> Output format [default: text] [possible values: text, json]
-h, --help Print help
Log levels:
-v, --verbose Enable verbose logging
-q, --quiet Print diagnostics, but nothing else
-s, --silent Disable all logging (but still exit with status code "1" upon detecting diagnostics)
Global options:
--config <CONFIG_OPTION> Either a path to a TOML configuration file (`pyproject.toml` or `ruff.toml`), or a TOML `<KEY> =
<VALUE>` pair (such as you might find in a `ruff.toml` configuration file) overriding a specific
configuration option. Overrides of individual settings using this option always take precedence over
all configuration files, including configuration files that were also specified using `--config`
--isolated Ignore all configuration files
```
- running original command
```shell
❯ target/debug/ruff config
cache-dir
extend
output-format
fix
unsafe-fixes
fix-only
show-fixes
required-version
preview
exclude
extend-exclude
extend-include
force-exclude
include
respect-gitignore
builtins
namespace-packages
target-version
src
line-length
indent-width
lint
format
analyze
```
## Summary
Adds a slightly more comprehensive documentation of our behavior
regarding type inference for public uses of symbols. In particular:
- What public type do we infer for `x: int = any()`?
- What public type do we infer for `x: Unknown = 1`?
## Summary
Found a comment that looks to be intended as docstring but accidentally
is just a normal comment.
Didn't create an issue as the readme said it's not neccessary for
trivial changes.
## Test Plan
<!-- How was it tested? -->
Can be tested by regenerating the docs.
Co-authored-by: Marcus Näslund <vidaochmarcus@gmail.com>
## Summary
On `main`, red-knot:
- Considers `P | Q` equivalent to `Q | P`
- Considered `tuple[P | Q]` equivalent to `tuple[Q | P]`
- Considers `tuple[P | tuple[P | Q]]` equivalent to `tuple[tuple[Q | P]
| P]`
- ‼️ Does _not_ consider `tuple[tuple[P | Q]]` equivalent to
`tuple[tuple[Q | P]]`
The key difference for the last one of these is that the union appears
inside a tuple that is directly nested inside another tuple.
This PR fixes this so that differently ordered unions are considered
equivalent even when they appear inside arbitrarily nested tuple types.
## Test Plan
- Added mdtests that fails on `main`
- Checked that all property tests continue to pass with this PR
This is a follow-up to #15702 that hopefully claws back the 1%
performance regression. Assuming it works, the trick is to iterate over
the constraints vectors via mut reference (aka a single pointer), so
that we're not copying `BitSet`s into and out of the zip tuples as we
iterate. We use `std::mem::take` as a poor-man's move constructor only
at the very end, when we're ready to emplace it into the result. (C++
idioms intended! 😄)
With local testing via hyperfine, I'm seeing this be 1-3% faster than
`main` most of the time — though a small number of runs (1 in 10,
maybe?) are a wash or have `main` faster. Codspeed reports a 2%
gain.
## Summary
Use `Unknown | T_inferred` as the type for *undeclared* public symbols.
## Test Plan
- Updated existing tests
- New test for external `__slots__` modifications.
- New tests for external modifications of public symbols.
**Summary**
Airflow 3.0 removes a set of deprecated context variables that were
phased out in 2.x. This PR introduces lint rules to detect usage of
these removed variables in various patterns, helping identify
incompatibilities. The removed context variables include:
```
conf
execution_date
next_ds
next_ds_nodash
next_execution_date
prev_ds
prev_ds_nodash
prev_execution_date
prev_execution_date_success
tomorrow_ds
yesterday_ds
yesterday_ds_nodash
```
**Detected Patterns and Examples**
The linter now flags the use of removed context variables in the
following scenarios:
1. **Direct Subscript Access**
```python
execution_date = context["execution_date"] # Flagged
```
2. **`.get("key")` Method Calls**
```python
print(context.get("execution_date")) # Flagged
```
3. **Variables Assigned from `get_current_context()`**
If a variable is assigned from `get_current_context()` and then used to
access a removed key:
```python
c = get_current_context()
print(c.get("execution_date")) # Flagged
```
4. **Function Parameters in `@task`-Decorated Functions**
Parameters named after removed context variables in functions decorated
with `@task` are flagged:
```python
from airflow.decorators import task
@task
def my_task(execution_date, **kwargs): # Parameter 'execution_date'
flagged
pass
```
5. **Removed Keys in Task Decorator `kwargs` and Other Scenarios**
Other similar patterns where removed context variables appear (e.g., as
part of `kwargs` in a `@task` function) are also detected.
```
from airflow.decorators import task
@task
def process_with_execution_date(**context):
execution_date = lambda: context["execution_date"] # flagged
print(execution_date)
@task(kwargs={"execution_date": "2021-01-01"}) # flagged
def task_with_kwargs(**context):
pass
```
**Test Plan**
Test fixtures covering various patterns of deprecated context usage are
included in this PR. For example:
```python
from airflow.decorators import task, dag, get_current_context
from airflow.models import DAG
from airflow.operators.dummy import DummyOperator
import pendulum
from datetime import datetime
@task
def access_invalid_key_task(**context):
print(context.get("conf")) # 'conf' flagged
@task
def print_config(**context):
execution_date = context["execution_date"] # Flagged
prev_ds = context["prev_ds"] # Flagged
@task
def from_current_context():
context = get_current_context()
print(context["execution_date"]) # Flagged
# Usage outside of a task decorated function
c = get_current_context()
print(c.get("execution_date")) # Flagged
@task
def some_task(execution_date, **kwargs):
print("execution date", execution_date) # Parameter flagged
@dag(
start_date=pendulum.datetime(2021, 1, 1, tz="UTC")
)
def my_dag():
task1 = DummyOperator(
task_id="task1",
params={
"execution_date": "{{ execution_date }}", # Flagged in template context
},
)
access_invalid_key_task()
print_config()
from_current_context()
dag = my_dag()
class CustomOperator(BaseOperator):
def execute(self, context):
execution_date = context.get("execution_date") # Flagged
next_ds = context.get("next_ds") # Flagged
next_execution_date = context["next_execution_date"] # Flagged
```
Ruff will emit `AIR302` diagnostics for each deprecated usage, with
suggestions when applicable, aiding in code migration to Airflow 3.0.
related: https://github.com/apache/airflow/issues/44409,
https://github.com/apache/airflow/issues/41641
---------
Co-authored-by: Wei Lee <weilee.rx@gmail.com>
## Summary
Fixes#9663 and also improves the fixes for
[RUF055](https://docs.astral.sh/ruff/rules/unnecessary-regular-expression/)
since regular expressions are often written as raw strings.
This doesn't include raw f-strings.
## Test Plan
Existing snapshots for RUF055 and PT009, plus a new `Generator` test and
a regression test for the reported `PIE810` issue.
## Summary
Another small PR to focus #15674 solely on the relevant changes. This
makes our Markdown tests less dependent on precise types of public
symbols, without actually changing anything semantically in these tests.
Best reviewed using ignore-whitespace-mode.
## Test Plan
Tested these changes on `main` and on the branch from #15674.
## Summary
Make the remaining `infer.rs` unit tests independent from public symbol
type inference decisions (see upcoming change in #15674).
## Test Plan
- Made sure that the unit tests actually fail if one of the
`assert_type` assertions is changed.
## Summary
Port comprehension tests from Rust to Markdown
I don' think the remaining tests in `infer.rs` should be ported to
Markdown, maybe except for the incremental-checking tests when (if ever)
we have support for that in the MD tests.
closes#13696
## Summary
- Port "deferred annotations" unit tests to Markdown
- Port `implicit_global_in_function` unit test to Markdown
- Removed `resolve_method` and `local_inference` unit tests. These seem
like relics from a time where type inference was in it's early stages.
There is no way that these tests would fail today without lots of other
things going wrong as well.
part of #13696
based on #15683
## Test Plan
New MD tests for existing Rust unit tests.
## Summary
- Add feature to specify a custom typeshed from within Markdown-based
tests
- Port "builtins" unit tests from `infer.rs` to Markdown tests, part of
#13696
## Test Plan
- Tests for the custom typeshed feature
- New Markdown tests for deleted Rust unit tests
## Summary
Addresses the second follow up to #15565 in #15642. This was easier than
expected by using this cool destructuring syntax I hadn't used before,
and by assuming
[PYI059](https://docs.astral.sh/ruff/rules/generic-not-last-base-class/)
(`generic-not-last-base-class`).
## Test Plan
Using an existing test, plus two new tests combining multiple base
classes and multiple generics. It looks like I deleted a relevant test,
which I did, but I meant to rename this in #15565. It looks like instead
I copied it and renamed the copy.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR extends our [PEP 695](https://peps.python.org/pep-0695) handling
from the type aliases handled by `UP040` to generic function and class
parameters, as suggested in the latter two examples from #4617:
```python
# Input
T = TypeVar("T", bound=float)
class A(Generic[T]):
...
def f(t: T):
...
# Output
class A[T: float]:
...
def f[T: float](t: T):
...
```
I first implemented this as part of `UP040`, but based on a brief
discussion during a very helpful pairing session with @AlexWaygood, I
opted to split them into rules separate from `UP040` and then also
separate from each other. From a quick look, and based on [this
issue](https://github.com/asottile/pyupgrade/issues/836), I'm pretty
sure neither of these rules is currently in pyupgrade, so I just took
the next available codes, `UP046` and `UP047`.
The last main TODO, noted in the rule file and in the fixture, is to
handle generic method parameters not included in the class itself, `S`
in this case:
```python
T = TypeVar("T")
S = TypeVar("S")
class Foo(Generic[T]):
def bar(self, x: T, y: S) -> S: ...
```
but Alex mentioned that that might be okay to leave for a follow-up PR.
I also left a TODO about handling multiple subclasses instead of bailing
out when more than one is present. I'm not sure how common that would
be, but I can still handle it here, or follow up on that too.
I think this is unrelated to the PR, but when I ran `cargo dev
generate-all`, it removed the rule code `PLW0101` from
`ruff.schema.json`. It seemed unrelated, so I left that out, but I
wanted to mention it just in case.
## Test Plan
New test fixture, `cargo nextest run`
Closes#4617, closes#12542
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Somehow, I managed to crash the `mdtest` runner today. I struggled to
reproduce this again to see if it's actually fixed (even with an
artificial `sleep` between the two `cargo test` invocations), but the
original backtrace clearly showed that this is where the problem
originated from. And it seems like a clear TOCTOU problem.
## Summary
Raise "invalid-assignment" diagnostics for incorrect assignments to
attributes, for example:
```py
class C:
var: str = "a"
C.var = 1 # error: "Object of type `Literal[1]` is not assignable to `str`"
```
closes#15456
## Test Plan
- Updated test assertions
- New test for assignments to module-attributes
## Summary
This PR generalizes some of the logic we have in `Type::is_subtype_of`
and `Type::is_disjoint_from` so that we fallback to the instance type of
the metaclass more often in `Type::ClassLiteral` and `Type::SubclassOf`
branches. This simplifies the code (we end up with one less branch in
`is_subtype_of`, and we can remove a helper method that's no longer
used), makes the code more robust (any fixes made to subtyping or
disjointness of instance types will automatically improve our
understanding of subtyping/disjointness for class-literal types and
`type[]` types) and more elegantly expresses the type-system invariants
encoded in these branches.
## Test Plan
No new tests added (it's a pure refactor, adding no new functionality).
All existing tests pass, however, including the property tests.
The AST generator creates a reference enum for each syntax group — an
enum where each variant contains a reference to the relevant syntax
node. Previously you could customize the name of the reference enum for
a group — primarily because there was an existing `ExpressionRef` type
that wouldn't have lined up with the auto-derived name `ExprRef`. This
follow-up PR is a simple search/replace to switch over to the
auto-derived name, so that we can remove this customization point.
This is a minor cleanup to the AST generation script to make a clearer
separation between nodes that do appear in a group enum, and those that
don't. There are some types and methods that we create for every syntax
node, and others that refer to the group that the syntax node belongs
to, and which therefore don't make sense for ungrouped nodes. This new
separation makes it clearer which category each definition is in, since
you're either inside of a `for group in ast.groups` loop, or a `for node
in ast.all_nodes` loop.
## Summary
Test executables usually write failure messages (including panics) to
stdout, but I just managed to make a mdtest crash with
```
thread 'mdtest__unary_not' has overflowed its stack
fatal runtime error: stack overflow
```
which is printed to stderr. This test simply appends stderr to stdout
(`stderr=subprocess.STDOUT` can not be used with `capture_output`)
## Test Plan
Make sure that the error message is now visible in the output of `uv -q
run crates/red_knot_python_semantic/mdtest.py`
## Summary
The `Options` struct is intended to capture the user's configuration
options but
`EnvironmentOptions::venv_path` supports both a `SitePackages::Known`
and `SitePackages::Derived`.
Users should only be able to provide `SitePackages::Derived`—they
specify a path to a venv, and Red Knot derives the path to the
site-packages directory. We'll only use the `Known` variant once we
automatically discover the Python installation.
That's why this PR changes `EnvironmentOptions::venv_path` from
`Option<SitePackages>` to `Option<SystemPathBuf>`.
This requires making some changes to the file watcher test, and I
decided to use `extra_paths` over venv path
because our venv validation is annoyingly correct -- making mocking a
venv rather involved.
## Test Plan
`cargo test`
## Summary
We were mistakenly using `CommentRanges::has_comments` to determine
whether our edits
were safe, which sometimes expands the checked range to the end of a
line. But in order to
determine safety we need to check exactly the range we're replacing.
This bug affected the rules `runtime-cast-value` (`TC006`) and
`quoted-type-alias` (`TC008`)
although it was very unlikely to be hit for `TC006` and for `TC008` we
never hit it because we
were checking the wrong expression.
## Test Plan
`cargo nextest run`
This commit fixes RUF055 rule to format `re.fullmatch(pattern, var)` to
`var == pattern` instead of the current `pattern == var` behaviour. This
is more idiomatic and easy to understand.
## Summary
This changes the current formatting behaviour of `re.fullmatch(pattern,
var)` to format it to `var == pattern` instead of `pattern == var`.
## Test Plan
I used a code file locally to see the updated formatting behaviour.
Fixes https://github.com/astral-sh/ruff/issues/14733
## Summary
As more and more tests move to Markdown, running the mdtest suite
becomes one of the most common tasks for developers working on Red Knot.
There are a few pain points when doing so, however:
- The `build.rs` script enforces recompilation (~five seconds) whenever
something changes in the `resource/mdtest` folder. This is strictly
necessary, because whenever files are added or removed, the test harness
needs to be updated. But this is very rarely the case! The most common
scenario is that a Markdown file has *changed*, and in this case, no
recompilation is necessary. It is currently not possible to distinguish
these two cases using `cargo::rerun-if-changed`. One can work around
this by running the test executable manually, but it requires finding
the path to the correct `mdtest-<random-hash>` executable.
- All Markdown tests are run by default. This is needed whenever Rust
code changes, but while working on the tests themselves, it is often
much more convenient to only run the tests for a single file. This can
be done by using a `mdtest__path_to_file` filter, but this needs to be
manually spelled out or copied from the test output.
- `cargo`s test output for a failing Markdown test is often
unnecessarily verbose. Unless there is an *actual* panic somewhere in
the code, mdtests usually fail with the explicit *"Some tests failed"*
panic in the mdtest suite. But in those cases, we are not interested in
the pointer to the source of this panic, but only in the mdtest suite
output.
This PR adds a Markdown test runner tool that attempts to make the
developer experience better.
Once it is started using
```bash
uv run -q crates/red_knot_python_semantic/mdtest.py
```
it will first recompile the tests once (if cargo requires it), find the
path to the `mdtest` executable, and then enter into a mode where it
watches for changes in the `red_knot_python_semantic` crate. Whenever …
* … a Markdown file changes, it will rerun the mdtest for this specific
file automatically (no recompilation!).
* … a Markdown file is added, it will recompile the tests and then run
the mdtest for the new file
* … Rust code is changed, it will recompile the tests and run all of
them
The tool also trims down `cargo test` output and only shows the actual
mdtest errors.
The tool will certainly require a few more iterations before it becomes
mature, but I'm curious to hear if there is any interest for something
like this.
## Test Plan
- Tested the new runner under various scenarios.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Rename two functions with outdated names (they used to return `Type`s):
* `bindings_ty` => `symbol_from_bindings` (returns `Symbol`)
* `declarations_ty` => `symbol_from_declarations` (returns a
`SymbolAndQualifiers` result)
I chose `symbol_from_*` instead of `*_symbol` as I found the previous
name quite confusing. Especially since `binding_ty` and `declaration_ty`
also exist (singular).
## Test Plan
—
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [notify](https://redirect.github.com/notify-rs/notify) |
workspace.dependencies | major | `7.0.0` -> `8.0.0` |
---
> [!WARNING]
> Some dependencies could not be looked up. Check the Dependency
Dashboard for more information.
---
### Release Notes
<details>
<summary>notify-rs/notify (notify)</summary>
###
[`v8.0.0`](https://redirect.github.com/notify-rs/notify/blob/HEAD/CHANGELOG.md#notify-800-2025-01-10)
[Compare
Source](https://redirect.github.com/notify-rs/notify/compare/notify-7.0.0...notify-8.0.0)
- CHANGE: update notify-types to version 2.0.0
- CHANGE: raise MSRV to 1.77 **breaking**
- FEATURE: add config option to disable following symbolic links
[#​635]
- FIX: unaligned access to FILE_NOTIFY_INFORMATION [#​647]
**breaking**
[#​635]: https://redirect.github.com/notify-rs/notify/pull/635
[#​647]: https://redirect.github.com/notify-rs/notify/pull/647
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS45Mi4wIiwidXBkYXRlZEluVmVyIjoiMzkuOTIuMCIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
In preperation for https://github.com/astral-sh/ruff/pull/15558
Isolate the `show_settings` test instead of reading Ruff's
`pyproject.toml` for better test isolation.
## Test Plan
`cargo test`
## Summary
I noticed this while reviewing
https://github.com/astral-sh/ruff/pull/15541 that the code inside the
large closure cannot be formatted by the Rust formatter. This PR
extracts the qualified name and inlines the match expression.
## Test Plan
`cargo clippy` and `cargo insta`
## Summary
Right now, these are being applied in random order, since if we have two
`RedefinitionWhileUnused`, it just takes the first-generated (whereas
the next comparator in the sort here orders by location)... Which means
we frequently have to re-run!
## Summary
The fix range for sorting imports accounts for trailing whitespace, but
we should only show the trimmed range to the user when displaying the
diagnostic. So this PR changes the diagnostic range.
Closes#15504
## Test Plan
Reviewed snapshot changes
## Summary
Added some extra notes on why you should have focused try...except
blocks to
[TRY300](https://docs.astral.sh/ruff/rules/try-consider-else/).
When fixing a violation of this rule, a co-worker of mine (very
understandably) asked why this was better. The current docs just say
putting the return in the else is "more explicit", but if you look at
the [linked reference in the python
documentation](https://docs.python.org/3/tutorial/errors.html) they are
more clear on why violations like this is bad:
> The use of the else clause is better than adding additional code to
the [try](https://docs.python.org/3/reference/compound_stmts.html#try)
clause because it avoids accidentally catching an exception that wasn’t
raised by the code being protected by the try … except statement.
This is my attempt at adding more context to the docs on this. Open to
suggestions for wording!
---------
Co-authored-by: dylwil3 <dylwil3@gmail.com>
In the following situation:
```python
class Grandparent:
__slots__ = "a"
class Parent(Grandparent): ...
class Child(Parent):
__slots__ = "a"
```
the message for `W0244` now specifies that `a` is overwriting a slot
from `Grandparent`.
To implement this, we introduce a helper function `iter_super_classes`
which does a breadth-first traversal of the superclasses of a given
class (as long as they are defined in the same file, due to the usual
limitations of the semantic model).
Note: Python does not allow conflicting slots definitions under multiple
inheritance. Unless I'm misunderstanding something, I believe It follows
that the subposet of superclasses of a given class that redefine a given
slot is in fact totally ordered. There is therefore a unique _nearest_
superclass whose slot is being overwritten. So, you know, in case anyone
was super worried about that... you can just chill.
This is a followup to #9640 .
## Summary
Add support for `typing.ClassVar`, i.e. emit a diagnostic in this
scenario:
```py
from typing import ClassVar
class C:
x: ClassVar[int] = 1
c = C()
c.x = 3 # error: "Cannot assign to pure class variable `x` from an instance of type `C`"
```
## Test Plan
- New tests for the `typing.ClassVar` qualifier
- Fixed one TODO in `attributes.md`
## Summary
Resolves#15016.
## Test Plan
Generate the docs with:
```console
uv run --with-requirements docs/requirements-insiders.txt scripts/generate_mkdocs.py
```
and, check whether the mapping was created in `mkdocs.generated.yml` and run the server using:
```console
uvx --with-requirements docs/requirements-insiders.txt -- mkdocs serve -f mkdocs.insiders.yml -o
```
While looking into potential AST optimizations, I noticed the `AstNode`
trait and `AnyNode` type aren't used anywhere in Ruff or Red Knot. It
looks like they might be historical artifacts of previous ways of
consuming AST nodes?
- `AstNode::cast`, `AstNode::cast_ref`, and `AstNode::can_cast` are not
used anywhere.
- Since `cast_ref` isn't needed anymore, the `Ref` associated type isn't
either.
This is a pure refactoring, with no intended behavior changes.
This PR replaces most of the hard-coded AST definitions with a
generation script, similar to what happens in `rust_python_formatter`.
I've replaced every "rote" definition that I could find, where the
content is entirely boilerplate and only depends on what syntax nodes
there are and which groups they belong to.
This is a pretty massive diff, but it's entirely a refactoring. It
should make absolutely no changes to the API or implementation. In
particular, this required adding some configuration knobs that let us
override default auto-generated names where they don't line up with
types that we created previously by hand.
## Test plan
There should be no changes outside of the `rust_python_ast` crate, which
verifies that there were no API changes as a result of the
auto-generation. Aggressive `cargo clippy` and `uvx pre-commit` runs
after each commit in the branch.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fixes parentheses not being stripped in C401. Pretty much the same as
#11607 which fixed it for C400.
## Test Plan
`cargo nextest run`
## Summary
This is a small, tentative step towards the bigger goal of understanding
instance attributes.
- Adds partial support for pure instance variables declared in the class
body, i.e. this case:
```py
class C:
variable1: str = "a"
variable2 = "b"
reveal_type(C().variable1) # str
reveal_type(C().variable2) # Unknown | Literal["b"]
```
- Adds `property` as a known class to query for `@property` decorators
- Splits up various `@Todo(instance attributes)` cases into
sub-categories.
## Test Plan
Modified existing MD tests.
## Summary
This PR adds support for configuring Red Knot in the `tool.knot` section
of the project's
`pyproject.toml` section. Options specified on the CLI precede the
options in the configuration file.
This PR only supports the `environment` and the `src.root` options for
now.
Other options will be added as separate PRs.
There are also a few concerns that I intentionally ignored as part of
this PR:
* Handling of relative paths: We need to anchor paths relative to the
current working directory (CLI), or the project (`pyproject.toml` or
`knot.toml`)
* Tracking the source of a value. Diagnostics would benefit from knowing
from which configuration a value comes so that we can point the user to
the right configuration file (or CLI) if the configuration is invalid.
* Schema generation and there's a lot more; see
https://github.com/astral-sh/ruff/issues/15491
This PR changes the default for first party codes: Our existing default
was to only add the project root. Now, Red Knot adds the project root
and `src` (if such a directory exists).
Theoretically, we'd have to add a file watcher event that changes the
first-party search paths if a user later creates a `src` directory. I
think this is pretty uncommon, which is why I ignored the complexity for
now but I can be persuaded to handle it if it's considered important.
Part of https://github.com/astral-sh/ruff/issues/15491
## Test Plan
Existing tests, new file watching test demonstrating that changing the
python version and platform is correctly reflected.
## Summary
Closes https://github.com/astral-sh/ruff/issues/15508
For any two instance types `T` and `S`, we know they are disjoint if
either `T` is final and `T` is not a subclass of `S` or `S` is final and
`S` is not a subclass of `T`.
Correspondingly, for any two types `type[T]` and `S` where `S` is an
instance type, `type[T]` can be said to be disjoint from `S` if `S` is
disjoint from `U`, where `U` is the type that represents all instances
of `T`'s metaclass.
And a heterogeneous tuple type can be said to be disjoint from an
instance type if the instance type is disjoint from `tuple` (a type
representing all instances of the `tuple` class at runtime).
## Test Plan
- A new mdtest added. Most of our `is_disjoint_from()` tests are not
written as mdtests just yet, but it's pretty hard to test some of these
edge cases from a Rust unit test!
- Ran `QUICKCHECK_TESTS=1000000 cargo test --release -p
red_knot_python_semantic -- --ignored types::property_tests::stable`
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Add a setting to allow ignoring one line docstrings for the pydoclint
rules.
Resolves#13086
Part of #12434
## Test Plan
Run tests with setting enabled.
---------
Co-authored-by: dylwil3 <dylwil3@gmail.com>
## Summary
This fixes the infinite loop reported in #14389 by raising an error to
the user about conflicting ICN001 (`unconventional-import-alias`) and
I002 (`missing-required-import`) configuration options.
## Test Plan
Added a CLI integration test reproducing the old behavior and then
confirming the fix.
Closes#14389
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This fixes the infinite loop reported in #12897, where an
`unused-import` that is undefined at the scope of `__all__` is "fixed"
by adding it to `__all__` repeatedly. These changes make it so that only
imports in the global scope will be suggested to add to `__all__` and
the unused local import is simply removed.
## Test Plan
Added a CLI integration test that sets up the same module structure as
the original report
Closes#12897
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Ref: https://github.com/astral-sh/ruff/pull/15387#discussion_r1917796907
This PR updates `F722` to show syntax error message instead of the
string content.
I think it's more useful to show the syntax error message than the
string content. In the future, when the diagnostics renderer is more
capable, we could even highlight the exact location of the syntax error
along with the annotation string.
This is also in line with how we show the diagnostic in red knot.
## Test Plan
Update existing test snapshots.
## Summary
Resolves#9467
Parse quoted annotations as if the string content is inside parenthesis.
With this logic `x` and `y` in this example are equal:
```python
y: """
int |
str
"""
z: """(
int |
str
)
"""
```
Also this rule only applies to triple
quotes([link](https://github.com/python/typing-council/issues/9#issuecomment-1890808610)).
This PR is based on the
[comments](https://github.com/astral-sh/ruff/issues/9467#issuecomment-2579180991)
on the issue.
I did one extra change, since we don't want any indentation tokens I am
setting the `State::Other` as the initial state of the Lexer.
Remaining work:
- [x] Add a test case for red-knot.
- [x] Add more tests.
## Test Plan
Added a test which previously failed because quoted annotation contained
indentation.
Added an mdtest for red-knot.
Updated previous test.
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
Allow links to issues that appear on the same line as the TODO
directive, if they conform to the format that VSCode's GitHub PR
extension produces.
Revival of #9627 (the branch was stale enough that rebasing was a lot
harder than just making the changes anew). Credit should go to the
author of that PR though.
Closes#8061
Co-authored-by: Martin Bernstorff <martinbernstorff@gmail.com>
Instead of doing this on a lint-by-lint basis, we now just do it right
before rendering. This is more broadly applicable.
Note that this doesn't fix the diagnostic rendering for the Python
parser. But that's using a different path anyway (`annotate-snippets` is
only used in tests).
Previously, these were pointing to the right place, but were missing the
`^`. With the `annotate-snippets` upgrade, the `^` was added, but they
started pointing to the end of the previous line instead of the
beginning of the following line. In this case, we really want it to
point to the beginning of the following line since we're calling out
indentation issues.
As in a prior commit, we fix this by tweaking the offsets emitted by the
lint itself. Instead of an empty range at the beginning of the line, we
point to the first character in the line. This "forces" the renderer to
point to the beginning of the line instead of the end of the preceding
line.
The end effect here is that the rendering is fixed by adding `^` in the
proper location.
This update includes some missing `^` in the diagnostic annotations.
This update also includes some shifting of "syntax error" annotations to
the end of the preceding line. I believe this is technically a
regression, but fixing them has proven quite difficult. I *think* the
best way to do that might be to tweak the spans generated by the Python
parser errors, but I didn't want to dig into that. (Another approach
would be to change the `annotate-snippets` rendering, but when I tried
that and managed to fix these regressions, I ended up causing a bunch of
other regressions.)
Ref 77d454525e (r1915458616)
This change also requires some shuffling to the offsets we generate for
the diagnostic. Previously, we were generating an empty range
immediately *after* the line terminator and immediate before the first
byte of the subsequent line. How this is rendered is somewhat open to
interpretation, but the new version of `annotate-snippets` chooses to
render this at the end of the preceding line instead of the beginning of
the following line.
In this case, we want the diagnostic to point to the beginning of the
following line. So we either need to change `annotate-snippets` to
render such spans at the beginning of the following line, or we need to
change our span to point to the first full character in the following
line. The latter will force `annotate-snippets` to move the caret to the
proper location.
I ended up deciding to change our spans instead of changing how
`annotate-snippets` renders empty spans after a line terminator. While I
didn't investigate it, my guess is that they probably had good reason
for doing so, and it doesn't necessarily strike me as _wrong_.
Furthermore, fixing up our spans seems like a good idea regardless, and
was pretty easy to do.
This looks like a bug fix since the caret is now pointing right at the
position of the unprintable character. I'm not sure if this is a result
of an improvement via the `annotate-snippets` upgrade, or because of
more accurate tracking of annotation ranges even after unprintable
characters are replaced. I'm tempted to say the former since in theory
the offsets were never wrong before because they were codepoint offsets.
Regardless, this looks like an improvement.
This updates snapshots where long lines now get trimmed with
`annotate-snippets`. And an ellipsis is inserted to indicate trimming.
This is a little hokey to test since in tests we don't do any styling.
And I believe this just uses the default "max term width" for rendering.
But in real life, it seems like a big improvement to have long lines
trimmed if they would otherwise wrap in the terminal. So this seems like
an improvement to me.
There are some other fixes here that overlap with previous categories.
We do this because `...` is valid Python, which makes it pretty likely
that some line trimming will lead to ambiguous output. So we add support
for overriding the cut indicator. This also requires changing some of
the alignment math, which was previously tightly coupled to `...`.
For Ruff, we go with `…` (`U+2026 HORIZONTAL ELLIPSIS`) for our cut
indicator.
For more details, see the patch sent to upstream:
https://github.com/rust-lang/annotate-snippets-rs/pull/172
This fix was sent upstream and the PR description includes more details:
https://github.com/rust-lang/annotate-snippets-rs/pull/170
Without this fix, there was an errant snapshot diff that looked like
this:
|
1 | version = "0.1.0"
2 | # Ensure that the spans from toml handle utf-8 correctly
3 | authors = [
| ___________^
4 | | { name = "Z͑ͫ̓ͪ̂ͫ̽͏̴̙...A̴̵̜̰͔ͫ͗͢L̠ͨͧͩ͘G̴̻͈͍̑͗̎̅͛́Ǫ̵̹̻̝̳͂̌̌͘", email = 1 }
5 | | ]
| |_^ RUF200
|
That ellipsis should _not_ be inserted since the line is not actually
truncated. The handling of line length (in bytes versus actual rendered
length) wasn't quite being handled correctly in all cases.
With this fix, there's (correctly) no snapshot diff.
The change to the rendering code is elaborated on in more detail here,
where I attempted to upstream it:
https://github.com/rust-lang/annotate-snippets-rs/pull/169
Otherwise, the snapshot diff also shows a bug fix: a `^` is now rendered
where as it previously was not.
This one almost looks like it fits into the other failure categories,
but without identifying root causes, it's hard to say for sure. The span
here does end after a line terminator, so it feels like it's like the
rest.
I also isolated this change since I found the snapshot diff pretty hard
to read and wanted to look at it more closely. In this case, the before
is:
E204.py:31:2: E204 [*] Whitespace after decorator
|
30 | # E204
31 | @ \
| __^
32 | | foo
| |_^ E204
33 | def baz():
34 | print('baz')
|
= help: Remove whitespace
And the after is:
E204.py:31:2: E204 [*] Whitespace after decorator
|
30 | # E204
31 | @ \
| ^^ E204
32 | foo
33 | def baz():
34 | print('baz')
|
= help: Remove whitespace
The updated rendering is clearly an improvement, since `foo` itself is
not really the subject of the diagnostic. The whitespace is.
Also, the new rendering matches the span fed to `annotate-snippets`,
where as the old rendering does not.
I separated out this snapshot update since the string of `^` including
whitespace looked a little odd. I investigated this one specifically,
and indeed, our span in this case is telling `annotate-snippets` to
point at the whitespace. So this is `annotate-snippets` doing what it's
told with a mildly sub-optimal span.
For clarity, the before rendering is:
skip.py:34:1: I001 [*] Import block is un-sorted or un-formatted
|
32 | import sys; import os # isort:skip
33 | import sys; import os # isort:skip # isort:skip
34 | / import sys; import os
|
= help: Organize imports
And now after is:
skip.py:34:1: I001 [*] Import block is un-sorted or un-formatted
|
32 | import sys; import os # isort:skip
33 | import sys; import os # isort:skip # isort:skip
34 | import sys; import os
| ^^^^^^^^^^^^^^^^^^^^^^^^^ I001
|
= help: Organize imports
This is a clear bug fix since it adds in the `I001` annotation, even
though the carets look a little funny by including the whitespace
preceding `import sys; import os`.
This group of updates is similar to the last one, but they call out the
fact that while the change is an improvement, it does still seem to be a
little buggy.
As one example, previously we would have this:
|
1 | / from __future__ import annotations
2 | |
3 | | from typing import Any
4 | |
5 | | from requests import Session
6 | |
7 | | from my_first_party import my_first_party_object
8 | |
9 | | from . import my_local_folder_object
10 | |
11 | |
12 | |
13 | | class Thing(object):
| |_^ I001
14 | name: str
15 | def __init__(self, name: str):
|
= help: Organize imports
And now here's what it looks like after:
|
1 | / from __future__ import annotations
2 | |
3 | | from typing import Any
4 | |
5 | | from requests import Session
6 | |
7 | | from my_first_party import my_first_party_object
8 | |
9 | | from . import my_local_folder_object
10 | |
11 | |
12 | |
| |__^ Organize imports
13 | class Thing(object):
14 | name: str
15 | def __init__(self, name: str):
|
= help: Organize imports
So at least now, the diagnostic is not pointing to a completely
unrelated thing (`class Thing`), but it's still not quite pointing to
the imports directly. And the `^` is a bit offset. After looking at
some examples more closely, I think this is probably more of a bug
with how we're generating offsets, since we are actually pointing to
a location that is a few empty lines _below_ the last import. And
`annotate-snippets` is rendering that part correctly. However, the
offset from the left (the `^` is pointing at `r` instead of `f` or even
at the end of `from . import my_local_folder_object`) appears to be a
problem with `annotate-snippets` itself.
We accept this under the reasoning that it's an improvement, albeit not
perfect.
I believe this case is different from the last in that it happens when
the end of a *multi-line* annotation occurs after a line terminator.
Previously, the diagnostic would render on the next line, which is
definitely a bit weird. This new update renders it at the end of the
line the annotation ends on.
In some cases, the annotation was previously rendered to point at source
lines below where the error occurred, which is probably pretty
confusing.
This looks like a bug fix that occurs when the annotation is a
zero-width span immediately following a line terminator. Previously, the
caret seems to be rendered on the next line, but it should be rendered
at the end of the line the span corresponds to.
I admit that this one is kinda weird. I would somewhat expect that our
spans here are actually incorrect, and that to obtain this sort of
rendering, we should identify a span just immediately _before_ the line
terminator and not after it. But I don't want to dive into that rabbit
hole for now (and given how `annotate-snippets` now renders these
spans, perhaps there is more to it than I see), and this does seem like
a clear improvement given the spans we feed to `annotate-snippets`.
The previous rendering just seems wrong in that a `^` is omitted. The
new version of `annotate-snippets` seems to get this right. I checked a
pseudo random sample of these, and it seems to only happen when the
position pointed at a line terminator.
It's hard to grok the change from the snapshot diffs alone, so here's
one example. Before:
PYI021.pyi:15:5: PYI021 [*] Docstrings should not be included in stubs
|
14 | class Baz:
15 | """Multiline docstring
| _____^
16 | |
17 | | Lorem ipsum dolor sit amet
18 | | """
| |_______^ PYI021
19 |
20 | def __init__(self) -> None: ...
|
= help: Remove docstring
And now after:
PYI021.pyi:15:5: PYI021 [*] Docstrings should not be included in stubs
|
14 | class Baz:
15 | / """Multiline docstring
16 | |
17 | | Lorem ipsum dolor sit amet
18 | | """
| |_______^ PYI021
19 |
20 | def __init__(self) -> None: ...
|
= help: Remove docstring
I personally think both of these are fine. If we felt strongly, I could
investigate reverting to the old style, but the new style seems okay to
me.
In other words, these updates I believe are just cosmetic and not a bug
fix.
These updates center around the addition of annotations in the
diagnostic rendering. Previously, the annotation was just not rendered
at all. With the `annotate-snippets` upgrade, it is now rendered. I
examined a pseudo random sample of these, and they all look correct.
As will be true in future batches, some of these snapshots also have
changes to whitespace in them as well.
These snapshot changes should *all* only be a result of changes to
trailing whitespace in the output. I checked a psuedo random sample of
these, and the whitespace found in the previous snapshots seems to be an
artifact of the rendering and _not_ of the source data. So this seems
like a strict bug fix to me.
There are other snapshots with whitespace changes, but they also have
other changes that we split out into separate commits. Basically, we're
going to do approximately one commit per category of change.
This represents, by far, the biggest chunk of changes to snapshots as a
result of the `annotate-snippets` upgrade.
Previously, we were replacing unprintable ASCII characters with a
printable representation of them via fancier Unicode characters. Since
`annotate-snippets` used to use codepoint offsets, this didn't make our
ranges incorrect: we swapped one codepoint for another.
But now, with the `annotate-snippets` upgrade, we use byte offsets
(which is IMO the correct choice). However, this means our ranges can be
thrown off since an ASCII codepoint is always one byte and a non-ASCII
codepoint is always more than one byte.
Instead of tweaking the `ShowNonprinting` trait and making it more
complicated (which is used in places other than this diagnostic
rendering it seems), we instead change `replace_whitespace` to handle
non-printable characters. This works out because `replace_whitespace`
was already updating the annotation range to account for the tab
replacement. We copy that approach for unprintable characters.
This is pretty much just moving to the new API and taking care to use
byte offsets. This is *almost* enough. The next commit will fix a bug
involving the handling of unprintable characters as a result of
switching to byte offsets.
This is a tiny change that, perhaps slightly shady, permits us to use
the `annotate-snippets` renderer without its mandatory header (which
wasn't there in `annotate-snippets 0.9`). Specifically, we can now do
this:
Level::None.title("")
The combination of a "none" level and an empty label results in the
`annotate-snippets` header being skipped entirely. (Not even an empty
line is written.)
This is maybe not the right API for upstream `annotate-snippets`, but
it's very easy for us to do and unblocks the upgrade (albeit relying on
a vendored copy).
Ref https://github.com/rust-lang/annotate-snippets-rs/issues/167
This merely adds the crate to our repository. Some cosmetic changes are
made to make it work in our repo and follow our conventions, such as
changing the name to `ruff_annotate_snippets`. We retain the original
license information. We do drop some things, such as benchmarks, but
keep tests and examples.
## Summary
The initial purpose was to fix#15043, where code like this:
```python
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/test")
def handler(echo: str = Query("")):
return echo
```
was being fixed to the invalid code below:
```python
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/test")
def handler(echo: Annotated[str, Query("")]): # changed
return echo
```
As @MichaReiser pointed out, the correct fix is:
```python
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/test")
def handler(echo: Annotated[str, Query()] = ""): # changed
return echo
```
After fixing the issue for `Query`, I realized that other classes like
`Path`, `Body`, `Cookie`, `Header`, `File`, and `Form` also looked
susceptible to this issue. The last few commits should handle these too,
which I think means this will also close#12913.
I had to reorder the arguments to the `do_stuff` test case because the
new fix removes some default argument values (eg for `Path`:
`some_path_param: str = Path()` becomes `some_path_param: Annotated[str,
Path()]`).
There's also #14484 related to this rule. I'm happy to take a stab at
that here or in a follow up PR too.
## Test Plan
`cargo test`
I also checked the fixed output with `uv run --with fastapi
FAST002_0.py`, but it required making a bunch of additional changes to
the test file that I wasn't sure we wanted in this PR.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
If `S <: T`, then `~T <: ~S`. This test currently fails with example
like:
```
S = tuple[()]
T = ~Literal[True] & ~Literal[False]
```
`T` is equivalent to `~(Literal[True] | Literal[False])` and therefore
equivalent to `~bool`, but the minimal example for a failure is what is
stated above. We correctly recognize that `S <: T`, but fail to see that
`~T <: ~S`, i.e. `bool <: ~tuple[()]`.
This is why the tests goes into the "flaky" section as well.
## Test Plan
```
export QUICKCHECK_TESTS=100000
while cargo test --release -p red_knot_python_semantic -- --ignored types::property_tests::flaky::negation_reverses_subtype_order; do :; done
```
## Summary
Adds some initial tests for class and instance attributes, mostly to
document (and discuss) what we want to support eventually. These
tests are not exhaustive yet. The idea is to specify the coarse-grained
behavior first.
Things that we'll eventually want to test:
- Interplay with inheritance
- Support `Final` in addition to `ClassVar`
- Specific tests for `ClassVar`, like making sure that we support things
like `x: Annotated[ClassVar[int], "metadata"]`
- … or making sure that we raise an error here:
```py
class Foo:
def __init__(self):
self.x: ClassVar[str] = "x"
```
- Add tests for `__new__` in addition to the tests for `__init__`
- Add tests that show that we use the union of types if multiple methods
define the symbol with different types
- Make sure that diagnostics are raised if, e.g., the inferred type of
an assignment within a method does not match the declared type in the
class body.
- https://github.com/astral-sh/ruff/pull/15474#discussion_r1916556284
- Method calls are completely left out for now.
- Same for `@property`
- … and the descriptor protocol
## Test Plan
New Markdown tests
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
The next sync of typeshed would have failed without manual changes
anyway, so I'm doing one manual sync + the required changes in our
`sys.platform` tests (which are necessary because of my tiny typeshed PR
here: https://github.com/python/typeshed/pull/13378).
closes#15485 (the next run of the pipeline in two weeks should be fine
as the bug has been fixed upstream)
## Summary
Adds two additional tests for `is_equivalent_to` so that we cover all
properties of an [equivalence relation].
## Test Plan
```
while cargo test --release -p red_knot_python_semantic -- --ignored types::property_tests::stable; do :; done
```
[equivalence relation]:
https://en.wikipedia.org/wiki/Equivalence_relation
## Summary
This PR fixes the `show_*_msg` macros to pass all the tokens instead of
just a single token. This allows for using various expressions right in
the macro similar to how it would be in `format_args!`.
## Test Plan
`cargo clippy`
## Summary
This PR creates separate functions to check whether the document path is
excluded for linting or formatting. The main motivation is to avoid the
double `Option` for the call sites and makes passing the correct
settings simpler.
## Summary
This changeset adds new tests for public uses of symbols,
considering all possible declaredness and boundness states.
Note that this is a mere documentation of the current behavior. There is
still an [open ticket] questioning some of these choices (or unintential
behaviors).
## Test plan
Made sure that the respective test fails if I add the questionable case
again in `symbol_by_id`:
```rs
Symbol::Type(inferred_ty, Boundness::Bound) => {
Symbol::Type(inferred_ty, Boundness::Bound)
}
```
[open ticket]: https://github.com/astral-sh/ruff/issues/14297
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Replace typo "security_managr" in AIR303 as "security_manager"
## Test Plan
<!-- How was it tested? -->
a test fixture has been updated
## Summary
Simplification follow-up to #15413.
There's no need to have a dedicated `CallOutcome` variant for every
known function, it's only necessary if the special-cased behavior of the
known function includes emitting extra diagnostics. For `typing.cast`,
there's no such need; we can use the regular `Callable` outcome variant,
and update the return type according to the cast. (This is the same way
we already handle `len`.)
One reason to avoid proliferating unnecessary `CallOutcome` variants is
that currently we have to explicitly add emitting call-binding
diagnostics, for each outcome variant. So we were previously wrongly
silencing any binding diagnostics on calls to `typing.cast`. Fixing this
revealed a separate bug, that we were emitting a bogus error anytime
more than one keyword argument mapped to a `**kwargs` parameter. So this
PR also adds test and fix for that bug.
## Test Plan
Existing `cast` tests pass unchanged, added new test for `**kwargs` bug.
## Summary
I noticed this while trying out
https://github.com/astral-sh/ruff-vscode/issues/665 that we use the
`Display` implementation to show the error which hides the context. This
PR changes it to use the `Debug` implementation and adds the message as
a context.
## Test Plan
**Before:**
```
0.001228084s ERROR main ruff_server::session::index::ruff_settings: Unable to find editor-specified configuration file: Failed to parse /private/tmp/hatch-test/ruff.toml
```
**After:**
```
0.002348750s ERROR main ruff_server::session::index::ruff_settings: Unable to load editor-specified configuration file
Caused by:
0: Failed to parse /private/tmp/hatch-test/ruff.toml
1: TOML parse error at line 2, column 18
|
2 | extend-select = ["ASYNC101"]
| ^^^^^^^^^^
Unknown rule selector: `ASYNC101`
```
## Summary
In `SymbolState` merging, use `BitSet::union` instead of inserting
declarations one by one. This used to be the case but was changed in
https://github.com/astral-sh/ruff/pull/15019 because we had to iterate
over declarations anyway.
This is an alternative to https://github.com/astral-sh/ruff/pull/15419
by @MichaReiser. It's similar in performance, but a bit more
declarative and less imperative.
## Summary
Follow-up PR from https://github.com/astral-sh/ruff/pull/15415🥲
The exact same property test already exists:
`intersection_assignable_to_both` and
`all_type_pairs_can_be_assigned_from_their_intersection`
## Test Plan
`cargo test -p red_knot_python_semantic -- --ignored
types::property_tests::flaky`
## Summary
Implements upstream diagnostics `PT029`, `PT030`, `PT031` that function
as pytest.warns corollaries of `PT010`, `PT011`, `PT012` respectively.
Most of the implementation and documentation is designed to mirror those
existing diagnostics.
Closes#14239
## Test Plan
Tests for `PT029`, `PT030`, `PT031` largely copied from `PT010`,
`PT011`, `PT012` respectively.
`cargo nextest run`
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
A small PR to reduce some of the code duplication between the various
branches, make it a little more readable and move the API closer to what
we already have for `KnownClass`
## Summary
The cause of this bug is from
https://github.com/astral-sh/ruff/pull/12575 which was itself a bug fix
but the fix wasn't completely correct.
fixes: #14768
fixes: https://github.com/astral-sh/ruff-vscode/issues/644
## Test Plan
Consider the following three cells:
1.
```python
class Foo:
def __init__(self):
self.x = 1
def __str__(self):
return f"Foo({self.x})"
```
2.
```python
def hello():
print("hello world")
```
3.
```python
y = 1
```
The test case is moving cell 2 to the top i.e., cell 2 goes to position
1 and cell 1 goes to position 2.
Before this fix, it can be seen that the cells were pushed at the end of
the vector:
```
12.643269917s INFO ruff:main ruff_server::edit:📓 Before update: [
NotebookCell {
document: TextDocument {
contents: "class Foo:\n def __init__(self):\n self.x = 1\n\n def __str__(self):\n return f\"Foo({self.x})\"",
},
},
NotebookCell {
document: TextDocument {
contents: "def hello():\n print(\"hello world\")",
},
},
NotebookCell {
document: TextDocument {
contents: "y = 1",
},
},
]
12.643777667s INFO ruff:main ruff_server::edit:📓 After update: [
NotebookCell {
document: TextDocument {
contents: "y = 1",
},
},
NotebookCell {
document: TextDocument {
contents: "class Foo:\n def __init__(self):\n self.x = 1\n\n def __str__(self):\n return f\"Foo({self.x})\"",
},
},
NotebookCell {
document: TextDocument {
contents: "def hello():\n print(\"hello world\")",
},
},
]
```
After the fix in this PR, it can be seen that the cells are being pushed
at the correct `start` index:
```
6.520570917s INFO ruff:main ruff_server::edit:📓 Before update: [
NotebookCell {
document: TextDocument {
contents: "class Foo:\n def __init__(self):\n self.x = 1\n\n def __str__(self):\n return f\"Foo({self.x})\"",
},
},
NotebookCell {
document: TextDocument {
contents: "def hello():\n print(\"hello world\")",
},
},
NotebookCell {
document: TextDocument {
contents: "y = 1",
},
},
]
6.521084792s INFO ruff:main ruff_server::edit:📓 After update: [
NotebookCell {
document: TextDocument {
contents: "def hello():\n print(\"hello world\")",
},
},
NotebookCell {
document: TextDocument {
contents: "class Foo:\n def __init__(self):\n self.x = 1\n\n def __str__(self):\n return f\"Foo({self.x})\"",
},
},
NotebookCell {
document: TextDocument {
contents: "y = 1",
},
},
]
```
## Summary
[**Rendered version of the new test
suite**](https://github.com/astral-sh/ruff/blob/david/intersection-type-tests/crates/red_knot_python_semantic/resources/mdtest/intersection_types.md)
Moves most of our existing intersection-types tests to a dedicated
Markdown test suite, extends the test coverage, unifies the notation for
these tests, groups tests into a proper structure, and adds some
explanations for various simplification strategies.
This changeset also:
- Adds a new simplification where `~Never` is removed from
intersections.
- Adds a new simplification where adding `~object` simplifies the whole
intersection to `Never`
- Avoids unnecessary assignment-checks between inferred and declared
type. This was added to this changeset to avoid many false positive
errors in this test suite.
Resolves the task described in this old comment
[here](e01da82a5a..e7e432bca2 (r1819924085)).
## Test Plan
Running the new Markdown tests
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Prompted by
> One nit: I think we need to consider `Any` and `Unknown` and `Todo` as
all (gradually) equivalent to each other, and thus `type & Any` and
`type & Unknown` and `type & Todo` as also equivalent. The distinction
between `Any` vs `Unknown` vs `Todo` is entirely about
provenance/debugging, there is no type level distinction. (And I've been
wondering if the `Any` vs `Unknown` distinction is really worth it.)
The thought here is that _most_ places want to treat `Any`, `Unknown`,
and `Todo` identically. So this PR simplifies things by having a single
`Type::Any` variant, and moves the provenance part into a new `AnyType`
type. If you need to treat e.g. `Todo` differently, you still can by
pattern-matching into the `AnyType`. But if you don't, you can just use
`Type::Any(_)`.
(This would also allow us to (more easily) distinguish "unknown via an
unannotated value" from "unknown because of a typing error" should we
want to do that in the future)
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This moves almost all of our existing `UnionBuilder` tests to a
Markdown-based test suite.
I see how this could be a more controversial change, since these tests
where written specifically for `UnionBuilder`, and by creating the union
types using Python type expressions, we add an additional layer on top
(parsing and inference of these expressions) that moves these tests away
from clean unit tests more in the direction of integration tests. Also,
there are probably a few implementation details of `UnionBuilder` hidden
in the test assertions (e.g. order of union elements after
simplifications).
That said, I think we would like to see all those properties that are
being tested here from *any* implementation of union types. And the
Markdown tests come with the usual advantages:
- More consice
- Better readability
- No re-compiliation when working on tests
- Easier to add additional explanations and structure to the test suite
This changeset adds a few additional tests, but keeps the logic of the
existing tests except for a few minor modifications for consistency.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: T-256 <132141463+T-256@users.noreply.github.com>
## Summary
The symlink-approach in the typeshed-sync workflow caused some problems
on Windows, even though it seemed to work fine in CI:
https://github.com/astral-sh/ruff/pull/15138#issuecomment-2578642129
Here, we rely on `build.rs` to patch typeshed instead, which allows us
to get rid of the modifications in the workflow (thank you
@MichaReiser for the idea).
## Test Plan
- Made sure that changes to `knot_extensions.pyi` result in a recompile
of `red_knot_vendored`.
Stabilise [`slice-to-remove-prefix-or-suffix`](https://docs.astral.sh/ruff/rules/slice-to-remove-prefix-or-suffix/) (`FURB188`) for the Ruff 0.9 release.
This is a stylistic rule, but I think it's a pretty uncontroversial one. There are no open issues or PRs regarding it and it's been in preview for a while now.
More refinements to the panic messages for failing mdtests to mimic the
output of the default panic hook more closely:
- We now print out `Box<dyn Any>` if the panic payload is not a string
(which is typically the case for salsa panics).
- We now include the panic's backtrace if you set the `RUST_BACKTRACE`
environment variable.
## Summary
- Add a workflow to run property tests on a daily basis (based on
`daily_fuzz.yaml`)
- Mark `assignable_to_is_reflexive` as flaky (related to #14899)
- Add new (failing) `intersection_assignable_to_both` test (also related
to #14899)
## Test Plan
Ran:
```bash
export QUICKCHECK_TESTS=100000
while cargo test --release -p red_knot_python_semantic -- \
--ignored types::property_tests::stable; do :; done
```
Observed successful property_tests CI run
## Summary
This changeset migrates all existing `is_assignable_to` tests to a
Markdown-based test. It also increases our test coverage in a hopefully
meaningful way (not claiming to be complete in any sense). But at least
I found and fixed one bug while doing so.
## Test Plan
Ran property tests to make sure the new test succeeds after fixing it.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
This fixes#15317. Our `catch_unwind` wrapper installs a panic hook that
captures (the rendered contents of) the panic info when a panic occurs.
Since the intent is that the caller will render the panic info in some
custom way, the hook silences the default stderr panic output.
However, the panic hook is a global resource, so if any one thread was
in the middle of a `catch_unwind` call, we would silence the default
panic output for _all_ threads.
The solution is to also keep a thread local that indicates whether the
current thread is in the middle of our `catch_unwind`, and to fall back
on the default panic hook if not.
## Test Plan
Artificially added an mdtest parse error, ran tests via `cargo test -p
red_knot_python_semantic` to run a large number of tests in parallel.
Before this patch, the panic message was swallowed as reported in
#15317. After, the panic message was shown.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Fix infinite loop issue reported here #15248.
The issue was caused by the break inside the if block, which caused the
flow to exit in an unforeseen way. This caused other issues, eventually
leading to an infinite loop.
Resolves#15248. Resolves#15336.
## Test Plan
Added failing code to fixture.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: dylwil3 <dylwil3@gmail.com>
## Summary
Refer to the VS Code PR
(https://github.com/astral-sh/ruff-vscode/pull/659) for details on the
change.
This PR changes the following:
1. Add tracing span for both request (request id and method name) and
notification (method name) handler
2. Remove the `RUFF_TRACE` environment variable. This was being used to
turn on / off logging for the server
3. Similarly, remove reading the `trace` value from the initialization
options
4. Remove handling the `$/setTrace` notification
5. Remove the specialized `TraceLogWriter` used for Zed and VS Code
(https://github.com/astral-sh/ruff/pull/12564)
Regarding the (5) for the Zed editor, the reason that was implemented
was because there was no way of looking at the stderr messages in the
editor which has been changed. Now, it captures the stderr as part of
the "Server Logs".
(82492d74a8/crates/language_tools/src/lsp_log.rs (L548-L552))
### Question
Regarding (1), I think having just a simple trace level message should
be good for now as the spans are not hierarchical. This could be tackled
with #12744. The difference between the two:
<details><summary>Using <code>tracing::trace</code></summary>
<p>
```
0.019243416s DEBUG ThreadId(08) ruff_server::session::index::ruff_settings: Ignored path via `exclude`: /Users/dhruv/playground/ruff/.vscode
0.026398750s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/playground/ruff
0.026802125s TRACE ruff:main ruff_server::server::api: Received notification "textDocument/didOpen"
0.026930666s TRACE ruff:main ruff_server::server::api: Received notification "textDocument/didOpen"
0.026962333s TRACE ruff:main ruff_server::server::api: Received request "textDocument/diagnostic" (1)
0.027042875s TRACE ruff:main ruff_server::server::api: Received request "textDocument/diagnostic" (2)
0.027097500s TRACE ruff:main ruff_server::server::api: Received request "textDocument/codeAction" (3)
0.027107458s DEBUG ruff:worker:0 ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/play.py
0.027123541s DEBUG ruff:worker:3 ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/organize_imports.py
0.027514875s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
0.285689833s TRACE ruff:main ruff_server::server::api: Received request "textDocument/codeAction" (4)
45.741101666s TRACE ruff:main ruff_server::server::api: Received notification "textDocument/didClose"
47.108745500s TRACE ruff:main ruff_server::server::api: Received notification "textDocument/didOpen"
47.109802041s TRACE ruff:main ruff_server::server::api: Received request "textDocument/diagnostic" (5)
47.109926958s TRACE ruff:main ruff_server::server::api: Received request "textDocument/codeAction" (6)
47.110027791s DEBUG ruff:worker:6 ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/play.py
51.863679125s TRACE ruff:main ruff_server::server::api: Received request "textDocument/hover" (7)
```
</p>
</details>
<details><summary>Using <code>tracing::trace_span</code></summary>
<p>
Only logging the enter event:
```
0.018638750s DEBUG ThreadId(11) ruff_server::session::index::ruff_settings: Ignored path via `exclude`: /Users/dhruv/playground/ruff/.vscode
0.025895791s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/playground/ruff
0.026378791s TRACE ruff:main notification{method="textDocument/didOpen"}: ruff_server::server::api: enter
0.026531208s TRACE ruff:main notification{method="textDocument/didOpen"}: ruff_server::server::api: enter
0.026567583s TRACE ruff:main request{id=1 method="textDocument/diagnostic"}: ruff_server::server::api: enter
0.026652541s TRACE ruff:main request{id=2 method="textDocument/diagnostic"}: ruff_server::server::api: enter
0.026711041s DEBUG ruff:worker:2 ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/organize_imports.py
0.026729166s DEBUG ruff:worker:1 ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/play.py
0.027023083s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
5.197554750s TRACE ruff:main notification{method="textDocument/didClose"}: ruff_server::server::api: enter
6.534458000s TRACE ruff:main notification{method="textDocument/didOpen"}: ruff_server::server::api: enter
6.535027958s TRACE ruff:main request{id=3 method="textDocument/diagnostic"}: ruff_server::server::api: enter
6.535271166s DEBUG ruff:worker:3 ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/organize_imports.py
6.544240583s TRACE ruff:main request{id=4 method="textDocument/codeAction"}: ruff_server::server::api: enter
7.049692458s TRACE ruff:main request{id=5 method="textDocument/codeAction"}: ruff_server::server::api: enter
7.508142541s TRACE ruff:main request{id=6 method="textDocument/hover"}: ruff_server::server::api: enter
7.872421958s TRACE ruff:main request{id=7 method="textDocument/hover"}: ruff_server::server::api: enter
8.024498583s TRACE ruff:main request{id=8 method="textDocument/codeAction"}: ruff_server::server::api: enter
13.895063666s TRACE ruff:main request{id=9 method="textDocument/codeAction"}: ruff_server::server::api: enter
14.774706083s TRACE ruff:main request{id=10 method="textDocument/hover"}: ruff_server::server::api: enter
16.058918958s TRACE ruff:main notification{method="textDocument/didChange"}: ruff_server::server::api: enter
16.060562208s TRACE ruff:main request{id=11 method="textDocument/diagnostic"}: ruff_server::server::api: enter
16.061109083s DEBUG ruff:worker:8 ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/play.py
21.561742875s TRACE ruff:main notification{method="textDocument/didChange"}: ruff_server::server::api: enter
21.563573791s TRACE ruff:main request{id=12 method="textDocument/diagnostic"}: ruff_server::server::api: enter
21.564206750s DEBUG ruff:worker:4 ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/play.py
21.826691375s TRACE ruff:main request{id=13 method="textDocument/codeAction"}: ruff_server::server::api: enter
22.091080125s TRACE ruff:main request{id=14 method="textDocument/codeAction"}: ruff_server::server::api: enter
```
</p>
</details>
**Todo**
- [x] Update documentation (I'll be adding a troubleshooting section
under "Editors" as a follow-up which is for all editors)
- [x] Check for backwards compatibility. I don't think this should break
backwards compatibility as it's mainly targeted towards improving the
debugging experience.
~**Before I go on to updating the documentation, I'd appreciate initial
review on the chosen approach.**~
resolves: #14959
## Test Plan
Refer to the test plan in
https://github.com/astral-sh/ruff-vscode/pull/659.
Example logs at `debug` level:
```
0.010770083s DEBUG ThreadId(15) ruff_server::session::index::ruff_settings: Ignored path via `exclude`: /Users/dhruv/playground/ruff/.vscode
0.018101916s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/playground/ruff
0.018559916s DEBUG ruff:worker:4 ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/play.py
0.018992375s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
23.408802375s DEBUG ruff:worker:11 ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/play.py
24.329127416s DEBUG ruff:worker:6 ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/play.py
```
Example logs at `trace` level:
```
0.010296375s DEBUG ThreadId(13) ruff_server::session::index::ruff_settings: Ignored path via `exclude`: /Users/dhruv/playground/ruff/.vscode
0.017422583s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/playground/ruff
0.018034458s TRACE ruff:main notification{method="textDocument/didOpen"}: ruff_server::server::api: enter
0.018199708s TRACE ruff:worker:0 request{id=1 method="textDocument/diagnostic"}: ruff_server::server::api: enter
0.018251167s DEBUG ruff:worker:0 request{id=1 method="textDocument/diagnostic"}: ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/play.py
0.018528708s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
1.611798417s TRACE ruff:worker:1 request{id=2 method="textDocument/codeAction"}: ruff_server::server::api: enter
1.861757542s TRACE ruff:worker:4 request{id=3 method="textDocument/codeAction"}: ruff_server::server::api: enter
7.027361792s TRACE ruff:worker:2 request{id=4 method="textDocument/codeAction"}: ruff_server::server::api: enter
7.851361500s TRACE ruff:worker:5 request{id=5 method="textDocument/codeAction"}: ruff_server::server::api: enter
7.901690875s TRACE ruff:main notification{method="textDocument/didChange"}: ruff_server::server::api: enter
7.903063167s TRACE ruff:worker:10 request{id=6 method="textDocument/diagnostic"}: ruff_server::server::api: enter
7.903183500s DEBUG ruff:worker:10 request{id=6 method="textDocument/diagnostic"}: ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/play.py
8.702385292s TRACE ruff:main notification{method="textDocument/didChange"}: ruff_server::server::api: enter
8.704106625s TRACE ruff:worker:3 request{id=7 method="textDocument/diagnostic"}: ruff_server::server::api: enter
8.704304875s DEBUG ruff:worker:3 request{id=7 method="textDocument/diagnostic"}: ruff_server::resolve: Included path via `include`: /Users/dhruv/playground/ruff/lsp/play.py
8.966853458s TRACE ruff:worker:9 request{id=8 method="textDocument/codeAction"}: ruff_server::server::api: enter
9.229622792s TRACE ruff:worker:6 request{id=9 method="textDocument/codeAction"}: ruff_server::server::api: enter
10.513111583s TRACE ruff:worker:7 request{id=10 method="textDocument/codeAction"}: ruff_server::server::api: enter
```
## Summary
Adds a type-check-time Python API that allows us to create and
manipulate types and to test various of their properties. For example,
this can be used to write a Markdown test to make sure that `A & B` is a
subtype of `A` and `B`, but not of an unrelated class `C` (something
that requires quite a bit more code to do in Rust):
```py
from knot_extensions import Intersection, is_subtype_of, static_assert
class A: ...
class B: ...
type AB = Intersection[A, B]
static_assert(is_subtype_of(AB, A))
static_assert(is_subtype_of(AB, B))
class C: ...
static_assert(not is_subtype_of(AB, C))
```
I think this functionality is also helpful for interactive debugging
sessions, in order to query various properties of Red Knot's type
system. Which is something that otherwise requires a custom Rust unit
test, some boilerplate code and constant re-compilation.
## Test Plan
- New Markdown tests
- Tested the modified typeshed_sync workflow locally
## Summary
`Type[Any]` should be assignable to `object`. All types should be
assignable to `object`.
We specifically didn't understand the former; this PR adds a test for
it, and a case to ensure that `Type[Any]` is assignable to anything that
`type` is assignable to (which includes `object`).
This PR also adds a property test that all types are assignable to
object. In order to make it pass, I added a special case to check early
if we are assigning to `object` and just return `true`. In principle,
once we get all the more general cases correct, this special case might
be removable. But having the special case for now allows the property
test to pass.
And we add a property test that all types are subtypes of object. This
failed for the case of an intersection with no positive elements (that
is, a negation type). This really does need to be a special case for
`object`, because there is no other type we can know that a negation
type is a subtype of.
## Test Plan
Added unit test and property test.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
When removing `int` in calls like `int(expr)` we may need to keep
parentheses around `expr` even when it is a function call or subscript,
since there may be newlines in between the function/value name and the
opening parentheses/bracket of the argument.
This PR implements that logic.
Closes#15263
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
We now support class patterns in a match statement, adding a narrowing
constraint that within the body of that match arm, we can assume that
the subject is an instance of that class.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This implements checking of calls.
I ended up following Micha's original suggestion from back when the
signature representation was first introduced, and flattening it to a
single array of parameters. This turned out to be easier to manage,
because we can represent parameters using indices into that array, and
represent the bound argument types as an array of the same length.
Starred and double-starred arguments are still TODO; these won't be very
useful until we have generics.
The handling of diagnostics is just hacked into `return_ty_result`,
which was already inconsistent about whether it emitted diagnostics or
not; now it's even more inconsistent. This needs to be addressed, but
could be a follow-up.
The new benchmark errors here surface the need for intersection support
in `is_assignable_to`.
Fixes#14161.
## Test Plan
Added mdtests.
Note: `PLW0101` remains in testing rather than preview, so this PR does
not modify any public behavior (hence the title beginning with
`internal` rather than `pylint`, for the sake of the changelog.)
Fixes an error in the processing of `try` statements in the control flow
graph builder.
When processing a try statement, the block following a `return` was
forced to point to the `finally` block. However, if the return was _in_
the `finally` block, this caused the block to point to itself. In the
case where the whole `try-finally` statement was also included inside of
a loop, this caused an infinite loop in the builder for the control flow
graph as it attempted to resolve edges.
Closes#15248
## Test function
### Source
```python
def l():
while T:
try:
while ():
if 3:
break
finally:
return
```
### Control Flow Graph
```mermaid
flowchart TD
start(("Start"))
return(("End"))
block0[["`*(empty)*`"]]
block1[["Loop continue"]]
block2["return\n"]
block3[["Loop continue"]]
block4["break\n"]
block5["if 3:
break\n"]
block6["while ():
if 3:
break\n"]
block7[["Exception raised"]]
block8["try:
while ():
if 3:
break
finally:
return\n"]
block9["while T:
try:
while ():
if 3:
break
finally:
return\n"]
start --> block9
block9 -- "T" --> block8
block9 -- "else" --> block0
block8 -- "Exception raised" --> block7
block8 -- "else" --> block6
block7 --> block2
block6 -- "()" --> block5
block6 -- "else" --> block2
block5 -- "3" --> block4
block5 -- "else" --> block3
block4 --> block2
block3 --> block6
block2 --> return
block1 --> block9
block0 --> return
```
## Summary
When debugging, I frequently want to know which symbols are being looked
up. `symbol_by_id` adds tracing information, but it only shows the
`ScopedSymbolId`. Since `symbol_by_id` is only called from `symbol`, it
seems reasonable to move the tracing call one level up from
`symbol_by_id` to `symbol`, where we can also show the name of the
symbol.
**Before**:
```
6 └─┐red_knot_python_semantic::types::infer::infer_expression_types{expression=Id(60de), file=/home/shark/tomllib_modified/_parser.py}
6 └─┐red_knot_python_semantic::types::symbol_by_id{symbol=ScopedSymbolId(33)}
6 ┌─┘
6 └─┐red_knot_python_semantic::types::symbol_by_id{symbol=ScopedSymbolId(123)}
6 ┌─┘
6 └─┐red_knot_python_semantic::types::symbol_by_id{symbol=ScopedSymbolId(54)}
6 ┌─┘
6 └─┐red_knot_python_semantic::types::symbol_by_id{symbol=ScopedSymbolId(122)}
6 ┌─┘
6 └─┐red_knot_python_semantic::types::symbol_by_id{symbol=ScopedSymbolId(165)}
6 ┌─┘
6 ┌─┘
6 └─┐red_knot_python_semantic::types::symbol_by_id{symbol=ScopedSymbolId(32)}
6 ┌─┘
6 └─┐red_knot_python_semantic::types::symbol_by_id{symbol=ScopedSymbolId(232)}
6 ┌─┘
6 ┌─┘
6 ┌─┘
6┌─┘
```
**After**:
```
5 └─┐red_knot_python_semantic::types::infer::infer_expression_types{expression=Id(60de), file=/home/shark/tomllib_modified/_parser.py}
5 └─┐red_knot_python_semantic::types::symbol{name="dict"}
5 ┌─┘
5 └─┐red_knot_python_semantic::types::symbol{name="dict"}
5 ┌─┘
5 └─┐red_knot_python_semantic::types::symbol{name="list"}
5 ┌─┘
5 └─┐red_knot_python_semantic::types::symbol{name="list"}
5 ┌─┘
5 └─┐red_knot_python_semantic::types::symbol{name="isinstance"}
5 ┌─┘
5 └─┐red_knot_python_semantic::types::symbol{name="isinstance"}
5 ┌─┘
5 ┌─┘
5 └─┐red_knot_python_semantic::types::symbol{name="ValueError"}
5 ┌─┘
5 └─┐red_knot_python_semantic::types::symbol{name="ValueError"}
5 ┌─┘
5 ┌─┘
5 ┌─┘
5┌─┘
```
## Test Plan
```
cargo run --bin red_knot -- --current-directory path/to/tomllib -vvv
```
## Summary
While looking at #14899, I looked at seeing if I could get shrinking on
the examples. It turned out to be straightforward, with a couple of
caveats.
I'm calling `clone` a lot during shrinking. Since by the shrink step
we're already looking at a test failure this feels fine? Unless I
misunderstood `quickcheck`'s core loop
When shrinking `Intersection`s, in order to just rely on `quickcheck`'s
`Vec` shrinking without thinking about it too much, the shrinking
strategy is:
- try to shrink the negative side (keeping the positive side the same)
- try to shrink the positive side (keeping the negative side the same)
This means that you can't shrink from `(A & B & ~C & ~D)` directly to
`(A & ~C)`! You would first need an intermediate failure at `(A & B &
~C)` or `(A & ~C & ~D)`. This feels good enough. Shrinking the negative
side first also has the benefit of trying to strip down negative
elements in these intersections.
## Test Plan
`cargo test -p red_knot_python_semantic -- --ignored
types::property_tests::stable` still fails as it current does on `main`,
but now the errors seem more minimal.
## Summary
Adds `class-as-data-structure` rule (`B903`). Also compare pylint's `too-few-public-methods` (`PLR0903`).
Took some creative liberty with this by allowing the class to have any
decorators or base classes. There are years-old issues on pylint that
don't approve of the strictness when it comes to these things.
Especially considering that dataclass is a decorator and namedtuple _can
be_ a base class. I feel ignoring those explicitly is redundant all
things considered, but it's not a hill I'm willing to die on!
See: #970
## Test Plan
`cargo test`
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: dylwil3 <dylwil3@gmail.com>
Just like in #15045 for unary expressions: In binary expressions, we
were only looking for dunder expressions for `Type::Instance` types. We
had some special cases for coercing the various `Literal` types into
their corresponding `Instance` types before doing the lookup. But we can
side-step all of that by using the existing `Type::to_meta_type` and
`Type::to_instance` methods.
## Summary
This PR upgrades zizmor to the latest release in our CI. zizmor is a
static analyzer checking for security issues in GitHub workflows. The
new release finds some new issues in our workflows; this PR fixes some
of the issues, and adds ignores for some other issues.
The issues fixed in this PR are new cases of zizmor's
[`template-injection`](https://woodruffw.github.io/zizmor/audits/#template-injection)
rule being emitted. The issues I'm ignoring for now are all to do with
the
[`cache-poisoning`](https://woodruffw.github.io/zizmor/audits/#cache-poisoning)
rule. The main reason I'm fixing some but ignoring others is that I'm
confident fixing the template-injection diagnostics won't have any
impact on how our workflows operate in CI, but I'm worried that fixing
the cache-poisoning diagnostics could slow down our CI a fair bit. I
don't mind if somebody else is motivated to try to fix these
diagnostics, but for now I think I'd prefer to just ignore them; it
doesn't seem high-priority enough to try to fix them right now :-)
## Test Plan
- `uvx pre-commit run -a --hook-stage=manual` passes locally
- Let's see if CI passes on this PR...
Resolves#14840
## Summary
Usage of ellipsis literal as default argument is allowed in stub files.
## Test Plan
Added mdtest for both python files and stub files.
---------
Co-authored-by: Carl Meyer <carl@oddbird.net>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
The test expression in an `elif` clause is evaluated whether or not we
take the branch. Our control flow model for if/elif chains failed to
reflect this, causing wrong inference in cases where an assignment
expression occurs inside an `elif` test expression. Our "no branch taken
yet" snapshot (which is the starting state for every new elif branch)
can't simply be the pre-if state, it must be updated after visiting each
test expression.
Once we do this, it also means we no longer need to track a vector of
narrowing constraints to reapply for each new branch, since our "branch
not taken" state (which is the initial state for each branch) is
continuously updated to include the negative narrowing constraints of
all previous branches.
Fixes#15033.
## Test Plan
Added mdtests.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
We understand `sys.version_info` branches now! As such, I _believe_ this
branch is no longer required; all tests pass without it. I also ran
`QUICKCHECK_TESTS=100000 cargo test -p red_knot_python_semantic --
--ignored types::property_tests::stable`, and no tests failed except for
the known issue with `Type::is_assignable_to()`
(https://github.com/astral-sh/ruff/issues/14899)
## Test Plan
See above
This updates the mdtest harness to catch any panics that occur during
type checking, and to display the panic message as an mdtest failure.
(We don't know which specific line causes the failure, so we attribute
panics to the first line of the test case.)
The default logging level for diagnostics includes logs written using
the `log` crate with level `error`, `warn`, and `info`. An unsuccessful
fix attached to a diagnostic via `try_set_fix` or `try_set_optional_fix`
was logged at level `error`. Note that the user would see these messages
even without passing `--fix`, and possibly also on lines with `noqa`
comments.
This PR changes the logging level here to a `debug`. We also found
ad-hoc instances of error logging in the implementations of several
rules, and have replaced those with either a `debug` or call to
`try_set{_optional}_fix`.
Closes#15229
## Summary
This PR re-introduces the control-flow graph implementation which was
first introduced in #5384, and then removed in #9463 due to not being
feature complete. Mainly, it lacked the ability to process
`try`-`except` blocks, along with some more minor bugs.
Closes#8958 and #8959 and #14881.
## Overview of Changes
I will now highlight the major changes implemented in this PR, in order
of implementation.
1. Introduced a post-processing step in loop handling to find any
`continue` or `break` statements within the loop body and redirect them
appropriately.
2. Introduced a loop-continue block which is always placed at the end of
loop blocks, and ensures proper looping regardless of the internal logic
of the block. This resolves#8958.
3. Implemented `try` processing with the following logic (resolves
#8959):
1. In the example below the cfg first encounters a conditional
`ExceptionRaised` forking if an exception was (or will be) raised in the
try block. This is not possible to know (except for trivial cases) so we
assume both paths can be taken unconditionally.
2. Going down the `try` path the cfg goes `try`->`else`->`finally`
unconditionally.
3. Going down the `except` path the cfg will meet several conditional
`ExceptionCaught` which fork depending on the nature of the exception
caught. Again there's no way to know which exceptions may be raised so
both paths are assumed to be taken unconditionally.
4. If none of the exception blocks catch the exception then the cfg
terminates by raising a new exception.
5. A post-processing step is also implemented to redirect any `raises`
or `returns` within the blocks appropriately.
```python
def func():
try:
print("try")
except Exception:
print("Exception")
except OtherException as e:
print("OtherException")
else:
print("else")
finally:
print("finally")
```
```mermaid
flowchart TD
start(("Start"))
return(("End"))
block0[["`*(empty)*`"]]
block1["print(#quot;finally#quot;)\n"]
block2["print(#quot;else#quot;)\n"]
block3["print(#quot;try#quot;)\n"]
block4[["Exception raised"]]
block5["print(#quot;OtherException#quot;)\n"]
block6["try:
print(#quot;try#quot;)
except Exception:
print(#quot;Exception#quot;)
except OtherException as e:
print(#quot;OtherException#quot;)
else:
print(#quot;else#quot;)
finally:
print(#quot;finally#quot;)\n"]
block7["print(#quot;Exception#quot;)\n"]
block8["try:
print(#quot;try#quot;)
except Exception:
print(#quot;Exception#quot;)
except OtherException as e:
print(#quot;OtherException#quot;)
else:
print(#quot;else#quot;)
finally:
print(#quot;finally#quot;)\n"]
block9["try:
print(#quot;try#quot;)
except Exception:
print(#quot;Exception#quot;)
except OtherException as e:
print(#quot;OtherException#quot;)
else:
print(#quot;else#quot;)
finally:
print(#quot;finally#quot;)\n"]
start --> block9
block9 -- "Exception raised" --> block8
block9 -- "else" --> block3
block8 -- "Exception" --> block7
block8 -- "else" --> block6
block7 --> block1
block6 -- "OtherException" --> block5
block6 -- "else" --> block4
block5 --> block1
block4 --> return
block3 --> block2
block2 --> block1
block1 --> block0
block0 --> return
```
6. Implemented `with` processing with the following logic:
1. `with` statements have no conditional execution (apart from the
hidden logic handling the enter and exit), so the block is assumed to
execute unconditionally.
2. The one exception is that exceptions raised within the block may
result in control flow resuming at the end of the block. Since it is not
possible know if an exception will be raised, or if it will be handled
by the context manager, we assume that execution always continues after
`with` blocks even if the blocks contain `raise` or `return` statements.
This is handled in a post-processing step.
## Test Plan
Additional test fixtures and control-flow fixtures were added.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: dylwil3 <dylwil3@gmail.com>
## Summary
Remove `Type::tuple` in favor of `TupleType::from_elements`, avoid a few
intermediate `Vec`tors. Resolves an old [review
comment](https://github.com/astral-sh/ruff/pull/14744#discussion_r1867493706).
## Test Plan
New regression test for something I ran into while implementing this.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
During https://github.com/astral-sh/ruff/pull/15209, additional spaces
was accidentally added to the rule
`airflow.operators.latest_only.LatestOnlyOperator`. This PR fixes this
issue
## Test Plan
<!-- How was it tested? -->
A test fixture has been included for the rule.
## Summary
Airflow 3.0 removes various deprecated functions, members, modules, and
other values. They have been deprecated in 2.x, but the removal causes
incompatibilities that we want to detect. This PR add rules for the
following.
* Removed class attribute
* `airflow.providers_manager.ProvidersManager.dataset_factories` →
`airflow.providers_manager.ProvidersManager.asset_factories`
* `airflow.providers_manager.ProvidersManager.dataset_uri_handlers` →
`airflow.providers_manager.ProvidersManager.asset_uri_handlers`
*
`airflow.providers_manager.ProvidersManager.dataset_to_openlineage_converters`
→
`airflow.providers_manager.ProvidersManager.asset_to_openlineage_converters`
* `airflow.lineage.hook.DatasetLineageInfo.dataset` →
`airflow.lineage.hook.AssetLineageInfo.asset`
* Removed class method (subclasses in airflow should also checked)
* `airflow.secrets.base_secrets.BaseSecretsBackend.get_conn_uri` →
`airflow.secrets.base_secrets.BaseSecretsBackend.get_conn_value`
* `airflow.secrets.base_secrets.BaseSecretsBackend.get_connections` →
`airflow.secrets.base_secrets.BaseSecretsBackend.get_connection`
* `airflow.hooks.base.BaseHook.get_connections` → use `get_connection`
* `airflow.datasets.BaseDataset.iter_datasets` →
`airflow.sdk.definitions.asset.BaseAsset.iter_assets`
* `airflow.datasets.BaseDataset.iter_dataset_aliases` →
`airflow.sdk.definitions.asset.BaseAsset.iter_asset_aliases`
* Removed constructor args (subclasses in airflow should also checked)
* argument `filename_template`
in`airflow.utils.log.file_task_handler.FileTaskHandler`
* in `BaseOperator`
* `sla`
* `task_concurrency` → `max_active_tis_per_dag`
* in `BaseAuthManager`
* `appbuilder`
* Removed class variable (subclasses anywhere should be checked)
* in `airflow.plugins_manager.AirflowPlugin`
* `executors` (from #43289)
* `hooks`
* `operators`
* `sensors`
* Replaced names
* `airflow.hooks.base_hook.BaseHook` → `airflow.hooks.base.BaseHook`
* `airflow.operators.dagrun_operator.TriggerDagRunLink` →
`airflow.operators.trigger_dagrun.TriggerDagRunLink`
* `airflow.operators.dagrun_operator.TriggerDagRunOperator` →
`airflow.operators.trigger_dagrun.TriggerDagRunOperator`
* `airflow.operators.python_operator.BranchPythonOperator` →
`airflow.operators.python.BranchPythonOperator`
* `airflow.operators.python_operator.PythonOperator` →
`airflow.operators.python.PythonOperator`
* `airflow.operators.python_operator.PythonVirtualenvOperator` →
`airflow.operators.python.PythonVirtualenvOperator`
* `airflow.operators.python_operator.ShortCircuitOperator` →
`airflow.operators.python.ShortCircuitOperator`
* `airflow.operators.latest_only_operator.LatestOnlyOperator` →
`airflow.operators.latest_only.LatestOnlyOperator`
In additional to the changes above, this PR also add utility functions
and improve docstring.
## Test Plan
A test fixture is included in the PR.
## Summary
Changes two things about the entry:
* make the example valid TOML - inline tables must be a single line, at
least till v1.1.0 is released,
but also while in the future the toml version used by ruff might handle
it, it would probably be
good to stick to a spec that's readable by the vast majority of other
tools and versions as well,
especially if people are using `pyproject.toml`. The current example
leads to `ruff` failure.
See https://github.com/toml-lang/toml/pull/904
* adds a line about the ability to add non-Python files to the map,
which I think is a specific and
important feature people should know about (in fact, I would assume this
could potentially
become the single biggest use-case for this).
## Test Plan
Ran doc creation as described in the
[contribution](https://docs.astral.sh/ruff/contributing/#mkdocs) guide.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Part of #13773
This PR adds diagnostics when there is a length mismatch during
unpacking between the number of target expressions and the number of
types for the unpack value expression.
There are 3 cases of diagnostics here where the first two occurs when
there isn't a starred expression and the last one occurs when there's a
starred expression:
1. Number of target expressions is **less** than the number of types
that needs to be unpacked
2. Number of target expressions is **greater** then the number of types
that needs to be unpacked
3. When there's a starred expression as one of the target expression and
the number of target expressions is greater than the number of types
Examples for all each of the above cases:
```py
# red-knot: Too many values to unpack (expected 2, got 3) [lint:invalid-assignment]
a, b = (1, 2, 3)
# red-knot: Not enough values to unpack (expected 2, got 1) [lint:invalid-assignment]
a, b = (1,)
# red-knot: Not enough values to unpack (expected 3 or more, got 2) [lint:invalid-assignment]
a, *b, c, d = (1, 2)
```
The (3) case is a bit special because it uses a distinct wording
"expected n or more" instead of "expected n" because of the starred
expression.
### Location
The diagnostic location is the target expression that's being unpacked.
For nested targets, the location will be the nested expression. For
example:
```py
(a, (b, c), d) = (1, (2, 3, 4), 5)
# ^^^^^^
# red-knot: Too many values to unpack (expected 2, got 3) [lint:invalid-assignment]
```
For future improvements, it would be useful to show the context for why
this unpacking failed. For example, for why the expected number of
targets is `n`, we can highlight the relevant elements for the value
expression.
In the **ecosystem**, **Pyright** uses the target expressions for
location while **mypy** uses the value expression for the location. For
example:
```py
if 1:
# mypy: Too many values to unpack (2 expected, 3 provided) [misc]
# vvvvvvvvv
a, b = (1, 2, 3)
# ^^^^
# Pyright: Expression with type "tuple[Literal[1], Literal[2], Literal[3]]" cannot be assigned to target tuple
# Type "tuple[Literal[1], Literal[2], Literal[3]]" is incompatible with target tuple
# Tuple size mismatch; expected 2 but received 3 [reportAssignmentType]
# red-knot: Too many values to unpack (expected 2, got 3) [lint:invalid-assignment]
```
## Test Plan
Update existing test cases TODO with the error directives.
Fixes: #15176
## Summary
Neither of these rules make any sense in stub files. Technically TC007
should already not have triggered, due to the typing only context of the
binding, but it's better to be explicit.
Keeping TC008 enabled on the other hand makes sense to me, although we
could probably be more aggressive with unquoting in a typing runtime
context.
## Test Plan
`cargo nextest run`
## Summary
Ref:
3533d7f5b4 (r150651102)
This PR removes the `Ranged` implementation on `DefinitionKind` and
instead uses a method called `target_range` to avoid any confusion about
what range this is for i.e., it's not the range of the node that
represents the definition.
## Summary
Related to #13773
This PR adds support for unpacking `for` statement targets.
This involves updating the `value` field in the `Unpack` target to use
an enum which specifies the "where did the value expression came from?".
This is because for an iterable expression, we need to unpack the
iterator type while for assignment statement we need to unpack the value
type itself. And, this needs to be done in the unpack query.
### Question
One of the ways unpacking works in `for` statement is by looking at the
union of the types because if the iterable expression is a tuple then
the iterator type will be union of all the types in the tuple. This
means that the test cases that will test the unpacking in `for`
statement will also implicitly test the unpacking union logic. I was
wondering if it makes sense to merge these cases and only add the ones
that are specific to the union unpacking or for statement unpacking
logic.
## Test Plan
Add test cases involving iterating over a tuple type. I've intentionally
left out certain cases for now and I'm curious to know any thoughts on
the above query.
## Summary
Closes#14975 by modifying the docstring of the InvalidPyprojectToml
rule. Previously the docs were incorrectly stating that author name and
emails must be individual items in the authors list, rather than part of
a single object for each respective author.
## Test Plan
This was a docstring change, no tests needed.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [env_logger](https://redirect.github.com/rust-cli/env_logger) |
workspace.dependencies | patch | `0.11.5` -> `0.11.6` |
---
### Release Notes
<details>
<summary>rust-cli/env_logger (env_logger)</summary>
###
[`v0.11.6`](https://redirect.github.com/rust-cli/env_logger/blob/HEAD/CHANGELOG.md#0116---2024-12-20)
[Compare
Source](https://redirect.github.com/rust-cli/env_logger/compare/v0.11.5...v0.11.6)
##### Features
- Opt-in file and line rendering
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS44MC4wIiwidXBkYXRlZEluVmVyIjoiMzkuODAuMCIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [lsp-server](https://redirect.github.com/rust-lang/rust-analyzer)
([source](https://redirect.github.com/rust-lang/rust-analyzer/tree/HEAD/lib/lsp-server))
| workspace.dependencies | patch | `0.7.7` -> `0.7.8` |
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS44MC4wIiwidXBkYXRlZEluVmVyIjoiMzkuODAuMCIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [serde_json](https://redirect.github.com/serde-rs/json) |
workspace.dependencies | patch | `1.0.133` -> `1.0.134` |
---
### Release Notes
<details>
<summary>serde-rs/json (serde_json)</summary>
###
[`v1.0.134`](https://redirect.github.com/serde-rs/json/releases/tag/v1.0.134)
[Compare
Source](https://redirect.github.com/serde-rs/json/compare/v1.0.133...v1.0.134)
- Add `RawValue` associated constants for literal `null`, `true`,
`false`
([#​1221](https://redirect.github.com/serde-rs/json/issues/1221),
thanks [@​bheylin](https://redirect.github.com/bheylin))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS44MC4wIiwidXBkYXRlZEluVmVyIjoiMzkuODAuMCIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [syn](https://redirect.github.com/dtolnay/syn) |
workspace.dependencies | patch | `2.0.90` -> `2.0.91` |
---
### Release Notes
<details>
<summary>dtolnay/syn (syn)</summary>
###
[`v2.0.91`](https://redirect.github.com/dtolnay/syn/releases/tag/2.0.91)
[Compare
Source](https://redirect.github.com/dtolnay/syn/compare/2.0.90...2.0.91)
- Support parsing `Vec<Arm>` using `parse_quote!`
([#​1796](https://redirect.github.com/dtolnay/syn/issues/1796),
[#​1797](https://redirect.github.com/dtolnay/syn/issues/1797))
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS44MC4wIiwidXBkYXRlZEluVmVyIjoiMzkuODAuMCIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
This changeset adds support for precise type-inference and
boundness-handling of definitions inside control-flow branches with
statically-known conditions, i.e. test-expressions whose truthiness we
can unambiguously infer as *always false* or *always true*.
This branch also includes:
- `sys.platform` support
- statically-known branches handling for Boolean expressions and while
loops
- new `target-version` requirements in some Markdown tests which were
now required due to the understanding of `sys.version_info` branches.
closes#12700closes#15034
## Performance
### `tomllib`, -7%, needs to resolve one additional module (sys)
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|:---|---:|---:|---:|---:|
| `./red_knot_main --project /home/shark/tomllib` | 22.2 ± 1.3 | 19.1 |
25.6 | 1.00 |
| `./red_knot_feature --project /home/shark/tomllib` | 23.8 ± 1.6 | 20.8
| 28.6 | 1.07 ± 0.09 |
### `black`, -6%
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|:---|---:|---:|---:|---:|
| `./red_knot_main --project /home/shark/black` | 129.3 ± 5.1 | 119.0 |
137.8 | 1.00 |
| `./red_knot_feature --project /home/shark/black` | 136.5 ± 6.8 | 123.8
| 147.5 | 1.06 ± 0.07 |
## Test Plan
- New Markdown tests for the main feature in
`statically-known-branches.md`
- New Markdown tests for `sys.platform`
- Adapted tests for `EllipsisType`, `Never`, etc
## Summary
This PR fixes an issue where Ruff's `D403` rule
(`first-word-uncapitalized`) was not detecting some single-word edge
cases that are picked up by `pydocstyle`.
The change involves extracting the first word of the docstring by
identifying the first whitespace character. This is consistent with
`pydocstyle` which uses `.split()` - see
8d0cdfc93e/src/pydocstyle/checker.py (L581C13-L581C64)
## Example
Here is a playground example -
https://play.ruff.rs/eab9ea59-92cf-4e44-b1a9-b54b7f69b178
```py
def example1():
"""foo"""
def example2():
"""foo
Hello world!
"""
def example3():
"""foo bar
Hello world!
"""
def example4():
"""
foo
"""
def example5():
"""
foo bar
"""
```
`pydocstyle` detects all five cases:
```bash
$ pydocstyle test.py --select D403
dev/test.py:2 in public function `example1`:
D403: First word of the first line should be properly capitalized ('Foo', not 'foo')
dev/test.py:5 in public function `example2`:
D403: First word of the first line should be properly capitalized ('Foo', not 'foo')
dev/test.py:11 in public function `example3`:
D403: First word of the first line should be properly capitalized ('Foo', not 'foo')
dev/test.py:17 in public function `example4`:
D403: First word of the first line should be properly capitalized ('Foo', not 'foo')
dev/test.py:22 in public function `example5`:
D403: First word of the first line should be properly capitalized ('Foo', not 'foo')
```
Ruff (`0.8.4`) fails to catch example2 and example4.
## Test Plan
* Added two new test cases to cover the previously missed single-word
docstring cases.
## Summary
Refer:
https://github.com/astral-sh/ruff/issues/13773#issuecomment-2548020368
This PR adds support for unpacking union types.
Unpacking a union type requires us to first distribute the types for all
the targets that are involved in an unpacking. For example, if there are
two targets and a union type that needs to be unpacked, each target will
get a type from each element in the union type.
For example, if the type is `tuple[int, int] | tuple[int, str]` and the
target has two elements `(a, b)`, then
* The type of `a` will be a union of `int` and `int` which are at index
0 in the first and second tuple respectively which resolves to an `int`.
* Similarly, the type of `b` will be a union of `int` and `str` which
are at index 1 in the first and second tuple respectively which will be
`int | str`.
### Refactors
There are couple of refactors that are added in this PR:
* Add a `debug_assertion` to validate that the unpack target is a list
or a tuple
* Add a separate method to handle starred expression
## Test Plan
Update `unpacking.md` with additional test cases that uses union types.
This is done using parameter type hints style.
## Summary
This PR adds initial support for `type: ignore`. It doesn't do anything
fancy yet like:
* Detecting invalid type ignore comments
* Detecting type ignore comments that are part of another suppression
comment: `# fmt: skip # type: ignore`
* Suppressing specific lints `type: ignore [code]`
* Detecting unsused type ignore comments
* ...
The goal is to add this functionality in separate PRs.
## Test Plan
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fix#11482. Applies
https://github.com/adamchainz/flake8-comprehensions/pull/205 to ruff.
`C416` should be skipped if comprehension contains unpacking. Here's an
example:
```python
list_of_lists = [[1, 2], [3, 4]]
# ruff suggests `list(list_of_lists)` here, but that would change the result.
# `list(list_of_lists)` is not `[(1, 2), (3, 4)]`
a = [(x, y) for x, y in list_of_lists]
# This is equivalent to `list(list_of_lists)`
b = [x for x in list_of_lists]
```
## Test Plan
<!-- How was it tested? -->
Existing checks
---------
Signed-off-by: harupy <hkawamura0130@gmail.com>
## Summary
resolves#14883
This PR removes the known limitation section in the documentation of
`eq-without-hash`. That is not actually a limitation as a subclass
overriding the `__eq__` method would have its `__hash__` set to `None`
implicitly. The user should explicitly inherit the `__hash__` method
from the parent class.
## Test Plan
<img width="619" alt="Screenshot 2024-12-20 at 2 02 47 PM"
src="https://github.com/user-attachments/assets/552defcd-25e1-4153-9ab9-e5b9d5fbe8cc"
/>
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
Airflow 3.0 removes various deprecated functions, members, modules, and
other values. They have been deprecated in 2.x, but the removal causes
incompatibilities that we want to detect. This PR deprecates the
following names and add a function for removed methods
* `airflow.datasets.manager.DatasetManager.register_dataset_change` →
`airflow.assets.manager.AssetManager.register_asset_change`
* `airflow.datasets.manager.DatasetManager.create_datasets` →
`airflow.assets.manager.AssetManager.create_assets`
* `airflow.datasets.manager.DatasetManager.notify_dataset_created` →
`airflow.assets.manager.AssetManager.notify_asset_created`
* `airflow.datasets.manager.DatasetManager.notify_dataset_changed` →
`airflow.assets.manager.AssetManager.notify_asset_changed`
* `airflow.datasets.manager.DatasetManager.notify_dataset_alias_created`
→ `airflow.assets.manager.AssetManager.notify_asset_alias_created`
*
`airflow.providers.amazon.auth_manager.aws_auth_manager.AwsAuthManager.is_authorized_dataset`
→
`airflow.providers.amazon.auth_manager.aws_auth_manager.AwsAuthManager.is_authorized_asset`
* `airflow.lineage.hook.HookLineageCollector.create_dataset` →
`airflow.lineage.hook.HookLineageCollector.create_asset`
* `airflow.lineage.hook.HookLineageCollector.add_input_dataset` →
`airflow.lineage.hook.HookLineageCollector.add_input_asset`
* `airflow.lineage.hook.HookLineageCollector.add_output_dataset` →
`airflow.lineage.hook.HookLineageCollector.dd_output_asset`
* `airflow.lineage.hook.HookLineageCollector.collected_datasets` →
`airflow.lineage.hook.HookLineageCollector.collected_assets`
*
`airflow.providers_manager.ProvidersManager.initialize_providers_dataset_uri_resources`
→
`airflow.providers_manager.ProvidersManager.initialize_providers_asset_uri_resources`
## Test Plan
A test fixture is included in the PR.
When confronted with `raise from exc` the parser will now create a
`StmtRaise` that has `None` for the exception and `exc` for the cause.
Before, the parser created a `StmtRaise` with `from` for the exception,
no cause, and a spurious expression `exc` afterwards.
## Summary
A follow up PR on https://github.com/astral-sh/ruff/issues/14991
Ruff ignores hardcoded passwords for typed variables. Add a rule to
catch passwords in typed code bases
## Test Plan
Includes 2 more test typed variables
We have a handy `to_meta_type` that does the right thing for class
instances, and also works for all of the other types that are “instances
of” something. Unless I'm missing something, this should let us get rid
of the catch-all clause in one fell swoop.
cf #14548
## Summary
I'm currently on the fence about landing the #14760 PR because it's
unclear how we'd support tracking used and unused suppression comments
in a performant way:
* Salsa adds an "untracked" dependency to every query reading
accumulated values. This has the effect that the query re-runs on every
revision. For example, a possible future query
`unused_suppression_comments(db, file)` would re-run on every
incremental change and for every file. I don't expect the operation
itself to be expensive, but it all adds up in a project with 100k+ files
* Salsa collects the accumulated values by traversing the entire query
dependency graph. It can skip over sub-graphs if it is known that they
contain no accumulated values. This makes accumulators a great tool for
when they are rare; diagnostics are a good example. Unfortunately,
suppressions are more common, and they often appear in many different
files, making the "skip over subgraphs" optimization less effective.
Because of that, I want to wait to adopt salsa accumulators for type
check diagnostics (we could start using them for other diagnostics)
until we have very specific reasons that justify regressing incremental
check performance.
This PR does a "small" refactor that brings us closer to what I have in
#14760 but without using accumulators. To emit a diagnostic, a method
needs:
* Access to the db
* Access to the currently checked file
This PR introduces a new `InferContext` that holds on to the db, the
current file, and the reported diagnostics. It replaces the
`TypeCheckDiagnosticsBuilder`. We pass the `InferContext` instead of the
`db` to methods that *might* emit diagnostics. This simplifies some of
the `Outcome` methods, which can now be called with a context instead of
a `db` and the diagnostics builder. Having the `db` and the file on a
single type like this would also be useful when using accumulators.
This PR doesn't solve the issue that the `Outcome` types feel somewhat
complicated nor that it can be annoying when you need to report a
`Diagnostic,` but you don't have access to an `InferContext` (or the
file). However, I also believe that accumulators won't solve these
problems because:
* Even with accumulators, it's necessary to have a reference to the file
that's being checked. The struggle would be to get a reference to that
file rather than getting a reference to `InferContext`.
* Users of the `HasTy` trait (e.g., a linter) don't want to bother
getting the `File` when calling `Type::return_ty` because they aren't
interested in the created diagnostics. They just want to know what
calling the current expression would return (and if it even is a
callable). This is what the different methods of `Outcome` enable today.
I can ask for the return type without needing extra data that's only
relevant for emitting a diagnostic.
A shortcoming of this approach is that it is now a bit confusing when to
pass `db` and when an `InferContext`. An option is that we'd make the
`file` on `InferContext` optional (it won't collect any diagnostics if
`None`) and change all methods on `Type` to take `InferContext` as the
first argument instead of a `db`. I'm interested in your opinion on
this.
Accumulators are definitely harder to use incorrectly because they
remove the need to merge the diagnostics explicitly and there's no risk
that we accidentally merge the diagnostics twice, resulting in
duplicated diagnostics. I still value performance more over making our
life slightly easier.
Closes#14000
## Summary
For typing context bindings we know that they won't be available at
runtime. We shouldn't recommend a fix, that will result in name errors
at runtime.
## Test Plan
`cargo nextest run`
This tweaks the new semantics from #15026 a bit when a symbol could be
interpreted both as an attribute and a submodule of a package. For
`from...import`, we should actually prioritize the attribute, because of
how the statement itself is implemented [1].
> 1. check if the imported module has an attribute by that name
> 2. if not, attempt to import a submodule with that name and then check
the imported module again for that attribute
[1] https://docs.python.org/3/reference/simple_stmts.html#the-import-statement
## Summary
Fixes#14550.
Add `AlwaysTruthy` and `AlwaysFalsy` types, representing the set of objects whose `__bool__` method can only ever return `True` or `False`, respectively, and narrow `if x` and `if not x` accordingly.
## Test Plan
- New Markdown test for truthiness narrowing `narrow/truthiness.md`
- unit tests in `types.rs` and `builders.rs` (`cargo test --package
red_knot_python_semantic --lib -- types`)
## Summary
Fixes https://github.com/astral-sh/ruff/issues/15027
The `MemoryFileSystem::write_file` API automatically creates
non-existing ancestor directoryes
but we failed to update the status of the now created ancestor
directories in the `Files` data structure.
## Test Plan
Tested that the case in https://github.com/astral-sh/ruff/issues/15027
now passes regardless of whether the *Simple* case is commented out or
not
Fixes#15012.
```python
def f():
# panics when the code can't find the loop variable
values = [1, 2, 3]
result = []
for i in values:
result.append(i + 1)
del i
```
I'm not sure exactly why this test case panics, but I suspect the `del
i` removes the binding from the semantic model's symbols.
I changed the code to search for the correct binding by directly
iterating through the bindings. Since we know exactly which binding we
want, this should find the loop variable without any complications.
## Summary
This PR updates the logic when raising conflicting declarations
diagnostic to avoid the undeclared path if present.
The conflicting declaration diagnostics is added when there are two or
more declarations in the control flow path of a definition whose type
isn't equivalent to each other. This can be seen in the following
example:
```py
if flag:
x: int
x = 1 # conflicting-declarations: Unknown, int
```
After this PR, we'd avoid considering "Unknown" as part of the
conflicting declarations. This means we'd still flag it for the
following case:
```py
if flag:
x: int
else:
x: str
x = 1 # conflicting-declarations: int, str
```
A solution that's local to the exception control flow was also explored
which required updating the logic for merging the flow snapshot to avoid
considering declarations using a flag. This is preserved here:
https://github.com/astral-sh/ruff/compare/dhruv/control-flow-no-declarations?expand=1.
The main motivation to avoid that is we don't really understand what the
user experience is w.r.t. the Unknown type and the
conflicting-declaration diagnostics. This makes us unsure on what the
right semantics are as to whether that diagnostics should be raised or
not and when to raise them. For now, we've decided to move forward with
this PR and could decide to adopt another solution or remove the
conflicting-declaration diagnostics in the future.
Closes: #13966
## Test Plan
Update the existing mdtest case. Add an additional case specific to
exception control flow to verify that the diagnostic is not being raised
now.
When importing a nested module, we were correctly creating a binding for
the top-most parent, but we were binding that to the nested module, not
to that parent module. Moreover, we weren't treating those submodules as
members of their containing parents. This PR addresses both issues, so
that nested imports work as expected.
As discussed in ~Slack~ whatever chat app I find myself in these days
😄, this requires keeping track of which modules have been imported
within the current file, so that when we resolve member access on a
module reference, we can see if that member has been imported as a
submodule. If so, we return the submodule reference immediately, instead
of checking whether the parent module's definition defines the symbol.
This is currently done in a flow insensitive manner. The `SemanticIndex`
now tracks all of the modules that are imported (via `import`, not via
`from...import`). The member access logic mentioned above currently only
considers module imports in the file containing the attribute
expression.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
This PR introduces three changes to `D403`, which has to do with
capitalizing the first word in a docstring.
1. The diagnostic and fix now skip leading whitespace when determining
what counts as "the first word".
2. The name has been changed to `first-word-uncapitalized` from
`first-line-capitalized`, for both clarity and compliance with our rule
naming policy.
3. The diagnostic message and documentation has been modified slightly
to reflect this.
Closes#14890
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [colored](https://redirect.github.com/mackwic/colored) |
workspace.dependencies | minor | `2.1.0` -> `2.2.0` |
---
### Release Notes
<details>
<summary>mackwic/colored (colored)</summary>
###
[`v2.2.0`](https://redirect.github.com/mackwic/colored/compare/v2.1.0...v2.2.0)
[Compare
Source](https://redirect.github.com/mackwic/colored/compare/v2.1.0...v2.2.0)
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS41OC4xIiwidXBkYXRlZEluVmVyIjoiMzkuNTguMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Fixes#14969.
The issue was that this line:
```rust
let from_assign_to_loop = TextRange::new(binding_stmt.end(), for_stmt.start());
```
was not safe if the binding was after the target. The only way (at least
that I can think of) this can happen is if they are in different scopes,
so it now checks for that before checking if there are usages between
the two.
## Summary
The summary is misleading, as well as the
`whitespace-after-open-bracket` and `whitespace-before-close-bracket`
names - it's not only brackets, but also parentheses and braces. Align
the documentation with the actual behaviour.
Don't change the names, but align the documentation with the behaviour.
## Test Plan
No test (documentation).
## Summary
This change adds `name` and `default` functions to `TypeParam` to access
the corresponding attributes more conveniently. I currently have these
as helper functions in code built on top of ruff_python_ast, and they
seemed like they might be generally useful.
## Test Plan
Ran the checks listed in CONTRIBUTING.md#development.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
A class is an instance of its metaclass, so `ClassLiteral("ABC")` is not
disjoint from `Instance("ABCMeta")`. However, we erroneously consider
the two types disjoint on the `main` branch. This PR fixes that.
This bug was uncovered by adding some more core types to the property
tests that provide coverage for classes that have custom metaclasses.
The additions to the property tests are included in this PR.
## Test Plan
New unit tests and property tests added. Tested with:
- `cargo test -p red_knot_python_semantic`
- `QUICKCHECK_TESTS=100000 cargo test -p red_knot_python_semantic --
--ignored types::property_tests::stable`
The assignability property test fails on this branch, but that's a known
issue that exists on `main`, due to
https://github.com/astral-sh/ruff/issues/14899.
## Summary
Teach red-knot that `type[...]` is always disjoint from `None` and from
`LiteralString`. Fixes#14925.
This should properly be generalized to "all instances of final types
which are not subclasses of `type`", but until we support finality,
hardcoding `None` (which is known to be final) allows us to fix the
subtype transitivity property test.
## Test Plan
Existing tests pass, added new unit tests for `is_disjoint_from` and
`is_subtype_of`.
`QUICKCHECK_TESTS=100000 cargo test -p red_knot_python_semantic --
--ignored types::property_tests::stable` fails only the "assignability
is reflexive" test, which is known to fail on `main` (#14899).
The same command, with `property_tests.rs` edited to prevent generating
intersection tests (the cause of #14899), passes all quickcheck tests.
## Summary
This is not strictly required yet, but makes these tests future-proof.
They need a `python-version` requirement as they rely on language
features that are not available in 3.9.
## Summary
Many core Airflow features have been deprecated and moved to Airflow
Providers since users might need to install an additional package (e.g.,
`apache-airflow-provider-fab==1.0.0`); a separate rule (AIR303) is
created for this.
As some of the changes only relate to the module/package moved, instead
of listing out all the functions, variables, and classes in a module or
a package, it warns the user to import from the new path instead of the
specific name.
The following is the ones that has been moved to
`apache-airflow-provider-fab==1.0.0`
* module moved
* `airflow.api.auth.backend.basic_auth` →
`airflow.providers.fab.auth_manager.api.auth.backend.basic_auth`
* `airflow.api.auth.backend.kerberos_auth` →
`airflow.providers.fab.auth_manager.api.auth.backend.kerberos_auth`
* `airflow.auth.managers.fab.api.auth.backend.kerberos_auth` →
`airflow.providers.fab.auth_manager.api.auth.backend.kerberos_auth`
* `airflow.auth.managers.fab.security_manager.override` →
`airflow.providers.fab.auth_manager.security_manager.override`
* classes (e.g., functions, classes) moved
* `airflow.www.security.FabAirflowSecurityManagerOverride` →
`airflow.providers.fab.auth_manager.security_manager.override.FabAirflowSecurityManagerOverride`
* `airflow.auth.managers.fab.fab_auth_manager.FabAuthManager` →
`airflow.providers.fab.auth_manager.security_manager.FabAuthManager`
## Test Plan
A test fixture has been included for the rule.
## Summary
Add support for `typing.TYPE_CHECKING` and
`typing_extensions.TYPE_CHECKING`.
relates to: https://github.com/astral-sh/ruff/issues/14170
## Test Plan
New Markdown-based tests
## Summary
This PR extends the mdtest configuration with a `log` setting that can
be any of:
* `true`: Enables tracing
* `false`: Disables tracing (default)
* String: An ENV_FILTER similar to `RED_KNOT_LOG`
```toml
log = true
```
Closes https://github.com/astral-sh/ruff/issues/13865
## Test Plan
I changed a test and tried `log=true`, `log=false`, and `log=INFO`
## Summary
This PR renames the `--custom-typeshed-dir`, `target-version`, and
`--current-directory` cli options to `--typeshed`,
`--python-version`, and `--project` as discussed in the CLI proposal
document.
I added aliases for `--target-version` (for Ruff compat) and
`--custom-typeshed-dir` (for Alex)
## Test Plan
Long help
```
An extremely fast Python type checker.
Usage: red_knot [OPTIONS] [COMMAND]
Commands:
server Start the language server
help Print this message or the help of the given subcommand(s)
Options:
--project <PROJECT>
Run the command within the given project directory.
All `pyproject.toml` files will be discovered by walking up the directory tree from the project root, as will the project's virtual environment (`.venv`).
Other command-line arguments (such as relative paths) will be resolved relative to the current working directory."#,
--venv-path <PATH>
Path to the virtual environment the project uses.
If provided, red-knot will use the `site-packages` directory of this virtual environment to resolve type information for the project's third-party dependencies.
--typeshed-path <PATH>
Custom directory to use for stdlib typeshed stubs
--extra-search-path <PATH>
Additional path to use as a module-resolution source (can be passed multiple times)
--python-version <VERSION>
Python version to assume when resolving types
[possible values: 3.7, 3.8, 3.9, 3.10, 3.11, 3.12, 3.13]
-v, --verbose...
Use verbose output (or `-vv` and `-vvv` for more verbose output)
-W, --watch
Run in watch mode by re-running whenever files change
-h, --help
Print help (see a summary with '-h')
-V, --version
Print version
```
Short help
```
An extremely fast Python type checker.
Usage: red_knot [OPTIONS] [COMMAND]
Commands:
server Start the language server
help Print this message or the help of the given subcommand(s)
Options:
--project <PROJECT> Run the command within the given project directory
--venv-path <PATH> Path to the virtual environment the project uses
--typeshed-path <PATH> Custom directory to use for stdlib typeshed stubs
--extra-search-path <PATH> Additional path to use as a module-resolution source (can be passed multiple times)
--python-version <VERSION> Python version to assume when resolving types [possible values: 3.7, 3.8, 3.9, 3.10, 3.11, 3.12, 3.13]
-v, --verbose... Use verbose output (or `-vv` and `-vvv` for more verbose output)
-W, --watch Run in watch mode by re-running whenever files change
-h, --help Print help (see more with '--help')
-V, --version Print version
```
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Closes https://github.com/astral-sh/ruff/issues/14892, by adding
`sqlmodel.SQLModel` to the list of classes with default copy semantics.
## Test Plan
Added a test into `RUF012.py` containing the example from the original
issue.
## Summary
Regression test(s) for something that broken while implementing #14759.
We have similar tests for other control flow elements, but feel free to
let me know if this seems superfluous.
## Test Plan
New mdtests
## Summary
`PTH210` renamed to `invalid-pathlib-with-suffix` and extended to check for `.with_suffix(".")`. This caused the fix availability to be downgraded to "Sometimes", since there is no fix offered in this case.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Dylan <53534755+dylwil3@users.noreply.github.com>
## Summary
This PR changes our zizmor configuration to also flag low-severity
security issues in our GitHub Actions workflows. It's a followup to
https://github.com/astral-sh/ruff/pull/14844. The issues being fixed
here were all flagged by [zizmor's `template-injection`
rule](https://woodruffw.github.io/zizmor/audits/#template-injection):
> Detects potential sources of code injection via template expansion.
>
> GitHub Actions allows workflows to define template expansions, which
occur within special `${{ ... }}` delimiters. These expansions happen
before workflow and job execution, meaning the expansion of a given
expression appears verbatim in whatever context it was performed in.
>
> Template expansions aren't syntax-aware, meaning that they can result
in unintended shell injection vectors. This is especially true when
they're used with attacker-controllable expression contexts, such as
`github.event.issue.title` (which the attacker can fully control by
supplying a new issue title).
[...]
> To fully remediate the vulnerability, you should not use `${{
env.VARNAME }}`, since that is still a template expansion. Instead, you
should use `${VARNAME}` to ensure that the shell itself performs the
variable expansion.
## Test Plan
I tested that this passes all zizmore warnings by running `pre-commit
run -a zizmor` locally. The other test is obviously to check that the
workflows all still run correctly in CI 😄
## Summary
Using `typing.LiteralString` breaks as soon as we understand
`sys.version_info` branches, as it's only available in 3.11 and later.
## Test Plan
Made sure it didn't fail on my #14759 branch anymore.
We support using `typing.Type[]` as a base class (and we have tests for
it), but not yet `builtins.type[]`. At some point we should fix that,
but I don't think it';s worth spending much time on now (and it might be
easier once we've implemented generics?). This PR just adds a failing
test with a TODO.
## Summary
Fixes a small scoping issue in `DiagnosticId::matches`
Note: I don't think we should use `lint:id` in mdtests just yet. I worry
that it could lead to many unnecessary churns if we decide **not** to
use `lint:<id>` as the format (e.g., `lint/id`).
The reason why users even see `lint:<rule>` is because the mdtest
framework uses the diagnostic infrastructure
Closes#14910
## Test Plan
Added tests
## Summary
This is the third and last PR in this stack that adds support for
toggling lints at a per-rule level.
This PR introduces a new `LintRegistry`, a central index of known lints.
The registry is required because we want to support lint rules from many
different crates but need a way to look them up by name, e.g., when
resolving a lint from a name in the configuration or analyzing a
suppression comment.
Adding a lint now requires two steps:
1. Declare the lint with `declare_lint`
2. Register the lint in the registry inside the `register_lints`
function.
I considered some more involved macros to avoid changes in two places.
Still, I ultimately decided against it because a) it's just two places
and b) I'd expect that registering a type checker lint will differ from
registering a lint that runs as a rule in the linter. I worry that any
more opinionated design could limit our options when working on the
linter, so I kept it simple.
The second part of this PR is the `RuleSelection`. It stores which lints
are enabled and what severity they should use for created diagnostics.
For now, the `RuleSelection` always gets initialized with all known
lints and it uses their default level.
## Linter crates
Each crate that defines lints should export a `register_lints` function
that accepts a `&mut LintRegistryBuilder` to register all its known
lints in the registry. This should make registering all known lints in a
top-level crate easy: Just call `register_lints` of every crate that
defines lint rules.
I considered defining a `LintCollection` trait and even some fancy
macros to accomplish the same but decided to go for this very simplistic
approach for now. We can add more abstraction once needed.
## Lint rules
This is a bit hand-wavy. I don't have a good sense for how our linter
infrastructure will look like, but I expect we'll need a way to register
the rules that should run as part of the red knot linter. One way is to
keep doing what Ruff does by having one massive `checker` and each lint
rule adds a call to itself in the relevant AST visitor methods. An
alternative is that we have a `LintRule` trait that provides common
hooks and implementations will be called at the "right time". Such a
design would need a way to register all known lint implementations,
possibly with the lint. This is where we'd probably want a dedicated
`register_rule` method. A third option is that lint rules are handled
separately from the `LintRegistry` and are specific to the linter crate.
The current design should be flexible enough to support the three
options.
## Documentation generation
The documentation for all known lints can be generated by creating a
factory, registering all lints by calling the `register_lints` methods,
and then querying the registry for the metadata.
## Deserialization and Schema generation
I haven't fully decided what the best approach is when it comes to
deserializing lint rule names:
* Reject invalid names in the deserializer. This gives us error messages
with line and column numbers (by serde)
* Don't validate lint rule names during deserialization; defer the
validation until the configuration is resolved. This gives us more
control over handling the error, e.g. emit a warning diagnostic instead
of aborting when a rule isn't known.
One technical challenge for both deserialization and schema generation
is that the `Deserialize` and `JSONSchema` traits do not allow passing
the `LintRegistry`, which is required to look up the lints by name. I
suggest that we either rely on the salsa db being set for the current
thread (`salsa::Attach`) or build our own thread-local storage for the
`LintRegistry`. It's the caller's responsibility to make the lint
registry available before calling `Deserialize` or `JSONSchema`.
## CLI support
I prefer deferring adding support for enabling and disabling lints from
the CLI for now because I think it will be easier
to add once I've figured out how to handle configurations.
## Bitset optimization
Ruff tracks the enabled rules using a cheap copyable `Bitset` instead of
a hash map. This helped improve performance by a few percent (see
https://github.com/astral-sh/ruff/pull/3606). However, this approach is
no longer possible because lints have no "cheap" way to compute their
index inside the registry (other than using a hash map).
We could consider doing something similar to Salsa where each
`LintMetadata` stores a `LazyLintIndex`.
```
pub struct LazyLintIndex {
cached: OnceLock<(Nonce, LintIndex)>
}
impl LazyLintIndex {
pub fn get(registry: &LintRegistry, lint: &'static LintMetadata) {
let (nonce, index) = self.cached.get_or_init(|| registry.lint_index(lint));
if registry.nonce() == nonce {
index
} else {
registry.lint_index(lint)
}
}
```
Each registry keeps a map from `LintId` to `LintIndex` where `LintIndex`
is in the range of `0...registry.len()`. The `LazyLintIndex` is based on
the assumption that every program has exactly **one** registry. This
assumption allows to cache the `LintIndex` directly on the
`LintMetadata`. The implementation falls back to the "slow" path if
there is more than one registry at runtime.
I was very close to implementing this optimization because it's kind of
fun to implement. I ultimately decided against it because it adds
complexity and I don't think it's worth doing in Red Knot today:
* Red Knot only queries the rule selection when deciding whether or not
to emit a diagnostic. It is rarely used to detect if a certain code
block should run. This is different from Ruff where the rule selection
is queried many times for every single AST node to determine which rules
*should* run.
* I'm not sure if a 2-3% performance improvement is worth the complexity
I suggest revisiting this decision when working on the linter where a
fast path for deciding if a rule is enabled might be more important (but
that depends on how lint rules are implemented)
## Test Plan
I removed a lint from the default rule registry, and the MD tests
started failing because the diagnostics were no longer emitted.
This PR adds a syntax error if the parser encounters a `TryStmt` that
has except clauses both with and without a star.
The displayed error points to each except clause that contradicts the
original except clause kind. So, for example,
```python
try:
....
except: #<-- we assume this is the desired except kind
....
except*: #<--- error will point here
....
except*: #<--- and here
....
```
Closes#14860
This adds support for `type[Any]`, which represents an unknown type (not
an instance of an unknown type), and `type`, which we are choosing to
interpret as `type[object]`.
Closes#14546
## Summary
This is already several hundred lines of code, and it will get more
complex with call-signature checking.
## Test Plan
This is a pure code move; the moved code wasn't changed, just imports.
Existing tests pass.
## Summary
Add a `is_fully_static` premise to the equivalence on subtyping property tests.
## Test Plan
```
cargo test -p red_knot_python_semantic -- --ignored types::property_tests::stable
```
Without this, `cargo insta test` re-compiles every time it is run, even
if there are no changes. With this, I can re-run `cargo insta test` (or
other `cargo build` commands) without it resulting in re-compiles.
I made an identical change to uv a while back:
https://github.com/astral-sh/uv/pull/6825
## Summary
This is the second PR out of three that adds support for
enabling/disabling lint rules in Red Knot. You may want to take a look
at the [first PR](https://github.com/astral-sh/ruff/pull/14869) in this
stack to familiarize yourself with the used terminology.
This PR adds a new syntax to define a lint:
```rust
declare_lint! {
/// ## What it does
/// Checks for references to names that are not defined.
///
/// ## Why is this bad?
/// Using an undefined variable will raise a `NameError` at runtime.
///
/// ## Example
///
/// ```python
/// print(x) # NameError: name 'x' is not defined
/// ```
pub(crate) static UNRESOLVED_REFERENCE = {
summary: "detects references to names that are not defined",
status: LintStatus::preview("1.0.0"),
default_level: Level::Warn,
}
}
```
A lint has a name and metadata about its status (preview, stable,
removed, deprecated), the default diagnostic level (unless the
configuration changes), and documentation. I use a macro here to derive
the kebab-case name and extract the documentation automatically.
This PR doesn't yet add any mechanism to discover all known lints. This
will be added in the next and last PR in this stack.
## Documentation
I documented some rules but then decided that it's probably not my best
use of time if I document all of them now (it also means that I play
catch-up with all of you forever). That's why I left some rules
undocumented (marked with TODO)
## Where is the best place to define all lints?
I'm not sure. I think what I have in this PR is fine but I also don't
love it because most lints are in a single place but not all of them. If
you have ideas, let me know.
## Why is the message not part of the lint, unlike Ruff's `Violation`
I understand that the main motivation for defining `message` on
`Violation` in Ruff is to remove the need to repeat the same message
over and over again. I'm not sure if this is an actual problem. Most
rules only emit a diagnostic in a single place and they commonly use
different messages if they emit diagnostics in different code paths,
requiring extra fields on the `Violation` struct.
That's why I'm not convinced that there's an actual need for it and
there are alternatives that can reduce the repetition when creating a
diagnostic:
* Create a helper function. We already do this in red knot with the
`add_xy` methods
* Create a custom `Diagnostic` implementation that tailors the entire
diagnostic and pre-codes e.g. the message
Avoiding an extra field on the `Violation` also removes the need to
allocate intermediate strings as it is commonly the place in Ruff.
Instead, Red Knot can use a borrowed string with `format_args`
## Test Plan
`cargo test`
## Summary
This PR introduces a structured `DiagnosticId` instead of using a plain
`&'static str`. It is the first of three in a stack that implements a
basic rules infrastructure for Red Knot.
`DiagnosticId` is an enum over all known diagnostic codes. A closed enum
reduces the risk of accidentally introducing two identical diagnostic
codes. It also opens the possibility of generating reference
documentation from the enum in the future (not part of this PR).
The enum isn't *fully closed* because it uses a `&'static str` for lint
names. This is because we want the flexibility to define lints in
different crates, and all names are only known in `red_knot_linter` or
above. Still, lower-level crates must already reference the lint names
to emit diagnostics. We could define all lint-names in `DiagnosticId`
but I decided against it because:
* We probably want to share the `DiagnosticId` type between Ruff and Red
Knot to avoid extra complexity in the diagnostic crate, and both tools
use different lint names.
* Lints require a lot of extra metadata beyond just the name. That's why
I think defining them close to their implementation is important.
In the long term, we may also want to support plugins, which would make
it impossible to know all lint names at compile time. The next PR in the
stack introduces extra syntax for defining lints.
A closed enum does have a few disadvantages:
* rustc can't help us detect unused diagnostic codes because the enum is
public
* Adding a new diagnostic in the workspace crate now requires changes to
at least two crates: It requires changing the workspace crate to add the
diagnostic and the `ruff_db` crate to define the diagnostic ID. I
consider this an acceptable trade. We may want to move `DiagnosticId` to
its own crate or into a shared `red_knot_diagnostic` crate.
## Preventing duplicate diagnostic identifiers
One goal of this PR is to make it harder to introduce ambiguous
diagnostic IDs, which is achieved by defining a closed enum. However,
the enum isn't fully "closed" because it doesn't explicitly list the IDs
for all lint rules. That leaves the possibility that a lint rule and a
diagnostic ID share the same name.
I made the names unambiguous in this PR by separating them into
different namespaces by using `lint/<rule>` for lint rule codes. I don't
mind the `lint` prefix in a *Ruff next* context, but it is a bit weird
for a standalone type checker. I'd like to not overfocus on this for now
because I see a few different options:
* We remove the `lint` prefix and add a unit test in a top-level crate
that iterates over all known lint rules and diagnostic IDs to ensure the
names are non-overlapping.
* We only render `[lint]` as the error code and add a note to the
diagnostic mentioning the lint rule. This is similar to clippy and has
the advantage that the header line remains short
(`lint/some-long-rule-name` is very long ;))
* Any other form of adjusting the diagnostic rendering to make the
distinction clear
I think we can defer this decision for now because the `DiagnosticId`
contains all the relevant information to change the rendering
accordingly.
## Why `Lint` and not `LintRule`
I see three kinds of diagnostics in Red Knot:
* Non-suppressable: Reveal type, IO errors, configuration errors, etc.
(any `DiagnosticId`)
* Lints: code-related diagnostics that are suppressable.
* Lint rules: The same as lints, but they can be enabled or disabled in
the configuration. The majority of lints in Red Knot and the Ruff
linter.
Our current implementation doesn't distinguish between lints and Lint
rules because we aren't aware of a suppressible code-related lint that
can't be configured in the configuration. The only lint that comes to my
mind is maybe `division-by-zero` if we're 99.99% sure that it is always
right. However, I want to keep the door open to making this distinction
in the future if it proves useful.
Another reason why I chose lint over lint rule (or just rule) is that I
want to leave room for a future lint rule and lint phase concept:
* lint is the *what*: a specific code smell, pattern, or violation
* the lint rule is the *how*: I could see a future `LintRule` trait in
`red_knot_python_linter` that provides the necessary hooks to run as
part of the linter. A lint rule produces diagnostics for exactly one
lint. A lint rule differs from all lints in `red_knot_python_semantic`
because they don't run as "rules" in the Ruff sense. Instead, they're a
side-product of type inference.
* the lint phase is a different form of *how*: A lint phase can produce
many different lints in a single pass. This is a somewhat common pattern
in Ruff where running one analysis collects the necessary information
for finding many different lints
* diagnostic is the *presentation*: Unlike a lint, the diagnostic isn't
the what, but how a specific lint gets presented. I expect that many
lints can use one generic `LintDiagnostic`, but a few lints might need
more flexibility and implement their custom diagnostic rendering (at
least custom `Diagnostic` implementation).
## Test Plan
`cargo test`
## Summary
Add replacement fixes to deprecated arguments of a DAG.
Ref #14582#14626
## Test Plan
Diff was verified and snapshots were updated.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
Per suggestion in
https://github.com/astral-sh/ruff/pull/14802#discussion_r1875455417
This is a bit less error-prone and allows us to handle both expressions
in the current scope or a different scope. Also, there's currently no
need for this method outside of `TypeInferenceBuilder`, so no reason to
expose it in `types.rs`.
## Test Plan
Pure refactor, no functional change; existing tests pass.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Part 1 of the big change introduced in #14828. This temporarily causes
all fixes for `round(...)` to be considered unsafe, but they will
eventually be enhanced.
## Test Plan
`cargo nextest run` and `cargo insta test`.
## Summary
Upgrades to React 19. Closes
https://github.com/astral-sh/ruff/issues/14859
## Test Plan
I ran the playground locally and clicked through the different panels. I
didn't see any warning or error.
## Summary
Close#11243. Fix `pytest-parametrize-names-wrong-type (PT006)` to edit
both `argnames` and `argvalues` if both of them are single-element
tuples/lists.
```python
# Before fix
@pytest.mark.parametrize(("x",), [(1,), (2,)])
def test_foo(x):
...
# After fix:
@pytest.mark.parametrize("x", [1, 2])
def test_foo(x):
...
```
## Test Plan
New test cases
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
|
[python-jsonschema/check-jsonschema](https://redirect.github.com/python-jsonschema/check-jsonschema)
| repository | minor | `0.29.4` -> `0.30.0` |
Note: The `pre-commit` manager in Renovate is not supported by the
`pre-commit` maintainers or community. Please do not report any problems
there, instead [create a Discussion in the Renovate
repository](https://redirect.github.com/renovatebot/renovate/discussions/new)
if you have any questions.
---
### Release Notes
<details>
<summary>python-jsonschema/check-jsonschema
(python-jsonschema/check-jsonschema)</summary>
###
[`v0.30.0`](https://redirect.github.com/python-jsonschema/check-jsonschema/blob/HEAD/CHANGELOG.rst#0300)
[Compare
Source](https://redirect.github.com/python-jsonschema/check-jsonschema/compare/0.29.4...0.30.0)
- Update vendored schemas: azure-pipelines, bitbucket-pipelines,
buildkite,
circle-ci, cloudbuild, dependabot, github-workflows, gitlab-ci, mergify,
readthedocs, renovate, taskfile, woodpecker-ci (2024-11-29)
- Fix caching behavior to always use URL hashes as cache keys. This
fixes a
cache confusion bug in which the wrong schema could be retrieved from
the
cache. This resolves :cve:`2024-53848`. Thanks :user:`sethmlarson` for
reporting!
- Deprecate the `--cache-filename` flag. It no longer has any effect and
will
be removed in a future release.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS40Mi40IiwidXBkYXRlZEluVmVyIjoiMzkuNDIuNCIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
This PR introduces three changes to the diagnostic and fix behavior
(still under preview) for [boolean-chained-comparison
(PLR1716)](https://docs.astral.sh/ruff/rules/boolean-chained-comparison/#boolean-chained-comparison-plr1716).
1. We now offer a _fix_ in the case of parenthesized expressions like
`(a < b) and b < c`. The fix will merge the chains of comparisons and
then balance parentheses by _adding_ parentheses to one side of the
expression.
2. We now trigger a diagnostic (and fix) in the case where some
comparisons have multiple comparators like `a < b < c and c < d`.
3. When adjacent comparators are parenthesized, we prefer the left
parenthesization and apply the replacement to the whole parenthesized
range. So, for example, `a < (b) and ((b)) < c` becomes `a < (b) < c`.
While these seem like somewhat disconnected changes, they are actually
related. If we only offered (1), then we would see the following fix
behavior:
```diff
- (a < b) and b < c and ((c < d))
+ (a < b < c) and ((c < d))
```
This is because the fix which add parentheses to the first pair of
comparisons overlaps with the fix that removes the `and` between the
second two comparisons. So the latter fix is deferred. However, the
latter fix does not get a second chance because, upon the next lint
iteration, there is no violation of `PLR1716`.
Upon adopting (2), however, both fixes occur by the time ruff completes
several iterations and we get:
```diff
- (a < b) and b < c and ((c < d))
+ ((a < b < c < d))
```
Finally, (3) fixes a previously unobserved bug wherein the autofix for
`a < (b) and b < c` used to result in `a<(b<c` which gives a syntax
error. It could in theory have been fixed in a separate PR, but seems to
be on theme here.
----------
- Closes#13524
- (1), (2), and (3) are implemented in separate commits for ease of
review and modification.
- Technically a user can trigger an error in ruff (by reaching max
iterations) if they have a humongous boolean chained comparison with
differing parentheses levels.
## Summary
Minor change for the documentation of COM818 rule. This was a block
called “In the event that a tuple is intended”, but the suggested change
did not produce a tuple.
## Test Plan
```python
>>> import json
>>> (json.dumps({"bar": 1}),) # this is a tuple
('{"bar": 1}',)
>>> (json.dumps({"bar": 1})) # not a tuple
'{"bar": 1}'
```
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [pep440_rs](https://redirect.github.com/konstin/pep440-rs) |
workspace.dependencies | patch | `0.7.2` -> `0.7.3` |
---
### Release Notes
<details>
<summary>konstin/pep440-rs (pep440_rs)</summary>
###
[`v0.7.3`](https://redirect.github.com/konstin/pep440-rs/blob/HEAD/Changelog.md#073)
[Compare
Source](https://redirect.github.com/konstin/pep440-rs/compare/v0.7.2...v0.7.3)
- Use once_cell to lower MSRV
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOS40Mi40IiwidXBkYXRlZEluVmVyIjoiMzkuNDIuNCIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
A [recent exploit](https://github.com/advisories/GHSA-7x29-qqmq-v6qc)
brought attention to how easy it can be for attackers to use template
expansion in GitHub Actions workflows to inject arbitrary code into a
repository. That vulnerability [would have been caught by the zizmor
linter](https://blog.yossarian.net/2024/12/06/zizmor-ultralytics-injection),
which looks for potential security vulnerabilities in GitHub Actions
workflows. This PR adds [zizmor](https://github.com/woodruffw/zizmor) as
a pre-commit hook and fixes the high- and medium-severity warnings
flagged by the tool.
All the warnings fixed in this PR are related to this zizmor check:
https://woodruffw.github.io/zizmor/audits/#artipacked. The summary of
the check is that `actions/checkout` will by default persist git
configuration for the duration of the workflow, which can be insecure.
It's unnecessary unless you actually need to do things with `git` later
on in the workflow. None of our workflows do except for
`publish-docs.yml` and `sync-typeshed.yml`, so I set
`persist-credentials: true` for those two but `persist-credentials:
false` for all other uses of `actions/checkout`.
Unfortunately there are several warnings in `release.yml`, including
four high-severity warnings. However, this is a generated workflow file,
so I have deliberately excluded this file from the check. These are the
findings in `release.yml`:
<details>
<summary>release.yml findings</summary>
```
warning[artipacked]: credential persistence through GitHub Actions artifacts
--> /Users/alexw/dev/ruff/.github/workflows/release.yml:62:9
|
62 | - uses: actions/checkout@v4
| _________-
63 | | with:
64 | | submodules: recursive
| |_______________________________- does not set persist-credentials: false
|
= note: audit confidence → Low
warning[artipacked]: credential persistence through GitHub Actions artifacts
--> /Users/alexw/dev/ruff/.github/workflows/release.yml:124:9
|
124 | - uses: actions/checkout@v4
| _________-
125 | | with:
126 | | submodules: recursive
| |_______________________________- does not set persist-credentials: false
|
= note: audit confidence → Low
warning[artipacked]: credential persistence through GitHub Actions artifacts
--> /Users/alexw/dev/ruff/.github/workflows/release.yml:174:9
|
174 | - uses: actions/checkout@v4
| _________-
175 | | with:
176 | | submodules: recursive
| |_______________________________- does not set persist-credentials: false
|
= note: audit confidence → Low
warning[artipacked]: credential persistence through GitHub Actions artifacts
--> /Users/alexw/dev/ruff/.github/workflows/release.yml:249:9
|
249 | - uses: actions/checkout@v4
| _________-
250 | | with:
251 | | submodules: recursive
252 | | # Create a GitHub Release while uploading all files to it
| |_______________________________________________________________- does not set persist-credentials: false
|
= note: audit confidence → Low
error[excessive-permissions]: overly broad workflow or job-level permissions
--> /Users/alexw/dev/ruff/.github/workflows/release.yml:17:1
|
17 | / permissions:
18 | | "contents": "write"
... |
39 | | # If there's a prerelease-style suffix to the version, then the release(s)
40 | | # will be marked as a prerelease.
| |_________________________________^ contents: write is overly broad at the workflow level
|
= note: audit confidence → High
error[template-injection]: code injection via template expansion
--> /Users/alexw/dev/ruff/.github/workflows/release.yml:80:9
|
80 | - id: plan
| _________^
81 | | run: |
| |_________^
82 | || dist ${{ (inputs.tag && inputs.tag != 'dry-run' && format('host --steps=create --tag={0}', inputs.tag)) || 'plan' }} --out...
83 | || echo "dist ran successfully"
84 | || cat plan-dist-manifest.json
85 | || echo "manifest=$(jq -c "." plan-dist-manifest.json)" >> "$GITHUB_OUTPUT"
| ||__________________________________________________________________________________^ this step
| ||__________________________________________________________________________________^ inputs.tag may expand into attacker-controllable code
|
= note: audit confidence → Low
error[template-injection]: code injection via template expansion
--> /Users/alexw/dev/ruff/.github/workflows/release.yml:80:9
|
80 | - id: plan
| _________^
81 | | run: |
| |_________^
82 | || dist ${{ (inputs.tag && inputs.tag != 'dry-run' && format('host --steps=create --tag={0}', inputs.tag)) || 'plan' }} --out...
83 | || echo "dist ran successfully"
84 | || cat plan-dist-manifest.json
85 | || echo "manifest=$(jq -c "." plan-dist-manifest.json)" >> "$GITHUB_OUTPUT"
| ||__________________________________________________________________________________^ this step
| ||__________________________________________________________________________________^ inputs.tag may expand into attacker-controllable code
|
= note: audit confidence → Low
error[template-injection]: code injection via template expansion
--> /Users/alexw/dev/ruff/.github/workflows/release.yml:80:9
|
80 | - id: plan
| _________^
81 | | run: |
| |_________^
82 | || dist ${{ (inputs.tag && inputs.tag != 'dry-run' && format('host --steps=create --tag={0}', inputs.tag)) || 'plan' }} --out...
83 | || echo "dist ran successfully"
84 | || cat plan-dist-manifest.json
85 | || echo "manifest=$(jq -c "." plan-dist-manifest.json)" >> "$GITHUB_OUTPUT"
| ||__________________________________________________________________________________^ this step
| ||__________________________________________________________________________________^ inputs.tag may expand into attacker-controllable code
|
= note: audit confidence → Low
```
</details>
## Test Plan
`uvx pre-commit run -a`
Improves error message for [except*](https://peps.python.org/pep-0654/)
(Rules: B025, B029, B030, B904)
Example python snippet:
```python
try:
a = 1
except* ValueError:
a = 2
except* ValueError:
a = 2
try:
pass
except* ():
pass
try:
pass
except* 1: # error
pass
try:
raise ValueError
except* ValueError:
raise UserWarning
```
Error messages
Before:
```
$ ruff check --select=B foo.py
foo.py:6:9: B025 try-except block with duplicate exception `ValueError`
foo.py:11:1: B029 Using `except ():` with an empty tuple does not catch anything; add exceptions to handle
foo.py:16:9: B030 `except` handlers should only be exception classes or tuples of exception classes
foo.py:22:5: B904 Within an `except` clause, raise exceptions with `raise ... from err` or `raise ... from None` to distinguish them from errors in exception handling
Found 4 errors.
```
After:
```
$ ruff check --select=B foo.py
foo.py:6:9: B025 try-except* block with duplicate exception `ValueError`
foo.py:11:1: B029 Using `except* ():` with an empty tuple does not catch anything; add exceptions to handle
foo.py:16:9: B030 `except*` handlers should only be exception classes or tuples of exception classes
foo.py:22:5: B904 Within an `except*` clause, raise exceptions with `raise ... from err` or `raise ... from None` to distinguish them from errors in exception handling
Found 4 errors.
```
Closes https://github.com/astral-sh/ruff/issues/14791
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
This adds support for `type[a.X]`, where the `type` special form is
applied to a qualified name that resolves to a class literal. This works
for both nested classes and classes imported from another module.
Closes#14545
## Summary
Inferred and declared types for function parameters, in the function
body scope.
Fixes#13693.
## Test Plan
Added mdtests.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Airflow 3.0 removes various deprecated functions, members, modules, and
other values. They have been deprecated in 2.x, but the removal causes
incompatibilities that we want to detect. This PR deprecates the
following names.
* in `DAG`
* `sla_miss_callback` was removed
* in `airflow.operators.trigger_dagrun.TriggerDagRunOperator`
* `execution_date` was removed
* in `airflow.operators.weekday.DayOfWeekSensor`,
`airflow.operators.datetime.BranchDateTimeOperator` and
`airflow.operators.weekday.BranchDayOfWeekOperator`
* `use_task_execution_day` was removed in favor of
`use_task_logical_date`
The full list of rules we will extend
https://github.com/apache/airflow/issues/44556
## Test Plan
<!-- How was it tested? -->
A test fixture is included in the PR.
## Summary
`typing.Never` and `typing.LiteralString` are only conditionally
exported from `typing` for Python versions 3.11 and later. We run the
Markdown tests with the default Python version of 3.9, so here we change
the import to `typing_extensions` instead, and add a new test to make
sure we'll continue to understand the `typing`-version of these symbols
for newer versions.
This didn't cause problems so far, as we don't understand
`sys.version_info` branches yet.
## Test Plan
New Markdown tests to make sure this will continue to work in the
future.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/14778
The formatter incorrectly removed the inner implicitly concatenated
string for following single-line f-string:
```py
f"{'aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa' 'a' if True else ""}"
# formatted
f"{ if True else ''}"
```
This happened because I changed the `RemoveSoftlinesBuffer` in
https://github.com/astral-sh/ruff/pull/14489 to remove any content
wrapped in `if_group_breaks`. After all, it emulates an *all flat*
layout. This works fine when `if_group_breaks` is only used to **add**
content if the gorup breaks. It doesn't work if the same content is
rendered differently depending on if the group fits using
`if_group_breaks` and `if_groups_fits` because the enclosing `group`
might still *break* if the entire content exceeds the line-length limit.
This PR fixes this by unwrapping any `if_group_fits` content by removing
the `if_group_fits` start and end tags.
## Test Plan
added test
## Summary
This adds support for specifying the target Python version from a
Markdown test. It is a somewhat limited ad-hoc solution, but designed to
be future-compatible. TOML blocks can be added to arbitrary sections in
the Markdown block. They have the following format:
````markdown
```toml
[tool.knot.environment]
target-version = "3.13"
```
````
So far, there is nothing else that can be configured, but it should be
straightforward to extend this to things like a custom typeshed path.
This is in preparation for the statically-known branches feature where
we are going to have to specify the target version for lots of tests.
## Test Plan
- New Markdown test that fails without the explicitly specified
`target-version`.
- Manually tested various error paths when specifying a wrong
`target-version` field.
- Made sure that running tests is as fast as before.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/14807
I suspect that this broke when we updated notify, although I'm not quiet
sure how this *ever* worked...
The problem was that the file watcher didn't skip over `Access` events,
but Ruff itself accesses the `pyproject.toml` when checking the project.
That means, Ruff triggers `Access` events but it also schedules a
re-check on every `Access` event... and this goes one forever.
This PR skips over `Access` and `Other` event. `Access` events are
uninteresting because they're only reads, they don't change any file
metadata or content.
The `Other` events should be rare and are mainly to inform about file
watcher changes... we don't need those.
I also added an explicit handling for the `Rescan` event. File watchers
emit a `Rescan` event if they failed to capture some file watching
changes
and it signals that the program should assume that all files might have
changed (the program should do a rescan to *get up to date*).
## Test Plan
I tested that Ruff no longer loops when running `check --watch`. I
verified that Ruff rechecks file after making content changes.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
in unknown moment older versions became broken for windows-gnullvm
targets. this update shouldn't break anything
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
successfully built for windows-gnullvm with `cargo build`
<!-- How was it tested? -->
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
https://docs.astral.sh/ruff/integrations/#github-actions upgraded for
https://github.com/astral-sh/ruff-action/releases
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
@eifinger Your review, please.
## Summary
This is related to #13778, more specifically
https://github.com/astral-sh/ruff/issues/13778#issuecomment-2513556004.
This PR adds various test cases where a keyword is being where an
identifier is expected. The tests are to make sure that red knot doesn't
panic, raises the syntax error and the identifier is added to the symbol
table. The final part allows editor related features like renaming the
symbol.
## Summary
`typing_extensions` has a `>=3.13` re-export for the `typing.NoDefault`
singleton, but not for `typing._NoDefaultType`. This causes problems as
soon as we understand `sys.version_info` branches, so we explicity
switch to `typing._NoDefaultType` for Python 3.13 and later.
This is a part of #14759 that I thought might make sense to break out
and merge in isolation.
## Test Plan
New test that will become more meaningful with #12700
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
- Instead of seven (more or less similar) `setup_db` functions, use just
one in a single central place.
- For every test that needs customization beyond that, offer a
`TestDbBuilder` that can control the Python target version, custom
typeshed, and pre-existing files.
The main motivation for this is that we're soon going to need
customization of the Python version, and I didn't feel like adding this
to each of the existing `setup_db` functions.
## Summary
This changeset contains various improvements concerning non-fully-static
types and their relationships:
- Make sure that non-fully-static types do not participate in
equivalence or subtyping.
- Clarify what `Type::is_equivalent_to` actually implements.
- Introduce `Type::is_fully_static`
- New tests making sure that multiple `Any`/`Unknown`s inside unions and
intersections are collapsed.
closes#14524
## Test Plan
- Added new unit tests for union and intersection builder
- Added new unit tests for `Type::is_equivalent_to`
- Added new unit tests for `Type::is_subtype_of`
- Added new property test making sure that non-fully-static types do not
participate in subtyping
We already had a representation for the Any type, which we would use
e.g. for expressions without type annotations. We now recognize
`typing.Any` as a way to refer to this type explicitly. Like other
special forms, this is tracked correctly through aliasing, and isn't
confused with local definitions that happen to have the same name.
Closes#14544
## Summary
Minor change that uses two plain classes `A` and `B` instead of
`typing.Sized` and `typing.Hashable`.
The motivation is twofold: I remember that I was confused when I first
saw this test. Was there anything specific to `Sized` and `Hashable`
that was relevant here? (there is, these classes are not overlapping;
and you can build a proper intersection from them; but that's true for
almost all non-builtin classes).
I now ran into another problem while working on #14758: `Sized` and
`Hashable` are protocols that we don't fully understand yet. This
causing some trouble when trying to infer whether these are fully-static
types or not.
Closes: #14676
I think the consensus generally was to keep the rule as-is, but expand
the docs.
## Summary
Expands the docs for TC006 with an explanation for why the type
expression is always quoted, including mention of another potential
benefit to this style.
When fixing an invalid escape sequence in an f-string, each f-string
element is analyzed for valid escape characters prior to creating the
diagnostic and fix. This allows us to safely prefix with `r` to create a
raw string if no valid escape characters were found anywhere in the
f-string, and otherwise insert backslashes.
This fixes a bug in the original implementation: each "f-string part"
was treated separately, so it was not possible to tell whether a valid
escape character was or would be used elsewhere in the f-string.
Progress towards #11491 but format specifiers are not handled in this
PR.
## Summary
This PR adds a fuzzer harness for red knot that runs the type checker on
source code that contains invalid syntax.
Additionally, this PR also updates the `init-fuzzer.sh` script to
increase the corpus size to:
* Include various crates that includes Python source code
* Use the 3.13 CPython source code
And, remove any non-Python files from the final corpus so that when the
fuzzer tries to minify the corpus, it doesn't produce files that only
contains documentation content as that's just noise.
## Test Plan
Run `./fuzz/init-fuzzer.sh`, say no to the large dataset.
Run the fuzzer with `cargo +night fuzz run red_knot_check_invalid_syntax
-- -timeout=5`
## Summary
This PR makes changes to the `AIR001` rule as per
https://github.com/astral-sh/ruff/pull/14627#discussion_r1860212307.
Additionally,
* Avoid returning the `Diagnostic` and update the checker in the rule
logic for consistency
* Remove test case for different keyword position (I don't think it's
required here)
## Test Plan
Add test cases for multiple operators from various modules.
## Summary
Just some minor followups to the recently merged RUF052 rule, that was
added in bf0fd04:
- Some small tweaks to the docs
- A minor code-style nit
- Some more tests for my peace of mind, just to check that the new
methods on the semantic model are working correctly
I'm adding the "internal" label as this doesn't deserve a changelog
entry. RUF052 is a new rule that hasn't been released yet.
## Test Plan
`cargo test -p ruff_linter`
## Summary
This PR adds a new `property_tests` module with quickcheck-based tests
that verify certain properties of types. The following properties are
currently checked:
* `is_equivalent_to`:
* is reflexive: `T` is equivalent to itself
* `is_subtype_of`:
* is reflexive: `T` is a subtype of `T`
* is antisymmetric: if `S <: T` and `T <: S`, then `S` is equivalent to
`T`
* is transitive: `S <: T` & `T <: U` => `S <: U`
* `is_disjoint_from`:
* is irreflexive: `T` is not disjoint from `T`
* is symmetric: `S` disjoint from `T` => `T` disjoint from `S`
* `is_assignable_to`:
* is reflexive
* `negate`:
* is an involution: `T.negate().negate()` is equivalent to `T`
There are also some tests that validate higher-level properties like:
* `S <: T` implies that `S` is not disjoint from `T`
* `S <: T` implies that `S` is assignable to `T`
* A singleton type must also be single-valued
These tests found a few bugs so far:
- #14177
- #14195
- #14196
- #14210
- #14731
Some additional notes:
- Quickcheck-based property tests are non-deterministic and finding
counter-examples might take an arbitrary long time. This makes them bad
candidates for running in CI (for every PR). We can think of running
them in a cron-job way from time to time, similar to fuzzing. But for
now, it's only possible to run them locally (see instructions in source
code).
- Some tests currently find false positive "counterexamples" because our
understanding of equivalence of types is not yet complete. We do not
understand that `int | str` is the same as `str | int`, for example.
These tests are in a separate `property_tests::flaky` module.
- Properties can not be formulated in every way possible, due to the
fact that `is_disjoint_from` and `is_subtype_of` can produce false
negative answers.
- The current shrinking implementation is very naive, which leads to
counterexamples that are very long (`str & Any & ~tuple[Any] &
~tuple[Unknown] & ~Literal[""] & ~Literal["a"] | str & int & ~tuple[Any]
& ~tuple[Unknown]`), requiring the developer to simplify manually. It
has not been a major issue so far, but there is a comment in the code
how this can be improved.
- The tests are currently implemented using a macro. This is a single
commit on top which can easily be reverted, if we prefer the plain code
instead. With the macro:
```rs
// `S <: T` implies that `S` can be assigned to `T`.
type_property_test!(
subtype_of_implies_assignable_to, db,
forall types s, t. s.is_subtype_of(db, t) => s.is_assignable_to(db, t)
);
```
without the macro:
```rs
/// `S <: T` implies that `S` can be assigned to `T`.
#[quickcheck]
fn subtype_of_implies_assignable_to(s: Ty, t: Ty) -> bool {
let db = get_cached_db();
let s = s.into_type(&db);
let t = t.into_type(&db);
!s.is_subtype_of(&*db, t) || s.is_assignable_to(&*db, t)
}
```
## Test Plan
```bash
while cargo test --release -p red_knot_python_semantic --features property_tests types::property_tests; do :; done
```
## Summary
`KnownInstance::instance_fallback` may return instances of supertypes.
For example, it returns an instance of `_SpecialForm` for `Literal`.
This means it can't be used on the right-hand side of `is_subtype_of`
relationships, because it might lead to false positives.
I can lead to false negatives on the left hand side of `is_subtype_of`,
but this is at least a known limitation. False negatives are fine for
most applications, but false positives can lead to wrong results in
intersection-simplification, for example.
closes#14731
## Test Plan
Added regression test
## Summary
Simplify tuples containing `Never` to `Never`:
```py
from typing import Never
def never() -> Never: ...
reveal_type((1, never(), "foo")) # revealed: Never
```
I should note that mypy and pyright do *not* perform this
simplification. I don't know why.
There is [only one
place](5137fcc9c8/crates/red_knot_python_semantic/src/types/infer.rs (L1477-L1484))
where we use `TupleType::new` directly (instead of `Type::tuple`, which
changes behavior here). This appears when creating `TypeVar`
constraints, and it looks to me like it should stay this way, because
we're using `TupleType` to store a list of constraints there, instead of
an actual type. We also store `tuple[constraint1, constraint2, …]` as
the type for the `constraint1, constraint2, …` tuple expression. This
would mean that we infer a type of `tuple[str, Never]` for the following
type variable constraints, without simplifying it to `Never`. This seems
like a weird edge case that's maybe not worth looking further into?!
```py
from typing import Never
# vvvvvvvvvv
def f[T: (str, Never)](x: T):
pass
```
## Test Plan
- Added a new unit test. Did not add additional Markdown tests as that
seems superfluous.
- Tested the example above using red knot, mypy, pyright.
- Verified that this allows us to remove `contains_never` from the
property tests
(https://github.com/astral-sh/ruff/pull/14178#discussion_r1866473192)
This PR improves on #14477 by:
- Ensuring user's do not require the module alias "__debug__", which is unassignable
- Validating the linter settings for
`lint.flake8-import-conventions.extend-aliases` (whereas previously we
only did this for `lint.flake8-import-conventions.aliases`).
Closes#14662
Resolves https://github.com/astral-sh/ruff/issues/14547 by delegating
narrowing to `E` for `bool(E)` where `E` is some expression.
This change does not include other builtin class constructors which
should also work in this position, like `int(..)` or `float(..)`, as the
original issue does not mention these. It should be easy enough to add
checks for these as well if we want to.
I don't see a lot of markdown tests for malformed input, maybe there's a
better place for the no args and too many args cases to go?
I did see after the fact that it looks like this task was intended for a
new hire.. my apologies. I got here from
https://github.com/astral-sh/ruff/issues/13694, which is marked
help-wanted.
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
Seeing the fuzzing results from @dhruvmanila in #13778, I think we can
re-enable these tests. We also had one regression that would have been
caught by these tests, so there is some value in having them enabled.
## Summary
- Check if `hashlib` and `crypt` imports have been seen for `FURB181`
and `S324`
- Mark the fix for `FURB181` as safe: I think it was accidentally marked
as unsafe in the first place. The rule does not support user-defined
classes as the "fix safety" section suggests.
- Removed `hashlib._Hash`, as it's not part of the `hashlib` module.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
Updated the test snapshots
## Summary
Closes: https://github.com/astral-sh/ruff/issues/14593
The final type of a variable after if-statement without explicit else
branch should be similar to having an explicit else branch.
## Test Plan
Originally failed test cases from the bug are added.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
`bool()` is equal to `False`, and we infer `Literal[False]` for it. Which
means that the test here will fail as soon as we treat the body of
this `if` as unreachable.
## Summary
Make sure we run the tests for mdtest-only changes.
## Test Plan
Tested if positive glob patterns override negative patterns here:
https://codepen.io/mrmlnc/pen/OXQjMe
## Summary
This came up as part of #12927 when implementing
`SemanticModel::simulate_runtime_load`.
Should be fairly self-explanatory, if the scope returns a binding with
`BindingKind::Annotation` the bottom part of the loop gets skipped, so
there's no chance for `seen_function` to have been updated. So unless
there's something subtle going on here, like function scopes never
containing bindings with `BindingKind::Annotation`, this seems like a
bug.
## Test Plan
`cargo nextest run`
## Summary
Add social icons to the footer
`mkdocs-material` update is required for the `x-twitter` icon.
## Test Plan
Tested locally.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
This PR fixes a bug in the f-string formatting to not consider the
escaped newlines for `is_multiline`. This is done by checking if the
f-string is triple-quoted or not similar to normal string literals.
This is not required to be gated behind preview because the logic change
for `is_multiline` was added in
https://github.com/astral-sh/ruff/pull/14454.
## Test Plan
Add a test case which formats differently on `main`:
https://play.ruff.rs/ea3c55c2-f0fe-474e-b6b8-e3365e0ede5e
## Summary
This PR gets rid of the `requirements.in` and `requirements.txt` files
in the `scripts/fuzz-parser` directory, and replaces them with
`pyproject.toml` and `uv.lock` files. The script is renamed from
`fuzz-parser` to `py-fuzzer` (since it can now also be used to fuzz
red-knot as well as the parser, following
https://github.com/astral-sh/ruff/pull/14566), and moved from the
`scripts/` directory to the `python/` directory, since it's now a
(uv)-pip-installable project in its own right.
I've been resisting this for a while, because conceptually this script
just doesn't feel "complicated" enough to me for it to be a full-blown
package. However, I think it's time to do this. Making it a proper
package has several advantages:
- It means we can run it from the project root using `uv run` without
having to activate a virtual environment and ensure that all required
dependencies are installed into that environment
- Using a `pyproject.toml` file means that we can express that the
project requires Python 3.12+ to run properly; this wasn't possible
before
- I've been running mypy on the project locally when I've been working
on it or reviewing other people's PRs; now I can put the mypy config for
the project in the `pyproject.toml` file
## Test Plan
I manually tested that all the commands detailed in
`python/py-fuzzer/README.md` work for me locally.
---------
Co-authored-by: David Peter <sharkdp@users.noreply.github.com>
## Summary
fixes: #14608
The logic that was only applied for 3.12+ target version needs to be
applied for other versions as well.
## Test Plan
I've moved the existing test cases for 3.12 only to `f_string.py` so
that it's tested against the default target version.
I think we should probably enabled testing for two target version (pre
3.12 and 3.12) but it won't highlight any issue because the parser
doesn't consider this. Maybe we should enable this once we have target
version specific syntax errors in place
(https://github.com/astral-sh/ruff/issues/6591).
## Summary
Fix panics related to expressions without inferred types in invalid
syntax examples like:
```py
x: f"Literal[{1 + 2}]" = 3
```
where the `1 + 2` expression (and its sub-expressions) inside the
annotation did not have an inferred type.
## Test Plan
Added new corpus test.
## Summary
Remove entry that was prevously fixed in
5a30ec0df6.
## Test Plan
```sh
cargo test -p red_knot_workspace -- --ignored linter_af linter_gz
```
## Summary
This is about the easiest patch that I can think of. It has a drawback
in that there is no real guarantee this won't happen again. I think this
might be acceptable, given that all of this is a temporary thing.
And we also add a new CI job to prevent regressions like this in the
future.
For the record though, I'm listing alternative approaches I thought of:
- We could get rid of the debug/release distinction and just add `@Todo`
type metadata everywhere. This has possible affects on runtime. The main
reason I didn't follow through with this is that the size of `Type`
increases. We would either have to adapt the `assert_eq_size!` test or
get rid of it. Even if we add messages everywhere and get rid of the
file-and-line-variant in the enum, it's not enough to get back to the
current release-mode size of `Type`.
- We could generally discard `@Todo` meta information when using it in
tests. I think this would be a huge drawback. I like that we can have
the actual messages in the mdtest. And make sure we get the expected
`@Todo` type, not just any `@Todo`. It's also helpful when debugging
tests.
closes#14594
## Test Plan
```rs
cargo nextest run --release
```
## Summary
fixes: #13813
This PR fixes a bug in the formatting assignment statement when the
value is an f-string.
This is resolved by using custom best fit layouts if the f-string is (a)
not already a flat f-string (thus, cannot be multiline) and (b) is not a
multiline string (thus, cannot be flattened). So, it is used in cases
like the following:
```py
aaaaaaaaaaaaaaaaaa = f"testeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee{
expression}moreeeeeeeeeeeeeeeee"
```
Which is (a) `FStringLayout::Multiline` and (b) not a multiline.
There are various other examples in the PR diff along with additional
explanation and context as code comments.
## Test Plan
Add multiple test cases for various scenarios.
## Summary
This PR implements new rule discussed
[here](https://github.com/astral-sh/ruff/discussions/14449).
In short, it searches for assert messages which were unintentionally
used as a expression to be matched against.
## Test Plan
`cargo test` and review of `ruff-ecosystem`
Fix#14558
## Summary
- Add `typing.NoReturn` and `typing.Never` to known instances and infer
them as `Type::Never`
- Add `is_assignable_to` cases for `Type::Never`
I skipped emitting diagnostic for when a function is annotated as
`NoReturn` but it actually returns.
## Test Plan
Added tests from
https://github.com/python/typing/blob/main/conformance/tests/specialtypes_never.py
except from generics and checking if the return value of the function
and the annotations match.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Closes#14588
```py
x: Literal[42, "hello"] = 42 if bool_instance() else "hello"
reveal_type(x) # revealed: Literal[42] | Literal["hello"]
_ = ... if isinstance(x, str) else ...
# The `isinstance` test incorrectly narrows the type of `x`.
# As a result, `x` is revealed as Literal["hello"], but it should remain Literal[42, "hello"].
reveal_type(x) # revealed: Literal["hello"]
```
## Test Plan
mdtest included!
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This is just a small refactor to remove the `FormatFStringPart` as it's
only used in the case when the f-string is not implicitly concatenated
in which case the only part is going to be `FString`. In implicitly
concatenated f-strings, we use `StringLike` instead.
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fix#14525
## Test Plan
<!-- How was it tested? -->
New test cases
---------
Signed-off-by: harupy <hkawamura0130@gmail.com>
## Summary
Resolves#14289
The documentation for B028 no_explicit_stacklevel is updated to be more
clear.
---------
Co-authored-by: dylwil3 <dylwil3@gmail.com>
This PR adds a sometimes-available, safe autofix for [unraw-re-pattern
(RUF039)](https://docs.astral.sh/ruff/rules/unraw-re-pattern/#unraw-re-pattern-ruf039),
which prepends an `r` prefix. It is used only when the string in
question has no backslahses (and also does not have a `u` prefix, since
that causes a syntax error.)
Closes#14527
Notes:
- Test fixture unchanged, but snapshot changed to include fix messages.
- This fix is automatically only available in preview since the rule
itself is in preview
## Summary
This fix addresses panics related to invalid syntax like the following
where a `break` statement is used in a nested definition inside a
loop:
```py
while True:
def b():
x: int
break
```
closes#14342
## Test Plan
* New corpus regression tests.
* New unit test to make sure we handle nested while loops correctly.
This test is passing on `main`, but can easily fail if the
`is_inside_loop` state isn't properly saved/restored.
## Summary
Add support for (non-generic) type aliases. The main motivation behind
this was to get rid of panics involving expressions in (generic) type
aliases. But it turned out the best way to fix it was to implement
(partial) support for type aliases.
```py
type IntOrStr = int | str
reveal_type(IntOrStr) # revealed: typing.TypeAliasType
reveal_type(IntOrStr.__name__) # revealed: Literal["IntOrStr"]
x: IntOrStr = 1
reveal_type(x) # revealed: Literal[1]
def f() -> None:
reveal_type(x) # revealed: int | str
```
## Test Plan
- Updated corpus test allow list to reflect that we don't panic anymore.
- Added Markdown-based test for type aliases (`type_alias.md`)
## Summary
Fixes a panic related to sub-expressions of `typing.Union` where we fail
to store a type for the `int, str` tuple-expression in code like this:
```
x: Union[int, str] = 1
```
relates to [my
comment](https://github.com/astral-sh/ruff/pull/14499#discussion_r1851794467)
on #14499.
## Test Plan
New corpus test
## Summary
Adds meta information to `Type::Todo`, allowing developers to easily
trace back the origin of a particular `@Todo` type they encounter.
Instead of `Type::Todo`, we now write either `type_todo!()` which
creates a `@Todo[path/to/source.rs:123]` type with file and line
information, or using `type_todo!("PEP 604 unions not supported")`,
which creates a variant with a custom message.
`Type::Todo` now contains a `TodoType` field. In release mode, this is
just a zero-sized struct, in order not to create any overhead. In debug
mode, this is an `enum` that contains the meta information.
`Type` implements `Copy`, which means that `TodoType` also needs to be
copyable. This limits the design space. We could intern `TodoType`, but
I discarded this option, as it would require us to have access to the
salsa DB everywhere we want to use `Type::Todo`. And it would have made
the macro invocations less ergonomic (requiring us to pass `db`).
So for now, the meta information is simply a `&'static str` / `u32` for
the file/line variant, or a `&'static str` for the custom message.
Anything involving a chain/backtrace of several `@Todo`s or similar is
therefore currently not implemented. Also because we currently don't see
any direct use cases for this, and because all of this will eventually
go away.
Note that the size of `Type` increases from 16 to 24 bytes, but only in
debug mode.
## Test Plan
- Observed the changes in Markdown tests.
- Added custom messages for all `Type::Todo`s that were revealed in the
tests
- Ran red knot in release and debug mode on the following Python file:
```py
def f(x: int) -> int:
reveal_type(x)
```
Prints `@Todo` in release mode and `@Todo(function parameter type)` in
debug mode.
Fix#14498
## Summary
This PR adds `typing.Union` support
## Test Plan
I created new tests in mdtest.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
We should probably get rid of this entirely and subsume it's
functionality in the normal ecosystem checks? I don't think we're using
the black comparison tests anymore, but maybe someone wants it?
There are a few major parts to this:
1. Making the formatter script idempotent, so it can be run repeatedly
and is robust to changing commits
2. Reducing the overhead of the git operations, minimizing the data
transfer
3. Parallelizing all the git operations by repository
This reduces the setup time from 80s to 16s (locally).
The initial motivation for idempotency was to include the repositories
in the GitHub Actions cache. I'm not sure it's worth it yet — they're
about 1GB and would consume our limited cache space. Regardless, it
improves correctness for local invocations.
The total runtime of the job is reduced from ~4m to ~3m.
I also made some cosmetic changes to the output paths and such.
## Summary
- Expand some docs where they're unclear about the motivation, or assume
some knowledge that hasn't been introduced yet
- Add more links to external docs
- Rename PYI063 from `PrePep570PositionalArgument` to
`Pep484StylePositionalOnlyParameter`
- Rename the file `parenthesize_logical_operators.rs` to
`parenthesize_chained_operators.rs`, since the rule is called
`ParenthesizeChainedOperators`, not `ParenthesizeLogicalOperators`
## Test Plan
`cargo test`
## Summary
These rules were implemented in January, have been very stable, and have
no open issues about them. They were highly requested by the community
prior to being implemented. Let's stabilise them!
## Test Plan
Ecosystem check on this PR.
## Summary
Similar to https://github.com/astral-sh/uv/pull/9244, but we need to use
the `mkdocs.generated.yml` file because the `scripts/generate_mkdocs.py`
uses the `mkdocs.template.yml` to generate the final config.
This is one of the slowest remaining jobs in the pull request CI. We
could use a larger runner for a trivial speed-up (in exchange for $$),
but I don't think this is going to break often enough to merit testing
on every pull request commit? It's not a required job, so I don't feel
strongly about it, but it feels like a bit of a waste of compute.
Originally added in https://github.com/astral-sh/ruff/pull/11182
## Summary
closes#14279
### Limitations of the Current Implementation
#### Incorrect Error Propagation
In the current implementation of lexicographic comparisons, if the
result of an Eq operation is Ambiguous, the comparison stops
immediately, returning a bool instance. While this may yield correct
inferences, it fails to capture unsupported-operation errors that might
occur in subsequent comparisons.
```py
class A: ...
(int_instance(), A()) < (int_instance(), A()) # should error
```
#### Weak Inference in Specific Cases
> Example: `(int_instance(), "foo") == (int_instance(), "bar")`
> Current result: `bool`
> Expected result: `Literal[False]`
`Eq` and `NotEq` have unique behavior in lexicographic comparisons
compared to other operators. Specifically:
- For `Eq`, if any non-equal pair exists within the tuples being
compared, we can immediately conclude that the tuples are not equal.
- For `NotEq`, if any equal pair exists, we can conclude that the tuples
are unequal.
```py
a = (str_instance(), int_instance(), "foo")
reveal_type(a == a) # revealed: bool
reveal_type(a != a) # revealed: bool
b = (str_instance(), int_instance(), "bar")
reveal_type(a == b) # revealed: bool # should be Literal[False]
reveal_type(a != b) # revealed: bool # should be Literal[True]
```
#### Incorrect Support for Non-Boolean Rich Comparisons
In CPython, aside from `==` and `!=`, tuple comparisons return a
non-boolean result as-is. Tuples do not convert the value into `bool`.
Note: If all pairwise `==` comparisons between elements in the tuples
return Truthy, the comparison then considers the tuples' lengths.
Regardless of the return type of the dunder methods, the final result
can still be a boolean.
```py
from __future__ import annotations
class A:
def __eq__(self, o: object) -> str:
return "hello"
def __ne__(self, o: object) -> bytes:
return b"world"
def __lt__(self, o: A) -> float:
return 3.14
a = (A(), A())
reveal_type(a == a) # revealed: bool
reveal_type(a != a) # revealed: bool
reveal_type(a < a) # revealed: bool # should be: `float | Literal[False]`
```
### Key Changes
One of the major changes is that comparisons no longer end with a `bool`
result when a pairwise `Eq` result is `Ambiguous`. Instead, the function
attempts to infer all possible cases and unions the results. This
improvement allows for more robust type inference and better error
detection.
Additionally, as the function is now optimized for tuple comparisons,
the name has been changed from the more general
`infer_lexicographic_comparison` to `infer_tuple_rich_comparison`.
## Test Plan
mdtest included
Reduces Linux test CI to 1m 40s (16 core) or 2m 56s (8 core) to from 4m
25s. Times are approximate, as runner performance is pretty variable.
In uv, we use the 16 core runners.
## Summary
Previously, we panicked on expressions like `f"{v:{f'0.2f'}}"` because
we did not infer types for expressions nested inside format spec
elements.
## Test Plan
```
cargo nextest run -p red_knot_workspace -- --ignored linter_af linter_gz
```
## Summary
Add type narrowing for `type(x) is C` conditions (and `else` clauses of
`type(x) is not C` conditionals):
```py
if type(x) is A:
reveal_type(x) # revealed: A
else:
reveal_type(x) # revealed: A | B
```
closes: #14431, part of: #13694
## Test Plan
New Markdown-based tests.
## Summary
This patches up various missing paths where sub-expressions of type
annotations previously had no type attached. Examples include:
```py
tuple[int, str]
# ~~~~~~~~
type[MyClass]
# ~~~~~~~
Literal["foo"]
# ~~~~~
Literal["foo", Literal[1, 2]]
# ~~~~~~~~~~~~~
Literal[1, "a", random.illegal(sub[expr + ession])]
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
```
## Test Plan
```
cargo nextest run -p red_knot_workspace -- --ignored linter_af linter_gz
```
## Summary
Follow-up to #14371, this PR simplifies the visitor logic for list
expressions to remove the state management. We just need to make sure
that we visit the nested expressions using the `QuoteAnnotator` and not
the `Generator`. This is similar to what's being done for binary
expressions.
As per the
[grammar](https://typing.readthedocs.io/en/latest/spec/annotations.html#grammar-token-expression-grammar-annotation_expression),
list expressions can be present which can contain other type expressions
(`Callable`):
```
| <Callable> '[' <Concatenate> '[' (type_expression ',')+
(name | '...') ']' ',' type_expression ']'
(where name must be a valid in-scope ParamSpec)
| <Callable> '[' '[' maybe_unpacked (',' maybe_unpacked)*
']' ',' type_expression ']'
```
## Test Plan
`cargo insta test`
## Summary
Resolves#12616.
## Test Plan
`cargo nextest run` and `cargo insta test`.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Resolves#14378.
## Test Plan
`cargo nextest run` and `cargo insta test`.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Disable the no-panic tests for the linter corpus, as there are too many
problems right now, requiring linter-contributors to add their test
files to the allow-list.
We can still run the tests using `cargo test -p red_knot_workspace --
--ignored linter_af linter_gz`. This is also why I left the
`crates/ruff_linter/` entries in the allow list for now, even if they
will get out of sync. But let me know if I should rather remove them.
## Summary
Implements `redundant-bool-literal`
## Test Plan
<!-- How was it tested? -->
`cargo test`
The ecosystem results are all correct, but for `Airflow` the rule is not
relevant due to the use of overloading (and is marked as unsafe
correctly).
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
This PR splits the corpus tests into smaller chunks because running all
of them takes 8s on my windows machine and it's by far the longest test
in `red_knot_workspace`.
Splitting the tests has the advantage that they run in parallel. This PR
brings down the wall time from 8s to 4s.
This PR also limits the glob for the linter tests because it's common to
clone cpython into the `ruff_linter/resources/test` folder for
benchmarks (because that's what's written in the contributing guides)
## Test Plan
`cargo test`
## Summary
This PR adds autofix for `redundant-numeric-union` (`PYI041`)
There are some comments below to explain the reasoning behind some
choices that might help review.
<!-- What's the purpose of the change? What does it do, and why? -->
Resolves part of https://github.com/astral-sh/ruff/issues/14185.
## Test Plan
<!-- How was it tested? -->
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
This PR adds corrected handling of list expressions to the `Visitor`
implementation of `QuotedAnnotator` in `flake8_type_checking::helpers`.
Closes#14368
## Summary
- Add 383 files from `crates/ruff_python_parser/resources` to the test
corpus
- Add 1296 files from `crates/ruff_linter/resources` to the test corpus
- Use in-memory file system for tests
- Improve test isolation by cleaning the test environment between checks
- Add a mechanism for "known failures". Mark ~80 files as known
failures.
- The corpus test is now a lot slower (6 seconds).
Note:
While `red_knot` as a command line tool can run over all of these
files without panicking, we still have a lot of test failures caused by
explicitly "pulling" all types.
## Test Plan
Run `cargo test -p red_knot_workspace` while making sure that
- Introducing code that is known to lead to a panic fails the test
- Removing code that is known to lead to a panic from
`KNOWN_FAILURES`-files also fails the test
Fix: #13934
## Summary
Current implementation has a bug when the current annotation contains a
string with single and double quotes.
TL;DR: I think these cases happen less than other use cases of Literal.
So instead of fixing them we skip the fix in those cases.
One of the problematic cases:
```
from typing import Literal
from third_party import Type
def error(self, type1: Type[Literal["'"]]):
pass
```
The outcome is:
```
- def error(self, type1: Type[Literal["'"]]):
+ def error(self, type1: "Type[Literal[''']]"):
```
While it should be:
```
"Type[Literal['\'']"
```
The solution in this case is that we check if there’s any quotes same as
the quote style we want to use for this Literal parameter then escape
that same quote used in the string.
Also this case is not uncommon to have:
<https://grep.app/search?current=2&q=Literal["'>
But this can get more complicated for example in case of:
```
- def error(self, type1: Type[Literal["\'"]]):
+ def error(self, type1: "Type[Literal[''']]"):
```
Here we escaped the inner quote but in the generated annotation it gets
removed. Then we flip the quote style of the Literal paramter and the
formatting is wrong.
In this case the solution is more complicated.
1. When generating the string of the source code preserve the backslash.
2. After we have the annotation check if there isn’t any escaped quote
of the same type we want to use for the Literal parameter. In this case
check if we have any `’` without `\` before them. This can get more
complicated since there can be multiple backslashes so checking for only
`\’` won’t be enough.
Another problem is when the string contains `\n`. In case of
`Type[Literal["\n"]]` we generate `'Type[Literal["\n"]]'` and both
pyright and mypy reject this annotation.
https://pyright-play.net/?code=GYJw9gtgBALgngBwJYDsDmUkQWEMoAySMApiAIYA2AUAMaXkDOjUAKoiQNqsC6AXFAB0w6tQAmJYLBKMYAfQCOAVzCk5tMChjlUjOQCNytANaMGjABYAKRiUrAANLA4BGAQHJ2CLkVIVKnABEADoogTw87gCUfNRQ8VAITIyiElKksooqahpaOih6hiZmTNa29k7w3m5sHJy%2BZFRBoeE8MXEJScxAA
## Test Plan
I added test cases for the original code in the reported issue and two
more cases for backslash and new line.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
This PR fixes a bug in the Ruff language server where the
editor-specified configuration was resolved relative to the
configuration directory and not the current working directory.
The existing behavior is confusing given that this config file is
specified by the user and is not _discovered_ by Ruff itself. The
behavior of resolving this configuration file should be similar to that
of the `--config` flag on the command-line which uses the current
working directory:
3210f1a23b/crates/ruff/src/resolve.rs (L34-L48)
This creates problems where certain configuration options doesn't work
because the paths resolved in that case are relative to the
configuration directory and not the current working directory in which
the editor is expected to be in. For example, the
`lint.per-file-ignores` doesn't work as mentioned in the linked issue
along with `exclude`, `extend-exclude`, etc.
fixes: #14282
## Test Plan
Using the following directory tree structure:
```
.
├── .config
│ └── ruff.toml
└── src
└── migrations
└── versions
└── a.py
```
where, the `ruff.toml` is:
```toml
# 1. Comment this out to test `per-file-ignores`
extend-exclude = ["**/versions/*.py"]
[lint]
select = ["D"]
# 2. Comment this out to test `extend-exclude`
[lint.per-file-ignores]
"**/versions/*.py" = ["D"]
# 3. Comment both `per-file-ignores` and `extend-exclude` to test selection works
```
And, the content of `a.py`:
```py
"""Test"""
```
And, the VS Code settings:
```jsonc
{
"ruff.nativeServer": "on",
"ruff.path": ["/Users/dhruv/work/astral/ruff/target/debug/ruff"],
// For single-file mode where current working directory is `/`
// "ruff.configuration": "/tmp/ruff-repro/.config/ruff.toml",
// When a workspace is opened containing this path
"ruff.configuration": "./.config/ruff.toml",
"ruff.trace.server": "messages",
"ruff.logLevel": "trace"
}
```
I also tested out just opening the file in single-file mode where the
current working directory is `/` in VS Code. Here, the
`ruff.configuration` needs to be updated to use absolute path as shown
in the above VS Code settings.
## Summary
This PR adds support for parsing and inferring types within string
annotations.
### Implementation (attempt 1)
This is preserved in
6217f48924.
The implementation here would separate the inference of string
annotations in the deferred query. This requires the following:
* Two ways of evaluating the deferred definitions - lazily and eagerly.
* An eager evaluation occurs right outside the definition query which in
this case would be in `binding_ty` and `declaration_ty`.
* A lazy evaluation occurs on demand like using the
`definition_expression_ty` to determine the function return type and
class bases.
* The above point means that when trying to get the binding type for a
variable in an annotated assignment, the definition query won't include
the type. So, it'll require going through the deferred query to get the
type.
This has the following limitations:
* Nested string annotations, although not necessarily a useful feature,
is difficult to implement unless we convert the implementation in an
infinite loop
* Partial string annotations require complex layout because inferring
the types for stringified and non-stringified parts of the annotation
are done in separate queries. This means we need to maintain additional
information
### Implementation (attempt 2)
This is the final diff in this PR.
The implementation here does the complete inference of string annotation
in the same definition query by maintaining certain state while trying
to infer different parts of an expression and take decisions
accordingly. These are:
* Allow names that are part of a string annotation to not exists in the
symbol table. For example, in `x: "Foo"`, if the "Foo" symbol is not
defined then it won't exists in the symbol table even though it's being
used. This is an invariant which is being allowed only for symbols in a
string annotation.
* Similarly, lookup name is updated to do the same and if the symbol
doesn't exists, then it's not bounded.
* Store the final type of a string annotation on the string expression
itself and not for any of the sub-expressions that are created after
parsing. This is because those sub-expressions won't exists in the
semantic index.
Design document:
https://www.notion.so/astral-sh/String-Annotations-12148797e1ca801197a9f146641e5b71?pvs=4Closes: #13796
## Test Plan
* Add various test cases in our markdown framework
* Run `red_knot` on LibCST (contains a lot of string annotations,
specifically
https://github.com/Instagram/LibCST/blob/main/libcst/matchers/_matcher_base.py),
FastAPI (good amount of annotated code including `typing.Literal`) and
compare against the `main` branch output
## Summary
Add a typed representation of function signatures (parameters and return
type) and infer it correctly from a function.
Convert existing usage of function return types to use the signature
representation.
This does not yet add inferred types for parameters within function body
scopes based on the annotations, but it should be easy to add as a next
step.
Part of #14161 and #13693.
## Test Plan
Added tests.
Follow-up to #14287 : when checking that `name` is the same as `as_name`
in `import name as as_name`, we do not need to first do an early return
if `'.'` is found in `name`.
This PR handles a panic that occurs when applying unsafe fixes if a user
inserts a required import (I002) that has a "useless alias" in it, like
`import numpy as numpy`, and also selects PLC0414 (useless-import-alias)
In this case, the fixes alternate between adding the required import
statement, then removing the alias, until the recursion limit is
reached. See linked issue for an example.
Closes#14283
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
2 different fixers are available in ALE :
- ruff which runs `ruff check --fix` command (useful for example when
isort is enabled in lint config),
- ruff_format which runs `run format` command.
The documentation was missing `ruff` as a possible fixer in ALE.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
This fixes several panics related to invalid assignment targets. All of
these led to some a crash, previously:
```py
(x.y := 1) # only name-expressions are valid targets of named expressions
([x, y] := [1, 2]) # same
(x, y): tuple[int, int] = (2, 3) # tuples are not valid targets for annotated assignments
(x, y) += 2 # tuples are not valid targets for augmented assignments
```
closes#14321closes#14322
## Test Plan
I symlinked four files from `crates/ruff_python_parser/resources` into
the red knot corpus, as they seemed like ideal test files for this exact
scenario. I think eventually, it might be a good idea to simply include *all*
invalid-syntax examples from the parser tests into red knots corpus (I believe
we're actually not too far from that goal). Or expand the scope of the corpus
test to this directory. Then we can get rid of these symlinks again.
## Summary
This avoids a panic inside `TypeInferenceBuilder::infer_type_parameters`
when encountering generic type aliases:
```py
type ListOrSet[T] = list[T] | set[T]
```
To fix this properly, we would have to treat type aliases as being their own
annotation scope [1]. The left hand side is a definition for the type parameter
`T` which is being used in the special annotation scope on the right hand side.
Similar to how it works for generic functions and classes.
[1] https://docs.python.org/3/reference/compound_stmts.html#generic-type-aliasescloses#14307
## Test Plan
Added new example to the corpus.
When we look up the types of class bases or keywords (`metaclass`), we
currently do this little dance: if there are type params, then look up
the type using `SemanticModel` in the type-params scope, if not, look up
the type directly in the definition's own scope, with support for
deferred types.
With inference of function parameter types, I'm now adding another case
of this same dance, so I'm motivated to make it a bit more ergonomic.
Add support to `definition_expression_ty` to handle any sub-expression
of a definition, whether it is in the definition's own scope or in a
type-params sub-scope.
Related to both #13693 and #14161.
## Summary
Use the memory address to uniquely identify AST nodes, instead of
relying on source range and kind. The latter fails for ASTs resulting
from invalid syntax examples. See #14313 for details.
Also results in a 1-2% speedup
(https://codspeed.io/astral-sh/ruff/runs/67349cf55f36b36baa211360)
closes#14313
## Review
Here are the places where we use `NodeKey` directly or indirectly (via
`ExpressionNodeKey` or `DefinitionNodeKey`):
```rs
// semantic_index.rs
pub(crate) struct SemanticIndex<'db> {
// [...]
/// Map expressions to their corresponding scope.
scopes_by_expression: FxHashMap<ExpressionNodeKey, FileScopeId>,
/// Map from a node creating a definition to its definition.
definitions_by_node: FxHashMap<DefinitionNodeKey, Definition<'db>>,
/// Map from a standalone expression to its [`Expression`] ingredient.
expressions_by_node: FxHashMap<ExpressionNodeKey, Expression<'db>>,
// [...]
}
// semantic_index/builder.rs
pub(super) struct SemanticIndexBuilder<'db> {
// [...]
scopes_by_expression: FxHashMap<ExpressionNodeKey, FileScopeId>,
definitions_by_node: FxHashMap<ExpressionNodeKey, Definition<'db>>,
expressions_by_node: FxHashMap<ExpressionNodeKey, Expression<'db>>,
}
// semantic_index/ast_ids.rs
pub(crate) struct AstIds {
/// Maps expressions to their expression id.
expressions_map: FxHashMap<ExpressionNodeKey, ScopedExpressionId>,
/// Maps expressions which "use" a symbol (that is, [`ast::ExprName`]) to a use id.
uses_map: FxHashMap<ExpressionNodeKey, ScopedUseId>,
}
pub(super) struct AstIdsBuilder {
expressions_map: FxHashMap<ExpressionNodeKey, ScopedExpressionId>,
uses_map: FxHashMap<ExpressionNodeKey, ScopedUseId>,
}
```
## Test Plan
Added two failing examples to the corpus.
## Summary
Fixes a failing debug assertion that triggers for the following code:
```py
match some_int:
case x:=2:
pass
```
closes#14305
## Test Plan
Added problematic code example to corpus.
## Summary
Resolves#13217.
## Test Plan
`cargo nextest run` and `cargo insta test`.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
This PR improves the fix for `PYI055` to be able to handle nested and
mixed type unions.
It also marks the fix as unsafe when comments are present.
<!-- What's the purpose of the change? What does it do, and why? -->
## Test Plan
<!-- How was it tested? -->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
`pytest-raises-too-broad (PT011)` should be raised when
`expected_exception` is provided as a keyword argument.
```python
def test_foo():
with pytest.raises(ValueError): # raises PT011
raise ValueError("Can't divide 1 by 0")
# This is minor but a valid pytest.raises call
with pytest.raises(expected_exception=ValueError): # doesn't raise PT011 but should
raise ValueError("Can't divide 1 by 0")
```
`pytest.raises` doc:
https://docs.pytest.org/en/8.3.x/reference/reference.html#pytest.raises
## Test Plan
<!-- How was it tested? -->
Unit tests
Signed-off-by: harupy <hkawamura0130@gmail.com>
## Summary
- Emit diagnostics when looking up (possibly) unbound attributes
- More explicit test assertions for unbound symbols
- Review remaining call sites of `Symbol::ignore_possibly_unbound`. Most
of them are something like `builtins_symbol(self.db,
"Ellipsis").ignore_possibly_unbound().unwrap_or(Type::Unknown)` which
look okay to me, unless we want to emit additional diagnostics. There is
one additional case in enum literal handling, which has a TODO comment
anyway.
part of #14022
## Test Plan
New MD tests for (possibly) unbound attributes.
## Summary
This adds a new diagnostic when possibly unbound symbols are imported.
The `TODO` comment had a question mark, do I'm not sure if this is
really something that we want.
This does not touch the un*declared* case, yet.
relates to: #14022
## Test Plan
Updated already existing tests with new diagnostics
## Summary
Apart from one small functional change, this is mostly a refactoring of
the `Symbol` API:
- Rename `as_type` to the more explicit `ignore_possibly_unbound`, no
functional change
- Remove `unwrap_or_unknown` in favor of the more explicit
`.ignore_possibly_unbound().unwrap_or(Type::Unknown)`, no functional
change
- Consistently call it "possibly unbound" (not "may be unbound")
- Rename `replace_unbound_with` to `or_fall_back_to` and properly handle
boundness of the fall back. This is the only functional change (did not
have any impact on existing tests).
relates to: #14022
## Test Plan
New unit tests for `Symbol::or_fall_back_to`
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Related to #970. Implement [`shallow-copy-environ /
W1507`](https://pylint.readthedocs.io/en/stable/user_guide/messages/warning/shallow-copy-environ.html).
## Test Plan
<!-- How was it tested? -->
Unit test
---------
Co-authored-by: Simon Brugman <sbrugman@users.noreply.github.com>
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
The implicit namespace package rule currently fails to detect cases like
the following:
```text
foo/
├── __init__.py
└── bar/
└── baz/
└── __init__.py
```
The problem is that we detect a root at `foo`, and then an independent
root at `baz`. We _would_ detect that `bar` is an implicit namespace
package, but it doesn't contain any files! So we never check it, and
have no place to raise the diagnostic.
This PR adds detection for these kinds of nested packages, and augments
the `INP` rule to flag the `__init__.py` file above with a specialized
message. As a side effect, I've introduced a dedicated `PackageRoot`
struct which we can pass around in lieu of Yet Another `Path`.
For now, I'm only enabling this in preview (and the approach doesn't
affect any other rules). It's a bug fix, but it may end up expanding the
rule.
Closes https://github.com/astral-sh/ruff/issues/13519.
## Summary
It's only safe to enforce the `x in "1234567890"` case if `x` is exactly
one character, since the set on the right has been reordered as compared
to `string.digits`. We can't know if `x` is exactly one character unless
it's a literal. And if it's a literal, well, it's kind of silly code in
the first place?
Closes https://github.com/astral-sh/ruff/issues/13802.
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Fix `await-outside-async` to allow `await` at the top-level scope of a
notebook.
```python
# foo.ipynb
await asyncio.sleep(1) # should be allowed
```
## Test Plan
<!-- How was it tested? -->
A unit test
## Summary
Resolves#13833.
## Test Plan
`cargo nextest run` and `cargo insta test`.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
This PR accounts for further subtleties in `Decimal` parsing:
- Strings which are empty modulo underscores and surrounding whitespace
are skipped
- `Decimal("-0")` is skipped
- `Decimal("{integer literal that is longer than 640 digits}")` are
skipped (see linked issue for explanation)
NB: The snapshot did not need to be updated since the new test cases are
"Ok" instances and added below the diff.
Closes#14204
## Summary
Create definitions and infer types for PEP 695 type variables.
This just gives us the type of the type variable itself (the type of `T`
as a runtime object in the body of `def f[T](): ...`), with special
handling for its attributes `__name__`, `__bound__`, `__constraints__`,
and `__default__`. Mostly the support for these attributes exists
because it is easy to implement and allows testing that we are
internally representing the typevar correctly.
This PR doesn't yet have support for interpreting a typevar as a type
annotation, which is of course the primary use of a typevar. But the
information we store in the typevar's type in this PR gives us
everything we need to handle it correctly in a future PR when the
typevar appears in an annotation.
## Test Plan
Added mdtest.
## Summary
`Ty::BuiltinClassLiteral(…)` is a sub~~class~~type of
`Ty::BuiltinInstance("type")`, so it can't be disjoint from it.
## Test Plan
New `is_not_disjoint_from` test case
## Summary
Fix `Type::is_assignable_to` for union types on the left hand side (of
`.is_assignable_to`; or the right hand side of the `… = …` assignment):
`Literal[1, 2]` should be assignable to `int`.
## Test Plan
New unit tests that were previously failing.
## Summary
Minor fix to `Type::is_subtype_of` to make sure that Boolean literals
are subtypes of `int`, to match runtime semantics.
Found this while doing some property-testing experiments [1].
[1] https://github.com/astral-sh/ruff/pull/14178
## Test Plan
New unit test.
## Summary
Fixes#14114. I don't think I can really describe the problems with our
current architecture (and therefore the motivations for this PR) any
better than @carljm did in that issue, so I'll just copy it out here!
---
We currently represent "known instances" (e.g. special forms like
`typing.Literal`, which are an instance of `typing._SpecialForm`, but
need to be handled differently from other instances of
`typing._SpecialForm`) as an `InstanceType` with a `known` field that is
`Some(...)`.
This makes it easy to handle a known instance as if it were a regular
instance type (by ignoring the `known` field), and in some cases (e.g.
`Type::member`) that is correct and convenient. But in other cases (e.g.
`Type::is_equivalent_to`) it is not correct, and we currently have a bug
that we would consider the known-instance type of `typing.Literal` as
equivalent to the general instance type for `typing._SpecialForm`, and
we would fail to consider it a singleton type or a single-valued type
(even though it is both.)
An instance type with `known.is_some()` is semantically quite different
from an instance type with `known.is_none()`. The former is a singleton
type that represents exactly one runtime object; the latter is an open
type that represents many runtime objects, including instances of
unknown subclasses. It is too error-prone to represent these
very-different types as a single `Type` variant. We should instead
introduce a dedicated `Type::KnownInstance` variant and force ourselves
to handle these explicitly in all `Type` variant matches.
## Possible followups
There is still a little bit of awkwardness in our current design in some
places, in that we first infer the symbol `typing.Literal` as a
`_SpecialForm` instance, and then later convert that instance-type into
a known-instance-type. We could also use this `KnownInstanceType` enum
to account for other special runtime symbols such as `builtins.Ellipsis`
or `builtins.NotImplemented`.
I think these might be worth pursuing, but I didn't do them here as they
didn't seem essential right now, and I wanted to keep the diff
relatively minimal.
## Test Plan
`cargo test -p red_knot_python_semantic`. New unit tests added for
`Type::is_subtype_of`.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This adds type inference for comparison expressions involving
intersection types.
For example:
```py
x = get_random_int()
if x != 42:
reveal_type(x == 42) # revealed: Literal[False]
reveal_type(x == 43) # bool
```
closes#13854
## Test Plan
New Markdown-based tests.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
- Get rid of `Symbol::unwrap_or` (unclear semantics, not needed anymore)
- Introduce `Type::call_dunder`
- Emit new diagnostic for possibly-unbound `__iter__` methods
- Better diagnostics for callables with possibly-unbound /
possibly-non-callable `__call__` methods
part of: #14022closes#14016
## Test Plan
- Updated test for iterables with possibly-unbound `__iter__` methods.
- New tests for callables
## Summary
- Adds basic support for `type[C]` as a red knot `Type`. Some things
might not be supported yet, like `type[Any]`.
- Adds type narrowing for `issubclass` checks.
closes#14117
## Test Plan
New Markdown-based tests
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Implementation for one of the rules in
https://github.com/astral-sh/ruff/issues/1348
Refurb only deals only with classes with a single base, however the rule
is valid for any base.
(`str, Enum` is common prior to `StrEnum`)
## Test Plan
`cargo test`
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
Flake8-builtins provides two checks for arguments (really, parameters)
of a function shadowing builtins: A002 checks function definitions, and
A006 checks lambda expressions. This PR ensures that A002 is restricted
to functions rather than lambda expressions.
Closes#14135 .
## Summary
Related to
https://github.com/astral-sh/ruff/pull/13979#discussion_r1828305790,
this PR removes the `current_unpack` state field from
`SemanticIndexBuilder` and passes the `Unpack` ingredient via the
`CurrentAssignment` -> `DefinitionNodeRef` conversion to finally store
it on `DefintionNodeKind`.
This involves updating the lifetime of `AnyParameterRef` (parameter to
`declare_parameter`) to use the `'db` lifetime. Currently, all AST nodes
stored on various enums are marked with `'a` lifetime but they're always
utilized using the `'db` lifetime.
This also removes the dedicated `'a` lifetime parameter on
`add_definition` which is currently being used in `DefinitionNodeRef`.
As mentioned, all AST nodes live through the `'db` lifetime so we can
remove the `'a` lifetime parameter from that method and use the `'db`
lifetime instead.
FURB157 suggests replacing expressions like `Decimal("123")` with
`Decimal(123)`. This PR extends the rule to cover cases where the input
string to `Decimal` can be easily transformed into an integer literal.
For example:
```python
Decimal("1__000") # fix: `Decimal(1000)`
```
Note: we do not implement the full decimal parsing logic from CPython on
the grounds that certain acceptable string inputs to the `Decimal`
constructor may be presumed purposeful on the part of the developer. For
example, as in the linked issue, `Decimal("١٢٣")` is valid and equal to
`Decimal(123)`, but we do not suggest a replacement in this case.
Closes#13807
## Summary
- Store the expression type for annotations that are starred expressions
(see [discussion
here](https://github.com/astral-sh/ruff/pull/14091#discussion_r1828332857))
- Use `self.store_expression_type(…)` consistently throughout, as it
makes sure that no double-insertion errors occur.
closes#14115
## Test Plan
Added an invalid-syntax example to the corpus which leads to a panic on
`main`. Also added a Markdown test with a valid-syntax example that
would lead to a panic once we implement function parameter inference.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Adds more precise type inference for `… is …` and `… is not …` identity
checks in some limited cases where we statically know the answer to be
either `Literal[True]` or `Literal[False]`.
I found this helpful while working on type inference for comparisons
involving intersection types, but I'm not sure if this is at all useful
for real world code (where the answer is most probably *not* statically
known). Note that we already have *type narrowing* for identity tests.
So while we are already able to generate constraints for things like `if
x is None`, we can now — in some limited cases — make an even stronger
conclusion and infer that the test expression itself is `Literal[False]`
(branch never taken) or `Literal[True]` (branch always taken).
## Test Plan
New Markdown tests
Handling `Literal` type in annotations.
Resolves: #13672
## Implementation
Since Literals are not a fully defined type in typeshed. I used a trick
to figure out when a special form is a literal.
When we are inferring assignment types I am checking if the type of that
assignment was resolved to typing.SpecialForm and the name of the target
is `Literal` if that is the case then I am re creating a new instance
type and set the known instance field to `KnownInstance:Literal`.
**Why not defining a new type?**
From this [issue](https://github.com/python/typeshed/issues/6219) I
learned that we want to resolve members to SpecialMethod class. So if we
create a new instance here we can rely on the member resolving in that
already exists.
## Tests
https://typing.readthedocs.io/en/latest/spec/literal.html#equivalence-of-two-literals
Since the type of the value inside Literal is evaluated as a
Literal(LiteralString, LiteralInt, ...) then the equality is only true
when types and value are equal.
https://typing.readthedocs.io/en/latest/spec/literal.html#legal-and-illegal-parameterizations
The illegal parameterizations are mostly implemented I'm currently
checking the slice expression and the slice type to make sure it's
valid.
https://typing.readthedocs.io/en/latest/spec/literal.html#shortening-unions-of-literals
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR enables red-knot to support type narrowing based on `and` and
`or` conditionals, including nested combinations and their negation (for
`elif` / `else` blocks and for `not` operator). Part of #13694.
In order to address this properly (hopefully 😅), I had to run
`NarrowingConstraintsBuilder` functions recursively. In the first commit
I introduced a minor refactor - instead of mutating `self.constraints`,
the new constraints are now returned as function return values. I also
modified the constraints map to be optional, preventing unnecessary
hashmap allocations.
Thanks @carljm for your support on this :)
The second commit contains the logic and tests for handling boolean ops,
with improvements to intersections handling in `is_subtype_of` .
As I'm still new to Rust and the internals of type checkers, I’d be more
than happy to hear any insights or suggestions.
Thank you!
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Encountered this while running red-knot benchmarks on the `black`
codebase.
Fixes two of the issues in #13478.
## Test Plan
Added a regression test.
## Summary
Removes `Type::None` in favor of `KnownClass::NoneType.to_instance(…)`.
closes#13670
## Performance
There is a -4% performance regression on our red-knot benchmark. This is due to the fact that we now have to import `_typeshed` as a module, and infer types.
## Test Plan
Existing tests pass.
## Summary
This PR adds a new salsa query and an ingredient to resolve all the
variables involved in an unpacking assignment like `(a, b) = (1, 2)` at
once. Previously, we'd recursively try to match the correct type for
each definition individually which will result in creating duplicate
diagnostics.
This PR still doesn't solve the duplicate diagnostics issue because that
requires a different solution like using salsa accumulator or
de-duplicating the diagnostics manually.
Related: #13773
## Test Plan
Make sure that all unpack assignment test cases pass, there are no
panics in the corpus tests.
## Todo
- [x] Look at the performance regression
## Summary
The `commented-out-code` rule (ERA001) from `eradicate` is currently
flagging a very common idiom that marks Python strings as another
language, to help with syntax highlighting:

This PR adds this idiom to the list of allowed exceptions to the rule.
## Test Plan
I've added some additional test cases.
## Summary
Like https://github.com/astral-sh/ruff/pull/14063, but ensures that we
catch cases like `{1, True}` in which the items hash to the same value
despite not being identical.
## Summary
Removing more TODOs from the augmented assignment test suite. Now, if
the _target_ is a union, we correctly infer the union of results:
```python
if flag:
f = Foo()
else:
f = 42.0
f += 12
```
## Summary
One of the follow-ups from augmented assignment inference, now that
`Type::Unbound` has been removed.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR updates the metadata in the YAML frontmatter of the mkdocs
documentation to include the rule short code as a tag, so it can be
easily searched.
Ref: #13684
## Test Plan
<!-- How was it tested? -->
This has been tested locally using the documentation provided
[here](https://docs.astral.sh/ruff/contributing/#mkdocs) for generating
docs.
This generates docs that now have the tags section:
```markdown
---
description: Checks for abstract classes without abstract methods.
tags:
- B024
---
# abstract-base-class-without-abstract-method (B024)
... trimmed
```
I've also verified that this gives the ability to get straight to the
page via search when serving mkdocs locally.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
- Remove `Type::Unbound`
- Handle (potential) unboundness as a concept orthogonal to the type
system (see new `Symbol` type)
- Improve existing and add new diagnostics related to (potential)
unboundness
closes#13671
## Test Plan
- Update existing markdown-based tests
- Add new tests for added/modified functionality
## Summary
This PR fixes a panic which can occur in an unpack assignment when:
* (number of target expressions) - (number of tuple types) > 2
* There's a starred expression
The reason being that the `insert` panics because the index is greater
than the length.
This is an error case and so practically it should occur very rarely.
The solution is to resize the types vector to match the number of
expressions and then insert the starred expression type.
## Test Plan
Add a new test case.
## Summary
This PR creates a new `TypeCheckDiagnosticsBuilder` for the
`TypeCheckDiagnostics` struct. The main motivation behind this is to
separate the helpers required to build the diagnostics from the type
inference builder itself. This allows us to use such helpers outside of
the inference builder like for example in the unpacking logic in
https://github.com/astral-sh/ruff/pull/13979.
## Test Plan
`cargo insta test`
## Summary
These cases aren't handled correctly yet -- some of them are waiting on
refactors to `Unbound` before fixing. Part of #12699.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
I noticed that augmented assignments on floats were yielding "not
supported" diagnostics. If the dunder isn't bound at all, we should use
binary operator semantics, rather than treating it as not-callable.
## Summary
Minor follow-up to #13917 — thanks @AlexWaygood for the post-merge
review.
- Add
SliceLiteralType::as_tuple
- Use .expect() instead of SAFETY
comment
- Match on ::try_from
result
- Add TODO comment regarding raising a diagnostic for `"foo"["bar":"baz"]`
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Changes in this PR https://github.com/astral-sh/ruff/pull/13591 did not
allow correct discovery in pip build environments.
```python
# both of these variables are tuple[str, str] (length is 2)
first, second = os.path.split(paths[0]), os.path.split(paths[1])
# so these length checks are guaranteed to fail even for build environment folders
if (
len(first) >= 3
and len(second) >= 3
...
)
```
~~Here we instead use `pathlib`, and we check all `pip-build-env-` paths
for the folder that is expected to contain the `ruff` executable.~~
Here we update the logic to more properly split out the path components
that we use for `pip-build-env-` inspection.
## Test Plan
I've checked this manually against a workflow that was failing, I'm not
sure what to do for real tests. The same issues apply as with the
previous PR.
---------
Co-authored-by: Jonathan Surany <jsurany@bloomberg.net>
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
This PR adds support for heterogenous `tuple` annotations to red-knot.
It does the following:
- Extends `infer_type_expression` so that it understands tuple
annotations
- Changes `infer_type_expression` so that `ExprStarred` nodes in type
annotations are inferred as `Todo` rather than `Unknown` (they're valid
in PEP-646 tuple annotations)
- Extends `Type::is_subtype_of` to understand when one heterogenous
tuple type can be understood to be a subtype of another (without this
change, the PR would have introduced new false-positive errors to some
existing mdtests).
## Summary
- Add a new `Type::SliceLiteral` variant
- Infer `SliceLiteral` types for slice expressions, such as
`<int-literal>:<int-literal>:<int-literal>`.
- Infer "sliced" literal types for subscript expressions using slices,
such as `<string-literal>[<slice-literal>]`.
- Infer types for expressions involving slices of tuples:
`<tuple>[<slice-literal>]`.
closes#13853
## Test Plan
- Unit tests for indexing/slicing utility functions
- Markdown-based tests for
- Subscript expressions `tuple[slice]`
- Subscript expressions `string_literal[slice]`
- Subscript expressions `bytes_literal[slice]`
## Summary
This does two things:
- distribute negated intersections when building up intersections (i.e.
going from `A & ~(B & C)` to `(A & ~B) | (A & ~C)`) (fixing #13931)
## Test Plan
`cargo test`
## Summary
This PR adds type narrowing in `and` and `or` expressions, for example:
```py
class A: ...
x: A | None = A() if bool_instance() else None
isinstance(x, A) or reveal_type(x) # revealed: None
```
## Test Plan
New mdtests 😍
## Summary
After #13918 has landed, narrowing constraint negation became easy, so
adding support for `not` operator.
## Test Plan
Added a new mdtest file for `not` expression.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
As python uses short-circuiting boolean operations in runtime, we should
mimic that logic in redknot as well.
For example, we should detect that in the following code `x` might be
undefined inside the block:
```py
if flag or (x := 1):
print(x)
```
## Test Plan
Added mdtest suit for boolean expressions.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Add support for type narrowing in elif and else scopes as part of
#13694.
## Test Plan
- mdtest
- builder unit test for union negation.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Previously, this would fail with
```
AttributeError: 'str' object has no attribute 'is_file'
```
if I tried to use the `--knot-path` option. I wish we had a type checker
for Python*.
## Test Plan
```sh
uv run benchmark --knot-path ~/.cargo-target/release/red_knot
```
\* to be fair, this would probably require special handling for
`argparse` in the typechecker.
## Summary
`ruff check` has not been the default in a long time. However, the help
message and code comment still designate it as the default. The remark
should have been removed in the deprecation PR #10169.
## Test Plan
Not tested.
## Summary
Add type narrowing for `isinstance(object, classinfo)` [1] checks:
```py
x = 1 if flag else "a"
if isinstance(x, int):
reveal_type(x) # revealed: Literal[1]
```
closes#13893
[1] https://docs.python.org/3/library/functions.html#isinstance
## Test Plan
New Markdown-based tests in `narrow/isinstance.md`.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR updates the fix generation logic for auto-quoting an annotation
to generate an edit even when there's a quote character present.
The logic uses the visitor pattern, maintaining it's state on where it
is and generating the string value one node at a time. This can be
considered as a specialized form of `Generator`. The state required to
maintain is whether we're currently inside a `typing.Literal` or
`typing.Annotated` because the string value in those types should not be
un-quoted i.e., `Generic[Literal["int"]]` should become
`"Generic[Literal['int']]`, the quotes inside the `Literal` should be
preserved.
Fixes: https://github.com/astral-sh/ruff/issues/9137
## Test Plan
Add various test cases to validate this change, validate the snapshots.
There are no ecosystem changes to go through.
---------
Signed-off-by: Shaygan <hey@glyphack.com>
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
A minor quality-of-life improvement: add
[`#[track_caller]`](https://doc.rust-lang.org/reference/attributes/codegen.html#the-track_caller-attribute)
attribute to `Type::expect_xyz()` methods and some `TypeInference` methods such that the panic-location
is reported one level higher up in the stack trace.
before: reports location inside the `Type::expect_class_literal()`
method. Not very useful.
```
thread 'types::infer::tests::deferred_annotation_builtin' panicked at crates/red_knot_python_semantic/src/types.rs:304:14:
Expected a Type::ClassLiteral variant
```
after: reports location at the `Type::expect_class_literal()` call site,
where the error was made.
```
thread 'types::infer::tests::deferred_annotation_builtin' panicked at crates/red_knot_python_semantic/src/types/infer.rs:4302:14:
Expected a Type::ClassLiteral variant
```
## Test Plan
Called `expect_class_literal()` on something that's not a
`Type::ClassLiteral` and saw that the error was reported at the call
site.
## Summary
* Rename `Type::Class` => `Type::ClassLiteral`
* Rename `Type::Function` => `Type::FunctionLiteral`
* Do not rename `Type::Module`
* Remove `*Literal` suffixes in `display::LiteralTypeKind` variants, as
per clippy suggestion
* Get rid of `Type::is_class()` in favor of `is_subtype_of(…, 'type')`;
modifiy `is_subtype_of` to support this.
* Add new `Type::is_xyz()` methods and use them instead of matching on
`Type` variants.
closes#13863
## Test Plan
New `is_subtype_of_class_literals` unit test.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
- Properly treat the empty intersection as being of type `object`.
- Consequently, change the simplification method to explicitly add
`Never` to the positive side of the intersection when collapsing a type
such as `int & str` to `Never`, as opposed to just clearing both the
positive and the negative side.
- Minor code improvement in `bindings_ty`: use `peekable()` to check
whether the iterator over constraints is empty, instead of handling
first and subsequent elements separately.
fixes#13870
## Test Plan
- New unit tests for `IntersectionBuilder` to make sure the empty
intersection represents `object`.
- Markdown-based regression test for the original issue in #13870
## Summary
This PR updates `ruff` to match `uv` updated [docker releases
approach](https://github.com/astral-sh/uv/blob/main/.github/workflows/build-docker.yml).
It's a combined PR with changes from these PR's
* https://github.com/astral-sh/uv/pull/6053
* https://github.com/astral-sh/uv/pull/6556
* https://github.com/astral-sh/uv/pull/6734
* https://github.com/astral-sh/uv/pull/7568
Summary of changes / features
1. This change would publish an additional tags that includes only
`major.minor`.
For a release with `x.y.z`, this would publish the tags:
* ghcr.io/astral-sh/ruff:latest
* ghcr.io/astral-sh/ruff:x.y.z
* ghcr.io/astral-sh/ruff:x.y
2. Parallelizes multi-platform builds using multiple workers (hence the
new docker-build / docker-publish jobs), which cuts docker releases time
in half.
3. This PR introduces additional images with the ruff binaries from
scratch for both amd64/arm64 and makes the mapping easy to configure by
generating the Dockerfile on the fly. This approach focuses on
minimizing CI time by taking advantage of dedicating a worker per
mapping (20-30s~ per job). For example, on release `x.y.z`, this will
publish the following image tags with format
`ghcr.io/astral-sh/ruff:{tag}` with manifests for both amd64/arm64. This
also include `x.y` tags for each respective additional tag. Note, this
version does not include the python based images, unlike `uv`.
* From **scratch**: `latest`, `x.y.z`, `x.y` (currently being published)
* From **alpine:3.20**: `alpine`, `alpine3.20`, `x.y.z-alpine`,
`x.y.z-alpine3.20`
* From **debian:bookworm-slim**: `debian-slim`, `bookworm-slim`,
`x.y.z-debian-slim`, `x.y.z-bookworm-slim`
* From **buildpack-deps:bookworm**: `debian`, `bookworm`,
`x.y.z-debian`, `x.y.z-bookworm`
4. This PR also fixes `org.opencontainers.image.version` for all tags
(including the one from `scratch`) to contain the right release version
instead of branch name `main` (current behavior).
```
> docker inspect ghcr.io/astral-sh/ruff:0.6.4 | jq -r
'.[0].Config.Labels'
{
...
"org.opencontainers.image.version": "main"
}
```
Closes https://github.com/astral-sh/ruff/issues/13481
## Test Plan
Approach mimics `uv` with almost no changes so risk is low but I still
tested the full workflow.
* I have a working CI release pipeline on my fork run
https://github.com/samypr100/ruff/actions/runs/10966657733
* The resulting images were published to
https://github.com/samypr100/ruff/pkgs/container/ruff
Add the following subtype relations:
- `BooleanLiteral <: object`
- `IntLiteral <: object`
- `StringLiteral <: object`
- `LiteralString <: object`
- `BytesLiteral <: object`
Added a test case for `bool <: int`.
## Test Plan
New unit tests.
Add type narrowing for `!=` expression as stated in
#13694.
### Test Plan
Add tests in new md format.
---------
Co-authored-by: David Peter <mail@david-peter.de>
## Summary
A small fix for comparisons of multiple comparators.
Instead of comparing each comparator to the leftmost item, we should
compare it to the closest item on the left.
While implementing this, I noticed that we don’t yet narrow Yoda
comparisons (e.g., `True is x`), so I didn’t change that behavior in
this PR.
## Test Plan
Added some mdtests 🎉
## Summary
Just a drive-by change that occurred to me while I was looking at
`Type::is_subtype_of`: the existing pattern for unions on the *right
hand side*:
```rs
(ty, Type::Union(union)) => union
.elements(db)
.iter()
.any(|&elem_ty| ty.is_subtype_of(db, elem_ty)),
```
is not (generally) correct if the *left hand side* is a union.
## Test Plan
Added new test cases for `is_subtype_of` and `!is_subtype_of`
## Summary
- Consistent naming: `BoolLiteral` => `BooleanLiteral` (it's mainly the
`Ty::BoolLiteral` variant that was renamed)
I tripped over this a few times now, so I thought I'll smooth it out.
- Add a new test case for `Literal[True] <: bool`, as suggested here:
https://github.com/astral-sh/ruff/pull/13781#discussion_r1804922827
Remove unnecessary uses of `.as_ref()`, `.iter()`, `&**` and similar, mostly in situations when iterating over variables. Many of these changes are only possible following #13826, when we bumped our MSRV to 1.80: several useful implementations on `&Box<[T]>` were only stabilised in Rust 1.80. Some of these changes we could have done earlier, however.
Implemented some points from
https://github.com/astral-sh/ruff/issues/12701
- Handle Unknown and Any in Unary operation
- Handle Boolean in binary operations
- Handle instances in unary operation
- Consider division by False to be division by zero
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
- Refactored comparison type inference functions in `infer.rs`: Changed
the return type from `Option` to `Result` to lay the groundwork for
providing more detailed diagnostics.
- Updated diagnostic messages.
This is a small step toward improving diagnostics in the future.
Please refer to #13787
## Test Plan
mdtest included!
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This fixes an edge case that @carljm and I missed when implementing
https://github.com/astral-sh/ruff/pull/13800. Namely, if the left-hand
operand is the _exact same type_ as the right-hand operand, the
reflected dunder on the right-hand operand is never tried:
```pycon
>>> class Foo:
... def __radd__(self, other):
... return 42
...
>>> Foo() + Foo()
Traceback (most recent call last):
File "<python-input-1>", line 1, in <module>
Foo() + Foo()
~~~~~~^~~~~~~
TypeError: unsupported operand type(s) for +: 'Foo' and 'Foo'
```
This edge case _is_ covered in Brett's blog at
https://snarky.ca/unravelling-binary-arithmetic-operations-in-python/,
but I missed it amongst all the other subtleties of this algorithm. The
motivations and history behind it were discussed in
https://mail.python.org/archives/list/python-dev@python.org/thread/7NZUCODEAPQFMRFXYRMGJXDSIS3WJYIV/
## Test Plan
I added an mdtest for this cornercase.
## Summary
- Add `Type::is_disjoint_from` as a way to test whether two types
overlap
- Add a first set of simplification rules for intersection types
- `S & T = S` for `S <: T`
- `S & ~T = Never` for `S <: T`
- `~S & ~T = ~T` for `S <: T`
- `A & ~B = A` for `A` disjoint from `B`
- `A & B = Never` for `A` disjoint from `B`
- `bool & ~Literal[bool] = Literal[!bool]`
resolves one item in #12694
## Open questions:
- Can we somehow leverage the (anti) symmetry between `positive` and
`negative` contributions? I could imagine that there would be a way if
we had `Type::Not(type)`/`Type::Negative(type)`, but with the
`positive`/`negative` architecture, I'm not sure. Note that there is a
certain duplication in the `add_positive`/`add_negative` functions (e.g.
`S & ~T = Never` is implemented twice), but other rules are actually not
perfectly symmetric: `S & T = S` vs `~S & ~T = ~T`.
- I'm not particularly proud of the way `add_positive`/`add_negative`
turned out. They are long imperative-style functions with some
mutability mixed in (`to_remove`). I'm happy to look into ways to
improve this code *if we decide to go with this approach* of
implementing a set of ad-hoc rules for simplification.
- ~~Is it useful to perform simplifications eagerly in
`add_positive`/`add_negative`? (@carljm)~~ This is what I did for now.
## Test Plan
- Unit tests for `Type::is_disjoint_from`
- Observe changes in Markdown-based tests
- Unit tests for `IntersectionBuilder::build()`
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Minor cleanup and consistent formatting of the Markdown-based tests.
- Removed lots of unnecessary `a`, `b`, `c`, … variables.
- Moved test assertions (`# revealed:` comments) closer to the tested
object.
- Always separate `# revealed` and `# error` comments from the code by
two spaces, according to the discussion
[here](https://github.com/astral-sh/ruff/pull/13746/files#r1799385758).
This trades readability for consistency in some cases.
- Fixed some headings
## Summary
This pull request resolves some rule thrashing identified in #12427 by
allowing for unused arguments when using `NotImplementedError` with a
variable per [this
comment](https://github.com/astral-sh/ruff/issues/12427#issuecomment-2384727468).
**Note**
This feels a little heavy-handed / edge-case-prone. So, to be clear, I'm
happy to scrap this code and just update the docs to communicate that
`abstractmethod` and friends should be used in this scenario (or
similar). Just let me know what you'd like done!
fixes: #12427
## Test Plan
I added a test-case to the existing `ARG.py` file and ran...
```sh
cargo run -p ruff -- check crates/ruff_linter/resources/test/fixtures/flake8_unused_arguments/ARG.py --no-cache --preview --select ARG002
```
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
This PR updates the language server to avoid indexing the workspace for
single-file mode.
**What's a single-file mode?**
When a user opens the file directly in an editor, and not the folder
that represents the workspace, the editor usually can't determine the
workspace root. This means that during initializing the server, the
`workspaceFolders` field will be empty / nil.
Now, in this case, the server defaults to using the current working
directory which is a reasonable default assuming that the directory
would point to the one where this open file is present. This would allow
the server to index the directory itself for any config file, if
present.
It turns out that in VS Code the current working directory in the above
scenario is the system root directory `/` and so the server will try to
index the entire root directory which would take a lot of time. This is
the issue as described in
https://github.com/astral-sh/ruff-vscode/issues/627. To reproduce, refer
https://github.com/astral-sh/ruff-vscode/issues/627#issuecomment-2401440767.
This PR updates the indexer to avoid traversing the workspace to read
any config file that might be present. The first commit
(8dd2a31eef)
refactors the initialization and introduces two structs `Workspaces` and
`Workspace`. The latter struct includes a field to determine whether
it's the default workspace. The second commit
(61fc39bdb6)
utilizes this field to avoid traversing.
Closes: #11366
## Editor behavior
This is to document the behavior as seen in different editors. The test
scenario used has the following directory tree structure:
```
.
├── nested
│ ├── nested.py
│ └── pyproject.toml
└── test.py
```
where, the contents of the files are:
**test.py**
```py
import os
```
**nested/nested.py**
```py
import os
import math
```
**nested/pyproject.toml**
```toml
[tool.ruff.lint]
select = ["I"]
```
Steps:
1. Open `test.py` directly in the editor
2. Validate that it raises the `F401` violation
3. Open `nested/nested.py` in the same editor instance
4. This file would raise only `I001` if the `nested/pyproject.toml` was
indexed
### VS Code
When (1) is done from above, the current working directory is `/` which
means the server will try to index the entire system to build up the
settings index. This will include the `nested/pyproject.toml` file as
well. This leads to bad user experience because the user would need to
wait for minutes for the server to finish indexing.
This PR avoids that by not traversing the workspace directory in
single-file mode. But, in VS Code, this means that per (4), the file
wouldn't raise `I001` but only raise two `F401` violations because the
`nested/pyproject.toml` was never resolved.
One solution here would be to fix this in the extension itself where we
would detect this scenario and pass in the workspace directory that is
the one containing this open file in (1) above.
### Neovim
**tl;dr** it works as expected because the client considers the presence
of certain files (depending on the server) as the root of the workspace.
For Ruff, they are `pyproject.toml`, `ruff.toml`, and `.ruff.toml`. This
means that the client notifies us as the user moves between single-file
mode and workspace mode.
https://github.com/astral-sh/ruff/pull/13770#issuecomment-2416608055
### Helix
Same as Neovim, additional context in
https://github.com/astral-sh/ruff/pull/13770#issuecomment-2417362097
### Sublime Text
**tl;dr** It works similar to VS Code except that the current working
directory of the current process is different and thus the config file
is never read. So, the behavior remains unchanged with this PR.
https://github.com/astral-sh/ruff/pull/13770#issuecomment-2417362097
### Zed
Zed seems to be starting a separate language server instance for each
file when the editor is running in a single-file mode even though all
files have been opened in a single editor instance.
(Separated the logs into sections separated by a single blank line
indicating 3 different server instances that the editor started for 3
files.)
```
0.000053375s INFO main ruff_server::server: No workspace settings found for file:///Users/dhruv/projects/ruff-temp, using default settings
0.009448792s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/projects/ruff-temp
0.009906334s DEBUG ruff:main ruff_server::resolve: Included path via `include`: /Users/dhruv/projects/ruff-temp/test.py
0.011775917s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
0.000060583s INFO main ruff_server::server: No workspace settings found for file:///Users/dhruv/projects/ruff-temp/nested, using default settings
0.010387125s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/projects/ruff-temp/nested
0.011061875s DEBUG ruff:main ruff_server::resolve: Included path via `include`: /Users/dhruv/projects/ruff-temp/nested/nested.py
0.011545208s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
0.000059125s INFO main ruff_server::server: No workspace settings found for file:///Users/dhruv/projects/ruff-temp/nested, using default settings
0.010857583s INFO main ruff_server::session::index: Registering workspace: /Users/dhruv/projects/ruff-temp/nested
0.011428958s DEBUG ruff:main ruff_server::resolve: Included path via `include`: /Users/dhruv/projects/ruff-temp/nested/other.py
0.011893792s INFO ruff:main ruff_server::server: Configuration file watcher successfully registered
```
## Test Plan
When using the `ruff` server from this PR, we see that the server starts
quickly as seen in the logs. Next, when I switch to the release binary,
it starts indexing the root directory.
For more details, refer to the "Editor Behavior" section above.
Summary
---------
PEP 695 Generics introduce a scope inside a class statement's arguments
and keywords.
```
class C[T](A[T]): # the T in A[T] is not from the global scope but from a type-param-specfic scope
...
```
When doing inference on the class bases, we currently have been doing
base class expression lookups in the global scope. Not an issue without
generics (since a scope is only created when generics are present).
This change instead makes sure to stop the global scope inference from
going into expressions within this sub-scope. Since there is a separate
scope, `check_file` and friends will trigger inference on these
expressions still.
Another change as a part of this is making sure that `ClassType` looks
up its bases in the right scope.
Test Plan
----------
`cargo test --package red_knot_python_semantic generics` will run the
markdown test that previously would panic due to scope lookup issues
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Carl Meyer <carl@astral.sh>
This reverts https://github.com/astral-sh/ruff/pull/13799, and restores
the previous behavior, which I think was the most pragmatic and useful
version of the divide-by-zero error, if we will emit it at all.
In general, a type checker _does_ emit diagnostics when it can detect
something that will definitely be a problem for some inhabitants of a
type, but not others. For example, `x.foo` if `x` is typed as `object`
is a type error, even though some inhabitants of the type `object` will
have a `foo` attribute! The correct fix is to make your type annotations
more precise, so that `x` is assigned a type which definitely has the
`foo` attribute.
If we will emit it divide-by-zero errors, it should follow the same
logic. Dividing an inhabitant of the type `int` by zero may not emit an
error, if the inhabitant is an instance of a subclass of `builtins.int`
that overrides division. But it may emit an error (more likely it will).
If you don't want the diagnostic, you can clarify your type annotations
to require an instance of your safe subclass.
Because the Python type system doesn't have the ability to explicitly
reflect the fact that divide-by-zero is an error in type annotations
(e.g. for `int.__truediv__`), or conversely to declare a type as safe
from divide-by-zero, or include a "nonzero integer" type which it is
always safe to divide by, the analogy doesn't fully apply. You can't
explicitly mark your subclass of `int` as safe from divide-by-zero, we
just semi-arbitrarily choose to silence the diagnostic for subclasses,
to avoid false positives.
Also, if we fully followed the above logic, we'd have to error on every
`int / int` because the RHS `int` might be zero! But this would likely
cause too many false positives, because of the lack of a "nonzero
integer" type.
So this is just a pragmatic choice to emit the diagnostic when it is
very likely to be an error. It's unclear how useful this diagnostic is
in practice, but this version of it is at least very unlikely to cause
harm.
If the LHS is just `int` or `float` type, that type includes custom
subclasses which can arbitrarily override division behavior, so we
shouldn't emit a divide-by-zero error in those cases.
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Add type inference for comparisons involving union types. For example:
```py
one_or_two = 1 if flag else 2
reveal_type(one_or_two <= 2) # revealed: Literal[True]
reveal_type(one_or_two <= 1) # revealed: bool
reveal_type(one_or_two <= 0) # revealed: Literal[False]
```
closes#13779
## Test Plan
See `resources/mdtest/comparison/unions.md`
## Summary
Fixes the bug described in #13514 where an unbound public type defaulted
to the type or `Unknown`, whereas it should only be the type if unbound.
## Test Plan
Added a new test case
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This PR adds a debug assertion that asserts that `TypeInference::extend`
is only called on results that have the same scope.
This is critical because `expressions` uses `ScopedExpressionId` that
are local and merging expressions from different
scopes would lead to incorrect expression types.
We could consider storing `scope` only on `TypeInference` for debug
builds. Doing so has the advantage that the `TypeInference` type is
smaller of which we'll have many. However, a `ScopeId` is a `u32`... so
it shouldn't matter that much and it avoids storing the `scope` both on
`TypeInference` and `TypeInferenceBuilder`
## Test Plan
`cargo test`
## Summary
This PR implements comparisons for (tuple, tuple).
It will close#13688 and complete an item in #13618 once merged.
## Test Plan
Basic tests are included for (tuple, tuple) comparisons.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Just a small simplification to remove some unnecessary complexity here.
Rather than using separate branches for subscript expressions involving
boolean literals, we can simply convert them to integer literals and
reuse the logic in the `IntLiteral` branches.
## Test Plan
`cargo test -p red_knot_python_semantic`
## Summary
This PR adds support for unpacking tuple expression in an assignment
statement where the target expression can be a tuple or a list (the
allowed sequence targets).
The implementation introduces a new `infer_assignment_target` which can
then be used for other targets like the ones in for loops as well. This
delegates it to the `infer_definition`. The final implementation uses a
recursive function that visits the target expression in source order and
compares the variable node that corresponds to the definition. At the
same time, it keeps track of where it is on the assignment value type.
The logic also accounts for the number of elements on both sides such
that it matches even if there's a gap in between. For example, if
there's a starred expression like `(a, *b, c) = (1, 2, 3)`, then the
type of `a` will be `Literal[1]` and the type of `b` will be
`Literal[2]`.
There are a couple of follow-ups that can be done:
* Use this logic for other target positions like `for` loop
* Add diagnostics for mis-match length between LHS and RHS
## Test Plan
Add various test cases using the new markdown test framework.
Validate that existing test cases pass.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Porting infer tests to new markdown tests framework.
Link to the corresponding issue: #13696
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
- Fix a bug with `… is not …` type guards.
Previously, in an example like
```py
x = [1]
y = [1]
if x is not y:
reveal_type(x)
```
we would infer a type of `list[int] & ~list[int] == Never` for `x`
inside the conditional (instead of `list[int]`), since we built a
(negative) intersection with the type of the right hand side (`y`).
However, as this example shows, this assumption can only be made for
singleton types (types with a single inhabitant) such as `None`.
- Add support for `… is …` type guards.
closes#13715
## Test Plan
Moved existing `narrow_…` tests to Markdown-based tests and added new
ones (including a regression test for the bug described above). Note
that will create some conflicts with
https://github.com/astral-sh/ruff/pull/13719. I tried to establish the
correct organizational structure as proposed in
https://github.com/astral-sh/ruff/pull/13719#discussion_r1800188105
Address a potential point of confusion that bit a contributor in
https://github.com/astral-sh/ruff/pull/13719
Also remove a no-longer-accurate line about bare `error: ` assertions
(which are no longer allowed) and clarify another point about which
kinds of error assertions to use.
## Summary
Fixes#13708.
Silence `undefined-reveal` diagnostic on any line including a `#
revealed:` assertion.
Add more context to un-silenced `undefined-reveal` diagnostics in mdtest
test failures. This doesn't make the failure output less verbose, but it
hopefully clarifies the right fix for an `undefined-reveal` in mdtest,
while still making it clear what red-knot's normal diagnostic for this
looks like.
## Test Plan
Added and updated tests.
This adds documentation for the new test framework.
I also added documentation for the planned design of features we haven't
built yet (clearly marked as such), so that this doc can become the sole
source of truth for the test framework design (we don't need to refer
back to the original internal design document.)
Also fixes a few issues in the test framework implementation that were
discovered in writing up the docs.
---------
Co-authored-by: T-256 <132141463+T-256@users.noreply.github.com>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
Adds a markdown-based test framework for writing tests of type inference
and type checking. Fixes#11664.
Implements the basic required features. A markdown test file is a suite
of tests, each test can contain one or more Python files, with
optionally specified path/name. The test writes all files to an
in-memory file system, runs red-knot, and matches the resulting
diagnostics against `Type: ` and `Error: ` assertions embedded in the
Python source as comments.
We will want to add features like incremental tests, setting custom
configuration for tests, writing non-Python files, testing syntax
errors, capturing full diagnostic output, etc. There's also plenty of
room for improved UX (colored output?).
## Test Plan
Lots of tests!
Sample of the current output when a test fails:
```
Running tests/inference.rs (target/debug/deps/inference-7c96590aa84de2a4)
running 1 test
test inference::path_1_resources_inference_numbers_md ... FAILED
failures:
---- inference::path_1_resources_inference_numbers_md stdout ----
inference/numbers.md - Numbers - Floats
/src/test.py
line 2: unexpected error: [invalid-assignment] "Object of type `Literal["str"]` is not assignable to `int`"
thread 'inference::path_1_resources_inference_numbers_md' panicked at crates/red_knot_test/src/lib.rs:60:5:
Some tests failed.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
inference::path_1_resources_inference_numbers_md
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.19s
error: test failed, to rerun pass `-p red_knot_test --test inference`
```
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Fixed a TODO by adding another TODO. It's the red-knot way!
## Summary
`builtins.type` can be subscripted at runtime on Python 3.9+, even
though it has no `__class_getitem__` method and its metaclass (which
is... itself) has no `__getitem__` method. The special case is
[hardcoded directly into `PyObject_GetItem` in
CPython](744caa8ef4/Objects/abstract.c (L181-L184)).
We just have to replicate the special case in our semantic model.
This will fail at runtime on Python <3.9. However, there's a bunch of
outstanding questions (detailed in the TODO comment I added) regarding
how we deal with subscriptions of other generic types on lower Python
versions. Since we want to avoid too many false positives for now, I
haven't tried to address this; I've just made `type` subscriptable on
all Python versions.
## Test Plan
`cargo test -p red_knot_python_semantic --lib`
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Treat async generators as "await" in ASYNC100.
Fixes#13637
## Test Plan
Updated snapshot
## Summary
Implements string literal comparisons and fallbacks to `str` instance
for `LiteralString`.
Completes an item in #13618
## Test Plan
- Adds a dedicated test with non exhaustive cases
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Implements the comparison operator for `[Type::IntLiteral]` and
`[Type::BooleanLiteral]` (as an artifact of special handling of `True` and
`False` in python).
Sets the framework to implement more comparison for types known at
static time (e.g. `BooleanLiteral`, `StringLiteral`), allowing us to only
implement cases of the triplet `<left> Type`, `<right> Type`, `CmpOp`.
Contributes to #12701 (without checking off an item yet).
## Test Plan
- Added a test for the comparison of literals that should include most
cases of note.
- Added a test for the comparison of int instances
Please note that the cases do not cover 100% of the branches as there
are many and the current testing strategy with variables make this
fairly confusing once we have too many in one test.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Resolves https://github.com/astral-sh/ruff/issues/9962 by allowing a
configuration setting `allowed-unused-imports`
TODO:
- [x] Figure out the correct name and place for the setting; currently,
I have added it top level.
- [x] The comparison is pretty naive. I tried using `glob::Pattern` but
couldn't get it to work in the configuration.
- [x] Add tests
- [x] Update documentations
## Test Plan
`cargo test`
Resolves https://github.com/astral-sh/ruff/issues/13321.
Contents of overlay:
```bash
/private/var/folders/v0/l8q3ghks2gs5ns2_p63tyqh40000gq/T/pip-build-env-e0ukpbvo/overlay/bin:
total 26M
-rwxr-xr-x 1 bgabor8 staff 26M Oct 1 08:22 ruff
drwxr-xr-x 3 bgabor8 staff 96 Oct 1 08:22 .
drwxr-xr-x 4 bgabor8 staff 128 Oct 1 08:22 ..
```
Python executable:
```bash
'/Users/bgabor8/git/github/ruff-find-bin-during-build/.venv/bin/python'
```
PATH is:
```bash
['/private/var/folders/v0/l8q3ghks2gs5ns2_p63tyqh40000gq/T/pip-build-env-e0ukpbvo/overlay/bin',
'/private/var/folders/v0/l8q3ghks2gs5ns2_p63tyqh40000gq/T/pip-build-env-e0ukpbvo/normal/bin',
'/Library/Frameworks/Python.framework/Versions/3.11/bin',
'/Library/Frameworks/Python.framework/Versions/3.12/bin',
```
Not sure where to add tests, there does not seem to be any existing one.
Can someone help me with that?
Closes https://github.com/astral-sh/ruff/issues/13545
As described in the issue, we move comments before the inner `if`
statement to before the newly constructed `elif` statement (previously
`else`).
## Summary
fix#13602
Currently, `UP043` only applies to typing.Generator, but it should also
support collections.abc.Generator.
This update ensures `UP043` correctly handles both
`collections.abc.Generator` and `collections.abc.AsyncGenerator`
### UP043
> `UP043`
> Python 3.13 introduced the ability for type parameters to specify
default values. As such, the default type arguments for some types in
the standard library (e.g., Generator, AsyncGenerator) are now optional.
> Omitting type parameters that match the default values can make the
code more concise and easier to read.
```py
Generator[int, None, None] -> Generator[int]
```
## Summary
...and remove periods from messages that don't span more than a single
sentence.
This is more consistent with how we present user-facing messages in uv
(which has a defined style guide).
## Summary
You can now call `return_ty_result` to operate on a `Result` directly
thereby using your own diagnostics, as in:
```rust
return dunder_getitem_method
.call(self.db, &[slice_ty])
.return_ty_result(self.db, value.as_ref().into(), self)
.unwrap_or_else(|err| {
self.add_diagnostic(
(&**value).into(),
"call-non-callable",
format_args!(
"Method `__getitem__` is not callable on object of type '{}'.",
value_ty.display(self.db),
),
);
err.return_ty()
});
```
While looking into https://github.com/astral-sh/ruff/issues/13545 I
noticed that we return `None` here if you pass a block of comments. This
is annoying because it causes `adjust_indentation` to fall back to
LibCST which panics when it cannot find a statement.
Adds a diagnostic for division by the integer zero in `//`, `/`, and
`%`.
Doesn't handle `<int> / 0.0` because we don't track the values of float
literals.
This variant shows inference that is not yet implemented..
## Summary
PR #13500 reopened the idea of adding a new type variant to keep track
of not-implemented features in Red Knot.
It was based off of #12986 with a more generic approach of keeping track
of different kind of unknowns. Discussion in #13500 agreed that keeping
track of different `Unknown` is complicated for now, and this feature is
better achieved through a new variant of `Type`.
### Requirements
Requirements for this implementation can be summed up with some extracts
of comment from @carljm on the previous PR
> So at the moment we are leaning towards simplifying this PR to just
use a new top-level variant, which behaves like Any and Unknown but
represents inference that is not yet implemented in red-knot.
> I think the general rule should be that Todo should propagate only
when the presence of the input Todo caused the output to be unknown.
>
> To take a specific example, the inferred result of addition must be
Unknown if either operand is Unknown. That is, Unknown + X will always
be Unknown regardless of what X is. (Same for X + Unknown.) In this
case, I believe that Unknown + Todo (or Todo + Unknown) should result in
Unknown, not result in Todo. If we fix the upstream source of the Todo,
the result would still be Unknown, so it's not useful to propagate the
Todo in this case: it wrongly suggests that the output is unknown
because of a todo item.
## Test Plan
This PR does not introduce new tests, but it did required to edit some
tests with the display of `[Type::Todo]` (currently `@Todo`), which
suggests that those test are placeholders requirements for features we
don't support yet.
While working on https://github.com/astral-sh/ruff/pull/13576 I noticed
that it was really hard to tell which assertion failed in some of these
test cases. This could be expanded to elsewhere, but I've heard this
test suite format won't be around for long?
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
There was a typo in the links of the docs of PTH116, where Path.stat
used to link to Path.group.
Another rule, PTH202, does it correctly:
ec72e675d9/crates/ruff_linter/src/rules/flake8_use_pathlib/rules/os_path_getsize.rs (L33)
This PR only fixes a one word typo.
## Test Plan
<!-- How was it tested? -->
I did not test that the doc generation framework picked up these
changes, I assume it will do it successfully.
## Summary
Following #13449, this PR adds custom handling for the bool constructor,
so when the input type has statically known truthiness value, it will be
used as the return value of the bool function.
For example, in the following snippet x will now be resolved to
`Literal[True]` instead of `bool`.
```python
x = bool(1)
```
## Test Plan
Some cargo tests were added.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Implement inference for `f-string`, contributes to #12701.
### First Implementation
When looking at the way `mypy` handles things, I noticed the following:
- No variables (e.g. `f"hello"`) ⇒ `LiteralString`
- Any variable (e.g. `f"number {1}"`) ⇒ `str`
My first commit (1ba5d0f13fdf70ed8b2b1a41433b32fc9085add2) implements
exactly this logic, except that we deal with string literals just like
`infer_string_literal_expression` (if below `MAX_STRING_LITERAL_SIZE`,
show `Literal["exact string"]`)
### Second Implementation
My second commit (90326ce9af5549af7b4efae89cd074ddf68ada14) pushes
things a bit further to handle cases where the expression within the
`f-string` are all literal values (string representation known at static
time).
Here's an example of when this could happen in code:
```python
BASE_URL = "https://httpbin.org"
VERSION = "v1"
endpoint = f"{BASE_URL}/{VERSION}/post" # Literal["https://httpbin.org/v1/post"]
```
As this can be sightly more costly (additional allocations), I don't
know if we want this feature.
## Test Plan
- Added a test `fstring_expression` covering all cases I can think of
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
Related to https://github.com/astral-sh/ruff/issues/13524
Doesn't offer a valid fix, opting to instead just not offer a fix at
all. If someone points me to a good way to handle parenthesis here I'm
down to try to fix the fix separately, but it looks quite hard.
## Summary
Building ruff on AIX breaks on `tiki-jemalloc-sys` due to OS header
incompatibility
## Test Plan
`cargo test`
Co-authored-by: Henry Jiang <henry.jiang1@ibm.com>
In https://github.com/astral-sh/ruff/pull/13503, we added supported for
detecting variadic keyword arguments as dictionaries, here we use the
same strategy for detecting variadic positional arguments as tuples.
Closes https://github.com/astral-sh/ruff/issues/13266
Avoids false negatives for shadowed bindings that aren't actually
references to the loop variable. There are some shadowed bindings we
need to support still, e.g., `del` requires the loop variable to exist.
## Summary
I think we should also make the change that @BurntSushi recommended in
the linked issue, but this gets rid of the panic.
See: https://github.com/astral-sh/ruff/issues/13483
See: https://github.com/astral-sh/ruff/issues/13442
## Test Plan
```
warning: `ruff analyze graph` is experimental and may change without warning
{
"/Users/crmarsh/workspace/django/django/__init__.py": [
"/Users/crmarsh/workspace/django/django/apps/__init__.py",
"/Users/crmarsh/workspace/django/django/conf/__init__.py",
"/Users/crmarsh/workspace/django/django/urls/__init__.py",
"/Users/crmarsh/workspace/django/django/utils/log.py",
"/Users/crmarsh/workspace/django/django/utils/version.py"
],
"/Users/crmarsh/workspace/django/django/__main__.py": [
"/Users/crmarsh/workspace/django/django/core/management/__init__.py"
ruff failed
Cause: Broken pipe (os error 32)
```
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [unicode_names2](https://redirect.github.com/progval/unicode_names2) |
workspace.dependencies | minor | `1.2.2` -> `1.3.0` |
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOC44MC4wIiwidXBkYXRlZEluVmVyIjoiMzguODAuMCIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
## Summary
This PR changes removes the typeshed stubs from the vendored file system
shipped with ruff
and instead ships an empty "typeshed".
Making the typeshed files optional required extracting the typshed files
into a new `ruff_vendored` crate. I do like this even if all our builds
always include typeshed because it means `red_knot_python_semantic`
contains less code that needs compiling.
This also allows us to use deflate because the compression algorithm
doesn't matter for an archive containing a single, empty file.
## Test Plan
`cargo test`
I verified with ` cargo tree -f "{p} {f}" -p <package> ` that:
* red_knot_wasm: enables `deflate` compression
* red_knot: enables `zstd` compression
* `ruff`: uses stored
I'm not quiet sure how to build the binary that maturin builds but
comparing the release artifact size with `strip = true` shows a `1.5MB`
size reduction
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
For reasons I haven't investigated, this speeds up the resolver about 2x
(from 6.404s to 3.612s on an extremely large codebase).
## Test Plan
\cc @BurntSushi
```
[andrew@duff rippling]$ time ruff analyze graph --preview > /dev/null
real 3.274
user 16.039
sys 7.609
maxmem 11631 MB
faults 0
[andrew@duff rippling]$ time ruff-patch analyze graph --preview > /dev/null
real 1.841
user 14.625
sys 3.639
maxmem 7173 MB
faults 0
[andrew@duff rippling]$ time ruff-patch2 analyze graph --preview > /dev/null
real 2.087
user 15.333
sys 4.869
maxmem 8642 MB
faults 0
```
Where that's `main`, then (`ruff-patch`) using the version with no
`File`, no `SemanticModel`, then (`ruff-patch2`) using `File`.
Avoid quadratic time in subsumed elements when adding a super-type of
existing union elements.
Reserve space in advance when adding multiple elements (from another
union) to a union.
Make union elements a `Box<[Type]>` instead of an `FxOrderSet`; the set
doesn't buy much since the rules of union uniqueness are defined in
terms of supertype/subtype, not in terms of simple type identity.
Move sealed-boolean handling out of a separate `UnionBuilder::simplify`
method and into `UnionBuilder::add`; now that `add` is iterating
existing elements anyway, this is more efficient.
Remove `UnionType::contains`, since it's now `O(n)` and we shouldn't
really need it, generally we care about subtype/supertype, not type
identity. (Right now it's used for `Type::Unbound`, which shouldn't even
be a type.)
Add support for `is_subtype_of` for the `object` type.
Addresses comments on https://github.com/astral-sh/ruff/pull/13401
This was mentioned in an earlier review, and seemed easy enough to just
do it. No need to repeat all the types twice when it gives no additional
information.
## Summary
This PR adds an experimental Ruff subcommand to generate dependency
graphs based on module resolution.
A few highlights:
- You can generate either dependency or dependent graphs via the
`--direction` command-line argument.
- Like Pants, we also provide an option to identify imports from string
literals (`--detect-string-imports`).
- Users can also provide additional dependency data via the
`include-dependencies` key under `[tool.ruff.import-map]`. This map uses
file paths as keys, and lists of strings as values. Those strings can be
file paths or globs.
The dependency resolution uses the red-knot module resolver which is
intended to be fully spec compliant, so it's also a chance to expose the
module resolver in a real-world setting.
The CLI is, e.g., `ruff graph build ../autobot`, which will output a
JSON map from file to files it depends on for the `autobot` project.
This fixes the last panic on checking pandas.
(Match statement became an `if let` because clippy decided it wanted
that once I added the additional line in the else case?)
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Support using `reveal_type` without importing it, as implied by the type
spec and supported by existing type checkers.
We use `typing_extensions.reveal_type` for the implicit built-in; this
way it exists on all Python versions. (It imports from `typing` on newer
Python versions.)
Emits an "undefined name" diagnostic whenever `reveal_type` is
referenced in this way (in addition to the revealed-type diagnostic when
it is called). This follows the mypy example (with `--enable-error-code
unimported-reveal`) and I think provides a good (and easily
understandable) balance for user experience. If you are using
`reveal_type` for quick temporary debugging, the additional
undefined-name diagnostic doesn't hinder that use case. If we make the
revealed-type diagnostic a non-failing one, the undefined-name
diagnostic can still be a failing diagnostic, helping prevent
accidentally leaving it in place. For any use cases where you want to
leave it in place, you can always import it to avoid the undefined-name
diagnostic.
In the future, we can easily provide configuration options to a) turn
off builtin-reveal_type altogether, and/or b) silence the undefined-name
diagnostic when using it, if we have users on either side (loving or
hating pseudo-builtin `reveal_type`) who are dissatisfied with this
compromise.
After looking at more cases (for example, the case in the added test in
this PR), I realized that our previous rule, "if a symbol has any
declarations, use only declarations for its public type" is not
adequate. Rather than using `Unknown` as fallback if the symbol is not
declared in some paths, we need to use the inferred type as fallback in
that case.
For the paths where the symbol _was_ declared, we know that any bindings
must be assignable to the declared type in that path, so this won't
change the overall declared type in those paths. But for paths where the
symbol wasn't declared, this will give us a better type in place of
`Unknown`.
Before `typing.reveal_type` existed, there was
`typing_extensions.reveal_type`. We should support both.
Also adds a test to verify that we can handle aliasing of `reveal_type`
to a different name.
Adds a bit of code to ensure that if we have a union of different
`reveal_type` functions (e.g. a union containing both
`typing_extensions.reveal_type` and `typing.reveal_type`) we still emit
the reveal-type diagnostic only once. This is probably unlikely in
practice, but it doesn't hurt to handle it smoothly. (It comes up now
because we don't support `version_info` checks yet, so
`typing_extensions.reveal_type` is actually that union.)
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
I noticed that this pattern sometimes occurs in typeshed:
```
if ...:
from foo import bar
else:
def bar(): ...
```
If we have the rule that symbols with declarations only use declarations
for the public type, then this ends up resolving as `Unknown |
Literal[bar]`, because we didn't consider the import to be a
declaration.
I think the most straightforward thing here is to also consider imports
as declarations. The same rationale applies as for function and class
definitions: if you shadow an import, you should have to explicitly
shadow with an annotation, rather than just doing it
implicitly/accidentally.
We may also ultimately need to re-evaluate the rule that public type
considers only declarations, if there are declarations.
Add support for the `typing.reveal_type` function, emitting a diagnostic
revealing the type of its single argument. This is a necessary piece for
the planned testing framework.
This puts the cart slightly in front of the horse, in that we don't yet
have proper support for validating call signatures / argument types. But
it's easy to do just enough to make `reveal_type` work.
This PR includes support for calling union types (this is necessary
because we don't yet support `sys.version_info` checks, so
`typing.reveal_type` itself is a union type), plus some nice
consolidated error messages for calls to unions where some elements are
not callable. This is mostly to demonstrate the flexibility in
diagnostics that we get from the `CallOutcome` enum.
Use declared types in inference and checking. This means several things:
* Imports prefer declarations over inference, when declarations are
available.
* When we encounter a binding, we check that the bound value's inferred
type is assignable to the live declarations of the bound symbol, if any.
* When we encounter a declaration, we check that the declared type is
assignable from the inferred type of the symbol from previous bindings,
if any.
* When we encounter a binding+declaration, we check that the inferred
type of the bound value is assignable to the declared type.
The documented configuration did not work. On failure, ALE suggest to
run `ALEFixSuggest`, into with it documents the working configuration
key
'ruff_format' - Fix python files with the ruff formatter.
Fix an inaccuracy in the documentation, regarding the ALE plugin for the
Vim text editor.
Add support for declared types to the semantic index. This involves a
lot of renaming to clarify the distinction between bindings and
declarations. The Definition (or more specifically, the DefinitionKind)
becomes responsible for determining which definitions are bindings,
which are declarations, and which are both, and the symbol table
building is refactored a bit so that the `IS_BOUND` (renamed from
`IS_DEFINED` for consistent terminology) flag is always set when a
binding is added, rather than being set separately (and requiring us to
ensure it is set properly).
The `SymbolState` is split into two parts, `SymbolBindings` and
`SymbolDeclarations`, because we need to store live bindings for every
declaration and live declarations for every binding; the split lets us
do this without storing more than we need.
The massive doc comment in `use_def.rs` is updated to reflect bindings
vs declarations.
The `UseDefMap` gains some new APIs which are allow-unused for now,
since this PR doesn't yet update type inference to take declarations
into account.
## Summary
Follow-up from #13268, this PR updates the test case to use
`assert_snapshot` now that the output is limited to only include the
rules with diagnostics.
## Test Plan
`cargo insta test`
Add `::is_empty` and `::union` methods to the `BitSet` implementation.
Allowing unused for now, until these methods become used later with the
declared-types implementation.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
These are quite incomplete, but I needed to start stubbing them out in
order to build and test declared-types.
Allowing unused for now, until they are used later in the declared-types
PR.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR adds a new `Type` variant called `TupleType` which is used for
heterogeneous elements.
### Display notes
* For an empty tuple, I'm using `tuple[()]` as described in the docs:
https://docs.python.org/3/library/typing.html#annotating-tuples
* For nested elements, it'll use the literal type instead of builtin
type unlike Pyright which does `tuple[Literal[1], tuple[int, int]]`
instead of `tuple[Literal[1], tuple[Literal[2], Literal[3]]]`. Also,
mypy would give `tuple[builtins.int, builtins.int]` instead of
`tuple[Literal[1], Literal[2]]`
## Test Plan
Update test case to account for the display change and add cases for
multiple elements and nested tuple elements.
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This PR adds support for control flow for match statement.
It also adds the necessary infrastructure required for narrowing
constraints in case blocks and implements the logic for
`PatternMatchSingleton` which is either `None` / `True` / `False`. Even
after this the inferred type doesn't get simplified completely, there's
a TODO for that in the test code.
## Test Plan
Add test cases for control flow for (a) when there's a wildcard pattern
and (b) when there isn't. There's also a test case to verify the
narrowing logic.
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
When a type of the form `Literal["..."]` would be constructed with too
large of a string, this PR converts it to `LiteralString` instead.
We also extend inference for binary operations to include the case where
one of the operands is `LiteralString`.
Closes#13224
Pull the tests from `types.rs` into `infer.rs`.
All of these are integration tests with the same basic form: create a
code sample, run type inference or check on it, and make some assertions
about types and/or diagnostics. These are the sort of tests we will want
to move into a test framework with a low-boilerplate custom textual
format. In the meantime, having them together (and more importantly,
their helper utilities together) means that it's easy to keep tests for
related language features together (iterable tests with other iterable
tests, callable tests with other callable tests), without an artificial
split based on tests which test diagnostics vs tests which test
inference. And it allows a single test to more easily test both
diagnostics and inference. (Ultimately in the test framework, they will
likely all test diagnostics, just in some cases the diagnostics will
come from `reveal_type()`.)
My plan for handling declared types is to introduce a `Declaration` in
addition to `Definition`. A `Declaration` is an annotation of a name
with a type; a `Definition` is an actual runtime assignment of a value
to a name. A few things (an annotated function parameter, an
annotated-assignment with an RHS) are both a `Definition` and a
`Declaration`.
This more cleanly separates type inference (only cares about
`Definition`) from declared types (only impacted by a `Declaration`),
and I think it will work out better than trying to squeeze everything
into `Definition`. One of the tests in this PR
(`annotation_only_assignment_transparent_to_local_inference`)
demonstrates one reason why. The statement `x: int` should have no
effect on local inference of the type of `x`; whatever the locally
inferred type of `x` was before `x: int` should still be the inferred
type after `x: int`. This is actually quite hard to do if `x: int` is
considered a `Definition`, because a core assumption of the use-def map
is that a `Definition` replaces the previous value. To achieve this
would require some hackery to effectively treat `x: int` sort of as if
it were `x: int = x`, but it's not really even equivalent to that, so
this approach gets quite ugly.
As a first step in this plan, this PR stops treating AnnAssign with no
RHS as a `Definition`, which fixes behavior in a couple added tests.
This actually makes things temporarily worse for the ellipsis-type test,
since it is defined in typeshed only using annotated assignments with no
RHS. This will be fixed properly by the upcoming addition of
declarations, which should also treat a declared type as sufficient to
import a name, at least from a stub.
Initially I had deferred annotation name lookups reuse the "public
symbol type", since that gives the correct "from end of scope" view of
reaching definitions that we want. But there is a key difference; public
symbol types are based only on definitions in the queried scope (or
"name in the given namespace" in runtime terms), they don't ever look up
a name in nonlocal/global/builtin scopes. Deferred annotation resolution
should do this lookup.
Add a test, and fix deferred name resolution to support
nonlocal/global/builtin names.
Fixes#13176
## Summary
Part of #13085, this PR updates the comprehension definition to handle
multiple targets.
## Test Plan
Update existing semantic index test case for comprehension with multiple
targets. Running corpus tests shouldn't panic.
Add support for non-local name lookups.
There's one TODO around annotated assignments without a RHS; these need
a fair amount of attention, which they'll get in an upcoming PR about
declared vs inferred types.
Fixes#11663
Test coverage for #13131 wasn't as good as I thought it was, because
although we infer a lot of types in stubs in typeshed, we don't check
typeshed, and therefore we don't do scope-level inference and pull all
types for a scope. So we didn't really have good test coverage for
scope-level inference in a stub. And because of this, I got the code for
supporting that wrong, meaning that if we did scope-level inference with
deferred types, we'd end up never populating the deferred types in the
scope's `TypeInference`, which causes panics like #13160.
Here I both add test coverage by running the corpus tests both as `.py`
and as `.pyi` (which reveals the panic), and I fix the code to support
deferred types in scope inference.
This also revealed a problem with deferred types in generic functions,
which effectively span two scopes. That problem will require a bit more
thought, and I don't want to block this PR on it, so for now I just
don't defer annotations on generic functions.
Fixes#13160.
## Summary
Follow-up to #13147, this PR implements the `AstNode` for `Identifier`.
This makes it easier to create the `NodeKey` in red knot because it uses
a generic method to construct the key from `AnyNodeRef` and is important
for definitions that are created only on identifiers instead of
`ExprName`.
## Test Plan
`cargo test` and `cargo clippy`
## Summary
This PR adds definition for match patterns.
## Test Plan
Update the existing test case for match statement symbols to verify that
the definitions are added as well.
This PR contains the following updates:
| Package | Type | Update | Change |
|---|---|---|---|
| [quick-junit](https://redirect.github.com/nextest-rs/quick-junit) |
workspace.dependencies | minor | `0.4.0` -> `0.5.0` |
---
### Release Notes
<details>
<summary>nextest-rs/quick-junit (quick-junit)</summary>
###
[`v0.5.0`](https://redirect.github.com/nextest-rs/quick-junit/blob/HEAD/CHANGELOG.md#050---2024-09-01)
[Compare
Source](https://redirect.github.com/nextest-rs/quick-junit/compare/quick-junit-0.4.0...quick-junit-0.5.0)
##### Changed
- The `Output` type, which strips invalid XML characters from a string,
has been renamed to
`XmlString`.
- All internal storage now uses `XmlString` rather than `String`.
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend Renovate](https://mend.io/renovate/).
View the [repository job
log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOC41Ni4wIiwidXBkYXRlZEluVmVyIjoiMzguNTkuMiIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
---------
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
The `SequenceIndexVisitor` currently does not recurse into
subexpressions of subscripts when searching for subscript accesses that
would trigger this rule. That means that we don't currently detect
violations of the rule on snippets like this:
```py
data = {"a": 1, "b": 2}
column_names = ["a", "b"]
for index, column_name in enumerate(column_names):
_ = data[column_names[index]]
```
Fixes#13183
## Test Plan
`cargo test -p ruff_linter`
The `UnionBuilder` builds `builtins.bool` when handed `Literal[True]`
and `Literal[False]`.
Caveat: If the builtins module is unfindable somehow, the builder falls
back to the union type of these two literals.
First task from #12694
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Adds basic support for inferring the type resulting from a call
expression. This only works for the *result* of call expressions; it
performs no inference on parameters. It also intentionally does nothing
with class instantiation, `__call__` implementors, or lambdas.
## Test Plan
Adds a test that it infers the right thing!
---------
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
- Introduce methods for inferring annotation and type expressions.
- Correctly infer explicit return types from functions where they are
simple names that can be resolved in scope.
Contributes to #12701 by way of helping unlock call expressions (this
does not remotely finish that, as it stands, but it gets us moving that
direction).
## Test Plan
Added a test for function return types which use the name form of an
annotation expression, since this is aiming toward call expressions.
When we extend this to working for other annotation and type expression
positions, we should add explicit tests for those as well.
---------
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
Extends deletions for RUF100, deleting trailing text from noqa
directives, while preserving upcoming comments on the same line if any.
In cases where it deletes a comment up to another comment on the same
line, the whitespace between them is now shown to be in the autofix in
the diagnostic as well. Leading whitespace before the removed comment is
not, though.
Fixes#12251
## Test Plan
`cargo test`
Prototype deferred evaluation of type expressions by deferring
evaluation of class bases in a stub file. This allows self-referential
class definitions, as occur with the definition of `str` in typeshed
(which inherits `Sequence[str]`).
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
Just what it says on the tin: adds basic `EllipsisType` inference for
any time `...` appears in the AST.
## Test Plan
Test that `x = ...` produces exactly what we would expect.
---------
Co-authored-by: Carl Meyer <carl@oddbird.net>
## Summary
The resulting type when multiplying a string literal by an integer
literal is one of two types:
- `StringLiteral`, in the case where it is a reasonably small resulting
string (arbitrarily bounded here to 4096 bytes, roughly a page on many
operating systems), including the fully expanded string.
- `LiteralString`, matching Pyright etc., for strings larger than that.
Additionally:
- Switch to using `Box<str>` instead of `String` for the internal value
of `StringLiteral`, saving some non-trivial byte overhead (and keeping
the total number of allocations the same).
- Be clearer and more accurate about which types we ought to defer to in
`StringLiteral` and `LiteralString` member lookup.
## Test Plan
Added a test case covering multiplication times integers: positive,
negative, zero, and in and out of bounds.
---------
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
Co-authored-by: Carl Meyer <carl@astral.sh>
## Summary
This fixes the outstanding TODO and make it easier to work with new
cases. (Tidy first, *then* implement, basically!)
## Test Plan
After making this change all the existing tests still pass. A classic
refactor win. 🎉
# Summary
Add support for the first unary operator: negating integer literals. The
resulting type is another integer literal, with the value being the
negated value of the literal. All other types continue to return
`Type::Unknown` for the present, but this is designed to make it easy to
extend easily with other combinations of operator and operand.
Contributes to #12701.
## Test Plan
Add tests with basic negation, including of very large integers and
double negation.
## Summary
Introduce a `StringLiteralType` with corresponding `Display` type and a
relatively basic test that the resulting representation is as expected.
Note: we currently always allocate for `StringLiteral` types. This may
end up being a perf issue later, at which point we may want to look at
other ways of representing `value` here, i.e. with some kind of smarter
string structure which can reuse types. That is most likely to show up
with e.g. concatenation.
Contributes to #12701.
## Test Plan
Added a test for individual strings with both single and double quotes
as well as concatenated strings with both forms.
## Summary
Now that Ruff provides a formatter, there is no need to rely on Black to
check that the docs are formatted correctly in
`check_docs_formatted.py`. This PR swaps out Black for the Ruff
formatter and updates inconsistencies between the two.
This PR will be a precursor to another PR
([branch](https://github.com/calumy/ruff/tree/format-pyi-in-docs)),
updating the `check_docs_formatted.py` script to check for pyi files,
fixing #11568.
## Test Plan
- CI to check that the docs are formatted correctly using the updated
script.
## Summary
Noticed there was a wrong tip on the Contributing guide, `cargo
benchmark lexer` wouldn't run any benches.
Probably a missed update on #9535
It may make sense to remove the `cargo benchmark` command from the guide
altogether, but up to the mantainers.
This PR has the `SemanticIndexBuilder` visit function definition
annotations before adding the function symbol/name to the builder.
For example, the following snippet no longer causes a panic:
```python
def bool(x) -> bool:
Return True
```
Note: This fix changes the ordering of the global symbol table.
Closes#13069
## Summary
This PR adds symbols introduced by `for` loops to red-knot:
- `x` in `for x in range(10): pass`
- `x` and `y` in `for x, y in d.items(): pass`
- `a`, `b`, `c` and `d` in `for [((a,), b), (c, d)] in foo: pass`
## Test Plan
Several tests added, and the assertion in the benchmarks has been
updated.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR simplifies the virtual file support in the red knot core,
specifically:
* Update `File::add_virtual_file` method to `File::virtual_file` which
will always create a new virtual file and override the existing entry in
the lookup table
* Add `VirtualFile` which is a wrapper around `File` and provides
methods to increment the file revision / close the virtual file
* Add a new `File::try_virtual_file` to lookup the `VirtualFile` from
`Files`
* Add `File::sync_virtual_path` which takes in the `SystemVirtualPath`,
looks up the `VirtualFile` for it and calls the `sync` method to
increment the file revision
* Removes the `virtual_path_metadata` method on `System` trait
## Test Plan
- [x] Make sure the existing red knot tests pass
- [x] Updated code works well with the LSP
## Summary
This PR adds support for `textDocument/didChange` notification.
There seems to be a bug (probably in Salsa) where it panics with:
```
2024-08-22 15:33:38.802 [info] panicked at /Users/dhruv/.cargo/git/checkouts/salsa-61760caba2b17ca5/f608ff8/src/tracked_struct.rs:377:9:
two concurrent writers to Id(4800), should not be possible
```
## Test Plan
https://github.com/user-attachments/assets/81055feb-ba8e-4acf-ad2f-94084a3efead
## Summary
This PR adds basic support for files outside of any workspace in the red
knot server.
This also limits the red knot server to only work in a single workspace.
The server will not start if there are multiple workspaces.
## Test Plan
https://github.com/user-attachments/assets/de601387-0ad5-433c-9d2c-7b6ae5137654
## Summary
This PR adds the `bytes` type to red-knot:
- Added the `bytes` type
- Added support for bytes literals
- Support for the `+` operator
Improves on #12701
Big TODO on supporting and normalizing r-prefixed bytestrings
(`rb"hello\n"`)
## Test Plan
Added a test for a bytes literals, concatenation, and corner values
The `SemanticIndexBuilder` was causing a cycle in a salsa query by
attempting to resolve the target before the value in a named expression
(e.g. `x := x+1`). This PR swaps the order, avoiding a panic.
Closes#13012.
## Summary
This PR removes notebook sync support from server capabilities because
it isn't tested, it'll be added back once we actually add full support
for notebook.
## Summary
When following the step-by-step instructions to run the benchmarks in
`CONTRIBUTING.md`, I encountered two errors:
**Error 1:**
`bash: hyperfine: command not found`
**Solution**: I updated the instructions to include the step of
installing the benchmark tool.
**Error 2:**
```shell
$ ./target/release/ruff ./crates/ruff_linter/resources/test/cpython/
error: `ruff <path>` has been removed. Use `ruff check <path>` instead.
```
**Solution**: I added `check`.
## Test Plan
I tested it by running the benchmark-related commands in a new workspace
within GitHub Codespaces.
## Summary
This PR adds symbols and definitions introduced by `with` statements.
The symbols and definitions are introduced for each with item. The type
inference is updated to call the definition region type inference
instead.
## Test Plan
Add test case to check for symbol table and definitions.
## Summary
Provide instructions to use Ruff together with other servers in the Kate
editor.
Because Kate does not support running multiple servers for the same
language, one needs to use the ``python-lsp-server`` (pylsp) tool.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
This PR adds symbols introduced by `match` statements.
There are three patterns that introduces new symbols:
* `as` pattern
* Sequence pattern
* Mapping pattern
The recursive nature of the visitor makes sure that all symbols are
added.
## Test Plan
Add test case for all types of patterns that introduces a symbol.
## Summary
This PR adds definition for augmented assignment. This is similar to
annotated assignment in terms of implementation.
An augmented assignment should also record a use of the variable but
that's a TODO for now.
## Test Plan
Add test case to validate that a definition is added.
## Summary
As suggested by @MichaReiser in
https://github.com/astral-sh/ruff/pull/12886#pullrequestreview-2237679793,
this adds an exemption to `RUF027` for `fastAPI` paths, which require
template strings rather than eagerly evaluated f-strings.
## Test Plan
I added a fixture that causes Ruff to emit a false-positive error on
`main` but no longer does with this PR.
Extend the `UseDefMap` to also track which constraints (provided by e.g.
`if` tests) apply to each visible definition.
Uses a custom `BitSet` and `BitSetArray` to track which constraints
apply to which definitions, while keeping data inline as much as
possible.
## Summary
This PR is a pure refactor to simplify some of the logic for `RUF027`.
This will make it easier to file some followup PRs to help reduce the
false positives from this rule. I'm separating the refactor out into a
separate PR so it's easier to review, and so I can double-check from the
ecosystem report that this doesn't have any user-facing impact.
## Test Plan
`cargo test -p ruff_linter --lib`
## Summary
This PR adds support for adding symbols and definitions for function and
lambda parameters to the semantic index.
### Notes
* The default expression of a parameter is evaluated in the enclosing
scope (not the type parameter or function scope).
* The annotation expression of a parameter is evaluated in the type
parameter scope if they're present other in the enclosing scope.
* The symbols and definitions are added in the function parameter scope.
### Type Inference
There are two definitions `Parameter` and `ParameterWithDefault` and
their respective `*_definition` methods on the type inference builder.
These methods are preferred and are re-used when checking from a
different region.
## Test Plan
Add test case for validating that the parameters are defined in the
function / lambda scope.
### Benchmark update
Validated the difference in diagnostics for benchmark code between
`main` and this branch. All of them are either directly or indirectly
referencing one of the function parameters. The diff is in the PR description.
This adds the `fast-api-unused-path-parameter` lint rule, as described
in #12632.
I'm still pretty new to rust, so the code can probably be improved, feel
free to tell me if there's any changes i should make.
Also, i needed to add the `add_parameter` edit function, not sure if it
was in the scope of the PR or if i should've made another one.
If a builtin is conditionally shadowed by a global, we didn't correctly
fall back to builtins for the not-defined-in-globals path (see added
test for an example.)
List and set comprehensions using `async for` cannot be replaced with
underlying generators; this PR modifies C419 to skip such
comprehensions.
Closes#12891.
## Summary
Occasionally, we receive bug reports that imports in `src` directories
aren't correctly detected. The root of the problem is that we default to
`src = ["."]`, so users have to set `src = ["src"]` explicitly. This PR
extends the default to cover _both_ of them: `src = [".", "src"]`.
Closes https://github.com/astral-sh/ruff/issues/12454.
## Test Plan
I replicated the structure described in
https://github.com/astral-sh/ruff/issues/12453, and verified that the
imports were considered sorted, but that adding `src = ["."]` showed an
error.
## Summary
This PR adds very basic support for using the line / column information
from the diagnostic message. This makes it easier to validate
diagnostics in an editor as oppose to going through the diff one
diagnostic at a time and confirming it at the location.
## Summary
This PR adds a fallback logic for `is_python_notebook` to check the
`kernelspec.language` field.
Reference implementation in VS Code:
1c31e75898/extensions/ipynb/src/deserializers.ts (L20-L22)
It's also required for the kernel to provide the `language` they're
implementing based on
https://jupyter-client.readthedocs.io/en/stable/kernels.html#kernel-specs
reference although that's for the `kernel.json` file but is also
included in the notebook metadata.
Closes: #12281
## Test Plan
Add a test case for `is_python_notebook` and include the test notebook
for round trip validation.
The test notebook contains two cells, one is JavaScript (denoted via the
`vscode.languageId` metadata) and the other is Python (no metadata). The
notebook metadata only contains `kernelspec` and the `language_info` is
absent.
I also verified that this is a valid notebook by opening it in Jupyter
Lab, VS Code and using `nbformat` validator.
## Summary
This PR adds support for VS Code specific cell metadata to consider when
collecting valid code cells.
For context, Ruff only runs on valid code cells. These are the code
cells that doesn't contain cell magics. Previously, Ruff only used the
notebook's metadata to determine whether it's a Python notebook. But, in
VS Code, a notebook's preferred language might be Python but it could
still contain code cells for other languages. This can be determined
with the `metadata.vscode.languageId` field.
### References:
* https://code.visualstudio.com/docs/languages/identifiers
* e6c009a3d4/extensions/ipynb/src/serializers.ts (L104-L107)
*
e6c009a3d4/extensions/ipynb/src/serializers.ts (L117-L122)
This brings us one step closer to fixing #12281.
## Test Plan
Add test cases for `is_valid_python_code_cell` and an integration test
case which showcase running it end to end. The test notebook contains a
JavaScript code cell and a Python code cell.
## Summary
This PR fixes a bug in the semantic model where it would evaluate the
default parameter value in the type parameter scope. For example,
```py
def foo[T1: int](a = T1):
pass
```
Here, the `T1` in `a = T1` is undefined but Ruff doesn't flag it
(https://play.ruff.rs/ba2f7c2f-4da6-417e-aa2a-104aa63e6d5e).
The fix here is to evaluate the default parameter value in the
_enclosing_ scope instead.
## Test Plan
Add a test case which includes the above code under `F821`
(`undefined-name`) and validate the snapshot.
## Summary
See #12703. This only addresses the first bullet point, adding a space
after the comma in the suggested fix from list/tuple to string.
## Test Plan
Updated the snapshots and compared.
## Summary
This PR adds scope and definition for comprehension nodes. This includes
the following nodes:
* List comprehension
* Dictionary comprehension
* Set comprehension
* Generator expression
### Scope
Each expression here adds it's own scope with one caveat - the `iter`
expression of the first generator is part of the parent scope. For
example, in the following code snippet the `iter1` variable is evaluated
in the outer scope.
```py
[x for x in iter1]
```
> The iterable expression in the leftmost for clause is evaluated
directly in the enclosing scope and then passed as an argument to the
implicitly nested scope.
>
> Reference:
https://docs.python.org/3/reference/expressions.html#displays-for-lists-sets-and-dictionaries
There's another special case for assignment expressions:
> There is one special case: an assignment expression occurring in a
list, set or dict comprehension or in a generator expression (below
collectively referred to as “comprehensions”) binds the target in the
containing scope, honoring a nonlocal or global declaration for the
target in that scope, if one exists.
>
> Reference: https://peps.python.org/pep-0572/#scope-of-the-target
For example, in the following code snippet, the variables `a` and `b`
are available after the comprehension while `x` isn't:
```py
[a := 1 for x in range(2) if (b := 2)]
```
### Definition
Each comprehension node adds a single definition, the "target" variable
(`[_ for target in iter]`). This has been accounted for and a new
variant has been added to `DefinitionKind`.
### Type Inference
Currently, type inference is limited to a single scope. It doesn't
_enter_ in another scope to infer the types of the remaining expressions
of a node. To accommodate this, the type inference for a **scope**
requires new methods which _doesn't_ infer the type of the `iter`
expression of the leftmost outer generator (that's defined in the
enclosing scope).
The type inference for the scope region is split into two parts:
* `infer_generator_expression` (similarly for comprehensions) infers the
type of the `iter` expression of the leftmost outer generator
* `infer_generator_expression_scope` (similarly for comprehension)
infers the type of the remaining expressions except for the one
mentioned in the previous point
The type inference for the **definition** also needs to account for this
special case of leftmost generator. This is done by defining a `first`
boolean parameter which indicates whether this comprehension definition
occurs first in the enclosing expression.
## Test Plan
New test cases were added to validate multiple scenarios. Refer to the
documentation for each test case which explains what is being tested.
Make `cargo doc -p red_knot_python_semantic --document-private-items`
run warning-free. I'd still like to do this for all of ruff and start
enforcing it in CI (https://github.com/astral-sh/ruff/issues/12372) but
haven't gotten to it yet. But in the meantime I'm trying to maintain it
for at least `red_knot_python_semantic`, as it helps to ensure our doc
comments stay up to date.
A few of the comments I just removed or shortened, as their continued
relevance wasn't clear to me; please object in review if you think some
of them are important to keep!
Also remove a no-longer-needed `allow` attribute.
For type narrowing, we'll need intersections (since applying type
narrowing is just a type intersection.)
Add `IntersectionBuilder`, along with some tests for it and
`UnionBuilder` (renamed from `UnionTypeBuilder`).
We use smart builders to ensure that we always keep these types in
disjunctive normal form (DNF). That means that we never have deeply
nested trees of unions and intersections: unions flatten into unions,
intersections flatten into intersections, and intersections distribute
over unions, so the most complex tree we can ever have is a union of
intersections. We also never have a single-element union or a
single-positive-element intersection; these both just simplify to the
contained type.
Maintaining these invariants means that `UnionBuilder` doesn't
necessarily end up building a `Type::Union` (e.g. if you only add a
single type to the union, it'll just return that type instead), and
`IntersectionBuilder` doesn't necessarily build a `Type::Intersection`
(if you add a union to the intersection, we distribute the intersection
over that union, and `IntersectionBuilder` will end up returning a
`Type::Union` of intersections).
We also simplify intersections by ensuring that if a type and its
negation are both in an intersection, they simplify out. (In future this
should also respect subtyping, not just type identity, but we don't have
subtyping yet.) We do implement subtyping of `Never` as a special case
for now.
Most of this PR is unused for now until type narrowing lands; I'm just
breaking it out to reduce the review fatigue of a single massive PR.
## Summary
I'm not sure if this is useful but this is a hacky implementation to add
the filename and row / column numbers to the current Red Knot
diagnostics.
## Summary
Related to https://github.com/astral-sh/ruff-vscode/issues/571, this PR
updates the settings index builder to trace all the errors it
encountered. Without this, there's no way for user to know that
something failed and some of the capability might not work as expected.
For example, in the linked PR, the settings were invalid which means
notebooks weren't included and there were no log messages for it.
## Test Plan
Create an invalid `ruff.toml` file:
```toml
[tool.ruff]
extend-exclude = ["*.ipynb"]
```
Logs:
```
2024-08-12 18:33:09.873 [info] [Trace - 6:33:09 PM] 12.217043000s ERROR ruff:main ruff_server::session::index::ruff_settings: Failed to parse /Users/dhruv/playground/ruff/pyproject.toml
```
Notification Preview:
<img width="483" alt="Screenshot 2024-08-12 at 18 33 20"
src="https://github.com/user-attachments/assets/a4f303e5-f073-454f-bdcd-ba6af511e232">
Another way to trigger is to provide an invalid `cache-dir` value:
```toml
[tool.ruff]
cache-dir = "$UNKNOWN"
```
Same notification preview but different log message:
```
2024-08-12 18:41:37.571 [info] [Trace - 6:41:37 PM] 21.700112208s ERROR ThreadId(30) ruff_server::session::index::ruff_settings: Error while resolving settings from /Users/dhruv/playground/ruff/pyproject.toml: Invalid `cache-dir` value: error looking key 'UNKNOWN' up: environment variable not found
```
With multiple `pyproject.toml` file:
```
2024-08-12 18:41:15.887 [info] [Trace - 6:41:15 PM] 0.016636833s ERROR ThreadId(04) ruff_server::session::index::ruff_settings: Error while resolving settings from /Users/dhruv/playground/ruff/pyproject.toml: Invalid `cache-dir` value: error looking key 'UNKNOWN' up: environment variable not found
2024-08-12 18:41:15.888 [info] [Trace - 6:41:15 PM] 0.017378833s ERROR ThreadId(13) ruff_server::session::index::ruff_settings: Failed to parse /Users/dhruv/playground/ruff/tools/pyproject.toml
```
[](https://renovatebot.com)
This PR contains the following updates:
| Package | Change | Age | Adoption | Passing | Confidence |
|---|---|---|---|---|---|
| [mkdocs](https://togithub.com/mkdocs/mkdocs)
([changelog](https://www.mkdocs.org/about/release-notes/)) | `==1.5.0`
-> `==1.6.0` |
[](https://docs.renovatebot.com/merge-confidence/)
|
[](https://docs.renovatebot.com/merge-confidence/)
|
[](https://docs.renovatebot.com/merge-confidence/)
|
[](https://docs.renovatebot.com/merge-confidence/)
|
---
### Release Notes
<details>
<summary>mkdocs/mkdocs (mkdocs)</summary>
### [`v1.6.0`](https://togithub.com/mkdocs/mkdocs/releases/tag/1.6.0)
[Compare
Source](https://togithub.com/mkdocs/mkdocs/compare/1.5.3...1.6.0)
#### Local preview
- `mkdocs serve` no longer locks up the browser when more than 5 tabs
are open. This is achieved by closing the polling connection whenever a
tab becomes inactive. Background tabs will no longer auto-reload either
- that will instead happen as soon the tab is opened again. Context:
[#​3391](https://togithub.com/mkdocs/mkdocs/issues/3391)
- New flag `serve --open` to open the site in a browser.\
After the first build is finished, this flag will cause the default OS
Web browser to be opened at the home page of the local site.\
Context: [#​3500](https://togithub.com/mkdocs/mkdocs/issues/3500)
##### Drafts
> \[!warning]
> **Changed from version 1.5:**
>
> **The `exclude_docs` config was split up into two separate concepts.**
The `exclude_docs` config no longer has any special behavior for `mkdocs
serve` - it now always completely excludes the listed documents from the
site.
If you wish to use the "drafts" functionality like the `exclude_docs`
key used to do in MkDocs 1.5, please switch to the **new config key
`draft_docs`**.
See
[documentation](https://www.mkdocs.org/user-guide/configuration/#exclude_docs).
Other changes:
- Reduce warning levels when a "draft" page has a link to a non-existent
file. Context:
[#​3449](https://togithub.com/mkdocs/mkdocs/issues/3449)
#### Update to deduction of page titles
MkDocs 1.5 had a change in behavior in deducing the page titles from the
first heading. Unfortunately this could cause unescaped HTML tags or
entities to appear in edge cases.
Now tags are always fully sanitized from the title. Though it still
remains the case that
[`Page.title`](https://www.mkdocs.org/dev-guide/api/#mkdocs.structure.files.pages.Page.title)
is expected to contain HTML entities and is passed directly to the
themes.
Images (notably, emojis in some extensions) get preserved in the title
only through their `alt` attribute's value.
Context: [#​3564](https://togithub.com/mkdocs/mkdocs/issues/3564),
[#​3578](https://togithub.com/mkdocs/mkdocs/issues/3578)
#### Themes
- Built-in themes now also support Polish language
([#​3613](https://togithub.com/mkdocs/mkdocs/issues/3613))
##### "readthedocs" theme
- Fix: "readthedocs" theme can now correctly handle deeply nested nav
configurations (over 2 levels deep), without confusedly expanding all
sections and jumping around vertically.
([#​3464](https://togithub.com/mkdocs/mkdocs/issues/3464))
- Fix: "readthedocs" theme now shows a link to the repository (with a
generic logo) even when isn't one of the 3 known hosters.
([#​3435](https://togithub.com/mkdocs/mkdocs/issues/3435))
- "readthedocs" theme now also has translation for the word "theme" in
the footer that mistakenly always remained in English.
([#​3613](https://togithub.com/mkdocs/mkdocs/issues/3613),
[#​3625](https://togithub.com/mkdocs/mkdocs/issues/3625))
##### "mkdocs" theme
The "mkdocs" theme got a big update to a newer version of Bootstrap,
meaning a slight overhaul of styles. Colors (most notably of
admonitions) have much better contrast.
The "mkdocs" theme now has support for dark mode - both automatic (based
on the OS/browser setting) and with a manual toggle. Both of these
options are **not** enabled by default and need to be configured
explicitly.\
See `color_mode`, `user_color_mode_toggle` in
[**documentation**](https://www.mkdocs.org/user-guide/choosing-your-theme/#mkdocs).
> \[!warning]
> **Possible breaking change:**
>
> jQuery is no longer included into the "mkdocs" theme. If you were
relying on it in your scripts, you will need to separately add it first
(into mkdocs.yml) as an extra script:
>
> ```yaml
> extra_javascript:
> - https://code.jquery.com/jquery-3.7.1.min.js
> ```
>
> Or even better if the script file is copied and included from your
docs dir.
Context: [#​3493](https://togithub.com/mkdocs/mkdocs/issues/3493),
[#​3649](https://togithub.com/mkdocs/mkdocs/issues/3649)
#### Configuration
##### New "`enabled`" setting for all plugins
You may have seen some plugins take up the convention of having a
setting `enabled: false` (or usually controlled through an environment
variable) to make the plugin do nothing.
Now *every* plugin has this setting. Plugins can still *choose* to
implement this config themselves and decide how it behaves (and unless
they drop older versions of MkDocs, they still should for now), but now
there's always a fallback for every plugin.
See
[**documentation**](https://www.mkdocs.org/user-guide/configuration/#enabled-option).
Context: [#​3395](https://togithub.com/mkdocs/mkdocs/issues/3395)
#### Validation
##### Validation of hyperlinks between pages
##### Absolute links
> Historically, within Markdown, MkDocs only recognized **relative**
links that lead to another physical `*.md` document (or media file).
This is a good convention to follow because then the source pages are
also freely browsable without MkDocs, for example on GitHub. Whereas
absolute links were left unmodified (making them often not work as
expected or, more recently, warned against).
If you dislike having to always use relative links, now you can opt into
absolute links and have them work correctly.
If you set the setting `validation.links.absolute_links` to the new
value `relative_to_docs`, all Markdown links starting with `/` will be
understood as being relative to the `docs_dir` root. The links will then
be validated for correctness according to all the other rules that were
already working for relative links in prior versions of MkDocs. For the
HTML output, these links will still be turned relative so that the site
still works reliably.
So, now any document (e.g. "dir1/foo.md") can link to the document
"dir2/bar.md" as `[link](/dir2/bar.md)`, in addition to the previously
only correct way `[link](../dir2/bar.md)`.
You have to enable the setting, though. The default is still to just
skip any processing of such links.
See
[**documentation**](https://www.mkdocs.org/user-guide/configuration/#validation-of-absolute-links).
Context: [#​3485](https://togithub.com/mkdocs/mkdocs/issues/3485)
##### Absolute links within nav
Absolute links within the `nav:` config were also always skipped. It is
now possible to also validate them in the same way with
`validation.nav.absolute_links`. Though it makes a bit less sense
because then the syntax is simply redundant with the syntax that comes
without the leading slash.
##### Anchors
There is a new config setting that is recommended to enable warnings
for:
```yaml
validation:
anchors: warn
```
Example of a warning that this can produce:
```text
WARNING - Doc file 'foo/example.md' contains a link '../bar.md#some-heading', but the doc 'foo/bar.md' does not contain an anchor '#some-heading'.
```
Any of the below methods of declaring an anchor will be detected by
MkDocs:
```markdown
#### Heading producing an anchor
#### Another heading {#custom-anchor-for-heading-using-attr-list}
<a id="raw-anchor"></a>
[](){#markdown-anchor-using-attr-list}
```
Plugins and extensions that insert anchors, in order to be compatible
with this, need to be developed as treeprocessors that insert `etree`
elements as their mode of operation, rather than raw HTML which is
undetectable for this purpose.
If you as a user are dealing with falsely reported missing anchors and
there's no way to resolve this, you can choose to disable these messages
by setting this option to `ignore` (and they are at INFO level by
default anyway).
See
[**documentation**](https://www.mkdocs.org/user-guide/configuration/#validation).
Context: [#​3463](https://togithub.com/mkdocs/mkdocs/issues/3463)
Other changes:
- When the `nav` config is not specified at all, the `not_in_nav`
setting (originally added in 1.5.0) gains an additional behavior:
documents covered by `not_in_nav` will not be part of the automatically
deduced navigation. Context:
[#​3443](https://togithub.com/mkdocs/mkdocs/issues/3443)
- Fix: the `!relative` YAML tag for `markdown_extensions` (originally
added in 1.5.0) - it was broken in many typical use cases.
See
[**documentation**](https://www.mkdocs.org/user-guide/configuration/#paths-relative-to-the-current-file-or-site).
Context: [#​3466](https://togithub.com/mkdocs/mkdocs/issues/3466)
- Config validation now exits on first error, to avoid showing bizarre
secondary errors. Context:
[#​3437](https://togithub.com/mkdocs/mkdocs/issues/3437)
- MkDocs used to shorten error messages for unexpected errors such as
"file not found", but that is no longer the case, the full error message
and stack trace will be possible to see (unless the error has a proper
handler, of course). Context:
[#​3445](https://togithub.com/mkdocs/mkdocs/issues/3445)
#### Upgrades for plugin developers
##### Plugins can add multiple handlers for the same event type, at
multiple priorities
See
[`mkdocs.plugins.CombinedEvent`](https://www.mkdocs.org/dev-guide/plugins/#mkdocs.plugins.CombinedEvent)
in
[**documentation**](https://www.mkdocs.org/dev-guide/plugins/#event-priorities).
Context: [#​3448](https://togithub.com/mkdocs/mkdocs/issues/3448)
##### Enabling true generated files and expanding the
[`File`](https://www.mkdocs.org/dev-guide/api/#mkdocs.structure.files.File)
API
See
[**documentation**](https://www.mkdocs.org/dev-guide/api/#mkdocs.structure.files.File).
- There is a new pair of attributes
[`File.content_string`](https://www.mkdocs.org/dev-guide/api/#mkdocs.structure.files.File.content_string]/\[\`content_bytes\`]\[mkdocs.structure.files.File.content_bytes)
that becomes the official API for obtaining the content of a file and is
used by MkDocs itself.
This replaces the old approach where one had to manually read the file
located at
[`File.abs_src_path`](https://www.mkdocs.org/dev-guide/api/#mkdocs.structure.files.File.abs_src_path),
although that is still the primary action that these new attributes do
under the hood.
- The content of a `File` can be backed by a string and no longer has to
be a real existing file at `abs_src_path`.
It is possible to **set** the attribute `File.content_string` or
`File.content_bytes` and it will take precedence over `abs_src_path`.
Further, `abs_src_path` is no longer guaranteed to be present and can be
`None` instead. MkDocs itself still uses physical files in all cases,
but eventually plugins will appear that don't populate this attribute.
- There is a new constructor
[`File.generated()`](https://www.mkdocs.org/dev-guide/api/#mkdocs.structure.files.File.generated)
that should be used by plugins instead of the `File()` constructor. It
is much more convenient because one doesn't need to manually look up the
values such as `docs_dir` and `use_directory_urls`. Its signature is one
of:
```python
f = File.generated(config: MkDocsConfig, src_uri: str, content: str |
bytes)
f = File.generated(config: MkDocsConfig, src_uri: str, abs_src_path:
str)
```
This way, it is now extremely easy to add a virtual file even from a
hook:
```python
def on_files(files: Files, config: MkDocsConfig):
files.append(File.generated(config, 'fake/path.md', content="Hello,
world!"))
```
For large content it is still best to use physical files, but one no
longer needs to manipulate the path by providing a fake unused
`docs_dir`.
- There is a new attribute
[`File.generated_by`](https://www.mkdocs.org/dev-guide/api/#mkdocs.structure.files.File.generated_by)
that arose by convention - for generated files it should be set to the
name of the plugin (the key in the `plugins:` collection) that produced
this file. This attribute is populated automatically when using the
`File.generated()` constructor.
- It is possible to set the
[`edit_uri`](https://www.mkdocs.org/dev-guide/api/#mkdocs.structure.files.File.edit_uri)
attribute of a `File`, for example from a plugin or hook, to make it
different from the default (equal to `src_uri`), and this will be
reflected in the edit link of the document. This can be useful because
some pages aren't backed by a real file and are instead created
dynamically from some other source file or script. So a hook could set
the `edit_uri` to that source file or script accordingly.
- The `File` object now stores its original `src_dir`, `dest_dir`,
`use_directory_urls` values as attributes.
- Fields of `File` are computed on demand but cached. Only the three
above attributes are primary ones, and partly also
[`dest_uri`](https://www.mkdocs.org/dev-guide/api/#mkdocs.structure.files.File.dest_uri).
This way, it is possible to, for example, overwrite `dest_uri` of a
`File`, and `abs_dest_path` will be calculated based on it. However you
need to clear the attribute first using `del f.abs_dest_path`, because
the values are cached.
- `File` instances are now hashable (can be used as keys of a `dict`).
Two files can no longer be considered "equal" unless it's the exact same
instance of `File`.
Other changes:
- The internal storage of `File` objects inside a `Files` object has
been reworked, so any plugins that choose to access `Files._files` will
get a deprecation warning.
- The order of `File` objects inside a `Files` collection is no longer
significant when automatically inferring the `nav`. They get forcibly
sorted according to the default alphabetic order.
Context: [#​3451](https://togithub.com/mkdocs/mkdocs/issues/3451),
[#​3463](https://togithub.com/mkdocs/mkdocs/issues/3463)
#### Hooks and debugging
- Hook files can now import adjacent \*.py files using the `import`
statement. Previously this was possible to achieve only through a
`sys.path` workaround. See the new mention in
[documentation](https://www.mkdocs.org/user-guide/configuration/#hooks).
Context: [#​3568](https://togithub.com/mkdocs/mkdocs/issues/3568)
- Verbose `-v` log shows the sequence of plugin events in more detail -
shows each invoked plugin one by one, not only the event type. Context:
[#​3444](https://togithub.com/mkdocs/mkdocs/issues/3444)
#### Deprecations
- Python 3.7 is no longer supported, Python 3.12 is officially
supported. Context:
[#​3429](https://togithub.com/mkdocs/mkdocs/issues/3429)
- The theme config file `mkdocs_theme.yml` no longer executes YAML tags.
Context: [#​3465](https://togithub.com/mkdocs/mkdocs/issues/3465)
- The plugin event `on_page_read_source` is soft-deprecated because
there is always a better alternative to it (see the new `File` API or
just `on_page_markdown`, depending on the desired interaction).
When multiple plugins/hooks apply this event handler, they trample over
each other, so now there is a warning in that case.
See
[**documentation**](https://www.mkdocs.org/dev-guide/plugins/#on_page_read_source).
Context: [#​3503](https://togithub.com/mkdocs/mkdocs/issues/3503)
##### API deprecations
- It is no longer allowed to set `File.page` to a type other than `Page`
or a subclass thereof. Context:
[#​3443](https://togithub.com/mkdocs/mkdocs/issues/3443) -
following the deprecation in version 1.5.3 and
[#​3381](https://togithub.com/mkdocs/mkdocs/issues/3381).
- `Theme._vars` is deprecated - use `theme['foo']` instead of
`theme._vars['foo']`
- `utils`: `modified_time()`, `get_html_path()`, `get_url_path()`,
`is_html_file()`, `is_template_file()` are removed. `path_to_url()` is
deprecated.
- `LiveReloadServer.watch()` no longer accepts a custom callback.
Context: [#​3429](https://togithub.com/mkdocs/mkdocs/issues/3429)
#### Misc
- The `sitemap.xml.gz` file is slightly more reproducible and no longer
changes on every build, but instead only once per day (upon a date
change). Context:
[#​3460](https://togithub.com/mkdocs/mkdocs/issues/3460)
Other small improvements; see [commit
log](https://togithub.com/mkdocs/mkdocs/compare/1.5.3...1.6.0).
### [`v1.5.3`](https://togithub.com/mkdocs/mkdocs/releases/tag/1.5.3)
[Compare
Source](https://togithub.com/mkdocs/mkdocs/compare/1.5.2...1.5.3)
- Fix `mkdocs serve` sometimes locking up all browser tabs when
navigating quickly
([#​3390](https://togithub.com/mkdocs/mkdocs/issues/3390))
- Add many new supported languages for "search" plugin - update
lunr-languages to 1.12.0
([#​3334](https://togithub.com/mkdocs/mkdocs/issues/3334))
- Bugfix (regression in 1.5.0): In "readthedocs" theme the styling of
"breadcrumb navigation" was broken for nested pages
([#​3383](https://togithub.com/mkdocs/mkdocs/issues/3383))
- Built-in themes now also support Chinese (Traditional, Taiwan)
language
([#​3370](https://togithub.com/mkdocs/mkdocs/issues/3370))
- Plugins can now set `File.page` to their own subclass of `Page`. There
is also now a warning if `File.page` is set to anything other than a
strict subclass of `Page`.
([#​3367](https://togithub.com/mkdocs/mkdocs/issues/3367),
[#​3381](https://togithub.com/mkdocs/mkdocs/issues/3381))
Note that just instantiating a `Page` [sets the file
automatically](f94ab3f62d/mkdocs/structure/pages.py (L34)),
so care needs to be taken not to create an unneeded `Page`.
Other small improvements; see [commit
log](https://togithub.com/mkdocs/mkdocs/compare/1.5.2...1.5.3).
### [`v1.5.2`](https://togithub.com/mkdocs/mkdocs/releases/tag/1.5.2)
[Compare
Source](https://togithub.com/mkdocs/mkdocs/compare/1.5.1...1.5.2)
- Bugfix (regression in 1.5.0): Restore functionality of
`--no-livereload`.
([#​3320](https://togithub.com/mkdocs/mkdocs/issues/3320))
- Bugfix (regression in 1.5.0): The new page title detection would
sometimes be unable to drop anchorlinks - fix that.
([#​3325](https://togithub.com/mkdocs/mkdocs/issues/3325))
- Partly bring back pre-1.5 API: `extra_javascript` items will once
again be mostly strings, and only sometimes `ExtraStringValue` (when the
extra `script` functionality is used).
Plugins should be free to append strings to `config.extra_javascript`,
but when reading the values, they must still make sure to read it as
`str(value)` in case it is an `ExtraScriptValue` item. For querying the
attributes such as `.type` you need to check `isinstance` first. Static
type checking will guide you in that.
([#​3324](https://togithub.com/mkdocs/mkdocs/issues/3324))
See [commit
log](https://togithub.com/mkdocs/mkdocs/compare/1.5.1...1.5.2).
### [`v1.5.1`](https://togithub.com/mkdocs/mkdocs/releases/tag/1.5.1)
[Compare
Source](https://togithub.com/mkdocs/mkdocs/compare/1.5.0...1.5.1)
- Bugfix (regression in 1.5.0): Make it possible to treat
`ExtraScriptValue` as a path. This lets some plugins still work despite
the breaking change.
- Bugfix (regression in 1.5.0): Prevent errors for special setups that
have 3 conflicting files, such as `index.html`, `index.md` *and*
`README.md`
([#​3314](https://togithub.com/mkdocs/mkdocs/issues/3314))
See [commit
log](https://togithub.com/mkdocs/mkdocs/compare/1.5.0...1.5.1).
</details>
---
### Configuration
📅 **Schedule**: Branch creation - "before 4am on Monday" (UTC),
Automerge - At any time (no schedule defined).
🚦 **Automerge**: Disabled by config. Please merge this manually once you
are satisfied.
♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the
rebase/retry checkbox.
🔕 **Ignore**: Close this PR and you won't be reminded about this update
again.
---
- [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check
this box
---
This PR was generated by [Mend
Renovate](https://www.mend.io/free-developer-tools/renovate/). View the
[repository job log](https://developer.mend.io/github/astral-sh/ruff).
<!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzOC4yMC4xIiwidXBkYXRlZEluVmVyIjoiMzguMjAuMSIsInRhcmdldEJyYW5jaCI6Im1haW4iLCJsYWJlbHMiOlsiaW50ZXJuYWwiXX0=-->
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
In most cases we should suggest a ternary operator, but there are three
edge cases where a binary operator is more appropriate.
Given an if-else block of the form
```python
if test:
target_var = body_value
else:
target_var = else_value
```
This PR updates the check for SIM108 to the following:
- If `test == body_value` and preview enabled, suggest to replace with
`target_var = test or else_value`
- If `test == not body_value` and preview enabled, suggest to replace
with `target_var = body_value and else_value`
- If `not test == body_value` and preview enabled, suggest to replace
with `target_var = body_value and else_value`
- Otherwise, suggest to replace with `target_var = body_value if test
else else_value`
Closes#12189.
## Summary
Adding parentheses to a tuple in a subscript with elements that include
slice expressions causes a syntax error. For example, `d[(1,2,:)]` is a
syntax error.
So, when `lint.ruff.parenthesize-tuple-in-subscript = true` and the
tuple includes a slice expression, we skip this check and fix.
Closes#12766.
> ~Builtins are also more efficient than `for` loops.~
Let's not promise performance because this code transformation does not
deliver.
Benchmark written by @dcbaker
> `any()` seems to be about 1/3 as fast (Python 3.11.9, NixOS):
```python
loop = 'abcdef'.split()
found = 'f'
nfound = 'g'
def test1():
for x in loop:
if x == found:
return True
return False
def test2():
return any(x == found for x in loop)
def test3():
for x in loop:
if x == nfound:
return True
return False
def test4():
return any(x == nfound for x in loop)
if __name__ == "__main__":
import timeit
print('for loop (found) :', timeit.timeit(test1))
print('for loop (not found):', timeit.timeit(test3))
print('any() (found) :', timeit.timeit(test2))
print('any() (not found) :', timeit.timeit(test4))
```
```
for loop (found) : 0.051076093994197436
for loop (not found): 0.04388196699437685
any() (found) : 0.15422860698890872
any() (not found) : 0.15568504799739458
```
I have retested with longer lists and on multiple Python versions with
similar results.
Implements the new fixable lint rule `RUF031` which checks for the use or omission of parentheses around tuples in subscripts, depending on the setting `lint.ruff.parenthesize-tuple-in-getitem`. By default, the use of parentheses is considered a violation.
## Summary
Follow-up from https://github.com/astral-sh/ruff/pull/12725, this is
just a small refactor to use a wrapper struct instead of type alias for
workspace settings index. This avoids the need to have the
`register_workspace_settings` as a static method on `Index` and instead
is a method on the new struct itself.
## Summary
This PR updates the server to ignore non-file workspace URL.
This is to avoid crashing the server if the URL scheme is not "file".
We'd still raise an error if the URL to file path conversion fails.
Also, as per the docs of
[`to_file_path`](https://docs.rs/url/2.5.2/url/struct.Url.html#method.to_file_path):
> Note: This does not actually check the URL’s scheme, and may give
nonsensical results for other schemes. It is the user’s responsibility
to check the URL’s scheme before calling this.
resolves: #12660
## Test Plan
I'm not sure how to test this locally but the change is small enough to
validate on its own.
## Summary
This PR updates the Renovate config to account for the
`requirements*.txt` files in `docs/` directory.
The `mkdocs-material` upgrade is ignored because we use commit SHA for
the insider version and it should match the corresponding public version
as per the docs:
https://squidfunk.github.io/mkdocs-material/insiders/upgrade/
(`9.x.x-insiders-4.x.x`).
## Test Plan
```console
❯ renovate-config-validator
(node:83193) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
INFO: Validating .github/renovate.json5
INFO: Config validated successfully
```
## Summary
This PR updates the `red_knot` CLI to make the subcommand optional.
## Test Plan
Run the following commands:
* `cargo run --bin red_knot --
--current-directory=~/playground/ruff/type_inference` (no subcommand
requirement)
* `cargo run --bin red_knot -- server` (should start the server)
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Resolves#12636
Consider docstrings which begin with the word "Returns" as having
satisfactorily documented they're returns. For example
```python
def f():
"""Returns 1."""
return 1
```
is valid.
## Test Plan
Added example to test fixture.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
Removes set comprehension as a violation for `sum` when checking `C419`,
because set comprehension may de-duplicate entries in a generator,
thereby modifying the value of the sum.
Closes#12690.
## Summary
Running `mkdocs server -f mkdocs.insiders.yml` gave warnings about these
broken links.
## Test plan
I built the docs locally and verified that the updated links work
properly.
## Summary
Make it a violation of `C409` to call `tuple` with a list or set
comprehension, and
implement the (unsafe) fix of calling the `tuple` with the underlying
generator instead.
Closes#12648.
## Test Plan
Test fixture updated, cargo test, docs checked for updated description.
## Summary
Adds autofix for `RUF007`
## Test Plan
`cargo test`, however I get errors for `test resolver::tests::symlink
... FAILED` which seems to not be my fault
Since `ruff-lsp` has been (semi-)deprecated for sometime, it wouldn't
make sense to mention it in the most prominent sections of the `README`.
Instead, they should point to the new <i>[Editor
Integrations](https://docs.astral.sh/ruff/editors/)</i> documentation
page.
## Summary
Fixes#12630.
DOC501 and DOC502 now understand functions with constructs like this to
be explicitly raising `TypeError` (which should be documented in a
function's docstring):
```py
try:
foo():
except TypeError:
...
raise
```
I made an exception for `Exception` and `BaseException`, however.
Constructs like this are reasonably common, and I don't think anybody
would say that it's worth putting in the docstring that it raises "some
kind of generic exception":
```py
try:
foo()
except BaseException:
do_some_logging()
raise
```
## Test Plan
`cargo test -p ruff_linter --lib`
## Summary
Please see
https://github.com/astral-sh/ruff/pull/12605#discussion_r1699957443 for
a description of the issue.
They way I fixed it is to get the *last* timeout item in the `with`, and
if it's an `async with` and there are items after it, then don't trigger
the lint.
## Test Plan
Updated the fixture with some more cases.
Changes the red-knot benchmark to run on the stdlib "tomllib" library
(which is self-contained, four files, uses type annotations) instead of
on very small bits of handwritten code.
Also remove the `without_parse` benchmark: now that we are running on
real code that uses typeshed, we'd either have to pre-parse all of
typeshed (slow) or find some way to determine which typeshed modules
will be used by the benchmark (not feasible with reasonable complexity.)
## Test Plan
`cargo bench -p ruff_benchmark --bench red_knot`
## Summary
This PR separates the current `red_knot` crate into two crates:
1. `red_knot` - This will be similar to the `ruff` crate, it'll act as
the CLI crate
2. `red_knot_workspace` - This includes everything except for the CLI
functionality from the existing `red_knot` crate
Note that the code related to the file watcher is in
`red_knot_workspace` for now but might be required to extract it out in
the future.
The main motivation for this change is so that we can have a `red_knot
server` command. This makes it easier to test the server out without
making any changes in the VS Code extension. All we need is to specify
the `red_knot` executable path in `ruff.path` extension setting.
## Test Plan
- `cargo build`
- `cargo clippy --workspace --all-targets --all-features`
- `cargo shear --fix`
## Summary
There's still a problem here. Given:
```python
class Class():
pass
# comment
# another comment
a = 1
```
We only add one newline before `a = 1` on the first pass, because
`max_precedling_blank_lines` is 1... We then add the second newline on
the second pass, so it ends up in the right state, but the logic is
clearly wonky.
Closes https://github.com/astral-sh/ruff/issues/11508.
I hit this `todo!` trying to run type inference over some real modules.
Since it's a one-liner to implement it, I just did that rather than
changing to `Type::Unknown`.
## Summary
@zanieb noticed while we were discussing #12595 that this flag is now
unnecessary, so remove it and the flags which reference it.
## Test Plan
Question for maintainers: is there a test to add *or* remove here? (I’ve
opened this as a draft PR with that in view!)
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
- Add the popular LLM Ops project Dify to the user list in Readme, as
Dify introduced Ruff for lining since Feb 2024 in
https://github.com/langgenius/dify/pull/2366
## Summary
This pull request adds support for logging via `$/logTrace` RPC
messages. It also enables that code path for when a client is Zed editor
or VS Code (as there's no way for us to generically tell whether a client prefers
`$/logTrace` over stderr.
Related to: #12523
## Test Plan
I've built Ruff from this branch and tested it manually with Zed.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Extend `flake8-builtins` to imports, lambda-arguments, and modules to be
consistent with original checker
[flake8_builtins](https://github.com/gforcada/flake8-builtins/blob/main/flake8_builtins.py).
closes#12540
## Details
- Implement builtin-import-shadowing (A004)
- Stop tracking imports shadowing in builtin-variable-shadowing (A001)
in preview mode.
- Implement builtin-lambda-argument-shadowing (A005)
- Implement builtin-module-shadowing (A006)
- Add new option `linter.flake8_builtins.builtins_allowed_modules`
## Test Plan
cargo test
## Summary
If an import is marked as "required", we should never flag it as unused.
In practice, this is rare, since required imports are typically used for
`__future__` annotations, which are always considered "used".
Closes https://github.com/astral-sh/ruff/issues/12458.
Now that we have builtins available, resolve some simple cases to the
right builtin type.
We should also adjust the display for types to include their module
name; that's not done yet here.
## Summary
This PR adds support for untitled files in the Red Knot project.
Refer to the [design
discussion](https://github.com/astral-sh/ruff/discussions/12336) for
more details.
### Changes
* The `parsed_module` always assumes that the `SystemVirtual` path is of
`PySourceType::Python`.
* For the module resolver, as suggested, I went ahead by adding a new
`SystemOrVendoredPath` enum and renamed `FilePathRef` to
`SystemOrVendoredPathRef` (happy to consider better names here).
* The `file_to_module` query would return if it's a
`FilePath::SystemVirtual` variant because a virtual file doesn't belong
to any module.
* The sync implementation for the system virtual path is basically the
same as that of system path except that it uses the
`virtual_path_metadata`. The reason for this is that the system
(language server) would provide the metadata on whether it still exists
or not and if it exists, the corresponding metadata.
For point (1), VS Code would use `Untitled-1` for Python files and
`Untitled-1.ipynb` for Jupyter Notebooks. We could use this distinction
to determine whether the source type is `Python` or `Ipynb`.
## Test Plan
Added test cases in #12526
Extend red-knot type inference to cover all syntax, so that inferring
types for a scope gives all expressions a type. This means we can run
the red-knot semantic lint on all Python code without panics. It also
means we can infer types for `builtins.pyi` without panics.
To keep things simple, this PR intentionally doesn't add any new type
inference capabilities: the expanded coverage is all achieved with
`Type::Unknown`. But this puts the skeleton in place for adding better
inference of all these language features.
I also had to add basic Salsa cycle recovery (with just `Type::Unknown`
for now), because some `builtins.pyi` definitions are cyclic.
To test this, I added a comprehensive corpus of test snippets sourced
from Cinder under [MIT
license](https://github.com/facebookincubator/cinder/blob/cinder/3.10/cinderx/LICENSE),
which matches Ruff's license. I also added to this corpus some
additional snippets for newer language features: all the
`27_func_generic_*` and `73_class_generic_*` files, as well as
`20_lambda_default_arg.py`, and added a test which runs semantic-lint
over all these files. (The test doesn't assert the test-corpus files are
lint-free; just that they are able to lint without a panic.)
## Summary
Right now, in the isort comment model, there's nowhere for trailing
comments on the _statement_ to go, as in:
```python
from mylib import (
MyClient,
MyMgmtClient,
) # some comment
```
If the comment is on the _alias_, we do preserve it, because we attach
it to the alias, as in:
```python
from mylib import (
MyClient,
MyMgmtClient, # some comment
)
```
Similarly, if the comment is trailing on an import statement
(non-`from`), we again attach it to the alias, because it can't be
parenthesized, as in:
```python
import foo # some comment
```
This PR adds logic to track and preserve those trailing comments.
We also no longer drop several other comments, like:
```python
from mylib import (
# some comment
MyClient
)
```
Closes https://github.com/astral-sh/ruff/issues/12487.
## Summary
When working on improving Ruff integration with Zed I noticed that it
errors out when we try to resolve a code action of a `QUICKFIX` kind;
apparently, per @dhruvmanila we shouldn't need to resolve it, as the
edit is provided in the initial response for the code action. However,
it's possible for the `resolve` call to fill out other fields (such as
`command`).
AFAICT Helix also tries to resolve the code actions unconditionally (as
in, when either `edit` or `command` is absent); so does VSC. They can
still apply the quickfixes though, as they do not error out on a failed
call to resolve code actions - Zed does. Following suit on Zed's side
does not cut it though, as we still get a log request from Ruff for that
failure (which is surfaced in the UI).
There are also other language servers (such as
[rust-analyzer](c1c9e10f72/crates/rust-analyzer/src/handlers/request.rs (L1257)))
that fill out both `command` and `edit` fields as a part of code action
resolution.
This PR makes the resolve calls for quickfix actions return the input
value.
## Test Plan
N/A
Add support for while-loop control flow.
This doesn't yet include general support for terminals and reachability;
that is wider than just while loops and belongs in its own PR.
This also doesn't yet add support for cyclic definitions in loops; that
comes with enough of its own complexity in Salsa that I want to handle
it separately.
Add a lint rule to detect if a name is definitely or possibly undefined
at a given usage.
If I create the file `undef/main.py` with contents:
```python
x = int
def foo():
z
return x
if flag:
y = x
y
```
And then run `cargo run --bin red_knot -- --current-directory
../ruff-examples/undef`, I get the output:
```
Name 'z' used when not defined.
Name 'flag' used when not defined.
Name 'y' used when possibly not defined.
```
If I modify the file to add `y = 0` at the top, red-knot re-checks it
and I get the new output:
```
Name 'z' used when not defined.
Name 'flag' used when not defined.
```
Note that `int` is not flagged, since it's a builtin, and `return x` in
the function scope is not flagged, since it refers to the global `x`.
## Summary
This PR fixes a bug to raise a syntax error when an unparenthesized
generator expression is used as an argument to a call when there are
more than one argument.
For reference, the grammar is:
```
primary:
| ...
| primary genexp
| primary '(' [arguments] ')'
| ...
genexp:
| '(' ( assignment_expression | expression !':=') for_if_clauses ')'
```
The `genexp` requires the parenthesis as mentioned in the grammar. So,
the grammar for a call expression is either a name followed by a
generator expression or a name followed by a list of argument. In the
former case, the parenthesis are excluded because the generator
expression provides them while in the later case, the parenthesis are
explicitly provided for a list of arguments which means that the
generator expression requires it's own parenthesis.
This was discovered in https://github.com/astral-sh/ruff/issues/12420.
## Test Plan
Add test cases for valid and invalid syntax.
Make sure that the parser from CPython also raises this at the parsing
step:
```console
$ python3.13 -m ast parser/_.py
File "parser/_.py", line 1
total(1, 2, x for x in range(5), 6)
^^^^^^^^^^^^^^^^^^^
SyntaxError: Generator expression must be parenthesized
$ python3.13 -m ast parser/_.py
File "parser/_.py", line 1
sum(x for x in range(10), 10)
^^^^^^^^^^^^^^^^^^^^
SyntaxError: Generator expression must be parenthesized
```
## Summary
This PR removes unused dependencies from `fuzz` crate and syncs the
`similar` crate to the workspace version. This will help in resolve
https://github.com/astral-sh/ruff/pull/12442.
## Test Plan
Build the fuzz crate:
For Mac (it requires the nightly build):
```
cargo +nightly fuzz build
```
## Summary
Fix panic reported in #12428. Where a string would sometimes get split
within a character boundary. This bypasses the need to split the string.
This does not guarantee the correct formatting of the docstring, but
neither did the previous implementation.
Resolves#12428
## Test Plan
Test case added to fixture
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Just updating the README to reflect that IBM has been using ruff for a
year already: https://github.com/Qiskit/qiskit/pull/10116.
## Summary
These are the first rules implemented as part of #458, but I plan to
implement more.
Specifically, this implements `docstring-missing-exception` which checks
for raised exceptions not documented in the docstring, and
`docstring-extraneous-exception` which checks for exceptions in the
docstring not present in the body.
## Test Plan
Test fixtures added for both google and numpy style.
When poring over traces, the ones that just include a definition or
symbol or expression ID aren't very useful, because you don't know which
file it comes from. This adds that information to the trace.
I guess the downside here is that if calling `.file(db)` on a
scope/definition/expression would execute other traced code, it would be
marked as outside the span? I don't think that's a concern, because I
don't think a simple field access on a tracked struct should ever
execute our code. If I'm wrong and this is a problem, it seems like the
tracing crate has this feature where you can record a field as
`tracing::field::Empty` and then fill in its value later with
`span.record(...)`, but when I tried this it wasn't working for me, not
sure why.
I think there's a lot more we can do to make our tracing output more
useful for debugging (e.g. record an event whenever a
definition/symbol/expression/use id is created with the details of that
definition/symbol/expression/use), this is just dipping my toes in the
water.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR updates D301 rule to allow inclduing escaped docstring, e.g.
`\"""Foo.\"""` or `\"\"\"Bar.\"\"\"`, within a docstring.
Related issue: #12152
## Test Plan
Add more test cases to D301.py and update the snapshot file.
<!-- How was it tested? -->
In preparation for supporting resolving builtins, simplify the benchmark
so it doesn't look up `str`, which is actually a complex builtin to deal
with because it inherits `Sequence[str]`.
Co-authored-by: Alex Waygood <alex.waygood@gmail.com>
Per comments in https://github.com/astral-sh/ruff/pull/12269, "module
global" is kind of long, and arguably redundant.
I tried just using "module" but there were too many cases where I felt
this was ambiguous. I like the way "global" works out better, though it
does require an understanding that in Python "global" generally means
"module global" not "globally global" (though in a sense module globals
are also globally global since modules are singletons).
Support falling back to a global name lookup if a name isn't defined in
the local scope, in the cases where that is correct according to Python
semantics.
In class scopes, a name lookup checks the local namespace first, and if
the name isn't found there, looks it up in globals.
In function scopes (and type parameter scopes, which are function-like),
if a name has any definitions in the local scope, it is a local, and
accessing it when none of those definitions have executed yet just
results in an `UnboundLocalError`, it does not fall back to a global. If
the name does not have any definitions in the local scope, then it is an
implicit global.
Public symbol type lookups never include such a fall back. For example,
if a name is not defined in a class scope, it is not available as a
member on that class, even if a name lookup within the class scope would
have fallen back to a global lookup.
This PR makes the `@override` lint rule work again.
Not yet included/supported in this PR:
* Support for free variables / closures: a free symbol in a nested
function-like scope referring to a symbol in an outer function-like
scope.
* Support for `global` and `nonlocal` statements, which force a symbol
to be treated as global or nonlocal even if it has definitions in the
local scope.
* Module-global lookups should fall back to builtins if the name isn't
found in the module scope.
I would like to expose nicer APIs for the various kinds of symbols
(explicit global, implicit global, free, etc), but this will also wait
for a later PR, when more kinds of symbols are supported.
We can't just directly update the `release.yml` file because that's
auto-generated using `cargo-dist`. So, update the permissions in
`Cargo.toml` and then use `cargo dist generate` to make sure there's no
diff.
Adds inference tests sufficient to give full test coverage of the
`UseDefMapBuilder::merge` method.
In the process I realized that we could implement visiting of if
statements in `SemanticBuilder` with fewer `snapshot`, `restore`, and
`merge` operations, so I restructured that visit a bit.
I also found one correctness bug in the `merge` method (it failed to
extend the given snapshot with "unbound" for any missing symbols,
meaning we would just lose the fact that the symbol could be unbound in
the merged-in path), and two efficiency bugs (if one of the ranges to
merge is empty, we can just use the other one, no need for copies, and
if the ranges are overlapping -- which can occur with nested branches --
we can still just merge them with no copies), and fixed all three.
## Summary
This PR adds VS Code specific extension settings in the online
documentation.
The content is basically taken from the `package.json` file in the
`ruff-vscode` repository.
## Summary
Following the stabilization of the Ruff language server, we need to
update our versioning policy to account for any changes in it. This
could be server settings, capability, etc.
This PR also adds a new section for the VS Code extension which is
adopted from [Biome's versioning
policy](https://biomejs.dev/internals/versioning/#visual-studio-code-extension)
for the same.
---------
Co-authored-by: Zanie Blue <contact@zanie.dev>
## Summary
This PR allows us to fix both expressions in `foo == "a" or foo == "b"
or ("c" != bar and "d" != bar)`, but limits the rule to consecutive
comparisons, following https://github.com/astral-sh/ruff/issues/7797.
I think this logic was _probably_ added because of
https://github.com/astral-sh/ruff/pull/12368 -- the intent being that
we'd replace the _entire_ expression.
## Summary
This PR adds documentation for the Ruff language server.
It mainly does the following:
1. Combines various READMEs containing instructions for different editor
setup in their respective section on the online docs
2. Provide an enumerated list of server settings. Additionally, it also
provides a section for VS Code specific options.
3. Adds a "Features" section which enumerates all the current
capabilities of the native server
For (2), the settings documentation is done manually but a future
improvement (easier after `ruff-lsp` is deprecated) is to move the docs
in to Rust struct and generate the documentation from the code itself.
And, the VS Code extension specific options can be generated by diffing
against the `package.json` in `ruff-vscode` repository.
### Structure
1. Setup: This section contains the configuration for setting up the
language server for different editors
2. Features: This section contains a list of capabilities provided by
the server along with short GIF to showcase it
3. Settings: This section contains an enumerated list of settings in a
similar format to the one for the linter / formatter
4. Migrating from `ruff-lsp`
> [!NOTE]
>
> The settings page is manually written but could possibly be
auto-generated via a macro similar to `OptionsMetadata` on the
`ClientSettings` struct
resolves: #11217
## Test Plan
Generate and open the documentation locally using:
1. `python scripts/generate_mkdocs.py`
2. `mkdocs serve -f mkdocs.insiders.yml`
## Summary
This PR removes the requirement of `--preview` flag to run the `ruff
server` and instead considers it to be an indicator to turn on preview
mode for the linter and the formatter.
resolves: #12161
## Test Plan
Add test cases to assert the `preview` value is updated accordingly.
In an editor context, I used the local `ruff` executable in Neovim with
the `--preview` flag and verified that the preview-only violations are
being highlighted.
Running with:
```lua
require('lspconfig').ruff.setup({
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
})
```
The screenshot shows that `E502` is highlighted with the below config in
`pyproject.toml`:
<img width="877" alt="Screenshot 2024-07-17 at 16 43 09"
src="https://github.com/user-attachments/assets/c7016ef3-55b1-4a14-bbd3-a07b1bcdd323">
## Summary
This PR updates the settings index building logic in the language server
to consider the fallback settings for applying ignore filters in
`WalkBuilder` and the exclusion via `exclude` / `extend-exclude`.
This flow matches the one in the `ruff` CLI where the root settings is
built by (1) finding the workspace setting in the ancestor directory (2)
finding the user configuration if that's missing and (3) fallback to
using the default configuration.
Previously, the index building logic was being executed before (2) and
(3). This PR reverses the logic so that the exclusion /
`respect_gitignore` is being considered from the default settings if
there's no workspace / user settings. This has the benefit that the
server no longer enters the `.git` directory or any other excluded
directory when a user opens a file in the home directory.
Related to #11366
## Test plan
Opened a test file from the home directory and confirmed with the debug
trace (removed in #12360) that the server excludes the `.git` directory
when indexing.
## Summary
Add new rule and implement for `unnecessary default type arguments`
under the `UP` category (`UP043`).
```py
// < py313
Generator[int, None, None]
// >= py313
Generator[int]
```
I think that as Python 3.13 develops, there might be more default type
arguments added besides `Generator` and `AsyncGenerator`. So, I made
this more flexible to accommodate future changes.
related issue: #12286
## Test Plan
snapshot included..!
## Summary
Pretty sure this should still be an error, but also, I think I added
this because of ecosystem CI? So want to see what pops up.
Closes https://github.com/astral-sh/ruff/issues/12164.
## Summary
This is the _intended_ default that PEP 597 _wants_, but it's not
backwards compatible. The fix is already unsafe, so it's better for us
to recommend the desired and expected behavior.
Closes https://github.com/astral-sh/ruff/issues/12069.
Improve semantic index tests with better assertions than just `.len()`,
and re-add use-definition test that was commented out in the switch to
Salsa initially.
Implements definition-level type inference, with basic control flow
(only if statements and if expressions so far) in Salsa.
There are a couple key ideas here:
1) We can do type inference queries at any of three region
granularities: an entire scope, a single definition, or a single
expression. These are represented by the `InferenceRegion` enum, and the
entry points are the salsa queries `infer_scope_types`,
`infer_definition_types`, and `infer_expression_types`. Generally
per-scope will be used for scopes that we are directly checking and
per-definition will be used anytime we are looking up symbol types from
another module/scope. Per-expression should be uncommon: used only for
the RHS of an unpacking or multi-target assignment (to avoid
re-inferring the RHS once per symbol defined in the assignment) and for
test nodes in type narrowing (e.g. the `test` of an `If` node). All
three queries return a `TypeInference` with a map of types for all
definitions and expressions within their region. If you do e.g.
scope-level inference, when it hits a definition, or an
independently-inferable expression, it should use the relevant query
(which may already be cached) to get all types within the smaller
region. This avoids double-inferring smaller regions, even though larger
regions encompass smaller ones.
2) Instead of building a control-flow graph and lazily traversing it to
find definitions which reach a use of a name (which is O(n^2) in the
worst case), instead semantic indexing builds a use-def map, where every
use of a name knows which definitions can reach that use. We also no
longer track all definitions of a symbol in the symbol itself; instead
the use-def map also records which defs remain visible at the end of the
scope, and considers these the publicly-visible definitions of the
symbol (see below).
Major items left as TODOs in this PR, to be done in follow-up PRs:
1) Free/global references aren't supported yet (only lookup based on
definitions in current scope), which means the override-check example
doesn't currently work. This is the first thing I'll fix as follow-up to
this PR.
2) Control flow outside of if statements and expressions.
3) Type narrowing.
There are also some smaller relevant changes here:
1) Eliminate `Option` in the return type of member lookups; instead
always return `Type::Unbound` for a name we can't find. Also use
`Type::Unbound` for modules we can't resolve (not 100% sure about this
one yet.)
2) Eliminate the use of the terms "public" and "root" to refer to
module-global scope or symbols. Instead consistently use the term
"module-global". It's longer, but it's the clearest, and the most
consistent with typical Python terminology. In particular I don't like
"public" for this use because it has other implications around author
intent (is an underscore-prefixed module-global symbol "public"?). And
"root" is just not commonly used for this in Python.
3) Eliminate the `PublicSymbol` Salsa ingredient. Many non-module-global
symbols can also be seen from other scopes (e.g. by a free var in a
nested scope, or by class attribute access), and thus need to have a
"public type" (that is, the type not as seen from a particular use in
the control flow of the same scope, but the type as seen from some other
scope.) So all symbols need to have a "public type" (here I want to keep
the use of the term "public", unless someone has a better term to
suggest -- since it's "public type of a symbol" and not "public symbol"
the confusion with e.g. initial underscores is less of an issue.) At
least initially, I would like to try not having special handling for
module-global symbols vs other symbols.
4) Switch to using "definitions that reach end of scope" rather than
"all definitions" in determining the public type of a symbol. I'm
convinced that in general this is the right way to go. We may want to
refine this further in future for some free-variable cases, but it can
be changed purely by making changes to the building of the use-def map
(the `public_definitions` index in it), without affecting any other
code. One consequence of combining this with no control-flow support
(just last-definition-wins) is that some inference tests now give more
wrong-looking results; I left TODO comments on these tests to fix them
when control flow is added.
And some potential areas for consideration in the future:
1) Should `symbol_ty` be a Salsa query? This would require making all
symbols a Salsa ingredient, and tracking even more dependencies. But it
would save some repeated reconstruction of unions, for symbols with
multiple public definitions. For now I'm not making it a query, but open
to changing this in future with actual perf evidence that it's better.
## Summary
I believe these should always bind more tightly -- e.g., in:
```python
for _ in bar(baz for foo in [1]):
pass
```
The inner `baz` and `foo` should be considered comprehension variables,
not for loop bindings.
We need to revisit this more holistically. In some of these cases,
`BindingKind` should probably be a flag, not an enum, since the values
aren't mutually exclusive. Separately, we should probably be more
precise in how we set it (e.g., by passing down from the parent rather
than sniffing in `handle_node_store`).
Closes https://github.com/astral-sh/ruff/issues/12339
When there is a function or class definition at the end of a suite
followed by the beginning of an alternative block, we have to insert a
single empty line between them.
In the if-else-statement example below, we insert an empty line after
the `foo` in the if-block, but none after the else-block `foo`, since in
the latter case the enclosing suite already adds empty lines.
```python
if sys.version_info >= (3, 10):
def foo():
return "new"
else:
def foo():
return "old"
class Bar:
pass
```
To do so, we track whether the current suite is the last one in the
current statement with a new option on the suite kind.
Fixes#12199
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR updates the server to build the settings index in parallel using
similar logic as `python_files_in_path`.
This should help with https://github.com/astral-sh/ruff/issues/11366 but
ideally we would want to build it lazily.
## Test Plan
`cargo insta test`
## Summary
I don't know that there's more to do here. We could consider not raising
the violation at all for arguments, but that would have some false
negatives and could also be surprising to users.
Closes https://github.com/astral-sh/ruff/issues/12267.
## Summary
Ensures that, e.g., the following is not considered a
redefinition-without-use:
```python
import contextlib
foo = None
with contextlib.suppress(ImportError):
from some_module import foo
```
Closes https://github.com/astral-sh/ruff/issues/12309.
## Summary
Closes https://github.com/astral-sh/ruff/issues/12291.
## Test Plan
```shell
❯ cargo run check ../uv/foo --select INP
/Users/crmarsh/workspace/uv/foo/bar/baz.py:1:1: INP001 File `/Users/crmarsh/workspace/uv/foo/bar/baz.py` is part of an implicit namespace package. Add an `__init__.py`.
Found 1 error.
```
## Summary
I don't fully understand the purpose of this. In #7905, it was just
copied over from the previous non-preview implementation. But it means
that (e.g.) we don't treat `type(self.foo)` as a type -- which is wrong.
Closes https://github.com/astral-sh/ruff/issues/12290.
## Summary
In order to use single quotes with both the ruff linter and the ruff
formatter,
two different rules must be applied. This was not clear to me when
internet searching "configure ruff single quotes" and it eventually
I filed this issue:
https://github.com/astral-sh/ruff/issues/12003
## Summary
Update the name of `ASYNC109` to match
[upstream](https://flake8-async.readthedocs.io/en/latest/rules.html).
Also update to the functionality to match upstream by supporting
additional context managers from `asyncio` and `anyio`. This doesn't
change any of the detection functionality, but recommends additional
context managers from `asyncio` and `anyio` depending on context.
Part of https://github.com/astral-sh/ruff/issues/12039.
## Test Plan
Added fixture for asyncio recommendation
## Summary
S113 exists because `requests` doesn't have a default timeout, so
request without timeout may hang indefinitely
> B113: Test for missing requests timeout
This plugin test checks for requests or httpx calls without a timeout
specified.
>
> Nearly all production code should use this parameter in nearly all
requests, **Failure to do so can cause your program to hang
indefinitely.**
But httpx has default timeout 5s, so S113 for httpx request without
`timeout` argument is a false positive, only valid case would be
`timeout=None`.
https://www.python-httpx.org/advanced/timeouts/
> HTTPX is careful to enforce timeouts everywhere by default.
>
> The default behavior is to raise a TimeoutException after 5 seconds of
network inactivity.
## Test Plan
snap updated
Tested on Fedora 40 with Podman 5.1.1 and ruff "0.5.0" and "latest".
source: https://unix.stackexchange.com/q/651198
## Error without fix
````
$ podman run --rm -it -v .:/io ghcr.io/astral-sh/ruff:latest check
error: Failed to initialize cache at /io/.ruff_cache: Permission denied (os error 13)
warning: Encountered error: Permission denied (os error 13)
All checks passed!
$ podman run --rm -it -v .:/io ghcr.io/astral-sh/ruff:latest format
error: Failed to initialize cache at /io/.ruff_cache: Permission denied (os error 13)
error: Encountered error: Permission denied (os error 13)
````
## Summary
Running ruff by using a docker container requires `:Z` when mounting the
current directory on Fedora with SELinux and Podman.
## Test Plan
````
$ podman run --rm -it -v .:/io:Z ghcr.io/astral-sh/ruff:latest check
$ podman run --rm -it -v .:/io:Z ghcr.io/astral-sh/ruff:0.5.0 check
````
Intern types using Salsa interning instead of in the `TypeInference`
result.
This eliminates the need for `TypingContext`, and also paves the way for
finer-grained type inference queries.
## Summary
This PR fixes the bug where the server was not considering the
`cells.structure.didOpen` field to sync up the new content of the newly
added cells.
The parameters corresponding to this request provides two fields to get
the newly added cells:
1. `cells.structure.array.cells`: This is a list of `NotebookCell` which
doesn't contain any cell content. The only useful information from this
array is the cell kind and the cell document URI which we use to
initialize the new cell in the index.
2. `cells.structure.didOpen`: This is a list of `TextDocumentItem` which
corresponds to the newly added cells. This actually contains the text
content and the version.
This wasn't a problem before because we initialize the cell with an
empty string and this isn't a problem when someone just creates an empty
cell. But, when someone copy-pastes a cell, the cell needs to be
initialized with the content.
fixes: #12201
## Test Plan
First, let's see the panic in action:
1. Press <kbd>Esc</kbd> to allow using the keyboard to perform cell
actions (move around, copy, paste, etc.)
2. Copy the second cell with <kbd>c</kbd> key
3. Delete the second cell with <kbd>dd</kbd> key
4. Paste the copied cell with <kbd>p</kbd> key
You can see that the content isn't synced up because the `unused-import`
for `sys` is still being highlighted but it's being used in the second
cell. And, the hover isn't working either. Then, as I start editing the
second cell, it panics.
https://github.com/astral-sh/ruff/assets/67177269/fc58364c-c8fc-4c11-a917-71b6dd90c1ef
Now, here's the preview of the fixed version:
https://github.com/astral-sh/ruff/assets/67177269/207872dd-dca6-49ee-8b6e-80435c7ef22e
This reverts commit b28dc9ac14.
We're not ready to stabilize the server yet. There's some pending work
for the VS Code extension and documentation improvements.
This change is to unblock Ruff release.
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This is the implementation for the new rule of `pycodestyle (E204)`. It
follows the guidlines described in the contributing site, and as such it
has a new file named `whitespace_after_decorator.rs`, a new test file
called `E204.py`, and as such invokes the `function` in the `AST
statement checker` for functions and functions in classes. Linking #2402
because it has all the pycodestyle rules.
## Test Plan
<!-- How was it tested? -->
The file E204.py, has a `decorator` defined called wrapper, and this
decorator is used for 2 cases. The first one is when a `function` which
has a `decorator` is called in the file, and the second one is when
there is a `class` and 2 `methods` are defined for the `class` with a
`decorator` attached it.
Test file:
``` python
def foo(fun):
def wrapper():
print('before')
fun()
print('after')
return wrapper
# No error
@foo
def bar():
print('bar')
# E204
@ foo
def baz():
print('baz')
class Test:
# No error
@foo
def bar(self):
print('bar')
# E204
@ foo
def baz(self):
print('baz')
```
I am still new to rust and any suggestion is appreciated. Specially with
the way im using native ruff utilities.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Fixes a few typos and consistency issues in the "Settings"
documentation:
- use "Ruff" consistently in the few places where "ruff" is used
- use double quotes in the few places where single quotes are used
- add backticks around rule codes where they are currently missing
- update a few example values where they are the same as the defaults,
for consistency
2nd commit might be controversial, as there are many options mentioned
where we don't currently link to the documentation sections, so maybe
it's done on purpose, as this will also appear in the JSON schema where
it's not desirable? If that's the case, I can easily drop it.
## Test Plan
Local testing.
## Summary
This PR fixes various bugs for computing the replacement range between
the original and modified source for the language server.
1. When finding the end offset of the source and modified range, we
should apply `zip` on the reversed iterator. The bug was that it was
reversing the already zipped iterator. The problem here is that the
length of both slices aren't going to be the same unless the source
wasn't modified at all. Refer to the [Rust
playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=44f860d31bd26456f3586b6ab530c22f)
where you can see this in action.
2. Skip the first line when computing the start offset because the first
line start value will always be 0 and the default value of the source /
modified range start is also 0. So, comparing 0 and 0 is not useful
which means we can skip the first value.
3. While iterating in the reverse direction, we should only stop if the
line start is strictly less than the source start i.e., we should use
`<` instead of `<=`.
fixes: #12128
## Test Plan
Add test cases where the text is being inserted, deleted, and replaced
between the original and new source code, validate the replacement
ranges.
## Summary
Bandit now also reports `B113` on `httpx`
(https://github.com/PyCQA/bandit/pull/1060). This PR implements the same
logic, to detect missing or `None` timeouts for `httpx` alongside
`requests`.
## Test Plan
Snapshot tests.
Hi all!
## Summary
Fix a typo.
## Test Plan
URL was tested with curl.
Not much left to say, except that I originally saw this issue on the
blog post: https://astral.sh/blog/ruff-v0.5.0
Not sure how it is related to the CHANGELOG.md file, so the post might
need fixing as well.
Thanks for this incredible tool!
Signed-off-by: Thomas Faivre <thomas.faivre@6wind.com>
Closes https://github.com/astral-sh/ruff/issues/12158
Hashing `Path` does not take into account path separators so `foo/bar`
is the same as `foobar` which is no good for our case. I'm guessing this
is an upstream bug, perhaps introduced by
45082b077b?
I'm investigating that further.
## Summary
Follow-up to https://github.com/astral-sh/ruff/pull/12129 to remove the
`demisto/content` from ecosystem checks. The previous PR removed it from
the deprecated script which I didn't notice until recently.
## Test Plan
Ecosystem comment
## Summary
This PR updates the linter, specifically the token-based rules, to work
on the tokens that come after a syntax error.
For context, the token-based rules only diagnose the tokens up to the
first lexical error. This PR builds up an error resilience by
introducing a `TokenIterWithContext` which updates the `nesting` level
and tries to reflect it with what the lexer is seeing. This isn't 100%
accurate because if the parser recovered from an unclosed parenthesis in
the middle of the line, the context won't reduce the nesting level until
it sees the newline token at the end of the line.
resolves: #11915
## Test Plan
* Add test cases for a bunch of rules that are affected by this change.
* Run the fuzzer for a long time, making sure to fix any other bugs.
## Summary
This PR updates Ruff to **not** generate auto-fixes if the source code
contains syntax errors as determined by the parser.
The main motivation behind this is to avoid infinite autofix loop when
the token-based rules are run over any source with syntax errors in
#11950.
Although even after this, it's not certain that there won't be an
infinite autofix loop because the logic might be incorrect. For example,
https://github.com/astral-sh/ruff/issues/12094 and
https://github.com/astral-sh/ruff/pull/12136.
This requires updating the test infrastructure to not validate for fix
availability status when the source contained syntax errors. This is
required because otherwise the fuzzer might fail as it uses the test
function to run the linter and validate the source code.
resolves: #11455
## Test Plan
`cargo insta test`
## Summary
This PR updates various references in the linter to compute the
line-width for summing the width of each `char` in a `str` instead of
computing the width of the `str` itself.
Refer to #12133 for more details.
fixes: #12130
## Test Plan
Add a file with null (`\0`) character which is zero-width. Run this test
case on `main` to make sure it panics and switch over to this branch to
make sure it doesn't panic now.
## Summary
Use the following to reproduce this:
```console
$ cargo run -- check --select=E275,E203 --preview --no-cache ~/playground/ruff/src/play.py --fix
debug error: Failed to converge after 100 iterations in `/Users/dhruv/playground/ruff/src/play.py` with rule codes E275:---
yield,x
---
/Users/dhruv/playground/ruff/src/play.py:1:1: E275 Missing whitespace after keyword
|
1 | yield,x
| ^^^^^ E275
|
= help: Added missing whitespace after keyword
Found 101 errors (100 fixed, 1 remaining).
[*] 1 fixable with the `--fix` option.
```
## Test Plan
Add a test case and run `cargo insta test`.
## Summary
Unfortunately `demisto/content` uses an explicit `select` for `E999`, so
it will _always_ fail in preview. And they're on a fairly old version.
I'd like to keep checking it, but seems easiest for now to just disable
it.
In response, I've added a few new repos.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
This patch inverts the defaults for
[pytest-fixture-incorrect-parentheses-style
(PT001)](https://docs.astral.sh/ruff/rules/pytest-fixture-incorrect-parentheses-style/)
and [pytest-incorrect-mark-parentheses-style
(PT003)](https://docs.astral.sh/ruff/rules/pytest-incorrect-mark-parentheses-style/)
to prefer dropping superfluous parentheses.
Presently, Ruff defaults to adding superfluous parentheses on pytest
mark and fixture decorators for documented purpose of consistency; for
example,
```diff
import pytest
-@pytest.mark.foo
+@pytest.mark.foo()
def test_bar(): ...
```
This behaviour is counter to the official pytest recommendation and
diverges from the flake8-pytest-style plugin as of version 2.0.0 (see
https://github.com/m-burst/flake8-pytest-style/issues/272). Seeing as
either default satisfies the documented benefit of consistency across a
codebase, it makes sense to change the behaviour to be consistent with
pytest and the flake8 plugin as well.
This change is breaking, so is gated behind preview (at least under my
understanding of Ruff versioning). The implementation of this gating
feature is a bit hacky, but seemed to be the least disruptive solution
without performing invasive surgery on the `#[option()]` macro.
Related to #8796.
### Caveat
Whilst updating the documentation, I sought to reference the pytest
recommendation to drop superfluous parentheses, but couldn't find any
official instruction beyond it being a revealed preference within the
pytest documentation code examples (as well as the linked issues from a
core pytest developer). Thus, the wording of the preference is
deliberately timid; it's to cohere with pytest rather than follow an
explicit guidance.
## Test Plan
`cargo nextest run`
I also ran
```sh
cargo run -p ruff -- check crates/ruff_linter/resources/test/fixtures/flake8_pytest_style/PT001.py --no-cache --diff --select PT001
```
and compared against it with `--preview` to verify that the default does
change under preview (I also repeated this with `echo
'[tool.ruff]\npreview = true' > pyproject.toml` to verify that it works
with a configuration file).
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Implement mutable-contextvar-default (B039) which was added to
flake8-bugbear in https://github.com/PyCQA/flake8-bugbear/pull/476.
This rule is similar to [mutable-argument-default
(B006)](https://docs.astral.sh/ruff/rules/mutable-argument-default) and
[function-call-in-default-argument
(B008)](https://docs.astral.sh/ruff/rules/function-call-in-default-argument),
except that it checks the `default` keyword argument to
`contextvars.ContextVar`.
```
B039.py:19:26: B039 Do not use mutable data structures for ContextVar defaults
|
18 | # Bad
19 | ContextVar("cv", default=[])
| ^^ B039
20 | ContextVar("cv", default={})
21 | ContextVar("cv", default=list())
|
= help: Replace with `None`; initialize with `.set()` after checking for `None`
```
In the upstream flake8-plugin, this rule is written expressly as a
corollary to B008 and shares much of its logic. Likewise, this
implementation reuses the logic of the Ruff implementation of B008,
namely
f765d19402/crates/ruff_linter/src/rules/flake8_bugbear/rules/function_call_in_argument_default.rs (L104-L106)
and
f765d19402/crates/ruff_linter/src/rules/flake8_bugbear/rules/mutable_argument_default.rs (L106)
Thus, this rule deliberately replicates B006's and B008's heuristics.
For example, this rule assumes that all functions are mutable unless
otherwise qualified. If improvements are to be made to B039 heuristics,
they should probably be made to B006 and B008 as well (whilst trying to
match the upstream implementation).
This rule does not have an autofix as it is unknown where the ContextVar
next used (and it might not be within the same file).
Closes#12054
## Test Plan
`cargo nextest run`
## Summary
This adds a fix for the `duplicate-bases` rule that removes the
duplicate base from the class definition.
## Test Plan
`cargo nextest run duplicate_bases`, `cargo insta review`.
## Summary
These are now `post-announce-jobs`. So if they fail, the release itself
will still succeed, which seems ok. (If we make them `publish-jobs`,
then we might end up publishing to PyPI but failing the release itself
if one of these fails.)
The intent is that these are still runnable via `workflow_dispatch` too.
Closes https://github.com/astral-sh/ruff/issues/12074.
## Summary
`ruff server` has reached a point of stabilization, and `--preview` is
no longer required as a flag.
`--preview` is still supported as a flag, since future features may be
need to gated behind it initially.
## Test Plan
A simple way to test this is to run `ruff server` from the command line.
No error about a missing `--preview` argument should be reported.
## Summary
Follow-up to #11902
This PR simplifies the `LinterResult` struct by avoiding the generic and
not store the `ParseError`.
This is possible because the callers already have access to the
`ParseError` via the `Parsed` output. This also means that we can
simplify the return type of `check_path` and avoid the generic `T` on
`LinterResult`.
## Test Plan
`cargo insta test`
## Summary
Follow-up to #11901
This PR avoids displaying the syntax errors as log message now that the
`E999` diagnostic cannot be disabled.
For context on why this was added, refer to
https://github.com/astral-sh/ruff/pull/2505. Basically, we would allow
ignoring the syntax error diagnostic because certain syntax feature
weren't supported back then like `match` statement. And, if a user
ignored `E999`, Ruff would give no feedback if the source code contained
any syntax error. So, this log message was a way to indicate to the user
even if `E999` was disabled.
The current state of the parser is such that (a) it matches with the
latest grammar and (b) it's easy to add support for any new syntax.
**Note:** This PR doesn't remove the `DisplayParseError` struct because
it's still being used by the formatter.
## Test Plan
Update existing snapshots from the integration tests.
## Summary
This PR updates the way syntax errors are handled throughout the linter.
The main change is that it's now not considered as a rule which involves
the following changes:
* Update `Message` to be an enum with two variants - one for diagnostic
message and the other for syntax error message
* Provide methods on the new message enum to query information required
by downstream usages
This means that the syntax errors cannot be hidden / disabled via any
disablement methods. These are:
1. Configuration via `select`, `ignore`, `per-file-ignores`, and their
`extend-*` variants
```console
$ cargo run -- check ~/playground/ruff/src/lsp.py --extend-select=E999
--no-preview --no-cache
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.10s
Running `target/debug/ruff check /Users/dhruv/playground/ruff/src/lsp.py
--extend-select=E999 --no-preview --no-cache`
warning: Rule `E999` is deprecated and will be removed in a future
release. Syntax errors will always be shown regardless of whether this
rule is selected or not.
/Users/dhruv/playground/ruff/src/lsp.py:1:8: F401 [*] `abc` imported but
unused
|
1 | import abc
| ^^^ F401
2 | from pathlib import Path
3 | import os
|
= help: Remove unused import: `abc`
```
3. Command-line flags via `--select`, `--ignore`, `--per-file-ignores`,
and their `--extend-*` variants
```console
$ cargo run -- check ~/playground/ruff/src/lsp.py --no-cache
--config=~/playground/ruff/pyproject.toml
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.11s
Running `target/debug/ruff check /Users/dhruv/playground/ruff/src/lsp.py
--no-cache --config=/Users/dhruv/playground/ruff/pyproject.toml`
warning: Rule `E999` is deprecated and will be removed in a future
release. Syntax errors will always be shown regardless of whether this
rule is selected or not.
/Users/dhruv/playground/ruff/src/lsp.py:1:8: F401 [*] `abc` imported but
unused
|
1 | import abc
| ^^^ F401
2 | from pathlib import Path
3 | import os
|
= help: Remove unused import: `abc`
```
This also means that the **output format** needs to be updated:
1. The `code`, `noqa_row`, `url` fields in the JSON output is optional
(`null` for syntax errors)
2. Other formats are changed accordingly
For each format, a new test case specific to syntax errors have been
added. Please refer to the snapshot output for the exact format for
syntax error message.
The output of the `--statistics` flag will have a blank entry for syntax
errors:
```
315 F821 [ ] undefined-name
119 [ ] syntax-error
103 F811 [ ] redefined-while-unused
```
The **language server** is updated to consider the syntax errors by
convert them into LSP diagnostic format separately.
### Preview
There are no quick fixes provided to disable syntax errors. This will
automatically work for `ruff-lsp` because the `noqa_row` field will be
`null` in that case.
<img width="772" alt="Screenshot 2024-06-26 at 14 57 08"
src="https://github.com/astral-sh/ruff/assets/67177269/aaac827e-4777-4ac8-8c68-eaf9f2c36774">
Even with `noqa` comment, the syntax error is displayed:
<img width="763" alt="Screenshot 2024-06-26 at 14 59 51"
src="https://github.com/astral-sh/ruff/assets/67177269/ba1afb68-7eaf-4b44-91af-6d93246475e2">
Rule documentation page:
<img width="1371" alt="Screenshot 2024-06-26 at 16 48 07"
src="https://github.com/astral-sh/ruff/assets/67177269/524f01df-d91f-4ac0-86cc-40e76b318b24">
## Test Plan
- [x] Disablement methods via config shows a warning
- [x] `select`, `extend-select`
- [ ] ~`ignore`~ _doesn't show any message_
- [ ] ~`per-file-ignores`, `extend-per-file-ignores`~ _doesn't show any
message_
- [x] Disablement methods via command-line flag shows a warning
- [x] `--select`, `--extend-select`
- [ ] ~`--ignore`~ _doesn't show any message_
- [ ] ~`--per-file-ignores`, `--extend-per-file-ignores`~ _doesn't show
any message_
- [x] File with syntax errors should exit with code 1
- [x] Language server
- [x] Should show diagnostics for syntax errors
- [x] Should not recommend a quick fix edit for adding `noqa` comment
- [x] Same for `ruff-lsp`
resolves: #8447
The motivation for this rule is solid; it's been in preview for a long
time; the implementation and tests seem sound; there are no open issues
regarding it, and as far as I can tell there never have been any.
The only issue I see is that the docs don't really describe the rule
accurately right now; I fix that in this PR.
## Summary
This PR migrates our release workflow to
[`cargo-dist`](https://github.com/axodotdev/cargo-dist). The primary
motivation here is that we want to ship dedicated installers for Ruff
that work across platforms, and `cargo-dist` gives us those installers
out-of-the-box. The secondary motivation is that `cargo-dist` formalizes
some of the patterns that we've built up over time in our own release
process.
At a high level:
- The `release.yml` file is generated by `cargo-dist` with `cargo dist
generate`. It doesn't contain any modifications vis-a-vis the generated
file. (If it's edited out of band from generation, the release fails.)
- Our customizations are inserted as custom steps within the
`cargo-dist` workflow. Specifically, `build-binaries` builds the wheels
and packages them into binaries (as on `main`), while `build-docker.yml`
builds the Docker image. `publish-pypi.yml` publishes the wheels to
PyPI. This is effectively our `release.yaml` (on `main`), broken down
into individual workflows rather than steps within a single workflow.
### Changes from `main`
The workflow is _nearly_ unchanged. We kick off a release manually via
the GitHub Action by providing a tag. If the tag doesn't match the
`Cargo.toml`, the release fails. If the tag matches an already-existing
release, the release fails.
The release proceeds by (in order):
0. Doing some upfront validation via `cargo-dist`.
1. Creating the wheels and archives.
2. Building and pushing the Docker image.
3. Publishing to PyPI (if it's not a "dry run").
4. Creating the GitHub Release (if it's not a "dry run").
5. Notifying `ruff-pre-commit` (if it's not a "dry run").
There are a few changes in the workflow as compared to `main`:
- **We no longer validate the SHA** (just the tag). It's not an input to
the job. The Axo team is considering whether / how to support this.
- **Releases are now published directly** (rather than as draft). Again,
the Axo team is considering whether / how to support this. The downside
of drafts is that the URLs aren't stable, so the installers don't work
_as long as the release is in draft_. This is fine for our workflow. It
seems like the Axo team will add it.
- Releases already contain the latest entry from the changelog (we don't
need to copy it over). This "Just Works", which is nice, though we'll
still want to edit them to add contributors.
There are also a few **breaking changes** for consumers of the binaries:
- **We no longer include the version tag in the file name**. This
enables users to install via `/latest` URLs on GitHub, and is part of
the cargo-dist paradigm.
- **Archives now include an extra level of nesting,** which you can
remove with `--strip-components=1` when untarring.
Here's an example release that I created -- I omitted all the artifacts
since I was just testing a workflow, so none of the installers or links
work, but it gives you a sense for what the release looks like:
https://github.com/charliermarsh/cargodisttest/releases/tag/0.1.13.
### Test Plan
I ran a successful release to completion last night, and installed Ruff
via the installer:


The piece I'm least confident about is the Docker push. We build the
image, but the push fails in my test repo since I haven't wired up the
credentials.
## Summary
This rule removes `PLR1701` and redirects it to `SIM101`.
In addition to that, the `SIM101` autofix has been fixed to add padding
if required.
### `PLR1701` has bugs
It also seems that the implementation of `PLR1701` is incorrect in
multiple scenarios. For example, the following code snippet:
```py
# There are two _different_ variables `a` and `b`
if isinstance(a, int) or isinstance(b, bool) or isinstance(a, float):
pass
# There's another condition `or 1`
if isinstance(self.k, int) or isinstance(self.k, float) or 1:
pass
```
is fixed to:
```py
# Fixed to only considering variable `a`
if isinstance(a, (float, int)):
pass
# The additional condition is not present in the fix
if isinstance(self.k, (float, int)):
pass
```
Playground: https://play.ruff.rs/6cfbdfb7-f183-43b0-b59e-31e728b34190
## Documentation Preview
### `PLR1701`
<img width="1397" alt="Screenshot 2024-06-25 at 11 14 40"
src="https://github.com/astral-sh/ruff/assets/67177269/779ee84d-7c4d-4bb8-a3a4-c2b23a313eba">
## Test Plan
Remove the test cases for `PLR1701`, port the padding test case to
`SIM101` and update the snapshot.
## Summary
This PR splits the re-lexing logic into two parts:
1. `TokenSource`: The token source will be responsible to find the
position the lexer needs to be moved to
2. `Lexer`: The lexer will be responsible to reduce the nesting level
and move itself to the new position if recovered from a parenthesized
context
This split makes it easy to find the new lexer position without needing
to implement the backwards lexing logic again which would need to handle
cases involving:
* Different kinds of newlines
* Line continuation character(s)
* Comments
* Whitespaces
### F-strings
This change did reveal one thing about re-lexing f-strings. Consider the
following example:
```py
f'{'
# ^
f'foo'
```
Here, the quote as highlighted by the caret (`^`) is the start of a
string inside an f-string expression. This is unterminated string which
means the token emitted is actually `Unknown`. The parser tries to
recover from it but there's no newline token in the vector so the new
logic doesn't recover from it. The previous logic does recover because
it's looking at the raw characters instead.
The parser would be at `FStringStart` (the one for the second line) when
it calls into the re-lexing logic to recover from an unterminated
f-string on the first line. So, moving backwards the first character
encountered is a newline character but the first token encountered is an
`Unknown` token.
This is improved with #12067fixes: #12046fixes: #12036
## Test Plan
Update the snapshot and validate the changes.
## Summary
This PR fixes the lexer logic to **not** consume the newline character
for an unterminated string literal.
Currently, the lexer would consume it to be part of the string itself
but that would be bad for recovery because then the lexer wouldn't emit
the newline token ever. This PR fixes that to avoid consuming the
newline character in that case.
This was discovered during https://github.com/astral-sh/ruff/pull/12060.
## Test Plan
Update the snapshots and validate them.
## Summary
This PR fixes a bug introduced in
https://github.com/astral-sh/ruff/pull/12008 which didn't consider the
two character newline after the line continuation character.
For example, consider the following code highlighted with whitespaces:
```py
call(foo # comment \\r\n
\r\n
def bar():\r\n
....pass\r\n
```
The lexer is at `def` when it's running the re-lexing logic and trying
to move back to a newline character. It encounters `\n` and it's being
escaped (incorrect) but `\r` is being escaped, so it moves the lexer to
`\n` character. This creates an overlap in token ranges which causes the
panic.
```
Name 0..4
Lpar 4..5
Name 5..8
Comment 9..20
NonLogicalNewline 20..22 <-- overlap between
Newline 21..22 <-- these two tokens
NonLogicalNewline 22..23
Def 23..26
...
```
fixes: #12028
## Test Plan
Add a test case with line continuation and windows style newline
character.
## Summary
(I'm pretty sure I added this in the parser re-write but must've got
lost in the rebase?)
This PR raises a syntax error if the type parameter list is empty.
As per the grammar, there should be at least one type parameter:
```
type_params:
| invalid_type_params
| '[' type_param_seq ']'
type_param_seq: ','.type_param+ [',']
```
Verified via the builtin `ast` module as well:
```console
$ python3.13 -m ast parser/_.py
Traceback (most recent call last):
[..]
File "parser/_.py", line 1
def foo[]():
^
SyntaxError: Type parameter list cannot be empty
```
## Test Plan
Add inline test cases and update the snapshots.
## Summary
Right now, it's inconsistent... We sometimes match against the name, and
sometimes against the alias (`asname`). I could see a case for always
matching against the name, but matching against both seems fine too,
since the rule is really about the combination of the two?
Closes https://github.com/astral-sh/ruff/issues/12031.
## Summary
This PR fixes a bug where Ruff would raise `E203` for f-string debug
expression. This isn't valid because whitespaces are important for debug
expressions.
fixes: #12023
## Test Plan
Add test case and make sure there are no snapshot changes.
## Summary
This PR updates the parser test infrastructure to validate the token
ranges.
From the code documentation:
```
/// Verifies that:
/// * the ranges are strictly increasing when loop the tokens in insertion order
/// * all ranges are within the length of the source code
```
Follow-up from #12016 and #12017resolves: #11938
## Test Plan
Make sure that there are no failures.
## Summary
This PR updates the unterminated string error range to not include the
final newline character.
This is a follow-up to #12016 and required for #12019
This is not done for when the unterminated string goes till the end of
file (not a newline character). The unterminated f-string range is
correct.
### Why is this required for #12019 ?
Because otherwise the token ranges will overlap. For example:
```py
f"{"
f"{foo!r"
```
Here, the re-lexing logic recovers from an unterminated f-string and
thus emitting a `Newline` token for the one at the end of the first
line. But, currently the `Unknown` and the `Newline` token would overlap
because the `Unknown` token (unterminated string literal) range would
include the newline character.
## Test Plan
Update and validate the snapshot.
## Summary
This PR fixes the range highlighted for the line continuation error.
Previously, it would highlight an incorrect range:
```
1 | call(a, b, \\\
| ^^ Syntax Error: unexpected character after line continuation character
2 |
3 | def bar():
|
```
And now:
```
|
1 | call(a, b, \\\
| ^ Syntax Error: unexpected character after line continuation character
2 |
3 | def bar():
|
```
This is implemented by avoiding to update the token range for the
`Unknown` token which is emitted when there's a lexical error. Instead,
the `push_error` helper method will be responsible to update the range
to the error location.
This actually becomes a requirement which can be seen in follow-up PRs.
## Test Plan
Update and validate the snapshot.
## Summary
This PR fixes a bug where the re-lexing logic didn't consider the line
continuation character being present before the newline character. This
meant that the lexer was being moved back to the newline character which
is actually ignored via `\`.
Considering the following code:
```py
f'middle {'string':\
'format spec'}
```
The old token stream is:
```
...
Colon 18..19
FStringMiddle 19..29 (flags = F_STRING)
Newline 20..21
Indent 21..29
String 29..42
Rbrace 42..43
...
```
Notice how the ranges are overlapping between the `FStringMiddle` token
and the tokens emitted after moving the lexer backwards.
After this fix, the new token stream which is without moving the lexer
backwards in this scenario:
```
FStringStart 0..2 (flags = F_STRING)
FStringMiddle 2..9 (flags = F_STRING)
Lbrace 9..10
String 10..18
Colon 18..19
FStringMiddle 19..29 (flags = F_STRING)
FStringEnd 29..30 (flags = F_STRING)
Name 30..36
Name 37..41
Unknown 41..44
Newline 44..45
```
fixes: #12004
## Test Plan
Add test cases and update the snapshots.
## Summary
This PR updates `F811` rule to include assignment as possible shadowed
binding. This will fix issue: #11828 .
## Test Plan
Add a test file, F811_30.py, which includes a redefinition after an
assignment and a verified snapshot file.
## Summary
Addresses #11974 to add a `RUF` rule to replace `print` expressions in
`assert` statements with the inner message.
An autofix is available, but is considered unsafe as it changes
behaviour of the execution, notably:
- removal of the printout in `stdout`, and
- `AssertionError` instance containing a different message.
While the detection of the condition is a straightforward matter,
deciding how to resolve the print arguments into a string literal can be
a relatively subjective matter. The implementation of this PR chooses to
be as tolerant as possible, and will attempt to reformat any number of
`print` arguments containing single or concatenated strings or variables
into either a string literal, or a f-string if any variables or
placeholders are detected.
## Test Plan
`cargo test`.
## Examples
For ease of discussion, this is the diff for the tests:
```diff
# Standard Case
# Expects:
# - single StringLiteral
-assert True, print("This print is not intentional.")
+assert True, "This print is not intentional."
# Concatenated string literals
# Expects:
# - single StringLiteral
-assert True, print("This print" " is not intentional.")
+assert True, "This print is not intentional."
# Positional arguments, string literals
# Expects:
# - single StringLiteral concatenated with " "
-assert True, print("This print", "is not intentional")
+assert True, "This print is not intentional"
# Concatenated string literals combined with Positional arguments
# Expects:
# - single stringliteral concatenated with " " only between `print` and `is`
-assert True, print("This " "print", "is not intentional.")
+assert True, "This print is not intentional."
# Positional arguments, string literals with a variable
# Expects:
# - single FString concatenated with " "
-assert True, print("This", print.__name__, "is not intentional.")
+assert True, f"This {print.__name__} is not intentional."
# Mixed brackets string literals
# Expects:
# - single StringLiteral concatenated with " "
-assert True, print("This print", 'is not intentional', """and should be removed""")
+assert True, "This print is not intentional and should be removed"
# Mixed brackets with other brackets inside
# Expects:
# - single StringLiteral concatenated with " " and escaped brackets
-assert True, print("This print", 'is not "intentional"', """and "should" be 'removed'""")
+assert True, "This print is not \"intentional\" and \"should\" be 'removed'"
# Positional arguments, string literals with a separator
# Expects:
# - single StringLiteral concatenated with "|"
-assert True, print("This print", "is not intentional", sep="|")
+assert True, "This print|is not intentional"
# Positional arguments, string literals with None as separator
# Expects:
# - single StringLiteral concatenated with " "
-assert True, print("This print", "is not intentional", sep=None)
+assert True, "This print is not intentional"
# Positional arguments, string literals with variable as separator, needs f-string
# Expects:
# - single FString concatenated with "{U00A0}"
-assert True, print("This print", "is not intentional", sep=U00A0)
+assert True, f"This print{U00A0}is not intentional"
# Unnecessary f-string
# Expects:
# - single StringLiteral
-assert True, print(f"This f-string is just a literal.")
+assert True, "This f-string is just a literal."
# Positional arguments, string literals and f-strings
# Expects:
# - single FString concatenated with " "
-assert True, print("This print", f"is not {'intentional':s}")
+assert True, f"This print is not {'intentional':s}"
# Positional arguments, string literals and f-strings with a separator
# Expects:
# - single FString concatenated with "|"
-assert True, print("This print", f"is not {'intentional':s}", sep="|")
+assert True, f"This print|is not {'intentional':s}"
# A single f-string
# Expects:
# - single FString
-assert True, print(f"This print is not {'intentional':s}")
+assert True, f"This print is not {'intentional':s}"
# A single f-string with a redundant separator
# Expects:
# - single FString
-assert True, print(f"This print is not {'intentional':s}", sep="|")
+assert True, f"This print is not {'intentional':s}"
# Complex f-string with variable as separator
# Expects:
# - single FString concatenated with "{U00A0}", all placeholders preserved
condition = "True is True"
maintainer = "John Doe"
-assert True, print("Unreachable due to", condition, f", ask {maintainer} for advice", sep=U00A0)
+assert True, f"Unreachable due to{U00A0}{condition}{U00A0}, ask {maintainer} for advice"
# Empty print
# Expects:
# - `msg` entirely removed from assertion
-assert True, print()
+assert True
# Empty print with separator
# Expects:
# - `msg` entirely removed from assertion
-assert True, print(sep=" ")
+assert True
# Custom print function that actually returns a string
# Expects:
@@ -100,4 +100,4 @@
# Use of `builtins.print`
# Expects:
# - single StringLiteral
-assert True, builtins.print("This print should be removed.")
+assert True, "This print should be removed."
```
## Known Issues
The current implementation resolves all arguments and separators of the
`print` expression into a single string, be it
`StringLiteralValue::single` or a `FStringValue::single`. This:
- potentially joins together strings well beyond the ideal character
limit for each line, and
- does not preserve multi-line strings in their original format, in
favour of a single line `"...\n...\n..."` format.
These are purely formatting issues only occurring in unusual scenarios.
Additionally, the autofix will tolerate `print` calls that were
previously invalid:
```python
assert True, print("this", "should not be allowed", sep=42)
```
This will be transformed into
```python
assert True, f"this{42}should not be allowed"
```
which some could argue is an alteration of behaviour.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Documentation mentions:
> PEP 563 enabled the use of a number of convenient type annotations,
such as `list[str]` instead of `List[str]`
but it meant [PEP 585](https://peps.python.org/pep-0585/) instead.
[PEP 563](https://peps.python.org/pep-0563/) is the one defining `from
__future__ import annotations`.
## Test Plan
No automated test required, just verify that
https://peps.python.org/pep-0585/ is the correct reference.
## Summary
I look at the token stream a lot, not specifically in the playground but
in the terminal output and it's annoying to scroll a lot to find
specific location. Most of the information is also redundant.
The final format we end up with is: `<kind> <range> (flags = ...)` e.g.,
`String 0..4 (flags = BYTE_STRING)` where the flags part is only
populated if there are any flags set.
## Summary
Fixes#11651.
Fixes#11851.
We were double-closing a notebook document from the index, once in
`textDocument/didClose` and then in the `notebookDocument/didClose`
handler. The second time this happens, taking a snapshot fails.
I've rewritten how we handle snapshots for closing notebooks / notebook
cells so that any failure is simply logged instead of propagating
upwards. This implementation works consistently even if we don't receive
`textDocument/didClose` notifications for each specific cell, since they
get closed (and the diagnostics get cleared) in the notebook document
removal process.
## Test Plan
1. Open an untitled, unsaved notebook with the `Create: New Jupyter
Notebook` command from the VS Code command palette (`Ctrl/Cmd + Shift +
P`)
2. Without saving the document, close it.
3. No error popup should appear.
4. Run the debug command (`Ruff: print debug information`) to confirm
that there are no open documents
## Summary
This PR does some housekeeping into moving certain structs into related
modules. Specifically,
1. Move `LexicalError` from `lexer.rs` to `error.rs` which also contains
the `ParseError`
2. Move `Token`, `TokenFlags` and `TokenValue` from `lexer.rs` to
`token.rs`
## Summary
This PR removes the duplication around `is_trivia` functions.
There are two of them in the codebase:
1. In `pycodestyle`, it's for newline, indent, dedent, non-logical
newline and comment
2. In the parser, it's for non-logical newline and comment
The `TokenKind::is_trivia` method used (1) but that's not correct in
that context. So, this PR introduces a new `is_non_logical_token` helper
method for the `pycodestyle` crate and updates the
`TokenKind::is_trivia` implementation with (2).
This also means we can remove `Token::is_trivia` method and the
standalone `token_source::is_trivia` function and use the one on
`TokenKind`.
## Test Plan
`cargo insta test`
## Summary
Closes#11914.
This PR introduces a snapshot test that replays the LSP requests made
during a document formatting request, and confirms that the notebook
document is updated in the expected way.
## Summary
Fixes#11911.
`shellexpand` is now used on `logFile` to expand the file path, allowing
the usage of `~` and environment variables.
## Test Plan
1. Set `logFile` in either Neovim or Helix to a file path that needs
expansion, like `~/.config/helix/ruff_logs.txt`.
2. Ensure that `RUFF_TRACE` is set to `messages` or `verbose`
3. Open a Python file in Neovim/Helix
4. Confirm that a file at the path specified was created, with the
expected logs.
## Summary
This PR updates the logical line rules entry-point function to only run
the logic if any of the rules within that group is enabled.
Although this shouldn't really give any performance improvements, it's
better not to do additional work if we can. This is also consistent with
how other rules are run.
## Test Plan
`cargo insta test`
## Summary
This PR avoids moving back the lexer for a triple-quoted f-string during
the re-lexing phase.
The reason this is a problem is that for a triple-quoted f-string the
newlines are part of the f-string itself, specifically they'll be part
of the `FStringMiddle` token. So, if we moved the lexer back, there
would be a `Newline` token whose range would be in between an
`FStringMiddle` token. This creates a panic in downstream usage.
fixes: #11937
## Test Plan
Add test cases and validate the snapshots.
## Summary
This PR avoids the `depth` counter when detecting indentation from
non-logical lines because it seems to never be used. It might have been
a leftover when the logic was added originally in #11608.
## Test Plan
`cargo insta test`
## Summary
This PR updates the linter to show all the parse errors as diagnostics
instead of just the first one.
Note that this doesn't affect the parse error displayed as error log
message. This will be removed in a follow-up PR.
### Breaking?
I don't think this is a breaking change even though this might give more
diagnostics. The main reason is that this shouldn't affect any users
because it'll only give additional diagnostics in the case of multiple
syntax errors.
## Test Plan
Add an integration test case which would raise more than one parse
error.
## Summary
This PR updates the re-lexing logic to avoid consuming the trailing
whitespace and move the lexer explicitly to the last newline character
encountered while moving backwards.
Consider the following code snippet as taken from the test case
highlighted with whitespace (`.`) and newline (`\n`) characters:
```py
# There are trailing whitespace before the newline character but those whitespaces are
# part of the comment token
f"""hello {x # comment....\n
# ^
y = 1\n
```
The parser is at `y` when it's trying to recover from an unclosed `{`,
so it calls into the re-lexing logic which tries to move the lexer back
to the end of the previous line. But, as it consumed all whitespaces it
moved the lexer to the location marked by `^` in the above code snippet.
But, those whitespaces are part of the comment token. This means that
the range for the two tokens were overlapping which introduced the
panic.
Note that this is only a bug when there's a comment with a trailing
whitespace otherwise it's fine to move the lexer to the whitespace
character. This is because the lexer would just skip the whitespace
otherwise. Nevertheless, this PR updates the logic to move it explicitly
to the newline character in all cases.
fixes: #11929
## Test Plan
Add test cases and update the snapshot. Make sure that it doesn't panic
on the code snippet in the linked issue.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
related to https://github.com/astral-sh/ruff/issues/5306
The check right now only checks in the first 1024 bytes, and that's
really not enough when there's a docstring at the beginning of a file.
A more proper fix might be needed, which might be more complex (and I
don't have the `rust` skills to implement that). But this temporary
"fix" might enable more users to use this.
Context: We want to use this rule in
https://github.com/scikit-learn/scikit-learn/ and we got blocked because
of this hardcoded rule (which TBH took us quite a while to figure out
why it was failing since it's not documented).
## Test Plan
This is already kinda tested, modified the test for the new byte number.
<!-- How was it tested? -->
## Summary
This PR removes most of the syntax errors from the test cases. This
would create noise when https://github.com/astral-sh/ruff/pull/11901 is
complete. These syntax errors are also just noise for the test itself.
## Test Plan
Update the snapshots and verify that they're still the same.
## Summary
This PR is a follow-up on #11845 to add the re-lexing logic for normal
list parsing.
A normal list parsing is basically parsing elements without any
separator in between i.e., there can only be trivia tokens in between
the two elements. Currently, this is only being used for parsing
**assignment statement** and **f-string elements**. Assignment
statements cannot be in a parenthesized context, but f-string can have
curly braces so this PR is specifically for them.
I don't think this is an ideal recovery but the problem is that both
lexer and parser could add an error for f-strings. If the lexer adds an
error it'll emit an `Unknown` token instead while the parser adds the
error directly. I think we'd need to move all f-string errors to be
emitted by the parser instead. This way the parser can correctly inform
the lexer that it's out of an f-string and then the lexer can pop the
current f-string context out of the stack.
## Test Plan
Add test cases, update the snapshots, and run the fuzzer.
## Summary
Fixes https://github.com/astral-sh/ruff-vscode/issues/496.
Cells are no longer removed from the notebook index when a notebook gets
updated, but rather when `textDocument/didClose` is called for them.
This solves an issue where their premature removal from the notebook
cell index would cause their URL to be un-queryable in the
`textDocument/didClose` handler.
## Test Plan
Create and then delete a notebook cell in VS Code. No error should
appear.
## Summary
This PR implements the re-lexing logic in the parser.
This logic is only applied when recovering from an error during list
parsing. The logic is as follows:
1. During list parsing, if an unexpected token is encountered and it
detects that an outer context can understand it and thus recover from
it, it invokes the re-lexing logic in the lexer
2. This logic first checks if the lexer is in a parenthesized context
and returns if it's not. Thus, the logic is a no-op if the lexer isn't
in a parenthesized context
3. It then reduces the nesting level by 1. It shouldn't reset it to 0
because otherwise the recovery from nested list parsing will be
incorrect
4. Then, it tries to find last newline character going backwards from
the current position of the lexer. This avoids any whitespaces but if it
encounters any character other than newline or whitespace, it aborts.
5. Now, if there's a newline character, then it needs to be re-lexed in
a logical context which means that the lexer needs to emit it as a
`Newline` token instead of `NonLogicalNewline`.
6. If the re-lexing gives a different token than the current one, the
token source needs to update it's token collection to remove all the
tokens which comes after the new current position.
It turns out that the list parsing isn't that happy with the results so
it requires some re-arranging such that the following two errors are
raised correctly:
1. Expected comma
2. Recovery context error
For (1), the following scenarios needs to be considered:
* Missing comma between two elements
* Half parsed element because the grammar doesn't allow it (for example,
named expressions)
For (2), the following scenarios needs to be considered:
1. If the parser is at a comma which means that there's a missing
element otherwise the comma would've been consumed by the first `eat`
call above. And, the parser doesn't take the re-lexing route on a comma
token.
2. If it's the first element and the current token is not a comma which
means that it's an invalid element.
resolves: #11640
## Test Plan
- [x] Update existing test snapshots and validate them
- [x] Add additional test cases specific to the re-lexing logic and
validate the snapshots
- [x] Run the fuzzer on 3000+ valid inputs
- [x] Run the fuzzer on invalid inputs
- [x] Run the parser on various open source projects
- [x] Make sure the ecosystem changes are none
How was this working for anyone else? The `prettier` path did not exist
on my machine. Also added `--force` to the push because otherwise you
can't re-run the script for a given Ruff commit.
## Summary
This PR updates the server capabilities to include the commands that
Ruff supports. This is similar to how there's a list of possible code
actions supported by the server.
I noticed this when I was trying to find whether Helix supported
workspace commands or not based on Jane's comment
(https://github.com/astral-sh/ruff/pull/11831#discussion_r1634984921)
and I found the `:lsp-workspace-command` in the editor but it didn't
show up anything in the picker.
So, I looked at the implementation in Helix
(9c479e6d2d/helix-term/src/commands/typed.rs (L1372-L1384))
which made me realize that Ruff doesn't provide this in its
capabilities. Currently, this does require `ruff` to be first in the
list of language servers in the user config but that should be resolved
by https://github.com/helix-editor/helix/pull/10176. So, the following
config should work:
```toml
[[language]]
name = "python"
# Ruff should come first until https://github.com/helix-editor/helix/pull/10176 is released
language-servers = ["ruff", "pyright"]
```
## Test Plan
1. Neovim's server capabilities output should include the supported
commands:
```
executeCommandProvider = {
commands = { "ruff.applyFormat", "ruff.applyAutofix", "ruff.applyOrganizeImports", "ruff.printDebugInformation" },
workDoneProgress = false
},
```
2. Helix should now display the commands to pick from when
`:lsp-workspace-command` is invoked:
<img width="832" alt="Screenshot 2024-06-13 at 08 47 14"
src="https://github.com/astral-sh/ruff/assets/67177269/09048ecd-c974-4e09-ab56-9482ff3d780b">
## Summary
This PR adds a new enum to determine the kind of terminator token i.e.,
is it actually terminates the list or is it used for error recovery.
This is important because the parser should take the error recovery
route in case the terminator token is used for better error recovery.
This will then try to re-lex the token if it's the case.
I haven't updated any reference to use this new enum as otherwise it'll
update the snapshots. I plan to do that in a follow-up PR so that it's
easier to reason about.
## Test plan
`cargo insta test`
## Summary
This PR separates the terminator token for f-string elements depending
on the context. A list of f-string element can occur either in a regular
f-string or a format spec of an f-string. The terminator token is
different depending on that context.
## Test Plan
`cargo insta test` and verify the updated snapshots.
## Summary
This PR re-uses the `ruff_python_trivia::is_python_whitespace` in the
lexer instead of defining its own. This was mainly to avoid circular
dependency which was resolved in #11261.
## Summary
Add Constraint nodes to flow graph, and narrow types based on that (only
`is None` and `is not None` narrowing supported for now, to prototype
the structure.)
Also add simplification of zero- and one-element unions and
intersections, and flattening of intersections.
There's a lot more normalization logic needed for unions and
intersections (as is obvious from the inferred type in the added
`narrow_none` test), but this will be non-trivial and I'd rather do it
in a separate PR.
Here's a flowchart diagram for the code in the added `narrow_none` test:

The top branch is for the `if` expression in the initial assignment to
`x`; that `Constraint` node would only affect the type of `flag`, which
we don't care about in this test.
The second branch is for the `if` statement, with `Constraint` node
affecting the type of `x`.
## Test Plan
Added tests.
## Summary
Fixes#11744.
We now show a distinct popup message when we fail to get a document
snapshot during command execution. This message more clearly
communicates the issue to the user, instead of a generic "ruff
encountered an error" message.
## Test Plan
Try running `Fix all auto-fixable problems` on an incompatible file (for
example: `settings.json`). You should see the following popup message:
<img width="456" alt="Screenshot 2024-06-11 at 11 47 16 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/3a28e3d7-3896-4dd0-b117-f87300dd3b68">
## Summary
Closes#11715.
Introduces a new command, `ruff.printDebugInformation`. This will print
useful information about the status of the server to `stderr`.
Right now, the information shown by this command includes:
* The path to the server executable
* The version of the executable
* The text encoding being used
* The number of open documents and workspaces
* A list of registered configuration files
* The capabilities of the client
## Test Plan
First, checkout and use [the corresponding `ruff-vscode`
PR](https://github.com/astral-sh/ruff-vscode/pull/495).
Running the `Print debug information` command in VS Code should show
something like the following in the Output channel:
<img width="991" alt="Screenshot 2024-06-11 at 11 41 46 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/ab93c009-bb7b-4291-b057-d44fdc6f9f86">
## Summary
Fixes#10968.
Fixes#11545.
The server's tracing system has been rewritten from the ground up. The
server now has trace level and log level settings which restrict the
tracing events and spans that get logged.
* A `logLevel` setting has been added, which lets a user set the log
level. By default, it is set to `"info"`.
* A `logFile` setting has also been added, which lets the user supply an
optional file to send tracing output (it does not have to exist as a
file yet). By default, if this is unset, tracing output will be sent to
`stderr`.
* A `$/setTrace` handler has also been added, and we also set the trace
level from the initialization options. For editors without direct
support for tracing, the environment variable `RUFF_TRACE` can override
the trace level.
* Small changes have been made to how we display tracing output. We no
longer use `tracing-tree`, and instead use
`tracing_subscriber::fmt::Layer` to format output. Thread names are now
included in traces, and I've made some adjustment to thread worker names
to be more useful.
## Test Plan
In VS Code, with `ruff.trace.server` set to its default value, no logs
from Ruff should appear.
After changing `ruff.trace.server` to either `messages` or `verbose`,
you should see log messages at `info` level or higher appear in Ruff's
output:
<img width="1005" alt="Screenshot 2024-06-10 at 10 35 04 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/6050d107-9815-4bd2-96d0-e86f096a57f5">
In Helix, by default, no logs from Ruff should appear.
To set the trace level in Helix, you'll need to modify your language
configuration as follows:
```toml
[language-server.ruff]
command = "/Users/jane/astral/ruff/target/debug/ruff"
args = ["server", "--preview"]
environment = { "RUFF_TRACE" = "messages" }
```
After doing this, logs of `info` level or higher should be visible in
Helix:
<img width="1216" alt="Screenshot 2024-06-10 at 10 39 26 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/8ff88692-d3f7-4fd1-941e-86fb338fcdcc">
You can use `:log-open` to quickly open the Helix log file.
In Neovim, by default, no logs from Ruff should appear.
To set the trace level in Neovim, you'll need to modify your
configuration as follows:
```lua
require('lspconfig').ruff.setup {
cmd = {"/path/to/debug/executable", "server", "--preview"},
cmd_env = { RUFF_TRACE = "messages" }
}
```
You should see logs appear in `:LspLog` that look like the following:
<img width="1490" alt="Screenshot 2024-06-11 at 11 24 01 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/576cd5fa-03cf-477a-b879-b29a9a1200ff">
You can adjust `logLevel` and `logFile` in `settings`:
```lua
require('lspconfig').ruff.setup {
cmd = {"/path/to/debug/executable", "server", "--preview"},
cmd_env = { RUFF_TRACE = "messages" },
settings = {
logLevel = "debug",
logFile = "your/log/file/path/log.txt"
}
}
```
The `logLevel` and `logFile` can also be set in Helix like so:
```toml
[language-server.ruff.config.settings]
logLevel = "debug"
logFile = "your/log/file/path/log.txt"
```
Even if this log file does not exist, it should now be created and
written to after running the server:
<img width="1148" alt="Screenshot 2024-06-10 at 10 43 44 AM"
src="https://github.com/astral-sh/ruff/assets/19577865/ab533cf7-d5ac-4178-97f1-e56da17450dd">
## Summary
We recently updated our old formatting and linting setup in Streamlit to
use ruff: https://github.com/streamlit/streamlit/pull/8849
Thanks for this excellent tool :)
## Test Plan
This PR only contains changes to the Readme.
## Summary
This PR updates the parser to remove building the `CommentRanges` and
instead it'll be built by the linter and the formatter when it's
required.
For the linter, it'll be built and owned by the `Indexer` while for the
formatter it'll be built from the `Tokens` struct and passed as an
argument.
## Test Plan
`cargo insta test`
## Summary
The fix for E203 now produces the same result as ruff format in cases
where a slice ends on a colon and the closing square bracket is on the
following line.
Refers to https://github.com/astral-sh/ruff/issues/10973
## Test Plan
The minimal reproduction case in the ticket was added as test case
producing no error. Additional cases with multiple spaces or a tab
before the colon where added to make sure that the rule still finds
these.
## Summary
As-is, we're using the URL path for all files, leading us to use paths
like:
```
/c%3A/Users/crmar/workspace/fastapi/tests/main.py
```
This doesn't match against per-file ignores and other patterns in Ruff
configuration.
This PR modifies the LSP to use the real file path if available, and the
virtual file path if not.
Closes https://github.com/astral-sh/ruff/issues/11751.
## Test Plan
Ran the LSP on Windows. In the FastAPI repo, added:
```toml
[tool.ruff.lint.per-file-ignores]
"tests/**/*.py" = ["F401"]
```
And verified that an unused import was ignored in `tests` after this
change, but not before.
## Summary
This PR removes the `result-like` dependency and instead implement the
required functionality. The motivation being that `noqa.is_enabled()` is
easier to read than `noqa.into()`.
For context, I was just trying to understand the syntax error workflow
and I saw these flags which were being converted via `into`. I always
find `into` confusing because you never know what's it being converted
into unless you know the type. Later realized that it's just a boolean
flag. After removing the usages from these two flags, it turns out that
the dependency is only being used in one rule so I thought to remove
that as well.
## Test Plan
`cargo insta test`
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
This PR implements the [consider dict
items](https://pylint.pycqa.org/en/latest/user_guide/messages/convention/consider-using-dict-items.html)
rule from Pylint. Enabling this rule flags:
```python
ORCHESTRA = {
"violin": "strings",
"oboe": "woodwind",
"tuba": "brass",
"gong": "percussion",
}
for instrument in ORCHESTRA:
print(f"{instrument}: {ORCHESTRA[instrument]}")
for instrument in ORCHESTRA.keys():
print(f"{instrument}: {ORCHESTRA[instrument]}")
for instrument in (inline_dict := {"foo": "bar"}):
print(f"{instrument}: {inline_dict[instrument]}")
```
For not using `items()` to extract the value out of the dict. We ignore
the case of an assignment, as you can't modify the underlying
representation with the value in the list of tuples returned.
## Test Plan
<!-- How was it tested? -->
`cargo test`.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
## Summary
Definitions are used in symbol table and in flow graph, and aren't
inherently owned by one or the other; move them into their own
submodule.
## Test Plan
Existing tests.
## Summary
Add support for inferring int literal types from basic arithmetic on int
literals. Just to begin showing examples of resolving more complex
expression types, and because this will be useful in testing walrus
expressions.
## Test Plan
Added test.
## Summary
After looking at this a bit, I think it does make sense to have
`Unbound` as part of the `Definition` enum; if we are modeling `Unbound`
as a type (which currently we are), then every symbol implicitly starts
each scope with a "definition" as unbound, and the cleanest way to model
that is as a real `Definition`. We should be able to handle a definition
of "unbound" anywhere we handle definitions.
But the name `None` wasn't clear enough; changing the name to `Unbound`
and adding a doc comment.
Also change `[first].into_iter()` to `std::iter::once(first)`, from
post-land code review on a prior PR.
## Test Plan
Existing tests.
## Summary
This PR is a follow-up to #11740 to restrict access to the `Parsed`
output by replacing the `parsed` API function with a more specific one.
Currently, that is `comment_ranges` but the linked PR exposes a `tokens`
method.
The main motivation is so that there's no way to get an incorrect
information from the checker. And, it also encapsulates the source of
the comment ranges and the tokens itself. This way it would become
easier to just update the checker if the source for these information
changes in the future.
## Test Plan
`cargo insta test`
## Summary
This PR fixes a bug where the checker would require the tokens for an
invalid offset w.r.t. the source code.
Taking the source code from the linked issue as an example:
```py
relese_version :"0.0is 64"
```
Now, this isn't really a valid type annotation but that's what this PR
is fixing. Regardless of whether it's valid or not, Ruff shouldn't
panic.
The checker would visit the parsed type annotation (`0.0is 64`) and try
to detect any violations. Certain rule logic requests the tokens for the
same but it would fail because the lexer would only have the `String`
token considering original source code. This worked before because the
lexer was invoked again for each rule logic.
The solution is to store the parsed type annotation on the checker if
it's in a typing context and use the tokens from that instead if it's
available. This is enforced by creating a new API on the checker to get
the tokens.
But, this means that there are two ways to get the tokens via the
checker API. I want to restrict this in a follow-up PR (#11741) to only
expose `tokens` and `comment_ranges` as methods and restrict access to
the parsed source code.
fixes: #11736
## Test Plan
- [x] Add a test case for `F632` rule and update the snapshot
- [x] Check all affected rules
- [x] No ecosystem changes
## Summary
This PR updates the return type of `parse_type_annotation` from `Expr`
to `Parsed<ModExpression>`. This is to allow accessing the tokens for
the parsed sub-expression in the follow-up PR.
## Test Plan
`cargo insta test`
## Summary
This change adds a GitHub Actions CI job to check that the project
builds and test pass under the declared minimum supported rust compiler.
I have bumped the msrv to 1.74 as that is the lowest version I could get
this project to build on.
## Test Plan
The CI job has run on this PR, and will also run on the main branch.
## Summary
This PR fixes a bug where the lexer didn't consider the BOM into the
start offset.
fixes: #11731
## Test Plan
Add multiple test cases which involves BOM character in the source for
the lexer and verify the snapshot.
## Summary
This PR updates the lexer checkpoint to store the cursor offset instead
of cloning the cursor itself. This reduces the size of `LexerCheckpoint`
from 136 to 112 bytes and also removes the need for lifetime.
## Test Plan
`cargo insta test`
## Summary
Ensures that we respect per-file ignores and exemptions for these rules.
Specifically, we allow:
```python
# ruff: noqa: PGH004
```
...to ignore `PGH004`.
## Summary
Should resolve https://github.com/astral-sh/ruff/issues/11454.
This is my first PR to `ruff`, so I may have missed something.
If I understood the suggestion in the issue correctly, rule `PGH004`
should be set to `Preview` again.
## Test Plan
Created two fixtures derived from the issue.
## Summary
Switch name resolution in `infer_expression_type` from resolving the
public type of a symbol, to resolving the reachable definitions of that
symbol from the reference point, using the flow graph.
This surfaced a bug in the flow graph implementation and a bug in symbol
table building, both of which are also fixed here.
The bug in flow graph implementation was that when we pushed and popped
scopes, we didn't maintain a stack of "current flow nodes" in all
stacked scopes, to be restored when we returned to that scope. Now we
do.
The bug in symbol table building that we didn't visit the parts of
functions and class definitions in the correct scopes. E.g. decorators
should be visited in the outer scope, arguments should be visited inside
the type-params scope (if any) but not inside the function body scope,
and only the body itself should actually be visited inside the body
scope. Fixing this requires that we no longer use `walk_stmt` here,
instead we have to visit each individual component.
## Test Plan
Added test.
## Summary
Rename `infer_symbol_type` to `infer_symbol_public_type`, and allow it
to work on symbols with more than one definition. For now, use the most
cautious/sound inference, which is the union of all definitions. We can
prune this union more in future by eliminating definitions if we can
show that they can't be visible (this requires both that the symbol is
definitely later reassigned, and that there is no intervening
call/import that might be able to see the over-written definition).
## Test Plan
Added a test showing inference of union from multiple definitions.
## Summary
This PR fixes a bug where the `Generator` wouldn't add a newline before
a type alias statement. This is because it wasn't using the `statement`
macro which takes care of the newline.
Without this fix, a code like:
```py
type X = int
type Y = str
```
The generator would produce:
```py
type X = inttype Y = str
```
## Test Plan
Add a test case.
## Summary
This PR removes the following dependencies from the `ruff_python_parser`
crate:
* `anyhow` (moved to dev dependencies)
* `is-macro`
* `itertools`
The main motivation is that they aren't used much.
Additionally, it updates the return type of `parse_type_annotation` to
use a more specific `ParseError` instead of the generic `anyhow::Error`.
## Test Plan
`cargo insta test`
## Summary
This PR updates the logic for parsing type annotation to accept a
`ExprStringLiteral` node instead of the string value and the range.
The main motivation of this change is to simplify the implementation of
`parse_type_annotation` function with:
* Use the `opener_len` and `closer_len` from the string flags to get the
raw contents range instead of extracting it via
* `str::leading_quote(expression).unwrap().text_len()`
* `str::trailing_quote(expression).unwrap().text_len()`
* Avoid comparing the string content if we already know that it's
implicitly concatenated
## Test Plan
`cargo insta test`
## Summary
This PR re-orders the lexer methods in the following order:
1. `next_token`
2. `lex_token`
3. `eat_indentation`
4. `handle_indentation`
5. `skip_whitespace`
6. `consume_ascii_character`
7. `try_single_char_prefix`
8. `try_double_char_prefix`
9. `lex_identifier`
10. `lex_fstring_start`
11. `lex_fstring_middle_or_end`
12. `lex_string`
13. `lex_number`
14. `lex_number_radix`
15. `lex_decimal_number`
16. `radix_run`
17. `lex_comment`
18. `lex_ipython_escape_command`
19. `consume_end`
Following was considered for the ordering:
* 1 is the main entry point which delegates to 2
* 3, 4, 5 are all related to whitespace which is done first
* 6 is the entrypoint for an ascii character which delegates to 9, 12,
13, 17, 18, 19
* Others are grouped around similar kind of methods
## Summary
This PR updates the entire parser stack in multiple ways:
### Make the lexer lazy
* https://github.com/astral-sh/ruff/pull/11244
* https://github.com/astral-sh/ruff/pull/11473
Previously, Ruff's lexer would act as an iterator. The parser would
collect all the tokens in a vector first and then process the tokens to
create the syntax tree.
The first task in this project is to update the entire parsing flow to
make the lexer lazy. This includes the `Lexer`, `TokenSource`, and
`Parser`. For context, the `TokenSource` is a wrapper around the `Lexer`
to filter out the trivia tokens[^1]. Now, the parser will ask the token
source to get the next token and only then the lexer will continue and
emit the token. This means that the lexer needs to be aware of the
"current" token. When the `next_token` is called, the current token will
be updated with the newly lexed token.
The main motivation to make the lexer lazy is to allow re-lexing a token
in a different context. This is going to be really useful to make the
parser error resilience. For example, currently the emitted tokens
remains the same even if the parser can recover from an unclosed
parenthesis. This is important because the lexer emits a
`NonLogicalNewline` in parenthesized context while a normal `Newline` in
non-parenthesized context. This different kinds of newline is also used
to emit the indentation tokens which is important for the parser as it's
used to determine the start and end of a block.
Additionally, this allows us to implement the following functionalities:
1. Checkpoint - rewind infrastructure: The idea here is to create a
checkpoint and continue lexing. At a later point, this checkpoint can be
used to rewind the lexer back to the provided checkpoint.
2. Remove the `SoftKeywordTransformer` and instead use lookahead or
speculative parsing to determine whether a soft keyword is a keyword or
an identifier
3. Remove the `Tok` enum. The `Tok` enum represents the tokens emitted
by the lexer but it contains owned data which makes it expensive to
clone. The new `TokenKind` enum just represents the type of token which
is very cheap.
This brings up a question as to how will the parser get the owned value
which was stored on `Tok`. This will be solved by introducing a new
`TokenValue` enum which only contains a subset of token kinds which has
the owned value. This is stored on the lexer and is requested by the
parser when it wants to process the data. For example:
8196720f80/crates/ruff_python_parser/src/parser/expression.rs (L1260-L1262)
[^1]: Trivia tokens are `NonLogicalNewline` and `Comment`
### Remove `SoftKeywordTransformer`
* https://github.com/astral-sh/ruff/pull/11441
* https://github.com/astral-sh/ruff/pull/11459
* https://github.com/astral-sh/ruff/pull/11442
* https://github.com/astral-sh/ruff/pull/11443
* https://github.com/astral-sh/ruff/pull/11474
For context,
https://github.com/RustPython/RustPython/pull/4519/files#diff-5de40045e78e794aa5ab0b8aacf531aa477daf826d31ca129467703855408220
added support for soft keywords in the parser which uses infinite
lookahead to classify a soft keyword as a keyword or an identifier. This
is a brilliant idea as it basically wraps the existing Lexer and works
on top of it which means that the logic for lexing and re-lexing a soft
keyword remains separate. The change here is to remove
`SoftKeywordTransformer` and let the parser determine this based on
context, lookahead and speculative parsing.
* **Context:** The transformer needs to know the position of the lexer
between it being at a statement position or a simple statement position.
This is because a `match` token starts a compound statement while a
`type` token starts a simple statement. **The parser already knows
this.**
* **Lookahead:** Now that the parser knows the context it can perform
lookahead of up to two tokens to classify the soft keyword. The logic
for this is mentioned in the PR implementing it for `type` and `match
soft keyword.
* **Speculative parsing:** This is where the checkpoint - rewind
infrastructure helps. For `match` soft keyword, there are certain cases
for which we can't classify based on lookahead. The idea here is to
create a checkpoint and keep parsing. Based on whether the parsing was
successful and what tokens are ahead we can classify the remaining
cases. Refer to #11443 for more details.
If the soft keyword is being parsed in an identifier context, it'll be
converted to an identifier and the emitted token will be updated as
well. Refer
8196720f80/crates/ruff_python_parser/src/parser/expression.rs (L487-L491).
The `case` soft keyword doesn't require any special handling because
it'll be a keyword only in the context of a match statement.
### Update the parser API
* https://github.com/astral-sh/ruff/pull/11494
* https://github.com/astral-sh/ruff/pull/11505
Now that the lexer is in sync with the parser, and the parser helps to
determine whether a soft keyword is a keyword or an identifier, the
lexer cannot be used on its own. The reason being that it's not
sensitive to the context (which is correct). This means that the parser
API needs to be updated to not allow any access to the lexer.
Previously, there were multiple ways to parse the source code:
1. Passing the source code itself
2. Or, passing the tokens
Now that the lexer and parser are working together, the API
corresponding to (2) cannot exists. The final API is mentioned in this
PR description: https://github.com/astral-sh/ruff/pull/11494.
### Refactor the downstream tools (linter and formatter)
* https://github.com/astral-sh/ruff/pull/11511
* https://github.com/astral-sh/ruff/pull/11515
* https://github.com/astral-sh/ruff/pull/11529
* https://github.com/astral-sh/ruff/pull/11562
* https://github.com/astral-sh/ruff/pull/11592
And, the final set of changes involves updating all references of the
lexer and `Tok` enum. This was done in two-parts:
1. Update all the references in a way that doesn't require any changes
from this PR i.e., it can be done independently
* https://github.com/astral-sh/ruff/pull/11402
* https://github.com/astral-sh/ruff/pull/11406
* https://github.com/astral-sh/ruff/pull/11418
* https://github.com/astral-sh/ruff/pull/11419
* https://github.com/astral-sh/ruff/pull/11420
* https://github.com/astral-sh/ruff/pull/11424
2. Update all the remaining references to use the changes made in this
PR
For (2), there were various strategies used:
1. Introduce a new `Tokens` struct which wraps the token vector and add
methods to query a certain subset of tokens. These includes:
1. `up_to_first_unknown` which replaces the `tokenize` function
2. `in_range` and `after` which replaces the `lex_starts_at` function
where the former returns the tokens within the given range while the
latter returns all the tokens after the given offset
2. Introduce a new `TokenFlags` which is a set of flags to query certain
information from a token. Currently, this information is only limited to
any string type token but can be expanded to include other information
in the future as needed. https://github.com/astral-sh/ruff/pull/11578
3. Move the `CommentRanges` to the parsed output because this
information is common to both the linter and the formatter. This removes
the need for `tokens_and_ranges` function.
## Test Plan
- [x] Update and verify the test snapshots
- [x] Make sure the entire test suite is passing
- [x] Make sure there are no changes in the ecosystem checks
- [x] Run the fuzzer on the parser
- [x] Run this change on dozens of open-source projects
### Running this change on dozens of open-source projects
Refer to the PR description to get the list of open source projects used
for testing.
Now, the following tests were done between `main` and this branch:
1. Compare the output of `--select=E999` (syntax errors)
2. Compare the output of default rule selection
3. Compare the output of `--select=ALL`
**Conclusion: all output were same**
## What's next?
The next step is to introduce re-lexing logic and update the parser to
feed the recovery information to the lexer so that it can emit the
correct token. This moves us one step closer to having error resilience
in the parser and provides Ruff the possibility to lint even if the
source code contains syntax errors.
## Summary
Implement support for RDJson output for `ruff check`, as requested in
#8655.
## Test Plan
Tested using a snapshot test. Same approach as for e.g. the JSON output
formatter.
## Additional info
I tried to keep the implementation close to the JSON implementation.
I had to deviate a bit to make the `suggestions` key work: If there are
no suggestions, then setting `suggestions` to `null` is invalid
according to the JSONSchema. Therefore, I opted for a slightly more
complex implementation, that skips the `suggestions` key entirely if
there are no fixes available for the given diagnostic. Maybe it would
have been easier to set `"suggestions": []`, but I ended up doing it
this way.
I didn't consider notebooks, as I _think_ that RDJson doesn't work with
notebooks. This should be confirmed, and if so, there should be some
form of warning or error emitted when trying to output diagnostics for a
notebook.
I also didn't consider `ruff format`, as this comment:
https://github.com/astral-sh/ruff/issues/8655#issuecomment-1811446160
suggests that that wouldn't be compatible.
I'm new to Rust, any feedback is appreciated. 🙂 I
implemented this in order to have a productive rainy saturday afternoon,
I'm not knowledgeable about RDJson beyond the sources linked in the
issue.
## Summary
This just ensures that PRs labelled with `red-knot` are automatically
filtered out from the auto-generated changelog (which we then manually
finalize anyway).
## Summary
This PR implements the rule B901, which is part of the opinionated rules
of `flake8-bugbear`.
This rule seems to be desired in `ruff` as per
https://github.com/astral-sh/ruff/issues/3758 and
https://github.com/astral-sh/ruff/issues/2954#issuecomment-1441162976.
## Test Plan
As this PR was made closely following the
[CONTRIBUTING.md](8a25531a71/CONTRIBUTING.md),
it tests using the snapshot approach, that is described there.
## Sources
The implementation is inspired by [the original implementation in the
`flake8-bugbear`
repository](d1aec4cbef/bugbear.py (L1092)).
The error message and [test
file](d1aec4cbef/tests/b901.py)
where also copied from there.
The documentation I came up with on my own and needs improvement. Maybe
the example given in
https://github.com/astral-sh/ruff/issues/2954#issuecomment-1441162976
could be used, but maybe they are too complex, I'm not sure.
## Open Questions
- [ ] Documentation. (See above.)
- [x] Can I access the parent in a visitor?
The [original
implementation](d1aec4cbef/bugbear.py (L1100))
references the `yield` statement's parent to check if it is an
expression statement. I didn't find a way to do this in `ruff` and used
the `is_expresssion_statement` field on the visitor instead. What are
your thoughts on this? Is it possible and / or desired to access the
parent node here?
- [x] Is `Option::is_some(...)` -> `...unwrap()` the right thing to do?
Referring to [this piece of
code](9d5a280f71/crates/ruff_linter/src/rules/flake8_bugbear/rules/return_x_in_generator.rs (L91-L96)).
From my understanding, the `.unwrap()` is safe, because it is checked
that `return_` is not `None`. However, I feel like I missed a more
elegant solution that does both in one.
## Other
I don't know a lot about this rule, I just implemented it because I
found it in a
https://github.com/astral-sh/ruff/labels/good%20first%20issue.
I'm new to Rust, so any constructive critisism is appreciated.
---------
Co-authored-by: Charlie Marsh <charlie.r.marsh@gmail.com>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Introduces the skeleton of the flow graph. So far it doesn't actually
handle any non-linear control flow :) But it does show how we can go
from an expression that references a symbol, backward through the flow
graph, to find reachable definitions of that symbol.
Adding non-linear control flow will mean adding flow nodes with multiple
predecessors, which will introduce more complexity into
`ReachableDefinitionsIterator.next()`. But one step at a time.
## Test Plan
Added a (very basic) test.
## Summary
Give red-knot the ability to infer int literal types. This is quick and
easy, mostly because these types are a convenient way to observe
control-flow handling with simple assignments.
## Test Plan
Added test.
## Summary
- Ever since https://github.com/godotengine/godot/pull/90457 was merged
into the `master` branch, Godot has been using ruff for linting and
formatting Python files. As such, this PR adds Godot to the "Who's Using
Ruff?" section of the main `README.md` file.
## Test Plan
- N/A
## Summary
In the [roadmap for `ruff
server`](https://github.com/astral-sh/ruff/discussions/10581) support
for vim and kate is listed. Therefore I added setup guides for them
based on the neovim guide. As I don't use pyright I wasn't able to
translate the corresponding part from the neovim guide.
## Test Plan
Doesn't apply.
* Potentially resolves#11619 (nondeterministic hashmap order across
different architectures) in F401 by replacing a hashmap with
nondeterministic traversal order with an ordered mapping.
I'm not sure how to test this with our CI/CD. I don't have an s390x
machine at home. Should I try it in Qemu?
## Summary
In an `__init__.py` file, it's not uncommon to lack a logical indent
(since it may just contain imports). In such cases, we were always
falling back to four-space indent. This PR adds detection for indents
within import groups.
Closes https://github.com/astral-sh/ruff/issues/11606.
## Summary
This PR aims to close#10095 by adding an option
`init-allow-undef-export` to the `pyflakes` settings. This option is
currently set to `true` such that behavior is kept identical.
But setting this option to `false` will lead to `F822` warnings to be
shown in all files, **including** `__init__.py` files.
As I've mentioned on #10095, I think `init-allow-undef-export=false`
would be the more user-friendly default option, as it creates fewer
surprises. @charliermarsh what do you think about making that the
default?
With this option in place, it's a single line fix for people that rely
on the old behavior.
And thinking longer term, for future major releases, one could probably
consider deprecating the option and eventually having people just `noqa`
these warnings if they are not wanted.
## Test Plan
I've added a `test_init_f822_enabled` test which repeats the test that
is done in the `init` test but this time with
`init-allow-undef-export=false` and the snap file correctly shows that
ruff will then trigger the otherwise suppressed F822 warning.
closes#10095
## Summary
Removed stray space in sample code snippet that is against ruff's own
default formatting rules.
This documentation appears on
https://docs.astral.sh/ruff/rules/unused-import/
## Test Plan
This is a trivially obvious change, verifiable with `ruff format
--check`
## Summary
Closes https://github.com/astral-sh/ruff/issues/11587.
## Test Plan
- Added a lint error to `test_server.py` in `vscode-ruff`.
- Validated that, prior to this change, diagnostics appeared in the
file.
- Validated that, with this change, no diagnostics were shown.
- Validated that, with this change, no diagnostics were fixed on-save.
## Summary
- Implements `Y066` from `flake8-pyi` as `PYI066`
- Fixes `PYI006` not being raised for `elif` clauses. This would have
conflicted with PYI006's implementation, so decided to do it in the same
PR.
## Test Plan
`cargo test` / `cargo insta review`
* Add a module type, `ModuleTypeId`
* Add an attribute lookup method `get_member` for `Type`
* Only implemented for `ModuleTypeId` and `ClassTypeId`
* [x] Should this be a trait?
*Answer: no*
* [x] Uses `unwrap`, but we should remove that. Maybe add a new variant
to `QueryError`?
*Answer: Return `Option<Type>` as is done elsewhere*
* Add `infer_definition_type` case for `Import`
* Add `infer_expr_type` case for `Attribute`
* Add a test to exercise these
* [x] remove all NOTE/FIXME/TODO after discussing with reviewers
## Summary
This PR ensures that if a variable is bound via `global`, and then the
`global` is read, the originating variable is also marked as read. It's
not perfect, in that it won't detect _rebindings_, like:
```python
from app import redis_connection
def func():
global redis_connection
redis_connection = 1
redis_connection()
```
So, above, `redis_connection` is still marked as unused.
But it does avoid flagging `redis_connection` as unused in:
```python
from app import redis_connection
def func():
global redis_connection
redis_connection()
```
Closes https://github.com/astral-sh/ruff/issues/11518.
## Summary
Follow up to https://github.com/astral-sh/ruff/pull/11521
Removes the extra added complexity for catch all match cases. This
matches the implementation of plain `else` statements.
## Test Plan
Added new test cases.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
## Summary
This PR fixes the bug to avoid flattening the global-only settings for
the new server.
This was added in https://github.com/astral-sh/ruff/pull/11497, possibly
to correctly de-serialize an empty value (`{}`). But, this lead to a bug
where the configuration under the `settings` key was not being read for
global-only variant.
By using #[serde(default)], we ensure that the settings field in the
`GlobalOnly` variant is optional and that an empty JSON object `{}` is
correctly deserialized into `GlobalOnly` with a default `ClientSettings`
instance.
fixes: #11507
## Test Plan
Update the snapshot and existing test case. Also, verify the following
settings in Neovim:
1. Nothing
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
}
```
2. Empty dictionary
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
init_options = vim.empty_dict(),
}
```
3. Empty `settings`
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
init_options = {
settings = vim.empty_dict(),
},
}
```
4. With some configuration:
```lua
ruff = {
cmd = {
'/Users/dhruv/work/astral/ruff/target/debug/ruff',
'server',
'--preview',
},
init_options = {
settings = {
configuration = '/tmp/ruff-repro/pyproject.toml',
},
},
}
```
## Summary
This PR brings back the functionality to remove empty strings when
converting to an f-string in `UP032`.
For context, https://github.com/astral-sh/ruff/pull/8712 added this
functionality to remove _trailing_ empty strings but it got removed in
https://github.com/astral-sh/ruff/pull/8697 possibly unexpectedly so.
There's one difference which is that this PR will remove _any_ empty
strings and not just trailing ones. For example,
```diff
--- /Users/dhruv/playground/ruff/src/UP032.py
+++ /Users/dhruv/playground/ruff/src/UP032.py
@@ -1,7 +1,5 @@
(
- "{a}"
- ""
- "{b}"
- ""
-).format(a=1, b=1)
+ f"{1}"
+ f"{1}"
+)
```
## Test Plan
Run `cargo insta test` and update the snapshots.
## Summary
This PR updates the sequence sorting (`RUF022` and `RUF023`) to avoid
using the owned data from the string token. Instead, we will directly
use the reference to the data on the AST. This does introduce a lot of
lifetimes but that's required.
The main motivation for this is to allow removing the `lex_starts_at`
usage easily.
### Alternatives
1. Extract the raw string content (stripping the prefix and quotes)
using the `Locator` and use that for comparison
2. Build up an
[`IndexVec`](3e30962077/crates/ruff_index/src/vec.rs)
and use the newtype index in place of the string value itself. This also
does require lifetimes so we might as well just use the method in this
PR.
## Test Plan
`cargo insta test` and no ecosystem changes
## Summary
Fixes#11506.
`RuffSettingsIndex::new` now searches for configuration files in parent
directories.
## Test Plan
I confirmed that the original test case described in the issue worked as
expected.
## Summary
Concurrent GitLab runners clone projects into separate directories, e.g.
`{builds_dir}/$RUNNER_TOKEN_KEY/$CONCURRENT_ID/$NAMESPACE/$PROJECT_NAME`.
Since the fingerprint uses the full path to the file, the fingerprints
calculated by Ruff are different depending on which concurrent runner it
executes on, so often an MR will appear to remove all existing issues
and add them with new fingerprints.
I've adjusted the fingerprint function to use the project relative path,
which fixes this. Unfortunately this will have a breaking change for any
current users of this output - the fingerprints will change and appear
in GitLab as all linting messages having been fixed and then created.
## Test Plan
`cargo nextest run`
Running `ruff check --output-format gitlab` in a git repo, moving the
repo and running again, verifying no diffs between the outputs
## Summary
Fixes#11534.
`DocumentQuery::source_type` now returns `PySourceType::Stub` when the
document is a `.pyi` file.
## Test Plan
I confirmed that stub-specific rule violations appeared with a build
from this PR (they were not visible from a `main` build).
<img width="1066" alt="Screenshot 2024-05-24 at 2 15 38 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/cd519b7e-21e4-41c8-bc30-43eb6d4d438e">
Hi!
I left out some of the functions in the migration rule which became
removed in NumPy 2.0:
- `np.alltrue`
- `np.anytrue`
- `np.cumproduct`
- `np.product`
Addressing: https://github.com/numpy/numpy/issues/26493
## Summary
<!-- What's the purpose of the change? What does it do, and why? -->
Current doc says `sys.version[0]` will select the first digit of a major
version number (correct) then as an example says
> e.g., `"3.10"` would evaluate to `"1"`
(would actually evaluate to `"3"`). Changed the example version to a
two-digit number to make the problem more clear.
## Test Plan
<!-- How was it tested? -->
ran the following:
- `cargo run -p ruff -- check
crates/ruff_linter/resources/test/fixtures/flake8_2020/YTT301.py
--no-cache`
- `cargo insta review`
- `cargo test`
which all passed.
## Summary
Rule `logging-warn` (`G010`) prescribes a change from `warn` to
`warning` and has a corresponding autofix, but the autofix is mistakenly
titled ```"Convert to `warn`"``` instead of ```"Convert to `warning`"```
(the latter is what the autofix actually does). Seems to be a plain
typo.
## Summary
Fixes#11516
`ruff server` was sending both regular source actions and notebook
source actions back when passed an empty action filter. This PR makes a
few small changes so that notebook source actions are not sent when
regular source actions are sent, which means that an empty filter will
only return regular source actions.
## Test Plan
I confirmed that duplicate code actions no longer appeared in Neovim,
using a configuration similar to the one from the original issue.
<img width="509" alt="Screenshot 2024-05-23 at 11 48 48 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/9a5d6907-dd41-48bd-b015-8a344c5e0b3f">
## Summary
It turns out that `singledispatch` does end up evaluating all arguments,
even though only the first is used to dispatch.
Closes https://github.com/astral-sh/ruff/issues/11520.
## Summary
Addresses #8451 by implementing rule 116 to add an unsafe fix when sleep
is used with a >24 hour interval to instead consider sleeping forever.
This rule is added as async instead as I my understanding was that these
trio rules would be moved to async anyway.
There are a couple of TODOs, which address further extending the rule by
adding support for lookups and evaluations, and also supporting `anyio`.
## Summary
This PR updates the `FA102` rule logic to use the `Importer` which is
available on the `Checker`.
The main motivation is that this would make updating the `Importer` to
use the `Tokens` struct which will be required to remove the
`lex_starts_at` usage in `Insertion::start_of_block` method.
## Test Plan
`cargo insta test`
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11236.
This PR fixes several issues, most of which relate to non-VS Code
editors (Helix and Neovim).
1. Global-only initialization options are now correctly deserialized
from Neovim and Helix
2. Empty diagnostics are now published correctly for Neovim and Helix.
3. A workspace folder is created at the current working directory if the
initialization parameters send an empty list of workspace folders.
4. The server now gracefully handles opening files outside of any known
workspace, and will use global fallback settings taken from client
editor settings and a user settings TOML, if it exists.
## Test Plan
I've tested to confirm that each issue has been fixed.
* Global-only initialization options are now correctly deserialized from
Neovim and Helix + the server gracefully handles opening files outside
of any known workspace
https://github.com/astral-sh/ruff/assets/19577865/4f33477f-20c8-4e50-8214-6608b1a1ea6b
* Empty diagnostics are now published correctly for Neovim and Helix
https://github.com/astral-sh/ruff/assets/19577865/c93f56a0-f75d-466f-9f40-d77f99cf0637
* A workspace folder is created at the current working directory if the
initialization parameters send an empty list of workspace folders.
https://github.com/astral-sh/ruff/assets/19577865/b4b2e818-4b0d-40ce-961d-5831478cc726
## Summary
Similar to #11414, this PR extends `UP037` to flag quoted annotations
that are located in positions that won't be evaluated at runtime.
For example, the quotes on `Tuple` are unnecessary in:
```python
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from typing import Tuple
def foo():
x: "Tuple[int, int]" = (0, 0)
foo()
```
## Summary
Recent changes made in the [Jupyter Notebook feature
PR](https://github.com/astral-sh/ruff/pull/11206) caused automatic
configuration reloading to stop working. This was because we would check
for paths to reload using the changed path, when we should have been
using the parent path of the changed path (to get the directory it was
changed in).
Additionally, this PR fixes an issue where `ruff.toml` and `.ruff.toml`
files were not being automatically reloaded.
Finally, this PR improves configuration reloading by actively publishing
diagnostics for notebook documents (which won't be affected by the
workspace refresh since they don't use pull diagnostics). It will also
publish diagnostics for text documents if pull diagnostics aren't
supported.
## Test Plan
To test this, open an existing configuration file in a codebase, and
make modifications that will affect one or more open Python / Jupyter
Notebook files. You should observe that the diagnostics for both kinds
of files update automatically when the file changes are saved.
Here's a test video showing what a successful test should look like:
https://github.com/astral-sh/ruff/assets/19577865/7172b598-d6de-4965-b33c-6cb8b911ef6c
## Summary
Previously, `ruff.applyFormat`, seen in VS Code as the command `Ruff:
Format Document`, would only format the currently active notebook cell
inside a notebook document. This PR makes `ruff.applyFormat` format the
entire notebook document at once, operating on each code cell in order.
## Test Plan
1. Open a notebook document that has multiple unformatted code cells.
2. Run `Ruff: Format Document` through the Command Palette
(`Ctrl/Cmd+Shift+P` by default)
3. Observe that all code cells in the notebook have been formatted.
## Summary
This PR moves the `has_comments` function from `Indexer` to
`CommentRanges`. The main motivation is that the `CommentRanges` will
now be built by the parser which is shared between the linter and the
formatter. Thus, the `CommentRanges` will be removed from the `Indexer`.
## Test Plan
`cargo test`
## Summary
When using `add_rule.py`, it produces the following line in `codes.rs`
```
(Flake8Async, "102") => (RuleGroup::Stable, rules::flake8-async::rules::BlockingOsCallInAsyncFunction),
```
Causing a syntax error.
This PR resolves that issue so that the script can be used again.
## Test Plan
Tested manually in new rule creation
## Summary
Matching Pylint, we now omit the `try` body itself from branch counting.
Each `except` counts as a branch, as does the `else` and the `finally`.
Closes https://github.com/astral-sh/ruff/issues/11205.
## Summary
Closes https://github.com/astral-sh/ruff/issues/10858.
`ruff server` now supports `*.ipynb` (aka Jupyter Notebook) files.
Extensive internal changes have been made to facilitate this, which I've
done some work to contextualize with documentation and an pre-review
that highlights notable sections of the code.
`*.ipynb` cells should behave similarly to `*.py` documents, with one
major exception. The format command `ruff.applyFormat` will only apply
to the currently selected notebook cell - if you want to format an
entire notebook document, use `Format Notebook` from the VS Code context
menu.
## Test Plan
The VS Code extension does not yet have Jupyter Notebook support
enabled, so you'll first need to enable it manually. To do this,
checkout the `pre-release` branch and modify `src/common/server.ts` as
follows:
Before:

After:

I recommend testing this PR with large, complicated notebook files. I
used notebook files from [this popular
repository](https://github.com/jakevdp/PythonDataScienceHandbook/tree/master/notebooks)
in my preliminary testing.
The main thing to test is ensuring that notebook cells behave the same
as Python documents, besides the aforementioned issue with
`ruff.applyFormat`. You should also test adding and deleting cells (in
particular, deleting all the code cells and ensure that doesn't break
anything), changing the kind of a cell (i.e. from markup -> code or vice
versa), and creating a new notebook file from scratch. Finally, you
should also test that source actions work as expected (and across the
entire notebook).
Note: `ruff.applyAutofix` and `ruff.applyOrganizeImports` are currently
broken for notebook files, and I suspect it has something to do with
https://github.com/astral-sh/ruff/issues/11248. Once this is fixed, I
will update the test plan accordingly.
---------
Co-authored-by: nolan <nolan.king90@gmail.com>
The wording 'negative comparison' is a rather vague description of the
'is not' operation and does not describe what the 'not in' operation
does (potentially copied from 'is not'). This was replaced with more
precise language to describe the operators taken from the official
python docs[1].
Both rules didn't have a strong reasoning besides 'it's bad, use the
other'. The origin of these rules seems to be PEP8[2] which prefers 'is
not' over 'not ... is' for readability. This is now reflected in the
description.
[1]:
https://docs.python.org/3/reference/expressions.html#membership-test-operations
[2]: https://peps.python.org/pep-0008/#programming-recommendations
## Summary
If an annotation won't be evaluated at runtime, we don't need to flag
`from __future__ import annotations` as required. This applies both to
quoted annotations and annotations outside of runtime-evaluated
positions, like:
```python
def main() -> None:
a_list: list[str] | None = []
a_list.append("hello")
```
Closes https://github.com/astral-sh/ruff/issues/11397.
## Summary
* Update documentation for F401 following recent PRs
* #11168
* #11314
* Deprecate `ignore_init_module_imports`
* Add a deprecation pragma to the option and a "warn user once" message
when the option is used.
* Restore the old behavior for stable (non-preview) mode:
* When `ignore_init_module_imports` is set to `true` (default) there are
no `__init_.py` fixes (but we get nice fix titles!).
* When `ignore_init_module_imports` is set to `false` there are unsafe
`__init__.py` fixes to remove unused imports.
* When preview mode is enabled, it overrides
`ignore_init_module_imports`.
* Fixed a bug in fix titles where `import foo as bar` would recommend
reexporting `bar as bar`. It now says to reexport `foo as foo`. (In this
case we don't issue a fix, fwiw; it was just a fix title bug.)
## Test plan
Added new fixture tests that reuse the existing fixtures for
`__init__.py` files. Each of the three situations listed above has
fixture tests. The F401 "stable" tests cover:
> * When `ignore_init_module_imports` is set to `true` (default) there
are no `__init_.py` fixes (but we get nice fix titles!).
The F401 "deprecated option" tests cover:
> * When `ignore_init_module_imports` is set to `false` there are unsafe
`__init__.py` fixes to remove unused imports.
These complement existing "preview" tests that show the new behavior
which recommends fixes in `__init__.py` according to whether the import
is 1st party and other circumstances (for more on that behavior see:
#11314).
## Summary
This is a follow-up PR to #11445 update the `E27` rules to consider soft
keywords as well.
## Test Plan
Add test cases consisting of soft keywords and update the snapshot.
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
The recent issues with the windows CI seem to be caused by
https://github.com/nextest-rs/nextest/issues/1493. With this
https://github.com/nextest-rs/nextest/issues/1493#issuecomment-2106331574
as a fix.
(Let's see if it works)
## Summary
Something's up with this repo -- they added a post-checkout hook? So
let's just remove it for now. We should go through and add a new batch
of repositories some time.
## Summary
We weren't treating the escaped newline as a valid condition to trigger
the safer fix (add an extra backslash before each invalid escape
sequence).
Closes https://github.com/astral-sh/ruff/issues/11461.
## Summary
This PR updates the `TokenKind::is_keyword` check to include soft
keywords. To account for this change, it adds a new
`is_non_soft_keyword` method.
The usage in logical line rules were updated to use the
`is_non_soft_keyword` method but it'll be updated to use `is_keyword` in
a follow-up PR (#11446).
While, the parser usages were kept as is. And because of that, the
snapshots for two test cases were updated in a better direction.
## Test Plan
`cargo insta test`
## Summary
We already have handling for "references that get quoted within our
quoted references", but we were assuming a specific ordering in the way
edits were generated.
Closes https://github.com/astral-sh/ruff/issues/11449.
Fixes#11246
## Summary
This change adds an intermediate additional search path for
`find_ruff_bin`.
I would have added this path as the last one, except that the last one
is the one reported to the user, so I made this one second to last.
## Test Plan
It's shown to work with this command:
```
~ @ pip-run git+https://github.com/jaraco/ruff@feature/honor-install-target-bin -- -m ruff --version
ruff 0.4.4
```
I tried running the same command on Windows, which should work in
theory, but building ruff from source on Windows is complicated. Even
after installing Rust, ruff fails to build when `libmimalloc-sys` fails
to build because `gcc` isn't installed (and the error message points to
a [broken
anchor](https://github.com/rust-lang/cc-rs#compile-time-requirements)).
I was really hoping Rust would get us away from the Windows as
second-class-citizen model :(.
This is useful for extracting the defaults in order to construct
equivalent configs by external scripts. This is my first non-hello-world
rust code, comments and suggested tests appreciated.
## Summary
We already have `ruff linter --output-format json`, this provides `ruff
config x --output-format json` as well. I plan to use this to construct
an equivalent config snippet to include in some managed repos, so when
we update their version of ruff and it adds new lints, they get a PR
that includes the commented-out new lints.
Note that the no-args form of `ruff config` ignores output-format
currently, but probably should obey it (although array-of-strings
doesn't seem that useful, looking for input on format).
## Test Plan
I could use a hand coming up with a typical way to write automated tests
for this.
```sh-session
(.venv) [timhatch:ruff ]$ ./target/debug/ruff config lint.select
A list of rule codes or prefixes to enable. Prefixes can specify exact
rules (like `F841`), entire categories (like `F`), or anything in
between.
When breaking ties between enabled and disabled rules (via `select` and
`ignore`, respectively), more specific prefixes override less
specific prefixes.
Default value: ["E4", "E7", "E9", "F"]
Type: list[RuleSelector]
Example usage:
``toml
# On top of the defaults (`E4`, E7`, `E9`, and `F`), enable flake8-bugbear (`B`) and flake8-quotes (`Q`).
select = ["E4", "E7", "E9", "F", "B", "Q"]
``
(.venv) [timhatch:ruff ]$ ./target/debug/ruff config lint.select --output-format json
{
"Field": {
"doc": "A list of rule codes or prefixes to enable. Prefixes can specify exact\nrules (like `F841`), entire categories (like `F`), or anything in\nbetween.\n\nWhen breaking ties between enabled and disabled rules (via `select` and\n`ignore`, respectively), more specific prefixes override less\nspecific prefixes.",
"default": "[\"E4\", \"E7\", \"E9\", \"F\"]",
"value_type": "list[RuleSelector]",
"scope": null,
"example": "# On top of the defaults (`E4`, E7`, `E9`, and `F`), enable flake8-bugbear (`B`) and flake8-quotes (`Q`).\nselect = [\"E4\", \"E7\", \"E9\", \"F\", \"B\", \"Q\"]",
"deprecated": null
}
}
```
## Summary
As discussed in issue #11408, PLR0912 has a broader definition of
"branches" than I expected. This updates the documentation to include
this definition.
I also updated the example to include several different types of
branches, while still maintaining dictionary lookup as an alternative
solution. (Crafting a realistic example was quite a challenge 😅).
Closes https://github.com/astral-sh/ruff/issues/11408.
## Summary
CONTRIBUTING.md says that `cargo dev print-ast` uses the old RuffPython
parser, even though, as far as I can tell, it uses the shiny new parser.
This PR fixes this.
## Test Plan
CI jobs should do the trick -- I didn't modify any code.
## Summary
This moves the string-prefix enumerations in `ruff_python_ast` to a
separate submodule. I think this helps clarify that these prefixes are
purely abstract: they only depend on each other, and do not depend on
any of the other code in `nodes.rs` in any way. Moreover, while various
AST nodes _use_ them, they're not really nodes themselves, so they feel
slightly out of place in `nodes.rs`.
I considered moving all of them to `str.rs`, but it felt like enough
code that it could be a separate submodule.
## Test Plan
`cargo test`
Followup on #11168 and resolve#10391
# User facing changes
* F401 now recommends a fix to add unused import bindings to to
`__all__` if a single `__all__` list or tuple is found in `__init__.py`.
* If there are no `__all__` found in the file, fall back to recommending
redundant-aliases.
* If there are multiple `__all__` or only one but of the wrong type (non
list or tuple) then diagnostics are generated without fixes.
* `fix_title` is updated to reflect what the fix/recommendation is.
Subtlety: For a renamed import such as `import foo as bees`, we can
generate a fix to add `bees` to `__all__` but cannot generate a fix to
produce a redundant import (because that would break uses of the binding
`bees`).
# Implementation changes
* Add `name` field to `ImportBinding` to contain the name of the
_binding_ we want to add to `__all__` (important for the `import foo as
bees` case). It previously only contained the `AnyImport` which can give
us information about the import but not the binding.
* Add `binding` field to `UnusedImport` to contain the same. (Naming
note: the field `name` field already existed on `UnusedImport` and
contains the qualified name of the imported symbol/module)
* Change `fix_by_reexporting` to branch on the size of `dunder_all:
Vec<&Expr>`
* For length 0 call the edit-producing function `make_redundant_alias`.
* For length 1 call edit-producing function `add_to_dunder_all`.
* Otherwise, produce no fix.
* Implement the edit-producing function `add_to_dunder_all` and add unit
tests.
* Implement several fixture tests: empty `__all__ = []`, nonempty
`__all__ = ["foo"]`, mis-typed `__all__ = None`, plus-eq `__all__ +=
["foo"]`
* `UnusedImportContext::Init` variant now has two fields: whether the
fix is in `__init__.py` and how many `__all__` were found.
# Other changes
* Remove a spurious pattern match and instead use field lookups b/c the
addition of a field would have required changing the unrelated pattern.
* Tweak input type of `make_redundant_alias`
---------
Co-authored-by: Alex Waygood <Alex.Waygood@Gmail.com>
## Summary
This PR follows up from #11420 to move `UP034` to use `TokenKind`
instead of `Tok`.
The main reason to have a separate PR is so that the reviewing is easy.
This required a lot more updates because the rule used an index (`i`) to
keep track of the current position in the token vector. Now, as it's
just an iterator, we just use `next` to move the iterator forward and
extract the relevant information.
This is part of https://github.com/astral-sh/ruff/issues/11401
## Test Plan
`cargo test`
## Summary
This PR moves the following rules to use `TokenKind` instead of `Tok`:
* `PLE2510`, `PLE2512`, `PLE2513`, `PLE2514`, `PLE2515`
* `E701`, `E702`, `E703`
* `ISC001`, `ISC002`
* `COM812`, `COM818`, `COM819`
* `W391`
I've paused here because the next set of rules
(`pyupgrade::rules::extraneous_parentheses`) indexes into the token
slice but we only have an iterator implementation. So, I want to isolate
that change to make sure the logic is still the same when I move to
using the iterator approach.
This is part of #11401
## Test Plan
`cargo test`
## Summary
Alternative to #11237
This PR adds a new `Tokens` struct which is a newtype wrapper around a
vector of lexer output. This allows us to add a `kinds` method which
returns an iterator over the corresponding `TokenKind`. This iterator is
implemented as a separate `TokenKindIter` struct to allow using the type
and provide additional methods like `peek` directly on the iterator.
This exposes the linter to access the stream of `TokenKind` instead of
`Tok`.
Edit: I've made the necessary downstream changes and plan to merge the
entire stack at once.
## Summary
This PR updates the linter benchmark to use the `tokenize` function
instead of the lexer.
The linter expects the token list to be up to and including the first
error which is what the `ruff_python_parser::tokenize` function returns.
This was not a problem before because the benchmarks only uses valid
Python code.
## Summary
This PR adds a newtype wrapper around `Vec<FStringElement>` that derefs
to a `&Vec<FStringElement>`.
Both f-string and format specifier are made up of `Vec<FStringElement>`.
By creating a newtype wrapper around it, we can share the methods for
both parent types.
## Summary
This PR adds support to iterate over each part of a string-like
expression.
This similar to the one in the formatter:
128414cd95/crates/ruff_python_formatter/src/string/any.rs (L121-L125)
Although I don't think it's a 1-1 replacement in the formatter because
the one implemented in the formatter has another information for certain
variants (as can be seen for `FString`).
The main motivation for this is to avoid duplication for rules which
work only on the parts of the string and doesn't require any information
from the parent node. Here, the parent node being the expression node
which could be an implicitly concatenated string.
This PR also updates certain rule implementation to make use of this and
avoids logic duplication.
## Summary
This PR renames `AnyStringKind` to `AnyStringFlags` and `AnyStringFlags`
to `AnyStringFlagsInner`.
The main motivation is to have consistent usage of "kind" and "flags".
For each string kind, it's "flags" like `StringLiteralFlags`,
`BytesLiteralFlags`, and `FStringFlags` but it was `AnyStringKind` for
the "any" variant.
## Summary
Changes `future-rewritable-type-annotation` (`FA100`) message to be less
confusing. Uses phrasing from the rule documentation to be consistent.
For example,
```
from_typing_import.py:5:13: FA100 Add `from __future__ import annotations` to rewrite `typing.List` more succinctly
```
Closes#10573.
## Test Plan
`cargo nextest run`
## Summary
Should this consider the decorator only if the name is actually a
property or is the logic in this PR correct?
fixes: #11358
## Test Plan
Add test case.
## Summary
This PR fixes a bug where the auto-fix for `TCH005` would delete the
entire `if` statement.
The fix in this PR is to not consider it a violation if there are any
`elif`/`else` blocks. This also matches the behavior of the original
plugin.
fixes: #11368
## Test plan
Add test cases.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/10594.
Code actions to disable a diagnostic via `noqa` comment are now
available.
https://github.com/astral-sh/ruff/assets/19577865/6d3bcf11-a9d9-499b-8c7f-a10cd39cfbba
`DiagnosticFix` has been changed so that `noqa` code actions appear even
for diagnostics with no available quick fix. It can contain quick fix
edits, `noqa` comment edits, or both.
## Test Plan
The scenarios that need to be tested are as follows:
* A code action to disable a diagnostic should be available for every
diagnostic.
* Using this code action should append to the appropriate line with the
diagnostic, or modify an existing `noqa` comment.
* Adding a `noqa` comment manually should make a diagnostic disappear
* `Fix all auto-fixable problems` should not add `noqa` comments
* Removing a code from a `noqa` comment should make the diagnostic
re-appear
## Summary
`--add-noqa` now runs in two stages: first, the linter finds all
diagnostics that need noqa comments and generate edits on a per-line
basis. Second, these edits are applied, in order, to the document.
A public-facing function, `generate_noqa_edits`, has also been
introduced, which returns noqa edits generated on a per-diagnostic
basis. This will be used by `ruff server` for noqa comment quick-fixes.
## Test Plan
Unit tests have been updated.
## Summary
This PR adds updates the semantic model to detect attribute docstring.
Refer to [PEP 258](https://peps.python.org/pep-0258/#attribute-docstrings)
for the definition of an attribute docstring.
This PR doesn't add full support for it but only considers string
literals as attribute docstring for the following cases:
1. A string literal following an assignment statement in the **global
scope**.
2. A global class attribute
For an assignment statement, it's considered an attribute docstring only
if the target expression is a name expression (`x = 1`). So, chained
assignment, multiple assignment or unpacking, and starred expression,
which are all valid in the target position, aren't considered here.
In `__init__` method, an assignment to the `self` variable like `self.x = 1`
is also a candidate for an attribute docstring. **This PR does not
support this position.**
## Test Plan
I used the following source code along with a print statement to verify
that the attribute docstring detection is correct.
Refer to the PR description for the code snippet.
I'll add this in the follow-up PR
(https://github.com/astral-sh/ruff/pull/11302) which uses this method.
## Summary
Lots of TODOs and things to clean up here, but it demonstrates the
working lint rule.
## Test Plan
```
➜ cat main.py
from typing import override
from base import B
class C(B):
@override
def method(self): pass
➜ cat base.py
class B: pass
➜ cat typing.py
def override(func):
return func
```
(We provide our own `typing.py` since we don't have typeshed vendored or
type stub support yet.)
```
➜ ./target/debug/red_knot main.py
...
1 0.012086s TRACE red_knot Main Loop: Tick
[crates/red_knot/src/main.rs:157:21] diagnostics = [
"Method C.method is decorated with `typing.override` but does not override any base class method",
]
```
If we add `def method(self): pass` to class `B` in `base.py` and run
red_knot again, there is no lint error.
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
<!--
Thank you for contributing to Ruff! To help us out with reviewing,
please consider the following:
- Does this pull request include a summary of the change? (See below.)
- Does this pull request include a descriptive title?
- Does this pull request include references to any relevant issues?
-->
## Summary
Resolves#11263
Detect `pathlib.Path.open` calls which do not specify a file encoding.
## Test Plan
Test cases added to fixture.
---------
Co-authored-by: Dhruv Manilawala <dhruvmanila@gmail.com>
This PR vendors typeshed!
- The first commit vendors the stdlib directory from typeshed into a new crates/red_knot/vendored_typeshed directory.
- The second commit adjusts various linting config files to make sure that the vendored code is excluded from typo checks, formatting checks, etc.
- The LICENSE and README.md files are also vendored, but all other directories and files (stubs, scripts, tests, test_cases, etc.) are excluded. We should have no need for them (except possibly stubs/, discussed in more depth below).
- Similar to the way pyright has a commit.txt file in its vendored copy of typeshed, to indicate which typeshed commit the vendored code corresponds to, I've also added a crates/red_knot/vendored_typeshed/source_commit.txt file in the third commit of this PR.
One open question is: should we vendor the stdlib and stubs directories, or just the stdlib directory? The stubs/ directory contains stubs for 162 third-party packages outside the stdlib. Mypy and typeshed_client1 only vendor the stdlib directory; pyright and pyre vendor both the stdlib and stubs directories; pytype vendors the entire typeshed repo (scripts/, tests/ and all).
In this PR, I've chosen to copy mypy and typeshed_client. Unlike vendoring the stdlib, which is unavoidable if we want to do typechecking of the stdlib, it's not strictly necessary to vendor the stubs directory: each subdirectory in stubs is published to PyPI as a standalone stubs distribution that can be (uv)-pip-installed into a virtual environment. It might be useful for our users if we vendored those stubs anyway, but there are costs as well as benefits to doing so (apart from just the sheer amount of vendored code in the ruff repository), so I'd rather consider it separately.
Resolves https://github.com/astral-sh/ruff/issues/11313
## Summary
PLR0912(too-many-branches) did not count branches inside with: blocks.
With this fix, the branches inside with statements are also counted.
## Test Plan
Added a new test case.
## Summary
After checking the links, I found that one link leads to 404. Correct me
if i'm wrong, but I think the link I changed to is the supposed one
## Summary
This PR removes the cyclic dev dependency some of the crates had with
the parser crate.
The cyclic dependencies are:
* `ruff_python_ast` has a **dev dependency** on `ruff_python_parser` and
`ruff_python_parser` directly depends on `ruff_python_ast`
* `ruff_python_trivia` has a **dev dependency** on `ruff_python_parser`
and `ruff_python_parser` has an indirect dependency on
`ruff_python_trivia` (`ruff_python_parser` - `ruff_python_ast` -
`ruff_python_trivia`)
Specifically, this PR does the following:
* Introduce two new crates
* `ruff_python_ast_integration_tests` and move the tests from the
`ruff_python_ast` crate which uses the parser in this crate
* `ruff_python_trivia_integration_tests` and move the tests from the
`ruff_python_trivia` crate which uses the parser in this crate
### Motivation
The main motivation for this PR is to help development. Before this PR,
`rust-analyzer` wouldn't provide any intellisense in the
`ruff_python_parser` crate regarding the symbols in `ruff_python_ast`
crate.
```
[ERROR][2024-05-03 13:47:06] .../vim/lsp/rpc.lua:770 "rpc" "/Users/dhruv/.cargo/bin/rust-analyzer" "stderr" "[ERROR project_model::workspace] cyclic deps: ruff_python_parser(Idx::<CrateData>(50)) -> ruff_python_ast(Idx::<CrateData>(37)), alternative path: ruff_python_ast(Idx::<CrateData>(37)) -> ruff_python_parser(Idx::<CrateData>(50))\n"
```
## Test Plan
Check the logs of `rust-analyzer` to not see any signs of cyclic
dependency.
## Summary
While I was here, I also updated the rule to use
`function_type::classify` rather than hard-coding `staticmethod` and
friends.
Per Carl:
> Enum instances are already referred to by the class, forming a cycle
that won't get collected until the class itself does. At which point the
`lru_cache` itself would be collected, too.
Closes https://github.com/astral-sh/ruff/issues/9912.
## Summary
Historically, we only ignored `flake8-blind-except` if you re-raised or
logged the exception as a _direct_ child statement; but it could be
nested somewhere. This was just a known limitation at the time of adding
the previous logic.
Closes https://github.com/astral-sh/ruff/issues/11289.
## Summary
A follow-up to https://github.com/astral-sh/ruff/pull/11222. `ruff
server` stalls during shutdown with Neovim because after it receives an
exit notification and closes the I/O thread, it attempts to log a
success message to `stderr`. Removing this log statement fixes this
issue.
## Test Plan
Track the instances of `ruff` in the OS task manager as you open and
close Neovim. A new instance should appear when Neovim starts and it
should disappear once Neovim is closed.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11258.
This PR fixes the settings resolver to match the expected behavior when
file-based configuration is not available.
## Test Plan
In a workspace with no file-based configuration, set a setting in your
editor and confirm that this setting is used instead of the default.
## Summary
Users can now include tildes and environment variables in the provided
path, just like with `--config`.
Closes#11277.
## Test Plan
Set the configuration path to `"ruff.configuration": "~/x.toml"`;
verified that the server attempted to read from `/Users/crmarsh/x.toml`.
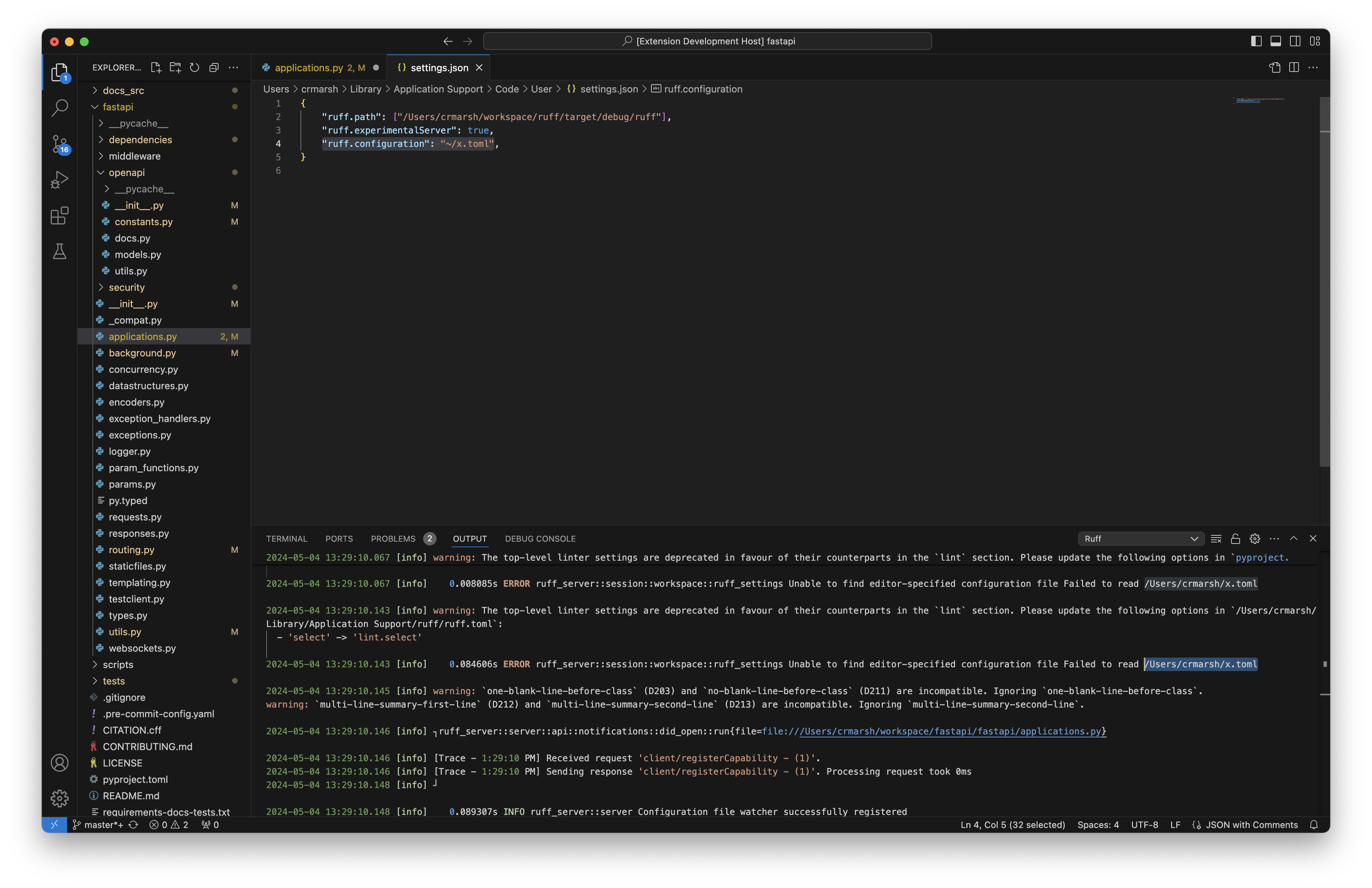
## Summary
Change `hardcoded-tmp-directory-extend` example to follow the schema:
1e91a09918/ruff.schema.json (L896-L901)
<!-- What's the purpose of the change? What does it do, and why? -->
## Summary
In #9218 `Rule::NeverUnion` was partially removed from a
`checker.any_enabled` call. This makes the change consistent.
## Test Plan
`cargo test`
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11207.
The server would hang after handling a shutdown request on
`IoThreads::join()` because a global sender (`MESSENGER`, used to send
`window/showMessage` notifications) would remain allocated even after
the event loop finished, which kept the writer I/O thread channel open.
To fix this, I've made a few structural changes to `ruff server`. I've
wrapped the send/receive channels and thread join handle behind a new
struct, `Connection`, which facilitates message sending and receiving,
and also runs `IoThreads::join()` after the event loop finishes. To
control the number of sender channels, the `Connection` wraps the sender
channel in an `Arc` and only allows the creation of a wrapper type,
`ClientSender`, which hold a weak reference to this `Arc` instead of
direct channel access. The wrapper type implements the channel methods
directly to prevent access to the inner channel (which would allow the
channel to be cloned). ClientSender's function is analogous to
[`WeakSender` in
`tokio`](https://docs.rs/tokio/latest/tokio/sync/mpsc/struct.WeakSender.html).
Additionally, the receiver channel cannot be accessed directly - the
`Connection` only exposes an iterator over it.
These changes will guarantee that all channels are closed before the I/O
threads are joined.
## Test Plan
Repeatedly open and close an editor utilizing `ruff server` while
observing the task monitor. The net total amount of open `ruff`
instances should be zero once all editor windows have closed.
The following logs should also appear after the server is shut down:
<img width="835" alt="Screenshot 2024-04-30 at 3 56 22 PM"
src="https://github.com/astral-sh/ruff/assets/19577865/404b74f5-ef08-4bb4-9fa2-72e72b946695">
This can be tested on VS Code by changing the settings and then checking
`Output`.
* Add `decorators: Vec<Type>` to `FunctionType` struct
* Thread decorators through two `add_function` definitions
* Populate decorators at the callsite in `infer_symbol_type`
* Small test
Resolves#10390 and starts to address #10391
# Changes to behavior
* In `__init__.py` we now offer some fixes for unused imports.
* If the import binding is first-party this PR suggests a fix to turn it
into a redundant alias.
* If the import binding is not first-party, this PR suggests a fix to
remove it from the `__init__.py`.
* The fix-titles are specific to these new suggested fixes.
* `checker.settings.ignore_init_module_imports` setting is
deprecated/ignored. There is probably a documentation change to make
that complete which I haven't done.
---
<details><summary>Old description of implementation changes</summary>
# Changes to the implementation
* In the body of the loop over import statements that contain unused
bindings, the bindings are partitioned into `to_reexport` and
`to_remove` (according to how we want to resolve the fact they're
unused) with the following predicate:
```rust
in_init && is_first_party(checker, &import.qualified_name().to_string())
// true means make it a reexport
```
* Instead of generating a single fix per import statement, we now
generate up to two fixes per import statement:
```rust
(fix_by_removing_imports(checker, node_id, &to_remove, in_init).ok(),
fix_by_reexporting(checker, node_id, &to_reexport, dunder_all).ok())
```
* The `to_remove` fixes are unsafe when `in_init`.
* The `to_explicit` fixes are safe. Currently, until a future PR, we
make them redundant aliases (e.g. `import a` would become `import a as
a`).
## Other changes
* `checker.settings.ignore_init_module_imports` is deprecated/ignored.
Instead, all fixes are gated on `checker.settings.preview.is_enabled()`.
* Got rid of the pattern match on the import-binding bound by the inner
loop because it seemed less readable than referencing fields on the
binding.
* [x] `// FIXME: rename "imports" to "bindings"` if reviewer agrees (see
code)
* [x] `// FIXME: rename "node_id" to "import_statement"` if reviewer
agrees (see code)
<details>
<summary><h2>Scope cut until a future PR</h2></summary>
* (Not implemented) The `to_explicit` fixes will be added to `__all__`
unless it doesn't exist. When `__all__` doesn't exist they're resolved
by converting to redundant aliases (e.g. `import a` would become `import
a as a`).
---
</details>
# Test plan
* [x] `crates/ruff_linter/resources/test/fixtures/pyflakes/F401_24`
contains an `__init__.py` with*out* `__all__` that exercises the
features in this PR, but it doesn't pass.
* [x]
`crates/ruff_linter/resources/test/fixtures/pyflakes/F401_25_dunder_all`
contains an `__init__.py` *with* `__all__` that exercises the features
in this PR, but it doesn't pass.
* [x] Write unit tests for the new edit functions in
`fix::edits::make_redundant_alias`.
</details>
---------
Co-authored-by: Micha Reiser <micha@reiser.io>
## Summary
This PR removes the `ImportMap` implementation and all its routing
through ruff.
The import map was added in https://github.com/astral-sh/ruff/pull/3243
but we then never ended up using it to do cross file analysis.
We are now working on adding multifile analysis to ruff, and revisit
import resolution as part of it.
```
hyperfine --warmup 10 --runs 20 --setup "./target/release/ruff clean" \
"./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I" \
"./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I"
Benchmark 1: ./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
Time (mean ± σ): 37.6 ms ± 0.9 ms [User: 52.2 ms, System: 63.7 ms]
Range (min … max): 35.8 ms … 39.8 ms 20 runs
Benchmark 2: ./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
Time (mean ± σ): 36.0 ms ± 0.7 ms [User: 50.3 ms, System: 58.4 ms]
Range (min … max): 34.5 ms … 37.6 ms 20 runs
Summary
./target/release/ruff-import check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I ran
1.04 ± 0.03 times faster than ./target/release/ruff check crates/ruff_linter/resources/test/cpython -e -s --extend-select=I
```
I suspect that the performance improvement should even be more
significant for users that otherwise don't have any diagnostics.
```
hyperfine --warmup 10 --runs 20 --setup "cd ../ecosystem/airflow && ../../ruff/target/release/ruff clean" \
"./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I" \
"./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I"
Benchmark 1: ./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I
Time (mean ± σ): 53.7 ms ± 1.8 ms [User: 68.4 ms, System: 63.0 ms]
Range (min … max): 51.1 ms … 58.7 ms 20 runs
Benchmark 2: ./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I
Time (mean ± σ): 50.8 ms ± 1.4 ms [User: 50.7 ms, System: 60.9 ms]
Range (min … max): 48.5 ms … 55.3 ms 20 runs
Summary
./target/release/ruff-import check ../ecosystem/airflow -e -s --extend-select=I ran
1.06 ± 0.05 times faster than ./target/release/ruff check ../ecosystem/airflow -e -s --extend-select=I
```
## Test Plan
`cargo test`
## Summary
Fixes#11185Fixes#11214
Document path and package information is now forwarded to the Ruff
linter, which allows `per-file-ignores` to correctly match against the
file name. This also fixes an issue where the import sorting rule didn't
distinguish between third-party and first-party packages since we didn't
pass in the package root.
## Test Plan
`per-file-ignores` should ignore files as expected. One quick way to
check is by adding this to your `pyproject.toml`:
```toml
[tool.ruff.lint.per-file-ignores]
"__init__.py" = ["ALL"]
```
Then, confirm that no diagnostics appear when you add code to an
`__init__.py` file (besides syntax errors).
The import sorting fix can be verified by failing to reproduce the
original issue - an `I001` diagnostic should not appear in
`other_module.py`.
## Summary
Fixes https://github.com/astral-sh/ruff/issues/11158.
A settings file in the ruff user configuration directory will be used as
a configuration fallback, if it exists.
## Test Plan
Create a `pyproject.toml` or `ruff.toml` configuration file in the ruff
user configuration directory.
* On Linux, that will be `$XDG_CONFIG_HOME/ruff/` or `$HOME/.config`
* On macOS, that will be `$HOME/Library/Application Support`
* On Windows, that will be `{FOLDERID_LocalAppData}`
Then, open a file inside of a workspace with no configuration. The
settings in the user configuration file should be used.
Thank you for taking the time to report an issue! We're glad to have you involved with Ruff.
If you're filing a bug report, please consider including the following information:
* List of keywords you searched for before creating this issue. Write them down here so that others can find this issue more easily and help provide feedback.
e.g. "RUF001", "unused variable", "Jupyter notebook"
* A minimal code snippet that reproduces the bug.
* The command you invoked (e.g., `ruff /path/to/file.py --fix`), ideally including the `--isolated` flag.
* The current Ruff settings (any relevant sections from your `pyproject.toml`).
description:Report an error or unexpected behavior
body:
- type:markdown
attributes:
value:|
Thank you for taking the time to report an issue! We're glad to have you involved with Ruff.
**Before reporting, please make sure to search through [existing issues](https://github.com/astral-sh/ruff/issues?q=is:issue+is:open+label:bug) (including [closed](https://github.com/astral-sh/ruff/issues?q=is:issue%20state:closed%20label:bug)).**
- type:textarea
attributes:
label:Summary
description:|
A clear and concise description of the bug, including a minimal reproducible example.
Be sure to include the command you invoked (e.g., `ruff check /path/to/file.py --fix`), ideally including the `--isolated` flag and
the current Ruff settings (e.g., relevant sections from your `pyproject.toml`).
If possible, try to include the [playground](https://play.ruff.rs) link that reproduces this issue.
validations:
required:true
- type:input
attributes:
label:Version
description:What version of ruff are you using? (see `ruff version`)
description: "Weekly update of the Monaco editor",
},
{
groupName: "strum",
matchManagers: ["cargo"],
matchPackagePatterns: ["strum"],
matchPackageNames: ["strum"],
description: "Weekly update of strum dependencies",
},
{
groupName: "ESLint",
matchManagers: ["npm"],
matchPackageNames: ["eslint"],
allowedVersions: "<9",
description: "Constraint ESLint to version 8 until TypeScript-eslint supports ESLint 9", // https://github.com/typescript-eslint/typescript-eslint/issues/8211
Ruff will default to the _latest_ supported Python version (3.14) when
checking for syntax errors without a Python version configured. The default
in all other cases, like applying lint rules, remains at the minimum
supported Python version (3.10).
## 0.13.0
- **Several rules can now add `from __future__ import annotations` automatically**
`TC001`, `TC002`, `TC003`, `RUF013`, and `UP037` now add `from __future__ import annotations` as part of their fixes when the
`lint.future-annotations` setting is enabled. This allows the rules to move
more imports into `TYPE_CHECKING` blocks (`TC001`, `TC002`, and `TC003`),
use PEP 604 union syntax on Python versions before 3.10 (`RUF013`), and
unquote more annotations (`UP037`).
- **Full module paths are now used to verify first-party modules**
Ruff now checks that the full path to a module exists on disk before
categorizing it as a first-party import. This change makes first-party
import detection more accurate, helping to avoid false positives on local
directories with the same name as a third-party dependency, for example. See
the [FAQ
section](https://docs.astral.sh/ruff/faq/#how-does-ruff-determine-which-of-my-imports-are-first-party-third-party-etc) on import categorization for more details.
- **Deprecated rules must now be selected by exact rule code**
Ruff will no longer activate deprecated rules selected by their group name
or prefix. As noted below, the two remaining deprecated rules were also
removed in this release, so this won't affect any current rules, but it will
still affect any deprecations in the future.
- **The deprecated macOS configuration directory fallback has been removed**
Ruff will no longer look for a user-level configuration file at
`~/Library/Application Support/ruff/ruff.toml` on macOS. This feature was
This is a follow-up to release 0.10.0. Because of a mistake in the release process, the `requires-python` inference changes were not included in that release. Ruff 0.11.0 now includes this change as well as the stabilization of the preview behavior for `PGH004`.
- **Changes to how the Python version is inferred when a `target-version` is not specified** ([#16319](https://github.com/astral-sh/ruff/pull/16319))
In previous versions of Ruff, you could specify your Python version with:
- The `target-version` option in a `ruff.toml` file or the `[tool.ruff]` section of a pyproject.toml file.
- The `project.requires-python` field in a `pyproject.toml` file with a `[tool.ruff]` section.
These options worked well in most cases, and are still recommended for fine control of the Python version. However, because of the way Ruff discovers config files, `pyproject.toml` files without a `[tool.ruff]` section would be ignored, including the `requires-python` setting. Ruff would then use the default Python version (3.9 as of this writing) instead, which is surprising when you've attempted to request another version.
In v0.10, config discovery has been updated to address this issue:
- If Ruff finds a `ruff.toml` file without a `target-version`, it will check
for a `pyproject.toml` file in the same directory and respect its
`requires-python` version, even if it does not contain a `[tool.ruff]`
section.
- If Ruff finds a user-level configuration, the `requires-python` field of the closest `pyproject.toml` in a parent directory will take precedence.
- If there is no config file (`ruff.toml`or `pyproject.toml` with a
`[tool.ruff]` section) in the directory of the file being checked, Ruff will
search for the closest `pyproject.toml` in the parent directories and use its
`requires-python` setting.
## 0.10.0
- **Changes to how the Python version is inferred when a `target-version` is not specified** ([#16319](https://github.com/astral-sh/ruff/pull/16319))
Because of a mistake in the release process, the `requires-python` inference changes are not included in this release and instead shipped as part of 0.11.0.
You can find a description of this change in the 0.11.0 section.
Previously, Ruff only recognized typechecking blocks that tested the `typing.TYPE_CHECKING` symbol. Now, Ruff recognizes any local variable named `TYPE_CHECKING`. This release also removes support for the legacy `if 0:` and `if False:` typechecking checks. Use a local `TYPE_CHECKING` variable instead.
The syntax for both file-level and in-line suppression comments has been unified and made more robust to certain errors. In most cases, this will result in more suppression comments being read by Ruff, but there are a few instances where previously read comments will now log an error to the user instead. Please refer to the documentation on [_Error suppression_](https://docs.astral.sh/ruff/linter/#error-suppression) for the full specification.
- **Avoid unnecessary parentheses around with statements with a single context manager and a trailing comment** ([#14005](https://github.com/astral-sh/ruff/pull/14005))
This change fixes a bug in the formatter where it introduced unnecessary parentheses around with statements with a single context manager and a trailing comment. This change may result in a change in formatting for some users.
- **Bump alpine default tag to 3.21 for derived Docker images** ([#16456](https://github.com/astral-sh/ruff/pull/16456))
Alpine 3.21 was released in Dec 2024 and is used in the official Alpine-based Python images. Now the ruff:alpine image will use 3.21 instead of 3.20 and ruff:alpine3.20 will no longer be updated.
- **\[`unsafe-markup-use`\]: `RUF035` has been recoded to `S704`** ([#15957](https://github.com/astral-sh/ruff/pull/15957))
## 0.9.0
Ruff now formats your code according to the 2025 style guide. As a result, your code might now get formatted differently. See the [changelog](./CHANGELOG.md#090) for a detailed list of changes.
## 0.8.0
- **Default to Python 3.9**
Ruff now defaults to Python 3.9 instead of 3.8 if no explicit Python version is configured using [`ruff.target-version`](https://docs.astral.sh/ruff/settings/#target-version) or [`project.requires-python`](https://packaging.python.org/en/latest/guides/writing-pyproject-toml/#python-requires) ([#13896](https://github.com/astral-sh/ruff/pull/13896))
- **Changed location of `pydoclint` diagnostics**
[`pydoclint`](https://docs.astral.sh/ruff/rules/#pydoclint-doc) diagnostics now point to the first-line of the problematic docstring. Previously, this was not the case.
If you've opted into these preview rules but have them suppressed using
[`noqa`](https://docs.astral.sh/ruff/linter/#error-suppression) comments in
some places, this change may mean that you need to move the `noqa` suppression
comments. Most users should be unaffected by this change.
- **Use XDG (i.e. `~/.local/bin`) instead of the Cargo home directory in the standalone installer**
Previously, Ruff's installer used `$CARGO_HOME` or `~/.cargo/bin` for its target install directory. Now, Ruff will be installed into `$XDG_BIN_HOME`, `$XDG_DATA_HOME/../bin`, or `~/.local/bin` (in that order).
This change is only relevant to users of the standalone Ruff installer (using the shell or PowerShell script). If you installed Ruff using uv or pip, you should be unaffected.
- **Changes to the line width calculation**
Ruff now uses a new version of the [unicode-width](https://github.com/unicode-rs/unicode-width) Rust crate to calculate the line width. In very rare cases, this may lead to lines containing Unicode characters being reformatted, or being considered too long when they were not before ([`E501`](https://docs.astral.sh/ruff/rules/line-too-long/)).
## 0.7.0
- The pytest rules `PT001` and `PT023` now default to omitting the decorator parentheses when there are no arguments
- Detect imports in `src` layouts by default for `isort` rules ([#12848](https://github.com/astral-sh/ruff/pull/12848))
- The pytest rules `PT001` and `PT023` now default to omitting the decorator parentheses when there are no arguments ([#12838](https://github.com/astral-sh/ruff/pull/12838)).
- Lint and format Jupyter Notebook by default ([#12878](https://github.com/astral-sh/ruff/pull/12878)).
You can disable specific rules for notebooks using [`per-file-ignores`](https://docs.astral.sh/ruff/settings/#lint_per-file-ignores):
```toml
[tool.ruff.lint.per-file-ignores]
"*.ipynb" = ["E501"] # disable line-too-long in notebooks
```
If you'd prefer to either only lint or only format Jupyter Notebook files, you can use the
section-specific `exclude` option to do so. For example, the following would only lint Jupyter
Notebook files and not format them:
```toml
[tool.ruff.format]
exclude = ["*.ipynb"]
```
And, conversely, the following would only format Jupyter Notebook files and not lint them:
```toml
[tool.ruff.lint]
exclude = ["*.ipynb"]
```
You can completely disable Jupyter Notebook support by updating the [`extend-exclude`](https://docs.astral.sh/ruff/settings/#extend-exclude) setting:
```toml
[tool.ruff]
extend-exclude = ["*.ipynb"]
```
## 0.5.0
- Follow the XDG specification to discover user-level configurations on macOS (same as on other Unix platforms)
- Selecting `ALL` now excludes deprecated rules
- The released archives now include an extra level of nesting, which can be removed with `--strip-components=1` when untarring.
- The release artifact's file name no longer includes the version tag. This enables users to install via `/latest` URLs on GitHub.
## 0.3.0
### Ruff 2024.2 style
@@ -109,7 +335,7 @@ flag or `unsafe-fixes` configuration option can be used to enable unsafe fixes.
See the [docs](https://docs.astral.sh/ruff/configuration/#fix-safety) for details.
### Remove formatter-conflicting rules from the default rule set ([#7900](https://github.com/astral-sh/ruff/pull/7900))
### Remove formatter-conflicting rules from the default rule set ([#7900](https://github.com/astral-sh/ruff/pull/7900))
Previously, Ruff enabled all implemented rules in Pycodestyle (`E`) by default. Ruff now only includes the
Pycodestyle prefixes `E4`, `E7`, and `E9` to exclude rules that conflict with automatic formatters. Consequently,
@@ -122,8 +348,8 @@ This change only affects those using Ruff under its default rule set. Users that
### Remove support for emoji identifiers ([#7212](https://github.com/astral-sh/ruff/pull/7212))
Previously, Ruff supported the non-standardcompliant emoji identifiers e.g. `📦 = 1`.
We decided to remove this non-standard language extension, and Ruff now reports syntax errors for emoji identifiers in your code, the same as CPython.
Previously, Ruff supported non-standards-compliant emoji identifiers such as `📦 = 1`.
We decided to remove this non-standard language extension. Ruff now reports syntax errors for invalid emoji identifiers in your code, the same as CPython.
RUFF_UPDATE_SCHEMA=1 cargo test# Rust testing and updating ruff.schema.json
pre-commit run --all-files --show-diff-on-failure # Rust and Python formatting, Markdown and Python linting, etc.
uvx pre-commit run --all-files --show-diff-on-failure # Rust and Python formatting, Markdown and Python linting, etc.
```
These checks will run on GitHub Actions when you open your pull request, but running them locally
will save you time and expedite the merge process.
If you're using VS Code, you can also install the recommended [rust-analyzer](https://marketplace.visualstudio.com/items?itemName=rust-lang.rust-analyzer) extension to get these checks while editing.
Note that many code changes also require updating the snapshot tests, which is done interactively
after running `cargo test` like so:
@@ -168,7 +160,7 @@ At a high level, the steps involved in adding a new lint rule are as follows:
1. Create a file for your rule (e.g., `crates/ruff_linter/src/rules/flake8_bugbear/rules/assert_false.rs`).
1. In that file, define a violation struct (e.g., `pub struct AssertFalse`). You can grep for
`#[violation]` to see examples.
`#[derive(ViolationMetadata)]` to see examples.
1. In that file, define a function that adds the violation to the diagnostic list as appropriate
(e.g., `pub(crate) fn assert_false`) based on whatever inputs are required for the rule (e.g.,
@@ -278,7 +270,7 @@ These represent, respectively: the schema used to parse the `pyproject.toml` fil
intermediate representation; and the final, internal representation used to power Ruff.
To add a new configuration option, you'll likely want to modify these latter few files (along with
`arg.rs`, if appropriate). If you want to pattern-match against an existing example, grep for
`args.rs`, if appropriate). If you want to pattern-match against an existing example, grep for
`dummy_variable_rgx`, which defines a regular expression to match against acceptable unused
variables (e.g., `_`).
@@ -288,32 +280,71 @@ Note that plugin-specific configuration options are defined in their own modules
Finally, regenerate the documentation and generated code with `cargo dev generate-all`.
### Opening a PR
After you finish your changes, the next step is to open a PR. By default, two
sections will be filled into the PR body: the summary and the test plan.
#### The summary
The summary is intended to give us as maintainers information about your PR.
This should typically include a link to the relevant issue(s) you're addressing
in your PR, as well as a summary of the issue and your approach to fixing it. If
you have any questions about your approach or design, or if you considered
alternative approaches, that can also be helpful to include.
AI can be helpful in generating both the code and summary of your PR, but a
successful contribution should still be carefully reviewed by you and the
summary editorialized before submitting a PR. A great summary is thorough but
also succinct and gives us the context we need to review your PR.
You can find examples of excellent issues and PRs by searching for the
1. Highlight any breaking changes in `BREAKING_CHANGES.md`
1. Run `cargo check`. This should update the lock file with new versions.
1. Create a pull request with the changelog and version updates
1. Merge the PR
1. Run the [release workflow](https://github.com/astral-sh/ruff/actions/workflows/release.yaml) with:
1. Run the [release workflow](https://github.com/astral-sh/ruff/actions/workflows/release.yml) with:
- The new version number (without starting `v`)
- The commit hash of the merged release pull request on `main`
1. The release workflow will do the following:
1. Build all the assets. If this fails (even though we tested in step 4), we haven't tagged or
uploaded anything, you can restart after pushing a fix.
uploaded anything, you can restart after pushing a fix. If you just need to rerun the build,
make sure you're [re-running all the failed
jobs](https://docs.github.com/en/actions/managing-workflow-runs/re-running-workflows-and-jobs#re-running-failed-jobs-in-a-workflow) and not just a single failed job.
1. Upload to PyPI.
1. Create and push the Git tag (as extracted from `pyproject.toml`). We create the Git tag only
after building the wheels and uploading to PyPI, since we can't delete or modify the tag ([#4468](https://github.com/astral-sh/ruff/issues/4468)).
1. Attach artifacts to draft GitHub release
1. Trigger downstream repositories. This can fail non-catastrophically, as we can run any
downstream jobs manually if needed.
1. Publish the GitHub release
1. Open the draft release in the GitHub release section
1. Copy the changelog for the release into the GitHub release
- See previous releases for formatting of section headers
1. Append the contributors from the `bump.sh` script
1. Verify the GitHub release:
1. The changelog should match the content of `CHANGELOG.md`
1. If needed, [update the schemastore](https://github.com/astral-sh/ruff/blob/main/scripts/update_schemastore.py).
1. One can determine if an update is needed when
`git diff old-version-tag new-version-tag -- ruff.schema.json` returns a non-empty diff.
1. Run `uv run --only-dev --no-sync scripts/update_schemastore.py --proto <https|ssh>`
1. Once run successfully, you should follow the link in the output to create a PR.
1. If needed, update the `ruff-lsp` and `ruff-vscode` repositories.
1. If needed, update the [`ruff-lsp`](https://github.com/astral-sh/ruff-lsp) and
[`ruff-vscode`](https://github.com/astral-sh/ruff-vscode) repositories and follow
the release instructions in those repositories. `ruff-lsp` should always be updated
before `ruff-vscode`.
This step is generally not required for a patch release, but should always be done
for a minor release.
## Ecosystem CI
@@ -373,13 +444,21 @@ GitHub Actions will run your changes against a number of real-world projects fro
report on any linter or formatter differences. You can also run those checks locally via:
You can run `poetry install` from `./scripts/benchmarks` to create a working environment for the
You can run `uv venv --project ./scripts/benchmarks`, activate the venv and then run `uv sync --project ./scripts/benchmarks` to create a working environment for the
above. All reported benchmarks were computed using the versions specified by
`./scripts/benchmarks/pyproject.toml` on Python 3.11.
@@ -529,10 +614,12 @@ You can run the benchmarks with
cargo benchmark
```
`cargo benchmark` is an alias for `cargo bench -p ruff_benchmark --bench linter --bench formatter --`
#### Benchmark-driven Development
Ruff uses [Criterion.rs](https://bheisler.github.io/criterion.rs/book/) for benchmarks. You can use
`--save-baseline=<name>` to store an initial baseline benchmark (e.g. on `main`) and then use
`--save-baseline=<name>` to store an initial baseline benchmark (e.g., on `main`) and then use
`--benchmark=<name>` to compare against that benchmark. Criterion will print a message telling you
if the benchmark improved/regressed compared to that baseline.
@@ -567,7 +654,7 @@ cargo install critcmp
#### Tips
- Use `cargo bench -p ruff_benchmark <filter>` to only run specific benchmarks. For example: `cargo benchmark lexer`
- Use `cargo bench -p ruff_benchmark <filter>` to only run specific benchmarks. For example: `cargo bench -p ruff_benchmark lexer`
to only run the lexer benchmarks.
- Use `cargo bench -p ruff_benchmark -- --quiet` for a more cleaned up output (without statistical relevance)
- Use `cargo bench -p ruff_benchmark -- --quick` to get faster results (more prone to noise)
@@ -602,8 +689,7 @@ Then convert the recorded profile
perf script -F +pid > /tmp/test.perf
```
You can now view the converted file with [firefox profiler](https://profiler.firefox.com/), with a
more in-depth guide [here](https://profiler.firefox.com/docs/#/./guide-perf-profiling)
You can now view the converted file with [firefox profiler](https://profiler.firefox.com/). To learn more about Firefox profiler, read the [Firefox profiler profiling-guide](https://profiler.firefox.com/docs/#/./guide-perf-profiling).
An alternative is to convert the perf data to `flamegraph.svg` using
# To allow `#[allow(clippy::all)]` in `crates/ruff_python_parser/src/python.rs`.
needless_continue="allow"# An explicit continue can be more readable, especially if the alternative is an empty block.
unnecessary_debug_formatting="allow"# too many instances, the display also doesn't quote the path which is often desired in logs where we use them the most often.
# Without the hashes we run into a `rustfmt` bug in some snapshot tests, see #13250
needless_raw_string_hashes="allow"
# Disallowed restriction lints
ignore_without_reason="allow"# Too many exsisting instances, and there's no auto fix.
print_stdout="warn"
print_stderr="warn"
dbg_macro="warn"
@@ -152,16 +251,33 @@ get_unwrap = "warn"
rc_buffer="warn"
rc_mutex="warn"
rest_pat_in_fully_bound_structs="warn"
# nursery rules
redundant_clone="warn"
debug_assert_with_mut_call="warn"
unused_peekable="warn"
# This lint sometimes flags code whose `if` and `else`
# bodies could be flipped when a `!` operator is removed.
# While perhaps sometimes a good idea, it is also often
# not a good idea due to other factors impacting
# readability. For example, if flipping the bodies results
# in the `if` being an order of magnitude bigger than the
# `else`, then some might consider that harder to read.
if_not_else="allow"
# Diagnostics are not actionable: Enable once https://github.com/rust-lang/rust-clippy/issues/13774 is resolved.
large_stack_arrays="allow"
[profile.release]
# Note that we set these explicitly, and these values
# were chosen based on a trade-off between compile times
@@ -28,15 +28,14 @@ An extremely fast Python linter and code formatter, written in Rust.
- ⚡️ 10-100x faster than existing linters (like Flake8) and formatters (like Black)
- 🐍 Installable via `pip`
- 🛠️ `pyproject.toml` support
- 🤝 Python 3.12 compatibility
- ⚖️ Drop-in parity with [Flake8](https://docs.astral.sh/ruff/faq/#how-does-ruff-compare-to-flake8), isort, and Black
- 🤝 Python 3.14 compatibility
- ⚖️ Drop-in parity with [Flake8](https://docs.astral.sh/ruff/faq/#how-does-ruffs-linter-compare-to-flake8), isort, and [Black](https://docs.astral.sh/ruff/faq/#how-does-ruffs-formatter-compare-to-black)
- 📦 Built-in caching, to avoid re-analyzing unchanged files
- 📏 Over [800 built-in rules](https://docs.astral.sh/ruff/rules/), with native re-implementations
of popular Flake8 plugins, like flake8-bugbear
- ⌨️ First-party [editor integrations](https://docs.astral.sh/ruff/integrations/) for
[VS Code](https://github.com/astral-sh/ruff-vscode) and [more](https://github.com/astral-sh/ruff-lsp)
- 🌎 Monorepo-friendly, with [hierarchical and cascading configuration](https://docs.astral.sh/ruff/configuration/#pyprojecttoml-discovery)
- ⌨️ First-party [editor integrations](https://docs.astral.sh/ruff/editors) for [VS Code](https://github.com/astral-sh/ruff-vscode) and [more](https://docs.astral.sh/ruff/editors/setup)
- 🌎 Monorepo-friendly, with [hierarchical and cascading configuration](https://docs.astral.sh/ruff/configuration/#config-file-discovery)
Ruff aims to be orders of magnitude faster than alternative tools while integrating more
functionality behind a single, common interface.
@@ -90,8 +89,7 @@ creator of [isort](https://github.com/PyCQA/isort):
> Just switched my first project to Ruff. Only one downside so far: it's so fast I couldn't believe
> it was working till I intentionally introduced some errors.
[**Tim Abbott**](https://github.com/astral-sh/ruff/issues/465#issuecomment-1317400028), lead
developer of [Zulip](https://github.com/zulip/zulip):
[**Tim Abbott**](https://github.com/zulip/zulip/pull/23431#issuecomment-1302557034), lead developer of [Zulip](https://github.com/zulip/zulip) (also [here](https://github.com/astral-sh/ruff/issues/465#issuecomment-1317400028)):
> This is just ridiculously fast... `ruff` is amazing.
@@ -110,16 +108,47 @@ For more, see the [documentation](https://docs.astral.sh/ruff/).
1. [Who's Using Ruff?](#whos-using-ruff)
1. [License](#license)
## Getting Started
## Getting Started<a id="getting-started"></a>
For more, see the [documentation](https://docs.astral.sh/ruff/).
### Installation
Ruff is available as [`ruff`](https://pypi.org/project/ruff/) on PyPI:
Ruff is available as [`ruff`](https://pypi.org/project/ruff/) on PyPI.
Invoke Ruff directly with [`uvx`](https://docs.astral.sh/uv/):
```shell
uvx ruff check # Lint all files in the current directory.
uvx ruff format # Format all files in the current directory.
```
Or install Ruff with `uv` (recommended), `pip`, or `pipx`:
Ruff can also be used as a [VS Code extension](https://github.com/astral-sh/ruff-vscode) or
alongside any other editor through the [Ruff LSP](https://github.com/astral-sh/ruff-lsp).
Ruff can also be used as a [VS Code extension](https://github.com/astral-sh/ruff-vscode) or with [various other editors](https://docs.astral.sh/ruff/editors/setup).
Ruff can also be used as a [GitHub Action](https://github.com/features/actions) via
This is the first release which uses the `CHANGELOG` file. See [GitHub Releases](https://github.com/astral-sh/ruff/releases) for prior changelog entries.
Read Ruff's new [versioning policy](https://docs.astral.sh/ruff/versioning/).
### Breaking changes
- Unsafe fixes are no longer displayed or applied without opt-in ([#7769](https://github.com/astral-sh/ruff/pull/7769))
- Drop formatting specific rules from the default set ([#7900](https://github.com/astral-sh/ruff/pull/7900))
- The deprecated `format` setting has been removed ([#7984](https://github.com/astral-sh/ruff/pull/7984))
- The `format` setting cannot be used to configure the output format, use `output-format` instead
- The `RUFF_FORMAT` environment variable is ignored, use `RUFF_OUTPUT_FORMAT` instead
- The `--format` option has been removed from `ruff check`, use `--output-format` instead
### Rule changes
- Extend `reimplemented-starmap` (`FURB140`) to catch calls with a single and starred argument ([#7768](https://github.com/astral-sh/ruff/pull/7768))
- Improve cases covered by `RUF015` ([#7848](https://github.com/astral-sh/ruff/pull/7848))
- Update `SIM15` to allow `open` followed by `close` ([#7916](https://github.com/astral-sh/ruff/pull/7916))
- Respect `msgspec.Struct` default-copy semantics in `RUF012` ([#7786](https://github.com/astral-sh/ruff/pull/7786))
- Add `sqlalchemy` methods to \`flake8-boolean-trap\`\` exclusion list ([#7874](https://github.com/astral-sh/ruff/pull/7874))
- Add fix for `PLR1714` ([#7910](https://github.com/astral-sh/ruff/pull/7910))
- Add fix for `PIE804` ([#7884](https://github.com/astral-sh/ruff/pull/7884))
- Add fix for `PLC0208` ([#7887](https://github.com/astral-sh/ruff/pull/7887))
- Add fix for `PYI055` ([#7886](https://github.com/astral-sh/ruff/pull/7886))
- Update `non-pep695-type-alias` to require `--unsafe-fixes` outside of stub files ([#7836](https://github.com/astral-sh/ruff/pull/7836))
- Improve fix message for `UP018` ([#7913](https://github.com/astral-sh/ruff/pull/7913))
- Update `PLW3201` to support `Enum` [sunder names](https://docs.python.org/3/library/enum.html#supported-sunder-names) ([#7987](https://github.com/astral-sh/ruff/pull/7987))
### Preview features
- Only show warnings for empty preview selectors when enabling rules ([#7842](https://github.com/astral-sh/ruff/pull/7842))
- Add `unnecessary-key-check` to simplify `key in dct and dct[key]` to `dct.get(key)` ([#7895](https://github.com/astral-sh/ruff/pull/7895))
- Add `assignment-in-assert` to prevent walrus expressions in assert statements ([#7856](https://github.com/astral-sh/ruff/pull/7856))
- Allow bindings to be created and referenced within annotations ([#7885](https://github.com/astral-sh/ruff/pull/7885))
- Show per-cell diffs when analyzing notebooks over `stdin` ([#7789](https://github.com/astral-sh/ruff/pull/7789))
- Avoid curly brace escape in f-string format spec ([#7780](https://github.com/astral-sh/ruff/pull/7780))
- Fix lexing single-quoted f-string with multi-line format spec ([#7787](https://github.com/astral-sh/ruff/pull/7787))
- Consider nursery rules to be in-preview for `ruff rule` ([#7812](https://github.com/astral-sh/ruff/pull/7812))
- Report precise location for invalid conversion flag ([#7809](https://github.com/astral-sh/ruff/pull/7809))
- Visit pattern match guard as a boolean test ([#7911](https://github.com/astral-sh/ruff/pull/7911))
- Respect `--unfixable` in `ISC` rules ([#7917](https://github.com/astral-sh/ruff/pull/7917))
- Fix edge case with `PIE804` ([#7922](https://github.com/astral-sh/ruff/pull/7922))
- Show custom message in `PTH118` for `Path.joinpath` with starred arguments ([#7852](https://github.com/astral-sh/ruff/pull/7852))
- Fix false negative in `outdated-version-block` when using greater than comparisons ([#7920](https://github.com/astral-sh/ruff/pull/7920))
- Avoid converting f-strings within Django `gettext` calls ([#7898](https://github.com/astral-sh/ruff/pull/7898))
- Fix false positive in `PLR6301` ([#7933](https://github.com/astral-sh/ruff/pull/7933))
- Treat type aliases as typing-only expressions e.g. resolves false positive in `TCH004` ([#7968](https://github.com/astral-sh/ruff/pull/7968))
- Resolve `cache-dir` relative to project root ([#7962](https://github.com/astral-sh/ruff/pull/7962))
- Respect subscripted base classes in type-checking rules e.g. resolves false positive in `TCH003` ([#7954](https://github.com/astral-sh/ruff/pull/7954))
- Fix JSON schema limit for `line-length` ([#7883](https://github.com/astral-sh/ruff/pull/7883))
- Update GitHub actions example in docs to use `--output-format` ([#8014](https://github.com/astral-sh/ruff/pull/8014))
- Document `lint.preview` and `format.preview` ([#8032](https://github.com/astral-sh/ruff/pull/8032))
- Clarify that new rules should be added to `RuleGroup::Preview`. ([#7989](https://github.com/astral-sh/ruff/pull/7989))
## 0.1.2
This release includes the Beta version of the Ruff formatter — an extremely fast, Black-compatible Python formatter.
Try it today with `ruff format`! [Check out the blog post](https://astral.sh/blog/the-ruff-formatter) and [read the docs](https://docs.astral.sh/ruff/formatter/).
- Add hidden `--extension` to override inference of source type from file extension ([#8373](https://github.com/astral-sh/ruff/pull/8373))
### Configuration
- Account for selector specificity when merging `extend_unsafe_fixes` and `override extend_safe_fixes` ([#8444](https://github.com/astral-sh/ruff/pull/8444))
- Add support for disabling cache with `RUFF_NO_CACHE` environment variable ([#8538](https://github.com/astral-sh/ruff/pull/8538))
### Bug fixes
- \[`E721`\] Flag comparisons to `memoryview` ([#8485](https://github.com/astral-sh/ruff/pull/8485))
- Allow collapsed-ellipsis bodies in other statements ([#8499](https://github.com/astral-sh/ruff/pull/8499))
- Avoid `D301` autofix for `u` prefixed strings ([#8495](https://github.com/astral-sh/ruff/pull/8495))
- Only flag `flake8-trio` rules when `trio` import is present ([#8550](https://github.com/astral-sh/ruff/pull/8550))
- Reject more syntactically invalid Python programs ([#8524](https://github.com/astral-sh/ruff/pull/8524))
- Avoid raising `TRIO115` violations for `trio.sleep(...)` calls with non-number values ([#8532](https://github.com/astral-sh/ruff/pull/8532))
- Fix `F841` false negative on assignment to multiple variables ([#8489](https://github.com/astral-sh/ruff/pull/8489))
### Documentation
- Fix link to isort `known-first-party` ([#8562](https://github.com/astral-sh/ruff/pull/8562))
- Add notes on fix safety to a few rules ([#8500](https://github.com/astral-sh/ruff/pull/8500))
- \[`flake8-boolean-trap`\] Extend `boolean-type-hint-positional-argument` (`FBT001`) to include booleans in unions ([#7501](https://github.com/astral-sh/ruff/pull/7501))
- \[`flake8-pie`\] Extend `reimplemented-list-builtin` (`PIE807`) to `dict` reimplementations ([#8608](https://github.com/astral-sh/ruff/pull/8608))
- \[`flake8-pie`\] Extend `unnecessary-pass` (`PIE790`) to include ellipses (`...`) ([#8641](https://github.com/astral-sh/ruff/pull/8641))
- \[`flake8-pie`\] Implement fix for `unnecessary-spread` (`PIE800`) ([#8668](https://github.com/astral-sh/ruff/pull/8668))
- \[`pycodestyle`\] Implement fix for `multiple-spaces-after-keyword` (`E271`) and `multiple-spaces-before-keyword` (`E272`) ([#8622](https://github.com/astral-sh/ruff/pull/8622))
- \[`pycodestyle`\] Implement fix for `multiple-spaces-after-operator` (`E222`) and `multiple-spaces-before-operator` (`E221`) ([#8623](https://github.com/astral-sh/ruff/pull/8623))
- \[`pyflakes`\] Extend `is-literal` (`F632`) to include comparisons against mutable initializers ([#8607](https://github.com/astral-sh/ruff/pull/8607))
- \[`flake8-boolean-trap`\] Allow booleans in `@override` methods ([#8882](https://github.com/astral-sh/ruff/pull/8882))
- \[`flake8-bugbear`\] Avoid `B015`,`B018` for last expression in a cell ([#8815](https://github.com/astral-sh/ruff/pull/8815))
- \[`flake8-pie`\] Allow ellipses for enum values in stub files ([#8825](https://github.com/astral-sh/ruff/pull/8825))
- \[`flake8-pyi`\] Check PEP 695 type aliases for `snake-case-type-alias` and `t-suffixed-type-alias` ([#8966](https://github.com/astral-sh/ruff/pull/8966))
- \[`flake8-pyi`\] Check for kwarg and vararg `NoReturn` type annotations ([#8948](https://github.com/astral-sh/ruff/pull/8948))
- \[`flake8-simplify`\] Omit select context managers from `SIM117` ([#8801](https://github.com/astral-sh/ruff/pull/8801))
- \[`pep8-naming`\] Allow Django model loads in `non-lowercase-variable-in-function` (`N806`) ([#8917](https://github.com/astral-sh/ruff/pull/8917))
- \[`pycodestyle`\] Avoid `E703` for last expression in a cell ([#8821](https://github.com/astral-sh/ruff/pull/8821))
- \[`pycodestyle`\] Update `E402` to work at cell level for notebooks ([#8872](https://github.com/astral-sh/ruff/pull/8872))
- \[`pydocstyle`\] Avoid `D100` for Jupyter Notebooks ([#8816](https://github.com/astral-sh/ruff/pull/8816))
- \[`pylint`\] Implement fix for `unspecified-encoding` (`PLW1514`) ([#8928](https://github.com/astral-sh/ruff/pull/8928))
### Formatter
- Avoid unstable formatting in ellipsis-only body with trailing comment ([#8984](https://github.com/astral-sh/ruff/pull/8984))
- Inline trailing comments for type alias similar to assignments ([#8941](https://github.com/astral-sh/ruff/pull/8941))
- Insert trailing comma when function breaks with single argument ([#8921](https://github.com/astral-sh/ruff/pull/8921))
### CLI
- Update `ruff check` and `ruff format` to default to the current directory ([#8791](https://github.com/astral-sh/ruff/pull/8791))
- Stop at the first resolved parent configuration ([#8864](https://github.com/astral-sh/ruff/pull/8864))
### Configuration
- \[`pylint`\] Default `max-positional-args` to `max-args` ([#8998](https://github.com/astral-sh/ruff/pull/8998))
- \[`pylint`\] Add `allow-dunder-method-names` setting for `bad-dunder-method-name` (`PLW3201`) ([#8812](https://github.com/astral-sh/ruff/pull/8812))
- \[`isort`\] Add support for `from-first` setting ([#8663](https://github.com/astral-sh/ruff/pull/8663))
- \[`isort`\] Add support for `length-sort` settings ([#8841](https://github.com/astral-sh/ruff/pull/8841))
### Bug fixes
- Add support for `@functools.singledispatch` ([#8934](https://github.com/astral-sh/ruff/pull/8934))
- Avoid off-by-one error in stripping noqa following multi-byte char ([#8979](https://github.com/astral-sh/ruff/pull/8979))
- Avoid off-by-one error in with-item named expressions ([#8915](https://github.com/astral-sh/ruff/pull/8915))
- Avoid syntax error via invalid ur string prefix ([#8971](https://github.com/astral-sh/ruff/pull/8971))
- Avoid underflow in `get_model` matching ([#8965](https://github.com/astral-sh/ruff/pull/8965))
- Avoid unnecessary index diagnostics when value is modified ([#8970](https://github.com/astral-sh/ruff/pull/8970))
- Convert over-indentation rule to use number of characters ([#8983](https://github.com/astral-sh/ruff/pull/8983))
- Detect implicit returns in auto-return-types ([#8952](https://github.com/astral-sh/ruff/pull/8952))
- Fix start >= end error in over-indentation ([#8982](https://github.com/astral-sh/ruff/pull/8982))
- Ignore `@overload` and `@override` methods for too-many-arguments checks ([#8954](https://github.com/astral-sh/ruff/pull/8954))
- Lexer start of line is false only for `Mode::Expression` ([#8880](https://github.com/astral-sh/ruff/pull/8880))
- Mark `pydantic_settings.BaseSettings` as having default copy semantics ([#8793](https://github.com/astral-sh/ruff/pull/8793))
- Respect dictionary unpacking in `NamedTuple` assignments ([#8810](https://github.com/astral-sh/ruff/pull/8810))
- Respect local subclasses in `flake8-type-checking` ([#8768](https://github.com/astral-sh/ruff/pull/8768))
- Support type alias statements in simple statement positions ([#8916](https://github.com/astral-sh/ruff/pull/8916))
- \[`flake8-annotations`\] Avoid filtering out un-representable types in return annotation ([#8881](https://github.com/astral-sh/ruff/pull/8881))
- \[`flake8-pie`\] Retain extra ellipses in protocols and abstract methods ([#8769](https://github.com/astral-sh/ruff/pull/8769))
- \[`flake8-pyi`\] Respect local enum subclasses in `simple-defaults` (`PYI052`) ([#8767](https://github.com/astral-sh/ruff/pull/8767))
- \[`flake8-trio`\] Use correct range for `TRIO115` fix ([#8933](https://github.com/astral-sh/ruff/pull/8933))
- \[`flake8-trio`\] Use full arguments range for zero-sleep-call ([#8936](https://github.com/astral-sh/ruff/pull/8936))
- \[`isort`\] fix: mark `__main__` as first-party import ([#8805](https://github.com/astral-sh/ruff/pull/8805))
- \[`pep8-naming`\] Avoid `N806` errors for type alias statements ([#8785](https://github.com/astral-sh/ruff/pull/8785))
- \[`perflint`\] Avoid `PERF101` if there's an append in loop body ([#8809](https://github.com/astral-sh/ruff/pull/8809))
- \[`pycodestyle`\] Allow space-before-colon after end-of-slice ([#8838](https://github.com/astral-sh/ruff/pull/8838))
- \[`pydocstyle`\] Avoid non-character breaks in `over-indentation` (`D208`) ([#8866](https://github.com/astral-sh/ruff/pull/8866))
- \[`pydocstyle`\] Ignore underlines when determining docstring logical lines ([#8929](https://github.com/astral-sh/ruff/pull/8929))
- \[`pylint`\] Extend `self-assigning-variable` to multi-target assignments ([#8839](https://github.com/astral-sh/ruff/pull/8839))
- \[`tryceratops`\] Avoid repeated triggers in nested `tryceratops` diagnostics ([#8772](https://github.com/astral-sh/ruff/pull/8772))
### Documentation
- Add advice for fixing RUF008 when mutability is not desired ([#8853](https://github.com/astral-sh/ruff/pull/8853))
- Added the command to run ruff using pkgx to the installation.md ([#8955](https://github.com/astral-sh/ruff/pull/8955))
- Document fix safety for flake8-comprehensions and some pyupgrade rules ([#8918](https://github.com/astral-sh/ruff/pull/8918))
- Fix doc formatting for zero-sleep-call ([#8937](https://github.com/astral-sh/ruff/pull/8937))
- Remove duplicate imports from os-stat documentation ([#8930](https://github.com/astral-sh/ruff/pull/8930))
- Replace generated reference to MkDocs ([#8806](https://github.com/astral-sh/ruff/pull/8806))
- Update Arch Linux package URL in installation.md ([#8802](https://github.com/astral-sh/ruff/pull/8802))
- \[`flake8-pyi`\] Fix error in `t-suffixed-type-alias` (`PYI043`) example ([#8963](https://github.com/astral-sh/ruff/pull/8963))
- \[`flake8-pyi`\] Improve motivation for `custom-type-var-return-type` (`PYI019`) ([#8766](https://github.com/astral-sh/ruff/pull/8766))
## 0.1.8
This release includes opt-in support for formatting Python snippets within
docstrings via the `docstring-code-format` setting.
[Check out the blog post](https://astral.sh/blog/ruff-v0.1.8) for more details!
### Preview features
- Add `"preserve"` quote-style to mimic Black's skip-string-normalization ([#8822](https://github.com/astral-sh/ruff/pull/8822))
- \[`ruff`\] Add `never-union` rule to detect redundant `typing.NoReturn` and `typing.Never` ([#9217](https://github.com/astral-sh/ruff/pull/9217))
### CLI
- Add paths to TOML parse errors ([#9358](https://github.com/astral-sh/ruff/pull/9358))
- Add row and column numbers to formatter parse errors ([#9321](https://github.com/astral-sh/ruff/pull/9321))
- Improve responsiveness when invoked via Python ([#9315](https://github.com/astral-sh/ruff/pull/9315))
- Short rule messages should not end with a period ([#9345](https://github.com/astral-sh/ruff/pull/9345))
### Configuration
- Respect runtime-required decorators on functions ([#9317](https://github.com/astral-sh/ruff/pull/9317))
### Bug fixes
- Avoid `asyncio-dangling-task` for nonlocal and global bindings ([#9263](https://github.com/astral-sh/ruff/pull/9263))
- Escape trailing placeholders in rule documentation ([#9301](https://github.com/astral-sh/ruff/pull/9301))
- Fix continuation detection following multi-line strings ([#9332](https://github.com/astral-sh/ruff/pull/9332))
- Fix scoping for generators in named expressions in classes ([#9248](https://github.com/astral-sh/ruff/pull/9248))
- Port from obsolete wsl crate to is-wsl ([#9356](https://github.com/astral-sh/ruff/pull/9356))
- Remove special pre-visit for module docstrings ([#9261](https://github.com/astral-sh/ruff/pull/9261))
- Respect `__str__` definitions from super classes ([#9338](https://github.com/astral-sh/ruff/pull/9338))
- Respect `unused-noqa` via `per-file-ignores` ([#9300](https://github.com/astral-sh/ruff/pull/9300))
- Respect attribute chains when resolving builtin call paths ([#9309](https://github.com/astral-sh/ruff/pull/9309))
- Treat all `typing_extensions` members as typing aliases ([#9335](https://github.com/astral-sh/ruff/pull/9335))
- Use `Display` for formatter parse errors ([#9316](https://github.com/astral-sh/ruff/pull/9316))
- Wrap subscripted dicts in parens for f-string conversion ([#9238](https://github.com/astral-sh/ruff/pull/9238))
- \[`flake8-annotations`\] Avoid adding return types to stub methods ([#9277](https://github.com/astral-sh/ruff/pull/9277))
- \[`flake8-annotations`\] Respect mixed `return` and `raise` cases in return-type analysis ([#9310](https://github.com/astral-sh/ruff/pull/9310))
- \[`flake8-bandit`\] Don't report violations when `SafeLoader` is imported from `yaml.loader` (`S506`) ([#9299](https://github.com/astral-sh/ruff/pull/9299))
- \[`pylint`\] Avoid panic when comment is preceded by Unicode ([#9331](https://github.com/astral-sh/ruff/pull/9331))
- \[`pylint`\] Change `PLR0917` error message to match other `PLR09XX` messages ([#9308](https://github.com/astral-sh/ruff/pull/9308))
- \[`refurb`\] Avoid false positives for `math-constant` (`FURB152`) ([#9290](https://github.com/astral-sh/ruff/pull/9290))
### Documentation
- Expand target name for better rule documentation ([#9302](https://github.com/astral-sh/ruff/pull/9302))
- Fix typos found by codespell ([#9346](https://github.com/astral-sh/ruff/pull/9346))
- \[`ruff`\] Add `parenthesize-chained-operators` (`RUF021`) to enforce parentheses in `a or b and c` ([#9440](https://github.com/astral-sh/ruff/pull/9440))
### Rule changes
- \[`flake8-boolean-trap`\] Allow Boolean positional arguments in setters ([#9429](https://github.com/astral-sh/ruff/pull/9429))
- \[`flake8-builtins`\] Restrict `builtin-attribute-shadowing` (`A003`) to actual shadowed references ([#9462](https://github.com/astral-sh/ruff/pull/9462))
- \[`flake8-pyi`\] Add fix for `generator-return-from-iter-method` (`PYI058`) ([#9355](https://github.com/astral-sh/ruff/pull/9355))
- \[`pyflakes`\] Don't flag `redefined-while-unused` (`F811`) in `if` branches ([#9418](https://github.com/astral-sh/ruff/pull/9418))
- \[`pyupgrade`\] Add some additional Python 3.12 typing members to `deprecated-import` ([#9445](https://github.com/astral-sh/ruff/pull/9445))
- \[`ruff`\] Add fix for `parenthesize-chained-operators` (`RUF021`) ([#9449](https://github.com/astral-sh/ruff/pull/9449))
- \[`ruff`\] Include subscripts and attributes in static key rule (`RUF011`) ([#9416](https://github.com/astral-sh/ruff/pull/9416))
- \[`ruff`\] Support variable keys in static dictionary key rule (`RUF011`) ([#9411](https://github.com/astral-sh/ruff/pull/9411))
### Formatter
- Generate deterministic IDs when formatting notebooks ([#9359](https://github.com/astral-sh/ruff/pull/9359))
- Allow `# fmt: skip` with interspersed same-line comments ([#9395](https://github.com/astral-sh/ruff/pull/9395))
- Parenthesize breaking named expressions in match guards ([#9396](https://github.com/astral-sh/ruff/pull/9396))
### Bug fixes
- Add cell indexes to all diagnostics ([#9387](https://github.com/astral-sh/ruff/pull/9387))
- Avoid infinite loop in constant vs. `None` comparisons ([#9376](https://github.com/astral-sh/ruff/pull/9376))
- Handle raises with implicit alternate branches ([#9377](https://github.com/astral-sh/ruff/pull/9377))
- Ignore trailing quotes for unclosed l-brace errors ([#9388](https://github.com/astral-sh/ruff/pull/9388))
- Respect multi-segment submodule imports when resolving qualified names ([#9382](https://github.com/astral-sh/ruff/pull/9382))
- Use `DisplayParseError` for stdin parser errors ([#9409](https://github.com/astral-sh/ruff/pull/9409))
- Use `comment_ranges` for isort directive extraction ([#9414](https://github.com/astral-sh/ruff/pull/9414))
- Use transformed source code for diagnostic locations ([#9408](https://github.com/astral-sh/ruff/pull/9408))
- \[`flake8-pyi`\] Exclude `warnings.deprecated` and `typing_extensions.deprecated` arguments ([#9423](https://github.com/astral-sh/ruff/pull/9423))
- \[`flake8-pyi`\] Fix false negative for `unused-private-protocol` (`PYI046`) with unused generic protocols ([#9405](https://github.com/astral-sh/ruff/pull/9405))
- \[`pydocstyle`\] Disambiguate argument descriptors from section headers ([#9427](https://github.com/astral-sh/ruff/pull/9427))
- \[`pylint`\] Homogenize `PLR0914` message to match other `PLR09XX` rules ([#9399](https://github.com/astral-sh/ruff/pull/9399))
- \[`ruff`\] Allow `Hashable = None` in type annotations (`RUF013`) ([#9442](https://github.com/astral-sh/ruff/pull/9442))
Check out the [blog post](https://astral.sh/blog/ruff-v0.10.0) for a migration guide and overview of the changes!
### Breaking changes
See also, the "Remapped rules" section which may result in disabled rules.
- **Changes to how the Python version is inferred when a `target-version` is not specified** ([#16319](https://github.com/astral-sh/ruff/pull/16319))
Because of a mistake in the release process, the `requires-python` inference changes are not included in this release and instead shipped as part of 0.11.0.
You can find a description of this change in the 0.11.0 section.
Previously, Ruff only recognized typechecking blocks that tested the `typing.TYPE_CHECKING` symbol. Now, Ruff recognizes any local variable named `TYPE_CHECKING`. This release also removes support for the legacy `if 0:` and `if False:` typechecking checks. Use a local `TYPE_CHECKING` variable instead.
The syntax for both file-level and in-line suppression comments has been unified and made more robust to certain errors. In most cases, this will result in more suppression comments being read by Ruff, but there are a few instances where previously read comments will now log an error to the user instead. Please refer to the documentation on [_Error suppression_](https://docs.astral.sh/ruff/linter/#error-suppression) for the full specification.
- **Avoid unnecessary parentheses around with statements with a single context manager and a trailing comment** ([#14005](https://github.com/astral-sh/ruff/pull/14005))
This change fixes a bug in the formatter where it introduced unnecessary parentheses around with statements with a single context manager and a trailing comment. This change may result in a change in formatting for some users.
- **Bump alpine default tag to 3.21 for derived Docker images** ([#16456](https://github.com/astral-sh/ruff/pull/16456))
Alpine 3.21 was released in Dec 2024 and is used in the official Alpine-based Python images. Now the ruff:alpine image will use 3.21 instead of 3.20 and ruff:alpine3.20 will no longer be updated.
- [`bad-staticmethod-argument`](https://docs.astral.sh/ruff/rules/bad-staticmethod-argument/) (`PLW0211`) [`invalid-first-argument-name-for-class-method`](https://docs.astral.sh/ruff/rules/invalid-first-argument-name-for-class-method/) (`N804`): `__new__` methods are now no longer flagged by `invalid-first-argument-name-for-class-method` (`N804`) but instead by `bad-staticmethod-argument` (`PLW0211`)
- [`bad-str-strip-call`](https://docs.astral.sh/ruff/rules/bad-str-strip-call/) (`PLE1310`): The rule now applies to objects which are known to have type `str` or `bytes`.
- [`custom-type-var-for-self`](https://docs.astral.sh/ruff/rules/custom-type-var-for-self/) (`PYI019`): More accurate detection of custom `TypeVars` replaceable by `Self`. The range of the diagnostic is now the full function header rather than just the return annotation.
- [`invalid-argument-name`](https://docs.astral.sh/ruff/rules/invalid-argument-name/) (`N803`): Ignore argument names of functions decorated with `typing.override`
- [`invalid-envvar-default`](https://docs.astral.sh/ruff/rules/invalid-envvar-default/) (`PLW1508`): Detect default value arguments to `os.environ.get` with invalid type.
- [`pytest-raises-with-multiple-statements`](https://docs.astral.sh/ruff/rules/pytest-raises-with-multiple-statements/) (`PT012`) [`pytest-warns-with-multiple-statements`](https://docs.astral.sh/ruff/rules/pytest-warns-with-multiple-statements/) (`PT031`): Allow `for` statements with an empty body in `pytest.raises` and `pytest.warns``with` statements.
- [`redundant-open-modes`](https://docs.astral.sh/ruff/rules/redundant-open-modes/) (`UP015`): The diagnostic range is now the range of the redundant mode argument where it previously was the range of the entire open call. You may have to replace your `noqa` comments when suppressing `UP015`.
- [`stdlib-module-shadowing`](https://docs.astral.sh/ruff/rules/stdlib-module-shadowing/) (`A005`): Changes the default value of `lint.flake8-builtins.strict-checking` from `true` to `false`.
- [`type-none-comparison`](https://docs.astral.sh/ruff/rules/type-none-comparison/) (`FURB169`): Now also recognizes `type(expr) is type(None)` comparisons where `expr` isn't a name expression.
The following fixes or improvements to fixes have been stabilized:
- Remove logging output for `ruff.printDebugInformation` ([#16617](https://github.com/astral-sh/ruff/pull/16617))
### Configuration
- \[`flake8-builtins`\] Deprecate the `builtins-` prefixed options in favor of the unprefixed options (e.g. `builtins-allowed-modules` is now deprecated in favor of `allowed-modules`) ([#16092](https://github.com/astral-sh/ruff/pull/16092))
This is a follow-up to release 0.10.0. Because of a mistake in the release process, the `requires-python` inference changes were not included in that release. Ruff 0.11.0 now includes this change as well as the stabilization of the preview behavior for `PGH004`.
### Breaking changes
- **Changes to how the Python version is inferred when a `target-version` is not specified** ([#16319](https://github.com/astral-sh/ruff/pull/16319))
In previous versions of Ruff, you could specify your Python version with:
- The `target-version` option in a `ruff.toml` file or the `[tool.ruff]` section of a pyproject.toml file.
- The `project.requires-python` field in a `pyproject.toml` file with a `[tool.ruff]` section.
These options worked well in most cases, and are still recommended for fine control of the Python version. However, because of the way Ruff discovers config files, `pyproject.toml` files without a `[tool.ruff]` section would be ignored, including the `requires-python` setting. Ruff would then use the default Python version (3.9 as of this writing) instead, which is surprising when you've attempted to request another version.
In v0.10, config discovery has been updated to address this issue:
- If Ruff finds a `ruff.toml` file without a `target-version`, it will check
for a `pyproject.toml` file in the same directory and respect its
`requires-python` version, even if it does not contain a `[tool.ruff]`
section.
- If Ruff finds a user-level configuration, the `requires-python` field of the closest `pyproject.toml` in a parent directory will take precedence.
- If there is no config file (`ruff.toml`or `pyproject.toml` with a
`[tool.ruff]` section) in the directory of the file being checked, Ruff will
search for the closest `pyproject.toml` in the parent directories and use its
`requires-python` setting.
### Stabilization
The following behaviors have been stabilized:
- [`blanket-noqa`](https://docs.astral.sh/ruff/rules/blanket-noqa/) (`PGH004`): Also detect blanked file-level noqa comments (and not just line level comments).
### Preview features
- [syntax-errors] Tuple unpacking in `for` statement iterator clause before Python 3.9 ([#16558](https://github.com/astral-sh/ruff/pull/16558))
## 0.11.1
### Preview features
- \[`airflow`\] Add `chain`, `chain_linear` and `cross_downstream` for `AIR302` ([#16647](https://github.com/astral-sh/ruff/pull/16647))
- [syntax-errors] Improve error message and range for pre-PEP-614 decorator syntax errors ([#16581](https://github.com/astral-sh/ruff/pull/16581))
- [syntax-errors] PEP 701 f-strings before Python 3.12 ([#16543](https://github.com/astral-sh/ruff/pull/16543))
- [syntax-errors] Parenthesized context managers before Python 3.9 ([#16523](https://github.com/astral-sh/ruff/pull/16523))
- [syntax-errors] Star annotations before Python 3.11 ([#16545](https://github.com/astral-sh/ruff/pull/16545))
- [syntax-errors] Star expression in index before Python 3.11 ([#16544](https://github.com/astral-sh/ruff/pull/16544))
- [syntax-errors] Unparenthesized assignment expressions in sets and indexes ([#16404](https://github.com/astral-sh/ruff/pull/16404))
### Bug fixes
- Server: Allow `FixAll` action in presence of version-specific syntax errors ([#16848](https://github.com/astral-sh/ruff/pull/16848))
- \[`flake8-bandit`\] Allow raw strings in `suspicious-mark-safe-usage` (`S308`) #16702 ([#16770](https://github.com/astral-sh/ruff/pull/16770))
- \[`refurb`\] Avoid panicking `unwrap` in `verbose-decimal-constructor` (`FURB157`) ([#16777](https://github.com/astral-sh/ruff/pull/16777))
- Fix `--statistics` reporting for unsafe fixes ([#16756](https://github.com/astral-sh/ruff/pull/16756))
### Rule changes
- \[`flake8-executables`\] Allow `uv run` in shebang line for `shebang-missing-python` (`EXE003`) ([#16849](https://github.com/astral-sh/ruff/pull/16849),[#16855](https://github.com/astral-sh/ruff/pull/16855))
- [syntax-errors] Duplicate type parameter names ([#16858](https://github.com/astral-sh/ruff/pull/16858))
- [syntax-errors] Irrefutable `case` pattern before final case ([#16905](https://github.com/astral-sh/ruff/pull/16905))
- [syntax-errors] Multiple assignments in `case` pattern ([#16957](https://github.com/astral-sh/ruff/pull/16957))
- [syntax-errors] Single starred assignment target ([#17024](https://github.com/astral-sh/ruff/pull/17024))
- [syntax-errors] Starred expressions in `return`, `yield`, and `for` ([#17134](https://github.com/astral-sh/ruff/pull/17134))
- [syntax-errors] Store to or delete `__debug__` ([#16984](https://github.com/astral-sh/ruff/pull/16984))
### Bug fixes
- Error instead of `panic!` when running Ruff from a deleted directory (#16903) ([#17054](https://github.com/astral-sh/ruff/pull/17054))
- [syntax-errors] Fix false positive for parenthesized tuple index ([#16948](https://github.com/astral-sh/ruff/pull/16948))
### CLI
- Check `pyproject.toml` correctly when it is passed via stdin ([#16971](https://github.com/astral-sh/ruff/pull/16971))
### Configuration
- \[`flake8-import-conventions`\] Add import `numpy.typing as npt` to default `flake8-import-conventions.aliases` ([#17133](https://github.com/astral-sh/ruff/pull/17133))
### Documentation
- \[`refurb`\] Document why `UserDict`, `UserList`, and `UserString` are preferred over `dict`, `list`, and `str` (`FURB189`) ([#16927](https://github.com/astral-sh/ruff/pull/16927))
## 0.11.4
### Preview features
- \[`ruff`\] Implement `invalid-rule-code` as `RUF102` ([#17138](https://github.com/astral-sh/ruff/pull/17138))
- [syntax-errors] Detect duplicate keys in `match` mapping patterns ([#17129](https://github.com/astral-sh/ruff/pull/17129))
- [syntax-errors] Detect duplicate attributes in `match` class patterns ([#17186](https://github.com/astral-sh/ruff/pull/17186))
- [syntax-errors] Detect invalid syntax in annotations ([#17101](https://github.com/astral-sh/ruff/pull/17101))
### Bug fixes
- [syntax-errors] Fix multiple assignment error for class fields in `match` patterns ([#17184](https://github.com/astral-sh/ruff/pull/17184))
- Don't skip visiting non-tuple slice in `typing.Annotated` subscripts ([#17201](https://github.com/astral-sh/ruff/pull/17201))
- [syntax-errors] Async comprehension in sync comprehension ([#17177](https://github.com/astral-sh/ruff/pull/17177))
- [syntax-errors] Check annotations in annotated assignments ([#17283](https://github.com/astral-sh/ruff/pull/17283))
- [syntax-errors] Extend annotation checks to `await` ([#17282](https://github.com/astral-sh/ruff/pull/17282))
### Bug fixes
- \[`flake8-pie`\] Avoid false positive for multiple assignment with `auto()` (`PIE796`) ([#17274](https://github.com/astral-sh/ruff/pull/17274))
### Rule changes
- \[`ruff`\] Fix `RUF100` to detect unused file-level `noqa` directives with specific codes (#17042) ([#17061](https://github.com/astral-sh/ruff/pull/17061))
- \[`flake8-pytest-style`\] Avoid false positive for legacy form of `pytest.raises` (`PT011`) ([#17231](https://github.com/astral-sh/ruff/pull/17231))
### Documentation
- Fix formatting of "See Style Guide" link ([#17272](https://github.com/astral-sh/ruff/pull/17272))
## 0.11.6
### Preview features
- Avoid adding whitespace to the end of a docstring after an escaped quote ([#17216](https://github.com/astral-sh/ruff/pull/17216))
- Raise syntax error when `\` is at end of file ([#17409](https://github.com/astral-sh/ruff/pull/17409))
## 0.11.7
### Preview features
- \[`airflow`\] Apply auto fixes to cases where the names have changed in Airflow 3 (`AIR301`) ([#17355](https://github.com/astral-sh/ruff/pull/17355))
- \[`perflint`\] Implement fix for `manual-dict-comprehension` (`PERF403`) ([#16719](https://github.com/astral-sh/ruff/pull/16719))
- [syntax-errors] Make duplicate parameter names a semantic error ([#17131](https://github.com/astral-sh/ruff/pull/17131))
- \[`pylint`\] make fix unsafe if delete comments (`PLR1730`) ([#17459](https://github.com/astral-sh/ruff/pull/17459))
### Documentation
- Add fix safety sections to docs for several rules ([#17410](https://github.com/astral-sh/ruff/pull/17410),[#17440](https://github.com/astral-sh/ruff/pull/17440),[#17441](https://github.com/astral-sh/ruff/pull/17441),[#17443](https://github.com/astral-sh/ruff/pull/17443),[#17444](https://github.com/astral-sh/ruff/pull/17444))
## 0.11.8
### Preview features
- \[`airflow`\] Apply auto fixes to cases where the names have changed in Airflow 3 (`AIR302`, `AIR311`) ([#17553](https://github.com/astral-sh/ruff/pull/17553), [#17570](https://github.com/astral-sh/ruff/pull/17570), [#17571](https://github.com/astral-sh/ruff/pull/17571))
- \[`flake8-pyi`\] Ensure `Literal[None,] | Literal[None,]` is not autofixed to `None | None` (`PYI061`) ([#17659](https://github.com/astral-sh/ruff/pull/17659))
- \[`flake8-use-pathlib`\] Avoid suggesting `Path.iterdir()` for `os.listdir` with file descriptor (`PTH208`) ([#17715](https://github.com/astral-sh/ruff/pull/17715))
- \[`flake8-use-pathlib`\] Fix `PTH104` false positive when `rename` is passed a file descriptor ([#17712](https://github.com/astral-sh/ruff/pull/17712))
- \[`flake8-use-pathlib`\] Fix `PTH116` false positive when `stat` is passed a file descriptor ([#17709](https://github.com/astral-sh/ruff/pull/17709))
- \[`flake8-use-pathlib`\] Fix `PTH123` false positive when `open` is passed a file descriptor from a function call ([#17705](https://github.com/astral-sh/ruff/pull/17705))
- \[`pycodestyle`\] Fix duplicated diagnostic in `E712` ([#17651](https://github.com/astral-sh/ruff/pull/17651))
- \[`pylint`\] Detect `global` declarations in module scope (`PLE0118`) ([#17411](https://github.com/astral-sh/ruff/pull/17411))
- [syntax-errors] Make `async-comprehension-in-sync-comprehension` more specific ([#17460](https://github.com/astral-sh/ruff/pull/17460))
### Configuration
- Add option to disable `typing_extensions` imports ([#17611](https://github.com/astral-sh/ruff/pull/17611))
### Documentation
- Fix example syntax for the `lint.pydocstyle.ignore-var-parameters` option ([#17740](https://github.com/astral-sh/ruff/pull/17740))
- \[`flake8-bandit`\] Mark tuples of string literals as trusted input in `S603` ([#17801](https://github.com/astral-sh/ruff/pull/17801))
- \[`isort`\] Check full module path against project root(s) when categorizing first-party imports ([#16565](https://github.com/astral-sh/ruff/pull/16565))
- \[`ruff`\] Add new rule `in-empty-collection` (`RUF060`) ([#16480](https://github.com/astral-sh/ruff/pull/16480))
### Bug fixes
- Fix missing `combine` call for `lint.typing-extensions` setting ([#17823](https://github.com/astral-sh/ruff/pull/17823))
- \[`flake8-async`\] Fix module name in `ASYNC110`, `ASYNC115`, and `ASYNC116` fixes ([#17774](https://github.com/astral-sh/ruff/pull/17774))
- \[`pyupgrade`\] Add spaces between tokens as necessary to avoid syntax errors in `UP018` autofix ([#17648](https://github.com/astral-sh/ruff/pull/17648))
- \[`refurb`\] Fix false positive for float and complex numbers in `FURB116` ([#17661](https://github.com/astral-sh/ruff/pull/17661))
- [parser] Flag single unparenthesized generator expr with trailing comma in arguments. ([#17893](https://github.com/astral-sh/ruff/pull/17893))
### Documentation
- Add instructions on how to upgrade to a newer Rust version ([#17928](https://github.com/astral-sh/ruff/pull/17928))
- Update code of conduct email address ([#17875](https://github.com/astral-sh/ruff/pull/17875))
- Add fix safety sections to `PLC2801`, `PLR1722`, and `RUF013` ([#17825](https://github.com/astral-sh/ruff/pull/17825), [#17826](https://github.com/astral-sh/ruff/pull/17826), [#17759](https://github.com/astral-sh/ruff/pull/17759))
- Add link to `check-typed-exception` from `S110` and `S112` ([#17786](https://github.com/astral-sh/ruff/pull/17786))
### Other changes
- Allow passing a virtual environment to `ruff analyze graph` ([#17743](https://github.com/astral-sh/ruff/pull/17743))
## 0.11.10
### Preview features
- \[`ruff`\] Implement a recursive check for `RUF060` ([#17976](https://github.com/astral-sh/ruff/pull/17976))
- \[`airflow`\] Enable autofixes for `AIR301` and `AIR311` ([#17941](https://github.com/astral-sh/ruff/pull/17941))
- \[`airflow`\] Apply try catch guard to all `AIR3` rules ([#17887](https://github.com/astral-sh/ruff/pull/17887))
- \[`flake8-bugbear`\] Ignore `B028` if `skip_file_prefixes` is present ([#18047](https://github.com/astral-sh/ruff/pull/18047))
- \[`flake8-pie`\] Mark autofix for `PIE804` as unsafe if the dictionary contains comments ([#18046](https://github.com/astral-sh/ruff/pull/18046))
- \[`flake8-simplify`\] Correct behavior for `str.split`/`rsplit` with `maxsplit=0` (`SIM905`) ([#18075](https://github.com/astral-sh/ruff/pull/18075))
- \[`flake8-simplify`\] Fix `SIM905` autofix for `rsplit` creating a reversed list literal ([#18045](https://github.com/astral-sh/ruff/pull/18045))
- \[`flake8-use-pathlib`\] Suppress diagnostics for all `os.*` functions that have the `dir_fd` parameter (`PTH`) ([#17968](https://github.com/astral-sh/ruff/pull/17968))
- \[`refurb`\] Mark autofix as safe only for number literals (`FURB116`) ([#17692](https://github.com/astral-sh/ruff/pull/17692))
### Rule changes
- \[`flake8-bandit`\] Skip `S608` for expressionless f-strings ([#17999](https://github.com/astral-sh/ruff/pull/17999))
- \[`flake8-pytest-style`\] Don't recommend `usefixtures` for `parametrize` values (`PT019`) ([#17650](https://github.com/astral-sh/ruff/pull/17650))
- \[`pyupgrade`\] Add `resource.error` as deprecated alias of `OSError` (`UP024`) ([#17933](https://github.com/astral-sh/ruff/pull/17933))
### CLI
- Disable jemalloc on Android ([#18033](https://github.com/astral-sh/ruff/pull/18033))
- \[`airflow`\] Add autofixes for `AIR302` and `AIR312` ([#17942](https://github.com/astral-sh/ruff/pull/17942))
- \[`airflow`\] Move rules from `AIR312` to `AIR302` ([#17940](https://github.com/astral-sh/ruff/pull/17940))
- \[`airflow`\] Update `AIR301` and `AIR311` with the latest Airflow implementations ([#17985](https://github.com/astral-sh/ruff/pull/17985))
- \[`flake8-simplify`\] Enable fix in preview mode (`SIM117`) ([#18208](https://github.com/astral-sh/ruff/pull/18208))
### Bug fixes
- Fix inconsistent formatting of match-case on `[]` and `_` ([#18147](https://github.com/astral-sh/ruff/pull/18147))
- \[`pylint`\] Fix `PLW1514` not recognizing the `encoding` positional argument of `codecs.open` ([#18109](https://github.com/astral-sh/ruff/pull/18109))
### CLI
- Add full option name in formatter warning ([#18217](https://github.com/astral-sh/ruff/pull/18217))
### Documentation
- Fix rendering of admonition in docs ([#18163](https://github.com/astral-sh/ruff/pull/18163))
- \[`flake8-print`\] Improve print/pprint docs for `T201` and `T203` ([#18130](https://github.com/astral-sh/ruff/pull/18130))
- \[`airflow`\] Add unsafe fix for module moved cases (`AIR301`,`AIR311`,`AIR312`,`AIR302`) ([#18367](https://github.com/astral-sh/ruff/pull/18367),[#18366](https://github.com/astral-sh/ruff/pull/18366),[#18363](https://github.com/astral-sh/ruff/pull/18363),[#18093](https://github.com/astral-sh/ruff/pull/18093))
- \[`refurb`\] Add coverage of `set` and `frozenset` calls (`FURB171`) ([#18035](https://github.com/astral-sh/ruff/pull/18035))
- \[`refurb`\] Mark `FURB180` fix unsafe when class has bases ([#18149](https://github.com/astral-sh/ruff/pull/18149))
### Bug fixes
- \[`perflint`\] Fix missing parentheses for lambda and ternary conditions (`PERF401`, `PERF403`) ([#18412](https://github.com/astral-sh/ruff/pull/18412))
- \[`pyupgrade`\] Apply `UP035` only on py313+ for `get_type_hints()` ([#18476](https://github.com/astral-sh/ruff/pull/18476))
- \[`pyupgrade`\] Make fix unsafe if it deletes comments (`UP004`,`UP050`) ([#18393](https://github.com/astral-sh/ruff/pull/18393), [#18390](https://github.com/astral-sh/ruff/pull/18390))
### Rule changes
- \[`fastapi`\] Avoid false positive for class dependencies (`FAST003`) ([#18271](https://github.com/astral-sh/ruff/pull/18271))
### Documentation
- Update editor setup docs for Neovim and Vim ([#18324](https://github.com/astral-sh/ruff/pull/18324))
### Other changes
- Support Python 3.14 template strings (t-strings) in formatter and parser ([#17851](https://github.com/astral-sh/ruff/pull/17851))
- [`collection-literal-concatenation`] (`RUF005`) now recognizes slices, in
addition to list literals and variables.
- The fix for [`readlines-in-for`] (`FURB129`) is now marked as always safe.
- [`if-else-block-instead-of-if-exp`] (`SIM108`) will now further simplify
expressions to use `or` instead of an `if` expression, where possible.
- [`unused-noqa`] (`RUF100`) now checks for file-level `noqa` comments as well
as inline comments.
- [`subprocess-without-shell-equals-true`] (`S603`) now accepts literal strings,
as well as lists and tuples of literal strings, as trusted input.
- [`boolean-type-hint-positional-argument`] (`FBT001`) now applies to types that
include `bool`, like `bool | int` or `typing.Optional[bool]`, in addition to
plain `bool` annotations.
- [`non-pep604-annotation-union`] (`UP007`) has now been split into two rules.
`UP007` now applies only to `typing.Union`, while
[`non-pep604-annotation-optional`] (`UP045`) checks for use of
`typing.Optional`. `UP045` has also been stabilized in this release, but you
may need to update existing `include`, `ignore`, or `noqa` settings to
accommodate this change.
### Preview features
- \[`ruff`\] Check for non-context-manager use of `pytest.raises`, `pytest.warns`, and `pytest.deprecated_call` (`RUF061`) ([#17368](https://github.com/astral-sh/ruff/pull/17368))
- [syntax-errors] Raise unsupported syntax error for template strings prior to Python 3.14 ([#18664](https://github.com/astral-sh/ruff/pull/18664))
### Bug fixes
- Add syntax error when conversion flag does not immediately follow exclamation mark ([#18706](https://github.com/astral-sh/ruff/pull/18706))
- Add trailing space around `readlines` ([#18542](https://github.com/astral-sh/ruff/pull/18542))
- Fix `\r` and `\r\n` handling in t- and f-string debug texts ([#18673](https://github.com/astral-sh/ruff/pull/18673))
- Hug closing `}` when f-string expression has a format specifier ([#18704](https://github.com/astral-sh/ruff/pull/18704))
- \[`flake8-pyi`\] Avoid syntax error in the case of starred and keyword arguments (`PYI059`) ([#18611](https://github.com/astral-sh/ruff/pull/18611))
- \[`flake8-return`\] Fix `RET504` autofix generating a syntax error ([#18428](https://github.com/astral-sh/ruff/pull/18428))
- \[`pep8-naming`\] Suppress fix for `N804` and `N805` if the recommended name is already used ([#18472](https://github.com/astral-sh/ruff/pull/18472))
- \[`pycodestyle`\] Avoid causing a syntax error in expressions spanning multiple lines (`E731`) ([#18479](https://github.com/astral-sh/ruff/pull/18479))
- \[`pyupgrade`\] Suppress `UP008` if `super` is shadowed ([#18688](https://github.com/astral-sh/ruff/pull/18688))
- \[`refurb`\] Parenthesize lambda and ternary expressions (`FURB122`, `FURB142`) ([#18592](https://github.com/astral-sh/ruff/pull/18592))
- \[`ruff`\] Handle extra arguments to `deque` (`RUF037`) ([#18614](https://github.com/astral-sh/ruff/pull/18614))
- \[`ruff`\] Preserve parentheses around `deque` in fix for `unnecessary-empty-iterable-within-deque-call` (`RUF037`) ([#18598](https://github.com/astral-sh/ruff/pull/18598))
- \[`ruff`\] Validate arguments before offering a fix (`RUF056`) ([#18631](https://github.com/astral-sh/ruff/pull/18631))
- \[`ruff`\] Skip fix for `RUF059` if dummy name is already bound ([#18509](https://github.com/astral-sh/ruff/pull/18509))
- \[`pylint`\] Fix `PLW0128` to check assignment targets in square brackets and after asterisks ([#18665](https://github.com/astral-sh/ruff/pull/18665))
### Rule changes
- Fix false positive on mutations in `return` statements (`B909`) ([#18408](https://github.com/astral-sh/ruff/pull/18408))
- Treat `ty:` comments as pragma comments ([#18532](https://github.com/astral-sh/ruff/pull/18532))
- \[`flake8-pyi`\] Apply `custom-typevar-for-self` to string annotations (`PYI019`) ([#18311](https://github.com/astral-sh/ruff/pull/18311))
- \[`pyupgrade`\] Don't offer a fix for `Optional[None]` (`UP007`, `UP045)` ([#18545](https://github.com/astral-sh/ruff/pull/18545))
- \[`refurb`\] Make the fix for `FURB163` unsafe for `log2`, `log10`, `*args`, and deleted comments ([#18645](https://github.com/astral-sh/ruff/pull/18645))
### Server
- Support cancellation requests ([#18627](https://github.com/astral-sh/ruff/pull/18627))
### Documentation
- Drop confusing second `*` from glob pattern example for `per-file-target-version` ([#18709](https://github.com/astral-sh/ruff/pull/18709))
- \[`flake8-pytest-style`\] Enforce `pytest` import for decorators ([#18779](https://github.com/astral-sh/ruff/pull/18779))
- \[`flake8-pytest-style`\] Mark autofix for `PT001` and `PT023` as unsafe if there's comments in the decorator ([#18792](https://github.com/astral-sh/ruff/pull/18792))
- \[`flake8-pytest-style`\] `PT001`/`PT023` fix makes syntax error on parenthesized decorator ([#18782](https://github.com/astral-sh/ruff/pull/18782))
- \[`flake8-raise`\] Make fix unsafe if it deletes comments (`RSE102`) ([#18788](https://github.com/astral-sh/ruff/pull/18788))
- \[`flake8-simplify`\] Fix `SIM911` autofix creating a syntax error ([#18793](https://github.com/astral-sh/ruff/pull/18793))
- \[`flake8-simplify`\] Preserve original behavior for `except ()` and bare `except` (`SIM105`) ([#18213](https://github.com/astral-sh/ruff/pull/18213))
- \[`perflint`\] Fix `PERF101` autofix creating a syntax error and mark autofix as unsafe if there are comments in the `list` call expr ([#18803](https://github.com/astral-sh/ruff/pull/18803))
- \[`perflint`\] Fix false negative in `PERF401` ([#18866](https://github.com/astral-sh/ruff/pull/18866))
- \[`pylint`\] Avoid flattening nested `min`/`max` when outer call has single argument (`PLW3301`) ([#16885](https://github.com/astral-sh/ruff/pull/16885))
- \[`pylint`\] Fix `PLC2801` autofix creating a syntax error ([#18857](https://github.com/astral-sh/ruff/pull/18857))
- \[`pylint`\] Mark `PLE0241` autofix as unsafe if there's comments in the base classes ([#18832](https://github.com/astral-sh/ruff/pull/18832))
- \[`pylint`\] Suppress `PLE2510`/`PLE2512`/`PLE2513`/`PLE2514`/`PLE2515` autofix if the text contains an odd number of backslashes ([#18856](https://github.com/astral-sh/ruff/pull/18856))
- \[`refurb`\] Detect more exotic float literals in `FURB164` ([#18925](https://github.com/astral-sh/ruff/pull/18925))
- \[`refurb`\] Fix `FURB163` autofix creating a syntax error for `yield` expressions ([#18756](https://github.com/astral-sh/ruff/pull/18756))
- \[`refurb`\] Mark `FURB129` autofix as unsafe if there's comments in the `readlines` call ([#18858](https://github.com/astral-sh/ruff/pull/18858))
- \[`ruff`\] Fix false positives and negatives in `RUF010` ([#18690](https://github.com/astral-sh/ruff/pull/18690))
- Fix casing of `analyze.direction` variant names ([#18892](https://github.com/astral-sh/ruff/pull/18892))
### Rule changes
- Fix f-string interpolation escaping in generated fixes ([#18882](https://github.com/astral-sh/ruff/pull/18882))
- \[`flake8-return`\] Mark `RET501` fix unsafe if comments are inside ([#18780](https://github.com/astral-sh/ruff/pull/18780))
- \[`flake8-async`\] Fix detection for large integer sleep durations in `ASYNC116` rule ([#18767](https://github.com/astral-sh/ruff/pull/18767))
- \[`flake8-async`\] Mark autofix for `ASYNC115` as unsafe if the call expression contains comments ([#18753](https://github.com/astral-sh/ruff/pull/18753))
- \[`flake8-bugbear`\] Mark autofix for `B004` as unsafe if the `hasattr` call expr contains comments ([#18755](https://github.com/astral-sh/ruff/pull/18755))
- \[`flake8-comprehension`\] Mark autofix for `C420` as unsafe if there's comments inside the dict comprehension ([#18768](https://github.com/astral-sh/ruff/pull/18768))
- \[`flake8-comprehensions`\] Handle template strings for comprehension fixes ([#18710](https://github.com/astral-sh/ruff/pull/18710))
- \[`pyflakes`\] Mark `F504`/`F522`/`F523` autofix as unsafe if there's a call with side effect ([#18839](https://github.com/astral-sh/ruff/pull/18839))
- \[`pylint`\] Allow fix with comments and document performance implications (`PLW3301`) ([#18936](https://github.com/astral-sh/ruff/pull/18936))
- \[`pylint`\] Detect more exotic `NaN` literals in `PLW0177` ([#18630](https://github.com/astral-sh/ruff/pull/18630))
- \[`pylint`\] Fix `PLC1802` autofix creating a syntax error and mark autofix as unsafe if there's comments in the `len` call ([#18836](https://github.com/astral-sh/ruff/pull/18836))
- \[`pyupgrade`\] Extend version detection to include `sys.version_info.major` (`UP036`) ([#18633](https://github.com/astral-sh/ruff/pull/18633))
- \[`ruff`\] Add lint rule `RUF064` for calling `chmod` with non-octal integers ([#18541](https://github.com/astral-sh/ruff/pull/18541))
- Use updated pre-commit id ([#18718](https://github.com/astral-sh/ruff/pull/18718))
- \[`perflint`\] Small docs improvement to `PERF401` ([#18786](https://github.com/astral-sh/ruff/pull/18786))
- \[`pyupgrade`\]: Use `super()`, not `__super__` in error messages (`UP008`) ([#18743](https://github.com/astral-sh/ruff/pull/18743))
- \[`flake8-pie`\] Small docs fix to `PIE794` ([#18829](https://github.com/astral-sh/ruff/pull/18829))
- \[`flake8-pyi`\] Correct `collections-named-tuple` example to use PascalCase assignment ([#16884](https://github.com/astral-sh/ruff/pull/16884))
- \[`flake8-pie`\] Add note on type checking benefits to `unnecessary-dict-kwargs` (`PIE804`) ([#18666](https://github.com/astral-sh/ruff/pull/18666))
- \[`pycodestyle`\] Clarify PEP 8 relationship to `whitespace-around-operator` rules ([#18870](https://github.com/astral-sh/ruff/pull/18870))
### Other changes
- Disallow newlines in format specifiers of single quoted f- or t-strings ([#18708](https://github.com/astral-sh/ruff/pull/18708))
- \[`flake8-logging`\] Add fix safety section to `LOG002` ([#18840](https://github.com/astral-sh/ruff/pull/18840))
- \[`pyupgrade`\] Add fix safety section to `UP010` ([#18838](https://github.com/astral-sh/ruff/pull/18838))
## 0.12.2
### Preview features
- \[`flake8-pyi`\] Expand `Optional[A]` to `A | None` (`PYI016`) ([#18572](https://github.com/astral-sh/ruff/pull/18572))
- \[`pyupgrade`\] Mark `UP008` fix safe if no comments are in range ([#18683](https://github.com/astral-sh/ruff/pull/18683))
### Bug fixes
- \[`flake8-comprehensions`\] Fix `C420` to prepend whitespace when needed ([#18616](https://github.com/astral-sh/ruff/pull/18616))
- \[`perflint`\] Fix `PERF403` panic on attribute or subscription loop variable ([#19042](https://github.com/astral-sh/ruff/pull/19042))
- \[`pydocstyle`\] Fix `D413` infinite loop for parenthesized docstring ([#18930](https://github.com/astral-sh/ruff/pull/18930))
- \[`pylint`\] Fix `PLW0108` autofix introducing a syntax error when the lambda's body contains an assignment expression ([#18678](https://github.com/astral-sh/ruff/pull/18678))
- \[`refurb`\] Fix false positive on empty tuples (`FURB168`) ([#19058](https://github.com/astral-sh/ruff/pull/19058))
- \[`ruff`\] Allow more `field` calls from `attrs` (`RUF009`) ([#19021](https://github.com/astral-sh/ruff/pull/19021))
- \[`ruff`\] Fix syntax error introduced for an empty string followed by a u-prefixed string (`UP025`) ([#18899](https://github.com/astral-sh/ruff/pull/18899))
### Rule changes
- \[`flake8-executable`\] Allow `uvx` in shebang line (`EXE003`) ([#18967](https://github.com/astral-sh/ruff/pull/18967))
- \[`pandas`\] Avoid flagging `PD002` if `pandas` is not imported ([#18963](https://github.com/astral-sh/ruff/pull/18963))
- \[`pyupgrade`\] Avoid PEP-604 unions with `typing.NamedTuple` (`UP007`, `UP045`) ([#18682](https://github.com/astral-sh/ruff/pull/18682))
### Documentation
- Document link between `import-outside-top-level (PLC0415)` and `lint.flake8-tidy-imports.banned-module-level-imports` ([#18733](https://github.com/astral-sh/ruff/pull/18733))
- Fix description of the `format.skip-magic-trailing-comma` example ([#19095](https://github.com/astral-sh/ruff/pull/19095))
- \[`airflow`\] Make `AIR302` example error out-of-the-box ([#18988](https://github.com/astral-sh/ruff/pull/18988))
- \[`airflow`\] Make `AIR312` example error out-of-the-box ([#18989](https://github.com/astral-sh/ruff/pull/18989))
- \[`flake8-annotations`\] Make `ANN401` example error out-of-the-box ([#18974](https://github.com/astral-sh/ruff/pull/18974))
- \[`flake8-async`\] Make `ASYNC100` example error out-of-the-box ([#18993](https://github.com/astral-sh/ruff/pull/18993))
- \[`flake8-async`\] Make `ASYNC105` example error out-of-the-box ([#19002](https://github.com/astral-sh/ruff/pull/19002))
- \[`flake8-async`\] Make `ASYNC110` example error out-of-the-box ([#18975](https://github.com/astral-sh/ruff/pull/18975))
- \[`flake8-async`\] Make `ASYNC210` example error out-of-the-box ([#18977](https://github.com/astral-sh/ruff/pull/18977))
- \[`flake8-async`\] Make `ASYNC220`, `ASYNC221`, and `ASYNC222` examples error out-of-the-box ([#18978](https://github.com/astral-sh/ruff/pull/18978))
- \[`flake8-async`\] Make `ASYNC251` example error out-of-the-box ([#18990](https://github.com/astral-sh/ruff/pull/18990))
- \[`flake8-bandit`\] Make `S201` example error out-of-the-box ([#19017](https://github.com/astral-sh/ruff/pull/19017))
- \[`flake8-bandit`\] Make `S604` and `S609` examples error out-of-the-box ([#19049](https://github.com/astral-sh/ruff/pull/19049))
- \[`flake8-bugbear`\] Make `B028` example error out-of-the-box ([#19054](https://github.com/astral-sh/ruff/pull/19054))
- \[`flake8-bugbear`\] Make `B911` example error out-of-the-box ([#19051](https://github.com/astral-sh/ruff/pull/19051))
- \[`flake8-datetimez`\] Make `DTZ011` example error out-of-the-box ([#19055](https://github.com/astral-sh/ruff/pull/19055))
- \[`flake8-datetimez`\] Make `DTZ901` example error out-of-the-box ([#19056](https://github.com/astral-sh/ruff/pull/19056))
- \[`flake8-pyi`\] Make `PYI032` example error out-of-the-box ([#19061](https://github.com/astral-sh/ruff/pull/19061))
- \[`flake8-pyi`\] Make example error out-of-the-box (`PYI014`, `PYI015`) ([#19097](https://github.com/astral-sh/ruff/pull/19097))
- \[`flake8-pyi`\] Make example error out-of-the-box (`PYI042`) ([#19101](https://github.com/astral-sh/ruff/pull/19101))
- \[`flake8-pyi`\] Make example error out-of-the-box (`PYI059`) ([#19080](https://github.com/astral-sh/ruff/pull/19080))
- \[`flake8-pyi`\] Make example error out-of-the-box (`PYI062`) ([#19079](https://github.com/astral-sh/ruff/pull/19079))
- \[`flake8-pytest-style`\] Make example error out-of-the-box (`PT023`) ([#19104](https://github.com/astral-sh/ruff/pull/19104))
- \[`flake8-pytest-style`\] Make example error out-of-the-box (`PT030`) ([#19105](https://github.com/astral-sh/ruff/pull/19105))
- \[`flake8-quotes`\] Make example error out-of-the-box (`Q003`) ([#19106](https://github.com/astral-sh/ruff/pull/19106))
- \[`flake8-simplify`\] Make example error out-of-the-box (`SIM110`) ([#19113](https://github.com/astral-sh/ruff/pull/19113))
- \[`flake8-simplify`\] Make example error out-of-the-box (`SIM113`) ([#19109](https://github.com/astral-sh/ruff/pull/19109))
- \[`flake8-simplify`\] Make example error out-of-the-box (`SIM401`) ([#19110](https://github.com/astral-sh/ruff/pull/19110))
- \[`pyflakes`\] Fix backslash in docs (`F621`) ([#19098](https://github.com/astral-sh/ruff/pull/19098))
- \[`pylint`\] Fix `PLC0415` example ([#18970](https://github.com/astral-sh/ruff/pull/18970))
## 0.12.3
### Preview features
- \[`flake8-bugbear`\] Support non-context-manager calls in `B017` ([#19063](https://github.com/astral-sh/ruff/pull/19063))
- \[`flake8-use-pathlib`\] Add autofixes for `PTH203`, `PTH204`, `PTH205` ([#18922](https://github.com/astral-sh/ruff/pull/18922))
### Bug fixes
- \[`flake8-return`\] Fix false-positive for variables used inside nested functions in `RET504` ([#18433](https://github.com/astral-sh/ruff/pull/18433))
- Treat form feed as valid whitespace before a line continuation ([#19220](https://github.com/astral-sh/ruff/pull/19220))
- \[`flake8-type-checking`\] Fix syntax error introduced by fix (`TC008`) ([#19150](https://github.com/astral-sh/ruff/pull/19150))
- \[`pyupgrade`\] Keyword arguments in `super` should suppress the `UP008` fix ([#19131](https://github.com/astral-sh/ruff/pull/19131))
### Documentation
- \[`flake8-pyi`\] Make example error out-of-the-box (`PYI007`, `PYI008`) ([#19103](https://github.com/astral-sh/ruff/pull/19103))
- \[`flake8-simplify`\] Make example error out-of-the-box (`SIM116`) ([#19111](https://github.com/astral-sh/ruff/pull/19111))
- \[`flake8-type-checking`\] Make example error out-of-the-box (`TC001`) ([#19151](https://github.com/astral-sh/ruff/pull/19151))
- \[`flake8-use-pathlib`\] Make example error out-of-the-box (`PTH210`) ([#19189](https://github.com/astral-sh/ruff/pull/19189))
- \[`pycodestyle`\] Make example error out-of-the-box (`E272`) ([#19191](https://github.com/astral-sh/ruff/pull/19191))
- \[`pycodestyle`\] Make example not raise unnecessary `SyntaxError` (`E114`) ([#19190](https://github.com/astral-sh/ruff/pull/19190))
- \[`pydoclint`\] Make example error out-of-the-box (`DOC501`) ([#19218](https://github.com/astral-sh/ruff/pull/19218))
- \[`flake8-use-pathlib`\] Fix false negative on direct `Path()` instantiation (`PTH210`) ([#19388](https://github.com/astral-sh/ruff/pull/19388))
- \[`flake8-django`\] Fix `DJ008` false positive for abstract models with type-annotated `abstract` field ([#19221](https://github.com/astral-sh/ruff/pull/19221))
- \[`isort`\] Fix `I002` import insertion after docstring with multiple string statements ([#19222](https://github.com/astral-sh/ruff/pull/19222))
- \[`isort`\] Treat form feed as valid whitespace before a semicolon ([#19343](https://github.com/astral-sh/ruff/pull/19343))
- \[`pydoclint`\] Fix `SyntaxError` from fixes with line continuations (`D201`, `D202`) ([#19246](https://github.com/astral-sh/ruff/pull/19246))
- \[`refurb`\] `FURB164` fix should validate arguments and should usually be marked unsafe ([#19136](https://github.com/astral-sh/ruff/pull/19136))
### Rule changes
- \[`flake8-use-pathlib`\] Skip single dots for `invalid-pathlib-with-suffix` (`PTH210`) on versions >= 3.14 ([#19331](https://github.com/astral-sh/ruff/pull/19331))
- \[`pep8_naming`\] Avoid false positives on standard library functions with uppercase names (`N802`) ([#18907](https://github.com/astral-sh/ruff/pull/18907))
- \[`pycodestyle`\] Handle brace escapes for t-strings in logical lines ([#19358](https://github.com/astral-sh/ruff/pull/19358))
- \[`pylint`\] Extend invalid string character rules to include t-strings ([#19355](https://github.com/astral-sh/ruff/pull/19355))
- \[`ruff`\] Allow `strict` kwarg when checking for `starmap-zip` (`RUF058`) in Python 3.14+ ([#19333](https://github.com/astral-sh/ruff/pull/19333))
### Documentation
- \[`flake8-type-checking`\] Make `TC010` docs example more realistic ([#19356](https://github.com/astral-sh/ruff/pull/19356))
- Make more documentation examples error out-of-the-box ([#19288](https://github.com/astral-sh/ruff/pull/19288),[#19272](https://github.com/astral-sh/ruff/pull/19272),[#19291](https://github.com/astral-sh/ruff/pull/19291),[#19296](https://github.com/astral-sh/ruff/pull/19296),[#19292](https://github.com/astral-sh/ruff/pull/19292),[#19295](https://github.com/astral-sh/ruff/pull/19295),[#19297](https://github.com/astral-sh/ruff/pull/19297),[#19309](https://github.com/astral-sh/ruff/pull/19309))
## 0.12.5
### Preview features
- \[`flake8-use-pathlib`\] Add autofix for `PTH101`, `PTH104`, `PTH105`, `PTH121` ([#19404](https://github.com/astral-sh/ruff/pull/19404))
- \[`ruff`\] Support byte strings (`RUF055`) ([#18926](https://github.com/astral-sh/ruff/pull/18926))
### Bug fixes
- Fix `unreachable` panic in parser ([#19183](https://github.com/astral-sh/ruff/pull/19183))
- \[`flake8-pyi`\] Skip fix if all `Union` members are `None` (`PYI016`) ([#19416](https://github.com/astral-sh/ruff/pull/19416))
- \[`pylint`\] Handle empty comments after line continuation (`PLR2044`) ([#19405](https://github.com/astral-sh/ruff/pull/19405))
### Rule changes
- \[`pep8-naming`\] Fix `N802` false positives for `CGIHTTPRequestHandler` and `SimpleHTTPRequestHandler` ([#19432](https://github.com/astral-sh/ruff/pull/19432))
## 0.12.6
### Preview features
- \[`flake8-commas`\] Add support for trailing comma checks in type parameter lists (`COM812`, `COM819`) ([#19390](https://github.com/astral-sh/ruff/pull/19390))
- \[`pylint`\] Implement auto-fix for `missing-maxsplit-arg` (`PLC0207`) ([#19387](https://github.com/astral-sh/ruff/pull/19387))
- \[`ruff`\] Offer fixes for `RUF039` in more cases ([#19065](https://github.com/astral-sh/ruff/pull/19065))
### Bug fixes
- Support `.pyi` files in ruff analyze graph ([#19611](https://github.com/astral-sh/ruff/pull/19611))
- \[`flake8-pyi`\] Preserve inline comment in ellipsis removal (`PYI013`) ([#19399](https://github.com/astral-sh/ruff/pull/19399))
- \[`perflint`\] Ignore rule if target is `global` or `nonlocal` (`PERF401`) ([#19539](https://github.com/astral-sh/ruff/pull/19539))
- \[`pyupgrade`\] Fix `UP030` to avoid modifying double curly braces in format strings ([#19378](https://github.com/astral-sh/ruff/pull/19378))
- \[`refurb`\] Ignore decorated functions for `FURB118` ([#19339](https://github.com/astral-sh/ruff/pull/19339))
- \[`refurb`\] Mark `int` and `bool` cases for `Decimal.from_float` as safe fixes (`FURB164`) ([#19468](https://github.com/astral-sh/ruff/pull/19468))
- \[`ruff`\] Fix `RUF033` for named default expressions ([#19115](https://github.com/astral-sh/ruff/pull/19115))
### Rule changes
- \[`flake8-blind-except`\] Change `BLE001` to permit `logging.critical(..., exc_info=True)` ([#19520](https://github.com/astral-sh/ruff/pull/19520))
### Performance
- Add support for specifying minimum dots in detected string imports ([#19538](https://github.com/astral-sh/ruff/pull/19538))
## 0.12.7
This is a follow-up release to 0.12.6. Because of an issue in the package metadata, 0.12.6 failed to publish fully to PyPI and has been yanked. Similarly, there is no GitHub release or Git tag for 0.12.6. The contents of the 0.12.7 release are identical to 0.12.6, except for the updated metadata.
## 0.12.8
### Preview features
- \[`flake8-use-pathlib`\] Expand `PTH201` to check all `PurePath` subclasses ([#19440](https://github.com/astral-sh/ruff/pull/19440))
### Bug fixes
- \[`flake8-blind-except`\] Change `BLE001` to correctly parse exception tuples ([#19747](https://github.com/astral-sh/ruff/pull/19747))
- \[`flake8-errmsg`\] Exclude `typing.cast` from `EM101` ([#19656](https://github.com/astral-sh/ruff/pull/19656))
- \[`flake8-simplify`\] Fix raw string handling in `SIM905` for embedded quotes ([#19591](https://github.com/astral-sh/ruff/pull/19591))
- \[`flake8-import-conventions`\] Avoid false positives for NFKC-normalized `__debug__` import aliases in `ICN001` ([#19411](https://github.com/astral-sh/ruff/pull/19411))
- \[`isort`\] Fix syntax error after docstring ending with backslash (`I002`) ([#19505](https://github.com/astral-sh/ruff/pull/19505))
- \[`pylint`\] Mark `PLC0207` fixes as unsafe when `*args` unpacking is present ([#19679](https://github.com/astral-sh/ruff/pull/19679))
- \[`pyupgrade`\] Prevent infinite loop with `I002` (`UP010`, `UP035`) ([#19413](https://github.com/astral-sh/ruff/pull/19413))
- \[`ruff`\] Parenthesize generator expressions in f-strings (`RUF010`) ([#19434](https://github.com/astral-sh/ruff/pull/19434))
### Rule changes
- \[`eradicate`\] Don't flag `pyrefly` pragmas as unused code (`ERA001`) ([#19731](https://github.com/astral-sh/ruff/pull/19731))
### Documentation
- Replace "associative" with "commutative" in docs for `RUF036` ([#19706](https://github.com/astral-sh/ruff/pull/19706))
- Fix copy and line separator colors in dark mode ([#19630](https://github.com/astral-sh/ruff/pull/19630))
- Fix link to `typing` documentation ([#19648](https://github.com/astral-sh/ruff/pull/19648))
- \[`refurb`\] Make more examples error out-of-the-box ([#19695](https://github.com/astral-sh/ruff/pull/19695),[#19673](https://github.com/astral-sh/ruff/pull/19673),[#19672](https://github.com/astral-sh/ruff/pull/19672))
### Other changes
- Include column numbers in GitLab output format ([#19708](https://github.com/astral-sh/ruff/pull/19708))
- Always expand tabs to four spaces in diagnostics ([#19618](https://github.com/astral-sh/ruff/pull/19618))
- Update pre-commit's `ruff` id ([#19654](https://github.com/astral-sh/ruff/pull/19654))
## 0.12.9
### Preview features
- \[`airflow`\] Add check for `airflow.secrets.cache.SecretCache` (`AIR301`) ([#17707](https://github.com/astral-sh/ruff/pull/17707))
- \[`ruff`\] Offer a safe fix for multi-digit zeros (`RUF064`) ([#19847](https://github.com/astral-sh/ruff/pull/19847))
### Bug fixes
- \[`flake8-blind-except`\] Fix `BLE001` false-positive on `raise ... from None` ([#19755](https://github.com/astral-sh/ruff/pull/19755))
- \[`flake8-comprehensions`\] Fix false positive for `C420` with attribute, subscript, or slice assignment targets ([#19513](https://github.com/astral-sh/ruff/pull/19513))
- \[`flake8-simplify`\] Fix handling of U+001C..U+001F whitespace (`SIM905`) ([#19849](https://github.com/astral-sh/ruff/pull/19849))
### Rule changes
- \[`pylint`\] Use lowercase hex characters to match the formatter (`PLE2513`) ([#19808](https://github.com/astral-sh/ruff/pull/19808))
### Documentation
- Fix `lint.future-annotations` link ([#19876](https://github.com/astral-sh/ruff/pull/19876))
### Other changes
- Build `riscv64` binaries for release ([#19819](https://github.com/astral-sh/ruff/pull/19819))
- Add rule code to error description in GitLab output ([#19896](https://github.com/astral-sh/ruff/pull/19896))
- Improve rendering of the `full` output format ([#19415](https://github.com/astral-sh/ruff/pull/19415))
Below is an example diff for [`F401`](https://docs.astral.sh/ruff/rules/unused-import/):
```diff
-unused.py:8:19: F401 [*] `pathlib` imported but unused
+F401 [*] `pathlib` imported but unused
+ --> unused.py:8:19
|
7 | # Unused, _not_ marked as required (due to the alias).
8 | import pathlib as non_alias
- | ^^^^^^^^^ F401
+ | ^^^^^^^^^
9 |
10 | # Unused, marked as required.
|
- = help: Remove unused import: `pathlib`
+help: Remove unused import: `pathlib`
```
For now, the primary difference is the movement of the filename, line number, and column information to a second line in the header. This new representation will allow us to make further additions to Ruff's diagnostics, such as adding sub-diagnostics and multiple annotations to the same snippet.
## 0.12.10
### Preview features
- \[`flake8-simplify`\] Implement fix for `maxsplit` without separator (`SIM905`) ([#19851](https://github.com/astral-sh/ruff/pull/19851))
- \[`flake8-use-pathlib`\] Add fixes for `PTH102` and `PTH103` ([#19514](https://github.com/astral-sh/ruff/pull/19514))
- \[`pyupgrade`\] Avoid reporting `__future__` features as unnecessary when they are used (`UP010`) ([#19769](https://github.com/astral-sh/ruff/pull/19769))
- \[`pyflakes`\] Fix `allowed-unused-imports` matching for top-level modules (`F401`) ([#20115](https://github.com/astral-sh/ruff/pull/20115))
- \[`ruff`\] Fix false positive for t-strings in `default-factory-kwarg` (`RUF026`) ([#20032](https://github.com/astral-sh/ruff/pull/20032))
- \[`ruff`\] Preserve relative whitespace in multi-line expressions (`RUF033`) ([#19647](https://github.com/astral-sh/ruff/pull/19647))
### Rule changes
- \[`ruff`\] Handle empty t-strings in `unnecessary-empty-iterable-within-deque-call` (`RUF037`) ([#20045](https://github.com/astral-sh/ruff/pull/20045))
### Documentation
- Fix incorrect `D413` links in docstrings convention FAQ ([#20089](https://github.com/astral-sh/ruff/pull/20089))
- \[`flake8-use-pathlib`\] Update links to the table showing the correspondence between `os` and `pathlib` ([#20103](https://github.com/astral-sh/ruff/pull/20103))
## 0.12.12
### Preview features
- Show fixes by default ([#19919](https://github.com/astral-sh/ruff/pull/19919))
- \[`airflow`\] Convert `DatasetOrTimeSchedule(datasets=...)` to `AssetOrTimeSchedule(assets=...)` (`AIR311`) ([#20202](https://github.com/astral-sh/ruff/pull/20202))
- \[`airflow`\] Improve the `AIR002` error message ([#20173](https://github.com/astral-sh/ruff/pull/20173))
- \[`airflow`\] Move `airflow.operators.postgres_operator.Mapping` from `AIR302` to `AIR301` ([#20172](https://github.com/astral-sh/ruff/pull/20172))
- \[`flake8-use-pathlib`\] Make `PTH119` and `PTH120` fixes unsafe because they can change behavior ([#20118](https://github.com/astral-sh/ruff/pull/20118))
- \[`pylint`\] Add U+061C to `PLE2502` ([#20106](https://github.com/astral-sh/ruff/pull/20106))
- \[`ruff`\] Fix false negative for empty f-strings in `deque` calls (`RUF037`) ([#20109](https://github.com/astral-sh/ruff/pull/20109))
### Bug fixes
- Less confidently mark f-strings as empty when inferring truthiness ([#20152](https://github.com/astral-sh/ruff/pull/20152))
- \[`fastapi`\] Fix false positive for paths with spaces around parameters (`FAST003`) ([#20077](https://github.com/astral-sh/ruff/pull/20077))
- \[`flake8-comprehensions`\] Skip `C417` when lambda contains `yield`/`yield from` ([#20201](https://github.com/astral-sh/ruff/pull/20201))
- \[`perflint`\] Handle tuples in dictionary comprehensions (`PERF403`) ([#19934](https://github.com/astral-sh/ruff/pull/19934))
### Rule changes
- \[`pycodestyle`\] Preserve return type annotation for `ParamSpec` (`E731`) ([#20108](https://github.com/astral-sh/ruff/pull/20108))
### Documentation
- Add fix safety sections to docs ([#17490](https://github.com/astral-sh/ruff/pull/17490),[#17499](https://github.com/astral-sh/ruff/pull/17499))
Check out the [blog post](https://astral.sh/blog/ruff-v0.13.0) for a migration
guide and overview of the changes!
### Breaking changes
- **Several rules can now add `from __future__ import annotations` automatically**
`TC001`, `TC002`, `TC003`, `RUF013`, and `UP037` now add `from __future__ import annotations` as part of their fixes when the
`lint.future-annotations` setting is enabled. This allows the rules to move
more imports into `TYPE_CHECKING` blocks (`TC001`, `TC002`, and `TC003`),
use PEP 604 union syntax on Python versions before 3.10 (`RUF013`), and
unquote more annotations (`UP037`).
- **Full module paths are now used to verify first-party modules**
Ruff now checks that the full path to a module exists on disk before
categorizing it as a first-party import. This change makes first-party
import detection more accurate, helping to avoid false positives on local
directories with the same name as a third-party dependency, for example. See
the [FAQ
section](https://docs.astral.sh/ruff/faq/#how-does-ruff-determine-which-of-my-imports-are-first-party-third-party-etc) on import categorization for more details.
- **Deprecated rules must now be selected by exact rule code**
Ruff will no longer activate deprecated rules selected by their group name
or prefix. As noted below, the two remaining deprecated rules were also
removed in this release, so this won't affect any current rules, but it will
still affect any deprecations in the future.
- **The deprecated macOS configuration directory fallback has been removed**
Ruff will no longer look for a user-level configuration file at
`~/Library/Application Support/ruff/ruff.toml` on macOS. This feature was
- \[`flake8-use-pathlib`\] Make `PTH111` fix unsafe because it can change behavior ([#20215](https://github.com/astral-sh/ruff/pull/20215))
- \[`pycodestyle`\] Fix `E301` to only trigger for functions immediately within a class ([#19768](https://github.com/astral-sh/ruff/pull/19768))
- \[`refurb`\] Mark `single-item-membership-test` fix as always unsafe (`FURB171`) ([#20279](https://github.com/astral-sh/ruff/pull/20279))
### Bug fixes
- Handle t-strings for token-based rules and suppression comments ([#20357](https://github.com/astral-sh/ruff/pull/20357))
- \[`flake8-bandit`\] Fix truthiness: dict-only `**` displays not truthy for `shell` (`S602`, `S604`, `S609`) ([#20177](https://github.com/astral-sh/ruff/pull/20177))
- \[`flake8-simplify`\] Fix diagnostic to show correct method name for `str.rsplit` calls (`SIM905`) ([#20459](https://github.com/astral-sh/ruff/pull/20459))
- \[`flynt`\] Use triple quotes for joined raw strings with newlines (`FLY002`) ([#20197](https://github.com/astral-sh/ruff/pull/20197))
- \[`pyupgrade`\] Fix false positive when class name is shadowed by local variable (`UP008`) ([#20427](https://github.com/astral-sh/ruff/pull/20427))
- \[`pyupgrade`\] Prevent infinite loop with `I002` and `UP026` ([#20327](https://github.com/astral-sh/ruff/pull/20327))
- \[`ruff`\] Recognize t-strings, generators, and lambdas in `invalid-index-type` (`RUF016`) ([#20213](https://github.com/astral-sh/ruff/pull/20213))
- \[`flake8-comprehensions`\] Preserve trailing commas for single-element lists (`C409`) ([#19571](https://github.com/astral-sh/ruff/pull/19571))
- \[`flake8-pyi`\] Avoid syntax error from conflict with `PIE790` (`PYI021`) ([#20010](https://github.com/astral-sh/ruff/pull/20010))
- \[`flake8-simplify`\] Correct fix for positive `maxsplit` without separator (`SIM905`) ([#20056](https://github.com/astral-sh/ruff/pull/20056))
- \[`pyupgrade`\] Fix `UP008` not to apply when `__class__` is a local variable ([#20497](https://github.com/astral-sh/ruff/pull/20497))
- \[`ruff`\] Fix `B004` to skip invalid `hasattr`/`getattr` calls ([#20486](https://github.com/astral-sh/ruff/pull/20486))
- \[`ruff`\] Replace `-nan` with `nan` when using the value to construct a `Decimal` (`FURB164` ) ([#20391](https://github.com/astral-sh/ruff/pull/20391))
### Documentation
- Add 'Finding ways to help' to CONTRIBUTING.md ([#20567](https://github.com/astral-sh/ruff/pull/20567))
- Update import path to `ruff-wasm-web` ([#20539](https://github.com/astral-sh/ruff/pull/20539))
- \[`flake8-bandit`\] Clarify the supported hashing functions (`S324`) ([#20534](https://github.com/astral-sh/ruff/pull/20534))
### Other changes
- \[`playground`\] Allow hover quick fixes to appear for overlapping diagnostics ([#20527](https://github.com/astral-sh/ruff/pull/20527))
- \[`playground`\] Fix non‑BMP code point handling in quick fixes and markers ([#20526](https://github.com/astral-sh/ruff/pull/20526))
### Contributors
- [@BurntSushi](https://github.com/BurntSushi)
- [@mtshiba](https://github.com/mtshiba)
- [@second-ed](https://github.com/second-ed)
- [@danparizher](https://github.com/danparizher)
- [@ShikChen](https://github.com/ShikChen)
- [@PieterCK](https://github.com/PieterCK)
- [@GDYendell](https://github.com/GDYendell)
- [@RazerM](https://github.com/RazerM)
- [@TaKO8Ki](https://github.com/TaKO8Ki)
- [@amyreese](https://github.com/amyreese)
- [@ntbre](https://github.com/ntBre)
- [@MichaReiser](https://github.com/MichaReiser)
## 0.13.3
Released on 2025-10-02.
### Preview features
- Display diffs for `ruff format --check` and add support for different output formats ([#20443](https://github.com/astral-sh/ruff/pull/20443))
- \[`pyflakes`\] Handle some common submodule import situations for `unused-import` (`F401`) ([#20200](https://github.com/astral-sh/ruff/pull/20200))
- \[`ruff`\] Do not flag `%r` + `repr()` combinations (`RUF065`) ([#20600](https://github.com/astral-sh/ruff/pull/20600))
### Bug fixes
- \[`cli`\] Add conflict between `--add-noqa` and `--diff` options ([#20642](https://github.com/astral-sh/ruff/pull/20642))
- \[`pylint`\] Exempt required imports from `PLR0402` ([#20381](https://github.com/astral-sh/ruff/pull/20381))
- \[`pylint`\] Fix missing `max-nested-blocks` in settings display ([#20574](https://github.com/astral-sh/ruff/pull/20574))
- \[`pyupgrade`\] Prevent infinite loop with `I002` and `UP026` ([#20634](https://github.com/astral-sh/ruff/pull/20634))
### Rule changes
- \[`flake8-simplify`\] Improve help message clarity (`SIM105`) ([#20548](https://github.com/astral-sh/ruff/pull/20548))
### Documentation
- Add the *The Basics* title back to CONTRIBUTING.md ([#20624](https://github.com/astral-sh/ruff/pull/20624))
- Fixed documentation for try_consider_else ([#20587](https://github.com/astral-sh/ruff/pull/20587))
- \[`isort`\] Clarify dependency between `order-by-type` and `case-sensitive` settings ([#20559](https://github.com/astral-sh/ruff/pull/20559))
- \[`pylint`\] Clarify fix safety to include left-hand hashability (`PLR6201`) ([#20518](https://github.com/astral-sh/ruff/pull/20518))
### Other changes
- \[`playground`\] Fix quick fixes for empty ranges in playground ([#20599](https://github.com/astral-sh/ruff/pull/20599))
- [`module-import-not-at-top-of-file`](https://docs.astral.sh/ruff/rules/module-import-not-at-top-of-file/) (`E402`) allows `sys.path` modifications between imports
- [`reimplemented-container-builtin`](https://docs.astral.sh/ruff/rules/reimplemented-container-builtin/) (`PIE807`) includes lambdas that can be replaced with `dict`
- [`unnecessary-placeholder`](https://docs.astral.sh/ruff/rules/unnecessary-placeholder/) (`PIE790`) applies to unnecessary ellipses (`...`)
- [`if-else-block-instead-of-dict-get`](https://docs.astral.sh/ruff/rules/if-else-block-instead-of-dict-get/) (`SIM401`) applies to `if-else` expressions
- Format module-level docstrings ([#9725](https://github.com/astral-sh/ruff/pull/9725))
### Formatter
- Add `--range` option to `ruff format` ([#9733](https://github.com/astral-sh/ruff/pull/9733))
- Don't trim last empty line in docstrings ([#9813](https://github.com/astral-sh/ruff/pull/9813))
### Bug fixes
- Skip empty lines when determining base indentation ([#9795](https://github.com/astral-sh/ruff/pull/9795))
- Drop `__get__` and `__set__` from `unnecessary-dunder-call` ([#9791](https://github.com/astral-sh/ruff/pull/9791))
- Respect generic `Protocol` in ellipsis removal ([#9841](https://github.com/astral-sh/ruff/pull/9841))
- Revert "Use publicly available Apple Silicon runners (#9726)" ([#9834](https://github.com/astral-sh/ruff/pull/9834))
### Performance
- Skip LibCST parsing for standard dedent adjustments ([#9769](https://github.com/astral-sh/ruff/pull/9769))
- Remove CST-based fixer for `C408` ([#9822](https://github.com/astral-sh/ruff/pull/9822))
- Add our own ignored-names abstractions ([#9802](https://github.com/astral-sh/ruff/pull/9802))
- Remove CST-based fixers for `C400`, `C401`, `C410`, and `C418` ([#9819](https://github.com/astral-sh/ruff/pull/9819))
- Use `AhoCorasick` to speed up quote match ([#9773](https://github.com/astral-sh/ruff/pull/9773))
- Remove CST-based fixers for `C405` and `C409` ([#9821](https://github.com/astral-sh/ruff/pull/9821))
- Add fast-path for comment detection ([#9808](https://github.com/astral-sh/ruff/pull/9808))
- Invert order of checks in `zero-sleep-call` ([#9766](https://github.com/astral-sh/ruff/pull/9766))
- Short-circuit typing matches based on imports ([#9800](https://github.com/astral-sh/ruff/pull/9800))
- Run dunder method rule on methods directly ([#9815](https://github.com/astral-sh/ruff/pull/9815))
- Track top-level module imports in the semantic model ([#9775](https://github.com/astral-sh/ruff/pull/9775))
- Slight speed-up for lowercase and uppercase identifier checks ([#9798](https://github.com/astral-sh/ruff/pull/9798))
- Remove LibCST-based fixer for `C403` ([#9818](https://github.com/astral-sh/ruff/pull/9818))
### Documentation
- Update `max-pos-args` example to `max-positional-args` ([#9797](https://github.com/astral-sh/ruff/pull/9797))
- Fixed example code in `weak_cryptographic_key.rs` ([#9774](https://github.com/astral-sh/ruff/pull/9774))
- Fix references to deprecated `ANN` rules in changelog ([#9771](https://github.com/astral-sh/ruff/pull/9771))
- Fix default for `max-positional-args` ([#9838](https://github.com/astral-sh/ruff/pull/9838))
## 0.2.2
Highlights include:
- Initial support formatting f-strings (in `--preview`).
- Support for overriding arbitrary configuration options via the CLI through an expanded `--config` argument (e.g., `--config "lint.isort.combine-as-imports=false"`).
- Significant performance improvements in Ruff's lexer, parser, and lint rules.
- \[`ruff`\] Ensure closing parentheses for multiline sequences are always on their own line (`RUF022`, `RUF023`) ([#9793](https://github.com/astral-sh/ruff/pull/9793))
- \[`pycodestyle`\] Allow `os.environ` modifications between imports (`E402`) ([#10066](https://github.com/astral-sh/ruff/pull/10066))
- \[`pycodestyle`\] Don't warn about a single whitespace character before a comma in a tuple (`E203`) ([#10094](https://github.com/astral-sh/ruff/pull/10094))
### Rule changes
- \[`eradicate`\] Detect commented out `case` statements (`ERA001`) ([#10055](https://github.com/astral-sh/ruff/pull/10055))
- \[`eradicate`\] Detect single-line code for `try:`, `except:`, etc. (`ERA001`) ([#10057](https://github.com/astral-sh/ruff/pull/10057))
- \[`flake8-boolean-trap`\] Allow boolean positionals in `__post_init__` ([#10027](https://github.com/astral-sh/ruff/pull/10027))
- \[`isort`\]: Use one blank line after imports in typing stub files ([#9971](https://github.com/astral-sh/ruff/pull/9971))
- \[`pylint`\] New Rule `dict-iter-missing-items` (`PLE1141`) ([#9845](https://github.com/astral-sh/ruff/pull/9845))
- \[`pylint`\] Ignore `sys.version` and `sys.platform` (`PLR1714`) ([#10054](https://github.com/astral-sh/ruff/pull/10054))
- \[`pyupgrade`\] Detect literals with unary operators (`UP018`) ([#10060](https://github.com/astral-sh/ruff/pull/10060))
- \[`ruff`\] Expand rule for `list(iterable).pop(0)` idiom (`RUF015`) ([#10148](https://github.com/astral-sh/ruff/pull/10148))
### Formatter
This release introduces the Ruff 2024.2 style, stabilizing the following changes:
- Prefer splitting the assignment's value over the target or type annotation ([#8943](https://github.com/astral-sh/ruff/pull/8943))
- Remove blank lines before class docstrings ([#9154](https://github.com/astral-sh/ruff/pull/9154))
- Wrap multiple context managers in `with` parentheses when targeting Python 3.9 or newer ([#9222](https://github.com/astral-sh/ruff/pull/9222))
- Add a blank line after nested classes with a dummy body (`...`) in typing stub files ([#9155](https://github.com/astral-sh/ruff/pull/9155))
- Reduce vertical spacing for classes and functions with a dummy (`...`) body ([#7440](https://github.com/astral-sh/ruff/issues/7440), [#9240](https://github.com/astral-sh/ruff/pull/9240))
- Add a blank line after the module docstring ([#8283](https://github.com/astral-sh/ruff/pull/8283))
- Parenthesize long type hints in assignments ([#9210](https://github.com/astral-sh/ruff/pull/9210))
- Preserve indent for single multiline-string call-expressions ([#9673](https://github.com/astral-sh/ruff/pull/9637))
- Normalize hex escape and unicode escape sequences ([#9280](https://github.com/astral-sh/ruff/pull/9280))
- Format module docstrings ([#9725](https://github.com/astral-sh/ruff/pull/9725))
### CLI
- Explicitly disallow `extend` as part of a `--config` flag ([#10135](https://github.com/astral-sh/ruff/pull/10135))
- Remove `build` from the default exclusion list ([#10093](https://github.com/astral-sh/ruff/pull/10093))
- Deprecate `ruff <path>`, `ruff --explain`, `ruff --clean`, and `ruff --generate-shell-completion` in favor of `ruff check <path>`, `ruff rule`, `ruff clean`, and `ruff generate-shell-completion` ([#10169](https://github.com/astral-sh/ruff/pull/10169))
- Remove the deprecated CLI option `--format` from `ruff rule` and `ruff linter` ([#10170](https://github.com/astral-sh/ruff/pull/10170))
### Bug fixes
- \[`flake8-bugbear`\] Avoid adding default initializers to stubs (`B006`) ([#10152](https://github.com/astral-sh/ruff/pull/10152))
- \[`flake8-type-checking`\] Respect runtime-required decorators for function signatures ([#10091](https://github.com/astral-sh/ruff/pull/10091))
- \[`pycodestyle`\] Mark fixes overlapping with a multiline string as unsafe (`W293`) ([#10049](https://github.com/astral-sh/ruff/pull/10049))
- \[`pydocstyle`\] Trim whitespace when removing blank lines after section (`D413`) ([#10162](https://github.com/astral-sh/ruff/pull/10162))
- \[`pylint`\] Delete entire statement, including semicolons (`PLR0203`) ([#10074](https://github.com/astral-sh/ruff/pull/10074))
- \[`flake8-debugger`\] Check for use of `debugpy` and `ptvsd` debug modules (#10177) ([#10194](https://github.com/astral-sh/ruff/pull/10194))
- \[`pyupgrade`\] Generate diagnostic for all valid f-string conversions regardless of line length (`UP032`) ([#10238](https://github.com/astral-sh/ruff/pull/10238))
- \[`pep8_naming`\] Add fixes for `N804` and `N805` ([#10215](https://github.com/astral-sh/ruff/pull/10215))
### CLI
- Colorize the output of `ruff format --diff` ([#10110](https://github.com/astral-sh/ruff/pull/10110))
- Make `--config` and `--isolated` global flags ([#10150](https://github.com/astral-sh/ruff/pull/10150))
- Correctly expand tildes and environment variables in paths passed to `--config` ([#10219](https://github.com/astral-sh/ruff/pull/10219))
### Configuration
- Accept a PEP 440 version specifier for `required-version` ([#10216](https://github.com/astral-sh/ruff/pull/10216))
- Remove trailing space from `CapWords` message ([#10220](https://github.com/astral-sh/ruff/pull/10220))
- Respect external codes in file-level exemptions ([#10203](https://github.com/astral-sh/ruff/pull/10203))
- \[`flake8-raise`\] Avoid false-positives for parens-on-raise with `future.exception()` (`RSE102`) ([#10206](https://github.com/astral-sh/ruff/pull/10206))
- \[`pylint`\] Add fix for unary expressions in `PLC2801` ([#9587](https://github.com/astral-sh/ruff/pull/9587))
- \[`ruff`\] Fix RUF028 not allowing `# fmt: skip` on match cases ([#10178](https://github.com/astral-sh/ruff/pull/10178))
## 0.3.2
### Preview features
- Improve single-`with` item formatting for Python 3.8 or older ([#10276](https://github.com/astral-sh/ruff/pull/10276))
### Rule changes
- \[`pyupgrade`\] Allow fixes for f-string rule regardless of line length (`UP032`) ([#10263](https://github.com/astral-sh/ruff/pull/10263))
- \[`pycodestyle`\] Include actual conditions in E712 diagnostics ([#10254](https://github.com/astral-sh/ruff/pull/10254))
### Bug fixes
- Fix trailing kwargs end of line comment after slash ([#10297](https://github.com/astral-sh/ruff/pull/10297))
- \[`flake8_comprehensions`\] Handled special case for `C400` which also matches `C416` ([#10419](https://github.com/astral-sh/ruff/pull/10419))
- \[`flake8-bandit`\] Implement upstream updates for `S311`, `S324` and `S605` ([#10313](https://github.com/astral-sh/ruff/pull/10313))
- \[`pyflakes`\] Remove `F401` fix for `__init__` imports by default and allow opt-in to unsafe fix ([#10365](https://github.com/astral-sh/ruff/pull/10365))
- \[`pylint`\] Include builtin warnings in useless-exception-statement (`PLW0133`) ([#10394](https://github.com/astral-sh/ruff/pull/10394))
### CLI
- Add message on success to `ruff check` ([#8631](https://github.com/astral-sh/ruff/pull/8631))
### Bug fixes
- \[`PIE970`\] Allow trailing ellipsis in `typing.TYPE_CHECKING` ([#10413](https://github.com/astral-sh/ruff/pull/10413))
- Avoid `TRIO115` if the argument is a variable ([#10376](https://github.com/astral-sh/ruff/pull/10376))
- \[`F811`\] Avoid removing shadowed imports that point to different symbols ([#10387](https://github.com/astral-sh/ruff/pull/10387))
- Fix `F821` and `F822` false positives in `.pyi` files ([#10341](https://github.com/astral-sh/ruff/pull/10341))
- Fix `F821` false negatives in `.py` files when `from __future__ import annotations` is active ([#10362](https://github.com/astral-sh/ruff/pull/10362))
- Fix case where `Indexer` fails to identify continuation preceded by newline #10351 ([#10354](https://github.com/astral-sh/ruff/pull/10354))
- Sort hash maps in `Settings` display ([#10370](https://github.com/astral-sh/ruff/pull/10370))
- Track conditional deletions in the semantic model ([#10415](https://github.com/astral-sh/ruff/pull/10415))
- \[`C413`\] Wrap expressions in parentheses when negating ([#10346](https://github.com/astral-sh/ruff/pull/10346))
- \[`pycodestyle`\] Do not ignore lines before the first logical line in blank lines rules. ([#10382](https://github.com/astral-sh/ruff/pull/10382))
- \[`pycodestyle`\] Do not trigger `E225` and `E275` when the next token is a ')' ([#10315](https://github.com/astral-sh/ruff/pull/10315))
- \[`pylint`\] Avoid false-positive slot non-assignment for `__dict__` (`PLE0237`) ([#10348](https://github.com/astral-sh/ruff/pull/10348))
- Gate f-string struct size test for Rustc < 1.76 ([#10371](https://github.com/astral-sh/ruff/pull/10371))
### Documentation
- Use `ruff.toml` format in README ([#10393](https://github.com/astral-sh/ruff/pull/10393))
- \[`RUF008`\] Make it clearer that a mutable default in a dataclass is only valid if it is typed as a ClassVar ([#10395](https://github.com/astral-sh/ruff/pull/10395))
- \[`pylint`\] Extend docs and test in `invalid-str-return-type` (`E307`) ([#10400](https://github.com/astral-sh/ruff/pull/10400))
- Remove `.` from `check` and `format` commands ([#10217](https://github.com/astral-sh/ruff/pull/10217))
## 0.3.4
### Preview features
- \[`flake8-simplify`\] Detect implicit `else` cases in `needless-bool` (`SIM103`) ([#10414](https://github.com/astral-sh/ruff/pull/10414))
- \[`flake8-pytest-style`\] Add automatic fix for `pytest-parametrize-values-wrong-type` (`PT007`) ([#10461](https://github.com/astral-sh/ruff/pull/10461))
- \[`pycodestyle`\] Allow SPDX license headers to exceed the line length (`E501`) ([#10481](https://github.com/astral-sh/ruff/pull/10481))
### Formatter
- Fix unstable formatting for trailing subscript end-of-line comment ([#10492](https://github.com/astral-sh/ruff/pull/10492))
### Bug fixes
- Avoid code comment detection in PEP 723 script tags ([#10464](https://github.com/astral-sh/ruff/pull/10464))
- Avoid incorrect tuple transformation in single-element case (`C409`) ([#10491](https://github.com/astral-sh/ruff/pull/10491))
- Bug fix: Prevent fully defined links [`name`](link) from being reformatted ([#10442](https://github.com/astral-sh/ruff/pull/10442))
- Consider raw source code for `W605` ([#10480](https://github.com/astral-sh/ruff/pull/10480))
- Docs: Link inline settings when not part of options section ([#10499](https://github.com/astral-sh/ruff/pull/10499))
- Don't treat annotations as redefinitions in `.pyi` files ([#10512](https://github.com/astral-sh/ruff/pull/10512))
- Fix `E231` bug: Inconsistent catch compared to pycodestyle, such as when dict nested in list ([#10469](https://github.com/astral-sh/ruff/pull/10469))
- Fix pylint upstream categories not showing in docs ([#10441](https://github.com/astral-sh/ruff/pull/10441))
- Add missing `Options` references to blank line docs ([#10498](https://github.com/astral-sh/ruff/pull/10498))
- 'Revert "F821: Fix false negatives in .py files when `from __future__ import annotations` is active (#10362)"' ([#10513](https://github.com/astral-sh/ruff/pull/10513))
- Apply NFKC normalization to unicode identifiers in the lexer ([#10412](https://github.com/astral-sh/ruff/pull/10412))
- Avoid failures due to non-deterministic binding ordering ([#10478](https://github.com/astral-sh/ruff/pull/10478))
- \[`flake8-bugbear`\] Allow tuples of exceptions (`B030`) ([#10437](https://github.com/astral-sh/ruff/pull/10437))
- \[`flake8-quotes`\] Avoid syntax errors due to invalid quotes (`Q000, Q002`) ([#10199](https://github.com/astral-sh/ruff/pull/10199))
- \[`flake8-comprehensions`\] Handled special case for `C401` which also matches `C416` ([#10596](https://github.com/astral-sh/ruff/pull/10596))
- \[`flake8-pyi`\] Mark `unaliased-collections-abc-set-import` fix as "safe" for more cases in stub files (`PYI025`) ([#10547](https://github.com/astral-sh/ruff/pull/10547))
- \[`numpy`\] Add `row_stack` to NumPy 2.0 migration rule ([#10646](https://github.com/astral-sh/ruff/pull/10646))
- \[`pycodestyle`\] Allow cell magics before an import (`E402`) ([#10545](https://github.com/astral-sh/ruff/pull/10545))
- \[`pycodestyle`\] Avoid blank line rules for the first logical line in cell ([#10291](https://github.com/astral-sh/ruff/pull/10291))
- \[`refurb`\] Support `itemgetter` in `reimplemented-operator` (`FURB118`) ([#10526](https://github.com/astral-sh/ruff/pull/10526))
- \[`flake8_comprehensions`\] Add `sum`/`min`/`max` to unnecessary comprehension check (`C419`) ([#10759](https://github.com/astral-sh/ruff/pull/10759))
### Rule changes
- \[`pydocstyle`\] Require capitalizing docstrings where the first sentence is a single word (`D403`) ([#10776](https://github.com/astral-sh/ruff/pull/10776))
- \[`pycodestyle`\] Ignore annotated lambdas in class scopes (`E731`) ([#10720](https://github.com/astral-sh/ruff/pull/10720))
- \[`flake8-pyi`\] Various improvements to PYI034 ([#10807](https://github.com/astral-sh/ruff/pull/10807))
- \[`flake8-slots`\] Flag subclasses of call-based `typing.NamedTuple`s as well as subclasses of `collections.namedtuple()` (`SLOT002`) ([#10808](https://github.com/astral-sh/ruff/pull/10808))
- \[`pyflakes`\] Allow forward references in class bases in stub files (`F821`) ([#10779](https://github.com/astral-sh/ruff/pull/10779))
- \[`flake8-quotes`\] Add semantic model flag when inside f-string replacement field ([#10766](https://github.com/astral-sh/ruff/pull/10766))
- \[`pep8-naming`\] Recursively resolve `TypeDicts` for N815 violations ([#10719](https://github.com/astral-sh/ruff/pull/10719))
- \[`flake8-quotes`\] Respect `Q00*` ignores in `flake8-quotes` rules ([#10728](https://github.com/astral-sh/ruff/pull/10728))
- \[`flake8-simplify`\] Show negated condition in `needless-bool` diagnostics (`SIM103`) ([#10854](https://github.com/astral-sh/ruff/pull/10854))
- \[`ruff`\] Use within-scope shadowed bindings in `asyncio-dangling-task` (`RUF006`) ([#10793](https://github.com/astral-sh/ruff/pull/10793))
- \[`flake8-pytest-style`\] Fix single-tuple conversion in `pytest-parametrize-values-wrong-type` (`PT007`) ([#10862](https://github.com/astral-sh/ruff/pull/10862))
- \[`flake8-return`\] Ignore assignments to annotated variables in `unnecessary-assign` (`RET504`) ([#10741](https://github.com/astral-sh/ruff/pull/10741))
- \[`refurb`\] Do not allow any keyword arguments for `read-whole-file` in `rb` mode (`FURB101`) ([#10803](https://github.com/astral-sh/ruff/pull/10803))
Ruff's new parser is **>2x faster**, which translates to a **20-40% speedup** for all linting and formatting invocations.
There's a lot to say about this exciting change, so check out the [blog post](https://astral.sh/blog/ruff-v0.4.0) for more details!
See [#10036](https://github.com/astral-sh/ruff/pull/10036) for implementation details.
### A new language server in Rust
With this release, we also want to highlight our new language server. `ruff server` is a Rust-powered language
server that comes built-in with Ruff. It can be used with any editor that supports the [Language Server Protocol](https://microsoft.github.io/language-server-protocol/) (LSP).
It uses a multi-threaded, lock-free architecture inspired by `rust-analyzer` and it will open the door for a lot
of exciting features. It’s also faster than our previous [Python-based language server](https://github.com/astral-sh/ruff-lsp)
-- but you probably guessed that already.
`ruff server` is only in alpha, but it has a lot of features that you can try out today:
- Lints Python files automatically and shows quick-fixes when available
- Formats Python files, with support for range formatting
- Comes with commands for quickly performing actions: `ruff.applyAutofix`, `ruff.applyFormat`, and `ruff.applyOrganizeImports`
- Supports `source.fixAll` and `source.organizeImports` source actions
- Automatically reloads your project configuration when you change it
To setup `ruff server` with your editor, refer to the [README.md](https://github.com/astral-sh/ruff/blob/main/crates/ruff_server/README.md).
### Preview features
- \[`pycodestyle`\] Do not trigger `E3` rules on `def`s following a function/method with a dummy body ([#10704](https://github.com/astral-sh/ruff/pull/10704))
- \[`pylint`\] Omit stubs from `invalid-bool` and `invalid-str-return-type` ([#11008](https://github.com/astral-sh/ruff/pull/11008))
- \[`ruff`\] New rule `unused-async` (`RUF029`) to detect unneeded `async` keywords on functions ([#9966](https://github.com/astral-sh/ruff/pull/9966))
- \[`flake8-bugbear`\] Document explicitly disabling strict zip (`B905`) ([#11040](https://github.com/astral-sh/ruff/pull/11040))
- \[`flake8-type-checking`\] Mention `lint.typing-modules` in `TCH001`, `TCH002`, and `TCH003` ([#11144](https://github.com/astral-sh/ruff/pull/11144))
- \[`isort`\] Improve documentation around custom `isort` sections ([#11050](https://github.com/astral-sh/ruff/pull/11050))
- \[`pylint`\] Fix documentation oversight for `invalid-X-returns` ([#11094](https://github.com/astral-sh/ruff/pull/11094))
### Performance
- Use `matchit` to resolve per-file settings ([#11111](https://github.com/astral-sh/ruff/pull/11111))
## 0.4.3
### Enhancements
- Add support for PEP 696 syntax ([#11120](https://github.com/astral-sh/ruff/pull/11120))
### Preview features
- \[`refurb`\] Use function range for `reimplemented-operator` diagnostics ([#11271](https://github.com/astral-sh/ruff/pull/11271))
- \[`refurb`\] Ignore methods in `reimplemented-operator` (`FURB118`) ([#11270](https://github.com/astral-sh/ruff/pull/11270))
- \[`pyflakes`\] Distinguish between first-party and third-party imports for fix suggestions ([#11168](https://github.com/astral-sh/ruff/pull/11168))
### Rule changes
- \[`flake8-bugbear`\] Ignore non-abstract class attributes when enforcing `B024` ([#11210](https://github.com/astral-sh/ruff/pull/11210))
- \[`flake8-logging`\] Include inline instantiations when detecting loggers ([#11154](https://github.com/astral-sh/ruff/pull/11154))
- \[`pylint`\] Also emit `PLR0206` for properties with variadic parameters ([#11200](https://github.com/astral-sh/ruff/pull/11200))
- \[`ruff`\] Detect duplicate codes as part of `unused-noqa` (`RUF100`) ([#10850](https://github.com/astral-sh/ruff/pull/10850))
### Formatter
- Avoid multiline expression if format specifier is present ([#11123](https://github.com/astral-sh/ruff/pull/11123))
### LSP
- Write `ruff server` setup guide for Helix ([#11183](https://github.com/astral-sh/ruff/pull/11183))
-`ruff server` no longer hangs after shutdown ([#11222](https://github.com/astral-sh/ruff/pull/11222))
-`ruff server` reads from a configuration TOML file in the user configuration directory if no local configuration exists ([#11225](https://github.com/astral-sh/ruff/pull/11225))
-`ruff server`: Support a custom TOML configuration file ([#11140](https://github.com/astral-sh/ruff/pull/11140))
-`ruff server`: Support setting to prioritize project configuration over editor configuration ([#11086](https://github.com/astral-sh/ruff/pull/11086))
### Bug fixes
- Avoid debug assertion around NFKC renames ([#11249](https://github.com/astral-sh/ruff/pull/11249))
- \[`pyflakes`\] Prioritize `redefined-while-unused` over `unused-import` ([#11173](https://github.com/astral-sh/ruff/pull/11173))
- \[`ruff`\] Respect `async` expressions in comprehension bodies ([#11219](https://github.com/astral-sh/ruff/pull/11219))
- \[`pygrep_hooks`\] Fix `blanket-noqa` panic when last line has noqa with no newline (`PGH004`) ([#11108](https://github.com/astral-sh/ruff/pull/11108))
- \[`perflint`\] Ignore list-copy recommendations for async `for` loops ([#11250](https://github.com/astral-sh/ruff/pull/11250))
- \[`flake8-boolean-trap`\] Allow passing booleans as positional-only arguments in code such as `set(True)` ([#11287](https://github.com/astral-sh/ruff/pull/11287))
- \[`flake8-bugbear`\] Ignore enum classes in `cached-instance-method` (`B019`) ([#11312](https://github.com/astral-sh/ruff/pull/11312))
### Server
- Expand tildes when resolving Ruff server configuration file ([#11283](https://github.com/astral-sh/ruff/pull/11283))
- Fix `ruff server` hanging after Neovim closes ([#11291](https://github.com/astral-sh/ruff/pull/11291))
- Editor settings are used by default if no file-based configuration exists ([#11266](https://github.com/astral-sh/ruff/pull/11266))
### Bug fixes
- \[`pylint`\] Consider `with` statements for `too-many-branches` (`PLR0912`) ([#11321](https://github.com/astral-sh/ruff/pull/11321))
- \[`flake8-blind-except`, `tryceratops`\] Respect logged and re-raised expressions in nested statements (`BLE001`, `TRY201`) ([#11301](https://github.com/astral-sh/ruff/pull/11301))
- Recognise assignments such as `__all__ = builtins.list(["foo", "bar"])` as valid `__all__` definitions ([#11335](https://github.com/astral-sh/ruff/pull/11335))
## 0.4.5
### Ruff's language server is now in Beta
`v0.4.5` marks the official Beta release of `ruff server`, an integrated language server built into Ruff.
`ruff server` supports the same feature set as `ruff-lsp`, powering linting, formatting, and
code fixes in Ruff's editor integrations -- but with superior performance and
no installation required. We'd love your feedback!
You can enable `ruff server` in the [VS Code extension](https://github.com/astral-sh/ruff-vscode?tab=readme-ov-file#enabling-the-rust-based-language-server) today.
To read more about this exciting milestone, check out our [blog post](https://astral.sh/blog/ruff-v0.4.5)!
- \[`pyflakes`\] Enable `F822` in `__init__.py` files by default ([#11370](https://github.com/astral-sh/ruff/pull/11370))
### Formatter
- Fix incorrect placement of trailing stub function comments ([#11632](https://github.com/astral-sh/ruff/pull/11632))
### Server
- Respect file exclusions in `ruff server` ([#11590](https://github.com/astral-sh/ruff/pull/11590))
- Add support for documents not exist on disk ([#11588](https://github.com/astral-sh/ruff/pull/11588))
- Add Vim and Kate setup guide for `ruff server` ([#11615](https://github.com/astral-sh/ruff/pull/11615))
### Bug fixes
- Avoid removing newlines between docstring headers and rST blocks ([#11609](https://github.com/astral-sh/ruff/pull/11609))
- Infer indentation with imports when logical indent is absent ([#11608](https://github.com/astral-sh/ruff/pull/11608))
- Use char index rather than position for indent slice ([#11645](https://github.com/astral-sh/ruff/pull/11645))
- \[`flake8-comprehension`\] Strip parentheses around generators in `C400` ([#11607](https://github.com/astral-sh/ruff/pull/11607))
- Mark `repeated-isinstance-calls` as unsafe on Python 3.10 and later ([#11622](https://github.com/astral-sh/ruff/pull/11622))
## 0.4.8
### Performance
- Linter performance has been improved by around 10% on some microbenchmarks by refactoring the lexer and parser to maintain synchronicity between them ([#11457](https://github.com/astral-sh/ruff/pull/11457))
- \[`pygrep_hooks`\] Check blanket ignores via file-level pragmas (`PGH004`) ([#11540](https://github.com/astral-sh/ruff/pull/11540))
### Rule changes
- \[`pyupgrade`\] Update `UP035` for Python 3.13 and the latest version of `typing_extensions` ([#11693](https://github.com/astral-sh/ruff/pull/11693))
- \[`numpy`\] Update `NPY001` rule for NumPy 2.0 ([#11735](https://github.com/astral-sh/ruff/pull/11735))
### Server
- Formatting a document with syntax problems no longer spams a visible error popup ([#11745](https://github.com/astral-sh/ruff/pull/11745))
### CLI
- Add RDJson support for `--output-format` flag ([#11682](https://github.com/astral-sh/ruff/pull/11682))
### Bug fixes
- \[`pyupgrade`\] Write empty string in lieu of panic when fixing `UP032` ([#11696](https://github.com/astral-sh/ruff/pull/11696))
- \[`flake8-simplify`\] Simplify double negatives in `SIM103` ([#11684](https://github.com/astral-sh/ruff/pull/11684))
- Ensure the expression generator adds a newline before `type` statements ([#11720](https://github.com/astral-sh/ruff/pull/11720))
- Respect per-file ignores for blanket and redirected noqa rules ([#11728](https://github.com/astral-sh/ruff/pull/11728))
- \[`pycodestyle`\] Adapt fix for `E203` to work identical to `ruff format` ([#10999](https://github.com/astral-sh/ruff/pull/10999))
### Formatter
- Fix formatter instability for lines only consisting of zero-width characters ([#11748](https://github.com/astral-sh/ruff/pull/11748))
### Server
- Add supported commands in server capabilities ([#11850](https://github.com/astral-sh/ruff/pull/11850))
- Use real file path when available in `ruff server` ([#11800](https://github.com/astral-sh/ruff/pull/11800))
- Improve error message when a command is run on an unavailable document ([#11823](https://github.com/astral-sh/ruff/pull/11823))
- Introduce the `ruff.printDebugInformation` command ([#11831](https://github.com/astral-sh/ruff/pull/11831))
- Tracing system now respects log level and trace level, with options to log to a file ([#11747](https://github.com/astral-sh/ruff/pull/11747))
### CLI
- Handle non-printable characters in diff view ([#11687](https://github.com/astral-sh/ruff/pull/11687))
### Bug fixes
- \[`refurb`\] Avoid suggesting starmap when arguments are used outside call (`FURB140`) ([#11830](https://github.com/astral-sh/ruff/pull/11830))
- \[`flake8-bugbear`\] Avoid panic in `B909` when checking large loop blocks ([#11772](https://github.com/astral-sh/ruff/pull/11772))
- \[`refurb`\] Fix misbehavior of `operator.itemgetter` when getter param is a tuple (`FURB118`) ([#11774](https://github.com/astral-sh/ruff/pull/11774))
## 0.4.10
### Parser
- Implement re-lexing logic for better error recovery ([#11845](https://github.com/astral-sh/ruff/pull/11845))
### Rule changes
- \[`flake8-copyright`\] Update `CPY001` to check the first 4096 bytes instead of 1024 ([#11927](https://github.com/astral-sh/ruff/pull/11927))
- \[`pycodestyle`\] Update `E999` to show all syntax errors instead of just the first one ([#11900](https://github.com/astral-sh/ruff/pull/11900))
### Server
- Add tracing setup guide to Helix documentation ([#11883](https://github.com/astral-sh/ruff/pull/11883))
- Add tracing setup guide to Neovim documentation ([#11884](https://github.com/astral-sh/ruff/pull/11884))
- Defer notebook cell deletion to avoid an error message ([#11864](https://github.com/astral-sh/ruff/pull/11864))
### Security
- Guard against malicious ecosystem comment artifacts ([#11879](https://github.com/astral-sh/ruff/pull/11879))
Check out the [blog post](https://astral.sh/blog/ruff-v0.5.0) for a migration guide and overview of the changes!
### Breaking changes
See also, the "Remapped rules" section which may result in disabled rules.
- Follow the XDG specification to discover user-level configurations on macOS (same as on other Unix platforms)
- Selecting `ALL` now excludes deprecated rules
- The released archives now include an extra level of nesting, which can be removed with `--strip-components=1` when untarring.
- The release artifact's file name no longer includes the version tag. This enables users to install via `/latest` URLs on GitHub.
- The diagnostic ranges for some `flake8-bandit` rules were modified ([#10667](https://github.com/astral-sh/ruff/pull/10667)).
### Deprecations
The following rules are now deprecated:
- [`syntax-error`](https://docs.astral.sh/ruff/rules/syntax-error/) (`E999`): Syntax errors are now always shown
### Remapped rules
The following rules have been remapped to new rule codes:
- [`blocking-http-call-in-async-function`](https://docs.astral.sh/ruff/rules/blocking-http-call-in-async-function/): `ASYNC100` to `ASYNC210`
- [`open-sleep-or-subprocess-in-async-function`](https://docs.astral.sh/ruff/rules/open-sleep-or-subprocess-in-async-function/): `ASYNC101` split into `ASYNC220`, `ASYNC221`, `ASYNC230`, and `ASYNC251`
- [`blocking-os-call-in-async-function`](https://docs.astral.sh/ruff/rules/blocking-os-call-in-async-function/): `ASYNC102` has been merged into `ASYNC220` and `ASYNC221`
- [`trio-timeout-without-await`](https://docs.astral.sh/ruff/rules/trio-timeout-without-await/): `TRIO100` to `ASYNC100`
- [`trio-sync-call`](https://docs.astral.sh/ruff/rules/trio-sync-call/): `TRIO105` to `ASYNC105`
- [`trio-async-function-with-timeout`](https://docs.astral.sh/ruff/rules/trio-async-function-with-timeout/): `TRIO109` to `ASYNC109`
- [`trio-unneeded-sleep`](https://docs.astral.sh/ruff/rules/trio-unneeded-sleep/): `TRIO110` to `ASYNC110`
- [`trio-zero-sleep-call`](https://docs.astral.sh/ruff/rules/trio-zero-sleep-call/): `TRIO115` to `ASYNC115`
- [`repeated-isinstance-calls`](https://docs.astral.sh/ruff/rules/repeated-isinstance-calls/): `PLR1701` to `SIM101`
### Stabilization
The following rules have been stabilized and are no longer in preview:
- [`is-literal`](https://docs.astral.sh/ruff/rules/is-literal/) (`F632`) now warns for identity checks against list, set or dictionary literals
- [`needless-bool`](https://docs.astral.sh/ruff/rules/needless-bool/) (`SIM103`) now detects `if` expressions with implicit `else` branches
- [`module-import-not-at-top-of-file`](https://docs.astral.sh/ruff/rules/module-import-not-at-top-of-file/) (`E402`) now allows `os.environ` modifications between import statements
- [`type-comparison`](https://docs.astral.sh/ruff/rules/type-comparison/) (`E721`) now allows idioms such as `type(x) is int`
- [`yoda-condition`](https://docs.astral.sh/ruff/rules/yoda-conditions/) (`SIM300`) now flags a wider range of expressions
### Removals
The following deprecated settings have been removed:
-`output-format=text`; use `output-format=concise` or `output-format=full`
-`tab-size`; use `indent-width`
The following deprecated CLI options have been removed:
-`--show-source`; use `--output-format=full`
-`--no-show-source`; use `--output-format=concise`
The following deprecated CLI commands have been removed:
-`ruff <path>`; use `ruff check <path>`
-`ruff --clean`; use `ruff clean`
-`ruff --generate-shell-completion`; use `ruff generate-shell-completion`
- \[`pycodestyle`\] Whitespace after decorator (`E204`) ([#12140](https://github.com/astral-sh/ruff/pull/12140))
- \[`pytest`\] Reverse `PT001` and `PT0023` defaults ([#12106](https://github.com/astral-sh/ruff/pull/12106))
### Rule changes
- Enable token-based rules on source with syntax errors ([#11950](https://github.com/astral-sh/ruff/pull/11950))
- \[`flake8-bandit`\] Detect `httpx` for `S113` ([#12174](https://github.com/astral-sh/ruff/pull/12174))
- \[`numpy`\] Update `NPY201` to include exception deprecations ([#12065](https://github.com/astral-sh/ruff/pull/12065))
- \[`pylint`\] Generate autofix for `duplicate-bases` (`PLE0241`) ([#12105](https://github.com/astral-sh/ruff/pull/12105))
### Server
- Avoid syntax error notification for source code actions ([#12148](https://github.com/astral-sh/ruff/pull/12148))
- Consider the content of the new cells during notebook sync ([#12203](https://github.com/astral-sh/ruff/pull/12203))
- Fix replacement edit range computation ([#12171](https://github.com/astral-sh/ruff/pull/12171))
### Bug fixes
- Disable auto-fix when source has syntax errors ([#12134](https://github.com/astral-sh/ruff/pull/12134))
- Fix cache key collisions for paths with separators ([#12159](https://github.com/astral-sh/ruff/pull/12159))
- Make `requires-python` inference robust to `==` ([#12091](https://github.com/astral-sh/ruff/pull/12091))
- Use char-wise width instead of `str`-width ([#12135](https://github.com/astral-sh/ruff/pull/12135))
- \[`pycodestyle`\] Avoid `E275` if keyword followed by comma ([#12136](https://github.com/astral-sh/ruff/pull/12136))
- \[`pycodestyle`\] Avoid `E275` if keyword is followed by a semicolon ([#12095](https://github.com/astral-sh/ruff/pull/12095))
- \[`pylint`\] Skip [dummy variables](https://docs.astral.sh/ruff/settings/#lint_dummy-variable-rgx) for `PLR1704` ([#12190](https://github.com/astral-sh/ruff/pull/12190))
### Performance
- Remove allocation in `parse_identifier` ([#12103](https://github.com/astral-sh/ruff/pull/12103))
- Use `CompactString` for `Identifier` AST node ([#12101](https://github.com/astral-sh/ruff/pull/12101))
## 0.5.2
### Preview features
- Use `space` separator before parenthesized expressions in comprehensions with leading comments ([#12282](https://github.com/astral-sh/ruff/pull/12282))
- \[`flake8-async`\] Update `ASYNC100` to include `anyio` and `asyncio` ([#12221](https://github.com/astral-sh/ruff/pull/12221))
- \[`flake8-async`\] Update `ASYNC109` to include `anyio` and `asyncio` ([#12236](https://github.com/astral-sh/ruff/pull/12236))
- \[`flake8-async`\] Update `ASYNC110` to include `anyio` and `asyncio` ([#12261](https://github.com/astral-sh/ruff/pull/12261))
- \[`flake8-async`\] Update `ASYNC115` to include `anyio` and `asyncio` ([#12262](https://github.com/astral-sh/ruff/pull/12262))
- \[`flake8-async`\] Update `ASYNC116` to include `anyio` and `asyncio` ([#12266](https://github.com/astral-sh/ruff/pull/12266))
### Rule changes
- \[`flake8-return`\] Exempt properties from explicit return rule (`RET501`) ([#12243](https://github.com/astral-sh/ruff/pull/12243))
- Formatter: Insert empty line between suite and alternative branch after function/class definition ([#12294](https://github.com/astral-sh/ruff/pull/12294))
- \[`flake8-bugbear`\] Detect enumerate iterations in `loop-iterator-mutation` (`B909`) ([#12366](https://github.com/astral-sh/ruff/pull/12366))
- \[`flake8-bugbear`\] Remove `discard`, `remove`, and `pop` allowance for `loop-iterator-mutation` (`B909`) ([#12365](https://github.com/astral-sh/ruff/pull/12365))
- \[`pylint`\] Allow `repeated-equality-comparison` for mixed operations (`PLR1714`) ([#12369](https://github.com/astral-sh/ruff/pull/12369))
- \[`pylint`\] Ignore `self` and `cls` when counting arguments (`PLR0913`) ([#12367](https://github.com/astral-sh/ruff/pull/12367))
- \[`pylint`\] Use UTF-8 as default encoding in `unspecified-encoding` fix (`PLW1514`) ([#12370](https://github.com/astral-sh/ruff/pull/12370))
### Server
- Build settings index in parallel for the native server ([#12299](https://github.com/astral-sh/ruff/pull/12299))
- Use fallback settings when indexing the project ([#12362](https://github.com/astral-sh/ruff/pull/12362))
- Consider `--preview` flag for `server` subcommand for the linter and formatter ([#12208](https://github.com/astral-sh/ruff/pull/12208))
### Bug fixes
- \[`flake8-comprehensions`\] Allow additional arguments for `sum` and `max` comprehensions (`C419`) ([#12364](https://github.com/astral-sh/ruff/pull/12364))
- \[`pylint`\] Avoid dropping extra boolean operations in `repeated-equality-comparison` (`PLR1714`) ([#12368](https://github.com/astral-sh/ruff/pull/12368))
- \[`pylint`\] Consider expression before statement when determining binding kind (`PLR1704`) ([#12346](https://github.com/astral-sh/ruff/pull/12346))
### Documentation
- Add docs for Ruff language server ([#12344](https://github.com/astral-sh/ruff/pull/12344))
- Migrate to standalone docs repo ([#12341](https://github.com/astral-sh/ruff/pull/12341))
- Update versioning policy for editor integration ([#12375](https://github.com/astral-sh/ruff/pull/12375))
### Other changes
- Publish Wasm API to npm ([#12317](https://github.com/astral-sh/ruff/pull/12317))
## 0.5.4
### Rule changes
- \[`ruff`\] Rename `RUF007` to `zip-instead-of-pairwise` ([#12399](https://github.com/astral-sh/ruff/pull/12399))
### Bug fixes
- \[`flake8-builtins`\] Avoid shadowing diagnostics for `@override` methods ([#12415](https://github.com/astral-sh/ruff/pull/12415))
- \[`flake8-comprehensions`\] Insert parentheses for multi-argument generators ([#12422](https://github.com/astral-sh/ruff/pull/12422))
- \[`pydocstyle`\] Handle escaped docstrings within docstring (`D301`) ([#12192](https://github.com/astral-sh/ruff/pull/12192))
### Documentation
- Fix GitHub link to Neovim setup ([#12410](https://github.com/astral-sh/ruff/pull/12410))
- Fix `output-format` default in settings reference ([#12409](https://github.com/astral-sh/ruff/pull/12409))
## 0.5.5
### Preview features
- \[`fastapi`\] Implement `fastapi-redundant-response-model` (`FAST001`) and `fastapi-non-annotated-dependency`(`FAST002`) ([#11579](https://github.com/astral-sh/ruff/pull/11579))
- \[`pydoclint`\] Implement `docstring-missing-exception` (`DOC501`) and `docstring-extraneous-exception` (`DOC502`) ([#11471](https://github.com/astral-sh/ruff/pull/11471))
### Rule changes
- \[`numpy`\] Fix NumPy 2.0 rule for `np.alltrue` and `np.sometrue` ([#12473](https://github.com/astral-sh/ruff/pull/12473))
- \[`numpy`\] Ignore `NPY201` inside `except` blocks for compatibility with older numpy versions ([#12490](https://github.com/astral-sh/ruff/pull/12490))
- \[`pep8-naming`\] Avoid applying `ignore-names` to `self` and `cls` function names (`N804`, `N805`) ([#12497](https://github.com/astral-sh/ruff/pull/12497))
### Formatter
- Fix incorrect placement of leading function comment with type params ([#12447](https://github.com/astral-sh/ruff/pull/12447))
### Server
- Do not bail code action resolution when a quick fix is requested ([#12462](https://github.com/astral-sh/ruff/pull/12462))
### Bug fixes
- Fix `Ord` implementation of `cmp_fix` ([#12471](https://github.com/astral-sh/ruff/pull/12471))
- Raise syntax error for unparenthesized generator expression in multi-argument call ([#12445](https://github.com/astral-sh/ruff/pull/12445))
- \[`pydoclint`\] Fix panic in `DOC501` reported in [#12428](https://github.com/astral-sh/ruff/pull/12428) ([#12435](https://github.com/astral-sh/ruff/pull/12435))
- \[`flake8-bugbear`\] Allow singleton tuples with starred expressions in `B013` ([#12484](https://github.com/astral-sh/ruff/pull/12484))
### Documentation
- Add Eglot setup guide for Emacs editor ([#12426](https://github.com/astral-sh/ruff/pull/12426))
- Add note about the breaking change in `nvim-lspconfig` ([#12507](https://github.com/astral-sh/ruff/pull/12507))
- Add note to include notebook files for native server ([#12449](https://github.com/astral-sh/ruff/pull/12449))
- Add setup docs for Zed editor ([#12501](https://github.com/astral-sh/ruff/pull/12501))
## 0.5.6
Ruff 0.5.6 automatically enables linting and formatting of notebooks in _preview mode_.
You can opt-out of this behavior by adding `*.ipynb` to the `extend-exclude` setting.
```toml
[tool.ruff]
extend-exclude=["*.ipynb"]
```
### Preview features
- Enable notebooks by default in preview mode ([#12621](https://github.com/astral-sh/ruff/pull/12621))
- \[`flake8-builtins`\] Implement import, lambda, and module shadowing ([#12546](https://github.com/astral-sh/ruff/pull/12546))
- \[`pydoclint`\] Add `docstring-missing-returns` (`DOC201`) and `docstring-extraneous-returns` (`DOC202`) ([#12485](https://github.com/astral-sh/ruff/pull/12485))
### Rule changes
- \[`flake8-return`\] Exempt cached properties and other property-like decorators from explicit return rule (`RET501`) ([#12563](https://github.com/astral-sh/ruff/pull/12563))
### Server
- Make server panic hook more error resilient ([#12610](https://github.com/astral-sh/ruff/pull/12610))
- Use `$/logTrace` for server trace logs in Zed and VS Code ([#12564](https://github.com/astral-sh/ruff/pull/12564))
- Keep track of deleted cells for reorder change request ([#12575](https://github.com/astral-sh/ruff/pull/12575))
### Configuration
- \[`flake8-implicit-str-concat`\] Always allow explicit multi-line concatenations when implicit concatenations are banned ([#12532](https://github.com/astral-sh/ruff/pull/12532))
### Bug fixes
- \[`flake8-async`\] Avoid flagging `asyncio.timeout`s as unused when the context manager includes `asyncio.TaskGroup` ([#12605](https://github.com/astral-sh/ruff/pull/12605))
- \[`flake8-slots`\] Avoid recommending `__slots__` for classes that inherit from more than `namedtuple` ([#12531](https://github.com/astral-sh/ruff/pull/12531))
- \[`isort`\] Avoid marking required imports as unused ([#12537](https://github.com/astral-sh/ruff/pull/12537))
- \[`isort`\] Preserve trailing inline comments on import-from statements ([#12498](https://github.com/astral-sh/ruff/pull/12498))
- \[`pycodestyle`\] Add newlines before comments (`E305`) ([#12606](https://github.com/astral-sh/ruff/pull/12606))
- \[`pycodestyle`\] Don't attach comments with mismatched indents ([#12604](https://github.com/astral-sh/ruff/pull/12604))
- \[`pyflakes`\] Fix preview-mode bugs in `F401` when attempting to autofix unused first-party submodule imports in an `__init__.py` file ([#12569](https://github.com/astral-sh/ruff/pull/12569))
- \[`pylint`\] Respect start index in `unnecessary-list-index-lookup` ([#12603](https://github.com/astral-sh/ruff/pull/12603))
- \[`pyupgrade`\] Avoid recommending no-argument super in `slots=True` dataclasses ([#12530](https://github.com/astral-sh/ruff/pull/12530))
- \[`pyupgrade`\] Use colon rather than dot formatting for integer-only types ([#12534](https://github.com/astral-sh/ruff/pull/12534))
- Fix NFKC normalization bug when removing unused imports ([#12571](https://github.com/astral-sh/ruff/pull/12571))
### Other changes
- Consider more stdlib decorators to be property-like ([#12583](https://github.com/astral-sh/ruff/pull/12583))
- Improve handling of metaclasses in various linter rules ([#12579](https://github.com/astral-sh/ruff/pull/12579))
- Improve consistency between linter rules in determining whether a function is property ([#12581](https://github.com/astral-sh/ruff/pull/12581))
## 0.5.7
### Preview features
- \[`flake8-comprehensions`\] Account for list and set comprehensions in `unnecessary-literal-within-tuple-call` (`C409`) ([#12657](https://github.com/astral-sh/ruff/pull/12657))
- \[`flake8-pyi`\] Add autofix for `future-annotations-in-stub` (`PYI044`) ([#12676](https://github.com/astral-sh/ruff/pull/12676))
- \[`flake8-return`\] Avoid syntax error when auto-fixing `RET505` with mixed indentation (space and tabs) ([#12740](https://github.com/astral-sh/ruff/pull/12740))
- \[`pydoclint`\] Add `docstring-missing-yields` (`DOC402`) and `docstring-extraneous-yields` (`DOC403`) ([#12538](https://github.com/astral-sh/ruff/pull/12538))
- \[`pydoclint`\] Avoid `DOC201` if docstring begins with "Return", "Returns", "Yield", or "Yields" ([#12675](https://github.com/astral-sh/ruff/pull/12675))
- \[`pydoclint`\] Deduplicate collected exceptions after traversing function bodies (`DOC501`) ([#12642](https://github.com/astral-sh/ruff/pull/12642))
- \[`pydoclint`\] Ignore `DOC` errors for stub functions ([#12651](https://github.com/astral-sh/ruff/pull/12651))
- \[`pydoclint`\] Teach rules to understand reraised exceptions as being explicitly raised (`DOC501`, `DOC502`) ([#12639](https://github.com/astral-sh/ruff/pull/12639))
- \[`ruff`\] Mark `RUF023` fix as unsafe if `__slots__` is not a set and the binding is used elsewhere ([#12692](https://github.com/astral-sh/ruff/pull/12692))
### Rule changes
- \[`refurb`\] Add autofix for `implicit-cwd` (`FURB177`) ([#12708](https://github.com/astral-sh/ruff/pull/12708))
- \[`ruff`\] Add autofix for `zip-instead-of-pairwise` (`RUF007`) ([#12663](https://github.com/astral-sh/ruff/pull/12663))
- \[`tryceratops`\] Add `BaseException` to `raise-vanilla-class` rule (`TRY002`) ([#12620](https://github.com/astral-sh/ruff/pull/12620))
### Server
- Ignore non-file workspace URL; Ruff will display a warning notification in this case ([#12725](https://github.com/astral-sh/ruff/pull/12725))
### CLI
- Fix cache invalidation for nested `pyproject.toml` files ([#12727](https://github.com/astral-sh/ruff/pull/12727))
- \[`flake8-bandit`\] Avoid false-positives for list concatenations in SQL construction (`S608`) ([#12720](https://github.com/astral-sh/ruff/pull/12720))
- \[`flake8-bugbear`\] Treat `return` as equivalent to `break` (`B909`) ([#12646](https://github.com/astral-sh/ruff/pull/12646))
- \[`flake8-comprehensions`\] Set comprehensions not a violation for `sum` in `unnecessary-comprehension-in-call` (`C419`) ([#12691](https://github.com/astral-sh/ruff/pull/12691))
- \[`flake8-simplify`\] Parenthesize conditions based on precedence when merging if arms (`SIM114`) ([#12737](https://github.com/astral-sh/ruff/pull/12737))
- \[`pydoclint`\] Try both 'Raises' section styles when convention is unspecified (`DOC501`) ([#12649](https://github.com/astral-sh/ruff/pull/12649))
Check out the [blog post](https://astral.sh/blog/ruff-v0.6.0) for a migration guide and overview of the changes!
### Breaking changes
See also, the "Remapped rules" section which may result in disabled rules.
- Lint and format Jupyter Notebook by default ([#12878](https://github.com/astral-sh/ruff/pull/12878)).
- Detect imports in `src` layouts by default for `isort` rules ([#12848](https://github.com/astral-sh/ruff/pull/12848))
- The pytest rules `PT001` and `PT023` now default to omitting the decorator parentheses when there are no arguments ([#12838](https://github.com/astral-sh/ruff/pull/12838)).
- [`cancel-scope-no-checkpoint`](https://docs.astral.sh/ruff/rules/cancel-scope-no-checkpoint/) (`ASYNC100`): Support `asyncio` and `anyio` context managers.
- [`async-function-with-timeout`](https://docs.astral.sh/ruff/rules/async-function-with-timeout/) (`ASYNC109`): Support `asyncio` and `anyio` context managers.
- [`async-busy-wait`](https://docs.astral.sh/ruff/rules/async-busy-wait/) (`ASYNC110`): Support `asyncio` and `anyio` context managers.
- [`async-zero-sleep`](https://docs.astral.sh/ruff/rules/async-zero-sleep/) (`ASYNC115`): Support `anyio` context managers.
- [`long-sleep-not-forever`](https://docs.astral.sh/ruff/rules/long-sleep-not-forever/) (`ASYNC116`): Support `anyio` context managers.
- \[`flake8-simplify`\] Further simplify to binary in preview for (`SIM108`) ([#12796](https://github.com/astral-sh/ruff/pull/12796))
- \[`pyupgrade`\] Show violations without auto-fix (`UP031`) ([#11229](https://github.com/astral-sh/ruff/pull/11229))
### Rule changes
- \[`flake8-import-conventions`\] Add `xml.etree.ElementTree` to default conventions ([#12455](https://github.com/astral-sh/ruff/pull/12455))
- \[`flake8-pytest-style`\] Add a space after comma in CSV output (`PT006`) ([#12853](https://github.com/astral-sh/ruff/pull/12853))
### Server
- Show a message for incorrect settings ([#12781](https://github.com/astral-sh/ruff/pull/12781))
### Bug fixes
- \[`flake8-async`\] Do not lint yield in context manager (`ASYNC100`) ([#12896](https://github.com/astral-sh/ruff/pull/12896))
- \[`flake8-comprehensions`\] Do not lint `async for` comprehensions (`C419`) ([#12895](https://github.com/astral-sh/ruff/pull/12895))
- \[`flake8-return`\] Only add return `None` at end of a function (`RET503`) ([#11074](https://github.com/astral-sh/ruff/pull/11074))
- \[`flake8-type-checking`\] Avoid treating `dataclasses.KW_ONLY` as typing-only (`TCH003`) ([#12863](https://github.com/astral-sh/ruff/pull/12863))
- \[`pep8-naming`\] Treat `type(Protocol)` et al as metaclass base (`N805`) ([#12770](https://github.com/astral-sh/ruff/pull/12770))
- \[`pydoclint`\] Don't enforce returns and yields in abstract methods (`DOC201`, `DOC202`) ([#12771](https://github.com/astral-sh/ruff/pull/12771))
- \[`ruff`\] Skip tuples with slice expressions in (`RUF031`) ([#12768](https://github.com/astral-sh/ruff/pull/12768))
- \[`ruff`\] Ignore unparenthesized tuples in subscripts when the subscript is a type annotation or type alias (`RUF031`) ([#12762](https://github.com/astral-sh/ruff/pull/12762))
- \[`ruff`\] Ignore template strings passed to logging and `builtins._()` calls (`RUF027`) ([#12889](https://github.com/astral-sh/ruff/pull/12889))
- \[`ruff`\] Do not remove parens for tuples with starred expressions in Python \<=3.10 (`RUF031`) ([#12784](https://github.com/astral-sh/ruff/pull/12784))
- Evaluate default parameter values for a function in that function's enclosing scope ([#12852](https://github.com/astral-sh/ruff/pull/12852))
### Other changes
- Respect VS Code cell metadata when detecting the language of Jupyter Notebook cells ([#12864](https://github.com/astral-sh/ruff/pull/12864))
- Respect `kernelspec` notebook metadata when detecting the preferred language for a Jupyter Notebook ([#12875](https://github.com/astral-sh/ruff/pull/12875))
## 0.6.1
This is a hotfix release to address an issue with `ruff-pre-commit`. In v0.6,
Ruff changed its behavior to lint and format Jupyter notebooks by default;
however, due to an oversight, these files were still excluded by default if
Ruff was run via pre-commit, leading to inconsistent behavior.
This has [now been fixed](https://github.com/astral-sh/ruff-pre-commit/pull/96).
- \[`flake8-simplify`\] Extend `open-file-with-context-handler` to work with other standard-library IO modules (`SIM115`) ([#12959](https://github.com/astral-sh/ruff/pull/12959))
- \[`ruff`\] Avoid `unused-async` for functions with FastAPI route decorator (`RUF029`) ([#12938](https://github.com/astral-sh/ruff/pull/12938))
- \[`ruff`\] Ignore `fstring-missing-syntax` (`RUF027`) for `fastAPI` paths ([#12939](https://github.com/astral-sh/ruff/pull/12939))
- \[`ruff`\] Implement check for Decimal called with a float literal (RUF032) ([#12909](https://github.com/astral-sh/ruff/pull/12909))
### Rule changes
- \[`flake8-bugbear`\] Update diagnostic message when expression is at the end of function (`B015`) ([#12944](https://github.com/astral-sh/ruff/pull/12944))
- \[`flake8-pyi`\] Skip type annotations in `string-or-bytes-too-long` (`PYI053`) ([#13002](https://github.com/astral-sh/ruff/pull/13002))
- \[`flake8-type-checking`\] Always recognise relative imports as first-party ([#12994](https://github.com/astral-sh/ruff/pull/12994))
- \[`flake8-unused-arguments`\] Ignore unused arguments on stub functions (`ARG001`) ([#12966](https://github.com/astral-sh/ruff/pull/12966))
- \[`pylint`\] Ignore augmented assignment for `self-cls-assignment` (`PLW0642`) ([#12957](https://github.com/astral-sh/ruff/pull/12957))
### Server
- Show full context in error log messages ([#13029](https://github.com/astral-sh/ruff/pull/13029))
### Bug fixes
- \[`pep8-naming`\] Don't flag `from` imports following conventional import names (`N817`) ([#12946](https://github.com/astral-sh/ruff/pull/12946))
- \[`pylint`\] - Allow `__new__` methods to have `cls` as their first argument even if decorated with `@staticmethod` for `bad-staticmethod-argument` (`PLW0211`) ([#12958](https://github.com/astral-sh/ruff/pull/12958))
- Expand note to use Ruff with other language server in Kate ([#12806](https://github.com/astral-sh/ruff/pull/12806))
- Update example for `PT001` as per the new default behavior ([#13019](https://github.com/astral-sh/ruff/pull/13019))
- \[`perflint`\] Improve docs for `try-except-in-loop` (`PERF203`) ([#12947](https://github.com/astral-sh/ruff/pull/12947))
- \[`pydocstyle`\] Add reference to `lint.pydocstyle.ignore-decorators` setting to rule docs ([#12996](https://github.com/astral-sh/ruff/pull/12996))
## 0.6.3
### Preview features
- \[`flake8-simplify`\] Extend `open-file-with-context-handler` to work with `dbm.sqlite3` (`SIM115`) ([#13104](https://github.com/astral-sh/ruff/pull/13104))
- \[`pycodestyle`\] Disable `E741` in stub files (`.pyi`) ([#13119](https://github.com/astral-sh/ruff/pull/13119))
- \[`pydoclint`\] Avoid `DOC201` on explicit returns in functions that only return `None` ([#13064](https://github.com/astral-sh/ruff/pull/13064))
### Rule changes
- \[`flake8-async`\] Disable check for `asyncio` before Python 3.11 (`ASYNC109`) ([#13023](https://github.com/astral-sh/ruff/pull/13023))
### Bug fixes
- \[`FastAPI`\] Avoid introducing invalid syntax in fix for `fast-api-non-annotated-dependency` (`FAST002`) ([#13133](https://github.com/astral-sh/ruff/pull/13133))
- \[`flake8-implicit-str-concat`\] Normalize octals before merging concatenated strings in `single-line-implicit-string-concatenation` (`ISC001`) ([#13118](https://github.com/astral-sh/ruff/pull/13118))
- \[`flake8-pytest-style`\] Improve help message for `pytest-incorrect-mark-parentheses-style` (`PT023`) ([#13092](https://github.com/astral-sh/ruff/pull/13092))
- \[`pylint`\] Avoid autofix for calls that aren't `min` or `max` as starred expression (`PLW3301`) ([#13089](https://github.com/astral-sh/ruff/pull/13089))
- \[`ruff`\] Add `datetime.time`, `datetime.tzinfo`, and `datetime.timezone` as immutable function calls (`RUF009`) ([#13109](https://github.com/astral-sh/ruff/pull/13109))
- \[`ruff`\] Extend comment deletion for `RUF100` to include trailing text from `noqa` directives while preserving any following comments on the same line, if any ([#13105](https://github.com/astral-sh/ruff/pull/13105))
- Fix dark theme on initial page load for the Ruff playground ([#13077](https://github.com/astral-sh/ruff/pull/13077))
## 0.6.4
### Preview features
- \[`flake8-builtins`\] Use dynamic builtins list based on Python version ([#13172](https://github.com/astral-sh/ruff/pull/13172))
- \[`pydoclint`\] Permit yielding `None` in `DOC402` and `DOC403` ([#13148](https://github.com/astral-sh/ruff/pull/13148))
- \[`pylint`\] Update diagnostic message for `PLW3201` ([#13194](https://github.com/astral-sh/ruff/pull/13194))
- \[`flake8-pyi`\] Respect `pep8_naming.classmethod-decorators` settings when determining if a method is a classmethod in `custom-type-var-return-type` (`PYI019`) ([#13162](https://github.com/astral-sh/ruff/pull/13162))
- \[`flake8-pyi`\] Teach various rules that annotations might be stringized ([#12951](https://github.com/astral-sh/ruff/pull/12951))
- \[`pylint`\] Avoid `no-self-use` for `attrs`-style validators ([#13166](https://github.com/astral-sh/ruff/pull/13166))
- \[`pylint`\] Recurse into subscript subexpressions when searching for list/dict lookups (`PLR1733`, `PLR1736`) ([#13186](https://github.com/astral-sh/ruff/pull/13186))
- \[`pyupgrade`\] Detect `aiofiles.open` calls in `UP015` ([#13173](https://github.com/astral-sh/ruff/pull/13173))
- \[`pyupgrade`\] Mark `sys.version_info[0] < 3` and similar comparisons as outdated (`UP036`) ([#13175](https://github.com/astral-sh/ruff/pull/13175))
### CLI
- Enrich messages of SARIF results ([#13180](https://github.com/astral-sh/ruff/pull/13180))
- Handle singular case for incompatible rules warning in `ruff format` output ([#13212](https://github.com/astral-sh/ruff/pull/13212))
### Bug fixes
- \[`pydocstyle`\] Improve heuristics for detecting Google-style docstrings ([#13142](https://github.com/astral-sh/ruff/pull/13142))
- \[`refurb`\] Treat `sep` arguments with effects as unsafe removals (`FURB105`) ([#13165](https://github.com/astral-sh/ruff/pull/13165))
## 0.6.5
### Preview features
- \[`pydoclint`\] Ignore `DOC201` when function name is "**new**" ([#13300](https://github.com/astral-sh/ruff/pull/13300))
- \[`eradicate`\] Ignore script-comments with multiple end-tags (`ERA001`) ([#13283](https://github.com/astral-sh/ruff/pull/13283))
- \[`pyflakes`\] Improve error message for `UndefinedName` when a builtin was added in a newer version than specified in Ruff config (`F821`) ([#13293](https://github.com/astral-sh/ruff/pull/13293))
### Server
- Add support for extensionless Python files for server ([#13326](https://github.com/astral-sh/ruff/pull/13326))
- Fix configuration inheritance for configurations specified in the LSP settings ([#13285](https://github.com/astral-sh/ruff/pull/13285))
### Bug fixes
- \[`ruff`\] Handle unary operators in `decimal-from-float-literal` (`RUF032`) ([#13275](https://github.com/astral-sh/ruff/pull/13275))
### CLI
- Only include rules with diagnostics in SARIF metadata ([#13268](https://github.com/astral-sh/ruff/pull/13268))
### Playground
- Add "Copy as pyproject.toml/ruff.toml" and "Paste from TOML" ([#13328](https://github.com/astral-sh/ruff/pull/13328))
- Fix errors not shown for restored snippet on page load ([#13262](https://github.com/astral-sh/ruff/pull/13262))
## 0.6.6
### Preview features
- \[`refurb`\] Skip `slice-to-remove-prefix-or-suffix` (`FURB188`) when non-trivial slice steps are present ([#13405](https://github.com/astral-sh/ruff/pull/13405))
- Add a subcommand to generate dependency graphs ([#13402](https://github.com/astral-sh/ruff/pull/13402))
### Formatter
- Fix placement of inline parameter comments ([#13379](https://github.com/astral-sh/ruff/pull/13379))
### Server
- Fix off-by one error in the `LineIndex::offset` calculation ([#13407](https://github.com/astral-sh/ruff/pull/13407))
### Bug fixes
- \[`fastapi`\] Respect FastAPI aliases in route definitions ([#13394](https://github.com/astral-sh/ruff/pull/13394))
- \[`pydocstyle`\] Respect word boundaries when detecting function signature in docs ([#13388](https://github.com/astral-sh/ruff/pull/13388))
### Documentation
- Add backlinks to rule overview linter ([#13368](https://github.com/astral-sh/ruff/pull/13368))
- Fix documentation for editor vim plugin ALE ([#13348](https://github.com/astral-sh/ruff/pull/13348))
- Fix rendering of `FURB188` docs ([#13406](https://github.com/astral-sh/ruff/pull/13406))
## 0.6.7
### Preview features
- Add Python version support to ruff analyze CLI ([#13426](https://github.com/astral-sh/ruff/pull/13426))
- Add `exclude` support to `ruff analyze` ([#13425](https://github.com/astral-sh/ruff/pull/13425))
- Fix parentheses around return type annotations ([#13381](https://github.com/astral-sh/ruff/pull/13381))
### Rule changes
- \[`pycodestyle`\] Fix: Don't autofix if the first line ends in a question mark? (D400) ([#13399](https://github.com/astral-sh/ruff/pull/13399))
### Bug fixes
- Respect `lint.exclude` in ruff check `--add-noqa` ([#13427](https://github.com/astral-sh/ruff/pull/13427))
### Performance
- Avoid tracking module resolver files in Salsa ([#13437](https://github.com/astral-sh/ruff/pull/13437))
- Use `forget` for module resolver database ([#13438](https://github.com/astral-sh/ruff/pull/13438))
## 0.6.8
### Preview features
- Remove unnecessary parentheses around `match case` clauses ([#13510](https://github.com/astral-sh/ruff/pull/13510))
- Parenthesize overlong `if` guards in `match..case` clauses ([#13513](https://github.com/astral-sh/ruff/pull/13513))
- Detect basic wildcard imports in `ruff analyze graph` ([#13486](https://github.com/astral-sh/ruff/pull/13486))
- \[`lake8-simplify`\] Detect `SIM910` when using variadic keyword arguments, i.e., `**kwargs` ([#13503](https://github.com/astral-sh/ruff/pull/13503))
- \[`pyupgrade`\] Avoid false negatives with non-reference shadowed bindings of loop variables (`UP028`) ([#13504](https://github.com/astral-sh/ruff/pull/13504))
### Bug fixes
- Detect tuples bound to variadic positional arguments i.e. `*args` ([#13512](https://github.com/astral-sh/ruff/pull/13512))
- Exit gracefully on broken pipe errors ([#13485](https://github.com/astral-sh/ruff/pull/13485))
- Avoid panic when analyze graph hits broken pipe ([#13484](https://github.com/astral-sh/ruff/pull/13484))
### Performance
- Reuse `BTreeSets` in module resolver ([#13440](https://github.com/astral-sh/ruff/pull/13440))
- Skip traversal for non-compound statements ([#13441](https://github.com/astral-sh/ruff/pull/13441))
## 0.6.9
### Preview features
- Fix codeblock dynamic line length calculation for indented docstring examples ([#13523](https://github.com/astral-sh/ruff/pull/13523))
- \[`refurb`\] Mark `FURB118` fix as unsafe ([#13613](https://github.com/astral-sh/ruff/pull/13613))
### Rule changes
- \[`pydocstyle`\] Don't raise `D208` when last line is non-empty ([#13372](https://github.com/astral-sh/ruff/pull/13372))
- \[`pylint`\] Preserve trivia (i.e. comments) in `PLR5501` autofix ([#13573](https://github.com/astral-sh/ruff/pull/13573))
### Configuration
- \[`pyflakes`\] Add `allow-unused-imports` setting for `unused-import` rule (`F401`) ([#13601](https://github.com/astral-sh/ruff/pull/13601))
### Bug fixes
- Support ruff discovery in pip build environments ([#13591](https://github.com/astral-sh/ruff/pull/13591))
- \[`flake8-bugbear`\] Avoid short circuiting `B017` for multiple context managers ([#13609](https://github.com/astral-sh/ruff/pull/13609))
- \[`pylint`\] Do not offer an invalid fix for `PLR1716` when the comparisons contain parenthesis ([#13527](https://github.com/astral-sh/ruff/pull/13527))
- \[`pyupgrade`\] Fix `UP043` to apply to `collections.abc.Generator` and `collections.abc.AsyncGenerator` ([#13611](https://github.com/astral-sh/ruff/pull/13611))
- \[`refurb`\] Fix handling of slices in tuples for `FURB118`, e.g., `x[:, 1]` ([#13518](https://github.com/astral-sh/ruff/pull/13518))
### Documentation
- Update GitHub Action link to `astral-sh/ruff-action` ([#13551](https://github.com/astral-sh/ruff/pull/13551))
- \[`refurb`\] Count codepoints not bytes for `slice-to-remove-prefix-or-suffix (FURB188)` ([#13631](https://github.com/astral-sh/ruff/pull/13631))
### Rule changes
- \[`pylint`\] Mark `PLE1141` fix as unsafe ([#13629](https://github.com/astral-sh/ruff/pull/13629))
- \[`flake8-async`\] Consider async generators to be "checkpoints" for `cancel-scope-no-checkpoint` (`ASYNC100`) ([#13639](https://github.com/astral-sh/ruff/pull/13639))
- \[`flake8-bugbear`\] Do not suggest setting parameter `strict=` to `False` in `B905` diagnostic message ([#13656](https://github.com/astral-sh/ruff/pull/13656))
- \[`flake8-todos`\] Only flag the word "TODO", not words starting with "todo" (`TD006`) ([#13640](https://github.com/astral-sh/ruff/pull/13640))
- \[`flake8-use-pathlib`\] Fix `PTH123` false positive when `open` is passed a file descriptor ([#13616](https://github.com/astral-sh/ruff/pull/13616))
- \[`flake8-bandit`\] Detect patterns from multi line SQL statements (`S608`) ([#13574](https://github.com/astral-sh/ruff/pull/13574))
- \[`flake8-pyi`\] - Fix dropped expressions in `PYI030` autofix ([#13727](https://github.com/astral-sh/ruff/pull/13727))
## 0.7.1
### Preview features
- Fix `E221` and `E222` to flag missing or extra whitespace around `==` operator ([#13890](https://github.com/astral-sh/ruff/pull/13890))
- Formatter: Alternate quotes for strings inside f-strings in preview ([#13860](https://github.com/astral-sh/ruff/pull/13860))
- Formatter: Join implicit concatenated strings when they fit on a line ([#13663](https://github.com/astral-sh/ruff/pull/13663))
- \[`pylint`\] Restrict `iteration-over-set` to only work on sets of literals (`PLC0208`) ([#13731](https://github.com/astral-sh/ruff/pull/13731))
### Rule changes
- \[`flake8-type-checking`\] Support auto-quoting when annotations contain quotes ([#11811](https://github.com/astral-sh/ruff/pull/11811))
### Server
- Avoid indexing the workspace for single-file mode ([#13770](https://github.com/astral-sh/ruff/pull/13770))
### Bug fixes
- Make `ARG002` compatible with `EM101` when raising `NotImplementedError` ([#13714](https://github.com/astral-sh/ruff/pull/13714))
### Other changes
- Introduce more Docker tags for Ruff (similar to uv) ([#13274](https://github.com/astral-sh/ruff/pull/13274))
## 0.7.2
### Preview features
- Fix formatting of single with-item with trailing comment ([#14005](https://github.com/astral-sh/ruff/pull/14005))
- \[`pyupgrade`\] Add PEP 646 `Unpack` conversion to `*` with fix (`UP044`) ([#13988](https://github.com/astral-sh/ruff/pull/13988))
### Rule changes
- Regenerate `known_stdlibs.rs` with stdlibs 2024.10.25 ([#13963](https://github.com/astral-sh/ruff/pull/13963))
- \[`flake8-no-pep420`\] Skip namespace package enforcement for PEP 723 scripts (`INP001`) ([#13974](https://github.com/astral-sh/ruff/pull/13974))
### Server
- Fix server panic when undoing an edit ([#14010](https://github.com/astral-sh/ruff/pull/14010))
### Bug fixes
- Fix issues in discovering ruff in pip build environments ([#13881](https://github.com/astral-sh/ruff/pull/13881))
- \[`flake8-type-checking`\] Fix false positive for `singledispatchmethod` (`TCH003`) ([#13941](https://github.com/astral-sh/ruff/pull/13941))
- \[`flake8-type-checking`\] Treat return type of `singledispatch` as runtime-required (`TCH003`) ([#13957](https://github.com/astral-sh/ruff/pull/13957))
### Documentation
- \[`flake8-simplify`\] Include caveats of enabling `if-else-block-instead-of-if-exp` (`SIM108`) ([#14019](https://github.com/astral-sh/ruff/pull/14019))
- \[`flake8-pyi`\] Improve autofix for nested and mixed type unions for `unnecessary-type-union` (`PYI055`) ([#14272](https://github.com/astral-sh/ruff/pull/14272))
- \[`flake8-pyi`\] Mark fix as unsafe when type annotation contains comments for `duplicate-literal-member` (`PYI062`) ([#14268](https://github.com/astral-sh/ruff/pull/14268))
### Server
- Use the current working directory to resolve settings from `ruff.configuration` ([#14352](https://github.com/astral-sh/ruff/pull/14352))
### Bug fixes
- Avoid conflicts between `PLC014` (`useless-import-alias`) and `I002` (`missing-required-import`) by considering `lint.isort.required-imports` for `PLC014` ([#14287](https://github.com/astral-sh/ruff/pull/14287))
- \[`flake8-type-checking`\] Skip quoting annotation if it becomes invalid syntax (`TCH001`)
- \[`flake8-pyi`\] Avoid using `typing.Self` in stub files pre-Python 3.11 (`PYI034`) ([#14230](https://github.com/astral-sh/ruff/pull/14230))
- \[`flake8-pytest-style`\] Flag `pytest.raises` call with keyword argument `expected_exception` (`PT011`) ([#14298](https://github.com/astral-sh/ruff/pull/14298))
- \[`flake8-simplify`\] Infer "unknown" truthiness for literal iterables whose items are all unpacks (`SIM222`) ([#14263](https://github.com/astral-sh/ruff/pull/14263))
- \[`flake8-type-checking`\] Fix false positives for `typing.Annotated` (`TCH001`) ([#14311](https://github.com/astral-sh/ruff/pull/14311))
- \[`pylint`\] Allow `await` at the top-level scope of a notebook (`PLE1142`) ([#14225](https://github.com/astral-sh/ruff/pull/14225))
- \[`pylint`\] Fix miscellaneous issues in `await-outside-async` detection (`PLE1142`) ([#14218](https://github.com/astral-sh/ruff/pull/14218))
- \[`pyupgrade`\] Avoid applying PEP 646 rewrites in invalid contexts (`UP044`) ([#14234](https://github.com/astral-sh/ruff/pull/14234))
- \[`pyupgrade`\] Detect permutations in redundant open modes (`UP015`) ([#14255](https://github.com/astral-sh/ruff/pull/14255))
- \[`refurb`\] Avoid triggering `hardcoded-string-charset` for reordered sets (`FURB156`) ([#14233](https://github.com/astral-sh/ruff/pull/14233))
- \[`refurb`\] Further special cases added to `verbose-decimal-constructor` (`FURB157`) ([#14216](https://github.com/astral-sh/ruff/pull/14216))
- \[`refurb`\] Use `UserString` instead of non-existent `UserStr` (`FURB189`) ([#14209](https://github.com/astral-sh/ruff/pull/14209))
Check out the [blog post](https://astral.sh/blog/ruff-v0.8.0) for a migration guide and overview of the changes!
### Breaking changes
See also, the "Remapped rules" section which may result in disabled rules.
- **Default to Python 3.9**
Ruff now defaults to Python 3.9 instead of 3.8 if no explicit Python version is configured using [`ruff.target-version`](https://docs.astral.sh/ruff/settings/#target-version) or [`project.requires-python`](https://packaging.python.org/en/latest/guides/writing-pyproject-toml/#python-requires) ([#13896](https://github.com/astral-sh/ruff/pull/13896))
- **Changed location of `pydoclint` diagnostics**
[`pydoclint`](https://docs.astral.sh/ruff/rules/#pydoclint-doc) diagnostics now point to the first-line of the problematic docstring. Previously, this was not the case.
If you've opted into these preview rules but have them suppressed using
[`noqa`](https://docs.astral.sh/ruff/linter/#error-suppression) comments in
some places, this change may mean that you need to move the `noqa` suppression
comments. Most users should be unaffected by this change.
- **Use XDG (i.e. `~/.local/bin`) instead of the Cargo home directory in the standalone installer**
Previously, Ruff's installer used `$CARGO_HOME` or `~/.cargo/bin` for its target install directory. Now, Ruff will be installed into `$XDG_BIN_HOME`, `$XDG_DATA_HOME/../bin`, or `~/.local/bin` (in that order).
This change is only relevant to users of the standalone Ruff installer (using the shell or PowerShell script). If you installed Ruff using uv or pip, you should be unaffected.
- **Changes to the line width calculation**
Ruff now uses a new version of the [unicode-width](https://github.com/unicode-rs/unicode-width) Rust crate to calculate the line width. In very rare cases, this may lead to lines containing Unicode characters being reformatted, or being considered too long when they were not before ([`E501`](https://docs.astral.sh/ruff/rules/line-too-long/)).
- [`ambiguous-variable-name`](https://docs.astral.sh/ruff/rules/ambiguous-variable-name/) (`E741`): Violations in stub files are now ignored. Stub authors typically don't control variable names.
- [`printf-string-formatting`](https://docs.astral.sh/ruff/rules/printf-string-formatting/) (`UP031`): Report all `printf`-like usages even if no autofix is available
- \[`flake8-datetimez`\] Exempt `min.time()` and `max.time()` (`DTZ901`) ([#14394](https://github.com/astral-sh/ruff/pull/14394))
- \[`flake8-pie`\] Mark fix as unsafe if the following statement is a string literal (`PIE790`) ([#14393](https://github.com/astral-sh/ruff/pull/14393))
- \[`flake8-pyi`\] New rule `redundant-none-literal` (`PYI061`) ([#14316](https://github.com/astral-sh/ruff/pull/14316))
- \[`flake8-pyi`\] Add autofix for `redundant-numeric-union` (`PYI041`) ([#14273](https://github.com/astral-sh/ruff/pull/14273))
- \[`ruff`\] New rule `map-int-version-parsing` (`RUF048`) ([#14373](https://github.com/astral-sh/ruff/pull/14373))
- \[`ruff`\] New rule `redundant-bool-literal` (`RUF038`) ([#14319](https://github.com/astral-sh/ruff/pull/14319))
- \[`ruff`\] New rule `unraw-re-pattern` (`RUF039`) ([#14446](https://github.com/astral-sh/ruff/pull/14446))
- \[`pylint`\] Autofix suggests using sets when possible (`PLR1714`) ([#14372](https://github.com/astral-sh/ruff/pull/14372))
### Rule changes
- [`invalid-pyproject-toml`](https://docs.astral.sh/ruff/rules/invalid-pyproject-toml/) (`RUF200`): Updated to reflect the provisionally accepted [PEP 639](https://peps.python.org/pep-0639/).
- \[`flake8-pyi`\] Avoid panic in unfixable case (`PYI041`) ([#14402](https://github.com/astral-sh/ruff/pull/14402))
- \[`flake8-type-checking`\] Correctly handle quotes in subscript expression when generating an autofix ([#14371](https://github.com/astral-sh/ruff/pull/14371))
- \[`pylint`\] Suggest correct autofix for `__contains__` (`PLC2801`) ([#14424](https://github.com/astral-sh/ruff/pull/14424))
### Configuration
- Ruff now emits a warning instead of an error when a configuration [`ignore`](https://docs.astral.sh/ruff/settings/#lint_ignore)s a rule that has been removed ([#14435](https://github.com/astral-sh/ruff/pull/14435))
- Ruff now validates that `lint.flake8-import-conventions.aliases` only uses valid module names and aliases ([#14477](https://github.com/astral-sh/ruff/pull/14477))
## 0.8.1
### Preview features
- Formatter: Avoid invalid syntax for format-spec with quotes for all Python versions ([#14625](https://github.com/astral-sh/ruff/pull/14625))
- Formatter: Consider quotes inside format-specs when choosing the quotes for an f-string ([#14493](https://github.com/astral-sh/ruff/pull/14493))
- Formatter: Do not consider f-strings with escaped newlines as multiline ([#14624](https://github.com/astral-sh/ruff/pull/14624))
- Formatter: Fix f-string formatting in assignment statement ([#14454](https://github.com/astral-sh/ruff/pull/14454))
- Formatter: Fix unnecessary space around power operator (`**`) in overlong f-string expressions ([#14489](https://github.com/astral-sh/ruff/pull/14489))
- \[`airflow`\] Avoid implicit `schedule` argument to `DAG` and `@dag` (`AIR301`) ([#14581](https://github.com/astral-sh/ruff/pull/14581))
- \[`refurb`\] Fix bug where methods defined using lambdas were flagged by `FURB118` ([#14639](https://github.com/astral-sh/ruff/pull/14639))
- \[`ruff`\] Auto-add `r` prefix when string has no backslashes for `unraw-re-pattern` (`RUF039`) ([#14536](https://github.com/astral-sh/ruff/pull/14536))
- \[`ruff`\] Detect redirected-noqa in file-level comments (`RUF101`) ([#14635](https://github.com/astral-sh/ruff/pull/14635))
- \[`ruff`\] Mark fixes for `unsorted-dunder-all` and `unsorted-dunder-slots` as unsafe when there are complex comments in the sequence (`RUF022`, `RUF023`) ([#14560](https://github.com/astral-sh/ruff/pull/14560))
### Bug fixes
- Avoid fixing code to `None | None` for `redundant-none-literal` (`PYI061`) and `never-union` (`RUF020`) ([#14583](https://github.com/astral-sh/ruff/pull/14583), [#14589](https://github.com/astral-sh/ruff/pull/14589))
- \[`flake8-bugbear`\] Fix `mutable-contextvar-default` to resolve annotated function calls properly (`B039`) ([#14532](https://github.com/astral-sh/ruff/pull/14532))
- \[`flake8-pyi`, `ruff`\] Fix traversal of nested literals and unions (`PYI016`, `PYI051`, `PYI055`, `PYI062`, `RUF041`) ([#14641](https://github.com/astral-sh/ruff/pull/14641))
- \[`flake8-pyi`\] Avoid rewriting invalid type expressions in `unnecessary-type-union` (`PYI055`) ([#14660](https://github.com/astral-sh/ruff/pull/14660))
- \[`flake8-type-checking`\] Avoid syntax errors and type checking problem for quoted annotations autofix (`TC003`, `TC006`) ([#14634](https://github.com/astral-sh/ruff/pull/14634))
- \[`pylint`\] Do not wrap function calls in parentheses in the fix for unnecessary-dunder-call (`PLC2801`) ([#14601](https://github.com/astral-sh/ruff/pull/14601))
- \[`airflow`\] Check `AIR001` from builtin or providers `operators` module ([#14631](https://github.com/astral-sh/ruff/pull/14631))
- \[`flake8-pytest-style`\] Remove `@` in `pytest.mark.parametrize` rule messages ([#14770](https://github.com/astral-sh/ruff/pull/14770))
- \[`pandas-vet`\] Skip rules if the `panda` module hasn't been seen ([#14671](https://github.com/astral-sh/ruff/pull/14671))
- \[`pylint`\] Fix false negatives for `ascii` and `sorted` in `len-as-condition` (`PLC1802`) ([#14692](https://github.com/astral-sh/ruff/pull/14692))
- \[`refurb`\] Guard `hashlib` imports and mark `hashlib-digest-hex` fix as safe (`FURB181`) ([#14694](https://github.com/astral-sh/ruff/pull/14694))
### Configuration
- \[`flake8-import-conventions`\] Improve syntax check for aliases supplied in configuration for `unconventional-import-alias` (`ICN001`) ([#14745](https://github.com/astral-sh/ruff/pull/14745))
- \[`pep8-naming`\] Avoid false positive for `class Bar(type(foo))` (`N804`) ([#14683](https://github.com/astral-sh/ruff/pull/14683))
- \[`pycodestyle`\] Handle f-strings properly for `invalid-escape-sequence` (`W605`) ([#14748](https://github.com/astral-sh/ruff/pull/14748))
- \[`pylint`\] Ignore `@overload` in `PLR0904` ([#14730](https://github.com/astral-sh/ruff/pull/14730))
- \[`refurb`\] Handle non-finite decimals in `verbose-decimal-constructor` (`FURB157`) ([#14596](https://github.com/astral-sh/ruff/pull/14596))
- \[`ruff`\] Avoid emitting `assignment-in-assert` when all references to the assigned variable are themselves inside `assert`s (`RUF018`) ([#14661](https://github.com/astral-sh/ruff/pull/14661))
### Documentation
- Improve docs for `flake8-use-pathlib` rules ([#14741](https://github.com/astral-sh/ruff/pull/14741))
- Improve error messages and docs for `flake8-comprehensions` rules ([#14729](https://github.com/astral-sh/ruff/pull/14729))
- \[`flake8-type-checking`\] Expands `TC006` docs to better explain itself ([#14749](https://github.com/astral-sh/ruff/pull/14749))
## 0.8.3
### Preview features
- Fix fstring formatting removing overlong implicit concatenated string in expression part ([#14811](https://github.com/astral-sh/ruff/pull/14811))
- \[`airflow`\]: Extend rule to include deprecated names for Airflow 3.0 (`AIR302`) ([#14765](https://github.com/astral-sh/ruff/pull/14765) and [#14804](https://github.com/astral-sh/ruff/pull/14804))
- \[`flake8-bugbear`\] `itertools.batched()` without explicit `strict` (`B911`) ([#14408](https://github.com/astral-sh/ruff/pull/14408))
- \[`flake8-use-pathlib`\] Dotless suffix passed to `Path.with_suffix()` (`PTH210`) ([#14779](https://github.com/astral-sh/ruff/pull/14779))
- \[`pylint`\] Include parentheses and multiple comparators in check for `boolean-chained-comparison` (`PLR1716`) ([#14781](https://github.com/astral-sh/ruff/pull/14781))
- \[`ruff`\] Do not simplify `round()` calls (`RUF046`) ([#14832](https://github.com/astral-sh/ruff/pull/14832))
- \[`ruff`\] Don't emit `used-dummy-variable` on function parameters (`RUF052`) ([#14818](https://github.com/astral-sh/ruff/pull/14818))
- \[`ruff`\] Mark autofix for `RUF052` as always unsafe ([#14824](https://github.com/astral-sh/ruff/pull/14824))
- \[`ruff`\] Teach autofix for `used-dummy-variable` about TypeVars etc. (`RUF052`) ([#14819](https://github.com/astral-sh/ruff/pull/14819))
### Rule changes
- \[`flake8-bugbear`\] Offer unsafe autofix for `no-explicit-stacklevel` (`B028`) ([#14829](https://github.com/astral-sh/ruff/pull/14829))
- \[`flake8-pyi`\] Skip all type definitions in `string-or-bytes-too-long` (`PYI053`) ([#14797](https://github.com/astral-sh/ruff/pull/14797))
- \[`pyupgrade`\] Do not report when a UTF-8 comment is followed by a non-UTF-8 one (`UP009`) ([#14728](https://github.com/astral-sh/ruff/pull/14728))
- \[`pyupgrade`\] Mark fixes for `convert-typed-dict-functional-to-class` and `convert-named-tuple-functional-to-class` as unsafe if they will remove comments (`UP013`, `UP014`) ([#14842](https://github.com/astral-sh/ruff/pull/14842))
### Bug fixes
- Raise syntax error for mixing `except` and `except*` ([#14895](https://github.com/astral-sh/ruff/pull/14895))
- \[`flake8-bugbear`\] Fix `B028` to allow `stacklevel` to be explicitly assigned as a positional argument ([#14868](https://github.com/astral-sh/ruff/pull/14868))
- \[`flake8-bugbear`\] Skip `B028` if `warnings.warn` is called with `*args` or `**kwargs` ([#14870](https://github.com/astral-sh/ruff/pull/14870))
- \[`flake8-comprehensions`\] Skip iterables with named expressions in `unnecessary-map` (`C417`) ([#14827](https://github.com/astral-sh/ruff/pull/14827))
- \[`flake8-pyi`\] Also remove `self` and `cls`'s annotation (`PYI034`) ([#14801](https://github.com/astral-sh/ruff/pull/14801))
- \[`flake8-pytest-style`\] Fix `pytest-parametrize-names-wrong-type` (`PT006`) to edit both `argnames` and `argvalues` if both of them are single-element tuples/lists ([#14699](https://github.com/astral-sh/ruff/pull/14699))
- \[`perflint`\] Improve autofix for `PERF401` ([#14369](https://github.com/astral-sh/ruff/pull/14369))
- \[`pylint`\] Fix `PLW1508` false positive for default string created via a mult operation ([#14841](https://github.com/astral-sh/ruff/pull/14841))
## 0.8.4
### Preview features
- \[`airflow`\] Extend `AIR302` with additional functions and classes ([#15015](https://github.com/astral-sh/ruff/pull/15015))
- \[`airflow`\] Implement `moved-to-provider-in-3` for modules that has been moved to Airflow providers (`AIR303`) ([#14764](https://github.com/astral-sh/ruff/pull/14764))
- \[`flake8-use-pathlib`\] Extend check for invalid path suffix to include the case `"."` (`PTH210`) ([#14902](https://github.com/astral-sh/ruff/pull/14902))
- \[`perflint`\] Fix panic in `PERF401` when list variable is after the `for` loop ([#14971](https://github.com/astral-sh/ruff/pull/14971))
- \[`perflint`\] Simplify finding the loop target in `PERF401` ([#15025](https://github.com/astral-sh/ruff/pull/15025))
- \[`pylint`\] Preserve original value format (`PLR6104`) ([#14978](https://github.com/astral-sh/ruff/pull/14978))
- \[`ruff`\] Avoid false positives for `RUF027` for typing context bindings ([#15037](https://github.com/astral-sh/ruff/pull/15037))
- \[`ruff`\] Check for ambiguous pattern passed to `pytest.raises()` (`RUF043`) ([#14966](https://github.com/astral-sh/ruff/pull/14966))
### Rule changes
- \[`flake8-bandit`\] Check `S105` for annotated assignment ([#15059](https://github.com/astral-sh/ruff/pull/15059))
- \[`flake8-pyi`\] More autofixes for `redundant-none-literal` (`PYI061`) ([#14872](https://github.com/astral-sh/ruff/pull/14872))
- \[`pydocstyle`\] Skip leading whitespace for `D403` ([#14963](https://github.com/astral-sh/ruff/pull/14963))
- \[`ruff`\] Skip `SQLModel` base classes for `mutable-class-default` (`RUF012`) ([#14949](https://github.com/astral-sh/ruff/pull/14949))
### Bug
- \[`perflint`\] Parenthesize walrus expressions in autofix for `manual-list-comprehension` (`PERF401`) ([#15050](https://github.com/astral-sh/ruff/pull/15050))
### Server
- Check diagnostic refresh support from client capability which enables dynamic configuration for various editors ([#15014](https://github.com/astral-sh/ruff/pull/15014))
## 0.8.5
### Preview features
- \[`airflow`\] Extend names moved from core to provider (`AIR303`) ([#15145](https://github.com/astral-sh/ruff/pull/15145), [#15159](https://github.com/astral-sh/ruff/pull/15159), [#15196](https://github.com/astral-sh/ruff/pull/15196), [#15216](https://github.com/astral-sh/ruff/pull/15216))
- \[`airflow`\] Extend rule to check class attributes, methods, arguments (`AIR302`) ([#15054](https://github.com/astral-sh/ruff/pull/15054), [#15083](https://github.com/astral-sh/ruff/pull/15083))
- \[`fastapi`\] Update `FAST002` to check keyword-only arguments ([#15119](https://github.com/astral-sh/ruff/pull/15119))
- \[`flake8-type-checking`\] Disable `TC006` and `TC007` in stub files ([#15179](https://github.com/astral-sh/ruff/pull/15179))
- \[`flake8-simplify`\] More precise inference for dictionaries (`SIM300`) ([#15164](https://github.com/astral-sh/ruff/pull/15164))
- \[`flake8-use-pathlib`\] Catch redundant joins in `PTH201` and avoid syntax errors ([#15177](https://github.com/astral-sh/ruff/pull/15177))
- \[`pycodestyle`\] Preserve original value format (`E731`) ([#15097](https://github.com/astral-sh/ruff/pull/15097))
- \[`pydocstyle`\] Split on first whitespace character (`D403`) ([#15082](https://github.com/astral-sh/ruff/pull/15082))
- \[`pyupgrade`\] Add all PEP-585 names to `UP006` rule ([#5454](https://github.com/astral-sh/ruff/pull/5454))
### Configuration
- \[`flake8-type-checking`\] Improve flexibility of `runtime-evaluated-decorators` ([#15204](https://github.com/astral-sh/ruff/pull/15204))
- \[`pydocstyle`\] Add setting to ignore missing documentation for `*args` and `**kwargs` parameters (`D417`) ([#15210](https://github.com/astral-sh/ruff/pull/15210))
- \[`ruff`\] Add an allowlist for `unsafe-markup-use` (`RUF035`) ([#15076](https://github.com/astral-sh/ruff/pull/15076))
### Bug fixes
- Fix type subscript on older python versions ([#15090](https://github.com/astral-sh/ruff/pull/15090))
- Use `TypeChecker` for detecting `fastapi` routes ([#15093](https://github.com/astral-sh/ruff/pull/15093))
- \[`pycodestyle`\] Avoid false positives and negatives related to type parameter default syntax (`E225`, `E251`) ([#15214](https://github.com/astral-sh/ruff/pull/15214))
### Documentation
- Fix incorrect doc in `shebang-not-executable` (`EXE001`) and add git+windows solution to executable bit ([#15208](https://github.com/astral-sh/ruff/pull/15208))
- Rename rules currently not conforming to naming convention ([#15102](https://github.com/astral-sh/ruff/pull/15102))
Check out the [blog post](https://astral.sh/blog/ruff-v0.9.0) for a migration guide and overview of the changes!
### Breaking changes
Ruff now formats your code according to the 2025 style guide. As a result, your code might now get formatted differently. See the formatter section for a detailed list of changes.
This release doesn’t remove or remap any existing stable rules.
### Stabilization
The following rules have been stabilized and are no longer in preview:
- [`pytest-parametrize-names-wrong-type`](https://docs.astral.sh/ruff/rules/pytest-parametrize-names-wrong-type/) (`PT006`): Detect [`pytest.parametrize`](https://docs.pytest.org/en/7.1.x/how-to/parametrize.html#parametrize) calls outside decorators and calls with keyword arguments.
- [`module-import-not-at-top-of-file`](https://docs.astral.sh/ruff/rules/module-import-not-at-top-of-file/) (`E402`): Ignore [`pytest.importorskip`](https://docs.pytest.org/en/7.1.x/reference/reference.html#pytest-importorskip) calls between import statements.
- [`mutable-dataclass-default`](https://docs.astral.sh/ruff/rules/mutable-dataclass-default/) (`RUF008`) and [`function-call-in-dataclass-default-argument`](https://docs.astral.sh/ruff/rules/function-call-in-dataclass-default-argument/) (`RUF009`): Add support for [`attrs`](https://www.attrs.org/en/stable/).
- [`bad-version-info-comparison`](https://docs.astral.sh/ruff/rules/bad-version-info-comparison/) (`PYI006`): Extend the rule to check non-stub files.
The following fixes or improvements to fixes have been stabilized:
This release introduces the new 2025 stable style ([#13371](https://github.com/astral-sh/ruff/issues/13371)), stabilizing the following changes:
- Format expressions in f-string elements ([#7594](https://github.com/astral-sh/ruff/issues/7594))
- Alternate quotes for strings inside f-strings ([#13860](https://github.com/astral-sh/ruff/pull/13860))
- Preserve the casing of hex codes in f-string debug expressions ([#14766](https://github.com/astral-sh/ruff/issues/14766))
- Choose the quote style for each string literal in an implicitly concatenated f-string rather than for the entire string ([#13539](https://github.com/astral-sh/ruff/pull/13539))
- Automatically join an implicitly concatenated string into a single string literal if it fits on a single line ([#9457](https://github.com/astral-sh/ruff/issues/9457))
- Remove the [`ISC001`](https://docs.astral.sh/ruff/rules/single-line-implicit-string-concatenation/) incompatibility warning ([#15123](https://github.com/astral-sh/ruff/pull/15123))
- Prefer parenthesizing the `assert` message over breaking the assertion expression ([#9457](https://github.com/astral-sh/ruff/issues/9457))
- Automatically parenthesize over-long `if` guards in `match``case` clauses ([#13513](https://github.com/astral-sh/ruff/pull/13513))
- More consistent formatting for `match``case` patterns ([#6933](https://github.com/astral-sh/ruff/issues/6933))
- Avoid unnecessary parentheses around return type annotations ([#13381](https://github.com/astral-sh/ruff/pull/13381))
- Keep the opening parentheses on the same line as the `if` keyword for comprehensions where the condition has a leading comment ([#12282](https://github.com/astral-sh/ruff/pull/12282))
- More consistent formatting for `with` statements with a single context manager for Python 3.8 or older ([#10276](https://github.com/astral-sh/ruff/pull/10276))
- Correctly calculate the line-width for code blocks in docstrings when using `max-doc-code-line-length = "dynamic"` ([#13523](https://github.com/astral-sh/ruff/pull/13523))
- \[`flake8-type-checking`\] Apply `quoted-type-alias` more eagerly in `TYPE_CHECKING` blocks and ignore it in stubs (`TC008`) ([#15180](https://github.com/astral-sh/ruff/pull/15180))
- \[`pylint`\] Ignore `eq-without-hash` in stub files (`PLW1641`) ([#15310](https://github.com/astral-sh/ruff/pull/15310))
- \[`pyupgrade`\] Split `UP007` into two individual rules: `UP007` for `Union` and `UP045` for `Optional` (`UP007`, `UP045`) ([#15313](https://github.com/astral-sh/ruff/pull/15313))
- \[`ruff`\] New rule that detects classes that are both an enum and a `dataclass` (`RUF049`) ([#15299](https://github.com/astral-sh/ruff/pull/15299))
- \[`ruff`\] Recode `RUF025` to `RUF037` (`RUF037`) ([#15258](https://github.com/astral-sh/ruff/pull/15258))
### Rule changes
- \[`flake8-builtins`\] Ignore [`stdlib-module-shadowing`](https://docs.astral.sh/ruff/rules/stdlib-module-shadowing/) in stub files(`A005`) ([#15350](https://github.com/astral-sh/ruff/pull/15350))
- \[`flake8-return`\] Add support for functions returning `typing.Never` (`RET503`) ([#15298](https://github.com/astral-sh/ruff/pull/15298))
### Server
- Improve the observability by removing the need for the ["trace" value](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#traceValue) to turn on or off logging. The server logging is solely controlled using the [`logLevel` server setting](https://docs.astral.sh/ruff/editors/settings/#loglevel)
which defaults to `info`. This addresses the issue where users were notified about an error and told to consult the log, but it didn’t contain any messages. ([#15232](https://github.com/astral-sh/ruff/pull/15232))
- Ignore diagnostics from other sources for code action requests ([#15373](https://github.com/astral-sh/ruff/pull/15373))
### CLI
- Improve the error message for `--config key=value` when the `key` is for a table and it’s a simple `value`
### Bug fixes
- \[`eradicate`\] Ignore metadata blocks directly followed by normal blocks (`ERA001`) ([#15330](https://github.com/astral-sh/ruff/pull/15330))
- \[`flake8-django`\] Recognize other magic methods (`DJ012`) ([#15365](https://github.com/astral-sh/ruff/pull/15365))
- \[`pycodestyle`\] Avoid false positives related to type aliases (`E252`) ([#15356](https://github.com/astral-sh/ruff/pull/15356))
- \[`pydocstyle`\] Avoid treating newline-separated sections as sub-sections (`D405`) ([#15311](https://github.com/astral-sh/ruff/pull/15311))
- \[`pyflakes`\] Remove call when removing final argument from `format` (`F523`) ([#15309](https://github.com/astral-sh/ruff/pull/15309))
- \[`refurb`\] Mark fix as unsafe when the right-hand side is a string (`FURB171`) ([#15273](https://github.com/astral-sh/ruff/pull/15273))
- \[`ruff`\] Treat `)` as a regex metacharacter (`RUF043`, `RUF055`) ([#15318](https://github.com/astral-sh/ruff/pull/15318))
- \[`ruff`\] Parenthesize the `int`-call argument when removing the `int` call would change semantics (`RUF046`) ([#15277](https://github.com/astral-sh/ruff/pull/15277))
## 0.9.1
### Preview features
- \[`pycodestyle`\] Run `too-many-newlines-at-end-of-file` on each cell in notebooks (`W391`) ([#15308](https://github.com/astral-sh/ruff/pull/15308))
- \[`ruff`\] Omit diagnostic for shadowed private function parameters in `used-dummy-variable` (`RUF052`) ([#15376](https://github.com/astral-sh/ruff/pull/15376))
- Preserve trailing end-of line comments for the last string literal in implicitly concatenated strings ([#15378](https://github.com/astral-sh/ruff/pull/15378))
### Server
- Fix a bug where the server and client notebooks were out of sync after reordering cells ([#15398](https://github.com/astral-sh/ruff/pull/15398))
- \[`pyupgrade`\] Add rules to use PEP 695 generics in classes and functions (`UP046`, `UP047`) ([#15565](https://github.com/astral-sh/ruff/pull/15565), [#15659](https://github.com/astral-sh/ruff/pull/15659))
- \[`flake8-bugbear`\] Do not raise error if keyword argument is present and target-python version is less or equals than 3.9 (`B903`) ([#15549](https://github.com/astral-sh/ruff/pull/15549))
- \[`flake8-comprehensions`\] strip parentheses around generators in `unnecessary-generator-set` (`C401`) ([#15553](https://github.com/astral-sh/ruff/pull/15553))
- \[`flake8-pytest-style`\] Rewrite references to `.exception` (`PT027`) ([#15680](https://github.com/astral-sh/ruff/pull/15680))
- \[`flake8-simplify`\] Mark fixes as unsafe (`SIM201`, `SIM202`) ([#15626](https://github.com/astral-sh/ruff/pull/15626))
- \[`flake8-type-checking`\] Fix some safe fixes being labeled unsafe (`TC006`,`TC008`) ([#15638](https://github.com/astral-sh/ruff/pull/15638))
- \[`isort`\] Omit trailing whitespace in `unsorted-imports` (`I001`) ([#15518](https://github.com/astral-sh/ruff/pull/15518))
- \[`pydoclint`\] Allow ignoring one line docstrings for `DOC` rules ([#13302](https://github.com/astral-sh/ruff/pull/13302))
- \[`pyflakes`\] Apply redefinition fixes by source code order (`F811`) ([#15575](https://github.com/astral-sh/ruff/pull/15575))
- \[`pyflakes`\] Avoid removing too many imports in `redefined-while-unused` (`F811`) ([#15585](https://github.com/astral-sh/ruff/pull/15585))
- \[`pyflakes`\] Group redefinition fixes by source statement (`F811`) ([#15574](https://github.com/astral-sh/ruff/pull/15574))
- \[`pylint`\] Include name of base class in message for `redefined-slots-in-subclass` (`W0244`) ([#15559](https://github.com/astral-sh/ruff/pull/15559))
- \[`ruff`\] Update fix for `RUF055` to use `var == value` ([#15605](https://github.com/astral-sh/ruff/pull/15605))
### Formatter
- Fix bracket spacing for single-element tuples in f-string expressions ([#15537](https://github.com/astral-sh/ruff/pull/15537))
- Fix unstable f-string formatting for expressions containing a trailing comma ([#15545](https://github.com/astral-sh/ruff/pull/15545))
### Performance
- Avoid quadratic membership check in import fixes ([#15576](https://github.com/astral-sh/ruff/pull/15576))
### Server
- Allow `unsafe-fixes` settings for code actions ([#15666](https://github.com/astral-sh/ruff/pull/15666))
### Bug fixes
- \[`flake8-bandit`\] Add missing single-line/dotall regex flag (`S608`) ([#15654](https://github.com/astral-sh/ruff/pull/15654))
- \[`flake8-import-conventions`\] Fix infinite loop between `ICN001` and `I002` (`ICN001`) ([#15480](https://github.com/astral-sh/ruff/pull/15480))
- \[`flake8-simplify`\] Do not emit diagnostics for expressions inside string type annotations (`SIM222`, `SIM223`) ([#15405](https://github.com/astral-sh/ruff/pull/15405))
- \[`pyflakes`\] Treat arguments passed to the `default=` parameter of `TypeVar` as type expressions (`F821`) ([#15679](https://github.com/astral-sh/ruff/pull/15679))
- \[`pyupgrade`\] Avoid syntax error when the iterable is a non-parenthesized tuple (`UP028`) ([#15543](https://github.com/astral-sh/ruff/pull/15543))
- \[`ruff`\] Exempt `NewType` calls where the original type is immutable (`RUF009`) ([#15588](https://github.com/astral-sh/ruff/pull/15588))
- Preserve raw string prefix and escapes in all codegen fixes ([#15694](https://github.com/astral-sh/ruff/pull/15694))
### Documentation
- Generate documentation redirects for lowercase rule codes ([#15564](https://github.com/astral-sh/ruff/pull/15564))
-`TRY300`: Add some extra notes on not catching exceptions you didn't expect ([#15036](https://github.com/astral-sh/ruff/pull/15036))
- \[`airflow`\] Update `AIR302` to check for deprecated context keys ([#15144](https://github.com/astral-sh/ruff/pull/15144))
- \[`flake8-bandit`\] Permit suspicious imports within stub files (`S4`) ([#15822](https://github.com/astral-sh/ruff/pull/15822))
- \[`pylint`\] Do not trigger `PLR6201` on empty collections ([#15732](https://github.com/astral-sh/ruff/pull/15732))
- \[`refurb`\] Do not emit diagnostic when loop variables are used outside loop body (`FURB122`) ([#15757](https://github.com/astral-sh/ruff/pull/15757))
- \[`ruff`\] Add support for more `re` patterns (`RUF055`) ([#15764](https://github.com/astral-sh/ruff/pull/15764))
- \[`ruff`\] Check for shadowed `map` before suggesting fix (`RUF058`) ([#15790](https://github.com/astral-sh/ruff/pull/15790))
- \[`ruff`\] Do not emit diagnostic when all arguments to `zip()` are variadic (`RUF058`) ([#15744](https://github.com/astral-sh/ruff/pull/15744))
- \[`ruff`\] Parenthesize fix when argument spans multiple lines for `unnecessary-round` (`RUF057`) ([#15703](https://github.com/astral-sh/ruff/pull/15703))
### Rule changes
- Preserve quote style in generated code ([#15726](https://github.com/astral-sh/ruff/pull/15726), [#15778](https://github.com/astral-sh/ruff/pull/15778), [#15794](https://github.com/astral-sh/ruff/pull/15794))
- \[`flake8-bugbear`\] Exempt `NewType` calls where the original type is immutable (`B008`) ([#15765](https://github.com/astral-sh/ruff/pull/15765))
- \[`pylint`\] Honor banned top-level imports by `TID253` in `PLC0415`. ([#15628](https://github.com/astral-sh/ruff/pull/15628))
- \[`pyupgrade`\] Ignore `is_typeddict` and `TypedDict` for `deprecated-import` (`UP035`) ([#15800](https://github.com/astral-sh/ruff/pull/15800))
### CLI
- Fix formatter warning message for `flake8-quotes` option ([#15788](https://github.com/astral-sh/ruff/pull/15788))
- Implement tab autocomplete for `ruff config` ([#15603](https://github.com/astral-sh/ruff/pull/15603))
### Bug fixes
- \[`flake8-comprehensions`\] Do not emit `unnecessary-map` diagnostic when lambda has different arity (`C417`) ([#15802](https://github.com/astral-sh/ruff/pull/15802))
- \[`flake8-comprehensions`\] Parenthesize `sorted` when needed for `unnecessary-call-around-sorted` (`C413`) ([#15825](https://github.com/astral-sh/ruff/pull/15825))
- \[`pyupgrade`\] Handle end-of-line comments for `quoted-annotation` (`UP037`) ([#15824](https://github.com/astral-sh/ruff/pull/15824))
- Add references to `trio.run_process` and `anyio.run_process` ([#15761](https://github.com/astral-sh/ruff/pull/15761))
- Use `uv init --lib` in tutorial ([#15718](https://github.com/astral-sh/ruff/pull/15718))
## 0.9.5
### Preview features
- Recognize all symbols named `TYPE_CHECKING` for `in_type_checking_block` ([#15719](https://github.com/astral-sh/ruff/pull/15719))
- \[`flake8-comprehensions`\] Handle builtins at top of file correctly for `unnecessary-dict-comprehension-for-iterable` (`C420`) ([#15837](https://github.com/astral-sh/ruff/pull/15837))
- \[`flake8-pyi`\] Fix incorrect behaviour of `custom-typevar-return-type` preview-mode autofix if `typing` was already imported (`PYI019`) ([#15853](https://github.com/astral-sh/ruff/pull/15853))
- \[`flake8-pyi`\] Fix more complex cases (`PYI019`) ([#15821](https://github.com/astral-sh/ruff/pull/15821))
- \[`flake8-pyi`\] Make `PYI019` autofixable for `.py` files in preview mode as well as stubs ([#15889](https://github.com/astral-sh/ruff/pull/15889))
- \[`flake8-pyi`\] Remove type parameter correctly when it is the last (`PYI019`) ([#15854](https://github.com/astral-sh/ruff/pull/15854))
- \[`pylint`\] Fix missing parens in unsafe fix for `unnecessary-dunder-call` (`PLC2801`) ([#15762](https://github.com/astral-sh/ruff/pull/15762))
- \[`pyupgrade`\] Better messages and diagnostic range (`UP015`) ([#15872](https://github.com/astral-sh/ruff/pull/15872))
- \[`pyupgrade`\] Rename private type parameters in PEP 695 generics (`UP049`) ([#15862](https://github.com/astral-sh/ruff/pull/15862))
- \[`refurb`\] Also report non-name expressions (`FURB169`) ([#15905](https://github.com/astral-sh/ruff/pull/15905))
- \[`refurb`\] Mark fix as unsafe if there are comments (`FURB171`) ([#15832](https://github.com/astral-sh/ruff/pull/15832))
- \[`ruff`\] Classes with mixed type variable style (`RUF053`) ([#15841](https://github.com/astral-sh/ruff/pull/15841))
- \[`airflow`\] `BashOperator` has been moved to `airflow.providers.standard.operators.bash.BashOperator` (`AIR302`) ([#15922](https://github.com/astral-sh/ruff/pull/15922))
- \[`flake8-pyi`\] Add autofix for unused-private-type-var (`PYI018`) ([#15999](https://github.com/astral-sh/ruff/pull/15999))
- \[`flake8-pyi`\] Significantly improve accuracy of `PYI019` if preview mode is enabled ([#15888](https://github.com/astral-sh/ruff/pull/15888))
### Rule changes
- Preserve triple quotes and prefixes for strings ([#15818](https://github.com/astral-sh/ruff/pull/15818))
- \[`flake8-comprehensions`\] Skip when `TypeError` present from too many (kw)args for `C410`,`C411`, and `C418` ([#15838](https://github.com/astral-sh/ruff/pull/15838))
- \[`flake8-pyi`\] Rename `PYI019` and improve its diagnostic message ([#15885](https://github.com/astral-sh/ruff/pull/15885))
- \[`pyupgrade`\] Reuse replacement logic from `UP046` and `UP047` to preserve more comments (`UP040`) ([#15840](https://github.com/astral-sh/ruff/pull/15840))
- \[`ruff`\] Analyze deferred annotations before enforcing `mutable-(data)class-default` and `function-call-in-dataclass-default-argument` (`RUF008`,`RUF009`,`RUF012`) ([#15921](https://github.com/astral-sh/ruff/pull/15921))
- Config error only when `flake8-import-conventions` alias conflicts with `isort.required-imports` bound name ([#15918](https://github.com/astral-sh/ruff/pull/15918))
- Workaround Even Better TOML crash related to `allOf` ([#15992](https://github.com/astral-sh/ruff/pull/15992))
### Bug fixes
- \[`flake8-comprehensions`\] Unnecessary `list` comprehension (rewrite as a `set` comprehension) (`C403`) - Handle extraneous parentheses around list comprehension ([#15877](https://github.com/astral-sh/ruff/pull/15877))
- \[`flake8-comprehensions`\] Handle trailing comma in fixes for `unnecessary-generator-list/set` (`C400`,`C401`) ([#15929](https://github.com/astral-sh/ruff/pull/15929))
- \[`flake8-pyi`\] Fix several correctness issues with `custom-type-var-return-type` (`PYI019`) ([#15851](https://github.com/astral-sh/ruff/pull/15851))
- \[`pep8-naming`\] Consider any number of leading underscore for `N801` ([#15988](https://github.com/astral-sh/ruff/pull/15988))
- \[`pyflakes`\] Visit forward annotations in `TypeAliasType` as types (`F401`) ([#15829](https://github.com/astral-sh/ruff/pull/15829))
- \[`pylint`\] Correct min/max auto-fix and suggestion for (`PL1730`) ([#15930](https://github.com/astral-sh/ruff/pull/15930))
- \[`ruff`\] Skip type definitions for `missing-f-string-syntax` (`RUF027`) ([#16054](https://github.com/astral-sh/ruff/pull/16054))
### Rule changes
- \[`flake8-annotations`\] Correct syntax for `typing.Union` in suggested return type fixes for `ANN20x` rules ([#16025](https://github.com/astral-sh/ruff/pull/16025))
- \[`flake8-builtins`\] Match upstream module name comparison (`A005`) ([#16006](https://github.com/astral-sh/ruff/pull/16006))
- \[`flake8-comprehensions`\] Detect overshadowed `list`/`set`/`dict`, ignore variadics and named expressions (`C417`) ([#15955](https://github.com/astral-sh/ruff/pull/15955))
- \[`flake8-pie`\] Remove following comma correctly when the unpacked dictionary is empty (`PIE800`) ([#16008](https://github.com/astral-sh/ruff/pull/16008))
- \[`flake8-simplify`\] Only trigger `SIM401` on known dictionaries ([#15995](https://github.com/astral-sh/ruff/pull/15995))
- \[`pylint`\] Do not report calls when object type and argument type mismatch, remove custom escape handling logic (`PLE1310`) ([#15984](https://github.com/astral-sh/ruff/pull/15984))
- \[`pyupgrade`\] Comments within parenthesized value ranges should not affect applicability (`UP040`) ([#16027](https://github.com/astral-sh/ruff/pull/16027))
- \[`pyupgrade`\] Don't introduce invalid syntax when upgrading old-style type aliases with parenthesized multiline values (`UP040`) ([#16026](https://github.com/astral-sh/ruff/pull/16026))
- \[`pyupgrade`\] Ensure we do not rename two type parameters to the same name (`UP049`) ([#16038](https://github.com/astral-sh/ruff/pull/16038))
- \[`pyupgrade`\] \[`ruff`\] Don't apply renamings if the new name is shadowed in a scope of one of the references to the binding (`UP049`, `RUF052`) ([#16032](https://github.com/astral-sh/ruff/pull/16032))
- \[`ruff`\] Update `RUF009` to behave similar to `B008` and ignore attributes with immutable types ([#16048](https://github.com/astral-sh/ruff/pull/16048))
### Server
- Root exclusions in the server to project root ([#16043](https://github.com/astral-sh/ruff/pull/16043))
### Bug fixes
- \[`flake8-datetime`\] Ignore `.replace()` calls while looking for `.astimezone` ([#16050](https://github.com/astral-sh/ruff/pull/16050))
- \[`flake8-type-checking`\] Avoid `TC004` false positive where the runtime definition is provided by `__getattr__` ([#16052](https://github.com/astral-sh/ruff/pull/16052))
- Consider `__new__` methods as special function type for enforcing class method or static method rules ([#13305](https://github.com/astral-sh/ruff/pull/13305))
- \[`airflow`\] Improve the internal logic to differentiate deprecated symbols (`AIR303`) ([#16013](https://github.com/astral-sh/ruff/pull/16013))
- Fix unstable formatting of trailing end-of-line comments of parenthesized attribute values ([#16187](https://github.com/astral-sh/ruff/pull/16187))
### Server
- Fix handling of requests received after shutdown message ([#16262](https://github.com/astral-sh/ruff/pull/16262))
- Ignore `source.organizeImports.ruff` and `source.fixAll.ruff` code actions for a notebook cell ([#16154](https://github.com/astral-sh/ruff/pull/16154))
- Include document specific debug info for `ruff.printDebugInformation` ([#16215](https://github.com/astral-sh/ruff/pull/16215))
- Update server to return the debug info as string with `ruff.printDebugInformation` ([#16214](https://github.com/astral-sh/ruff/pull/16214))
### CLI
- Warn on invalid `noqa` even when there are no diagnostics ([#16178](https://github.com/astral-sh/ruff/pull/16178))
- Better error messages while loading configuration `extend`s ([#15658](https://github.com/astral-sh/ruff/pull/15658))
### Bug fixes
- \[`flake8-comprehensions`\] Handle trailing comma in `C403` fix ([#16110](https://github.com/astral-sh/ruff/pull/16110))
- \[`flake8-pyi`\] Avoid flagging `custom-typevar-for-self` on metaclass methods (`PYI019`) ([#16141](https://github.com/astral-sh/ruff/pull/16141))
- \[`pydocstyle`\] Handle arguments with the same names as sections (`D417`) ([#16011](https://github.com/astral-sh/ruff/pull/16011))
- \[`pylint`\] Correct ordering of arguments in fix for `if-stmt-min-max` (`PLR1730`) ([#16080](https://github.com/astral-sh/ruff/pull/16080))
- \[`pylint`\] Do not offer fix for raw strings (`PLE251`) ([#16132](https://github.com/astral-sh/ruff/pull/16132))
- \[`pyupgrade`\] Do not upgrade functional `TypedDicts` with private field names to the class-based syntax (`UP013`) ([#16219](https://github.com/astral-sh/ruff/pull/16219))
- \[`pyupgrade`\] Handle micro version numbers correctly (`UP036`) ([#16091](https://github.com/astral-sh/ruff/pull/16091))
- \[`ruff`\] Add more Pydantic models variants to the list of default copy semantics (`RUF012`) ([#16291](https://github.com/astral-sh/ruff/pull/16291))
### Server
- Avoid indexing the project if `configurationPreference` is `editorOnly` ([#16381](https://github.com/astral-sh/ruff/pull/16381))
- Avoid unnecessary info at non-trace server log level ([#16389](https://github.com/astral-sh/ruff/pull/16389))
- Expand `ruff.configuration` to allow inline config ([#16296](https://github.com/astral-sh/ruff/pull/16296))
- Notify users for invalid client settings ([#16361](https://github.com/astral-sh/ruff/pull/16361))
- \[`pylint`\] Convert `code` keyword argument to a positional argument in fix for (`PLR1722`) ([#16424](https://github.com/astral-sh/ruff/pull/16424))
### CLI
- Move rule code from `description` to `check_name` in GitLab output serializer ([#16437](https://github.com/astral-sh/ruff/pull/16437))
### Documentation
- \[`pydocstyle`\] Clarify that `D417` only checks docstrings with an arguments section ([#16494](https://github.com/astral-sh/ruff/pull/16494))
/// Returns a reference to the runtime of the current worker.
fnruntime(&self)-> &DbRuntime;
/// Returns a mutable reference to the runtime. Only one worker can hold a mutable reference to the runtime.
fnruntime_mut(&mutself)-> &mutDbRuntime;
/// Returns `Ok` if the queries have not been cancelled and `Err(QueryError::Cancelled)` otherwise.
fncancelled(&self)-> QueryResult<()>{
self.runtime().cancelled()
}
/// Returns `true` if the queries have been cancelled.
fnis_cancelled(&self)-> bool{
self.runtime().is_cancelled()
}
}
/// Database that supports running queries from multiple threads.
pubtraitParallelDatabase: Database+Send{
/// Creates a snapshot of the database state that can be used to query the database in another thread.
///
/// The snapshot is a read-only view of the database but query results are shared between threads.
/// All queries will be automatically cancelled when applying any mutations (calling [`HasJars::jars_mut`])
/// to the database (not the snapshot, because they're readonly).
///
/// ## Creating a snapshot
///
/// Creating a snapshot of the database's jars is cheap but creating a snapshot of
/// other state stored on the database might require deep-cloning data. That's why you should
/// avoid creating snapshots in a hot function (e.g. don't create a snapshot for each file, instead
/// create a snapshot when scheduling the check of an entire program).
///
/// ## Salsa compatibility
/// Salsa prohibits creating a snapshot while running a local query (it's fine if other workers run a query) [[source](https://github.com/salsa-rs/salsa/issues/80)].
/// We should avoid creating snapshots while running a query because we might want to adopt Salsa in the future (if we can figure out persistent caching).
/// Unfortunately, the infrastructure doesn't provide an automated way of knowing when a query is run, that's
/// why we have to "enforce" this constraint manually.
fnsnapshot(&self)-> Snapshot<Self>;
}
/// Readonly snapshot of a database.
///
/// ## Dead locks
/// A snapshot should always be dropped as soon as it is no longer necessary to run queries.
/// Storing the snapshot without running a query or periodically checking if cancellation was requested
/// can lead to deadlocks because mutating the [`Database`] requires cancels all pending queries
/// and waiting for all [`Snapshot`]s to be dropped.
warn_user!("`--show-source` with `--output-format=grouped` is deprecated, and will not show source files. Use `--output-format=full` to show source information.");
SerializationFormat::Grouped
}
(Some(fmt),Some(true))=>{
warn_user!("The `--show-source` argument is deprecated and has been ignored in favor of `--output-format={fmt}`.");
fmt
}
(Some(fmt),Some(false))=>{
warn_user!("The `--no-show-source` argument is deprecated and has been ignored in favor of `--output-format={fmt}`.");
fmt
}
(None,Some(true))=>{
warn_user!("The `--show-source` argument is deprecated. Use `--output-format=full` instead.");
SerializationFormat::Full
}
(None,Some(false))=>{
warn_user!("The `--no-show-source` argument is deprecated. Use `--output-format=concise` instead.");
SerializationFormat::Concise
}
(None,None)=>returnNone
}).map(|format|matchformat{
SerializationFormat::Text=>{
warn_user!("`--output-format=text` is deprecated. Use `--output-format=full` or `--output-format=concise` instead. `text` will be treated as `{}`.",SerializationFormat::default(preview));
SerializationFormat::default(preview)
},
other=>other
})
}
/// CLI settings that are distinct from configuration (commands, lists of files,
/// etc.).
#[allow(clippy::struct_excessive_bools)]
#[expect(clippy::struct_excessive_bools)]
pubstructCheckArguments{
pubadd_noqa: bool,
pubadd_noqa: Option<String>,
pubdiff: bool,
pubecosystem_ci: bool,
pubexit_non_zero_on_fix: bool,
pubexit_zero: bool,
pubfiles: Vec<PathBuf>,
@@ -985,7 +1090,7 @@ pub struct CheckArguments {
/// CLI settings that are distinct from configuration (commands, lists of files,
/// etc.).
#[allow(clippy::struct_excessive_bools)]
#[expect(clippy::struct_excessive_bools)]
pubstructFormatArguments{
pubcheck: bool,
pubno_cache: bool,
@@ -993,6 +1098,7 @@ pub struct FormatArguments {
pubfiles: Vec<PathBuf>,
pubstdin_filename: Option<PathBuf>,
pubrange: Option<FormatRange>,
pubexit_non_zero_on_format: bool,
}
/// A text range specified by line and column numbers.
@@ -1007,8 +1113,9 @@ impl FormatRange {
///
/// Returns an empty range if the start range is past the end of `source`.
write!(f,"the {range}s column is not a valid number ({inner})'\n {tip} The format is 'line:column'.")
write!(
f,
"the {range}s column is not a valid number ({inner})'\n {tip} The format is 'line:column'."
)
}
LineColumnParseError::LineParseError(inner)=>{
write!(f,"the {range} line is not a valid number ({inner})\n {tip} The format is 'line:column'.")
write!(
f,
"the {range} line is not a valid number ({inner})\n {tip} The format is 'line:column'."
)
}
LineColumnParseError::ZeroColumnIndex{line}=>{
write!(
f,
"the {range} column is 0, but it should be 1 or greater.\n {tip} The column numbers start at 1.\n {tip} Try {suggestion} instead.",
suggestion=format!("{line}:1").green().bold()
suggestion=format!("{line}:1").green().bold()
)
}
LineColumnParseError::ZeroLineIndex{column}=>{
write!(
f,
"the {range} line is 0, but it should be 1 or greater.\n {tip} The line numbers start at 1.\n {tip} Try {suggestion} instead.",
suggestion=format!("1:{column}").green().bold()
suggestion=format!("1:{column}").green().bold()
)
}
LineColumnParseError::ZeroLineAndColumnIndex=>{
write!(
f,
"the {range} line and column are both 0, but they should be 1 or greater.\n {tip} The line and column numbers start at 1.\n {tip} Try {suggestion} instead.",
suggestion="1:1".to_string().green().bold()
suggestion="1:1".to_string().green().bold()
)
}
}
}
}
/// CLI settings that are distinct from configuration (commands, lists of files, etc.).
#[derive(Clone, Debug)]
pubstructAnalyzeGraphArgs{
pubfiles: Vec<PathBuf>,
pubdirection: Direction,
pubpython: Option<PathBuf>,
}
/// Configuration overrides provided via dedicated CLI flags:
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}